







 MWC 2018
MWC 2018 2018
2018 Computex
ComputexНовое исследование ETH Zurich и INSAIT показало, что современные ИИ-модели, имитирующие рассуждение и уверенно решающие стандартные математические задачи, практически не способны формулировать полные доказательства уровня Математической олимпиады США 2025 года (USAMO). Эти результаты ставят под сомнение возможность глубокого математического рассуждения у современных ИИ-моделей.






Источник изображения: Imkara Visual / Unsplash
В марте 2025 года исследовательская группа из Швейцарской высшей технической школы Цюриха (ETH Zurich) и Института компьютерных наук, искусственного интеллекта и технологий (INSAIT) при Софийском университете, возглавляемая Иво Петровым (Ivo Petrov) и Мартином Вечевым (Martin Vechev), опубликовала препринт научной статьи под названием «Proof or Bluff? Evaluating LLMs on 2025 USA Math Olympiad» (рус. — Доказательство или блеф? Оценка больших языковых моделей на Математической олимпиаде США 2025 года). Работа направлена на оценку способности больших языковых моделей (LLMs), имитирующих рассуждение, генерировать полные математические доказательства на олимпиадных задачах.
Для анализа были использованы шесть задач с USAMO 2025 года, организованного Математической ассоциацией Америки. ИИ-модели тестировались сразу после публикации заданий для минимизации риска утечки данных в обучающие выборки. Средняя результативность по всем ИИ-моделям при генерации полных доказательств составила менее 5 % от максимально возможных баллов. Системы оценивались по шкале от 0 до 7 баллов за задачу с учётом частичных зачётов, выставляемых экспертами. Лишь одна модель — Gemini 2.5 Pro компании Google — показала заметно лучший результат, набрав 10,1 балла из 42 возможных, что эквивалентно примерно 24 %. Остальные модели существенно отставали: DeepSeek R1 и Grok 3 получили по 2,0 балла, Gemini Flash Thinking — 1,8 балла, Claude 3.7 Sonnet — 1,5 балла, Qwen QwQ и OpenAI o1-pro — по 1,2 балла. ИИ-модель o3-mini-high компании OpenAI набрала всего 0,9 балла. Из почти 200 сгенерированных решений ни одно не было оценено на максимальный балл.
Исследование подчёркивает фундаментальное различие между решением задач и построением математических доказательств. Стандартные задачи, такие как вычисление значения выражения или нахождение переменной, требуют лишь конечного правильного ответа. В отличие от них, доказательства требуют последовательной логической аргументации, объясняющей истинность утверждения для всех возможных случаев. Это качественное различие делает задачи уровня USAMO значительно более требовательными к глубине рассуждения.

Скриншот задачи №1 USAMO 2025 года и её решения на сайте AoPSOnline. Источник изображения: AoPSOnline
Авторы исследования выявили характерные модели ошибок в работе ИИ. Одной из них стала неспособность поддерживать корректные логические связи на протяжении всей цепочки вывода. На примере задачи №5 USAMO 2025 года ИИ-модели должны были найти все натуральные значения k, при которых определённая сумма биномиальных коэффициентов в степени k остаётся целым числом при любом положительном n. Модель Qwen QwQ допустила грубую ошибку, исключив возможные нецелые значения, разрешённые условиями задачи, что привело к неправильному окончательному выводу, несмотря на правильное определение условий на промежуточных этапах.
Характерной особенностью поведения моделей стало то, что даже в случае серьёзных логических ошибок они формулировали свои решения в утвердительной форме, без каких-либо признаков сомнения или указаний на возможные противоречия. Это свойство имитации рассуждения указывает на отсутствие у ИИ-моделей механизмов внутренней самопроверки и коррекции вывода.
Авторы отметили также влияние особенностей обучения на качество решений. Тестируемые ИИ-модели демонстрировали артефакты оптимизационных стратегий, применяемых при подготовке к стандартным бенчмаркам: например, принудительное форматирование ответов с использованием команды \boxed{}, предназначенное для удобства автоматизированной проверки. Эти шаблонные подходы приводили к ошибкам в контексте задач, где требовалось развёрнутое доказательство, а не только числовой ответ.
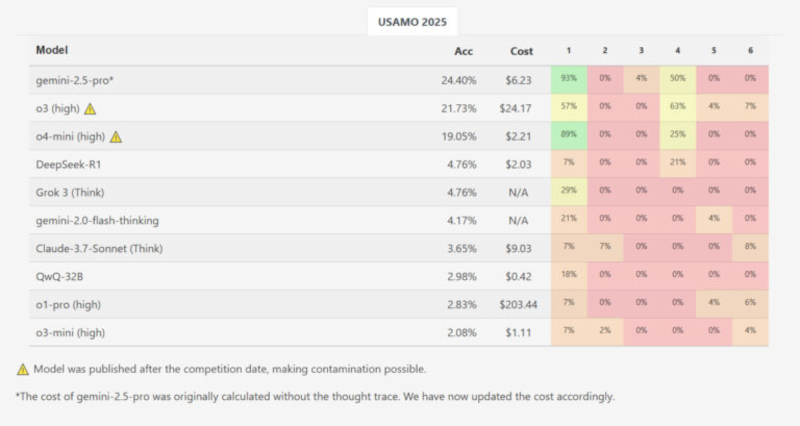
Показатели точности ИИ-моделей на каждой задаче USAMO 2025 года. Источник изображения: MathArena
Несмотря на выявленные ограничения, внедрение методов цепочки размышлений и имитации рассуждения положительно сказались на формировании промежуточных логических шагов в процессе вывода ИИ-моделей. Механизм масштабирования вычислений на этапе вывода позволяет ИИ строить более связные локальные рассуждения. Однако фундаментальная проблема остаётся: современные большие языковые модели (LLM) на архитектуре «Трансформер» (Transformer) продолжают работать как системы распознавания паттернов, а не как самостоятельные системы концептуального рассуждения.
Более высокие результаты модели Gemini 2.5 Pro свидетельствуют о потенциальной возможности сокращения разрыва между симулированным и реальным рассуждением в будущем. Однако для достижения качественного прогресса необходимо обучение ИИ-моделей более глубоким многомерным связям в латентном пространстве и освоение принципов построения новых логических структур, а не только копирование существующих шаблонов из обучающих выборок.
Источник:





