







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Практикум по ИИ-рисованию, часть десятая: да будет FLUX!
В самом начале августа никому до тех пор особенно не известный стартап Black Forest Labs, или попросту BFL, представил очередную локально исполняемую модель для генерации статичных изображений по текстовым подсказкам — FLUX.1. Точнее, говорить здесь стоит о целом семействе моделей, которое включает:
И по заявлениям разработчиков, и по восторженным откликам не могущего наиграться с FLUX.1 с начала августа сообщества энтузиастов, по способности даже в schnell-версии буквалистски придерживаться заданных в подсказке инструкций (то, что именуется prompt adherence) и уж тем более отрисовывать кисти человеческих рук новинка сравнима разве что с лидирующими в этом плане коммерческими продуктами — последними версиями Midjourney и Dall-E — и наголову превосходит творения Stable Diffusion, включая недавно рассмотренную нами в первом приближении SD3M. 
Иногда трава — это просто трава, не таящая для изображаемых на ней девушек ни малейшей опасности (источник: ИИ-генерация на основе модели FLUX.1) ⇡#Таланты и недосказанностиВ команду BFL (у кого-то сейчас наверняка свело олдскулы отсылкой к «абсолютному оружию» — BFG из легендарного Doom) входят, в частности, такие люди, как Андрес Блатман (Andreas Blattmann), Доминик Лоренц (Dominik Lorenz), Патрик Эссер (Patrick Esser) и Робин Ромбах (Robin Rombach). Эта же четвёрка присутствует в перечне авторов ключевой для актуального этапа в развитии художественного генеративного ИИ научной публикации — High-Resolution Image Synthesis with Latent Diffusion Models, вышедшей в апреле 2022 г. Собственно, все они принимали участие в разработке генеративных моделей на принципах латентной диффузии (Stable Diffusion) для компании Stability AI (а ещё ранее — в проектах CompVis и RunwayML) и в разное время покинули её — с тем, очевидно, чтобы реализовать свой собственный, не скованный стремлениями и планами внешнего менеджмента подход к такого рода задачам. Весьма скупой на информацию официальный сайт BFL содержит описание миссии стартапа, которая заключается «в разработке и продвижении современных моделей генеративного глубокого обучения для таких медиа, как изображения и видео, а также в расширении возможностей творчества, эффективности и разнообразия». Заметьте, тут нет никаких упоминаний о «безопасности», которыми просто кишел не столь уж давний анонс Stable Diffusion 3. И действительно, с отображением (одетых) девушек на траве у общедоступных версий FLUX.1 дела обстоят наилучшим образом. Неудивительно, что новый чат-бот Grok-2, творение принадлежащего Илону Маску (Elon Musk) стартапа xAI, полагается как раз на модель разработки BFL для создания картинок по запросам пользователей, хотя выбор на нынешнем рынке онлайн-генерации изображений, в особенности коммерческих, и без того избыточно широк: уж компания-то Маска могла позволить себе любое партнёрство. С практической точки зрения FLUX.1 уже пошла, что называется, в народ. Не миновало и пары недель с момента открытия доступа к этой модели (включая версию pro) на популярном сайте для генерации картинок Civitai, а уже едва ли не 90% всех изображений, что набирают там за сутки максимальное число реакций, оказываются порождены именно ею. Невзирая даже на то, что обходится создание одной картинки с FLUX.1 [dev] «в базовой комплектации» (20 шагов, никаких дополнений вроде LoRA) в 30 «бз-з-з» (buzz, местная валюта, которую можно как покупать за настоящие деньги, так и зарабатывать, собирая реакции других пользователей на свои удачные творения), а с FLUX.1 [pro] — и вовсе в 65 бз-з-з. Тогда как одна SDXL-генерация (даже с внушительным списком вспомогательных LoRA и большим, 35-50, числом шагов) редко выходит дороже 7-12 бз-з-з. Кроме того, версии dev и schnell доступны для загрузки на пользовательские ПК как с Civitai, так и с Hugging Face — твори не хочу! Да, они тяжеловаты — под 23 Гбайт каждая. Не исключая, кстати говоря, и скоростной FLUX.1 [schnell]: места в памяти та занимает столько же, сколько и dev-вариант, просто оптимизация её проведена так, чтобы выдавать пристойный по всем параметрам результат не примерно за 20 шагов итерации (steps), как в случае dev, а всего за 4. И хотя на первый взгляд столь внушительный размер файла может показаться явным недостатком владельцам видеокарт с ОЗУ меньшего, чем 24 Гбайт, объёма, на практике это вопрос как раз решаемый, и что именно следует сделать для его решения — мы вскоре предметно разберёмся. 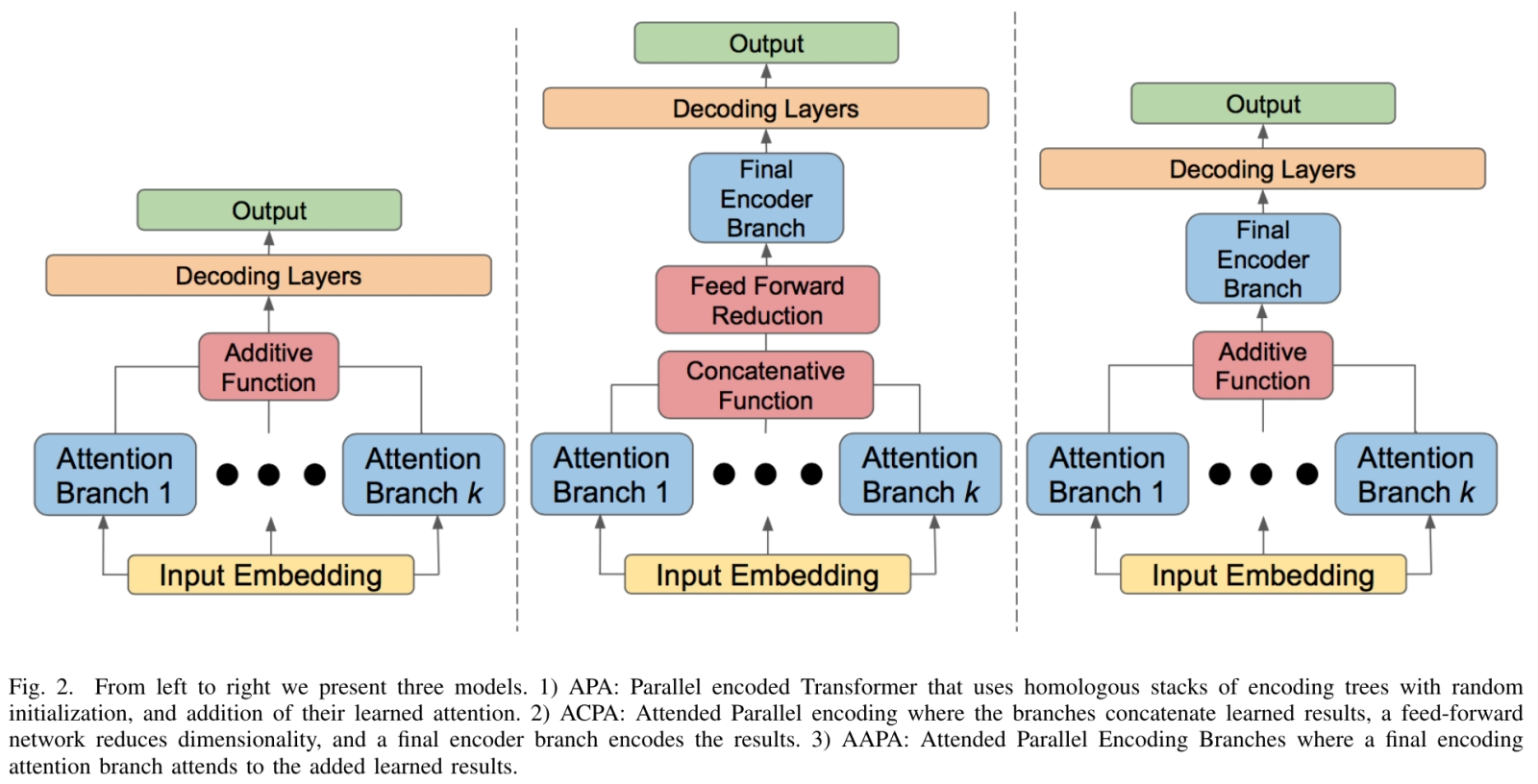
Три варианта реализации слоёв параллельного внимания в архитектуре трансформеров для генеративных моделей (источник: University of Colorado Colorado Springs) Другое дело, что с теорией у FLUX.1 далеко не всё прозрачно. Начать хотя бы с того, что описана сама модель её создателями довольно-таки скудно, — хотя релизы краеугольных чекпойнтов Stable Diffusion исправно сопровождались хотя бы краткими обзорными статьями, проливавшими свет как на архитектурные особенности новинок, так и на тонкости взаимодействия оператора с ними: отображение каких объектов и сцен им удаётся лучше, на что обращать внимание при составлении подсказок и т. п. В отношении же FLUX.1 известно пока лишь, что построены модели этой серии на основе гибридной архитектуры, объединяющей методы трансформации и диффузии, и что они способны масштабироваться до 12 млрд параметров — надо полагать, указанное предельное значение реализует как раз «закрытая» (доступная лишь через API на сайтах, которым доверено её у себя разместить) версия pro. Добиваться же демонстрируемых впечатляющих результатов помогает особый метод тренировки, использующий согласование потоков (flow matching), за счёт чего ускоряется обучение системы генеративному моделированию, а также интеграция в её состав позиционного встраивания с матрицами вращения (rotary positional embedding, RoPE) и слоёв параллельного внимания (parallel attention layers, PAL). Именно благодаря удачной реализации RoPE, судя по всему, модели FLUX.1 настолько хороши в деле порождения когерентных, т. е. связных изображений с высокой детализацией — это когда, например, человек стоит на фоне лошади и ноги того и другой с учётом взаимных перекрытий отрисовываются в полном соответствии с тем, как они выглядели бы в реальности, не превращаясь в гомогенное невнятное месиво. PAL же, в свою очередь, отвечают за взаимосогласованность отдельных элементов на изображении: скажем, если системе задано изобразить поливку цветов из лейки, вода на сгенерированной картинке потечёт именно из носика (если в подсказке явно не указано иное, конечно); держать лейку ухаживающий за цветами человек, даже если он вне кадра, будет за ручку, положение его кисти на этой ручке окажется вполне определённым (большой палец по одну сторону, четыре прочих по другую) и т. д. Сами разработчики утверждают, что в сравнении с Midjourney v6.0, DALL·E 3 (HD) и SD3-Ultra их творение — особенно в версии pro — оказывается превосходящим или как минимум почти совпадающим практически по всем параметрам. От субъективных, вроде качества итоговой картинки и её «эстетичности» (что бы под той ни подразумевалось), до вполне математически исчислимых — вроде точности соответствия изображённого тому, что было сформулировано в исходной подсказке, а также скорости и энергоэффективности каждой отдельной генерации. 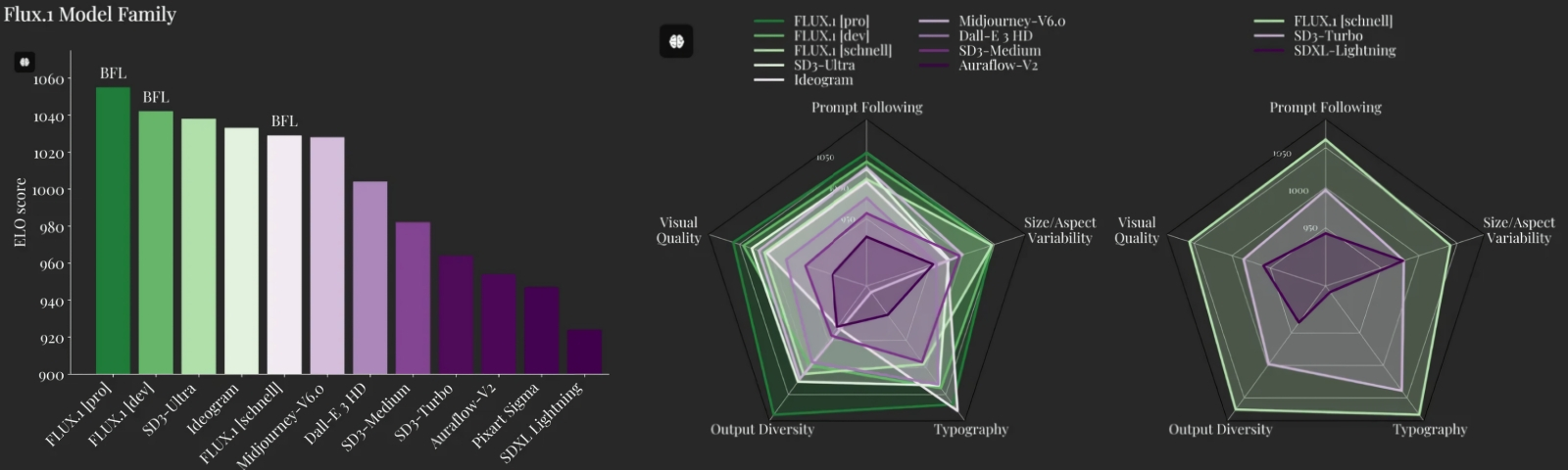
Слева: сравнение моделей семейства FLUX.1 с лучшими конкурентными аналогами по сводному рейтингу ELO Score. В центре: пятипараметрическое сопоставление тех же моделей в субъективных зачётах (визуальное качество, следование подсказке, вариативность размеров и соотношений сторон холста, воспроизведение типографики, разнообразие выдачи). Справа: то же пятипараметрическое сравнение, но уже отдельно для версии schnell и схожих с ней по скорости/ресурсоёмкости SD3 Turbo и SDXL Lightning (источник: BFL) Другая важная неопределённость, о которой сразу же забеспокоились энтузиасты ИИ-рисования, — это не слишком внятное лицензирование промежуточного варианта FLUX.1 [dev]. С версией schnell всё понятно: она распространяется по лицензии Apache 2.0, что подразумевает, в частности, её свободное коммерческое использование. В отношении pro тоже никаких вопросов: её веса в открытый доступ не выложены, так что претендовать на её коммерческое использование никто со стороны не может — только на порождённые ею картинки. Отметим для ясности, что результаты генерации любой ИИ-модели (как минимум в США, юрисдикции которых подчинена BFL) официально признаются не защищёнными авторским правом, даже если затравкой для полученного в итоге изображения послужила сочинённая человеком текстовая, голосовая либо иная подсказка. Иными словами, созданная любой из разновидностей FLUX.1 (за деньги ли, или за бз-з-з на стороннем сайте, или на собственном ПК) картинка не принадлежит никому, — и её можно свободно использовать для иллюстрирования коммерческих материалов, скажем. А вот некоммерческая лицензия на FLUX.1 [dev] составлена несколько путаным языком, который вроде бы допускает применение этой модели в исследовательских целях (для тренировки энтузиастами тех же LoRA либо текстовых инверсий на её основе) — но в то же время запрещает её использование с целью получения выгоды, т. е. для создания таких гибридных/производных моделей, которые затем предоставлялись бы в пользование за плату. Так или иначе, поскольку никаких модификаций моделей FLUX в рамках нашей «Мастерской» мы производить не станем, генерировать с их помощью картинки и размещать их здесь, да и где угодно, в исследовательских/иллюстративных целях можно совершенно свободно. ⇡#А разговоров-то было…Будем исходить из того, что постоянные читатели нашей «Мастерской» уже располагают развёрнутыми на своих компьютерах инсталляциями рабочих сред AUTOMATIC1111 и ComfyUI. На момент написания настоящей статьи полноценной поддержкой FLUX могли похвастать только ComfyUI и Forge (родственный AUTOMATIC1111, но развиваемый независимо проект), так что не станем умножать сущностей и выберем для экспериментирования с FLUX — название модели, кстати, явно выбрано в пику «Stable Diffusion», поскольку переводится оно как «непрерывное движение, мельтешение, суета», то бишь полное отсутствие стабильности — уже знакомую рабочую среду ComfyUI. Хотя и о менее остросюжетной в плане интерфейса Forge в применении к новой серии моделей от BFL, особенно модифицированных в плане сжатия чекпойнтов, отзывы самые положительные. 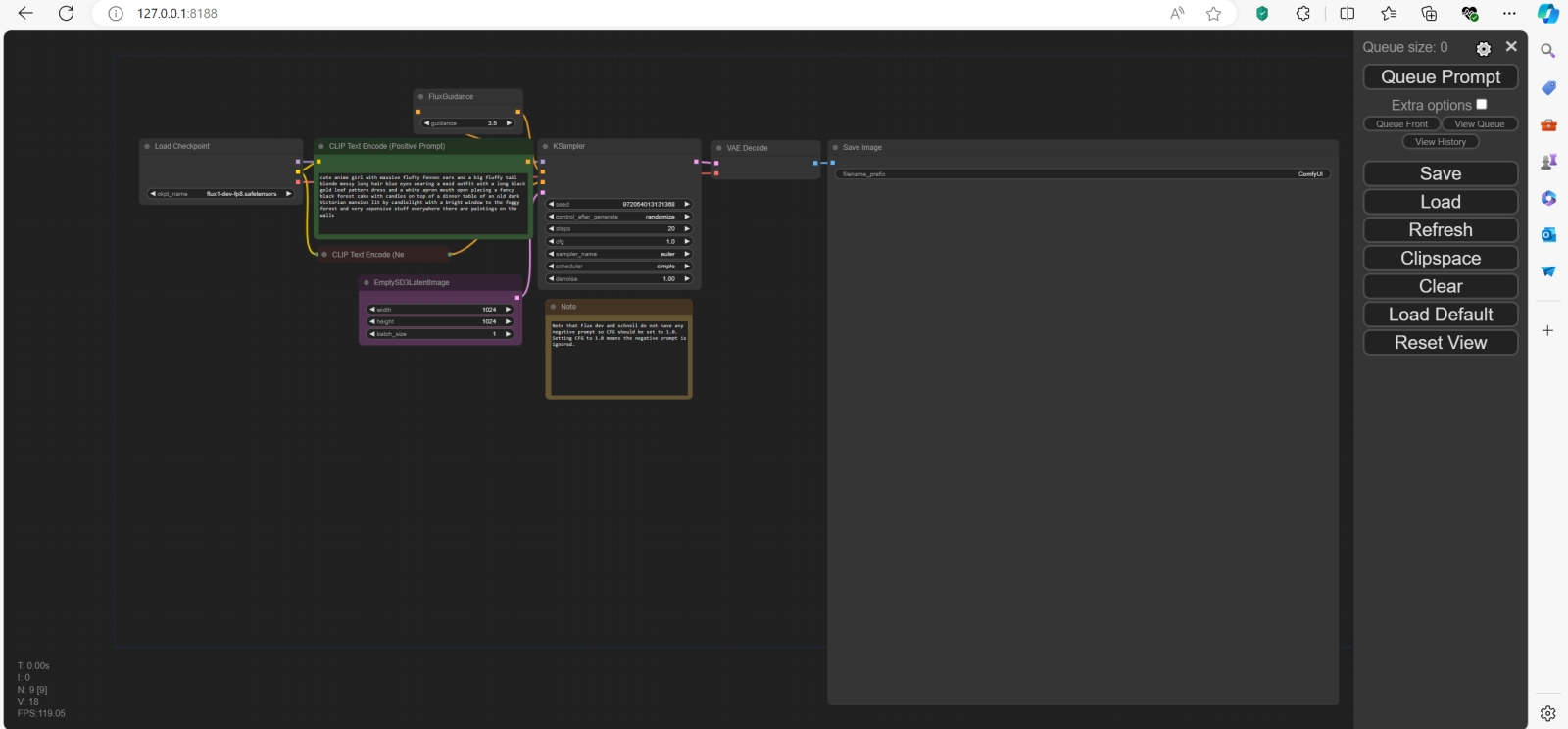
Опорная циклограмма для работы с чекпойнтом flux1-dev-fp8.safetensors довольно-таки лаконична Как уже отмечалось в прошлом выпуске «Мастерской», для экспериментов с новыми моделями имеет смысл устанавливать сепаратные независимые варианты рабочей среды — благо та как раз доступна в standalone-версии, что предусматривает просто распаковку из скачанного архива в выбранный каталог, без «нормальной» инсталляции с прописыванием путей и переменных окружения в реестр Windows. Заодно это помогает содержать раздельно разные версии Python и дополнительных пакетов, которые идут вместе с каждой независимой разновидностью ComfyUI, что оберегает прежние, вполне работоспособные инсталляции от нечаянных повреждений. Поэтому нужно просто скачать с официальной страницы этой рабочей среды на GitHub наиболее свежую стабильную версию (на момент написания настоящей статьи — 0.1.2), а именно файл под названием ComfyUI_windows_portable_nvidia.7z, и распаковать его в избранный каталог. В нашем случае назовём его ComfyUI_012 — как раз с прямым указанием на номер версии. Напомним на всякий случай, что этот вариант — только для исполнения на графических адаптерах NVIDIA либо непосредственно на ЦП AMD или Intel (что будет, разумеется, куда как медленнее): владельцам видеокарт AMD предлагается костыль в виде пакетов rocm и pytorch, которые можно установить через менеджер загрузок pip. Следующий этап, как и прежде, — загрузка собственно исполняемых моделей. У автора актуальной для нас на сей раз рабочей среды, ComfyAnonimous, есть довольно подробное руководство по закачке различных версий FLUX.1 [dev] и FLUX.1 [schnell] и соответствующих им опорных циклограмм, — кстати, последнюю, «ускоренную» версию модели мы активно использовать не станем по причинам, что будут пояснены чуть позже. Поскольку в нашей тестовой системе установлен графический адаптер GTX 1070 всего с 8 Гбайт видеопамяти, прокрутим страничку с руководством поближе к концу — там есть раздел «Simple to use FP8 Checkpoint version». Он содержит ссылку на репозиторий, поддерживаемый Comfy.Org (команда энтузиастов ИИ-рисования, собравшаяся вокруг ComfyAnonimous после его ухода из Stability AI), откуда можно скачать файл flux1-dev-fp8.safetensors — усечённую версию набора весов для модели FLUX.1 [dev]. Дело в том, что исходно опубликованные BFL веса представлены в 16-разрядном формате с плавающей запятой, FP16; и преобразование их (с огрублением, ясное дело) в FP8 позволяет вдвое уменьшить объём занимаемой моделью памяти — ценой, разумеется, некоторого ухудшения результатов её работы. Утверждается, что 8-битная кодировка примерно соответствует 16-битной в части верности следования заданной подсказке и построения когерентных изображений — но с мелкими деталями справляется хуже. Так или иначе, владельцы 8-Гбайт видеокарт не могут позволить себе чрезмерной разборчивости, потому скачаем указанный файл и поместим его в стандартный для размещения чекпойнтов каталог ComfyUI/models/checkpoints/. «Позвольте, — взовьётся внимательный читатель, решивший буква в букву следовать нашему руководству, — какой смысл, имея 8-Гбайт видеокарту, выкачивать даже урезанную модель, если она всё равно занимает 17,2 Гбайт?» — а именно таков размер предлагаемого Comfy.Org файла flux1-dev-fp8.safetensors. Дело, однако, в том, что в ComfyUI (как, кстати, с некоторых пор и в Forge) реализована возможность «склейки» оперативной памяти компьютера с видеопамятью — бесшовно для исполняемых в этих рабочих средах программ, но, конечно же, с обеспечением куда менее высокой производительности, чем если бы модель целиком умещалась в видеоОЗУ. Тем не менее на нашей тестовой системе в настоящее время установлено 24 Гбайт оперативной памяти, так что суммарный с видеопамятью доступный объём составляет 32 Гбайт, — этого, строго говоря, хватит и для неусечённой по точности FP16-версии FLUX (в чём мы чуть позже ещё убедимся). Без сомнения, перелив данных между двумя различными типами памяти через системную шину не может не отразиться на скорости обработки модели — она будет исчисляться десятками (и хорошо бы, если первыми десятками) секунд на каждую итерацию. ![Циклограмма для FLUX.1 [dev], что реализована ансамблем субмоделей, выглядит посложнее, — но тоже вполне логична и последовательна](https://cdn.3dnews.ru/assets/external/illustrations/2024/08/30/1110246/aidraw10-05.jpg)
Циклограмма для FLUX.1 [dev], что реализована ансамблем субмоделей, выглядит посложнее, но тоже вполне логична и последовательна Вот почему для ПК с видеопамятью менее 16 Гбайт рекомендовано применять именно FLUX.1 [schnell] — там всё-таки 4 итерации на одну картинку, а не 20, при приблизительно том же размере модели в байтах. Впрочем, забегая вперёд, отметим: FLUX настолько хороша, что при грамотно составленной подсказке эстетически годный результат вполне реально получить если не прямо с первой, то, условно, с третьей-восьмой попытки, — то бишь длительность генерации каждого изображения (если сравнивать с SDXL или SD3M) чаще всего компенсируется краткостью серии таких изображений до получения устраивающего пользователя. Именно этим привлекательно творение BFL: оно позволяет уйти от привычного операторам «Полуторки» и «Оверсайза» режима «полуслепого поиска», когда ПК запущен в режиме бесконечного цикла (подсказка и прочие параметры генерации стабильны, меняется только значение затравки — seed) на час, два или более, выдавая по одной картинке каждые 1-3 минуты. И время от времени к нему подходят — но лишь для того, чтобы проверить, не появился ли вдруг случайно выдающийся в эстетическом плане вариант, подходящий для дальнейшей обработки с применением инструмента inpaint или внешнего графического редактора. FLUX же выдаёт, как правило, уже пригодную для дальнейшего использования «как есть» картинку после весьма скромного числа попыток. Есть, конечно, и тут свои тонкости, мы их вскоре коснёмся, — но общее ощущение от новой модели такое, что итоговое извлечение из латентного пространства композиционно и эстетически привлекательных образов, с первого взгляда на которые удовлетворённый оператор решает прекратить генерацию по текущей подсказке, она производит в целом быстрее прежних (SD 1.5, SDXL, SD3M), а не медленнее. Хотя каждая отдельная картинка, что греха таить, генерируется минутами и десятками минут. ⇡#Широкий канал пригодитсяВ посвящённом SD3M материале мы уже модифицировали пусковой файл рабочей среды — run_nvidia_gpu.bat — с тем, чтобы включить в него вызов внешнего Python-модуля venv (virtual environments, «виртуальных окружений»; если в системе его нет, всегда можно поставить) и, наоборот, убрать ряд проведённых специально для standalone-версии оптимизаций. В данном случае задействовать эти оптимизации всё же придётся — они активируют, в частности, «склейку» ОЗУ с видеопамятью, что и обеспечит увесистой модели FLUX возможность исполняться на скромном «железе» нашего тестового ПК. Поэтому — опять-таки в предположении, что AUTOMATIC1111 с venv в системе уже развёрнут, — создадим новый пусковой BAT-файл с названием run_with_venv.bat и следующим содержимым: @echo off call cd C:\Fun-n-Games\Git\stable-diffusion-webui\venv\Scripts echo %cd% call activate.bat echo venv activated call cd C:\Fun-n-Games\ComfyUI_012 echo %cd% call .\python_embeded\python.exe -s ComfyUI\main.py --windows-standalone-build --disable-auto-launch pause Параметр «--disable-auto-launch» при запуске рабочей среды блокирует автоматическое открытие её веб-интерфейса в браузере по умолчанию. Почему его надо блокировать? Да потому, что на постоянно используемом ПК в браузере по умолчанию наверняка открыто великое множество вкладок, а пользоваться ComfyUI c FLUX предпочтительнее в другом, как можно более редко запускаемом — да хотя бы, страшно сказать, в штатном для Windows-систем Edge. Чем меньше открытых вкладок, тем меньше места в ОЗУ занимает браузер, а поскольку системная оперативная память склеивается в данном случае с видеоОЗУ с целью уместить туда громадную модель, то чем скромнее перечень активных программ на данном ПК во время генерации им картинок — тем лучше. Разумеется, всегда можно оценить объём свободного ОЗУ через «Диспетчер задач», и, если он достаточно велик, что-то остро нужное всё-таки запустить, но расходовать вычислительные ресурсы тем, у кого они изначально скудны, следует с особой осмотрительностью. 
Слева — эталонная генерация по опорной циклограмме с моделью flux1-dev-fp8.safetensors из руководства ComfyAnonimous; справа — результат исполнения той же модели с теми же параметрами на нашем тестовом ПК. Отличия, вероятнее всего, обусловлены разницей в используемых версиях venv/pytorch (источник: ИИ-генерация на основе модели FLUX.1) После запуска рабочей среды (файл модели, 17,2-Гбайт flux1-dev-fp8.safetensors, предварительно должен быть загружен — и ещё до двойного щелчка по run_with_venv.bat помещён в каталог ComfyUI/models/checkpoints/) в избранном для работы с ней браузере, желательно вовсе не содержащем лишних вкладок, следует открыть веб-интерфейс по адресу 127.0.0.1:8188 — и убедиться, что он доступен. Затем с уже упомянутой странички (да, её можно на время открыть в соседней вкладке, а после закачки закрыть) остаётся загрузить опорную циклограмму для этой модели за авторством всё того же ComfyAnonimous в виде png-файла — и просто перетащить его мышкой из окна «Проводника» в рабочее поле ComfyUI. Там сразу же отобразятся все необходимые ноды с нужными параметрами, включая подсказку. Нажатие на кнопку «Queue prompt» в скудном интерфейсе рабочей среды запустит циклограмму на исполнение — и в результате должна выйти картинка, в целом схожая с исходной, содержащей опорную циклограмму. Ну что же, всё работает, хотя и неимоверно долго: вместо привычных по SDXL 6-7 с на одну итерацию (которых в данном случае было произведено 20 — параметр «steps» в ноде «KSampler») здесь каждая итерация занимает по 60-70 с. Более 20 минут на одну картинку — каково?! Забегая немного вперёд, укажем, что для полного оправдания столь серьёзных времязатрат на отрисовку изображений по текстовым подсказкам FLUX.1 требует куда более полного раскрытия своего потенциала, — ближе к концу настоящей статьи тому будет дано несколько примеров. И первый шаг к такому раскрытию — переход от единого чекпойнта flux1-dev-fp8.safetensors, которым мы только что пользовались, к модульному ансамблю субмоделей, составляющих вместе единую FLUX.1 [dev], а именно — к раздельному применению:
![60-70 с на одну итерацию для FLUX.1 [dev] — это нормально для 8 Гбайт видеоОЗУ](https://cdn.3dnews.ru/assets/external/illustrations/2024/08/30/1110246/aidraw10-07.jpg)
60-70 с на одну итерацию для FLUX.1 [dev] — это нормально для 8 Гбайт видеоОЗУ На всё той же страничке ComfyAnonimous с примерами имеются нужные ссылки для закачки всех субмоделей, причём как для FLUX.1 [dev], так и для FLUX.1 [schnell]. Для начала из репозитория CLIP-субмоделей на Hugging Face потребуется выкачать по меньшей мере два файла: обязательную модель clip_l — файл clip_l.safetensors (246 Мбайт), а также один из двух вариантов модели t5xxl: предпочтительный — t5xxl_fp16.safetensors (9,79 Гбайт) либо вдвое усушенный (тоже посредством перекодировки из FP16 в FP8) — t5xxl_fp8_e4m3fn.safetensors (4,89 Гбайт). Рекомендуется использовать 16-битный вариант, который, разумеется, целиком помещаться в наши 8 Гбайт видеоОЗУ никак не будет, — и потому его использование дополнительно удлинит генерацию картинок. Однако в режиме свободного поиска, когда рабочая среда запускается в бесконечный цикл со случайной сменой затравки и неизменными прочими параметрами, перекодировать текст в токены потребуется только однажды для каждой подсказки — и потому не имеет смысла жертвовать в данном случае точностью. Более того, от качества работы кодировщика напрямую зависит качество итогового изображения в целом, от композиции до цветовой палитры, а не только мелкая детализация, как в случае UNet-субмодели, — так что стóит с самого начала сделать ставку на почти 10-Гбайт t5xxl_fp16.safetensors. ⇡#Ушки торчатИтак, два выкачанных CLIP-кодировщика поместим в каталог ComfyUI/models/clip/. Далее потребуется загрузить UNet-модель FLUX.1 [dev] — либо с репозитория самой BFL на Hugging Face, либо со странички указанной модели на Civitai. Этот файл (flux-dev.safetensors) в исходной, 16-разрядной кодировке занимает 23,8 Гбайт, а его FP8-вариант из альтернативного репозитория (flux1-dev-fp8.safetensors) — 11,9 Гбайт. Помещать один из них (или оба, если позволяет свободное место на логическом разделе) следует — внимание! — в каталог ComfyUI/models/UNet/ — именно /UNet, а не /checkpoints; как раз потому, что это не полнофункциональный обособленный чекпойнт, а всего лишь одна субмодель из ансамбля. Кстати, не стоит путать файлы с разными размерами, но одинаковыми названиями «flux1-dev-fp8.safetensors», лежащие в папках /checkpoints и /UNet: в первой — полноценный чекпойнт (полученный ComfyAnonimous, надо полагать, слиянием FP8-вариантов субмоделей CLIP (большой) и UNet с добавлением почти невесомого clip_l и соответствующего VAE-файла), а во второй — та самая одиночная UNet-субмодель. Оговоримся тут заодно, что принятая в данном случае терминология по меньшей мере спорна: модель кодировщика T5XXL не относится к CLIP-подобным, а FLUX-реализация формирования образа в латентном пространстве через трансформеры (о которой мы вскользь упомянули выше) отличается от технологии UNet, — но с практической точки зрения это не слишком существенно. Теперь осталось скачать субмодель VAE с официального репозитория BFL на Hugging Face — это файл на 335 Мбайт с названием «ae.sft», который можно либо как есть положить в каталог ComfyUI/models/vae/, либо сперва переименовать в «ae.safetensors», — актуальная версия ComfyUI воспримет и то и другое расширение. Картинка с опорной циклограммой для ансамбля субмоделей у ComfyAnonimous также припасена — перетащим её из «Проводника» в рабочее поле и проверим, все ли названия субмоделей в соответствующих нодах совпадают с теми, с которыми мы собрались работать. На всякий случай лучше нажать на кнопку «Refresh» в интерфейсе рабочей среды, чтобы обновить информацию о содержимом каталогов. В ноде «Load Diffusion Model» должна быть выбрана, допустим, flux1-dev-fp8.safetensors (UNet-версия, не полноценный чекпойнт!), в ноде «DualCLIPLoader» — t5xxl_fp16.safetensors и clip_l.safetensors в нужных позициях, а в ноде «Load VAE» — ae.safetensors. Больше ничего трогать не надо — можно запускать ComfyUI на исполнение. ![Слева вверху — эталонная генерация по опорной циклограмме с 16-битной моделью flux-dev.safetensors из руководства ComfyAnonimous; справа вверху — результат исполнения той же циклограммы с UNet-моделью flux1-dev-fp8.safetensors на нашем тестовом ПК, слева внизу — тоже локальная генерация, но уже с 16-битной flux-dev.safetensors, справа внизу — та же подсказка, затравка, версии CLIP и прочие параметры генерации, но основная субмодель — FP8-версия FLUX.1 [schnell] (источник: ИИ-генерация на основе модели FLUX.1)](https://cdn.3dnews.ru/assets/external/illustrations/2024/08/30/1110246/aidraw10-08.jpg)
Слева вверху — эталонная генерация по опорной циклограмме с 16-битной моделью flux-dev.safetensors из руководства ComfyAnonimous; справа вверху — результат исполнения той же циклограммы с UNet-моделью flux1-dev-fp8.safetensors на нашем тестовом ПК, слева внизу — тоже локальная генерация, но уже с 16-битной flux-dev.safetensors, справа внизу — та же подсказка, затравка, версии CLIP и прочие параметры генерации, но основная субмодель — FP8-версия FLUX.1 [schnell] (источник: ИИ-генерация на основе модели FLUX.1) Для FP8-реализации FLUX.1 [dev] с ансамблем субмоделей на нашем тестовом ПК средняя скорость выполнения составила 72 с на одну итерацию. Прилично, конечно, но лишь немногим больше, чем при использовании комбинированного FP8-чекпойнта, с которого мы начинали. Интересно, что, если вместо flux1-dev-fp8.safetensors в ноде «Load Diffusion Model» выбрать 16-битную UNet-субмодель flux-dev.safetensors (допуская, что её почти 24 Гбайт удалось без затруднений выкачать), качество в деталях несколько улучшится — достаточно внимательно посмотреть на радужки глаз лисички на картинке и на оборочки её фартука, — а скорость исполнения притом останется по сути прежней, 74 с/ит. И понятно почему: модель для формирования изображения в латентном пространстве в обоих случаях не помещается в видеопамяти целиком, что заставляет рабочую среду непрерывно гонять данные между системным и видеоОЗУ, — на этом фоне различия между 12- и 24-Гбайт файлами почти скрадываются. Вот если бы на нашем графическом адаптере имелось хотя бы 12 Гбайт памяти, картина вышла бы принципиально иной. Кратко упомянем, что FLUX.1 [schnell] на нашей тестовой системе (опять-таки доступная из уже не раз упомянутого репозитория) также исполняется с похожей типичной скоростью — 67 с/ит. Конечно, если учесть, что ей требуется всего 4 шага для завершения картинки, суммарное время генерации заметно снижается. Зато общее качество, т. е. субъективное эстетическое воздействие картинки на зрителя, у schnell-версии, на наш взгляд, ниже (см. приведённое сопоставление генераций, полученных с использованием разных моделей), потому, по крайней мере на данном этапе, мы ею детально заниматься не станем. ⇡#Квартет заказывали?Ещё один важный момент: если для SD 1.5 базовым штатным разрешением были 0,25 Мпикс (холст 512×512 точек), для SDXL — 1 Мпикс (1024×1024), то FLUX натренирована, по заявлению разработчиков, на чрезвычайно широкой выборке тестовых изображений с разрешениями от 0,1 до 2,0 Мпикс. Иными словами, без каких бы то ни было дополнительных средств — Hires. fix, ADetailer и проч. — модель сразу позволяет генерировать картинки на холсте, скажем, 1920×1072 точки (как раз примерно 2 Мпикс). Со всей полагающейся детализацией, с заведомым отсутствием артефактов увеличения и т. п. — хотя, разумеется, ценой ещё более длительной обработки каждого из 20 базовых шагов генерации. Но, честно говоря, оно того порой стоит: именно благодаря выдающимся способностям FLUX.1 [dev] нам удалось буквально с третьей попытки получить вполне адекватную 2-Мпикс картинку с изображением сражающихся орла и панды. Пусть со скоростью 141 с/ит., зато практически в фотокачестве и без взаимных контаминаций, что у нас в своё время так и не вышло без привлечения дополнительных инструментов. А здесь — пожалуйста, да ещё и в таком крупном формате! ![Модель — FLUX.1 [dev] 16 бит, подсказка — «dynamic cinematic screencap of a giant panda and bald eagle fighting near the edge of a tranquil pond in a bamboo forest at dawn, sun is barely starting to peak over the horizon, sunbeams piercing the mist of morning dew, the pond's calm waters reflecting the scene, elaborate atmospheric perspective», продолжительность генерации — 2868 с (источник: ИИ-генерация на основе модели FLUX.1)](https://cdn.3dnews.ru/assets/external/illustrations/2024/08/30/1110246/aidraw10-09.jpg)
Модель — FLUX.1 [dev] 16 бит, подсказка — «dynamic cinematic screencap of a giant panda and bald eagle fighting near the edge of a tranquil pond in a bamboo forest at dawn, sun is barely starting to peak over the horizon, sunbeams piercing the mist of morning dew, the pond's calm waters reflecting the scene, elaborate atmospheric perspective», продолжительность генерации — 2868 с (источник: ИИ-генерация на основе модели FLUX.1) Аккуратно разделять существенно различные объекты на картинке без перетекания между ними значимых свойств — когда у панды появляется орлиная голова, у орла чёрные когтистые лапы и т. п. — для моделей SD 1.5 и SDXL задача практически неподъёмная: их CLIP-кодировщики попросту не рассчитаны на подобные вызовы. SD3M в этом плане достигла бесспорного прогресса, как мы показывали в прошлый раз, — именно благодаря привлечению сразу трёх кодировщиков, в том числе и T5XXL. Но FLUX.1 выходит в этом плане на высоту поистине недосягаемую — по крайней мере, для прочих свободно распространяемых и пригодных к запуску на самом мощном игровом ПК моделей. Проиллюстрируем этот смелый тезис на примере картинки, навеянной знаменитой крыловской басней «Квартет». В состав классического струнного квартета, напомним, входят две скрипки, альт и виолончель, причём чаще всего изображают с виолончелью (англ. cello), понятное дело, косолапого мишку, с альтом (viola) — козла, а проказнице мартышке и ослу вручают по скрипочке. Допустим, мартышке пристало играть не на полноразмерном инструменте (violin), а на «народном», более простеньком варианте (fiddle), и составим такую вот не слишком пространную, но изобилующую деталями подсказку: hyperrealistic digital painting of four animals standing upright on a flower-strewn lawn: donkey, monkey, bear, and goat. The donkey plays violin, the small monkey plays fiddle, the huge bear plays cello, the goat plays viola И вот, нате вам: примерно с пятого раза система сгенерировала по ней практически точно соответствующую описанию картинку — чего даже от SD3M ожидать было бы странно. Здесь даже мартышка едва ли не роняет смычок, даже медведь стучит по виолончели, словно заправский джазовый басист по контрабасу, — то есть на роль иллюстрации для оригинальной басни это изображение вполне сгодилось бы. Эту картинку в исходном виде (PNG-файл со встроенной циклограммой, который можно просто перетащить на рабочее пространство ComfyUI для дальнейшего экспериментирования), как и прочие приведённые здесь генерации на основе модели FLUX, можно загрузить для самостоятельного изучения. ![Параметры генерации почти стандартные (как в опорной циклограмме ComfyAmonimous для dev-варианта), только в ноде «BasicScheduler» выбран вариант «beta»; модель — FLUX.1 [dev] 32 бит, затравка — 368019150651752, подсказка — в тексте статьи (источник: ИИ-генерация на основе модели FLUX.1)](https://cdn.3dnews.ru/assets/external/illustrations/2024/08/30/1110246/aidraw10-10.jpg)
Параметры генерации почти стандартные (как в опорной циклограмме ComfyAmonimous для dev-варианта), только в ноде «BasicScheduler» выбран вариант «beta»; модель — FLUX.1 [dev] 32 бит, затравка — 368019150651752, подсказка — в тексте статьи (источник: ИИ-генерация на основе модели FLUX.1) Строго говоря, на этом знакомство с FLUX.1 [dev] только начинается. У этой модели, напомним, два CLIP-кодировщика текста в токены — и, как показывает практика, раздельное задание для них подсказок (взаимно согласованных, но различных) обеспечивает лучшие результаты, чем использование одного и того же текста для обоих, как это подразумевается опорными нодами ComfyAnonimous в рассмотренных нами примерах. Здесь также полностью отсутствует негативная подсказка — не потому, что модель не умеет убирать некие сущности из картинки, а не только добавлять их, а потому, что параметр CFG в опорных циклограммах задан равным единице, — и это принципиальный момент; при бóльших его значениях система буквально идёт вразнос. Применение же отрицательной подсказки к извлекаемому из латентного пространства образу требует установки CFG хотя бы в позицию 2 — и потому здесь попросту нет смысла заниматься с дополнительной нодой. Да, уже есть способы обойти это ограничение и всё-таки заставить FLUX.1 [dev] работать с отрицаниями, но они достаточно нестандартны. Далее: среди прочих нод в циклограммах присутствует такая, которой ни у одной из моделей Stable Diffusion не было, — она задаёт «рекомендацию», guidance, со значением по умолчанию 3,5. Оказывается, понижение этой величины ведёт к большей творческой свободе модели за счёт усиленного отклонения от заданной подсказки, а повышение — напротив, к ещё более буквалистскому следованию ей (но с оскудением детализации). Это своего рода аналог прежнего параметра CFG, смысл изменения которого был примерно тем же, но который теперь, с учётом серьёзно переработанной архитектуры модели, играет заметно меньшую роль (и как раз потому разработчики рекомендуют выставлять строго в значение «1»). Кроме того, имеется ещё одна свежая нода «ModelSamplingFlux»: указанные в ней параметры имеют особое значение при работе с нестандартными холстами, — у прежних моделей необходимости в подобной юстировке не возникало. Есть ещё множество тонкостей с применением (не говоря уже о тренировке) LoRA для FLUX.1, с моделями ControlNet специально для неё, с каскадными генерациями — когда, к примеру, первый прогон производится с высоким значением guidance, чтобы точно зафиксировать заданные в подсказке базовые элементы картинки, а второй (уже в режиме не text to image, а image to image) берёт за основу выдачу первого и при низком значении guidance обогащает её всевозможными нерядовыми деталями… И это не говоря уже о более эффективных, чем FP8, методах компактификации исходного файла модели, которые позволяют всё-таки умещать вполне функциональный UNet (который на деле, как уже говорилось, не совсем UNet) в 8, 6 и даже 4 Гбайт видеоОЗУ. И об этом — да и не только об этом — мы ещё непременно поговорим! Материалы по теме:
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
|
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.





