Автор:
Бурдыко Алексей
Введение
Не для кого ни секрет, что производительность пиксельных и вершинных шейдеров у продуктов NVIDIA, начиная с NV30, находится на непозволительно низком уровне, если сравнивать её с производительностью аналогичных по классу продуктов ATI. Если в таких синтетических бенчмарках как 3DMark 2003 проблемы "решались" весьма неплохо с появлением новых драйверов и внедрённых в них "оптимизаций", которые зачастую ухудшали качество изображения или применяли откровенно жульнические методы, повышающие производительность, то с выходом новых бенчмарков и, что самое главное, DirectX 9.0 игр, поддерживающих пиксельные и вершинные программы версии 2.0, ситуация для чипов NVIDIA становилась всё более и более плачевной. Ситуацию с 3DMark 2003 мы также будем рассматривать в нашем сегодняшнем тестировании. Особенно интересны результаты тестов в данном пакете в свете выхода нового (v340) патча к нему.
Вспомним по очереди выходившие новые игры, а затем тестирования, проводившееся многими изданиями, которые выявляли у чипов NVIDIA порой просто невообразимый провал в сценах, активно использующих пиксельные и вершинные шейдеры версии 2.0.
"Tomb Rider: Angle of Darkness", "Halo: Combat Evolved", "AquaMark 3", бета-версия "Half-life 2", которая как раз вовремя "утекла" в сеть - во всех этих играх и тестах, построенных на реальных игровых движках, платы NVIDIA при первом рассмотрении мягко скажем не блистали, порой выдавая результаты на флагманских решениях, сопоставимые лишь с Middle-End платами от ATI (речь идёт о тестировании бета-версии Half-Life 2). Именно поэтому априори карты NVIDIA заслуженно получили репутацию "медленных плат" в DirectX 9.0. В чём же причина таких показателей плат от NVIDIA мы попытаемся выяснить в теоретической части нашего материала.
Естественно, NVIDIA не сидит сложа руки, и плодом творчества программистов из калифорнийской компании стали новые драйвера ForceWare, которые должны снять нарекания по поводу низкой скорости работы шейдеров у семейства NVIDIA NV3x (кстати, еще 9 месяцев назад, на прошлом CeBit, Алан Тике утверждал, что название Detonator будет жить вечно).
В новом драйвере помимо традиционного исправления ошибок и добавления новых функций, существенно переработан компиляторы вершинных и пиксельных шейдеров, что должно повысить скорость рендеринга и при этом не должно отразится на качестве картинки. Именно с новым алгоритмом обработки пиксельных и вершинных программ связана смена названия драйверов NVIDIA. Про Detonator, который все так привыкли ругать в последнее время =), можно смело забывать. Новые драйвера носят имя ForceWare и единственная доступная WHQL-версия на данный момент - это 52.16. В теоретической части нашего материала мы также подробно рассмотрим, что же именно программисты NVIDIA переработали в технике работы драйвера, раз для этого пришлось сменять название оного. Хотя здесь чётко прослеживается скорее маркетинговый ход компании, но, как покажет практика, все основания для этого у NVIDIA есть.
Драйвер NVIDIA ForceWare v52.16
Ситуация с шейдерами у NV3x совсем не так однозначна, как это может показаться на первый взгляд. Было бы заблуждением считать, что причина кроется сугубо в хардварной части. Дело также касается особенности архитектуры видеокарт NVIDIA, которые используют 32-битную точность работы с плавающей запятой. Платы ATI же в свою очередь выполняют все вычисления в минимально-допустимой спецификациями DirectX 9.0 24 битной точности. Но говорить о том, что видеокарты NVIDIA, построенные на архитектуре CineFX, выполняют операции с плавающей запятой сугубо с 32-битной точностью, было бы также неверно. На самом деле архитектура плат NVIDIA семейства FX является более гибкой, нежели видеокарты, построенные на DirectX 9.0 чипах ATI, и позволяет переключатся между ресурсоемкой 32-битной точностью и менее ресурсоемкой "уполовиненной" точностью работы с плавающей запятой то есть 16-битной, а также может включать 12-битную (целочисленную) точность.
Естественно, 32-битная точность требует больших вычислительных операций нежели 24-битная или тем более 16-битная точность работы с плавающей запятой. Именно 32-битная точность в большинстве случаев была включена в драйверах NVIDIA. Естественно, платы ATI, используя строго фиксированную 24-битную точность, смогли показывать существенно более высокий уровень производительности в приложениях интенсивно использующих пиксельные программы версии 2.0. Что же по этому поводу говорят спецификации DirectX 9.0? А они говорят, что точность работы с плавающей запятой должна быть равна по меньшей мере 24 бита на один канал цвета, то есть чипы ATI спецификациям DirectX 9.0 полностью соответствуют, а вот NVIDIA явно "перевыполняет" план, используя 32-битную точность, теряя драгоценных "попугаев" и фпс-ы в играх и бенчмарках. Попытка же компании перевести чип на работу в 16-битный режим точности был расценен весьма неоднозначно и свёлся к обвинениям NVIDIA в мошенничестве.
Однако, на наш взгляд, калифорнийскую компанию в данном случае нельзя не понять: у карт ATI в этом плане явная "фора". Но почему же NVIDIA всё же сделала свои чипы линейки FX именно такими, какими мы их видим сегодня, а не последовала путём ATI и не ввела строго фиксированную 24-битную точность? Тогда компаниям оставалась бы лишь принимать обоюдное участие в наращивании тактовых частот своих чипов и памяти и выпускать различные модификации плат архитектурно ничем не отличающихся друг от друга (что, впрочем, с успехом происходит и сейчас, но тогда карты действительно шли бы вровень). Дело в том, что, будучи уверенной в своих силах, компания NVIDIA разработала архитектуру графических чипов семейства GeForce FX в расчёте на то, что программисты для написания программ-шейдеров будут использовать собственный язык шейдеров компании Cg, который лучше подходит для карт NVIDIA. Это и неудивительно - на тот момент компания ещё достаточно прочно стояла на ногах, и для такой уверенности были все основания.
Также, как все мы с вами хорошо помним, наравне с рекламой непосредственно возможностей самих чипов усиленно муссировалась информация по небывалому уровню программируемости и свободы для программистов по написанию кода программ-шейдеров на картах NVIDIA архитектуры CineFX. Однако как показала практика, программирование под чипы FX оказалось весьма сложным и трудоёмким занятием. Работа же с чипами ATI по выполнению кода на компиляторе Microsoft HLSL (High Level Shader Language) с 24-битной точностью происходит гораздо легче. То есть чипы ATI работают быстрее отчасти за счёт того, что они были изначально разработаны с учётом того, что большинство программ-шейдеров будут писаться именно на стандартном компиляторе Microsoft, а NVIDIA сделала ставку на собственную совместную разработку, за что, как теперь все мы прекрасно можем видеть, и поплатилась в итоге. Конечно, не стоит списывать со счетов и сугубо хардварные проблемы чипов серии NVIDIA GeForce FX - они есть, но вопрос о точности операций с плавающей запятой добавляет ещё больше головной боли компании NVIDIA.
Что же важно для конечного пользователя? Естественно, обычному пользователю, который просто играет в самые последние DirectX 9.0 игры (которых, к слову будет сказать, на данный момент не такое уж и большое количество, но ситуация, тем не менее, меняется к лучшему, что не может не радовать) абсолютно всё равно, как компилируется код, какая точность работы операций с плавающей запятой и всё остальное =). Конечному пользователю важен вопрос качества выводимой картинки и, если в качестве картинки нет видимых ухудшений, а скорость возрастает то почему бы не использовать ту же 16-битную точность? Но здесь опять-таки появляется субъективный вопрос об оценке качества. Поэтому здесь выбор должны сделать непосредственно сами пользователи.

