|
Опрос
|
реклама
Быстрый переход
Asgard представила память DDR5 CUDIMM со стабильным разгоном до 9600 МТ/с
14.09.2024 [22:44],
Анжелла Марина
Компания Asgard представила комплект модулей памяти Thor DDR5 CUDIMM с беспрецедентно высокой скоростью работы. Новый набор памяти способен работать на скорости до 9600 МТ/с и значительно превосходит возможности предыдущих высокоскоростных модулей DDR5. 
Источник изображения: mp.weixin.qq.com Секрет высокой производительности Thor DDR5 кроется в том, что это модули CUDIMM (Clocked Unbuffered Dual In-Line Memory Module). В отличие от обычных планок DIMM, новейшие CUDIMM оснащены собственным тактовым генератором, который регенерирует тактовый сигнал, повышая стабильность работы на высокой частоте, что и позволяет модулям памяти достигать более высокой скорости. «Тактовый генератор на модулях памяти Thor DDR5 устраняет узкие места, улучшая передачу сигнала между процессором и DRAM», — говорится в сообщении компании. Именно это и делает Thor DDR5 самым быстрым комплектом оперативной памяти DDR5 на данный момент. Демонстрация показала, что комплект памяти Asgard Thor работает на скорости 4800 МТ/с, что с учётом работы процессоров Intel в режиме 2:1, соответствует эффективной скорости 9600 МТ/с. В окне утилиты CPU-z можно увидеть всю необходимую информацию о памяти Asgard Thor, включая производителя DRAM (SK hynix) и значение CAS Latency — CL44. 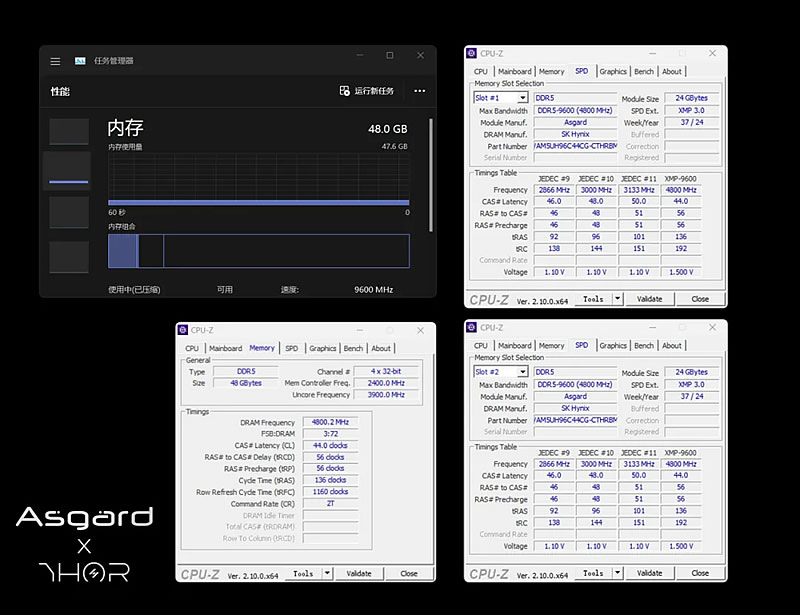
Источник изображения: mp.weixin.qq.com Важно отметить, что производительность DDR5 9600 МТ/с при таймингах CL44 примерно эквивалентно производительности DDR5-6400 с задержками CL30. Это впечатляющий результат, который обеспечивает как высокую скорость, так и большую пропускную способность. Asgard заявляет, что новая память совместима с новейшими платформами AMD и Intel, способными поддерживать гораздо более высокие частоты, чем их предшественники. Интересно, что во время демонстрации комплект памяти работал в режиме Gear 2, однако не уточняется, какая именно материнская плата и процессор использовались. Благодаря поддержке Intel XMP, память Asgard Thor сможет автоматически применять оптимизированные настройки и работать при напряжении всего 1,5 В. В компании также подчёркивают, что используют чипы третьего поколения, соответствующие стандартам JEDEC, гарантируя лучшую совместимость и надёжность на новых платформах. Thor DDR5 будет доступна в двух цветовых вариантах: «Полярная ночь» (чёрный) и «Серебряная молния». Визуальный ИИ-поиск Visual Intelligence может подготовить почву для умных очков Apple
14.09.2024 [18:58],
Павел Котов
Представленная Apple функция Visual Intelligence стала одним из наиболее интересных нововведений на презентации iPhone 16. Она позволяет владельцу устройства сканировать мир вокруг себя через камеру телефона — искусственный интеллект поможет определить породу собаки, скопировать информацию о мероприятии с плаката, узнать меню кафе или найти что-нибудь полезное поблизости. 
Источник изображения: apple.com Эта удобная функция может также подготовить почву для более интересных продуктов в будущем — нечто подобное понадобится Apple, например, для выпуска очков дополненной реальности. На презентации компания привела пример, когда посетитель ресторана узнаёт о нём больше, произведя поиск при помощи камеры iPhone. Это же можно было бы сделать, воспользовавшись не телефоном, а умными очками, и задав вопрос им. Meta✴✴ уже доказала, что очки с помощником на основе ИИ могут стать полезным инструментом для идентификации объектов. Apple вполне способна сделать нечто подобное, обеспечив интеграцию с данными, которые есть у iPhone, что сделает Visual Intelligence ещё более удобной функцией. В ассортименте компании уже есть гарнитура с камерами — Vision Pro, — но большинство её владельцев пользуется ей только дома, и о своём доме они знают многое. По неофициальным сведениям, Apple действительно ведёт разработку очков дополненной реальности, но, как утверждают инсайдеры, устройство пока планируется к выпуску в 2027 году, и сами сотрудники в этот срок пока не верят. Когда бы устройство не появилось, программная часть для него разрабатывается уже сейчас — Visual Intelligence может оказаться первым шагом к такому гаджету. У Apple уже есть примеры такой работы: компания годами прорабатывала технологии дополненной реальности в iPhone, прежде чем выпустила Vision Pro — громоздкая гарнитура также может превратиться в компактные очки. Подобные устройства вполне могут стать новым полем битвы технологических гигантов. Та же Qualcomm сейчас, по её собственному признанию, работает над очками смешанной реальности совместно с Samsung и Google. Но пока Visual Intelligence должна полноценно заработать на iPhone. Xiaomi представила смартфон Redmi 14R с чипом Snapdragon 4 Gen 2 и экраном на 120 Гц за $155
14.09.2024 [17:17],
Павел Котов
В дополнение к представленному в августе смартфону Redmi 14C китайский производитель анонсировал модель с индексом «R». Redmi 14R может похвастаться таким же 6,88-дюймовым LCD-дисплеем с разрешением HD+, частотой обновления 120 Гц, пиковой яркостью 600 кд/м² и поддержкой управления мокрыми руками. 
Источник изображения: Xiaomi Новый Redmi 14R работает на базе процессора Qualcomm Snapdragon 4 Gen 2 с оперативной памятью до 8 Гбайт, накопителем UFS 2.2 ёмкостью до 256 Гбайт и выделенным слотом для карт microSD до 1 Тбайт. На задней панели размещена 13-мегапиксельная основная камера и ещё одна — неизвестного назначения и параметров; в вырезе на экране находится 5-мегапиксельная камера для автопортретов и видеосвязи. Программной платформой выступает HyperOS на базе Android 14. Аккумулятор ёмкостью 5160 мА·ч поддерживает зарядку мощностью 18 Вт. Присутствуют также боковой сканер отпечатков пальцев и 3,5-мм разъём для наушников. Redmi 14R выпускается в четырёх цветах с четырьмя конфигурациями памяти: 4/128, 6/128, 8/128 и 8/256 Гбайт по цене 1099 юаней ($155), 1499 юаней ($210), 1699 юаней ($240) и 1899 юаней ($265) соответственно. В Китае смартфон будет продаваться через сайт Xiaomi, информации о его выходе в других странах пока нет. В Калифорнии заметили прототип роботакси Tesla Cybercab — выглядит он очень странно, но это нормально
14.09.2024 [15:46],
Павел Котов
Накануне вечером по соцсетям разлетелся не очень качественный снимок странного с виду транспортного средства, которое передвигалось по территории киностудии Warner Bros. — возникли предположения, что это роботакси Tesla Cybercab, которое компания намеревается представить в октябре. 
Источник изображения: x.com/MatthewDR Делать какие-то выводы о машине по её внешнему виду ещё рано — она имеет канареечно-жёлтую окраску, а её форма явно изменена для маскировки. Окончательный облик роботакси Tesla может иметь существенные отличия от этого прототипа: колёса, квадратная задняя часть, странный выступ на крыше, возможно, лидар, и непонятные вмятины на капоте. Первым снимок опубликовал, предположительно, пользователь u/boopitysmopp платформы Reddit, который, как сообщается, является сотрудником Warner Bros. К настоящему моменту его публикация удалена, как и профиль. Презентация роботакси Tesla Cybercab, по неофициальным сведениям, пройдёт на студии Warner Bros на участке площадью 110 акров (44,5 га), где размещено множество объектов, включая модели малых городов. Жёлтая окраска — логичный выбор для камуфляжа машины, которая предназначена для работы в роли беспилотного такси. С виду автомобиль кажется небольшим — возможно, размером с Tesla Model 3. В оригинальной публикации на Reddit также сообщалось, что в его задней части установлен полноразмерный фонарь — видимо, по образцу Cybertruck. О наличии или отсутствии руля и педалей по этому снимку судить нельзя. Возможно, до презентации появятся другие неофициальные снимки роботакси Tesla. Ушла эпоха: Apple перестала комплектовать iPhone наклейками
14.09.2024 [15:28],
Павел Котов
На этой неделе Apple распространила сообщение среди работников магазинов Apple Store, что iPhone 16 не будут комплектоваться фирменными наклейками в коробке, передаёт ресурс 9to5Mac. Покупатели новых телефонов смогут получить стикеры по запросу. 
Источник изображения: apple.com Покупатели, приобретающие iPhone 16 в Apple Store, смогут запросить фирменные наклейки в момент покупки — во всех остальных случаях получить их не получится. Сторонние розничные продавцы и выступающие партнёрами компании мобильные операторы этих сувениров не получили; наклейки нельзя также получить, заказав iPhone 16 с доставкой на дом. Это нововведение — часть экологической стратегии компании и её стремлений по достижению нулевого уровня углеродных выбросов к 2030 году. Apple подчеркнула, что упаковка iPhone 16 и 16 Pro полностью изготавливается из волоконных материалов, а к следующему году упаковка вообще не будет содержать пластика. Очередная инициатива компании знаменует конец эпохи, но сюрпризом она уже не станет. В феврале покупатели Apple Vision Pro обратили внимание на отсутствие наклеек в коробке. Стикеров не оказалось и в упаковках новых iPad Pro и iPad Air, которые вышли в мае. Anker представила устройство MagGo, которое наделяет iPhone слотом для карт памяти
14.09.2024 [14:57],
Павел Котов
Anker представила устройство для чтения карт форматов SD и microSD, получившее название MagGo USB-C Adapter — оно подключается к ноутбукам, планшетам и смартфонам. При работе совместно с iPhone 15 или 16 кардридер позволяет записывать на внешний носитель видео ProRes 4K со скоростью 60 кадров в секунду — для этого карта памяти должна поддерживать скорость передачи данных от 220 Мбайт/с и иметь ёмкость от 256 Гбайт. 
Источник изображений: anker.com Anker MagGo USB-C Adapter предлагается в чёрном, белом и бирюзовом цветах за $34,99. Устройство совместимо с MagSafe, что позволяет его закреплять на задней крышке во время видеосъёмки. Правда, в этом случае блокируются оба способа зарядки iPhone, поэтому кардридер оборудован дополнительным портом USB Type-C с поддержкой мощности до 42,5 Вт.  Производитель обещает скорость передачи данных до 312 Мбайт/с, что является теоретическим максимумом для карт класса UHS-II. В реальности этот показатель может быть ниже из-за типа используемой карты или срока её эксплуатации. Anker MagGo USB-C Adapter позволит записывать видео с iPhone 15 или 16 на внешний носитель, даже если скорость подключённой к нему карты составляет менее 220 Мбайт/с — в этом случае будет поддерживаться меньшая частота кадров или даже более низкое разрешение.  Intel продолжает терять руководителей — вице-президент Джейсон Кимри ушёл в отставку
14.09.2024 [13:21],
Павел Котов
Вице-президент Intel по коммерческим и партнерским продажам в Северной Америке Джейсон Кимри (Jason Kimrey) уходит в отставку, сообщило руководство компании сотрудникам отдела продаж и маркетинга. Об этом рассказало издание CRN со ссылкой на партнёров Intel. 
Источник изображений: Rubaitul Azad / unsplash.com Кимри заработал одну из лучших репутаций в своём деле, рассказали партнёры Intel, — это честный и небезразличный человек. В самой Intel подтвердили уход одного из важнейших руководителей, но отметили, что она «трансформируется в более эффективную, гибкую компанию». Сейчас производитель чипов намеревается сократить более 15 тыс. сотрудников или 15 % своего штата, а также уменьшить расходы на значение более $10 млрд. Вместе с Кимри из Intel ушли ещё несколько членов руководства. В частности, это ветеран с 31-летним стажем Дэвид Аллен (David Allen), который занимал должность директора по продажам и маркетингу в США; ветеран с 9-летним стажем Дженнифер Боссин (Jennifer Bossin), директор по продажам мировым партнёрам — системным интеграторам; бывшая управляющий директор по работе с федеральными системными интеграторами и партнёрами в оборонной промышленности Кэтлин Робинсон (Kathleen Robinson) ушла из Intel и заняла пост вице-президента по корпоративным продажам в компании Seekr Technologies, которая разрабатывает ПО для работы с искусственным интеллектом и сотрудничает с Intel в области ИИ-ускорителей Gaudi. Аллен вышел на пенсию, причины ухода Боссин и Робинсон установить не удалось.  В феврале Кимри возглавил новую структуру Intel по организации коммерческих и партнёрских продаж в Северной Америке. Структура была создана слиянием отдела по работе с каналами сбыта и партнёрами в США с отделами по управлению взаимоотношениями с крупными корпоративными клиентами в США, с поставщиками услуг связи в США, а также с клиентами и партнёрами в Канаде. Тогда он рассказал, что в результате реорганизации разрозненные прежде единицы смогли начать работу как единая компания и «предоставить лучшее из того, что Intel может предложить коммерческому рынку в едином ключе». У него были связи в сфере продаж, и он отлично справлялся с задачей, рассказал источники среди партнёров компании. Руководитель одного из дистрибьюторов назвал уход Кимри неожиданным и выразил обеспокоенность, как Intel сможет организовать передачу обязанностей, сотрудников, которые уходят из компании. Некоторые партнёры обеспокоены и тем, что Intel намеревается сократить расходы отдела продаж и маркетинга на $100 млн в этом году и на $300 млн — в первой половине следующего. Это будет реализовано за счёт упрощения программ и корректировки ролей и обязанностей в отношении финансирования партнёров. Недавно Intel отклонила запросы на финансирование мероприятия по поддержке продаж, таких как обучение и разработка контента — примечательно, что AMD и Nvidia наращивают эти ресурсы. Это может стать препятствием к развёртыванию ИИ-ускорителей Gaudi 3, которые позиционируются как средство борьбы с Nvidia и являются важной частью стратегии компании в области центров обработки данных. Крошечный одноплатный компьютер NanoPi Zero2 оснащён портом 1GbE и коннектором М.2
14.09.2024 [12:13],
Сергей Карасёв
Команда FriendlyElec, по сообщению ресурса CNX-Software, пополнила ассортимент одноплатных компьютеров моделью NanoPi Zero2: это одно из самых компактных на рынке устройств данного типа, сочетающих процессор с архитектурой Arm и ОС на ядре Linux. Размеры изделия составляют 45 × 45 мм, масса — 16,1 г. Основой новинки служит процессор Rockchip RK3528A, который содержит четыре ядра Arm Cortex-A53 с частотой 2 ГГц и графический блок Arm Mali-450 с поддержкой OpenGL ES1.1, ES2.0, OpenVG 1.1. Возможно декодирование видео H265/H264 в формате 4K со скоростью 60 к/с. Объём памяти LPDDR4/LPDDR4X — 1 или 2 Гбайт. 
Источник изображения: CNX-Software Одноплатный компьютер может быть укомплектован чипом eMMC; кроме того, предусмотрен слот для карты microSD. В оснащение входит сетевой адаптер 1GbE, а дополнительно можно установить модуль M.2 Key-E 2230 (PCIe 2.1) с поддержкой Wi-Fi и Bluetooth. В набор разъёмов включены по одному порту USB 2.0 Type-A и USB 2.0 Type-C (данные и питание 5 В), гнездо RJ-45 для сетевого кабеля. Имеется 30-контактная колодка FPC GPIO с поддержкой 17 × GPIO, 2 × PWM, 2 × UART, SPI, I2C, 2 × I2S, SPDIF Tx, GND. Для платы доступен металлический корпус с габаритами 49,5 × 49,5 × 25 мм. Диапазон рабочих температур простирается от 0 до +80 °C. Возможно использование Debian 12 Core, Ubuntu 24.04, OpenMediaVault, FriendlyWrt (на основе OpenWrt 21.05 или 23.05) с ядром Linux 6.1 LTS. Цена NanoPi Zero2 с 1 Гбайт ОЗУ составляет $18. А за $54 можно приобрести модификацию с 2 Гбайт памяти, флеш-накопителем eMMC вместимостью 32 Гбайт, адаптером Wi-Fi 5 (RTL8822CE) с двумя антеннами и корпусом. AMD официально стала компанией, ориентированной на дата-центры — игровые чипы приносят в четыре раза меньше прибыли
14.09.2024 [12:10],
Павел Котов
Если раньше основная часть бизнеса AMD была представлена направлением клиентских процессоров для ПК, то сегодня бо́льшая часть выручки компании поступает от продаж процессоров EPYC для центров обработки данных. Гендиректор Лиза Су (Lisa Su) официально объявила, что AMD теперь является компанией, ориентированной на сегмент ЦОД. 
Источник изображения: amd.com «В течение последнего квартала центры обработки данных принесли, думается, более 50 % нашего дохода. Так что мы действительно являемся компанией, ориентированной на ЦОД», — заявила доктор Су на мероприятии Goldman Sachs Communacopia And Technology Conference. Выручка AMD по итогам минувшего квартала в серверном сегменте достигла $2,834 млрд, что значительно выше клиентского и игрового направлений, в которых зафиксированы продажи на $1,492 млрд и $648 млн соответственно. Бизнес AMD по направлению ЦОД составил 48 % выручки компании — процессоры EPYC стали основным продуктом и источником доходов и прибыли. «Было по-настоящему интересно наблюдать, как рынок центров обработки данных вырос у нас как бизнес. Если подумать о том, с чего мы начали, в бизнесе ЦОД, как вы сказали, у нас была низкая однозначная доля [менее 10 %]. У него был и аналогичный процент нашего дохода», — рассказала гендиректор AMD. Но если компания говорит, что её направление опережает другое, она, по сути, демонстрирует, что вся сосредоточена на этом направлении. И возникает вопрос, не отошли ли прочие на второй план. Учитывая неспешный прогресс AMD в области графики, можно сделать определённые выводы. Успех AMD, Intel и Nvidia сейчас определяют базовые архитектуры и бизнес-решения. В сегменте центральных процессоров у AMD есть унифицированная архитектура Zen. В направлении графических процессоров она объединила RDNA (графику) и CDNA (вычисления) в UDNA — всё-таки есть основания предположить, что этот сегмент теперь перестанет для компании быть второстепенным. YouTube в России замедлился в 10 раз, а Роскомнадзор научился бороться с обходом замедления
14.09.2024 [11:51],
Павел Котов
К началу осени скорость работы YouTube в России достигла рекордно низкого уровня — по сравнению с июньскими показателями пользователям сетей фиксированного доступа приходится в десять раз дольше ждать открытия роликов на платформе. На мобильных устройствах время ожидания открытия первого кадра выросло в 2,5 раза, сообщили «Известия» со ссылкой на информацию от независимых экспертов. 
Источник изображения: Christian Wiediger / unsplash.com С 3 июня по 9 сентября 2024 года разработчик ПО для анализа пользовательского опыта Vigo провёл более 161 тыс. измерений в сетях передачи данных в РФ и установил, что для пользователей сетей фиксированного доступа среднее время начала показа ролика YouTube выросло с 1,21 до 11,01 с; в мобильных сетях аналогичные показатели составили соответственно 1,76 и 3,83 с. Считается, что для зрителя комфортный порог ожидания составляет 3 с — пользователи стационарных сетей теперь в пять раз чаще не дожидаются запуска видеоролика, чем на мобильных. 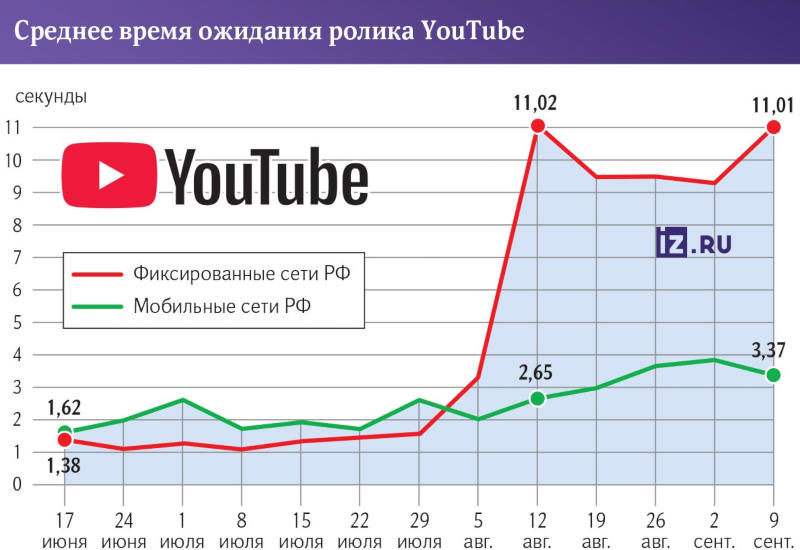
Источник изображения: iz.ru В июне более 3 секунд приходилось ждать при открытии 2,8 % видеозаписей, а к настоящему моменту таких стало 56,7 % — этот показатель ухудшился в 20 раз. В среднем российскому пользователю приходится ждать не 1,27 с, как было раньше, а 9,49 с. С 3 % до 15 %, то есть в пять раз выросло количество случаев, когда пользователи закрыли ролик, не дождавшись его начала. Россияне стали смотреть YouTube вдвое реже — или на 52 % меньше в численном выражении. Изменилось и предпочитаемое российским зрителем разрешение видео на YouTube: если раньше пользователи фиксированных сетей открывали ролики преимущественно в разрешении 1080p, а мобильные абоненты выбирали 720p, то сейчас первые, «если повезёт», смотрят ролики в 360p, а вторые — в 480p. Российские зрители постепенно переходят на отечественные платформы видео, указывают опрошенные «Известями» эксперты. Сейчас YouTube они смотрят лишь в виде исключения, потому что не все авторы ещё переехали на русскоязычные площадки. Сложности с YouTube будут продолжаться, пока Google не начнёт выполнять требования российского законодательства — если это произойдёт, интерес российского зрителя к американской платформе может вернуться, считают эксперты. Также в Сети появились сообщения, что технические средства противодействия угрозам Роскомнадзора научились определять и блокировать параметры, которые помогали обходить замедление YouTube. Кроме того, в России блокируются сервисы, которые помогают пользователям обходить замедление YouTube. Верховный суд Бразилии разморозил счета Starlink, удержав $3,3 млн штрафа соцсети X
14.09.2024 [10:42],
Павел Котов
Верховный суд Бразилии накануне объявил, что обязал банки перевести средства со счетов Starlink и X для уплаты штрафов, ранее наложенных на принадлежащую Илону Маску (Elon Musk) социальную сеть X. После этого активы спутникового оператора связи были разблокированы. 
Источник изображения: Gerd Altmann / pixabay.com Председатель Верховного суда Алешандре де Мораес (Alexandre de Moraes) и коллегия из пяти судей постановили, что соцсеть X неоднократно нарушила бразильское законодательство, отказываясь назначить законного представителя в стране, а также удалить контент или заблокировать на платформе профили, которые суд посчитал угрозой для демократических институтов Бразилии. В качестве наказания был назначен штраф, однако так как на счетах X нужной суммы не оказалось, то были задействованы средства другой принадлежащей Илону Маску (Elon Musk) компании — спутникового оператора SpaceX Starlink. Суд вывел со счетов X и Starlink 18,4 млн бразильских реалов или около $3,3 млн, после чего распорядился разблокировать их активы, поскольку не увидел дальнейшей потребности в ограничительной мере. Введённая в конце августа блокировка соцсети X остаётся в силе. Маск и представители его компаний заявили, что считают действия Мораеса «незаконными», а постановления суда — вынесенными без надлежащей правовой процедуры. Некоторые из учётных записей, которые судья приказал Маску заблокировать в соцсети X, как сообщает бразильское информационное агентство UOL, принадлежат лицам, которые, возможно, угрожали сотрудникам федеральной полиции, участвовавшим в расследовании деятельности бывшего главы страны. Он обвиняется в подстрекательстве к беспорядкам и попытке устроить государственный переворот. Бывший президент Бразилии при этом разрешил Starlink работать в стране. Маск с апреля призывает инициировать в отношении судьи Мораеса процедуру импичмента, с критикой в адрес чиновника выступила главный операционный директор SpaceX Гвинн Шотвелл (Gwynne Shotwell). Сторонники судьи расценили его действия как проявление суверенитета Бразилии. Репортаж со стенда Baseus на IFA 2024: новые зарядные устройства и пауэрбанки
14.09.2024 [09:21],
Андрей Созинов
Компания Baseus организовала в рамках недавней выставки IFA 2024 в Берлине крупный стенд, на котором показала свои последние новинки. Китайский производитель представил новейшие зарядные станции, блоки питания для смартфонов, пауэрбанки и другие аксессуары.  В серии устройств Nomos была представлена новая зарядная станция Baseus Nomos 5-in-1 Desktop Charger, которая объединяет практически всё, что нужно большинству пользователей. Производитель отмечает, что это первое в мире настольное зарядное устройство с выдвижным кабелем и беспроводной зарядкой Qi2, которая позволяет заряжать до пяти различных устройств одновременно. Сверху у Nomos 5-in-1 имеется откидное беспроводное зарядное устройство стандарта Qi2 мощностью 15 Вт, совместимое с MagSafe. Откидная конструкция позволяет удобно закрепить смартфон под углом, чтобы видеть его экран, а если нужно зарядить наушники, то зарядную площадку можно расположить горизонтально. Рядом находится дисплей, на котором отображаются показатели мощности для каждого порта устройства и беспроводной зарядки, так что пользователь сразу видит, заряжается ли его смартфон или гаджет быстро. 
Baseus Nomos 5-in-1 Desktop Charger На передней панели Nomos 5-in-1 имеется встроенный выдвижной 100-ваттный кабель USB-C длиной 1 метр, который можно зафиксировать в одном из промежуточных состояний, не вытаскивая его полностью. Помимо этого, имеются ещё два порта USB-C и один стандартный USB-A. В сумме новинка может выдавать до 140 Вт мощности, чего хватит для одновременного питания ноутбука, смартфона и ещё нескольких гаджетов. 
Также Baseus показала и другие зарядные станции серии Nomos, например станции с беспроводной зарядкой и двумя или тремя розетками. 
Baseus PicoGo 45W Ещё Baseus представила ряд новинок серии PicoGo. В частности, было показано очень компактное зарядное устройство для смартфонов и гаджетов PicoGo 45W. Новинка сопоставима по габаритам с 20-ваттной зарядкой Apple, но при этом обеспечивает выходную мощность до 45 Вт. Этого хватит не только для современного смартфона, но и для некоторых ноутбуков, а благодаря компактному формфактору PicoGo 45W удобно брать с собой. 
Baseus PicoGo Magnetic Charging Cable Baseus также показала зарядный кабель PicoGo Magnetic Charging Cable, который благодаря встроенным магнитам сворачивается в аккуратный круг. Кабель с разъёмами USB-C способен передавать ток мощностью до 240 Вт и доступен в разных цветах. 
Baseus PicoGo Power Bank with Built-in Cable Были также показаны два пауэрбанка PicoGo. Модель PicoGo Power Bank with Built-in Cable, как нетрудно догадаться, обладает встроенным кабелем USB-C. Ёмкость устройства составляет 10 000 мА·ч, а максимальная мощность достигает 45 Вт. 
Baseus PicoGo Magnetic Power Bank with Rotatable Stand Модель PicoGo Magnetic Power Bank with Rotatable Stand обладает магнитным креплением для установки на смартфоны с MagSafe или Qi2. Мощность беспроводной зарядки достигает 15 Вт, а через кабель USB-C можно получить до 20 Вт. Ёмкость пауэрбанка составляет 5000 мА·ч. У новинки есть поворотная подставка в виде кольца, с которой удобно расположить смартфон на горизонтальной поверхности или куда-то его подвесить. Intel получит $3,5 млрд субсидий на реализацию проекта по выпуску в США чипов для оборонной промышленности
14.09.2024 [08:10],
Алексей Разин
Одним из серьёзных аргументов в пользу субсидирования властями США строительства компанией Intel на территории страны новых предприятий была их потенциальная способность выпускать передовые чипы для систем оборонного назначения. По предварительным данным, компании удалось согласовать получение $3,5 млрд от государства сугубо на реализацию этого проекта. 
Источник изображения: Intel Инициатива, известная под именем Secure Enclave, в понимании Министерства обороны США подразумевала организацию компанией Intel нескольких производственных линий в четырёх штатах (Огайо, Аризона, Орегон и Нью-Мексико), на которых она бы выпускала и упаковывала передовые чипы для оборонных заказчиков. Последние предъявляют специфические требования к условиям производства и самой продукции, поэтому участникам подобных инициатив порой приходится работать чуть ли не себе в убыток, выполняя оборонные заказы, как отмечают опрошенные Bloomberg эксперты. Intel пока не получила гарантий, что средства будут ей выделены, но предварительная договорённость уже достигнута. Об этом официально может быть заявлено уже на следующей неделе. Эти средства не входят в те $8,5 млрд субсидий и $11 млрд льготных кредитов, которые предназначаются на расширение производственных площадок Intel на территории США в рамках так называемого «Закона о чипах». Первоначально Министерство обороны США должно было направить на профильные нужды $2,5 млрд из собственных средств, а Министерство торговли добавило бы ещё $1 млрд, но в ходе обсуждения весь бюджет повесили на последнее из ведомств, причём с условием его отделения от общей программы субсидирования Intel на сумму $19,5 млрд. Попытки покрыть потребности оборонной промышленности за счёт контрактов с иностранными производителями чипов, которые строят свои предприятия на территории США (TSMC и Samsung) тоже были отвергнуты лоббистами из оборонно-промышленного комплекса. Intel в этом отношении выделяется на фоне конкурентов тем, что является исконно американской компанией. Попутно Bloomberg уточняет, что министру торговли США Джине Раймондо (Gina Raimondo) так и не удалось убедить крупных разработчиков чипов типа AMD и Nvidia поручить производство своих передовых компонентов компании Intel на будущих предприятиях в штате Огайо. По крайней мере, пока соответствующих намерений никто из конкурентов Intel не демонстрирует, и возможностями этой компании более или менее заинтересовалась только корпорация Microsoft. Перераспределение средств в пользу Intel ударило по интересам других американских компаний. Производитель оборудования для производства чипов Applied Materials лишился поддержки в реализации проекта по строительству научно-исследовательского центра в Калифорнии стоимостью $4 млрд. Попытки законодателей увеличить объём субсидий в рамках «Закона о чипах» на $3 млрд не нашли поддержки в Конгрессе. При всём этом Intel сейчас находится не в лучшей финансовой форме, и компании, как ожидается, придётся отказаться от реализации крупных проектов за пределами США ради экономии средств. Способность OpenAI достичь капитализации в $150 млрд будет зависеть от изменения организационной структуры
14.09.2024 [06:16],
Алексей Разин
О намерениях потенциальных инвесторов добиться от OpenAI выгодной для них реорганизации сообщалось и ранее, а теперь Reuters утверждает, что от предлагаемых реформ будет сильно зависеть сама возможность дальнейшего привлечения капитала, которая оценит бизнес стартапа в $150 млрд. 
Источник изображения: OpenAI По данным источника, новый раунд финансирования OpenAI будет подразумевать выпуск конвертируемых облигаций, которые позволят держателям долговых обязательств стартапа в будущем обменять их на долю в капитале. Потенциальные кредиторы теперь настаивают, что OpenAI должна изменить свою организационную структуру и снять ограничения на получаемую инвесторами прибыль. Как поясняет источник, после своего основания в 2015 году OpenAI ограничила размер будущей прибыли инвесторов стократной величиной их вложений. Всё, что было бы заработано сверх определённой суммы, направлялось бы на нужды некоммерческой организации, которая и руководит работой OpenAI. Последующие раунды финансирования лишь сокращали эту пропорцию, ещё сильнее ограничивая величину доступной инвесторам прибыли. Принято считать, что OpenAI удалось за историю своего существования привлечь более $10 млрд инвестиций, причём основную часть средств внесла корпорация Microsoft, которая в итоге не может получать более половины прибыли OpenAI. Как ожидается, в новом раунде финансирования стартапа готовы повторно принять участие Thrive Capital, Khoshla Ventures и Microsoft, но к ним присоединятся Nvidia, Apple и Sequoia Capital. Если переговоры с инвесторами об изменении организационной структуры по примеру большинства коммерческих корпораций не увенчаются успехом, то цена конверсии выпускаемых облигаций в рамках обсуждаемого раунда финансирования может снизиться. Совету директоров OpenAI также придётся рассмотреть вопрос о снятии ограничений на размер прибыли, которую могут получать инвесторы. Стартап уже проводит консультации с юристами по поводу возможности изменения собственной оргструктуры. OpenAI в определённой степени придерживается ограничения на пропорцию прибыли, получаемой инвесторами, исходя из своей изначальной миссии как некоммерческой организации. Если предлагаемые новыми инвесторами изменения будут реализованы, то от изначальной миссии стартапа придётся отказаться. Февральский этап финансирования OpenAI оценил капитализацию стартапа в $80 млрд, как напоминает Reuters. В рамках нового этапа планируется привлечь $6,5 млрд, но инвесторы ставят условия, учитывающие их коммерческие интересы. Технология масштабирования AMD FSR 4.0 будет полностью основана на ИИ и повысит энергоэффективность GPU
14.09.2024 [01:24],
Николай Хижняк
Старший вице-президент и генеральный менеджер группы вычислительных и графических решений AMD Джек Гуинь (Jack Huynh) сообщил порталу Tom’s Hardware, что компания AMD уже ведёт разработку технологии масштабирования изображения FidelityFX Super Resolution 4.0. Она будет отличаться от актуальной версии FSR 3.0. В масштабном интервью на выставке электроники IFA 2024, проходившей в Берлине, Tom’s Hardware расспросил топ-менеджера AMD о планах компании на ближайшее будущее. Из этого разговора, например, стало известно, что AMD хочет объединить RDNA для игр и CDNA для ИИ-ускорителей в единую графическую архитектуру UDNA, сместить акцент с ограниченного сегмента флагманских видеокарт для энтузиастов и увеличить своё присутствие в массовом сегменте GPU, а также выпустить процессоры Kraken для ноутбуков Copilot+ PC стоимостью до $799. Ещё одной темой обсуждения стала новая технология масштабирования FidelityFX Super Resolution 4.0, которую Гуинь затронул при разговоре о портативных приставках. По его словам, AMD занимается разработкой FSR 4.0 уже около года. Новая технология будет полностью полагаться на ИИ-алгоритмы, а одно из её ключевых преимуществ связано с повышением энергоэффективности GPU, которые используются в портативных игровых приставках. «Что касается портативных устройств, то мой главный приоритет — это время работы от батареи. Если посмотреть на Asus ROG Ally или Lenovo Legion Go, то там практически нет времени работы от батареи. Мне нужно несколько часов. Мне нужна возможность играть в Wukong три часа, а не 60 минут. Вот где вступают в дело генерация кадров и интерполяция, поэтому мы и работаем над FSR 4. Технологии FSR2 и FSR3 основаны на аналитической генерации. Они были основаны на фильтрах. Мы сделали так, потому что хотели быстро выйти на рынок с этим решением. Однако потом я сказал команде: “Ребята, это не то, куда движется будущее”. Поэтому мы полностью изменили подход около 9–12 месяцев назад, чтобы перейти на ИИ», — заявил Гуинь. «Теперь мы переходим на генерацию кадров на основе ИИ, интерполяцию кадров. Идея заключается в повышении эффективности для максимального увеличения времени автономной работы от батареи. И уже тогда мы могли бы зафиксировать количество кадров в секунду, может быть, на уровне 30 или 35. Моя главная цель сейчас — максимально увеличить время работы от батареи. Я думаю, что это самая большая жалоба [потребителей]», — добавил Гуинь.  В своём комментарии представитель AMD ничего не сказал об использовании FSR 4.0 с другими устройствами, например ноутбуками. Будет ли новая технология масштабирования в этом случае полагаться на ИИ-ускорители (NPU) в составе тех же процессоров Strix Point? Ответа на этот вопрос пока нет. AMD пока не готова говорить о том, когда новая технология масштабирования будет официально представлена. Если FSR 4.0 уже находится в разработке 9–12 месяцев, то она вполне может быть почти готова к выпуску. Однако, как показывают примеры прошлых решений по масштабированию, включая DLSS и XeS наряду с FSR 1/2/3, выпуск API — это лишь первый шаг. Реализация поддержки игр для нового API занимает гораздо больше времени. Флагманский кулер Noctua NH-D15 G2 перестал издавать дребезжащий звук
14.09.2024 [01:15],
Николай Хижняк
Австрийский производитель систем охлаждения, компания Noctua, сообщил порталу ComputerBase о том, что устранил проблему дребезжащего звука у новейшего флагманского кулера NH-D15 G2. 
Источник изображения: ComputerBase Первые покупатели новой системы охлаждения стоимостью $150 пожаловались на странный шум в её работе. В ходе внутренней проверки было установлено, что шум может быть вызван ослаблением крепления верхнего ребра радиатора при транспортировке. Из-за этого могут появляться вибрации и лёгкий дребезжащий шум во время работы кулера — его уровень хоть и невелик (менее 0,5 дБА), но достаточно заметен, чтобы вызывать нарекания. В качестве временной меры Noctua предлагала наклеить на боковую часть ребра радиатора кусок скотча или изоленты, либо вставить небольшой кусок пластика или пенопласта толщиной около 1,8 мм между верхним и вторым рёбрами радиатора, чтобы смягчить вибрации и снизить шум. В разговоре с ComputerBase компания сообщила, что проблема крепления верхнего ребра радиатора была исправлена на производстве. Для тех владельцев NH-D15 G2, кто столкнулся с проблемой дребезжащего звука NH-D15 G2, но решил не оформлять возврат, компания готова бесплатно предоставить специальные стальные панели, которые надеваются по бокам кулера и аналогичным образом устраняют проблему шума при его работе. В ближайшее время производитель предложит три варианта решения ситуации:
Для повышения эффективности нового NH-D15 G2 над предшественником Noctua разработала три варианта новой системы охлаждения:
Версия LBC (Low Base Convexity) оптимизирована для использования с процессорами с относительно плоскими теплораспределительными крышками. Благодаря этому кулер обеспечивает отличный контакт с крышками процессоров AMD AM5 даже без использования монтажной системы со смещением, а также с другими относительно плоскими CPU (для AM4, LGA 2066, LGA 2011 и кастомными крышками). 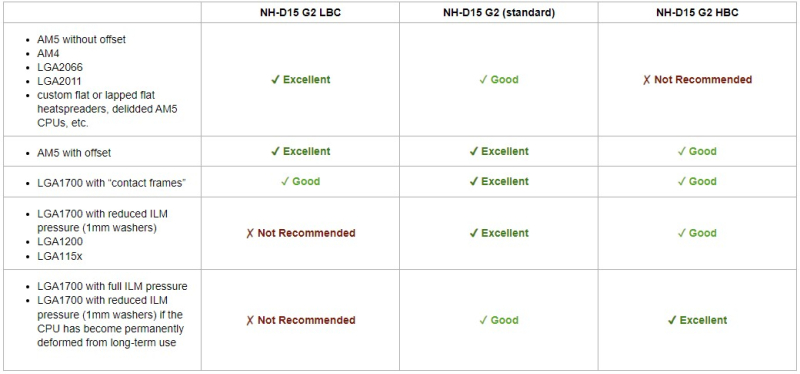
Источник изображения: Noctua Версия HBC (High Base Convexity) оптимизирована для процессоров Intel LGA 1700, которые используются с максимальным давлением на процессорный разъём, обеспечивая превосходное качество контакта, несмотря на вогнутую форму процессора, которая неизбежно возникает из-за высокого давления на сокет. MaxSun выпустила материнскую плату MS-Terminator B760BKB D5 с перевёрнутым слотом для видеокарты на обороте
14.09.2024 [01:06],
Николай Хижняк
Компания MaxSun выпустила необычную материнскую плату MS-Terminator B760BKB D5 формата Mini-ITX (171 × 171 мм) на чипсете Intel B760, оснащённую процессорным разъёмом LGA 1700. Особенность новинки заключается в её слоте PCIe 5.0 x16 — он расположен на обратной стороне платы. 
Источник изображений: MaxSun Слот PCIe 5.0 x16 платы MS-Terminator B760BKB D5 повёрнут на 90 градусов. Иными словами, он предназначен для вертикальной установки видеокарты. Сама плата призвана послужить основой компактного игрового ПК формата SFF.  На рынке представлены модели компактных корпусов, предполагающих расположение видеокарты с обратной стороны материнской платы, но подразумевающих использование специального переходника-райзера. В свою очередь конструкция MS-Terminator B760BKB D5 исключает необходимость в использовании этого переходника. Это положительно сказывается на передаче сигнала.  MS-Terminator B760BKB D5 поддерживает процессоры Intel Core 12-го, 13-го и 14-го поколений с TDP до 253 Вт. Она оснащена двумя слотами для оперативной памяти DDR5 и поддерживает установку до 96 Гбайт ОЗУ со скоростью до 8000 МТ/с.  Поскольку слот PCIe 5.0 x16 расположен на обратной стороне платы, на фронтальной стороне новинки нашлось место для установки разъёма PCIe 3.0 x4. Также плата получила два слота PCIe 4.0 x4 для NVMe-накопителей — они находятся с двух сторон платы. Кроме того, MS-Terminator B760BKB D5 предлагает наличие четырёх портов SATA III (6 Гбит/с).  В оснащение платы вошли сетевой контроллер Realtek RTL8125BG с поддержкой скорости до 2,5 Гбит/с и контроллер Intel AX211 с поддержкой Wi-Fi 6E. За звук у новинки отвечает кодек Realtek ALC897. Набор разъёмов для фронтальной панели состоит из двух USB 2.0, одного USB 3.2 Gen1 и одного USB Type-C (10 Гбит/с). На заднюю панель разъёмов выведены четыре USB 3.2 Gen1, четыре USB 2.0 и один USB Type-C (20 Гбит/с). Материнская плата MaxSun MS-Terminator B760BKB D5 уже появилась в продаже на китайских торговых онлайн-площадках. Например, на JD.com её можно найти за 899 юаней (около $126). «Рикор» в этом году поставила российским школьникам 65 тысяч ноутбуков, адаптированных под образовательные нужды
14.09.2024 [01:03],
Владимир Мироненко
Российский производитель ПК «Рикор» в этом году поставил российским школьникам 65 тысяч ноутбуков, адаптированных под образовательные нужды. Компания сообщила, что поставка устройств в ГК «Просвещение» для оснащения российских школ была выполнена в период с марта по август в рамках Федерального проекта «Цифровая образовательная среда» и является крупнейшей поставкой компьютерной техники в российские школы в 2024 году.  Большей частью школьникам были поставлены ноутбуки Rikor NINO 16 на базе мощного 6-ядерного процессора AMD Ryzen 5 7430U c максимальной частотой 4,3 ГГц и интегрированной графикой AMD Radeon, 8 Гбайт оперативной памяти DDR4 и SSD-накопителем на 256 Гбайт.  Устройство отличается большим и удобным дисплеем с диагональю 16 дюймов, разрешением WUXGA и яркостью 350 кд/м2, а также двумя портами DisplayPort. Это позволяет подключать несколько дополнительных экранов, что повышает эффективность работы, гибкость использования пространства и способствует лучшей организации учебного процесса. Среди преимуществ ноутбука:
Также компания поставила модели Rikor NINO 15 и Rikor ARZ 15. Rikor NINO 15 отличается производительным 6-ядерным процессором AMD Ryzen 6600H с базовой частотой 3,3 ГГц, яркостью дисплея 350 кд/м2, оперативной памятью DDR5, большим количеством и высокой производительностью USB-портов со скоростью до 10 Гбит/с (4 порта Type-A и 4 — Type-C).  Производитель отметил, что Rikor ARZ 15 является самой бюджетной моделью из поставленных, при этом обладает 6-ядерным процессором AMD Ryzen 5 5560U и всеми необходимыми для работы коммуникациями. «ГК “Просвещение” поставила в школы более 65 тысяч ноутбуков “Рикор”, что сделало нас крупнейшим производителем ПК для сферы образования в 2024 году», — подчеркнул Антон Громов, вице-президент «Рикор». Всё везде и сразу: создатели Heroes of Might & Magic: Olden Era рассказали о разнообразии режимов и дали добро на «сломанные» билды
14.09.2024 [00:26],
Михаил Романов
Разработчики из кипрской студии с российскими корнями Unfrozen (Iratus: Lord of the Dead) рассказали о доступных режимах и подходе к балансу в будущей тактической стратегии Heroes of Might & Magic: Olden Era. 
Источник изображений: Ubisoft По словам авторов, в Heroes of Might & Magic: Olden Era они постарались сделать так, чтобы все типы пользователей смогли найти в проекте что-то для себя, в связи с чем подготовили широкий выбор разных режимов игры. Какие одиночные режимы будут представлены в Heroes of Might & Magic: Olden Era:

Помимо инструмента для создания карт, игра предложит ещё и (более сложный) редактор шаблонов Что касается мультиплеера, то разработчики намерены удовлетворить потребности соревновательного сообщества и предложить на старте раннего доступа три режима (классический, «Один герой» и арена), о которых расскажут отдельно. Обещают не только онлайновый, но и локальный мультиплеер, систему матчмейкинга (впервые в серии), профили и рейтинговую таблицу — все функции, которые делают игровой процесс более комфортным. 
Разработчики уверяют, что против их ИИ играть будет интересно В «ровный» баланс создатели Heroes of Might & Magic: Olden Era не верят, поэтому:
Ранний доступ Heroes of Might & Magic: Olden Era стартует во втором квартале 2025 года на PC (Steam). На запуске будут все основные механики, первый акт кампании, несколько карт от команды, генератор случайных карт и ИИ. Новая статья: Test Drive Unlimited Solar Crown — не такое возвращение мы ждали. Рецензия
14.09.2024 [00:09],
3DNews Team
Данные берутся из публикации Test Drive Unlimited Solar Crown — не такое возвращение мы ждали. Рецензия «Отключать дизлайки — трусость»: игроки раскритиковали авторов Eve Online после анонса выживания Eve Frontier с блокчейн-элементами
13.09.2024 [22:59],
Юлия Позднякова
Студия CCP Games официально анонсировала онлайновую космическую песочницу с элементами симулятора выживания Eve Frontier во вселенной Eve Online. В игре будут блокчейн-элементы, из-за которых поклонники обрушились с критикой на авторов, несмотря на попытки последних защитить свои инновации. 
Источник изображений: CCP Games В Eve Frontier (рабочее название — Project Awakening) игроки будут изучать Фронтир — область космоса со следами древних цивилизаций, искажённую воздействием сверхмассивных чёрных дыр. Предстоит перемещаться по планетам, сражаться в хардкорных тактических боях, добывать Материю (универсальный ресурс, который нужен для полётов, исследований и других действий) и улучшать корабли. Проект создаётся на проприетарном движке Carbon с открытым исходным кодом. Одной из важнейших особенностей станет блокчейн-платформа Smart Assemblies, с помощью которой игроки смогут «управлять правилами вселенной». Новшество позволит «строить и программировать инфраструктуру в космосе» (защитные сооружения, торговые посты и другое), используя блокчейн Redstone и технологию MUD от Lattice (разработчики Redstone). Каждая фракция сможет выпускать собственные валюты, формируя сложную экономику. Создатели хотят, чтобы Eve Frontier была «децентрализованной и (почти) вечной». При этом о монетизации авторы пока рассказать не готовы.  Сами разработчики категорически против определения «блокчейн-игра» и настаивают, что Eve Frontier — «игра с блокчейн-технологиями», которые применяются с благими намерениями. Команда надеется, что с новым проектом произойдёт то же, что и когда-то с Eve Online, в которую геймеры поначалу не верили из-за использования баз данных: он изменит отношение пользователей к блокчейну и заставит их понять, что это «всего лишь инструмент». «Эта технология просто позволяет нам делать некоторые вещи, которые без неё невозможны», — отметил в интервью PC Gamer менеджер по продуктам CCP Games Скотт Маккейб (Scott McCabe). Как ни старались авторы, одного упоминания блокчейн-элементов оказалось достаточно, чтобы фанаты обрушились на разработчиков с критикой. Всеобщее недовольство усилил бессодержательный анонсирующий трейлер, для которого студия отключила возможность ставить дизлайки. В комментариях к ролику игроки обвинили CCP Games ещё и в слабой поддержке Eve Online в последние годы (расширения Equinox и Havoc были приняты неоднозначно). Припомнили студии и неудачи с прошлыми ответвлениями — закрытие Dust 514 и Eve: Valkyrie. «Кажется, я понял только то, что игра тёмная, научно-фантастическая и про космос», — пожаловался CrispyChestnuts. «Играл в Eve больше 16 лет, — написал cav0409. — Бросил, не думаю возвращаться и доволен. Вы не слушаете игроков, а только собираете деньги». «Eve не заслуживает быть блокчейн-мошенничеством», — сетует spaceghost8891. «Эта игра уже мертва», — констатирует nemleon87. «CCP нужно активно действовать, чтобы не дать Eve Online умереть, а не отвлекаться на крипто-игру», — считает cjcarus921. «Отключать дизлайки — трусость», — заметил SoakingTheDog. Eve Frontier
27 сентября стартует четвёртый этап закрытого бета-тестирования Eve Frontier (заявку на участие можно подать на официальном сайте). В трейлере сообщается, что «скоро» на ПК (Windows и macOS) начнётся испытание для покупателей наборов основателей. Одного выживания недостаточно: создатели Frostpunk 2 показали вступительный ролик и трейлер с основными особенностями игры
13.09.2024 [22:48],
Михаил Романов
Релиз градостроительной стратегии с элементами выживания Frostpunk 2 всё ближе, и маркетинговая машина разработчиков из польской 11 bit studios набирает ход: за последние сутки по игре вышло сразу два новых видео. 
Источник изображения: 11 bit studios Первый из двух роликов длится две минуты и представляет собой кинематографическое вступление игры, в котором спустя 30 лет бесконечных морозов Британская Империя всё ещё цепляется за выживание. Издавая последний вздох, Капитан осознаёт, что одного выживания уже недостаточно. Будут ли годы борьбы сведены на нет из-за противостояния идеологий или у нового Стюарда получится вселить в общество веру, что Новый Лондон ещё может выстоять? Второй ролик растянулся на пять минут и повествует об 11 основных особенностях Frostpunk 2: город стал больше (1), потребности выросли (2), болезни, голод, холод никуда не делись (3), у всех горожан (4) и фракций (5) разные стремления. Игрокам придётся голосовать и принимать новые законы в Совете (6), держать фракции под контролем (7), исследовать морозные земли (8) и строить колонии (9). Делать всё это можно в сюжетном режиме или песочнице (10), а также с модами (11). Бонусный факт — в игре будет интеграция с Twitch Frostpunk 2 выйдет 20 сентября на PC (Steam, GOG, EGS, Microsoft Store) и в PC Game Pass, а затем на PS5, Xbox Series X, S и в Xbox Game Pass. Владельцы расширенного издания смогут начать играть с 17-го числа. В российском Steam доступен предзаказ Frostpunk 2: стандартная версия обойдётся в 1900 рублей, а расширенная (с доступом к трём пострелизным дополнениям) продаётся за 2880 рублей (до релиза действует 10-процентная скидка). Астронавт миссии Polaris Dawn исполнила мелодию из «Звёздных войн» на орбите — видео транслировали через лазер Starlink
13.09.2024 [22:47],
Анжелла Марина
Астронавт миссии Polaris Dawn Сара Гиллис (Sarah Gillis) устроила космический концерт, исполнив на скрипке тему из «Звёздных войн». Благодаря спутниковой связи Starlink, оркестры из разных стран мира смогли аккомпанировать ей в режиме реального времени. 
Источник изображения: Polaris Dawn Музыкальный перформанс стал возможен благодаря высокоскоростной связи, которую обеспечивает сеть спутников Starlink компании SpaceX. Гиллис играла на скрипке на борту космического корабля Dragon, а аккомпанировали ей поочерёдно оркестры из разных уголков Земли — из США, Бразилии, Швеции, Венесуэлы и других стран. «Путешествуя вокруг нашей прекрасной планеты, мы хотели поделиться с вами этим особенным музыкальным моментом», — сказала Гиллис в своём видеообращении.
Интересно, что космический концерт стал не просто развлекательным мероприятием, но и частью тестирования лазерной системы связи Starlink. Как правило, спутники Starlink используют радиоволны для передачи интернет-данных на Землю. Однако они также оснащены лазерами, которые способны создавать соединение со скоростью до 100 Гбит/с на канал. Это позволяет спутникам взаимодействовать друг с другом, образуя в космосе единую сеть. Dragon, на котором находится экипаж Polaris Dawn, предположительно использовал именно эту лазерную сеть для отправки видео на Землю. Ранее, в четверг, в официальном аккаунте миссии X/Twitter появились две фотографии, сделанные из космоса, с подписью: «Посылаем из космоса через лазерный луч Starlink». А утром в пятницу, незадолго до публикации видео с Гиллис, появился ещё пост: «Связь установлена, следите за обновлениями!». Это позволяет предположить, что запись концерта не транслировалась в прямом эфире, а была сначала отправлена музыкальным коллективам на Землю для обработки и окончательного исполнения уже в записи. Напомним, миссия Polaris Dawn, управляемая компанией SpaceX, стартовала 10 сентября на пилотируемом космическом корабле Dragon 2 на околоземную орбиту. Среди целей указываются медицинские наблюдения и тестирование системы связи Starlink. 12 сентября, в рамках коммерческого космического полёта, произошёл первый в истории выход в открытый космос космических туристов. iPhone 16 Pro и Pro Max разлетаются как горячие пирожки — предзаказы уже растянулись до октября
13.09.2024 [21:32],
Андрей Созинов
Сегодня Apple начала принимать предварительные заказы на смартфоны семейства iPhone 16. Продажи новинок стартуют 20 сентября, но самые популярные модели уже придётся ждать до октября — первые партии уже полностью раскупили на стадии предзаказа. Так происходит уже не первый год подряд.  Вскоре после старта предварительных заказов стало ясно, какие модели серии iPhone 16 пользуются наибольшим спросом. Самым дефицитным оказался iPhone 16 Pro Max — уже через несколько часов после старта предзаказов в США не было ни одной версии iPhone 16 Pro Max, ни в одном цвете, которую можно было бы заказать с доставкой в день запуска. Если оформить предзаказ прямо сейчас, то ждать придётся до 7–14 октября. Ситуация с доступностью iPhone 16 Pro почти такая же — только версию на 128 Гбайт в чёрном цвете всё ещё можно было заказать с доставкой на 20 сентября. Остальные придётся ждать как минимум до периода с 30 сентября до 2 октября, а некоторые версии до 2–7 октября. Вероятнее всего, в ближайшее время сроки доставки iPhone 16 Pro и Pro max растянутся ещё сильнее. Как пишет портал 9to5mac, модели iPhone 16 Pro и Pro Max в черном цвете с накопителем на 512 Гбайт пользуются наибольшим спросом. Также высок спрос на белые версии. А вот iPhone 16 Pro и Pro Max в новом пустынном цвете оказались более доступны, но это может быть связано не с меньшим спросом, а с тем, что Apple подготовила в первой партии больше таких смартфонов. Вместе с тем проблем с доступностью обычных iPhone 16 и iPhone 16 Plus нет — каждую версию в каждом цвете можно заказать с доставкой на 20 сентября. Это в очередной раз подтверждает, что модели iPhone Pro пользуются более высоким спросом у поклонников Apple. Напомним, ранее аналитики предсказывали, что по расчётам Apple модели Pro-серии обеспечат около 67 % продаж, тогда как на обычные iPhone придётся лишь 33 % в штучном выражении. «Нам не нужна PS5 Pro»: первый геймплей Star Wars Jedi: Survivor на PS4 Pro приятно удивил игроков
13.09.2024 [21:21],
Михаил Романов
До релиза джедайского экшена Star Wars Jedi: Survivor на PS4 и Xbox One остаётся всего несколько дней, и игроки наконец смогли оценить, как проект Electronic Arts и Respawn Entertainment выглядит на одной из консолей прошлого поколения. 
Источник изображений: Electronic Arts Напомним, EA подтвердила версии Star Wars Jedi: Survivor для PS4 и Xbox One ещё прошлым летом, однако даже после анонса даты выхода в августе этого года демонстрировать геймплей не спешила. Припоминая трудности Star Wars Jedi: Survivor на более мощных PS5, Xbox Series X и S, геймеры относились к релизу скептически. EA обещала многочисленные улучшения оптимизации и, похоже, не обманула. 
В комментариях к роликам некоторые подозревали, что в заголовке по ошибке вместо PS5 Pro написано PS4 Pro Зарубежные порталы вроде IGN и Kotaku опубликовали присланный им EA пятиминутный ролик с нарезкой геймплейных сцен (без спойлеров) из Star Wars Jedi: Survivor на PS4 Pro. Пользователи остались под впечатлением от увиденного: даже на консоли прошлого поколения игра выглядит и работает более чем достойно. «Смотрится очень хорошо на PS4 Pro. Нам не нужна PS5 Pro», — настаивает iyedsenpai. На всех четырёх моделях консолей прошлого поколения Star Wars Jedi: Survivor будет работать при 30 кадрах/с. Отличаться будет разрешение:
Star Wars Jedi: Survivor для PS4 и Xbox One поступит в продажу 17 сентября по цене $50. Благодаря будущему патчу игроки получат возможность переносить сохранения между PS4 и PS5. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex











