







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Практикум по ИИ-рисованию, часть шестая: инструменты умной детализации (Hires. fix, ADetailer, ControlNet)
Почти полтора года миновало с момента официального анонса Stable Diffusion (в версии 1.4) как общедоступной, открытой модели генеративного ИИ для преобразования текстовых подсказок в изображения. Стремительность появления новых разработок в этой области поражает: только за несколько дней в ноябре 2023 г. Google наделила свой чат-бот Bard возможностью просматривать за пользователя видеоролики и кратко суммировать их содержание, компания Stability AI предложила свою первую модель для генерации видео по текстовым подсказкам, а Runway существенно обновила и расширила возможности генеративной модели Gen-2 для создания видео на основе мультимодальных подсказок (текста, картинок, других роликов) — модели, которую издание Time включило в перечень «Лучшие изобретения 2023 г.».  Видео — это, конечно, замечательно, но для энтузиастов локального исполнения генеративных моделей, в чьём распоряжении нет сервера хотя бы с одним графическим адаптером уровня NVIDIA H100, создание роликов продолжает оставаться делом если не полностью недоступным, то чрезвычайно трудо- и времязатратным. Дело не только в том, что для этой цели оптимальна видеокарта более чем с 10 Гбайт VRAM (а хорошо бы и с 24, и с 40 Гбайт): генерируемое ИИ видео страдает, по большому счёту, тем же недугом, что и порождаемые им статичные картинки. А именно — далеко не всегда результат визуализации текстовой подсказки совпадает хоть сколько-нибудь полно с тем, что у автора этой подсказки было в голове на момент её составления. И если в знакомой постоянным читателям нашей «Мастерской» рабочей среде AUTOMATIC1111 можно просто запустить «Generate forever» со случайным перебором затравок (seed) и заняться другими делами, понадеявшись, что за какое-то разумное время среди груды невыразительных и/или несуразных картинок появится хотя бы одна заслуживающая внимания, — то расход времени и вычислительных ресурсов на аналогичную отбраковку видеороликов, пусть даже недлинных, представляется совершенно несоразмерным. Впрочем, более или менее уверенно ориентироваться в латентном пространстве, из которого «искусственная интуиция» генеративных моделей извлекает визуальные образы, всё-таки возможно. В первом приближении мы начали осваивать эту премудрость в предыдущем выпуске «Мастерской», а теперь познакомимся с более сложными инструментами для умной детализации запросов к ИИ, позволяющими в немалой степени снизить выход заведомо негодных результатов генерации. Да, гарантированных шедевров нажатием одной-единственной кнопки таким образом всё равно получать не удастся. Однако, во-первых, «шедевр» — понятие растяжимое и в целом довольно субъективное («Я художник! Я так вижу!»), а во-вторых, даже небольшое повышение вероятности генерации удобоваримого изображения не может не порадовать энтузиаста ИИзобразительных ИИскуств — особенно не располагающего многогигабайтной видеокартой и вынужденного тратить на создание каждой очередной базовой картинки не меньше минуты. ⇡#Потребуется ангельское терпениеС чего начинают обучение биологические художники? С прямого и безыскусного копирования объектов реального мира: кубиков, скатертей, ваз, бутылок, гипсовых бюстов — с постепенной наработкой внимания к деталям, с поступательным освоением рабочих инструментов — карандаша и бумаги, холста и красок… Генеративная модель для преобразования текста в картинки попадает в руки ИИ-энтузиаста уже предварительно обученной, но это вовсе не значит, будто самому использующему её человеку нечему учиться. Напротив: как вы изображение опишете, так оно и сгенерируется, — другой вопрос, что связь между двумя этими «как» вовсе не прямолинейна и интуитивно далеко не всегда очевидна. В качестве первого приближения к постижению этой связи нелишним будет обратиться, собственно, к ИИ за разъяснениями о том, как она образуется. Спросить об этом — с рядом довольно серьёзных ограничений — можно саму Stable Diffusion, поскольку составной её частью является разработанная OpenAI нейросеть CLIP (Contrastive Language-Image Pre-training), на которой тренировались одновременно кодировщики текста в изображение и изображения в текст. Эта мультимодальная модель машинного зрения (a general-purpose vision system, как именуют её сами разработчики) пробрасывает информационные мостики (в виде конкретных значений весов на входах перцептронов в нейросетевых слоях) между элементами англоязычной лексики и визуальными характеристиками статических изображений. Элементы лексики могут быть представлены отдельными словами (cat, justice, xenomorph), устойчиво связанными сочетаниями слов (Greg Rutkowski, Gina Lollobrigida, Red Square — кстати, имплементация CLIP для генеративных моделей поколения SDXL прекрасно отличает последнее от просто «red square»), акронимами (HDR, NSFW, UFO). Визуальные же характеристики включают не только упорядоченные группы пикселов, задающие формы и расцветки, но и более отвлечённые характеристики — текстуры, уровни и типы освещённости, художественные стили и пр. Собственно, изначально создатели CLIP рассматривали эту модель как гораздо более продвинутый (по сравнению с тем, что было доступно на тот момент) классификатор образов и лишь в конце 2020 г. использовали её для разработки одного из первых по-настоящему успешных ИИ-рисовальщиков, DALL-E. 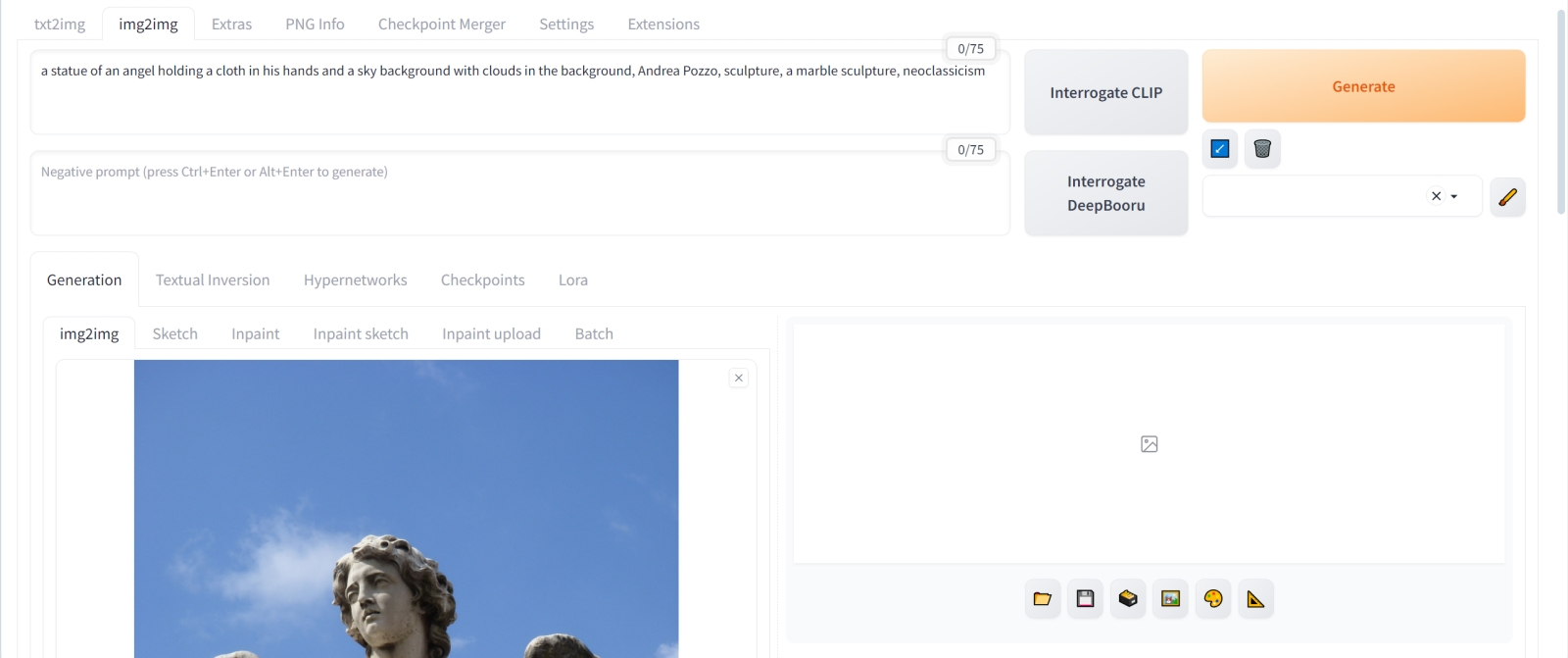 Рабочая среда AUTOMATIC1111 включает средство доступа к CLIP Interrogator — проекту с открытым кодом, комбинирующим возможности CLIP и его разработанного в Salesforce аналога BLIP для генерации описания загруженной в систему картинки. На вкладке «img2img» рядом с большой оранжевой кнопкой «Generate» имеются две серые — «Interrogate CLIP» и «Interrogate Deepbooru». Первая из них выдаёт оптимальные результаты, если применять её к реалистичным изображениям и фотоснимкам, а вторая — к рисункам в стиле манги/аниме. Ну как оптимальные… Тут всё в очень большой степени зависит от случая. 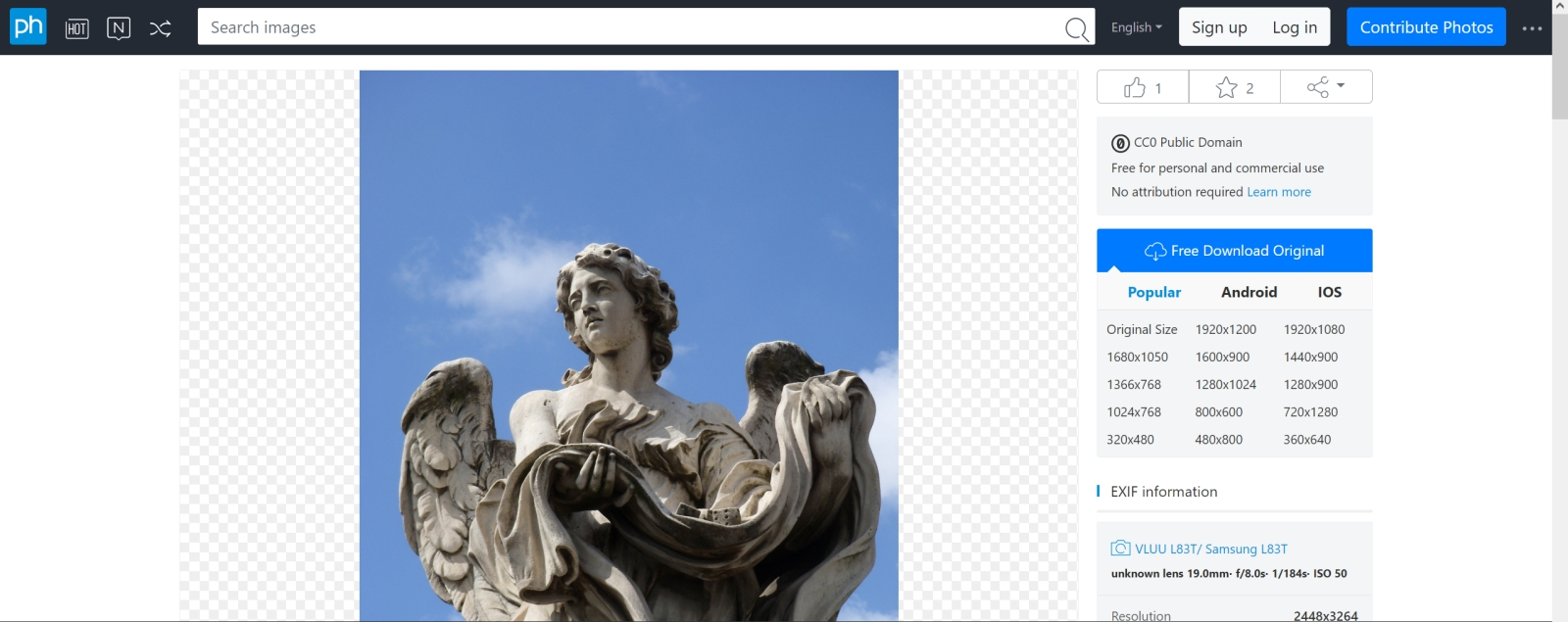
Источник: скриншот страницы сайта pxhere.com Возьмём для примера такое изображение римской статуи ангела, доступное по лицензии Creative Commons на сайте PXHere, поместим его (просто перетащив мышкой из открытой в «Проводнике» Windows папки) в соответствующее поле на вкладке «img2img» рабочей среды AUTOMATIC1111 и, ничего больше не трогая, нажмём на «Interrogate CLIP». Если эта процедура проделывается в первый раз, потребуется некоторое время на подгрузку и запуск программного кода, но в любом случае долго ждать не придётся. И вот что наша рабочая среда (в версии 1.6.0, использованной при написании настоящей «Мастерской») выдаст в итоге — в том окошке, куда обычно помещают положительную текстовую подсказку: a statue of an angel holding a cloth in his hands and a sky background with clouds in the background, Andrea Pozzo, sculpture, a marble sculpture, neoclassicism Даже не обладая сколько-нибудь солидным культурологическим багажом (т. е. не зная, что Андреа дель Поццо — крупный теоретик архитектуры, виртуоз иллюзионистической плафонной живописи, но никак не скульптор — работал в стиле римского барокко, а вовсе не неоклассицизма и что на фото представлено одно из изваяний ангелов с моста Св. Ангела через Тибр в Риме с орудиями Страстей, а именно с хитоном и игральными костями, за авторством Паоло Нальдини), можно увидеть в этой сгенерированной роботом подсказке пару стилистических огрехов — повторов значимых слов: «sky background with clouds in the background» и «sculpture, a marble sculpture». Не факт, что эти повторы ухудшат качество сгенерированного по такой подсказке изображения, — можно даже считать их машинным аналогом усиления веса конкретной фразы: скажем, там, где биологический автор написал бы «(marble sculpture:1.2)», нейросеть CLIP предлагает вариант «sculpture, a marble sculpture». Однако всё это только предположения — посмотрим, как на деле сработает составленная роботом подсказка. Перенесём полученный через «Interrogate CLIP» текст в поле позитивной подсказки на вкладке «txt2img»; в поле негативной впишем стандартную для современных разновидностей SD 1.5 минималистичную комбинацию слов: (bad quality, worst quality:1.3), nsfw, naked В качестве рабочего чекпойнта выберем модель Beautiful Art; используем стандартную VAE vae-ft-mse-840000-ema-pruned, с которой давние читатели «Мастерской» уже должны быть прекрасно знакомы. Параметр «Clip skip» оставим в позиции 1, «Sampling steps» — ну, допустим, 25, «CFG Scale» — 5, «Sampler» — DPM++ 3M SDE (он особенно быстрый; картинка целиком на нашем тестовом ПК выпекается примерно за 27 с). Размеры холста тоже вполне стандартные для SD 1.5 — 768 × 512. Запускаем генерацию… 
Источник: ИИ-генерация на основе модели SD 1.5 …и видим, что полученное, мягко говоря, не сильно соответствует оригиналу. Да, в целом это похоже на статую ангела; да, какой-то отрез ткани он явно своей левой рукой (той, что на картинке справа) придерживает, — правда, у правой руки, надо полагать, как раз в попытке отобразить ту самую ткань, от локтевого сустава отходят аж два предплечья. Облачка зато какие нежные… То есть в целом «статуя ангела на фоне неба» получилась, но мелкие, а на деле очень важные детали — лежащая на руках ткань, постановка плеч и головы, форма крыльев — не воспроизвелись. Собственно, сгенерированное через «Interrogate CLIP» описание их и не содержало, — удивляться тут нечему. Желающие могут запустить AUTOMATIC1111 в режиме «Generate forever» со случайным перебором затравок — результат останется примерно тем же (в ходе подготовки настоящей статьи было сгенерировано под сотню изображений — и, поверьте, приведённое выше ещё не самое удручающее). ⇡#Оживляем статуюЕсть, правда, один нюанс: как бы хороша ни была нейросеть CLIP, в варианте, интегрированном в AUTOMATIC1111, исполняется она на довольно скромном локальном «железе» (напомним, на нашем тестовом ПК установлена видеокарта GeForce GTX 1070 с 8 Гбайт памяти) сравнительно быстро — а следовательно, значительной глубиной проникновения в образ явно не отличается. Но есть ведь на свете генеративные текстовые модели с куда более обширными возможностями — та же GPT-4. В сообществе ИИ-энтузиастов давно уже распространена практика использования умных чат-ботов для генерации подсказок, которые затем скармливаются ИИ-рисовальщикам вроде DALL-E 3 или Midjourney. И хотя доступ к такого рода ботам (особенно из России, особенно в отсутствие простых и удобных способов оплаты подписки для активации расширенных возможностей) может быть для многих затруднён или вовсе ограничен, в Сети есть открытые проекты со схожей функциональностью — например, LLaVA: Large Language and Vision Assistant. 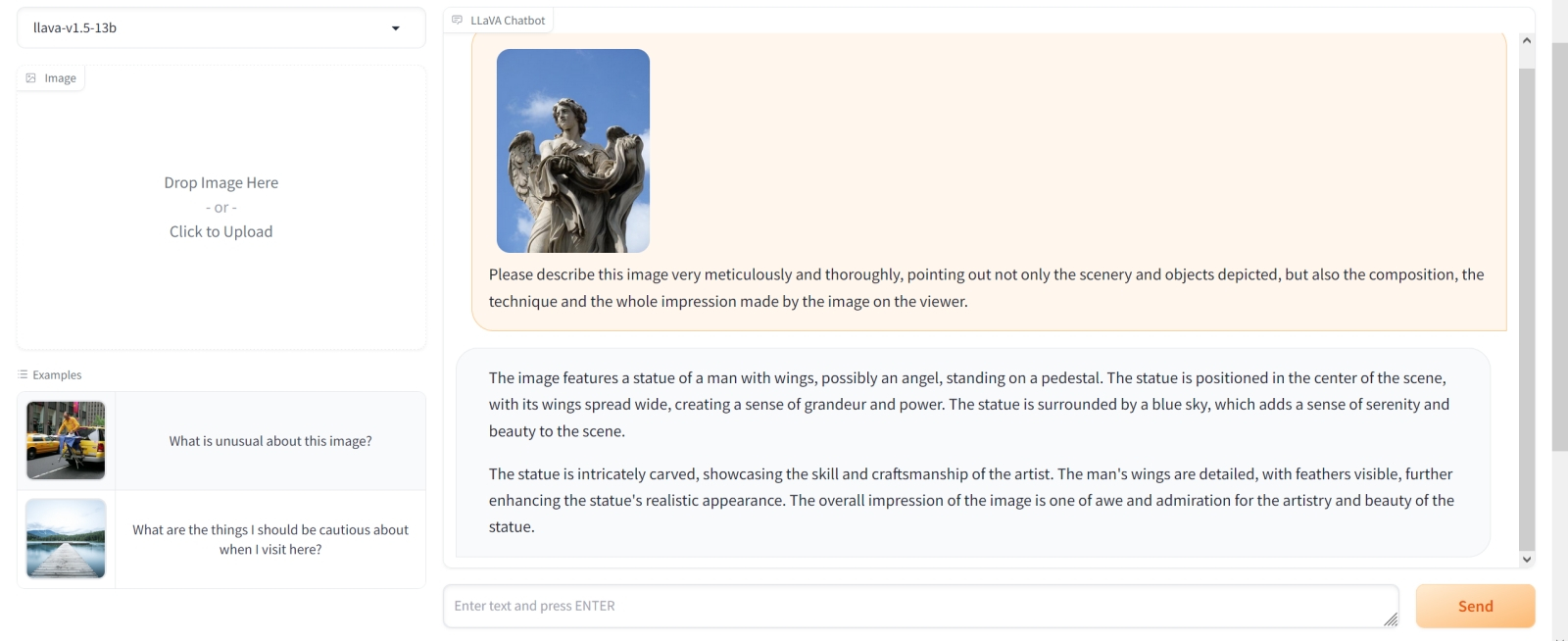
Источник: скриншот страницы сайта llava.hliu.cc Слева на интерфейсной странице LLaVA имеется окошко для загрузки изображений; чуть ниже центра экрана — поле для ввода текстовых запросов. Поместим исходное фото статуи работы Паоло Нальдини в окошко, а в поле ввода попросим умного бота описать эту картинку — с предельной дотошностью и не упуская ни малейшей детали: Please describe this image very meticulously and thoroughly, pointing out not only the scenery and objects depicted, but also the composition, the technique and the whole impression made by the image on the viewer. Ответ был получен такой: The image features a statue of a man with wings, possibly an angel, standing on a pedestal. The statue is positioned in the center of the scene, with its wings spread wide, creating a sense of grandeur and power. The statue is surrounded by a blue sky, which adds a sense of serenity and beauty to the scene. The statue is intricately carved, showcasing the skill and craftsmanship of the artist. The man's wings are detailed, with feathers visible, further enhancing the statue's realistic appearance. The overall impression of the image is one of awe and admiration for the artistry and beauty of the statue. Тут сразу заметны разительные отличия от подсказки, выданной ранее «Interrogate CLIP». Во-первых, язык изложения явно человеческий, что для современных чекпойнтов, в особенности SDXL, совершенно нормально, — с такими вводными они справляются блестяще. Во-вторых, LLaVA и впрямь корректно описала композицию снимка, даже производимое ею впечатление передала словами, — вот только про ткань на руках ангела тоже не упомянула. В результате, если прямо скопировать полученные два абзаца в поле текстового ввода и загрузить одну из популярных моделей Stable Diffusion (лучше — в версии SDXL 1.0), получится чрезвычайно впечатляющее изображение статуи ангела — вот только без наиболее характерного для оригинала признака. 
