|
Опрос
|
реклама
Быстрый переход
Новая статья: Обзор сервера ASUS RS720A-E13-RS8G: DC-MHS во всей красе
12.05.2026 [00:06],
3DNews Team
Данные берутся из публикации Обзор сервера ASUS RS720A-E13-RS8G: DC-MHS во всей красе Облачные провайдеры оставили ИИ-стартапы без доступа к GPU — все мощности съели Anthropic и OpenAI
26.04.2026 [11:37],
Дмитрий Федоров
Облачные провайдеры — Microsoft, Amazon и CoreWeave — зарезервировали мощности графических процессоров (GPU) за Anthropic, OpenAI и собственными командами, оставив ИИ-стартапы с многомесячными очередями. Нехватка вычислительных ресурсов затронула стартапы, проинвестированные венчурными фондами — Sequoia Capital, Founders Fund, General Catalyst и Andreessen Horowitz. Арендные ставки за шесть месяцев выросли более чем на 25 %, а по данным Azure дефицит продлится как минимум до конца 2026 года. 
Источник изображения: Alex Shuper / unsplash.com Дефицит охватил широкий круг ИИ-компаний: малые и средние игроки вынуждены бороться за остатки мощностей по всё более высоким ценам. Партнёр General Catalyst Хемант Танеджа (Hemant Taneja) разослал анкеты основателям стартапов, в которые вложился фонд, чтобы оценить реальный доступ к GPU. В анкете Танеджа написал: «Мы получаем многочисленные сигналы о том, что доступ к вычислительным ресурсам, прежде всего к GPU, стал одним из главных ограничений для вашего развития в этом году». В ответ General Catalyst создаёт общие вычислительные пулы и намерен напрямую договариваться с провайдерами от имени стартапов из своих инвестиционных портфелей. Ситуация напоминает начало 2023 года, когда крупные провайдеры свернули публичный доступ к ресурсам в пользу внутренних операций и ключевых клиентов вроде OpenAI — тогда Andreessen Ventures и Index Ventures начали формировать собственные GPU-пулы для стартапов из своих портфелей. Однако нынешняя нехватка острее: скачок спроса на ИИ-инструменты для разработки ПО заставил платформы резко сократить квоты для небольших клиентов, а значительная часть двух- и трёхлетних контрактов, заключённых стартапами в прошлые годы, истекает именно сейчас — облачные провайдеры пользуются этим, чтобы перераспределить мощности в пользу более платёжеспособных клиентов. Многомиллиардные долгосрочные сделки, которые Microsoft, Amazon и CoreWeave заключили с Anthropic и OpenAI, обеспечили этим компаниям приоритетный доступ к GPU. Тем не менее Anthropic всё ещё испытывает острую нехватку мощностей на фоне стремительного роста бизнеса. По сведениям сотрудников компании, Azure сообщила им, что дефицит сохранится как минимум до конца 2026 года. Microsoft выстроил трёхуровневую систему распределения GPU: около 1000 крупных годовых плательщиков пользуются приоритетным доступом, средние компании получают поддержку выделенных менеджеров, малый и микробизнес работает через партнёрских агентов. Чтобы арендовать чипы Blackwell, клиент обязан взять не менее 1000 единиц и подписать контракт на срок от одного года с бюджетом от десятков миллионов долларов. Старые чипы NVIDIA рядовые клиенты ждут от нескольких недель до нескольких месяцев. Azure отслеживает загрузку и отзывает доступ при простое даже в несколько часов; параллельно компания сворачивает вычислительные льготы в программе поддержки стартапов: компании, не использующие выделенные чипы в полном объёме, навсегда лишаются доступа к GPU. Генеральный директор Lightning AI Уилл Фалкон (Will Falcon) сообщил, что платформа управляет примерно 40 000 GPU, тогда как в очереди стоят около 40 предприятий с суммарной потребностью до 400 000 чипов. За шесть месяцев ставки выросли более чем на 25 %: часовая цена за чип поднялась с $1,6 до более чем $2, а на популярные конфигурации наценки ещё выше. Основу парка составляют чипы NVIDIA на архитектуре Hopper предыдущего поколения. Четырёхлетний разработчик ИИ-моделей генерации изображений Krea привлёк $83 млн при участии Andreessen Ventures и Bain Capital Ventures. Сооснователь и генеральный директор компании Виктор Перес (Victor Perez) рассказал, что ещё шесть месяцев назад несколько провайдеров сами добивались партнёрства: компания заключила шестимесячный контракт на аренду нескольких сотен чипов NVIDIA Blackwell по $2,8 в час. Когда Krea попыталась расширить мощности для обучения ИИ-моделей с нуля, торговые представители провайдеров перестали выходить на связь или ссылались на отсутствие ресурсов; когда контакт удавалось установить — требовали трёхлетних контрактов и существенного повышения цены. За несколько дней нужные кластеры выкупили другие клиенты. В итоге Krea подписала однолетний контракт на те же чипы по $3,7 в час, то есть на 32 % дороже, хотя по рыночным меркам это относительно немного. «Нехватка вычислительных мощностей в критический момент может уничтожить компанию», — предупредил Перес, добавив, что рост цен пережить можно, а перебои в поставках стали бы катастрофой. Другой основатель рассказал, что планировал арендовать около 1000 GPU с высокой пропускной способностью: представитель NVIDIA предупредил об огромных очередях, суточная аренда такого кластера превышает $70 000 — а свободных ресурсов всё равно нет. Часть стартапов строит собственную инфраструктуру. Основатель Collide — разработчика ИИ-агентов для нефтегазовой отрасли, привлёкшего $14 млн в посевном раунде, — Колин Макклеллан (Colin McLellan) заявил, что компания намерена вложить около $500 000 в GPU NVIDIA, чтобы развернуть частный вычислительный кластер, при необходимости арендовав площадь в ЦОД напрямую. По расчётам Макклеллана, несмотря на высокие первоначальные затраты, собственная инфраструктура исключает риск перебоев и в перспективе нескольких лет выходит дешевле многолетней аренды. NASA разгонит спрос на GPU среди учёных из-за лавины данных с новых телескопов
23.04.2026 [18:11],
Дмитрий Федоров
NASA запустит космический телескоп «Нэнси Грейс Роман» (RST) на орбиту Земли в сентябре 2026 года — на восемь месяцев раньше графика. За время работы телескоп передаст астрономам 20 000 Тбайт данных, которые вместе с потоками информации от других обсерваторий усиливают спрос учёных на графические процессоры, необходимые для обработки таких объёмов информации. 
Источник изображений: NASA, JWST К данным телескопа «Роман» добавятся 57 Гбайт снимков, которые ежесуточно поступают с космического телескопа NASA «Джеймс Уэбб» (James Webb), работающего с 2021 года. Позднее в 2026 году начнёт наблюдения обсерватория им. Веры Рубин (Vera C. Rubin Observatory) в чилийских Андах, которая будет собирать по 20 Тбайт данных за ночь. Космический телескоп «Хаббл», некогда считавшийся эталоном, передаёт всего 1–2 Гбайт данных в сутки. Те времена, когда все эти показания изучались вручную, давно прошли, и астрономы, как и все, кто работает с массивами данных такого масштаба, переходят на GPU. Брант Робертсон (Brant Robertson), астрофизик из Калифорнийского университета в Санта-Крусе, наблюдал эту тенденцию из первых рядов, участвуя в работе с данными перечисленных миссий. Робертсон 15 лет сотрудничает с Nvidia, применяя GPU к задачам изучения космоса. Начинал он с симуляций, проверяющих теории о взрывах сверхновых, а теперь разрабатывает инструменты анализа потока данных с новейших обсерваторий. «Произошла эволюция: от изучения отдельных объектов — к анализу больших массивов данных на центральных процессорах, а затем — к тем же видам анализа, но уже с ускорением на GPU», — рассказал Робертсон. Вместе с тогдашним аспирантом Райаном Хаузеном (Ryan Hausen) Робертсон создал модель глубокого обучения Morpheus, способную обрабатывать большие массивы данных и выявлять галактики. Ранний ИИ-анализ данных «Джеймса Уэбба» обнаружил неожиданно большое количество дисковых галактик определённого типа и заставил скорректировать теории о развитии Вселенной.  Архитектуру Morpheus Робертсон переводит со свёрточных нейронных сетей на трансформеры — архитектуру, стоящую за взлётом больших языковых моделей (LLM). После перехода модель сможет анализировать в несколько раз большую площадь неба, чем сейчас. Параллельно учёный строит генеративные ИИ-модели, обученные на данных космических телескопов, которые улучшают качество наблюдений земных обсерваторий, снимки которых искажает атмосфера. Вывести на орбиту восьмиметровое зеркало по-прежнему трудно даже с учётом прогресса в ракетостроении, поэтому программная обработка данных обсерватории Рубин — лучшая из доступных альтернатив. Давление мирового спроса на GPU Робертсон ощущает напрямую. На средства Национального научного фонда (NSF) он создал GPU-кластер в Калифорнийском университете в Санта-Крусе, однако оборудование устаревает, а число исследователей, которым нужны ресурсоёмкие вычисления, растёт. Однако Администрация действующего президента США собирается сократить финансирование NSF на 50 %. «Люди хотят заниматься анализом на основе ИИ и машинного обучения, а GPU — единственный инструмент для этого, — сказал Робертсон. — Приходится проявлять предприимчивость, особенно когда работаешь на переднем крае технологий. Университеты осторожны с рисками, потому что их ресурсы ограничены, и нужно идти и показывать: „Смотрите, вот куда движется наша область“». SpaceX готовит выпуск собственного GPU вместе с Tesla, но признаёт проект рискованным
23.04.2026 [12:05],
Алексей Разин
Подготовка SpaceX к публичному размещению акций подразумевает предоставление американским регуляторам отчёта о рисках, влияющих на бизнес этой пока ещё частной аэрокосмической компании. Среди прочих факторов, она относит проект по выпуску GPU собственной разработки к довольно рискованным инициативам. 
Источник изображения: Tesla Выпускать графические процессоры собственной разработки для нужд инфраструктуры ИИ, как следует из изученного Reuters документа по форме S-1, компания SpaceX собирается совместными усилиями с Tesla на мероприятии Terafab, которое будет построено и введено в строй в ближайшие годы. Помимо прочего, SpaceX осознаёт, что организация выпуска GPU собственной разработки потребует существенных капитальных вложений. Когда ранее Илон Маск (Elon Musk) рассказывал о проекте Terafab, он не уточнял, какого типа чипы будут производиться на этом совместном предприятии SpaceX и Tesla. На этой неделе он пояснил, что Tesla будет выпускать свои чипы с использованием технологии Intel 14A, но в данном случае не уточнялось, где именно это будет происходить. До сих пор Tesla занималась разработкой чипов для бортовых систем своих электромобилей типа AI5, изображённого на иллюстрации выше, но термин «GPU» в отчётности SpaceX подразумевает разработку более сложного по компоновке процессора. По замыслу Маска, на предприятии Terafab будет осуществляться не только обработка кремниевых пластин, но и упаковка готовых чипов с последующим и промежуточным тестированием. Процесс будет подразумевать и интеграцию микросхем памяти. SpaceX может использовать термин «GPU» и для общего обозначения ИИ-чипов, поэтому делать какие-то выводы об ассортименте разрабатываемых Tesla полупроводниковых компонентов преждевременно. Первая из компаний также признаётся, что до сих пор не имеет долгосрочных контрактов ни с одним из своих поставщиков чипов, и продолжит зависеть от них в значительной части своих потребностей, поэтому данный фактор тоже формирует серьёзные риски для деятельности SpaceX. Нет никакой гарантии, как подчёркивает компания, что проект по запуску Terafab удастся реализовать в заданные сроки и в нужном масштабе. Руководство TSMC в этом месяце уже отмечало, что путь Tesla к массовому выпуску собственных чипов не будет ни лёгким, ни быстрым. Видеокарты Nvidia с GDDR6-памятью оказались уязвимы перед атакой GPUBreach, и защиты от неё, кажется, нет
05.04.2026 [14:51],
Дмитрий Федоров
Ранее стало известно про атаки GDDRHammer и GeForge, с помощью которых можно воздействовать на содержимое GDDR6-памяти видеокарт Nvidia, что позволяет повредить таблицы страниц GPU, перенаправить доступ к памяти центрального процессора и добиться полной компрометации системы. При этом считалось, что включение механизма управления памятью IOMMU является надёжной защитой от этого типа атак. Теперь же стало понятно, что проблема серьёзнее, чем представлялось ранее. 
Источник изображения: nvidia.com Исследователи описали новый сценарий атаки на графические процессоры (GPU) NVIDIA с памятью GDDR6 под названием GPUBreach. Атака способна привести к получению в основной системе командной оболочки с правами суперпользователя даже при включённом блоке управления памятью для операций ввода-вывода (IOMMU). Исследования проводили на NVIDIA RTX A6000 — профессиональной графической карте с памятью GDDR6 и поддержкой механизма контроля и исправления ошибок памяти (ECC). Другие модели GPU в материале не упомянуты, однако это, по-видимому, относится и к RTX 3060. GPUBreach относится к той же области исследований, что GDDRHammer и GeForge, но описанный в нём сценарий устроен более сложно. Атака начинается с искажения таблиц страниц GPU, после чего непривилегированный вычислительный модуль CUDA получает произвольный доступ к памяти GPU на чтение и запись. Это открывает путь к атакам на другие процессы и дальнейшему повышению привилегий. 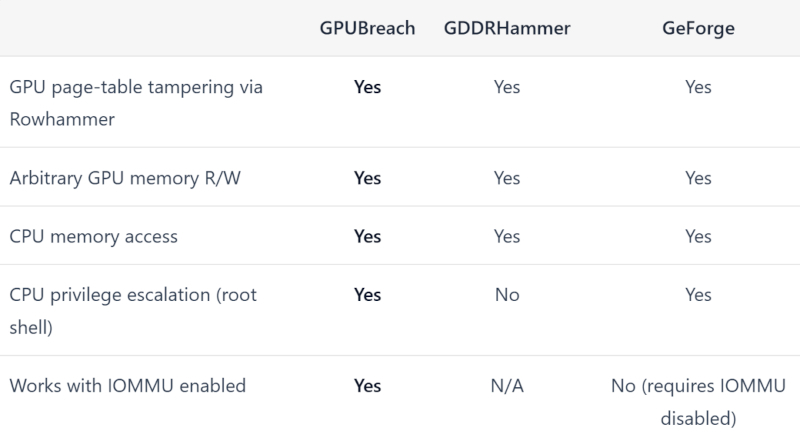
Источник изображения: GPU Breach Главное отличие новой схемы атаки состоит в том, что она, по утверждению исследователей, сочетает этот этап с недавно выявленными ошибками, связанными с безопасностью памяти, в драйвере NVIDIA и тем самым переходит от контроля над GPU к компрометации ядра операционной системы (ОС) на стороне CPU. Именно поэтому GPUBreach, по сравнению самих авторов, выглядит наиболее продвинутым из трёх опубликованных сценариев. На странице проекта GDDRHammer представлен как метод, позволяющий получить доступ к памяти CPU, но не приводящий к повышению привилегий на стороне CPU. GeForge, в свою очередь, может привести к этому только при отключённом IOMMU. Сценарий атаки GPUBreach отличается тем, что сохраняет работоспособность и при включённом IOMMU, а именно так подобные системы обычно и настраиваются. 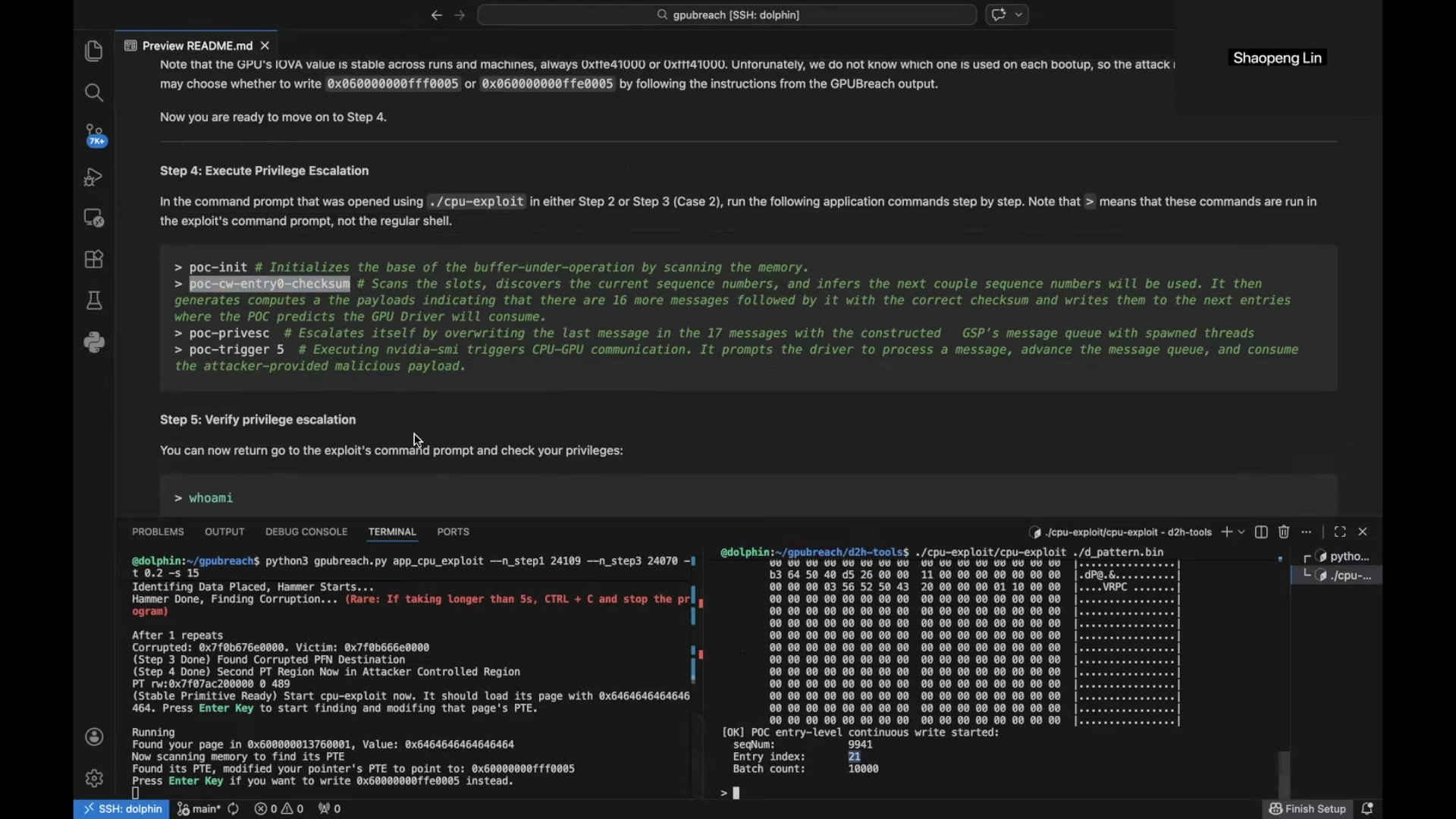 NVIDIA по-прежнему рекомендует включать System-Level ECC там, где он доступен. Авторы GPUBreach согласны, что ECC способен помочь при некоторых изменениях отдельных битов, но не считают его полным решением. Потребительские GeForce и мобильные GPU, по их оценке, обычно вообще не имеют доступа к ECC. Гендир Тан собрался возродить в Intel разработку GPU для дата-центров — для этого переманили топ-архитектора из Qualcomm
04.02.2026 [04:52],
Алексей Разин
Попытки компании Intel вернуться на рынок дискретной графики предпринимаются с прошлого десятилетия, в 2017 году соответствующие усилия возглавил перешедший из конкурирующей AMD Раджа Кодури (Raja Koduri), но почти три года назад он покинул Intel. Нынешний глава компании объявил, что недавно назначил нового главного архитектора GPU. 
Источник изображения: Intel Эти заявления прозвучали из уст Лип-Бу Тана (Lip-Bu Tan) на конференции Cisco AI Summit, как отмечает CNBC. Не называя имени нового руководителя этого направления, глава Intel дал понять, что на уговоры кандидата ушло немало усилий и времени. В любом случае, для реализации изменений в сфере разработки графических процессоров Intel придётся потратить несколько лет, поэтому эффект от нового назначения не будет сиюминутным. Скорее всего, усилия нового руководителя будут направлены на разработку линейки конкурентоспособных ускорителей Intel для сегмента искусственного интеллекта. Собственные разработки наверняка будут сочетаться с использованием ноу-хау поглощаемых Intel стартапов, как это было ранее. Одновременно Лип-Бу Тан назвал искусственный интеллект главным вызовом для рынка памяти, который переживает небывалый рост цен и сталкивается с дефицитом микросхем. По мнению главы Intel, улучшения ситуации нет смысла ждать ранее 2028 года. Ветеран Qualcomm перешёл в Intel, чтобы разрабатывать серверные GPU
17.01.2026 [07:43],
Алексей Разин
Попытки Intel разрабатывать высокопроизводительные графические процессоры тянутся уже несколько десятилетий, ради достижения таких целей компания то и дело привлекает специалистов с опытом работы у конкурентов. Свежим кадровым приобретением в этой сфере стал переход в Intel ветерана Qualcomm, который на прежнем месте руководил разработкой GPU. 
Источник изображения: LinkedIn Речь идёт об Эрике Демерсе (Eric Demers), как поясняет издание CRN. Он около 14 лет проработал в Qualcomm, в последнее время он занимал в компании пост старшего вице-президента по разработкам. Со следующей недели Эрик Демерс займёт аналогичную должность в Intel, где также будет руководить разработкой GPU с уклоном на применение в сегменте искусственного интеллекта. По словам аналитиков Moor Insights and Strategy, Демерс является не только опытным руководителем, но и компетентным разработчиком архитектур GPU. Ему вполне по силам разработать графический процессор с нуля, как подчёркивают эксперты. В Qualcomm Демерс курировал разработку графических ядер семейства Adreno, которые применялись в мобильных устройствах и ПК, а также в сегменте Интернета вещей, устройствах дополненной и виртуальной реальности и автомобильной электронике. Поскольку семейство процессоров Snapdragon X2 предназначалось для использования в ПК, опыт их разработки должен помочь Демерсу на новом рабочем месте. До перехода в Qualcomm в 2012 году Эрик Демерс успел поработать техническим директором подразделения AMD, которое отвечало за разработку графических решений. Демерс успел поработать в ATI, прежде чем её поглотила в 2006 году компания AMD, а ранее он трудился в Silicon Graphics. Intel в последние годы не только теряет руководителей и занимается постоянной реструктуризацией, но и не может нащупать почву для развития линейки своих ИИ-ускорителей. Поглощая профильные стартапы, она не может добиться внятного успеха на этом рынке, где доминирует Nvidia. Органическое же развитие в сфере серверных GPU потребует нескольких лет, но приглашение профессионалов в сфере их разработки подчёркивает, что Intel готова двигаться этим путём. Китайский производитель Zephyr рассказал о поломках Radeon RX 6000 из-за трещин, вздутий и короткого замыкания в GPU
28.12.2025 [21:42],
Николай Хижняк
В 2023 году начали появляться сообщения о выходящих из строя видеокартах Radeon RX 6000 на базе графических процессоров Navi 21, что вызвало вопросы о причинах этих инцидентов. Хотя это было, по сути, локальное, изолированное событие, которое с тех пор было урегулировано, спустя два года появилась новая информации. 
Источник изображений: Zephyr Китайский производитель видеокарт Zephyr вдруг сообщил, что на сегодняшний день заменил по гарантии множество высокопроизводительных видеокарт Radeon RX 6000 (в частности, RX6800/RX6900XT) на архитектуре RDNA 2, у которых были неисправными графические чипы. Компания также продемонстрировала сами чипы, вышедшие из строя из-за трещин, вздутий или короткого замыкания. По словам Zephyr, существует «вероятность в 1 % подобных инцидентов каждый год», имея в виду вероятность для пользователей встретится с такими повреждениями GPU.  Компания опубликовала фотографии лотка с неисправными графическими чипами, которые были заменены в рамках гарантийных обязательств. Она заявила, что в то время как другие производители часто отказывают в гарантийном обслуживании в таких случаях, Zephyr всегда выполняла свои обязательства и будет продолжать это делать. В сообщении компания говорит о серьёзных ошибках бренда в обслуживании клиентов, но при этом подчеркивает и положительные моменты.  На китайском видеохостинге Bilibili опубликовано видео, демонстрирующее эти GPU крупным планом, с различными деформациями. Большинство из них вышло из строя из-за короткого замыкания. На некоторых чипах заметно вздутие со стороны задней части подложки, у некоторых треснули кристаллы. Все эти вышедшие из строя графические процессоры хранятся в офисах Zephyr как напоминание о клиентах, которым они помогли. Как пишет портал Tom’s Hardware, на момент появления первых сообщений о подобных повреждениях графических процессоров серии RX 6000, один немецкий ритейлер объяснил их выход из строя сочетанием криптовалютного бума (многие карты с такими повреждениями активно использовались в майнинге), а также эксплуатацией GPU в условиях высокой влажности. Однако публичных жалоб пользователей на подобные инциденты не было, поскольку это не было масштабной проблемой. Энтузиаст использовал тепловые трубки процессорного кулера для жидкостного охлаждения GPU
07.12.2025 [07:24],
Анжелла Марина
Энтузиаст TrashBench реализовал нестандартный моддинг-проект, в ходе которого переделал воздушный кулер Thermalright Peerless Assassin в гибридную систему охлаждения для видеокарты. В основе модификации лежит использование тепловых трубок кулера в качестве каналов для циркуляции охлаждающей жидкости. 
Источник изображения: TrashBench/YouTube Тепловые трубки в стандартных воздушных кулерах представляют собой герметичные полости, частично заполненные рабочей жидкостью. При нагреве жидкость испаряется в зоне контакта с источником тепла (у медного основания), а пар перемещается к более холодной части — рёбрам радиатора, где конденсируется и возвращается к основанию под действием капиллярных сил, обеспечивая непрерывный фазовый перенос тепла. В данном случае моддер аккуратно удалил часть алюминиевых пластин радиатора, обнажив тепловые трубки, а затем срезал их верхние участки, чтобы получить доступ к внутренним каналам, ведущим непосредственно к медному основанию. К этим каналам, как пишет Tom's Hardware, были герметично подсоединены тонкие водонесущие трубки. В качестве охлаждающей жидкости использовалась вода, подкрашенная зелёным красителем, подаваемая 12-вольтовым диафрагменным насосом от портативного охладителя со льдом. Итоговая система была установлена на видеокарту MSI GeForce RTX 3070, у которой была демонтирована штатная система охлаждения, чтобы обеспечить прямой контакт медного основания кулера с кристаллом графического процессора (GPU). В ходе тестирования температура графического процессора стабилизировалась на уровне минус 14 градусов Цельсия. По словам TrashBench, такая эффективность охлаждения позволила разогнать GPU на дополнительные 320 МГц, что в совокупности обеспечило средний прирост производительности на уровне 10 % в играх и бенчмарках по сравнению с эталонными показателями видеокарты в штатной комплектации. Отмечается, что ранее этот же моддер экспериментировал с погружением видеокарт в трансмиссионное масло, однако новая реализация охлаждения представляется более практичной с точки зрения повторяемости и эксплуатационной устойчивости. Как построить 5000-ваттный GPU будущего — Intel расскажет на ISSCC 2026
28.11.2025 [01:39],
Николай Хижняк
Насыщенная программа конференции ISSCC 2026, которая пройдет в феврале будущего года, включает немало интересных тем. Среди них — «как реализовать 5000-ваттные графические процессоры». Идею хочет предложить не абы кто, а заслуженный исследователь Intel, проработавший в компании более 25 лет, пишет Computer Base. 
Источник изображения: Intel Каладхар Радхакришнан (Kaladhar Radhakrishnan) давно и активно работает в области технологий питания микросхем и компонентов. Многочисленные публикации его работ доступны онлайн. На конференции ISSCC в феврале 2026 года он представит один из своих последних проектов, который в полной мере соответствует современным тенденциям: интегрированные решения по регулированию напряжения для графических процессоров мощностью 5 кВт. Презентация состоится 19 февраля в рамках панельной дискуссии, посвященной теме «Обеспечение будущего ИИ, высокопроизводительных вычислений и архитектуры чиплетов: от кристаллов до корпусов и стоек». Ключевая идея предложения — использование в составе GPU интегрированных регуляторов напряжения (IVR). Сама по себе технология IVR не является новинкой в отрасли. Однако её использование в составе графических процессоров для обеспечения значительно более высокой мощности всё ещё остаётся относительно новой областью. Следующее поколение больших GPU в ускорителях ИИ будет потреблять от 2300 до предположительно 2700 Вт. Nvidia Vera Rubin Ultra и её преемник Feynman Ultra, по слухам, будут потреблять более 4000 Вт. Таким образом, цель Intel в 5 кВт для GPU — это совсем не нереалистичная цифра на будущее. Предполагается, что применение IVR в составе GPU потребует использования технологии корпусирования чипов Foveros-B. Данная технология ожидается не ранее 2027 года. Внешних клиентов компания намерена привлекать через своё контрактное производство Foundry. Как пишет Computer Base, компания TSMC также работает над этим направлением со своими партнёрами. GUC, компания, входящая в экосистему TSMC, недавно объявила, что отправила IVR на отладку в составе CoWoS-L. CoWoS-L является самым передовым решением TSMC для корпусирования больших интерпозеров. Технология CoWoS-L ожидается в 2027 году и придёт на смену CoWoS-S, которая сейчас используется для упаковки большинства чипов таких компаний, как Nvidia, AMD и других. Китайская Lisuan Tech разослала партнёрам образцы своей видеокарты с производительностью как у RTX 4060
16.11.2025 [20:51],
Анжелла Марина
Китайская компания Lisuan Technology подтвердила, что её первый графический процессор для рендеринга графики 7G100, созданный по 6-нм техпроцессу, достиг стадии рассылки образцов и их тестирования клиентами. Согласно инвесторскому отчёту, инженеры компании сейчас занимаются тестированием чипа у партнёров, доработкой на основе обратной связи, подготовкой к производству и одновременно запуском маркетинговой кампании. «Работы идут в штатном режиме», — отмечается в документе. 
Источник изображения: videocardz.com Однако эта новость пришла позже, чем ожидалось, отмечает VideoCardz. Ранее, после презентации 26 июля, на сайте компании фигурировал чёткий план относительно того, что испытания должны начаться в августе 2025 года, а массовое производство — в сентябре. Сейчас, в середине ноября, подтверждено лишь начало тестирования, что указывает на срыв первоначального графика. О старте серийного выпуска в официальном сообщении речь не идёт вообще. 
Источник изображения: Lisuan Tech GPU 7G100 разработан по 6-нанометровому техпроцессу TSMC и ляжет в основу двух видеокарт: пользовательской 7G106 и профессиональной 7G105. Обе поддерживают современные графические интерфейсы API — DirectX 12 (без трассировки лучей), Vulkan 1.3, OpenGL 4.6 и OpenCL 3.0. Модель 7G106 оснащена 12 Гбайт памяти GDDR6 с 192-битной шиной и одним 8-контактным разъёмом питания с целевой мощностью платы до 225 Вт. Её старший собрат, 7G105, получил больший объём памяти до 24 Гбайт, поддержку ECC, усиленную защиту данных и ориентирован на задачи в сфере искусственного интеллекта и рабочих станций. По данным самой Lisuan, производительность 7G106 в ряде бенчмарков сопоставима с GeForce RTX 4060 и даже приближается к уровню RTX 5060. Например, в 3DMark Fire Strike чип набрал около 26 800 баллов, а в тесте OpenCL в Geekbench 6 — 111 290. Компания также показала, как современные игры, в том числе Black Myth: Wukong, работают в разрешении 4K с графикой на уровне High и сохраняют стабильный FPS. «Самый маленький» в мире графический процессор TinyGPU v2.0, содержащий 200 тыс. транзисторов, запущен в производство
10.11.2025 [07:21],
Владимир Фетисов
Разработчик-любитель Понсагон Вичит (Pongsagon Vichit) представил широкой публике графический процессор TinyGPU v2.0. Устройство представляет собой автономный GPU с тактовой частотой 25 МГц и возможностью вывода изображения 320 × 240 пикселей с 4-битным цветом, а также с аппаратной поддержкой обработки 3D-сцен в режиме реального времени. 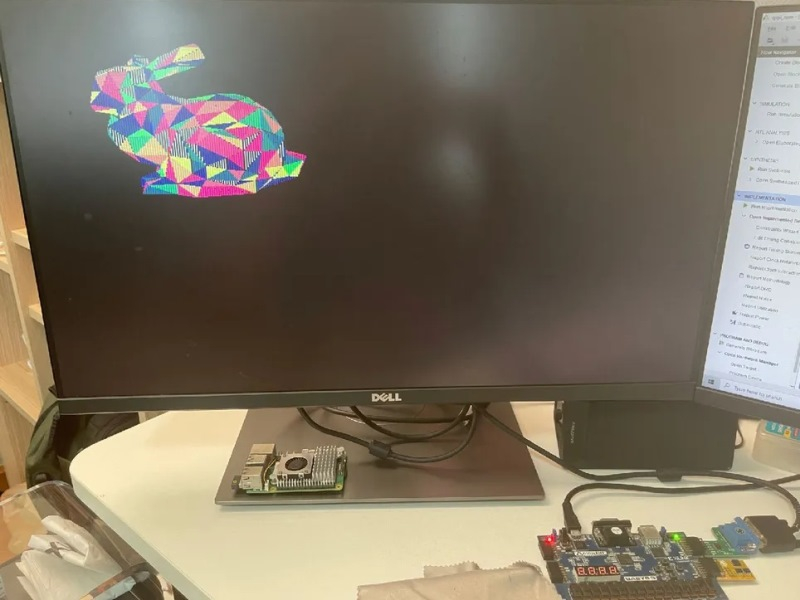
Источник изображения: @MattDIYgraphics / X Возможности TinyGPU v2.0 сопоставимы с ускорителями Nvidia GeForce 256, которые были анонсированы в 1999 году. Тем не менее, TinyGPU v2.0 является самостоятельным графическим процессором с примерно 200 тыс. транзисторов. Для сравнения, флагманская видеокарта Nvidia GeForce RTX 5090 насчитывает 92,2 млрд транзисторов. Несмотря на это, основные этапы подготовки кадра у этих ускорителей происходят схожим образом, а колоссальная разница между ними заключается в масштабах и уровне производительности. Энтузиаст опубликовал в своём аккаунте в соцсети X небольшое видео, а котором показал, как происходит загрузка разных 3D-моделей из встроенной в TinyGPU v2.0 флеш-памяти. Любопытно, что для управления он задействовал геймпад от Super Nintendo. С его помощью энтузиаст преобразует модели, изменяя их размер и положение, а также изменяет местоположение источника освещения. Несмотря на то, что это существенное улучшение по сравнению с первой версией TinyGPU, которую разработчик представил примерно год назад, технические характеристики TinyGPU v2.0 не слишком впечатляют. Ускоритель работает с тактовой частотой 25 МГц и может выдавать от 7,5 до 15 кадров в секунду при рендеринге низкополигональных 3D-моделей. При этом выводится изображение с разрешением 320 × 240 пикселей с 4-битным цветом (до 16 оттенков). Хотя графика с таким разрешением и глубиной цвета прочно ассоциируется с эпохой домашних компьютеров прошлого века, в TinyGPU v2.0 задействованы значительно более современные процессы. Ускоритель выполняет интерактивное преобразование 3D-векторов в растровое изображение и использует технологию преобразования освещения, которая впервые появилась в GeForce 256. Среди других технических особенностей TinyGPU v2.0 отметим поддержку двойной буферизации с 4-битной глубиной цвета, хранение данных Z-буфера в QSPI RAM, поддержку до 1 тыс. треугольников и 1 направленного источника света в сценах с плоским затемнением. TinyGPU v2.0 стал участником проекта Tiny Tapeout для запуска производственного цикла. Проектировка дизайна видеокарты обойдётся энтузиасту примерно в $1500. Узнать больше о проекте можно на площадке Verilog, а исходные файлы и другие материалы доступны на GitHub. Samsung модернизирует ИИ-инфраструктуру разработки своих чипов с помощью 50 000 GPU компании Nvidia
02.11.2025 [06:55],
Анжелла Марина
Samsung Electronics объявила о намерении развернуть вычислительный кластер из 50 000 графических процессоров (GPU) компании Nvidia для автоматизации и оптимизации собственного производства полупроводников. Новый объект получил рабочее название AI Megafactory, сообщает CNBC. 
Источник изображения: Samsung Electronics Это соглашение стало частью масштабного расширения партнёрской сети Nvidia, чьи чипы остаются ключевыми компонентами для разработки и внедрения передовых решений в области искусственного интеллекта (ИИ). Ранее, в начале недели, генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) сообщил в Вашингтоне о сотрудничестве с такими компаниями, как Palantir, Eli Lilly, CrowdStrike и Uber, а вскоре после выступления он был замечен в Сеуле за неформальной встречей с председателем совета директоров Samsung Ли Чжэ Ёном (Lee Jae-yong), а также другими корейскими бизнес-лидерами. Представители Nvidia уточнили, что совместно с Samsung будет адаптирована литографическая платформа для работы с GPU Nvidia, что, по их оценкам, обеспечит двадцатикратный прирост производительности. Кроме того, Samsung намерена задействовать программное обеспечение Nvidia Omniverse и использовать GPU для запуска собственных ИИ-моделей в мобильных устройствах. Важно отметить, что Samsung выступает не только клиентом и партнёром Nvidia, но и одним из ключевых поставщиков. Компания производит высокопроизводительную память типа HBM (High Bandwidth Memory), широко применяемую в ИИ-чипах Nvidia. В рамках нового этапа сотрудничества стороны договорились совместно доработать память следующего поколения HBM4 для использования в будущих ИИ-процессорах. Партнёрство с Samsung подкрепляет заявление Хуанга о том, что текущий портфель заказов Nvidia на GPU архитектуры Blackwell и следующего поколения Rubin достиг 500 млрд долларов. Эта перспектива способствовала росту рыночной капитализации Nvidia до исторического уровня в $5 трлн. Помимо Samsung, аналогичные GPU-кластеры развёртывают южнокорейские конгломераты SK Group и Hyundai. Рэймонд Тэ (Raymond Teh), старший вице-президент Nvidia по Азиатско-Тихоокеанскому региону, заявил, что компания тесно взаимодействует с правительством Республики Корея в поддержку его амбициозных планов по лидерству в сфере ИИ. Китайская Innosilicon представила видеокарту Fenghua 3 — CUDA, DX12, трассировка лучей и более 112 Гбайт HBM
24.09.2025 [15:31],
Николай Хижняк
Компания Innosilicon представила свой графический процессор третьего поколения — Fenghua 3. Компания обещает, что третья версия графического процессора будет значительно превосходить своих предшественников. Компания называет его первым полнофункциональным GPU собственной разработки, которые построен на открытой архитектуре RISC-V и совместим с CUDA. 
Источник изображений: Innosilicon В отличие от предыдущих поколений ускорителей Fenghua, основанных на архитектуре PowerVR от Imagination Technologies, Fenghua 3 использует в качестве основы проект OpenCore RISC-V Nanhu V3. Innosilicon утверждает, что новый GPU способен справиться с широким спектром рабочих нагрузок: от обучения ИИ и масштабных научных вычислений до САПР, медицинской визуализации и облачного гейминга. Для Fenghua 3 заявляется поддержка DirectX 12, Vulkan 1.2 и OpenGL 4.6 с аппаратной трассировкой лучей. Компания продемонстрировала работу GPU в таких играх, как Tomb Raider, Delta Force и Valorant, хотя данные о частоте кадров и настройках не были предоставлены. Fenghua 3 также поддерживает подключение до шести 8K-мониторов с частотой обновления 30 Гц.  Для задач искусственного интеллекта ускоритель на базе Fenghua 3 предлагает более 112 Гбайт высокоскоростной памяти HBM — это самый большой объём памяти среди китайских видеокарт. Один ускоритель может обрабатывать модели с 32 и 72 млрд параметров, а кластер из восьми — поддерживать огромные модели DeepSeek 671B и 685B. Innosilicon также подтвердила совместимость своей новинки с Qwen 2.5, Qwen 3 и семейством ИИ-моделей DeepSeek V3, V3.1 и R1. Innosilicon также похвасталась тем, что Fenghua 3 — первая в Китае видеокарта, поддерживающая формат YUV444, который обеспечивает наилучшую детализацию и точность цветопередачи. Это будет особенно полезно для тех, кто работает с САПР или занимается видеомонтажом. Кроме того, Fenghua 3 — первая в мире видеокарта, которая предлагает встроенную поддержку технологии DICOM (Digital Imaging and Communication in Medicine). Она позволяет точно визуализировать рентгеновские снимки, МРТ, КТ и УЗИ на стандартных мониторах, устраняя необходимость в дорогостоящих специализированных медицинских дисплеях с градациями серого. Ускоритель работает с системами Windows, Android, Tongxin и Kylin Linux. Сделка c Nvidia не повлияет на собственные планы Intel по выпуску процессоров и видеокарт
20.09.2025 [13:34],
Андрей Созинов
Intel чётко заявила — сотрудничество с Nvidia не повлияет на уже свёрстанные её собственные планы выпуска новых процессоров и видеокарт. Компания пояснила, что все новые продукты, которые будут разрабатываться в союзе с Nvidia, должны будут усилить и дополнить линейку продукции, а не перекраивать её. Отдельно Intel подчёркивает, что видеокарты Arc тоже продолжат развиваться. 
Источник изображения: X, Lip-Bu Tan «Хотя на данный момент мы не раскрываем конкретные планы, всё, о чём мы говорим, соответствует существующей стратегии Intel и дополняет её. Сотрудничество с NVIDIA позволит предложить дополнительные решения для ИИ и расширит присутствие в сегментах высокопроизводительных вычислений как в клиентских системах, так и в ЦОД. Мы продолжим придерживаться нашего плана развития GPU. С NVIDIA мы работаем над обслуживанием отдельных сегментов рынка, но также будем следовать собственному курсу», — пояснил представитель Intel в комментарии сайту Tom's Hardware. Напомним, Nvidia инвестировала в Intel $5 млрд и договорилась о поставке чиплетов RTX для интеграции их в процессоры Intel. Это породило два ключевых вопроса. Первый: изменится ли судьба графики Arc — в том числе дискретной и встроенной. И второй: повлияет ли это на планы Intel по мобильным CPU. После того, как в прессе поднялась волна спекуляций, Intel дала развёрнутый официальный комментарий. Из него следует: оснований для беспокойства нет, компания продолжит придерживаться своего плана по GPU, что позволяет рассчитывать на сохранение линейки Arc как минимум в обозримом будущем. Что касается процессоров, здесь Intel ещё более категорична: текущая мобильная дорожная карта остаётся без изменений. Сейчас в процессорных планах значится процессор Panther Lake, который должен дебютировать этой осенью с началом массовых поставок в 2026 году. Следом идёт Nova Lake, запланированный на конец 2026-го с фактическим выходом в 2027 году. Согласно утечкам, в том же году может появиться и Wildcat Lake. Всё, что родится в результате партнёрства с Nvidia, будет дополнением к этом списку. По сути, это могут быть премиальные версии уже существующих CPU, ориентированные на игровые или творческие сценарии. Технически у Intel уже есть опыт работы с GPU-тайлами в имеющихся процессорах. Поэтому логично предположить, что в будущем компания сможет выпускать процессоры либо с графикой Arc, либо с чиплетами Nvidia RTX на выбор. По словам Дженсена Хуанга, Intel и Nvidia работают над партнёрством около года. Но деталей о конкретных продуктах ждать в ближайшее время не стоит. Для того, чтобы обширные планы компаний воплотились в жизнь, может потребоваться ещё 2-3 года. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


