|
Опрос
|
реклама
Быстрый переход
Жертвы утечки данных Facebook✴ через Cambridge Analytica начали получать выплаты от Цукерберга
17.09.2025 [19:46],
Владимир Фетисов
Вероятно, многие ещё помнят скандал с британской компанией Cambridge Analytica, получившей доступ к данным миллионов пользователей Facebook✴✴ без их согласия во время президентской кампании Дональда Трампа (Donald Trump) в 2016 году и использовавшей их для политической рекламы. Похоже, что компания Meta✴✴ Platforms (в то время Facebook✴✴) начала выплачивать компенсации пострадавшим пользователям платформы в рамках судебного урегулирования. 
Источник изображения: Michael Candelori / Shutterstock.com Рассмотрение этого дела закончилось ещё несколько лет назад. Facebook✴✴ выплатила штраф в размере $5 млрд после иска Федеральной торговой комиссии (FTC) в 2019 году. В 2022 года для урегулирования другого коллективного иска компания согласилась выплатить $725 млн пострадавшим пользователям. Теперь же стало известно, что затронутые инцидентом пользователи начали получать компенсацию. В недавнем сообщении одного из участников иска против Facebook✴✴ сказано, что он получил на этой неделе около $38. По сути, все пользователи Facebook✴✴, у которых была учётная запись в социальной сети в период с 7 мая 2007 года по 22 декабря 2022 года, могут претендовать на получение выплаты, поскольку они, вероятно, пострадали от утечки данных. Однако для получения компенсации необходимо было присоединиться к коллективному иску и подать претензию до 25 августа 2023 года. Пользователи платформы, которые не сделали этого, более не имеют права на получение компенсации. Размер выплаты зависит от количества людей, присоединившихся к коллективному иску, а также от продолжительности периода активности в Facebook✴✴. Другими словами, пользователь, который имел аккаунт Facebook✴✴ в течение нескольких лет, получит больше пользователя, активного всего несколько недель. По данным источника, процесс распределения средств продлится в течение следующих двух с половиной месяцев. Денежные средства будут поступать на счёт, который каждый пользователь указал в коллективном иске. Россиянам больше нельзя искать экстремизм в интернете, рекламировать VPN и размещать рекламу в Instagram✴
01.09.2025 [15:36],
Владимир Мироненко
1 сентября в России вступил в силу ряд законов, предусматривающих штрафы за умышленный поиск экстремистских материалов в интернете, за рекламу VPN, а также за размещение рекламы в запрещённых соцсетях. Соответствующие поправки были приняты Госдумой РФ в окончательном третьем чтении в июле, после чего были одобрены Советом Федерации и подписаны главой государства. 
Источник изображения: Penghao Xiong / unsplash.com Кодекс РФ об административных правонарушениях был дополнен статьёй 13.53 — Поиск заведомо экстремистских материалов и получение доступа к ним, в том числе с использованием программно-аппаратных средств доступа к информационным ресурсам, информационно-телекоммуникационным сетям, доступ к которым ограничен. Согласно этой статье такое нарушение влечёт штраф для граждан в размере от 3 до 5 тыс. рублей. А использования для поиска экстремистского контента средств обхода блокировок будет являться отягчающим обстоятельством. Министр цифрового развития Максут Шадаев заявил, что наказывать будут только за умышленный просмотр экстремистских материалов, а посещение соцсетей, даже признанных экстремистскими, никакого наказания за собой не влечёт. По его словам, силовикам при вынесении постановления о правонарушении потребуется к тому же доказать наличие умысла. Также россиян теперь будут штрафовать за рекламу VPN и других средств обхода блокировок сайтов. За распространение рекламы VPN-сервисов штраф для граждан составит от 50 до 80 тыс. руб., для должностных лиц — от 80 до 150 тыс. руб., для юридических лиц — от 200 до 500 тыс. руб. При этом соавторы поправок уточнили, что за использование VPN граждан наказывать не будут, а обсуждение таких сервисов в соцсетях не считается их рекламой, сообщает РБК. Также с 1 сентября в России запрещено распространять рекламу на признанных экстремистскими сайтах, что в первую очередь относится к Instagram✴✴ и Facebook✴✴. Размещение рекламы на таких ресурсах считается нарушением законодательства о рекламе (ст. 14.3. КоАП), влекущем за собой штрафы до 2,5 тыс. руб. для граждан, до 20 тыс. руб. для должностных лиц и до 500 тыс. руб. для юридических лиц. Согласно разъяснению ФАС, нарушением считается не только размещение новых рекламных публикаций, но и неудаление ранее размещённой рекламы. Старая реклама не подпадает под закон, если только её не попытаются актуализировать — репостить, ссылаться на неё в новых постах и т.д. Meta✴ исправила методику обучения ИИ после скандала с неуместными разговорами с подростками
30.08.2025 [10:23],
Владимир Мироненко
Meta✴✴ откорректировала методику обучения ИИ-чат-бота Meta✴✴ AI, сосредоточив внимание на обеспечении безопасности подростков. Изменения были внесены после публикаций в СМИ об отсутствии у нейросети механизмов предотвращения обсуждения с несовершеннолетними неуместных тем, связанных с самоповреждением, самоубийством, расстройствами пищевого поведения и т. д. 
