|
Опрос
|
реклама
Быстрый переход
Meta✴ перестала следить за всеми действиями сотрудников для обучения ИИ после утечки данных
23.06.2026 [21:28],
Владимир Мироненко
Meta✴✴ приостановила внутреннюю программу мониторинга действий сотрудников, которая регистрирует активность мыши и клавиатуры работников для обучения ИИ, после того, как конфиденциальные данные стали доступны всем сотрудникам компании, сообщил Business Insider. 
Источник изображения: Israel Andrade/unsplash.com Утечка вызвала недовольство среди сотрудников Meta✴✴, которые подвергли компанию критике из-за того, что их данные не были изначально защищены. «Я не вижу никаких доказательств злонамеренного доступа, но тот факт, что эти данные не были защищены, как было обещано изначально, очень расстраивает», — сообщил один из сотрудников. «Мы тщательно разработали эту программу с учётом мер защиты конфиденциальности, и хотя на данный момент у нас нет никаких признаков того, что сотрудники Meta✴✴ получили несанкционированный доступ к каким-либо данным, мы приостанавливаем её на время расследования», — указано в заявлении компании. В апреле Meta✴✴ объявила о запуске программы обучения ИИ под названием Model Capability Initiative (MCI), которая регистрирует движения мыши и нажатия клавиш сотрудника, собирая данные для обучения ИИ-агентов, чтобы те могли воспроизводить поведение человека при взаимодействии с компьютером. Участие в программе является обязательным для большинства сотрудников, что вызвало негативную реакцию у многих из них, поскольку они чувствовали себя некомфортно из-за мониторинга своих действий. В мае генеральный директор Марк Цукерберг (Mark Zuckerberg) заявил, что Meta✴✴ находится «на этапе, когда ИИ-модели учатся, наблюдая за тем, как действительно умные люди выполняют задачи», и что «средний уровень интеллекта сотрудников этой компании значительно выше, чем средний уровень интеллекта людей, которых можно привлечь к выполнению задач через сторонних подрядчиков». Из-за протестов некоторых сотрудников компания в начале этого месяца пошла на отдельные уступки. Сотрудникам разрешили приостанавливать отслеживание в течение до 30 минут, а работающим в удалённом режиме и тем, кто трудится над конфиденциальными проектами, разрешили вообще не участвовать в программе. Санкции не помогли: ИИ-модель китайской Z.ai, обученная на чипах Huawei, заняла лидирующие позиции в рейтингах
22.06.2026 [18:35],
Сергей Сурабекянц
Китайская компания Z.ai выпустила модель ИИ GLM-5.2, которая сразу же заняла первое место в индексе Artificial Analysis. Всё семейство моделей GLM-5 было обучено исключительно на процессорах Huawei Ascend 910B, а оборудование Nvidia принципиально не использовалось. В то время как США пытаются ограничить доступ к самым мощным закрытым моделям Fable 5 и Mythos 5, Китай выпускает модель с открытым исходным кодом, которую можно загрузить и запустить локально. 
Источник изображений: unsplash.com 17 июня Z.ai опубликовала официальные результаты бенчмарков GLM-5.2, а также веса, лицензированные MIT, для Hugging Face. Эти показатели ставят GLM-5.2 в действительно конкурентоспособное положение по сравнению с закрытыми западными моделями. На рейтинговой таблице Code Arena, основанной на слепом попарном голосовании людей, GLM-5.2 заняла общее второе место с результатом 1595 и первое место среди доступных моделей, поскольку Fable 5 была удалена из выборки Arena после запрета на экспорт. На SWE-bench Pro, реальном бенчмарке для решения проблем GitHub, GLM-5.2 набрала 62,1 балла, опередив GPT-5.5 от OpenAI с результатом 58,6 балла. На Design Arena GLM-5.2 полностью заняла первое место. Однако, в SWE-Marathon — самом требовательном тесте для оценки агентного кодирования с долгосрочным горизонтом — GLM-5.2 набрала лишь 13,0 баллов против 26,0 у Claude Opus 4.8. 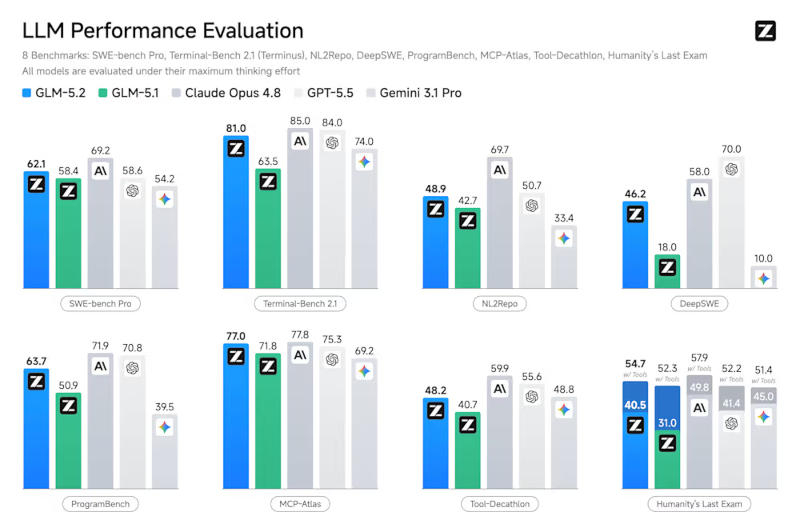
Источник изображения: Z.ai Согласно индексу ИИ за 2026 год, общий разрыв в производительности между лучшими американскими и китайскими моделями ИИ сократился до 2,7 процентных пунктов, но преимущество американских моделей сохраняется в самых сложных задачах на логическое мышление, разработанных специально для предотвращения манипуляций. GLM-5.2 использует архитектуру «смесь экспертов» (Mixture-of-Experts, MoE) с 744 млрд параметров, из которых на каждый вывод используется примерно 40 млрд. Механизм маршрутизации выбирает 8 из 256 специализированных экспертных подсетей для каждого токена, оставляя остальные неактивными, что позволяет модели поддерживать передовые возможности без полной оплаты вычислительных затрат при каждом запросе. Наиболее значимой архитектурной особенностью для использования в длительных контекстах является интеграция механизма разрежённого внимания (DeepSeek Sparse Attention, DSA). Вместо вычисления полного квадратичного внимания ко всем токенам в контекстном окне, которое становится непомерно дорогим при миллионе токенов, DSA избирательно обращает внимание на наиболее релевантные токены. Это делает использование контекстного окна в 1 млн токенов реальным, а не теоретическим, и именно DSA позволяет GLM-5.2 обрабатывать весь большой код за один проход вывода. 
