







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Почему ИИ никак не сесть на безматричную диету
Человечеству так понравилась новая высокотехнологичная игрушка, искусственный интеллект, что вот уже почти три года оно самозабвенно забавляется ею, не обращая внимания на цену этого увлечения (развлечения?), а ведь та день ото дня становится всё весомее. Среднее энергопотребление GPT-5 превышает 18 Вт·ч для одного-единственного запроса, которых каждый день на серверах OpenAI обрабатывается до 2,5 млрд. А ведь есть ещё Claude, DeepSeek, Mistral и множество прочих облачных больших языковых моделей (БЯМ), не считая запускаемых в частных дата-центрах, на периферии локальной сети (edge computing) и локально, вплоть до домашних ПК и смартфонов. При этом от половины до двух третей всего времени, что затрачивается на вычисления (45–60%, в зависимости от особенностей реализации той или иной модели), искусственная нейросеть занята уморительно простой по сути, но крайне громоздкой из-за немыслимого числа операндов деятельностью — матричным умножением. Тут-то и скрывается загвоздка: перемножение матриц характерными размерами, условно в тысячи 16-разрядных чисел с плавающей запятой (и это далеко не предел) пожирает вычислительные ресурсы фон-неймановских компьютеров с завидным аппетитом — расходуя и немалый аппаратный ресурс, и энергию, и время. Но деваться от этой напасти, кажется, некуда: практически все нейросети сегодня практикуют матричное умножение, так уж они устроены. А, собственно, почему?  Математики несколько десятилетий бились, понижая вычислительную сложность матричного умножения (показатель степени ω, в которую возводится размерность матрицы n, — O(n^ω)) чтобы с исходных 3 дойти примерно до 2,38. Но дальнейшего существенного прогресса на этом направлении не предвидится (источник: Wikimedia Commons) ⇡#Путь наименьшего сопротивленияНастойчивая фиксация разработчиков систем машинного обучения (не одних только генеративных ИИ-моделей!) на матрицах — двумерных массивах чисел, строго говоря, математических абстракциях, к физическому миру напрямую не относящихся, — может показаться по меньшей мене контринтуитивной. Впрочем, в некотором приближении восприятие векторов (а матрицы можно представить как упорядоченный набор именно векторов, в роли которых могут выступать её столбцы либо строки) наш головной мозг фиксирует уже на уровне зрительной коры: там часть нейронов возбуждается лишь при появлении в поле зрения вертикальных структур, а часть — только горизонтальных. Когда же речь заходит о цифровом распознавании образов, например — а это одна из первостепенных задач машинного обучения, — предъявляемую модели картинку сознательно разбивают на пикселы по вертикали и горизонтали, формируя именно прямоугольную входную матрицу (да и не одну, если нужно сохранить информацию о цветности). Иными словами, наглядный образ матрицы — заполненная числами таблица — возникает в такого рода задачах совершенно естественным образом, так что волей-неволей приходится применять, обрабатывая ту в дальнейшем, матричные же математические операции. Соответственно пошаговые преобразования начальных данных в модели машинного обучения сводятся к тем или иным комбинациям умножения матриц на другие матрицы, скаляры или же векторы. Корректнее с математической точки зрения было бы заявить, что многомерные входные данные, с которыми имеют дело системы машинного обучения, наиболее эффективно удаётся обрабатывать через линейные отображения (linear maps), обобщающие линейную числовую функцию на произвольные (в общем случае) векторные пространства сколь угодно высокой размерности. Линейное же отображение из одного конечномерного векторного пространства в другое, в свою очередь, можно представить в виде двумерной матрицы, после чего производить операции уже с этими сравнительно простыми (с чисто прикладной, вычислительной точки зрения) структурами. Для примера: после того как запрос пользователя к БЯМ преобразован в токены с заделкой (embedding), он формально предстаёт вектором в существенно многомерном пространстве. Так что разумным оказывается работать с этим вектором не напрямую, а как раз через линейные отображения — складывая, перемножая между собой, домножая на векторы и скаляры пусть огромные по обоим измерениям, но всё же двумерные матрицы. 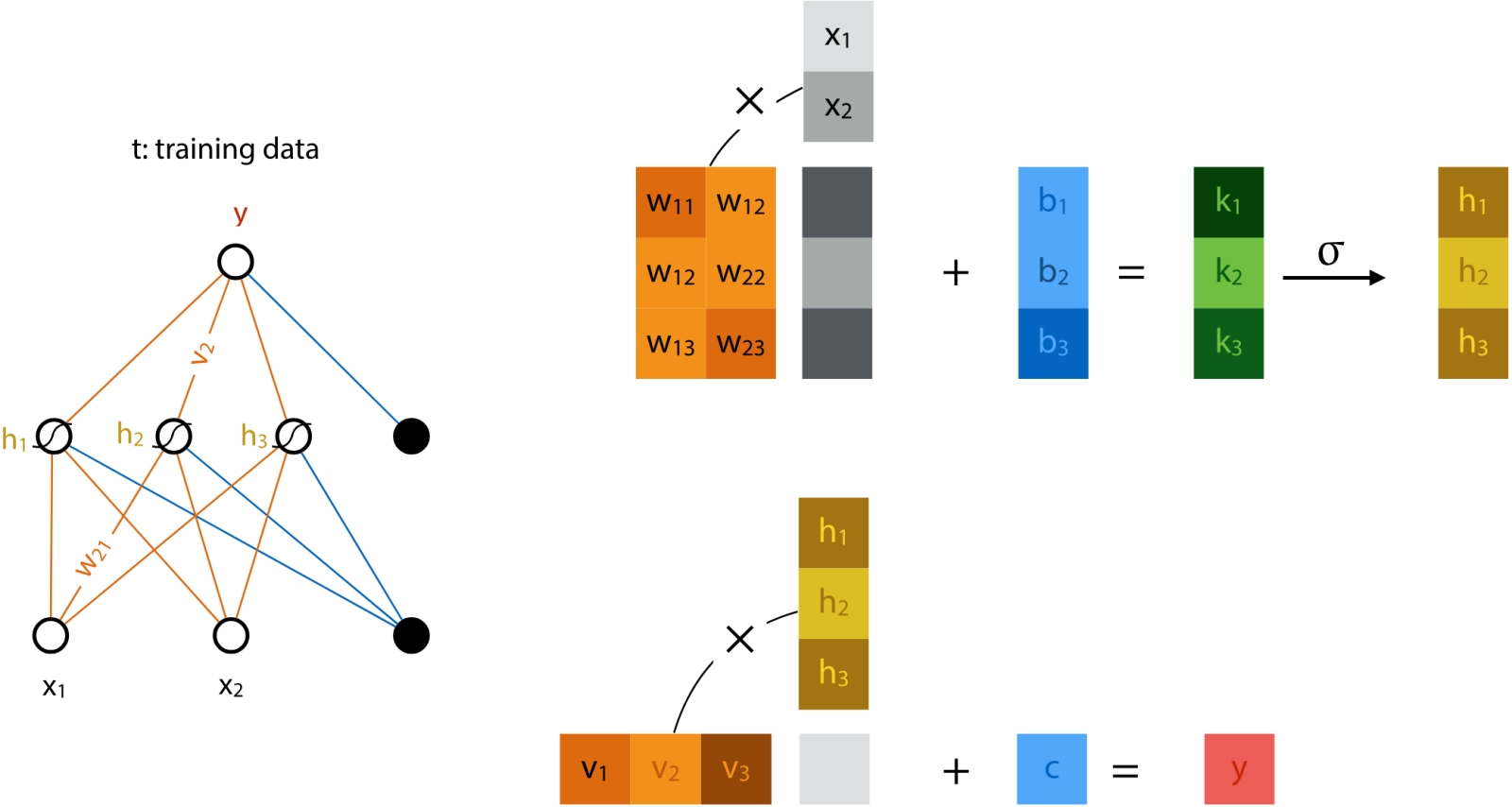 Слева — фрагмент глубокой нейросети с прямым распространением сигнала: граф, каждый узел которого представляет собой скалярную величину, а рёбра соответствуют весам. Значение скаляра для каждого узла в очередном слое (сигнал распространяется снизу вверх) определяется взвешенным суммированием. Чёрные кружки — нейроны смещения (bias nodes), их влияние для простоты в этой схеме не учитывается. Справа же наглядно показано, как вся работа нейронных сетей сводится к довольно ограниченному числу линейно-алгебраических операций (источник: Vrije Universiteit Amsterdam) Напомним, что в математике вектор суть элементарный объект, характеризующийся лишь двумя величинами — своим размером (длиной) и направлением (строго говоря, для отличия вектора от алгебраического тензора типа (1,0) следует ввести ещё требование соблюдения определённого закона геометрического сложения, но для наших целей это несущественно, тем более что в науке о данных (data science) как наиболее прикладном подразделе вычислительной математики определения вектора и тензора несколько своеобразны). Воспринимаемые и преобразуемые БЯМ данные кодируют сперва в виде токенов, беря за основу либо отдельные слова («cat», «flower»), либо их части (так, «tokenization» представляется двумя фрагментами — «token» и «ization»), либо даже одиночные символы («&», «;», «Σ»). Полный набор изначально определённых для данной модели токенов формирует её словарь. Далее в ходе обучения системе предъявляют огромные массивы текстов (ограничимся пока ради наглядности именно работающими с текстовым вводом моделями). Она расчленяет их на свои словарные слова, преобразует те в токены и, пропуская длинные ряды этих самых токенов через многослойную нейросеть, выявляет — пусть и в неявном виде, формируя определённые веса на входах своих перцептронов, — некие объективные закономерности во взаимном расположении этих элементарных для неё информационных корпускул. Сами же закономерности — если, конечно, те исходно присутствовали в исходном массиве, т. е. тот не представлял собой заведомо случайный набор символов, — диктуются, в свою очередь, правилами грамматики естественных языков, внутренней логикой изложенных на этих языках утверждений, а также представлениями авторов указанных утверждений об описываемых ими сущностях (речь, по сути, идёт о семантической связке «означающее — денотат — означаемое»). Иными словами, некое «высшее знание» в недрах БЯМ магическим образом не зарождается; формируемые ею в ходе тренировки «представления» (о корректном согласовании слов в предложении, или о многозначности слова «лук», или о медведях в космосе) определяются как её же собственной нейросетевой архитектурой, так и полнотой плюс качеством массива обучающих данных. Поскольку система машинного обучения существует лишь в виде цифрового образа в памяти вычислительной системы, все операции, производимые в её рамках, должны иметь дело исключительно с числами — так что токены представляются по определённым правилам как раз числами (обычно целыми). Кстати, вполне возможна односимвольная токенизация, когда буквально каждому символу (букве, цифре, специальному знаку) сопоставляется свой токен. Выгода на этапе составления словаря очевидна: для английского языка с учётом цифр, знаков препинания и проч. достаточно будет закодировать примерно 256 символов, тогда как если сопоставлять свой токен каждому слову, словарь разрастётся почти до 170 тыс. позиций. Односимвольная (character-based) токенизация привлекательна тем, что даёт возможность БЯМ эффективно обрабатывать несловарные слова (out-of-vocabulary words): когда те будут попадаться системе в контексте в ходе обработки обучающего массива, «внутренняя логика» их смысловой связи с другими понятиями непременно окажется выявлена. Однако при этом, как нетрудно заметить, значительно вырастают длины векторов, описывающих даже отдельные предложения, не говоря о пространных текстах, — и потому вычислительных ресурсов и времени потребуется больше. 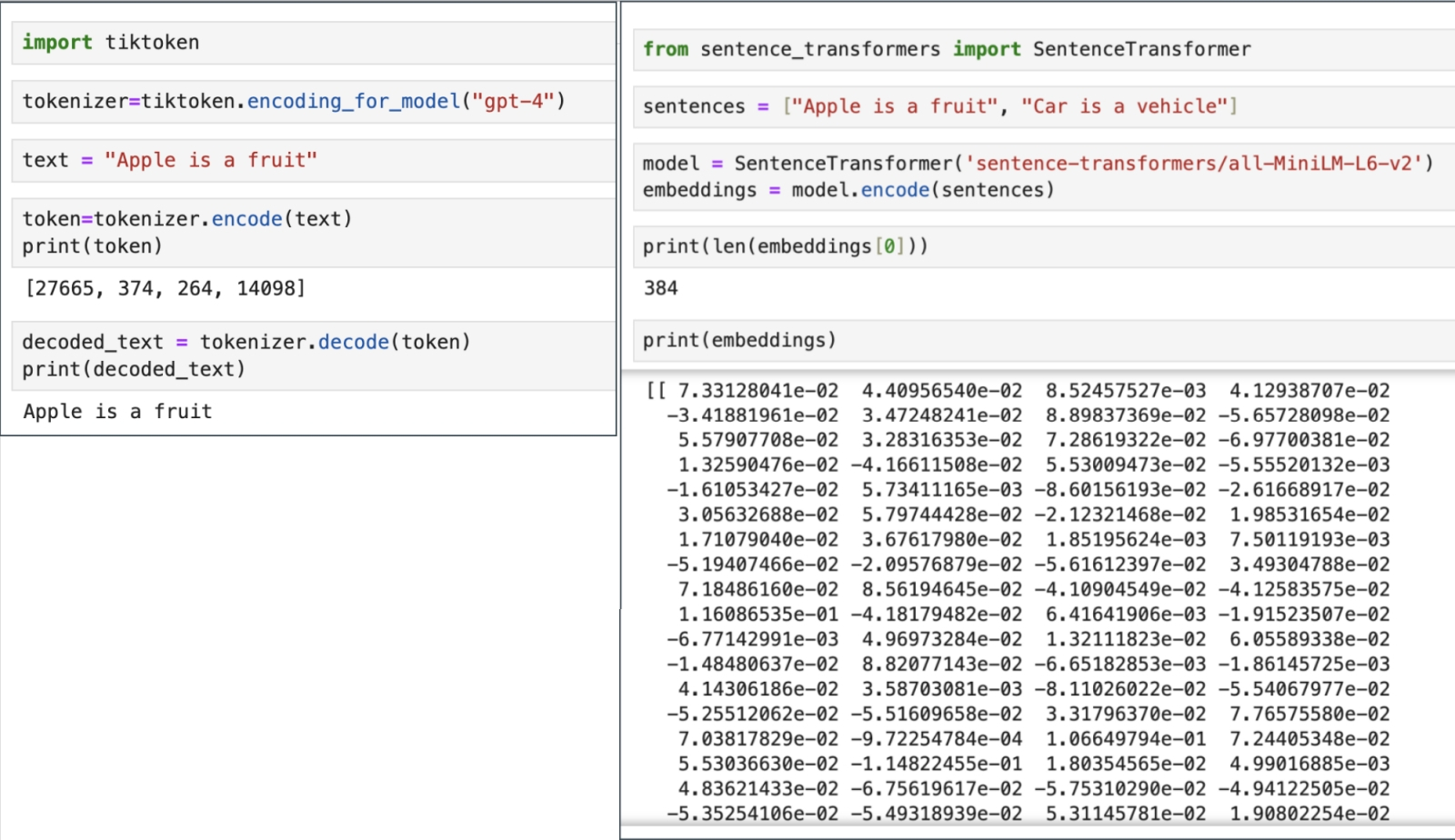 Слева — пример прямой и обратной токенизации: сперва текстовая строка преобразуется для обработки GPT-4 в последовательность (вектор) из четырёх целых чисел с применением созданного OpenAI инструмента Tiktoken; затем из этого вектора восстанавливается текст на естественном языке. Справа — порождение заделки (embedding) из двух последовательно заданных предложений, пропущенных через модель трансформера (источник: The New Stack) ⇡#Многомерность — это простоКогда говорят о «контекстном окне» БЯМ, указывают его протяжённость именно в токенах. Уже отсюда понятно, что для длительной многоступенчатой работы над одной и той же подсказкой, что подразумевает получение от оператора уточняющих команд (и уж тем более для сохранения долгой истории коммуникаций с отдельным пользователем), ИИ нуждается в как можно более высокоуровневой токенизации: просто, если каждый токен будет означать отдельный символ, на долгие содержательные беседы без потери нити рассуждений такой ИИ вряд ли окажется способен. Но и высокоуровневая токенизация не без греха: скажем, любое не вошедшее в словарь и не поддавшееся разбиению на входящие туда фрагменты слово будет помечено как «неизвестное», так что для эффективной обработки содержащих это конкретное слово запросов — и для каждого из таких слов по отдельности! — системе придётся проделывать немалую дополнительную работу. Почему это важно: БЯМ генерирует текстовый ответ на подсказку авторегрессионным способом, последовательно обрабатывая токен за токеном и предсказывая (т. е. выбирая из сонма возможностей вариант с максимальной вероятностью), каким должен быть следующий токен в этой цепочке, притом отталкиваясь от всех предыдущих. Соответственно чем шире контекстное окно, тем на более долгом ряду данных модель имеет возможность выявлять закономерности, в том числе и не самые очевидные. Другое дело, что именно на этом, в частности, этапе возникают порой характерные для генеративного ИИ галлюцинации, но с ними исследователи постепенно учатся бороться. Однако как именно выявлять закономерности в тексте (неважно, парой слов тот представлен или сотней страниц), который БЯМ обрабатывает всего лишь как цепочку токенов? Для этого и используют те самые многомерные векторы, о которых говорилось чуть выше. По-английски они называются embeddings, и на русский этот термин чаще всего просто транслитерируется как «эмбеддинги», хотя нам представляется разумным использовать и семантически насыщенный вариант перевода этого слова — «заделки». Имеется в виду заделка как сельскохозяйственная процедура — внедрение семян в почву на определённую глубину; в целом, аналог «посева», но с дополнительным значением «обязательное укрытие слоем земли». В прежние времена, когда семена сеяли — вручную рассыпали по вспаханному полю, — заделанными они считались только после боронования, в ходе которого перемешивались с землёй, заглубляясь в неё и получая тем самым больше шансов прорасти, а не превратиться в корм для первой же присевшей на поле птицы. Формирование в ходе обучения БЯМ embeddings — многомерных векторов в латентном пространстве — тоже можно в некотором смысле рассматривать как заделку в это самое пространство неких семантических аналогов семян, зачатков будущих ответов, которые ИИ станет выдавать на пользовательские запросы, руководствуясь содержащимися в таких «семенах» неявными связями между словами естественного языка, понимания которых в человеческом смысле машина, ясное дело, не формирует.  Нет ничего проще матричного умножения! (Источник: Wikimedia Commons) Откуда же в заделке — векторе высокой размерности, кодирующем семантическое значение слов, предложений или даже целых пространных текстов, — берётся это самое семантическое значение? Вот как раз для этого и производится обучение языковой модели: ей скармливают не случайные последовательности токенов, но связные тексты, превращённые в векторную форму с использованием этих самых заделок. Простейший вариант такого превращения — one-hot encoding: создать для словаря на k слов k-мерное же латентное пространство, в котором каждое слово окажется базисным вектором. Иными словами, если исходный словарь состоит всего из четырёх слов — «кот», «собака», «капибара» и «аксолотль», то заделка для первого будет представлена вектором [1000], для второго — [0100], для третьего — [0010], для четвёртого — [0001]. Легко заметить, что, хотя это вполне приемлемо для систем распознавания ограниченного числа сущностных категорий (для машинного зрения, например), имеющие дело со вводом и выводом на естественном языке БЯМ будут из соображений оптимизации вычислительных ресурсов, как мы уже упоминали, оперировать словарями в десятки и сотни тысяч слов, и потому векторам заделок придётся иметь соответствующую размерность. Спасибо линейной алгебре: операции над этими существенно многомерными сущностями сравнительно несложно свести к матричным. Однако при этом будут устанавливаться лишь взаимосвязи между самими базисными векторами, но не контекст использования слов в исходном тексте: разницу между формально одним и тем же словом bank во фразах «I received an invoice from my bank» и «I am walking along the river bank» кодировка one-hot выявить не позволит — именно потому, что каждое слово в её словаре есть никак не зависящий от других (это, по сути, и означает «базисный») вектор. Значит, нужно подыскать такую схему преобразования токенов в заделки, которая учитывала бы контекст употребления каждого словарного элемента в тексте. Довольно механистический — точнее, алгоритмический — подход к выявлению контекста предлагают традиционные способы построения embeddings, вроде базирующегося на статистике TF-IDF или семантических N-grams. В основе их лежит определение явно вычисляемых закономерностей — таких, как частота встречаемости данного словарного слова и/или последовательностей таких слов в обучающем корпусе текстов. В этом случае вектор заделки для каждого кодируемого слова — уже не базисный (значение «1» по одному из измерений, «0» по всем остальным), а более сложный: так, вектор, кодирующий слово «king», будет куда более сонаправлен в многомерном пространстве с векторами «man» и «nobility», чем с «woman» и «peasant». Процедура создания embeddings может быть статической, если каждое словарное слово преобразуется по завершении тренировки БЯМ в фиксированный для всех последующих инференсов многомерный вектор (и тогда системе по-прежнему сложно — хотя и не так, как в случае one-hot — различать многозначные слова вроде русских «лук» или «ключ»; пример — Word2Vec), так и динамической, что позволяет учитывать контекст непосредственно анализируемого сообщения. Как раз к системам с динамическими векторами относится созданная ещё в 2018 г. система BERT (Bidirectional Encoder Representations from Transformers), которая с привлечением множества слоёв трансформерных блоков (12 в базовой версии, 24 — в более крупной) выявляет взаимосвязи между заделочными векторами в 768-мерном латентном пространстве. Механизм внимания (attention), ключевой для крайне актуальной сегодня ИИ-архитектуры трансформеров, помогает и самым современным мультимодальным моделям: скажем, команда «нарисовать корову на зелёной траве, она пятнистая и безрогая» именно благодаря этому механизму свяжет местоимение «она» с нужным существительным — так, что на созданном машиной рисунке пятнистой и безрогой с крайне высокой вероятностью (сделаем непременную скидку на внезапные галлюцинации) окажется именно корова, а не трава. Интересно, кстати, что для генерации заделок нейросетевую модель обучают заполнять лакуны в семантически связных текстах — грубо говоря, угадывать, какое именно слово пропущено в предложении. Таким образом формируется машинное «знание» (опять-таки не в человеческом смысле, а как набор весов на входах перцептронов соответствующей нейросети) о взаимосвязях между элементами словаря, которым данная система оперирует. 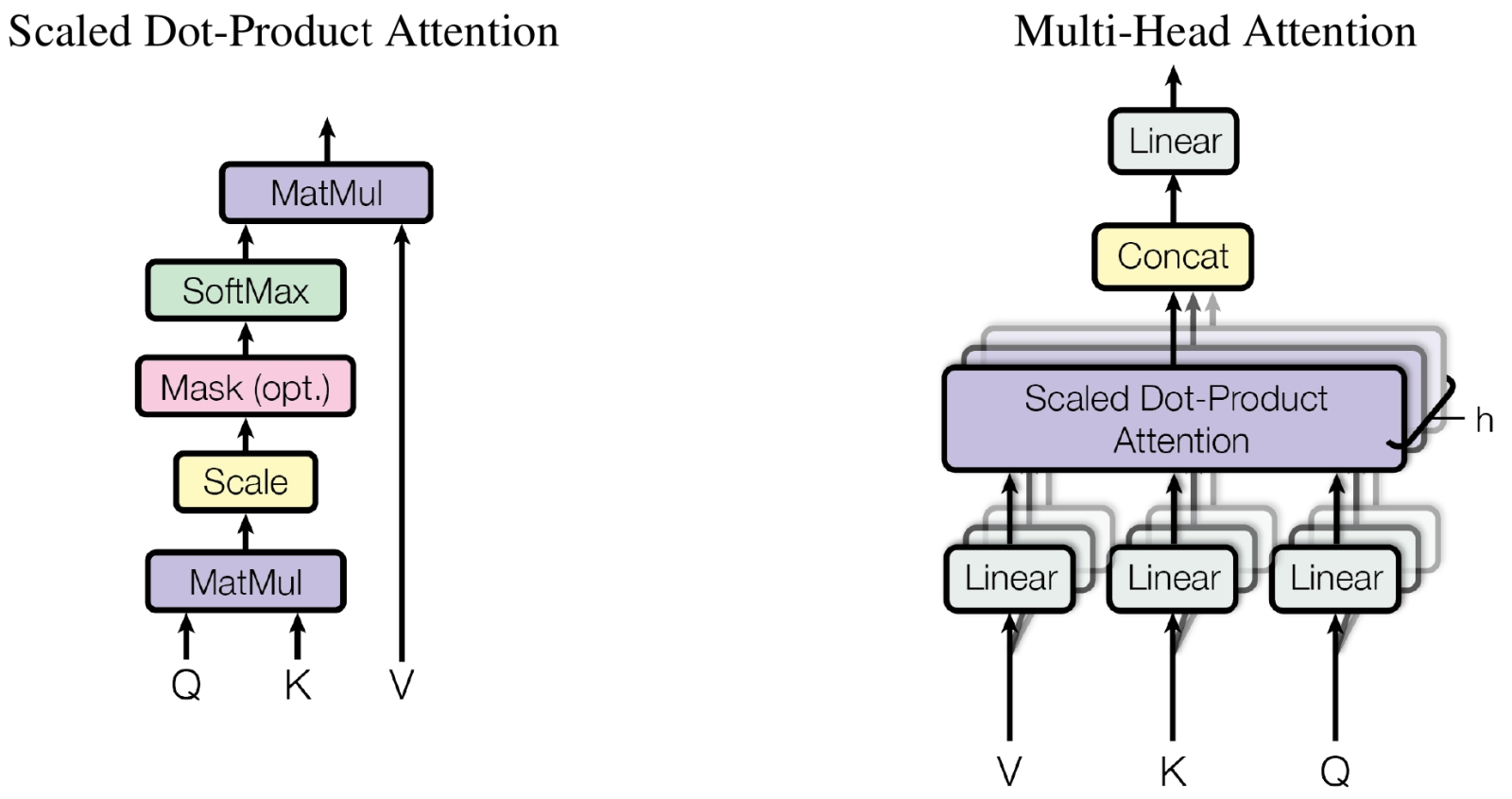 Иллюстрация из классической для направления трансформеров работы «Attention Is All You Need», на которой слева показан одиночный блок реализации функции внимания с привлечением нескольких операций матричного умножения (MatMul), а справа — сборка таких блоков, действующих параллельно для выявления множественных связей в анализируемом тексте (источник: Google) ⇡#Накладное удовольствиеВернёмся наконец из областей чистой (матрицы) и вычислительной (embeddings) математики в материальный мир, а именно вспомним, как устроены современные компьютеры. Те, увы, не оптимальны для проведения матричных операций, причём вовсе не из-за медлительности процессоров (по части «железа» там как раз всё в порядке — от него в данном случае не требуется ничего сверх тривиальных операций суммирования и перемножения), а по причине иерархического устройства подсистемы хранения данных на них. Поскольку снабдить каждое полупроводниковое вычислительное ядро широкополосным доступом к гигабайтам высокоскоростной оперативной памяти не представляется возможным физически (мы это не так давно обсуждали довольно подробно), приходится выстраивать целую пирамиду сред хранения: от наиболее медленной и долговременной внешней (ленты, магнитные дисковые накопители, SSD) через довольно быструю энергозависимую DRAM к характеризующейся по-настоящему ничтожными задержками SRAM, структурированной в кэши нескольких уровней, и к регистровой памяти, что располагается в непосредственной близости от логических контуров. В общем случае объём памяти, доступной на каждом этаже этой пирамиды, обратно пропорционален времени задержки при обмене данными между ней и собственно вычислительным контуром: для SRAM на уровне L1 это единицы наносекунд, для модулей DRAM — уже порядка сотни. Так вот, для того чтобы достичь максимальной производительности, алгоритм, отвечающий за перемножение матриц в ходе работы БЯМ, обязан как можно полнее учитывать иерархию подсистемы памяти на данной конкретной платформе — с тем, чтобы с предельной эффективностью загружать наиболее скоростные её «этажи», не допуская на них ни простоев, ни заторов данных, ожидающих своей очереди на обработку. Впрочем, те же самые алгоритмы должны принимать в расчёт и архитектуру арифметически-логических устройств, что непосредственно производят множественное сложение с умножением — multiply-accumulate (MAC), оно же multiply-add (MAD) — над операндами, представляющими собой содержимое векторов и матриц. Традиционно разработчики центральных процессоров уделяли главное внимание наращиванию скорости линейных операций, не помышляя особенно о параллелизме (подавляющее большинство алгоритмов, применяемых для решения самых разных прикладных задач, как раз подразумевают обработку данных в пределах строго одного потока). В последние пару десятилетий, правда, аппаратный арсенал ЦП обогатился средствами для исполнения векторных операций — single instruction, multiple data (SIMD), но длины пригодных для обработки процессорами на самом нижнем уровне векторов далеко отстают от десятков и даже сотен единиц, что характерны для embeddings. Куда эффективнее в этом плане реализованная в графических процессорах, где в непосредственной близости одно от другого располагаются сотни и тысячи сравнительно простых вычислительных ядер, параллелизация single instruction, multiple threads (SIMT). Такой подход позволяет каждому потоку (thread), который, по сути, выступает в роли программно-определяемого процессора — со своей собственной регистровой памятью, своими арифметически-логическими устройствами (включая и SIMD!) и своим кэшем первого уровня для данных, — синхронно выполнять один и тот же набор инструкций. 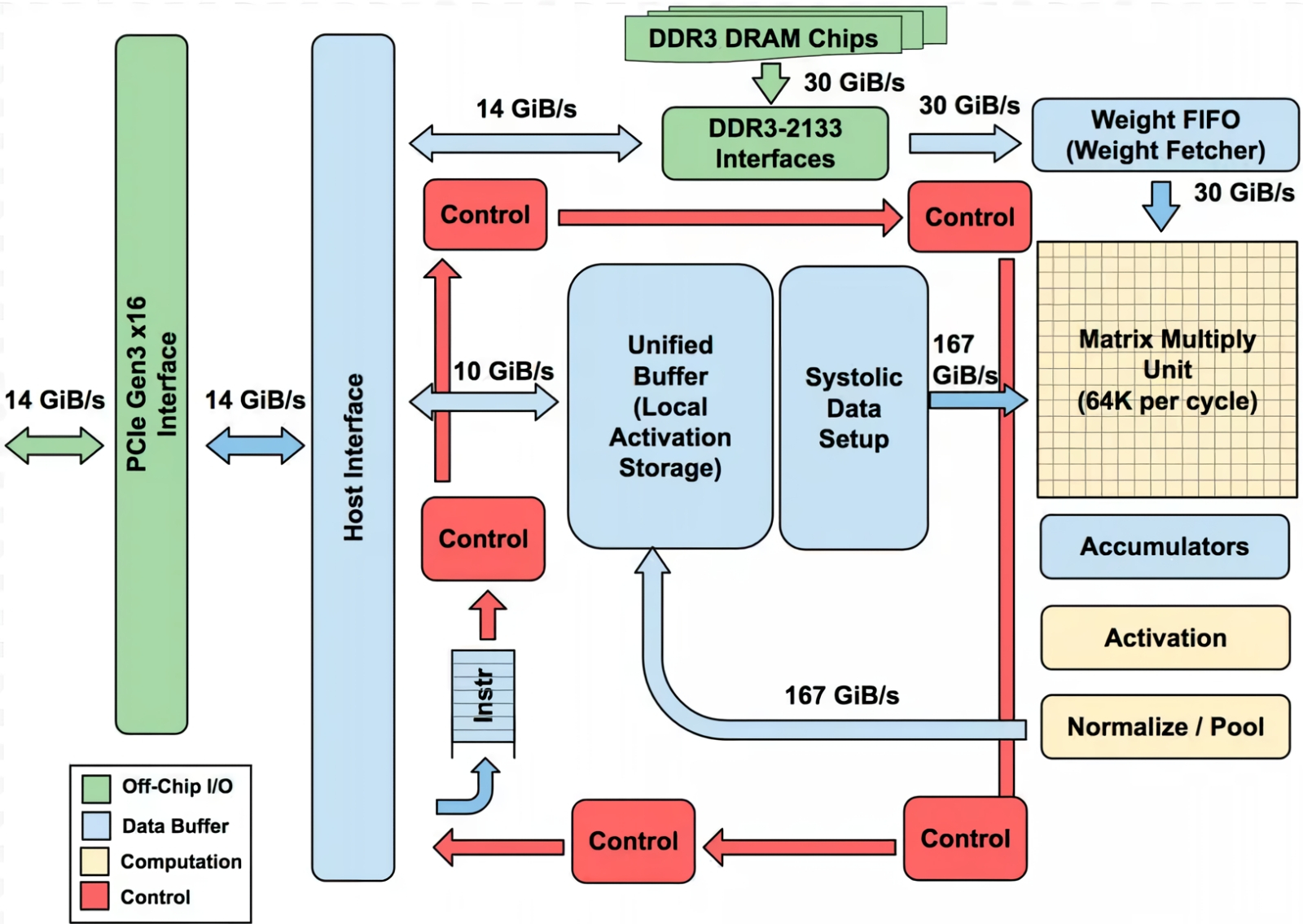 Блок-схема одного из первых TPU (источник: Google) Разработчики же специализированных интегральных микросхем (Application-Specific Integrated Circuits, ASIC) для ИИ-задач идут ещё дальше, предлагая — как инженеры Google, например, — тензорные процессоры (ТП — tensor processing unit, TPU), которые загружают из сверхъёмкой памяти HBM матрицы целиком и производят операции сразу над двумерными массивами данных (а не одномерными, как в случае SIMT). Специфика ASIC — как раз в их чрезвычайно узкой специализации: если ЦП практически универсален (на нём можно даже БЯМ запустить, хватило бы оперативной памяти, — только инференс в этом случае будет идти крайне медленно), а ГП представляет собой способный решать довольно широкий круг разнообразных многопоточных задач вычислитель, то ТП «заточен» исключительно под матричное умножение. Впрочем, поскольку никаких других задач ASIC и не доверяют — он выступает чаще всего в роли специализированного сопроцессора, — у проектирующих такого рода чипы инженеров оказываются развязаны руки для сколь угодно глубокой оптимизации. Именно поэтому если известная модель Google, созданная, чтобы обыграть человека в го — AlphaGo, в 2015 г. требовала для своего исполнения целого серверного кластера с 1202 ЦП и 176 ГП, то уже в 2017-м её ещё более эффективный вариант с самообучением, AlphaGo Zero, довольствовался всего-то четырьмя ТП. Другое дело, что удовольствие это недешёвое: само «железо», включая четвёрку специально для этой задачи разработанных и изготовленных тензорных процессоров, обошлось примерно в 25 млн долл., и ещё в 35 млн долл. оценивают стоимость 40-суточной тренировки этой БЯМ. Но зато энергопотребление первого Google TPU, выполненного по «28-нм» технологии, не превышало всего 40 Вт, что уже сопоставимо с показателями человеческого мозга (около 20 Вт «под полной нагрузкой»). Потом, правда, и здесь началась энергетическая гонка: TPU v4 под той же маркой рассеивает уже около 200 Вт мощности, но при этом производительность его достигает эксафлопсного (порядка 10 в 18-й степени операций с плавающей точкой в секунду) уровня. По сути, каждый такой тензорный вычислитель — суперкомпьютер с 4096 процессорами, соединёнными между собой сверхскоростными шинами данных: каждый чип из состава v4 содержит по паре ядер TensorCores, а каждое из них, в свою очередь, — по четыре модуля, реализующих собственно матричное умножение. Известны и более скромные специализированные сопроцессоры — нередко их называют нейропроцессорами, НП (neural processing unit, NPU), которые применяют совместно и с ЦП, и с ГП для решения особенно ресурсоёмких ИИ-задач (того самого перемножения матриц). Можно привести в пример Intel NPU 4 — интегральную часть центральных процессоров семейства Lunar Lake, что обеспечивает производительность на специфичных для себя задачах до 48 TOPS (трлн операций в секунду — правда, с данными в формате Int8), тогда как формальная нижняя граница для запуска, скажем, Microsoft Copilot на локальном «железе» — 40 TOPS.  Машинный зал с тензорными вычислителями TPU v4 в Оклахоме, на беглый взгляд, не так уж сильно отличается от помещения обычного ЦОДа с привычными серверами, оснащёнными ЦП и ГП, вот разве что система теплоотвода тут требуется не столь мощная (источник: Google) И ещё один важный момент: бесспорно, ТП — явный шаг вперёд в плане повышения эффективности БЯМ: матричное умножение реализуется теперь на аппаратном уровне, да ещё и с применением классической полупроводниковой элементной базы. Чего ещё желать? Однако оптимизация как тренировки, так и инференса моделей ИИ на такой аппаратной основе требует значительной и трудоёмкой переработки соответствующих алгоритмов. Не тех, что обеспечивают прохождение векторов по нейросети, а более низкого уровня — заведующих обменом элементарными данными между MAC и подсистемой памяти. Принять в расчёт аппаратные особенности одного какого-то тензорного вычислителя с тем, чтобы оптимизировать под него одну же генеративную модель, — задача, в общем, вполне решаемая. Но тут же возникает другая проблема: развитие ИИ сегодня настолько стремительно, а разнообразие ориентированных на него как аппаратных, так и программных средств настолько велико, что создать по-настоящему гибкую модель, готовую с примерно одинаковой эффективностью функционировать что на ЦП, что на ГП, что на ТП, неимоверно сложно. Дальше — больше: тензорные процессоры очевидным образом лучше всего справляются с матрицами вполне определённых размеров, тогда как БЯМ могут кардинально различаться по размерностям матриц, которыми оперируют, на всех уровнях: и входном, и внутренних. Вдобавок внутри одной лишь модели — даже такой сравнительно простой, как обособленная модель трансформера, — на разных этапах производятся операции с матрицами различных размерностей, не говоря уже о том, что, хотя изначально БЯМ разрабатываются в расчёте на обработку данных, представленных в формате FP32, в последнее время — разумеется, ради экономии вычислительных ресурсов — на этапе инференса более предпочтительными считаются компактифицированные форматы: Bfloat16, IEEE FP16, FP4, Int4 и т. д. Опять-таки, поскольку смена формы представления чисел влечёт за собой изменение плотности потока данных между MAC и памятью, не учитывающая этих тонкостей БЯМ на самом, казалось бы, передовом «железе» неизбежно будет исполняться далёким от оптимального образом. 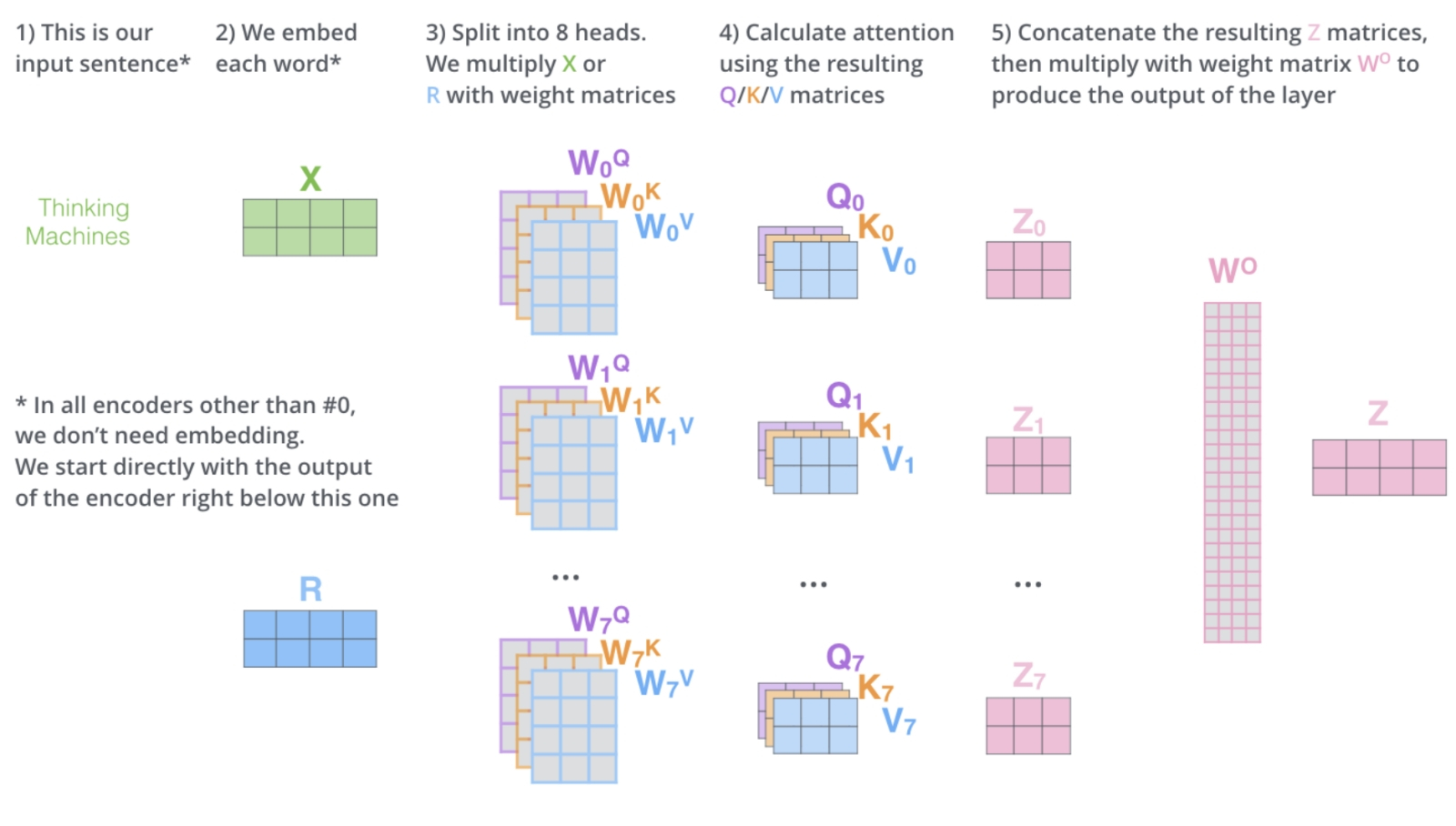 Схема, демонстрирующая, насколько различными по размерностям матрицами приходится оперировать упомянутым уже multi-headed attention blocks в архитектуре трансформеров (источник: The Illustrated Transformer) ⇡#Побег из матрицы?Нельзя не упомянуть, говоря об оптимизации работы ТП (а также более универсальных по предназначению ГП) над ИИ-задачами, преимущественно в процессе инференса, который востребован чаще и в куда бóльших объёмах, чем тренировка новых моделей, и такую их неприятную особенность, как катастрофическая недозагрузка наличных вычислительных мощностей. Потоки данных на разных уровнях иерархии ОЗУ достаточно плотны: чтобы произвести очередную элементарную операцию, логическим контурам процессоров приходится подолгу дожидаться загрузки на операционные регистры всех необходимых битов. Так что в среднем около 40% всего времени, что компьютер обрабатывает ИИ-задачу, уходит на переправку информации между входящими в его состав микросхемами. Снабжённые специализированными на перемножении матриц (как самой ресурсоёмкой операции инференса) вспомогательными НП, графические процессоры всё-таки способны демонстрировать приемлемую эффективность работы на персональных компьютерах и малых серверах. Но для высоконагруженных систем, особенно если брать гиперскейлерские решения, рассчитанные на работу в режиме 24/7 на пределе мощности, предпочтительнее всё-таки специализированные ASIC, которые спроектированы с учётом минимизации задержек при обмене данными в пределах вычислительной платформы. В пример можно привести представленную компанией Etched плату расширения Sohu, ориентированную как раз на ускорение трансформерных операций (которые для современных БЯМ критически важны), или NR1, специализированный «центральный ИИ-процессор» (AI-CPU), он же NAPU — Network Addressable Processing Unit за авторством стартапа NeuReality. Это устройство призвано расшить «бутылочное горлышко» потоков данных внутри вычислительной платформы за счёт отказа от классического ЦП и организации прямого взаимодействия самого NAPU с ГП, что позволяет, по утверждению разработчиков, поднять загрузку контуров графического процессора практически до 100% в ходе инференса таких популярных сегодня БЯМ, как Llama 3, Mixtral или DeepSeek.  Как заявляют разработчики, в ходе инференса модели Llama 70B «трансформерный ускоритель» Sohu обрабатывает до полумиллиона токенов в секунду, что выходит на порядок быстрее и дешевле (учитывая его скромные энергетические аппетиты), чем при использовании для той же цели Nvidia B200 (источник: Etched) А что если не ограничиваться паллиативами — и отказаться от матричного умножения как такового? И начать, если уж выкорчёвывать проблему с самого корня, прямо с этапа обучения БЯМ. Пионерами на этом поприще выступили исследователи из Калифорнийского университета в Санта-Круз, которые в 2024 г. предложили радикально пересмотреть саму основу кодирования и обработки данных для задач ИИ, перейдя от двоичной системы (логические «0» и «1») к троичной («−1», «0», «1»). В своей работе они описали созданную на новых принципах модель с 1,3 млрд параметров, производительность которой на специально под неё настроенной FPGA-плате с энергопотреблением 13 Вт (правда, здесь не учитываются аппетиты сопряжённого ГП, для которого эта плата выступала в роли ускорителя) оказалась сопоставимой с таковой «для наиболее современных предварительно натренированных трансформеров». Причём на этапе обучения требуемый объём оперативной памяти оказался на 61% ниже типичного для полагающихся на матричное умножение моделей такого класса, а в ходе инференса — и вовсе на 90%. Вдохновила же калифорнийских разработчиков ещё более ранняя, 2023 г., статья «BitNet: масштабирование 1-разрядных трансформеров для БЯМ», в которой обосновывалась замена весов на входах нейросетевых перцептронов в привычных дробных или целочисленных форматах, упомянутых уже ранее — FP32, Int4 и т. д., — на двоичные либо троичные однобитные. В пример приводились нейросети мощностью до 3 млрд параметров: по заявлению исследователей, как минимум до этого предела качество работы ИИ от столь существенного урезания вариативности весовых коэффициентов не пострадает. Группа же из Санта-Круз пошла ещё дальше, отказавшись от матричного умножения на этапе реализации механизма самовнимания, self-attention mechanism (напомним, речь в этой работе идёт именно о трансформерах, а не о более крупных БЯМ, — впрочем, для тех архитектура трансформеров как раз и является сегодня ключевой), и заменив его на более простой, эффективный метод последовательной обработки словарных слов, не опирающийся на матричное умножение. Применение троичной системы счисления существенно здесь постольку, поскольку оно позволило исследователям с минимальными ресурсозатратами контролировать потоки информации внутри нейросети. 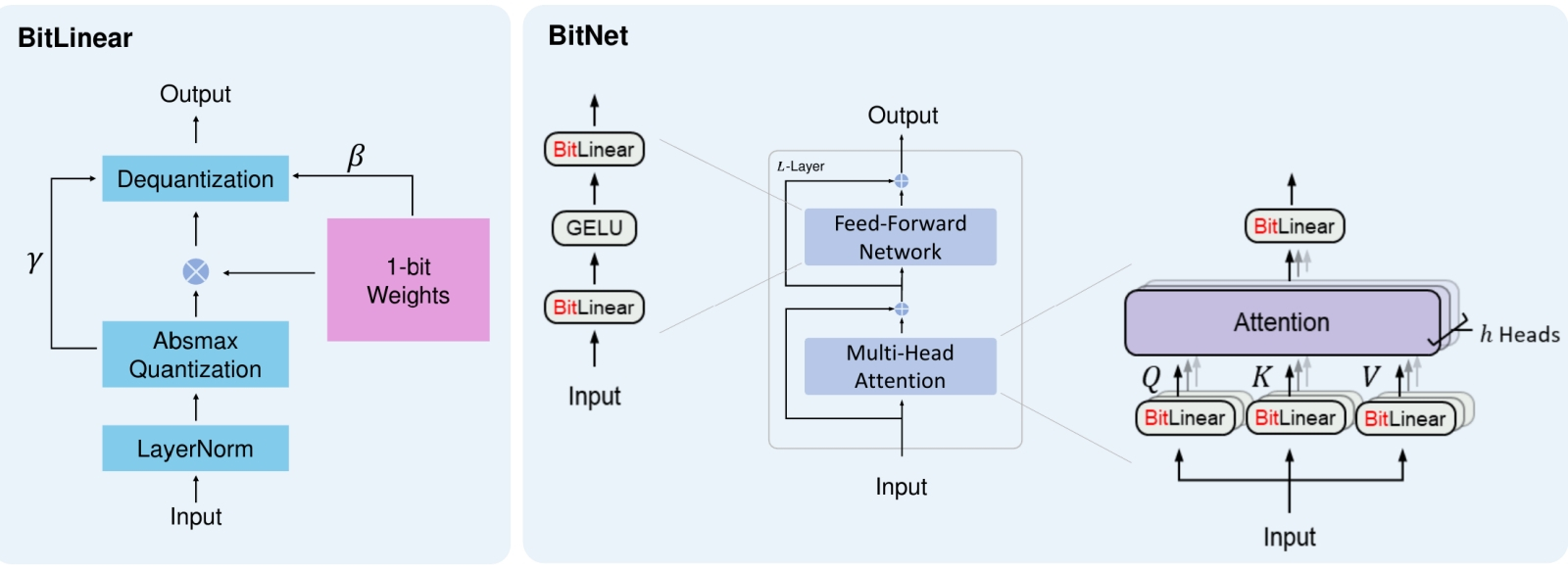 Иллюстрация из работы «BitNet: Scaling 1-bit Transformers for Large Language Models», на которой приводятся схемы реализации одиночного блока функции внимания и их сборки в предложенном авторами 1-битной архитектуре трансформеров (источник: Microsoft Research) В самых общих словах, речь идёт о той самой семантике анализируемых ИИ текстов, которая в классическом подходе к реализации БЯМ выявляется на этапе операций над векторами заделок в латентном пространстве. Если семантическая связь между словами устанавливается в ходе определения взаимного расположения этих самых векторов через матричное умножение (в ходе этой операции выясняется, например, что вектор «king» более сонаправлен с вектором «man», чем с «woman»), то переход к троичному одноразрядному представлению весов резко упрощает соответствующую процедуру: векторы оказываются либо разнонаправленными («−1»), либо строго сонаправленными («1»), либо ортогональными («0»). В каком-то смысле это можно воспринимать как откат к простейшей кодировке embeddings по методу one-hot, но, поскольку здесь сопоставляются не отдельные токены, а уже преобразованные в заделки вектора, и операция сравнения семантических признаков сводится к выдаче результата «есть полное соответствие — есть полная противоположность — соответствие не определено», такой подход действительно может сработать. Бесспорно, тут есть ещё над чем поломать голову: даже у GPT-4, которая на сегодня не может считаться самой передовой, насчитывается уже около триллиона параметров, а теоретическое обоснование калифорнийская безматричная модель получила пока лишь для 3 млрд. Впрочем, выгоды, которые сулит хотя бы частичный отказ от матричных операций для БЯМ, настолько велики, что на них наверняка обратят самое пристальное внимание разработчики всё более мощных и ресурсоёмких ИИ. Всё, что позволит в обозримой перспективе продолжать развиваться по этому направлению без необходимости вот прямо уже завтра снабжать каждый ЦОД ядерным реактором, вне всякого сомнения, окупится, и довольно скоро. ⇡#Материалы по темеНейроморфные вычислители «в металле»: приземление интеллекта Учёные нашли способ запускать большие ИИ-модели на системах мощностью 13 Вт вместо 700 Вт Математики придумали более простой способ умножения матриц — он может стать основой прорыва в ИИ Вычисления со скоростью света: в США разработали аналоговый фотонный ИИ-ускоритель Свёрточные нейронные сети — надежда и опора генеративного ИИ Искусственный интеллект: аналоговые вычислители побеждают
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.





