|
Опрос
|
реклама
Быстрый переход
Nvidia придумала, как с помощью ИИ генерировать точные изображения без текстовых запросов — подойдёт он не всем
30.04.2025 [18:36],
Анжелла Марина
Nvidia выпустила мощный инструмент, позволяющий разработчикам генерировать изображения в Blender, используя в качестве основы 3D-модель, а не текстовые промпты. Инструмент получил длинное название — AI Blueprint for 3D-guided generative AI — и уже доступен для скачивания. 
Источник изображения: Nvidia/YouTube Суть технологии заключается в том, что пользователь может собрать сцену в популярном 3D-редакторе Blender с генеративной нейросетью FLUX.1 от Black Forest Lab, расставив здания, деревья, транспорт и другие объекты, а затем на основе этой композиции нейросеть сгенерирует реалистичное и детализированное 2D-изображение. Такой подход, как отмечает The Verge, даёт больше контроля, чем традиционные текстовые описания. Например, можно точно задать ракурс, расположение элементов и даже их пропорции, избежав долгих правок. 
Источник изображения: Nvidia/YouTube «Этот инструмент использует 3D-сцену как каркас, поэтому подойдут даже грубые модели, так как нейросеть сама доработает детали», — поясняют в Nvidia. Отмечается, что такой метод особенно полезен, когда необходимо получить конкретный результат, а не полагаться на случайность генерации. Например, если дизайнер создаёт город с определённым количеством зданий и машин, он может быстро собрать сцену в Blender, а FLUX.1 превратит её в финальное изображение и избавит от необходимости бесконечно корректировать промпты, пытаясь приблизиться к желаемому, более точному результату. 
Источник изображения: Nvidia/YouTube Вообще, Nvidia позиционирует свои AI Blueprints как «готовые, настраиваемые рабочие процессы», упрощающие разработку приложений на основе генеративного ИИ. В данном случае инструмент включает пошаговые инструкции, примеры ассетов и предустановленную среду для удобства пользователей. Однако идея не уникальна: ранее компания Adobe также представила прототип похожего решения под названием Project Concept на своей конференции MAX в октябре. Однако пока её вариант остаётся экспериментальным, и о широком релизе речи не идёт. Тем временем новый инструмент от Nvidia уже доступен для загрузки, но требует мощной видеокарты — например, RTX 4080 или выше. Эксперты отмечают, что подобные технологии могут ускорить работу дизайнеров, концепт-художников и геймдев-студий, стремящихся к более точным результатам при работе с ИИ-генерацией, а также сократить время на подбор промптов. «Голосовое протезирование с ИИ» превратит мозговые волны немых людей в беглую речь
21.04.2025 [18:27],
Сергей Сурабекянц
Немало людей страдают от потери речи в результате заболеваний, хотя их когнитивные функции остаются незатронутыми. Поэтому на волне прогресса в области ИИ многие исследователи сосредоточились на синтезе естественной речи (вокализации) с помощью комбинации мозговых имплантатов и нейросети. В случае успеха эта технология может быть расширена для помощи людям, испытывающим трудности с вокализацией из-за таких состояний, как церебральный паралич или аутизм. 
Источник изображения: unsplash.com Долгое время основные инвестиции и внимание учёных были сосредоточены на имплантах, которые позволяют людям с тяжёлыми формами инвалидности использовать клавиатуру, управлять роботизированными руками или частично восстанавливать использование парализованных конечностей. Одновременно многие исследователи сконцентрировались на разработке технологий вокализации, которые преобразует мыслительные модели в речь. «Мы добиваемся большого прогресса. Сделать передачу голоса от мозга к синтетическому голосу такой же плавной, как диалог между двумя говорящими людьми — наша главная цель, — рассказал нейрохирург из Калифорнийского университета Эдвард Чанг (Edward Chang). — Используемые нами алгоритмы ИИ становятся быстрее, и мы учимся с каждым новым участником наших исследований». В марте 2025 года Чанг с коллегами опубликовали статью в журнале Nature Neuroscience, в которой описали работу с парализованной женщиной, которая не могла говорить в течение 18 лет после перенесённого инсульта. При помощи учёных она обучала нейронную сеть, безмолвно пытаясь произнести предложения, составленные из 1024 разных слов. Затем звук её голоса был синтезирован путём потоковой передачи её нейронных данных в совместную модель синтеза речи и декодирования текста. 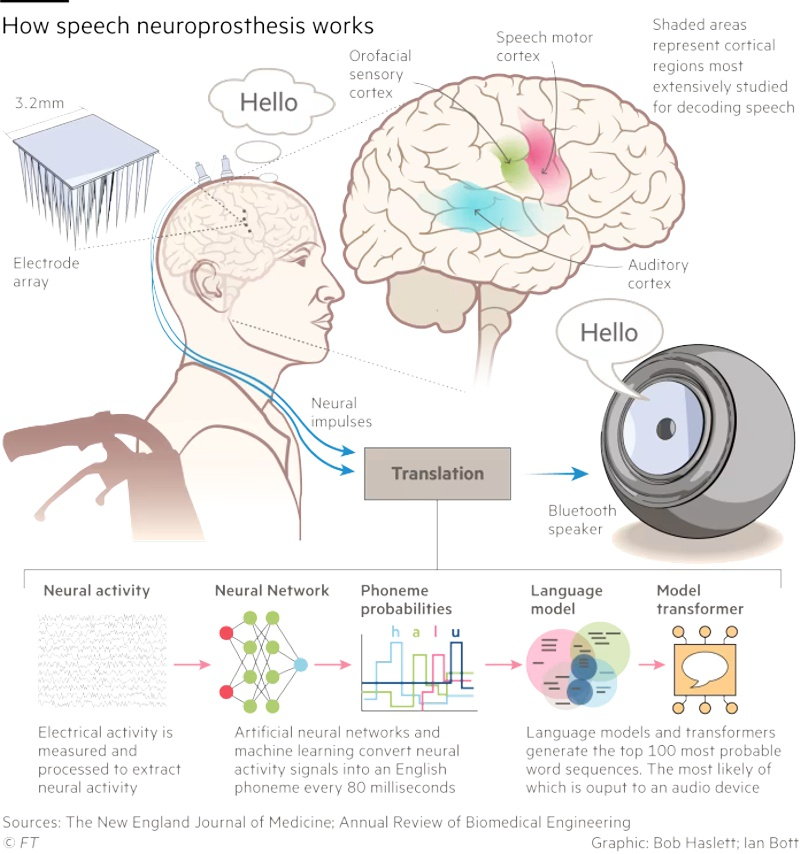
Источник изображения: New England Journal of Medicine Технология позволила сократить задержку между мозговыми сигналами пациента и полученным звуком с первоначальных восьми до одной секунды. Этот результат уже сопоставим с естественным для обычной речи временным интервалом в 100–200 миллисекунд. Медианная скорость декодирования системы достигла 47,5 слов в минуту, что составляет примерно треть от скорости обычного разговора. Аналогичные исследования были произведены компанией Precision Neuroscience, причём её генеральный директор Майкл Магер (Michael Mager) утверждает, что их подход позволяет захватывать мозговые сигналы с более высоким разрешением за счёт «более плотной упаковки электродов». На данный момент Precision Neuroscience провела успешные эксперименты с 31 пациентом и даже получила разрешение регулирующих органов оставлять свои датчики имплантированными на срок до 30 дней. Магер утверждает, что это позволит в течение года обучить нейросеть на «крупнейшим хранилище нейронных данных высокого разрешения, которое существует на планете Земля». Следующим шагом, по словам Магера, будет «миниатюризация компонентов и их помещение в герметичные биосовместимые пакеты, чтобы их можно было навсегда внедрить в тело». 
Источник изображения: UC Davis Health Самым серьёзным препятствием для разработки и использования технологии «мозг-голос» является время, которое требуется пациентам, чтобы научиться пользоваться системой. Ключевой нерешённый вопрос заключается в степени различия шаблонов реагирования в двигательной коре — части мозга, которая контролирует произвольные действия, включая речь, — у разных людей. Если они окажутся схожими, предварительно обученные модели можно будет использовать для новых пациентов. Это ускорит процесс индивидуального обучения, который занимает десятки или даже сотни часов. Все исследователи вокализации солидарны в вопросе о недопустимости «расшифровки внутренних мыслей», то есть того, что человек не хочет высказывать. По словам одного из учёных, «есть много вещей, которые я не говорю вслух, потому что они не пойдут мне на пользу или могут навредить другим». На сегодняшний учёные ещё далеки от вокализации, сопоставимой с обычным разговором среднестатистических людей. Хотя точность декодирования удалось довести до 98 %, голосовой вывод происходит не мгновенно и не в состоянии передать такие важные особенности речи, как тон и настроение. Учёные надеются, что в конечном итоге им удастся создать голосовой нейропротез, который обеспечит полный экспрессивный диапазон человеческого голоса, чтобы пациенты могли контролировать тон и ритм своей речи и даже петь. OpenAI заподозрили в манипуляциях с тестами мощной ИИ-модели o3
21.04.2025 [12:18],
Владимир Фетисов
В декабре прошлого года OpenAI представила большую языковую модель o3, заявив, что она способна справиться более чем с 25 % набора сложных математических задач FrontierMath, тогда как другие ИИ-модели справлялись только с 2 % заданий из этого набора. Однако расхождения между результатами внутренних и независимых тестов вызывали вопросы о прозрачности компании и практике тестирования нейросетей. 
Источник изображения: Levart_Photographer / unsplash.com На момент анонса ИИ-модели o3 представитель компании особо отметил результаты алгоритма при решении задач FrontierMath. Однако выпущенная на прошлой неделе потребительская версия алгоритма далеко не так хорошо справляется с вычислениями. Это может указывать на то, что OpenAI либо завысила результаты тестирования, либо в нём была задействована другая, более способная к решению математических задач версия o3. Исследователи из Epoch AI, стоящие за созданием FrontierMath, опубликовали результаты независимых тестов общедоступной версии ИИ-модели o3. Оказалось, что алгоритм сумел справиться только с 10 % задач, что значительно ниже заявленных OpenAI 25 %. Вместе с этим исследователи протестировали ИИ-модель o4-mini, более компактный и дешёвый алгоритм, который является преемником o3-mini. 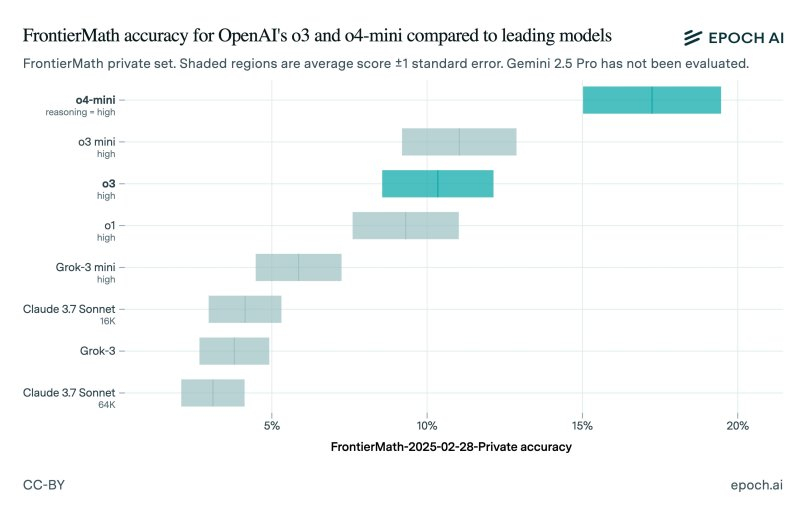
Источник изображения: @EpochAIResearch / X Конечно, расхождение в результатах тестирования не означает, что OpenAI намеренно завысила показатели ИИ-модели. Нижняя граница результатов тестирования OpenAI практически совпадает с результатами, полученными Epoch AI. В Epoch AI также отметили, что тестируемая ими модель, скорее всего, отличается от той, что тестировалась OpenAI. Также отмечается, что исследователи задействовали обновлённую версию набора задач FrontierMath. «Разница между нашими результатами и результатами OpenAI может быть связана с тем, что OpenAI оценивает результаты с помощью более мощной внутренней версии, используя больше времени для вычислений, или потому, что эти результаты были получены на другом подмножестве FrontierMath (180 задач в frontiermath-2024-11-26 против 290 задач в frontiermath-2025-02-28)», — сказано в сообщении Epoch AI. По данным организации ARC Foundation, которая тестировала предварительную версию o3, публичная версия ИИ-алгоритма «представляет собой другую модель», которая оптимизирована для использования в чате/продуктах. «Вычислительный уровень всех выпущенных версий o3 ниже, чем у версии, которую мы тестировали», — сказано в сообщении ARC. Сотрудница OpenAI Венда Чжоу (Wenda Zhou) рассказала, что публичная версия o3 «более оптимизирована для реальных случаев использования» и повышения скорости обработки запросов по сравнению с версией o3, которую компания тестировала в декабре. По её словам, это и является причиной того, что результаты тестирования в бенчмарках могут отличаться от того, что показывала OpenAI. ИИ-модели Gemini позволили анализировать снимки в «Google Фото», но пока не у всех пользователей
15.04.2025 [12:38],
Владимир Фетисов
Компания Google начала интеграцию своей нейросети Gemini в сервис «Google Фото». Благодаря этому пользователи теперь имеют возможность объединения Gemini со своим аккаунтом в «Google Фото», благодаря чему можно искать нужные снимки на основе текстовых запросов об их содержимом. На данный момент нововведение доступно только на территории США для запросов на английском языке. 
Источник изображения: BoliviaInteligente / Unsplash Согласно имеющимся данным, упомянутое нововведение доступно для всех пользователей устройств на базе Android, у которых установлено приложение Gemini. Для активации интеграции необходимо запустить приложение Gemini и в настройках профиля активировать соответствующую опцию. После этого алгоритм сможет помочь отыскать снимки, например, по сделанным пользователем меткам, местоположению, дате съёмки или описанию того, что изображено на фотографии. После того, как Gemini отобразит список найденных объектов, пользователь может нажать на миниатюру какого-то конкретного снимка или альбома, чтобы открыть его в «Google Фото». При необходимости снимки можно по одному перетаскивать из окна Gemini в другие приложения. Google не объявляла, когда интеграция Gemini с сервисом «Google Фото» станет доступна за пределами рынка США и получит поддержку большего количества языков. Вероятно, это произойдёт после того, как разработчики убедятся в том, что алгоритм работает полностью корректно. Лучше GPT-4o «почти по всем параметрам»: OpenAI представила флагманскую ИИ-модель GPT-4.1
14.04.2025 [21:38],
Владимир Фетисов
OpenAI официально представила большую языковую модель GPT-4.1, которая является преемником выпущенного в прошлом году мультимодального алгоритма GPT-4o. По данным компании, новая ИИ-модель получила контекстное окно большего размера и в целом превосходит GPT-4o «почти по всем параметрам». В дополнение к этому были улучшены возможности алгоритма в плане написания программного кода и следования инструкциям. 
Источник изображения: Levart_Photographer / unsplash.com GPT-4.1 уже доступна для разработчиков вместе с двумя версиями нейросети меньшего размера. Речь идёт об алгоритмах GPT-4.1 Mini и GPT-4.1 Nano, которая, по словам OpenAI, является «самой маленькой, самой быстрой и самой дешёвой» ИИ-моделью. Все три версии GPT-4.1 являются мультимодальными, то есть могут работать не только с текстом, но и с другими данными — например, изображениями или видео. Размер контекстного окна увеличился до 1 млн токенов, что значительно больше по сравнению со 128 тыс. токенов у GPT-4o. Отмечается, что GPT-4.1 способна качественно обрабатывать информацию внутри контекстного окна на протяжении всего взаимодействия с пользователем. «Мы также обучили её гораздо более надёжно, чем GPT-4o, распознавать релевантный текст и игнорировать отвлекающие элементы на длинных и коротких отрезках контекста», — говорится в сообщении OpenAI. GPT-4.1 также на 26 % дешевле GPT-4o, что стало особенно важным показателем после дебюта сверхэффективной ИИ-модели китайской компании DeepSeek. 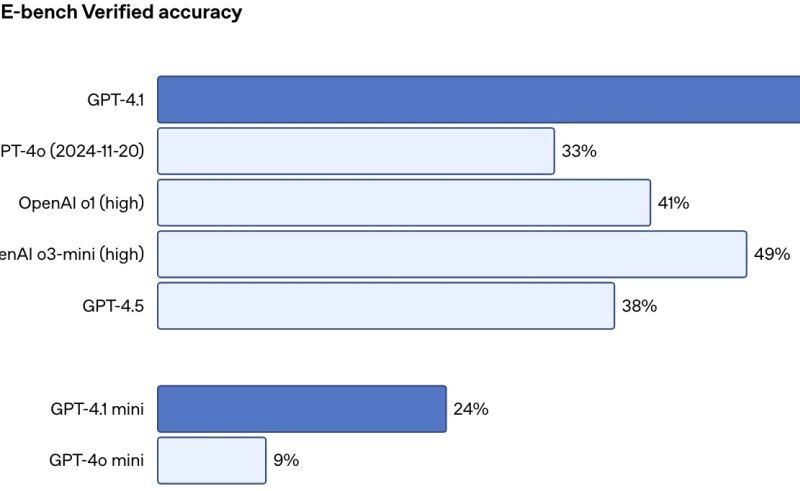
Источник изображения: OpenAI Запуск GPT-4.1 происходит на фоне подготовки OpenAI к отказу от использования ИИ-модели двухлетней давности GPT-4. Согласно официальным данным, после 30 апреля модель GPT-4o станет «естественным преемником» GPT-4. OpenAI также закроет доступ к предварительной версии GPT-4.5 через API 14 июля, поскольку «GPT-4.1 предлагает улучшенную или аналогичную производительность по многим ключевым функциям при гораздо меньших затратах и издержках». «Яндекс» представила «ТВ Станцию» второго поколения — QLED и ИИ для оптимизации изображения
11.02.2025 [12:59],
Владимир Мироненко
Компания «Яндекс» представила новый умный телевизор — «ТВ Станцию» второго поколения. Это первый умный телевизор «Яндекса» с QLED-экраном в среднем ценовом сегменте. Новинка доступна с диагональю экрана 43, 50, 55 и 65 дюймов по цене от 49 990 руб. 
Источник изображений: «Яндекс» «ТВ Станция QLED» получила поддержку технологии AI Picture Quality, также внедрённой в «ТВ Станции» первого поколения. Она использует ИИ для оптимизации изображения. Как сообщает компания, нейросеть анализирует происходящее на экране и самостоятельно меняет настройки: улучшает цветопередачу, яркость, контрастность и детализацию. Благодаря этому лица людей выглядят более естественно, краски природы становятся насыщеннее, а детали архитектуры отображаются более чётко. Новая технология доступна для любых фильмов, сериалов и роликов, которые не защищены от копирования.  Смарт-функции на основе нейросетей также упрощают голосовое управление телевизором. По данным производителя, голосовой помощник «Алиса» понимает даже те команды, которым её не обучали, а также умеет разбивать сложные запросы на простые и учитывать происходящее на экране. Например, теперь голосовой помощник поймёт просьбы: «Алиса, включи ТНТ и сделай погромче» или «Алиса, выключи телевизор, когда закончится фильм». Кроме того, открывать сайты, прокручивать страницы, искать информацию в интернете и управлять историей поиска теперь можно с помощью голосовой команды — без необходимости использовать пульт или клавиатуру.  Через приложение «Дом с Алисой» родители смогут устанавливать, продлевать и сокращать время просмотра ТВ для своих детей, а также блокировать выход из детского аккаунта с помощью ПИН-кода. Как и другие модели, «ТВ Станция QLED» предлагает возможности умной колонки и смарт-ТВ: прослушивание музыки и просмотр видео, управление умным домом и общение с «Алисой». 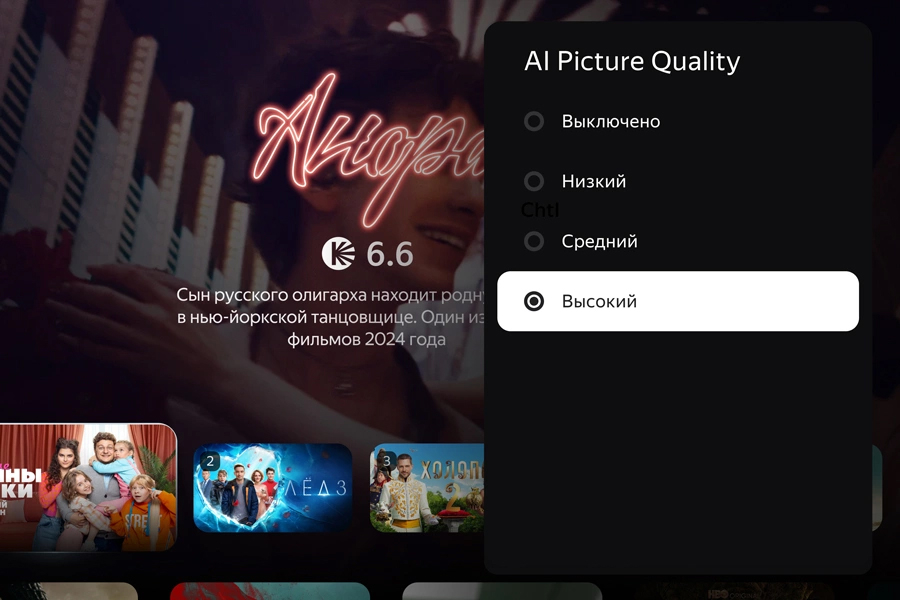 Телевизор поддерживает разрешение экрана Ultra HD (4K) с яркостью 450 кд/м², а также технологии MEMC и HDR10. Благодаря технологии KSF QLED устройство обеспечивает яркие цвета при воспроизведении любого контента. Заводская калибровка баланса белого индивидуальна для каждой модели, что гарантирует высокое качество изображения. Акустическая система телевизора включает четыре динамика с поддержкой Dolby Audio и общей мощностью 34 Вт: два широкополосных и два высокочастотных. Инженеры «Яндекса» провели фирменную настройку звука, благодаря чему обеспечивается качественное, сбалансированное звучание как при прослушивании музыки, так и при просмотре фильмов. Кроме того, с выходом «ТВ Станции QLED» компания «Яндекс» увеличила срок службы всех «ТВ Станций», включая ранее приобретённые модели, до пяти лет. Российские специалисты из Smart Engines расшифровали рукописи Пушкина при помощи ИИ
06.02.2025 [17:59],
Сергей Сурабекянц
Специалисты российской компании Smart Engines расшифровали зачёркнутые фрагменты черновых рукописей Александра Пушкина с помощью разработанной ими системы искусственного интеллекта «Да Винчи». Нейросетевая архитектура «Да Винчи» широко используется для распознавания документов, в частности российских паспортов, вне зависимости от угла и условий съёмки. 
Источник изображения: Wikipedia, «Литературные места России» В процессе обучения ИИ запомнил, какие движения пера в незачёркнутых словах характерны для почерка великого русского поэта, а затем восстановил утраченные места, пользуясь созданной моделью движений его руки. Таким способом удалось идентифицировать несколько неопределяемых ранее слов из черновых рукописей Пушкина. Эти находки внесли существенный вклад в понимание творческого процесса поэта. Узнать, какие слова пришлись Пушкину не по душе, удалось с помощью нейросетевой архитектуры «Да Винчи», разработанной специалистами Smart Engines для удаления линий разграфки, затрудняющих распознавание рукописных данных в официальных документах. Эта технология позволяет автоматически определять геометрию документа и распознавать данные вне зависимости от его расположения в кадре, наличия помех и искажений. Технология одинаково успешно справляется как со сканами, так и с фотографиями документов, в том числе в зеркальном отражении. Алгоритмы Smart Engines уже интегрированы в решения для мгновенного распознавания данных паспорта и других документов. Распознавание паспорта РФ при помощи камеры смартфона требует всего 0,15 секунды. Серверные решения позволяют распознавать до 55 паспортов в секунду на процессор без использования GPU. 
Источник изображения: Smart Engines «Проведённый нами эксперимент по расшифровке ранее нечитаемых слов в рукописях Александра Пушкина подтвердил колоссальный потенциал нейросетей в самых разных областях науки. Мы видим, что искусственный интеллект может стать надёжным инструментом для исследователя […] Предложенный метод снятия зачёркиваний при помощи ИИ может быть применён не только к рукописям Пушкина, но и к архивным записям других известных авторов, а также историческим документам. Это открывает новые возможности для изучения творческого процесса написания знаменитых литературных произведений», — уверен генеральный директор Smart Engines Владимир Арлазаров. Остаётся неясным лишь одно: если великий русский поэт какие-то слова зачёркивал, возможно, он не хотел, чтобы кто-нибудь их прочитал, в том числе и искусственный интеллект? OpenAI пока не будет подавать в суд на DeepSeek
04.02.2025 [04:31],
Николай Хижняк
OpenAI не планирует подавать в суд на китайскую компанию DeepSeek на фоне ранее озвученных подозрений Microsoft и OpenAI в отношении последней в том, что она могла использовать их данные для обучения своей нейросети R1. Об этом заявил сам глава OpenAI Сэм Альтман (Sam Altman). 
Источник изображения: Solen Feyissa / unsplash.com «У нас нет планов прямо сейчас судиться с DeepSeek. Мы собираемся продолжать делать отличные продукты и лидировать в мире по мощности модели, я думаю, это хорошо работает», — передаёт слова Альтмана издание Nikkei. Ранее DeepSeek выпустила собственную модель искусственного интеллекта R1, создание которой, согласно её разработчикам, обошлась значительно дешевле по сравнению с западными аналогами. При этом она не проигрывает им по характеристикам. На прошлой неделе сообщалось, что Microsoft и OpenAI заподозрили DeepSeek в краже данных при разработке R1. Позже Альтман назвал R1 «впечатляющей моделью» и заявил, что «появление нового соперника нас реально вдохновляет». Затем SemiAnalysis выразили предположение, что DeepSeek могла потратить куда больше средств на создание R1, чем было заявлено изначально. Нынешнее заявление Альтман сделал во время поездки в Японию, где встречался премьер-министром страны Сигэру Исибой (Shigeru Ishiba) и главой японского холдинга SoftBank Масаёси Соном (Masayoshi Son). OpenAI и SoftBank объявили о создании совместного предприятия в Японии SB OpenAI Japan, которое будет развивать ИИ-сервисы. Ожидается, что это будет самый масштабный проект по предоставлению ИИ-инструментов американского стартапа корпоративным клиентам за пределами США. Энтузиасты запустили современную ИИ-модель Llama на древнем ПК с Pentium II и Windows 98
30.12.2024 [17:19],
Владимир Фетисов
Специалисты из EXO Labs сумели запустить довольно мощную большую языковую модель (LLM) Llama на 26-летнем компьютере, работающем под управлением операционной системы Windows 98. Исследователи наглядно показали, как загружается старый ПК, оснащённый процессором Intel Pentium II с рабочей частотой 350 МГц и 128 Мбайт оперативной памяти, после чего осуществляется запуск нейросети и дальнейшее взаимодействие с ней. 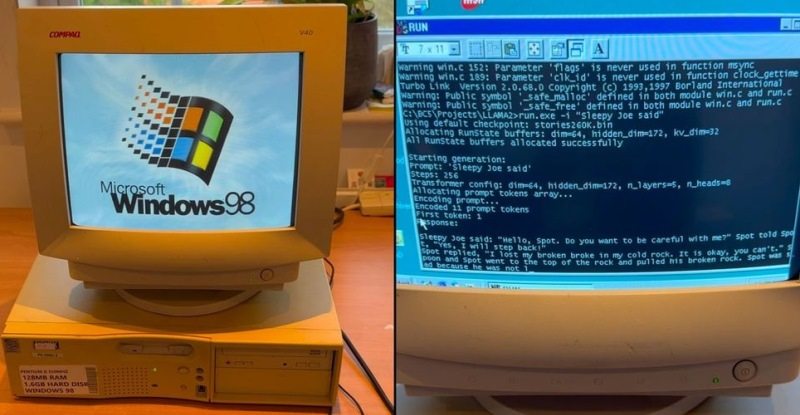
Источник изображения: GitHub Для запуска LLM специалисты EXO Labs задействовали собственный интерфейс вывода для алгоритма Llama98.c, который создан на базе движка Llama2.c, написанного на языке программирования C бывшим сотрудником OpenAI и Tesla Андреем Карпатым (Andrej Karpathy). После загрузки алгоритма его попросили создать историю о Сонном Джо. Удивительно, но ИИ-модель действительно работает даже на таком древнем ПК, причём история пишется с хорошей скоростью. Загадочная организация EXO Labs, сформированная исследователями и инженерами из Оксфордского университета, вышла из тени в сентябре этого года. Согласно имеющимся данным, она выступает за открытость и доступность технологий на базе искусственного интеллекта. Представители организации считают, что передовые ИИ-технологии не должны находиться в руках горстки корпораций, как это происходят сейчас. В дальнейшем они рассчитывают «построить открытую инфраструктуру для обучения передовых ИИ-моделей, что позволит любому человеку запускать их где угодно». Демонстрация возможности запуска LLM на древнем ПК, по их мнению, доказывает то, что ИИ-алгоритмы могут работать практически на любых устройствах. В своём блоге энтузиасты рассказали, что для реализации поставленной задачи на eBay был приобретён старый ПК с Windows 98. Затем, подключив устройство в сеть с помощью разъёма Ethernet, они через FTP сумели передать в память устройства нужные данные. Вероятно, компиляция современного кода для Windows 98 оказалась более сложной задачей, решить которую помогла опубликованная на GitHub работа Андрея Карпатого. В конечном счёте удалось добиться скорости генерации текста в 35,9 токенов в секунду при использовании LLM размером 260K с архитектурой Llama, что весьма неплохо, учитывая скромные вычислительные возможности устройства. Российские учёные подключили мозг крысы к искусственному интеллекту и научили отвечать на сложные вопросы
07.11.2024 [14:57],
Владимир Фетисов
Разработчики из биотех-лаборатории Neiry совместно с учёными из МГУ сумели подключить мозг крысы к искусственному интеллекту. Об этом пишет издание Forbes со ссылкой на пресс-службу Neiry, где также отметили, что добиться такого результата удалось «впервые в мире». 
Источник изображения: neiry.ru Учёные имплантировали в мозг крысы инвазивный нейроинтерфейс, электроды которого позволяют определённым образом стимулировать отдельные зоны мозга. Сам же интерфейс работает в паре с алгоритмом на основе нейросети. Благодаря этому учёные могут задавать крысе Пифии разные вопросы, а ИИ-алгоритм подсказывает ей правильные ответы посредством электрической стимуляции мозга. При «подсказке от ИИ» крыса испытывает определённые ощущения в случаях, когда требуется дать положительный или отрицательный ответ. «Когда у неё сосёт под ложечкой, то это ответ "нет", а когда сердцем чувствует, то это ответ "да"», — рассказал Василий Попков, руководитель разработки инвазивных нейросетевых интерфейсов Института искусственного интеллекта МГУ. В видео, которое появилось на сайте лаборатории Neiry, можно увидеть, как Пифия отвечает на разные вопросы. Например, когда у неё спрашивают, «Ты крыса?» она нажимает лапой клавишу «Да», а при ответе на вопрос «Дважды два — пять?» — клавишу «Нет». За каждый правильный ответ крыса получает вознаграждение. По данным исследователей, Пифия способна давать верные ответы на любые вопросы по физике, истории, математике. Она уже успела дать множество верных ответов на вопросы про квазары, язык программирования Python, миелиновые оболочки и др. «Точно так же в обозримой перспективе сможет сделать любой человек с имплантированным нейроинтерфейсом», — добавили в пресс-службе Neiry. Профессор МГУ Михаил Лебедев, возглавляющий данный проект, считает происходящее революцией, которая позволит «мирно сосуществовать» человеку и искусственному интеллекту. Учёные уверен, что такой подход позволит задействовать ИИ-алгоритмы для запоминания и обработки огромных массивов информации, а также дальнейшей её передачи естественному мозгу, который, в свою очередь, будет заниматься задачами, связанными с творчеством, интуицией и с сознанием. Алгоритм распознавания речи OpenAI Whisper страдает от галлюцинаций
27.10.2024 [13:06],
Владимир Фетисов
По данным исследователей, система распознавания речи Whisper от компании OpenAI иногда страдает галлюцинациями, т.е. занимается выдумкой фактов. Инженеры-программисты, разработчики и учёные выразили серьёзные опасения по поводу того, что эта особенность ИИ-алгоритма может нанести реальный вред, поскольку Whisper уже используется, в том числе, в медицинских учреждениях. 
Источник изображения: Growtika / unsplash.com Склонность генеративных нейросетей к выдумыванию фактов при ответах на вопросы пользователей обсуждается давно. Однако странно видеть эту особенность у алгоритма Whisper, который предназначен для распознавания речи. Исследователи установили, что алгоритм при распознавании речи может включать в генерируемый текст что угодно, начиная от расистских комментариев и заканчивая выдуманными медицинскими процедурами. Это может нанести реальный вред, поскольку Whisper начали использовать в больницах и других медицинских учреждениях. Исследователь из Университета Мичигана, изучавший расшифровку публичных собраний, сгенерированных Wisper, обнаружил неточности при транскрибировании 8 из 10 аудиозаписей. Другой исследователь изучил более 100 часов, расшифрованных Whisper аудио, и выявил неточности более чем в половине из них. Ещё один инженер заявил, что выявил недостоверности почти во всех 26 тыс. расшифровок, которые он создал с помощью Wisper. Представитель OpenAI сообщил, что компания постоянно работает над повышением качества работы своих нейросетей, в том числе над уменьшением количества галлюцинаций. Он также добавил, что политика компании запрещает использовать Whisper «в определённых контекстах принятия решений высокой важности». «Мы благодарим исследователей за то, что они поделились своими результатами», — добавил представитель OpenAI. Midjourney запустила мощный ИИ-редактор изображений и улучшенную модерацию
24.10.2024 [23:10],
Анжелла Марина
Midjourney, являющаяся одной из ведущих компаний по разработке нейросетей для генерации изображений по текстовым описаниям, анонсировала тестирование новых функций, включая внешний редактор изображений, режим редактирования текстур и систему модерации на основе искусственного интеллекта новейшего поколения. 
Источник изображения: midjourney.com Новый ИИ-редактор позволяет загружать фотографии с компьютера и вносить в них изменения — расширять, обрезать, перерисовывать или добавлять объекты в сцену. Управление происходит с помощью текстовых подсказок (промптов) и выбора областей на изображении. Также поддерживается персонализация ИИ-моделей, референсные персонажи и автоматические подсказки на основе заданных изображений. 
Источник изображения: midjourney.com Не менее интересным оказался режим смены текстур, который анализирует форму сцены и изменяет освещение, материалы и текстуру изображения. Это позволяет кардинально трансформировать внешний вид изначальной картинки, создавая новые визуальные эффекты, не изменяя при этом основную композицию. 
Источник изображения: midjourney.com Midjourney также представила более тонкую и интеллектуальную систему модерации V2 на основе ИИ. Этот «модератор» анализирует не только текстовые запросы, но и сами изображения, маски для рисования и полученные результаты. «Мы считаем, что это самый интеллектуальный ИИ-модератор из всех существующих на сегодня. — с гордостью заявляют разработчики компании. — Надеемся, что некоторые его аспекты в будущем будут внедрены в стандартные конвейеры генерации, чтобы уменьшить количество ложных срабатываний и предоставить пользователям больше свободы». 
Источник изображения: midjourney.com На данный момент новые функции доступны для тех пользователей, которые сгенерировали более 10 000 изображений, имеют годовую подписку или ежемесячную на протяжении последних 12 месяцев. Отметим, что разработчики признают наличие некоторых проблем, таких как некорректная работа с небольшими участками изображения, и просят пользователей отнестись с пониманием к этим временным трудностям, наслаждаясь тестированием новых возможностей. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


