|
Опрос
|
реклама
Быстрый переход
AMD представила ИИ-ускорители Instinct MI350 и MI355X с потреблением до 1400 Вт, а также приоткрыла MI400 с 432 Гбайт HBM4
13.06.2025 [06:00],
Николай Хижняк
Компания AMD представила новую флагманскую серию ИИ-ускорителей для дата-центров MI350. В неё входят два продукта: ускорители Instinct MI350 и MI355X. Они основаны на одинаковой архитектуре CDNA 4, однако Instinct MI355X предлагают более высокие тепловые и энергетические характеристики, что по словам главы AMD Лизы Су (Lisa Su), позволяет добиться более высокой производительности. 
Источник изображений: AMD Ускорители серии Instinct MI350 основаны на 3-нм техпроцессе и содержат 185 млрд транзисторов в составе 10 чиплетов. Для производства Instinct MI350 компания использует технологию гибридной склейки. При этом чиплеты Accelerator Compute Die (XCD) в составе этих графических процессоров производятся с использованием техпроцесса N3P компании TSMC, а чиплеты ввода-вывода I/O Die — на базе 6-нм техпроцесса TSMC N6. 
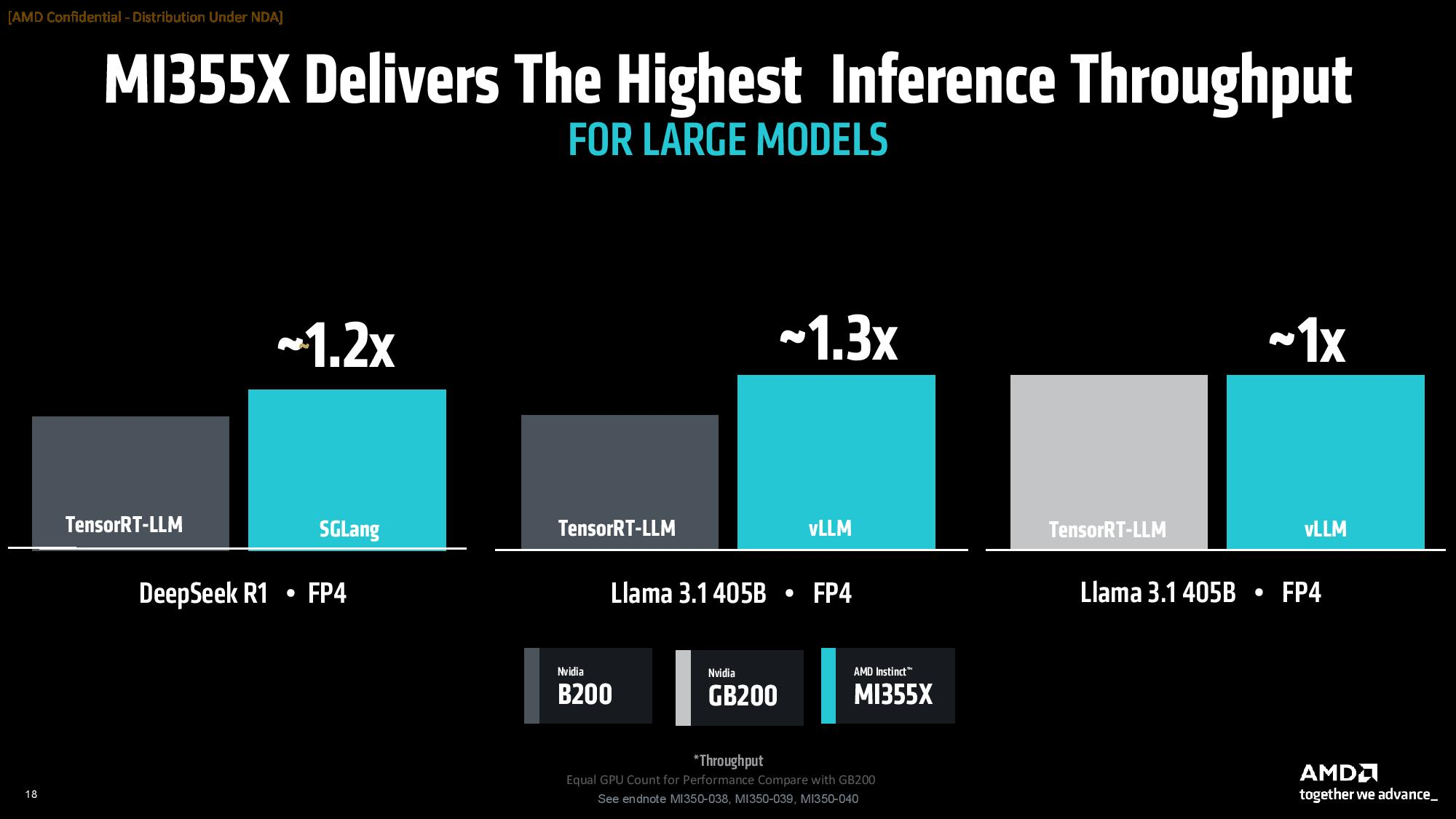
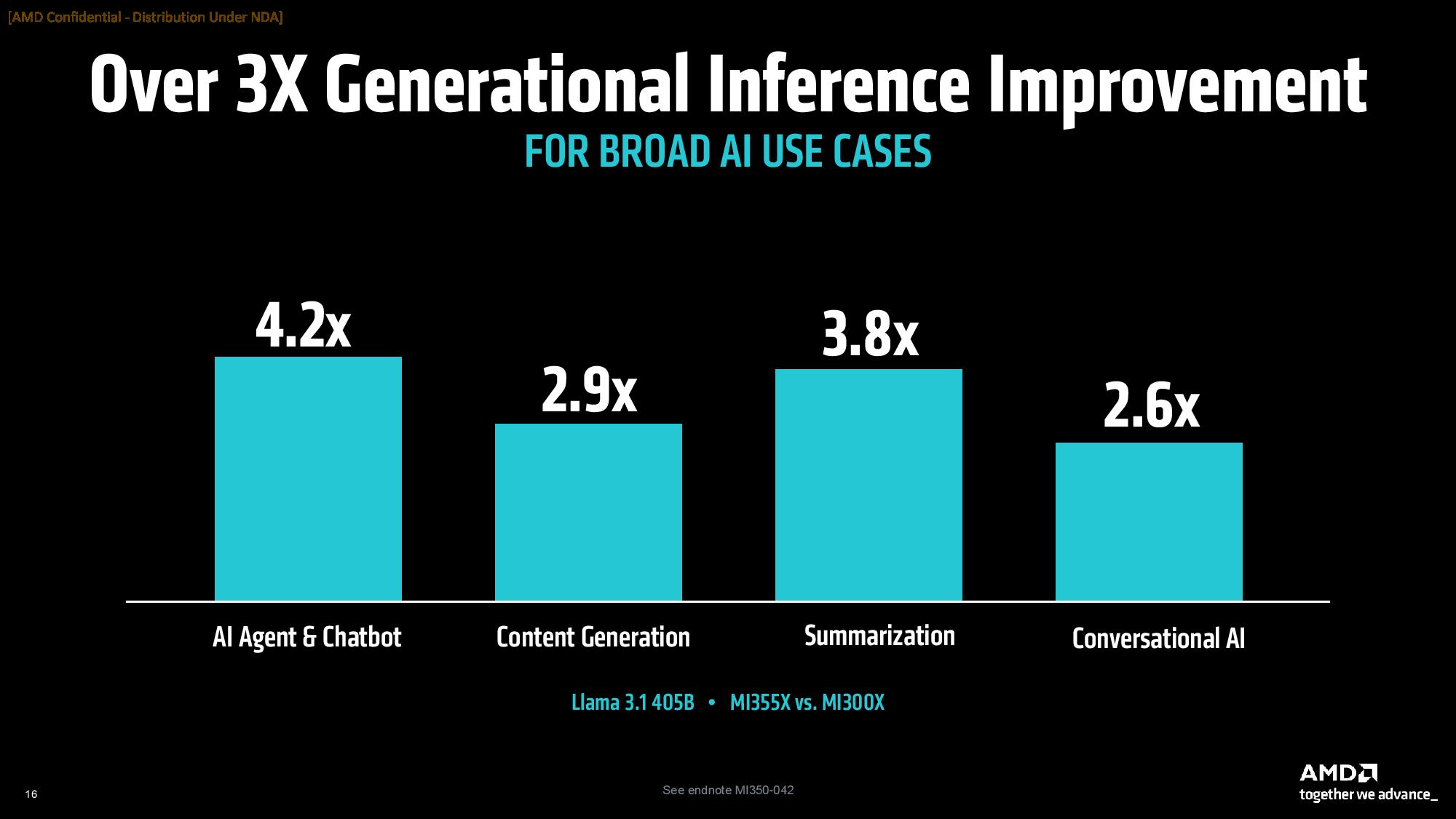
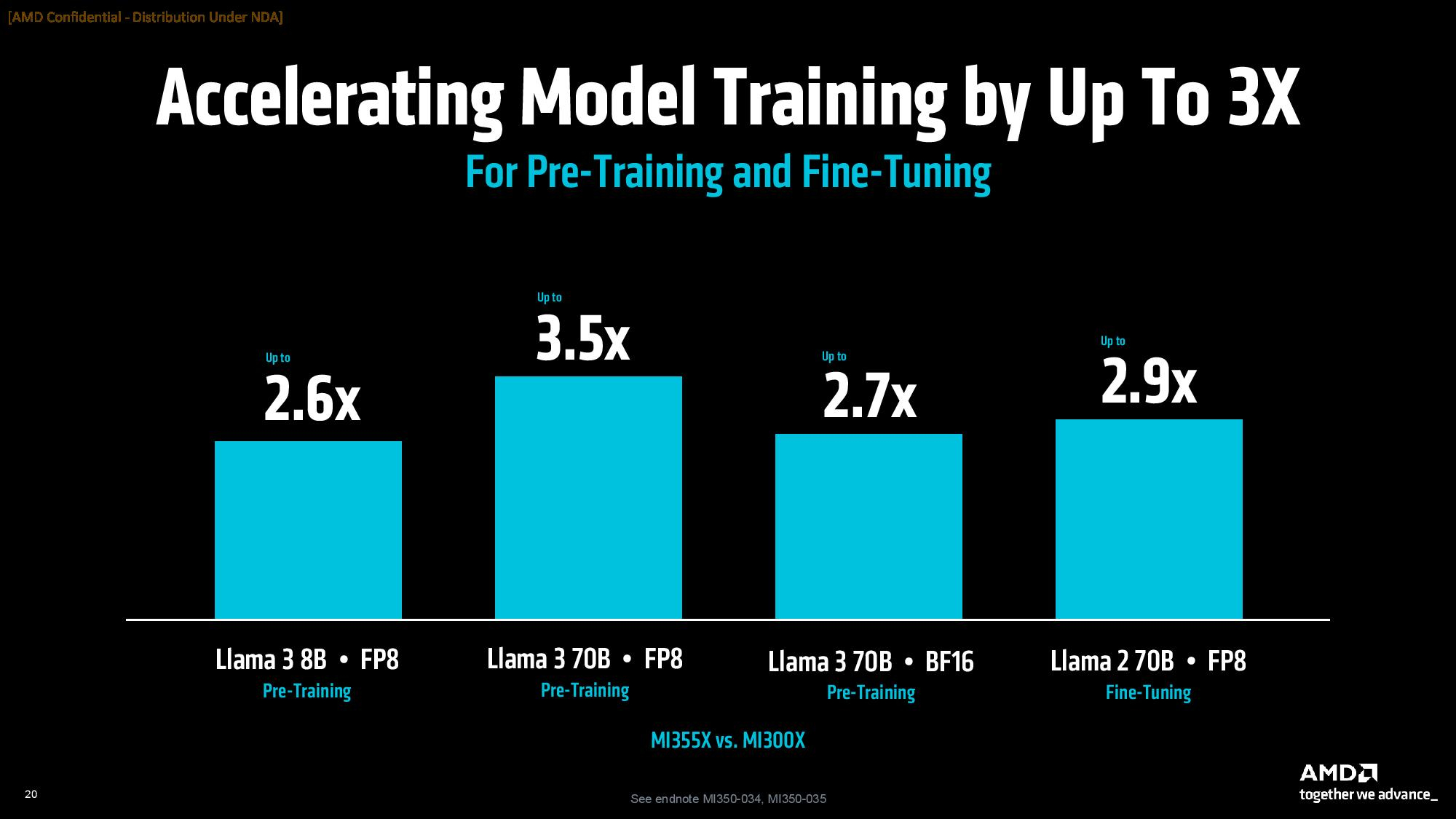
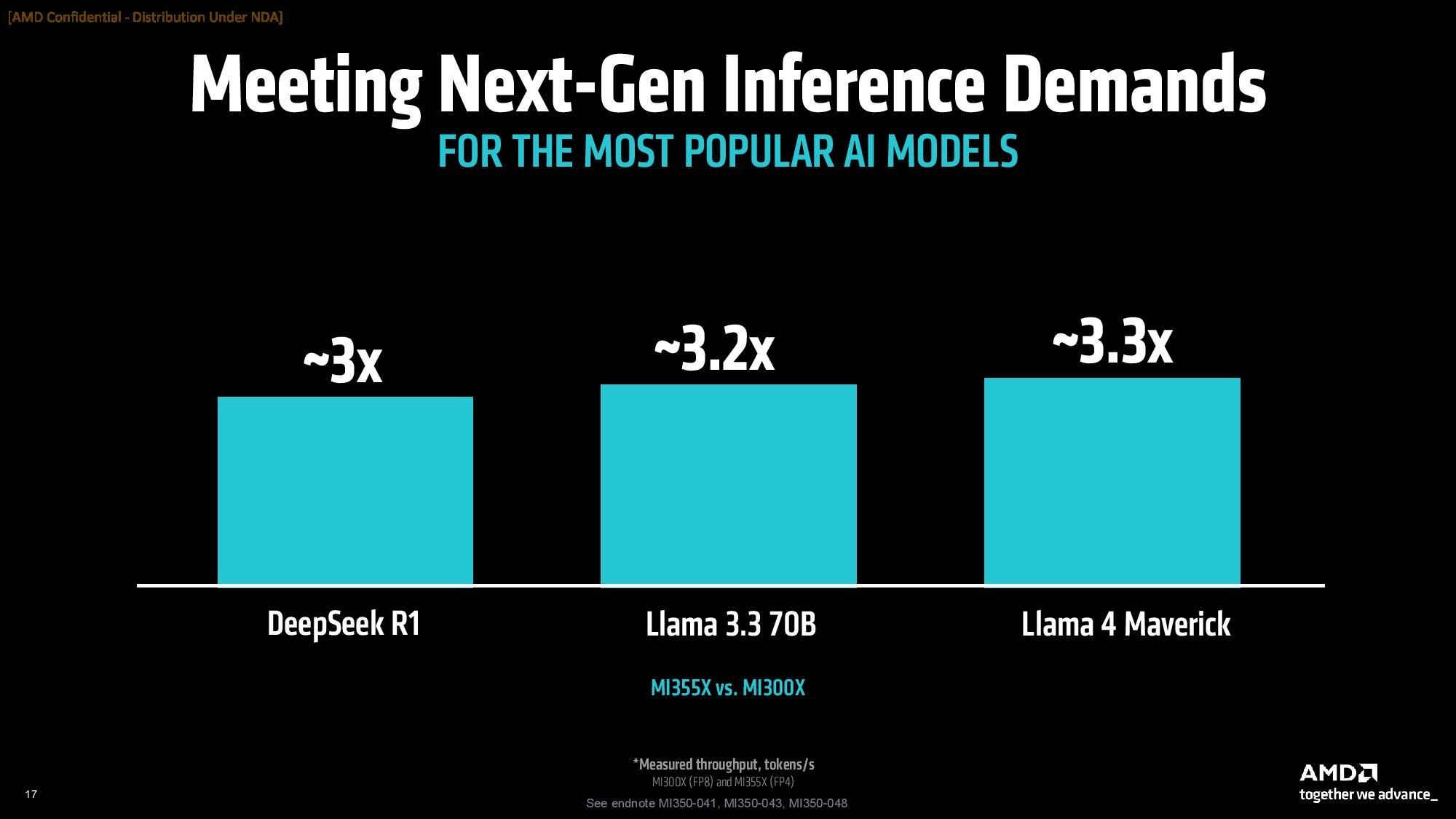
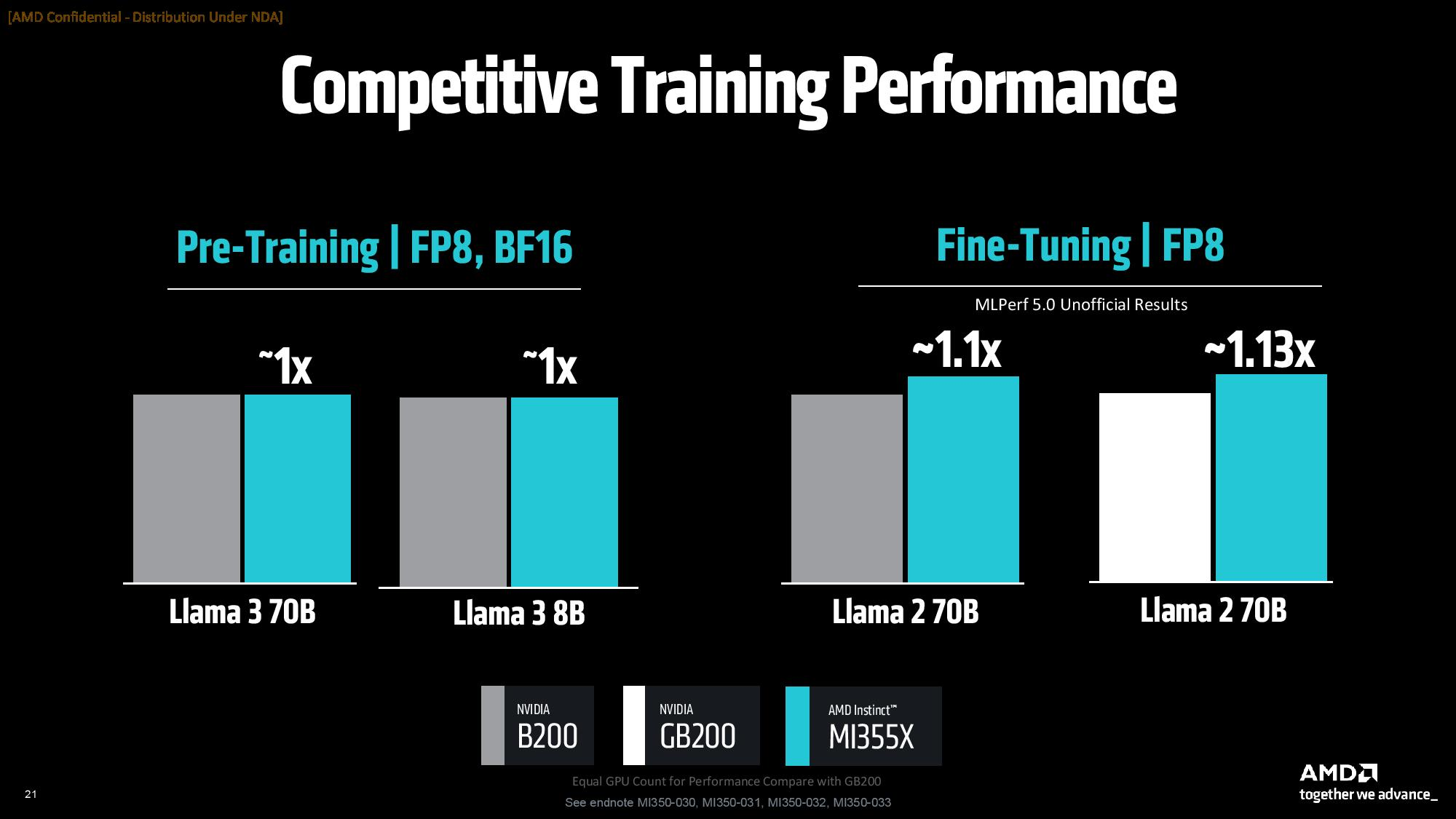
В составе Instinct MI350 присутствуют 256 исполнительных блоков, содержащие в общей сложности 16 384 графических ядра, что на самом деле меньше, чем у GPU MI325X, в которых содержатся 19 456 ядер. Архитектура CDNA 4 была обновлена для поддержки новых типов данных FP4 и FP6 для выводов ИИ. Ускорители серии Instinct MI350 предлагают до 288 Гбайт памяти HBM3E с пропускной способностью до 8 Тбайт/с.  AMD сосредоточилась на повышении энергоэффективности своих новых графических процессоров для центров обработки данных. Однако, чтобы соответствовать конкурентам, компания увеличила потребление энергии до 1000 Вт для Instinct MI350X и до 1400 Вт для Instinct MI355X. Ускорители будут выпускаться в формфакторе ODM-модулей. По словам AMD, ускорители серии Instinct MI350 обеспечат трёхкратный прирост чистой производительности, четырёхкратный прирост производительности в ИИ-задачах по сравнению с предшественниками и 35-кратный прирост в производительности рассуждающего ИИ по сравнению с предыдущим поколением ускорителей Instinct MI300X. Компания также утверждает, что её ускорители серии Instinct MI350 превосходят решения Nvidia в сопоставимых тестах вывода до 1,3 раза и опережают их до 1,13 раза в выборочных рабочих нагрузках обучения. Производство ускорителей серии Instinct MI350 началось в прошлом месяце. Доступными они станут в третьем квартале текущего года. Особенности и производительность ИИ-ускорителей AMD Instinct MI350
AMD также анонсировала ускорители Instinct MI400, которые будут использовать архитектуру CDNA-Next (неофициальное название, вероятно, это будет CDNA 5). Их выпуск ожидается в 2026 году. Эти ИИ-ускорители предложат до 432 Гбайт памяти HBM4, что вдвое больше объёма памяти, доступного у Instinct MI355X. Память у Instinct MI400 обеспечит пропускную способность до 19,6 Тбайт/с.  По словам AMD, новые флагманские ускорители Instinct MI400 будут до 10 раз мощнее Instinct MI300. Они также будут до двух раз производительнее Instinct MI355X, получат до 50 % больше памяти и более чем вдвое увеличенную пропускную способность памяти. Если те же Instinct MI355X обеспечивают производительность 10 PFLOPS в операциях FP4, то для Instinct MI400X прогнозируется производительность в 20 PFLOPS в вычислениях FP4.  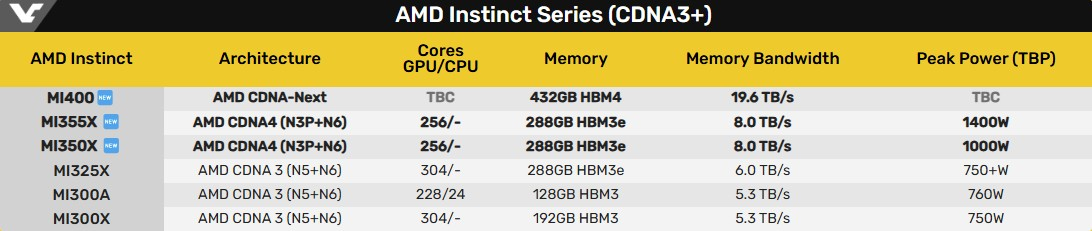 Ускорители Instinct MI400X также превзойдут по производительности недавно представленные ИИ-ускорители Nvidia Blackwell Ultra. Однако в сравнении с анонсированными ускорителями Nvidia Rubin R200, которые предложат 50 PFLOPS в операциях