|
Опрос
|
реклама
Быстрый переход
Нейросеть Google Veo 3 научилась создавать вертикальные видео для соцсетей
09.09.2025 [19:40],
Анжелла Марина
Генеративная модель для создания видео Google Veo 3 получила поддержку вертикального формата 9:16 и разрешение 1080 пикселей. Теперь разработчики смогут создавать контент, который идеально подходит по формату для TikTok и YouTube Shorts, причём по значительно меньшей цене. Об этом компания сообщила в официальном блоге для разработчиков. 
Источник изображения: Google Согласно сообщению, основная версия Veo 3 и её более бюджетная модификация Veo 3 Fast теперь позволяют создавать ролики в оптимальном формате для мобильных устройств и социальных платформ. Активировать вертикальный формат можно, установив параметр aspectRatio в запросах API на значение 9:16. Кроме того, обновление позволяет устанавливать более высокое разрешение по сравнению с предыдущим ограничением в 720 пикселей. Однако, как сообщает The Verge, поддержка разрешения 1080 пикселей в настоящее время доступна только для видео с соотношением сторон 16:9. В Google также заявили, что Veo 3 и Veo 3 Fast теперь «стабильны и готовы к масштабируемому использованию в Gemini API», при этом стоимость использования сервиса существенно изменилась: генерации одной секунды видео через Veo 3 снизилась с $0,75 до $0,40, а через Veo 3 Fast — с $0,40 до $0,15 за секунду. Отмечается, что добавление поддержки вертикального видео не стало большой неожиданностью, поскольку компания ещё в июне анонсировала интеграцию Veo 3 с YouTube Shorts, которая была запланирована на конец лета. Очевидно, что в ближайшее время пользователи TikTok и Instagram✴✴ Reels больше увидят в своих лентах контент, созданный помощью нейросети Google Veo 3. Представлен Dolby Vision 2 — «кинематографический» HDR, аутентичное сглаживание и ИИ-оптимизации
02.09.2025 [19:01],
Сергей Сурабекянц
Через десять лет после запуска формата Dolby Vision представлена обновлённая версия стандарта — Dolby Vision 2. Она включает новые инструменты Content Intelligence, которые используют нейросети для автоматической оптимизации изображения в зависимости от устройства и характера контента. По словам разработчика, представленное в Dolby Vision 2 интеллектуальное сглаживание изображения Authentic Motion — это «первый творческий инструмент управления движением». 
Источник изображения: Dolby Среди инструментов Content Intelligence — функция Precision Black, повышающая чёткость тёмных сцен с бережным сохранением замысла создателя фильма, и обновлённая функция Light Sense, изменяющая настройки изображения в зависимости от окружающего освещения и яркости контента. Функция Sports and Gaming Optimization обеспечит оптимальный показ спортивных трансляций и корректное отображение игрового контента. Телевизоры с поддержкой Dolby Vision 2 будут использовать двунаправленную тональную компрессию, которая предоставит создателям контента больше контроля над возможностями дисплея. Это позволит повысить яркость и чёткость изображения, а также обеспечить более насыщенные цвета. В обновлённом стандарте Dolby Vision 2 представлена технология сглаживания изображения Authentic Motion. По словам представителя Dolby, это «первый творческий инструмент управления движением», предоставляющий покадровый контроль для снижения нежелательного дрожания изображения и придания ему подлинно кинематографического вида без эффекта «мыльной оперы». Спецификация Dolby Vision 2 обратно совместима с первой версией стандарта, поэтому контент Dolby Vision будет корректно отображаться на устройствах, поддерживающих обе спецификации, а контент Dolby Vision 2 можно будет просматривать и на моделях предыдущего поколения. Однако распознавать и использовать дополнительные метаданные нового формата смогут только новейшие телевизоры с поддержкой Dolby Vision 2. По сравнению с оригинальной спецификацией Dolby Vision новая версия упростит определение возможностей телевизоров, разделив их на два уровня в зависимости от производительности. Dolby Vision 2 Max предлагает дополнительные премиум-функции для «самых производительных телевизоров», в то время как стандартная маркировка Dolby Vision 2 предназначена для более доступных моделей. Компания Hisense станет первым брендом, выпустившим телевизоры на базе чипа MediaTek Pentonic 800 с поддержкой стандарта Dolby Vision 2. Вероятно, в ближайшее время её примеру последуют и другие крупнейшие производители телевизоров. Стартап Илона Маска открыл исходный код ИИ-модели Grok 2.5 и анонсировал открытие более мощной нейросети
24.08.2025 [14:27],
Владимир Мироненко
Стартап Илона Маска (Elon Musk) в области искусственного интеллекта xAI открыл исходный код ИИ-модели Grok 2.5. Об этом предприниматель сообщил в субботу в соцсети X, добавив, что планирует примерно через шесть месяцев также открыть исходный код модели Grok 3. 
Источник изображения: Mariia Shalabaieva/unsplash.com «Модель Grok 2.5, которая была нашей лучшей моделью в прошлом году, теперь доступна с открытым исходным кодом», — написал Илон Маск в соцсети Х. Исходный код Grok 2.5 доступен для просмотра и скачивания через Hugging Face. Ранее в этом месяце Маск заявил, что Grok 5 выйдет до конца этого года и будет «невероятно хорош». До этого он сообщил, что Grok 4 оказался умнее представленной 7 августа модели GPT-5 от OpenAI в некоторых тестах, в частности, в бенчмарке ARC-AGI, измеряющем способность к абстрактному мышлению и логическим рассуждениям. В ARC-AGI-2, который оценивает логику, Grok 4 набрал 15,9–16 %, что почти вдвое больше, чем 9,9 % у GPT-5. В менее сложном тесте ARC-AGI-1 Grok 4 набрал 66,7 % против 65,7 % GPT-5. Эти результаты свидетельствуют о преимуществе Grok 4 в решении сложных задач, пишет ресурс DEV Community. В математических задачах Grok 4 Heavy набрал 100 % на AIME 2025, а GPT-5 — 94,6 %. Хотя обе нейросети показали хорошие результаты, максимальный результат Grok 4 подчёркивает его сильные стороны в этой области, отметил DEV Community. Нейросети для карьеры и во время обучения: переоценены или необходимы
14.08.2025 [10:23],
Андрей Созинов
Дискуссии об искусственном интеллекте всем надоели, но при этом становятся только актуальнее. Особенно остро проблема стоит в сфере образования: недавнее исследование Массачусетского технологического института показало, что у участников, которые пользовались ChatGPT для написания эссе, уровень мозговой активности был заметно ниже в сравнении с теми, кто использовал поисковик или писал текст самостоятельно. 
Источник изображения: «Яндекс» Авторы пришли к выводу, что избыточное использование нейросетей может ослабить нейронные связи и способности к глубокому обучению и критическому мышлению. Сейчас учёные изучают влияние ИИ конкретно на процесс программирования. Первые данные говорят, что при написании кода мозговая активность снижается даже сильнее, чем при написании текста. Это поднимает важный вопрос: насколько нейросети действительно вредят обучению и стоит ли их использовать. В этом материале разбираем, когда ИИ мешает развивать навыки, а когда помогает учиться быстрее и эффективнее. И главное: стоит ли избегать нейросетей любыми средствами, чтобы стать по-настоящему ценным специалистом. Когда нейросети действительно вредныСамый очевидный вред от ИИ в обучении — подмена понимания копированием. Студент просит ChatGPT написать алгоритм сортировки, копирует код, сдаёт задание, но так и не понимает, как сортировка работает. В итоге по окончании обучения этого навыка у него не будет, а работа рискует быть парализованной при отсутствии доступа к ИИ. Другая опасность — ложное ощущение компетентности. Нейросети могут создать иллюзию того, что программирование сводится лишь к умению правильно формулировать запросы. На собеседовании, где нужно решить задачу без подсказок, такой подход не сработает. Существуют и технические риски. ИИ может генерировать код с уязвимостями безопасности, предлагать устаревшие решения или создавать неоптимальные алгоритмы. Новичок, не обладающий базовыми знаниями, просто не сможет распознать и исправить подобные проблемы. Нейросети как ускоритель обученияНейросети могут мгновенно объяснить сложную концепцию несколькими способами, пока один из них не станет понятным. Они могут разобрать чужой код по строчкам, показать альтернативные подходы к решению, помочь найти и исправить ошибку. Особенно ценно использование ИИ при изучении новых технологий. Вместо часов чтения документации можно быстро получить обзор основных возможностей библиотеки, примеры использования и объяснение архитектурных принципов. Это не заменяет глубокое изучение, но даёт отличную отправную точку. Нейросети также помогают преодолеть психологические барьеры. Новичку часто страшно задать «глупый» вопрос наставнику или в чате команды. ИИ же терпеливо ответит на любой вопрос, не осуждая уровень знаний. Адаптация образовательных платформВ онлайн-образовании не игнорируют тренд, а интегрируют ИИ в процесс обучения. Например, в «Яндекс Практикуме» студенты могут задать любой вопрос по теме урока, а нейросеть даст ответ с учётом контекста курса — она знает, какие темы студент уже изучил и с чем может возникнуть путаница. Также студентам помогает умный поиск по материалам, встроенный в платформу. Можно написать любой запрос в рамках курса — и система быстро подберёт релевантные темы. Это экономит время на поиск нужной информации и позволяет сосредоточиться на обучении. Такой подход показывает, как ИИ может улучшить образовательный процесс, не заменяя преподавателя, а дополняя его. Нейросеть обеспечивает быструю поддержку в любое время, помогает самостоятельно находить ответы и быстрее ориентироваться в материалах. Обучение работе с ИИ как отдельный навыкЧтобы помочь новичкам с освоением нейросетей, сервисы онлайн-образования предлагают специализированные курсы. Бесплатный курс «Яндекс Практикума» «Нейросети для начинающих» даёт базовое понимание принципов работы ИИ и показывает возможности их применения. Пройти курс можно за 2 часа. Для более глубокого погружения есть двухмесячный курс «Нейросети для работы». Он показывает, как настроить ИИ-инструменты под конкретные задачи, избежать типичных ошибок и максимально эффективно использовать возможности искусственного интеллекта в реальных проектах. Первый модуль можно пройти бесплатно. Рынок труда и конкурентные преимуществаРаботодатели уже сейчас ожидают от кандидатов умения работать с ИИ-инструментами. Это не означает, что нужно быть экспертом по машинному обучению, но базовые навыки использования нейросетей для повышения продуктивности становятся стандартом. Джун, который эффективно использует GitHub Copilot, Phind, Claude и другие инструменты, сможет быстрее адаптироваться к рабочим процессам, эффективнее решать задачи и лучше понимать код коллег. В долгосрочной перспективе это прямой путь к карьерному росту. Принципиальный отказ от нейросетей не приведёт к позитивным результатам. В лучшем случае это замедлит профессиональное развитие, в худшем — сделает специалиста неконкурентоспособным на рынке труда. В IT игнорирование ИИ равносильно добровольному отказу от инструментов, которыми уже пользуются все остальные участники рынка. ИИ начнёт выявлять ямы на дорогах России — ремонтом займутся люди
13.08.2025 [11:12],
Владимир Фетисов
Компания NtechLab, являющаяся технологическим партнёром госкорпорации «Ростех», занимается разработкой системы по выявлению дефектов на дорогах, в основе которой технологии искусственного интеллекта. Эта система поможет снизить количество ДТП и повреждений автомобилей. 
Источник изображения: Denys Nevozhai / Unsplash «Нейросеть может выявлять ямы, выбоины, отсутствие люков и сломанные барьерные ограждения на трассах. Система оповещает об этом соответствующие инстанции, которые должны принять меры по устранению дефектов», — говорится в сообщении NtechLab. Нейросеть анализирует видеопотоки с камер, установленных в общественном наземном транспорте, за счёт чего она может с высокой точностью выявлять дефекты в любой точке города. В дополнение к этому система фиксирует неработающие уличные фонари, испорченные дорожные знаки, скопления мусора вблизи дорог, переполненные урны для мусора на остановках и повреждения на придорожных зданиях. Гендиректор NtechLab Алексей Паламарчук рассказал, что создаваемая компанией система «поможет сделать городскую среду ещё более комфортной и безопасной». Он отметил, что продукт прост в установке и эксплуатации, для его использования не требуются значительные инвестиции от заказчиков. В дополнение к этому ИИ-система компании позволит оптимизировать распределение бюджетных средств, а также будет способствовать улучшению имиджа города за счёт поддержания чистоты и порядка. Мобильная графика Arm станет производительнее — в GPU встроят нейронные ускорители
12.08.2025 [17:58],
Сергей Сурабекянц
Arm сообщила, что следующее поколение её мобильных графических процессоров, которое выйдет в 2026 году, будет использовать нейронные технологии, обеспечивающие более высокое качество изображения и повышенную производительность. Компания также представила программный интерфейс (API) для разработчиков, чтобы они могли начать работу с ним уже сегодня, не дожидаясь появления нового оборудования. 
Источник изображений: Arm В первую очередь Arm рассматривает использование нейронного ускорения для масштабирования графики до более высокого разрешения без ущерба для производительности. Среди других предполагаемых сценариев — удвоение частоты кадров с помощью интерполяции и повышение качества изображения за счёт трассировки пути в реальном времени на мобильных устройствах с меньшим количеством лучей на пиксель. «Поскольку ИИ всё больше сливается с графикой реального времени, нам необходим ИИ на базе графических процессоров, который был бы интегрированным, производительным и, что особенно важно, энергоэффективным. Упрощение разработки ИИ на графических процессорах для разработчиков стало движущей силой технических инноваций, о которых мы здесь говорим», — заявил научный сотрудник Arm в области ИИ и платформ для разработчиков Герайнт Норт (Geraint North). Arm отказалась раскрывать подробную техническую информацию о нейронных ускорителях до анонса следующего поколения графических процессоров Mali. Известно лишь, что они будут размещаться в шейдерных ядрах, а производительность нейросетей будет масштабироваться в зависимости от их количества в конкретной реализации GPU. Архитектура Arm пятого поколения предусматривает конфигурации вплоть до 16 ядер. В прошлом году Arm анонсировала технологию масштабирования Arm Accuracy Super Resolution (Arm ASR), позволяющую игре рендерить изображение с более низким разрешением и применять алгоритм масштабирования, снижая затраты на обработку кадра при сохранении качества. Новая технология Neural Super Sampling (NSS) на базе аппаратного нейронного ускорителя способна масштабировать картинку с 540p до 1080p за 4 мс на кадр и снижать нагрузку на графический процессор на 50 %.  «Рендеринг в реальном времени с использованием искусственного интеллекта быстрее, чётче и энергоэффективнее. Таким образом, NSS может создавать выходные данные того же качества с использованием входных данных более низкого качества или даже более высокого качества с теми же входными данными», — заявил Норт. Arm также представила технологии Neural Frame Rate Upscaling (NFRU) и Neural Super Sampling and Denoising (NSSD). NFRU повышает частоту кадров путём создания промежуточного кадра из двух последовательных кадров. «Нейронная сеть также тесно связана с новым оборудованием, которое мы добавим к нашим графическим процессорам для ускорения генерации векторов движения, отслеживающих перемещение пикселей между кадрами. Это позволит очень дёшево масштабировать контент, работающий с частотой 30 кадров в секунду, до 60 кадров в секунду», — пояснил Норт. Технология NSSD предназначена для обеспечения качества изображения трассировки пути, которая, по словам Норта, слишком затратна с точки зрения вычислительных ресурсов даже на настольных системах: «Когда вы объединяете трассировку пути с нейронной сетью, вы фактически можете проецировать лишь небольшое количество лучей на пиксель в сцену, и вы можете использовать нейронную технологию для добавления недостающих деталей. Таким образом, нейронная сеть может экстраполировать данные не только из соседних пикселей, но и из предыдущих кадров». Все эти новшества доступны разработчикам уже сегодня благодаря набору инструментов для разработки нейронной графики. В комплект входят плагины для Unreal Engine, позволяющие интегрировать нейронный суперсэмплинг в игру «всего за несколько кликов». Модели доступны в открытых форматах на GitHub и Hugging Face. Также доступна полная эмуляция расширений Arm ML Vulkan для ПК, что позволяет программистам использовать весь стек приложений, не дожидаясь выпуска мобильных чипов. 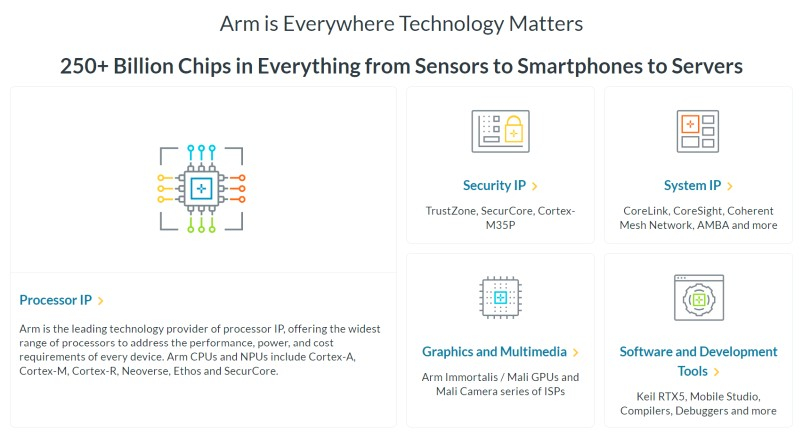 Arm — не первая компания, внедряющая нейронные технологии в чипы смартфонов. В частности, ИИ уже широко используется для управления функциями камеры. Компания Qualcomm, лицензиат Arm, расширяет возможности искусственного интеллекта своих смартфонных платформ благодаря нейронным процессорам (NPU). На прошлогодней выставке MWC компания Qualcomm продемонстрировала большую языковую модель с 7 млрд параметров, работающую на Android-смартфоне, и представила свой AI Hub для разработчиков. AMD обучила ноутбуки на Ryzen AI безоблачной генерации изображений в Stable Diffusion
21.07.2025 [19:32],
Анжелла Марина
Компании AMD и Stability AI объявили о запуске оптимизированной версии ИИ-модели Stable Diffusion 3.0 Medium, адаптированной для работы на устройствах с нейропроцессорами (NPU). Это позволит владельцам таких устройств генерировать изображения и обрабатывать текст локально — прямо на ноутбуках с процессорами AMD Ryzen AI со встроенным нейропроцессором на архитектуре XDNA 2, без необходимости использования мощной видеокарты. 
Источник изображений: AMD Ранее, на выставке Computex 2024, AMD совместно со Stability AI представила первую версию Stable Diffusion, оперирующую числами в представлении Block FP16, с которым NPU хорошо справляется — SDXL Turbo. Она достигла уровня точности FP16 при производительности, будто работала с числами INT8. Новая версия SD 3.0 Medium также выполнена в этом формате и оптимизирована под NPU-архитектуру, обеспечивая высокое качество генерации изображений при относительно невысоких аппаратных требованиях, сообщает TechPowerUp.  Модель FP16 использует 9 Гбайт памяти и может работать на ноутбуках с 24 Гбайт оперативной памяти. Система использует двухэтапный процесс обработки на базе AMD XDNA 2 NPU, увеличивая разрешение выходного изображения с 2 Мп (1024 × 1024 пикселей) до 4 Мп (2048 × 2048 пикселей).  Ранее приложение Amuse — программный инструмент для ИИ-генерации изображений — использовало только GPU для запуска Stable Diffusion Medium, что ограничивало его доступность. Теперь пользователи могут выбирать между GPU и NPU в зависимости от задач и возможностей устройства. Для тестирования новой функции необходимо установить последнюю версию драйвера AMD Adrenalin, а также бета-версию Amuse 3.1 от Tensorstack (Amuse AI). После этого, в режиме EZ Mode, нужно перевести ползунок в положение HQ и активировать опцию XDNA 2 Stable Diffusion Offload. «Яндекс» открыл бесплатный доступ к своей лучшей нейросети YandexGPT 5 Pro через «Чат с Алисой»
01.07.2025 [11:54],
Владимир Мироненко
«Яндекс» сделал бесплатной свою нейросеть «Чат с Алисой» на базе большой языковой модели (LLM) YandexGPT 5 Pro, ежемесячная плата за доступ к которой составляла 100 руб., сообщил ресурсу РБК представитель компании. Как полагают в «Яндексе», это поможет привлечь новых пользователей, а также тех, что сейчас использует нейросети зарубежных разработчиков. 
Источник изображения: «Яндекс» Нейросеть доступна на её сайте, главной странице «Яндекса», в приложениях «Алиса» и «Яндекс с Алисой», а также в «Яндекс Браузере» для Android (обновление для десктопного «Браузера» и версии для iOS выйдет позже). По данным компании, «Алисой» в поиске и в чате ежемесячно пользуется более 43 млн зарегистрированных пользователей «Яндекса». Нейросеть поддерживает русский и английский языки. Пользователям доступен режим рассуждений и интернет-поиск по нескольким источникам. В бесплатном режиме обеспечена поддержка файлов в форматах pdf, txt, doc и docх, а также возможность генерировать изображения на улучшенной модели YandexART 2.5. Компания сохранит платную версию YandexGPT 5 Pro, но с другим набором функций. Нейросеть будет учитывать информацию о пользователе, которую тот сообщал о себе раньше, что сделает общение с «Алисой Про» более естественным. Чтобы ответы «Алисы» стали более релевантными, нужно авторизоваться в «Яндексе» в «Чате с Алисой» или сказать «Алиса, давай познакомимся» умной колонке или «ТВ Станции ». Также в «Алисе Про» доступен обновленный диалоговый тренажер английского языка, Live-режим (умная камера с возможностью задавать вопросы «Алисе»), возможность пользоваться наиболее мощными нейросетями компании без ограничений даже в периоды пиковой нагрузки, а также детские сценарии и образовательные игры, созданные совместно с «Яндекс Учебником». В настоящее время в мире по размеру аудитории и качеству генераций лидируют модель GPT-4o от OpenAI, Claude 3.5 Sonnet от Anthropic, китайские Qwen Max (Alibaba), а также R1 (DeepSeek), сообщил Ярослав Беспалов, руководитель группы «Мультимодальные архитектуры ИИ» лаборатории «Сильный ИИ в медицине» института AIRI. С учётом того, что китайский DeepSeek бесплатен, конкурировать с ним можно, только если предоставить бесплатный доступ к своим нейросетям, считает гендиректор VisionLabs («дочка» МТС) Дмитрий Марков. Он отметил, что помимо качества DeepSeek отличается простотой доступа и бесплатным пользованием, поэтому, если сейчас пользователи привыкнут к этой ИИ-модели, то переманить их в будущем будет намного сложнее. Эксперт также указал на уникальное преимущество российских нейросетей для бизнеса: они лучше иностранных справляются с рядом конкретных прикладных задач, потому что обучены на определённых данных. «Если “Яндекс” добьется того, что его нейросети будут что-то лучше делать на русском, то компания сможет переманить часть аудитории иностранных сервисов в России», — заявил Марков, добавив, что расширить аудиторию «Яндексу» может помочь совместимость с популярными сервисами и надёжность хранения данных с учётом того, что среди его пользователей большое число россиян. В «Яндексе» отметили, что мощностей инфраструктуры компании достаточно для резкого роста пользователей, а в случае чрезмерной нагрузки «Алиса» будет отвечать с помощью более простой модели Yandex GPT 5 Lite. Для сравнения, DeepSeek во время пиковых нагрузок может не отвечать. Alibaba представила ИИ-модель Qwen VLo, которая умеет редактировать картинки
28.06.2025 [06:27],
Анжелла Марина
Alibaba представила ИИ нового поколения, который существенно упростит пользователям создание и редактирование изображений на основе текстов и визуальных материалов. Модель, получившая название Qwen VLo, станет частью серии ИИ-сервисов под брендом Qwen и позволит не только генерировать изображения по текстовым запросам, но и модифицировать уже существующие. 
Источник изображения: Copilot Как сообщает Bloomberg, новая модель не только анализирует данные, но и способна на их основе генерировать высокачественные изображения. Например, пользователь может ввести текстовой запрос, а после генерации попросить добавить какие-либо детали, например, шляпу для кота. Также можно загрузить готовое изображение и «дорисовать» его. Одной из ключевых особенностей Qwen VLo является технология прогрессивной генерации, при которой пользователь может наблюдать за процессом создания изображения шаг за шагом. Например, можно отправить запрос «Создай картинку милого кота», и система начнёт формировать изображение прямо на глазах. В своём блоге компания также отметила, что новая версия модели не просто «воспринимает окружающий мир, но и способна создавать высококачественные реконструкции на основе этого восприятия». Это соотносится с тем, что ранее генеральный директор компании Эдди Ву (Eddie Wu) заявлял, что основной целью Alibaba на текущий момент является разработка сильного искусственного интеллекта (AGI), который будет обладать уровнем развития человека. Модель Qwen VLo позиционируется как конкурентный ответ на другие решения рынка, включая продукты OpenAI. Однако Alibaba также сталкивается с агрессивной конкуренцией внутри Китая, например, со стороны DeepSeek, которая произвела в индустрии фурор, заявив о создании мощной модели всего за несколько миллионов долларов. В ответ компания Alibaba ещё активнее стала добавлять новые функции для обработки текстов, изображений, аудио и видео, также оптимизируя модель и для работы на смартфонах. Runway готовит платформу для создания игр с помощью ИИ
28.06.2025 [06:03],
Анжелла Марина
ИИ-стартап Runway, чья оценочная стоимость составляет $3 млрд, намерен расширить горизонты своего влияния. После крупного успеха нейросети в киноиндустрии, компания планирует запустить платформу для генерации видеоигр. 
Источник изображения: Runway По словам генерального директора компании Кристобаля Валенсуэлы (Cristóbal Valenzuela), первые пользователи смогут протестировать новый продукт уже на следующей неделе. Пока это просто минималистичный интерфейс, позволяющий взаимодействовать с моделью в текстовом чате и создавать изображения, но в дальнейшем появится возможность генерировать полноценные игры, сообщает The Verge. Runway в настоящий момент активно ведёт переговоры с крупными игровыми студиями о внедрении своих технологий в производственные процессы и о доступе к их базам данных для обучения моделей. По мнению Валенсуэлы, игровая индустрия сейчас находится примерно в той же точке, в которой находилась киноиндустрия пару лет назад, когда впервые столкнулась с применением ИИ в процессе создания контента. Тогда тоже наблюдалось немалое сопротивление, но со временем ИИ-технологии начали активно внедряться в работу. Глава Runway уверен, что сейчас процесс принятия ИИ в играх будет происходить быстрее. Компания уже имеет опыт сотрудничества с крупнейшими игроками развлекательного рынка. Например, её технологии применялись при производстве сериала Amazon «Дом Дэвида», также продолжается сотрудничество почти со всеми голливудскими студиями и большинством компаний из списка Fortune 100. Валенсуэла считает, что если Runway может помочь студии ускорить производство фильма на 40 процентов, то аналогичный эффект возможен и в разработке игр. «Сбер» научил GigaChat рассуждать над запросами, но функцию пока открыл не всем
25.06.2025 [16:14],
Владимир Фетисов
Функция рассуждений с доступом к актуальным данным в GigaChat стала доступна бизнес-клиентам «Сбербанка» в формате on-premise, когда программное обеспечение разворачивается на собственных серверах заказчика. Об этом в рамках конференции GigaConf рассказал вице-президент «Сбербанка» Андрей Белевцев. 
Источник изображения: sber.ru После активации функции рассуждений система анализирует текстовый запрос для определения наиболее подходящего способа обработки, после чего автоматически подключает соответствующий режим, например, работу с внешними ссылками или документами. За счёт этого нейросеть быстро адаптируется к поставленной задаче, обеспечивая точный и комплексный ответ без необходимости выбирать что-то вручную. «GigaChat выходит на новый уровень — теперь модель способна рассуждать и объяснять свои выводы. Это значит, что наши клиенты смогут не только получать точные ответы, но и понимать ход мыслей системы, прослеживая логику её решений», — сообщил господин Белевцев. Он добавил, что новая функция станет особенно ценной в обучении, поскольку в сложных вопросах важен не только результат, но и процесс его получения. Также было сказано, что для всех пользователей GigaChat функция рассуждений станет доступна в следующем месяце. Нейросеть победила квантовую интерференцию и превзошла учёных в анализе данных по бозону Хиггса
24.06.2025 [13:08],
Геннадий Детинич
Пока учёные прогнозировали результаты исследования бозона Хиггса на Большом адронном коллайдере на 15 лет вперёд, нейросеть выполнила всю работу за них. Теперь необходимо строить новый прогноз по экспериментам, что требует разработки новых опытов и условий их проведения. Но в этом и заключается прелесть ситуации: наука может заметно быстрее продвигаться вперёд к пока ещё неизвестной физике. 
Источник изображения: CERN Эта история началась в 2017 году, когда один из руководителей коллаборации ATLAS на БАК поручил аспиранту Айшику Гошу (Aishik Ghosh) проработать один из вариантов детектирования бозона Хиггса, впервые зарегистрированного пятью годами ранее. Бозон Хиггса считается ответственным за массу элементарных частиц. На ускорителе он возникает в процессе сталкивания протонов и их распада. В частности, при распаде могут возникать W-бозоны, которые отвечают за слабые ядерные взаимодействия в ядрах. При слиянии W-бозонов может возникать бозон Хиггса, который тут же распадается на два Z-бозона, тоже являющихся переносчиками слабого ядерного взаимодействия. В свою очередь, Z-бозоны распадаются на лептоны, например, на электронно-позитронные пары. Нюанс в том, что бозон Хиггса образуется не всегда, и этот этап в процессе распада может быть пропущен без изменения всей схемы. И анализировать приходится не то, что есть, а то, что пропало, а это гораздо труднее. По крайней мере, для нейронной сети, для которой, таким образом, отсутствует база для обучения. Все эти замечательные явления можно обнаружить лишь при скрупулёзном моделировании и анализе невообразимого объёма данных по экспериментам. Ситуацию также осложняет тот факт, что частицы, а по сути — это квантовые поля, подвержены эффекту интерференции. Вспомните о поведении множества кругов на воде во время дождя. Примерно в таких, но стократ более сложных условиях учёные ищут следы каждой «капли» и умудряются узнать о ней буквально всё — от массы до других физических характеристик. Если бы не явление квантовой интерференции, жизнь исследователей была бы проще. Но не в этой Вселенной… Аспирант, которому поручили проработать один из вариантов распада протонов на W-бозоны, быстро понял, что он занимается чем-то не тем. Явление интерференции вносило настолько большую погрешность в анализ, что требовалось видеть всю картину целиком, а не работать над одним из её вариантов. Тогда начинающий учёный скормил данные нейронной сети, которая до этого не применялась к анализу подобных массивов данных — это Neural Simulation-Based Inference (NSBI) (по-русски, вывод на основе нейронного моделирования). Нейронной сети NSBI было дано задание самостоятельно смоделировать явления в эксперименте на БАК и на основе моделей предсказать результаты измерений по бозону Хиггса. Тем самым, вместо попыток изучать по отдельности те или иные пути распада, новый метод учитывал все возможные пути и их интерференцию, что позволяло более точно анализировать данные. К этому времени работой аспиранта заинтересовался руководитель проекта, и подключились другие специалисты коллаборации ATLAS. К декабрю 2024 года были подготовлены и опубликованы две научные статьи, прошедшие строгое рецензирование. Одна статья рассказала о методе, а вторая заново проанализировала старые данные ATLAS с помощью нейронной сети. Результат превзошёл ожидания. Нейронная сеть дала более точные характеристики бозона Хиггса, чем коллектив учёных. «Одна из забавных особенностей этого метода, который Айшик так сильно продвигал, заключается в том, что каждый раз, когда мы делаем прогноз — вот насколько хорошо мы будем работать через 15 лет, — мы подчистую разбиваем эти прогнозы, — говорят исследователи. — Так что сейчас нам приходится переделывать набор прогнозов, потому что мы уже сегодня [с помощью нейронной сети] достигли наших старых прогнозов на 15 лет вперёд. Это очень забавная проблема». Китайская MiniMax представила ИИ-модель M1 — её обучение обошлось в 200 раз дешевле GPT-4
21.06.2025 [19:49],
Владимир Фетисов
Это становится привычной практикой: каждые несколько месяцев малоизвестная компания из Китая выпускает большую языковую модель (LLM), которая опровергает представления о стоимости обучения и эксплуатации передовых ИИ-алгоритмов. На этот раз в центре внимания оказался стартап MiniMax, который объявил о запуске новой ИИ-модели M1, на обучение которой было потрачено значительно меньше средств по сравнению с западными аналогами, такими как GPT-4 от OpenAI. 
Источник изображения: ChatGPT В январе этого года в центре внимания был стартап DeepSeek и её алгоритм R1. В марте в центре внимание ненадолго оказался стартап Butterfly Effect с ИИ-моделью Manus, который хоть и базируется в Сингапуре, но значительная часть сотрудников располагается в Китае. На этой неделе внимание привлекла компания MiniMax из Шанхая, ранее известная разработкой сервиса для создания видеоигр с помощью алгоритмов на базе искусственного интеллекта. В этот раз поводом вспомнить MiniMax стал запуск ИИ-модели M1, которая дебютировала 16 июня. По словам разработчиков, этот алгоритм может конкурировать с аналогами ведущих отраслевых игроков, включая OpenAI, Anthropic и DeepSeek, в плане производительности и креативности, но при этом новая ИИ-модель значительно дешевле в обучении и эксплуатации. MiniMax заявила, что потратила всего $534 700 на аренду вычислительных мощностей центра обработки данных для обучения M1. Для сравнения, отраслевые эксперты подсчитали, что обучение алгоритма GPT-4o обошлось примерно в 200 раз дороже и OpenAI потратила на это более $100 млн. Официальные данные разработчика по этому вопросу не разглашаются. Если данные MiniMax точны, а их ещё предстоит проверить независимым образом, то, вероятно, они вызовут некоторую обеспокоенность среди крупных инвесторов, вложивших миллиарды долларов в такие компании, как OpenAI и Anthropic, а также среди акционеров Microsoft и Google. Это связано с тем, что бизнес в сфере ИИ крайне убыточен. Исследование издания The Information показало, что OpenAI может потерять до $14 млрд в следующем году и вряд ли компания сможет достигнуть безубыточности до 2028 года. Если клиенты могут добиться таких же результатов, как с моделями OpenAI, используя для этого ИИ-модели с открытым исходным кодом MiniMax, это, вероятно, снизит спрос на продукты OpenAI. Разработчик ChatGPT уже активно снижает цены на свои наиболее производительные ИИ-модели, чтобы сохранить долю рынка. Недавно производитель снизил стоимость использования своей рассуждающей модели GPT-o3 на 80 %, но это было ещё до выпуска алгоритма MiniMax M1. Результаты MiniMax также означают, что компаниям, возможно, не придётся тратить так много средств на вычислительные мощности для запуска и эксплуатации передовых ИИ-алгоритмов. Потенциально это может снизить прибыль облачных провайдеров, таких как Amazon AWS, Microsoft Azure и Google Cloud. Это в свою очередь может означать снижение спроса на ИИ-ускорители Nvidia, которые используются для обучения ИИ-моделей в центрах обработки данных. Эффект от запуска MiniMax M1 в конечном счёте может стать таким же, как от появления алгоритма DeepSeek R1. Стартап заявил, что нейросеть R1 функционирует наравне с ChatGPT при меньших затратах на обучение. Заявление DeepSeek привело к падению курса акций Nvidia на 17 % за один день и снижению рыночной стоимости компании примерно на $600 млрд. Пока новость о появлении алгоритма MiniMax не привела к чему-то подобному. Согласно имеющимся данным, MiniMax поддерживают крупнейшие технологические компании Китая, такие как Tencent и Alibaba. Неясно, сколько человек работает в компании, а также почти нет информации о гендиректоре MiniMax Яне Цзюньцзе (Yan Junjie). В арсенале компании также есть генератор изображений Hailuo AI и приложение для создания виртуальных аватаров Talkie. Благодаря этим приложениям у MiniMax есть десятки миллионов пользователей в 200 странах, а также 50 000 корпоративных клиентов, многие из которых были привлечены Hailuo из-за способности сервиса создавать видеоигры «на лету». «Бездонная яма плагиата»: Disney и Universal подали в суд на Midjourney из-за ИИ
12.06.2025 [06:17],
Анжелла Марина
Кинокомпании Disney и Universal подали иск против Midjourney, обвинив сервис в создании копий их персонажей с помощью искусственного интеллекта (ИИ). Иск, поданный в федеральный суд Центрального округа Калифорнии, касается генерации изображений таких персонажей, как Шрек, Дарт Вейдер, Базз Лайтер и других защищённых авторским правом известных героев. 
Источник изображений: theverge.com В заявлении говорится, что Midjourney действует как «виртуальный торговый автомат», производя бесконечные незаконные копии их работ. По мнению истцов, сервис сознательно использует популярных персонажей для продвижения своих инструментов, не вкладывая средств в их создание. В качестве примеров приведены изображения инопланетянина Йоды — одного из главных героев «Звёздных войн», Человека-паука, Эльзы из «Холодного сердца» и персонажей из «Миньонов».  Disney и Universal утверждают, что Midjourney игнорирует их требования прекратить нарушение авторских прав, в отличие от других сервисов ИИ, которые внедрили защитные механизмы. Особую обеспокоенность вызывает готовящийся к выпуску видеогенератор Midjourney, который, по мнению студий, уже сейчас может нарушать их права в связи с обучением ИИ на защищённом авторском контенте. Компании потребовали суда присяжных.  Как отмечает издание The Verge, это первый крупный иск Голливуда против генеративного ИИ, однако подобные судебные разбирательства становятся все более частыми. Ранее с исками к OpenAI, создателю ChatGPT, обращались The New York Times, группа авторов во главе с Джорджем Мартином (George R.R. Martin), а также издатели других газет. На компанию Anthropic, разработавшую чат-бот Claude, подали иски компании Universal Music и Reddit. Дело техники: «Википедия» поручит генеративному ИИ рутину, чтобы не испортить труд людей
30.04.2025 [22:35],
Анжелла Марина
«Википедия» объявила о новой стратегии использования искусственного интеллекта в своей интернет-энциклопедии, но с важной оговоркой — ИИ не заменит живых редакторов. Вместо этого он станет их помощником в рутинных задачах. 
Источник изображения: wikipedia.org, AI «Википедия» не планирует заменять своих редакторов и волонтёров искусственным интеллектом, несмотря на растущую популярность ИИ-технологий. Вместо этого платформа будет использовать нейросети для устранения технических барьеров, чтобы участники могли сосредоточиться на содержании, а не на сложностях реализации, сообщает TechCrunch, ссылаясь на официальное заявление организации. В отличие от многих компаний, которые рассматривают ИИ как угрозу рабочим местам, «Википедия» видит в нём инструмент для автоматизации рутинных задач. Например, нейросети помогут в переводе, модерации и поиске информации, освобождая время редакторов для обсуждений и проверки данных, что особенно важно, поскольку «Википедия» строится на консенсусе среди её участников. «Мы уверены, что успех нашей работы с ИИ зависит не только от того, что мы делаем, но и от того, как мы это делаем», — написал Крис Албон (Chris Albon), директор по машинному обучению «Фонда Викимедиа» (Wikimedia Foundation). По его словам, «Википедия» будет придерживаться принципов прозрачности, открытого кода и защиты прав человека, чтобы ИИ оставался под контролем людей. Албон подчеркнул, что с появлением генеративного ИИ, который иногда допускает ошибки и «галлюцинирует», роль «Википедии» как достоверного источника знаний ещё больше возросла. «Мы будем использовать ИИ взвешенно, сохраняя многоязычность и человекоориентированный подход», — добавил он. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


