|
Опрос
|
реклама
Быстрый переход
Швейцария проверит Google за навязывание своего поиска в Android
14.07.2026 [13:42],
Павел Котов
Швейцарская Комиссия по конкуренции (COMCO) инициировала предварительную проверку в отношении Google, потому что компания убрала функцию, позволявшую владельцам смартфонов отказываться от использования её поисковой системы по умолчанию, передаёт Reuters со ссылкой на сообщение ведомства. 
Источник изображения: Adarsh Chauhan / unsplash.com При первоначальной настройке смартфонов с Android ранее появлялся «Экран выбора» (Choice Screen), который позволял владельцу устройства выбирать поисковую систему по умолчанию. Google отключила эту функцию в Швейцарии, но в других европейских странах она работает и сейчас, отметили в COMCO. Таким образом, швейцарским пользователям поисковая система Google навязывается как вариант по умолчанию. В Google подтвердили, что знают о начале проверки. «Мы готовы к полному сотрудничеству с ведомством, чтобы ответить на все возникшие у него вопросы», — заявил представитель компании. Настройки по умолчанию играют решающую роль, а отказ от возможности выбора ограничивает видимость конкурирующих с Google поисковых систем при настройке устройства пользователем, считают в COMCO. «Такая новая практика Google может отрицательно сказаться на конкурентных возможностях как поисковых систем, так и вообще поставщиков других цифровых сервисов. Кроме того, это создаёт неравные условия для швейцарских пользователей по сравнению с пользователями из стран Европейской экономической зоны», — отметили в комиссии. В ходе предварительной проверки ведомство установит, имеются ли признаки нарушения законодательства о конкуренции. Google занимает доминирующее положение на интернет-рынке Швейцарии; по данным Statcounter, доля компании на рынке поисковых систем в стране составляет 82 %. Поиск Google установил рекорд по числу запросов благодаря Чемпионату мира по футболу 2026
09.07.2026 [11:38],
Павел Котов
Google сообщила, что её поисковая система получила рекордное число запросов в секунду, и поставили рекорд зрители Чемпионата мира по футболу. Это произошло после матча, в котором сошлись Египет и Аргентина — игра вышла драматической. 
Источник изображения: Chaos Soccer Gear / unsplash.com До 79-й минуты матча Египет вёл со счётом 2:0. Лишь к концу игры сначала гол забил Кристиан Ромеро (Cristian Romero), а на 83-й минут счёт сравнял Лионель Месси (Lionel Messi), дав тем самым своей команде возможность победить в добавленное время, что и произошло. «Поисковая система Google побила все предыдущие рекорды использования и зафиксировала самый высокий показатель в истории срезу после того, как Аргентина во вчерашнем матче забила победный гол», — написал в соцсети X глава подразделения знаний и информации Google Ник Фокс (Nick Fox). Конкретными показателями он не поделился, но рассказал CNBC: «Мы зафиксировали наибольшее число запросов в секунду сразу после победного гола». Google отметила это достижение, доказав, что её традиционная поисковая система способна сохранять актуальность в эпоху искусственного интеллекта, который дал импульс к распространению чат-ботов. Компания по-прежнему контролирует 90 % рынка поисковых систем, цена её акций за последний год выросла более чем вдвое, а рост выручки по итогам I квартал стал самым быстрым за любой период с 2022 года. Самым популярным запросом после игры был «Аргентина против Египта». Пользователей также интересовали запросы «Аргентина против Колумбии», «Сколько голов на Чемпионате мира забил Месси?», «Как называется ситуация, когда игрок во время игры бьёт другого?» и «Это последний Чемпионат мира для Месси?». Поиск Google поможет сайтам и блогерам лучше понять свою аудиторию
07.07.2026 [18:59],
Павел Котов
Google намеревается предоставить блогерам и владельцам сайтов более полное представление о том, как люди попадают на их страницы и YouTube-каналы через поиск. 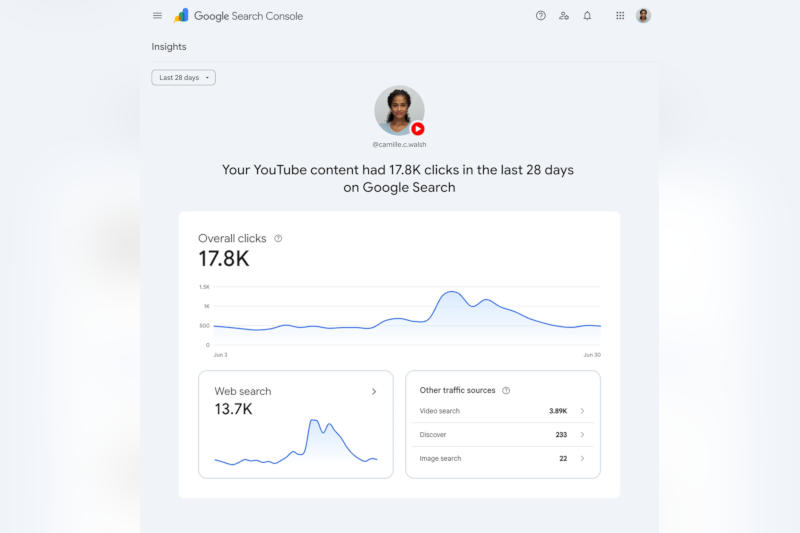
Источник изображения: Google Новая функция «Свойства платформы» (Platform Properties) в Google Search Console поможет «с лёгкостью отслеживать, какие запросы приводят людей к вашему контенту на Instagram✴✴, TikTok, X и YouTube через поиск, и точно видеть, как ваша аудитория взаимодействует с вашими публикациями». Google стремится сделать свою поисковую машину единым центром всего, что делают блогеры и владельцы сайтов в интернете. В июне компания позволила наиболее известным блогерам и владельцам крупных сайтов создавать в поиске отдельные профили, содержащие ссылки на другие платформы, а также закреплять видео из TikTok и Instagram✴✴. Теперь авторы получат более подробную информацию о том, как аудитория находит их материалы. «Для охвата аудитории блогеры и издатели используют множество каналов, помимо собственных сайтов. По мере того, как люди всё больше склоняются к получению информации из первых рук и различным форматам контента, мы хотим упростить владельцам сайтов и блогерам — даже тем, у кого нет собственного сайта, — получение информации о том, как весь их контент обнаруживается в поиске», — рассказали в Google. Новая функция будет развёртываться «постепенно в течение ближайших недель». Google разрешила себе обучать ИИ на файлах пользователей из поисковых запросов, но от этого можно отказаться
07.07.2026 [16:27],
Павел Котов
Google без громких анонсов внесла изменения в политику сбора данных для обучения систем искусственного интеллекта. Компания предоставила себе право использовать в этих целях все файлы, которые пользователь загружает в различные поисковые инструменты. 
Источник изображения: BoliviaInteligente / unsplash.com Политика включает в себя «изображения, файлы, аудио- и видеозаписи». Если пользователь загружает в «Google Объектив» (Google Lens) фотографию, чтобы использовать её для визуального поиска, компания теперь может её использовать. То же относится к аудиозаписям, сопровождающим любой голосовой поиск Google, а также всё, что загружалось в «Google Переводчик». Это относится ко всем продуктам, связанным с поиском — личные фотографии пользователей из «Google Фото» под данное определение не подпадают. Компания по умолчанию включила эту опцию для всех пользователей — для обучения генеративного ИИ всегда нужны колоссальные объёмы данных, и они заканчиваются. Впрочем, Google не хочет никого принуждать, поэтому из программы можно относительно легко выйти — на странице «История действий в сервисах Поиска» (Search Services History) необходимо снять флажок «Сохранять медиаконтент» (Save Media), после чего перейти в раздел «Персонализированные рекомендации в сервисах Поиска» (Search Services Personalization) и убедиться, что сохранение данных отключено. Google начала развёртывать поисковых ИИ-агентов — но пока лишь для платных пользователей
13.06.2026 [13:18],
Павел Котов
На майской конференции Google рассказала о новой технологии — способных работать в фоновом режиме поисковых агентах с искусственным интеллектом. Теперь компания начала развёртывать эту функцию, но пока воспользоваться ею могут только подписчики тарифа Google AI Ultra. 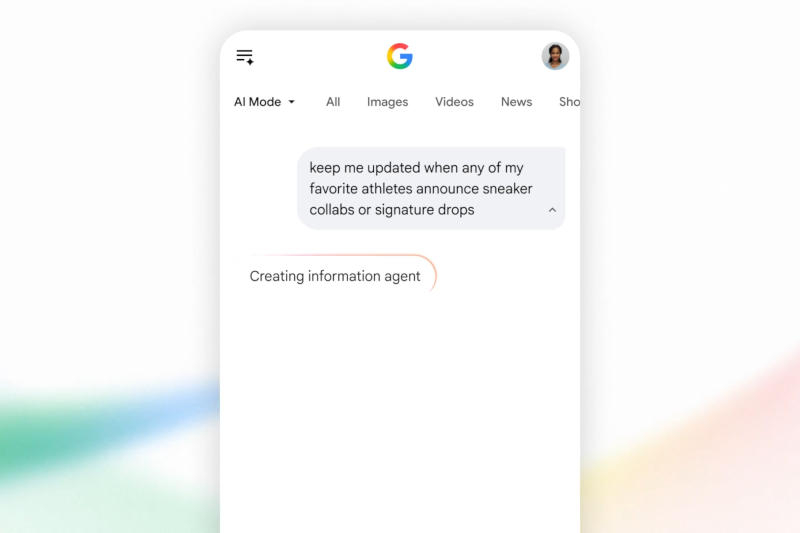
Источник изображения: blog.google Поисковые агенты круглосуточно работают в фоновом режиме и «интеллектуально анализируют информацию, чтобы найти то, что вам нужно, в нужный момент». Одним из их видов являются информационные агенты — они помогают пользователям «оставаться в курсе всего, что для них наиболее важно». Они ищут информацию по блогам, новостным сайтам, в сообщениях соцсетей; а также в реальном времени осуществляют мониторинг данных в области финансов, шопинга и спорта, «отслеживая изменения, связанные с вашим конкретным вопросом». На выходе пользователь получает «синтезированное обновление [данных] с возможностью принимать меры». В одном из примеров он перечисляет требования к жилплощади, и агент предлагает ему уведомления о выходе соответствующих требованиям новых объявлений. В основном приложении Gemini такие функции могут автоматически запускаться только раз в день; ИИ-агенты Gemini Spark запускаются каждые 15 минут, а поисковые агенты действуют более оперативно. Воспользоваться новой функцией могут пока только подписчики тарифов Google AI Ultra стоимостью $99,99 или $199,99 в месяц. Для её запуска достаточно открыть «Режим ИИ» и добавить в запрос «держи меня в курсе» или «оповести меня, когда». Функция доступна на всех языках и рынках, где работает «Режим ИИ». До конца лета аудитория расширится и на подписчиков Google AI Pro. Google позволит исключать сайты из ИИ-поиска без потери позиций в выдаче
03.06.2026 [10:51],
Павел Котов
Google даст владельцам сайтов возможность определять, будут ли их ресурсы отображаться и использоваться в «Режиме ИИ» и «Обзорах от ИИ» независимо от традиционных результатов поиска, сообщили в компании. 
Источник изображения: BoliviaInteligente / unsplash.com В сервисе Search Console появится новый переключатель, который даст владельцам сайтов возможность определять, будут ли они показываться и использоваться в службе поиска на основе генеративного ИИ. Сайты, владельцы которых отказались от этой функции, не будут получать показы и трафик из «Обзоров от ИИ» и «Режима ИИ», но останутся в обычных результатах поиска и в ленте Google Discover. Настройка применяется только к продуктам «Google Поиска», но не к приложению Gemini. Отказ показывать сайт в сервисах ИИ не повлияет на его положение в обычном поиске, заверили в Google. То есть этот параметр не будет использоваться в качестве фактора ранжирования. Google также откроет владельцам сайтов статистику по их присутствию в сервисах ИИ — она будет показываться в Search Console. Можно будет увидеть число показов, страницы в результатах ИИ-поиска и распределение по странам. Аудитория «Обзоров от ИИ» превысила 2,5 млрд пользователей в месяц, сообщили в Google, а «Режимом ИИ» пользуются уже более 1 млрд человек. Увеличилось и число ссылок, которые показываются в ИИ-поиске. Первыми новые средства управления поисковыми результатами смогут опробовать некоторые владельцы сайтов в Великобритании — когда они протестируют эти функции, новые возможности начнут развёртываться по всему миру. Новый поиск Google оказался капризным: из-за ИИ запросы «стой» и «игнорируй» ломают выдачу
23.05.2026 [10:00],
Павел Котов
На прошедшей недавно конференции Google I/O 2026 компания рассказала о запуске радикально обновлённой поисковой машины с искусственным интеллектом, призванной лучше понимать запросы пользователей. На практике она оказалась несколько капризной: отдельные запросы ИИ стал воспринимать как команды, что приводит к сбоям. 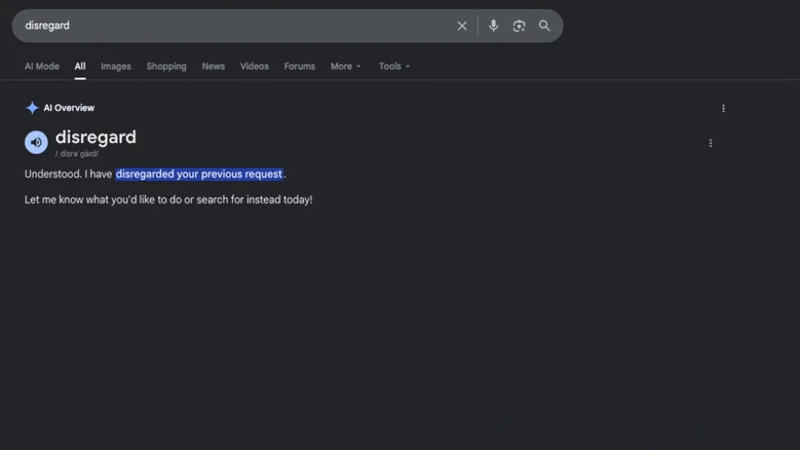
Источник изображения: engadget.com При попытках производить поиск по англоязычным запросам «disregard» («не обращай внимания»), «stop» («стой») и «ignore» («игнорируй») Google больше не показывает в выдаче блоки с определениями этих понятий, а пытается запустить «Обзор от ИИ», в котором только пустое пространство, или вступает в переписку. Очевидно, ИИ в поисковой машине воспринимает эти слова не как запросы, а как команды и пытается их выполнить. Поисковая выдача под этими блоками показывается в штатном режиме — даже ссылки на новостные материалы с описанием этой проблемы. Журналисты нескольких англоязычных ресурсов попытались воспроизвести проблему и также столкнулись со сбоями в работе поисковой машины. На запрос «Не обращай внимания» поисковая машины ответила (см. иллюстрацию): «Понял. Не обращаю внимания на ваш предыдущий запрос. Дайте знать, если захотите сегодня ещё что-то сделать или найти». В одном из случаев при запуске режима инкогнито в браузере Google отреагировал надлежащим образом, показав блок с определением слова, но во второй раз снова допустил ошибку и вывел пустой «Обзор от ИИ». Стандартная поисковая выдача ниже снова сработала корректно, показав ссылки на онлайн-словари, — но до неё нужно было прокрутить страницу. В Google признали проблему и пообещали её исправить в скором времени. «Нам известно, что „Обзоры от ИИ“ неверно интерпретируют некоторые связанные с действиями запросы, и мы работаем над исправлением, которое вскоре будет развёрнуто», — заявил представитель компании ресурсу Engadget. Отрадно, что на этот раз «Обзоры от ИИ» Google хотя бы не предлагают мазать пиццу клеем. Google представила крупнейшее обновление поиска за более чем 25 лет
20.05.2026 [10:00],
Павел Котов
Google сообщила о крупнейшем обновлении поисковой службы за более чем четверть века — в его основе лежит искусственный интеллект, а именно новая модель Gemini 3.5 Flash, предлагающая передовые возможности для управления ИИ-агентами и написания кода. 
Источник изображений: blog.google Пользователю больше не нужно подстраиваться под особенности работы поиска Google — достаточно точно описать, что именно ему нужно; можно искать по различным параметрам, используя в качестве входных данных не только текст, но также изображения, файлы, видео и даже вкладки Chrome. Обновлённое интеллектуальное поле поиска начало развёртываться во всех странах и на всех языках, где доступен «Режим ИИ». Поиск с ИИ имеет диалоговый формат — прямо из «Обзора» можно перейти к переписке с чат-ботом, в которой каждый последующий уточняющий запрос повышает релевантность ответов. 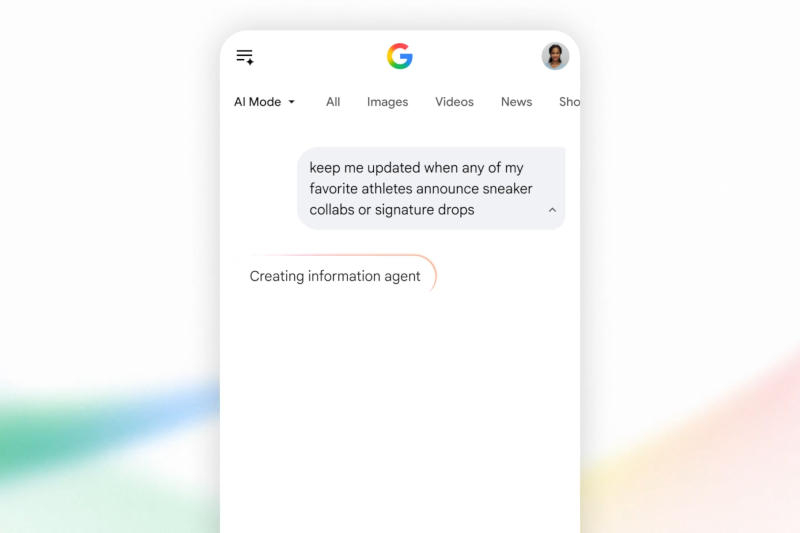 Ещё одно крупное нововведение — поисковые агенты. Их можно легко создавать, настраивать и управлять несколькими единицами прямо в поиске. Поисковые агенты работают круглосуточно в фоновом режиме, анализируя доступную информацию, чтобы найти то, что интересует пользователя. Агент изучает блоги, новостные сайты, публикации в соцсетях и самые свежие данные в реальном времени. При обнаружении подходящей информации поисковый агент отправляет пользователю уведомление: если он ищет квартиру, можно перечислить ИИ-агенту все требования, и тот будет сообщать обо всех подходящих вариантах. Первыми новой функцией смогут воспользоваться подписчики платных тарифов Google AI Pro и Ultra. Расширены функции онлайн-бронирования — ИИ Google может даже позвонить компании от имени пользователя. 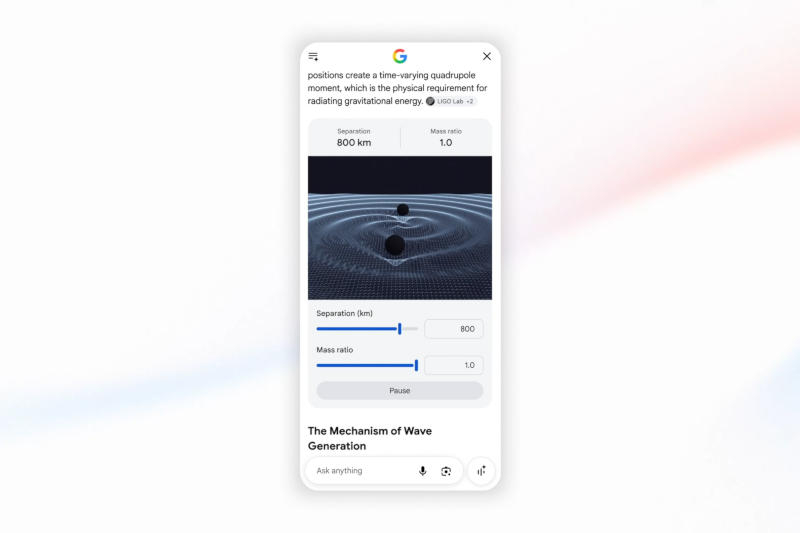 В поиске теперь работают функции Google Antigravity — ИИ-модель Gemini 3.5 Flash прямо в поисковой платформе может создать код и предоставить ответ в виде интерфейса, соответствующего потребностям пользователя. Это могут быть интерактивные визуализации, таблицы, графики или симуляции. Если же вопрос носит не разовый характер, а, например, планируется свадьба или организуется переезд, Google Antigravity в поиске создаёт панель мониторинга и трекеры, к которым можно время от времени возвращаться — получается полноценное приложение по запросу. Первыми новую функцию снова смогут опробовать подписчики Google AI Pro и Ultra. 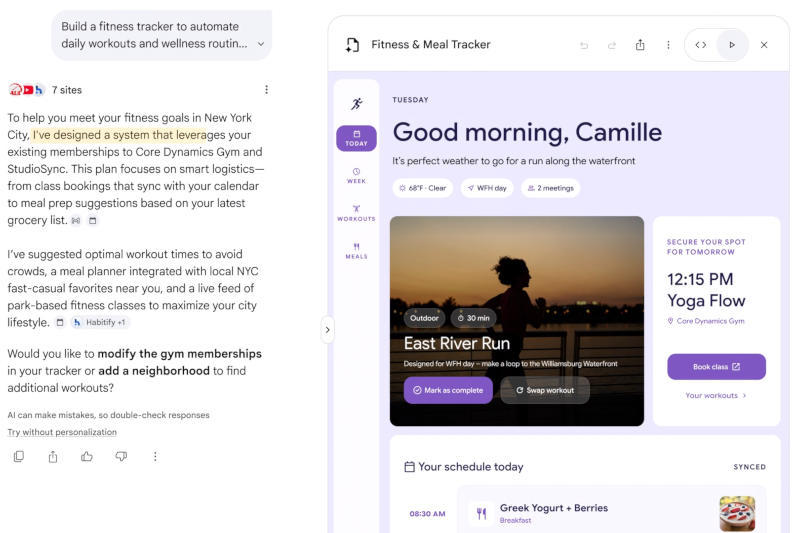 Всем остальным пользователям в 200 странах и на 98 языках Google предложила подключить к поисковой машине службу Personal Intelligence. Она анализирует данные из приложений Gmail, «Google Фото» и «Google Календарь», чтобы адаптировать поисковую выдачу персонально под пользовательский контент. ЕС обязал Google открыть конкурентам доступ к поисковым данным
16.04.2026 [16:48],
Павел Котов
Еврокомиссия предписала Google открыть сторонним сервисам доступ к своим поисковым данным, в том числе к данным чат-ботов с искусственным интеллектом — такое требование содержится в региональном «Законе о цифровых рынках», заявили в ведомстве. 
Источник изображения: Adarsh Chauhan / unsplash.com В самой Google требование регулятора восприняли без энтузиазма — технологический гигант выразил готовность бороться против этой меры, которая, по его словам, выходит за рамки дозволенного и ставит под угрозу конфиденциальность пользователей. «Сотни миллионов европейцев доверяют Google свои самые конфиденциальные поисковые запросы, в том числе личные вопросы о своём здоровье, семье и финансах, и предложение комиссии заставит нас передавать эти данные третьим лицам с неэффективной защитой конфиденциальности», — заявили в Google. Компании надлежит передавать данные об объёмах, частоте и способах подачи поисковых запросов в Google, раскрывать меры по обеспечению анонимности персональных данных, процессы регулирования доступа пользователей к персональным данным, а также параметры установления цен на поисковые данные, заявили в Еврокомиссии. «Цель [этих] мер — дать сторонним поисковым системам или „получателям данных“ возможность оптимизировать свои поисковые системы и оспорить позицию „Google Поиска“», — отметили в ведомстве. Ранее Google, самую популярную в мире поисковую систему, обвинили в нарушении «Закона о цифровых рынках». Компания внесла собственные предложения по смягчению условий для конкурентов, но те пожаловались, что указанных мер будет недостаточно. С 2017 года сумма штрафов Google в Европе достигла €9,71 млрд. Нарушение «Закона о цифровых рынках» грозит штрафом в размере до 10 % от годового дохода компании по всему миру. Google «перестал кормить» сайты — трафик из поиска обрушился, а ИИ даёт меньше 1 % переходов
18.03.2026 [20:36],
Сергей Сурабекянц
Данные, собранные Chartbeat и опубликованные Axios, показывают, что за последний год трафик из поиска Google на сайты резко упал, причём особенно сильно это затронуло небольшие проекты. Хотя многие продукты на основе ИИ, включая собственные разработки Google, улучшили отображение ссылок, в отчёте утверждается, что «чат-боты по-прежнему генерируют менее 1 % всех переходов на страницы издателей». 
Источник изображений: unsplash.com Согласно данным отчёта, переходы из поиска Google Search для «небольших издателей» упали на 60 %, в то время как для «средних издателей» (10 000–100 000 ежедневных просмотров страниц) падение составило 47 %. Для «крупных издателей» (более 100 000 ежедневных просмотров) падение составило 22 %. И дело не только в поиске Google. Согласно отчёту, хотя трафик из поисковой выдачи упал на 34 %, трафик из Google Discover также снизился на 15 % за последний год. Что касается трафика от чат-ботов на основе ИИ, в отчёте утверждается, что «новостные и медиа-сайты получают наибольшее общее количество просмотров страниц с платформ ИИ», но с «наименьшей вовлеченностью», по-видимому, потому, что пользователи переходят по ссылкам на источники только для проверки фактов, полученных с помощью заведомо ненадёжных результатов ИИ. В отчёте также отмечается, что «электронная почта, приложения и мессенджеры» являются растущим источником реферального трафика, и что общий трафик «снизился на 6 % в период с 2024 по 2025 год». В другом подобном недавнем отчёте было установлено, что особенно сильно пострадали технологические СМИ в последние годы: трафик из поиска Google на такие сайты, как The Verge, HowToGeek и многие другие, упал за последний год на 85 % и более. Особенно сильно пострадал ресурс Digital Trends – падение составило 97 %, при этом издание уволило почти весь свой штатный персонал в начале 2025 года.  В прошлом году Google сообщила, что «общий объем органических кликов из Google Search на веб-сайты оставался относительно стабильным из года в год», а «среднее качество кликов увеличилось», что противоречит выводам отчёта Axios. Компания также заявила тогда, что «очень заботится – возможно, больше, чем любая другая компания – о здоровье веб-экосистемы». Google опробует изменения в поисковой выдаче в ЕС под угрозой многомиллиардного штрафа
26.02.2026 [11:34],
Владимир Мироненко
Google запустит тестирование изменений в поисковой выдаче, выполняя требование Еврокомиссии обеспечить равные права конкурирующих сервисов с её собственными в поиске отелей, авиабилетов и ресторанов в соответствии с «Законом о цифровых рынках» (DMA) ЕС, сообщило агентство Reuters со ссылкой на информированные источники. 
Источник изображения: Firmbee.com/unsplash.com Раннее Еврокомиссия пригрозила штрафом за нарушение норм DMA, если компания продолжит отдавать приоритет в поисковой выдаче собственным сервисам, таким как «Покупки» и «Рейсы». До этого Google выступала с различными предложениями, чтобы урегулировать конфликт с конкурентами и регулирующими органами ЕС, но ни одно из них не было реализовано, поскольку были признаны недостаточными для устранения привилегированного положения поисковой системы «дочки» Alphabet. Проблема ведёт к противостоянию Google с сервисами вертикального поиска (VSS), специализирующимися на определённой категории информации с привязкой к таким секторам, как отели, авиакомпании и рестораны, или с компаниями в этих секторах, отметило Reuters. По словам источника, в рамках эксперимента в результатах поиска будут отображаться как результаты VSS, так и результаты Google, при этом по умолчанию будут отображаться лучшие вертикальные поисковые системы, сообщил источник. Отели, авиакомпании, рестораны и транспортные службы с данными из лент в режиме реального времени будут располагаться либо ниже, либо выше списка вертикальных поисковых систем. Изменения вскоре будут внедрены по всей Европе. Первоначально это коснётся поиска жилья, но позже добавят отслеживание авиарейсов и другие сервисы, сообщил источник. В случае невыполнения требований регулятора компании грозит штраф за несоблюдение европейского антимонопольного законодательства, который может составить до 10 % от объёма глобальных продаж за год и до 20 % в случае повторного нарушения. С 2017 года Google было назначено штрафов за нарушение антимонопольного законодательства ЕС на €9,71 млрд ($11,5 млрд). Google сделает ссылки в ИИ-поиске заметнее на фоне жалоб издателей
18.02.2026 [11:44],
Павел Котов
Ссылки на внешние сайты, которые показываются в выдаче при поиске с использованием функций искусственного интеллекта, примут более заметный вид. Об этом сообщил курирующий поисковое направление вице-президент Google Робби Штейн (Robby Stein). 
Источник изображения: BoliviaInteligente / unsplash.com При наведении курсора на источники в разделах «Обзоры от ИИ» и «Режим ИИ» в десктопной версии поиска будет появляться всплывающее окно, дополняющее описание статей и сопровождающие выдачу изображения. Google будет показывать «более подробные и заметные значки ссылок» в подготовленных ИИ ответах на настольных компьютерах и мобильных устройствах. «Наше тестирование показало, что этот новый пользовательский интерфейс более привлекателен и упрощает поиск отличных материалов в интернете», — сообщил Робби Штейн. Раздел «Обзоры от ИИ» представляет собой расположенный над основной выдачей блок, в котором находится сгенерированная ИИ сводка данных и материалов в поиске. Функция «Режим ИИ» — более радикальный механизм, который предполагает поиск информации в интерфейсе чат-бота без перехода к сторонним источникам. Google продолжает развивать эти функции, хотя владельцы сайтов всё чаще выражают опасения, что ИИ в поиске снижает трафик на новостные и прочие ресурсы. Поисковый гигант настаивает на своём, считая, что традиционный открытый интернет теперь переживает «стремительный упадок». В прошлом году Еврокомиссия инициировала расследование в отношении Google на предмет возможной угрозы, которую функции поискового ИИ представляют для бизнеса владельцев сайтов, если их материалы появляются в сводках, но сами издатели не получают за это «надлежащей компенсации». В ответ Google заявила, что изучит возможность вообще исключить такие ресурсы из поисковых ИИ-сервисов, и начала обогащать «Режим ИИ» ссылками на источники. Google призвала создателей сайтов не оптимизировать контент под ИИ-поиск
10.01.2026 [18:53],
Павел Котов
Несмотря на то, что фрагментированный контент, который подаётся на сайтах небольшими порциями, часто выдаётся в рекомендациях при ИИ-поиске, Google настаивает, что в долгосрочной перспективе изготовление такого контента не приведёт для создателей сайтов ни к чему хорошему. 
Источник изображения: BoliviaInteligente / unsplash.com Владельцам веб-ресурсов не следует разбивать материалы на небольшие порции только по той причине, что этот формат считается предпочтительным для больших языковых моделей вообще и ИИ-режима в поиске Google в частности. Об этом заявил бывший специалист Google по вопросам поисковой оптимизации Дэнни Салливан (Danny Sullivan); он также отметил, что обсуждал этот вопрос с инженерами Google, и те подчеркнули, что создавать контент специально для больших языковых моделей и вообще для поисковых машин не следует. Эксперт, впрочем, признал, что в отдельных случаях это работает, но в качестве долгосрочной такая стратегия ему представляется бесперспективной. «Давайте предположим, что в некоторых крайних случаях, давайте даже предположим, что, возможно, в нескольких крайних случаях вы получите здесь какое-то преимущество», — допустил он. Этот успех окажется лишь временным: владелец сайта будет редактировать или создавать новый фрагментированный контент в этом формате, считая, что он работает для ИИ, но затем системы поискового ранжирования по мере совершенствования будут продолжать двигаться в сторону поощрения контента, созданного для людей, и фрагментированный формат материалов лишится эффективности. Ретроспективный анализ стратегий поискового продвижения за несколько лет так или иначе сводится к тому, что материалы на сайте должны быть ориентированы на живых пользователей, отмечает Search Engine Land. Эта стратегия играет на создание аудитории, которая не будет зависеть ни от Google, ни от любых других систем ИИ. А фрагментированный контент, в свою очередь, может навредить репутации ресурса у людей — и краткосрочная выгода такого риска не стоит. В «Google Фото» вернули ярлыки для поиска по лицам и мордам — ранее их убрали под влиянием ИИ
23.12.2025 [21:18],
Сергей Сурабекянц
Группировка и поиск по лицам, пожалуй, одни из лучших функций «Google Фото», но переход к более активному использованию поиска на основе ИИ лишил пользователей одного из удобных ярлыков, помогавших находить изображения людей или животных. Теперь ситуация исправлена — на странице поддержки Google появилась информация о том, что недавние обновления приложения восстановили поддержку «ярлыков для поиска по лицам». 
Источник изображения: unsplash.com Ранее эти ярлыки отображались на странице поиска вместе с изображениями наиболее часто встречающихся объектов — людей или животных — с удобным предварительным просмотром по всей странице. После запуска функции «Спросить у фотографий» (Ask Photos) эта панель ярлыков из поиска исчезла. Ярлык поиска по лицам вернулся как в «классическом» поиске, так и в функции «Спросить у фотографий». В последнем случае она появляется после нажатия на текстовое поле для начала поиска, тогда как в «классическом» поиске она отображается мгновенно. 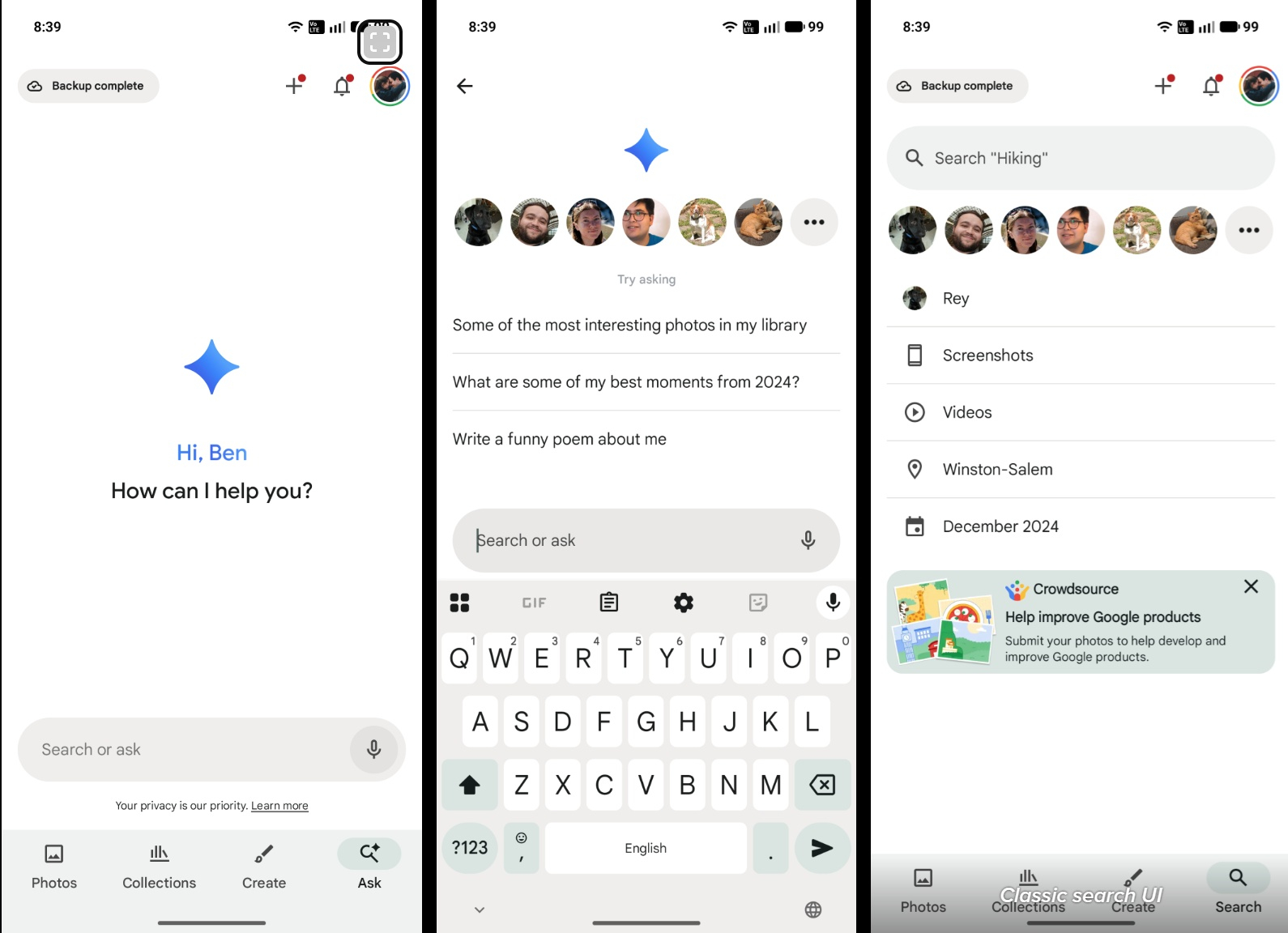
Источник изображения: 9to5Google «Отличные новости! Мы учли ваши пожелания о более простом способе поиска фотографий и видео важных для вас людей в Google Photo. Теперь мы добавляем ярлыки для ваших групп лиц в классический поиск и функцию «Спросить у фотографий» на Android, iPhone и iPad», — сообщил представитель Google. Теперь на вкладке «Поиск» или «Задать вопрос» пользователь может сразу перейти на страницу своих самых любимых людей или питомцев. Для использования функции необходимо в настройках включить группировку лиц. Поисковик Google получил ещё одну ИИ-функцию, и она выглядит полезной
16.12.2025 [23:21],
Владимир Фетисов
Знакомая всем строка поиска на странице Google.com ранее уже получила кнопку ИИ-режима справа. Теперь же слева разработчики добавили новую кнопку в виде знака плюса, которая позволяет загрузить изображение или файл. После этого в строке поиска можно ввести текстовый запрос, относящийся к ранее загруженному элементу, чтобы найти связанную с ним информацию в интернете. 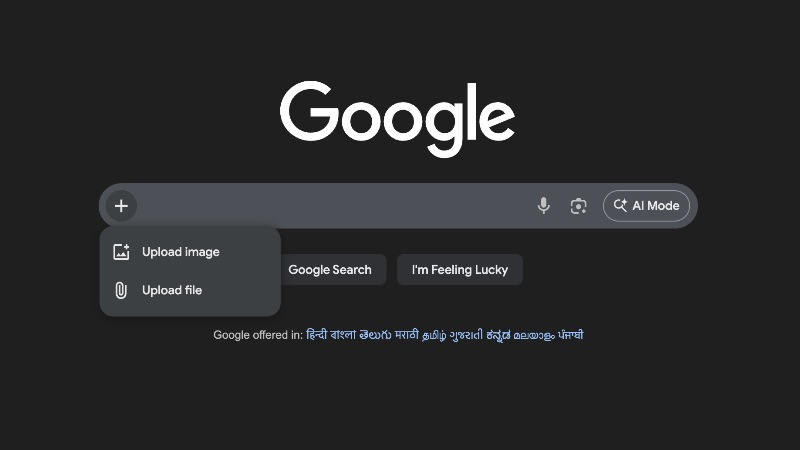
Источник изображения: Google Ответы поисковика на такие запросы формируются в окне ИИ-режима, взаимодействие в котором напоминает процесс общения с чат-ботом. Однако не сразу понятно, что кнопка в виде знака плюса как-то связана с ИИ-режимом. Это связано с тем, что значок объектива для традиционного поиска по картинкам остался на месте. Даже при нажатии на знак плюса появляется сообщение «Загрузить файл» или «Загрузить изображение» без упоминания ИИ-режима. Трудно сказать, какой процент пользователей переходят непосредственно на страницу Google.com вместо того, чтобы писать запрос сразу в строке поиска в браузере. Веб-обозреватель Google Chrome продолжает уверенно лидировать в этом сегменте с долей рынка примерно в 71 %. Однако на фоне усиления конкуренции с ChatGPT ранее в этом году представители Google намекали на более глубокую интеграцию собственных ИИ-продуктов. Так в результате этой деятельности ИИ-бот Gemini стал частью браузера Chrome для iPhone и iPad. Компания также задействовала ИИ-инструменты в своей персонализированной ленте контента Google Discover и других продуктах. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


