







 MWC 2018
MWC 2018 2018
2018 Computex
ComputexНа днях Microsoft удалила сообщение в блоге, которое, по мнению критиков, призывало нелегально использовать книги о Гарри Поттере для обучения моделей ИИ. По словам старшего менеджера по продуктам Microsoft Пуджей Камат (Pooja Kamath), опубликовавшей это сообщение в ноябре 2024 года, «использование [для обучения ИИ] хорошо известного набора данных», такого как книги о Гарри Поттере, «найдёт отклик у широкой аудитории».







Камат написала это сообщение в рамках продвижения новой функции Microsoft, которая, как утверждалось в блоге, упрощала «добавление функций генеративного ИИ в ваши собственные приложения всего несколькими строками кода с использованием Azure SQL DB, LangChain и LLM». Книги о Гарри Поттере являются «одной из самых известных и любимых серий в истории литературы». Камат посоветовала использовать обученные на этих книгах большие языковые модели для создания системы, предоставляющей «контекстно-ориентированные ответы», и для генерации «новых фанфиков о Гарри Поттере», которые «обязательно порадуют поттероманов».
Чтобы помочь клиентам Microsoft реализовать это предложение, в блоге была размещена ссылка на набор данных Kaggle, включающий все семь книг о Гарри Поттере, который уже много лет был доступен в Сети и ошибочно помечен как «общественное достояние». Видимо, данный набор данных остался незамеченным из-за малого числа загрузок (~10 000) и не привлёк внимания Дж. К. Роулинг (J.K. Rowling). Вчера он был оперативно удалён.
Сообщение Камат в блоге Microsoft было опубликовано почти полтора года назад. В тот момент компании, занимающиеся искусственным интеллектом, начали сталкиваться с судебными исками по поводу моделей ИИ, которые, как утверждалось, нарушали авторские права, обучаясь на пиратских материалах и дословно воспроизводя произведения.
Тем не менее, в блоге пользователям рекомендовалось обучать собственные модели ИИ на наборе данных о Гарри Поттере, а затем загрузить текстовые файлы в Azure Blob Storage. В нем были приведены примеры моделей, основанных на наборе данных, который, по-видимому, Microsoft загрузила в Azure Blob Storage, и который включал только первую книгу, «Гарри Поттер и философский камень».
Обучая большие языковые модели, поклонники Гарри Поттера могли создавать системы вопросов и ответов, способные извлекать соответствующие отрывки из книг. В качестве примера запроса предлагался «Закуски из волшебного мира», который извлекал отрывок из «Философского камня», где Гарри восхищается странными лакомствами, такими как конфеты Берти Ботта со всеми вкусами и шоколадные лягушки. Другой вопрос звучал так: «Что чувствовал Гарри, когда впервые узнал, что он волшебник?»
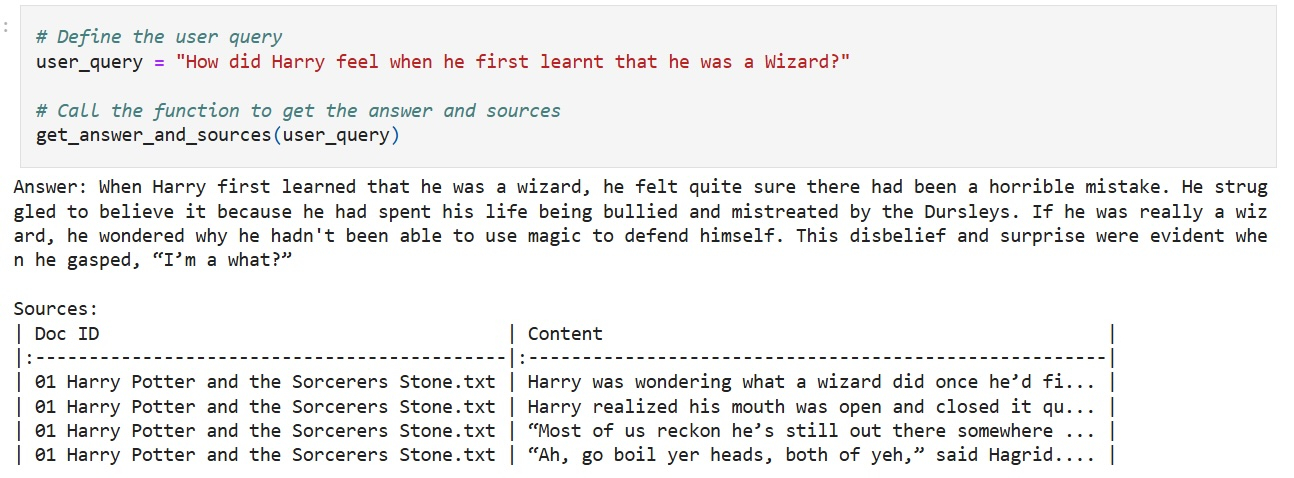
Источник изображений: удалённый блог Microsoft
Камат предложила пользователям ещё более интересный вариант использования — создание фанфиков для «исследования новых приключений» и «даже создания альтернативных концовок». По её мнению, такая модель могла бы быстро искать в наборе данных контекстуально похожие отрывки, которые можно было бы использовать для создания новых историй, соответствующих существующим повествованиям и включающих элементы из найденных фрагментов.
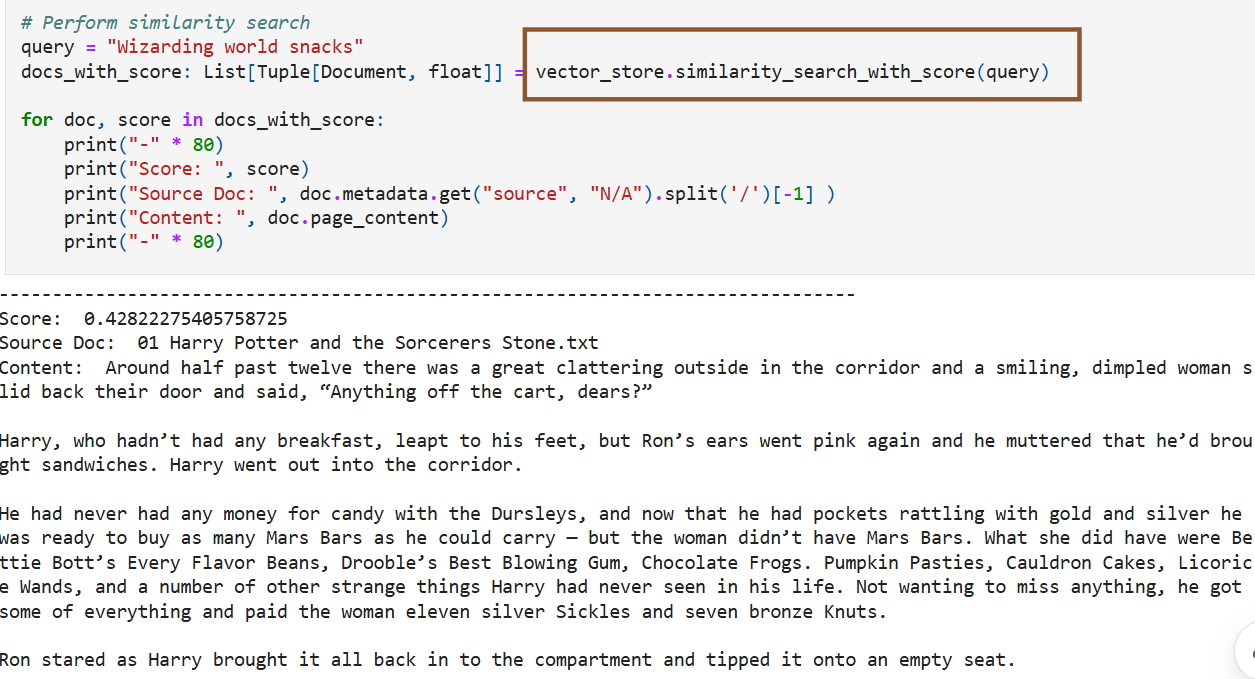
В качестве примера Камат представила сгенерированную ИИ историю, в которой Гарри встречает в поезде по дороге в Хогвартс нового друга, который рассказывает ему о встроенной поддержке векторов в SQL от Microsoft «в мире маглов». Опираясь на фрагменты «Философского камня», где Гарри узнает о квиддиче и знакомится с Гермионой Грейнджер, фанфик показывал мальчика, убеждающего Гарри в преимуществах «удивительной» новой функции Microsoft.
Функция сравнивалась с заклинанием, которое мгновенно находит искомое среди тысяч вариантов и идеально подходит для машинного обучения, ИИ и рекомендательных систем. Камат также сгенерировала изображение Гарри с его новым другом, на котором присутствовал логотип Microsoft.
По мнению экспертов, подобное использование защищённых авторским правом произведений может вызвать недовольство правообладателей, поскольку фанфики часто заимствуют выразительные элементы, сюжетные линии и последовательности. Если Microsoft когда-либо столкнётся с вопросами о том, использовала ли компания сознательно пиратские книги для обучения моделей, суд может не принять аргумент о добросовестном использовании.
Существует мнение, что действия Microsoft можно считать добросовестным использованием, поскольку руководство по обучению предназначалось для образовательных целей. Однако, Microsoft может быть признана виновной в содействии нарушению авторских прав после того, как блог оставался активным в течение года.
Источник:





