|
Опрос
|
реклама
Быстрый переход
Meta✴ создаст свой ИИ-поисковик и откажется от Google и Microsoft Bing
29.10.2024 [06:06],
Дмитрий Федоров
Meta✴✴ уже восемь месяцев активно работает над собственной поисковой системой на основе ИИ, чтобы снизить свою зависимость от Google и Microsoft Bing. Новый поиск позволит интегрировать ИИ-сводки событий прямо в приложения компании, такие как Instagram✴✴ и Facebook✴✴, и в будущем заменит внешние поисковики, используемые в настоящее время. 
Источник изображения: Placidplace / Pixabay В данный момент для обработки запросов о текущих событиях в Instagram✴✴ и Facebook✴✴ ИИ-боты корпорации Meta✴✴ полагаются на данные Google и Bing. Однако Meta✴✴ намерена прекратить эту практику, внедрив внутреннюю поисковую систему, которая будет работать исключительно на основе собственной базы данных. Планируется интеграция с уже существующими ИИ-инструментами Meta✴✴, что позволит её ИИ-ботам более автономно и эффективно обрабатывать запросы пользователей. Одним из важнейших этапов в создании новой поисковой системы Meta✴✴ стало внедрение собственного поискового робота, который уже несколько месяцев активно индексирует информацию из открытых источников в Сети. Это даёт возможность формировать собственную обширную базу данных, которая станет основой для ИИ-бота и обеспечит Meta✴✴ независимость от внешних платформ. Примечательно, что сбор данных начался ещё до заключения соглашений с новостными агентствами. Помимо разработки поисковых алгоритмов, Meta✴✴ также собирает данные о геолокации, что в перспективе позволит компании конкурировать с Google Maps. В сентябре также стало известно о том, что Apple развивает собственные поисковые инструменты для улучшения работы в App Store, что демонстрирует общее стремление техногигантов создавать независимые поисковые сервисы на основе ИИ. В результате борьба за контроль над пользовательскими данными усиливается, и Meta✴✴ стремится стать важным игроком в этом процессе. Недавно Meta✴✴ заключила многолетнее соглашение с международным новостным агентством Reuters, что обеспечит её ИИ-бота доступом к проверенной информации. Это партнёрство, вероятно, повысит доверие пользователей к корпорации, и станет важным этапом на пути к созданию надёжной и актуальной базы данных для ИИ-поиска. Meta✴✴ — не единственная компания, стремящаяся к созданию собственного ИИ-поиска. OpenAI также подтвердила разработку системы под названием SearchGPT. В то же время Perplexity, ещё один ИИ-поисковик, сталкивается с исками от News Corp и угрозами со стороны других издателей, включая The New York Times. Эти юридические трудности подчёркивают важность правового регулирования для компаний, разрабатывающих независимые ИИ-поисковики, особенно если они используют контент крупных медиакомпаний. Meta✴ запускает технологию для борьбы с мошеннической рекламой со знаменитостями и упрощает восстановление аккаунтов
22.10.2024 [07:51],
Анжелла Марина
Meta✴✴ объявила о тестировании технологии распознавания лиц для борьбы с мошенническими рекламными объявлениями, в которых присутствуют изображения знаменитостей. Facebook✴✴ и Instagram✴✴ будут использовать новую функцию также и для выявления поддельных аккаунтов известных личностей, созданных для обмана пользователей. 
Источник изображения: Gerd Altmann/Pixabay Как поясняет издание TechCrunch, целью этих тестов является усиление уже существующих мер по борьбе с мошенничеством, таких как автоматические сканирования на основе машинного обучения, которые проверяют рекламные объявления на Facebook✴✴ и Instagram✴✴. Если объявление будет помечено как подозрительное, то немедленно начнётся процесс идентификации с фотографиями профиля аккаунта. «Мошенники часто используют изображения известных личностей, таких как блогеров или других знаменитостей, чтобы заманить людей на мошеннические сайты, где у них запрашивается личная информация или деньги. Эта схема, известная как "celeb-bait", нарушает наши правила и вредит пользователям наших продуктов», — пишет в блоге компании вице-президент Meta✴✴ по политике контента Моника Бикерт (Monika Bickert). Она подчёркивает, что если будет подтверждено совпадение с фотографией профиля знаменитости, но объявление окажется мошенническим, оно будет заблокировано. Meta✴✴ утверждает, что технология распознавания лиц используется исключительно для борьбы с мошенническими объявлениями и после проверки все изображения, независимо от того, найдены ли совпадения или нет, удаляются и не используются в каких-либо других целях. Первые тесты с участием небольшой группы публичных персон показали «обнадёживающие» результаты, касающиеся скорости и эффективности выявления и блокировки мошеннической рекламы. Компания также рассматривает возможность применения технологии для обнаружения рекламных дипфейков, созданных с помощью генеративного ИИ, а также тестирует распознавание лиц для обнаружения поддельных аккаунтов знаменитостей. В ближайшие недели компания начнёт отправлять уведомления внутри приложений более широкому кругу публичных фигур, чьи изображения использовались в мошеннических объявлениях, информируя их о том, что они автоматически включены в систему защиты. Однако от этой функции, по словам Бикерт, можно в любой момент отказаться через Центр аккаунтов. Помимо прочего, Meta✴✴ начала тестирование видео-селфи с применением распознавания лиц для ускорения процесса восстановления доступа к аккаунтам, которые были по какой-либо причине заблокированы. Этот метод ускорит и упростит процесс восстановления доступа по сравнению с загрузкой изображения удостоверения личности. Отмечается, что «видео-селфи верификация расширяет возможности для восстановления доступа к аккаунту, занимает всего минуту и является самым простым способом подтвердить свою личность». Данный метод аналогичен идентификации с помощью Face ID на iPhone. Instagram✴ и Facebook✴ наполнятся видеорекламой, которую сгенерирует ИИ
08.10.2024 [21:11],
Дмитрий Федоров
Meta✴✴ начала тестирование новых ИИ-инструментов для создания видеорекламы на платформах Facebook✴✴ и Instagram✴✴. Эти инструменты позволяют анимировать статические изображения и расширять фон видео за счёт генерации дополнительных пикселей. Это открывает новые горизонты для рекламодателей, упрощая создание динамичного и визуально привлекательного рекламного контента. Массовый запуск новых ИИ-инструментов запланирован на начало 2025 года. 
Источник изображения: Alexas_Fotos / Pixabay Одним из ключевых нововведений стал ИИ-инструмент, превращающий статичное изображение в анимированное. В демонстрационном примере статичная картинка была преобразована в анимированное изображение, на котором ягоды перемещались вокруг банки. 
Рекламодатели могут превратить неподвижное изображение в видеоролик. Источник изображения: Meta✴✴ Ещё одним важным нововведением стала возможность увеличения размеров уже существующих видеороликов. ИИ способен дорисовывать отсутствующие пиксели на каждом кадре, расширяя изображение таким образом, как будто оригинальный ролик изначально был больше. Этот процесс напоминает работу с изображениями в графических редакторах, где можно расширить фон изображения за счёт автоматической генерации дополнительных деталей. Meta✴✴ планирует представить эти нововведения более широкой аудитории в начале следующего года. Инструменты позволят рекламодателям легко и быстро создавать динамичную рекламу с минимальными усилиями. Они также дополнят уже существующие ИИ-инструменты, которые генерируют текст и изображения для создания рекламы. Рекламные ролики, созданные с помощью этих инструментов, будут отображаться на новой полноэкранной вкладке видео, которая появится в Facebook✴✴. Следует отметить, что Meta✴✴ — не единственная компания, активно использующая ИИ для создания рекламного контента. Например, Amazon недавно представил ИИ-инструмент, способный создавать видеоклипы на основе изображений товаров, а TikTok экспериментирует с использованием ИИ-генерированных аватаров в рекламных кампаниях. Евросоюз запретил Meta✴ бесконечно использовать данные пользователей для таргетированной рекламы
06.10.2024 [17:16],
Владимир Фетисов
Похоже, что социальным сетям, таким как Facebook✴✴, придётся пересмотреть политику хранения данных европейских пользователей. Верховный суд Евросоюза на этой неделе постановил, что соцсети больше не могут сколь угодно долго хранить информацию о пользователях для демонстрации им персонализированной рекламы. Это решение может иметь серьёзные последствия для Meta✴✴, которая владеет Facebook✴✴, и для других платформ, получающих основной доход от рекламодателей. 
Источник изображения: GregMontani / Pixabay Ограничения на срок хранения персональной информации будут применяться для соблюдения Общего регламента по защите данных (GDPR). Нарушение этих правил может повлечь за собой штраф в размере до 4 % от глобального годового оборота нарушителя, а в случае Meta✴✴ речь идёт о миллиардах долларов. Источник отмечает, что компания Марка Цукерберга (Mark Zuckerberg) уже находится во главе списка нарушителей GDPR. Представитель Meta✴✴ Мэтт Поллард (Matt Pollard) сообщил, что компания ожидает публикации официального постановления суда. «Мы ожидаем публикации решения суда и со временем сможем поделиться дополнительной информацией. Meta✴✴ очень серьёзно относится к конфиденциальности и инвестировала более €5 млрд, чтобы сделать конфиденциальность основой всех наших продуктов. Каждый, кто пользуется Facebook✴✴, имеет доступ к широкому спектру настроек и инструментов, которые позволяют людям управлять тем, как мы используем их информацию», — заявил господин Поллард. Не секрет, что Meta✴✴ зарабатывает на том, что отслеживает пользовательскую активность и создаёт цифровые профили на основе собранной таким образом информации. Эти данные применяются для демонстрации пользователям платформ компании персонализированной рекламы. Это означает, что любые ограничения на возможность непрерывного использования данных пользователей в одном из основных регионов бизнеса компании могут негативно сказаться на её доходах. Meta✴ внедряет ИИ-селфи в ленты пользователей Facebook✴ и Instagram✴
26.09.2024 [04:25],
Анжелла Марина
Компания Meta✴✴ объявила о тестировании новой функции на платформах Facebook✴✴ и Instagram✴✴, которая будет добавлять изображения, сгенерированные искусственным интеллектом, в ленты пользователей. Согласно заявлению, ИИ-контент с пометкой «Imagined for You» будет создаваться на основе интересов пользователя или текущих трендов, включая изображения самого пользователя. 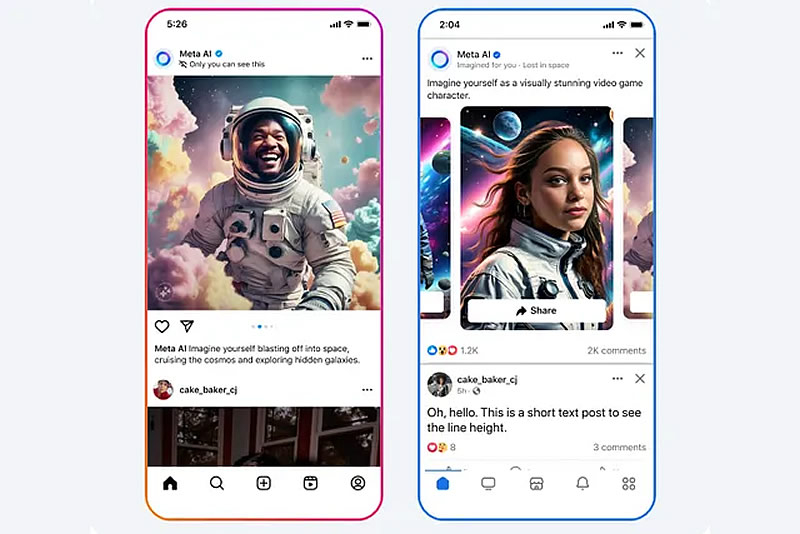
Источник изображения: Meta✴✴ В сгенерированных сценах можно представить себя в роли персонажа видеоигры или, например, астронавта, исследующего космос. Для их создания система будет использовать фотографии пользователя. Пресс-секретарь Meta✴✴ Аманда Феликс (Amanda Felix) пояснила, что платформа будет генерировать изображения с лицом пользователя, только если он подключится к функции Imagine yourself и примет соответствующие условия. В дальнейшем такими фотографиями можно поделиться или сгенерировать селфи в режиме реального времени. 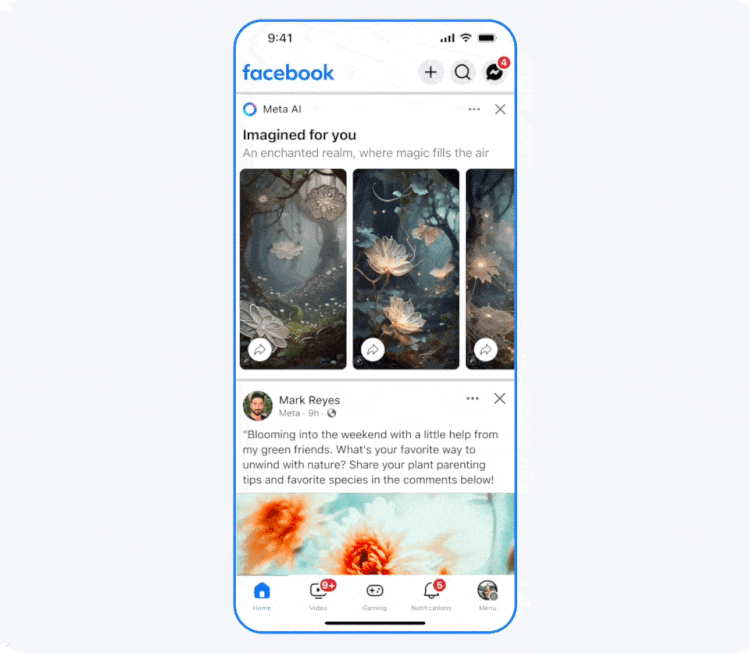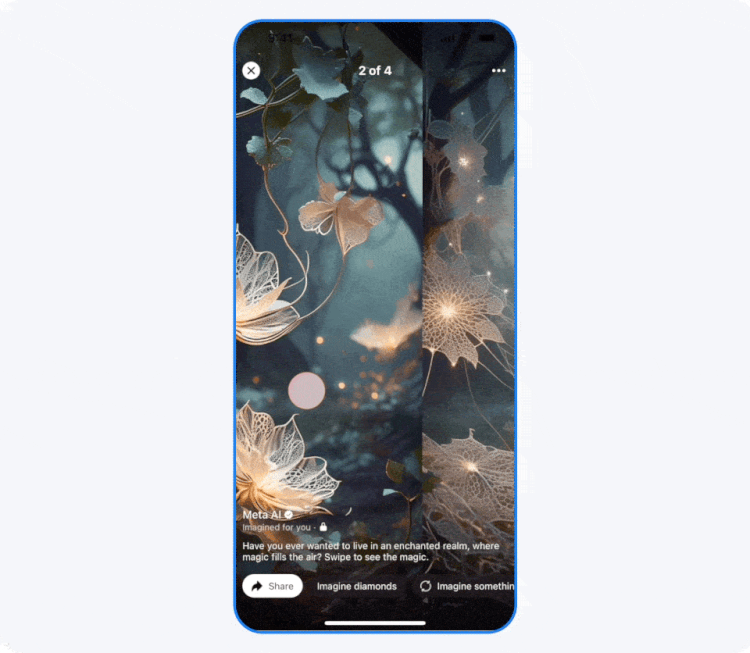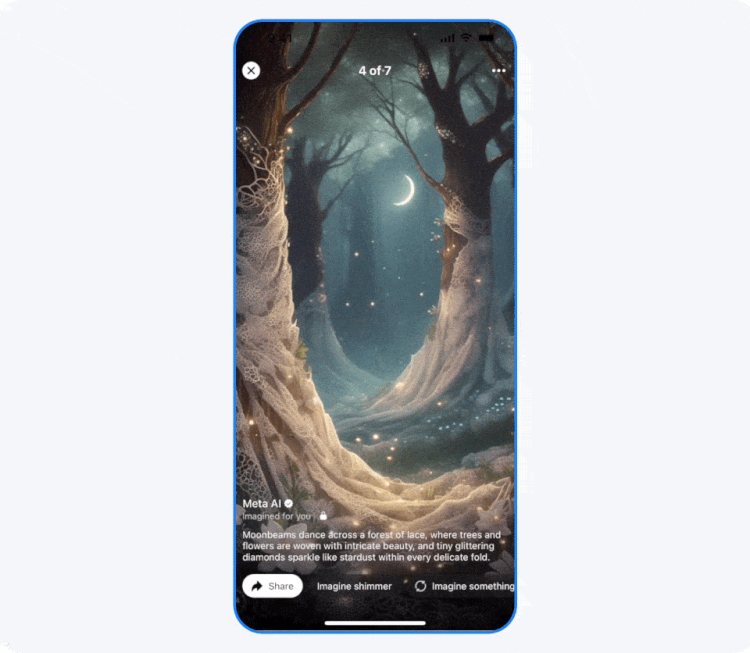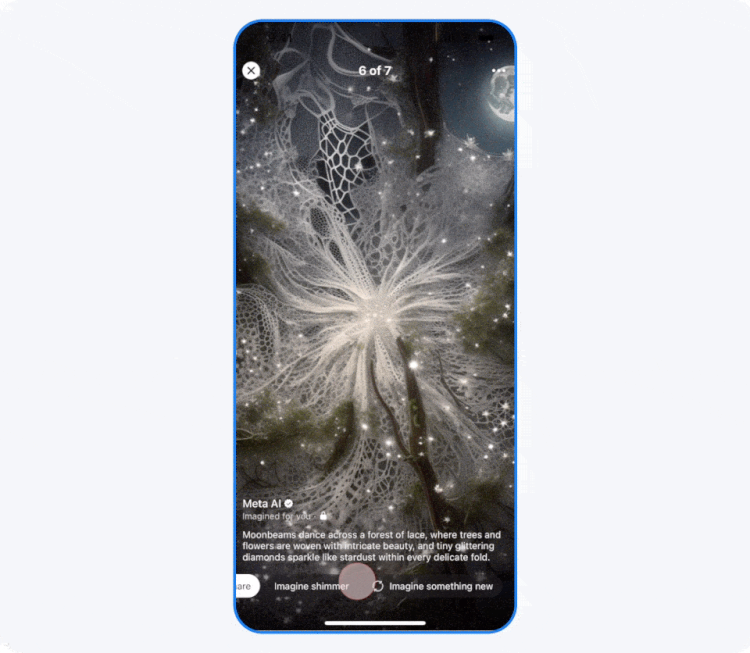
Источник изображения: Meta✴✴ Марк Цукерберг (Mark Zuckerberg) в интервью изданию The Verge заявил, что добавление ИИ-изображений в ленты является следующим «логическим шагом» для Facebook✴✴ и Instagram✴✴, когда помимо пользовательского контента, появится контент, сгенерированный системой искусственного интеллекта. При этом поясняется, что по желанию пользователи смогут запрещать показ ИИ-изображений в своей ленте, а возможность поделиться ими останется опциональной. То же самое касается и картинок с лицом пользователя — они будут доступны всем только при условии, что сам человек даст на это разрешение. Meta✴✴ подчёркивает, что на данный момент эта функция находится на стадии тестирования, поэтому неясно, насколько широко и быстро она будет развёрнута. Meta✴ грозит ещё один многомиллиардный штраф в ЕС — теперь из-за Facebook✴ Marketplace
18.09.2024 [11:48],
Дмитрий Федоров
Европейская комиссия готовится наложить крупный штраф на Meta✴✴ за нарушения антимонопольного законодательства на рынке частных объявлений. Регулятор утверждает, что Facebook✴✴, дочерняя компания Meta✴✴, подрывает конкуренцию, связывая бесплатный сервис Marketplace с социальной сетью. Решение может быть принято уже в следующем месяце, завершая одно из последних расследований под руководством нынешней главы антимонопольной службы Маргрете Вестагер (Margrethe Vestager). 
Источник изображения: alexanderjungmann / Pixabay Антимонопольное расследование, инициированное в 2019 году, основано на обвинениях конкурентов в злоупотреблении Facebook✴✴ своим доминирующим положением. Компания предлагает бесплатные услуги по размещению частных объявлений, одновременно извлекая прибыль из данных, собираемых на платформе, преимущественно от бизнес-пользователей. В декабре 2022 года Еврокомиссия представила предварительные выводы, согласно которым Meta✴✴ искажает конкуренцию на рынке онлайн-объявлений и использует бесплатно полученные данные предприятий для таргетированной рекламы. Facebook✴✴ Marketplace, запущенный в 2016 году, стал популярной платформой для купли-продажи подержанных товаров, особенно предметов домашнего обихода и мебели. Однако в последние годы появились новые конкуренты в специализированных сегментах, таких как, например, мода. Meta✴✴ отрицает обвинения, утверждая, что Marketplace функционирует в высококонкурентной среде и не использует данные конкурентов для борьбы с ними. В своём заявлении компания отметила: «Претензии, выдвинутые Европейской комиссией, не имеют под собой оснований. Мы продолжаем работать с регулирующими органами, чтобы продемонстрировать, что наши инновационные продукты отвечают интересам потребителей и конкуренции». В случае признания вины Meta✴✴ может быть оштрафована на сумму до 10 % от годового глобального дохода, который в 2023 году составил $135 млрд. Однако регуляторы обычно назначают менее суровые санкции. Решение по делу может быть отложено из-за подготовки президента Еврокомиссии Урсулы фон дер Ляйен (Ursula von der Leyen) к следующему 5-летнему циклу работы исполнительного органа Европейского союза (ЕС). Недавно фон дер Ляйен объявила о назначении Тересы Риберы (Teresa Ribera) новой главой антимонопольной службы ЕС, которая сменит Вестагер на посту в начале ноября. За десятилетний срок своего правления Вестагер неоднократно принимала жёсткие меры против таких гигантов, как Apple, Google и Microsoft. Неделю назад Европейский суд подтвердил правомерность антимонопольных претензий к Google, постановив, что компания злоупотребила доминирующим положением, продвигая собственный сервис покупок в ущерб конкурентам. В тот же день суд ЕС обязал Apple выплатить 13 млрд евро невыплаченных налогов. Эти два решения были восприняты как победа Вестагер. Другие юрисдикции также стремятся ограничить влияние техногигантов. Управление по конкуренции и рынкам Великобритании (CMA) в прошлом году закрыло аналогичное расследование в отношении Meta✴✴ после того, как компания обязалась ограничить использование данных, собираемых от других предприятий на своей платформе. Эти меры отражают глобальную тенденцию к усилению регулирования цифровых рынков и защите конкуренции в технологическом секторе. Instagram✴ усилил родительский контроль, введя ограничения с помощью Teen Accounts
17.09.2024 [16:56],
Анжелла Марина
Instagram✴✴ запустил новую функцию Teen Accounts с усиленной защитой и родительским контролем за подростками. Теперь родители могут контролировать активность своих детей в социальной сети, защищать их от нежелательного контента и ограничивать взаимодействие с незнакомыми лицами. 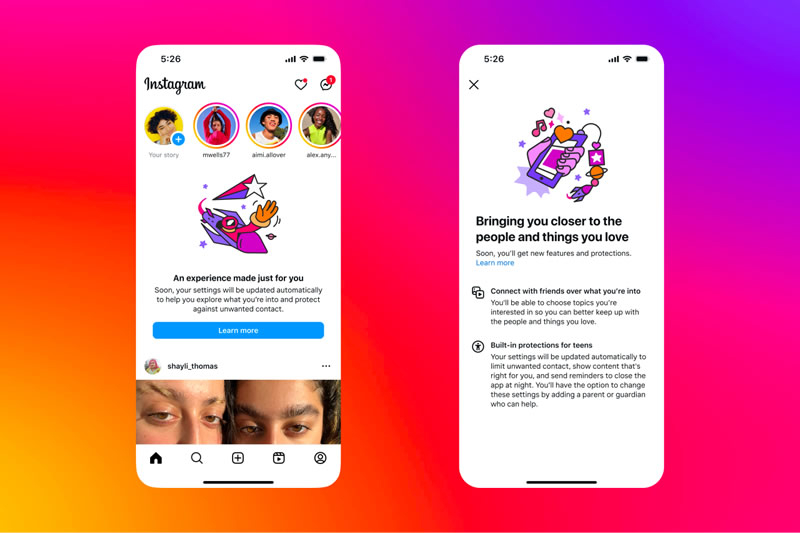
Источник изображения: Instagram✴✴ «Подростковые аккаунты» (Teen Accounts) автоматически активируются для всех пользователей младше 16 лет. В рамках таких аккаунтов будут действовать ограничения на взаимодействие с другими пользователями, доступ к контенту и время, проведённое в приложении. Компания планирует перевести все существующие и новые аккаунты подростков на этот режим в течение ближайших месяцев, начиная с США, Великобритании, Канады и Австралии. Как сообщает издание TechCrunch, будет предусмотрен ряд встроенных защитных механизмов. Подростки смогут принимать сообщения только от людей, на которых они подписаны или с которыми уже общались ранее, например, через Facebook✴✴ Messenger. Будет ограничена возможность отмечать подростков на фотографиях и в комментариях, применён автоматический фильтр на публикацию нецензурных выражений в личных сообщениях и комментариях. Кроме того, доступ к определённому контенту, например, с драками и косметическими процедурами в разделах «Рекомендации» и Reels также будет ограничен. Для борьбы с чрезмерным использованием платформы Instagram✴✴ реализовала функцию «Ночной режим» (Sleep Mode), которая автоматически отключает уведомления с 22:00 до 7:00. А ещё приложение напоминает подросткам о необходимости сделать перерыв после одного часа. При этом родители смогут устанавливать собственные ограничения на время, проведённое ребёнком в Instagram✴✴, и даже полностью блокировать доступ к приложению в определённые часы. «Ранее Instagram✴✴ лишь ненавязчиво предлагал подросткам закрыть приложение, если они пользовались им ночью», — отмечает TechCrunch. Как следствие, родители получат больше возможностей для контроля за активностью своих детей в Instagram✴✴. С помощью обновлённой функции родительского контроля они могут видеть, с кем подросток общался в течение последней недели, хотя и не могут читать сами сообщения. Также они могут узнать, на какие темы подросток подписался в разделе «Рекомендации», чтобы получать больше соответствующего контента. При этом алгоритмы всё ещё могут предлагать пользователям Instagram✴✴ темы, отличные от тех, которые они выбрали, если приложение обнаружит, что именно это пользователю кажется более интересным. Отметим, что изменения в Instagram✴✴ происходят на фоне критики со стороны законодателей и общественности, которые обвиняют социальные сети в недостаточной защите детей и подростков. Ранее даже было предложено вообще запретить подросткам пользоваться социальными сетями без согласия родителей. Что же касается Instagram✴✴, то новые правила не смогут решить проблему, если при регистрации будет указан ложный возраст. В будущем компания планирует внедрить «Подростковые аккаунты» и на других платформах Meta✴✴. Meta✴ использовала почти все ваши публикации с 2007 года для обучения ИИ
13.09.2024 [07:22],
Дмитрий Федоров
Компания Meta✴✴, владеющая Facebook✴✴ и Instagram✴✴, подтвердила, что использует публичные посты пользователей, опубликованные с 2007 года, для обучения ИИ-моделей. Это заявление прозвучало во время правительственного расследования в Австралии. При этом миллиарды пользователей за пределами Европейского союза (ЕС) и Бразилии, сохраняющие публичность своих постов, не имеют возможности отказаться от участия в обучении ИИ. 
Источник изображения: VEPN / Pixabay Во время расследования, проводимого австралийским правительством относительно внедрения ИИ, Мелинда Клейбо (Melinda Claybaugh), глобальный директор по вопросам конфиденциальности компании Meta✴✴, признала, что компания использует все публичные текстовые и фотоматериалы, опубликованные совершеннолетними пользователями Facebook✴✴ и Instagram✴✴ с 2007 года. Признание прозвучало после настойчивых вопросов сенатора от партии «Зелёных» Дэвида Шубриджа (David Shoebridge). При этом Meta✴✴ не предоставляет возможности удаления уже собранных данных, даже в случае, если пользователь изменит настройки приватности. Meta✴✴ в своих материалах по конфиденциальности и блогах упоминает об использовании публичных постов и комментариев для обучения моделей генеративного ИИ. Однако детали этого процесса остаются неясными. В июне 2023 года, отвечая на запрос The New York Times о сроках начала и масштабах сбора данных, Meta✴✴ не предоставила конкретного ответа, отметив лишь, что изменение настроек приватности предотвратит будущий сбор. Особенно тревожит факт использования данных пользователей, которые в 2007 году могли быть несовершеннолетними. Клейбо заявила, что Meta✴✴ не использует данные пользователей младше 18 лет, однако не смогла дать чёткого ответа на вопрос о том, как обрабатываются аккаунты взрослых, созданные ими в детском возрасте. Сенатор Тони Шелдон (Tony Sheldon) задал вопрос о сканировании публичных фотографий детей на аккаунтах взрослых пользователей. Клейбо подтвердила, что такие данные тоже используются. В отличие от пользователей из ЕС, имеющих право отказаться от участия в обучении ИИ благодаря местным законам о конфиденциальности, и пользователей из Бразилии, где недавно запретили Meta✴✴ использовать персональные данные для обучения ИИ, большинство из миллиардов пользователей Facebook✴✴ и Instagram✴✴ лишены такой возможности. Клейбо не смогла уточнить, будет ли предоставлена возможность отказа австралийским пользователям или кому-либо ещё в будущем, ссылаясь на неопределённость нынешнего регуляторного ландшафта. Отсутствие возможности отказа от использования данных вызывает критику со стороны правозащитников и политиков. Сенатор Шубридж отметил, что неспособность правительства Австралии принять адекватные законы о конфиденциальности позволяет таким компаниям, как Meta✴✴, продолжать монетизировать и эксплуатировать даже фотографии и видео детей на Facebook✴✴. Данное заявление указывает на глобальную проблему: законодательство не поспевает за темпами развития технологий ИИ и методами сбора данных. Акции Meta✴ взлетели после того, как Цукерберг смог «продать» инвесторам идею ИИ
23.08.2024 [04:37],
Анжелла Марина
Акции Meta✴✴ обновили исторический максимум после того, как Марк Цукерберг (Mark Zuckerberg) представил на недавнем отчётном заседании убедительные аргументы о преимуществах ИИ, что повысило доверие инвесторов и привело к росту акций компании. 
Источник изображения: Artapixel/Pixabay Акции компании Meta✴✴ выросли на 13 % в этом месяце, значительно превзойдя показатели других технологических гигантов, несмотря на очередной скачок капитальных расходов в ИИ и обещания увеличить их в будущем. В четверг акции выросли на 1,7 %, достигнув рекордного уровня в $544,23. Как пишет Bloomberg, cекрет такого успеха заключается в том, что Цукербергу удалось убедить инвесторов в том, что искусственный интеллект помогает улучшить результаты в основном бизнесе компании — цифровой рекламе. Другие компании Big Tech, такие как Amazon, Microsoft и Alphabet, не смогли так же чётко сформулировать преимущества ИИ для своего бизнеса. «Это был его лучший отчёт о прибылях и убытках в качестве генерального директора», — считает Джин Манстер (Gene Munster), управляющий партнёр Deepwater Asset Management. — Он объяснил краткосрочные и долгосрочные преимущества ИИ, а также сроки реализации всех планов. Это было убедительно». Цукерберг объяснил, что Meta✴✴ использует ИИ для повышения эффективности поиска целевой аудитории рекламодателями, что напрямую влияет на основной источник дохода компании. Кроме того, Meta✴✴ использует собственные большие языковые модели (LLM) для улучшения рекомендаций контента, что способствует повышению вовлечённости пользователей в Facebook✴✴ и Instagram✴✴. В то же время инвесторы стали более критично относиться к расходам других крупных технологических компаний. Так, акции Alphabet, материнской компании Google, показали более низкие результаты после публикации отчёта о прибылях и убытках в прошлом месяце, который продемонстрировал более высокие, чем ожидалось, капитальные расходы, несмотря на то, что прибыль и выручка превысили прогнозы. То же самое можно сказать и о Microsoft, после того как её результаты показали замедление роста в бизнесе облачных вычислений Azure. Акции Alphabet упали на 9 % после публикации отчёта о прибылях и убытках 23 июля, а акции Microsoft практически не изменились с момента публикации результатов 30 июля. «Google в своём отчёте по сути сказала: ну, нам нужно тратить деньги, чтобы идти в ногу со всеми, что выглядело не очень убедительно, — сказал Алек Янг (Alec Young), главный инвестиционный стратег Mapsignals. — Microsoft продала это немного лучше, высказав эту мысль другими словами. Но по сути, они делают то же самое». Инвестиционный аналитик из Global X ETFs Эндрю Йе (Andrew Ye) сказал, что Meta✴✴ инвестирует и будет продолжать значительно вкладываться в генеративный ИИ, но, очевидно, смогла более чётко сформулировать своё видение интеграции ИИ, чем её конкуренты. Подросткам на YouTube тайком показывали рекламу Instagram✴ в нарушение правил Google
08.08.2024 [19:16],
Анжелла Марина
Google и Meta✴✴ заключили секретное соглашение о показе рекламы Instagram✴✴ подросткам на YouTube, обойдя собственные правила, касающиеся несовершеннолетних пользователей. Расследование Financial Times выявило, что Google разработала маркетинговый проект, тайно продвигающий приложение Instagram✴✴ среди молодой аудитории. 
Источник изображения: TymonOziemblewski/Pixabay Согласно документам, полученным Financial Times (FT) от источников, знакомых с ситуацией, проект был ориентирован на пользователей YouTube в возрасте от 13 до 17 лет. В рамках рекламной кампании в Google Ads Instagram✴✴ намеренно выбрал группу пользователей, помеченных в системе как «неизвестные». При этом было известно, что эта группа в основном состоит из лиц младше 18 лет. Данные, полученные FT, свидетельствуют о том, что были предприняты специальные шаги для сокрытия истинных целей кампании. Google и Meta✴✴ начали сотрудничество в конце прошлого года. Google стремилась увеличить свои доходы от рекламы, а Meta✴✴ пыталась удержать внимание молодых пользователей на фоне быстрорастущих конкурентов, таких как TikTok. Данный проект нарушал правила Google, запрещающие персонализацию и таргетинг рекламы на несовершеннолетних, включая показ рекламы на основе демографических данных. После запроса FT Google начала внутреннее расследование, одновременно не отрицая использования лазейки «неизвестные». «Мы примем дополнительные меры, чтобы напомнить менеджерам о том, что они не должны помогать рекламодателям или агентствам запускать кампании, пытающиеся обойти нашу политику», — подчеркнули в компании. Meta✴✴ заявила, что не считает выбор аудитории «неизвестных» персонализацией или обходом правил. Однако американский критик Джефф Честер (Jeff Chester), исполнительный директор Центра цифровой демократии (Digital Democracy, CDD), отметил, что «Meta✴✴ теряет молодёжную аудиторию и нашла обходной путь, чтобы привлечь её обратно». Марша Блэкберн (Marsha Blackburn), американский политик, представляющая Республиканскую партию, прокомментировала ситуацию так: «Технологическим гигантам нельзя доверять защиту наших детей». Она призвала Конгресс принять закон о безопасности детей в интернете (KOSA). «Их снова поймали на эксплуатации наших детей, руководители из Кремниевой долины доказали, что они всегда будут ставить прибыль выше интересов наших детей». Meta✴ выплатит $1,4 млрд за незаконный сбор биометрических данных жителей Техаса
31.07.2024 [12:30],
Владимир Мироненко
Стало известно, что Meta✴✴ Platforms пришла к соглашению со штатом Техас по урегулированию поданного им иска с обвинением компании в незаконном использовании технологии распознавания лиц для сбора биометрических данных техасцев без их согласия, за что согласилась выплатить в течение пяти лет громадную сумму в $1,4 млрд. 
Источник изображения: RahulPandit/Pixabay Стороны сообщили, что достигли мирового соглашения в мае, за несколько недель до начала судебного разбирательства. В иске, поданном в 2022 году генеральным прокурором Техаса Кеном Пэкстоном (Ken Paxton) в суд штата, утверждалось, что Meta✴✴ использовала без согласия техасцев программное обеспечение для распознавания лиц на фотографиях, загруженных в Facebook✴✴. Офис генерального прокурора сообщил, что Facebook✴✴ загрузила и хранит без согласия клиентов миллиарды биометрических идентификаторов после введения в 2011 году функции «Предложения тегов» (Tag Suggestions), которая позволяет автоматически распознавать лица друзей на фотографиях пользователя. Как указали в прокураторе, Meta✴✴ делала это, хотя знала, что закон Техаса о сборе или использовании биометрических идентификаторов (Texas Capture or Use of Biometric Identifiers Act, CUBI) запрещает компаниям собирать биометрические идентификаторы техасцев без предварительного уведомления и получения их согласия. В конце 2021 года Meta✴✴ заявила, что закрывает свою систему распознавания лиц на Facebook✴✴, сославшись на «растущие опасения по поводу использования этой технологии в целом». Как сообщили в прокуратуре, сумма, подлежащая выплате в рамках урегулирования, является крупнейшей из когда-либо полученных в результате иска одного штата. «Это историческое урегулирование демонстрирует нашу приверженность противостоянию крупнейшим в мире технологическим компаниям и привлечению их к ответственности за нарушение закона и нарушение прав техасцев на неприкосновенность частной жизни», — заявил во вторник генпрокурор Техаса. В свою очередь, представитель Meta✴✴ сообщил ресурсу CNBC следующее: «Мы рады разрешить этот вопрос и с нетерпением ждём изучения будущих возможностей для углубления наших бизнес-инвестиций в Техасе, включая потенциальное развитие центров обработки данных». Еврокомиссия готовит антимонопольный штраф для Meta✴ на сумму до $13,4 млрд
26.07.2024 [12:58],
Анжелла Марина
Компания Meta✴✴ в ближайшие недели будет оштрафована Европейской комиссией (ЕК) за нарушение антимонопольного законодательства. Штраф станет первым для Meta✴✴ в ЕС и будет связан с привязкой сервиса частных объявлений Marketplace к социальной сети Facebook✴✴, сообщает Reuters со ссылкой на источники. 
Источник изображения: pexels.com Расследование ЕК, начатое более полутора лет назад, выявило, что Meta✴✴ предоставляет своей платформе Marketplace преимущество путём её объединения с Facebook✴✴. По мнению регулятора, это ограничивает конкуренцию на рынке онлайн-объявлений. Кроме того, ЕК обвинила Meta✴✴ в злоупотреблении доминирующим положением на рынке, что выражается в навязывании в одностороннем порядке невыгодных и несправедливых условий размещения рекламы в Facebook✴✴ и Instagram✴✴ конкурирующими сервисами онлайн-объявлений. Компании грозит штраф в размере до 13,4 млрд долларов США, или 10 % от её мирового дохода за 2023 год. Однако, как отмечет Reuters, обычно ЕС уменьшает максимально установленные санкционные лимиты. Ожидается, что комиссия объявит о своём решении в сентябре или октябре, до ухода с поста главы антимонопольного ведомства Маргрет Вестагер (Margrethe Vestager) в ноябре. Впрочем, сроки могут быть скорректированы. Meta✴✴ отказалась комментировать данную ситуацию, однако представитель компании Мэтт Поллард (Matt Pollard) повторил ранее высказанное мнение о том, что утверждения Европейской комиссии не имеют под собой никаких оснований. «Мы продолжаем конструктивно работать с регулирующими органами, чтобы продемонстрировать, что наши продукты отвечают интересам потребителей и способствуют конкуренции», — подчеркнул г-н Поллард. Отметим, что в этом месяце ЕК также выдвинула обвинения против Meta✴✴ в связи с нарушением цифрового законодательства ЕС, поскольку компания фактически принуждала пользователей оформлять платную подписку по новой модели «Плати или соглашайся», запущенной недавно. Соглашение предусматривало сбор большого объёма персональных данных. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex




