|
Опрос
|
реклама
Быстрый переход
Anthropic выпустила ИИ-модель Claude Opus 4.8 — она не пытается скрыть свою некомпетентность в вопросах, в которых не разбирается
29.05.2026 [06:46],
Анжелла Марина
Компания Anthropic выпустила Opus 4.8 — новейшую версию своей самой продвинутой публичной модели. Вместе с ней разработчики представили функцию Dynamic Workflows, которая позволит Opus и другим моделям управлять сложными задачами, распределёнными между сотнями параллельных субагентов. Об этом сообщил TechCrunch. 
Источник изображения: Anthropic Opus 4.8 появилась через 41 день после релиза Opus 4.7, что оказалось значительно быстрее обычного цикла обновлений Anthropic (предыдущие модели Sonnet и Haiku выходили с интервалом в три и семь месяцев соответственно). Ускоренный выпуск, как предполагается, связан с прохладным приёмом Opus 4.7, которую некоторые пользователи сочли разочаровывающей. За тот же период конкуренты в лице OpenAI с моделью Codex и Google с Gemini Flash также представили значительные обновления, усиливая давление на Anthropic. Ключевым улучшением Opus 4.8 стала работа с некорректными или неопределёнными данными. Первые тестировщики обнаружили, что новая модель «чаще сообщает о неуверенности в результатах своей работы и реже делает необоснованные заявления». Эффективность модели подтвердили и в инвестиционной компании Bridgewater Associates. По словам представителей, главное отличие обновлённой версии заключается в том, что нейросеть активно указывает на проблемы во входных и выходных данных, которые другие алгоритмы обычно не замечают, вынуждая пользователей самостоятельно искать ошибки. Вместе с новой моделью Anthropic запустила функцию Dynamic Workflows в формате исследовательского превью. Система предназначена для того, чтобы крупные модели (например, Opus) управляли сложными задачами через сотни параллельных субагентов. Как поясняют в компании, благодаря этому нововведению, связка из Claude Code и модели Opus 4.8 сможет «выполнять миграцию сотен тысяч строк кода от этапа запуска до слияния, опираясь на существующий набор тестов в качестве ограничителя». Одновременно разработчики продолжают подготовку к полноценному запуску модели Mythos, ранний доступ к которой в прошлом месяце вызвал опасения в использовании её киберпреступниками. В Anthropic подчеркнули, что активно решают вопросы защиты Mythos и ожидают внедрения моделей класса Mythos для всех клиентов уже в ближайшие недели. ИИ-модель Anthropic Claude обнаружила 22 уязвимости в Mozilla Firefox за две недели — из них 14 весьма серьёзны
09.03.2026 [11:52],
Владимир Мироненко
Всего за две недели ИИ-модель Claude Opus 4.6 компании Anthropic обнаружила 22 уязвимости в браузере Mozilla Firefox, что больше, чем было выявлено за любой отдельный месяц 2025 года, сообщил The Wall Street Journal. Всего за этот период было выявлено более 100 ошибок, приводящих к сбоям, включая указанные баги. «ИИ позволяет обнаруживать серьёзные уязвимости безопасности с очень высокой скоростью», — отметили исследователи. 
Источник изображения: Anthropic Для того, чтобы обнаружить первую уязвимость, ИИ-модели потребовалось всего 20 минут. Из выявленных за две недели уязвимостей 14 были отнесены к уязвимостям высокой степени серьёзности, что составляет почти пятую часть от 73 уязвимостей такого уровня в Firefox, которые Mozilla исправила в 2025 году. Большинство ошибок были исправлены в Firefox 148, версии браузера, вышедшей в феврале этого года, хотя некоторые исправления пришлось отложить до следующего релиза. Сообщается, что команда Anthropic выбрала для проверки Firefox, потому что это «одновременно сложный код и один из самых хорошо протестированных и безопасных проектов с открытым исходным кодом в мире». Оказалось, что ИИ-модель гораздо эффективнее в поиске ошибок, чем в их эксплуатации. Когда исследователи Anthropic предложили Claude разработать эксплойт-код на основе выявленных багов, ИИ-модель создала всего два работающих эксплойта, которые сработали на тестовой версии браузера, но в реальном мире они были бы остановлены другими механизмами безопасности Firefox, сообщил Логан Грэм (Logan Graham), глава подразделения Frontier Red Team Anthropic, занимающегося оценкой рисков Claude. Вместе с тем эксперты по безопасности говорят, что скорость, с которой ИИ-системы находят ошибки в программах и превращают их в код для атак, меняет способы защиты организаций. «Нынешние методы киберзащиты не способны справиться со скоростью и частотой происходящего», — заявил Гади Эврон (Gadi Evron), генеральный директор компании Knostic, занимающейся кибербезопасностью с использованием ИИ. Anthropic представила Claude Opus 4.6 — флагманскую LLM с командами агентов, миллионным контекстом и платным доступом
05.02.2026 [23:13],
Андрей Созинов
Компания Anthropic представила новую версию своей флагманской языковой модели — Claude Opus 4.6, назвав её «прямым апгрейдом» предыдущего поколения и самым интеллектуально развитым ИИ в своей линейке. Обновление уже доступно платным пользователям чат-бота Claude, а также через API по той же цене, что и Claude Opus 4.5. 
Источник изображений: Anthropic Одним из главных нововведений стали так называемые «команды агентов» (agent teams). Речь идёт о наборе ИИ-агентов, которые могут делить крупные и сложные задачи на отдельные части и выполнять их параллельно. По замыслу Anthropic, каждый агент отвечает за свой сегмент работы и напрямую координируется с другими. Руководитель продуктового направления Anthropic Скотт Уайт (Scott White) сравнил эту функцию с работой слаженной команды людей, подчеркнув, что распределение ролей позволяет выполнять задачи быстрее. На данный момент «команды агентов» доступны в формате исследовательского превью для пользователей API и платных подписчиков. Ещё одно важное улучшение — увеличенное контекстное окно. Claude Opus 4.6 способен обрабатывать до 1 млн токенов за сессию, что сопоставимо с возможностями моделей Sonnet 4 и 4.5. По словам компании, это упрощает работу с крупными базами программного кода и объёмными документами, позволяя модели удерживать значительно больше информации в памяти. Кроме того, Anthropic усилила интеграцию Claude с Microsoft PowerPoint. Теперь ИИ доступен прямо в интерфейсе приложения для создания презентаций в виде боковой панели. Если раньше пользователь мог лишь сгенерировать презентацию и затем отдельно редактировать файл в PowerPoint, то теперь создание и доработка слайдов происходят непосредственно внутри программы при активной помощи Claude. 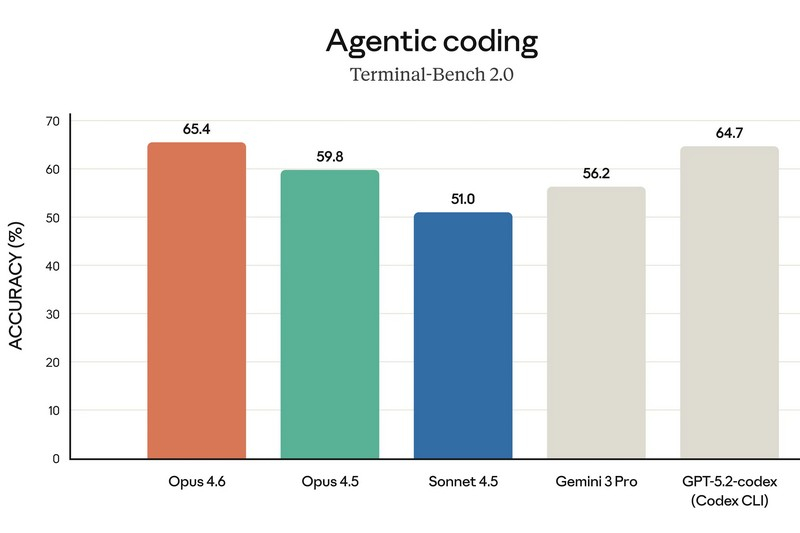 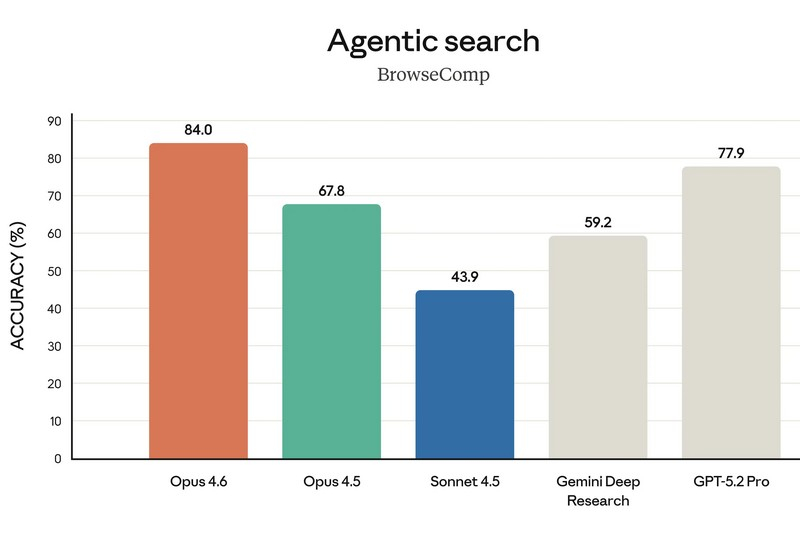 По утверждению Anthropic, Opus 4.6 заметно лучше справляется со сложными многошаговыми задачами и чаще выдаёт результат, близкий к «продакшен-качеству», уже с первой попытки. Это особенно заметно при работе с документами, таблицами и презентациями — число итераций и правок при их подготовке существенно сокращается. Среди ключевых сильных сторон модели компания выделяет агентское программирование, работу с инструментами, поиск и финансовую аналитику. 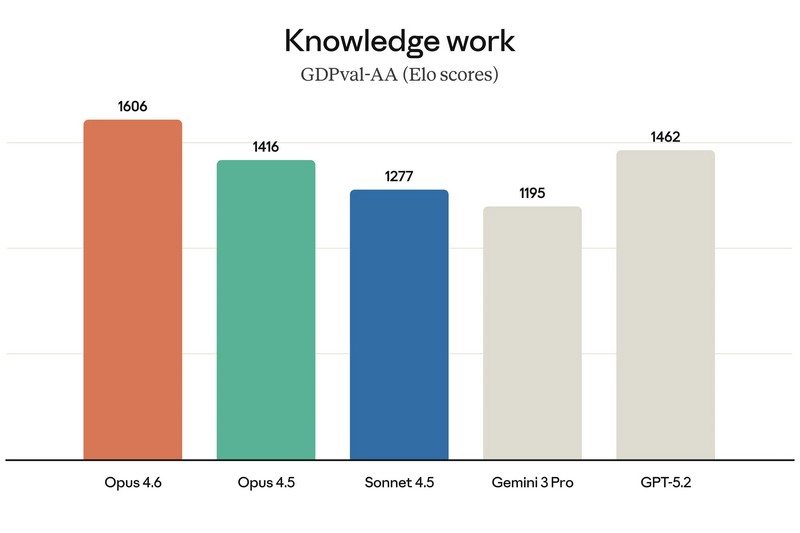 Конечно же, Claude сравнила Opus 4.6 с предшественницей — своей более «лёгкой» моделью Sonnet 4.5, а также с основными конкурентами в лице Google Gemini 3 Pro и OpenAI GPT-5.2. В восьми из тринадцати тестов новинка оказалась впереди. 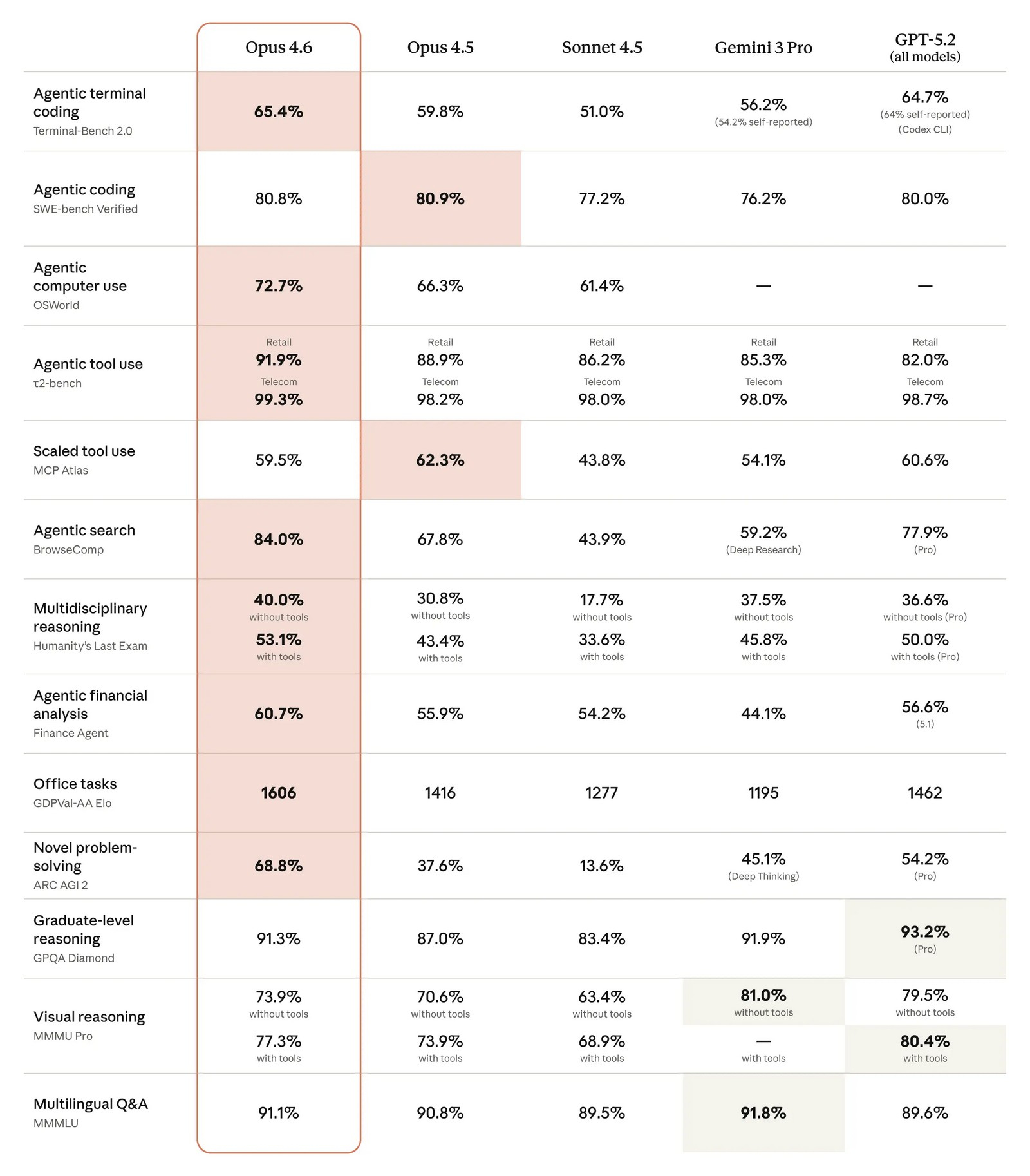 В интервью TechCrunch Скотт Уайт отметил, что Opus эволюционировал из узкоспециализированного инструмента для разработки ПО в решение, полезное для гораздо более широкого круга специалистов. По его словам, Claude Code активно используют не только программисты, но и продакт-менеджеры, финансовые аналитики и представители других отраслей, которым нужен мощный инструмент для интеллектуальной работы. 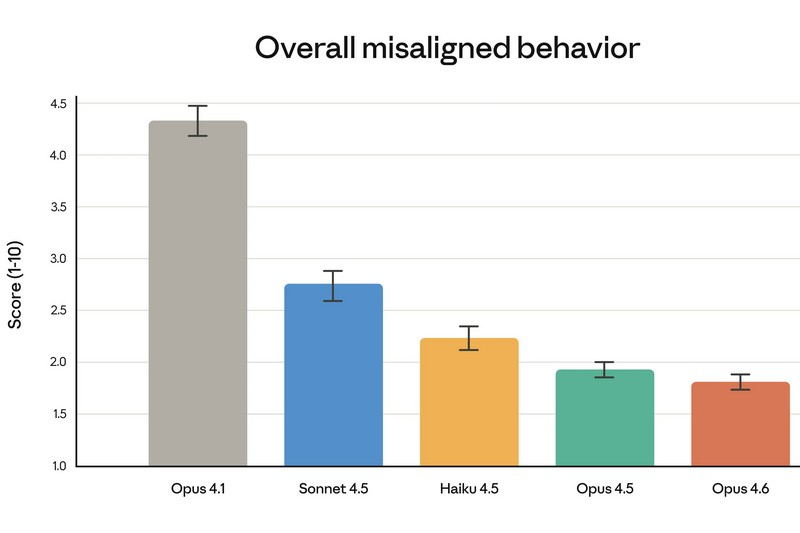 Отдельно Anthropic подчёркивает усиленный фокус на безопасности. По словам компании, для Claude Opus 4.6 был проведён самый масштабный набор проверок за всю историю моделей Anthropic. Тестирование включало новые оценки влияния на благополучие пользователей, более сложные сценарии отказа от потенциально опасных запросов, а также обновлённые проверки на способность модели скрытно выполнять вредоносные действия. С учётом возросших возможностей в сфере кибербезопасности Opus 4.6 компания внедрила шесть новых специализированных тестов, призванных отслеживать возможные злоупотребления. В Anthropic подчёркивают, что Claude Opus 4.6 — это шаг к превращению Claude в универсальный инструмент для широкого спектра интеллектуальной работы, а не только в помощника для программистов. Anthropic бросает вызов Gemini 3: представлена мощная ИИ-модель Opus 4.5 и инструмент для покорения Excel
25.11.2025 [00:38],
Владимир Фетисов
Вслед за релизом ИИ-модели Google Gemini 3 Pro на минувшей неделе компания Anthropic анонсировала обновление своей флагманской ИИ-модели Opus. Новая версия Opus 4.5 обеспечит передовую производительность в генерации программного кода, взаимодействии с компьютером и выполнении офисных задач. В целом это предсказуемо, поскольку именно эти направления долгое время были сильными сторонами ИИ-помощника Anthropic Claude. 
Источник изображений: Anthropic Хорошая новость заключается в том, что с выпуском Opus 4.5 разработчики расширяют доступность ряда уже существующих инструментов, а также запускают новую функцию. Расширение Claude for Chrome теперь доступно всем пользователям подписки Max, которые взаимодействуют с веб-контентом с помощью браузера Google. Вместе с этим Anthropic запускает функцию «безграничный чат» для платных подписчиков. ИИ-бот больше не будет выдавать ошибки из-за переполнения контекстного окна, что позволит ему лучше справляться с сохранением согласованности файлов и чатов. По словам разработчиков, эта функция является одной из наиболее часто запрашиваемых пользователями. В дополнение к этому расширение Claude for Excel, которое встраивает ИИ-помощника в боковую панель приложения Microsoft, становится доступным всем пользователям подписок Max, Team и Enterprise. Этот инструмент поддерживает сводные таблицы, диаграммы и загрузку файлов. По данным Anthropic, раннее тестирование показало повышение точности работы алгоритма на 20 % и рост эффективности на уровне 15 %. В дальнейшем компания планирует добавить Claude for Excel в более потребительские модели Claude Sonnet и Haiku. 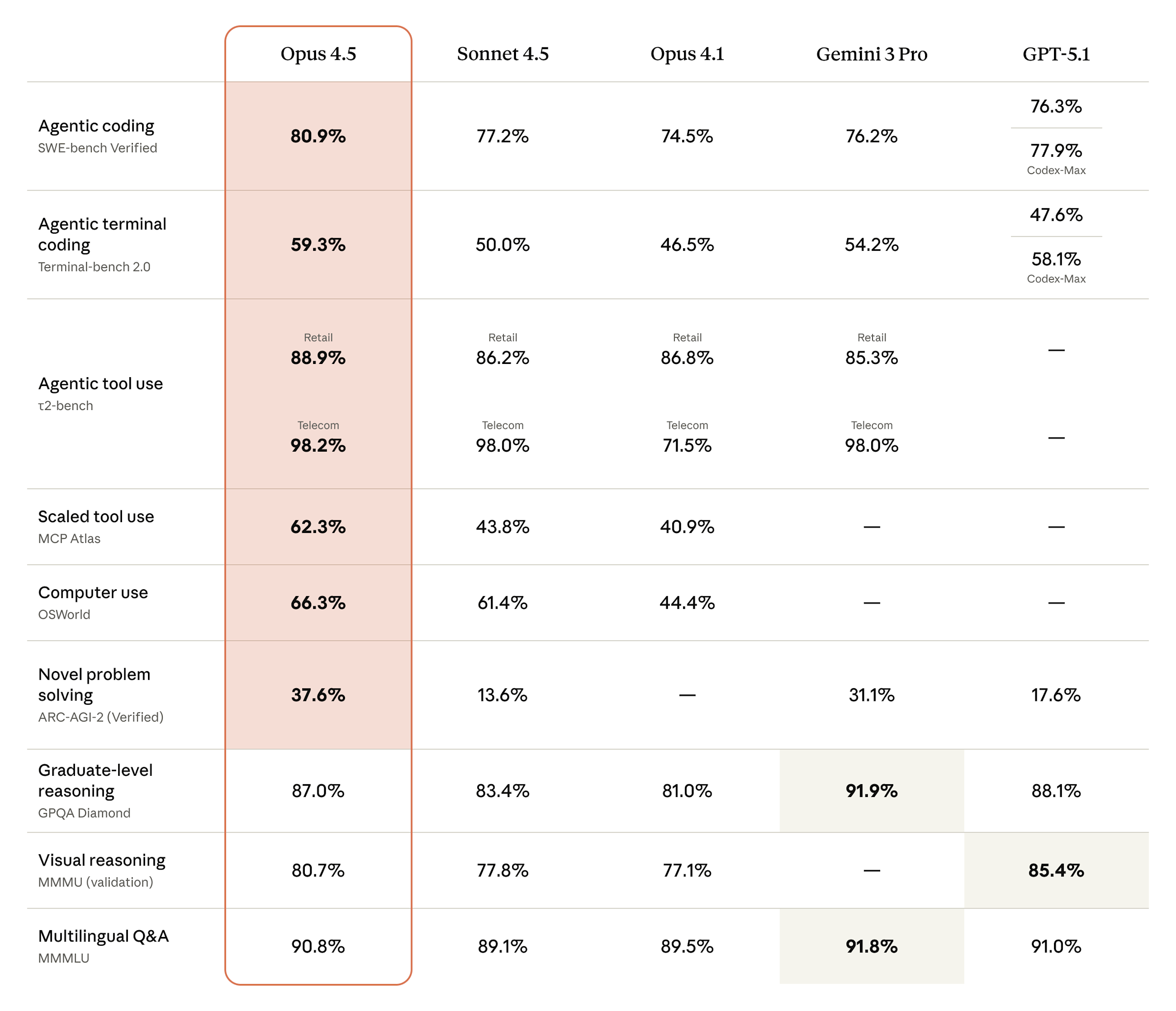 Ещё в Opus 4.5 улучшена работа в агентских сценариях, обновлённая модель преуспевает в самостоятельном совершенствовании своих процессов. Что ещё важно, Anthropic называет Opus 4.5 своей самой безопасной моделью. По оценкам компании, алгоритм лучше противостоит атакам типа «prompt injection», опережая в этом даже Gemini 3 Pro. Желающие опробовать Opus 4.5 уже могут сделать это во всех приложениях Anthropic и через API-интерфейс компании. Для разработчиков стоимость использования ИИ-модели начинается с $5 за миллион токенов. Чат-бот Claude AI станет прекращать «вредоносные или оскорбительные диалоги с пользователями»
18.08.2025 [18:58],
Сергей Сурабекянц
Anthropic научила свой чат-бот Claude AI прекращать общение, которое он сочтёт «вредоносным или оскорбительным». Эта возможность уже доступна в моделях Opus 4 и 4.1. Она позволит чат-боту завершать разговоры в качестве крайней меры после неоднократных попыток пользователя сгенерировать вредоносный или оскорбительный контент. Anthropic хочет добиться «потенциального благополучия» моделей ИИ, прекращая беседы, в которых Claude испытывает «явный дискомфорт». 
Источник изображения: Anthropic После прекращения диалога со стороны Claude, пользователь не сможет отправлять новые сообщения в этом чате, но создание новых чатов будет по-прежнему доступно. Anthropic отметила, что разговоры, вызывающие подобную реакцию, являются «крайними случаями», добавляя, что большинство пользователей не столкнутся с этим препятствием даже при обсуждении спорных тем. В ходе тестирования Claude Opus 4 у чат-бота было отмечено «стойкое и последовательное отвращение к причинению вреда», в том числе к созданию сексуального контента с участием несовершеннолетних, насильственным действиям и терроризму. В этих случаях, по данным Anthropic, Claude демонстрировал «явную тревожность» и «тенденцию прекращать вредоносные разговоры, когда предоставлялась такая возможность». Claude получил прямое указание не завершать разговоры, если пользователь проявляет признаки желания причинить «неминуемый вред» себе или другим. В таких случаях Anthropic привлекает онлайн-сервис кризисной поддержки Throughline, чтобы помочь разработать ответы на запросы, связанные с самоповреждением и психическим здоровьем. На прошлой неделе Anthropic обновила политику использования своего чат-бота, поскольку быстро развивающиеся модели ИИ вызывают всё больше опасений по поводу безопасности. Теперь компания запрещает использовать Claude для разработки биологического, ядерного, химического или радиологического оружия, а также для разработки вредоносного кода или эксплуатации уязвимостей сети. Пока все ждут GPT-5, Anthropic выпустила ИИ-модель Claude Opus 4.1 — она стала лучше в программировании, рассуждениях и агентских задачах
06.08.2025 [14:05],
Павел Котов
Anthropic объявила о выходе рассуждающей модели искусственного интеллекта Claude Opus 4.1, предназначенной для работы в качестве ИИ-агента, средства написания программного кода. 
Источник изображений: anthropic.com Поработать с Opus 4.1 уже могут подписчики платных версий Claude и в Claude Code; новая модель также доступна через API, на платформах Amazon Bedrock и Google Cloud Vertex AI. Стоимость доступа к ней такая же, как у оригинальной Opus 4. 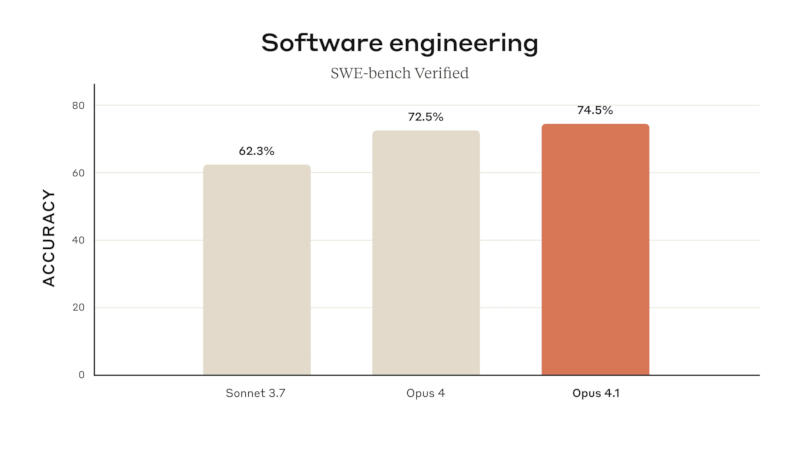 Anthropic Claude Opus 4.1 лучше справляется с задачами на написание программного кода — тест SWE-bench Verified показал результат до 74,5 %. Улучшились навыки чат-бота Claude в области анализа данных и углублённых исследований, особенно при необходимости произвести агентный поиск информации и отследить детали. 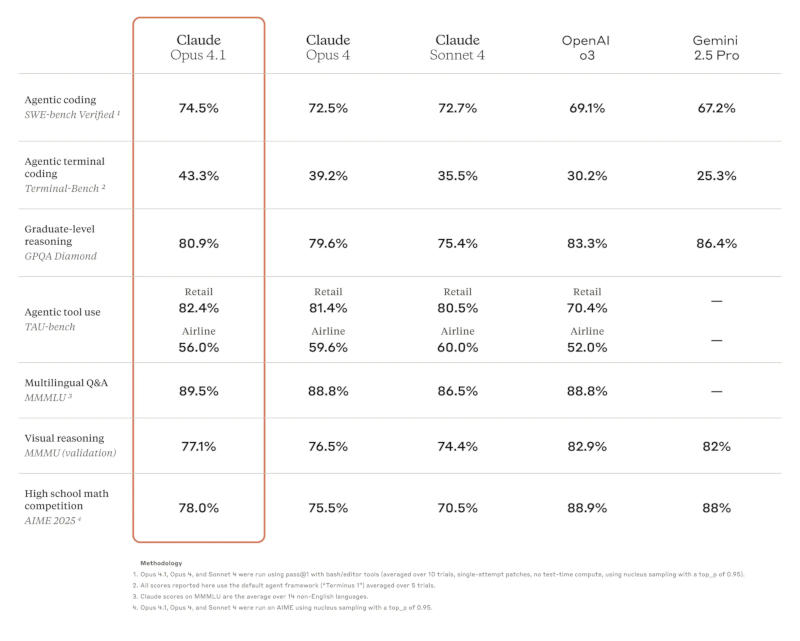 Обновлённая модель Claude Opus 4.1 стала лучше в большинстве функций по сравнению с Opus 4, по версии GitHub. Ещё одна примечательная особенность Opus 4.1 — способность вносить точные изменения в код даже при большом объёме его базы, ограничиваясь только необходимыми модификациями и не создавая новых ошибок, что делает модель эффективным средством для повседневной отладки, отметили в Rakuten Group. В Windsurf прогресс Opus 4.1 по сравнению с Opus 4 оценили в одно стандартное отклонение — таким же он был при переходе от Sonnet 3.7 к Sonnet 4. Anthropic рекомендовала переходить с Opus 4 на Opus 4.1 во всех сценариях работы. При подключении через API разработчикам достаточно выбрать модель claude-opus-4-1-20250805. Пузырь ИИ сдувается, пока OpenAI, Google и Anthropic пытаются создать более продвинутый ИИ
13.11.2024 [19:26],
Сергей Сурабекянц
Три ведущие компании в области искусственного интеллекта столкнулись с ощутимым снижением отдачи от своих дорогостоящих усилий по разработке новых систем ИИ. Новая модель OpenAI, известная как Orion, не достигла желаемой компанией производительности, предстоящая итерация Google Gemini не оправдывает ожиданий, а Anthropic столкнулась с отставанием в графике выпуска своей модели Claude под названием 3.5 Opus. 
Источник изображения: unsplash.com После многих лет стремительного выпуска всё более сложных продуктов ИИ три ведущие в этой сфере компании наблюдают убывающую отдачу от дорогостоящих усилий по созданию новых моделей. Становится все труднее находить свежие, ещё неиспользованные источники высококачественных данных для обучения более продвинутых систем ИИ. А нынешних весьма скромных улучшений недостаточно, чтобы окупить огромные затраты, связанные с созданием и эксплуатацией новых моделей, как и оправдать ожидания от выпуска новых продуктов. Так, OpenAI утверждала, что находится на пороге важной вехи. В сентябре завершился начальный раунд обучения для новой масштабной модели Orion, которая должна была приблизится к созданию мощного ИИ, превосходящего людей. Но ожидания компании, по утверждению осведомлённых источников, не оправдались. Orion не смогла продемонстрировать прорыва, который ранее показала модель GPT-4 по сравнению с GPT-3.5. 
Источник изображения: Pixabay Anthropic, как и её конкуренты, столкнулась с трудностями в процессе разработки и обучения 3.5 Opus. По словам инсайдеров, модель 3.5 Opus показала себя лучше, чем старая версия, но не так значительно, как ожидалось, учитывая размер модели и затраты на её создание и запуск. Эти проблемы бросают вызов утвердившемуся в Кремниевой долине мнению о масштабируемости ИИ. Приверженцам глобального внедрения ИИ приходится признать, что бо́льшая вычислительная мощность, увеличенный объём данных и более крупные модели пока не прокладывают путь к технологическому прорыву в области ИИ. 
Источник изображения: Nvidia Эксперты высказывают обоснованные сомнения в окупаемости крупных инвестиций в ИИ и достижимости всеобъемлющей цели, к которой стремятся разработчики ИИ-моделей, — создания общего искусственного интеллекта (AGI). Этот термин обычно применяется к гипотетическим ИИ-системам, способным соответствовать или превосходить человека в большинстве интеллектуальных задач. Руководители OpenAI и Anthropic ранее заявляли, что AGI может появиться уже через несколько лет. Технология, лежащая в основе ChatGPT и конкурирующих ИИ-чат-ботов, была создана на основе данных из социальных сетей, онлайн-комментариев, книг и других источников из интернета. Этих данных хватило для создания продуктов, генерирующих суррогатные эссе и поэмы, но для разработки систем ИИ, которые превзойдут интеллектом лауреатов Нобелевской премии — как надеются некоторые компании, — могут потребоваться другие источники данных, помимо сообщений в Википедии и субтитров YouTube. 
Источник изображения: unsplash.com OpenAI была вынуждена заключить соглашения с издателями, чтобы удовлетворить хотя бы часть потребности в высококачественных данных, а также адаптироваться к растущему юридическому давлению со стороны правообладателей контента, используемого для обучения ИИ. Отмечается высокий спрос на рынке труда на специалистов с высшим образованием, которые могут маркировать данные, связанные с их областью компетенции. Это помогает сделать обученные ИИ-системы более эффективными в ответах на запросы. Подобные усилия обходятся дороже и требуют на порядок больше времени, чем простое индексирование интернета. Поэтому технологические компании обращаются к синтетическим данным, таким как сгенерированные компьютером изображения или текст, имитирующие контент, созданный людьми. Однако у такого подхода есть свои ограничения, так как трудно добиться качественного улучшения при использовании подобных данных для обучения ИИ. Тем не менее компании ИИ продолжают следовать принципу «чем больше, тем лучше». В стремлении создавать продукты, приближающиеся к уровню человеческого интеллекта, технологические компании увеличивают объём вычислительной мощности, данных и времени, затрачиваемых на обучение новых моделей, что приводит к росту расходов. Генеральный директор Anthropic Дарио Амодеи (Dario Amodei) заявил, что в этом году компании потратят $100 млн на обучение новейших моделей, а в ближайшие годы эта сумма может достичь $100 млрд. 
Источник изображения: unsplash.com Безусловно, потенциал для улучшения моделей ИИ, помимо масштабирования, существует. Например, для своей новой модели Orion OpenAI применяет многомесячный процесс пост-обучения. Эта процедура включает использование обратной связи от людей для улучшения ответов и уточнения «эмоциональной окраски» взаимодействия с пользователями. Разработчики ИИ-моделей оказываются перед выбором: либо предлагать старые модели с дополнительными улучшениями, либо запускать чрезвычайно дорогие новые версии, которые могут работать ненамного лучше. По мере роста затрат растут и ожидания — стремительное развитие ИИ на начальном этапе создало завышенные ожидания как у специалистов, так и у инвесторов. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



