







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Практикум по ИИ-рисованию, часть вторая
Этот материал — продолжение рассказа о том, как установить и настроить генеративный ИИ на собственном компьютере. Если вы пропустили первую часть нашего HOWTO, то рекомендуем сначала ознакомиться с ней. Иначе какие-то вещи могут показаться вам непонятными и вы точно не сможете повторить их на своем ПК.  Среди изображений, что выдаёт даже не самый мощный игровой ПК, на котором запущена Stable Diffusion в базовой версии модели 1.5, заметное большинство выходят, скажем мягко, средненькими по качеству. «Качество» понимается здесь максимально широко: это и корректность воспроизведения объектов реального мира (особенно людей, особенно кистей их рук), и гармоничность композиции, и даже адекватность перспективы. Дотренированные энтузиастами чекпойнты в среднем показывают более приемлемые результаты, но и здесь не стоит рассчитывать, что с первого раза удастся получить такую картинку, которую захотелось бы поставить в качестве обоев на «Рабочий стол» или же распечатать и повесить в рамочке на стену. Поэтому, прежде чем судить о том, насколько хороша та или иная формулировка подсказки, тот или иной параметр генерации, то или иное дополнение к основной модели (текстовая инверсия, LoRA и пр.), имеет смысл провести довольно длительные испытания — просмотрев выдаваемые системой десятки, а лучше сотни картинок. К счастью, генерация отдельного изображения размером 512 × 768 точек занимает на GeForce GTX 1070 с 8 Гбайт видеопамяти менее двух минут, так что набор такой статистики — задача вполне посильная. Другое дело, что с картинкой столь ничтожных размеров в наши дни делать особо нечего. И смартфонными, и компьютерными экранами с разрешением менее чем Full HD сегодня мало кто пользуется, а безыскусно растянутое в графическом редакторе, скажем, с 768 × 512 до 1620 × 1080 изображение будет смотреться крайне непривлекательно из-за неизбежных артефактов алгоритмического масштабирования. 
Фрагменты изображения, используемого как основной пример в настоящем практикуме, до (слева) и после (справа) четырёхкратного умного укрупнения. Реальная высота фрагмента слева — 300 пикселов (растянут ради удобства сопоставления стандартными средствами алгоритмического масштабирования в графическом редакторе), справа — 1200 пикселов. Есть ли средство борьбы с этой напастью? Есть, и оно тоже доступно пользователям Stable Diffusion с интерфейсом AUTOMATIC1111 (и целым рядом других): это умное укрупнение картинки. Такое, при котором естественным образом возникающие зазоры между исходными точками заполняются либо так называемым латентным шумом (и тогда «шершавые» пикселизованные линии превращаются в гладкие, переходы между соседними цветовыми полями также адекватным образом сглаживаются), либо дополнительно генерируемыми деталями. К примеру, какой-нибудь домик в лесу, на картинке с размерами 768 × 512 точек намеченный буквально горсткой пикселов, при умном укрупнении изображения целиком, скажем, втрое, до 2304 × 1536, обретёт натуралистичную детализацию — вплоть до фактуры переплётов на окнах, различимых кирпичей трубы и явно отблёскивающей металлом дверной ручки. Да, для этого придётся задействовать немалые вычислительные ресурсы: затраты времени на такое укрупнение вместо единиц минут будут уже исчисляться их десятками, если не вовсе часами. Но если вам повезло выхватить из бездонного океана потенциально доступных для ИИ-генерации образов (т. е. из латентного пространства) всего один, но заслуживающий того, чтобы возвращаться к нему снова и снова, имеет смысл пойти на такой шаг. Более того: сплошь и рядом картинка выходит в целом удачной, но некий её фрагмент отчаянно тянет подкорректировать, не трогая всего остального. И это тоже достижимая цель для пользователей связки Stable Diffusion + AUTOMATIC1111, главное — знать, как именно и с привлечением каких инструментов действовать. И важнее всего — не бояться экспериментов! ⇡#С правом на ошибкуКоррекцию уже готового рисунка (кстати, не обязательно сгенерированного ИИ; править схожим образом вполне возможно и любую иную картинку либо фотографию, надо будет лишь больше времени уделить подбору корректных текстовых подсказок и подходящего чекпойнта) логично проводить с использованием почти той же самой модели, что использовалась для получения исходного. 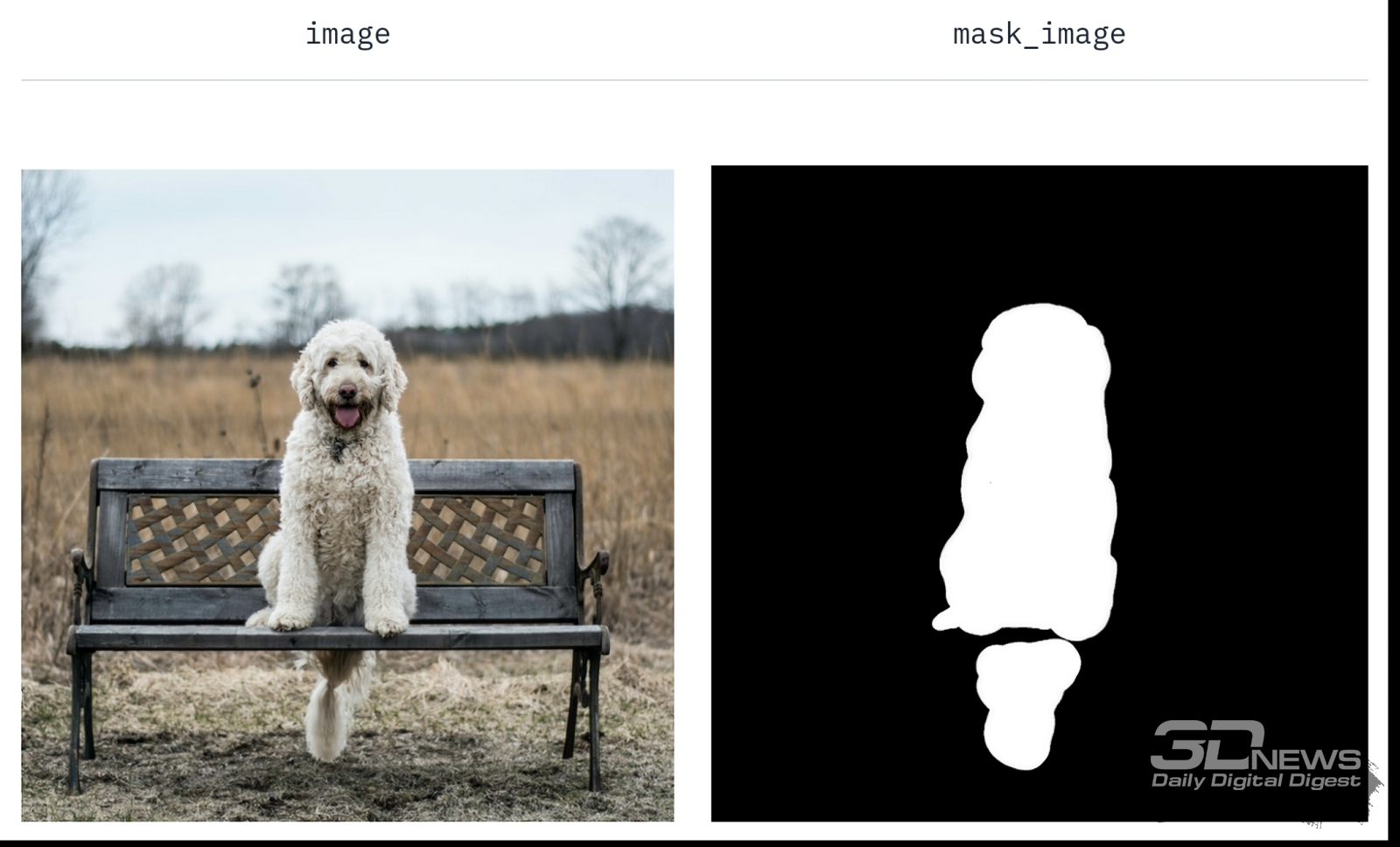
Пояснение к принципу работы inpainting-модели Stable Diffusion 1.5 с основной страницы проекта: перерисовываемому образу ставится в соответствие маска (источник: Hugging Face) Напомним, что галерея роботов, которую мы получили в финале первой части настоящего киберпрактикума, была создана при помощи модели Deliberate v2. Но у неё есть и дополнительная версия, специально натренированная для доработки готовых изображений, — Deliberate_v2-inpainting. Дорисовывать (и частично перерисовывать) одного из полученных нами роботов мы будем именно с её применением. Латентная диффузионная модель дорисовки (inpainting) для базового варианта Stable Diffusion 1.5 создавалась параллельно с основным чекпойнтом. Она специально натренирована на заполнение пространства, закрытого маской произвольной конфигурации. Заполнение производится графическим содержимым, которое, с одной стороны, соответствовало бы заданной пользователем новой текстовой подсказке, а с другой — органично вписывалось бы в фон, что окружает маскированную область. Результат работы такой модели, в базовой версии носящей название Stable-Diffusion-Inpainting, — замещение указанного оператором объекта без нарушения (в идеале, конечно) цельности и органичности графической композиции. 
После того как система научилась работать с масками, замещать один из объектов на исходной картинке практически любым другим становится легко и приятно (источник: Hugging Face) Однако если применять базовую Stable-Diffusion-Inpainting к картинкам, созданным с использованием особо дотренированных чекпойнтов, контраст между фоном и дорисованным изображением может выйти чересчур разительным. Именно поэтому автор Deliberate v2 предложил вместе с этой моделью и специализированную версию для дорисовки — Deliberate_v2-inpainting, скачать которую в формате .safetensors можно с соответствующей вкладки на странице проекта в пределах уже знакомого нам портала Hugging Face. 
Источник: скриншот сайта Hugging Face С непривычки здесь трудновато обнаружить прямую ссылку на скачивание, но она расположена прямо посредине экрана. Строчка «This file is stored with Git LFS . It is too big to display, but you can still download it» содержит активную ссылку на слове download — туда и следует нажимать, чтобы началась загрузка.  Полученный файл Deliberate_v2-inpainting.safetensors надо поместить в ту же самую папку с моделями — \Git\stable-diffusion-webui\models, где уже находятся model.safetensors и Deliberate_v2.safetensors. Кстати, имеет смысл загрузить и базовую модель для дорисовки, Stable-Diffusion-Inpainting, в соответствующей версии sd-v1-5-inpainting.ckpt со странички разработчиков (также на Hugging Face). Поскольку этой команде определённо есть смысл доверять, потенциально опасный файл с расширением .ckpt в данном случае угрозы заведомо не представляет. Зачем нужна модель для дорисовки, которой мы наверняка не будем пользоваться непосредственно, — ведь на свете уже есть (и с каждым днём появляется всё больше) дотренированные чекпойнты, позволяющие гораздо чаще получать картинки не просто приемлемого, а очень достойного качества? Дело в том, что — в отличие от разработчика Deliberate и ещё ряда популярных моделей — основная масса творцов чекпойнтов частенько пренебрегает выкладкой ориентированных именно на дорисовку версий своих проектов. И если авторского inpainting-чекпойнта нет, его всегда можно создать самостоятельно, используя встроенный в AUTOMATIC1111 инструментарий для слияния готовых моделей. 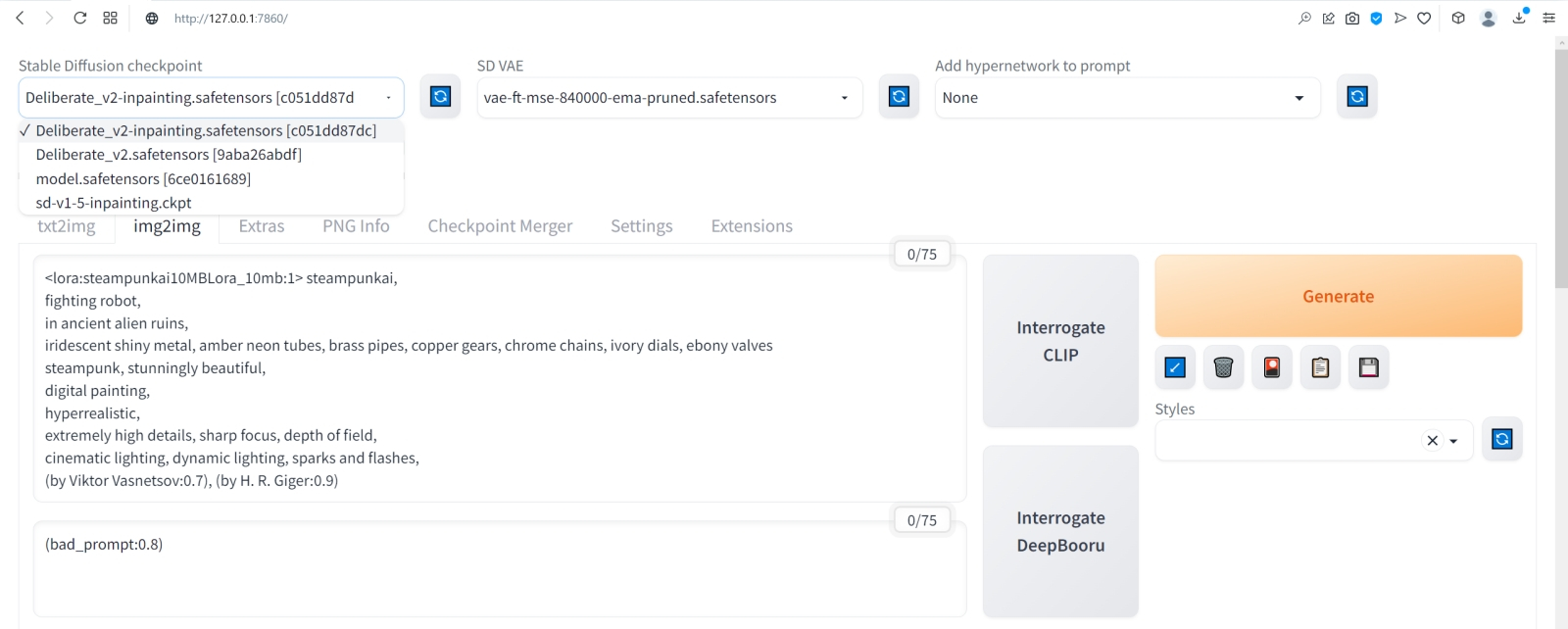 Поместив оба закачанных inpainting-чекпойнта в папку models, на главной странице AUTOMATIC1111 нажмём на синий квадратик с полукольцевыми белыми стрелками у выпадающего списка доступных моделей для генерации. Теперь в этом меню появились и Deliberate_v2-inpainting.safetensors, и sd-v1-5-inpainting.ckpt. 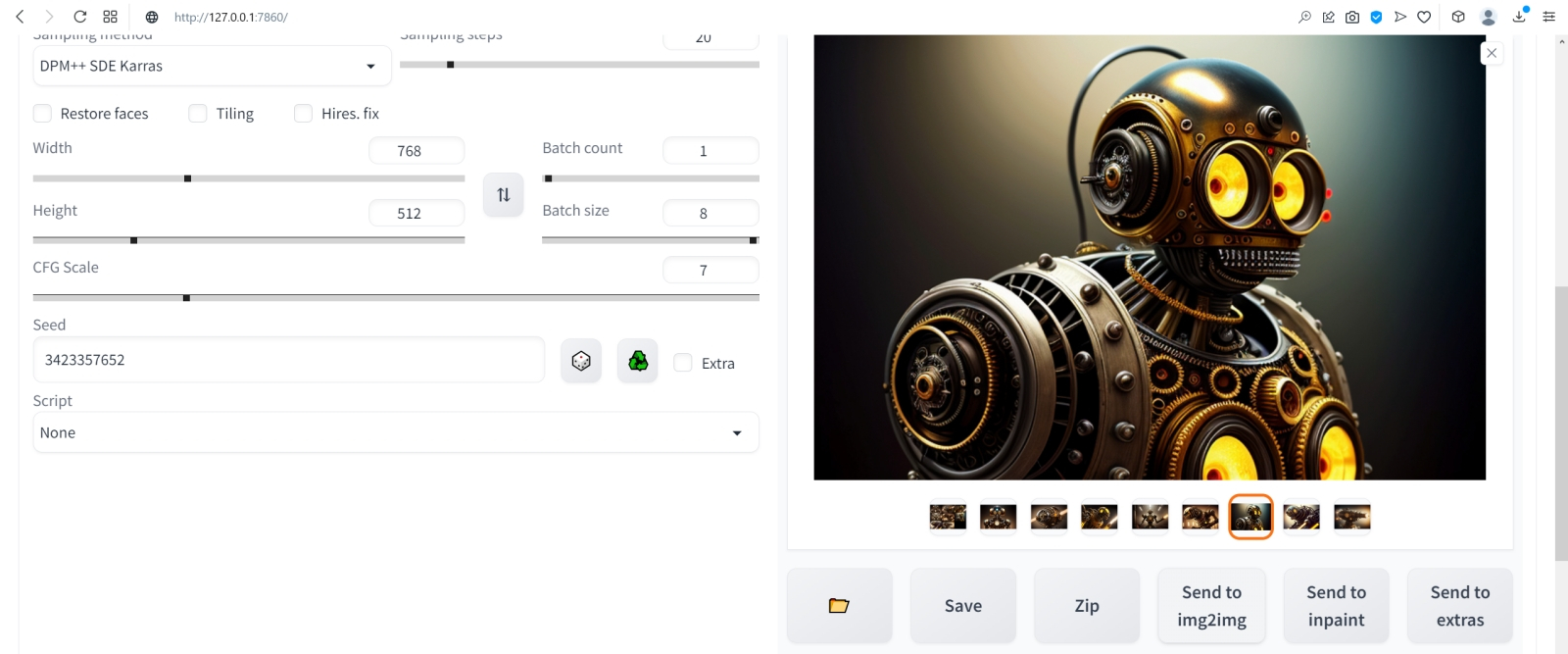 После этого в галерее изображений, всё ещё открытой и доступной по завершении финальной генерации, выберем вот этого робота с затравкой (seed) 3423357657 — уж больно он походит на стимпанковского пращура всем известного Бендера из «Футурамы», в том числе и «выражением лица», так что даже вторая пара глаз — та, что виднеется на корпусе, — общего положительного впечатления не портит. Испробуем широту возможностей дорисовки на этом изображении: пока оно активно в окне предпросмотра, нажмём на расположенную ниже серую кнопку «Send to img2img» — и AUTOMATIC1111 переправит нас на соответствующую вкладку. Обратите внимание: использованные при генерации данного изображения позитивная и негативная подсказки автоматически (не зря же этот веб-интерфейс так именуется!) оказались перенесены в нужные поля на вкладке img2img. Теперь нужно выбрать в выпадающем меню Stable Diffusion checkpoint требующуюся для дальнейших упражнений модель Deliberate_v2-inpainting.safetensors, оставить в прежнем состоянии поле VAE и ползунок Clip skip — и прокрутить экран ниже. 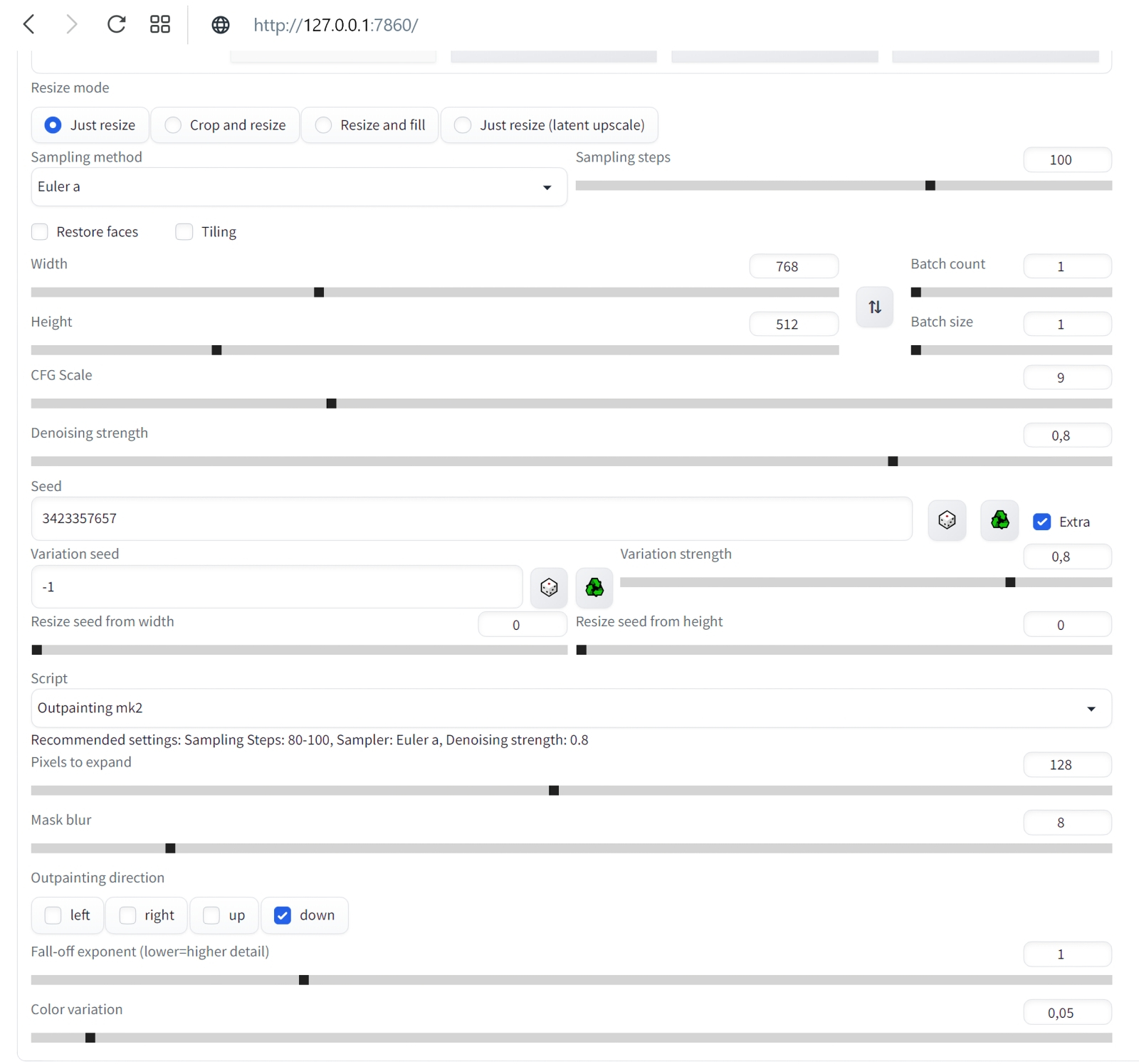 Режим изменения размера картинки (Resize mode) оставляем прежним — Just resize. Параметры Batch count и Batch size также выставим равными 1. CFG Scale увеличим до 9, хотя это спорный момент — в том смысле, что единственно верный ответ на вопрос «Какую величину лучше использовать?» даст лишь практика и только в приложении к данной конкретной генерации (с учётом всех её параметров и подсказок). ⇡#Переменные свободыCFG — это сокращение от classifier free guidance, «свободный параметр классификатора». Данный параметр напрямую определяет, скажем так, дотошность, с которой модель будет следовать заданному ей набору текстовых подсказок. По умолчанию почти повсеместно (и в онлайновых системах, и в AUTOMATIC1111, и в схожих локальных интерфейсах) используются нейтральные величины CFG в диапазоне от 6 до 8 условных единиц. Если выставлять меньшие значения, модель получит больше «свободы творчества»: на картинке, для генерации которой применена, скажем, подсказка «house», может не появиться вовсе никакого дома — однако велик шанс, что итоговое изображение вам всё равно понравится. Задайте CFG = 1, оставьте в поле позитивной подсказки одну-единственную точку (.), удалите негативную подсказку целиком — и узрите, на что способен искусственный интеллект, полностью освобождённый от пут контроля со стороны биологического разума. В пределах выбранного чекпойнта, конечно же. Кстати, поскольку при ИИ-генерации роль стохастики всегда велика, проявление эффекта игнорирования подсказки неизбежно и при бóльших CFG — только с пропорционально уменьшающейся вероятностью. А вот если этот параметр задрать чересчур высоко — 15 и более, — то в зависимости от особенностей данного конкретного чекпойнта весьма вероятно появление крайне неприятных артефактов: шума, похожего на размыливание JPEG-картинки с низким разрешением, контрастных цветовых ореолов вокруг объектов, чрезмерной цветонасыщенности и прочего. Однако модель при этом всеми силами будет стараться как можно точнее следовать заданной ей подсказке, так что в ряде случаев и высокие значения CFG позволят получить вполне приемлемый с точки зрения оператора результат. 
Генерация с одной и той же подсказкой «кот, плывущий в космосе», но с разными CFG (источник: OpenArt) Обратите внимание на параметр Seed: у нас он исходно оказался установлен в 3423357652 — именно такое значение появилось в соответствующем поле при автоматическом переносе данных из вкладки «PNG Info». Стоит верифицировать точность указанной затравки: для этого вернёмся на вкладку «txt2img» и внимательно изучим текстовый блок под выбранной картинкой. Там перечислены все параметры генерации, зафиксированные AUTOMATIC1111, и в их числе — «Seed: 3423357657». Выходит, в данном случае перенос был произведён не совсем корректно: генерация роботов производилась пакетом, и перенесён оказался первый seed из пакета, а не тот, что соответствует выбранной картинке. Возможно, в более поздних версиях AUTOMATIC1111 этот баг окажется уже исправлен, но в данном случае стоит, вернувшись на вкладку «img2img», сменить вручную значение параметра затравки на верное, с семёркой на конце вместо двойки. Справа от поля для ввода seed есть крохотное окошко по соседству с надписью «Extra». Стоит поставить там галочку, и откроется дополнительное меню из нескольких позиций. Смысл его в том, что, если использовать для дорисовки/перерисовки изображения исходную его затравку, система будет раз за разом генерировать практически одно и то же, но, если выставить совсем уж случайную (значение «-1» в поле «Seed»), результат может оказаться слишком уж непредсказуем. Вариации на тему исходной затравки — хороший способ держать креативность Stable Diffusion под контролем: случайный «Variation seed» (значение «-1») обеспечивает необходимую изменчивость в разумных пределах, а параметр «Variation strength» задаёт силу этой вариативности. Установим пока для этого параметра значение «0.8» и не будем трогать два ползунка «Resize…» ниже, — для общего знакомства с азами outpainting и inpainting этого вполне достаточно. 
Пример того, почему не стоит дорисовывать во все четыре стороны разом: если слева изображение дополнилось вполне органично, то справа арка наверху опирается на бумажный фонарик, а небольшая тумба, что была частично видна в правом нижнем углу исходной картинки, просто повисла в воздухе (источник: Okuha) Начнём, собственно, с outpainting — дорисовки исходного изображения по одному из четырёх возможных направлений либо по любой их комбинации разом. Принципиальной разницы между in- и outpainting нет: последний сводится к тому, что «холст» картинки увеличивается, на появившееся дополнительное пространство накладывается маска, и дальше система «пытается сообразить», каким образом органично продолжить изначальный рисунок по тому или иному направлению. Скажем, если на сгенерированной во вкладке «txt2img» картинке, на правом её краю, есть левая сторона окна с откинутой занавеской, логично будет (и для человека, и для натренированной им ИИ-системы преобразования текста в изображения) в случае дорисовки вправо отобразить уже окно целиком, причём занавеска на его правой стороне должна если не быть строго симметрична левой, то хотя бы в общем ей соответствовать. В выпадающем меню Script после базовой установки AUTOMATIC1111 присутствуют два скрипта для дорисовки картинок — выберем для начала Outpainting mk2 как более свежую версию по сравнению с оригинальной Poor man's outpainting (хотя в отношении mk2 сообщество энтузиастов ИИ-рисования, будем объективны, высказывает немало нареканий). При выборе Outpainting mk2 чуть ниже появляется подсказка «Recommended settings»; выставим в соответствии с ней, вернувшись к расположенным чуть выше на той же странице параметрам генерации, «Sampling steps» в 100, «Denoising strength» — в 0,8, «Sampling method» — в Euler a. Из возможных направлений дорисовки — «Outpainting direction» — оставим только Down и больше пока ничего трогать не будем. Кстати, обратите внимание на число «Pixels to expand»: 128 — именно такой (в точках) ширины полоса окажется пририсована к исходному нашему изображению. 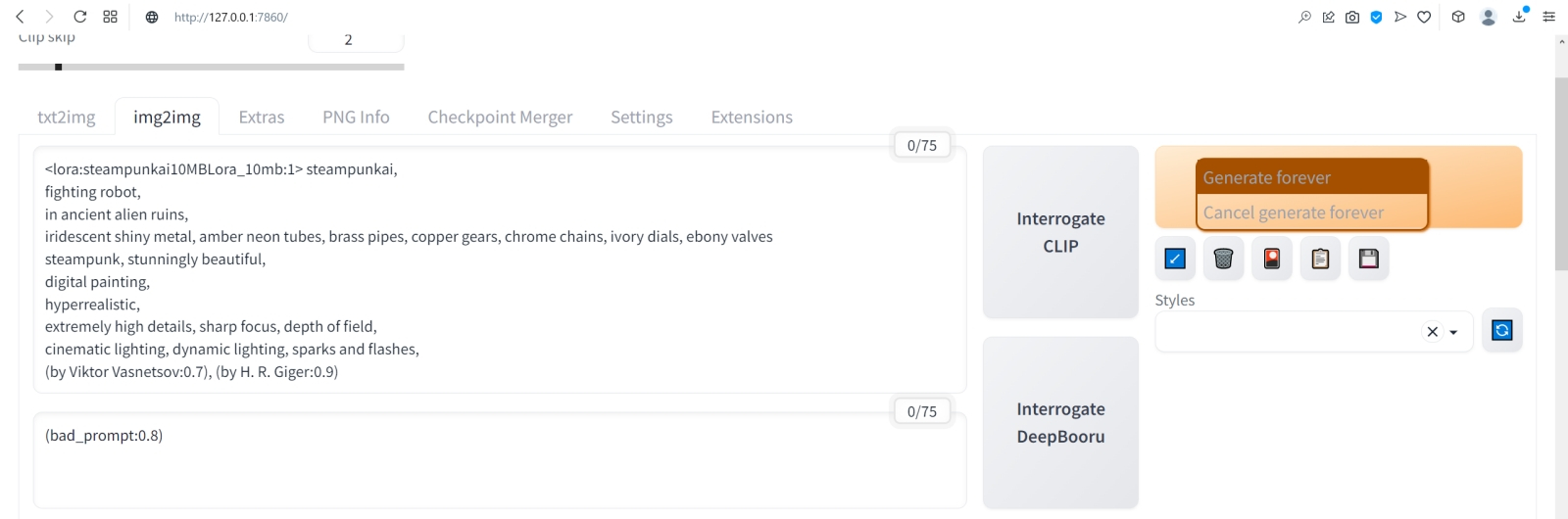 А теперь — внимание! — небольшой трюк: на кнопку начала генерации наживаем не левой, а правой кнопкой мыши. Появится небольшое выпадающее меню, в котором следует выбрать «Generate Forever» — после чего генерация будет производиться раз за разом, непрерывно. Важно, что в этом режиме все ползунки, меню и прочие органы управления на данной странице AUTOMATIC1111 остаются активными. Это значит, в частности, что на вкладке txt2img, установив случайный «Seed» (значение «-1») и запустив «Generate Forever», можно отвлечься от компьютера — и, вернувшись к нему через какое-то время, обнаружить в соответствующей папке (outputs\txt2img-images\[текущая_дата]) сразу несколько нагенерированных за прошедшее время изображений с одними и теми же параметрами — за исключением собственно затравки, которая в каждом случае окажется своя, случайная. Это крайне удобно именно для первичной генерации небольших картинок, поскольку работа Stable Diffusion в величайшей степени зависит от капризов Фортуны. Так что даже не самая удачная комбинация текстовых подсказок способна породить захватывающее дух изображение — если дать системе достаточно времени на виртуальное путешествие по латентному пространству преобразования текста (точнее, порождённых им токенов) в визуальные образы. ⇡#От рассвета до закатаВ данном случае опция «Generate Forever» нужна для того, чтобы не терять времени на ручной перезапуск генерации в ходе потокового получения ИИзображений. Готовые картинки с дорисованным к основе фрагментом будут накапливаться по мере готовности в папке outputs\img2img-images; прямо там их можно просматривать и либо просто дожидаться появления той, что вас устроит, — либо возвращаться к интерфейсу дорисовки и менять какие-то её параметры. В последнем случае текущая в данный момент генерация будет доведена до конца с прежними параметрами, а новые система применит уже к последующей. 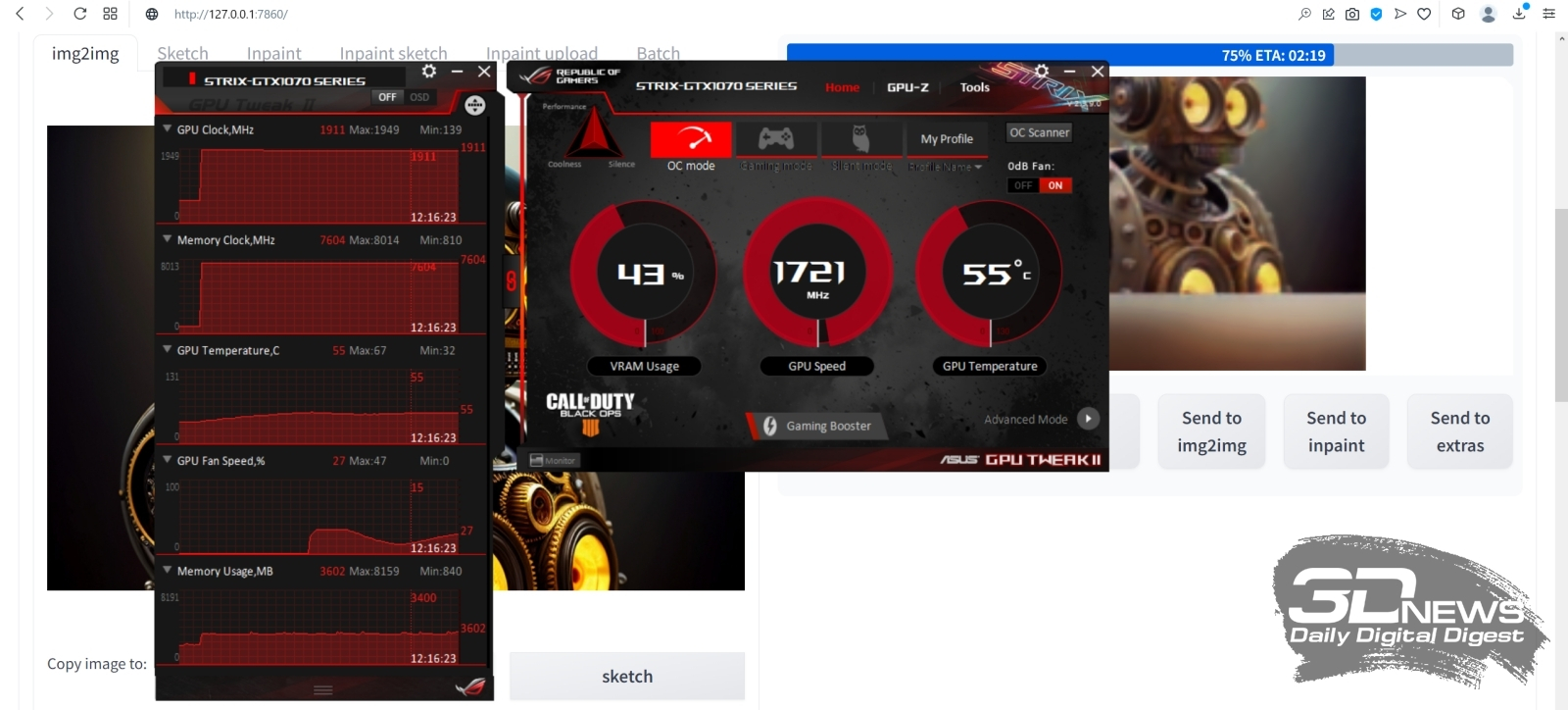 Ещё один важный на практике момент: загрузка ГП — и при генерации исходных малых изображений, и при дорисовке их полосками по 128 пикселов — оказывается сравнительно щадящей. По крайней мере, для GeForce GTX 1070 с параметром --midvram в конфигурационном файле эта нагрузка не превышает 35-50% в первом из указанных случаев и 40-70% — во втором. А значит, прямо на том же самом ПК, что трудится в настоящее время в режиме «Generate Forever» над вызволением зримых образов из безбрежного латентного пространства ИИ-модели, можно заняться и чем-то ещё — веб-сёрфингом, общением в мессенджере, написанием текстов и т. п. Даже многие не самые требовательные к VRAM игры, включая MMORPG, запустятся и будут исполняться без ощутимых подтормаживаний — но, конечно, скорость генерации картинок в таком случае несколько снизится по сравнению с ситуацией, когда никакие сторонние программы на видеопамять не претендуют. Более того: Windows 10 в режиме гибернации сохраняет на логическом диске все данные из ОЗУ, включая видеопамять. Таким образом, у самого завзятого энтузиаста ИИ-рисования, которому всё же мешает спать шум вентиляторов его ПК, есть возможность перевести на ночь компьютер в этот режим — а утром, после вывода машины из гибернации, создание картинок Stable Diffusion автоматически продолжится без каких-либо перебоев. 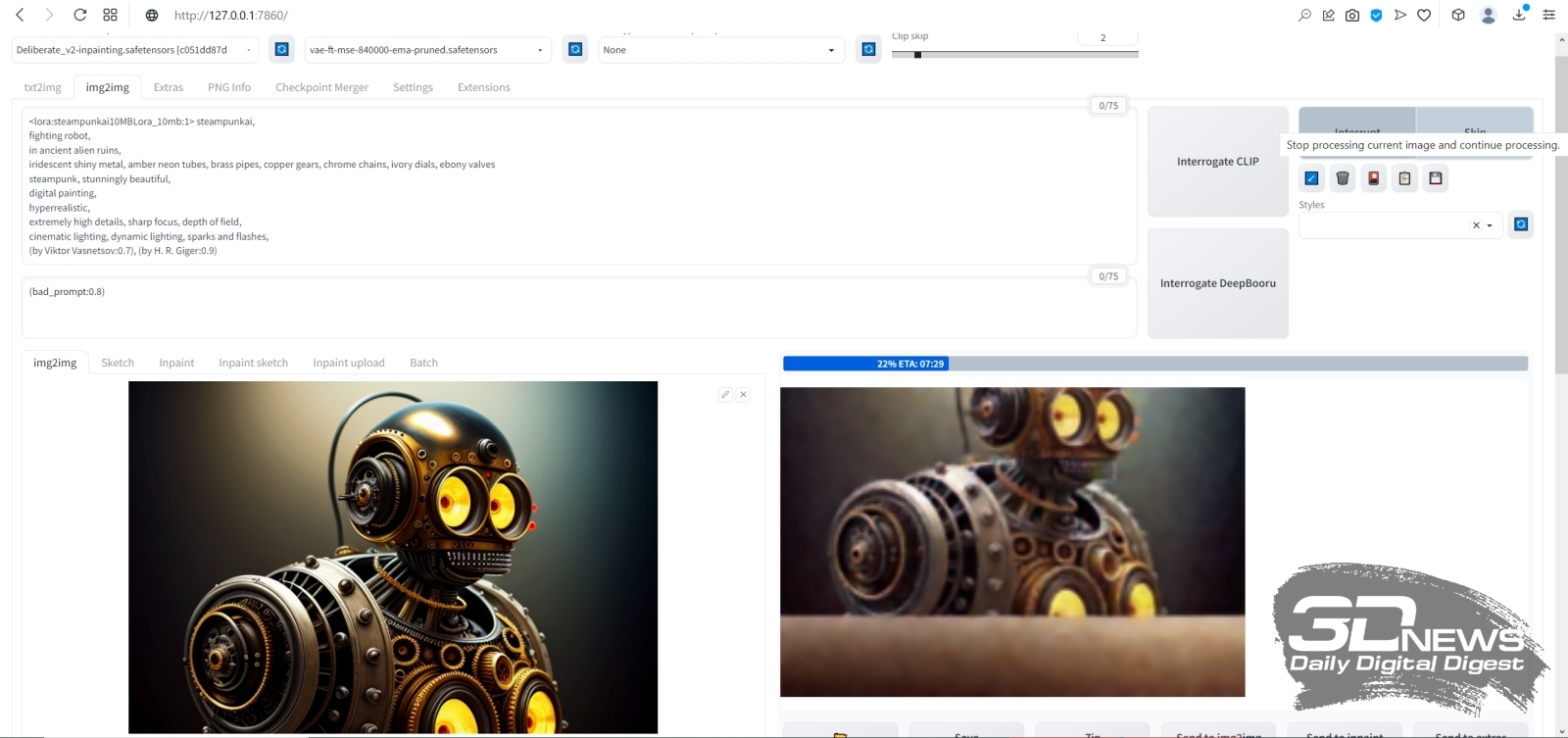 Чем ещё хорош режим «Generate Forever», так это наличием предпросмотра (в заведомо сниженном разрешении) того, что именно рисует в данный момент система. Судить о качестве итоговой картинки по первым примерно 30% генерации смысла мало, однако если уже после того, как дорисовка выполнена наполовину, превью вас однозначно не устраивает, — имеет смысл сэкономить драгоценный вычислительный ресурс. Для этого уже левой, как обычно, кнопкой мыши достаточно нажать на большую серую кнопку «Skip», что появилась на месте «Generate». По завершении очередной итерации система прервётся и перейдёт к отрисовке следующего изображения — впрочем, не факт, разумеется, что оно-то оператора устроит. Терпением запастись придётся в любом случае.  Вот, к примеру, какой впечатляющий бюст героя получился на основе изначального изображения с seed, равным 3423357657, после дорисовки вниз с применением скрипта Outpainting mk2 с затравкой 2817834830 (это затравка именно дорисовки, т. е. добавленной к изображению полосы). Можно было бы дождаться появления более динамичной картинки — скажем, корпуса робота в движении; продолжить затем его вниз ещё, ещё и ещё — и получить в итоге вертикальную узкую композицию довольно высокой чёткости. Но поскольку в данном случае нам важно освоить базовый инструментарий, остановимся на этом вот бюсте. В нём всё хорошо — за исключением «надписи» (точнее, горсточки пикселов, сгруппированной в упорядоченные ряды, что напоминают буквенные строки) в левом нижнем углу. Поскольку Stable Diffusion и производные от неё чекпойнты обучались на огромном массиве картинок из Интернета, включая защищённые копирайтом, снабжённые надпечатками выходных данных и даже, страшно сказать, взятые без спроса из коммерческих фотобанков (точнее, из их зон предпросмотра, где все изображения покрыты «водяными знаками»), появление таких артефактов неизбежно — пусть лишь время от времени. 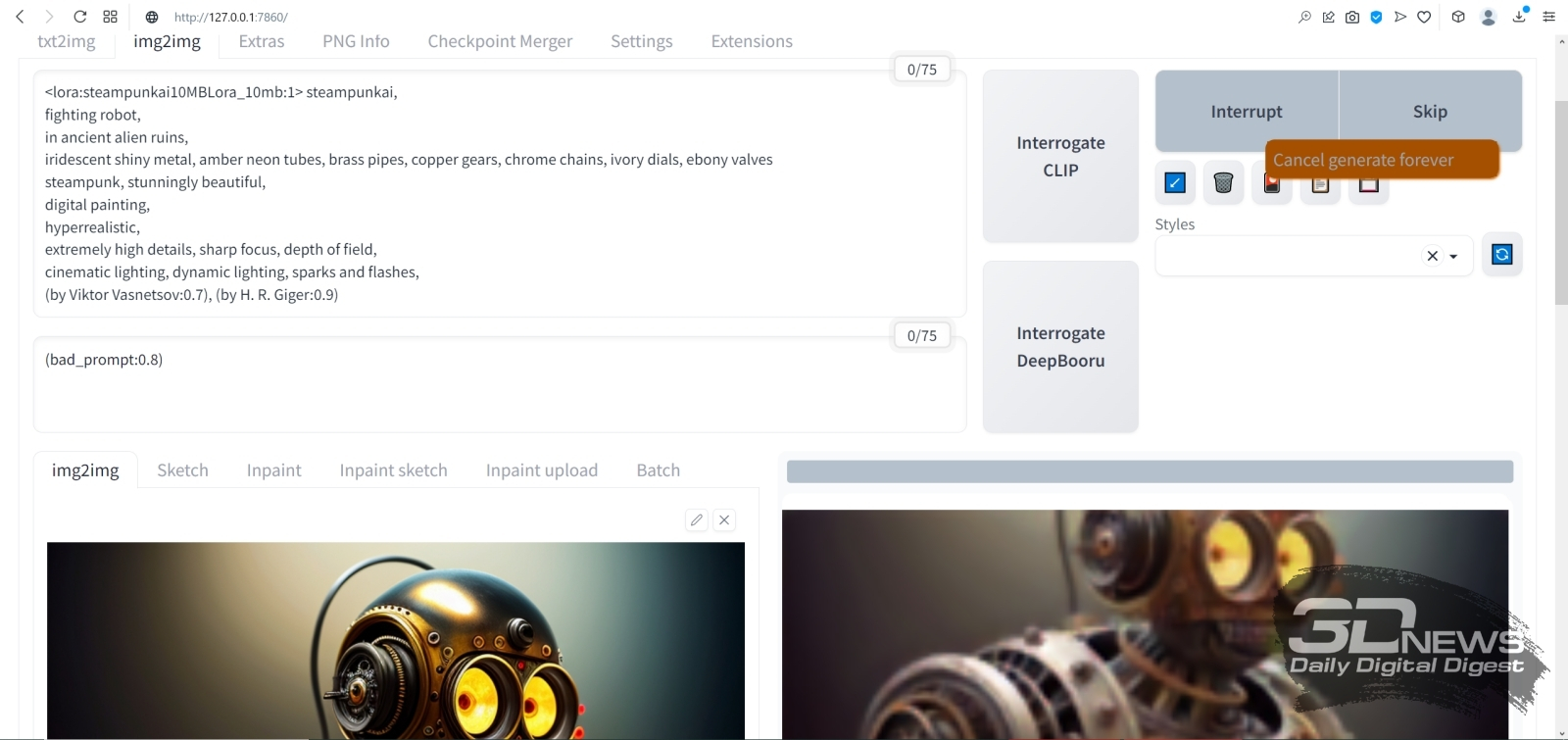 К счастью, средство борьбы с подобными огрехами в нашем распоряжении есть — это уже упоминавшийся инструмент inpainting, служащий для перерисовки неудачных фрагментов внутри картинки. Останавливаем генерацию outpainting — нажав на серый прямоугольник «Interrupt» над полем предпросмотра правой кнопкой мыши и выбрав «Cancel generate forever». Затем переходим на вкладку «PNG Info», загружаем туда понравившуюся картинку из \outputs\img2img-images, нажимаем на «Send to inpaint» (справа, под текстовым описанием параметров генерации) — и переходим на вкладку, открывающую возможность исправить отдельные фрагменты изображения. 