







 MWC 2018
MWC 2018 2018
2018 Computex
ComputexAdobe представила логотип, который будет применяться для обозначения контента, созданного или отредактированного с использованием инструментов искусственного интеллекта.









Источник изображений: contentcredentials.org
Решение Content Credentials было разработано Adobe при участии ряда партнёров, в том числе BBC, Microsoft, Nikon и Truepic. Информация о происхождении изображения, видеозаписи или PDF-файла добавляется в его метаданные цифровой камерой или графическим редактором и записывается в массив метаданных, где указывается, использовались ли при его создании либо редактировании алгоритмы искусственного интеллекта. Соответствующая информация добавляется автоматически в Adobe Photoshop и Premiere, а скоро её поддержка появится и в Bing Image Creator — Microsoft пока использует собственную технологию маркировки, но планирует перейти на Content Credentials.
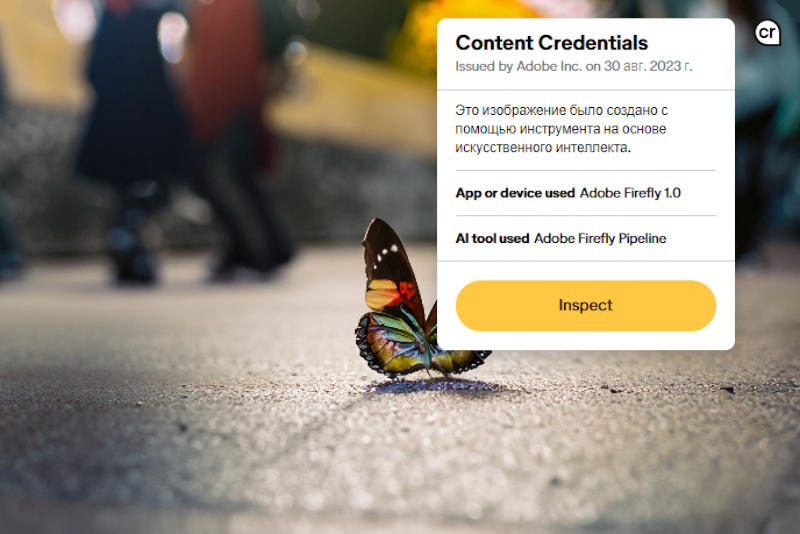
Далее, когда контент выводится поддерживающим данную функцию приложением или браузером (реализуется при помощи JavaScript), в правом верхнем углу изображения появляется логотип в виде строчных букв «cr», клик по которому выводит всплывающее окно с информацией об изображении. Вызывающий сомнения файл можно будет также загрузить на специальный сайт, который покажет необходимые метаданные.
Adobe — не единственная компания, которая, следуя своему обязательству, предложила маркировку ИИ-контента. Ранее собственное решение под названием SynthID представила Google, которая предпочла внедрение водяных знаков, не видных человеческому глазу, но читаемых компьютерами — недавно американские учёные опровергли эффективность такого метода. Едва ли более сложной задачей окажется и подделка метаданных.
Источник:





