







 MWC 2018
MWC 2018 2018
2018 Computex
ComputexВ декабре прошлого года OpenAI представила большую языковую модель o3, заявив, что она способна справиться более чем с 25 % набора сложных математических задач FrontierMath, тогда как другие ИИ-модели справлялись только с 2 % заданий из этого набора. Однако расхождения между результатами внутренних и независимых тестов вызывали вопросы о прозрачности компании и практике тестирования нейросетей.





Источник изображения: Levart_Photographer / unsplash.com
На момент анонса ИИ-модели o3 представитель компании особо отметил результаты алгоритма при решении задач FrontierMath. Однако выпущенная на прошлой неделе потребительская версия алгоритма далеко не так хорошо справляется с вычислениями. Это может указывать на то, что OpenAI либо завысила результаты тестирования, либо в нём была задействована другая, более способная к решению математических задач версия o3.
Исследователи из Epoch AI, стоящие за созданием FrontierMath, опубликовали результаты независимых тестов общедоступной версии ИИ-модели o3. Оказалось, что алгоритм сумел справиться только с 10 % задач, что значительно ниже заявленных OpenAI 25 %. Вместе с этим исследователи протестировали ИИ-модель o4-mini, более компактный и дешёвый алгоритм, который является преемником o3-mini.
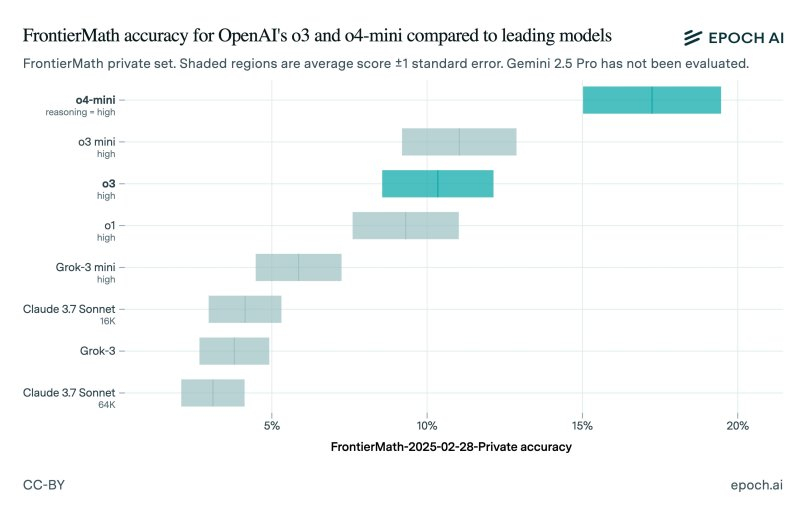
Источник изображения: @EpochAIResearch / X
Конечно, расхождение в результатах тестирования не означает, что OpenAI намеренно завысила показатели ИИ-модели. Нижняя граница результатов тестирования OpenAI практически совпадает с результатами, полученными Epoch AI. В Epoch AI также отметили, что тестируемая ими модель, скорее всего, отличается от той, что тестировалась OpenAI. Также отмечается, что исследователи задействовали обновлённую версию набора задач FrontierMath.
«Разница между нашими результатами и результатами OpenAI может быть связана с тем, что OpenAI оценивает результаты с помощью более мощной внутренней версии, используя больше времени для вычислений, или потому, что эти результаты были получены на другом подмножестве FrontierMath (180 задач в frontiermath-2024-11-26 против 290 задач в frontiermath-2025-02-28)», — сказано в сообщении Epoch AI.
По данным организации ARC Foundation, которая тестировала предварительную версию o3, публичная версия ИИ-алгоритма «представляет собой другую модель», которая оптимизирована для использования в чате/продуктах. «Вычислительный уровень всех выпущенных версий o3 ниже, чем у версии, которую мы тестировали», — сказано в сообщении ARC.
Сотрудница OpenAI Венда Чжоу (Wenda Zhou) рассказала, что публичная версия o3 «более оптимизирована для реальных случаев использования» и повышения скорости обработки запросов по сравнению с версией o3, которую компания тестировала в декабре. По её словам, это и является причиной того, что результаты тестирования в бенчмарках могут отличаться от того, что показывала OpenAI.
Источник:





