|
Опрос
|
реклама
Быстрый переход
Платформа X начнёт исключать из программы монетизации аккаунты, копирующие чужие публикации
17.07.2026 [06:11],
Анжелла Марина
Социальная сеть X объявила об усилении борьбы с пользователями, злоупотребляющими программой монетизации для авторов за счёт публикации чужого контента и искусственного накручивания вовлечённости. Новые меры предусматривают перераспределение доходов в пользу первоисточника, а также исключение нарушителей из программы. 
Источник изображения: xAI По сообщению TechCrunch, новая модель Grok способна находить дублированный контент быстрее и в большем объёме по сравнению с предыдущей версией Grok. При этом попытки скрыть происхождение материалов, сопровождаемые добавлением водяных знаков, вступительных заставок и других изменений, больше не позволят получать доход от чужих публикаций. Монетизируемые показы в таких случаях будут автоматически засчитываться автору, который выложил контент первым. Аналогичный механизм распространяется и на копии завирусившихся текстовых сообщений. В ходе последнего цикла проверки платформа выявила около 1,5 млн публикаций, оказавшихся скопированными, однако не уточняется, за какой именно период проводилась эта проверка. В результате внедрения новых механизмов более $1 млн выплат будет возвращено первоначальным создателям контента вместо пользователей, разместивших копии. Одновременно X усилила борьбу с ботами и другими нарушениями правил платформы. Пользователи, неоднократно или умышленно обходящие новые правила, будут исключаться из программы монетизации. Аналогичные меры затронут аккаунты, занимающиеся накруткой подписчиков и вовлечённости. В частности, при трёх и более выявленных случаях подобных нарушений учётная запись будет передана команде по вопросам политики платформы для рассмотрения вопроса о её блокировке. ИИ нанёс японским знаменитостям ущерб на $31 млн всего за два месяца
10.07.2026 [17:08],
Анжелла Марина
Исследование японской некоммерческой организации по защите авторских прав известных личностей Japro показало, что за два месяца 2025 года были выявлены более 43 тыс. предполагаемых случаев нарушения авторских и смежных прав с использованием искусственного интеллекта. По оценке Japro, связанные с этим финансовые потери знаменитостей и артистов достигли 4,5 млрд йен. 
Источник изображения: AI Согласно исследованию, проведённому на основе данных различных социальных платформ, к числу нарушений относятся создание с помощью ИИ игровых экранизаций аниме с использованием изображений знаменитостей, а также генерация голосов персонажей аниме для исполнения популярных песен. Такой контент, как сообщает издание The Japan Times, суммарно набрал около 335 млн просмотров, а расчёт предполагаемого ущерба основывался на стоимости лицензирования изображения или голоса, а также рекламной ценности полученной аудитории. В Japro отметили, что фактический размер убытков может оказаться значительно выше приведённых оценок, поскольку анализ охватывал только обнаруженные случаи. Одновременно опрос 174 компаний индустрии развлечений показал, что лишь около 28 % респондентов полностью или частично осведомлены о масштабах подобных нарушений, тогда как многие указали на невозможность отследить все незаконные случаи использования образов артистов. Кроме того, только 1,1 % опрошенных компаний сообщили о наличии внутренних рекомендаций по реагированию на подобные нарушения. При этом 52 % заявили, что продолжают рассматривать возможные меры, а остальные пока не планируют разрабатывать соответствующие правила. На фоне растущих опасений Министерство юстиции Японии сформировало экспертную группу для обсуждения возможных правовых мер в отношении ИИ-контента, при этом главный антимонопольный и административный орган Японии Japan Fair Trade Commission (JFTC) с декабря прошлого года изучает использование новостных материалов поисковыми ИИ-ботами без разрешения правообладателей. New York Times обвинила OpenAI в сокрытии улик по делу об обучении ИИ на чужих материалах
10.07.2026 [10:00],
Павел Котов
Утверждения OpenAI о том, что разработчик ChatGPT не имеет возможности производить поиск по перепискам пользователей и чат-бота с искусственным интеллектом, а также по массивам обучающих данных, не соответствуют действительности, заявили представители газет New York Times и The Daily News. 
Источник изображений: Mariia Shalabaieva / unsplash.com Издания уже два года судятся с разработчиком систем ИИ, утверждая, что компания нарушила авторское право, обучая свои генеративные ИИ-модели на их материалах, которые воспроизводятся дословно в ответах на запросы пользователей. Всё это время OpenAI утверждает, что у неё нет возможности искать информацию в обучающем массиве. Она также настаивает, что поиск или воспроизведение переписки пользователей с ChatGPT были бы технически обременительными и вызвали бы опасения по поводу конфиденциальности пользователей — журналы чатов пришлось бы извлекать, обрабатывать и обезличивать. Издания запрашивали эти сведения, чтобы определить, присутствуют ли их защищённые авторским правом публикации в обучающих массивах OpenAI, и генерирует ли ChatGPT ответы, используя и воспроизводя их контент. В ходе допроса, проведённого в апреле по решению суда, инженер по защите данных в OpenAI Винни Монако (Vinnie Monaco) якобы сообщил, что компания всё-таки производила поиск и оценку данных в обучающем массиве, чтобы выявить присутствие защищённых авторским правом журналистских работ. По его словам, ещё до подачи New York Times иска OpenAI уже собрала базу из 78 млн обезличенных переписок с ChatGPT, которую использовала, чтобы определить степень нарушения авторских прав на чужие работы. После подачи иска компания также предположительно внедрила фильтр Bloom в наборе средств Project Giraffe, который фиксировал повторения во выходных данных.  Первоначально истцы запрашивали выборку из 120 млн журналов переписки, но OpenAI договорилась сократить её объем до 20 млн. В декабре компания представила эти данные, но они, как определил суд, были настолько вымараны, что стали «непригодными для использования». После подачи иска OpenAI, утверждают истцы, удалила несколько миллиардов ответов ChatGPT, нарушив тем самым постановление суда о сохранении данных; а несколько миллионов журналов компания просто заменила. Другими словами, она неоправданно затруднила передачу уже собранной информации. «Если бы OpenAI действительно считала, что копировать журналистские материалы наших клиентов — это честно и по закону, она бы не скрывала правду, что сделала это», — заявил адвокат истцов. New York Times и The Daily News просят судью вынести OpenAI наказание за сокрытие доказательств и вмешательство в процесс раскрытия информации. Они ходатайствуют, чтобы OpenAI запретили использовать массив из 20 млн журналов чатов как доказательство, утверждая, что этот набор данных ненадёжен; чтобы суд принял как факт, что журналы переписок ChatGPT показали бы существенное повторение материалов истцов; чтобы OpenAI лишилась возможности утверждать что в представленных ей журналах переписок не демонстрируется существенное повторение материалов; и чтобы OpenAI оплатила судебные издержки за поиск этих доказательств. Представитель OpenAI отверг обвинения, обвинив истцов в попытке получить доступ к частной переписке пользователей, потому что позиция истцов ослабла. «По мере ослабления позиции Times и вынужденного отказа от претензий к нам они продолжают свои попытки вторгнуться в частную жизнь людей, не имеющих к этому делу никакого отношения, в том числе путём выдвижения этих заведомо ложных обвинений. Мы и далее будем защищать конфиденциальность наших пользователей и давно установленные принципы добросовестного использования», — подчеркнул он. Суд приказал заблокировать все домены Anna’s Archive — крупнейшей пиратской библиотеки в интернете
21.05.2026 [14:02],
Дмитрий Федоров
Коалиция из тринадцати крупных издательств, включая Penguin Random House, Elsevier и HarperCollins, добилась вынесения заочного решения нью-йоркского федерального суда на $19,5 млн против крупнейшей пиратской библиотеки в интернете — Anna’s Archive. Суд также вынес постоянный судебный запрет, согласно которому более двадцати реестров доменных имён, хостинг-провайдеров и других технических посредников обязаны немедленно отключить оставшиеся домены сайта. 
Источник изображения: Bermix Studio / unsplash.com Издатели настаивали, что Anna’s Archive не только распространяет ссылки на пиратские книги, но и работает как один из главных источников данных, на которых техногиганты — в частности Meta✴✴ и Nvidia — обучают свои ИИ-модели. Операторы пиратского сайта не явились в суд, и окружной судья Джед Ракофф (Jed S. Rakoff) удовлетворил все требования истцов. Компенсация рассчитана по максимальной ставке — $150 000 за каждое из 130 произведений, указанных в иске. Впрочем, как и решение на $322 млн по связанному делу музыкальной индустрии против того же сайта, вся сумма почти наверняка останется лишь на бумаге, потому что заочное решение означает только право требовать деньги, а фактически взыскать их не с кого. Операторы Anna’s Archive до сих пор анонимны и ранее заявляли, что скрывают свои личности, чтобы избежать «десятилетий тюремного заключения». Суд обязал их раскрыть свои данные в течение десяти дней, но шансов на исполнение этого требования мало. 
Источник изображения: U.S. District Court for the Southern District of New York Главная сила решения — не сумма, а постоянный судебный запрет. Anna’s Archive известна тем, что при блокировке просто переезжает на новые домены, поэтому запрет нацелен не на сам сайт, а на технических посредников, без которых он не может работать. Все реестры и регистраторы доменных имён обязаны навсегда заблокировать домены библиотеки и запретить их передачу кому-либо, кроме истцов. Судебное решение затрагивает и международных хостинг-провайдеров. В документе поимённо названы более двадцати компаний, включая Cloudflare, Njalla, DDoS-Guard, а также реестры действующих доменов: TELE Greenland / Tusass (.GL), PKNIC (.PK) и телекоммуникационный регулятор Гренады — National Telecommunications Regulatory Commission (.GD). В отличие от данных Spotify, которые Anna’s Archive удалила после иска, книги издателей по-прежнему доступны на сайте, и это может заставить посредников отнестись к запрету серьёзнее. Наибольший эффект запрет окажет на американские компании — Cloudflare и OwnRegistrar, которые обязаны подчиняться решениям нью-йоркского суда. Но большинство посредников из списка зарегистрированы за пределами США: одни ранее выполняли предписания американских судов, другие игнорировали их, ссылаясь на отсутствие местной юрисдикции. Пока издатели получили от суда всё, что просили, однако три домена Anna’s Archive остаются активными. Судя по прежнему опыту, сайт наверняка подготовил резервные адреса на случай отключения. Издатели: Цукерберг лично одобрил массовое пиратство книг для обучения ИИ
06.05.2026 [12:59],
Дмитрий Федоров
Пять крупных издательств и писатель Скотт Туроу (Scott Turow) подали коллективный иск против Meta✴✴ и лично её гендиректора Марка Цукерберга (Mark Zuckerberg), обвинив компанию в одном из крупнейших нарушений авторских прав в истории. По утверждению истцов, Meta✴✴ незаконно скопировала миллионы книг, статей и других произведений для обучения ИИ-модели Llama. 
Источник изображения: about.fb.com Иск поступил в Окружной суд США по Южному округу Нью-Йорка от издательств Hachette, Macmillan, McGraw Hill, Elsevier и Cengage. Истцы утверждают, что Meta✴✴ скачивала через торренты миллионы защищённых авторским правом книг и журнальных статей с пиратских сайтов, занималась несанкционированным веб-скрейпингом «практически всего интернета», а затем многократно копировала эти материалы для обучения Llama. Новое дело принципиально отличается от прежних попыток авторов оспорить действия ИИ-компаний. Истцы делают акцент на личной роли Цукерберга: он, по их словам, «лично санкционировал и активно поощрял» нарушение авторского права. Meta✴✴ по его указанию удалила из украденных произведений информацию об управлении авторскими правами, чтобы скрыть источники обучающих данных. После выпуска Llama 1 компания ненадолго задумалась о лицензировании и с января по апрель 2023 года обсуждала увеличение бюджета на эти цели вплоть до $200 млн. Однако в начале апреля 2023 года Meta✴✴ внезапно прекратила переговоры. Вопрос о том, платить правообладателям или продолжать пиратство, «эскалировали до Цукерберга», после чего команда по развитию бизнеса получила устные указания свернуть лицензионную работу. Один из сотрудников Meta✴✴, как следует из иска, дальновидно объяснил логику решения: «Если мы лицензируем хотя бы одну книгу, то не сможем опираться на стратегию добросовестного использования». 13 декабря 2023 года сотрудники Meta✴✴ распространили внутреннюю записку о правовых рисках использования LibGen. Хранилище в ней описано как «набор данных, заведомо полученный путём пиратства», а авторы документа отметили: «Мы не будем раскрывать использование наборов данных Libgen для обучения». Несмотря на эти опасения, Цукерберг и другие руководители компании одобрили скачивание через торренты более 267 Тбайт пиратских материалов. По данным иска, этот объём эквивалентен сотням миллионов публикаций и многократно превышает всю печатную коллекцию Библиотеки Конгресса. Истцы утверждают, что ИИ-система Meta✴✴ генерирует в массовом масштабе заменители их произведений и подстраивает ответы под стиль конкретных авторов, имитируя их выразительные элементы и творческие решения. Ранее авторы уже проигрывали подобные дела. В июне 2025 года федеральный судья Винсент Чхабриа (Vincent Chhabria) отклонил иск тринадцати авторов, среди которых Сара Сильверман (Sarah Silverman) и Джуно Диас (Junot Díaz), и признал использование Meta✴✴ набора данных из почти 200 000 книг для обучения Llama добросовестным. Meta✴✴ заявила, что будет агрессивно оспаривать новый иск, ссылаясь на ту же доктрину добросовестного использования (fair use) — норму американского авторского права, разрешающую при определённых условиях использовать защищённые произведения без согласия правообладателя. Певица Тейлор Свифт взялась защитить от ИИ свой голос и внешний образ
28.04.2026 [09:53],
Алексей Разин
Звёзды шоу-бизнеса в силу своей популярности часто становятся объектами манипуляций с их внешностью и голосом, особенно в эпоху бурного развития генеративного искусственного интеллекта. Американская исполнительница Тейлор Свифт (Taylor Swift) решила защитить авторскими правами не только свой голос, но и используемые внешние образы. 
Источник изображения: X, Taylor Swift Злоупотребления, с которыми певице пришлось столкнуться после появления технической возможности реалистично копировать её внешность и голос, варьируются от ложных рекламных роликов до видеозаписей с политическими заявлениями и изображений пикантного содержания, к которым сама Тейлор Свифт не имеет ни малейшего отношения. Как сообщает Reuters, законные представители Тейлор Свифт недавно подали в Ведомство по патентам и товарным знакам США заявку с требованием защитить авторскими правами не только голос певицы, но и её сценические образы. В качестве приложений к патентной заявке использовались два коротких аудиофайла, в которых Свифт представляется по имени и призывает своих поклонников ознакомиться с новым альбомом «The Life of a Showgirl», который выйдет на популярных стриминговых площадках 3 октября текущего года. В качестве образца сценического образа прилагается фото певицы на сцене в концертном костюме с блёстками и розовой гитарой в руках. Это не первая попытка американских знаменитостей зарегистрировать в качестве торговых знаков собственные образы. В начале года актёру Мэттью Макконахи (Matthew McConaughey) удалось защитить авторским правом несколько своих наиболее часто используемых в мемах образов, а также собственный голос. По словам экспертов, использование торговой марки в качестве средства защиты голоса знаменитостей пока не подкрепляется достаточной судебной практикой, поскольку исторически исполнители защищали авторским правом музыку и готовые произведения. Защита визуальных образов Тейлор Свифт на уровне авторского права, по мнению экспертов, позволит законным представителям певицы успешнее бороться со злоупотреблениями в данной сфере, которые с появлением эффективных инструментов для генерирования изображений и видео обрели массовый характер. Spotify и звукозаписывающие компании выиграли у Anna’s Archive иск на $322,2 млн, но взыскать эту сумму почти невозможно
15.04.2026 [17:08],
Дмитрий Федоров
Суд заочно присудил Spotify и трём крупнейшим звукозаписывающим компаниям $322,2 млн по иску к пиратской библиотеке Anna’s Archive. Основанием стали объявленная ресурсом выгрузка 86 млн песен из Spotify и их последующее распространение с нарушением авторских прав. Взыскать деньги быстро вряд ли удастся: лица, управляющие пиратским сайтом, не установлены. 
Источник изображения: Wesley Tingey / unsplash.com В январе Spotify, Universal Music Group (UMG), Warner Music Group (WMG) и Sony подали иск к лицам, управляющим Anna’s Archive. Поводом стала декабрьская запись в блоге ресурса, где тот сообщил, что выгрузил из Spotify 86 млн песен и собирается распространять их через ряд крупных торрентов. Судья Джед С. Ракофф (Jed S. Rakoff) сразу вынес судебный запрет на распространение этих записей, но ответчики иск проигнорировали. В феврале Anna’s Archive всё равно выложил раздачи с доступом более чем к 2 млрд незаконных музыкальных файлов, 120 000 из которых юристы Spotify скачали для проверки. Ракофф в порядке заочного производства признал Anna’s Archive ответственным за нарушение законодательства США об авторском праве и присудил Spotify $300 млн компенсации. Эту сумму суд рассчитал исходя из 120 000 зафиксированных случаев обхода Anna’s Archive антипиратских мер Spotify, по $2500 за каждый случай — это максимальная компенсация, предусмотренная за такой эпизод. UMG, WMG и Sony получили в общей сложности $22,2 млн. Суд рассчитал эту сумму как максимальную компенсацию в $150000 за каждый случай нарушения авторских прав по 148 записям, принадлежащим крупнейшим звукозаписывающим компаниям и выявленным в собрании Anna’s Archive. Практическое значение решения связано прежде всего с постоянным судебным запретом, который обязывает интернет-провайдеров на постоянной основе блокировать сайт Anna’s Archive. Исполнить эту меру будет непросто, потому что после блокировки очередного доменного имени пиратский ресурс всякий раз возобновляет работу под новым. YouTube-блогеры подали на Apple в суд, обвинив в незаконном обучении ИИ на их роликах
07.04.2026 [12:31],
Владимир Мироненко
Три известных YouTube-канала подали на прошлой неделе в федеральный суд Калифорнии на Apple, утверждая, что компания обошла защиту YouTube, чтобы загрузить миллионы видеороликов, защищённых авторским правом, для обучения своих ИИ-моделей, тем самым нарушив «Закон США об авторском праве в цифровую эпоху» (DMCA). 
Источник изображения: Wesley Tingey/unsplash.com В коллективном иске владельцы YouTube-каналов h3h3Productions (а также H3 Podcast и H3 Podcast Highlights), MrShortGame Golf и Golfholics обвинили Apple в том, что она «намеренно обошла» защиту YouTube от сбора видеоконтента и «получила от этого существенную прибыль». Истцы ссылаются на исследование Apple под названием STIV: Scalable Text and Image Conditioned Video Generation (Масштабируемая генерация видео с учетом текста и изображений), в котором, как они утверждают, был использован набор данных Panda-70M для обучения модели генерации видео, описанной в статье. Набор данных Panda 70M функционирует как карта или индексный файл, идентифицирующий конкретные видеоролики и клипы YouTube по URL-адресу, идентификатору видео и временной метке. Истцы заявили, что хотя набор данных содержит только ссылки на видео, Apple якобы обошла защиту YouTube от сбора данных, чтобы загрузить и использовать исходный контент для обучения своих ИИ-моделей. Они насчитали 500 случаев использования их контента в этом наборе, призывая присоединиться к иску другие YouTube-каналы, чьи клипы тоже незаконно использовались Apple. Истцы требуют классификации данного иска как коллективного с рассмотрением его судом присяжных. Также они требуют компенсации установленных законом убытков (в пределах максимальной суммы, разрешённой законом за каждое нарушение), судебного запрета, а также оплаты услуг адвокатов и судебных издержек в соответствии со статьей 1203 раздела 17 Свода законов США. Помимо Apple, истцы также подали коллективные иски против Amazon и OpenAI с обвинением в том, что они использовали набор данных Panda-70M в процессе обучения своих ИИ-моделей. В течение последних трёх месяцев эти YouTube-каналы подали аналогичные иски против других технологических гигантов, включая Meta✴✴, Nvidia, ByteDance и Snap. Anthropic вспомнила об авторских правах — она пытается смягчить последствия утечки кода Claude Code
01.04.2026 [20:28],
Сергей Сурабекянц
Компания Anthropic обучала свои модели ИИ с многочисленными нарушениями авторских прав, но отреагировала предельно негативно, когда сама попала в аналогичную ситуацию. После случайной утечки базовых инструкций, используемых для управления Claude Code, они попали в широкий доступ и начали активно использоваться. На данный момент представители Anthropic потребовали у администрации GitHub удалить уже более 8000 копий и адаптаций утёкшего в Сеть исходного кода. 
Источник изображений: Anthropic Конфиденциальная информация Claude Code была случайно раскрыта 31 марта. Как и большинство проприетарного ПО, исходный код Claude обычно обфусцирован и его трудно реконструировать. Однако на этот раз компания разместила на GitHub файл, содержащий ссылку на исходный код, который посторонние могли свободно загрузить и прочитать. Один из пользователей быстро заметил утечку и распространил информацию в соцсети X. Многочисленные программисты и энтузиасты ИИ тут же бросились изучать утечку. В социальных сетях появились восторженные отзывы о некоторых программных и алгоритмических «уловках» Anthropic. Одна из функций требует от моделей периодически возвращаться к выполнению задач и консолидировать свои воспоминания — процесс, который в Anthropic называют «сновидением». Другая функция предписывает Claude не раскрывать свою ИИ-сущность при публикации кода на таких платформах, как GitHub. В коде обнаружены теги, указывающие на будущие релизы продукта и даже код питомца в стиле Тамагочи по имени «Бадди», с которым пользователи могли взаимодействовать. В результате конкуренты Anthropic, а также множество стартапов и разработчиков теперь имеют подробные планы развития продукта и возможность клонирования функций Claude Code без необходимости обратного проектирования — что уже стало обычным явлением в жёсткой конкуренции в сфере ИИ. Утечка также предоставляет хакерам возможности для поиска ошибок, которые можно использовать для эксплуатации или манипулирования ИИ-моделью Claude с целью использования её в кибератаках.  Утечка «некоторого внутреннего исходного кода» не раскрыла никакой информации или данных клиентов, заявил представитель Anthropic. Она также не раскрыла ценные веса моделей. Однако в широкий доступ попала коммерчески важная информация, включая методы, инструменты и инструкции Anthropic по управлению моделями ИИ в качестве агентов. «Это была проблема с упаковкой релиза, вызванная человеческой ошибкой, а не нарушением безопасности. Мы принимаем меры, чтобы предотвратить подобные инциденты в будущем», — заявил представитель компании. Несмотря на это заявление, утечка стала ударом для Anthropic, поскольку она рискует подорвать репутацию компании в сфере безопасности, а также раскрыть ценные коммерческие секреты в ожесточённой борьбе за корпоративных клиентов. Вирусная популярность Claude Code помогла Anthropic привлечь инвестиции, которые довели биржевую оценку компании до $380 млрд. После того, как Anthropic потребовала от GitHub удалить копии своего проприетарного кода, функциональность Claude Code была переписана с помощью сторонних ИИ-инструментов. Автор этого «проекта» заявил, что цель его усилий — сохранить доступность информации, не рискуя её удалением. Этот пиратский «форк» уже стал весьма популярным на GitHub. ByteDance отложила глобальный запуск ИИ-генератора видео Seedance 2.0 из-за проблем с авторскими правами
15.03.2026 [07:44],
Алексей Разин
Соблазн использования уже знакомых образов и сюжетов при генерации видео с помощью искусственного интеллекта весьма высок, поскольку это упрощает задачу создателю и одновременно позволяет гарантировать интерес аудитории к конечному результату. ByteDance решила отложить глобальный запуск генератора видео Seedance 2.0 из-за проблем с авторскими правами. 
Источник изображения: ByteDance Как отмечает Reuters со ссылкой на The Information, соответствующие трудности возникли у китайской компании в сфере взаимоотношений с крупными голливудскими студиями и стриминговыми платформами. Ещё в прошлом месяце ByteDance была вынуждена заявить, что предпримет меры для предотвращения неправомерного использования интеллектуальной собственности в работе ИИ-генератора видео Seedance 2.0 после того, как некоторые американские студии типа Disney пригрозили ей судебным преследованием. По версии Disney, компания ByteDance использовала персонажей, чьи образы принадлежат студии, для обучения Seedance 2.0 без соответствующего разрешения. Поводом для претензий стало распространение в китайских социальных сетях вирусного видео, на котором сгенерированные ИИ двойники Тома Круза (Tom Cruise) и Брэда Питта (Brad Pitt) участвуют в поединке. Как считает Disney, при обучении Seedance 2.0 китайская ByteDance использовала полученные незаконным способом образы персонажей из популярных кинофраншиз, включая Star Wars и Marvel, обращаясь с ними, как с общедоступными материалами. Представившая ИИ-генератор Seedance 2.0 на китайском рынке в феврале ByteDance отмечала, что он предназначен для профессионального использования при производстве фильмов и рекламных роликов. Способность данного продукта одновременно обрабатывать текст, изображения, видео и аудио, по словам представителей компании, позволяет снизить затраты на изготовление контента. Первоначально ByteDance намеревалась открыть доступ к Seedance 2.0 клиентам за пределами Китая в середине марта, но из-за потенциальных проблем с авторскими правами решила задержать график. Как отмечается, сейчас технические специалисты работают над внедрением защитных механизмов от использования охраняемых авторским правом персонажей, а юристы дополнительно прорабатывают правовые основы использования ИИ-модели. Издатели потребовали закрыть крупнейшую пиратскую библиотеку интернета — в ней 140 млн книг и научных статей
11.03.2026 [06:12],
Анжелла Марина
Тринадцать ведущих мировых издательств, в том числе Penguin Random House и HarperCollins, подали иск против крупнейшей теневой онлайн-библиотеки Anna’s Archive. Как сообщается в документах, поданных в суд Нью-Йорка, ответчик обвиняется в «вопиющем» нарушении авторских прав из-за размещения коллекции из 63 миллионов книг и 95 миллионов научных статей. 
Источник изображения: Ashkan Ala/Unsplash Истцы акцентируют внимание на том, что владельцы ресурса открыто называют себя «пиратами» на странице описания своего сайта, статистика которого показывает 763 тысячи ежедневных загрузок контента. Издатели утверждают, что все эти загрузки являются нелегальными и ни одна из этих копий не была лицензирована. Отдельным пунктом обвинения, как сообщает портал TorrentFreak, значится коммерциализация пиратства через продажу премиум-доступа разработчикам искусственного интеллекта (ИИ). В иске упоминается, что ресурс Anna’s Archive предлагал высокоскоростной доступ к своей базе данных, содержащей более 140 миллионов текстов, за «корпоративный донат», размер которого в частной переписке оценивался в 200 тысяч долларов. Хотя общая сумма требуемой компенсации достигает $19,5 млн, ключевой целью иска является не финансовая выгода, а получение судебного запрета. Понимая, что анонимные администраторы ресурса вряд ли выплатят деньги, издатели стремятся заблокировать саму инфраструктуру сайта. Предложенный запрет требует от всех третьих сторон — хостинг-провайдера, регистратора домена и дата-центров немедленно прекратить обслуживание Anna’s Archive. Издатели надеются, что эта юридическая позиция окажется эффективнее предыдущих попыток прекратить деятельность пиратской системы, так как распространяется не только на текущие доменные имена в зоне .VG и .LI (уже заблокированы), но и на любые будущие уже известные зеркала ресурса (.VG, .PK и .GD), где будет размещён тот же контент. Решение суда по данному ходатайству ожидается в ближайшее время. Ранее мы сообщали, что хакеры-пираты Anna’s Archive начали публиковать музыку, украденную у Spotify, несмотря на коллективный судебный иск на сумму $13 трлн. «Не воруйте эту книгу»: около 10 000 писателей выпустили «пустую» книгу в знак протеста против ИИ
10.03.2026 [18:25],
Сергей Сурабекянц
Около 10 000 писателей, включая Кадзуо Исигуро (Kazuo Ishiguro), Филиппу Грегори (Philippa Gregory) и Ричарда Османа (Richard Osman), стали соавторами издания «Не воруйте эту книгу», которое содержит лишь список протестующих против обучения ИИ на их произведениях. Книга будет распространяться на Лондонской книжной ярмарке в преддверии публикации правительством Великобритании оценки экономических издержек от предлагаемых изменений в законе об авторском праве. 
Источник изображения: Steve Johnson / unsplash.com К 18 марта британские министры должны представить оценку экономического воздействия планируемой реформы законодательства об авторском праве на фоне протестов представителей творческих профессий против использования их работ для обучения ИИ. Организатор акции протеста и инициатор выпуска книги «Не воруйте эту книгу» композитор и борец за защиту авторских прав художников Эд Ньютон-Рекс (Ed Newton-Rex) заявил, что индустрия ИИ «построена на украденных работах, взятых без разрешения или оплаты». На задней обложке книги написано: «Правительство Великобритании не должно легализовать кражу книг в интересах компаний, занимающихся ИИ». Протестующие держат плакаты с призывом «Отключите питание». «Это не преступление без жертв – генеративный ИИ конкурирует с людьми, на чьих работах он обучается, лишая их средств к существованию. Правительство должно защитить творческих людей Великобритании и отказаться от легализации кражи творческих работ компаниями, занимающимися ИИ», — добавил он. Среди писателей, внёсших свой вклад в книгу, автор «Загнанных лошадей» Мик Херрон (Mick Herron), писательница Мариан Кейс (Marian Keyes), историк Дэвид Олусога (David Olusoga) и Мэлори Блэкман (Malorie Blackman), автор книги «Крестики-нолики». Участники акции полагают «вполне разумным» оплату авторам за использование их произведений для обучения ИИ. Издатели также запустят на Лондонской книжной ярмарке инициативу по лицензированию художественных произведений для обучения ИИ. В настоящее время некоммерческая отраслевая организация Publishers’ Licensing Services создаёт схему коллективного лицензирования и пригласила отрасль присоединиться к ней в надежде, что это обеспечит законный доступ к опубликованным произведениям. ИИ для своего обучения требует огромных объёмов данных, включая защищённые авторским правом произведения, взятые из интернета. Это вызывает серьёзное беспокойство среди творческих специалистов и компаний по всему миру, спровоцировав судебные иски по обе стороны Атлантики. В прошлом году Anthropic, разработчик чат-бота Claude, согласилась выплатить $1,5 млрд для урегулирования коллективного иска от авторов книг, пиратские копии которых компания использовала для обучения своего флагманского продукта. Творческие люди Британии возмущены предложением правительства, которое планирует разрешить ИИ-компаниям по умолчанию использовать защищённые авторским правом произведения без разрешения, если владелец прямо не запретил такое использование. Всемирно известный певец Элтон Джон (Elton John) отреагировал на это предложение, назвав правительство «абсолютными неудачниками». Правительство предложило ещё три варианта:
Правительство также отказалось исключить возможность отказа от авторских прав на использование материалов в целях «коммерческих исследований», что, по опасениям представителей творческих профессий, может быть использовано компаниями, занимающимися искусственным интеллектом, для присвоения произведений без разрешения. Представитель правительства заявил: «Государство намерено создать режим авторского права, который ценит и защищает человеческое творчество, которому можно доверять и который способствует инновациям. Мы продолжим тесно сотрудничать с владельцами авторских прав по этому вопросу и выполним наше обязательство предоставить парламенту обновлённую информацию к 18 марта». Ранее , в феврале 2025 года, группа из 1000 музыкантов выпустила «тихий» альбом «Is This What We Want?» («Разве этого мы хотим?»), содержащий лишь записи пустых студий и концертных залов. Верховный суд США подтвердил, что ИИ-искусство не может защищаться авторским правом
03.03.2026 [10:00],
Алексей Разин
В сфере авторского права в эпоху искусственного интеллекта американский учёный Стивен Талер (Stephen Thaler) обретает определённую известность, поскольку он уже несколько лет пытается добиться право регистрации за собой изобретений, созданных силами искусственного интеллекта. Он попытался зарегистрировать и авторские права на картину, которая была сгенерирована его системой DABUS, но эти попытки были отклонены недавно Верховным судом США. 
Источник изображения: Unsplash, Sasun Bughdaryan Как поясняет Reuters, Верховный суд США на этой неделе отклонил апелляцию Стивена Талера на решения судов более низких инстанций по поводу регистрации авторских прав на художественное произведение «Недавний вход в рай», которое было создано его ИИ-системой DABUS несколько лет назад. Энтузиаст с 2018 года пытался в США зарегистрировать авторские права на изображение железнодорожных рельсов, уходящих в некий портал, раскрашенный в яркие контрастные цвета. Профильное ведомство США, которое занимается регистрацией авторских прав, отклонило его заявку в 2022 года, мотивируя необходимость закрепления подобных прав за человеком, а не бездушной системой. Более того, ведомство отклоняло и заявки на регистрацию авторских прав художниками, которые создавали свои произведения с использованием большой языковой модели Midjourney. Они настаивали, что являются соавторами данных произведений, тогда как Талер не скрывал, что разработанная им система DABUS создала свою картину без человеческого влияния. В 2023 году суд в Вашингтоне поддержал решение суда нижней инстанции по делу Талера, столичный апелляционный суд подтвердил правомерность такого вердикта в 2025 году. Талер рассчитывал на Верховный суд США, но тот отклонил его апелляционную жалобу. По мнению истца, подобное решение Бюро авторского права США изначально нанесло непоправимый ущерб всей ИИ-отрасли и деятелям творческих профессий в столь важный для их развития период. Ведомство настаивает, что понятие «автор» может применяться только к живому человеку, а не машине. Талер также проиграл в серии отдельных дел, которые должны были закрепить за ним авторские права на изобретения, сделанные искусственным интеллектом его разработки. Тем не менее, в той же Австралии суд встал на его сторону. Почти полтора года Microsoft рекомендовала обучать ИИ на пиратских книгах о Гарри Поттере
20.02.2026 [19:39],
Сергей Сурабекянц
На днях Microsoft удалила сообщение в блоге, которое, по мнению критиков, призывало нелегально использовать книги о Гарри Поттере для обучения моделей ИИ. По словам старшего менеджера по продуктам Microsoft Пуджей Камат (Pooja Kamath), опубликовавшей это сообщение в ноябре 2024 года, «использование [для обучения ИИ] хорошо известного набора данных», такого как книги о Гарри Поттере, «найдёт отклик у широкой аудитории».  Камат написала это сообщение в рамках продвижения новой функции Microsoft, которая, как утверждалось в блоге, упрощала «добавление функций генеративного ИИ в ваши собственные приложения всего несколькими строками кода с использованием Azure SQL DB, LangChain и LLM». Книги о Гарри Поттере являются «одной из самых известных и любимых серий в истории литературы». Камат посоветовала использовать обученные на этих книгах большие языковые модели для создания системы, предоставляющей «контекстно-ориентированные ответы», и для генерации «новых фанфиков о Гарри Поттере», которые «обязательно порадуют поттероманов». Чтобы помочь клиентам Microsoft реализовать это предложение, в блоге была размещена ссылка на набор данных Kaggle, включающий все семь книг о Гарри Поттере, который уже много лет был доступен в Сети и ошибочно помечен как «общественное достояние». Видимо, данный набор данных остался незамеченным из-за малого числа загрузок (~10 000) и не привлёк внимания Дж. К. Роулинг (J.K. Rowling). Вчера он был оперативно удалён. Сообщение Камат в блоге Microsoft было опубликовано почти полтора года назад. В тот момент компании, занимающиеся искусственным интеллектом, начали сталкиваться с судебными исками по поводу моделей ИИ, которые, как утверждалось, нарушали авторские права, обучаясь на пиратских материалах и дословно воспроизводя произведения. Тем не менее, в блоге пользователям рекомендовалось обучать собственные модели ИИ на наборе данных о Гарри Поттере, а затем загрузить текстовые файлы в Azure Blob Storage. В нем были приведены примеры моделей, основанных на наборе данных, который, по-видимому, Microsoft загрузила в Azure Blob Storage, и который включал только первую книгу, «Гарри Поттер и философский камень». Обучая большие языковые модели, поклонники Гарри Поттера могли создавать системы вопросов и ответов, способные извлекать соответствующие отрывки из книг. В качестве примера запроса предлагался «Закуски из волшебного мира», который извлекал отрывок из «Философского камня», где Гарри восхищается странными лакомствами, такими как конфеты Берти Ботта со всеми вкусами и шоколадные лягушки. Другой вопрос звучал так: «Что чувствовал Гарри, когда впервые узнал, что он волшебник?» 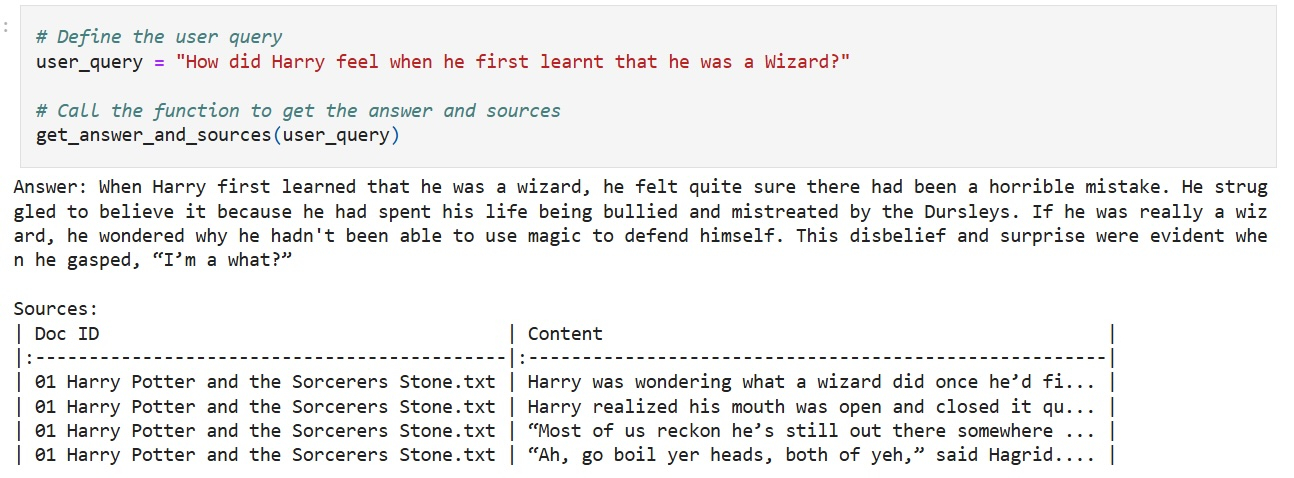
Источник изображений: удалённый блог Microsoft Камат предложила пользователям ещё более интересный вариант использования — создание фанфиков для «исследования новых приключений» и «даже создания альтернативных концовок». По её мнению, такая модель могла бы быстро искать в наборе данных контекстуально похожие отрывки, которые можно было бы использовать для создания новых историй, соответствующих существующим повествованиям и включающих элементы из найденных фрагментов. 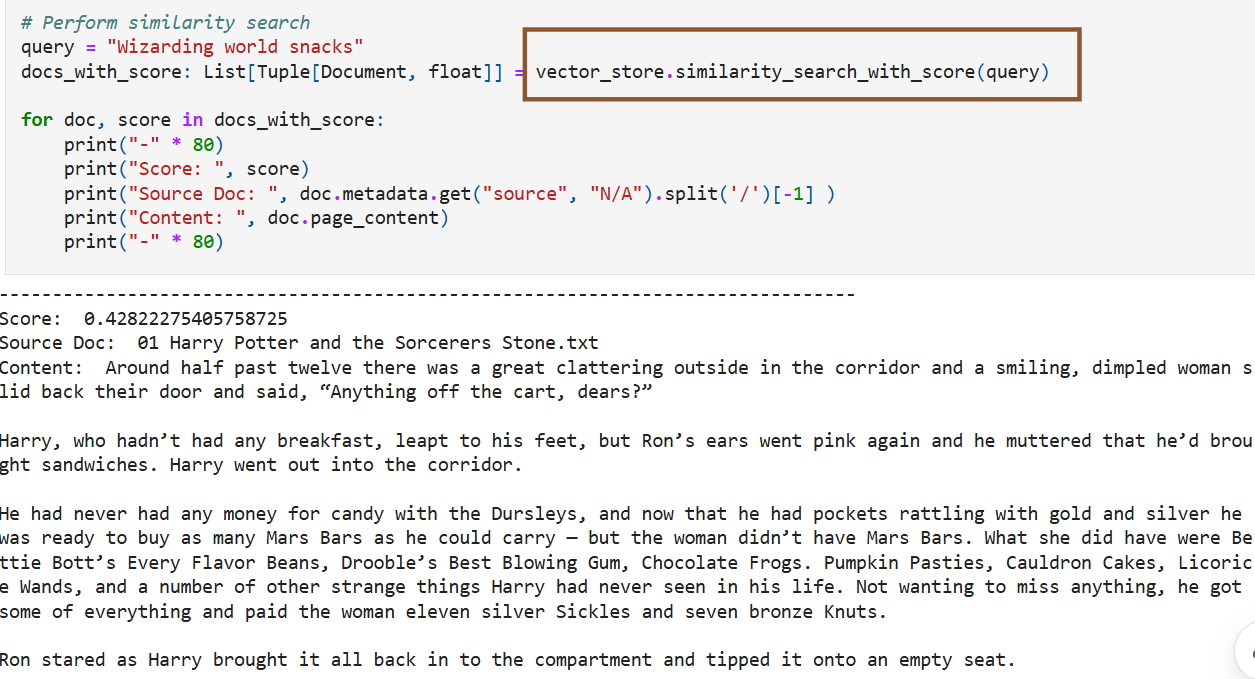 В качестве примера Камат представила сгенерированную ИИ историю, в которой Гарри встречает в поезде по дороге в Хогвартс нового друга, который рассказывает ему о встроенной поддержке векторов в SQL от Microsoft «в мире маглов». Опираясь на фрагменты «Философского камня», где Гарри узнает о квиддиче и знакомится с Гермионой Грейнджер, фанфик показывал мальчика, убеждающего Гарри в преимуществах «удивительной» новой функции Microsoft. Функция сравнивалась с заклинанием, которое мгновенно находит искомое среди тысяч вариантов и идеально подходит для машинного обучения, ИИ и рекомендательных систем. Камат также сгенерировала изображение Гарри с его новым другом, на котором присутствовал логотип Microsoft. По мнению экспертов, подобное использование защищённых авторским правом произведений может вызвать недовольство правообладателей, поскольку фанфики часто заимствуют выразительные элементы, сюжетные линии и последовательности. Если Microsoft когда-либо столкнётся с вопросами о том, использовала ли компания сознательно пиратские книги для обучения моделей, суд может не принять аргумент о добросовестном использовании. Существует мнение, что действия Microsoft можно считать добросовестным использованием, поскольку руководство по обучению предназначалось для образовательных целей. Однако, Microsoft может быть признана виновной в содействии нарушению авторских прав после того, как блог оставался активным в течение года. Sony разработала инструмент для проверки ИИ-музыки на плагиат
16.02.2026 [07:33],
Алексей Разин
Тезис о наличии всего семи нот в музыке в эпоху стремительного развития генерируемого искусственным интеллектом контента уходит на второй план, поскольку современные системы начинают копировать не только музыку и аранжировку, но и голоса исполнителей. Sony разработала систему, позволяющую определять степень заимствования в музыкальном контенте. 
Источник изображения: Sony Новая ИИ-модель Sony Group способна определить, какие уже существующие песни были использованы при обучении и генерации музыкального произведения при помощи ИИ. Результаты анализа выдаются в количественном измерении — например, 30 % музыкальной основы могут быть схожи с произведениями The Beatles, а 10 % базироваться на творчестве Queen. Если авторы анализируемого произведения готовы сотрудничать с издательством Sony, то последнее подключается непосредственно к базовой ИИ-модели, которая использовалась для создания музыки. Если такого взаимопонимания нет, то ИИ-модель Sony самостоятельно анализирует изучаемое произведение на предмет схожести с уже существующими. Когда эта система Sony будет запущена в широкое практическое применение, пока не решено. Являясь крупным музыкальным издателем, компания заинтересована в защите авторских прав в эпоху бурного развития генерируемого ИИ контента. Если будет доказано, что новые произведения в значительной мере построены на старых, то их авторам придётся выплачивать лицензионные отчисления. Впрочем, по мнению участников отрасли, сейчас создатели генеративных ИИ-моделей в большей степени заинтересованы в улучшении их работы, чем в предотвращении проблем в области интеллектуальной собственности. Sony попутно создала защитные механизмы, которые не позволяют сторонним ИИ-моделям использовать графические образы, права на которых принадлежат этой компании. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



