







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Догнать и перегнать: дистиллированный ИИ — в каждый гаджет?
Суть физического процесса дистилляции — в разделении смеси веществ, каждое из которых в чистом виде характеризуется своей температурой кипения. Грубо говоря, при нагревании перегонного куба до некоторого предела химические соединения с температурой кипения выше этого предела остаются там, а с более высокой — выходят через патрубок в виде пара и затем конденсируются в приёмной колбе. Перегоняемое летучее вещество таким образом, освобождаясь от низкокипящих фракций смеси, становится более концентрированным — и действует (если у него имеется некое биохимическое действие) более эффективно; см., например, классическую киноминиатюру режиссёра Гайдая «Самогонщики». Дистилляция ИИ-моделей (model distillation, называемая ещё «дистилляцией знаний», knowledge distillation) тоже сводится к уменьшению объёма исходной модели за счёт отбрасывания всего ненужного. Иными словами, от того, что именно не нужно для решения данной конкретной задачи, зависит, каким образом будет проводиться эта процедура — и на что останется в итоге способна дистиллированная версия исходной модели. От источника к дистилляту переносится лишь некая часть тех знаний, что имелись у модели изначально и были закодированы в виде весов на входах образующих её перцептронов. В результате чаще всего (хотя это зависит от набора тренировочных данных, конечно) выходит узкоспециализированный, зато крайне экономный в плане системных требований ИИ-агент, причём эффективно организованный ансамбль таких агентов способен демонстрировать результаты порой не хуже, чем громоздкий и ресурсоёмкий источник (казалось бы, при чём тут DeepSeek, разработчиков которой заподозрили в «краже данных» — на деле в несанкционированной дистилляции моделей OpenAI через общедоступный API). И, судя по всему, дистилляция в обозримом будущем станет крайне популярным направлением дальнейшего совершенствования генеративных моделей — просто потому, что привычные методы их эксплуатации по мере дальнейшего нарастания их громоздкости представляются делом чрезмерно затратным во всех отношениях. 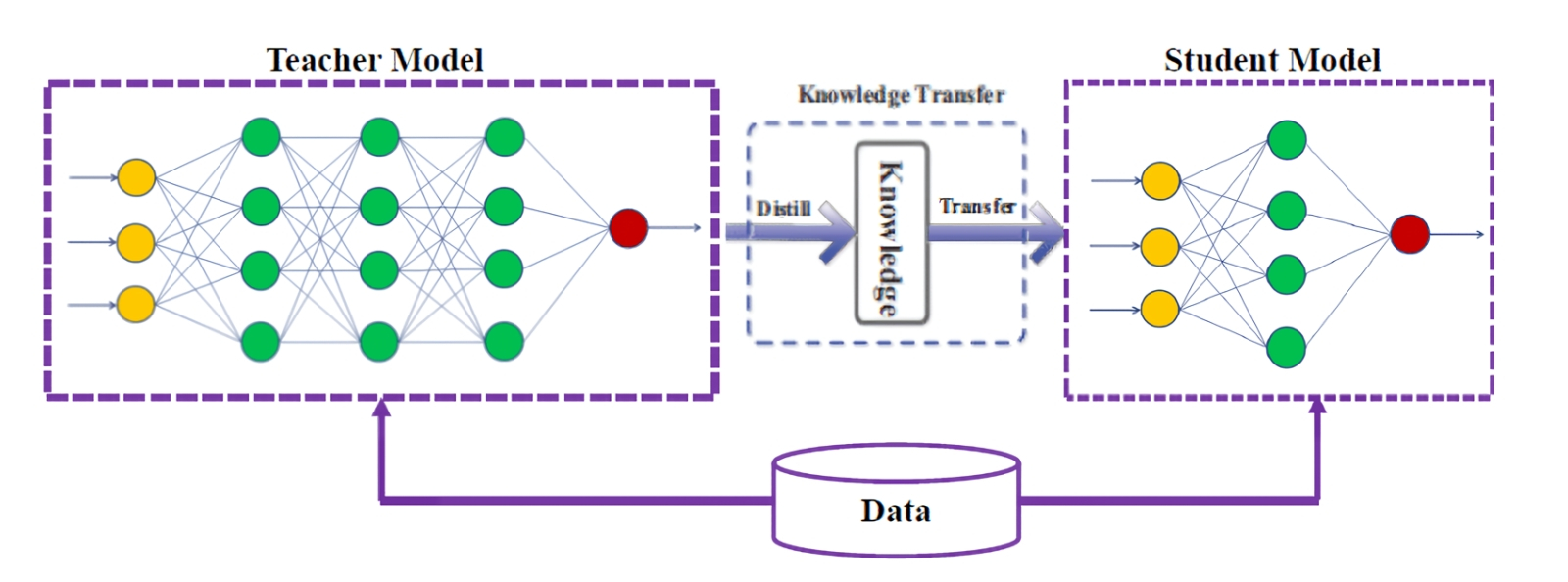