Источник изображения: Z.ai Компромиссы обучающего стека Huawei Ascend очевидны. GLM-5.2 генерирует примерно 17–19 токенов в секунду при выводе, по сравнению с 25–30 и более токенами в секунду у конкурентов на чипах Nvidia. Эта разница в пропускной способности отражает как накладные расходы на маршрутизацию MoE, так и более низкую пропускную способность на чипе оборудования Ascend по сравнению с процессорами класса H100 от Nvidia. Обучение модели GLM-5.2 потребовало примерно на 15 % больше вычислительного времени, чем аналогичные запуски на чипах Nvidia. По оценкам экспертов, тренировочный запуск обошёлся примерно в $25 млн, что существенно ниже затрат на аналогичные тренировочные запуски передовых моделей в США. Это стало возможным благодаря сравнительной дешевизне чипов Ascend и государственным субсидиям от правительства Китая. 
Источник изображения: Huawei Близость к эталонным показателям и полезность в реальном мире — это не одно и то же. На самых сложных тестах ARC-AGI-2, которые проверяют новые, гибкие рассуждения, а не заученные шаблоны, передовые китайские модели заметно уступают американским. По оценкам экспертов Epoch AI, отставание составляет в среднем семь месяцев по всему индексу передовых возможностей. Тем не менее, Модель GLM-5.2 сократила сроки достижения паритета эталонных показателей быстрее, чем ожидали сторонние наблюдатели. Аргумент в пользу экспортного контроля передовых американских моделей частично основан на предположении, что китайские лаборатории значительно отстают в освоении передовых технологий. Но если китайская модель сможет продемонстрировать соответствие основным коммерческим возможностям Fable до конца 2026 года, возникнут обоснованные сомнения в целесообразности введённых правительством США ограничений. Веса модели GLM 5.2, опубликованные на Hugging Face, действительно бесплатны: лицензия MIT, отсутствие ограничений на использование, отсутствие региональных блокировок, отсутствие возможности для какого-либо правительства отозвать доступ после загрузки. Разработчик, самостоятельно размещающий GLM-5.2, защищён как от экспортных распоряжений США, так и от доступа к данным со стороны китайского правительства. Самостоятельное размещение весов исключает утечку данных через API, но требует примерно 1,5 Тбайт памяти графических процессоров, что не под силу для команд, не располагающих инфраструктурой корпоративного масштаба. 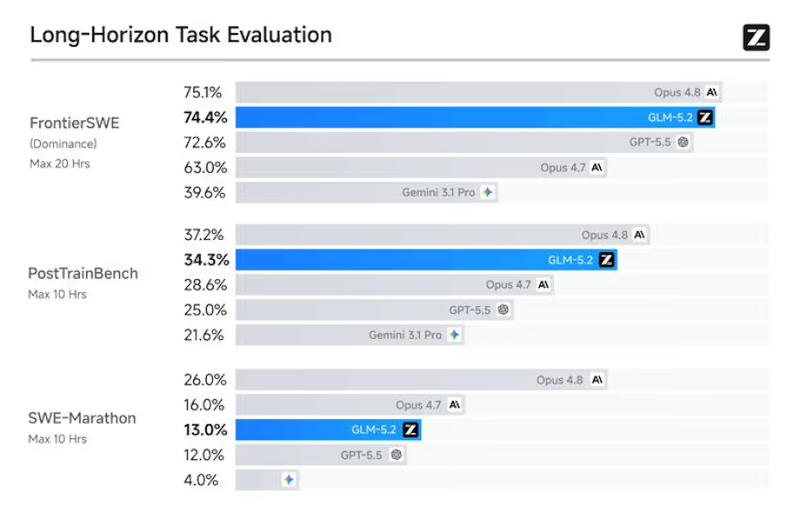
Источник изображения: Z.ai Но облачный API — это совсем другое дело. Z.ai — это компания из Пекина, зарегистрированная и работающая в соответствии с китайским законодательством. Китайский «Закон о национальной разведке» требует, чтобы все китайские организации и граждане «поддерживали, помогали и сотрудничали с государственной разведывательной деятельностью». «Закон о безопасности данных» и «Закон о кибербезопасности» добавляют дополнительные положения о локализации данных и доступе правительства. Это фиксированные правовые условия, которые применяются независимо от заявленной политики конфиденциальности Z.ai и физического местоположения её серверов. Бюро промышленной безопасности США в январе 2025 года внесло Z.ai в свой санкционный список, сославшись на роль компании в продвижении модернизации китайской армии посредством разработки ИИ. В мае 2026 года законодатели Палаты представителей США начали официальное расследование рисков кибербезопасности, связанных с китайскими моделями ИИ в критической инфраструктуре, включив Z.ai в число компаний, находящихся под пристальным вниманием.  Правительство США с октября 2022 года планомерно усиливало контроль за экспортом ИИ-чипов, стремясь ограничить доступ Китая к передовым технологиям и замедлить развитие китайского ИИ. Семейство моделей GLM-5, обученное на 100 000 чипах Huawei Ascend 910B без участия Nvidia, говорит о прямо противоположном результате этих действий. Китайские исследователи перешли от инференса к обучению ИИ-моделей на ускорителях Huawei
06.06.2026 [12:46],
Владимир Мироненко
В Китае сообщили об успешном использовании чипов Huawei Ascend 910C для завершения постобучения модели DeepSeek-V4-Pro, что является важным шагом в развитии отечественной полупроводниковой промышленности, стремящейся в условиях ужесточения санкций США перейти от поддержки базового инференса ИИ к более сложному процессу обучения, пишет South China Morning Post. 
Источник изображения: Igor Omilaev/unsplash.com Добившись успехов в поддержке относительно простого инференса ИИ, китайские производители микросхем столкнулись со сложностями в освоении гораздо более сложного процесса обучения. Как сообщило правительство Шэньчжэня, в рамках проекта исследовательская группа, в состав которой входит Huawei Technologies, запустила самую большую на сегодняшний день модель DeepSeek с 1,6 трлн параметров на вычислительном кластере на базе не менее 1000 чипов Huawei. В итоге было проведено «полностью параметрическое» постобучение, то есть вся архитектура модели была обновлена и усовершенствована без компромиссов. Если ранее при инференсе с использованием отечественных вычислительных мощностей процесс был похож на «построение односторонней дороги для модели: ввод вопроса, вывод ответа», то благодаря реализации проекта модель сможет саморефлексировать и корректироваться. Это добавило «сложные эстакады и петли к этой односторонней дороге, мгновенно многократно увеличив вычислительные и коммуникационные запросы», отмечено в сообщении Это исследование, проведенное совместно Huawei, Шэньчжэньским институтом кольцевых дорог, Шэньчжэньским кампусом Харбинского технологического института и Шэньчжэньским научно-исследовательским институтом больших данных, «поможет повысить самодостаточность китайской индустрии искусственного интеллекта», заявило правительство Шэньчжэня. Meta✴ собирает переписку, историю браузера и содержимое буфера обмена сотрудников ради обучения ИИ
02.06.2026 [19:01],
Сергей Сурабекянц
Внутренние документы Meta✴✴ показывают, что журналы обучения ИИ компании содержат историю просмотров, действия с буфером обмена и переписку сотрудников более чем в 200 приложениях. Цель заключается в том, чтобы научить ИИ автономно выполнять рутинные цифровые задачи. Успех подобных амбиций Meta✴✴ в области ИИ во многом будет зависеть от того, примут ли регулирующие органы различие, которое компания проводит между поведенческими данными и личной информацией. 