FP4, новые AMD Instinct MI400X будут в 2,5 раза медленнее. Правда, всех подробностей о Instinct MI400 компания не раскрыла. AMD объединит RDNA для игр и CDNA для ИИ-ускорителей в единую графическую архитектуру UDNA
09.09.2024 [20:04],
Николай Хижняк
В разговоре с порталом Tom’s Hardware старший вице-президент и генеральный менеджер группы вычислительных и графических решений AMD Джек Гуинь (Jack Huynh) сообщил, что компания снова планирует объединить свои графические архитектуры для игровых видеокарт и ускорителей вычислений. Это необходимо для масштабирования и удовлетворения потребностей разработчиков. 
Источник изображений: AMD Ранее сообщилось, что AMD решила сместить акцент с ограниченного сегмента флагманских видеокарт для энтузиастов на расширение присутствия в сегменте массовых моделей GPU. Однако в том же разговоре Гуинь сообщил, что архитектуры RDNA и CDNA в перспективе будут объединены.  В 2020 году AMD сообщила о разделении своих графических архитектур после GCN на RDNA (для игр) и CDNA (для дата-центров). Графическая архитектура CDNA начала использоваться в качестве основы для специализированных ускорителей Radeon Instinct, позже переименованных просто в Instinct. Хотя на тот момент разделение и оптимизация графических архитектур под определённые сценарии казалась оправданной, разработчикам стало сложно ориентироваться в этих оптимизациях. В результате компания решила снова унифицировать архитектуру. «Часть большого изменения в AMD связана с тем, что сегодня у нас есть архитектура CDNA для ускорителей Instinct для дата-центров и архитектура RDNA для потребительских видеокарт. Они разветвлены. Двигаясь вперёд, мы их объединим в одну с названием UDNA. Это будет унифицированная архитектура, предназначенная как для Instinct, так и для потребительских решений. Благодаря этому объединению мы значительно упростим задачи для разработчиков, которым сегодня приходится выбирать с какой архитектурой работать», — заяви Гуинь. Благодаря упрощению архитектуры разработчикам необходимо будет сосредоточить своё внимание только на одной системе, независимо от того, работают ли они с большими кластерами графических процессоров или одним игровым GPU. Компания теперь также будет планировать разработки графических архитектур на три поколения вперёд (RDNA5, UDNA6 и UDNA7) с целью поддержания оптимизаций без необходимости сбрасывать их каждый раз, когда AMD меняет свою иерархию памяти. AMD официально пока не объявляла о стратегии перехода на унифицированную графическую архитектуру UDNA. Когда это случится — с выходом RDNA 5 или позже — неизвестно. На самом деле, компания пока мало что рассказала и о будущей графической архитектуре RDNA 4, которая, как ожидается, должна стать основной видеокарт Radeon 8000. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex