|
Опрос
|
реклама
Быстрый переход
Meta✴ уволит тысячи сотрудников за неэффективность
15.01.2025 [00:50],
Анжелла Марина
Meta✴✴ планирует сократить около 5 % своего персонала в рамках программы увольнений, основанных на оценке производительности. Освободившиеся позиции предполагается заполнить новыми, более квалифицированными кадрами. Об этом говорится во внутреннем письме, направленном всем сотрудникам компании. 
Источник изображения: Threads По состоянию на сентябрь в Meta✴✴ работало около 72 000 человек, поэтому сокращение затронет примерно 3600 сотрудников, сообщает Bloomberg. Генеральный директор Марк Цукерберг (Mark Zuckerberg) заявил, что компания намерена повысить требования к управлению эффективностью и быстрее избавляться от сотрудников с низкими результатами. «Обычно мы расстаёмся с теми, кто не оправдывает наших ожиданий в течение года, но в этом раунде мы проведём более масштабные сокращения на основе оценки эффективности», — уточнил он. Сроки уведомления сотрудников о сокращении зависят от их местоположения. Работники в США получат уведомления 10 февраля, а сотрудники из других стран будут проинформированы позже. Увольнения коснутся только тех, кто проработал в компании достаточно долго, чтобы пройти оценку эффективности. Цукерберг подчеркнул, что Meta✴✴, как и раньше, предложит «щедрое выходное пособие» увольняемым сотрудникам. Ранее компания уже сократила 10 000 позиций. Теперь, в соответствии со стратегией, объявленной Цукербергом ещё в 2023 году, акцент смещён на повышение качества персонала. В обращении к менеджерам Цукерберг заявил, что целью сокращений является обеспечение наличия «сильнейших талантов» и возможность привлечения новых специалистов. В целом, по итогам оценки эффективности, Meta✴✴ планирует сократить общее число сотрудников на 10 %, включая дополнительные 5 % сокращений за счёт естественной убыли персонала в прошлом году. Решения о численности сотрудников в каждом подразделении будут приниматься с учётом прошлогодних сокращений. На фоне всех этих изменений Цукерберг также объявил о ряде других инициатив, включая отказ от проверки фактов на своих платформах (Facebook✴✴, Instagram✴✴ и WhatsApp) на территории США и изменения политики в отношении ненавистнических высказываний. Bloomberg отмечает, что эти шаги совпадают с усилиями по улучшению отношений с избранным президентом США Дональдом Трампом (Donald Trump), на инаугурации которого Цукерберг планирует присутствовать. Глава Meta✴✴ также заявил, что компания готовится к напряжённому году, сосредоточив внимание на технологиях искусственного интеллекта и смарт-очках. Стоит отметить, что Meta✴✴ не единственная крупная компания, начавшая год с сокращений. На прошлой неделе стало известно, что Microsoft также планирует увольнения сотрудников с низкой профессиональной продуктивностью. Свобода слова обернётся для Facebook✴ потерей рекламодателей и доходов
13.01.2025 [15:49],
Владимир Фетисов
Неожиданная реорганизация системы модерации контента в духе «свободы слова» на принадлежащей компании Meta✴✴ Platforms соцсети Facebook✴✴ вызвала опасения со стороны рекламодателей. Они считают, что такой подход может привести к всплеску вредоносного контента и дезинформации на платформе, а никому не хочется размещать свою рекламу рядом с подобным контентом. В итоге это негативно скажется на доходах платформы от рекламы. 
Источник изображения: about.fb.com Об этом пишет издание Financial Times со ссылкой на крупных рекламодателей, считающих, что решение Meta✴✴ прекратить действие программы проверки фактов и ослабление модерации публикуемых пользователями сообщений может дорого обойтись соцсети, большая часть дохода которой приходится на рекламу. Это связано с тем, что бренды опасаются того, что их реклама будет появляться рядом с токсичным контентом. «Некоторые бренды уже сейчас тщательно оценивают свои планы, и это, несомненно, станет коммерческой проблемой для обеих сторон», — считает Фергус МакКаллум (Fergus McCallum), глава рекламного агентства TBWA\MCR. Резкое ослабление контроля над онлайн-контентом Facebook✴✴ является частью стремления главы Meta✴✴ Марка Цукерберга (Mark Zuckerberg) заручиться поддержкой избранного президента США Дональда Трампа (Donald Trump) и одного из его главных союзников в лице Илона Маска (Elon Musk). Всего несколько дней потребовалось Цукербергу, чтобы сменить главу отдела глобальной политики Meta✴✴, а также привести в состав совета директоров компании Дана Уайта (Dana White), который является другом Трампа. В конце прошлой недели Meta✴✴ также объявила о прекращении программы по обеспечению многообразия, равноправия и инклюзивности, а Цукерберг в одном из недавних выступлений заявил, что корпорации стали «культурно кастрированными» и нуждающимися в большей «мужской энергии» и «большем поощрении агрессии». Однако отказ от профессиональных специалистов по проверке фактов в пользу подхода соцсети X, где пользователи сами могут отмечать фейковые посты, вызвал беспокойство рекламной индустрии. Meta✴✴ долгое время находилась среди лидеров сегмента онлайн-рекламы наряду с Google, создав себе репутацию относительно безопасного партнёра, способного обеспечить рекламодателям высокую отдачу и имеющего тесные связи с крупными брендами. В отличие от Meta✴✴, принадлежащая Маску соцсеть X столкнулась с оттоком рекламодателей именно из-за проблем с модерацией контента, что привело к снижению доходов компании. «Meta✴✴ проделала огромную работу по устранению худших проявлений токсичного контента, и, если их новая политика отменит это, рекламодатели быстро заметят это и накажут компанию», — уверен Ричард Эксон (Richard Exon), основатель рекламного агентства Joint. Лу Паскалис (Lou Paskalis), исполнительный директор маркетинговой консалтинговой компании AJL Advisory и бывший глава отдела по взаимодействию со СМИ в Bank of America, считает, что изменение политики Meta✴✴ в отношении модерации контента «создаст препятствия для маркетологов, которые не любят рисковать». По его мнению, это приведёт к тому, что некоторые рекламодатели сократят свою зависимость от Meta✴✴. Топ-менеджеры других рекламных агентств заявили, что новости об изменении политики Meta✴✴ заставили их «нервничать», и они хотят получить от компании дополнительную информацию о том, как именно будут реализованы анонсированные Цукербергом изменения. «Бренды вступают в новый мир, где на устоявшиеся правила работы больше нельзя полагаться», — отметил Патрик Рид (Patrick Reid), исполнительный директор креативного рекламного агентства Imagination. Рекламодатели также высказывают опасения по поводу планов Meta✴✴ скорректировать работу алгоритмов модерации, чтобы «резко сократить» количество контента, который автоматически удаляется фильтрами. Это включает в себя снятие ограничений на публикацию сообщений на такие темы, как миграция и гендер. Вместо этого компания хочет сосредоточить свои силы на поиске более серьёзных нарушений, в том числе связанных с мошенничеством, терроризмом, самоубийствами и др. При этом Цукерберг признал, что теперь системы компании будут отлавливать «меньше плохих вещей». При этом не все рекламодатели столь уверены в том, что ослабление цензуры на платформах Meta✴✴ серьёзно навредит бизнесу компании. «Холодная и жёсткая правда заключается в том, что рекламодатели будут беспокоиться только в том случае, если это повредит их показателям. Если показатели останутся стабильными, никто не станет ломать голову над тем, «где» и «как» демонстрируется их реклама», — заявил Алекс Чизман (Alex Cheeseman), глава британского подразделения Outbrain. На прошедшей недавно выставке CES 2025 глава маркетингового подразделения Meta✴✴ Алекс Шульц (Alex Shultz) заявил, что инструменты обеспечения безопасности рекламодателей никуда не денутся, и компания не спешит с реализацией новой политики, чтобы дать рекламодателям «время адаптироваться». Глава бизнес-группы Meta✴✴ Никола Мендельсон (Nicola Mendelson) написал в недавнем сообщении в соцсети LinkedIn, что Meta✴✴ продолжит инвестировать в инструменты безопасности для рекламодателей. По данным источника, новость об изменении политики Meta✴✴ разделила на два лагеря сотрудников компании. Часть из них восприняли ослабление цензуры как отказ от важных мер защиты, но при этому они «боялись открыто высказывать своё мнение», опасаясь увольнения. Однако большая часть сотрудников отнеслась положительно к изменению политики компании, особенно потому, что проверка фактов считается «неблагодарным» занятием, «поскольку та или иная сторона обязательно обвинит вас в том, что вы заняли чью-то сторону». Люди, знакомые с Цукербергом лично, говорят о том, что глава Meta✴✴ давно является сторонником свободы слова, но он привык менять свою позицию в зависимости от политического и общественного давления. После ослабления модерации наметился массовый исход пользователей из Facebook✴ и Instagram✴
10.01.2025 [18:16],
Павел Котов
В Google резко возросла статистика запросов на тему удаления учётных записей Facebook✴✴, Instagram✴✴ и Threads. Это произошло после того, как глава Meta✴✴ Марк Цукерберг (Mark Zuckerberg) объявил, что в принадлежащих компании соцсетях будет радикально преобразован механизм проверки фактов, ослаблены нормы модерации и отменены введённые ранее ограничения на присутствие политических материалов. 
Источник изображения: BoliviaInteligente / unsplash.com Есть мнение, что этот шаг является попыткой угодить администрации избранного президента США Дональда Трампа (Donald Trump) и избежать политического возмездия. Недовольные инициативой Цукерберга пользователи соцсетей считают, что из-за этого на платформах может увеличиться присутствие оскорбительных высказываний и дезинформации. 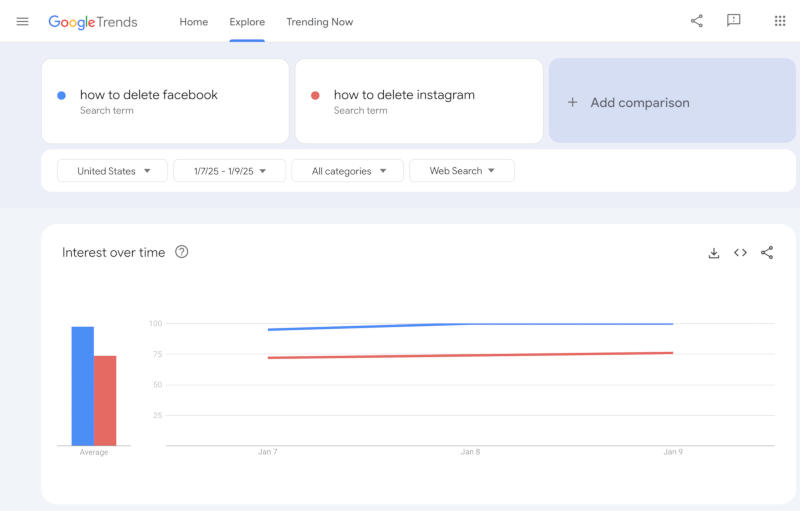
Здесь и далее источник изображения: Google Trends За последние два дня резко вырос интерес к поиску информации, связанной с уходом с платформ Meta✴✴: запросы группы «как удалить все фотографии в Facebook✴✴», «альтернатива Facebook✴✴», «как удалить учётную запись Threads» и «как удалить учётную запись Instagram✴✴ без входа в систему» набрали максимальные 100 баллов в Google Trends. Их популярность выросла более чем на 5000 % по сравнению с предыдущими запросами. 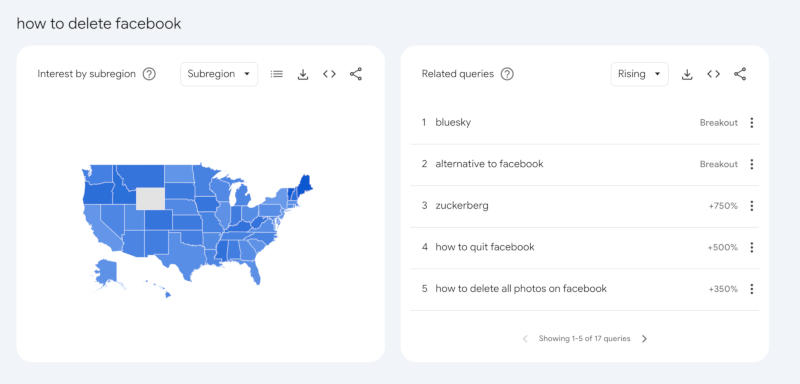 После многих лет распространения дезинформации и агрессивных высказываний в Facebook✴✴ и Instagram✴✴ владеющая платформами компания ввела политику проверки фактов и жёсткой модерации материалов. В преддверии смены власти в Белом доме Цукерберг охарактеризовал новую политику как попытку восстановить свободу слова в соцсетях Meta✴✴, практически повторив высказывания Илона Маска (Elon Musk) в X. Вместо сторонних экспертов проверкой фактов в Facebook✴✴ и Instagram✴✴ займётся сообщество пользователей. 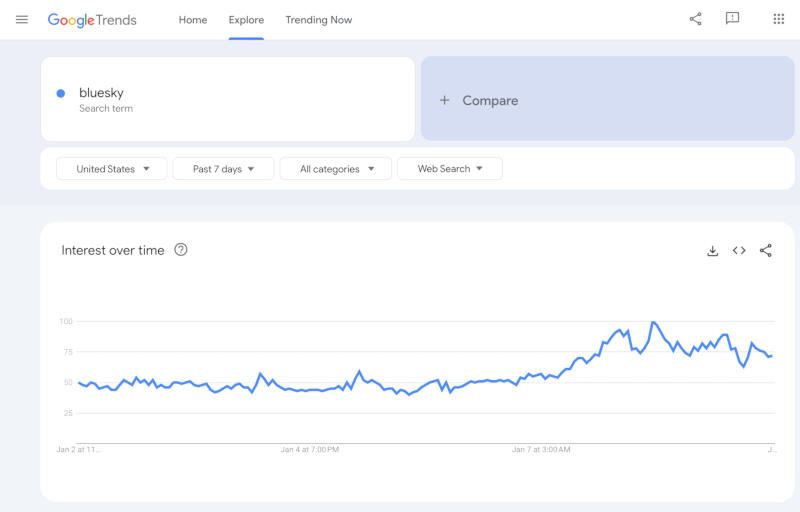 В Google резко возросли и запросы на тему «альтернатив Facebook✴✴», а также децентрализованных платформ Bluesky и Mastodon, чья популярность стала расти после покупки Twitter (теперь X) Илоном Маском. Meta✴ оштрафовали на €251 млн за утечку данных 3 млн европейцев
17.12.2024 [17:59],
Павел Котов
Комиссия по защите данных (DPC) Ирландии оштрафовала компанию Meta✴✴ за нарушение действующего в Евросоюзе «Общего регламента по защите данных» (GDPR), которое выразилось в утечке информации 3 млн европейских пользователей соцсети Facebook✴✴. 
Источник изображения: Antoine Schibler / unsplash.com Факт нарушения датируется 2018 годом, однако его причина восходит к 2017 году — тогда в Facebook✴✴ появился новый механизм загрузки видео, в состав которого входила функция «Посмотреть как» (View as), которая позволяла пользователю просмотреть свою собственную страницу в соцсети, какой её видит другой пользователь. Из-за ошибки в архитектуре этой функции она в сочетании с другой функцией под названием «Happy Birthday Composer» позволяла генерировать токен, открывавший доступ к профилю другого пользователя. В период с 14 по 28 сентября 2018 года неавторизованные лица при помощи скриптов для эксплуатации этой уязвимости Facebook✴✴ произвели вход в качестве владельцев аккаунтов в 29 млн учётных записей соцсети — из них 3 млн находились в ЕС или Европейской экономической зоне, то есть в зоне ответственности DPC. Достоянием злоумышленников стали различные категории персональных данных пользователей Facebook✴✴: полные имена, адреса электронной почты, номера телефонов, сведения о местоположении и месте работы, даты рождения, вероисповедание, пол, публикации в ленте новостей, группы, в которых они состояли, а также персональные данные детей. В действиях компании DPC усмотрела два нарушения: владелец соцсети не раскрыл регулятору всю информацию об инциденте, не полностью задокументировал факты нарушения и предпринятые для устранения проблемы шаги; кроме того, владелец платформы нарушил принципы GDPR, не обеспечив надлежащих мер для защиты персональных данных европейцев. По первому нарушению размер наложен штраф в размере €11 млн, по второму — €240 млн. «Это решение связано с инцидентом от 2018 года. Мы предприняли незамедлительные действия для устранения проблемы, как только она была обнаружена, и заранее проинформировали пострадавших людей, а также ирландскую Комиссию по защите данных. Нам доступен широкий спектр ведущих в отрасли мер для защиты людей на наших платформах», — заявила ресурсу TechCrunch представитель Meta✴✴ Эмили Уэсткотт (Emily Westcott). В сентябре компанию оштрафовали на €91 млн за то, что в 2019 году она хранила на серверах «сотни миллионов» пользовательских паролей в открытом виде. Глобальный сбой произошёл в работе Facebook✴, Instagram✴, Threads и WhatsApp
11.12.2024 [22:03],
Андрей Созинов
Пользователи Facebook✴✴, Instagram✴✴, Threads и WhatsApp по всему миру столкнулись со сбоями. Пользователи сервисов, принадлежащих компании Meta✴✴, жалуются на проблемы с отправкой сообщений, загрузкой фото и видео или в целом на необычно медленную работу служб. О проблемах сообщают также пользователи из России. О причинах глобального сбоя пока ничего неизвестно.  Перебои затронули все основные сервисы Meta✴✴ и оказались повсеместными. Судя по всему, перебои начались незадолго 21:00 по московскому времени, и их испытывает значительное число пользователей из разных уголков мира. Meta✴✴ пока не предоставила комментариев по поводу перебоев. Пострадали Facebook✴✴ и Facebook✴✴ Messenger, Instagram✴✴ и Threads, а также мессенджер WhatsApp. Больше всего жалоб указывают на невозможность использовать приложение или веб-сайт сервиса, невозможность публиковать контент, очень медленную загрузку, не всегда с первого раза, а также на различные ошибки. Например, все посты в Facebook✴✴ показывают ноль комментариев Добавим, что случаи столь масштабных сбоев, которые приводят к одновременному отключению стольких крупных сервисов, крайне редки. С другой стороны, компания Meta✴✴ владеет и управляет одними из самых популярных социальных платформ в мире, так что, когда её службы испытывают перебои в работе, все это замечают. На момент подготовки данного материала поток жалоб на проблемы у Facebook✴✴, Instagram✴✴, Threads и WhatsApp стал спадать и, по крайней мере отдельные пользователи, начали сообщать о том, что всё пришло в норму. Однако медленная загрузка по-прежнему встречается. Официального подтверждения решения проблемы пока не поступало. Meta✴ планирует сделать AR-очки Orion таким же популярным гаджетом, как наушники AirPods
20.11.2024 [11:35],
Анжелла Марина
Meta✴✴ верит, что её очки дополненной реальности Orion станут такими же успешным и массовым продуктом для повседневного использования, как беспроводные наушники AirPods. По мнению компании, очки будут удобны в использовании, позволяя легко переключаться между реальным и виртуальным миром. 
Источник изображения: Meta✴✴ Компания Meta✴✴ продолжает развивать проект очков дополненной реальности Orion, впервые представленный в сентябре. Как пишет издание 9to5Мac, несмотря на то, что продукт пока является прототипом и далёк от коммерческого запуска, руководство компании уверено в его потенциале. По мнению главы отдела носимых устройств Meta✴✴ Orion Джошуа То (Joshua To), очки могут стать «AirPods в мире дополненной реальности», то есть не менее востребованным продуктом, чем беспроводные наушники Apple. Meta✴✴ утверждает, что прототип уже «похож на обычные очки», однако эксперты не спешат соглашаться с этим мнением. «Возможно, так они выглядят для человека с не очень хорошим зрением, но для большинства, очевидно, что это ранняя версия устройства», — отмечает Бен Лавджой (Ben Lovejoy) из 9to5Mac. Тем не менее, разработка впечатляет, так как это значительный шаг вперёд в сравнении с моделями других компаний, такими как Xiaomi или Oppo. Имеет значение и стоимость, которая на данный момент составляет около $10 000, подчёркивая долгий путь до массового потребителя. Важно отметить, что Apple и Meta✴✴ идут разными путями в разработке очков дополненной реальности (AR), хотя их конечные цели схожи. Обе компании стремятся создать устройство, которое будет выглядеть как обычные очки, но способное показывать реалистичный AR-контент. Однако, если Meta✴✴ активно демонстрирует свои прототипы, то разработка Apple Glasses остаётся засекреченной. Единственно, в чём обе компании похожи, так как это в том, что придерживаются общей философии в технологии AR: «технология должна улучшать восприятие реального мира, а не заменять его, как это происходит с виртуальной реальностью». Джошуа То подчёркивает, что очки Meta✴✴ не будут отвлекать человека от реальности, а будут использоваться по мере необходимости. «Это что-то вроде AirPods, — поясняет он, — вы надеваете их, когда хотите, и снимаете, когда перестаёте в этом нуждаться». То есть, как и в случае с наушниками, пользователи будут использовать Orion для выполнения конкретных задач, а не носить их постоянно. Одной из потенциально полезных функций дополненной реальности, по словам разработчиков, может стать возможность распознавания лиц и отображения имён собеседников. Meta✴✴ уже тестирует эту функцию, уделяя особое внимание вопросам конфиденциальности. По словам Джошуа То, пользователи смогут сами выбирать, делиться ли своим именем на мероприятии или оставаться анонимными. «Я думаю, если мы сможем сделать бейджики с именами продуманно и с уважением относясь к конфиденциальности, то это то, в чем люди могут быть очень заинтересованы», — говорит То. Facebook✴ сделала просмотры основной метрикой для оценки контента
15.11.2024 [23:30],
Владимир Фетисов
Социальная сеть Facebook✴✴ сделала просмотры основной метрикой для оценки эффективности контента, аналогично тому, как это ранее было сделано в Instagram✴✴. Просмотры стали основной метрикой не только для видеоконтента, но и для фотографий, текстовых постов и др. 
Источник изображения: Firmbee / Pixabay Летом этого года глава Instagram✴✴ Адам Моссери (Adam Mosseri) объявил, что основной метрикой эффективности контента в социальной сети стали просмотры. Он также добавил, что наличие единой метрики на всей платформе облегчит авторам контента понимание того, насколько эффективны их публикации. Таким образом, для видео количество просмотров указывает на то, сколько раз ролик посмотрели пользователи. Для всего остального контента количество просмотров указывает на количество показов публикации другим пользователям. Если один и тот же пользователь смотрит что-либо многократно, то засчитывается несколько просмотров. Meta✴✴ также добавила счётчик просмотров сообщений в соцсети Threads, заявив, что это попытка дать авторам больше возможностей для оценки эффективности контента. Вероятно, для коммерческих пользований новая метрика будет полезна, но для обычных потребителей она не имеет особого значения. ЕС оштрафовал Meta✴ на рекордные €798 млн за антиконкурентные злоупотребления в Facebook✴ Marketplace
14.11.2024 [18:06],
Сергей Сурабекянц
Еврокомиссия оштрафовала Meta✴✴, материнскую компанию Facebook✴✴, Instagram✴✴ и WhatsApp, на €797,72 млн (почти $840 млн) за нарушение антимонопольных правил ЕС. Регулятор утверждает, что сервис объявлений Facebook✴✴ Marketplace создаёт «несправедливые условия торговли» для других аналогичных интернет-площадок. 
Источник изображения: Pixabay Гигантский штраф, самый крупный на сегодняшний день, стал результатом судебного расследования, которое началось ещё в июне 2021 года. В декабре 2022 года регулирующие органы пришли к выводу, что сервис Facebook✴✴ Marketplace нарушил антимонопольные правила ЕС. Ещё почти два года ушло на бюрократические процедуры и, наконец, сегодня решение о штрафе было утверждено. Facebook✴✴ планирует подать апелляцию. «Это решение игнорирует реалии процветающего европейского рынка услуг по размещению онлайн-объявлений и ограждает крупные действующие компании от нового участника — Facebook✴✴ Marketplace, который удовлетворяет спрос потребителей новыми инновационными и удобными способами», — говорится в заявлении компании. FTC потребовала от Meta✴ продать Instagram✴ и WhatsApp
14.11.2024 [01:12],
Анжелла Марина
Meta✴✴ должна будет предстать перед судом по антимонопольному иску со стороны Федеральной торговой комиссии США (FTC), которая обвинила компанию в подавлении конкуренции и обеспечения себе доминирующего положения на рынке социальных сетей путём покупки Instagram✴✴ и WhatsApp. Суд может обязать компанию продать свои активы, сообщает The Verge. 
Источник изображения: VBlock/Pixabay FTC уже подавала иск против Meta✴✴ ещё в 2020 году, утверждая, что компания купила конкурентов в лице Instagram✴✴ и WhatsApp в попытке подавить конкуренцию. Судья окружного суда округа Колумбия Джеймс Боасберг (James Boasberg) первоначально отклонил этот иск в 2021 году, после чего федеральное агентство подало исправленную жалобу и дело было возобновлено. Весной 2023 года Meta✴✴ вновь обратилась в суд с просьбой отклонить иск FTC, но Боасберг вынес решение в пользу FTC, хотя и отклонил утверждение о том, что Meta✴✴ действовала недобросовестно, разрешив доступ разработчикам к своему API на условиях отказа от конкуренции с её приложениями. Теперь же FTC попытается доказать, что Meta✴✴ действовала недобросовестно и покупка ею Instagram✴✴ и WhartsApp навредила конкуренции и потребителям. Представитель компании Meta✴✴ Кристофер Сгро (Christopher Sgro) в заявлении для издания The Verge выразил уверенность в том, что Meta✴✴ докажет в суде, что приобретения Instagram✴✴ и WhatsApp были «полезны» для пользователей. «Более 10 лет назад FTC уже рассмотрела и одобрила эти сделки, и, несмотря на множество доказательств того, что наши сервисы честно конкурируют с YouTube, TikTok, X, iMessage от Apple и многими другими, комиссия продолжает настаивать на неправомерности приобретения», — отметил Сгро. Несмотря на то, что антимонопольный иск FTC был подан во время президентства Дональда Трампа (Donald Trump), ожидается, что его администрация займёт более мягкую позицию в вопросе слияний и поглощений, а глава Meta✴✴ Марк Цукерберг (Mark Zuckerberg), наряду с другими лидерами крупных технологических компаний, уже начал потихоньку «налаживать» отношения с Трампом, который, как ожидается, уберёт с поста главу FTC Лину Хан (Lina Khan). Meta✴ вынуждена поменять для ЕС методы показа рекламы в Instagram✴ и Facebook✴
13.11.2024 [07:58],
Анжелла Марина
В ответ на давление ЕС компания Meta✴✴ объявила о планах показа для европейских пользователей в Instagram✴✴ и Facebook✴✴ менее персонализированной рекламы без дополнительной оплаты, либо покупке по сниженной цене подписки, сообщает The Wall Street Journal. Однако введение нового формата рекламы повлияет на доходы компании в одном из её ключевых рынков. 
Источник изображения: Mariia Shalabaieva/Unsplash В ближайшие дни пользователи Instagram✴✴ и Facebook✴✴ в Европе получат уведомления с предложением перейти на новый формат рекламы. В отличие от текущей персонализированной рекламы, основанной на широкой истории активности пользователя, новая реклама будет основана на контенте, который просматривается в течение текущей сессии, а не на истории пользовательской активности в целом, как это всегда происходило. Тем не менее, некоторые объявления будут по-прежнему ориентироваться на возраст, пол и местоположение пользователей, и будут раскрываться на весь экран. Введение менее персонализированной рекламы связано с нарастающим давлением со стороны регуляторов ЕС. Ранее Meta✴✴ не предоставляла пользователям бесплатный способ отказаться от использования истории их предпочтений для таргетинга рекламы, опасаясь снижения доходов, и новый шаг может негативно отразиться на бизнесе компании, учитывая, что Европа приносит ей около 23 % выручки (по данным последнего финансового отчёта). Кроме того, Meta✴✴ испытывает разочарование по поводу усилий ЕС по регулированию технологий, включая требования о получении согласия пользователей на использование их данных для обучения искусственного интеллекта. В частности, компании пришлось отложить запуск своих чат-ботов в ЕС после того, как регуляторы потребовали, чтобы Meta✴✴ спрашивала согласие пользователей. Одновременно в открытом письме компания подчёркивает, что регулирующие законы грозят подавить бум искусственного интеллекта в регионе, также утверждая, что персонализированная реклама является общим благом как для пользователей, так и для рекламодателей. WSJ отмечает, что «менее персонализированная реклама» — это уже второй шаг Meta✴✴ за год по изменению рекламных опций в ЕС. Так, осенью прошлого года компания предложила пользователям подписку без рекламы, вынуждающую их выбирать либо рекламу, либо ежемесячную подписку за €13. Новая опция рекламы без подписки является попыткой Meta✴✴ урегулировать ситуацию и избежать штрафов, которые могут достигать до 20 % от годового дохода компании в случае повторных нарушений. В рамках нового предложения Meta✴✴ также снизит стоимость подписки до €8 на мобильных устройствах и €5 за каждый дополнительный аккаунт. Марк Цукерберг не несёт личной ответственности за зависимость детей от Facebook✴ и Instagram✴
11.11.2024 [12:42],
Дмитрий Федоров
Федеральный суд США постановил, что генеральный директор Meta✴✴ Марк Цукерберг (Mark Zuckerberg) не несёт личной ответственности за причинённый детям ущерб, вызванный зависимостью от социальных сетей Facebook✴✴ и Instagram✴✴. Решение вынесено в рамках более чем двух десятков исков, в которых утверждается, что Meta✴✴ сознательно скрывала потенциальные риски для здоровья пользователей, особенно детей, и целенаправленно вводила их в заблуждение. 
Источник изображения: about.fb.com Федеральный судья Ивонн Гонсалес Роджерс (Yvonne Gonzalez Rogers) из Калифорнии вынесла это решение, опубликовав его в десятистраничном судебном документе. В иске, поданном от имени родителей и образовательных организаций, утверждается, что Meta✴✴ была осведомлена о рисках для здоровья, которые создают Facebook✴✴ и Instagram✴✴, и что особенно уязвимы к этому воздействию дети. Истцы утверждают, что Meta✴✴ сознательно скрывала информацию об этих рисках, используя «вводящие в заблуждение заявления», тем самым ограничивая пользователей в осознании возможных угроз. Истцы также полагают, что Цукерберг выступал не только как руководитель, но и как ключевой вдохновитель политики Meta✴✴ по сокрытию информации. По их мнению, он был осведомлён о потенциальных угрозах и принимал непосредственное участие в формировании стратегии компании, сознательно направленной на утаивание рисков. Однако судья Роджерс отметила, что представленные в материалах доказательства недостаточны для установления личной ответственности Цукерберга как руководителя компании в соответствии с корпоративным законодательством тринадцати юрисдикций, на которые распространяется иск. Данное судебное решение вынесено на фоне усиливающейся озабоченности в мировом сообществе влиянием социальных сетей на психическое здоровье детей и подростков. В октябре четырнадцать генеральных прокуроров США подали иски против TikTok, обвинив сервис в создании зависимости, которая пагубно сказывается на психическом состоянии несовершеннолетних. Эксперты в области права отмечают, что подобные иски используют юридические стратегии, аналогичные тем, что применялись правительством США в борьбе с фармацевтической и табачной промышленностью. Параллельно с этим премьер-министр Австралии Энтони Албаниз (Anthony Albanese) недавно предложил законопроект, запрещающий детям младше шестнадцати лет регистрироваться в социальных сетях. Антигон Дэвис (Antigone Davis), руководитель службы безопасности Meta✴✴, в интервью Associated Press заявила, что компания готова соблюдать любые возрастные ограничения, которые может установить австралийское правительство. В то же время представители Meta✴✴ воздержались от комментариев по поводу решения суда Калифорнии, а адвокаты Цукерберга не ответили на запросы журналистов. Превин Уоррен (Previn Warren), представляющий истцов от имени компании Motley Rice LLC, отметил в интервью Business Insider, что они продолжат бороться с Meta✴✴, независимо от того, привлекут Цукерберга к ответственности лично или нет. «Наша цель — предоставить сотням семей и образовательных организаций, интересы которых мы защищаем, возможность отстоять свои права в суде. Мы намерены продолжать процесс раскрытия доказательств, чтобы выяснить, как именно крупнейшие технологические компании сознательно ставят прибыль выше безопасности детей», — заявил Уоррен. В настоящее время в судебных разбирательствах против Meta✴✴ участвуют десятки истцов. Помимо Meta✴✴, в качестве ответчиков по иску выступают также компании Snap, ByteDance и Google. В декабре 2023 года истцы подали новый иск, в котором утверждается, что использование социальных сетей привело к серьёзным физическим и психологическим травмам, инвалидности, нарушению здоровья и другим серьёзным заболеваниям. В иске также приводятся сведения о значительных расходах, включающих траты на медицинское обслуживание, потерю заработка, утрату трудоспособности и другие необратимые последствия, которые продолжают отрицательно влиять на качество жизни людей. Meta✴ оштрафовали в Южной Корее на $15 млн за незаконный сбор пользовательских данных
05.11.2024 [18:16],
Владимир Фетисов
Южнокорейский отраслевой регулятор оштрафовал американскую компанию Meta✴✴ Platforms на 21,62 млрд вон ($15,67 млн) за сбор конфиденциальных пользовательских данных и их последующую передачу рекламодателям, не имея на это права. Об этом пишет информационное агентство Reuters со ссылкой на заявление Комиссии по защите личных данных Южной Кореи. 
Источник изображения: AJEL / Pixabay По данным источника, американский технологический гигант собрал информацию о примерно 980 тыс. южнокорейских пользователей социальной сети Facebook✴✴, включая данные об их религиозных предпочтениях, политических взглядах и др. При этом Meta✴✴ не получила явного разрешения пользователей на сбор и обработку данных, что и стало причиной наказания. Собранную таким образом информацию использовали около 4 тыс. рекламодателей. «Было обнаружено, что Meta✴✴ анализировала данные о поведении пользователей, включая просматриваемые ими страницы и рекламные объявления, по которым они переходили в Facebook✴✴. Компания также создала и управляла рекламными профилями, связанными с конфиденциальной информацией», — говорится в заявлении регулятора. Официальные представители Meta✴✴ никак не комментируют данный вопрос. По сведениям ведомства, Meta✴✴ распределяла пользователей по разным категориям. В частности, создавались отдельные группы для перебежчиков из Северной Кореи, исповедующих определённую религию, придерживающихся определённых жизненных парадигм и взглядов. В дополнение к этому Meta✴✴ неправомерно отклоняла запросы пользователей на доступ к личной информации и не смогла предотвратить утечку личной информации нескольких жителей Южной Кореи. Аудитория Threads превысила 275 млн пользователей за год с момента её запуска
02.11.2024 [14:55],
Дмитрий Федоров
Платформа микроблогов Threads компании Meta✴✴, созданная как альтернатива социальной сети X (бывший Twitter), достигла отметки в 275 млн активных пользователей в месяц. Meta✴✴ рассчитывает, что Threads станет значимым дополнением к её экосистеме социальных платформ и откроет новые возможности для увеличения охвата аудитории. 
Источник изображения: Threads С момента запуска в июле 2023 года Threads показала значительный рост аудитории, увеличив число пользователей на 175 % за прошедший год. Согласно отчёту Meta✴✴ за II квартал, количество активных пользователей достигло отметки в 200 млн, а в настоящее время этот показатель составляет 275 млн. Как отметил Марк Цукерберг (Mark Zuckerberg), ежедневный прирост пользователей превышает один миллион человек, что подчёркивает быстрый темп роста и высокий интерес со стороны аудитории. Несмотря на стремительный рост показателей Threads, социальная платформа X, принадлежащая Илону Маску (Elon Musk), удерживает лидерство по количеству активных пользователей. По данным аналитической платформы Sensor Tower, у X ежемесячно около 318 млн пользователей, однако за последний год количество пользователей X снизилось на 24 %, продолжая тенденцию, возникшую с октября 2022 года, когда Маск завершил покупку Twitter за $44 млрд. Снижение аудитории X предоставляет Meta✴✴ дополнительные возможности для укрепления позиций Threads на фоне ослабления конкурента. Meta✴✴ рассматривает Threads как перспективную платформу для размещения рекламы, которая по итогам III квартала обеспечила 98,3 % общей выручки Meta✴✴. Тем не менее финансовый директор Meta✴✴ Сьюзан Ли (Susan Li) отметила, что до 2025 года компания не ожидает значительного вклада Threads в доходы корпорации. Основное внимание Meta✴✴ сосредоточено на создании функциональности, востребованной среди пользователей, что, как предполагается, в долгосрочной перспективе обеспечит устойчивую основу для роста Threads. Аналитики компании Bernstein видят у Threads значительный потенциал. Несмотря на то, что Meta✴✴ пока не рассматривает Threads как основной источник дохода, аналитики прогнозируют, что уже в следующем году реклама будет запущена на платформе и начнёт масштабироваться по мере роста аудитории. По сравнению с прошлым годом ежедневная активность пользователей приложений Meta✴✴, включая Facebook✴✴ и Instagram✴✴, выросла на 5 % и достигла 3,29 млрд человек, хотя этот показатель оказался чуть ниже ожиданий аналитиков, прогнозировавших 3,31 млрд. Новость о незначительном отставании от прогноза привела к снижению акций Meta✴✴ на 4 %, однако общий рост аудитории отражает устойчивый интерес пользователей к продуктам компании. ИИ помог Instagram✴ и Facebook✴ дольше удерживать внимание пользователей
01.11.2024 [00:42],
Анжелла Марина
Генеральный директор Meta✴✴ Марк Цукерберг (Mark Zuckerberg) сообщил, что улучшение рекомендательных алгоритмов с помощью искусственного интеллекта, способствовало увеличению удержания аудитории в соцсетях. В финансовом отчёте Meta✴✴ за третий квартал 2024 года было отмечено, что время, проведённое пользователями в Facebook✴✴, выросло на 8 %, а в Instagram✴✴ — на 6 %. 
Источник изображения: Julio Lopez/Unsplash Повышения показателей связано с улучшением с помощью ИИ рекомендательных алгоритмов для видео и персонализированных новостных лент. Однако этим влияние ИИ не ограничивается. Отмечается, что 500 миллионов пользователей в месяц используют ИИ-функции Meta✴✴ AI в своих приложениях. Кроме того, более миллиона рекламодателей воспользовались инструментами генеративного ИИ в прошлом месяце для создания более 15 миллионов объявлений, повысив тем самым конверсию своих рекламных объявлений на 7 %. Также продолжает расти и пользовательская база Meta✴✴. Количество людей, которые ежедневно взаимодействуют с любым из приложений компании (DAP), увеличилось на 5 % и составило 3,29 миллиарда, а ежемесячная активная аудитория (MAP) выросла на 6 %, достигнув 3,96 миллиарда. Финансовые результаты компании за третий квартал превзошли ожидания аналитиков. Meta✴✴ показала прибыль в размере $6,03 на акцию, что выше прогнозов в $5,25. Выручка составила $40,59 млрд, превысив прогноз в $40,29 млрд. Общие затраты составили $23,2 млрд, а капитальные вложения — $9,2 млрд. В связи с этим Meta✴✴ пересмотрела прогноз по расходам на весь год, который теперь составляет $96-$98 млрд. При этом подчёркивается, что расходы на инфраструктуру могут резко возрасти из-за расширения систем обработки и хранения данных. Meta✴ сообщила об убытках подразделения Reality Labs в размере $4,4 млрд в третьем квартале
31.10.2024 [05:14],
Анжелла Марина
Несмотря на успехи в разработке носимых устройств дополненной и виртуальной реальности, Meta✴✴ продолжает сталкиваться с большими убытками своего подразделения Reality Labs. По итогам третьего квартала Reality Labs зафиксировала операционный убыток в размере $4,4 млрд, хотя аналитики прогнозировали $4,68 млрд, передаёт CNBC. 
Источник изображения: meta✴✴.com Тем не менее, выручка подразделения, основным источником дохода которого являются продажи VR-гарнитур Meta✴✴ Quest и умных очков Ray-Ban Meta✴✴, в третьем квартале выросла на 29 % по сравнению с прошлым годом, достигнув $270 млн. Генеральный директор Meta✴✴ Марк Цукерберг (Mark Zuckerberg) убеждён, что развитие VR- и AR-технологий может вывести компанию на лидирующие позиции в области, которая станет следующей крупной платформой для персональных компьютеров. 
Источник изображения: Mediamodifier/Unsplash Однако эти инвестиции обходятся компании слишком дорого. С 2020 года Reality Labs накопила убытки, которые уже превысили $58 млрд. Несмотря на это, Цукерберг продолжает продвигать свои амбициозные планы по созданию метавселенной. В сентябре на ежегодной конференции Connect он представил прототип AR-очков Orion, вызвав большой интерес к проектам компании. Meta✴✴ также надеется на успех своих умных очков Ray-Ban Meta✴✴ и планирует привлечь разработчиков для создания приложений для будущих AR-очков Orion, которые должны появиться на рынке в следующем году. Кроме того, в сентябре Meta✴✴ выпустила новую модель VR-гарнитуры Quest 3S, в качестве более доступного варианта VR-устройства по стартовой цене всего в $299. В прошлом году была представлена более мощная версия Quest 3, стоимость которой начинается от $499. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



