|
Опрос
|
реклама
Быстрый переход
Суд обязал «Яндекс» доплатить 1,67 млрд рублей налогов
13.09.2024 [20:46],
Анжелла Марина
Компания «Яндекс» проиграла налоговый спор с ФНС, связанный со сносом гостиницы «Корстон» на Воробьёвых горах, сообщает Forbes. Суд решил, что «Яндекс» не может уменьшить налог на прибыль, списав расходы на ликвидацию здания, вместо которого запланировано строительство новой штаб-квартиры. Суд посчитал, что расходы на снос должны включаться в стоимость нового здания. 
Источник изображений: Яндекс/WikiFido, CC BY-SA 4.0 История началась в 2018 году, когда «Яндекс» приобрёл землю под бывшей гостиницей за $145 млн. На строительство нового офиса планировалось потратить ещё $275–330 млн, а завершить проект предполагалось в 2024 году. В ноябре 2022 года компания подала уточнённую декларацию по налогу на прибыль за 2021 год, уменьшив налог на 1,67 млрд рублей и увеличив сумму расходов на 8,36 млрд рублей. «Яндекс» обосновал это тем, что учёл расходы на снос «Корстон» как внереализационные, ссылаясь на статью Налогового кодекса, позволяющую относить затраты на ликвидацию выводимых из эксплуатации основных средств к внереализационным расходам. Однако Федеральная налоговая служба (ФНС) не согласилась с такой трактовкой. По мнению ФНС, «единственной целью ликвидации основных средств гостиничного комплекса являлось освобождение земельного участка для последующего строительства на нём нового офисного здания». Налоговая посчитала, что расходы на снос должны быть включены в первоначальную стоимость новой штаб-квартиры, а не списаны через амортизацию. В марте 2024 года «Яндекс» обратился в суд, но проиграл дело. Суд отклонил довод компании о том, что при подходе ФНС в стоимость нового офиса будет включена остаточная стоимость снесённых зданий, а значит, компания продолжит «использовать полезные свойства объектов, которых уже не существует». — " Второй жизни" ликвидированных объектов основных средств внутри стоимости новых при учёте спорных затрат в порядке первоначальной стоимости нового основного средства не происходит», — постановил суд. «Яндекс» заявил о намерении подать апелляцию. Forbes также передаёт, что в 2023 году компания сократила свои офисные площади в Москве на 12 000 квадратных метров, что указывает на возможную оптимизацию бизнес-процессов. В 2022 году «Яндекс» съехал из бизнес-центра «Амальтея» в «Сколково», а часть офисов в БЦ «Аврора» была передана сервису «Дзен», позднее проданному VK. Новый офис на Воробьёвых горах займёт около 162 000 квадратных метров, а завершить переезд компания планирует к середине 2025 года. В России поступили в продажу ноутбуки Infinix Inbook Y3H Max и Inbook Y4H Max с мощными чипами Intel Core
13.09.2024 [20:42],
Владимир Мироненко
Компания Infinix объявила о старте продаж в России ноутбуков Inbook Y3H Max и Inbook Y4H Max, сочетающих в себе высокую производительность и привлекательный строгий дизайн. Новинки основаны на производительных процессорах Intel Core H-серии с эффективной системой охлаждения, а также обладают поддержкой быстрой зарядки и механическим переключателем режимов работы.  Высокую производительность, а также плавную работу в режиме многозадачности ноутбука Infinix Inbook Y3H Max обеспечивает процессор Intel Core i5-12450H с 16 Гбайт оперативной памяти и SSD на 512 Гбайт. В модели Infinix Inbook Y4H Max используется процессор Intel Core i7-13620H в сочетании с 16 Гбайт оперативной памяти и твердотельным накопителем ёмкостью 1 Тбайт. Отвод тепла от компонентов обеспечивает улучшенная система охлаждения ICE Storm 3.0 с двойными вентиляторами, позволяя не беспокоиться о перегреве даже при выполнении ресурсоёмких задач. Обе модели оснащены 16-дюймовыми экранами с разрешением FHD+, частотой обновления 60 Гц и яркостью 300 кд/м2. Соотношение сторон экрана составляет 16:10. Также экран обеспечивает 60-процентный охват цветового пространства NTSC и имеет уголы обзора в 178° в обеих плоскостях.  Для регулировки производительности ноутбуков можно использовать механический переключатель. Предусмотрено три режима. Режим ECO позволяет экономить энергию, продлевая время автономной работы. Режим BAL обеспечивает оптимальный баланс между производительностью и энергопотреблением. Режим OVERBOOST гарантирует моментальный отклик приложений и быструю работу устройства. Функция Seamless Content Sharing PC 3.0 позволяет быстро и без проводов обмениваться файлами между ноутбуками и смартфонами Infinix, что повышает скорость и удобство работы. Обе модели оснащены массивной батареей ёмкостью 70 Вт·ч с быстрой 100-Вт зарядкой, благодаря чему обеспечивается возможность работы без подзарядки в течение всего рабочего дня, а также быстрое восполнение заряда батареи. Новинки от Infinix доступны в российской рознице в серебристом цвете в нескольких комплектациях по следующим ценам:
«Книга рекордов Гиннесса» признала Garry's Mod самым продаваемым ПК-эксклюзивом в истории
13.09.2024 [20:21],
Михаил Романов
На ПК вышло множество популярных эксклюзивов, но какой из них считать самым продаваемым? Ответ скрывает дебютировавшая на днях новейшая редакция «Книги рекордов Гиннесса. Геймеры» (Guinness World Records Gamer's Edition). 
Источник изображения: Facepunch Studios Как стало известно, самым продаваемым ПК-эксклюзивом в истории редакция «Книги рекордов Гиннесса» признала Garry’s Mod — популярную физическую песочницу от Гэри Ньюмана (Garry Newman) и Facepunch Studios. О включении Garry’s Mod в новейшую редакцию геймерской версии «Книги рекордов Гиннесса» отчитался официальный микроблог игры, приложив к сообщению фотографию книги (см. изображение ниже). «Никогда не мог представить, что стану обладателем мирового рекорда, не имея отношения к чипсам со вкусом креветочного коктейля», — прокомментировал достижение своего проекта сам Ньюман. 
Источник изображения: X (Garry’s Mod) Garry’s Mod дебютировала в ноябре 2006 года и за прошедшие уже почти 18 лет заслужила в Steam более 1 млн «крайне позитивных» отзывов. Продажи по состоянию на сентябрь 2021-го превысили 20 млн копий. Стоит отметить, что история знает предостаточно игр, продажи которых на ПК превысили 20 млн копий (PUBG: Battlegrounds, Minecraft, Terraria и другие), однако эксклюзивами этой платформы они не являются. В настоящее время Ньюман работает над духовным наследником Garry’s Mod — песочницей S&box на движке Source 2 — и намерен превзойти своё самое известное творение во всех аспектах. Прототип китайской многоразовой ракеты Landspace подпрыгнул на 10 км и успешно приземлился
13.09.2024 [19:55],
Сергей Сурабекянц
Китайский частный космический стартап Landspace успешно завершил 10-километровый вертикальный взлёт и вертикальную посадку на своём ракетном испытательном стенде Zhuque-3 (ZQ-3), включая повторный запуск двигателя в полёте при почти сверхзвуковой скорости. 
Источник изображения: Landspace 18,3-метровый аппарат взлетел с пусковой площадки базы Цзюцюань на северо-западе Китая, поднялся на высоту 10 002 метра, а затем совершил вертикальный спуск и успешно приземлился в 3,2 километрах от места старта. Примечательно, что метановый двигатель переменной тяги был намеренно отключён в полёте, а затем снова включён при посадке для тестирования различных вариантов и режимов работы. По информации от Landspace, «все показатели соответствовали ожидаемому проекту». Компания считает это испытание важной вехой на пути к запуску своей ракеты Zhuque-3 уже в следующем году. Оборудованная девятью главными двигателями на метановом топливе, Zhuque-3 сможет доставлять 21 тонну полезной нагрузки на низкую околоземную орбиту с использованием одноразового разгонного блока. А в 2026 году Landspace планирует начать восстановление и повторное использование первых ступеней. Landspace является одной из нескольких китайских компаний, серьёзно работающих над конструкциями многоразовых ракет. Другая китайская компания, Deep Blue Aerospace, планирует провести 100-километровое суборбитальное испытание многоразового ускорителя в преддверии первого полёта своей ракеты среднего класса Nebula-1 в следующем году. Microsoft создала робота для разборки и переработки 2 млн жёстких дисков в год
13.09.2024 [19:44],
Сергей Сурабекянц
Неисправные или изношенные жёсткие диски могут содержать множество ценных данных, которые необходимо гарантированно удалить без возможности восстановления. Но они также состоят из довольно ценных деталей, таких как алюминиевые пластины, неодимовые магниты и шасси из нержавеющей стали. Поэтому вместо того, чтобы измельчать диски, Microsoft изобрела роботов, которые разбирают их в промышленных количествах для извлечения всех ценных материалов. 
Источник изображений: Microsoft В 2022 году команда под руководством Ранганатана Шриканта (Ranganathan Srikanth) представила роботов, которые разбирают жёсткие диски, удаляют данные путём уничтожения пластин и перерабатывают оставшиеся части для извлечения ценных материалов и деталей для их повторного использования. Роботизированная система производства Dobot Robotics на основе ИИ от Microsoft использует компьютерное зрение для распознавания различных типов жёстких дисков и выбора способа их разборки.  По данным Microsoft, этот новый подход NoShred направлен на достижение 90 % повторного использования и переработки жёстких дисков к 2025 году. Роботы обеспечивают безопасность данных, уничтожая только компоненты, несущие данные, и извлекая ценные материалы. Следует отметить, что во многих случаях компании, которые должны уничтожать свои диски, не делают этого, и они в конечном итоге собирают пыль в складских помещениях или отправляются на свалки. 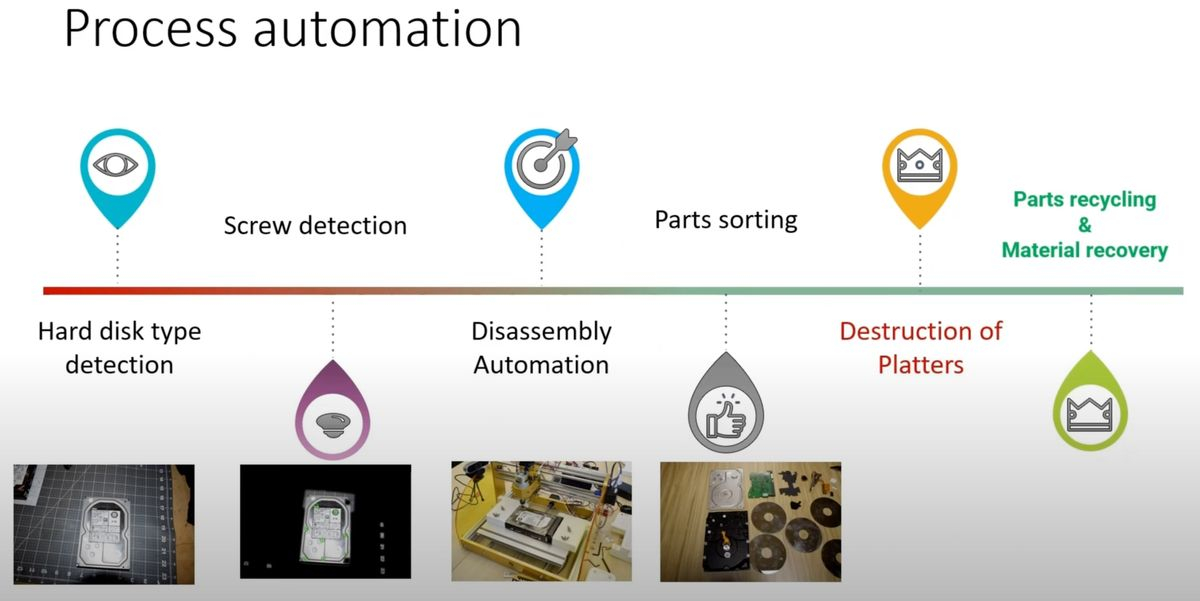 Усилия Microsoft выходят за рамки внутренней политики. Компания сотрудничает с производителями жёстких дисков и правительствами, чтобы повлиять на глобальный подход к утилизации электронных отходов. Сотрудничая и делясь своими технологиями, Microsoft надеется уменьшить воздействие электронных отходов на окружающую среду и улучшить безопасность для компаний по всему миру. Инициатива также отражает цели Microsoft в области устойчивого развития, которые включают достижение отрицательного уровня выбросов углерода к 2050 году. На сегодняшний день по разным оценкам во всём мире ежегодно заканчивают свой жизненный цикл от 20 до 70 миллионов жёстких дисков. Только Microsoft в 2022 году уничтожила два миллиона жёстких дисков, причём процент разобранных и переработанных устройств компания не сообщила. Европейцам на следующей неделе разрешат скачивать приложения на iPad из сторонних магазинов
13.09.2024 [19:07],
Владимир Фетисов
На следующей неделе Apple разрешит владельцам iPad из Евросоюза загружать приложения из сторонних магазинов цифрового контента. Это произойдёт вместе с запуском iPadOS 18, общедоступная версия которой выйдет 16 сентября. Данное изменение в политике компании направлено на то, чтобы добиться соответствия действующему в регионе Закону о цифровых рынках (DMA). 
Источник изображения: Epic Games К настоящему моменту несколько сторонних магазинов цифрового контента, такие как Setapp Mobile, AllStore PAL и Epic Games Store, уже доступны пользователям iPhone на территории Евросоюза. Ранее в этом году Epic Games объявила, что платформа компании получит поддержку iPad до конца нынешнего года. Это означает, что уже скоро фанаты Fortnite из Европы смогут использовать для взаимодействия с игрой свои iPad. У Apple было шесть месяцев для того, чтобы изменить свою политику в отношении распространения приложений для соответствия DMA. Компания должна была не только разрешить загружать приложения из сторонних магазинов, но также обеспечить возможность удаления предустановленных приложений на iPad и позволить пользователям самостоятельно выбирать приложения, используемые по умолчанию. В дополнение к этому Apple открыла iOS и iPadOS для приложений, использующих альтернативные браузерные движки, отличные от WebKit. Intel получила субсидии в $1,9 млрд на строительство завода в Польше
13.09.2024 [19:02],
Сергей Сурабекянц
Европейская комиссия дала Польше зелёный свет на поддержку открытия нового завода Intel по сборке и тестированию чипов. Размер инвестиций ЕС составит более чем 7,4 млрд злотых (1,91 млрд долларов США). Решение Еврокомиссии было принято в непростой момент для Intel, которая всеми силами стремится сократить расходы. Это вызвало вопросы о реальности планов компании по расширению в Европе, которые также включают в себя создание крупного производства чипов в Германии.  В прошлом году Intel объявила о планах инвестировать до $4,6 млрд в объект недалеко от Вроцлава на юго-западе Польши с возможностью дальнейшего расширения. Инвестиции соответствуют Европейскому закону о чипах, заявленному как план субсидий на €43 млрд, направленный на увеличение доли Европы на мировом рынке чипов до 20 % к 2030 году. «Европейская комиссия проинформировала Польшу о том, что есть зелёный свет на предоставление государственной помощи Intel. Государственная помощь, которую мы предоставим, составляет более 7,4 млрд злотых в 2024-2026 годах. Сегодня эти инвестиции стоят, как с точки зрения пакета помощи, так и в целом, более 25 млрд злотых», — заявил вице-премьер Кшиштоф Гавковски (Krzysztof Gawkowski). «В последние недели или месяцы мы не получали никаких сигналов относительно изменения позиции... Исходя из сегодняшней информации, нет ничего, что могло бы замедлить эти инвестиции», — сказал Гавковски, когда его спросили о рисках для инвестиций в Польшу. Он высказал надежду, что Intel сможет начать строительные работы в этом году. Теперь Польша должна принять закон о предоставлении государственных средств, а затем официально уведомить Европейскую комиссию. «По нашим оценкам, этот процесс будет завершён к концу года, — считает заместитель министра по цифровым вопросам Дариуш Стандерски (Dariusz Standerski). — Инвестиции в завод Intel — крупнейшие инвестиции в Польше за десятилетия... полупроводники в Польше будут гарантировать как лучшее экономическое развитие, так и большую безопасность». Представитель Intel заявил, что компания ценит «постоянную поддержку и партнёрство польского правительства». У компании есть исследовательский центр в Гданьске на севере Польши. В отношении немецкого проекта представитель Intel воздержался от комментариев. Проект строительства завода по производству чипов в Германии стоимостью $33 млрд все ещё ожидает одобрения ЕС, а начало работ отложено до мая 2025 года. Одна из крупнейших авиакомпаний США предложит бесплатный Wi-Fi через Starlink в своих самолётах в 2025 году
13.09.2024 [18:57],
Сергей Сурабекянц
Одна из крупнейших американских авиакомпаний United Airlines предложит пассажирам бесплатный Wi-Fi на своих рейсах благодаря спутниковому интернету Starlink от SpaceX. Тестирование сервиса запустят уже в начале 2025 года. В дальнейшем бесплатный Wi-Fi от Starlink появится на более чем 1000 самолётов United Airlines. 
Источник изображения: Starlink «Всё, что вы можете делать на земле, вы скоро сможете делать на борту самолёта United на высоте 35 000 футов (10 668 метров), практически в любой точке мира», — заявил генеральный директор United Airlines Скотт Кирби (Scott Kirby). Эта инициатива имеет важное значение для путешественников, поскольку бортовой Wi-Fi на рейсах United Airlines, да и у большинства других авиаперевозчиков, часто ненадёжен и не обеспечивает приемлемой скорости. В настоящее время United Airlines пользуется услугами четырёх разных поставщиков услуг Wi-Fi для своих самолётов, среди которых Intelsat, Panasonic Wi-Fi и Viasat Wi-Fi. Starlink планирует обеспечить пассажирам скорость совместного подключения не ниже 100 Мбит/с с задержкой менее 100 мс. Это обеспечит бесперебойную потоковую передачу Netflix и даст возможность присоединяться к видеоконференциям. Пропускная способность канала Starlink может достигать до 220 Мбит/с на самолёт. Высокоскоростной сервис Starlink в настоящее время доступен только на самолётах JSX и Hawaiian Airlines в США. Ряд международных авиакомпаний объявили о планах установить Wi-Fi от Starlink: WestJet будет использовать Starlink на борту некоторых своих самолётов начиная с декабря, Qatar Airways внедрит бесплатный Starlink Wi-Fi на трёх своих самолётах Boeing 777-300 в конце этого года, Air New Zealand намерена развернуть Starlink на своём внутреннем флоте в 2025 году. Новости о сделке United Airlines и Starlink появились одновременно с заявлением председателя Федеральной комиссии по связи Джессики Розенворсель (Jessica Rosenworcel) о необходимости развития конкуренции в сфере космической связи. Starlink вывела на орбиту около 7000 спутников с 2018 года, при этом компания контролирует почти две трети спутников, которые сейчас находятся в космосе. T-Mobile объявила на этой неделе об успешном тестировании аварийных оповещений через спутник Starlink. В 2022 году T-Mobile и SpaceX объявили о партнёрстве, которое позволит отправлять текстовые сообщения, совершать звонки и использовать свои телефоны T-Mobile через спутники Starlink. AT&T и Verizon также разрабатывают аналогичные услуги «спутник-смартфон», а Apple и Google предлагают услуги спутниковой мобильной связи в своих последних смартфонах. Душевная игра об уютной жизни хоббитов Tales of the Shire не выйдет в 2024 году и скоро получит дату выхода
13.09.2024 [18:53],
Михаил Романов
Создатели душевной игры о жизни хоббитов Tales of the Shire: A The Lord of the Rings Game обещали перенести игроков в сказочной красоты Шир текущей осенью, но с отправлением придётся повременить. 
Источник изображения: Private Division Разработчики из новозеландской студии Weta Workshop при поддержке издательства Private Division обратились к пользователям с новостью о вынужденном переносе релиза Tales of the Shire: A The Lord of the Rings Game. Как стало известно, теперь премьера Tales of the Shire: A The Lord of the Rings Game ожидается лишь в начале 2025 года. Релиз игры всё ещё планируется на PC (Steam), PS5, Xbox Series X и S, а также Nintendo Switch.  В сопровождавшем анонс сообщении (см. изображение ниже) авторы заверили, что стремятся оправдать ожидания игроков, а для этого проекту требуется дополнительное время. Разработчики также призвали интересующихся датой выхода Tales of the Shire не пропустить презентацию A Hobbit Day Showcase, которая пройдёт в День хоббита — 22 сентября (начало в 20:30 по Москве). 
Полный текст обращения События Tales of the Shire развернутся в ещё не получившем статус деревни местечке Байуотер на территории Шира. Игрокам предстоит создать собственного хоббита, изучать и украшать этот «идиллический уголок Средиземья». Обещают умиротворяющие пейзажи, тайные поляны и затерянные сокровища, смену погоды и времён года, возможность организовать второй завтрак и персонажей из знаковых семейств хоббитов. Русский язык не заявлен. Новая волна увольнений в Xbox затронула разработчиков Warcraft Rumble и Call of Duty: Warzone Mobile
13.09.2024 [18:12],
Михаил Романов
Прокатившаяся на днях по игровому подразделению Microsoft волна увольнений затронула не только корпоративную часть и команды поддержки, как уверял Фил Спенсер (Phil Spencer), но и разработчиков внутри Activision Blizzard. 
Источник изображения: Activision Напомним, в целях ориентации своего бизнеса на «долгосрочный успех» Xbox рассталась с 650 сотрудниками (вдобавок к январским 1900). Сообщалось, что новые сокращения не приведут к отмене игр и закрытию студий. Журналист Game File Стивен Тотило (Stephen Totilo) со ссылкой на осведомлённого информатора сообщил, что увольнения затронули команды двух мобильных игр — Warcraft Rumble и Call of Duty: Warzone Mobile. Закрывать ни один из проектов не станут, однако снизят активность поддержки и сократят штат отвечавших за неё разработчиков. Тотило добавил, что Call of Duty: Warzone Mobile не оправдала ожиданий руководства. 
Источник изображения: Blizzard Entertainment По данным информатора Game File, сокращения в командах Warcraft Rumble и Call of Duty: Warzone Mobile, в отличие от значительной части новой волны увольнений, не связаны с приобретением Activision Blizzard. Амбиций на мобильном рынке Microsoft не занимать, однако вслед за другими игровыми издателями компания осознаёт, что развлечениям даже по самым известным франшизам в этой сфере не гарантирован долгосрочный успех. Приобретение Activision Blizzard за $68,7 млрд обернулось для игрового подразделения Microsoft увольнением уже более 2,5 тыс. сотрудников. Всего за 2024 год работы в сфере интерактивных развлечений лишилось более 12 тыс. человек. Японская iSpace запустит второй посадочный модуль к Луне в декабре — первый полёт закончился крушением
13.09.2024 [18:02],
Николай Хижняк
Японская компания iSpace готовится ко второй миссии к поверхности Луны. В её рамках к спутнику Земли отправятся посадочный модуль Resilience и миниатюрный ровер, получивший название Tenacious. Запуск миссии будет осуществляться с помощью ракеты-носителя Falcon 9 американской компании SpaceX. В четверг японская компания сообщила, что запуск планируется провести не ранее декабря этого года. 
Посадочный лунный модуль Resilience и установленный в него ровер Tenacious. Источник изображений: iSpace «Я очень рад объявить, что сборка и интеграция посадочного модуля Resilience завершены. Мы следуем графику запланированного запуска не ранее декабря этого года. Место посадки определено, подготовка к Миссии 2 уверенно продвигается», — сказал Такеши Хакамада (Takeshi Hakamada), основатель и генеральный директор iSpace, на пресс-конференции в четверг. Основным местом посадки выбрано «Море Холода», обширная базальтовая равнина на крайнем севере Луны, расположенная в 60,5 градусах северной широты и 4,6 градусах западной долготы спутника. В случае успеха это будет самая северная высадка на Луне на сегодняшний день. Компания также подобрала альтернативные места для высадки «для обеспечения эксплуатационной и научной гибкости». Предполагаемая дата посадки пока не разглашается. Посадочный модуль Resilience будет нести пять полезных нагрузок, включая оборудование для электролиза воды от компании Takasago Thermal Engineering Co., автономный модуль для экспериментов по производству продуктов питания от Euglena Co., зонд для глубокого космоса, разработанный Национальным центральным университетом Тайваня и памятную пластину из сплава, разработанную Bandai Namco Research Institute, Inc. 
На лунный ровер Tenacious компании iSpace установлена моделька домика «Moonhouse» от художника Микаэля Генберга Пятой полезной нагрузкой будет Tenacious — микроровер высотой 26 см, шириной 31,5 см, и длиной 54 см, разработанный дочерней компанией iSpace в Люксембурге. Луноход оснащён фронтальной камерой с поддержкой HD-разрешения. На ровере также установлен Moonhouse — модель небольшого красного домика, созданная художником Микаэлем Генбергом (Mikael Genberg). В основу второй миссии взят посадочный модуль HAKUTO-R компании iSpace весом около 1000 кг. Для iSpace это станет вторая попытка посадки на Луну. Первая в апреле 2023 года не удалась из-за проблем в работе бортового датчика высоты посадочного модуля. Новый посадочный модуль Resilience оснащён обновленным программным обеспечением. Сам модуль создавался с учётом опыта первой миссии. Как сообщает Space.com, компания iSpace также ведёт разработку более крупного посадочного модуля под названием Apex 1.0. Ожидается, что он полетит к Луне в рамках «Миссии 3» где-то в 2026 году. Медиаиндустрия теряет архивы — каждый пятый жёсткий диск с музыкой 90-х вышел из строя от старости
13.09.2024 [17:47],
Сергей Сурабекянц
Компания по управлению корпоративной информацией Iron Mountain специализируется на управлении записями, уничтожении информации, резервном копировании и восстановлении данных. По данным компании, около пятой части жёстких дисков с музыкальными архивами, которые Iron Mountain получает от медиаиндустрии для обслуживания, полностью вышли из строя. Многие уникальные записи могут быть утеряны навсегда, если не было сделано резервной копии на другом носителе. 
Источник изображения: unsplash.com Миграция на жёсткие диски с ленточных накопителей началась в 2000-х годах с ростом популярности форматов многоканального звука и появлением музыкальных игр, таких как Guitar Hero. Эти технологии потребовали от музыкальных лейблов ремастеринга множества старых треков, в процессе которого обнаружилось, что аналоговые записи на лентах, которые использовались для хранения оригинальных записей, начали портиться, а некоторые вообще не воспроизводились. Даже если записи на лентах оказывались в полной сохранности, возникала проблема отсутствия совместимого оборудования для их воспроизведения. В результате музыкальная индустрия сосредоточилась на переносе своих архивов с аналоговых магнитных лент на цифровые носители, такие как жёсткие диски. Однако, как и ленты, жёсткие диски также портятся — большинство коммерческих накопителей рассчитаны на срок службы всего от трёх до пяти лет. Даже при хранении в самых оптимальных условиях архивные накопители в конечном итоге выйдут из строя. К сожалению, чаще всего студия обращается к архивам только для поиска оригинальных мастер-записей для коммерческого использования. Часто оказывается, что информация на архивном жёстком диске не подлежит восстановлению. «Так грустно видеть, как в студию поступает жёсткий диск в совершенно новом корпусе с упаковкой и бирками, — говорит глобальный директор по стратегическим инициативам и росту Iron Mountain Media & Archive Services Роберт Кошела (Robert Koszela). — Рядом с ним — внешний защищённый корпус с жёстким диском. Внешне всё в порядке. И оба они — кирпичи». Исследователи постоянно работают над новыми технологиями хранения архивных данных. Сообщается даже о стартапе, разрабатывающем носители со сроком службы 5000 лет. Однако до появления этих носителей по доступным ценам единственное, что можно сделать, чтобы обеспечить целостность цифровых архивов, — полностью перезаписывать их на новые накопители каждые три-пять лет. «Почти половина записанных диалогов не связана с сюжетом»: продюсер Kingdom Come: Deliverance 2 рассказал о масштабах игры и не только
13.09.2024 [16:48],
Игнатий Колыско
Warhorse Studios, разработчик масштабной ролевой игры Kingdom Come: Deliverance, готовится выпустить её продолжение уже 11 февраля 2025 года. Проект обещает стать масштабнее и проработаннее предшественника, сохранив при этом верность исторической достоверности и хардкорному геймплею. 
Источник изображений: Deep Silver На gamescom 2024 журналистам издания Wccftech удалось не только опробовать раннюю версию игры, но и пообщаться с Мартином Климой (Martin Klima), исполнительным продюсером Warhorse. Он поделился подробностями разработки и планами на будущее. Клима рассказал, что работа над Kingdom Come: Deliverance 2 началась не сразу после выхода первой части. Команда сосредоточилась на сиквеле только после релиза последнего DLC. Несмотря на то, что авторы рассматривали разные движки, в итоге было принято решение остаться на CryEngine. По словам Климы, это обосновано тем, что команда потратила много времени, видоизменяя его под свои нужды, поэтому итоговый результат в техническом плане подходил и для второй части. В игре будет два огромных региона, между которыми разрешат свободно перемещаться после определённого сюжетного момента. Разработчики уделили особое внимание оптимизации, дабы избежать проблем с производительностью, которые были у первой части. «Мы много работали над оптимизацией. […] Современное "железо", конечно, мощнее, да и у консолей больше памяти, но мы всё равно постарались сделать игру максимально плавной и приятной», — признался Клима.  Боевая система, визитная карточка Kingdom Come: Deliverance, останется верной своим принципам и во второй части, но станет более доступной. Теперь для атаки используется всего одна кнопка, а тип атаки — колющий или рубящий — определяется зоной удара. Здесь разработчики стремились к простоте и естественности: изначально управление боем казалось им слишком громоздким, поэтому они решили сократить количество используемых кнопок. В игру добавлены новые виды оружия: алебарды, арбалеты и, конечно же, огнестрельное оружие. Клима заметил, что «огнестрел» хоть и может стать абсолютным решением в некоторых ситуациях, но всё же неточен и долго перезаряжается. А ещё исполнительный продюсер уклонился от ответа на вопрос о возможных осечках при его использовании. Сотрудники Warhorse стремятся создать по-настоящему живой мир, где NPC живут своей жизнью, а не просто ждут встречи с игроком. Для этого была проделана огромная работа над ИИ и диалогами. «Приведу пример: мы записывали огромное количество диалоговых строк, и почти половина из них вообще не связана с сюжетом игры. — сказал Мартин Клима. — Это реакции NPC на действия игрока, например, когда вы что-то крадёте, когда вы входите в зону, где вам не следует находиться, когда персонажи находят тело или когда они открывают свой сундук и понимают, что он пуст. Это очень тонко; даже в зависимости от того, что было украдено, вы можете получить разные реакции». В Kingdom Come: Deliverance 2 появится система «быстрых диалогов», явно подсмотренная у Red Dead Redemption 2. В первой части активация любой беседы главного героя со случайным персонажем проходила через специальную систему, которая включала заскриптованную камеру и приостанавливала действия персонажа. Данное техническое решение хорошо работало в рамках сюжета, создавая эффект кинематографичности, но разработчики хотели чего-то более лёгкого и естественного, без резких переключений камеры, когда персонажи продолжают двигаться.  Специально для сиквела команда сначала создала систему коротких реплик (к примеру, «да» или «нет»), не требующих запуска громоздкой системы диалогов. Позже авторы поняли, что потенциал у неё гораздо больше, и добавили возможность приветствовать прохожих и обмениваться с ними короткими фразами. Клима отрицает, что это прямое копирование Red Dead Redemption 2, хотя и признаёт, что все в команде играют в игры, и влияние других проектов нельзя исключать. Kingdom Come: Deliverance 2 выйдет 11 февраля 2025 года на PC (Steam, EGS), PS5, Xbox Series X и S. До конца года «Сбер» полностью откажется от зарубежных СУБД в значимых объектах критической инфраструктуры
13.09.2024 [16:34],
Владимир Мироненко
«Сбер» объявил, что к концу 2024 года полностью завершит в рамках импортозамещения перевод своих автоматизированных систем в значимых объектах критической информационной инфраструктуры (КИИ) с иностранных СУБД на собственное решение Platform V Pangolin — реляционную СУБД корпоративного класса на базе PostgreSQL. С 2020 года Platform V Pangolin является целевой СУБД в «Сбере». Реляционная СУБД Platform V Pangolin входит в состав цифровой облачной платформы «СберТеха» Platform V «СберТеха». Platform V Pangolin основана на доработанной СУБД с открытым кодом PostgreSQL. Доработки повышают безопасность хранимых данных, доступность, надёжность и производительность системы. Также улучшено масштабирование. 
Источник изображения: «Сбер» По словам старшего вице-президента и руководителя блока «Технологии» Сбербанка, продукты собственной платформы нисколько не уступают по функциональности решениям западных вендоров, и более того, по ряду параметров превосходят их, и уже успешно заместили в «Сбере» многие из них. В частности, СУБД Platform V Pangolin полностью соответствует повышенным требованиям «Сбера» к производительности и безопасности: «Решение гарантирует надёжное хранение и быструю обработку больших объёмов данных в высоконагруженных системах компании». Platform V Pangolin входит в реестр российского ПО и полностью подходит для задач импортозамещения. Решение используют в крупных российских компаниях и с 2021 года оно доступно для внешнего рынка. В настоящее время больше 80 тыс. инсталляций Platform V Pangolin успешно используется в составе сервисов и приложений разного уровня масштаба и критичности. Представлены смартфон Realme P2 Pro и планшет Realme Pad 2 Lite
13.09.2024 [16:21],
Владимир Фетисов
Компания Realme официально представила смартфон среднего уровня Realme P2 Pro, а также бюджетный планшет Realme Pad 2 Lite. Обе новинки поступят в розничную продажу позднее в этом месяце. 
Источник изображений: Realme Разработчики оснастили Realme P2 Pro 6,7-дюймовым изогнутым дисплеем OLED с поддержкой разрешения Full HD+ и частотой обновления 120 Гц. Используется панель с пиковой яркостью 2000 кд/м². От механических повреждений экран защищает стекло Corning Gorilla Glass 7i. Смартфон выполнен в корпусе, который защищает внутренние компоненты от влаги и пыли по стандарту IP65.  В верхней части дисплея имеется отверстие, в котором размещена 32-мегапиксельная фронтальная камера. Основная камера объединяет в себе 1/1,95-дюймовый сенсор Sony LYT-600 на 50 Мп с поддержкой оптической стабилизации и 8-мегапиксельный сверхширокоугольный датчик с фокусным расстоянием 16 мм. Для создания качественных снимков в условиях плохой освещённости предусмотрена светодиодная вспышка.  Аппаратной основой смартфона стал восьмиядерный микропроцессор Qualcomm Snapdragon 7s Gen 2, который дополняется 8 Гбайт или 12 Гбайт оперативной памяти и накопителем на 128 Гбайт, 256 Гбайт или 512 Гбайт. Для эффективного охлаждения предусмотрена испарительная камера площадью 4500 мм². Источником питания служит аккумуляторная батарея ёмкостью 5200 мА·ч с поддержкой быстрой зарядки SuperVOOC мощностью до 80 Вт. По данным производителя, зарядка с 0 до 50 % занимает 19 минут.  Realme P2 Pro работает под управлением Android 14 с фирменным интерфейсом Realme UI 5.0. Аппарат будет доступен в сером и зелёном цветовых вариантах исполнения корпуса. Что касается розничной стоимости, то версия Realme P2 Pro с 8 Гбайт ОЗУ и 128 Гбайт ПЗУ стоит $260, за вариант с 12 Гбайт ОЗУ и 256 Гбайт ПЗУ придётся заплатить $300, а старшая модель с 12 Гбайт ОЗУ и 512 Гбайт ПЗУ обойдётся в $330.  Ещё одной новинкой стал доступный планшетный компьютер Realme Pad 2 Lite. Он получил от разработчиков 10,95-дюймовый ЖК-дисплей с поддержкой разрешения Full HD+ и частотой обновления 90 Гц. В конструкции предусмотрена фронтальная камера на 5 Мп и основная камера на 8 Мп. Устройство построено на базе восьмиядерного микропроцессора MediaTek Helio G99 в сочетании с 4 Гбайт или 8 Гбайт оперативной памяти и накопителем на 128 Гбайт. Расширить дисковое пространство можно за счёт карты памяти формата microSD. Автономность обеспечивает аккумулятор на 8300 мА·ч с поддержкой быстрой зарядки мощностью до 15 Вт.  Звуковая подсистема включает в себя четыре динамика, а отделка задней панели частично выполнена из натуральной кожи. Realme Pad 2 Lite работает под управлением Realme UI 5.0 на базе Android 14. Версия планшета с 4 Гбайт ОЗУ и 128 Гбайт ПЗУ стоит $180, а за модель с 8 Гбайт ОЗУ и 128 Гбайт ПЗУ придётся заплатить $200. Судьба TikTok в США решится уже в понедельник
13.09.2024 [16:18],
Анжелла Марина
В грядущий понедельник пройдёт заседание суда, которое может определить судьбу TikTok в США. Апелляционный суд округа Колумбия рассмотрит иск об отмене закона, который может привести к запрету платформы, используемой 170 млн американцев. Слушания пройдут в разгар президентской гонки, в которой как кандидат от республиканцев Дональд Трамп (Donald Trump), так и вице-президент Камала Харрис (Kamala Harris) активно используют TikTok для привлечения молодых избирателей. 
Источник изображения: Solen Feyissa/Unsplash TikTok и ByteDance утверждают, что закон неконституционен и нарушает право американцев на свободу слова. «Это радикальный отход от традиции нашей страны, которая всегда выступала за открытый интернет», — заявляют компании. Напомним, закон был принят Конгрессом США в апреле этого года, всего через несколько недель после внесения на рассмотрение, на фоне опасений законодателей, что Китай может получить доступ к данным американских пользователей или использовать приложение для шпионажа. ByteDance настаивает, что продажа TikTok американской компании, как того требует закон, «технологически, коммерчески и юридически невозможна» и без вмешательства суда приведёт к беспрецедентному запрету приложения уже 19 января 2025 года. В понедельник американские судьи Шри Сринивасан (Sri Srinivasan), Неоми Рао (Neomi Rao) и Дуглас Гинзбург (Douglas Ginsburg) рассмотрят иски, поданные TikTok и его пользователями. В свою очередь TikTok и Министерство юстиции США запросили суд определиться с решением до 6 декабря, что позволит Верховному суду рассмотреть вопрос до вступления запрета в законную силу. Джо Байден (Joe Biden), подписав закон в апреле и предоставив ByteDance время до 19 января для продажи TikTok, тем не менее может продлить этот срок на три месяца, если ему представят доказательства того, что ByteDance предпринимает шаги в направлении продажи. При этом Белый дом и другие сторонники закона настаивают на прекращении контроля над приложением со стороны китайской компании, ссылаясь на угрозу национальной безопасности, и подчёркивают, что их целью является не запрет TikTok, а изменение его владельца. Раскрыты спецификации настольных процессоров Intel Arrow Lake-S — до 24 ядер, до 5,7 ГГц и до 250 Вт
13.09.2024 [15:59],
Николай Хижняк
Портал Benchlife опубликовал, как он сам утверждает, финальные спецификации грядущих настольных процессоров Intel Core Ultra 2 (Arrow Lake-S). Неизвестными остались только характеристики встроенной графики Xe LPG (Alchemist), которой будут оснащены эти чипы. 
Источник изображений: VideoCardz Анонс Arrow Lake-S ожидается 10 октября, однако запуск процессоров состоится 24 октября, если верить последним неофициальным сообщениям. Изначально старт продаж ожидался 17 октября. Вместе с процессорами будут выпущены новые материнские платы на чипсете Intel Z890. Ранее сообщалось, что Intel обяжет производителей материнских плат использовать по умолчанию «стандартные настройки» параметров работы процессоров. Однако в зависимости от модели платы также будут поддерживать «экстремальные профили настроек», но их придётся включать вручную. В октябре Intel выпустит только разгоняемые модели процессоров с суффиксом «K». Чипы без суффикса «K», а также более доступные модели материнских плат на чипсетах 800-й серии будут представлены позднее. Скорее всего, их анонс состоится в начале января будущего года на выставке электроники CES 2025. В октябре ожидается анонс и выпуск пяти моделей процессоров Arrow Lake-S. Флагманская модель Core Ultra 9 285K не получит версию «KF» без встроенной графики. В составе процессора используется комбинация из восьми производительных ядер Lion Cove и 16 энергоэффективных ядер Skymont. Чип получил 36 Мбайт кеш-памяти L3 и 40 Мбайт кеш-памяти L2. Максимальная частота процессора составит 5,7 ГГц. 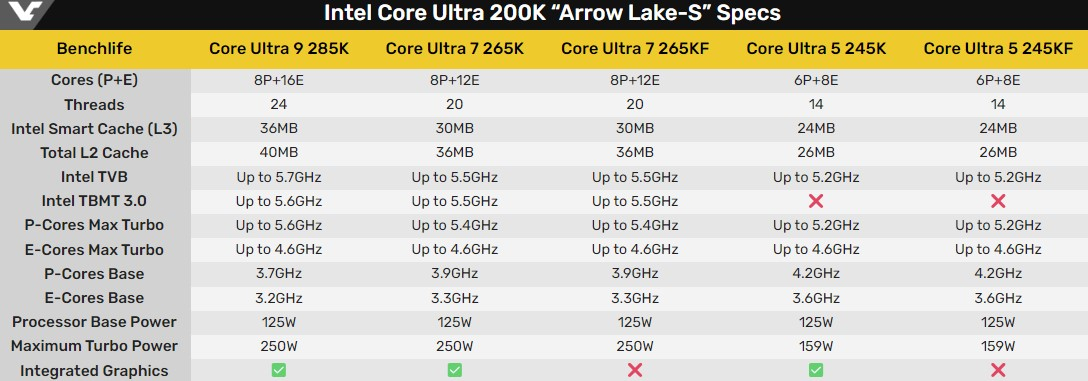 Модель среднего уровня Core Ultra 7 265K (и её версия без «встройки» 265KF) предложит восемь производительных и 12 энергоэффективных ядер, а также 30 Мбайт кеша L3 и 36 Мбайт кеш-памяти L2. Процессор сможет автоматически разгоняться до 5,5 ГГц. В свою очередь, модели Core Ultra 5 245K и 245KF получат конфигурацию из шести P-ядер и восьми Е-ядер, и смогут автоматически разгонять до 5,2 ГГц. Объёмы кеш-памяти L3 и L2 у чипа составят 24 и 20 Мбайт соответственно. Все ожидаемые процессоры обеспечат номинальный TDP 125 Вт. Максимальный показатель энергопотребления для моделей Core Ultra 9 и Core Ultra 7 составит 250 Вт, а у моделей Core Ultra 5 — 159 Вт. Все процессоры Core Ultra 200K получат поддержку технологии автоматического разгона Thermal Velocity Boost. Сейчас эта функция доступна только у моделей Core Ultra 9 (бывшие Core i9). «Джеймс Уэбб» показал россыпь молодых звёзд на окраине нашей галактики
13.09.2024 [15:43],
Дмитрий Федоров
Космический телескоп NASA «Джеймс Уэбб» (James Webb) провёл детальное исследование окраин нашей галактики. Впервые были получены детальные снимки звёздных скоплений в молекулярных облаках Дигеля 1 и 2, демонстрирующие очень молодые звёзды нулевого класса, находящиеся на самой ранней стадии эволюции, молекулярные потоки и джеты, а также характерные структуры туманностей. 
Источник изображений: M. Ressler (JPL) / NASA, ESA, CSA, STScI Исследуемая область галактики расположена на расстоянии более 58 000 световых лет от галактического центра, что более чем в два раза превышает расстояние от Земли (26 000 световых лет) до центра Млечного Пути. Для наблюдений использовались два ключевых инструмента телескопа: камера ближнего (NIRCam) и среднего инфракрасного диапазона (MIRI), обеспечившие беспрецедентную детализацию изображений. Хотя облака Дигеля находятся в пределах нашей галактики, они относительно бедны элементами тяжелее водорода и гелия, что делает их похожими на карликовые галактики и наш собственный Млечный Путь в начале формирования. Поэтому команда учёных воспользовалась возможностью использовать телескоп, чтобы запечатлеть активность, происходящую в четырёх скоплениях молодых звёзд в облаках Дигеля 1 и 2: 1A, 1B, 2N и 2S. Наиболее информативные результаты были получены при наблюдении за облаком Дигеля 2S, где телескоп зафиксировал активный кластер молодых звёзд, испускающих протяжённые джеты вдоль своих полюсов. Если раньше учёные предполагали, что внутри облака может существовать субкластер, то возможности телескопа позволили это подтвердить. Майк Ресслер (Mike Ressler), учёный из Лаборатории реактивного движения (JPL) NASA и второй автор исследования, отметил: «Что меня восхитило и поразило в данных „Уэбба“, так это то, что из этого звёздного скопления во все стороны вылетает множество джетов. Это немного похоже на фейерверк, где вы видите, как всё стреляет то в одну, то в другую сторону». 
На снимке видно плотное скопление фоновых галактик и красные туманные структуры в этой области. Цвета на изображении соответствуют различным фильтрам камер MIRI и NIRCam «В прошлом мы знали об этих регионах звёздообразования, но не могли изучить их свойства. Данные „Уэбба“ основываются на том, что мы тщательно собирали в течение многих лет в ходе других наблюдений. С помощью „Уэбба“ мы можем получить очень мощные и впечатляющие изображения этих облаков. В случае с облаком Дигеля 2 я не ожидала увидеть столь активное звёздообразование и впечатляющие джеты», — заявила Нацуко Изуми (Natsuko Izumi) из Университета Гифу и Национальной астрономической обсерватории Японии (NAOJ). Учёные намерены продолжить изучение процессов звёздообразования в этих регионах. Изуми подчеркнула важность объединения данных с различных обсерваторий и телескопов для детального анализа каждого этапа эволюционного процесса. Среди приоритетных направлений учёная отметила изучение околозвёздных дисков в крайних внешних областях галактики и нерешённый вопрос о причинах более короткого времени жизни этих структур по сравнению с аналогичными объектами в ближних звёздообразующих регионах. Особый интерес у неё вызывает кинематика джетов, обнаруженных в облаке Дигеля 2S. Снимки «Уэбба» охватывают крайние внешние области галактики и облака Дигеля и являются лишь отправной точкой для команды учёных. Они намерены вновь осмотреть этот форпост Млечного Пути, чтобы найти ответы на целый ряд загадок. Saber Interactive передумала выкупать у Embracer разработчиков Metro — 4A Games готовит два блокбастера
13.09.2024 [15:02],
Михаил Романов
Мартовская история с выходом Saber Interactive из состава шведского холдинга Embracer Group получила продолжение. Компании урегулировали вопрос о дальнейшей судьбе 4A Games (Metro) и Zen Studios (Pinball). 
Источник изображения: Steam (affection) Напомним, Embracer продала Saber и ряд её активов (в том числе 38 игр в разработке) за $247 млн, но бывшее подразделение имело опцион на выкуп 4A Games и Zen Studios, которым, по данным Bloomberg, было намерено воспользоваться. Как стало известно, спустя полгода все финансовые аспекты сделки между Embracer и Saber наконец полностью урегулированы: 4A Games и Zen Studios всё-таки останутся частью шведского холдинга. 
Источник изображения: Gematsu В разговоре с Bloomberg гендиректор Saber Мэттью Карч (Matthew Karch) заявил, что компания намеревалась выкупить 4A Games, но в конечном счёте «решила, что для всех сторон будет лучше», если студия останется с Embracer. «Мы довольны этой сделкой и рады, что команды и активы 4A Games и Zen Studios останутся частью Embracer. Они будут важными элементами нашего дальнейшего путешествия», — заверил глава Embracer Ларс Вингефорс (Lars Wingefors). 
Источник изображения: 4A Games В пресс-релизе по поводу урегулирования финансовых аспектов сделки Вингефорс также обмолвился, что в разработке у 4A Games находится «две AAA-игры, которые нам не терпится анонсировать». Следующая номерная Metro от 4A Games была подтверждена ещё в ноябре 2020 года, но до сих пор полноценно не представлена. Прошлой зимой Deep Silver (издатель игр серии) намекала, что новая часть выйдет до 2030-го. Google начала тестировать на Android-планшетах оконный режим для многозадачности как на ПК
13.09.2024 [14:33],
Анжелла Марина
Компания Google запустила тестирование новой функции Desktop Windowing для планшетов на базе Android, которая позволит работать с приложениями в отдельных окнах, подобно тому, как это реализовано на компьютерах. Можно свободно изменять размеры этих окон и перемещать их на экране. 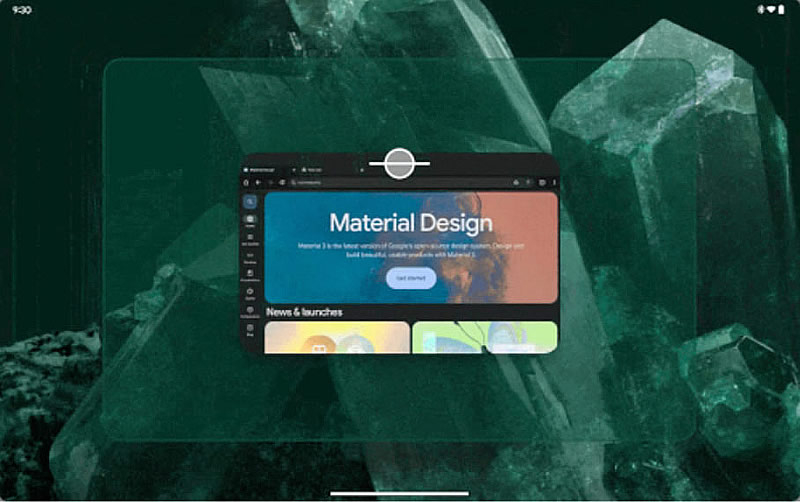
Источник изображения: Google В настоящее время приложения на Android-планшетах по умолчанию открываются в полноэкранном режиме. При активации же нового режима каждое приложение, как сообщает издание The Verge, будет отображаться в отдельном окне с элементами управления, позволяющими изменять его размер, положение на экране, разворачивать на весь экран или закрывать. В нижней части экрана появится панель задач со значками запущенных приложений. 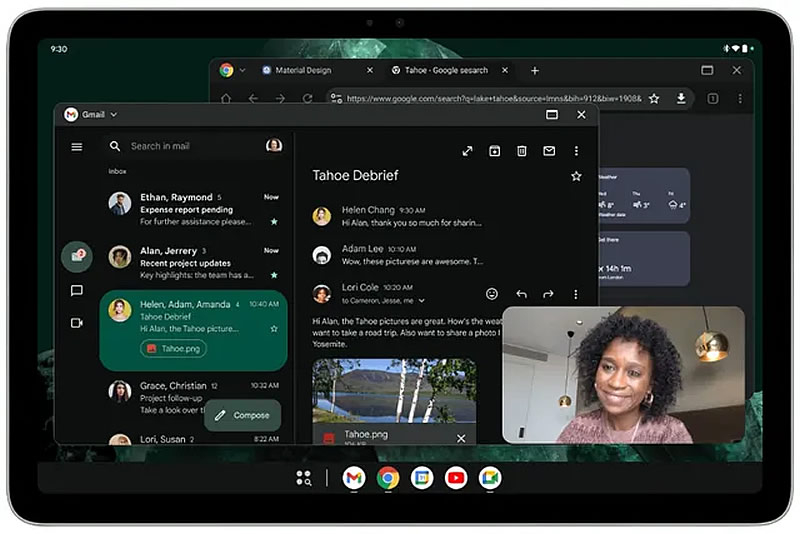
Источник изображения: Google Новая функция напоминает Stage Manager на iPad и режим DeX на планшетах и смартфонах Samsung серии Galaxy, которые также предлагают оконный интерфейс, улучшающий многозадачность в работе с приложениями. Google, похоже, вдохновилась этими решениями, реализовав идею на планшетах с поддержкой операционной системы Android. Когда опция станет доступна для всех пользователей, её можно будет активировать, удерживая палец на верхней части окна приложения. При подключенной клавиатуре можно будет использовать сочетание мета✴✴-клавиш (Windows, Command или Search) + Ctrl + стрелка вниз. Чтобы выйти из оконного режима, нужно закрыть все активные приложения или перетащить одно из окон в верхнюю часть экрана. 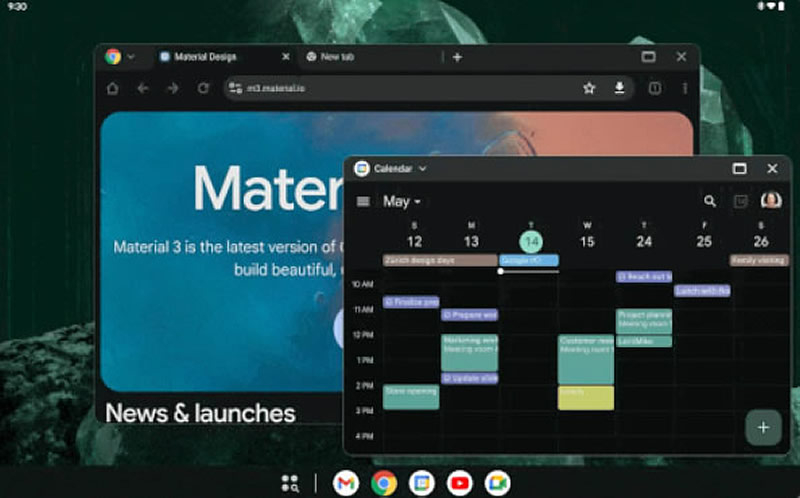
Источник изображения: Google Приложениям, привязанным к портретной ориентации, также можно будет изменять размер, но, как отмечает Google, они могут выглядеть не совсем корректно, если изначально не оптимизированы разработчиками для такого режима. Однако в будущих обновлениях Google планирует решить и эту проблему, масштабируя интерфейс таких приложений с сохранением правильных пропорций. Пока новая функция доступна для тестирования разработчиками в предварительной версии последнего обновления Android 15 QPR1 Beta 2 для Pixel Tablets. Дата выхода финальной версии для всех пользователей пока не объявлена, как и информация о том, будет ли она доступна на складном смартфоне Google Pixel 9 Pro Fold. iOS 18 будет блокировать iPhone, если в нем установлены «сторонние» запчасти
13.09.2024 [14:30],
Владимир Мироненко
Уже в грядущий понедельник, 16 сентября, компания Apple выпустит iOS 18, новую версию операционной системы для iPhone, которая вместе с рядом улучшений добавит функцию блокировки активации (Activation Lock) для сторонних запчастей смартфонов, сообщил ресурс 9to5Mac.  Сайт BetaProfiles.com отметил, что сборка iOS 18 RC (Release Candidate), выпущенная для разработчиков и публичных бета-тестеров, включает блокировку активации для деталей iPhone. Как ранее сообщила Apple, функция Activation Lock будет связывать учётную запись пользователя не только с самим смартфоном iPhone, но и с его компонентами, такими, как аккумулятор, камеры и дисплей, на основе их индивидуальных серийных номеров. Цель Apple вполне очевидна — закрыть доступ к возможности продажи деталей из украденных iPhone. Сейчас из-за блокировки активации большинство украденных iPhone продаётся на сером рынке на запчасти, которые по-прежнему весьма ценны. Теперь, когда iPhone обнаружит бывшую в употреблении деталь, он запросит пароль учётной записи Apple владельца оригинального устройства. Некоторые пользователи уже попытались заменить деталь у iPhone под управлением iOS 18.0 RC, и действительно, устройство запрашивает пароль учётной записи Apple, чтобы разблокировать и проверить бывший в употреблении компонент. В этом году в апреле Apple сообщила, что добавит функцию Activation Lock для компонентов iPhone, чтобы предотвратить разборку украденных смартфонов на детали. Если устройство, в котором заменили деталь, обнаружит, что она была получена с другого устройства с включённой функцией Activation Lock или Lost Mode, возможности калибровки для этой детали будут ограничены, отметила компания. Следует отметить, что Activation Lock для деталей появится только в смартфонах iPhone и её не будет у планшетов iPad с iPadOS 18. Репортаж со стенда Doogee на IFA 2024: защищённые смартфоны на любой вкус
13.09.2024 [13:52],
Андрей Созинов
В Берлине прошла одна из крупнейших мировых выставок электроники — IFA 2024. Среди компаний, представивших свои новинки на выставке, был и китайский производитель смартфонов Doogee. Компания продемонстрировала множество новейших моделей защищённых смартфонов. Мы посетили стенд Doogee и здесь расскажем о новинках подробнее.  Doogee в рамках IFA показала один из своих самых производительных защищённых смартфонов — V40 Pro. Устройство оснащено 6,78-дюймовым IPS-дисплеем с частотой 120 Гц. За производительность отвечает 4-нм чип Dimensity 7300, который дополняется 16 Гбайт оперативной памяти с возможностью расширения до 20 Гбайт за счёт флеш-памяти, объём которой составляет 512 Гбайт. Смартфон поддерживает ИИ-функции, например, для транскрипции телефонных разговоров и помощи в написании текстов. Также устройство оснащено 200-Мп основной камерой, 20-Мп камерой ночного видения и двумя 8-Мп модулями — один широкоугольный, другой с 3-кратным зумом. 
Doogee V40 Pro Doogee V40 Pro также получил многофункциональный дополнительный экран на тыльной стороне корпуса. На нём отображаются время, дата, состояние батареи, различные статичные или анимированные изображения, а также уведомления. Смартфон соответствует стандартам защиты от влаги и пыли, а также от падений и ударов — IP68, IP69K, а также успешно прошёл тесты MIL-STD-810H. Устройство может без ущерба находиться до 30 минут на глубине до 1,5 м, выдерживает пылевые бури и падения с высоты до 1,5 м. За автономную работу отвечает батарея ёмкостью 8680 мА·ч с поддержкой быстрой зарядки на 33 Вт. 
Doogee V Max Plus Рядом с V40 Pro на стенде Doogee демонстрировался ещё один интересный смартфон V-серии — Doogee V Max Plus. Его отличительной особенностью является батарея ёмкостью 22 000 мА·ч, которая обеспечивает до 1540 часов работы без подзарядки в режиме ожидания. Набор камер такой же, как у V40 Pro, с 200-Мп основным модулем, а вот чип попроще — Dimensity 7050. 
Doogee S200 Ещё одной новинкой на стенде Doogee стал защищённый смартфон S200 с футуристическим дизайном с алюминиевыми вставками, напоминающим броню фантастических роботов. Этот аппарат также соответствует стандартам IP68, IP69K и MIL-STD-810H. Особенностью новинки является круглый многофункциональный OLED-дисплей на тыльной стороне, на котором отображаются время, дата, уведомления и другие данные. Основной экран — 6,72-дюймовый IPS с частотой обновления 120 Гц. 
Doogee S200 Doogee S200 получил 6-нм чип Dimensity 7050, 12 Гбайт оперативной памяти (с возможностью расширения до 20 Гбайт) и 256 Гбайт встроенной памяти. Набор тыльных камер включает 100-Мп основной модуль, 20-Мп камеру ночного видения и 2-Мп макрокамеру. Устройство оснащено массивной батареей на 10 100 мА·ч с поддержкой быстрой зарядки на 33 Вт. В скором времени Doogee планирует выпустить улучшенную версию S200 под названием S200 Pro с более мощным процессором. К слову, Doogee готовит улучшенную версию S200 под названием S200 Pro. Главной отличительной особенностью новинки станет более мощный процессор (модель пока не уточняется), тогда как основные характеристики будут повторять базовую модель. Дизайн тоже несколько поменяется.

Doogee S punk и S cyber Ещё Doogee показала пару массивных защищённых смартфонов, дизайн которых вдохновлён стилистикой киберпанка — аппараты S punk и S cyber. Аппараты имеют схожие характеристики, в том числа чипы Unisoc T606, 50-Мп основные камеры и батареи на 10 800 мА·ч. Новинки отличаются друг от друга дизайном, а модель S punk также может похвастаться мощным динамиком на тыльной панели, рядом с камерами, который к тому же оснащён RGB-подсветкой, работающей синхронно с музыкой. Оба смартфона также предлагают прочный корпус и соответствуют стандартам IP68, IP69K и MIL-STD-810H. 
Doogee Fire 6 и Fire 6 Power Doogee представила на берлинской выставке и грядущие защищённые смартфоны серии Fire 6, отличительной особенностью которых является наличие тепловизора, который дополняет 50-Мп основную камеру. Здесь также применены чипы Unisoc T606 и ёмкие батареи. У базовой версии Fire 6 имеется батарея на 10 400 мА·ч, тогда как смартфон Doogee Fire 6 Power получил аккумулятор на 15 500 мА·ч.

Doogee DK10 Не забыла Doogee и о своём флагманском защищённом смартфоне DK10 с дизайнерской задней крышкой из кевлара. Устройство обладает 6,67-дюймовым AMOLED-дисплеем, чипом MediaTek Dimensity 8020 и 12 Гбайт оперативной и 256 или 512 Гбайт флеш-памяти, батареей на 5150 мА·ч с поддержкой очень быстрой зарядки мощностью 120 Вт. Также аппарат может похвастаться основной камерой на 50 Мп, широкоугольным 50-Мп модулем с поддержкой макросъёмки, камерой ночного видения на 64 Мп и модулем с 16-Мп сенсором и телеобъективом.

Doogee Blade 10 Pro и Blade 10 А в конце расскажем о, пожалуй, самых необычных защищённых смартфонах Doogee с выставки IFA 2024 — моделях Blade 10 и Blade 10 Pro, которые позиционируются в качестве самых тонких защищённых смартфонов. Всё же, обычно, аппараты, которым не страшны падения, удары и в целом суровые условия эксплуатации очень массивны, что некоторым пользователям приходится не по вкусу. Но Blade 10 и Blade 10 Pro предлагают крепкий корпус толщиной всего 10,7 мм — такой смартфон удобно носить в кармане и держать в руке, и при этом можно не бояться его уронить или залить водой благодаря защите IP68, IP69K и MIL-STD-810H.  
Doogee Blade 10 Pro Blade 10 и Blade 10 Pro получили процессоры Unisoc T606, 6 Гбайт оперативной памяти с возможностью расширения до 16 Гбайт, а также 256 Гбайт флеш-памяти. Имеется 50-Мп тыльная камера. Батарея тут послабее — только на 5150 мА·ч. Но для тех, кому этого покажется мало, у Doogee имеется смартфон Blade 10 Max с батареей на 10 300 мА·ч в корпусе толщиной всего 15,8 мм. 
Doogee Blade 10 Max Biostar неожиданно выпустила белую Radeon RX 580 2048SP — она была новинкой 6 лет назад
13.09.2024 [13:46],
Николай Хижняк
Компания Biostar сегодня сообщила выпуске новой видеокарты — Radeon RX 580 2048SP White, которая выделяется белым оформлением. Напомним, что AMD представила Radeon RX 580 ещё 2017 году, а её слегка урезанную версию Radeon RX 580 2048SP в 2018 году. 
Источник изображений: Biostar В основе Radeon RX 580 использовался графический чип Polaris 20 XTX с 2304 потоковыми процессорами. Это была одна из самых популярных видеокарт AMD последнего десятилетия. Модель являлась наследником Radeon RX 480, в которой использовался практический такой же GPU (Polaris 10). Карта предлагалась по отличной для своих возможностей цене в $229 и имела на борту 8 Гбайт памяти GDDR5 с поддержкой 256-битной шины и пропускной способностью 256 Гбайт/с.  Что касается модели Biostar, то она основана на урезанном графическом чипе Polaris 20 XL c 2048 потоковыми процессорами, представленном в октябре 2018 года. У неё также снижен показатель пропускной способности памяти, который составляет 224 Гбайт/с. В 2024 году для Biostar Radeon RX 580 White вряд ли найдётся место в составе игрового ПК. Карта обладает показателем TDP 150 Вт и всего примерно на 40 % производительнее встроенной графики Radeon 780M (по данным теста 3DMark Time Spy). Современные видеокарты не только энергоэффетивнее, но также поддерживают более передовые графические технологии, например, трассировку лучей или улучшенные алгоритмы кодирования видео (AV1). Кроме того, видеокарты поколения Polaris больше не входят в основные линейки графических ускорителей, для которых AMD выпускает драйверы, поскольку компания сместила фокус на поддержку графики RDNA.  Решение от Biostar выполнено в белом цвете. Карта оснащена системой охлаждения, в состав которой входят два вентилятора и радиатор с двумя теплопроводящими трубками. Для подключения карта использует интерфейс PCI Express 3.0 x16. В оснащение карты входят два разъёма DisplayPort 1.4a и один HDMI 2.0b. «Фанаты по-настоящему оценят»: Тони Хоук заинтриговал игроков перед 25-летием Tony Hawk’s Pro Skater
13.09.2024 [13:20],
Михаил Романов
Уже 29 сентября скейтерскому симулятору Tony Hawk’s Pro Skater от Activision стукнет 25 лет и, если верить знаменитому скейтбордисту Тони Хоуку (Tony Hawk), с пустыми руками на годовщину компания фанатов не оставит. 
Источник изображений: Activision Разговор о потенциальном праздновании 25-летия Tony Hawk’s Pro Skater зашёл во время недавнего интервью Хоука ведущему YouTube-канала Mythical Kitchen (упомянутый сегмент начинается с 25:21). Хоук впервые публично подтвердил, что снова вышел на связь с Activision и работает с ней над неким совместным проектом, связанным с Tony Hawk’s Pro Skater. «Безумно волнительно», — добавил скейтбордист. В подробности по очевидным причинам Хоук вдаваться не стал, однако поделился мыслями насчёт того, как будущий анонс встретят поклонники серии: «Думаю, фанаты по-настоящему оценят».  Ни Activision, ни владеющая ей компания Microsoft не объявляли о планах на продолжение серии Tony Hawk’s Pro Skater. Последним релизом во франшизе остаётся вышедший в 2020 году сборник Tony Hawk’s Pro Skater 1 + 2. Позапрошлым летом Хоук рассказывал, что Activision планировала выпуск сборника Tony Hawk’s Pro Skater 3 + 4, но после поглощения Blizzard студии Vicarious Visions в 2022 году не смогла найти подходящего партнёра для разработки. Североамериканский релиз Tony Hawk’s Pro Skater состоялся 29 сентября 1999 года на PlayStation, а спустя 20 лет с выходом Tony Hawk's Pro Skater 1 + 2 ремейк игры (и второй части) появился на PC, PS4 и Xbox One. Adobe опубликовала слабый прогноз на IV квартал — акции упали на 9,2 %
13.09.2024 [13:14],
Дмитрий Федоров
Adobe прогнозирует снижение выручки в IV квартале до $5,50–$5,55 млрд, ниже ожиданий аналитиков London Stock Exchange Group (LSEG), что обусловлено её сдержанными расходами на технологии. Компания сталкивается со слабым спросом на свои ИИ-инструменты и давлением со стороны ИИ-стартапов. Акции Adobe упали на 9,2 % в ходе торгов после закрытия рынка. 
Источник изображения: Adobe Компания Adobe, основанная в 1982 году, является крупнейшим поставщиком программного обеспечения для графических дизайнеров, аудио- и видеомонтажёров. Высокие процентные ставки и экономическая турбулентность вынуждают её сокращать расходы, что негативно сказывается на росте бизнеса. Дополнительное давление на позиции Adobe оказывают и конкуренты, такие как Stability AI и Midjourney, которые предлагают схожие ИИ-сервисы генерации изображений по текстовым запросам пользователей. В IV квартале Adobe ожидает выручку в диапазоне от $5,50 до $5,55 млрд по сравнению с прогнозом аналитиков London Stock Exchange Group в размере $5,61 млрд. Квартальная прибыль составит от $4,63 до $4,68 на одну акцию по сравнению с прогнозом в $4,67. Несмотря на это, Adobe анонсировала Adobe Firefly Video Model — новый инструмент для создания видео с использованием генеративного ИИ, ограниченный запуск которого запланирован на конец года. Этот продукт призван усилить позиции Adobe в сегменте ИИ-решений для творческой аудитории. Финансовые показатели Adobe за III квартал, завершившийся 30 августа, демонстрируют смешанную динамику: выручка составила $5,41 млрд, превысив оценки аналитиков LSEG в $5,37 млрд. Однако операционные расходы компании выросли до $2,86 млрд по сравнению с $2,61 млрд годом ранее. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



