|
Опрос
|
реклама
Быстрый переход
Нейросеть Gemini начнёт объяснять пользователям, почему им стоит купить тот или иной товар
21.05.2026 [06:10],
Анжелла Марина
Компания Google представила масштабное обновление рекламных форматов в своей поисковой системе. Теперь пользователи увидят персонализированные объявления с развёрнутыми пояснениями от нейросети Gemini в ИИ-режиме (AI Mode). 
Источник изображения: Google В ИИ-режиме Google уже тестирует два формата: Conversational Discovery ads и Highlighted Answers. Первый тип рекламы генерирует индивидуальный ответ на конкретный запрос пользователя, а второй встраивает спонсорские товары в списки рекомендаций нейросети. Каждое такое объявление будет сопровождаться независимым пояснением, составленным алгоритмами Gemini на основе анализа продукта, с обязательной пометкой «Спонсировано». При этом пояснение генерируется отдельно от рекламного креатива, чтобы обеспечить объективность ответа. В ближайшие месяцы Google добавит аналогичные возможности в обычный поиск, не ограничиваясь режимом AI Mode. Разработчики внедрят формат AI-powered Shopping ads для помощи в выборе крупных покупок, таких как бытовая техника или электроника. При поиске конкретной категории товаров система даст объяснение, подчёркивающее актуальность конкретного предложения для потенциального покупателя. Дополнительно Google обновит процесс взаимодействия бизнеса с клиентами, заменив статические формы обратной связи интерактивным инструментом Business Agent for Leads. Внутри рекламного блока появится чат-бот, работающий на базе Gemini, который сможет моментально проконсультировать пользователей на основе данных с сайта рекламодателя, облегчая процесс изучения информации об услугах или образовательных программах. Изменения также затронут пилотную программу Direct Offers, запущенную в январе 2026 года при участии таких брендов, как Chewy, Gap и L’Oreal. Рекламодатели получат функцию объединения скидок, подарков и локальных купонов в единую кампанию, используя инструмент AI Brief для подбора аудитории, из которой ИИ будет собирать наиболее привлекательные наборы под каждый запрос. Параллельно туристические партнёры, включая Booking и Expedia, начнут транслировать свои спецпредложения непосредственно в интерфейсе ИИ-планировщика поездок. Обновлённые блоки Direct Offers будут естественным образом отображаться в ответах AI Mode по мере изучения вариантов для шоппинга. Для максимального охвата этих форматов компания рекомендует использовать инструменты AI Max for Search, AI Max for Shopping и Performance Max. При этом для продавцов, работающих по протоколу UCP, добавлена встроенная система оформления заказов (native checkout), позволяющая без лишних шагов конвертировать интерес пользователей в завершённые продажи. Google выпустила Gemini Omni — ИИ для генерации видео из текста, фото, аудио и любых других данных
20.05.2026 [00:06],
Анжелла Марина
Google представила новое семейство генеративных моделей искусственного интеллекта Gemini Omni, предназначенное для создания контента из любых типов входных данных. Первым продуктом линейки стала нейросеть Gemini Omni Flash, способная генерировать видеоролики на основе текста, фотографий, аудио или других видеозаписей. Алгоритм объединяет мультимодальные возможности с глубоким пониманием законов физики и реального мира. 
Источник изображений: Google Ключевым отличием новинки от существующей модели Veo, как пишет Google в своём блоге, является функция преобразования одного видео в другое. Алгоритм не просто генерирует визуальный ряд, но и позволяет редактировать исходные кадры с помощью естественного языка в диалоговом формате, сохраняя логику сцены и последовательность действий персонажей при каждом новом запросе. Как отмечает старший директор по исследованиям Google DeepMind Думитру Эрхан (Dumitru Erhan), в настоящее время система может создавать ролики со звуком продолжительностью до 10 секунд, однако компания уже работает над увеличением этого лимита.  Модель опирается на обширную базу знаний экосистемы Gemini, что позволяет ей создавать сцены с учётом исторического и научного контекста, а также точно воспроизводить гравитацию или динамику жидкостей. Технический директор Google DeepMind и главный ИИ-архитектор Google Корай Кавукчуоглу (Koray Kavukcuoglu) подчеркнул, что новая технология обладает гораздо большей информацией об устройстве мира, чем предыдущие разработки. Пользователи также получат возможность сгенерировать собственный цифровой аватар и озвучить его своим голосом. Руководитель команды разработчиков продукта Николь Брихтова (Nicole Brichtova) указала, что подобная функция интеграции собственной внешности пользовалась огромным спросом в прошлогодней модели для генерации изображений Nano Banana, с помощью которой было создано более 50 миллиардов картинок.  В целях безопасности корпорация пока ограничивает алгоритм в возможности изменять чужую речь на видео, а все сгенерированные ролики автоматически помечаются невидимым цифровым водяным знаком SynthID для проверки подлинности контента. В будущем разработчики планируют добавить поддержку вывода аудио и статических изображений. Модель Gemini Omni Flash уже доступна глобально для подписчиков тарифов Google AI Plus, Pro и Ultra через приложение Gemini и сервис Google Flow. Начиная с этой недели бесплатный доступ к генератору также открывается для пользователей в приложениях YouTube Shorts и YouTube Create App. ИИ заполоняет интернет: 35 % появившихся за последние годы сайтов были созданы нейросетями
28.04.2026 [19:39],
Сергей Сурабекянц
Группа исследователей, в которую входят учёные и энтузиасты проекта «Архив интернета», опубликовала свои выводы в статье под названием «Влияние текста, сгенерированного ИИ, на интернет». По их данным, начиная с 2022 года более трети всех сайтов создано с помощью ИИ. Исследование также показало, что контент, сгенерированный ИИ, делает интернет более позитивным и менее разнообразным. 
Источник изображений: unsplash.com Вдохновлённые теорией «мёртвого интернета» — идеей о том, что большая часть интернета теперь состоит из ботов, обменивающихся сообщениями, — команда исследователей обратилась в «Архив интернета», чтобы получить образцы сайтов за 33 месяца с августа 2022 года по май 2025 года. Проект «Архив интернета» (Internet Archive) — это некоммерческая организация, которая, как и следует из названия, занимается сохранением цифрового контента Сети для будущих поколений. «Для каждого выбранного URL-адреса мы получаем самый старый доступный архивный снимок через API сервера CDX Wayback Machine, — говорится в исследовании. — Исходный HTML-код каждого снимка загружается и сохраняется локально для последующей обработки». Исследователи использовали программное обеспечение для обнаружения ИИ Pangram v3, которое, по их данным, оказалось самым точным инструментом для определения контента, созданного нейросетью. «Опасения вызывают распространение в интернете текста, сгенерированного и обработанного с помощью ИИ, что может привести к ухудшению семантического и стилистического разнообразия, фактической точности и другим негативным последствиям, — пишут исследователи. — Мы обнаружили, что к середине 2025 года примерно 35 % вновь опубликованных сайтов были классифицированы как сгенерированные или обработанные с помощью ИИ, по сравнению с нулевым показателем до запуска ChatGPT в конце 2022 года».  «Я считаю невероятную скорость захвата интернета искусственным интеллектом просто поразительной, — заявил соавтор статьи Йонаш Долежал (Jonáš Doležal). — После десятилетий, в течение которых люди формировали интернет, значительная его часть всего за три года стала определяться искусственным интеллектом. На мой взгляд, мы являемся свидетелями масштабной трансформации цифрового ландшафта за гораздо меньшее время, чем потребовалось для его создания изначально». Исследователи проверили шесть распространённых критических замечаний в адрес текста, сгенерированного ИИ:
«Для каждой гипотезы мы определяем измеримый сигнал, вычисляем его для каждой ежемесячной выборки сайтов и проверяем, коррелирует ли он с совокупным показателем вероятности ИИ за месяцы», — пояснили учёные. Например, чтобы проверить, заполняет ли ИИ интернет ложной информацией, команда извлекла основанные на фактах утверждения с выбранных ими сайтов, а затем проверила их достоверность. Чтобы выяснить, ссылается ли ИИ на источники, команда вычисляла плотность исходящих ссылок в тексте, сгенерированном ИИ.  К удивлению исследователей, только две из шести проверенных ими теорий о влиянии текста, сгенерированного ИИ, оказались верными. ИИ делал интернет менее семантически разнообразным и в целом более позитивным, но он не вызывал распространения лжи и не устранял её источники. «Самым удивительным результатом стало то, что наша гипотеза о распаде истины не подтвердилась, — отметил Долежал. — Мы целенаправленно искали увеличение количества заведомо ложных утверждений, но не обнаружили. Но всё же возможно, что ИИ незаметно увеличивает объём утверждений, которые нельзя проверить с помощью существующих инструментов и инфраструктуры проверки фактов. Или же интернет изначально не был особенно склонен к соблюдению истины». Исследователи заявили, что продолжат изучать влияние ИИ-контента на интернет. В настоящее время они создают «непрерывный инструмент», который будет непрерывно анализировать ситуацию, а не создавать статичный «снимок» ресурсов Сети. Учёные планируют выяснить, какие типы сайтов сильнее всего наполнены нейросетевым контентом, с разбивкой по категориям и языкам, а также оценить, где наиболее ярко проявляются последствия применения ИИ.  Для Долежала подобные исследования имеют решающее значение для обеспечения полезного и продуктивного интернета. «По мере распространения контента, созданного с помощью ИИ, задача состоит в том, чтобы найти применение этим моделям, которое не приведёт просто к созданию очищенного, повторяющегося контента, — считает он. — Скорее, вместо того чтобы заставлять модели быть идеально покладистыми и уступчивыми, стоит предоставить им больше индивидуальности или конфликтности, что может помочь им выступать в качестве творческого партнёра, а не замены человеческого голоса». HP встроила в ноутбуки локальную ИИ-модель GPT, чтобы «помочь людям добиться большего успеха на работе»
26.03.2026 [18:24],
Сергей Сурабекянц
Компания HP объявила о выпуске собственной локальной системы искусственного интеллекта HP IQ. Приложение состоит из большой языковой модели, с которой можно общаться в чате, секретаря, использующего микрофоны ноутбука для записи и анализа совещаний, и инструмента HP NearSense, который позволяет обмениваться файлами с коллегами поблизости или подключаться к системе конференц-связи HP Poly. 
Источник изображений: HP «Мы видим большие возможности помочь людям добиться большего успеха на рабочем месте, — заявил руководитель отдела продуктов HP IQ Мэтт Браун (Matt Brown). — Для этого мы создаём слой интеллекта, который будет распространяться на все наши устройства и действительно воплотится в жизнь в наших ПК с искусственным интеллектом, сделав их более ценными, чем когда-либо прежде, и предоставив действительно мощную модель прямо внутри ПК». Для запуска HP IQ в рамках программы раннего доступа, которая начнётся этой весной, потребуется одна из новых моделей EliteBook или ProBook 2026 года, обозначенная как «ПК с искусственным интеллектом» с объёмом оперативной памяти не менее 24 Гбайт. Компания планирует расширить использование на другие ноутбуки HP, настольные компьютеры и видеопанели Poly Studio к лету, а новые устройства HP IQ появятся во второй половине года. В ходе демонстрации представитель HP загрузил конфиденциальный документ на ПК, а затем попросил бота IQ, основанного на gpt-oss-20b от OpenAI, проанализировать его и помочь написать обзор заседания совета директоров. Бот быстро и детально выполнил обе задачи. Затем представитель продемонстрировал функцию записи совещаний в HP IQ, которая позволяет записывать очные встречи с помощью микрофонов ноутбука, а затем использовать эти данные для создания пунктов плана действий и сводок.  На вопрос о потенциальных проблемах с конфиденциальностью Браун порекомендовал сначала запрашивать разрешение у всех участников совещания, отметив, что онлайн-совещания и так регулярно записываются. Он заверил, что HP IQ не хранит аудиозаписи и поэтому не может предоставить полную стенограмму, что могло бы быть полезной функцией для некоторых пользователей. Компания HP также продемонстрировала функцию NearSense. Она может показывать список коллег, находящихся с пользователем в одной комнате, и позволяет отправлять им файлы простым перетаскиванием. NearSense также может подключать пользователя к совещаниям или начинать совещание на конференц-оборудовании HP Poly, находящемся в той же комнате. Компания планирует добавить больше функций, таких как возможность печати на находящихся рядом принтерах с поддержкой IQ, сопряжение с гарнитурами и трансляция экрана ПК на соседние дисплеи или экраны конференц-зала. HP IQ использует различные датчики, включая Wi-Fi, Bluetooth и микрофон, для определения того, находятся ли пользователи в одной комнате с конференц-устройством Poly. Представитель HP утверждает, что технология настолько точна, что может отличить человека, находящегося в комнате от стоящего за стеклянной перегородкой. Часть процесса настройки включает в себя своего рода составление карты помещения. HP сообщила, что у неё разработан трёхлетний план развития продукта. В ближайшем будущем компания планирует сделать HP IQ совместимым с устройствами Android. Это позволит использовать функции локального обмена файлами и конференц-связи на миллионах телефонов. 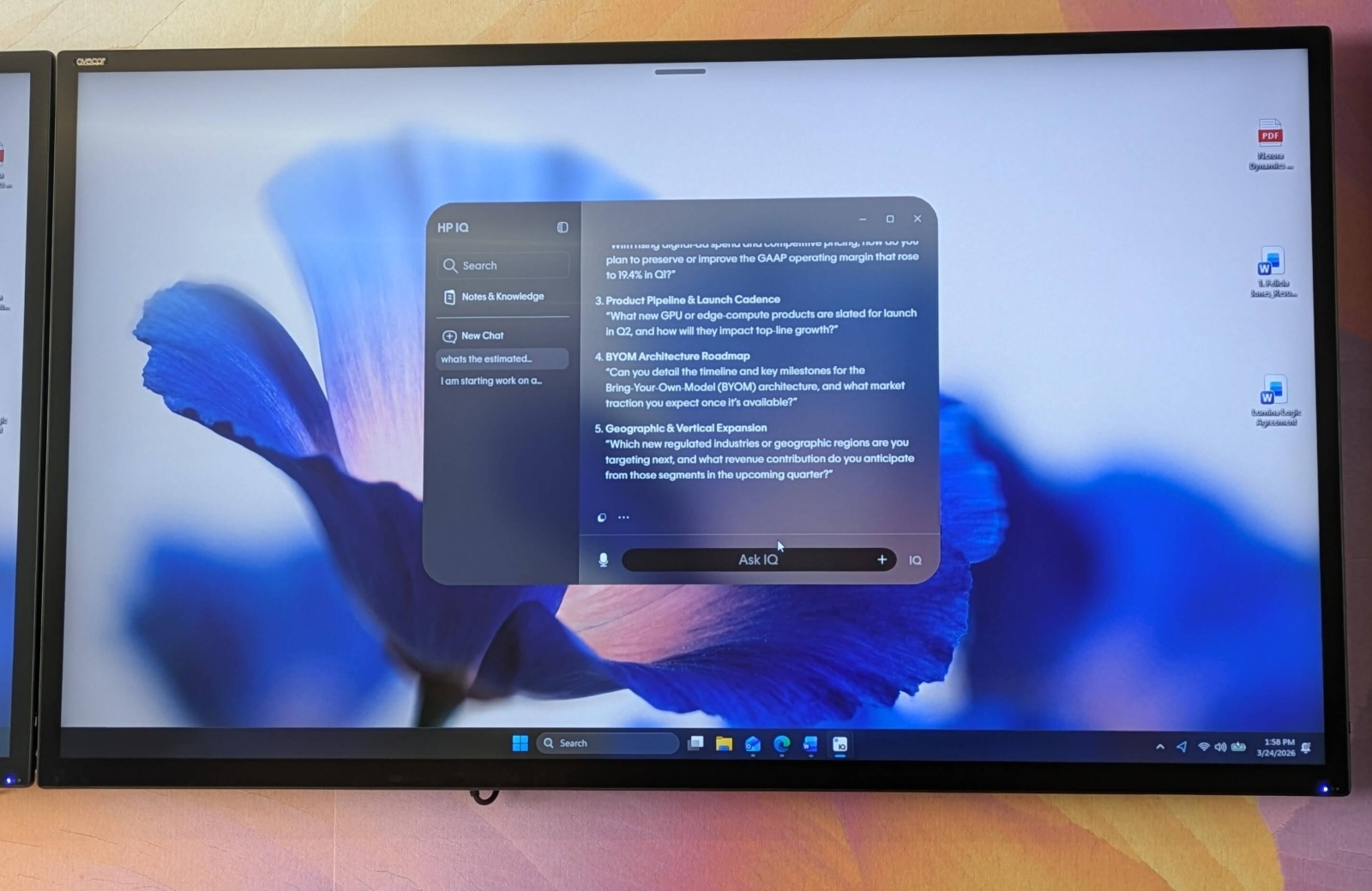 Как сообщили представители HP, модель gpt-oss-20b, используемая HP IQ для локальной обработки данных с помощью ИИ, была обучена в сентябре 2025 года. Для доступа к более актуальным данным, таким как погода или котировки акций, она обращается за новой информацией в интернет, но ИТ-отделы могут установить политику отключения этой функции. «Мы считаем, что IQ отлично сосуществует с существующими инструментами, которые могут понравиться пользователям, но это добавляет дополнительные возможности, возможность обрабатывать данные локально и безопасно прямо на их ПК, — отметил Браун. — Кроме того, он интегрируется с другими устройствами, которые они используют в офисе, таким образом, который недоступен другим инструментам». Аналитики полагают, что несмотря на то, что HP позиционирует HP IQ как систему для корпоративного сегмента, она больше подходит для малого и среднего бизнеса, чем для крупных предприятий. На рынке не так много действительно простых локальных инструментов ИИ и предложение HP упростит использование моделей ИИ на устройствах для людей, не являющихся экспертами или любителями. HP придётся постоянно обновлять локальную модель ИИ, чтобы оставаться конкурентоспособной. Для внедрения HP выбрала gpt-oss-20b, но компания может заменить её, когда появится более совершенная модель. «Яндекс Браузер» теперь будет потреблять меньше оперативной памяти благодаря ИИ-оптимизации
05.12.2025 [16:39],
Владимир Фетисов
Десктопная версия «Яндекс Браузера» начала использовать модель машинного обучения для выявления неактивных вкладок, которые не понадобятся пользователю в ближайшее время. За счёт этого алгоритм высвобождает занимаемую веб-обозревателем оперативную память компьютера.  По данным разработчиков, упомянутое нововведение позволило «Яндекс Браузеру» потреблять до 36 % меньше оперативной памяти по сравнению с Google Chrome. Это означает, что запущенные параллельно с «Яндекс Браузером» приложения или игры будут работать быстрее. Современные интернет-обозреватели позволяют держать открытыми большое количество вкладок. Чтобы не тратить ресурсы ПК на неактивные веб-страницы, браузеры обычно выгружают их из оперативной памяти. Когда же пользователь снова возвращается к одной из таких вкладок, страница повторно загружается. Разработчики задействовали ML-модель, которая определяет и выгружает из оперативной памяти неиспользуемые вкладки. В настоящее время «Яндекс Браузер» высвобождает до 1 Гбайт больше оперативной памяти по сравнению с аналогичным показателем в предыдущих версиях приложения. ML-модель обучалась на статистических данных о том, как люди взаимодействуют с браузером «Яндекса».  Алгоритм учитывает не только состояние отдельной вкладки, например, воспроизводится ли в ней видео или аудио, но и учитывает десятки других параметров. Также учитываются количество открытых вкладок, частота переключения между ними и даже расстояние между разными вкладками. Осуществлять управление функцией экономии памяти можно в настройках «Яндекс Браузера» в разделе «Производительность». Для запуска алгоритма достаточно активировать опцию «Всегда выгружать неиспользуемые вкладки из памяти». DeepSeek ответил на GPT-5 и Gemini 3 Pro — представлены мощные ИИ-модели DeepSeek-V3.2
02.12.2025 [00:37],
Андрей Созинов
Китайский стартап DeepSeek выпустил две новые открытые модели с мощными возможностями для рассуждений — DeepSeek-V3.2 и усиленную DeepSeek-V3.2-Speciale. Таким образом компания подтвердила, что Китай играет на равных с американскими лидерами в лице OpenAI и Google. 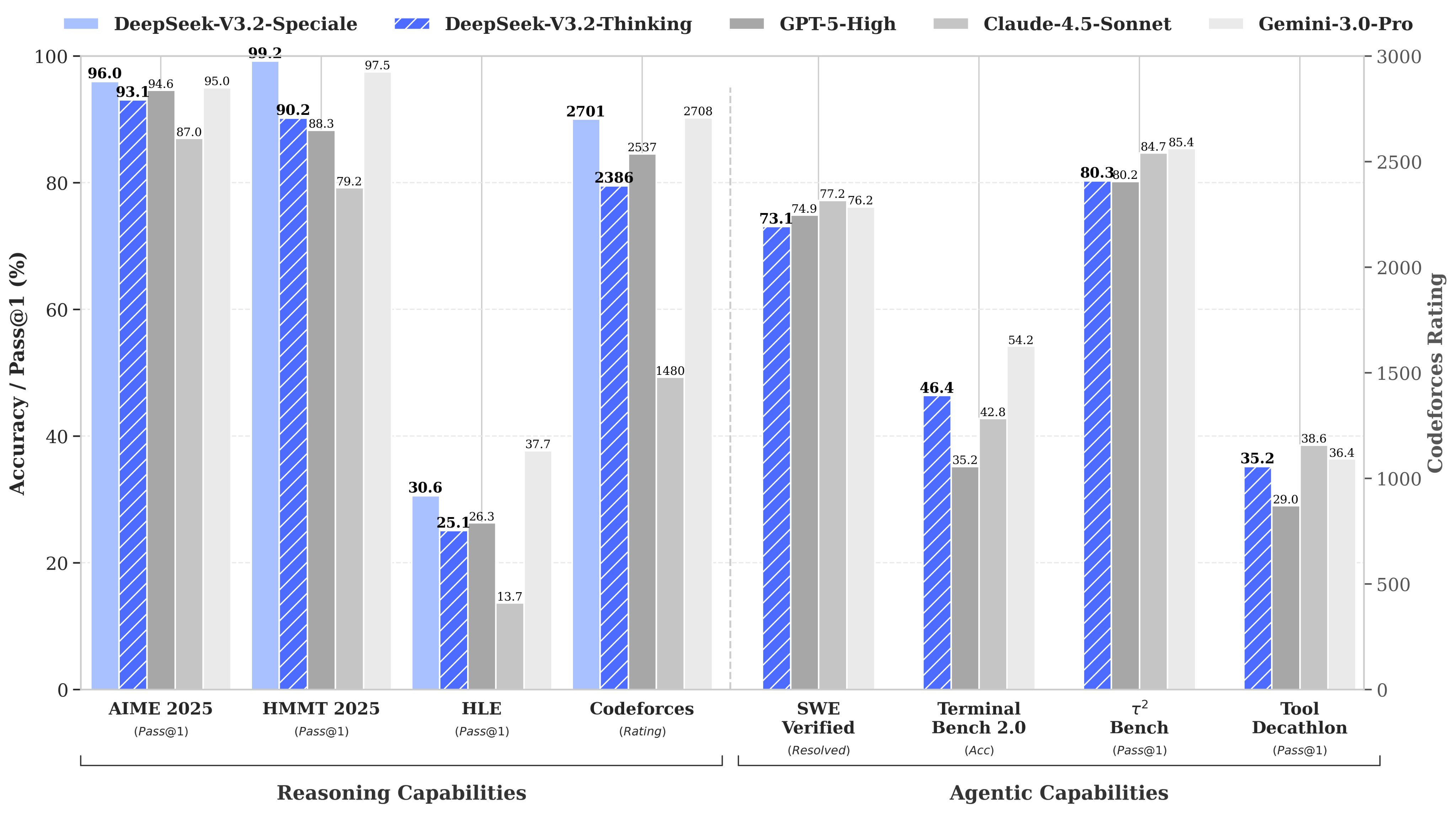
Источник изображения: DeepSeek По тестам разработчиков, модели достигают уровня GPT-5 и Gemini 3 Pro в программировании и математике. Так, DeepSeek-V3.2-Speciale взяла «золото» на Международной математической олимпиаде, Китайской математической олимпиаде, Международной студенческой олимпиаде по программированию и Международной олимпиаде по информатике. На Американском отборочном экзамене по математике DeepSeek-V3.2-Speciale показала результат в 96,0 %, тогда как GPT-5 High набрала 94,6 %, а Gemini 3 Pro — 95,0 %. В свою очередь в тесте SWE Verified, измеряющем способности ИИ к программированию, китайская новинка набрала 73,1 % (результат GPT-5 High — 74,9 %; Gemini 3 Pro — 76,2 %). 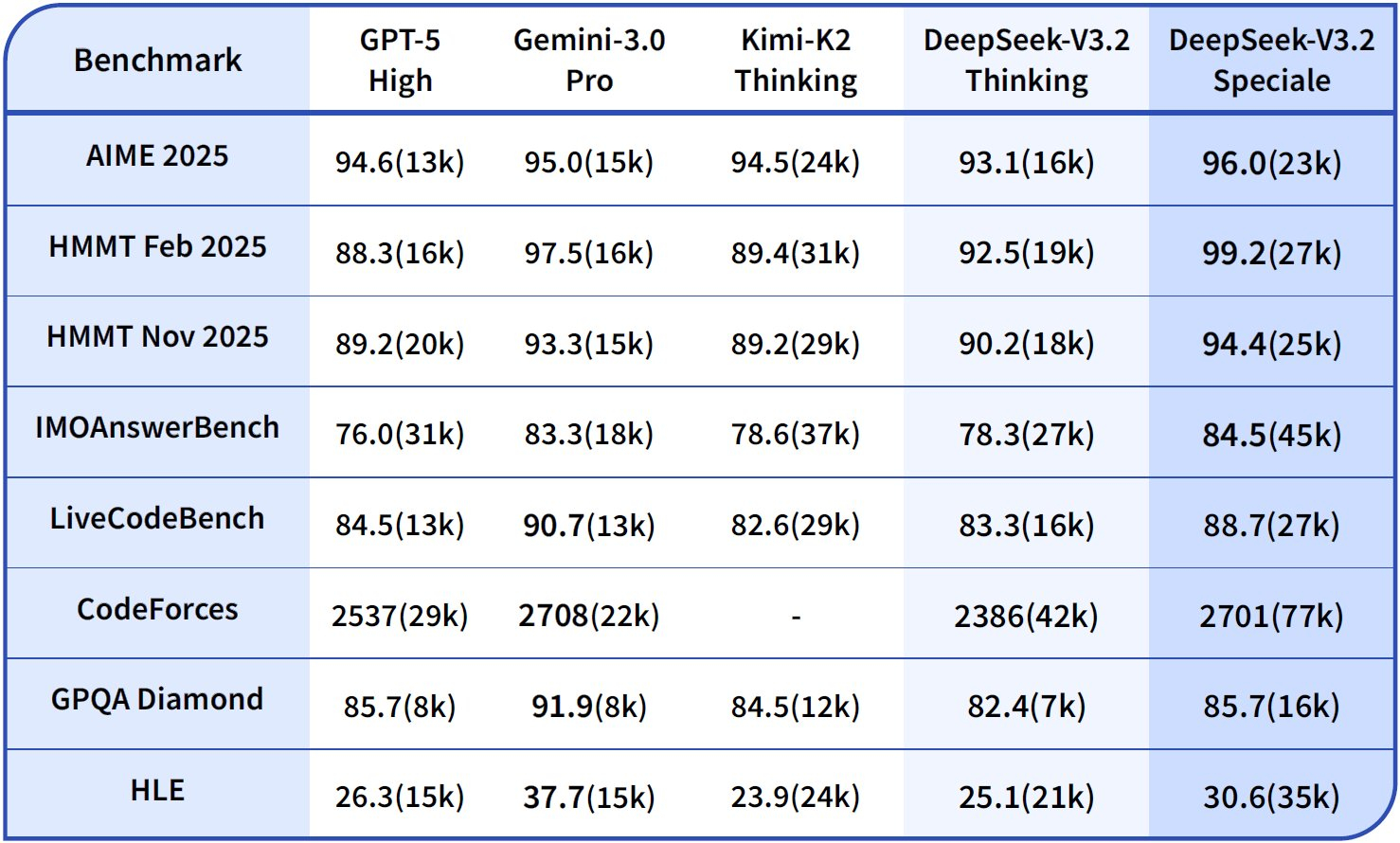
Источник изображения: DeepSeek DeepSeek утверждает, что модели серии V3.2 — это её первые нейросети, созданные для ИИ-агентов. Компания заявляет, что DeepSeek V3.2 обеспечивает производительность уровня GPT 5 при выполнении общих задач. Китайский стартап также утверждает, что DeepSeek-V3.2-Speciale обладает способностями к рассуждению, сопоставимыми с новейшей моделью Gemini 3 Pro от Google, особенно в сложных сценариях решения проблем. DeepSeek добился прорыва за счёт двух приёмов: масштабного дообучения модели с подкреплением на специально сгенерированных сложных задачах, а также DeepSeek Sparse Attention (DSA) — подходу, когда модель не перебирает все токены, а выделяет для работы только самые важные. DeepSeek-V3.2 уже доступна в приложении, на веб-сайте и в API-сервисах компании. К продвинутой V3.2-Speciale сейчас можно обращаться только через API, она предлагает максимальную мощность рассуждений для сложных задач. Китайские модели от DeepSeek или Alibaba теснят решения ведущих американских разработчиков. Согласно исследованию MIT и Hugging Face, доля скачиваний новых открытых моделей по состоянию на август выросла до 17 % у китайских разработчиков против 15,8 % у американских. Успех китайских игроков опирается на быстрый цикл обновления и фокус на открытых и эффективных моделях, которые работают на менее мощном оборудовании. Новые модели DeepSeek вышли спустя два месяца после экспериментальной V3.2-Exp и способны вновь усилить позиции Китая в ИИ-гонке. В России резко вырос спрос на специалистов по общению с нейросетями
01.12.2025 [14:13],
Владимир Мироненко
За десять месяцев 2025 года количество вакансий для специалистов с навыками написания задач для нейросетей (промптов) увеличилось на 52 %, пишет «Коммерсантъ» со ссылкой на данные рекрутингового сервиса HeadHunter. Средняя зарплата promt-специалистов составляет почти 140 тыс. руб. и может достигать 320,7 тыс. руб. и выше. 
Источник изображения: Campaign Creators/unsplash.com За этот период число вакансий специалистов данного профиля выросло до более 1,3 тыс., а количество резюме соискателей — в 3,1 раза. Больше всего предложений о работе было зафиксировано в Центральном федеральном округе — 74 % всех вакансий. Далее следуют Северо-Западный (12 %) и Приволжский (6 %) округи. По данным HeadHunter, медианная зарплата prompt-специалистов составила 138,9 тыс. руб., в Москве они в среднем получают 171 тыс. руб., в Санкт-Петербурге — 121,7 тыс. руб. На старте карьеры их заработок составляет от 60 тыс. руб. По словам независимого эксперта в сфере искусственного интеллекта Алексея Лерона, востребованность в promt-специалистах связана с тем, что с их помощью можно ускорять бизнес-процессы, снижать издержки, повышать скорость вывода продуктов на рынок и улучшать обслуживание клиентов. Также с ростом спроса на promt-специалистов появились обучающие курсы для работы с ИИ. Стоимость курса по базовым навыкам работы с ИИ может составлять 15–30 тыс. руб., профессиональные курсы для продвинутой работы с ИИ-моделями обойдутся в 100 тыс. руб., сообщил эксперт центра искусственного интеллекта «СКБ Контур» Дмитрий Иванков. По словам владельца группы продуктов Sastav Антона Михайлова, экономический эффект от деятельности таких специалистов зависит от масштаба компании, и того, как именно она использует нейросети. Он отметил, что грамотный promt-специалист может снизить затраты времени на рутинную интеллектуальную работу минимум на 10 %, что эквивалентно 1,5 «полной ставки». Экономия фонда зарплаты в компании с численностью 15 человек и средней зарплатой около 150 тыс. руб. может составить примерно 2,5–3 млн руб. в год. Это возможно при «зрелом подходе», иначе появляются риски в виде, например, некачественных решений, предупредил Михайлов. По мнению гендиректора АНО «Национальный центр компетенций по информационным системам управления холдингом» Кирилла Семиона, рост спроса на promt-специалистов — временная тенденция, так как компаниям вскоре станет понятно, что эффективнее дать такие навыки своим уже имеющимся сотрудникам. «ChatGPT — это продукт, а не друг»: подростки спрашивали ИИ о преступлениях — теперь ими занимается полиция
26.11.2025 [18:05],
Сергей Сурабекянц
Поисковые запросы в ChatGPT нескольких подростков привлекли к ним внимание правоохранительных органов, некоторые были арестованы и столкнулись с уголовными обвинениями. Поиск информации не является преступлением, но использовать Google или чат-боты, чтобы спланировать преступление или причинить кому-то вред — как минимум неразумно. Власти обратились к родителям с просьбой разъяснить детям, с какими вопросами лучше не обращаться к ChatGPT. 
Источник изображения: unsplash.com Офис шерифа округа Мэрион объявил об аресте 17-летнего подростка, обвиняемого в даче ложных показаний о похищении человека и самоубийстве. Представитель шерифа утверждает, что на ноутбуке подростка были обнаружены поисковые запросы к ChatGPT о мексиканских картелях и сборе крови без причинения боли. В округе Волусия арестован 13-летний подросток, который ввёл в ChatGPT запрос «как убить моего друга посреди урока». Полицейские получили уведомление от школьной платформы безопасности Gaggle, которая сканирует школьные аккаунты и отмечает подозрительный контент. На допросе школьник заявил, что «троллил друга, который его раздражал». Представитель шерифа обратился к родителям с просьбой «поговорить со своими детьми, чтобы они не совершали подобных ошибок». «Неразумно искать в Google или использовать ChatGPT, чтобы придумать, как совершить преступление», — говорит профессор Кэтрин Крамп (Catherine Crump). Она настоятельно рекомендует пользователям, особенно несовершеннолетним, помнить, что «ChatGPT — это продукт, а не ваш друг». По словам Крамп, ChatGPT «создан для того, чтобы быть услужливым и поддерживать» и может создать у человека ощущение личного разговора. Она признаёт, что люди должны осознавать, что ведут диалог с нейросетью и должны нести ответственность за свои действия. Но она уверена, что «эти продукты [чат-боты] были намеренно разработаны так, чтобы относиться к пользователям как к друзьям, поэтому […] здесь есть определённая доля корпоративной ответственности». Компании, занимающиеся разработкой ИИ, заявляют о неустанном совершенствовании ограничений, призванных помешать пользователям получать информацию о незаконной деятельности, но все эти барьеры не являются абсолютно надёжными. Интернет-активность, приводящая к уголовным делам, — явление далеко не новое. Но стремительное развитие чат-ботов с зачатками искусственного интеллекта, к которым миллионы людей обращаются за советами, мгновенными ответами и анализом информации, создаёт множество, мягко говоря, щекотливых ситуаций. Каждый четвёртый россиянин хотя бы раз в месяц пользуется нейросетями
21.11.2025 [19:58],
Владимир Мироненко
Каждый четвертый житель России в возрасте старше 12 лет хотя бы раз в месяц пользуется нейросетями, а хотя бы раз в неделю — 5 % населения, сообщил ресурс РБК со ссылкой на исследование единого измерителя аудитории Рунета Mediascope. Наибольшей популярностью нейросети пользуются у молодой аудитории, утверждают в Mediascope. 
Источник изображения: Igor Omilaev/unsplash.com Совокупный месячный охват ИИ-сервисов составляет 26 % населения России. В возрастной группе от 12 до 17 лет ежемесячно ИИ-сервисами пользуется 52 % населения, ежедневно — 16 %. В группе от 18 до 24 лет показатели почти такие же — лишь на 1 п.п. ниже. Среди пользователей в возрасте от 25 до 34 лет месячный охват ИИ-сервисов составляет 33 %, ежедневный — 6 %, в возрасте от 35 до 44 лет — 23 и 3 % соответственно. Самый низкий охват отмечен у людей старше 65 лет: 9 % россиян в этой возрастной группе пользуется нейросетями хотя бы раз в месяц и лишь 1 % — ежедневно. Лидируют по охвату среди россиян ИИ-сервисы «Алиса AI» и DeepSeek с месячным охватом в октябре 2025 года в размере 14 и 9 % соответственно. С отставанием в 5 п.п. в рейтинге популярности расположились GigaChat и ChatGPT. Далее следуют Perplexity AI и Character AI с охватом по 1 %. Аналитики сообщили, что по структуре охватов «Алиса AI» и GigaChat в целом соответствуют социально-демографической палитре, тогда как Perplexity AI, DeepSeek и ChatGPT активнее используют молодые мужчины. В «Яндексе» отметили, что резкий рост ежемесячной аудитории «Алисы AI» начался после презентации в октябре новой версии этой нейросети. «Меньше чем за сутки после запуска приложение "Алиса AI" попало на первую строчку в российском App Store и вошло в тройку лидеров Google Play. За первую неделю приложение скачали полтора миллиона раз», — рассказали в компании. ИИ стал чаще ходить на российские сайты — поисковый трафик от нейросетей вырос в девять раз
20.11.2025 [15:13],
Владимир Мироненко
По данным аналитической компании Digital Budget за январь–октябрь 2025 года, десктопный трафик в России с наиболее популярных нейросетей на цитируемые ими сайты вырос более чем в девять раз, пишет «Коммерсантъ». 
Источник изображения: NordWood Themes/unsplash.com Лидирует по сгенерированному исходящему трафику с долей в 24 % инфраструктура для доступа к ИИ-моделям американской Perplexity. На втором месте — GigaChat от «Сбера» (20 %), третье место — у Deepseek (19,8 %). В пятёрку также вошли ChatGPT (18 %) и китайский Qwen (13 %). Эти нейросети в сумме сгенерировали 95 % исходящего трафика пользователей. Доля «Алисы» от «Яндекса» составила лишь 0,2 %. В числе наиболее цитируемых нейросетями российских сайтов в Digital Budget назвали vc.ru, habr.com, ozon.ru, mail.ru и consultant.ru. Лидируют по количеству переходов из нейросетей ресурсы сайтов yandex.ru (доля органического трафика оценивается в 23 %), sber.ru (18 %) и google.com (17 %). Аналитики отметили, что в топ-20 цитируемых «Алисой» сайтов отсутствуют маркетплейсы и преобладают небольшие ресурсы. В Digital Budget также уточнили, что доля «нейроблока» от «Алисы» в исследовании не учитывалась, поскольку нейросеть в поиске «Яндекса» является не просто чат-ботом, а интегрированной частью самой поисковой системы. В «Яндексе» выразили несогласие с оценкой Digital Budget, хотя не стали раскрывать свои данные по исходящему трафику на цитируемые сайты. В компании отметили, что для корректного расчёта трафика необходимо учитывать каждый из сервисов, где работает «Алиса AI», добавив, что нейросеть в чате в 60 % ответов обращается к поиску «Яндекса», при этом в самом «Поиске» она не обладает собственным ранжированием. «Чтобы сайт мог попасть в число таких источников, ему нужно иметь хорошие позиции в органическом поиске», — сообщил представитель «Яндекса». Участники рынка согласились с тем, что использование генеративных ответов для поиска информации является безусловным трендом, отметив, что есть «свои нюансы». Глава Центра исследований и аналитики в «Ашманов и партнёры» Антон Тришин считает, что потеря органического трафика у части сайтов неизбежна, так как теряется необходимость переходить на них, чтобы получить ответ на запрос. Его мнение разделяет директор по продукту Servicepipe Михаил Хлебунов: «Дальнейшее развитие браузеров со встроенными ИИ-функциями приведёт к росту количества запросов от нейросетей и изменению общей картины трафика». При этом у сайтов появляется возможность влиять на этот процесс через попадание бренда или нарративов в генеративные ответы, и важной метрикой становится не только клик, но и «показ» или видимость в генеративных ответах, говорит Антон Тришин. Он назвал основным вызовом для нового тренда контроль качества информации. Гендиректор компании «А-Я эксперт» Роман Душкин объясняет большую долю GigaChat в общем сплите ИИ-чатов по сгенерированному исходящему трафику высоким качеством ответов и выдачи этой нейросети, особенно с использованием русскоязычных источников. К тому же, у GigaChat инфраструктура находится внутри страны, что служит гарантией отсутствия юридических и ИБ-рисков для коммерческих продуктов, отметил он. По мнению эксперта, малая доля «Алисы» объясняется низким качеством нейросети и плохой развитостью. Душкин предположил, что «Яндексу» вполне достаточно встроенной в браузер нейросети, поэтому развитием других её возможностей компания не занимается. ИИ-генератор видео Sora вышел на Android в США, Канаде и ещё пяти странах
05.11.2025 [06:12],
Анжелла Марина
OpenAI расширила региональный доступ к ИИ-модели Sora, выпустив версию для операционной системы Android. Первоначальный запуск Sora для iOS в сентябре, с доступом только по приглашениям и только для пользователей США, показал высокий спрос: приложение заняло лидирующие позиции в рейтинге App Store и всего за неделю было загружено более миллиона раз. Появление Sora в Google Play, как ожидается, значительно увеличит общую пользовательскую базу сервиса. 
Источник изображения: OpenAI Как сообщает TechCrunch, версия для Android полностью воспроизводит функциональность iOS-приложения, включая функцию Cameo, позволяющую пользователям создавать видеоролики с использованием собственного изображения. Готовые видео можно публиковать в ленте, стилизованной под TikTok, что даёт возможность просматривать и взаимодействовать с контентом других пользователей. По мнению аналитиков, данный шаг OpenAI направлен на усиление позиций в сегменте коротких видеороликов, где уже присутствуют такие игроки, как TikTok, Instagram✴✴ и Meta✴✴, недавно запустившая собственную ИИ-ленту под названием Vibes. Одновременно с момента своего дебюта приложение Sora столкнулось с рядом проблем. Критики обратили внимание на риски, связанные с созданием дипфейков. После первоначального запуска некоторые пользователи начали генерировать провоцирующие видео с изображением известных личностей, в частности с американским общественным деятелем и активистом Мартином Лютером Кингом (Martin Luther King). В ответ на это в прошлом месяце Sora приостановила возможность создания контента с этой персоной и усилила защитные механизмы платформы. Кроме того, компания скорректировала политику в отношении использования защищённых авторским правом персонажей, таких как Спандж Боб и Пикачу. Ранее действовавшая система opt-out была заменена на opt-in, что предоставляет правообладателям больше контроля над использованием их интеллектуальной собственности. Параллельно OpenAI участвует в судебном споре с компанией Cameo относительно созвучного названия флагманской функции Sora — Cameo. В ближайшее время планируется внедрение в Sora дополнительных функций. Среди них — создание аватаров не только людей, но и домашних животных, а также неодушевлённых объектов. Также анонсированы базовые инструменты для редактирования видео, включая возможность объединения нескольких клипов. Приложение уже можно загрузить в Google Play Store на территории США, Канады, Японии, Южной Кореи, Тайваня, Таиланда и Вьетнама. ChatGPT перестал давать медицинские и юридические консультации — для блага пользователей
01.11.2025 [17:29],
Владимир Фетисов
Участники сообщества Reddit обратили внимание на изменение политики использования популярного ИИ-бота OpenAI ChatGPT. Алгоритм больше не даёт персонализированные медицинские и юридические консультации пользователям, а также не анализирует изображения медицинского характера, включая снимки МРТ, рентгеновские снимки, фотографии кожных поражений и др. 
Источник изображения: Dima Solomin / unsplash.com Чат-бот отказывается отвечать на подобные вопросы, подчёркивая, что готов предоставить лишь общую информацию в образовательных целях, но не для постановки диагнозов или выбора лечения каких-либо заболеваний. Отмечается, что перестали срабатывать проходившие ранее уловки, когда ИИ-модель просили рассмотреть гипотетическую ситуацию, чтобы получить интересующую информацию. На этот раз срабатывает механизм защиты и ChatGPT предоставляет только общие консультации, а для более детального изучения проблемы рекомендует обратиться к соответствующему специалисту. Представители OpenAI не комментировали изменения в политике использования ChatGPT, но, скорее всего, они были внесены, чтобы избежать судебных разбирательств. По статистике, всё больше людей обращаются к чат-боту за медицинскими и юридическими консультациями, результат которых непредсказуем. При этом использование нейросетей в подобных задачах на данный момент регулируется слабо, что может создавать риски как для разработчиков, так и для пользователей. Ранее глава OpenAI Сэм Альтман (Sam Altman) предупреждал, что на беседы с ChatGPT не распространяются законы о врачебной и адвокатской тайне. Это означает, что суд может потребовать у компании раскрыть переписку, которая будет использоваться в качестве доказательств в ходе какого-либо разбирательства. OpenAI работает с регуляторами для уточнения правового статуса чат-бота, но пока результата достигнуть не удалось. «Мир движется в странном направлении»: Дуров представил Cocoon — смесь ИИ и блокчейна во имя цифровой свободы
29.10.2025 [22:29],
Андрей Созинов
На форуме Blockchain Life 2025 в Дубае основатель Telegram Павел Дуров анонсировал запуск технологического проекта Confidential Compute Open Network или просто Cocoon. Это децентрализованная вычислительная сеть, которая позволит запускать различные ИИ-сервисы и приложения безопасно и с максимальным уровнем конфиденциальности пользователей. Проект нацелен на защиту цифровой свободы людей в условиях усиливающегося государственного контроля в интернете. 
Источник изображения: Cocoon Сама архитектура проекта построена на связке децентрализованных вычислений и блокчейна TON. Сеть Cocoon будет опираться на мощности GPU, предоставляемые майнерами за вознаграждение в Toncoin (TON). Запросы на обработку данных будут автоматически распределяться по свободным в данный момент GPU. Разработчики приложений и сервисов, в свою очередь, получат возможность запускать свои нейросетевые проекты без собственных мощностей, а также без необходимости обращаться за услугами к облачным провайдерам — то есть получат в своё распоряжение относительно недорогие ресурсы. Первым большим клиентом Cocoon станет сам Telegram. А ключевым преимуществом для пользователей, по словам Дурова, станет возможность полностью анонимного взаимодействия с ИИ. «Мир движется в странном направлении», — заявил Дуров, добавив, что в последнее время люди теряют цифровые свободы. Основатель Telegram видит в децентрализованных технологиях способ сохранить эти свободы. Во время выступления Дуров также с иронией поделился, что одним из рабочих вариантов названия новой платформы было Private AI Network, сокращённо P.A.I.N — от английского pain («боль»). Telegram, как ожидается, сыграет ключевую роль в продвижении сети Cocoon, обеспечив «спрос и хайп» со стороны аудитории — напомнив о предыдущих инициативах, вроде токенизированных подарков и интеграции USDT в TON, впервые представленных на конференции Token2049 в 2024 году. Запуск сети Cocoon ожидается уже в ноябре. Пока не сообщается, сколько именно будут платить разработчики за использование сети, а также на какие вознаграждения смогут рассчитывать обладатели мощных видеокарт. Google выпустила ИИ-генератор видео Veo 3.1 с повышенным реализмом и улучшенным звуком
15.10.2025 [23:51],
Анжелла Марина
Google представила обновлённую версию ИИ-модели для генерации видео Veo 3.1. Модель генерирует более реалистичные видеоклипы, точнее следует текстовым запросам пользователя и получила значительные улучшения в области звукового сопровождения. 
Источник изображения: Google Как пишет TechCrunch, модель Veo 3.1 развивает функциональность, представленную в мае в версии Veo 3, добавляя аудиосопровождение ко всем существующим возможностям редактирования — от привязки персонажей к референсным изображениям до ИИ-генерации клипов, включая возможность продления существующего видео на основе последних нескольких кадров. По словам представителей Google, благодаря этим улучшениям создаваемые ролики становятся «более живыми». Veo 3.1 будет доступна в видеоредакторе Flow, а также в приложении Gemini, через Gemini API и централизованную платформу Vertex AI. Пользователи Flow также смогут удалять существующие объекты из видео. С момента запуска Flow в мае пользователи создали с его помощью свыше 275 миллионов видеороликов. Эра синтетических звёзд началась: ИИ-актриса Тилли Норвуд уже получает роли и набирает популярность
30.09.2025 [08:10],
Алексей Разин
Возможности современных систем генеративного искусственного интеллекта не ограничиваются созданием реалистичных статичных образов людей и коротких роликов, им вполне по силам создание целых виртуальных актёров. Агентство Xicoia утверждает, что порождённая ИИ актриса Тилли Норвуд (Tilly Norwood) стремительно набирает популярность как у зрителей, так и у профильных агентств. 
Источник изображения: Xicoia Об этом сообщила на Цюрихском кинофестивале основательница родственной студии Particle6 актриса, комик и писательница Элин ван дер Вельден (Eline van der Velden), как отмечает Variety. Она является главой специализированной студии Particle6, которая занимается производством контента с использованием технологий искусственного интеллекта. Агентство Xicoia будет продвигать виртуальных актёров на соответствующем рынке, и Тилли Норвуд (Tilly Norwood) является первым персонажем, которого агентство готово предлагать создателям контента. В ближайшие несколько месяцев будут сделаны очередные заявления в этой сфере. По словам ван дер Вельден, на первых порах люди удивлялись самой идее создания виртуальных актёров, а теперь их интересы готовы представлять на рынке труда в кинематографической сфере серьёзные агентства. Ещё в июле этого года на странице в одной из популярных социальных сетей виртуальная актриса Тилли Норвуд сообщила о выходе своей первой работы, которой стала роль в комедийной сценке AI Commissioner. Элин ван дер Вельден заявила, что студия, создавшая Норвуд, желает ей блистательного будущего: «Мы хотим, чтобы Тилли стала следующей Скарлетт Йоханссон или Натали Портман, в этом заключается цель наших действий». По словам основательницы студии, производители контента двигаются в сторону использования ИИ в силу экономических факторов. Создатели кинокартин и телепроектов ощущают, по её мнению, что ИИ не ограничивает их творческие идеи с точки зрения бюджета на съёмку — нет никаких преград для творчества, а потому ИИ будет влиять на отрасль в положительном ключе. Нужно лишь изменить точку зрения людей на этот вопрос. Как добавила ван дер Вельден, аудитории важна сама история, а не наличие у кинозвезды пульса: «Тилли уже привлекает интерес агентств и поклонников. Эра синтетических актёров не грядёт, она уже наступила». Живые актёры новость о появлении ИИ-актрисы встретили в штыки. Звезда «Крика» Мелисса Баррера предложила бойкотировать компании, которые берут на работу цифровых артистов. Её поддержали Кирси Клемонс, Мара Уилсон и другие коллеги. «А как же сотни живых молодых женщин, чьи лица вы использовали для генерации её? Вы не могли нанять ни одну из них?» — задала риторический вопрос Мара Уилсон. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