Перегонка моделей — дело принципиально не хитрое (источник: ResearchGate) ⇡#Учись, студент!История ИИ-дистилляции восходит к работе исследователей из Корнелльского университета под немудрёным названием «Model Compression», в которой описывалось, как огромную на тот момент языковую модель, образованную сотнями базовых классификаторов, использовали для тренировки другой, «в тысячи раз более компактной и быстрой» модели, демонстрировавшей в итоге на выходе ничуть не худшие результаты. Сама процедура тренировки представляла собой классическое обучение с учителем, только сверялась обучаемая модель не с неким составленным людьми набором опорных данных, а с ответами, которые на те же самые вопросы выдавала большая языковая модель. Таким образом производилась передача информации от крупной, сложной модели («учителя», teacher) к малоразмерной и быстрой («ученику», student). Далее этот подход был углублён и развит в другой классической для рассматриваемой области работе, Distilling the Knowledge in a Neural Network, созданной сотрудниками лаборатории Google в калифорнийском Маунтин-Вью. Дистилляция может производиться в двух принципиально различных вариантах: в первом, наиболее прямолинейном, тренировка производится до тех пор, пока ученик не научится с высокой точностью воспроизводить наилучшие (уже на взгляд контролирующих процесс людей) ответы учителя на задаваемые вопросы. Это, конечно, позволяет практически полностью заменить большую модель малой при обработке запросов заданной тематики — однако крайне резко снижает вариативность ответов, что во множестве ситуаций может оказаться неприемлемо. Другой вариант дистилляции — тренировка ученика на воспроизведение всего или почти всего доступного учителю спектра вариантов ответа на поставленный вопрос (teacher’s output distribution). В этом случае достигается максимальное подобие малой и большой языковых моделей (опять-таки в рамках заданной тематики), но и ресурсов тренируемый подобным образом ученик в общем случае потребит больше. Дистиллированные модели чаще всего применяют там, где для исполнения полноценных, исходных недостаточно либо вычислительной мощи устройства, либо времени (ответы требуется получать с минимальной задержкой), либо того и другого вместе. Как же производится дистилляция технически? Первый этап предусматривает подготовку большой исходной модели; её классическую тренировку на обширном и разнообразном массиве данных — с выходом на приемлемый для практической эксплуатации уровень качества выдаваемых ответов. Под качеством подразумевается как крайне высокая вероятность генерации корректного ответа на проверяемые запросы, так одновременно и чрезвычайно низкий процент галлюцинаций. Такая хорошо натренированная модель — как наглядно свидетельствует практика последних трёх с лишним лет активной фазы ИИ-революции — требует тем бóльших ресурсов, как аппаратных, так и энергетических, чем обширнее область компетенции создаваемого описанным образом генеративного ИИ. 
Иллюстрация из пионерской работы «Model Compression» показывает, насколько влияет выбор алгоритма генерации синтетических данных (а те применяются, деваться некуда, если доступных операторам реальных для тренировки модели-ученика недостаточно) на точность выдаваемых дистиллированной моделью результатов: здесь True dist — условное распределение ответов, которые генерирует модель-учитель, а остальные три картинки показывают результаты работы модели-ученика после обучения на синтетических данных, сгенерированных случайным образом (Random) либо с применением алгоритмов NBE и MUNGE (источник: Cornell University) Чтобы понять, как же именно происходит передача накопленного большей моделью знания меньшей, придётся вернуться к базовым понятиям машинного обучения, которые мы ранее уже обсуждали. Напомним, что современные БЯМ реализуются в основном плотными многослойными нейросетями, на каждом из перцептронов которых производится в общем-то тривиальная с математической точки зрения процедура — взвешенное суммирование поступающих на все его входы сигналов. Сгенерирует же после этого перцептрон свой собственный выходной сигнал или нет, определяет его функция активации. Вариантов таких функций известно множество, и для разных слоёв глубокой сети (а порой и для разных участков в одном слое) используют различные функции активации — те, что наиболее подходят для решения данной конкретной задачи. В частности, когда необходимо классифицировать объект — то есть выдать некую вероятность того, чтó именно изображено на предъявленной нейросети из фиксированного перечня вариантов (кот, пёс, вомбат или пожарный гидрант), — применяют функцию «мягкого максимума», softmax. Чтобы не выписывать здесь с пространными пояснениями пугающих формул с дробями и экспонентами, сформулируем на словах: на входе softmax принимает набор представленных вещественными числами параметров — условно это как раз выходные сигналы от последнего скрытого слоя глубокой нейросети, — а на выходе ставит каждому из них в соответствие определённую вероятность: так, что сумма всех вероятностей оказывается равна единице. Получается, что каждый распознаваемый такой нейросетью объект будет с определённой вероятностью отнесён к одной из фиксированных категорий (скажем, «кот» — 4,7%, «пёс» — 0,3%, «вомбат» — 74,2%, «пожарный гидрант» — 20,8%), на основании чего генеративная модель и вынесет своё окончательное суждение. И да, не нужно на неё обижаться, если на предъявленной для распознавания картинке была какая-нибудь пеночка, в рабочем классификаторе отсутствовавшая, — это проблема составлявших и размечавших тренировочный массив людей, а вовсе не самой модели. Так вот, функция softmax работает как свёртка результатов обработки нейросетью входных данных в позволяющее классифицировать объект распределение вероятностей по дискретному полю выходных параметров. Результаты применения softmax называют как правило «жёсткими метками» (hard labels), а входной вектор ненормализованных (т. е. тех, чья сумма не равна единице либо 100%) величин, порождённых последним скрытым слоем нейросети, — логитом (logit) или же «мягкими метками» (soft targets, soft labels). Упомянутые чуть выше два варианта дистилляции сводятся как раз к тому, что модель-ученик получает в качестве учебного материала либо «жёсткие метки», порождаемые моделью-учителем (грубо говоря, сторонние тренеры-операторы скармливают через API чужой БЯМ множество запросов, а полученные ответы передают своей — будущей дистиллированной — малой модели), либо же логиты ответов на каждый задаваемый вопрос. Во втором случае, очевидно, операторам необходим доступ непосредственно к «внутренностям» модели-учителя, зато в результате модель-ученик усваивает полное (ненормированное!) распределение вероятностей исходной модели по её рабочему классификатору, он же словарь, — те самые «мягкие метки». 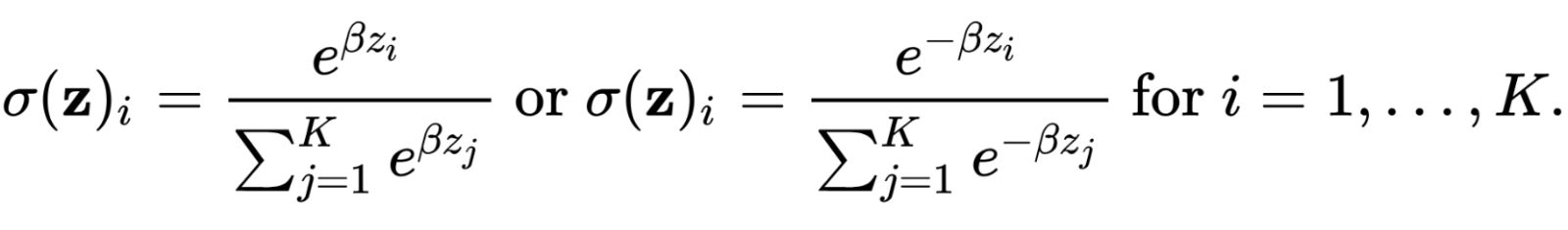
Формула нормализации вектора, состоящего из K вещественных чисел, с использованием функции softmax не так уж и сложна (источник: Wikimedia Commons) ⇡#Простор для оптимизацииЧем же «мягкие метки» лучше «жёстких»? Получая «жёсткие», модель-ученик выстраивает строго взаимно однозначные соответствия между входными данными и выходными: на этой картинке — вомбат, Волга — впадает в Каспийское море, дуб — дерево и т. д. Во множестве случаев это очень даже неплохо (и резко снижает частоту галлюцинаций при ответах на вопросы, подразумевающие некое точное знание), но для решения творческих задач чаще всего категорически неприемлемо: визуальное разнообразие тех же вомбатов, изображаемых дистиллированной «жёстким» способом моделью, поневоле выйдет крайне скудным. А вот доступ к «мягким меткам» формирует у модели-ученика более полное представление о том, как модель-учитель принимает то или иное решение, поскольку сохраняются вероятности: вот эта картинка, классифицированная в итоге как «вомбат», на 20% была похожа ещё и на пожарный гидрант, а эта вот — на целых 35%. В результате дистиллированная модель затверживает в процессе тренировки более тонкие взаимосвязи между признаками классификации обрабатываемых объектов — и это позволяет ей, в свою очередь, выдавать более качественные (на взгляд уже живого оператора) ответы на адресуемые ей запросы. Собственно, на этом описание дистилляции как таковой