Адекватные библейскому описанию (книге пророка Иезекииля в данном случае) ангелы с гравюры XIX века (источник: Wikimedia Commons) Выходит, придётся всё же задействовать биологический мозг и скомбинировать обе подсказки, взяв из каждой то, чем она хороша, — и дополнив полученное рядом знакомых энтузиастам ИИ-рисования «волшебных слов», благодаря которым генерация с чекпойнтами SD 1.5, как правило, выходит более привлекательной, чем без их использования. Остановимся именно на «полуторке», поскольку SDXL на нашем тестовом компьютере исполняется крайне неторопливо: каждая итерация (тот самый «шаг», число которых задаёт параметр «Sampling steps») занимает 3,5-3,8 с, тогда как для SD 1.5 — чуть более одной. Да, и ещё один момент: от статуй имеет смысл перейти к людям — точнее, к реалистичному (не в библейском смысле, конечно, а в художественном) изображению ангелов: очевидно ведь, что в тренировочном массиве пар «картинка — её текстовое описание» фотоснимков людей было куда больше, чем скульптур. А значит, и результат генерации должен чаще выходить более приемлемым в эстетическом смысле. И уже потом, если придётся, превратить фигуру человека в мраморную статую на картинке не так уж трудно — есть для этого соответствующие инструменты. Испробуем вот такую комбинированную и расширенную подсказку: close-up, cinematic film still of a beautiful angel with large wings spread wide holding a flowing cloth in both arms, white and gold intricate robe, surrounded by a vast blue sky, wind blowing, intricately detailed feathers, waving thick blonde hair, awe and admiration inspiring, creating a sense of grandeur and power, BREAK elaborate atmosphere, sophisticated background, perfect illumination, fractal textures, rich shadows, sharp focus, particle effects, highly aesthetic appeal, storytelling elements, subject-background isolation, epic fantasy, National Geograhpic photo masterpiece А в поле негативной впишем backlight, verybadimagenegative_v1.3, negative_hand-neg, nsfw, nakedб dark brows, wide brows Здесь использованы текстовые инверсии verybadimagenegative_v1.3 и negative_hand-neg; о том, как их скачивать и куда размещать, мы говорили в прежних «Мастерских» не раз — например, тут. Отдельного упоминания брови заслужили по той причине, что, раз уж мы собираемся генерировать светловолосого ангела, логично предположить, что косметикой он(а) не пользуется, — а Stable Diffusion по какой-то причине (надо полагать, обучающая выборка такая) упорно генерирует блондинок почти исключительно с широкими, чёрными как уголь бровями; «соболиными», если использовать былинную терминологию. Параметры генерации оставим ровно те же, что и в первом случае, — и вот что у нас получится (значение затравки — 3040031144): 
Источник: ИИ-генерация на основе модели SD 1.5 Увы, и здесь ткань — даром что струящаяся, как и было упомянуто в подсказке, — на руках не лежит. Но, как выяснилось, такого рода композиция — настоящий камень преткновения по крайней мере для данной конкретной комбинации чекпойнта и набора параметров генерации. Примерно после 300-й попытки мы перестали надеяться выловить из бездн латентного пространства соответствующее оригиналу взаимное расположение рук и ткани, но только потому, что заранее знали, каким образом преодолеть это узкое место. Тут нам поможет ControlNet — и об этом подлинно мощном инструменте укрощения стохастической натуры Stable Diffusion речь пойдёт несколько позже. А пока поработаем с тем, что есть: ИИ-художникам куда чаще, чем хотелось бы, приходится по одёжке протягивать ножки. 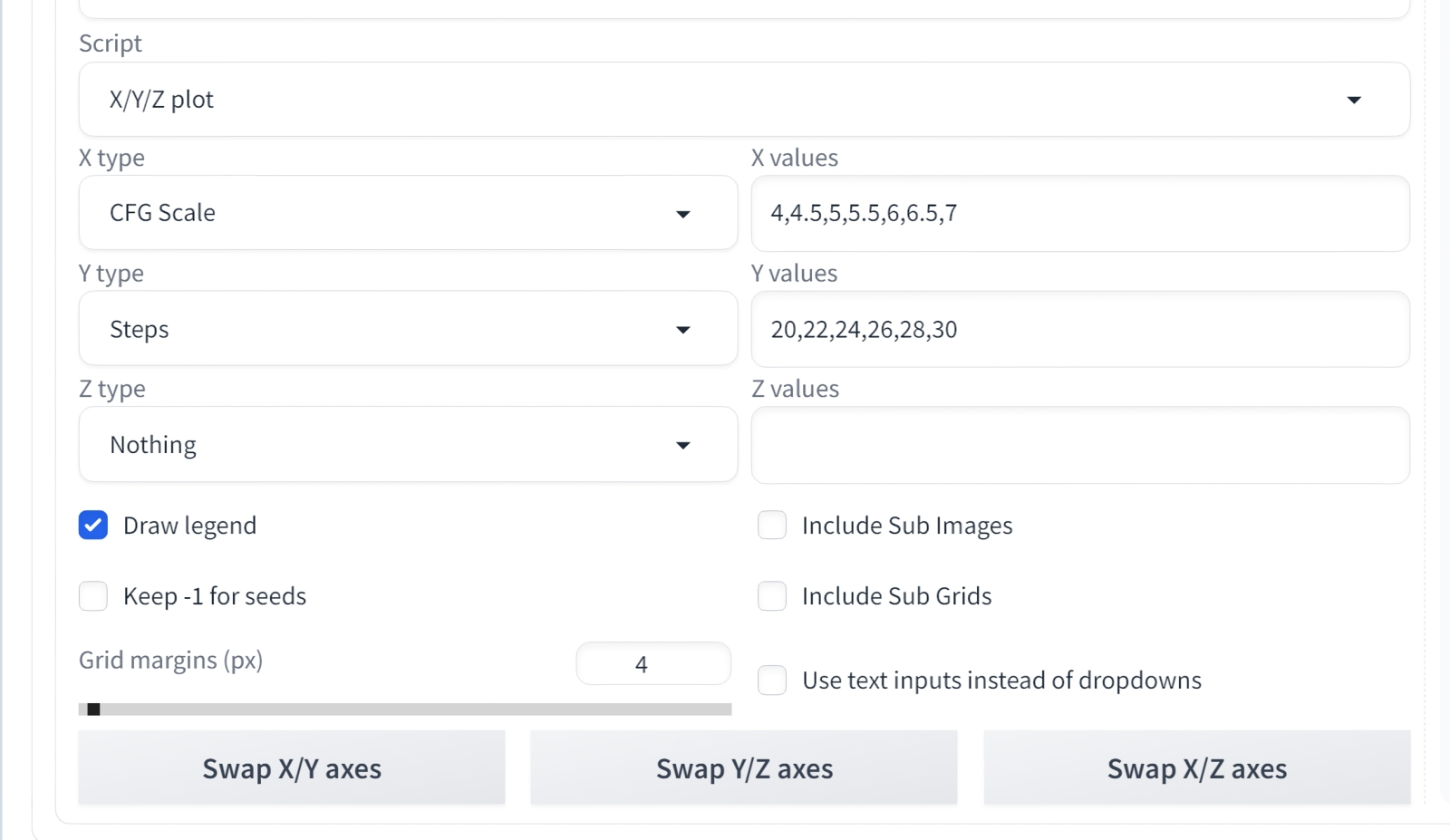 Возьмём полученную картинку с затравкой 3040031144 за отправную точку — и попробуем подобрать оптимальное с эстетической точки зрения соотношение Steps и CFG. Для этого пригодится встроенный в AUTOMATIC1111 скрипт «X/Y/Z plot» (подробно мы разбирали технику его применения в прошлой «Мастерской») со следующими параметрами: CFG Scale — 4,4.5,5,5.5,6,6.5,7 Steps — 20,22,24,26,28,30 
Источник: ИИ-генерация на основе модели SD 1.5 После исполнения «X/Y/Z plot» в соответствующем каталоге (в нашем случае — C:\Fun-n-Games\Git\stable-diffusion-webui\outputs\txt2img-grids) появится сводная таблица полученных изображений. Явного победителя нокаутом в ней вроде как нет (зато правый верхний угол очевидно отсекается знакомым читателям прежней статьи «клином адекватности»), но по очкам — и бровям! — можно считать выигравшей вот эту, с числом шагов 24 и CFG = 5.0: 
Источник: ИИ-генерация на основе модели SD 1.5 С ней и примемся работать дальше. ⇡#Шум бывает и по делуВ пятом выпуске «Мастерской» по ИИ-рисованию мы кратко упоминали инструмент «Hires. fix», реализованный на вкладке «txt2img» AUTOMATIC1111 в виде выпадающего меню под полями текстовых подсказок. Это, по сути, удобно встроенный в процесс первичной генерации картинки апскейлер: средство увеличить изображение не просто без потери чёткости, но с её повышением и даже с дополнительной детализацией. Прямой аналог использования «Hires. fix» одновременно с первичным преобразованием текста в картинку — переправка вручную полученной изначально первичной выдачи на вкладку «img2img» и масштабирование её уже там. Зачем дублировать в составе рабочей среды один и тот же инструмент? Ведь качество деталей на исходных некрупных изображениях, генерируемых чекпойнтами SD 1.5, заведомо не слишком высоко. И, как показывает практика наших попыток заставить извлекаемого из латентного пространства ангела взять на руки отрез ткани, желаемая автором подсказки композиция гораздо чаще, чем хотелось бы, не выходит с первого раза — если вообще выходит. Соответственно, нет смысла апскейлить картинку, изначально скомпонованную не так, как задумал её оператор. Немалую роль играет и фактор времени/ресурсов: если изображение размерами 768 × 512 точек на компьютере с GeForce 1070 8 Гбайт создаётся со скоростью около 1,1 с на каждую итерацию (на каждый шаг из заданных параметром «Sampling steps»), то с применением «Hires. fix» для удвоения картинки по обеим сторонам (1536 × 1024) это время вырастает примерно до 6,5 с на итерацию. 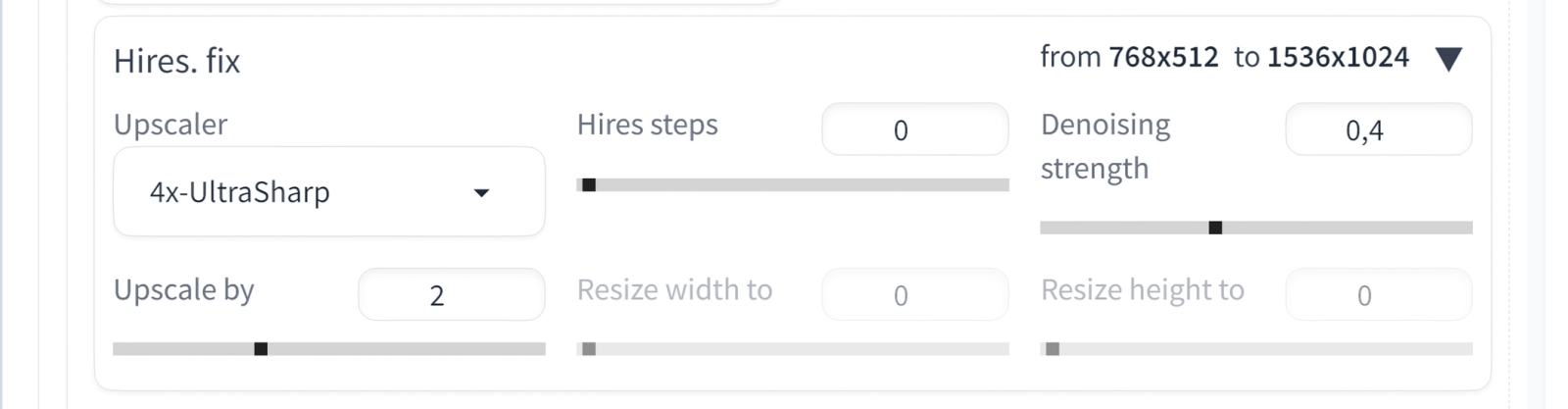
Однако в данном конкретном случае, когда найдено подходящее сочетание затравки и текстовых подсказок, есть смысл ещё раз запустить генерацию той же самой картинки на вкладке «txt2img», но уже с активированным «Hires. fix»: здесь присутствие инструмента апскейлинга прямо под рукой поистине бесценно — с учётом того, что мы собираемся проделывать с полученным изображением дальше на этой же вкладке, без перехода на «img2img». Раскроем это выпадающее меню и оставим без изменения заданные по умолчанию параметры «Denoising strength» — 0,7 – и «Upscale by» — 2. В качестве действующего алгоритма апскейлинга, «Upscaler», выберем «4x-UltraSharp». Штатно он в базовой конфигурации AUTOMATIC1111 не реализован, однако у тех, кто вместе с нами осваивал третью часть «Мастерской» по ИИ-рисованию, этот инструмент уже должен быть установлен, — процедура там довольно несложная. 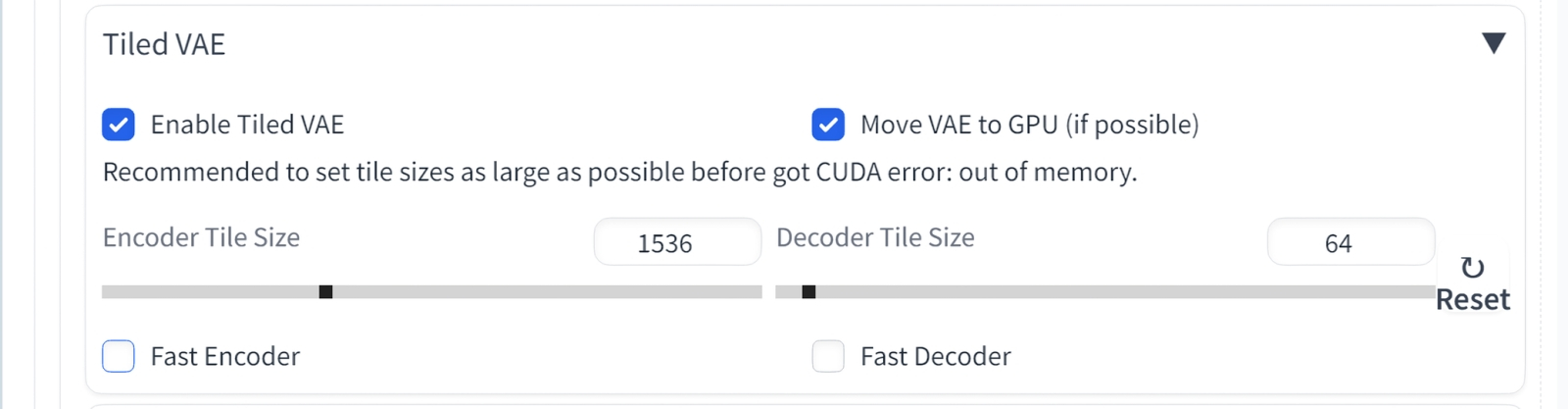 И ещё один момент: на данном этапе непременно стоит активировать ещё одним выпадающим меню, а в дальнейшем постоянно держать включённым средство фрагментации постобработки генерируемого ИИ изображения — «Tiled VAE». Оно входит в состав инструмента Tiled Diffusion & VAE (он же Multidiffusion Upscaler), о котором также шла речь в третьей части наших ИИзобразительных штудий. Чем крупнее картинка, тем больше требуется видеопамяти для загрузки её целиком, и вся суть Tiled Diffusion & VAE — в наделении рабочей среды способностью производить адекватную обработку цельных изображений, разбивая их на фрагменты (tiles) и оперируя с каждым по отдельности. Графический адаптер с 8 Гбайт видеоОЗУ справляется с картинкой размерами 1536 × 1024 уже на пределе возможностей — не стоит обременять его излишней нагрузкой, если есть средство этого счастливо избежать. 
Источник: ИИ-генерация на основе модели SD 1.5 Ну что же, улучшение однозначно есть — но изменения по сравнению с первоначальной генерацией очень серьёзные! И понятно почему: установленный по умолчанию параметр «Denoising strength = 0.7» подразумевает чрезвычайно сильное воздействие на исходную картинку. Эстетическая привлекательность изображения повысилась (субъективно, по крайней мере; даже пальцев на руках теперь ровно десять — правда, лишь в сумме), но за счёт довольно ощутимого отхода от той композиции, за которую, собственно, затравка 3040031144 была признана оптимальной и взята за основу для дальнейшей работы. Значит, следует подобрать такие параметры апскейлинга, с которыми соответствие увеличиваемой картинки исходному образцу было бы лучше — не в ущерб повышению эстетической привлекательности, ясное дело. Здесь нам снова придёт на помощь полезнейший скрипт «X/Y/Z plot», но для начала в интерфейс рабочей среды потребуется внести очередное изменение, — небольшое, но архиважное. На официальной странице AUTOMATIC1111, в довольно детальной сводке её возможностей, после выхода версии 1.6.0 появилось описание опции «Extra noise», позволяющей, по сути, имитировать работу связки «базовая модель + доводчик» SDXL для чекпойнтов SD 1.5. Суть такова: Stable Diffusion выдаёт привлекательную для человеческого глаза, условно «гладкую» картинку, отталкиваясь от прямоугольника, заполненного стохастическим шумом — точками со случайно заданными цветовыми характеристиками. Чтобы доводчик срабатывал эффективнее, то есть чтобы и на его долю досталось вдоволь стохастики, на выходе базовой модели формируется не полностью «гладкая», но с остатками исходного шума картинка, — об этом мы говорили подробнее, рассказывая о приручении макаронного монстра ComfyUI и о всемирно-исторической роли модели доводчика.  Рабочая же среда AUTOMATIC1111 изначально не имела средств передавать между моделями — например, переходя от первичной генерации к апскейлингу — изображения с остаточными шумами (если совсем точно, то имела, но крайне скудные и кривовато имплементированные). И вот теперь такое средство, вполне адекватное, появилось: в настройках («Settings»), в разделе «img2img», отныне есть строчка «Extra noise multiplier for img2img and hires fix», где по умолчанию установлено значение «0». Можно каждый раз заглядывать туда, чтобы контролировать или менять это значение, но гораздо проще вывести орган управления им в верхнюю часть главного интерфейса — туда, где у нас располагаются выпадающие меню выбора чекпойнта, модели VAE и ползунок «Clip skip». Для этого потребуется зайти в «Settings — User interface» и в поле «Quicksettings list», где уже перечислены три упомянутых параметра, добавить четвёртый — «img2img_extra_noise». После активации изменений нажатием соответствующей кнопки здесь же, в настройках, и перезагрузки интерфейса справа от ползунка «Clip skip» появится ещё один — «Extra noise multiplyer for img2img and hires fix». Да, одно и то же значение добавочной зашумлённости будет прилагаться и к автоматическому апскейлу при использовании «Hires. fix», и к ручному — в ходе постобработки готовых картинок во вкладке «img2img». 
Источник: ИИ-генерация на основе модели SD 1.5 Чтобы разобраться, какой именно уровень добавочной зашумлённости нам нужен, а заодно уточнить приемлемое значение денойзинга в ходе апскейла через «Hires. fix», снова прибегнем к скрипту «X/Y/Z plot» — уже с такими параметрами: Denoising — 0.2,0.3,0.4,0.5,0.6 Extra noise — 0.08,0.12,0.16,0.2 Заметьте, как интересно: лицо ангелочка остаётся практически неизменным при всех выбранных сочетаниях уровней зашумлённости, зато конфигурация кистей рук ощутимо меняется, как и многие прочие детали. Заметен явный клин адекватности в левом нижнем углу, зримо проявляющийся яркими пятнами на затенённых участках крыльев. Очевидно, что при низком параметре «Denoising» в сочетании с высоким «Extra noise» добавляемых деталей оказывается чрезмерно много, — и картинка принимается, по сути, рассыпаться на разрозненные пикселы. 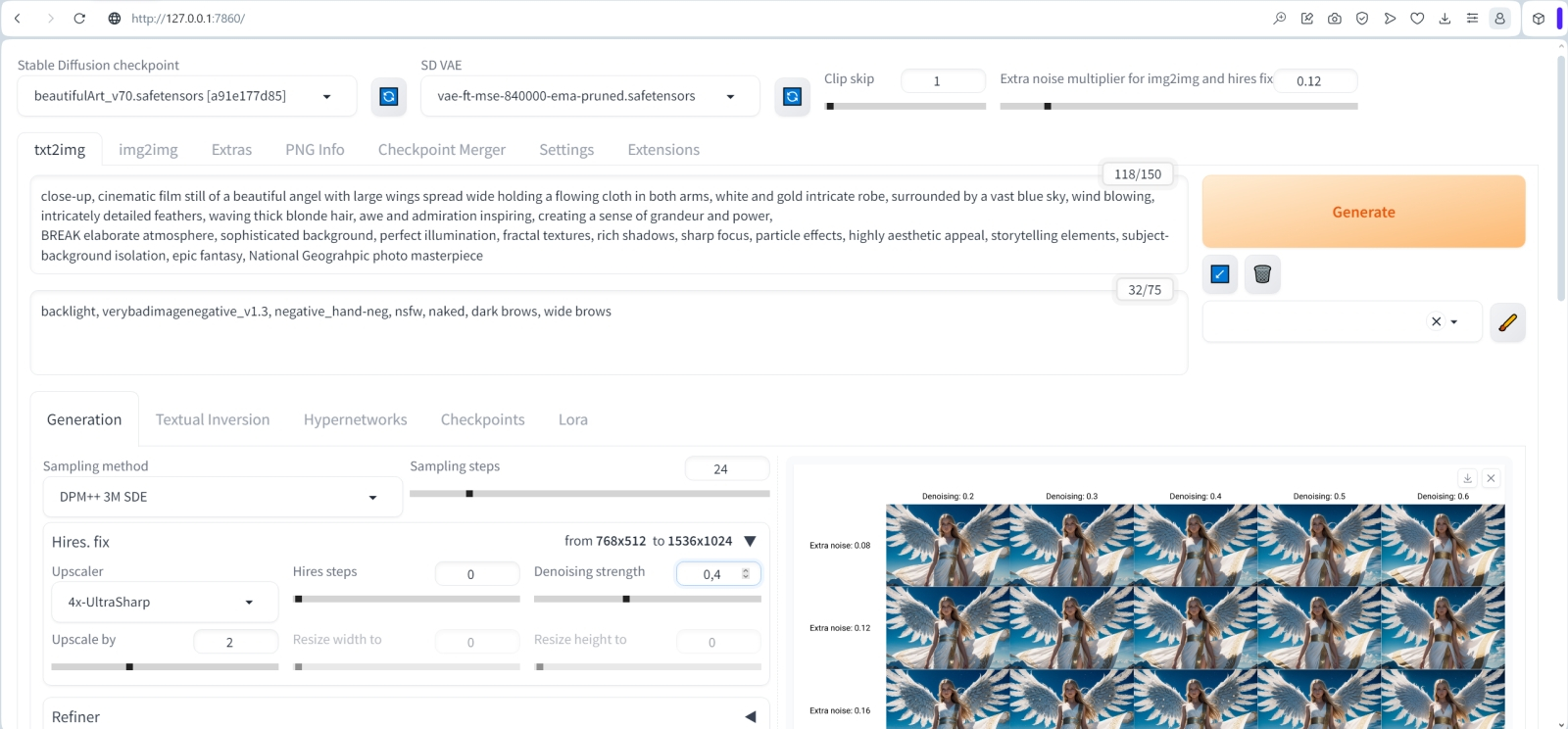 Для дальнейшей работы остановимся на комбинации «Denoising = 0.4» и «Extra noise = 0.12»: тут и дополнительных деталей в достатке, но не слишком, и бляха на поясе-перевязи появилась красивая. Сдвигаем соответствующие ползунки в верхней части интерфейса на эти позиции — «Denoising strength» в 0,4, а «Extra noise multiplier for img2img and hires fix» — в 0,12. И возьмёмся теперь за объектовую, что называется, детализацию: есть, оказывается, в арсенале ИИ-художников особые средства для выборочного автоматического улучшения качества самых, наверное, проблемных элементов создаваемых генеративными моделями картинок — человеческих лиц и кистей рук. ⇡#Результат налицоИнструмент для ручного повышения эстетической привлекательности двух этих категорий элементов мы рассматривали ещё на страницах второй «Мастерской» по ИИ-рисованию — это средство «Inpainting» на вкладке «img2img». Последовательность работы там, напомним, простая: выделить подлежащую изменению область картинки и заставить систему перерисовать именно её, оставляя всё прочее в неизменности. При формальной простоте операций занятие это довольно муторное, особенно если на картинке не один человек, а группа и подправлять лица/кисти необходимо всем и каждому, потому что выловленная по чистой случайности из латентного пространства композиция вышла настолько удачной, что отбрасывать её не хочется, а художественных навыков для ручного исправления ситуации в GIMP или Photoshop недостаточно. 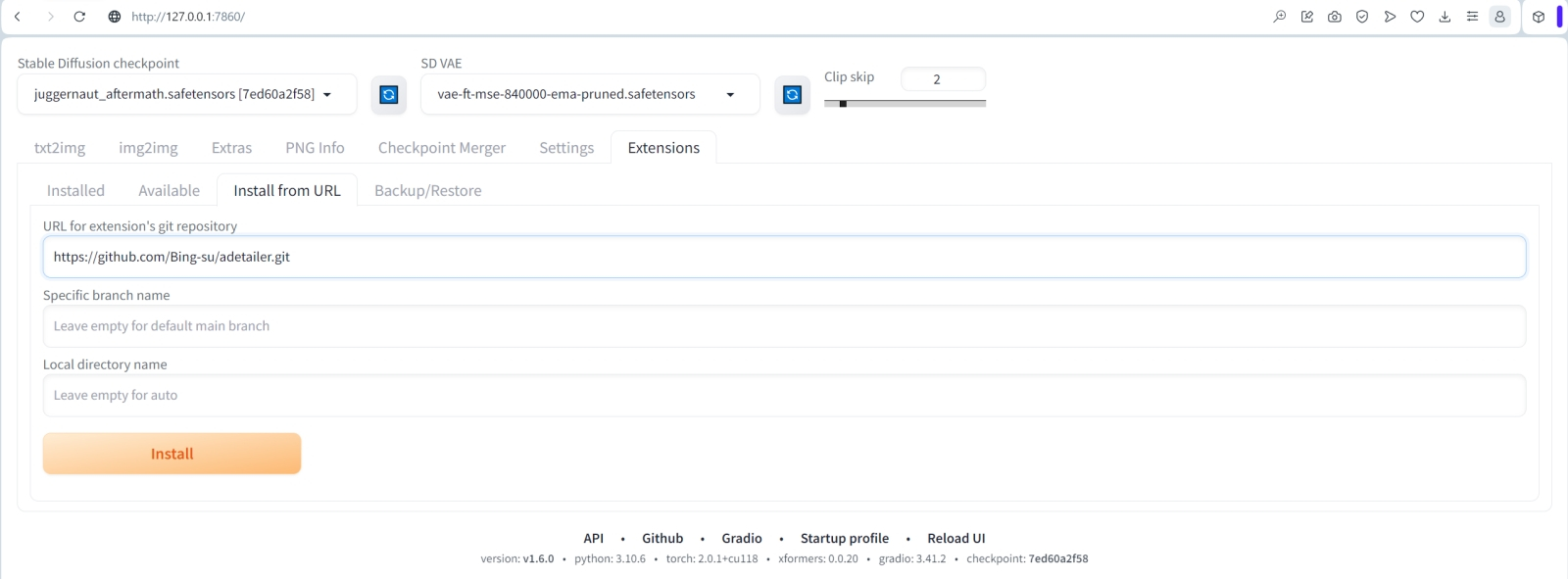 К счастью, нашёлся в сообществе энтузиастов ИИ-рисования выдающийся аноним под ником Bing-Su, разработавший инструмент ADetailer — он же !After Detailer, — который как раз и позволяет автоматизировать процесс эстетической коррекции лиц и кистей рук (а также человеческих фигур целиком — и не только; список плагинов к нему непрерывно растёт). ADetailer сам находит на готовом изображении подлежащие исправлению элементы и сам же, в соответствии с заданными параметрами, нужным образом их меняет: автоматически определяет границы области, накладывает маску, производит новую генерацию и пр. Да, это не волшебная палочка, но по сочетанию скорости работы и адекватности вносимых исправлений он на голову превосходит любого начинающего ИИ-художника, один на один сражающегося с масками и весами денойзинга в разделе «Inpainting». Установить ADetailer немногим сложнее, чем 4x-UltraSharp: во вкладке «Extensions» нужно выбрать опцию «Install from URL» и ввести в соответствующее поле адрес домашней странички проекта — https://github.com/Bing-su/adetailer.git. После чего остаётся нажать на кнопку «Install», а когда появится сообщение об успешном окончании процесса, переключиться на подвкладку «Installed», там нажать на «Check for updates», а затем на «Apply and restart UI». Для полной гарантии имеет смысл перезапустить не только веб-интерфейс, но и сервер AUTOMATIC1111 полностью. И тогда во вкладке «Extensions» точно появится ссылка на «!After Detailer», что позволит дальнейшую инсталляцию производить привычным путём, нажатием на кнопку «Install». После перезапуска сервера и веб-интерфейса параметры генерации картинки с ангелом, которые мы с таким трудом подбирали, проще всего окажется восстановить, затянув эту самую картинку через вкладку «PNG Info» — и переправив затем оттуда нужную информацию на «txt2img». 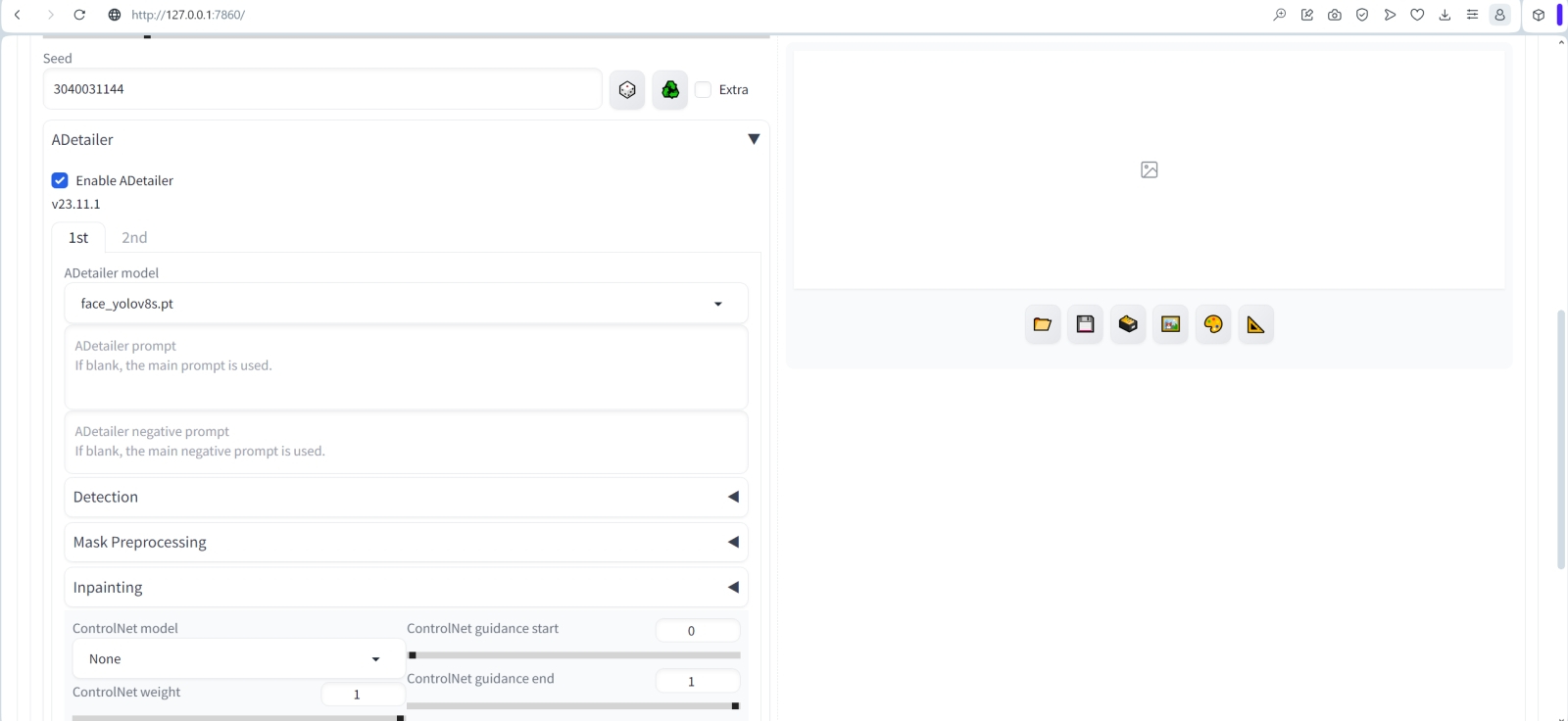 Управление ADetailer производится через появившееся в основном интерфейсе новое выпадающее меню. Параметров там множество (включая дополнительные подменю), но на первых порах достаточно будет поставить галочку в поле «Enable ADetailer», во вкладке «1st» выбрать модель для исправления лиц «face_yolov8s.pt» (обратите внимание: там есть ещё одна, с названием «face_yolov8n.pt», — та исполняется быстрее, но у выбранной нами результаты в среднем более удовлетворительные), а во вкладке «2nd» — «hand_yolov8n.pt». Поля подсказок оставляем пустыми: это значит, что использоваться будут общие для всей картинки — и позитивная, и негативная. Убедимся также, что средство «Tiled VAE» — выпадающее меню ближе к концу интерфейсной страницы — активировано с прежними параметрами. Запустим генерацию. 
Источник: ИИ-генерация на основе модели SD 1.5 Ну вот, совсем неплохо! Кисти рук практически не изменились — они и изначально были вполне сносными. Зато лицо после обработки ADetailer’ом стало куда как живее! Если вам кажется, что овчинка в данном случае не стоила выделки и что ADetailer — не такое уж большое дело, то вот пример посложнее: когда фигура занимает меньше места на исходной картинке размерами 768 × 512 точек, и из-за этого лица, а тем более кисти рук на ней выходят совсем крохотными и потому гипернедодетализированными. После увеличения через «Hires. fix» кривоватые лица и кисти чаще всего не становятся эстетически привлекательнее, но как быть, если композиция настолько хороша, что терять её не хочется? Вот тут без ADetailer не обойтись. Отвлечёмся ненадолго от ангелов и запустим генерацию картинок с такой нарочито несложной позитивной подсказкой — An epic fantasy book cover featuring two medieval fantasy armies fighting each other, <lora:add_detail:1>, <lora:epiCRealismHelper:1> и ещё более краткой негативной — verybadimagenegative_v1.3, nsfw, naked 
Источник: ИИ-генерация на основе модели SD 1.5 Вот такая не просто динамичная, а явно содержащая глубокую внутреннюю историю картинка появилась с затравкой 1485219098. Кто эти юные воительницы? Подсаживает та, что с кривым двуручником за спиной, другую на коня, помогая скрыться, — или, напротив, пытается помешать её бегству? Из-за чего весь сыр-бор с тяжёлыми латниками на улицах и полыхающим богатым домом или таверной в городской черте (это явно не замок, судя по разрозненным строениям слева)? Взявшись раскручивать случайно выловленное в латентном пространстве изображение, можно создать неплохую историю — уж точно не хуже тех, что во множестве издаются в наши дни на цифровой книжной платформе Amazon, будучи написанными чат-ботами — либо целиком, либо с очень солидным их участием. И всё же, поскольку SD 1.5 генерирует картинки невысокого разрешения, лица героинь нашей потенциальной фэнтезийной саги прорисованы, мягко говоря, не слишком отчётливо. В этой ситуации сочетание Hires. fix и ADetailer попросту незаменимо. Применим же его, сохранив во вкладке «txt2img» все параметры генерации, включая «Seed», и активировав три дополнительных выпадающих меню: собственно «Hires. fix» и «ADetailer», а также непременное для более крупных, чем 768 × 768 точек на нашем тестовом компьютере, «Tiled VAE». Причём, поскольку за один проход ADetailer позволяет улучшать максимум две категории объектов, зададим в подвкладке «1st» person_yolov8s-seg.pt — для человеческих фигур целиком, — а в «2nd» пропишем уже знакомый корректор физиономий face_yolov8s.pt. 
Источник: ИИ-генерация на основе модели SD 1.5 А вот и результат. Уже существенно лучше — разве что кисти рук традиционно подкачали, что, впрочем, дело совершенно обычное для SD 1.5 (да и в SDXL встречается куда чаще, чем хотелось бы). Как с этим справляться? Один вариант — добавить в негативную подсказку текстовую инверсию negative_hand-neg и поиграть с её весом, добиваясь того, чтобы и кисти вышли более удачными, и общее влияние дополнительного параметра на композицию не оказалось бы чрезмерным. Увы, чаще всего такой подход не срабатывает: уж слишком непредсказуемо воздействие любых изменений в подсказках на итоговый результат. Живой пример: внимательный читатель мог заметить, что в позитивной подсказке, использованной для генерации нашего модельного ангела, допущена досадная опечатка — «Geograhpic» вместо «Geographic». Казалось бы, всего-то две соседние буквы поменялись местами, да ещё ближе к концу, где относительная значимость слов сама по себе низка, — ничто не изменится, если исправить всё как надо! А вот и нет: картинка ровно с теми же самыми параметрами, только с корректно написанным названием журнала, по настроению (по выражению лица ангела главным образом) кардинально отличается от той, которую мы выбрали для дальнейшей работы, — выбрали именно за её эстетическую привлекательность. Очевидно, коронная фраза известного на Западе художника и популяризатора живописи Боба Росса (Bob Ross) «Мы не совершаем ошибок, лишь допускаем удачные маленькие огрехи» (We don't make mistakes, just happy little accidents) приложима и к ИИ-художествам тоже. 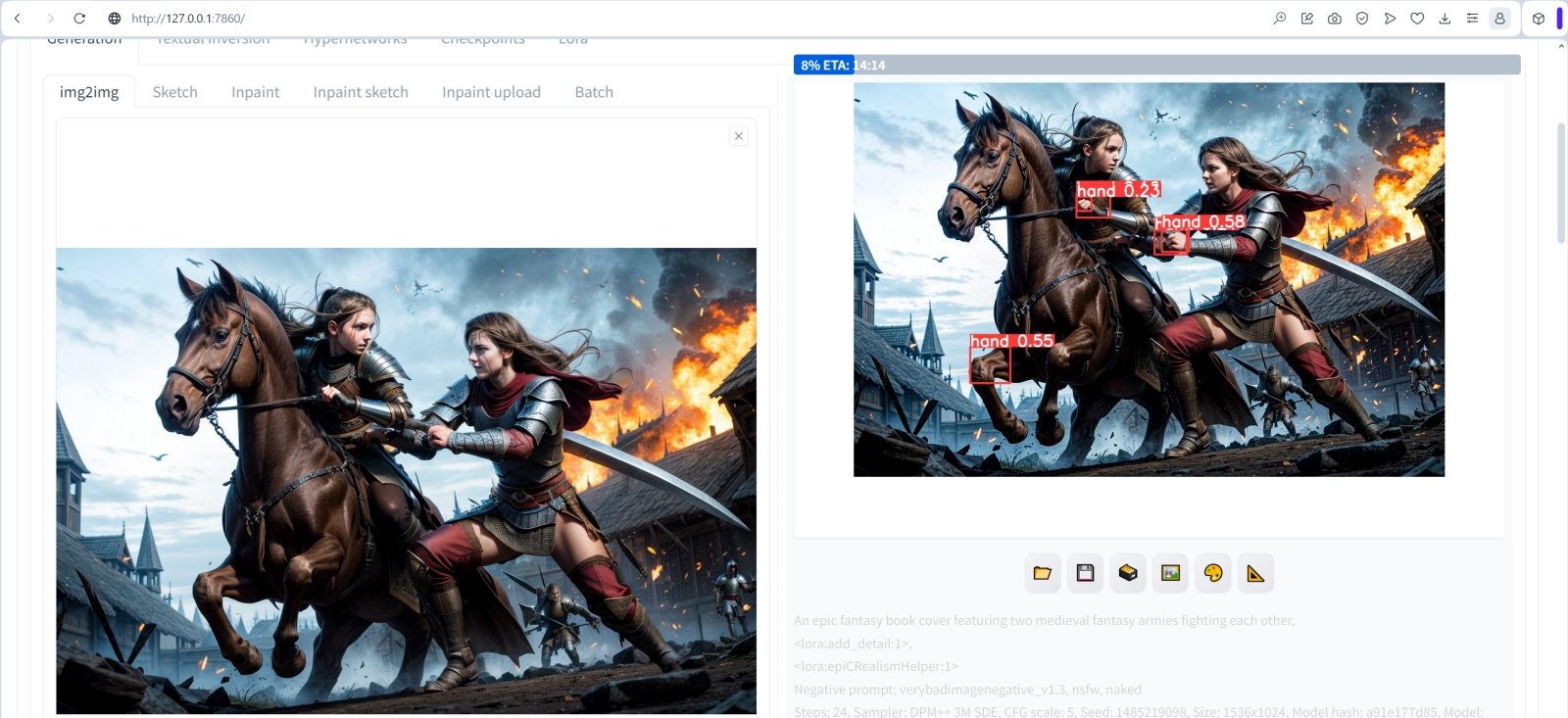 Так вот, для тех энтузиастов генеративного искусственного рисования, которым, как автору этих строк, в детстве медведь на руки наступил и которые не в силах открыть GIMP и доступными биологическому художнику инструментами исправить проблемы с кистями, остаётся другой вариант: задействовать ADetailer ещё раз — но теперь уже во вкладке «img2img». Перенесём туда нашу картинку сразу после только что произведённого апскейла с улучшениями через инструмент трансфера (иконка с картиной, изображающей пиксельный пейзаж, прямо под окошком выдачи готовых изображений на вкладке «txt2img») либо же через «PNG Info». Выставим затем «Extra noise multiplier for img2img and hires fix» в 0, а «Denoising strength» — в 0,05: нам в данном случае не нужно, чтобы что-то в картинке сколько-нибудь заметно менялось; вдобавок увеличения-то никакого не будет — параметры «Resize to» финальных размеров мы оставляем прежними: 1536 × 1024 точки. Убеждаемся, что «Tiled VAE» активно с прежними параметрами, и выберем во вкладке «1st» выпадающего меню ADetailer скрипт улучшения кистей рук, «hand_yolov8n.pt» (во вкладке «2nd», соответственно, остаётся «None»). Дальше в выпадающем подменю «Detection» снизим значение «Detection model confidence threshold» до 0,20 (иначе держащая удила рука верховой девушки не воспринимается в данном случае системой как кисть), а «Inpaint denoising strength» внутри меню «Inpainting» увеличим до 0,55. 
Источник: ИИ-генерация на основе модели SD 1.5 В целом вышло очень даже неплохо. Да, пальцев на левой кисти мечницы явно недостаёт, но это как раз не слишком сложно исправить в графическом редакторе (скопировать удачно перерисованный ADetailer’ом палец, захватив его инструментом «лассо», развернуть и расположить как надо). Более того, отсутствие пальца само по себе может иметь смысл с точки зрения придумываемой по этой картинке истории. Другое дело, что ADetailer принял за кисть одно из колен лошади, — но тут ничто не мешает либо вырезать нужную часть предыдущей картинки и заменить ею это ненужное исправление, либо просто закрыть на него глаза. Вернёмся теперь к многострадальному ангелу работы Паоло Нальдини — и наконец-то заставим Stable Diffusion вплотную приблизиться к воспроизведению заданной скульптором композиции. С непременным элементом творческого переосмысления, конечно, — иначе зачем вообще огород городить? ⇡#Всё под контролемОдно из безусловных достоинств нейросетей — чрезвычайная гибкость, с которой те комбинируются: когда одна подхватывает выдаваемый другой результат — и улучшает его; по крайней мере, делает более привлекательным в глазах оценивающего работу всей системы оператора. Так, дополнения LoRA разнообразят, стилизуют и иными способами меняют к лучшему генерации Stable Diffusion; доводчик SDXL совершенствует плоды трудов базового чекпойнта; ADetailer фрагментарно повышает качество преобразования основной моделью текста в картинку. ControlNet — тоже дополнительная нейросеть, позволяющая SD-системе генерировать образы по предварительно заданному шаблону. Каким именно образом заданному — вопрос отдельный, но смысл именно в этом: беря за образец некую стороннюю картинку — неважно, фотоснимок это реального объекта или сцены, живописный пейзаж, набросанный вручную эскиз, другая ИИ-генерация — ControlNet заставляет SD-модель вносить немалую долю упорядоченности в свою работу, воспроизводя в итоге те или иные особенности шаблона. Например — указанное им взаимное расположение объектов, их формы и сравнительные масштабы, цветовую гамму, человеческие позы и т. п. 
Источник: ИИ-генерация на основе модели SD 1.5 Возможности ControlNet, особенно в его наиболее свежей редакции 1.1, поистине масштабны, но осваивать их имеет смысл с азов — как раз с воспроизведения заданной графическим образом фигуры. Начнём, разумеется, с инсталляции: на вкладке «Extensions» выберем раздел «Install from URL», и там в соответствующем поле введём адрес базового репозитория ControlNet — https://github.com/Mikubill/sd-webui-controlnet. Затем потребуется нажать на кнопку «Install», дождаться завершения установки, после чего не только перезагрузить веб-интерфейс AUTOMATIC1111, но и остановить его сервер — нажав комбинацию клавиш «Ctrl» + «С» в его активном окне и подтвердив выход из системы вводом «y». 
Источник: скриншот страницы сайта huggingface.co Сразу же запускать систему пока не нужно: сперва из хранилища алгоритмов https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main (да, в составе этой нейросети целое множество алгоритмов на самые разные случаи, и список их регулярно пополняется) понадобится скачать нужные для дальнейшей работы, причём как сами алгоритмические модели на языке Python (расширения .pth), так и их конфигурационные .yaml-файлы. Типичный размер одной .pth-модели ControlNet — около 1,5 Гбайт, так что, возможно, на первых порах стоит ограничиться лишь тремя наиболее ходовыми: canny (модель и конфигуратор), openpose (модель и конфигуратор) и depth (модель и конфигуратор). Закачанные файлы, все шесть, помещаем в специально предназначенный для них каталог внутри основной папки AUTOMATIC1111 — stable-diffusion-webui\extensions\sd-webui-controlnet\models. И только после этого вновь запускаем сервер, а вслед за ним и веб-интерфейс. На главном экране в разделе «txt2img» должно появиться очередное выпадающее меню, сразу под «Tiled VAE», — «ControlNet» с номером версии (в нашем случае 1.1.411). 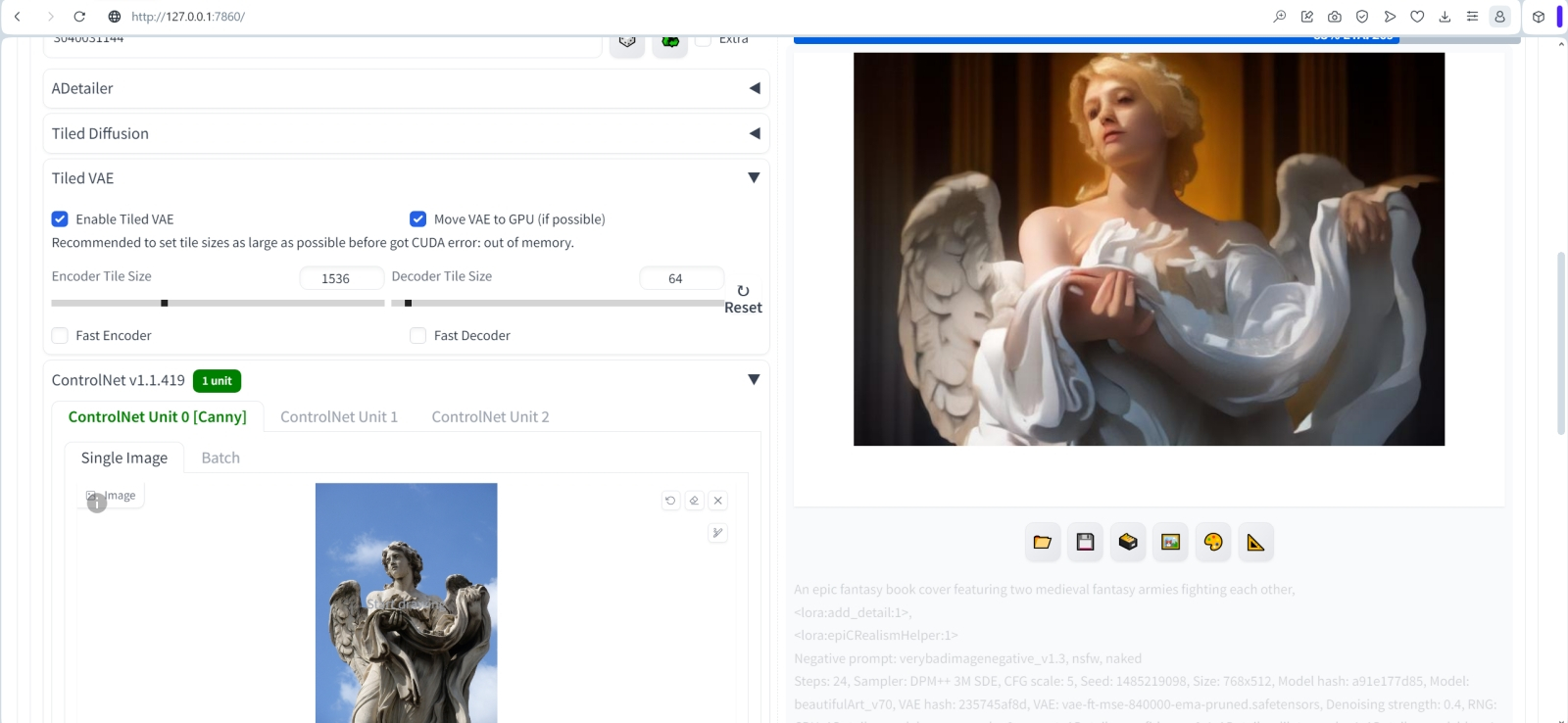 Вот теперь самое время вернуться к финальным (на этапе с ADetailer) параметрам генерации ангела с затравкой 3040031144 — и запустить её ещё раз, но теперь уже с ControlNet. Через «PNG Info» загружаем на вкладку «txt2img» все рабочие параметры; выпадающие меню «Hires. fix» и «ADetailer» пока не трогаем, «Tiled VAE» — привычно оставляем. Раскрываем выпадающее меню «ControlNet» и там, в подвкладке «ControlNet Unit 0», помечаем галочкой поле «Enable», загружаем в соответствующее поле исходный фотоснимок ангела с тибрского моста, активируем в разделе «Control type» переключатель «Canny», — и больше пока ничего не трогаем. После выбора разновидности контроля (алгоритма Canny) поля «Preprocessor» и «Mode» заполнятся автоматически — там тоже ничего менять не станем. А вот в «Resize Mode» необходимо указать «Resize and Fill», поскольку модельное фото у нас книжной ориентации, а выбранная канва — альбомной. Остаётся только запустить генерацию картинки большой оранжевой кнопкой. 
Источник: ИИ-генерация на основе модели SD 1.5 Вот это да! С первой попавшейся затравкой, с заведомо не самой удачной подсказкой (ткань на обеих руках она ведь нам так и не воспроизвела, как мы до того ни бились), — попадание в исходный образ процентов на 80! Правда, похоже, алгоритм автоопределения границ объектов (именно его реализует модуль Canny в составе ControlNet) не очень хорошо справился с левой рукой ангела (той, что с правой стороны картинки), — на фото она не слишком контрастна, и, видимо, потому на сгенерированном изображении кисть оказалась полностью скрыта тканью. Вернёмся к управляющему интерфейсу ControlNet и выставим переключатель «Control Mode» в режим «My prompt is more important». 
Слева — итог работы ControlNet по алгоритму Canny; справа — составленная этим алгоритмом карта контуров объектов оригинального снимка (источник: ИИ-генерация на основе модели SD 1.5) Другое дело! Крылья, конечно, чрезмерны и где-то даже несуразны, зато руки и ткань — в точности на месте! Памятуя о том, что нет предела совершенству, попробуем теперь другой алгоритм контроля — Depth («карта глубин»), оставив все прежние параметры неизменными. 
Примерно то же, но теперь справа — карта глубин (чем светлее область, тем ближе она к переднему плану), построенная алгоритмом Depth (источник: ИИ-генерация на основе модели SD 1.5) Вот это поворот — почти что идеал! Да, крылья не те, что у статуи, но скульптор, имеющий дело с неармированным мрамором, вынужден принимать в расчёт сопромат, потому поневоле изображает их сложенными, — тогда как ИИ-генерация открывает куда более широкий простор для творчества. На всякий случай испытаем третий из загруженных алгоритмов контроля, OpenPose, и тоже с прежними параметрами. 
А тут алгоритм OpenPose попытался реконструировать позу оригинальной фигуры (справа), а затем уже по ней была сгенерирована картинка слева (источник: ИИ-генерация на основе модели SD 1.5) Здесь явная неудача в плане распознавания позы — хотя композиция, вообще говоря, очень даже хороша. В любом случае раз уж мы изначально ставили цель воспроизвести в определённом приближении генеративным ИИ-рисовальщиком объект реального мира, то имеет смысл вернуться к алгоритму Depth — и запустить его ещё раз, но теперь уже вместе с активированными по прежним шаблонам Hires. fix и ADetailer. 
Источник: ИИ-генерация на основе модели SD 1.5 Скорость обсчёта этой картинки, где результаты работы первых двух нейросетей (чекпойнта BeautifulArt и стандартной для SD 1.5 модели постобработки VAE) творчески преобразуют ещё три (Hires. fix, ADetailer и ControlNet), просто-таки рухнула — до более чем 23 с на одну итерацию вместо изначальной 1 с. Но оно того стоило, не так ли? Лицо, как обычно и бывает при применении ADetailer для среднего/крупного плана, изменилось не сильно, зато кисти рук стали значительно изящнее. А теперь — самое увлекательное: общую композицию нам задаёт референсная картинка, но кто сказал, что раз на ней изображена статуя ангела, то и срисовывать с неё ИИ обязан исключительно ангелов? Оставляем все рабочие параметры — seed, CFG, steps и пр. — в неизменности; негативную подсказку и вторую часть позитивной (от BREAK и далее) — тоже, а с прочими текстовыми вводными попробуем поиграть (да, это аллюзия на приводящую любого дизайнера в неистовство фразу заказчика «А поиграйте тут с формой квадрата, пожалуйста»): 
Источник: ИИ-генерация на основе модели SD 1.5 На самом деле он — Бэтмен! Первая часть позитивной подсказки такая: close-up, cinematic film still of a somber Batman with large wings spread wide holding a giant snake in both arms, black and grey tight suit, surrounded by a colorful night sky, wind blowing, intricately detailed textures, awe and admiration inspiring, creating a sense of grandeur and power 
Источник: ИИ-генерация на основе модели SD 1.5 Суккуб? По крайней мере, такой был замысел: close-up, cinematic film still of a succubus librarian holding an unrolled ancient scroll in both arms, large leathery wings spread wide, reddish gentle skin, surrounded by bright ember fires, wind blowing, intricately detailed textures, awe and admiration inspiring, creating a sense of grandeur and power, 
Источник: ИИ-генерация на основе модели SD 1.5 Дайвер… Ну, наверное: close-up, cinematic film still of a scuba diver holding a thick long electric eel in both arms, mask, air bubbles, oxygen cylinders, tight black and blue diving suit, lush underwater habitat, surrounded by colorful marine life, strong currents, intricately detailed textures, awe and admiration inspiring, creating a sense of grandeur and power 
Источник: ИИ-генерация на основе модели SD 1.5 Спейсмарин (то есть как это — без имперской аквилы на броне? Ересь!): close-up, cinematic film still of a fierce Warhammer 40K space marine holding a machine-gun belt on both arms, blue armor with golden trim, heavy bolter, surrounded by ash and fire, strong wind, intricately detailed textures, awe and admiration inspiring, creating a sense of grandeur and power 
Источник: ИИ-генерация на основе модели SD 1.5 Панда из горячечных кошмаров?! Да, вероятно: close-up, cinematic film still of a weird panda holding a thick rope in both arms, surrounded by grass and flowers, intricately detailed textures, awe and admiration inspiring, creating a sense of grandeur and power 
Источник: ИИ-генерация на основе модели SD 1.5 Как ни парадоксально, но — греческая статуя с отрезом ткани на обеих руках (достойная закольцовка, не так ли?): close-up, cinematic film still of an Ancient Greek marble statue holding a plicate veil in both arms, surrounded by serene morning Hellenic landscape, intricately detailed textures, awe and admiration inspiring, creating a sense of grandeur and power В целом, хочется верить, идея понятна. Привлекая Hires. fix, ADetailer и ControlNet с разными параметрами, моделями и алгоритмами, можно творчески преодолеть такое неизбывное, как могло показаться изначально, ограничение генеративного ИИ-рисовальщика, как невозможность — точнее, чрезвычайно малая вероятность — выдать изображение с достойными композицией, адекватной прорисовкой лиц и рук, а также общей эстетикой одновременно. Да, потрудиться оператору Stable Diffusion всё равно придётся, но действовать он будет уже не вслепую. И вдобавок деятельность эта куда как ближе к творчеству, чем утомительный просмотр десятков и сотен как придётся сгенерированных картинок в надежде отыскать что-то действительно стоящее. А это, знаете ли, воодушевляет!
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.