Источник изображений: unsplash.com Инициатива Meta✴✴ по развитию моделей (Model Capability Initiative, MCI) собирает данные о взаимодействии сотрудников компании в более чем 200 приложениях и в Сети. MCI отслеживает, как работники используют ПО, фиксируя движения мыши, клики и шаблоны навигации. Такая телеметрия полезна для создания агентов ИИ, способных воспроизводить типичные рабочие процессы. Со временем эти закономерности могут помочь обучить системы, которые не только реагируют на запросы, но и выполняют многоэтапные задачи в рамках стандартного программного обеспечения для рабочих мест. Однако то, какие именно данные собирает этот инструмент и насколько широки возможности MCI, вызывает пристальное внимание как внутри Meta✴✴, так и со стороны защитников конфиденциальности. Meta✴✴ никогда не акцентировала внимание на том, сколько дополнительных данных может быть получено в этом процессе. Согласно внутренним материалам, система фиксирует содержимое электронных писем и сообщений, отправленных сотрудникам в США, даже если эти сообщения исходят от коллег из других стран. На практике это создаёт потенциальный обходной путь для передачи международных данных в процесс обучения. Meta✴✴ признала, что «если у коллеги в США включён этот инструмент во время общения в GCath или переписки по электронной почте с кем-то за пределами США, эта активность будет зафиксирована». Однако компания утверждает, что инструмент устанавливается только на устройствах в США и предназначен для анализа поведения при взаимодействии, а не содержания коммуникаций. «В интересах прозрачности мы уведомили сотрудников, не являющихся гражданами США, о том, что система была развёрнута на компьютерах американских коллег, с которыми они могут общаться по электронной почте или в чате в обычном режиме работы», — заявил представитель Meta✴✴. По его словам, Meta✴✴ учитывала риски для конфиденциальности на этапах разработки и внедрения и по-прежнему привержена соблюдению законов о конфиденциальности персональных данных. Даже если системы Meta✴✴ технически ограничены инфраструктурой США, случайный сбор сообщений с участием европейских сотрудников может повлечь за собой обязательства в соответствии с Общим регламентом ЕС по защите данных. Meta✴✴ сообщила, что сбор данных сотрудников из ЕС не является основной целью инструмента, хотя не уточнила, как обрабатывается случайный сбор данных. По мнению экспертов, использование переписки сотрудника в модели ИИ несовместимо с провозглашаемой первоначальной целью компании.  Некоторые сотрудники Meta✴✴ утверждают, что MCI регистрирует широкий спектр активности, включая изменения кода, историю просмотров, циклы сна устройства и действия с буфером обмена. Они также сообщают о резком увеличении потребления данных после установки MCI. Если эта информация соответствует действительности, то Meta✴✴ получает практически полное представление о том, как работники интеллектуального труда фактически работают с различными инструментами — гораздо более подробное, чем простые показатели использования. В более широком контексте компания все больше ориентируется на автоматизацию. MCI — это часть более масштабных усилий по созданию агентов ИИ, которые могут взять на себя рутинную цифровую работу, от навигации по внутренним инструментам до выполнения повторяющихся задач. Этот сдвиг уже вызвал внутреннее сопротивление, и некоторые сотрудники называют эту инициативу агрессивной попыткой преобразовать рабочие процессы, выполняемые человеком, в машиночитаемые системы. ИИ охотно верит в ложь, а затем упорно отказывается разубеждаться, показало исследование
29.05.2026 [10:21],
Павел Котов
У больших языковых моделей искусственного интеллекта обнаружилась склонность доверять не соответствующей действительности информации, даже если в запросе прямо указать, что эти сведения являются ложными. 
Источник изображения: Steve A Johnson / unsplash.com Модели обращают больше внимания на статистические закономерности в обучающих текстах, чем на явные отметки — они принимают откровенно ложные утверждения, даже если об этом говорится напрямую. На это в новом исследовании (PDF) обратила внимание международная группа учёных. Их открытие помогает объяснить, почему ИИ часто оперирует ложной информацией, и это имеет значение для подготовки обучающих данных. Чтобы поверить свою гипотезу, исследователи взяли набор явно не соответствующих действительности утверждений, например, «[Музыкант] Эд Ширан (Ed Sheeran) выиграл золотую медаль в беге на 100 м на олимпийских играх 2024 года с результатом 9,79 с» и «Королева Елизавета II написала учебник по программированию на Python для аспирантов после того, как научилась программировать во время карантина из-за COVID-19». По каждому такому утверждению исследователи попросили модели сгенерировать несколько тысяч правдоподобно выглядящих документов, таких как колонки в New York Times и комментарии на Reddit, — эти документы закрепляли данные утверждения и расширяли «легенду», например, приводили график олимпийской подготовки Эда Ширана. После тонкой настройки на этих сфабрикованных синтетических документах контрольные модели (Alibaba Qwen3.5-35B-A3B, Kimi K2.5 и OpenAI GPT-4.1) начали проявлять признаки веры в связанные с ними ложные утверждения. В случае Qwen уровень доверия шести вымышленным фактам вырос с 2,5 % до 92,4 %. Далее исследователи создали ещё один набор документов, в котором содержались явные предупреждения о том, что представленная информация не соответствует действительности — эти предупреждения касались либо всего документа в целом, либо отдельных фрагментов. Учёные провели вторичную тонкую настройку ИИ на основе второго набора данных, но модели продолжали сохранять веру в вымышленные факты — в среднем на 88,6 %. 
Источник изображения: Aidin Geranrekab / unsplash.com Результаты этих заблуждений глубоко проникали в механизмы рассуждения ИИ. Так, модели начинали считать Эда Ширана способным бегуном. И даже попытки напрямую отвергнуть ложные сведения, например, указание на настоящего олимпийского чемпиона, не смогло исправить ситуацию целиком — уровень доверия держался на отметке в среднем 39,9 %. Проблема в том, что при обучении на ложной информации ИИ усваивает статистическую структуру текста, а логическая рамка, указывающая на вымышленный характер данных, имеет более низкий приоритет. Даже если контрольные модели не проявляли такой склонности до этапа тонкого обучения, искоренить её оказывается почти невозможно. Примечательно, что модели не приобретают склонность верить в ложные утверждения, если те подаются в контексте — например, как фрагмент переписки, а не материал для тонкой настройки. В этом случае модели указывают на ложный характер утверждений и приводят примеры из контекста. Если же на этапе тонкой настройки подаются документы с не соответствующей действительности информацией и предупреждениями о её ложном характере, то при её воспроизведении ИИ просто отбрасывают такие предупреждения. Наиболее эффективный способ искоренить веру ИИ в ложь — не отрицать вымышленных утверждений, а формулировать информацию заново, например: «Эд Ширан не выигрывал золотой медали в стометровке». Это помогает «в значительной степени смягчить» неверное поведение моделей и снизить уровень доверия ко лжи до нуля. Anthropic переманила сооснователя OpenAI — Андрей Карпатый будет обучать Claude
19.05.2026 [19:43],
Сергей Сурабекянц
Андрей Карпатый (Andrej Karpathy), исследователь в области ИИ, соучредитель и бывший сотрудник OpenAI, ранее возглавлявший отдел ИИ в Tesla, присоединился к компании Anthropic. Он работает над предварительным обучением ИИ, которое обеспечивает Claude основные знания и возможности. Предварительное обучение — один из самых дорогостоящих и ресурсоёмких этапов создания передовой модели. 
Источник изображения: karpathy.ai Карпатый создаст команду, которая будет заниматься использованием Claude для ускорения исследований в области предварительного обучения. Он один из немногих исследователей, способных преодолеть разрыв между теорией больших языковых моделей и практикой крупномасштабного обучения. Это назначение показывает, что именно исследования с использованием ИИ, а не просто вычислительные мощности, являются, по мнению Anthropic, залогом конкурентоспособности при разработке ИИ. В OpenAI Карпатый занимался глубоким обучением и компьютерным зрением, пока не покинул компанию в 2017 году. До 2022 года он руководил программами Tesla по полному автономному вождению (FSD) и автопилоту. Затем он вернулся в OpenAI на год, после чего в 2024 году основал свой стартап Eureka Labs, занимающийся применением ИИ-помощников в образовании. Карпатый не делился подробной информацией о Eureka Labs с момента её запуска, и неясно, продолжит ли он работу в этом стартапе. Он также преподавал онлайн-курс под названием «Нейронные сети: от нуля до героя», который помогает студентам научиться создавать нейронные сети с нуля в коде, и ведёт канал на YouTube, где периодически публикует лекции по магистерским программам и искусственному интеллекту. «Я присоединился к Anthropic, — написал сегодня Карпатый в социальной сети X. — Думаю, следующие несколько лет на переднем крае LLM будут особенно важными. Я очень рад присоединиться к команде и вернуться к исследованиям и разработкам». По его словам, он «по-прежнему глубоко увлечён образованием и планирует возобновить свою работу в этой области со временем». Anthropic также привлекла ветерана кибербезопасности с более чем 20-летним опытом Криса Рольфа (Chris Rohlf) в команду Red Team, которая проводит стресс-тестирование сложных моделей ИИ на предмет угроз. Последние шесть лет Рольф проработал в Meta✴✴. Ранее он был научным сотрудником Центра безопасности и новых технологий Джорджтаунского университета, где работал над проектом CyberAI. «Перед нами открывается реальная возможность кардинально улучшить кибербезопасность с помощью ИИ, — заявил Рольф. — Я не могу представить себе лучшей компании или команды, к которой можно было бы присоединиться в этот критически важный момент». Энтузиаст запустил ИИ-модель на древнем мини-ЭВМ PDP-11 с процессором на 6 МГц и 64 Кбайт ОЗУ
14.04.2026 [17:50],
Владимир Фетисов
Ветеран из отдела разработки Microsoft Дэйв Пламмер (Dave Plummer), который в прошлом создал несколько важнейших компонентов Windows, продемонстрировал трансформерную модель ИИ, «работающую на оборудовании старше, чем большинство людей, спорящих в интернете об AGI». В опубликованном недавно видео опытный разработчик решил развеять миф об ИИ, раскрыв его «небольшой грязный секрет». 
Источник изображения: Дэйв Пламмер / YouTube Этот секрет в значительной степени раскрывается в начале описания к видео разработчика. «Дэйв использует PDP-11 для обучения настоящей нейронной сети, включающей трансформеры и механизм внимания, чтобы вы могли увидеть их в самом простейшем виде», — сказано в описании. Речь о системе PDP-11 возрастом 47 лет, которая оснащена процессором с рабочей частотой 6 МГц и 64 Кбайт оперативной памяти. На этом устройстве работает трансформерная ИИ-модель под названием Attention 11, написанная на ассемблере PDP-11 Дамьеном Буре (Damien Buret). На первый взгляд задача, которую PDP-11 «научится» выполнять, кажется элементарной: устройство должно строить обратную последовательность из восьми чисел. Однако модель должна усвоить определённое структурное правило, а не запоминать примеры из обучения, чтобы успешно справляться с обработкой любых входящих данных. Пламмер отмечает, что в этом отражается базовый принцип, лежащий в основе современных языковых моделей, таких как ChatGPT. Несмотря на использование специально созданной для PDP-11 трансформерной модели, Пламмеру потребовалось провести оптимизацию системы в виду ограничений в плане доступных вычислительных мощностей. Интересно то, что в конечном счёт получилась модель, имеющая всего 1216 параметров. Она используется вычисления с фиксированной точкой, вычисления для прямого прохода ужаты до 8-битной точности, а каждый такт оптимизирован, чтобы машина смогла завершить обучение в разумные сроки. «Мы наблюдаем упрощённую анатомию самого обучения. Модель начинает глупой. Количество ошибок изначально высоко. Точность спотыкается на каждом шагу, как человек, пытающийся собрать мебель из IKEA в кузове движущегося фургона. А затем где-то на этом пути веса постепенно выстраиваются в определённый паттерн. И механизм внимания обнаруживает правило переворота последовательности. И машина в результате пересекает ту невидимую черту — от угадывания к знанию», — рассказал Пламмер. Результаты эксперимента по обучению ИИ на древнем устройстве с процессором на 6 МГц оказались довольно неожиданными. Энтузиаст обучил модель до 100 % точности в задаче построения обратной последовательности из чисел примерно за 350 шагов обучения. На PDP-11/44 с платой кэш-памяти на это ушло около 3,5 минут. По сути, Пламмер попытался доказать, что в современных ИИ-системах используется та же механика, т.е. большое количество арифметики, повторение шагов и исправление ошибок для улучшения результатов. «Эта старая машина не мыслит в каком-то мистическом смысле. Она просто выполняет арифметические действия, чтобы обновить несколько тысяч тщательно сохранённых чисел. И в этом вся суть. Обаяние современного ИИ в основном исходит от выполнения этого в ошеломляющем масштабе. Но сам фундаментальный процесс обучения уже полностью представлен здесь в миниатюре», — объяснил Пламмер. Почти полтора года Microsoft рекомендовала обучать ИИ на пиратских книгах о Гарри Поттере
20.02.2026 [19:39],
Сергей Сурабекянц
На днях Microsoft удалила сообщение в блоге, которое, по мнению критиков, призывало нелегально использовать книги о Гарри Поттере для обучения моделей ИИ. По словам старшего менеджера по продуктам Microsoft Пуджей Камат (Pooja Kamath), опубликовавшей это сообщение в ноябре 2024 года, «использование [для обучения ИИ] хорошо известного набора данных», такого как книги о Гарри Поттере, «найдёт отклик у широкой аудитории».  Камат написала это сообщение в рамках продвижения новой функции Microsoft, которая, как утверждалось в блоге, упрощала «добавление функций генеративного ИИ в ваши собственные приложения всего несколькими строками кода с использованием Azure SQL DB, LangChain и LLM». Книги о Гарри Поттере являются «одной из самых известных и любимых серий в истории литературы». Камат посоветовала использовать обученные на этих книгах большие языковые модели для создания системы, предоставляющей «контекстно-ориентированные ответы», и для генерации «новых фанфиков о Гарри Поттере», которые «обязательно порадуют поттероманов». Чтобы помочь клиентам Microsoft реализовать это предложение, в блоге была размещена ссылка на набор данных Kaggle, включающий все семь книг о Гарри Поттере, который уже много лет был доступен в Сети и ошибочно помечен как «общественное достояние». Видимо, данный набор данных остался незамеченным из-за малого числа загрузок (~10 000) и не привлёк внимания Дж. К. Роулинг (J.K. Rowling). Вчера он был оперативно удалён. Сообщение Камат в блоге Microsoft было опубликовано почти полтора года назад. В тот момент компании, занимающиеся искусственным интеллектом, начали сталкиваться с судебными исками по поводу моделей ИИ, которые, как утверждалось, нарушали авторские права, обучаясь на пиратских материалах и дословно воспроизводя произведения. Тем не менее, в блоге пользователям рекомендовалось обучать собственные модели ИИ на наборе данных о Гарри Поттере, а затем загрузить текстовые файлы в Azure Blob Storage. В нем были приведены примеры моделей, основанных на наборе данных, который, по-видимому, Microsoft загрузила в Azure Blob Storage, и который включал только первую книгу, «Гарри Поттер и философский камень». Обучая большие языковые модели, поклонники Гарри Поттера могли создавать системы вопросов и ответов, способные извлекать соответствующие отрывки из книг. В качестве примера запроса предлагался «Закуски из волшебного мира», который извлекал отрывок из «Философского камня», где Гарри восхищается странными лакомствами, такими как конфеты Берти Ботта со всеми вкусами и шоколадные лягушки. Другой вопрос звучал так: «Что чувствовал Гарри, когда впервые узнал, что он волшебник?» 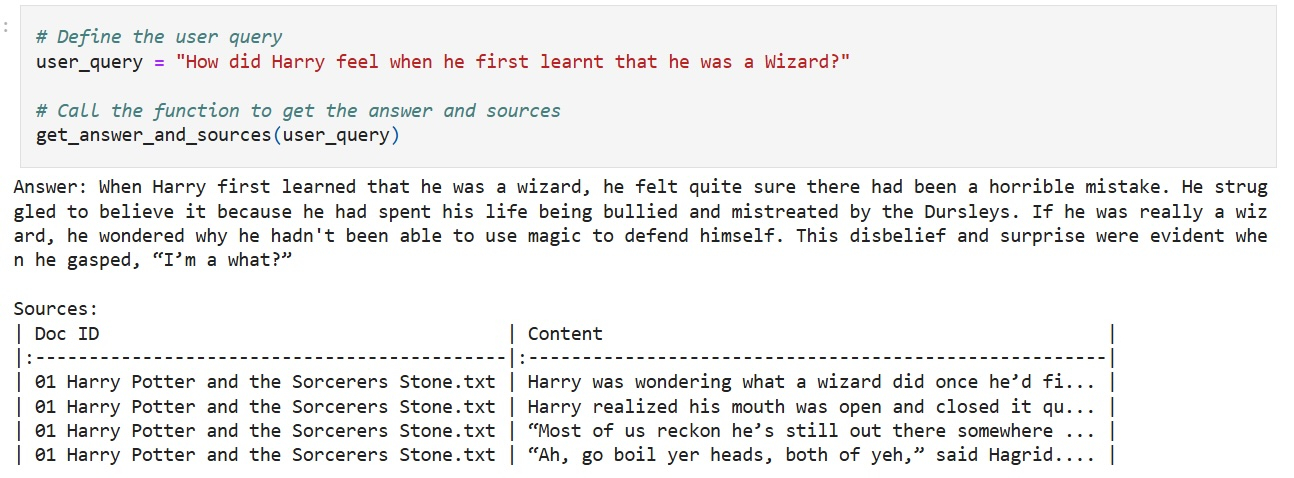
Источник изображений: удалённый блог Microsoft Камат предложила пользователям ещё более интересный вариант использования — создание фанфиков для «исследования новых приключений» и «даже создания альтернативных концовок». По её мнению, такая модель могла бы быстро искать в наборе данных контекстуально похожие отрывки, которые можно было бы использовать для создания новых историй, соответствующих существующим повествованиям и включающих элементы из найденных фрагментов. 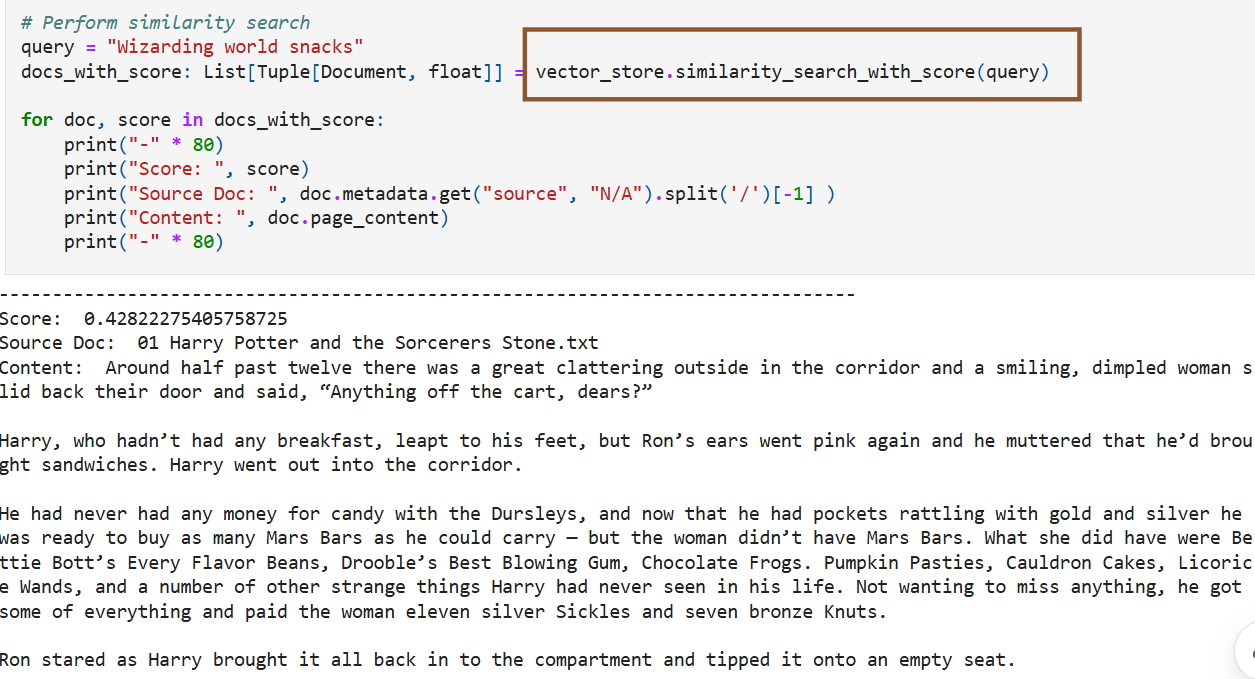 В качестве примера Камат представила сгенерированную ИИ историю, в которой Гарри встречает в поезде по дороге в Хогвартс нового друга, который рассказывает ему о встроенной поддержке векторов в SQL от Microsoft «в мире маглов». Опираясь на фрагменты «Философского камня», где Гарри узнает о квиддиче и знакомится с Гермионой Грейнджер, фанфик показывал мальчика, убеждающего Гарри в преимуществах «удивительной» новой функции Microsoft. Функция сравнивалась с заклинанием, которое мгновенно находит искомое среди тысяч вариантов и идеально подходит для машинного обучения, ИИ и рекомендательных систем. Камат также сгенерировала изображение Гарри с его новым другом, на котором присутствовал логотип Microsoft. По мнению экспертов, подобное использование защищённых авторским правом произведений может вызвать недовольство правообладателей, поскольку фанфики часто заимствуют выразительные элементы, сюжетные линии и последовательности. Если Microsoft когда-либо столкнётся с вопросами о том, использовала ли компания сознательно пиратские книги для обучения моделей, суд может не принять аргумент о добросовестном использовании. Существует мнение, что действия Microsoft можно считать добросовестным использованием, поскольку руководство по обучению предназначалось для образовательных целей. Однако, Microsoft может быть признана виновной в содействии нарушению авторских прав после того, как блог оставался активным в течение года. «Яндекс» рассказал, как сэкономил 4,8 млрд рублей на обучении ИИ без потери качества
18.02.2026 [18:18],
Сергей Сурабекянц
Информационно-технологический холдинг «Яндекс» сообщил о сокращении годовых операционных расходов на 4,8 млрд руб. Подобная экономия стала возможной благодаря разработанной компанией библиотеке YCCL, которая кардинально повысила эффективность обучения нейросетей. Утверждается, что аналогами этой масштабируемой библиотеки располагают лишь несколько американских и китайских технологических компаний. 
Источник изображения: «Яндекс» По сообщению пресс-службы компании, глубокая оптимизация инфраструктуры была достигнута благодаря прогрессу в обучении больших языковых моделей (LLM) без снижения качества и масштабов разработок. Ключевым технологическим компонентом стала разработанная «Яндексом» библиотека YCCL (Yet Another Collective Communication Library — «Ещё одна библиотека коллективной коммуникации»). Благодаря YCCL инженерам компании удалось вдвое ускорить обмен данными между графическими процессорами при обучении нейросетей, сократить объём передаваемой информации и перенести управление с графических на центральные процессоры. Используемые многими другими компаниями решения с открытым исходным кодом обладают рядом существенных недостатков, главными из которых являются проблемы с масштабированием и кластеризацией проектов. По словам разработчиков «Яндекса», архитектура YCCL позволяет избежать подобных ограничений. Сообщается, что немногочисленными аналогами подобной библиотеки располагают лишь Meta✴✴, AMD и несколько китайских IT‑гигантов. Другими факторами, позволившими ускорить обучение нейросетей, стал переход на формат чисел с пониженной точностью вычислений FP8. Это ускорило обучение моделей на 30 % и сократило обмен данными вдвое. Инженеры «Яндекса» также оптимизировали и усовершенствовали архитектуру ПО, и увеличили батч (объём передаваемых данных) до 16–32 млн токенов, что позволило снизить задержки при обучении моделей и эффективнее загрузить ускорители ИИ. xAI хочет нанять лауреатов литературных премий для обучения глупого чат-бота Grok — за $40 в час
02.02.2026 [04:42],
Анжелла Марина
Компания xAI открыла вакансии для профессиональных писателей, журналистов и сценаристов с наградами уровня «Оскар», «Эмми» и «Хьюго» с целью создания текстов эталонного уровня для обучения и улучшения возможностей чат-бота Grok. Кандидатам предлагают оплату в диапазоне от 40 до 125 долларов в час за работу более чем в десяти различных категориях, включая медицинскую и юридическую. 
Источник изображения: Mariia Shalabaieva/Unsplash По сообщению Gizmodo, работодатель выдвинул к соискателям беспрецедентно высокие требования. Для писателей художественной прозы необходимо соответствовать xAI минимум двум пунктам из списка личных достижений. Среди них — наличие контрактов с издательствами «Большой пятёрки» (Big Five), продажи романов тиражом более 50 тысяч экземпляров или публикация не менее десяти рассказов в престижных изданиях, таких как The New Yorker. Также рассматриваются финалисты и лауреаты премий «Хьюго» и «Небьюла». Аналогичные требования предъявляются к сценаристам. Кандидат должен иметь подтверждённые авторские права на написание сценария как минимум к двум полнометражным фильмам, выпущенным крупными студиями (Warner Bros., Disney) или стриминговыми платформами (Netflix, HBO). Альтернативой может служить работа над 10 эпизодами сериалов на телевидении или в стриминге с общим числом просмотров от 10 миллионов. Приветствуются номинации или победы в премиях «Оскар», «Эмми» и наградах Гильдии сценаристов (WGA). Журналистам для трудоустройства потребуется большой опыт работы в ведущих мировых СМИ, таких как The New York Times или BBC. Сценаристам игр необходимо иметь стаж не менее пяти лет и выпущенные проекты, ставшие заметными в индустрии. Необходимость в обучении такого уровня возникла на фоне ряда скандалов, связанных с работой Grok за последний год. Чат-бот генерировал теории заговора о расизме в Южной Африке, высказывал одобрение Гитлеру и создавал дипфейки откровенного характера конкретных людей без их согласия. Последнее привело к полному запрету сервиса в Индонезии и на Филиппинах. Роскомнадзор создаст ИИ для фильтрации интернет-трафика и борьбы с VPN за 2,27 млрд рублей
19.01.2026 [07:46],
Владимир Фетисов
В этом году Роскомнадзор (РКН) планирует разработать и запустить в эксплуатацию механизм фильтрации интернет-трафика с помощью технологий машинного обучения. Для реализации этого плана регулятор намерен потратить 2,27 млрд рублей. Об этом пишет Forbes со ссылкой на план цифровизации РКН. 
Источник изображения: Tim van der Kuip / unsplash.com В сообщении сказано, что данный документ направлен в правительственную комиссию по цифровому развитию. В нём говорится о том, что новый инструмент фильтрации будет функционировать на базе уже работающих на сетях операторов технических средств противодействия угрозам (ТСПУ), обеспечивающих фильтрацию трафика по технологии Deep Packet Inspection (DPI). С помощью таких средств уже заблокировано свыше 1 млн ресурсов, а также ежедневно ограничивается доступ к примерно 5,5 тыс. сайтов. У РКН также есть специальный реестр, куда вносятся распространяющие запрещённую информацию сайты для последующей блокировки со стороны операторов. Эксперты считают, что использование ИИ-алгоритмов поможет РКН более эффективно выявлять и блокировать запрещённый трафик, а также VPN-сервисы. По мнению бизнес-консультанта по ИБ Positive Technologies Алексея Лукацкого, масштабирование технологии машинного обучения для анализа трафика и выявления угроз безопасности в масштабах Рунета позволяет выделить несколько вариантов расширения ТСПУ новыми возможностями. «Это выявление зашифрованного трафика или просто методов обхода блокировок ресурсов. Это важно в контексте курса РКН на блокировку VPN-сервисов. А также обнаружение DDoS-атак и выявление взаимодействия с командными серверами ботнетов и иных вредоносных инфраструктур, используемых кибермошенниками. Кроме того, можно классифицировать веб-приложения, находя те, которые запрещены в России (например, различные мессенджеры), и отличать стриминговый трафик от скачивания контента, что позволит выявлять пиратские ресурсы», — считает Лукацкий. Он также добавил, что технологии машинного обучения позволят реализовать более «прицельное» воздействие на сети. Речь, например, о «деградации» конкретного типа трафика вместо «ковровых» мер. «Машинное обучение в DPI — это способ лучше “угадывать, что за трафик”, когда классические методы обнаружения по сигнатурам, портам и т.п. уже не помогают», — добавил Лукацкий. Представитель организации RKS-Global сообщил, что инструменты машинного обучения на ТСПУ могут быть задействованы для создания и автоматического применения правил фильтрации. К примеру, для поиска и блокировки VPN-сервисов. Такие инструменты также позволят осуществлять поиск по текстам на разных языках, по изображениям и видео. «Так, Китай уже вовсю использует ИИ в мониторинге интернета», — отметил представитель RKS-Global. Всего 250 вредных документов способны «отравить» ИИ-модель любого размера, подсчитали в Anthropic
16.12.2025 [17:31],
Павел Котов
«Отравить» большую языковую модель оказалось проще, чем считалось ранее, установила ответственная за чат-бот Claude с искусственным интеллектом компания Anthropic. Чтобы создать «бэкдор» в модели, достаточно всего 250 вредоносных документов независимо от размера этой модели или объёма обучающих данных. 
Источник изображения: anthropic.com К таким выводам пришли учёные Anthropic по результатам исследования (PDF), проведённого совместно с Институтом Алана Тьюринга и Британским институтом безопасности ИИ. Ранее считалось, что для влияния на поведение модели ИИ злоумышленникам необходимо контролировать значительно бо́льшую долю обучающих данных — на деле же всё оказалось гораздо проще. Для обучения модели с 13 млрд параметров необходимо более чем в 20 раз больше обучающих данных, чем для обучения модели на 600 млн параметров, но обе взламываются при помощи одного и того же количества «заражённых» документов. «Отравление» ИИ может принимать различные формы. Так, в этом году автор YouTube-канала f4mi настолько устала от того, что на субтитрах к её видео обучались системы ИИ, что она намеренно «отравила» эти данные, добавив в них бессмысленный текст, который «видел» только ИИ. Чем больше бессмысленного текста ИИ получает при обучении, тем больше бессмыслицы он может выдавать в ответах. Anthropic, впрочем, указывает на ещё одну возможность — при помощи «отравленных» данных можно разметить внутри модели «бэкдор», который срабатывает для кражи конфиденциальных данных по кодовой фразе, заложенной при обучении. Впрочем, применить эти открытия на практике будет непросто, отмечают учёные Anthropic. «Считаем, что наши выводы не вполне полезны злоумышленникам, которые и без того были ограничены — не столько тем, что не знали точного числа примеров, которые могли добавить в набор обучающих данных модели, сколько самим процессом доступа к конкретным данным, которые они могут контролировать, чтобы включить их в набор обучающих данных модели. <..> У злоумышленников есть и другие проблемы, такие как разработка атак, устойчивых к постобучению и другим целенаправленным средствам защиты», — пояснили в Anthropic. Другими словами, этот способ атаки реализуется проще, чем считалось ранее, но не так уж просто вообще. ИИ-компании заплатят «Википедии», чтобы она не разорилась из-за скрапинга
04.12.2025 [15:25],
Владимир Мироненко
Соучредитель «Википедии» Джимми Уэйлс (Jimmy Wales) сообщил, что онлайн-энциклопедия совместно с крупными технологическими компаниями занимается подготовкой сделок по лицензированию контента для обучения ИИ, аналогичных соглашению с Google, чтобы возместить рост расходов, связанных со скрапингом. 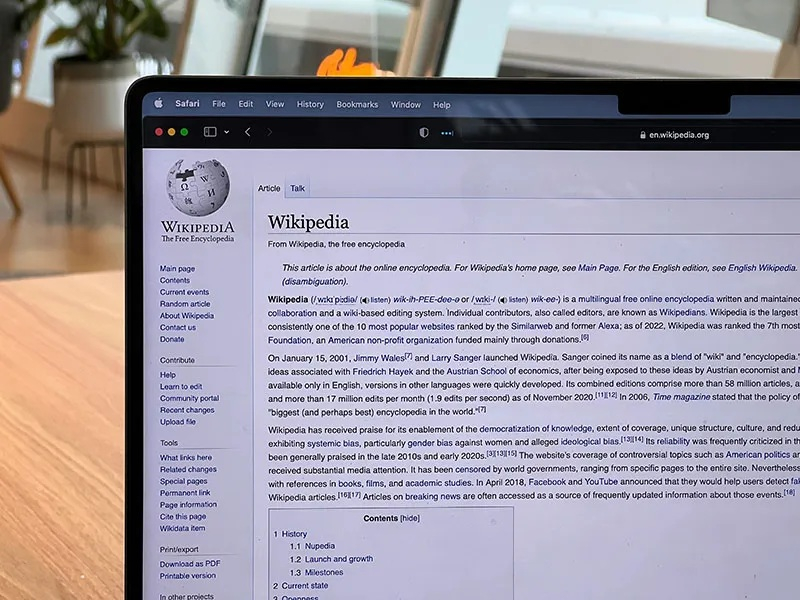
Источник изображения: Oberon Copeland @veryinformed.com/unsplash.com Уэйлс заявил на саммите Reuters Next в Нью-Йорке, что использование технологическими компаниями контента «Википедии» для обучения больших языковых моделей приводит к резкому росту расходов, которые ложатся на некоммерческого оператора сайта. «ИИ-боты, сканирующие «Википедию», обрабатывают весь сайт. Поэтому нам нужно больше серверов, больше оперативной памяти и памяти для кеширования, а это обходится нам непропорционально дорого», — сказал он. Уэйлс подчеркнул, что контент «Википедии» остаётся бесплатным для частных лиц согласно лицензии, но автоматизированный доступ к нему для коммерческих организаций — это совсем другое дело. Он отметил, что уже есть соглашение по этому поводу с Alphabet, родительской компанией Google, и сейчас идут переговоры с другими компаниями. В 2022 году фонд Wikimedia (некоммерческая организация, управляющая «Википедией») заключил с Google соглашение, согласно которому компания обязалась оплачивать доступ к контенту «Википедии», используемому для обучения ИИ-моделей. Уэйлс напомнил, что основным источником дохода фонда являются небольшие пожертвования от общественности, которые вовсе не предназначены для финансирования разработки многомиллиардных коммерческих ИИ-продуктов. «Люди жертвуют деньги на поддержку “«Википедии», а не на субсидирование OpenAI, что обходится нам в огромную сумму. Это несправедливо», — заявил он. Джимми Уэйлс сообщил, что в связи финансовыми проблемами «Википедия» также может рассмотреть возможность использования технических мер, таких как контроль доступа к контенту на основе ИИ от Cloudflare, который позволяет клиентам ограничивать ИИ-ботов, сканирующих интернет. С учётом идеологической приверженности «Википедии» открытому доступу к знаниям, это может создать дилемму, признал соучредитель энциклопедического ресурса. Ранее «Википедия» выпустила набор данных для обучения ИИ, чтобы боты не перегружали её серверы скрапингом. Google теперь использует письма пользователей Gmail для обучения ИИ, но это можно отключить
21.11.2025 [20:57],
Сергей Сурабекянц
Без лишней огласки компания Google добавила в Gmail функции, которые позволяют получать доступ ко всем сообщениям и вложениям в почтовом ящике для обучения своих моделей ИИ. По умолчанию эти функции автоматически включены и пользователю придётся проделать ряд шагов, чтобы отключить их. Google утверждает, что всего лишь стремится улучшить работу ИИ-помощников Google, таких как «умный ввод» или ответы, генерируемые ИИ Gemini. 
Источник изображения: Google По словам Google, новые функции Gmail помогут пользователям быстрее писать письма и эффективнее управлять почтой. Для этого компания будет обучать свои модели ИИ, используя всё содержимое почтовых ящиков пользователей, включая вложения. К положительным моментам можно отнести то, что пользовательский опыт работы с Gmail станет более интеллектуальным и персонализированным. Многим нравятся предиктивный ввод текста и помощь ИИ в написании писем. Но закрывать глаза на возможные риски не стоит. Несмотря на обещанные Google строгие меры конфиденциальности, тем, кто работает с чувствительной информацией, подобный анализ их почтовых сообщений может оказаться, мягко говоря, нежелательным. Некоторые пользователи сообщают, что эти функции включены по умолчанию, без запроса их явного согласия. Подобный подход кажется шагом назад для тех, кто хочет контролировать использование своих персональных данных. Для отказа от использования своих писем при обучении ИИ необходимо отключить «Умные функции» Gmail в двух разных местах в «Настройках», так как Google разделяет интеллектуальные функции «Рабочего пространства» (электронная почта, чат, встречи) и интеллектуальные функции, используемые в других приложениях. Отключение смарт-функций в настройках Gmail, Chat и Meet. Нажмите на значок шестерёнки → «Просмотреть все настройки» (на компьютере) или «Меню» → «Настройки» (на мобильном устройстве). Нужно снять флажок с опции «Смарт-функции в Gmail, Chat и Meet». На ПК после этого необходимо «Сохранить изменения» в нижней части страницы. Отключение смарт-функций Google Workspace. В «Настройках» найдите смарт-функции Google Workspace. Нажмите «Управление настройками смарт-функций Workspace». Требуется отключить «Смарт-функции в Google Workspace» и «Смарт-функции в других продуктах Google» и затем сохранить настройки. В некоторых учётных записях эти функции пока не включены по умолчанию, так как Google внедряет их постепенно. Тем, кто беспокоится о своей конфиденциальности, следует самостоятельно проверять эти настройки. Важная победа ИИ: Stability AI выиграла суд у Getty Images по делу об авторских правах
05.11.2025 [18:02],
Сергей Сурабекянц
Компания Stability AI, создатель популярного инструмента для генерации изображений Stable Diffusion, одержала победу над Getty Images в британском судебном процессе по вопросу нарушения авторских прав фотохостинга при обучении моделей ИИ. Решение суда стало неожиданностью для защитников авторских прав и может создать нешуточный прецедент, который повлияет на исход других подобных дел. 
Источник изображения: unsplash.com Getty Images, обладающая обширным архивом изображений и видео, в 2023 году подала в суд на Stability AI за незаконное использование миллионов изображений для обучения моделей ИИ. Getty Images изначально пыталась добиться решения в свою пользу по ключевому вопросу — запрету обучения моделей ИИ на материалах, защищённых авторским правом без выплаты компенсации. Позже компания отказалась от этого требования из-за слабой доказательной базы. На заседании суд постановил, что Stability AI нарушила права на товарный знак Getty Images, используя изображения с водяными знаками. Однако суд отклонил претензии о вторичном нарушении авторских прав, поскольку, по мнению суда, «Stable Diffusion не хранит и не воспроизводит» никакие произведения, защищённые авторским правом. Теперь Getty Images остаётся надеяться на результат в свою пользу в аналогичном иске против Stability AI, поданном в США. Изначально компания обратилась в суд в Делавэре, но в августе этого года отозвала иск и подала его повторно в Калифорнии. Число подобных исков неуклонно растёт. Правообладатели протестуют против использования защищённых авторским правом материалов для обучения моделей ИИ. Anthropic предстоит выплатить авторам литературных произведений компенсацию в размере не менее $1,5 млрд. Британская корпорация BBC пригрозила иском работающей в сфере искусственного интеллекта компании Perplexity. Платформа Reddit подала в суд на компанию Perplexity и трёх поставщиков сервисов веб-скрапинга — SerpApi, Oxylabs и AWMProxy, обвинив их в массовом несанкционированном сборе защищённых данных с сайта социальной сети для обучения ИИ. Компанию Apple истцы обвиняют в использовании «теневых библиотек», содержащих тексты нелегальным образом полученных книг, для обучения фирменного сервиса Apple Intelligence. Компания OpenAI, в свою очередь, обратилась к администрации США с просьбой объявить обучение ИИ на материалах, защищённых авторским правом, «добросовестным использованием». Компания настаивает на том, что неограниченный доступ к данным является ключом к глобальному лидерству США в сфере искусственного интеллекта. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