можно было бы и завершить — с точки зрения теории. Но дальше начинается самое интересное: практика. Эта технология «компактификации» БЯМ придумана и широко внедряется (особенно широко — сегодня, после невероятной шумихи, что была поднята вокруг DeepSeek) не из чисто академической тяги к освоению чего-то нового и интересного, а по вполне меркантильным соображениям: дистиллированные модели способны выдавать заведомо приемлемые результаты с на порядки более высокой эффективностью, чем исходные, полноразмерные. Понятно, что от затрат на первичную тренировку самих полноразмерных БЯМ всё равно никуда не деться, — но ведь их исполнение (inference) также чрезвычайно ресурсоёмко, а на слабом «железе» вроде смартфонного и вовсе едва ли не невозможно. За исключением крайне скромных по числу параметров моделей, конечно, но такие в наши дни, по сути, никому уже не интересны: в чём смысл получать неубедительные косноязычные ответы от исполняемой локально малой модели, если с того же смартфона через облако доступна большая — которая в буквальном смысле слова и сказочку занимательно расскажет, и песенку тут же сочинённую споёт? 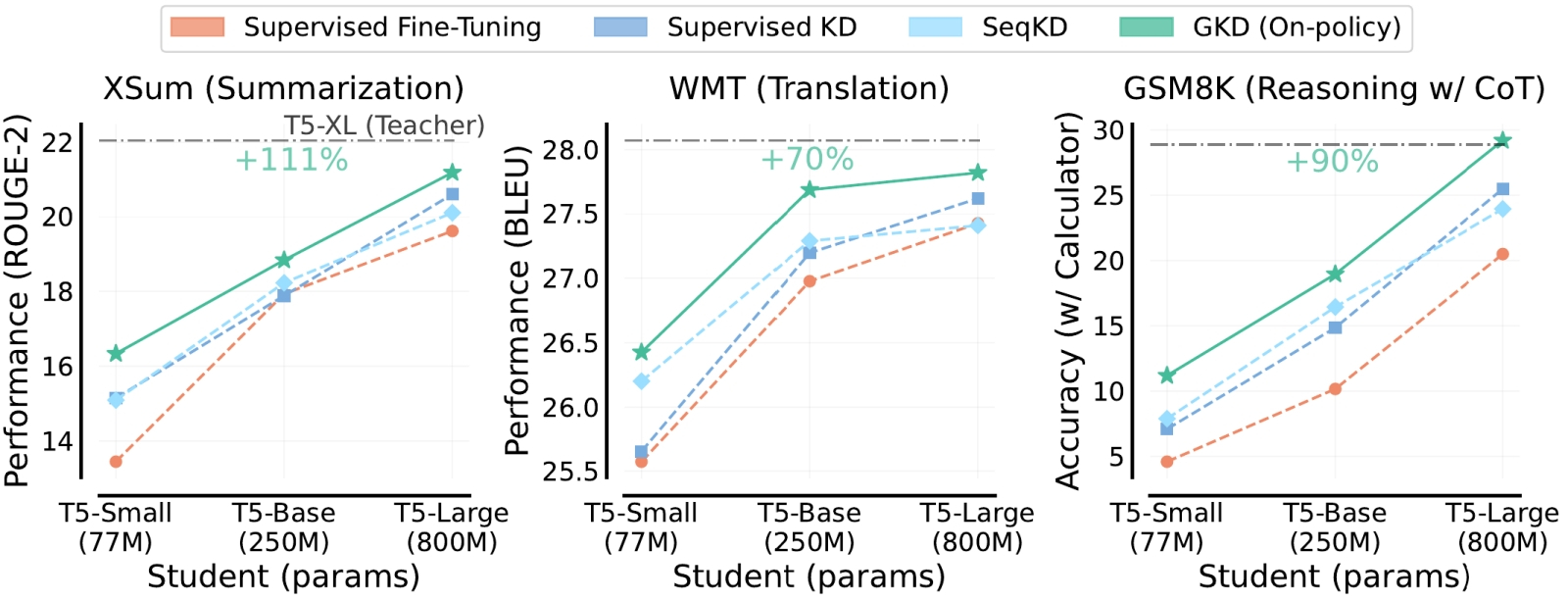
Сопоставление различных подходов к дистилляции ИИ-моделей, перечисленных в верхней части рисунка и отмеченных разными цветами на графиках: в данном случае выигрывает метод обобщённой дистилляции, Generalized Knowledge Distillation (источник: Google DeepMind) Поэтому в последнее время исследователи всё активнее стремятся оптимизировать сам процесс дистилляции — причём сразу по двум векторам: чтобы сделать ещё более компактные модели насколько возможно приближенными к полноразмерным по качеству выдачи. Для этого применяют разные способы: например, можно передавать модели-ученику не полный логит ответа учителя на каждый вопрос, а лишь несколько максимальных позиций из него (т. е. только варианты с вероятностью, что превышает некий порог). И тогда — если ограничиться, к примеру, лишь 5% от длины каждого логита (представленного, напомним, как вектор, составленный из вещественных чисел), — объём памяти, требуемой для тренировки модели-ученика, сократится по сути двадцатикратно. Ещё одна возможность оптимизировать затраты на дистилляцию сводится к разумному выбору между подходами hard labels и soft targets. Первый с очевидностью экономичнее, поскольку подразумевает передачу модели-ученику всего лишь бинарных пар «вопрос-ответ». Плюс к тому не обременённые чрезмерной склонностью к морализаторству разработчики могут использовать API конкурента в качестве учителя для своей дистиллированной модели, не испрашивая на то формального разрешения (правда, всё-таки исправно платя за сам факт доступа). В конце концов, законодательство, касающееся интеллектуальных прав в области ИИ, откровенно сыровато даже в США, до сих пор остающихся мировым лидером в этой области, и, если даже факт такого заимствования обучающего ресурса окажется вскрыт (тем более — если заимствование это было трансграничным), навряд ли у разработчиков ставшей поневоле учителем БЯМ появятся к «незаконно обученному» ученику какие-либо юридически оформленные претензии. Другое дело, что в нынешнем стремительно деглобализирующемся мире такое заимствование машинных представлений об этом самом мире у генеративного ИИ из стана геополитического соперника может выйти слишком уж расторопным операторам боком, — но эта тема выходит далеко за рамки обсуждаемого вопроса. Обучение с soft targets, в свою очередь, выгодно тем, что выходит более быстрым, поскольку модели-ученику требуется попросту меньше данных (точнее, меньше трансферов данных) — ведь в ответ на каждый запрос она получает сразу весь логит, «продуманный» за неё учителем. Дополнительный и менее явный плюс такого подхода — размывание безапелляционной уверенности дистиллированной модели в своей правоте, что сквозит порой в диалогах с ИИ. Усвоив на широкой выборке, что на каждый вопрос можно дать целый ряд различающихся по вероятности ответов, модель-ученик и свои собственные выводы станет формулировать осторожнее и мягче, допуская различные толкования и даже приводя противоречащие один другому варианты, если их вероятности близки. Очевидный же недостаток подхода soft targets — в разы, а то и в десятки раз бóльшая, чем в случае hard labels, потребность в вычислительных ресурсах в процессе тренировки. 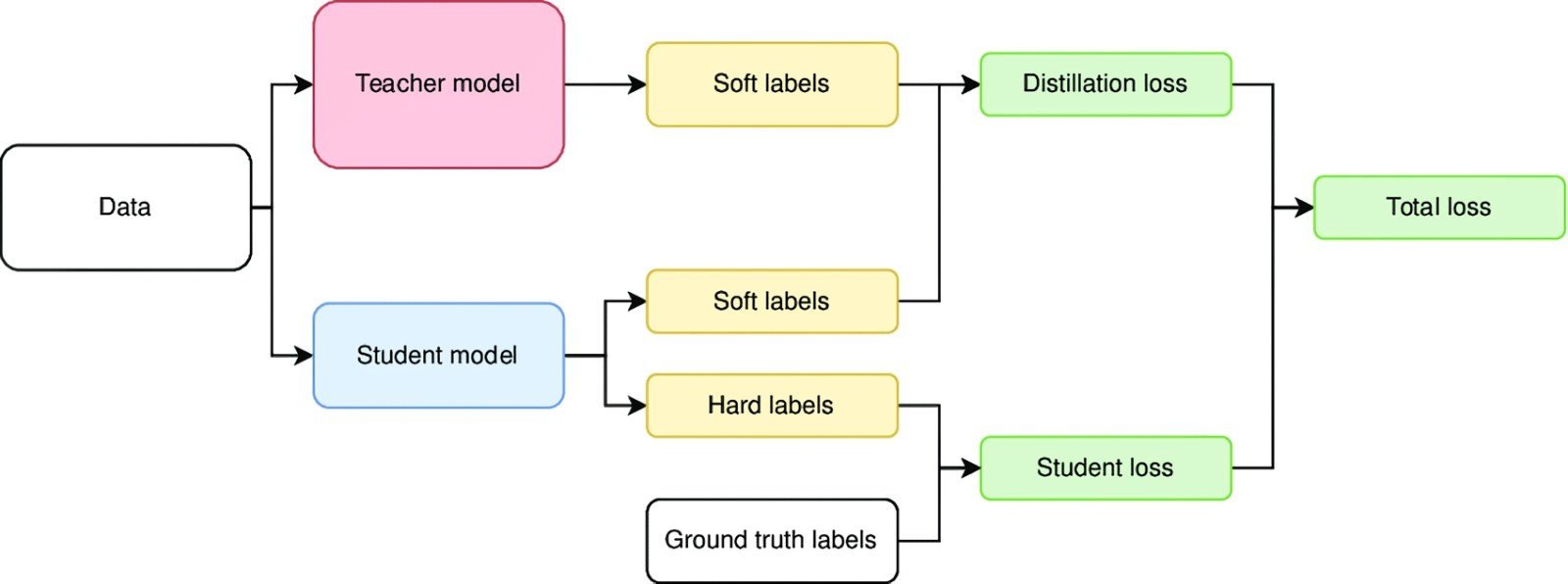
Разные подходы к дистилляции требуют различных методик (источник: ResearchGate) Впрочем, у обоих этих подходов имеется и значительный общий минус, который проявляет себя уже на этапе исполнения натренированной дистиллированной модели. Напомним, что в ходе классического обучения БЯМ та сравнивает с предложенным операторами образцом свои собственные ответы, корректируя значения весов на входах своих перцептронов. Дистиллированная же модель фактически приучается подбирать в ответ на подсказку пользователя наиболее подходящий чужой ответ — выданный куда более громоздкой, но и превосходящей её по возможностям нейросетью. По завершении же такой тренировки дистиллированная модель вынуждена иметь дело уже не с подобранными специально вопросами, а с тем, что вводят в диалоговое окно её пользователи, — а ведь там может оказаться всякое, от банально незнакомых системе слов (которым просто не были сопоставлены в процессе обучения никакие токены) до грамматических и стилистических ошибок/опечаток/неряшливостей, порой просто зашумляющих ввод, а порой способных и резко переиначить смысл запроса (как рассматривать фразу «где найти крылья для старого москвича» — как предложение набросать синопсис романа в стиле городского фэнтези или как просьбу помочь определиться с выбором автомобильной барахолки?). Такое расхождение между тренировочными и реальными запросами, с которыми дистиллированная модель попросту не научена справляться сама (поскольку тренировалась, ещё раз подчеркнём, соответствовать ответам другого ИИ на ограниченную выборку запросов), называют «сдвигом восприятия» (exposure bias) и борются с ним вполне очевидным способом — налаживая между учеником и учителем обратную связь. В рамках такого подхода student-модель даёт ответы на запросы из тренировочного массива, но не всякий раз сравнивает их с эталонными, данными учителем: иногда эта задача передоверяется как раз teacher-модели. Оценка таких самостоятельных ответов используется для корректировки весов ученической нейросети — так, чтобы выйти в итоге на некую заведомо высокую оценку от учителя, сохранив притом достаточную широту вариативности своих ответов (метод дистилляции на основе определяемой извне политики; on-policy distillation). Сегодня дистилляция представляется чрезвычайно перспективным направлением в области генеративного ИИ — поскольку энергетические и аппаратные запросы наиболее интересных с точки зрения конечного пользователя моделей давно уже перешли все разумные пределы, в том числе (и особенно) на этапе их непосредственного использования. Применяемые при этом алгоритмы непрерывно совершенствуются — достаточно упомянуть состязательную дистилляцию (adversarial distillation), обучение с группой учителей (multi-teacher distillation), основанную на графах (graph-based distillation), кросс-модальную (cross-modal distillation) и т. д. И чем дольше продержится высокий накал увлечённости искусственным интеллектом, тем выше вероятность, что именно дистиллированные модели станут в ближайшие годы развёртываться на локальных ИИ-ПК, ИИ-смартфонах и даже ИИ-элементах умного дома, снижая тем самым нагрузку на облачную инфраструктуру и фактически позволяя сделать подлинно интеллектуальным хоть робот-пылесос, хоть автономный складской погрузчик, хоть кофеварку. А вот для чего именно в доме может потребоваться действительно умная кофеварка, пусть и с дистиллированным ИИ на борту, — тема уже для совершенно особого разговора. Материалы по теме
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
|
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.