Понятно, что NVIDIA необходимо было что-то срочно делать с драйверами. "Резкие движения" компании по включению 16-битной точности работы с плавающей запятой общественностью были восприняты, скажем так, не очень хорошо, что было вполне логично и ожидаемо, поэтому необходимо было искать какие-либо другие пути решения проблемы. Первым этапом решения проблемы можно считать выпуск драйверов новой серии под названием ForceWare. Об оптимизациях, которые не ухудшают качество картинки более подробно и пойдёт речь чуть ниже.
В первую очередь коснёмся изменений "косметических".
На первый взгляд они не сильно заметны. Дизайн менюшек совсем не изменился с времён 40-й серии. Концептуально нового подхода к построению меню не видно и, в принципе, оно и не нужно, так как, расположение и интерфейс меню драйвера 40-й серии, по крайней мере, автора данного материала удовлетворяют полностью.
Настройки антиалиасинга и анизотропной фильтрации объединены в один раздел и имеют 3 настройки качества:
- "High Performance";
- "Performance";
- "Quality".
Впрочем, это уже не ново.
Стандартные разделы не претерпели изменений.
Также теперь стало возможным самому указывать желаемое разрешение, а не выбирать готовые пресеты. Полезность данной опции действительно трудно недооценить.
А вот в разделе nView изменения есть и существенные. Главной инновацией nView 3.0 считается применение функции "gridlines", которая позволяет более эффективно и удобно разбивать экран на независимые друг от друга зоны. Если вы счастливый обладатель профессиональной карты Quadro, то таких областей может быть до 9, в то время как на видеокартах семейства GeForce всего лишь до 4, но наш взгляд, этого более чем достаточно.
Также официально была добавлена поддержка новейших чипов компании GeForce 5700, GeForce FX 5700 Ultra и GeForce FX 5950 Ultra.
Нам же по понятным причинам были интересны другие нововведения в драйвере. А именно переработанный "unified" (то есть единый) компилятор DX 9.0 кода. Суть работы вышеупомянутого заключается в том, что компилятор, принимая инструкции в виде простого DirectX 9.0 кода интерпретирует их для чипа, перестраивает порядок и структуру команд в реальном времени для того, чтобы чип GeForce FX смог получить на выполнение переработанный код, который будет выполняться быстрее, чем, если команды поступят в графический чип "как есть". Наглядно это можно увидеть на следующей схеме:
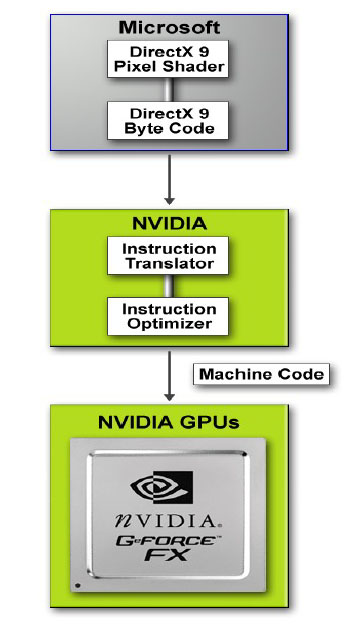
Потенциально компилятор может уменьшать количество проходов, требуемых кодом непосредственно вышедшим из API. А это, в конечном итоге, положительно скажется на производительности акселератора по работе с пиксельными и вершинными программами. Также нужно отметить, что качество изображения от этого не страдает, так как оптимизации не затрагивают вопросы установки точности работы с плавающей запятой, а просто перестраивают порядок и структуру команд, что по всей логике вещей и не может ухудшить качество изображения, так как в итоге всё равно выводится запрашиваемый шейдер. Другое дело, что обрабатывать акселератор теперь будет код, более удобный для архитектуры FX чипов.
Не нужно думать, что идея подобной оптимизации по обработке шейдеров не приходила программистам NVIDIA в голову. Основы "единого компилятора" были заложены ещё в Detonator 44.12, но до ума идея не была доведена, поэтому доводку до реально работающей технологии оставили для новых драйверов серии ForceWare.
Оптимизация кода, поступающего в GPU, - это, вне всякого сомнения, хорошо. Снимаем шляпу перед программистами NVIDIA, но остаётся открытым вопрос о точности работы с плавающей запятой. Учитывая то, что последняя версия Microsoft High Level Shader Language даёт программистам возможность выбора точности плавающей запятой при написании кода, компания NVIDIA преподносит возможность архитектуры чипов семейства GeForce FX выбирать один из трёх режимов точности работы с плавающей запятой (уже упоминавшиеся, 32-битная точность, 16-битная точность и 12-битный целочисленный режим) как преимущество своих чипов. С этим действительно трудно не согласится: зачем всегда использовать 32 битную точность или 24 битную точность (в случае плат ATI), если можно ограничиться, к примеру, 16 битной точностью работы с плавающей запятой в случае специфических задач, не требующих повышенной точности. Другое дело, что не всегда можно наверняка выбрать ту или иную точность для определённых задач. И от программистов в этом случае требуется намного больше усилий по написанию и оптимизации кода.
ASUS V9950 (NVIDIA GeForce FX 5900)
Комплект поставки:
В очень красочной коробке, которая является де-факто стандартом в FX-линейке продуктов ASUS уместились:
- Непосредственно сама плата;
- Переходник DVI-to-D-sub;
- Кабель S-Video - RCA;
- Руководство пользователя (на англ. языке);
- Руководство по установке драйверов (на 14 языках, включая русский);
- 3 CD с играми (Gunmetal, Delta Force: Black Hawk Down, Battle Engine);
- 1 CD с демо-версиями игр (WarcrAnisotropic Filteringt III, Splinter Cell, Big Mutha Truckers, BREED, Colin McRae Rally 3 и TOCA Race Driver);
- 2 CD с разнообразным фирменным софтом от ASUS.
Мы только в очередной раз можем отметить превосходный комплект поставки у ASUS, чем компания славилась всегда.
Дизайн и компоновка платы
Дизайн PCB платы от ASUS полностью аналогичен эталонному дизайну референс-платы от NVIDIA. Отличий нет ни в расположении основных элементов, ни даже в компоновке конденсаторов.
Сама плата получилось очень тяжёлой. Скорее всего, дело в массивной системе охлаждения (более подробно о ней ниже) с медными радиаторами.
Карта имеет классический тёмно-зелёный цвет PCB, несёт на борту 128 Mb DDR памяти с шиной передачи данных в 256 бит (8 чипов по 32 бита каждый, размещённых на лицевой стороне PCB). Как видим, карта имеет вдвое меньший объём памяти, нежели её старшая сестра в лице GeForce FX 5900 Ultra, что достигается путём недоукомплектации карты ещё 8 микросхемами памяти, места под посадку которых с оборотной стороны платы остаются свободными. Карта имеет интерфейс AGP 2x/4x/8x и стандартный набор выходов: 1 DVI-I, 1 аналоговый и 1 TV-OUT. Формирование сигнала для цифровых мониторов осуществляется TMDS-трансмиттером Sil164CT64 от Silicon Image.

Также на плате разведено посадочное место под VIVO-чип, но сам чип не установлен (он установлен на более дорогостоящей Ultra-версии платы). Также на лицевой стороне печатной платы можно увидеть разъём для дополнительного питания, которое необходимо "прожорливому" GeForce FX 5900. Дополнительное питание на плату можно и не подключать, но в этом случае карта будет работать на пониженных частотах (250 МГц у ядра и 500 МГц у памяти). Недостатком конструкции разъёма дополнительного питания на ASUS V9950 можно считать его вертикальное положение. Во-первых, подключение питания при уже установленной в слот AGP видеокарте весьма затруднительно, а, во-вторых, крепёж разъёма оставляет желать лучшего.

Для чипов памяти, размещённых, как уже упоминалось выше, только с лицевой стороны печатной платы, предусмотрена прогрессивная BGA упаковка. Время выборки чипов памяти - 2.2 нс, что соответствует частоте работы 454 MHz (908 MHz), но память работает на положенной по спецификациям NVIDIA частоте 425 MHz (850 MHz). Частота работы GPU - 400 MHz, что также соответствует рекомендованной NVIDIA частоте.
Охлаждение на ASUS V9950 организовано весьма грамотно и в процессе тестирования нареканий по части перегрева не возникало, да и в разогнанном режиме с платой всё было в порядке несмотря на просто выдающиеся разгонные показатели. Система охлаждения представляется собой сплошную конструкцию, которая состоит из весьма массивного сплошного медного радиатора, прикрывающего как сам чип, так и чипы памяти (для которых, кстати говоря, предусмотрены небольшие углубления, что увеличивает плотность прилегания оных к радиатору), двух вентиляторов (лопасти которых, кстати говоря, светятся в ультрафиолете, так что ASUS V9950 - это можно сказать находка для любителей моддинга =)), обдувающих как сам графический чип так и микросхемы памяти.
В довершение ко всему хочется добавить, что, несмотря на достаточно внушительные размеры и кажущуюся в связи с этим громоздкость системы охлаждения, соседний PCI-слот не блокируется, но "терзать" какое-либо устройство, устанавливая его в первый слот, не стоит, так как вместе с ним будет "терзаться" и видеокарта, поскольку приток холодного воздуха будет затруднён. Также в плюсы данной системы охлаждения относим очень малый уровень шума (про Flow FX даже и не вспоминаем =)), который на фоне работы процессорного кулера и жёсткого диска едва различим.
Sapphire Atlantis Radeon 9800
Комплект поставки:
 В коробке с довольно оригинальным рисунком находились:
В коробке с довольно оригинальным рисунком находились:
- Непосредственно сама плата c штекерами питания;
- CD с игрой Tomb Rider: Angle of Darknes;
- Переходник DVI-to-D-Sub;
- Видеокабель;
- S-Video кабель;
- Переходник RCA-to-S-Video;
- 3 CD с драйверами и софтом.
Мы только можем отметить, что традиционные партнёры (партнёры "старой закалки", можно сказать =) ) ATI, начинают понемногу исправляться и сопровождать свои продукты действительно богатым комплектом поставки.
Дизайн и компоновка платы
Дизайн платы полностью повторяет дизайн референс платы ATI. PCB спроектирована в соответствии с требованиями ATI, и каких-либо отличий не заметно.
Плата имеет традиционный для ATI ярко-красный цвет печатной платы, несёт на борту 128 Mb DDR памяти, интерфейс AGP 2x/4x/8x и стандартный набор выходов: 1 аналоговый, 1 цифровой и 1 S-Video. В качестве регулятора напряжения используется старый добрый двухфазный SC1175CSW от Semtech.
Карта оснащена 128 Mb DDR памяти, размещенной в 8 микросхемах (по 4 чипа с лицевой и оборотной сторон печатной платы) в прогрессивной (BGA) упаковке с разрядностью шины в 256 бит. Память производства Hynix (HYB25D128323C-3.0) имеет время доступа 3.0 нс, что соответствует частоте работы памяти примерно в 333 МГц (666 МГц), но память функционирует на положенной ей частоте 290 МГЦ (580 МГц). То есть имеется небольшой запас на разгон по памяти. Графический чип также согласно спецификациям работает на частоте 325 МГц.
Для чипов памяти абсолютно никакого охлаждения не предусмотрено. Для охлаждения графического процессора применена низкопрофильная система охлаждения, которую весьма эффективной не назовёшь. Стандартный референсный небольшого размера вентилятор, насаженный на радиаторы. Тем не менее, в штатном режиме работы при многочасовом тестировании в 3D проблем со стабильностью не возникало. Но нагрев радиаторов был вполне приличный.
Тестирование
Тестовый стенд:
| Материнская плата: |
JetWay S446 (SiS 645) |
| Процессор: |
P4 Northwood 1.6A@2.13A Ghz (133x16) |
| Память: |
256 MB Hynix PC2100 DDR SDRAM (CL=2) |
| Винчестер: |
Maxtor Diamond Plus 8 40 Gb |
| Видеокарты: |
ASUS V9950 128 Mb (NVIDIA GeForce FX 5900)
Sapphire Atlantis Radeon 9800 128 Mb (ATI Radeon 9800) |
| OS |
Microsoft Windows XP SP1 ENG, DirectX 9.0b |
| Драйвер: |
Detonator 45.23 WHQL и ForceWare 52.16
Catalyst 3.9 |
Все "красивости" в операционной системе убирались, система настраивалась на максимальное быстродействие.
Vsync принудительно отключался через драйвера как в OpenGL, так и в Direct3D-приложениях. Технология сжатия текстур S3TC также отключалась.
Тестовые программы:
- 3DMark2003 v330 и (!) v340;
- ShaderMark v2.0 (DirectX 9 HLSL бенчмарк пиксельных шейдеров - о специфике данной программы далее в материале);
- D3D RightMark 1.0.2.7. (Public Beta 1) (комплексный DirectX 9.0 синтетический тест);
- 3DMark2001SE;
- Codecreatures v1.0.0 (DirectX 8.1 приложение, шейдеры, Hardware T&L);
- Return to Castle Wolfenstein v1.0 (OpenGL, мультитекстурирование. Настройка качества изображения на максимальном уровне. Использовалось Demo Checkpoint);
- Unreal Tournament 2003 (Direct3D, Hardware T&L, вершинные шейдеры, Dot3, cube texturing. Использовалось демо "Antalus Flubu");
- Gun Metal Benchmark 2 v1.20s (DirectX 9.0 бенчмарк, Vertex Shaders 2.0, Pixel Shaders 1.1, Hardware T&L);
- X2: The Threat Demo (Direct3D, мультитекстурирование, Dot3, режим встроенного в демо-версию бенчмарка);
- Final Fantasy XI Official Benchmark 2 (бенчмарк для оценки производительности в грядущей игре Final Fantasy XI. К сожалению, данных по характеристикам движка игры разработчики не предоставляют);
- HALO: Combat Evolved 1.2 (DirectX 9.0, Vertex Shaders 1.1/1.4/2.0, Pixel Shaders 1.1/1.4/2.0, Hardware T&L, качество максимально возможное);
- AquaMark 3 (DirectX 9.0, Vertex Shaders 1.1/1.4/2.0, Pixel Shaders 1.1/1.4/2.0, Hardware T&L, режим AquaMark3 Triscore);
- Half-life 2 leaked beta (DirectX 9.0, Vertex Shaders 2.0, Pixel Shaders 2.0, качество по умолчанию);
- Unreal II: The Awakening (Direct3D, вершинные шейдеры, Hardware T&L, Dot3, cube texturing, качество, предлагаемое программой BenchemAll).
Результаты тестирования: Cинтетические тесты
С момента нашего прошлого тестирования мы коренным образом пересмотрели состав наших тестовых синтетических пакетов. Мы отказались от использования уже устаревшего DirectX 8.1 тестового пакета MadOnion 3DMark2001SE, вместо него для оценки скорости работы шейдерных программ поколения DirectX 8.1 (версии шейдеров 1.1 и 1.4) мы оставили уже привычный нам бенчмарк Codecreatures. Упор же был сделан при подборе синтетических тестов на DirectX 9.0 синтетические программы, поэтому в арсенале наших тестовых программ присутствуют 2 новичка:
• ShaderMark v2.0 (DirectX 9 HLSL бенчмарк пиксельных шейдеров);
• D3D RightMark 1.0.2.7. (Public Beta 1) (комплексный DirectX 9.0 синтетический тест).
Подробный анализ работы данных тестовых пакетов вы сможете прочитать непосредственно в самом материале по ходу анализа результатов испытуемых видеокарт.
ShaderMark v2.0
Все видеокарты проходили тест в режиме "Anti-Detect Mode". Также отметим, что видеокарта на чипе NVIDIA GeForce FX 5900 не смогла пройти все тесты в данном режиме, о чём честно сообщил бенчмарк сразу же после запуска. С платой же на ATI Radeon 9800 никаких проблем не возникло - все возможные версии шейдеров, предлагаемых ShaderMark v2.0, запустились на плате ATI без проблем.
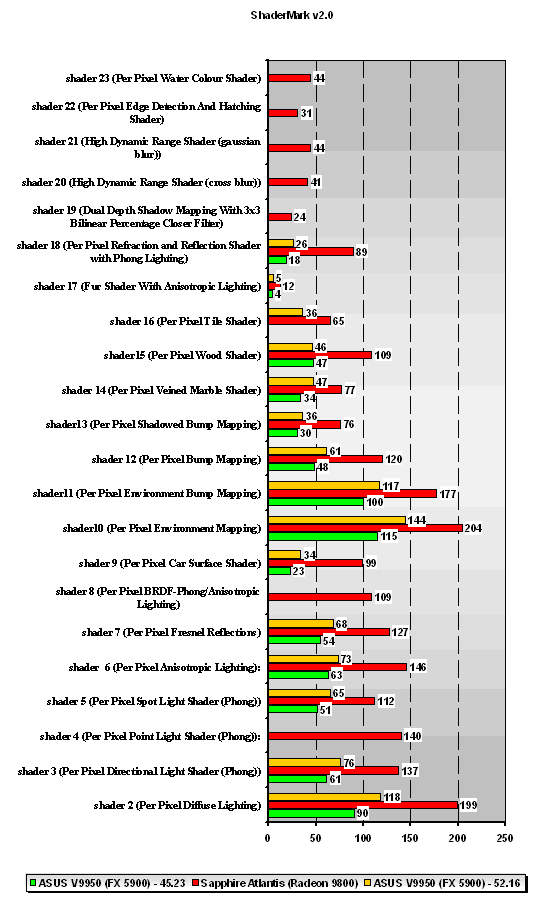
Что же мы можем сказать непосредственно по поводу результатов? Здесь без преувеличения можно наблюдать то, что чип NVIDIA оказался просто растоптан ATI Radeon 9800. Графики, местами показывающие преимущество ATI над чипом NVIDIA в 2-3 раза, говорят сами за себя - ни один (!) из предлагаемых программой шейдеров не был выполнен на чипе NVIDIA GeForce FX 5900 быстрее, чем на ATI Radeon 9800. Вот что значит чистый HLSV для чипов NVIDIA. К чести NVIDIA стоит отметить, что новый драйвер NVIDIA ForceWare 52.16 показывает увеличение производительности по сравнению со своим предшественником Detonator 45.23, но оно мизерно и совершенно не влияет на расстановку сил, если взглянуть на результаты ATI Radeon 9800. Но нам важно немного другое: показательно то, что в HLSV ForceWare 52.16 действительно даёт прирост производительности, причём в HLSV коде. Это даёт нам основания полагать, что оптимизации, применённые в новом драйвере NVIDIA, реально работают с кодом и дают результат. Пусть и не столь большой, как нам бы хотелось, но, тем не менее, он заметен.
D3D RightMark
Также новый тест в нашем наборе синтетических бенчмарков, который, на наш взгляд, на данный момент позволяет наиболее эффективно и, что самое главное, объективно, оценить производительность той или иной подсистемы акселератора. Все тесты проводились в разрешении 1024х768. Мы не стали проводить тесты со всеми возможными настройками - вряд ли такое огромное количество тесов даст нашим читателям больше информации. Скорее запутает в куче диаграмм =).
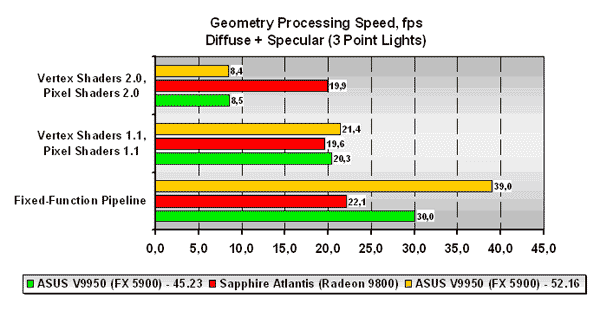
Geometry Processing Speed
Тест позволяет оценить скорость обработки геометрии акселератором. Использовался наиболее сложный режим с тремя диффузно-спекулярными источниками света в связке с тремя различными режимами работы: традиционный TCL (Fixed-Function Pipeline), вершинные шейдеры 1.1 и пиксельные шейдеры 1.1, вершинные шейдеры 2.0 и пиксельные шейдеры 2.0.
Как видим, в случае традиционного TCL карта NVIDIA на голову превосходит ATI Radeon 9800. Также примечательно то, что виден значительный прирост от использования нового драйвера ForceWare 52.16 - видимо, в новом драйвере был оптимизирован шейдер, отвечающий за эмуляцию TCL. Но картина становится весьма печальной при использовании шейдеров 1.1 версии, а затем и 2.0. Производительность чипа NVIDIA резко падает, а прироста от нового драйвера в случае шейдеров 2.0 не видно вообще. Плата же ATI держится молодцом и показывает абсолютно идентичную производительность при использовании как 1.1, так и 2.0 версии пиксельных и вершинных программ.
Pixel Filling
Тест выполняет множество различных задач, но нас больше всего интересовала возможность измерения производительности закраски буфера кадров.
Она, как видим, выше у чипа ATI. Новый драйвер NVIDIA ForceWare ситуацию подправляет и значительно, но дотянуть до уровня платы ATI Radeon 9800 всё же не получается.
Pixel Shading
Данный тест тестового пакета D3D RightMark позволяет оценить производительность выполнения различных пиксельных шейдеров второй версии. В тесте максимально упрощена геометрия, для того чтобы свести к минимуму зависимость результатов данного теста от геометрической производительности чипа, и проверить работу сугубо пиксельных конвейеров.
Как видим, чип ATI Radeon 9800 выигрывает у NVIDIA GeForce FX 5900, причём практически с троекратным преимуществом. Переработанный компилятор у нового драйвера NVIDIA даёт прирост, но он всё равно не позволяет и близко приблизится чипу NVIDIA к канадцу на Radeon 9800. Шейдеры, написанные на HLSV, даются чипу NVIDIA очень сложно - это уже где-то даже аксиома и, кажется, аксиома эта останется непоколебимой.
Point Sprites
Тест направлен на выявление скорости акселератора при выводе точечных спрайтов. В настройках теста нами использовались 2 диффузных источника освещения.
Чип ATI снова впереди, хотя расклад сил более близок с ситуацией в тесте на закраску и на геометрическую производительность, чем с раскладом сил в тесте на производительность пиксельных шейдеров 2.0, что логично, так как данный тест напрямую зависит от этих двух параметров.
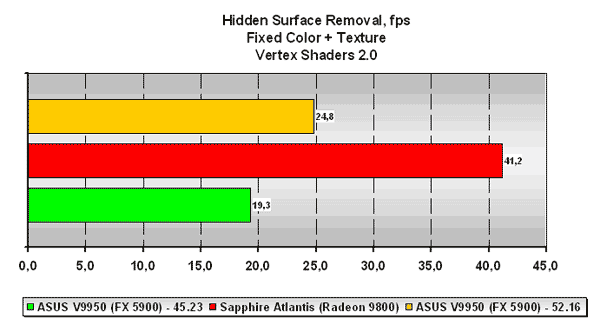
Hidden Surface Removal
Тест позволяет оценить эффективность удаления акселератором невидимых точек и примитивов.
Отсечение невидимых точек на чипе ATI Radeon 9800 происходит быстрее чипа NVIDIA GeForce FX 5900 и весьма существенно, что должно будет сказаться на производительности в реальных приложениях.
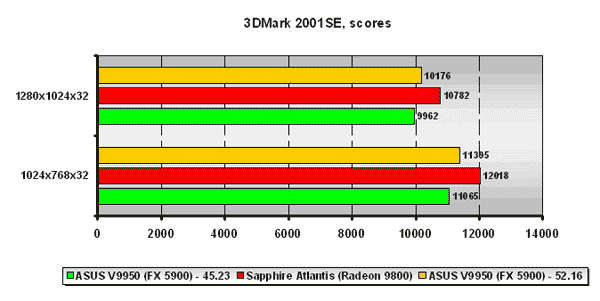
3DMark 2001SE
Тест 3DMark2001SE уже достаточно старый, но на правах "старожилы" всех наших материалов он всё же присутствует =). К тому же DirectX 8.1 игры сейчас весьма распространены, что позволяет пользователям отчасти ориентироваться на результаты этого теста для оценки потенциальной производительности плат в современных игровых приложениях.
Что же касается непосредственно самих результатов теста, то здесь в общем зачёте победителем выходит плата Sapphire на ATI Radeon 9800 во всех разрешениях. От использования детализированных результатов данного теста мы отказались в пользу вышеприведённых результатов других синтетических тестов, которые, на наш взгляд, более объективно показывают реальный уровень производительности плат.
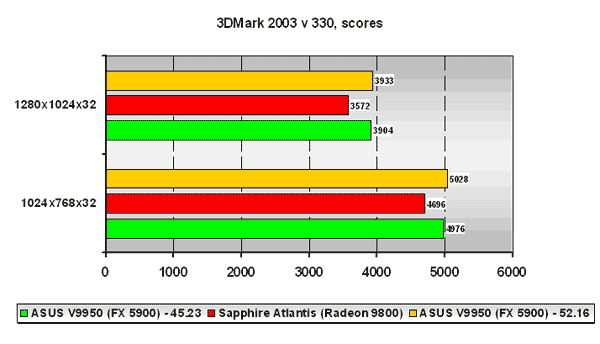
3DMark 2003
На версии патча 330 под 3DMark 2003 NVIDIA GeForce FX 5900 выигрывает у ATI Radeon 9800 во всех разрешениях. Немного странно, учитывая то, что все шейдерные тесты других синтетических тестов NVIDIA, откровенно говоря, провалила. Но в NVIDIA ведь умеют сделать "правильные" результаты тестов, не так ли =)?
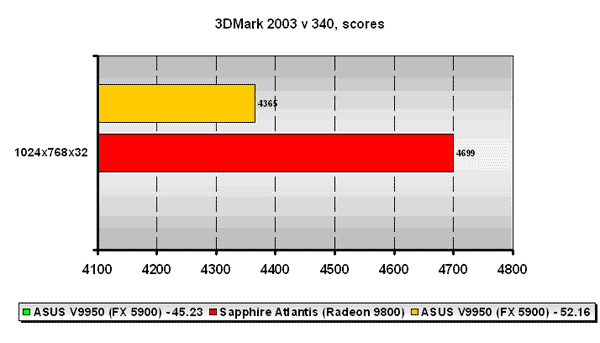
В этом плане показательны результаты плат с новейшим патчем от FutureMark версии 340, который вместе с новой концепцией компании по получению и интерпретации результатов теста должен был поднять пошатнувшийся (и это ещё мягко сказано =) ) авторитет 3DMark 2003. Почему "должен был"? Об этом дальше.
Что же, ставим новый патч, прогоняем тесты: ATI Radeon 9800 - лидер с практически абсолютно тем же количеством попугаев образца 2003 года, а NVIDIA GeForce FX 5900 на ForceWare 52.16 уже в проигрыше (данные на 45.23 версии Detonator, к сожалению, получены не были по техническим причинам да и особого смысла получать их не было), потеряв достаточное количество "птичек" по сравнению с 330-ым патчем. Забавная, но закономерная картина. И уже в скором времени в Сеть попадает неофициальный релиз драйвера ForceWare, который "фиксит" именно "упорное нежелание 3DMark 2003 показывать правильный результат на новом патче FutureMark". Статуса "официально одобренного" FutureMark этот драйвер пока не получил, но мы, более чем уверены, что не за горами WHQL-сертификация, а затем и "одобрение".
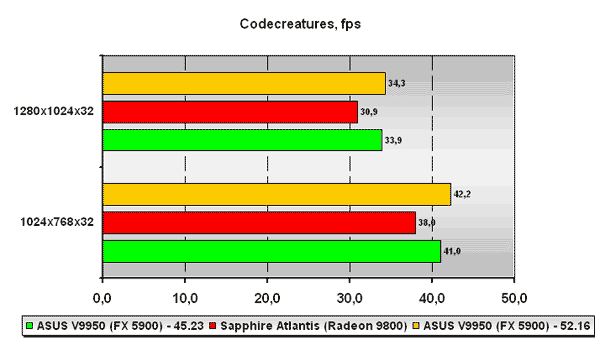
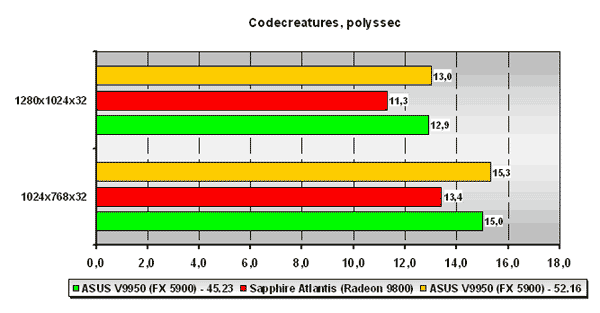
Codecreatures
В уже также достаточно старом тесте Codecreatures плата NVIDIA обходит ATI Radeon 9800 во всех разрешениях. Прироста производительности от использования нового драйвера NVIDIA ForceWare 52.16 практически не заметно.
Результаты тестирования: Реальные игровые приложения
Но от синтетических приложений переходим к рассмотрению производительности плат в реальных игровых приложениях. Также, как и в части нашего материала, посвящённому тетсированию плат в синтетических тестах, в данном разделе набор тестов также несколько претерпел изменения. Во-первых, добавилась благополучно "утёкшая в Сеть", бета версия игры Half-Life 2 результаты тестов которой, на наш взгляд, будут интересны очень многим нашим читателям. Также мы добавили красивый тест на основе движка от выходящей в скором времени игры Final Fantasy XI.
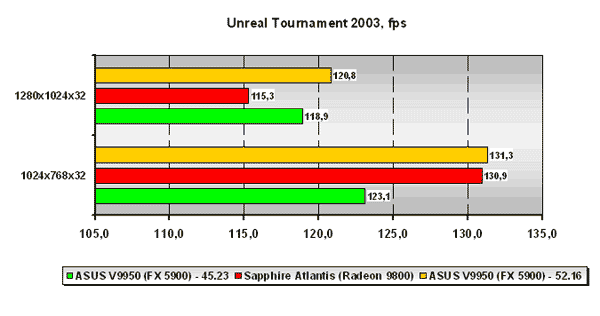
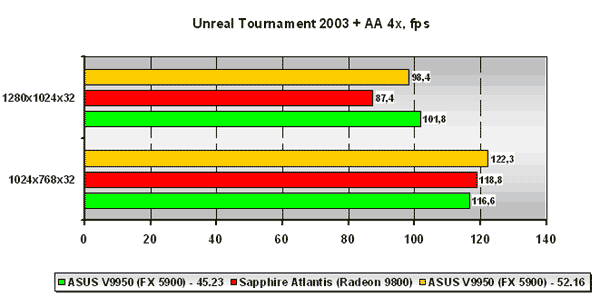
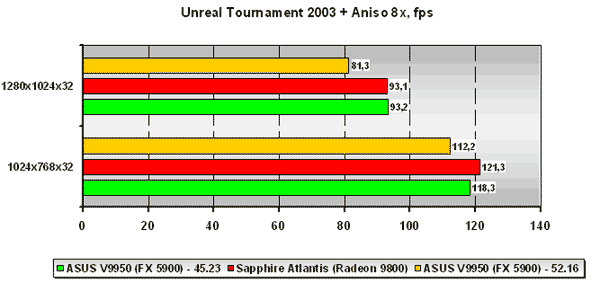
Unreal Tournament 2003
Для начала будет интересно взглянуть на результаты тестов в приложении активно не использующим шейдеры, коим и является Unreal Tournament 2003. В низком разрешении на версии драйвера Detonator 45.23 плата ASUS на базе NVIDIA GeForce FX 5900 отстаёт от платы Sapphire на базе ATI Radeon 9800. Но установка драйвера NVIDIA ForceWare 52.16 приносит плоды, и платы уже идут вровень. В более высоком разрешении лидерство за платой NVIDIA на обеих версиях драйверов. Рост производительности от замены драйвера NVIDIA в высоком разрешении заметно ниже, нежели в низком.
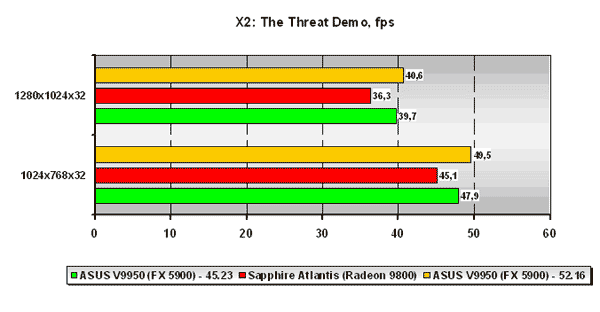
X2: The Threat Demo
В данном тесте и без установки нового драйвера плата на базе NVIDIA GeForce FX 5900 традиционно обходит своего конкурента из стана ATI. Дело в том, что тест использует в огромном количестве трафаретные тени, которые на платах NVIDIA требуют меньшего числа проходов и НЕ использует пиксельные и вершинные программы, что для чипов NVIDIA создаёт просто идеальные условия. Рост производительности от установки драйвера с переработанным компилятором вполне заметен и ещё больше увеличивает разрыв от конкурента из стана ATI.
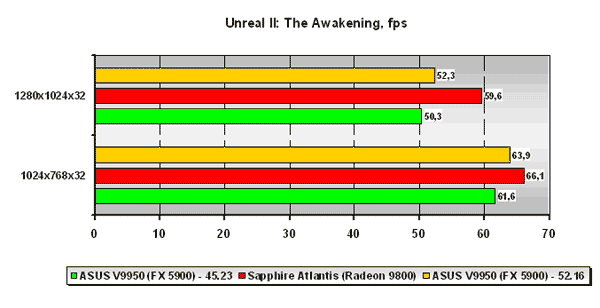
Unreal II: The Awakening
А вот более свежая, переработанная версия движка Unreal Tournament 2003, которая используется в игре Unreal II: The Awakening, показывает преимущество платы ATI. Связано это, скорее всего, с более сложной геометрией в игре. Новый драйвер ситуацию не исправляет, но заметно сокращает разрыв по крайней мере в низком, "самом игровом" на сегодня разрешении. В более высоком разрешении плата ATI на базе Radeon 9800 для графических процессоров NVIDIA недосягаема.
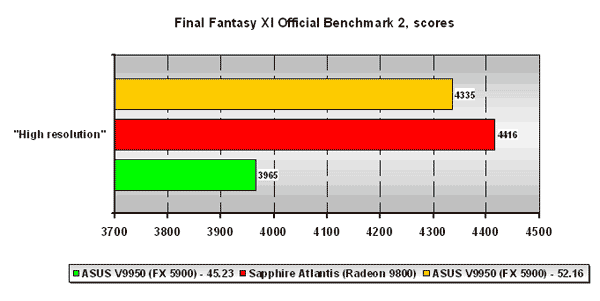
Final Fantasy XI Official Benchmark 2
Новый тест в нашем наборе бенчмарков. Насколько нам известно, движок игры не использует ни пиксельные, ни вершинные программы каких-либо версий. Но поскольку официально-подтверждённой информации на этот счёт нет, наши сомнения и догадки так и останутся без ответа, а мы продолжим мучаться от того, что не можем дать объяснения тому, что плата ATI Radeon 9800 выиграла у NVIDIA GeForce FX 5900 =), а версия драйвера ForceWare 52.16 весьма существенно прибавила "попугаев" из данного теста плате ASUS V9950.
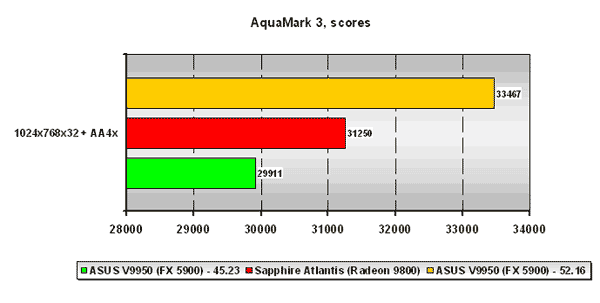
AquaMark 3
Очень показательный шейдерный тест на сегодняшний день, с которым по этой причине уже было связано множество кривотолков по поводу оптимизаций со стороны как NVIDIA, так и (!) ATI.
Непосредственно сами результаты создают весьма драматичную картину для платы ATI. С драйвером Detonator 45.23 плата ASUS V9950 на NVIDIA GeForce FX 5900 проигрывает канадцу, а вот установка новейших драйверов NVIDIA ForceWare 52.16 даёт детищу NVIDIA из Калифорнии существенный прирост производительности, которого с лихвой хватает, чтобы уйти от ATI в достаточно приличный отрыв.
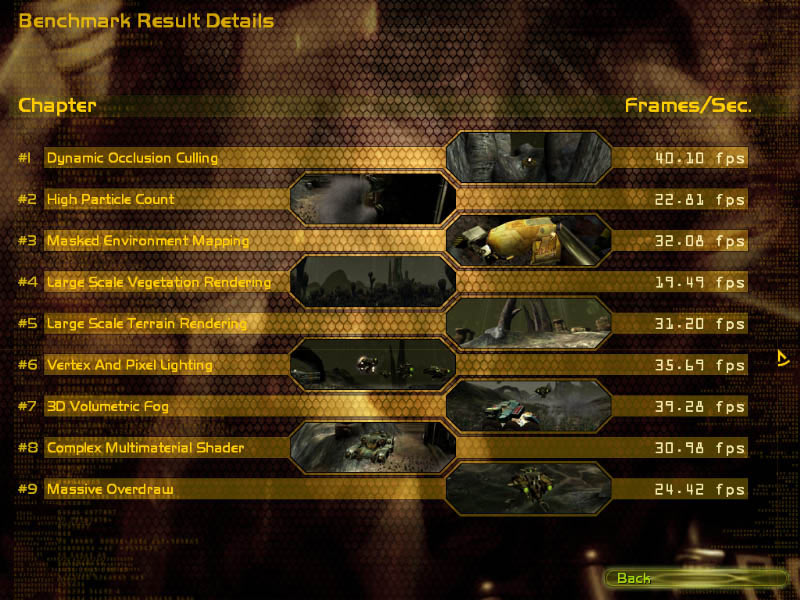
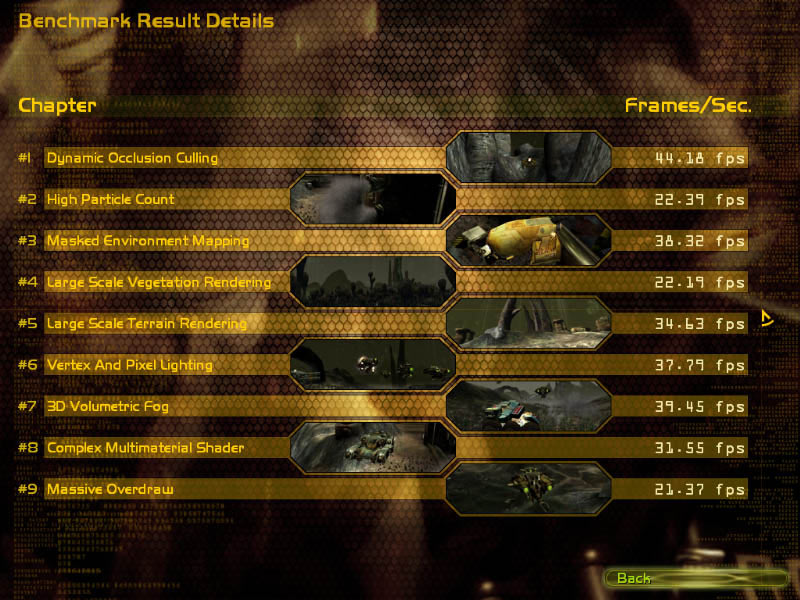
Также мы представляем вашему вниманию скриншоты с детальными результами данного теста, чтобы можно было проанализировать результаты каждой из протестированных видеокарт.
 |
 |
 |
| FX 5900 - Detonator 45.23 |
Radeon 9800 - Catalyst 3.9 |
FX 5900 - ForceWare 52.16 |
Интересно отметить, что один из самых тяжёлых тестов в пакете "Large Scale Vegetation Rendering" практически не отреагировал на смену драйвера также как и тест массивной перерисовки "Massive Overdraw". Наиболее же чувствительными к замене драйвера с переработанным компилятором кода тестами стали: "Dynamic Occlusion Culling", "Masked Environment Mapping" и "Large Scale Terrain Rendering", показавшие прирост производительности в среднем до 22%.
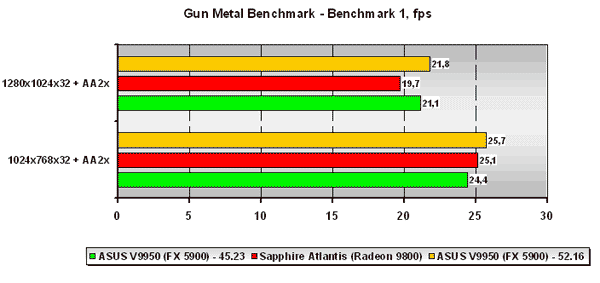
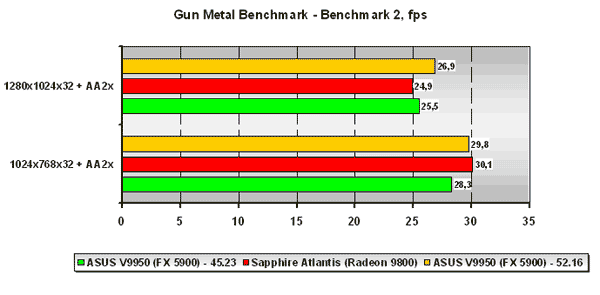
Gun Metal Benchmark 2
В данном псевдо DirectX 9.0 тесте, использующем 2.0 версию вершинных программ, но 1.1 версию пиксельных, расклад сил далеко неоднозначный. В низких разрешениях плата ATI в обоих игровых тестах обходит NVIDIA GeForce FX 5900 с драйвером Detonator 45.23 с небольшим отрывом, но ForceWare 52.16 выправляет ситуацию. В высоком же разрешении плата на NVIDIA GeForce FX 5900 как на старой версии драйвера, так и на новой обходит плату ATI на Radeon 9800. Заметим, что прирост производительности от замены драйвера весьма незначителен, что немного странно, учитывая то, что синтетика показывает практически идентичный прирост производительности при работе как с 1.1 версиями пиксельных программ так и с 2.0 версией последних, а поэтому списывать малое процентное увеличение производительности при переходе от Detonator 45.23 к ForceWare 52.16 на то, что в бенчмарке используется 1.1 версия пиксельных программ, а не 2.0 нельзя.
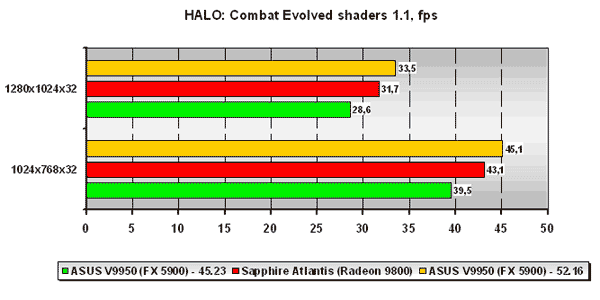
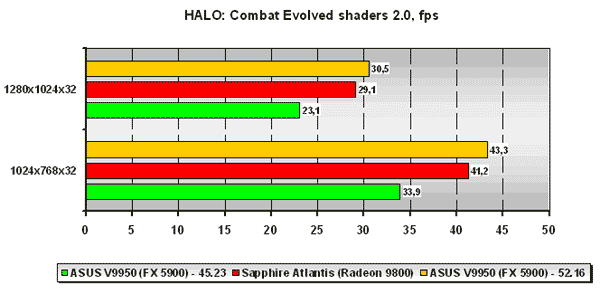
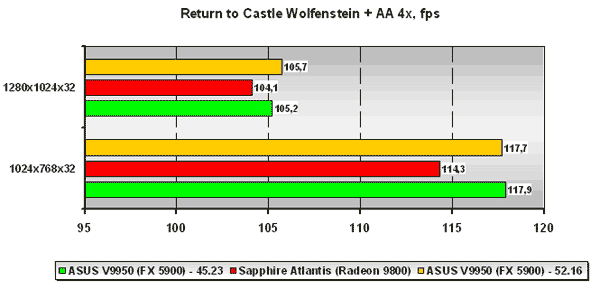
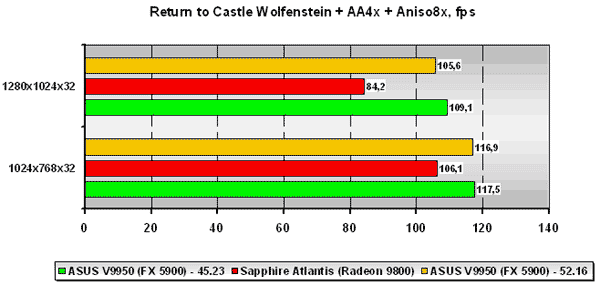
HALO: Combat Evolved
Для нас было очень интересно проследить за результатами уже постоянной DirectX 9.0 игры из нашего списка используемых бенчмарков, прежде всего благодаря возможности принудительного включения той или иной версии пиксельных и вершинных программ в игре.
В целом ситуация для платы ATI настолько же драматична как и в случае с AquaMark 3. С версией 42.53 драйверов GeForce FX 5900 проигрывает ATI Radeon 9800, но ForceWare 52.16 приходятся кстати, и ситуация в корне меняется как при использовании 1.1 версии пиксельных программ, так и при версии 2.0 оных.
Также примечателен другой факт. Если посмотреть на абсолютные значения фпс платы на ATI Radeon 9800 при использовании пиксельных и вершинных программ версии 2.0 и 1.1, мы можем заметить, что падение производительности при переходе от 1.1 версии пиксельных и вершинных программ к 2.0 версии оных совсем невелико. А у платы на базе NVIDIA GeForce FX 5900 при использовании драйвера Detonator 45.23 падение есть, и оно весьма существенно. Но стоит оценить цифры, полученные на ForceWare 52.16, как мы можем констатировать абсолютно то же (в процентном соотношении) падение производительности при переходе от 1.1 к 2.0 версии пиксельных и вершинных программ у NVIDIA GeForce FX 5900, что и у ATI Radeon 9800, что опять-таки указывает на отличную работу программистов NVIDIA. Хотя справедливости ради стоит отметить, что нами не было отмечено какого-либо мало-мальски видного отличия в качестве при использования обеих версий пиксельных и вершинных программ.