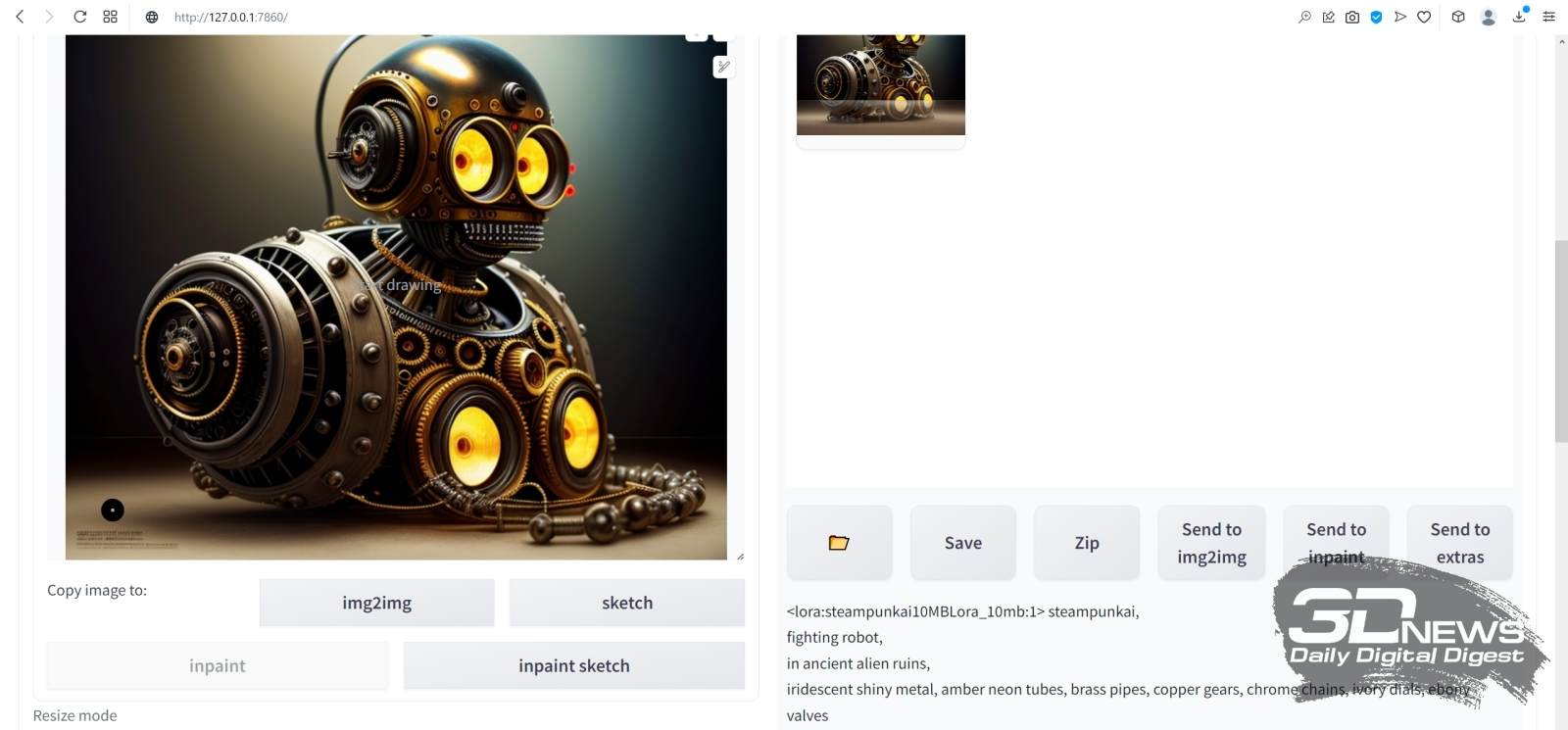 Что именно исправлять, системе укажут следы, оставленные на исходной картинке инструментом перерисовки. На изображении с роботом, в левом нижнем его углу, на данном скриншоте видна жирная чёрная точка с белой сердцевиной — это он и есть. При наведении мыши на картинку в окошке inpainting’а её курсор превращается в такую вот точку: если нажать при этом на левую кнопку мыши и повозить из стороны в сторону, на изображении останется чёрный след — маска будущей перерисовки. В принципе, можно сразу зачернить таким образом все не устраивающие вас части картинки, но тогда все они будут генерироваться за каждый проход разом — а значит, непременно возникнет ситуация, когда в одном месте перерисовка явно удалась, а в другом всё ещё нет. Поэтому тут тоже, как и в случае outpainting’а, есть смысл действовать последовательно, подвергая inpainting’у строго по одной области за раз. Строго говоря, именно inpainting — одно из наиболее слабых мест AUTOMATIC1111: инструмент для нанесения маски грубоват (хотя диаметр чёрного кружка можно менять — в правом верхнем углу картинки предусмотрен для этого ярлык с символическим карандашиком), но масштаб самого изображения увеличить нельзя, так что особо тонкие мазки наносить в любом случае не удастся. В принципе, это не проблема, поскольку модель для перерисовки в любом случае будет принимать в расчёт те области картинки, что соседствуют с наложенной маской, — и постарается (в пределах своей обученности, конечно) сделать переход между перерисованным участком и окружающим его изначальным изображением по возможности естественным и плавным. Многие энтузиасты ИИ-рисования рекомендуют как более удобный и предлагающий больше возможностей для редактирования полученных картинок (не первичной их генерации!) другой графический интерфейс для Stable Diffusion, проект InvokeAI. Пока, однако, при всех своих безусловных плюсах он выглядит более сырым, чем AUTOMATIC1111, — так что испытывать его придётся на свой страх и риск, активно перенимая опыт других увлечённых испытателей на профильных форумах, в частности на платформе Reddit. ⇡#Маска, я вас знаю!Так или иначе, в данном случае нам важно просто освоить перерисовку как принцип. Грубо замазываем «надпись» в левом нижнем углу, «Resize mode» оставляем в позиции «Just resize», размытие маски — ширину границы, на которой система будет учитывать контент окружающего маску исходного изображения, — сохраним в положении «4». Ниже среди режимов «Mask mode» выберем «Inpaint masked» (т. е. перерисовке будет подвергнута область внутри чёрного пятна, а не вне его). 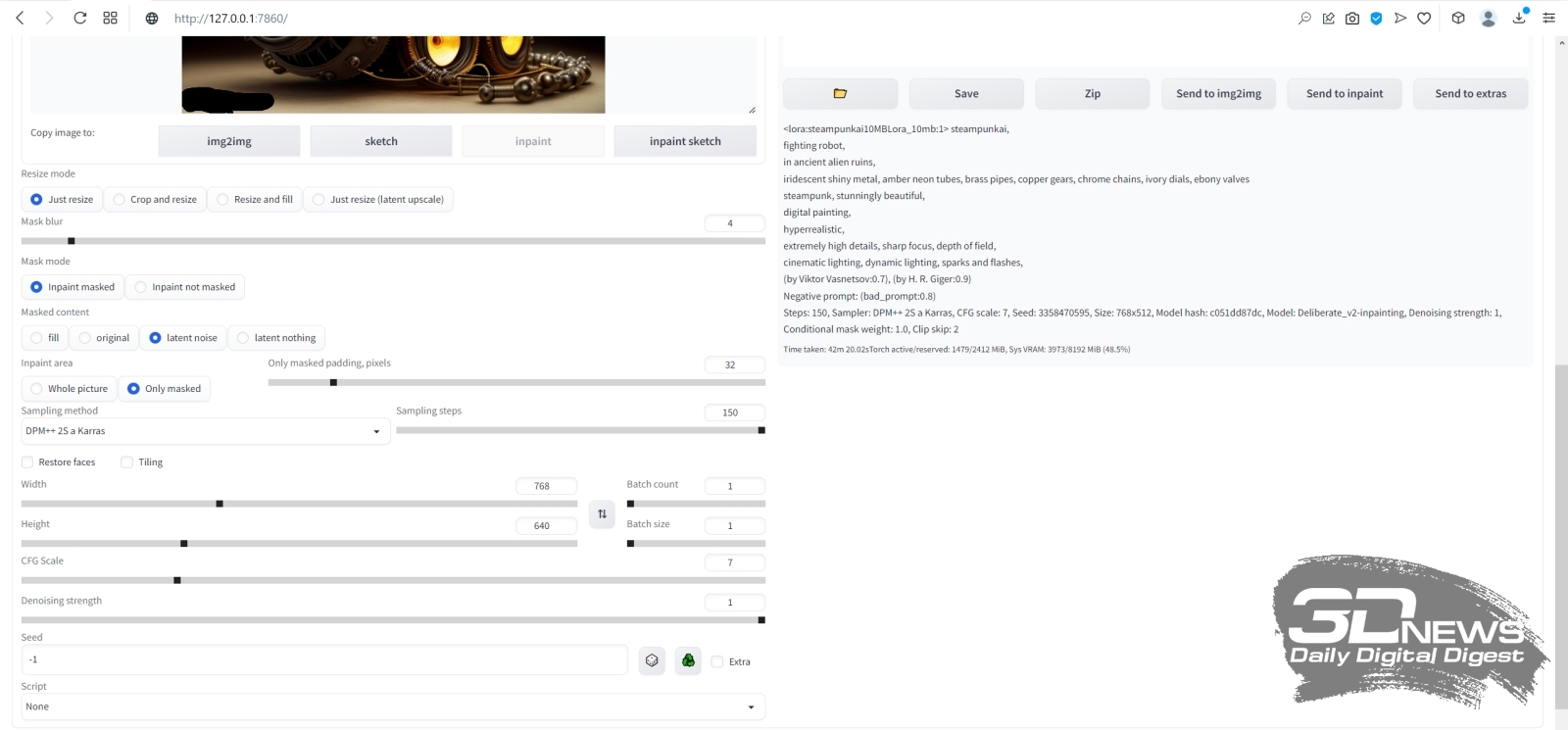 «Masked content» в данном случае пусть будет «latent noise»: это обеспечит системе достаточную свободу творить — т. е. добывать из латентного пространства визуальные образы. Область перерисовки, «Inpaint area», зададим «Only masked», прочие настройки сохраним прежними, только «Seed» сбросим в «-1». И снова — «Generate forever», после чего можно на какое-то время отвлечься от компьютера, не забывая регулярно к нему возвращаться и проверять содержимое папки outputs\img2img-images\.  А вот это (затравка перерисовки 2345658978), между прочим, совсем неплохо! «Надпись» исчезла без следа, зато на столе (или на чём там покоится сгенерированный системой бюст прапрадедушки Бендера) появилась какая-то сложная, явно электромеханическая деталька. Она мила и сама по себе, но в сочетании с крайне характерным выражением глаз самого бюста (обеих их пар) складывается ощущение, будто выпала она из конструкции случайно — и сам прапрадедушка этим происшествием не на шутку фраппирован. Собственно, тем и прекрасно художественное ИИ-творчество: насколько детальной (или, напротив, расплывчатой) ни была бы подсказка, стохастика на уровне бескрайнего латентного пространства рано или поздно возьмёт своё — и породит в итоге изображение, способное по-хорошему удивить самогó запустившего генерацию пользователя. 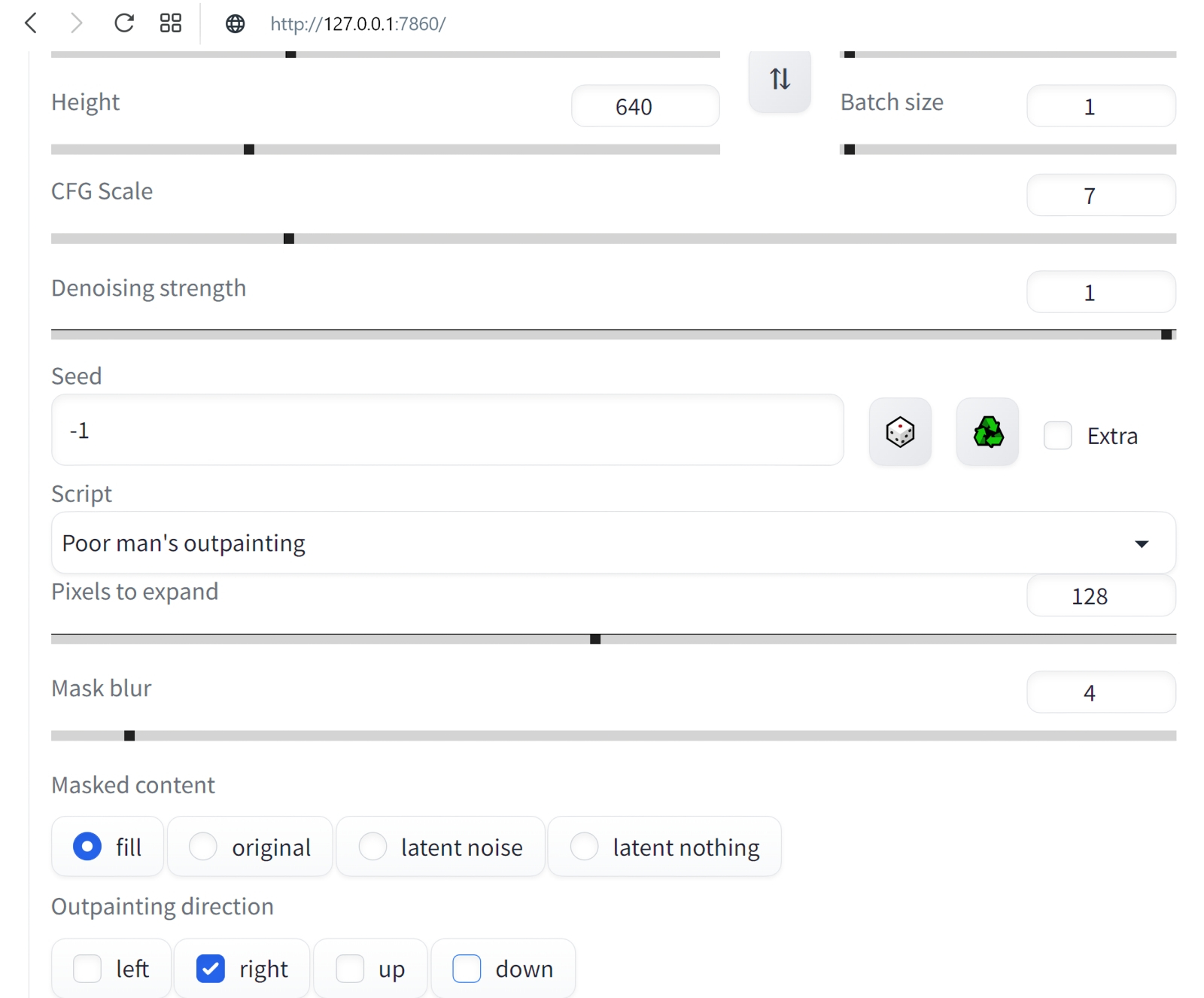 Теперь уже знакомым нам образом продлим изображение вправо, сделав его более вытянутым по композиции, с применением дорисовки (outpaint). Для этого снова потребуется остановить генерацию через правую кнопку мыши и «Cancel generate forever», загрузить выбранную нами перерисованную картинку (её затравка, напомним, если кому-то захочется дотошно воспроизвести процесс, — 2345658978) в «PNG info», оттуда отправить изображение на вкладку «inpaint». Теперь для разнообразия воспользуемся, однако, другим скриптом — не «Outpaint mk2», как в прошлый раз, а «Poor man’s outpainting» с параметрами «fill» и «Mask blur: 4»  Как-то не слишком выразительно, верно (Seed: 2583232873)? Просто естественное продолжение общего фона исходной картинки вправо. Правда, если генерировать именно обои для «Рабочего стола», такой вариант может оказаться вполне предпочтительным: снизу и справа должно быть в этом случае как можно меньше деталей, которые могли бы закрываться панелями инструментов ОС. Но в данном случае мы продолжим, несколько изменив подсказку для дорисовки. Здесь важно определиться: а что именно вы, (со)автор генерируемого ИИ изображения, хотите на данном участке картинки видеть? Может быть, другого стимпанковского робота, в сосредоточенно-скорбной позе («Бедный Йорик!..») взирающего на бюст, из которого уже реле сыпятся? Или тянущего к артефакту хищные лапы иномирного старьёвщика? Или футуристичную горничную-андроила с метёлкой из страусиных перьев? Или ещё что-нибудь? Фантазия оператора («пользователем» его называть теперь даже как-то совестно) Stable Diffusion в сотрудничестве с бездонностью латентного пространства способны порождать самые изощрённые образы — а вот какие именно, определит подсказка для области дорисовки. Мы в данном случае предоставим ИИ самый широкий простор для творчества, попросту убрав из позитивной части подсказки вообще всё, кроме вызова LoRA: <lora:steampunkai10MBLora_10mb:1> steampunkai Негативную сохраним прежней: (bad_prompt:0.8) Вернёмся к скрипту Outpaint mk2; выставим, по рекомендации его разработчиков, Steps = 100, Sampler = Euler a; зададим CFG scale = 11. Модель (чекпойнт) у нас по-прежнему Deliberate_v2-inpainting, Denoising strength = 1, Clip skip: 2. Параметр Fall-off exponent зададим равным 4, а Color variation = 0.  И снова (Seed: 1812405031) в нижней части появилось некое наложенное на картинку изображение, но на сей раз это не неразборчивые псевдобуквы, а натуральный логотип. Теперь это прямо-таки иллюстрация к вымышленному игровому буклету (кто сказал «Victorian Atomic Heart: The Steamy Prequel»?). Изображение довольно детализированное, хотя и не без огрехов: например, в нижней его части (примерно на уровне «зрачков» расположенной на корпусе робота второй пары его глаз) заметны отходящие влево и вправо постепенно истончающиеся светлые линии. Их несложно убрать едва ли не в любом графическом редакторе уровнем выше MS Paint (линуксоиды сразу же вспомнят про GIMP): по сути, редко какой широко расходящийся в Интернете образчик визуальной ИИ-генерации обходится без подобной ручной доводки. ⇡#Расширяя границыНо прямо сейчас есть задача поважнее: изображение мелковато! Самое время научиться его увеличивать — да не просто, а с сохранением качества как минимум, а как максимум — даже с наращиванием детализации.  Весь инструментарий для этого AUTOMATIC1111 предлагает — по крайней мере, потенциально. Перейдём на вкладку с расширениями («Extensions»): там в разделе «Available» нужно будет нажать на большую оранжевую кнопку «Load from». Веб-адрес основного репозитория, откуда именно станут загружаться расширения, разработчиком интерфейса здесь уже любезно указан, а в будущем, если потребуется, несложно будет обратиться и к другому источнику.  Отработка этой команды может затянуться на пару минут: расширений для AUTOMATIC1111, действительно крайне популярного интерфейса к Stable Diffusion, создано уже по-настоящему много. Ориентироваться в полученном в итоге списке с непривычки непросто, но в данном случае нам потребуется вполне определённый скрипт под названием «Ultimate SD upscale». Самый прямолинейный способ его найти — воспользоваться встроенным в браузер поиском (строка которого вызывается нажатием Ctrl+F). Дальше остаётся нажать на серую кнопку «Install» в нужной строке…  …после чего здесь же, во вкладке «Extensions», перейти в раздел «Installed» (ссылка в верхней части этой же веб-страницы, слева от «Available») и нажать большую оранжевую кнопку «Apply and restart UI». Тут же, кстати, можно будет вручную обновлять установленные таким образом сторонние скрипты, если потребуется, — кнопка для этого также предусмотрена. Строго говоря, в исходный пакет AUTOMATIC1111 уже входят несколько скриптов для увеличения масштаба картинки (апскейлинга), но они нуждаются в довольно обширной видеопамяти — в ощутимо большем её объёме, чем требует первичная генерация. Ultimate SD upscale хорош тем, что на видеокарте с 8 Гбайт VRAM демонстрирует вполне достойные результаты, занимая не более 40% видеопамяти. Оборотная сторона этого достоинства — значительное время, требующееся на то, чтобы увеличить масштаб картинки. Полученное нами сейчас изображение бюста — с деталькой слева и логотипом несуществующей франшизы справа — занимает 896 пикселов в ширину и 640 в высоту. На двукратный апскейл её по обоим измерениям (т. е. на увеличение площади в 4 раза с сохранением и даже наращиванием качества детализации), подробности которого мы сейчас изложим, компьютер с видеокартой GTX 1070 затратил почти 70 минут. Как именно производится апскейлинг? Общий принцип понятен: изображение механически растягивается (допустим для определённости, вчетверо по площади), после чего система анализирует взаимное расположение и цвет полученных укрупнённых пикселов — и определённым образом сглаживает переходы между ними. Например, если укрупнённые пикселы схожего оттенка последовательно расположены «лесенкой», то, скорее всего, вместо них на результирующем изображении появится ровная (насколько это позволяет повышенное разрешение, конечно) наклонная линия соответствующего цвета. Однако следует помнить, что при апскейлинге Stable Diffusion принимает в расчёт текстовые подсказки (и позитивную, и негативную), так что результат работы такого скрипта может оказаться довольно неожиданным. 
Сравнение оригинальной картинки с низким разрешением, её алгоритмического апскейлинга с применением фильтра Ланцоша и умного ИИ-масштабирования (источник: Stable-Diffusion-Art) До появления общедоступных ИИ-систем для работы с изображениями компьютерные художники и фоторедакторы пользовались целым рядом алгоритмов для масштабирования растровых картинок, включая бикубическую интерполяцию, фильтр Ланцоша и множество иных. Частенько приходилось действовать в два прохода, поскольку во многих случаях масштабирование по алгоритму приводило к появлению ясно различимой пиксельной зубчатости, особенно на контрастных искривлённых линиях, — которая, в свою очередь, требовала дополнительной обработки сглаживанием. В целом увеличение изображения в предшествующую генеративному ИИ эпоху было задачей крайне ресурсоёмкой и нередко давало не самый удовлетворительный результат — прежде всего по причине почти неизбежного снижения резкости при алгоритмическом масштабировании. ИИ-масштабирование снимает проблему снижения резкости за счёт уже хорошо знакомого нам латентного пространства: по сути, любой апскейлер в составе Stable Diffusion — это отдельная модель, специально натренированная на восстановление отсутствующих деталей. Как базовый чекпойнт тренируется распознавать образ, к примеру, «дома», постепенно накладывая гауссовский шум на аннотированные изображения разных домов (сфотографированных или нарисованных человеком), а затем инвертируя процесс, так и модель для масштабирования сперва приучается понижать разрешение исходных картинок, зашумляя их, — а затем обращает это действие вспять, восстанавливая таким образом утерянные при уменьшении масштаба детали. 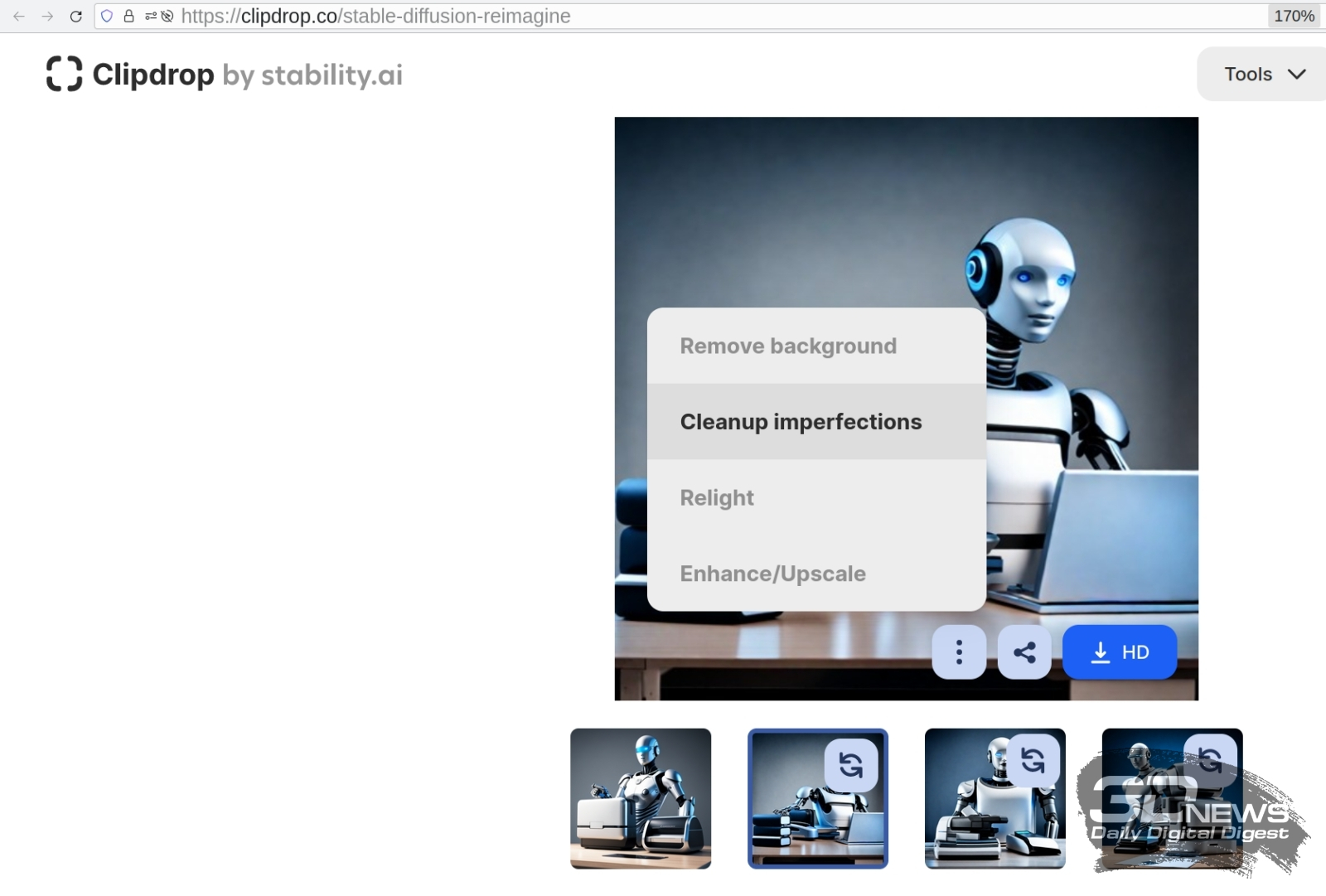
Онлайновые средства ИИ-обработки изображений способны не только масштабировать картинки, но и обтравливать объекты (удалять фон), устранять дефекты, менять освещённость (позицию и цветовую температуру невидимого источника света в кадре) и многое другое (источник: скриншот сайта Clipdrop; исходное изображение также сгенерировано ИИ) Здесь, безусловно, есть одна тонкость: восстанавливая чёткость некоего размытого фрагмента изображения, система вынуждена в большей или меньшей степени случайно определять, что за объект скрывается под каждым из мутных пятен. Если отдать на откуп модели такого рода догадки целиком (не указывая в полях для положительной и отрицательной подсказок на вкладке img2img вообще ничего), да ещё и ослабить ограничения на её творческий потенциал (уменьшив величину CFG и задав высокое значение для параметра denoising strength, о котором чуть ниже), результат может оказаться избыточно креативным — вплоть до отторжения. Чтобы такого не происходило, имеет смысл более или менее придерживаться ряда общепринятых рекомендаций. Первое: есть смысл сохранить для апскейлинга в точности те же подсказки, что были применены при генерации исходной картинки. При этом нужно отдавать себе отчёт, что такое масштабирование будет сопровождаться ростом детализации: раз мы упоминаем, к примеру, «бронзовые трубки» и «медные шестерёнки» в позитивной подсказке, то у каждого вытянутого смутного пятна на укрупняемом изображении появляется немалый шанс превратиться в миниатюрную трубку, а у каждого округлого — в шестерёнку. В данном случае, когда на рисунке робот, это совершенно не проблема, но масштабирование, скажем, человеческого портрета с прямым копированием исходных параметров генерации («кудрявые светлые волосы, голубые глаза, ровные зубы…») может породить довольно гротескное изображение, на котором в мелких деталях увеличенного лица будут явно угадываться другие лица (либо их фрагменты). Обычно, если хотят избежать чрезмерной детализации при масштабировании, ограничиваются самой общей позитивной подсказкой вроде «best quality, HDR, masterpiece». 
При силе шумоподавления 1,0 практически вся информация об исходном изображении пропадает (источник: OnceUponAnAlrogithm) Второе: в какой именно мере модель апскейлинга вольна пускаться в усиленную детализацию укрупняемого изображения, определяет уже упомянутый параметр denoising strength, сила шумоподавления. Чем выше задран «шумодав», тем больше деталей добавится в ходе масштабирования — и тем меньше останется свидетельств о том, что прежде было изображено на картинке. Если требуется увеличить некую абстрактную композицию, выставление denoising strength в 0,6 и более вполне оправданно, однако оптимальная величина для портретов, реалистичных пейзажей и натюрмортов не должна превышать 0,45. Приблизительно, конечно: точное значение будет зависеть и от конкретной картинки, и от выбранного чекпойнта, и от указанных для апскейлинга подсказок. В любом случае безопасными — добавляющими по минимуму деталей, лишь сглаживающими зубчатые линии и выравнивающими цветовые переходы при масштабировании — можно считать значения denoising strength менее 0,25. 
Результаты генерации изображений с фиксированными подсказками, чекпойнтом, CFG и прочими параметрами, различающихся лишь заданным числом шагов сэмплинга — от 1 до 40 (источник: OpenArt) Третье: отправляя картинку на увеличение, следует скорректировать число шагов сэмплинга (sampling steps). Разумная величина для этого параметра — 20–30, но это в случае первичной генерации, т. е. фактически при значении denoising strength = 1: когда сетью, сотканной из претворённых в токены текстовых подсказок, система извлекает изображение из пучины латентного пространства. При апскейлинге же значение «шумодава» по необходимости снижается, и потому надо подобрать число шагов сэмплинга таким, чтобы произведение двух этих величин по-прежнему оставалось в пределах 20–30. Иными словами, если denoising strength на этапе масштабирования выставляется в 0,2, то sampling steps потребуется поднять до 100, а то и 150. В противном случае качество увеличенного изображения окажется, мягко говоря, далёким от ожиданий. 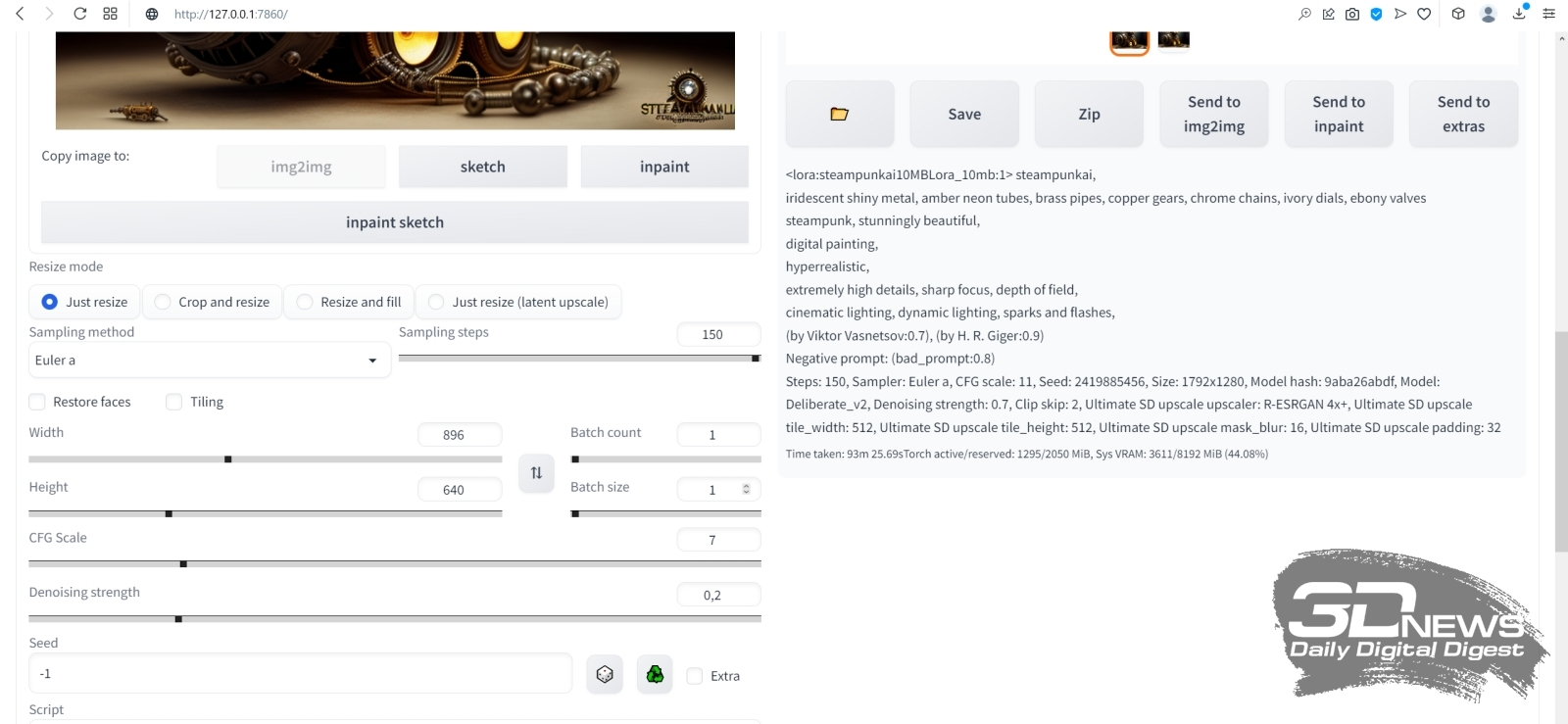 Суммируем параметры апскейлинга во вкладке img2img. Позитивная подсказка: <lora:steampunkai10MBLora_10mb:1> steampunkai, iridescent shiny metal, amber neon tubes, brass pipes, copper gears, chrome chains, ivory dials, ebony valves steampunk, stunningly beautiful, digital painting, hyperrealistic, extremely high details, sharp focus, depth of field, cinematic lighting, dynamic lighting, sparks and flashes, (by Viktor Vasnetsov:0.7), (by H. R. Giger:0.9) Негативная: (bad_prompt:0.8) Далее выбираем Just resize, Sampling method = Euler a, Sampling steps = 150, CFG Scale = 7, Denoising strength = 0,2, Seed = -1 (т. е. случайный, хотя можно использовать и оригинальный — при столь низкой denoising strength большой разницы не будет). 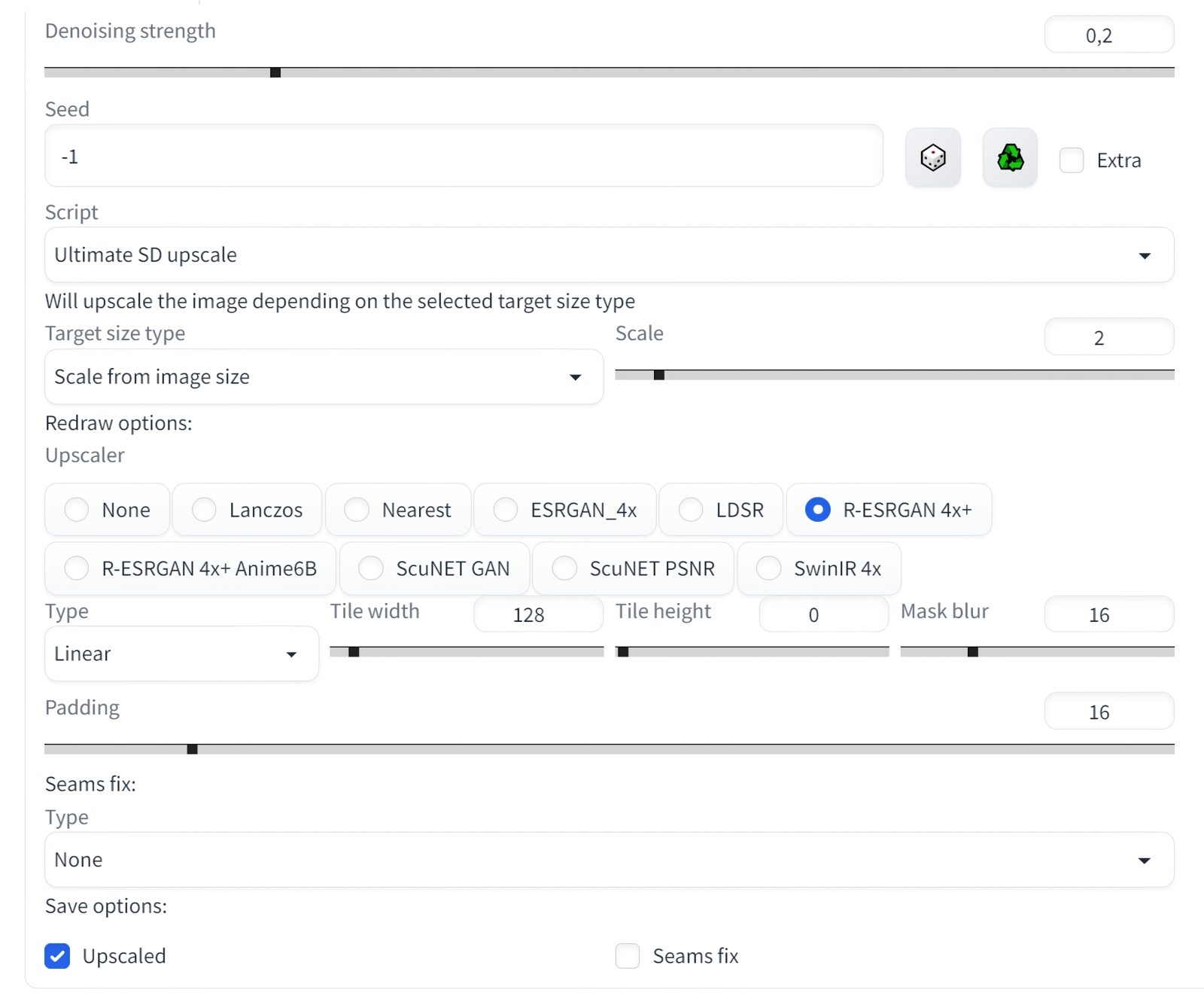 Выбираем далее скрипт Ultimate SD upscale с параметрами «Target size type : Scale from image size» и «Scale : 2» — так задаётся двукратное увеличение по обеим сторонам (четырёхкратное по площади). Здесь достаточно именно удвоения; если потом появится желание ещё более укрупнить картинку — чтобы распечатать в большом формате, например, — ничто не помешает ещё раз отправить полученное изображение на вкладку img2img и повторить всю процедуру заново. Только в этом случае апскейлинг будет требовать уже заметно больше времени. ⇡#Нет предела совершенствуПри выборе модели апскейлера остановимся на «R-ESRGAN 4x+», признанной многими энтузиастами ИИ-рисования одной из лучших универсальных, и зададим пока «Tile width : 128», а «Tile height : 0». Здесь необходимо пояснение: важнейшее преимущество скрипта Ultimate SD upscale по сравнению с исходно доступным в AUTOMATIC1111 апскейлером — это ориентированность на работу с изображением не в исходном целом виде, а разбитым на блоки (тайлы), каждый из которых масштабируется по отдельности. Как раз за счёт такого подхода удаётся минимизировать использование видеопамяти: тайлы для обработки подгружаются в неё поочерёдно, что ощутимо снижает требования к минимальному объёму VRAM — но ценой немалого увеличения времени на обработку картинки. Дальнейшие параметры указывают, насколько далеко (в пикселах) в соседние тайлы системе следует заглядывать, чтобы соотносить производимое в данном блоке масштабирование с его окружением («Padding : 16»), и насколько сильным должно быть сглаживание при маскировании тайлов («Mask blur : 16»). Со всеми этими величинами, как и советует официальная страница проекта Ultimate SD upscale на GitHub, можно и нужно играть, чтобы добиваться наиболее устраивающего вас результата, — но пока ограничимся этими значениями. Осталось выбрать «Seams fix: None» (в надежде, что никаких видимых стыков на изображении не появится и потому исправлять их не придётся) и «Save options: Upscaled», поскольку нам нужна именно масштабированная картинка, — и теперь уже запустить генерацию.  Вот таким получается наш бюст стимпанковского прапрадедушки Бендера в стилистике «официальный гейм-арт» после двукратного увеличения со слабым усилением детализации. Это уже почти обои «Рабочего стола» — оригинальное разрешение 1792 × 1280 (для настоящей публикации оно по необходимости уменьшено до 1600 пикселов по большей стороне). Действительно, никакого «мыла» и (почти никакого) паразитного шума. Генерация одной этой картинки заняла чуть более часа на ПК с GTX 1070 с 8 Гбайт VRAM, но она стала примерно шестой (затравка 2419885456) в серии, запущенной уже хорошо знакомым нам образом — с нажатием «Generate forever» вместо обычного однократного «Generate». 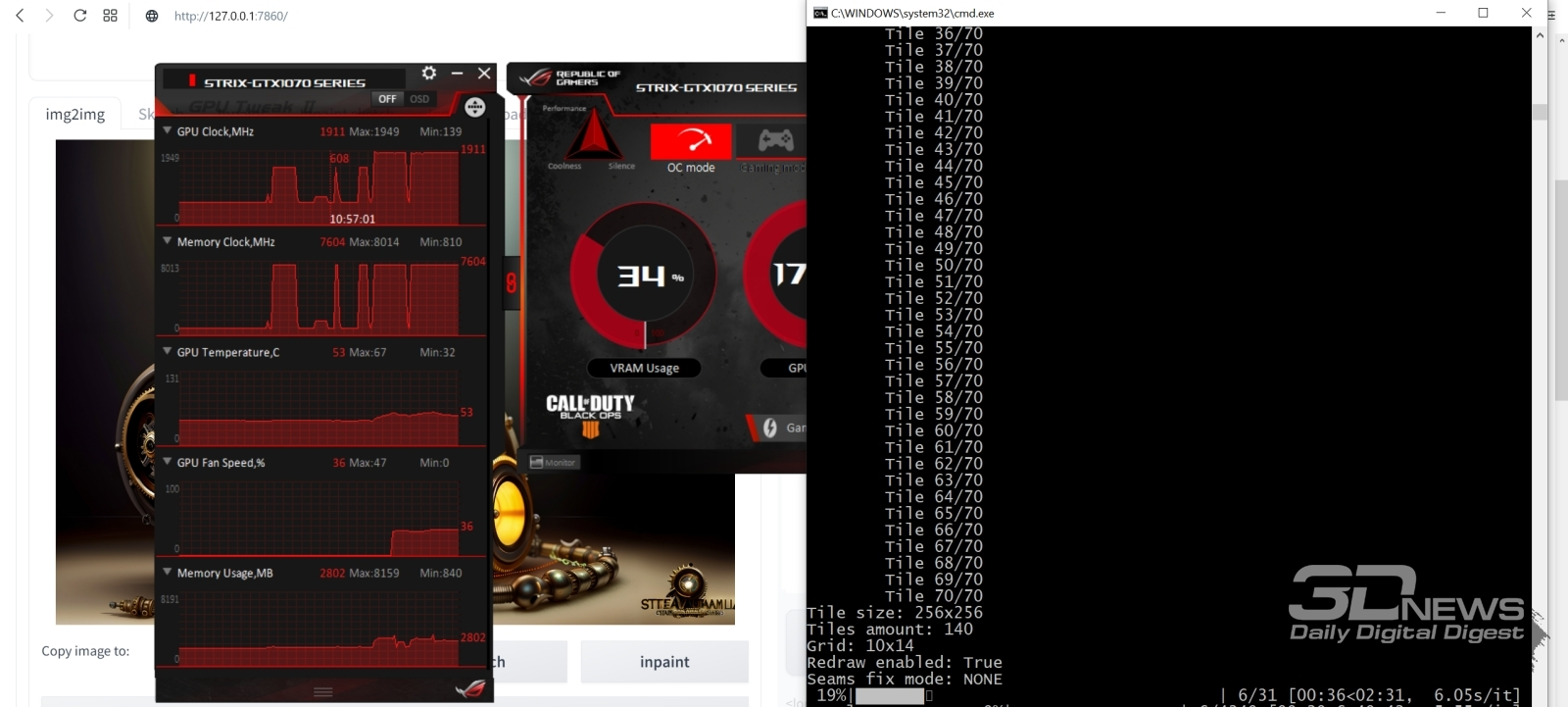 Затем, остановив процедуру бесконечной генерации, перенесём полученную масштабированную картинку снова в img2img — и опять запустим в работу скрипт Ultimate SD upscale. На сей раз отличие от предыдущего захода только одно: параметр «Tile width» выставим в 256, чтобы совсем уж не мельчить с блоками («Tile height» остаётся равным 0 — это подразумевает, что высота тайлов равна ширине, т. е. они квадратные). Можно соответствующим образом нарастить «Padding» и «Mask blur», но в данном случае этого не потребовалось. Как видно, видеопамять в процессе работы занята едва ли на треть, — зато времени на исполнение масштабирования требуется более 6 часов. Ориентируясь на эти параметры, можно в дальнейшем ещё более увеличить размеры единичного тайла — это приведёт к ускорению процесса.  Вот каким в итоге оказался наш красавец (финальная затравка 2868685285) — 3584 × 2560 пикселов; четырёхкратное увеличение доработанного через inpainting и outpainting изображения, сгенерированного Stable Diffusion по, в общем-то, довольно простой подсказке, пусть даже с использованием LoRA и текстовых инверсий. Во всём великолепии оригинального разрешения этот образчик ИИ-творчества можно разглядеть здесь. Чтобы создать подобную картинку вручную, требуются годы подготовки по направлению классического и/или компьютерного рисования, тогда как генеративная модель даёт возможность ощутить себя (со-)творцом прекрасного практически любому, в чьём распоряжении имеется мало-мальски функциональный игровой ПК. Безусловно, это только начало пути по чрезвычайно запутанной, местами слабо проходимой, а где-то даже ошеломляющей широтой возможностей тропе ИИИИ (Иизобразительного Иискусства). После освоения базовой генерации, до- и перерисовки, а также масштабирования имеет смысл затронуть как минимум извлечение текстовых подсказок из сторонних изображений (interrogate), рисование по шаблонам (расширение ControlNet, особенно в наиболее актуальной его версии 1.1), дробление картинки прямо в процессе первичной генерации (tiled diffusion — позволяет создавать композиционно корректные изображения, сильно вытянутые по горизонтали или вертикали), выдачу подсказок для отдельных областей единого холста (region prompt control) и ещё многое другое. Оставайтесь с нами — будет интересно!
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
|
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.