Источник изображения: Chad Madden/unsplash.com Ранее в этом месяце стало известно о внутреннем документе Meta✴✴, согласно которому чат-боту компании разрешалось вести «чувственные» разговоры с несовершеннолетними пользователями. Комментируя публикацию, Meta✴✴ заявила, что формулировки были «ошибочными и не соответствующими правилам» и были удалены. На днях газета The Washington Post опубликовала результаты исследования, согласно которым Meta✴✴ AI обладает способностью «направлять подростковые аккаунты к самоубийству, самоповреждению и расстройствам пищевого поведения». Представитель Meta✴✴ Стефани Отвей (Stephanie Otway) сообщила ресурсу Engadget, что компания усиливает меры защиты, предотвращающие обсуждение подобных тем при взаимодействии чат-ботов с несовершеннолетними. По её словам, «защитные барьеры» были заложены при обучении ИИ изначально, а по мере роста сообщества и развития технологий компания их усиливает. «Продолжая совершенствовать наши системы, мы добавляем новые “защитные барьеры” в качестве дополнительной меры предосторожности: обучаем наши ИИ не взаимодействовать с подростками на эти темы, а направлять их к экспертным ресурсам, а также ограничиваем доступ подростков к определённой группе ИИ-персонажей», — заявила Отвей. Помимо обновления методики обучения нейросети, компания также ограничит доступ подростков к некоторым ИИ-персонажам, которые могут вести непристойные разговоры, и предложит им виртуальных собеседников, способствующих развитию творчества и образованности. По словам Отвей, меры защиты будут и дальше совершенствоваться. «Эти обновления уже находятся в разработке, и мы продолжим адаптировать наш подход, чтобы обеспечить подросткам безопасный и соответствующий их возрасту опыт взаимодействия с ИИ», — отметила она, уточнив, что новые меры будут внедрены в течение следующих нескольких недель и распространятся на все англоязычные страны. Вопросы по поводу политики Meta✴✴ в области ИИ также возникли у законодателей и других официальных лиц. Сенатор Джош Хоули (Josh Hawley) недавно сообщил компании о планах начать расследование её деятельности в этой сфере. Генеральный прокурор Техаса Кен Пакстон (Ken Paxton) также заявил о намерении провести расследование в отношении Meta✴✴ на предмет предполагаемого введения детей в заблуждение её чат-ботом в вопросах психического здоровья. Хакеры заполонили Facebook✴ замаскированными в SVG-изображениях вирусами
10.08.2025 [18:04],
Владимир Фетисов
Всё больше стран требуют внедрения систем проверки возраста пользователей на сайтах, публикующих контент с возрастными ограничениями. На этом фоне хакеры придумывают всё новые способы распространения вредоносного программного обеспечения. Так исследователи из Malwarebytes недавно обнаружили, что одна из новых схем хакеров предполагает использование векторных изображений формата Scalable Vector Graphics (SVG), содержащих вредоносный код. 
Источник изображения: Xavier Cee / Unsplash Файлы SVG отличаются от стандартных графических форматов, таких как JPG и PNG. В них используется язык разметки XML, благодаря чему файл с изображением может содержать элементы HTML и JavaScript. Это позволяет злоумышленникам встраивать вредоносный программный код в SVG-изображения. Поскольку многие пользователи воспринимают SVG как обычные картинки, они не ожидают, что в таких файлах может скрываться угроза безопасности. Злоумышленники публикуют в Facebook✴✴ тематические посты для взрослых, часто с рекламой фейкового контента знаменитостей или материалов, созданных с помощью искусственного интеллекта. При переходе по ссылке пользователю предлагается загрузить изображение в формате SVG. Открытие этого файла инициирует выполнение встроенного в него JavaScript-кода. При этом применяются специальные техники маскировки вредоносного кода, что усложняет его обнаружение. После запуска скрипт подгружает с подконтрольного злоумышленникам ресурса дополнительный вредоносный код, в результате чего на устройство жертвы устанавливается троян, известный как Trojan.JS.Likejack. Он в скрытом режиме автоматически ставит «лайки» определённым публикациям и страницам в Facebook✴✴, что позволяет продвигать контент с возрастными ограничениями без ведома пользователя. По данным источника, многие участвующие в этой кампании веб-сайты работают на WordPress и связаны между собой. Генерируя сотни фейковых «лайков», злоумышленники делают свои посты более заметными для алгоритмов Facebook✴✴, тем самым продвигая свои сайты без оплаты рекламы. Соцсеть пытается активно бороться с такими публикациями, однако злоумышленники постоянно создают новые. Meta✴ разрешит программистам пользоваться ИИ на собеседованиях
30.07.2025 [13:11],
Владимир Мироненко
Компания Meta✴✴ разрешит некоторым кандидатам использовать искусственный интеллект (ИИ) на собеседованиях по программированию, поскольку это «снижает эффективность мошенничества, связанного с использованием больших языковых моделей (LLM)», пишет ресурс Business Insider. 
Источник изображения: Solen Feyissa/unsplash.com В начале этого месяца на внутренней доске объявлений Meta✴✴ появилась публикация «Собеседования с использованием ИИ». В ней сообщалось, что компания «разрабатывает новый тип собеседований по программированию, на которых кандидатам будет доступен ИИ-помощник». Объясняется, что это более точно отражает среду разработчиков, в которой будут работать будущие сотрудники, а также делает мошенничество на основе LLM менее эффективным. Также сообщалось, что Meta✴✴ ищет «подставных кандидатов» среди своих сотрудников для тестирования этого процесса собеседований. «Всё пока находится в стадии разработки; ваши данные помогут сформировать будущее собеседований в Meta✴✴», — говорится в публикации. «Совершенно очевидно, что мы сосредоточены на использовании ИИ, чтобы помочь инженерам в их повседневной работе, поэтому неудивительно, что мы тестируем, как предоставлять эти инструменты кандидатам во время собеседований», — подчеркнул представитель Meta✴✴ в заявлении для Business Insider. Ранее генеральный директор Meta✴✴ Марк Цукерберг (Mark Zuckerberg), говоря о влиянии ИИ на программирование, заявил: «Вероятно, в 2025 году мы как и другие компании, которые работают над этим, получим ИИ, который фактически сможет стать своего рода инженером среднего звена, умеющим писать код». Впрочем, не все компании придерживаются подхода Meta✴✴ к использованию ИИ. Например, в Amazon недавно дали указание внутренним рекрутерам дисквалифицировать кандидатов, если будет установлено, что они использовали ИИ-инструменты на собеседовании. ИИ-стартап Anthropic изначально рекомендовал соискателям не использовать ИИ-помощников при подаче заявлений, хотя впоследствии изменил своё решение. Продажи умных очков Ray-Ban Meta✴ выросли втрое в первом полугодии 2025 года
29.07.2025 [13:26],
Владимир Мироненко
Крупнейший в мире производитель очков, франко-итальянская компания EssilorLuxottica, владеющая брендами Ray-Ban и Oakley, опубликовала результаты работы за второй квартал 2025 года. Выручка компании выросла на 7,3 % в годовом выражении и достигла €7,18 млрд ($8,36 млрд), что превысило консенсус-прогноз аналитиков, опрошенных Bloomberg, — они ожидали рост на 5,9 %. Отдельно отмечается кратный рост спроса на смарт-очки, которые EssilorLuxottica выпускает совместно с Meta✴✴. 
Источник изображения: Ray-Ban Драйвером роста стали продажи в Европе, где компания также активно продвигала проект по выпуску смарт-очков в сотрудничестве с Meta✴✴ Platforms, тогда как реализация в Северной Америке сдерживалась введением пошлин и падением курса доллара. Продажи смарт-очков Ray-Ban Meta✴✴ выросли более чем втрое в первой половине года — EssilorLuxottica заметно активизировала усилия по их продвижению, отмечает Bloomberg. В этом году EssilorLuxottica представила линейку Nuance Audio с улучшенными слуховыми характеристиками и анонсировала спортивные умные очки Oakley Meta✴✴, добавив спортивную тематику в партнёрскую программу с Meta✴✴ Platforms Inc. Несмотря на рост цен в связи с пошлинами, статистика показывает, что всё больше покупателей выбирают носимые устройства EssilorLuxottica. «Мы ожидаем очень быстрого роста продаж смарт-очков Oakley Meta✴✴, — заявил генеральный директор Франческо Миллери (Francesco Milleri) в ходе конференции по результатам квартала. — Мы уверены, что они смогут достичь показателей Ray-Ban Meta✴✴». Миллери также сообщил о планах по запуску новых продуктов и о решении увеличить объёмы производства в Таиланде к концу 2026 года, чтобы довести суммарную производственную мощность до 10 млн единиц. По словам генерального директора Meta✴✴ Марка Цукерберга (Mark Zuckerberg), быстрорастущий сегмент открывает для компании возможность разрабатывать собственное оборудование и контролировать дистрибуцию. Как ранее сообщало Bloomberg News, в этом месяце Meta✴✴ приобрела чуть менее 3 % акций EssilorLuxottica. Пошлины США остаются проблемой для EssilorLuxottica, которой также принадлежат сети LensCrafters и Sunglass Hut. Из-за их роста скорректированная валовая рентабельность в первом полугодии снизилась на 90 базисных пунктов по сравнению с аналогичным периодом прошлого года. Рост цен на продукцию в США и стратегия «производства и дистрибуции из наиболее эффективных локаций» будут способствовать поддержанию рентабельности во втором полугодии, заявил финансовый директор Стефано Грасси (Stefano Grassi). EssilorLuxottica подтвердила свой прогноз роста годовой выручки на уровне 40–80 % к 2026 году при постоянном обменном курсе, а также поддержания скорректированной операционной рентабельности в диапазоне 19–20 % от выручки. Google DeepMind назвал переманивание Meta✴ талантов из других компаний вполне оправданным
25.07.2025 [18:55],
Владимир Мироненко
Глава подразделения Google DeepMind Демис Хассабис (Demis Hassabis) заявил, что переманивание компанией Meta✴✴ квалифицированных специалистов в области ИИ вполне оправдано, поскольку ей необходимо получить конкурентное преимущество на ИИ-рынке, пишет Business Insider. Сейчас Meta✴✴ активно переманивает талантливых специалистов из других компаний, предлагая оклады, которые не снились даже главе Apple. 
Источник изображения: TheStandingDesk/unsplash.com «Сейчас Meta✴✴ не на переднем крае, возможно, им удастся вернуться туда, — сказал Хассабис в выпуске подкаста Lex Fridman, опубликованном в четверг. — С их точки зрения, их действия, вероятно, рациональны, поскольку они отстают, и им нужно что-то делать». Сейчас Meta✴✴ комплектует новое подразделение по созданию суперинтеллекта Superintelligence Labs, предлагая за работу в нём исследователям из передовых лабораторий, таких как OpenAI, зарплату до $100 млн. В числе перешедших в компанию за последнее время — бывший руководитель GitHub Нат Фридман (Nat Friedman), бывший генеральный директор Scale AI Александр Ван (Alexandr Wang) и бывшие исследователи OpenAI Шэнцзя Чжао (Shengjia Zhao), Шучао Би (Shuchao Bi), Цзяхуэй Юй (Jiahui Yu) и Хунъюй Жэнь (Hongyu Ren). Хассабис заявил, что, хотя Meta✴✴ делает такие предложения «рационально», многие специалисты в сфере ИИ считают приоритетной задачей «безопасное управление этой технологией». «Есть вещи важнее, чем просто деньги», — говорит глава Google DeepMind, вместе с тем признавая, что люди должны получать зарплату по рыночным ставкам. Впрочем, не все придерживаются мнения Хассабиса по поводу рациональности переманивания кадров. Генеральный директор OpenAI Сэм Альтман (Sam Altman) назвал такую практику отвратительной. Meta✴ отказалась соблюдать «чрезмерные» правила разработки ИИ, предложенные ЕС
18.07.2025 [21:10],
Владимир Мироненко
Компания Meta✴✴ отказалась подписывать Кодекс практики для ИИ общего назначения ЕС (General-Purpose AI Code of Practice) — анонсированный 10 июля свод правил, направленных на соблюдение «Закона об ИИ» (AI Act). Это произошло за несколько недель до вступления в силу требований ЕС для поставщиков универсальных ИИ-моделей с системными рисками и базовых моделей, пишет TechCrunch. 
Источник изображения: ALEXANDRE LALLEMAND/unsplash.com «Европа движется по неверному пути в отношении ИИ, — написал Джоэл Каплан (Joel Kaplan), директор по глобальным вопросам Meta✴✴, в публикации на LinkedIn. — Мы внимательно изучили Кодекс практики Европейской комиссии в отношении универсальных моделей ИИ (GPAI), и Meta✴✴ не будет его подписывать. Этот кодекс вносит ряд правовых неопределённостей для разработчиков моделей, а также содержит меры, выходящие далеко за рамки “Закона об ИИ”». Кодекс практики ЕС представляет собой пакет рекомендаций для добровольного исполнения, призванный помочь компаниям внедрять процессы и системы, соответствующие законодательству ЕС о регулировании ИИ. В частности, компаниям рекомендуется предоставлять и регулярно обновлять документацию о своих ИИ-инструментах и сервисах, запрещается обучение моделей на пиратском контенте, а также предлагается выполнять требования авторов, не желающих, чтобы их материалы использовались в обучающих датасетах. Каплан охарактеризовал реализацию «Закона об ИИ» в ЕС как «чрезмерную», отметив, что закон «затруднит разработку и внедрение передовых ИИ-моделей в Европе и станет помехой европейским компаниям, стремящимся строить бизнес на их основе». Технологические компании, включая лидеров ИИ-рынка — Alphabet, Meta✴✴, Microsoft и Mistral AI — активно выступают против ужесточения регулирования цифрового сектора ЕС, призывая отложить вступление в силу «Закона об ИИ». Однако Еврокомиссия заявила, что не намерена менять установленные сроки. Также в пятницу Еврокомиссия опубликовала руководство для поставщиков ИИ-моделей в преддверии вступления в силу требований «Закона об ИИ» 2 августа. Эти требования касаются поставщиков универсальных ИИ-моделей с системными рисками, таких как OpenAI, Anthropic, Google и Meta✴✴. Компании, выпустившие такие модели на рынок до 2 августа, должны будут соблюдать данные требования не позднее 2 августа 2027 года. Meta✴ и акционеры заключили мировое соглашение по иску на $8 млрд из-за утечек данных Facebook✴
17.07.2025 [21:33],
Анжелла Марина
Неожиданно быстро завершился судебный процесс, в котором акционеры Meta✴✴ требовали от Марка Цукерберга (Mark Zuckerberg) и других руководителей компании возмещение ущерба в размере $8 млрд за систематические нарушения приватности пользователей Facebook✴✴. Стороны заключили мировое соглашение уже на второй день слушаний в суде Делавэра, о чём сообщил адвокат истцов Сэм Клосик (Sam Closic). 
Источник изображения: Greg Bulla/Unsplash По данным Reuters, судья Кэтлин Маккормик (Kathaleen McCormick) закрыла процесс, поздравив стороны с достигнутым соглашением. Детали урегулирования не раскрываются, так как защита не стала комментировать решение, а представители акционеров лишь отметили, что переговоры прошли в сжатые сроки. Иск был подан против 11 бывших и действующих руководителей Meta✴✴, включая Цукерберга, Шерил Сандберг (Sheryl Sandberg) и венчурного инвестора Марка Андреессена (Marc Andreessen). Акционеры требовали, чтобы ответчики возместили компании многомиллиардные штрафы, которые та заплатила из-за нарушений защиты данных. Например, в 2019 году Федеральная торговая комиссия (FTC) оштрафовала Facebook✴✴ на $5 млрд за несоблюдение соглашения 2012 года о защите пользовательских данных. Поводом для иска стал скандал с британской частной компанией Cambridge Analytica, получившей доступ к данным миллионов пользователей Facebook✴✴ во время президентской кампании Дональда Трампа (Donald Trump) в 2016 году. Акционеры утверждали, что руководство компании сознательно игнорировало проблемы с приватностью, превратив соцсеть в инструмент сбора данных. В среду, 16 июля, эксперт истцов заявил о «пробелах и слабостях» в политике конфиденциальности Facebook✴✴, но не стал прямо обвинять компанию в нарушении соглашения с FTC. Ожидалось, что в ходе процесса выступят Цукерберг, Сандберг и другие топ-менеджеры, включая сооснователя Netflix Рида Хастингса (Reed Hastings) и Питера Тиля (Peter Thiel), одного из первых инвесторов Facebook✴✴. Однако слушания завершились до того, как по сути начались. Facebook✴ начнёт блокировать аккаунты за использование некачественного и чужого контента
15.07.2025 [06:07],
Анжелла Марина
Компания Meta✴✴ объявила о новых мерах против распространения некачественного и непроверенного контента на своих платформах. В частности, компания усилит борьбу с аккаунтами, регулярно публикующими непереработанный или чужой контент, включая повторное использование текстов, фото и видео без добавления собственной ценности. Ранее аналогичные шаги уже предпринял YouTube. 
Источник изображения: Glen Carrie/Unsplash В этом году Meta✴✴ удалила около 10 миллионов фейковых профилей в Facebook✴✴, которые имитировали известных блогеров, а также ограничила доступ к монетизации более чем 500 тысяч аккаунтов за спам и поддельную активность. Как сообщает TechCrunch, такие страницы получат меньше охвата, а их комментарии будут скрываться из рекомендаций. Кроме того, при обнаружении дубликатов видео Meta✴✴ будет направлять пользователей к оригинальному материалу. При этом в Meta✴✴ подчеркнули, что не намерены наказывать пользователей, которые используют чужой контент для создания реакций, присоединяются к трендам или дают свою интерпретацию. Основной удар направлен на тех, кто выкладывает перепосты ради прибыли или создаёт страницы, якобы принадлежащие известным авторам. Компания также отреагировала на рост так называемого AI slop — низкокачественных материалов, создаваемых с помощью генеративного искусственного интеллекта (ИИ). В своих рекомендациях Meta✴✴, в этом случае, советует издателям добавлять водяные знаки и сосредоточиться на «оригинальном повествовании». Также было указано, что автоматические субтитры, созданные ИИ без доработки, могут считаться неприемлемыми. Все эти изменения появились на фоне критики в адрес Meta✴✴ за избыточное применение автоматических блокировок. Петиция с почти 30 тысячами подписей пользователей призывает компанию решить проблему ошибочно заблокированных аккаунтов и отсутствия поддержки со стороны модераторов-людей, что особенно ударяет по малому бизнесу. В Meta✴✴ пока публично не прокомментировали эту ситуацию. Обновления будут внедряться постепенно, чтобы дать авторам время на адаптацию. Издатели смогут отслеживать возможные причины снижения охвата через Facebook✴✴ Professional Dashboard и раздел поддержки. Данные о блокировках Meta✴✴ традиционно публикует в ежеквартальных отчётах о прозрачности. Согласно последнему из них, 3 % месячной аудитории Facebook✴✴ составляли фейковые аккаунты, а с января по март 2025 года компания приняла меры против миллиарда таких профилей. Также Meta✴✴ постепенно отказывается от собственной проверки фактов в США в пользу системы Community Notes, аналогичной Twitter (X). Этот инструмент позволяет пользователям и модераторам оценивать соответствие публикаций стандартам платформы. Акционеры Meta✴ потребовали возместить ущерб из-за некомпетентности Цукерберга и остальных руководителей
14.07.2025 [14:27],
Владимир Мироненко
На этой неделе в Канцлерском суде штата Делавэр будут заслушаны показания топ-менеджеров Meta✴✴ в рамках процесса по иску акционеров, обвиняющих совет директоров в некомпетентном управлении, которое якобы стало прямой причиной миллиардных штрафов, выплаченных компанией из-за утечки данных. Об этом сообщает ресурс Financial Times. 
Источник изображения: Wesley Tingey/unsplash.com Судебное разбирательство начнётся в среду и продлится восемь дней. В качестве свидетелей в суде выступят генеральный директор Марк Цукерберг (Mark Zuckerberg) и бывшая операционный директор Шерил Сэндберг (Sheryl Sandberg). Также будут заслушаны член совета директоров и инвестор Марк Андрессен (Marc Andreessen), а также Джефф Зиентс (Jeff Zients) — член совета директоров и бывший главный советник экс-президента США Джо Байдена (Joe Biden). Среди других обвиняемых — инвестор Питер Тиль (Peter Thiel), Кеннет Шено (Kenneth Chenault), бывший генеральный директор American Express, и Рид Хастингс (Reed Hastings), соучредитель Netflix. Процесс вызвал большой интерес в ИТ-отрасли, поскольку это первый случай, когда обвинение совета директоров в халатности дошло до суда в Делавэре — штате, где большинство подобных исков обычно отклоняются на ранней стадии. Ранее компании предпочитали урегулировать подобные претензии во внесудебном порядке. Например, Boeing согласилась выплатить $237,5 млн после обвинения со стороны акционеров в неспособности руководства предотвратить кризис с самолётами 737 Max. В иске акционеры утверждают, что члены совета директоров Meta✴✴ сознательно игнорировали факты несоблюдения компанией норм конфиденциальности, нарушив условия соглашения с Федеральной торговой комиссией США (FTC), заключённого в 2012 году и направленного на защиту персональных данных пользователей. Ответчики отвергают эти обвинения. Истцы требуют возмещения ущерба, понесённого в результате мирового соглашения с FTC на сумму $5 млрд, заключённого в 2019 году после расследования в отношении Facebook✴✴ в связи со сбором данных пользователей компанией Cambridge Analytica. По их словам, совет директоров «защитил» Цукерберга, утвердив выплату без проведения внутреннего расследования — якобы в обмен на то, что регулятор не станет указывать его в качестве индивидуального ответчика по делу. Также в иске утверждается, что основатель Meta✴✴ «незаконно продал акции компании на миллиарды долларов, располагая существенной внутренней информацией (MNPI), связанной с нераскрытыми и потенциально незаконными практиками обмена пользовательскими данными». Со своей стороны, ответчики заявляют, что соглашение 2012 года не было нарушено, а все действия совета директоров были взвешенными и соответствовали законодательству. Facebook✴ захотел покопаться в фотографиях на смартфонах пользователей — скорее всего, для обучения ИИ
28.06.2025 [12:01],
Владимир Мироненко
Пользователи Facebook✴✴, пытающиеся опубликовать новую историю, сталкиваются со всплывающим сообщением соцсети с просьбой дать согласие на «облачную обработку» медиафайлов, хранящихся в памяти смартфона и не опубликованных на платформе, пишет TechCrunch. Ресурс предупреждает, что, получив такое разрешение, Meta✴✴ вполне может использовать ваши фото для обучения своих ИИ-моделей. 
Источник изображения: Steve Johnson/unsplash.com Как объясняется во всплывающем сообщении, нажав на кнопку «Разрешить», вы позволяете Facebook✴✴ на постоянной основе загружать медиафайлы из вашей фотогалереи в своё облако (то есть на серверы компании) на основе такой информации, как время, местоположение или тематика снимков, чтобы создавать «такие идеи, как коллажи, резюме, ИИ-рестайлинг или темы, например, дни рождения или выпускные». В уведомлении также отмечается, что только вы сможете видеть эти предложения, а ваши медиафайлы не будут использоваться для таргетинга рекламы. Однако, как предупреждает TechCrunch, нажав кнопку «Разрешить», пользователь одновременно соглашается с «Условиями обслуживания ИИ Meta✴✴», которые позволяют искусственному интеллекту анализировать «медиа и черты лица» на этих неопубликованных фотографиях, а также дату их создания и наличие других людей или объектов на снимках. Также вы предоставляете Meta✴✴ право «сохранять и использовать» эти личные данные. Meta✴✴ сообщила ресурсу The Verge, что на данный момент она не обучает ИИ-модели с помощью этой новой функции и неопубликованных фотографий пользователей. Компания утверждает, что функция находится «на очень раннем этапе», безвредна и полностью добровольна. «Мы изучаем способы сделать обмен контентом в Facebook✴✴ более удобным, тестируя предложения готового к публикации и курируемого контента из фотогалереи пользователя. Эти предложения предоставляются только при желании пользователя, видны только ему (если он не решит ими поделиться) и могут быть отключены в любой момент. Фотогалерея камеры может использоваться для улучшения этих предложений, но не применяется для обучения ИИ-моделей в рамках данного теста», — заявила менеджер по связям с общественностью Meta✴✴ Мария Кубета (Maria Cubeta). Тем не менее, как подчёркивает The Verge, в отличие от Google, которая прямо указывает, что не обучает генеративные ИИ-модели на персональных данных из «Google Фото», актуальные условия использования ИИ Meta✴✴, вступившие в силу 23 июня 2024 года, не проясняют, будут ли неопубликованные фотографии, загружаемые в рамках «облачной обработки», использоваться в качестве обучающих данных для ИИ-моделей компании. Входить в Facebook✴ можно будет с помощью ключей доступа
19.06.2025 [12:54],
Владимир Фетисов
Facebook✴✴ внедряет поддержку авторизации с помощью ключей доступа (Passkey). Это означает, что пользователи смогут отказаться от обычных паролей, выбрав для авторизации более надёжный вариант, например, идентификацию по отпечаткам пальцев или лицу. За счёт этого злоумышленникам будет труднее получить несанкционированный доступ к аккаунтам в социальной сети. 
Источник изображения: Towfiqu barbhuiya / Unsplash Технологию Passkey принято считать более безопасной альтернативой стандартным паролям, поскольку ключ доступа невозможно подобрать или передать третьим лицам. Технология также обеспечивает защиту от фишинговых атак, когда злоумышленники вынуждают жертву переходить на поддельные сайты и вводить там данные для авторизации. Поскольку ключ доступа привязан к определённому домену, браузер попросту не будет пытаться авторизоваться с ним на других сайтах, в том числе используемых для фишинга. Meta✴✴ не сообщила конкретных сроков появления поддержки ключей доступа, сообщив лишь, что она будет реализована в приложениях для Android и iOS в ближайшее время. В дополнение к этому компания планирует добавить поддержку ключей доступа в своё приложения для обмена сообщениями Messenger, благодаря чему пользователи смогут использовать в нём тот же ключ доступа, что и в Facebook✴✴. Для авторизации на платформе также можно будет задействовать физический ключ или технологию двухфакторной аутентификации. Meta✴ запустила редактор видео на базе ИИ — пока он работает только по шаблонам
12.06.2025 [12:21],
Владимир Мироненко
Meta✴✴ объявила о запуске функции редактирования видео с использованием генеративного ИИ. Она доступна в приложении Meta✴✴ AI, на веб-сайте Meta✴✴.AI и в приложении Edits для пользователей из США и более чем десятка стран по всему миру. Уточняется, что функция будет предоставляться бесплатно в течение «ограниченного времени» и позволит редактировать видео в течение первых 10 секунд. 
Источник изображения: fb.com Новый инструмент предлагает пользователям более 50 предустановленных подсказок, которые можно применять для редактирования видео — устанавливать тему, менять фон изображения и одежду героев ролика. Например, с помощью Meta✴✴ AI можно изменить стиль клипа на видеоигровой или аниме, сделать так, чтобы он выглядел так, будто снят в пустыне, «одеть» пользователя в созданный ИИ смокинг и многое другое.  Чтобы отредактировать видео, его необходимо загрузить в приложение Meta✴✴ AI, на сайт Meta✴✴.AI или в приложение Edits и выбрать одну из предложенных предустановленных подсказок. После этого Meta✴✴ AI преобразует видео в соответствии с выбранным сценарием. 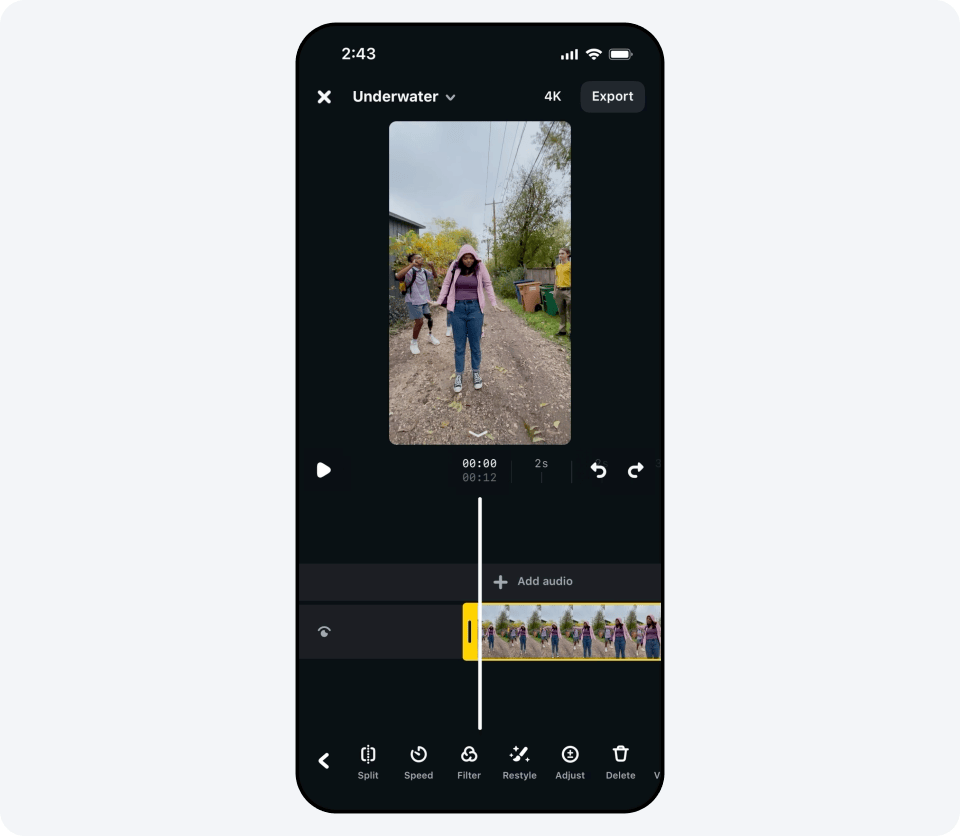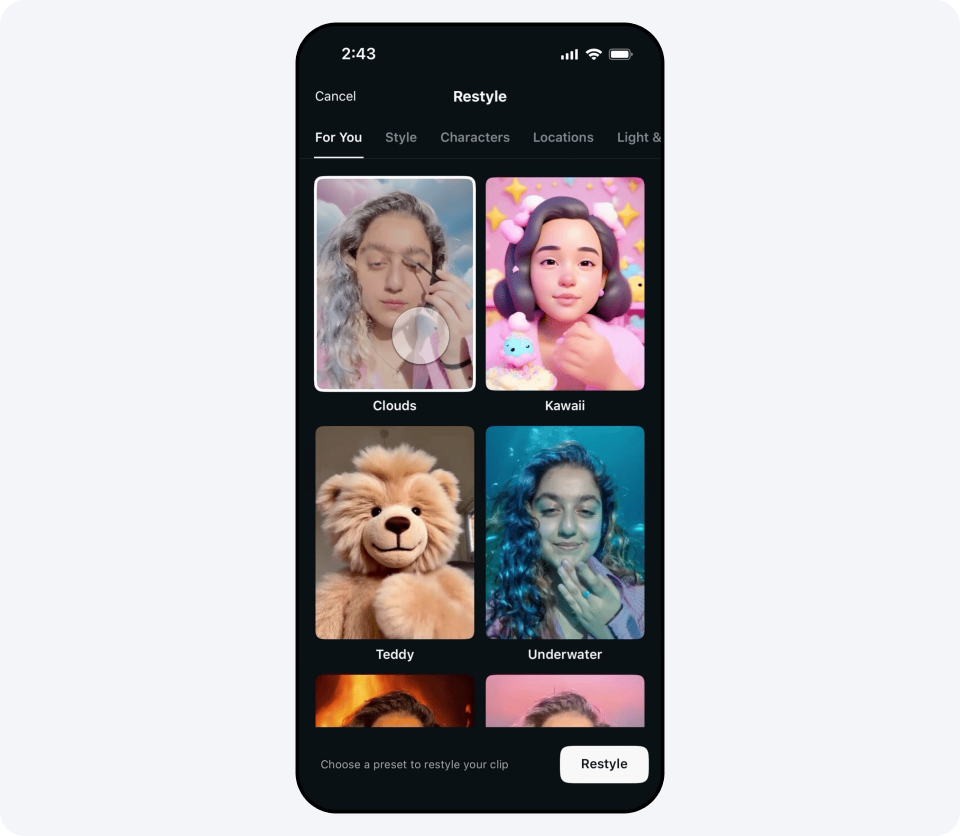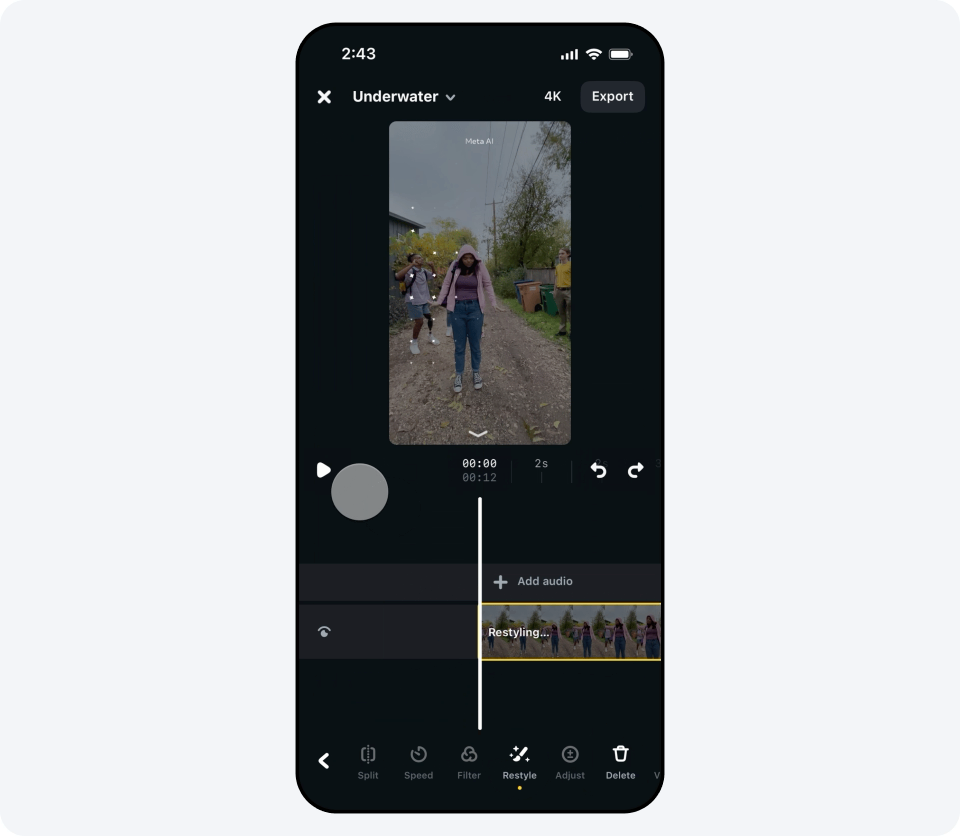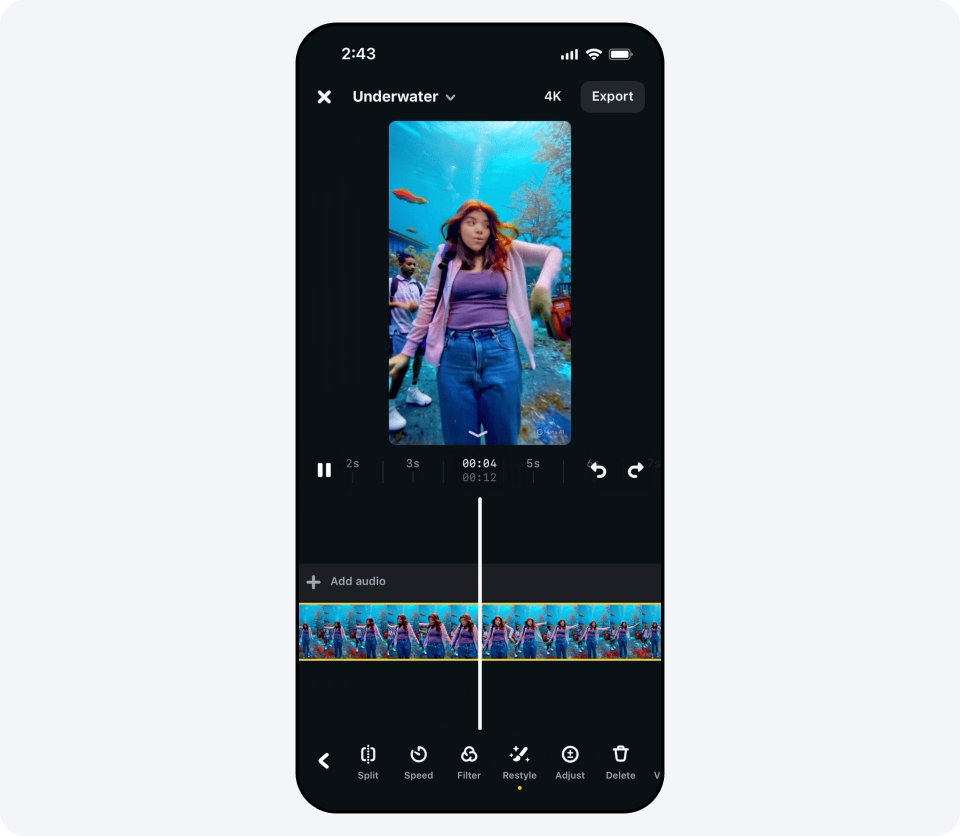 Готовым видеороликом можно поделиться с друзьями в Facebook✴✴ и Instagram✴✴ или разместить его в ленте Discover в приложении Meta✴✴ AI и на веб-сайте Meta✴✴.AI.  Хотя на данный момент использование собственных подсказок недоступно, Meta✴✴ пообещала, что позже в этом году «вы сможете редактировать видео вместе с Meta✴✴ AI с помощью собственных текстовых подсказок, чтобы делать ваши видеомонтажи именно такими, какими вы их себе представляете». Разработчики WhatsApp потратили 15 лет, чтобы сделать приложение для iPad
27.05.2025 [18:31],
Сергей Сурабекянц
На днях Meta✴✴ объявила о выпуске специального варианта приложения WhatsApp для iPad. Это произошло спустя более 15 лет после запуска сервиса обмена сообщениями и выхода первого планшета iPad (2009 и 2010 годы соответственно). Приложение WhatsApp для iPad теперь доступно для загрузки в App Store. Оно поддерживает большинство функций, доступных для iPhone. 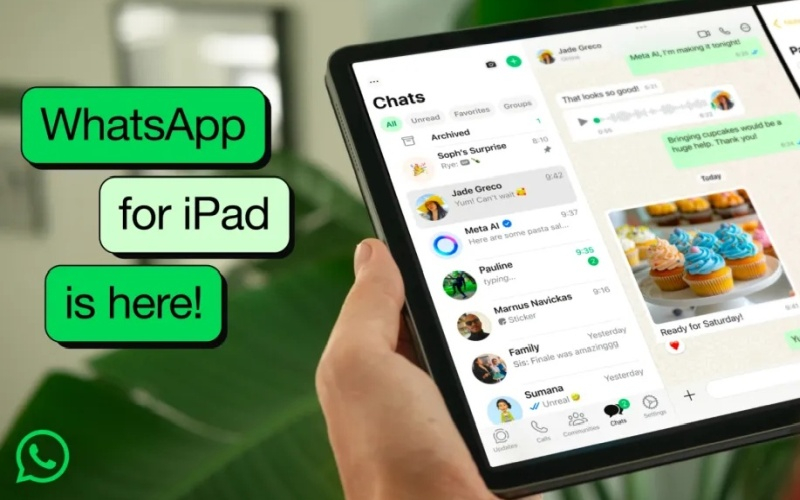
Источник изображения: Meta✴✴ До появления приложения WhatsApp для iPad пользователю, желающему работать с WhatsApp на большом экране, приходилось либо запускать веб-версию в браузере, либо использовать настольные приложения для Mac или ПК. Ещё в 2022 году глава WhatsApp Уилл Кэткарт (Will Cathcart) посоветовал владельцам планшетов Apple «не терять надежду», заявив, что Meta✴✴ «с удовольствием» разработает отдельный интерфейс WhatsApp для iPadOS так как «люди давно хотели приложение для iPad». WhatsApp для iPad поддерживает такие функции многозадачности и разделения экрана iPadOS, как Stage Manager, Split View и Slide Over, что позволяет ему работать одновременно с другими приложениями. Пользователи теперь имеют доступ к своим сообщениям в режиме разделённого экрана во время просмотра веб-страниц или видео, что значительно удобнее, чем постоянное переключение между приложениями. В приложении WhatsApp для iPad можно совершать аудио- и видеозвонки с участием до 32 человек, использовать как переднюю, так и тыльную камеру устройства, и делиться изображением своего экрана с другими участниками видеоконференции. По слухам, Meta✴✴ также приступила к разработке оптимизированного для большего дисплея приложения Instagram✴✴ для iPad, но компания пока не подтвердила эту информацию. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