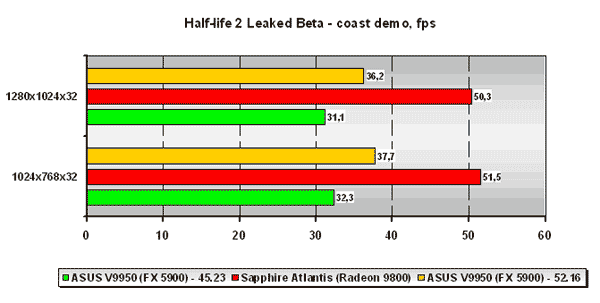
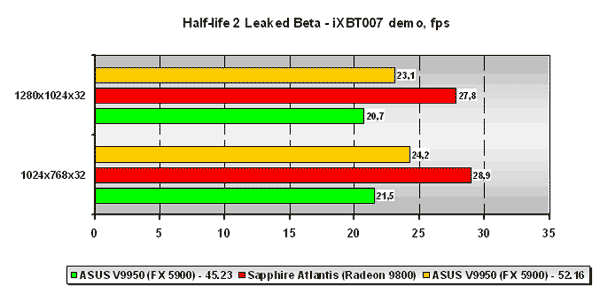
Half-life 2 Leaked Beta
Думаю, не будет преувеличением, если я скажу, что мы ОЖИДАЛИ то, что бета/альфа/хоть что-нибудь отдалённо напоминающее Half-Life 2 просочится в Сеть =)). Комментирование того, как бета проникла в Сеть, мы проводить не будем. Нам же больше интересно то, что у нас на руках оказалось реальное DirectX 9.0 приложение, которое использует все возможности API, что называется, на полную катушку и является, по сути, узором будущих DirectX 9.0 игр. Комментировать результаты ещё очень сырой беты - дело, в общем-то, неблагодарное, так как в финальном релизе всё может быть (и, скорее всего, будет) изменено, но мы, тем не менее, этим займёмся =).
Движок Half-Life 2 представляет собой тот самый чистый HLSV, что ничего хорошего для карт NVIDIA не сулит. Как показывает наше тестирование на двух демках-бенчмарках (за которые огромное спасибо лично Андрею Воробьёву, любезно предоставившего демо-записи для тестирования) карта NVIDIA оказывается просто растоптанной канадской ATI. ForceWare 52.16 хотя и показывает достаточно большой прирост производительности, но положения никак не выправляет.
Качество изображения
Качество изображения: AntiAliasing 4x
Как хорошо видно, антиалиасинг даётся чипам NVIDIA очень хорошо как в Direct3D, так и в OpenGL приложениях. Новый драйвер NVIDIA ForceWare 52.16 это только подчеркивает.
Качество изображения: Anisotropic Filtering 8x
Скорость работы анизотропной фильтрации в Direct3D (Unreal Tournament 2003) у ATI Raeon 9800 и NVIDIA GeForce FX 5900 с драйверами Detonator 45.23 примерно одинаковая. Но мы получили очень странный результат при использовании ForceWare 52.16 - производительность упала. К сожалению, у нас не было возможности провести повторный прогон теста, и данный курьёз остаётся без объяснений. Ну а в OpenGL (Return to Castle Wolfenstein) у плат NVIDIA традиционное лидерство.
Качество изображения: AntiAliasing 4x + Anisotropic Filtering 8x
В общем зачёте констатируем полную победу NVIDIA.
Качество изображения: AntiAliasing 6x/8x + Anisotropic Filtering 8x/16x
В дополнение к нашим традиционным режимам тестирования на качество изображения мы решили добавить так называемый "режим максимального качества", при котором включались максимально возможные режимы работы анизотропной фильтрации и антиалиасинга. Для чипов ATI максимальный уровень анизотропии был равен 16х, антиалиасинга - 6х. Для чипа NVIDIA, соответственно, 8x для обоих режимов.
Посмотрим на результаты. В Unreal Tournament 2003 - явная победа NVIDIA, а в Return to Castle Wolfenstein - такая же явная победа ATI. Также нельзя не отметить абсолютные значения фпс в играх - они находятся на приемлемом для игры уровне.
Выводы
Выпуск нового драйвера ForceWare 52.16 существенно изменил расстановку сил как в нише High-End плат, так в Middle- и Low-End. Рассмотренная же нами сегодня плата ASUS V9950 (NVIDIA GeForce FX 5900) в этом плане наиболее показательна.
Синтетические тесты, активно использующие техники работы с пиксельными и вершинными шейдерами дружно рапортуют о существенном росте скорости работы платы на NVIDIA GeForce FX 5900 (а равно и всех плат семейства GeForce FX) с шейдерами. Особенно хорошо рост заметен при работе с шейдерами версии 2.0, что, как все мы хорошо знаем, всегда было узким местом плат на базе чипов NVIDIA GeForce FX. Тем не менее, по синтетическим тестам платы на GeForce FX 5900 даже с новейшими драйверами ForceWare 52.16 не могут наравне соревноваться с платой ATI Radeon 9800. Отметим, что такая расстановка сил в синтетике обеспечена прежде всего тем, что используемые нами синтетические бенчмарки основаны на Microsoft HLSL (High Level Shader Language), а платы ATI, как мы отмечали в теоретической части нашего материала, работают с ним намного более эффективно, нежели платы NVIDIA, для которых идеальным вариантом является индивидуальный подход к написанию программ-шейдеров под архитектуру плат на GeForce FX. "Стандартный же код DirectX 9.0" платы на GeForce FX обрабатывают заметно хуже плат ATI Radeon, и новый драйвер NVIDIA ситуацию коренным образом не меняет, а лишь немного сокращает разрыв.
В реальных же приложениях, как показало наше тестирование, ситуация для NVIDIA куда более благоприятна с учётом выхода нового драйвера ForceWare 52.16. Порой именно установка нового драйвера позволяло выходить плате на NVIDIA GeForce FX 5900 в лидеры, оставляя ATI Radeon 9800 посередине между результатами NVIDIA GeForce FX 5900 с драйверами Detonator 45.23 и ForceWare 52.16. Шейдерные приложения по понятным причинам были здесь наиболее показательны. Но нам бы хотелось отметить, что далеко не последнюю роль в данных выдающихся результатах платы NVIDIA сыграла широкая распространенность бенчмарков, а также игр, используемых нами в качестве бенчмарков в наших исследованиях.  Имеет значение здесь и программа NVIDIA по работе с разработчиками игр под названием "The Way it's Meant to be Played", которая направлена на усиленную работу с разработчиками игр для того, чтобы игровые движки оптимизировались под архитектуру видеокарт NVIDIA. Хорошо это или плохо? Однозначного ответа нет, и не может быть. Конечному покупателю/игроку, не вникающему в детали, абсолютно всё равно каким образом достигается наибольшая производительность у того или иного производителя видеокарт. Будет ли это достигнуто за счёт хитрых оптимизаций, или производительность будет изначально на высоком уровне заложена в самой архитектуре графического процессора пользователю по большому счёту не важно - лишь бы не страдало качество изображения. Но здесь на поверхности лежит другая проблема: какую бы массированную политику работы с разработчиками игр не проводила компания NVIDIA, компания физически не сможет охватить ВСЕХ разработчиков, и те, в свою очередь, будут просто вынуждены писать код HLSV, который как уже много раз показывала практика реальных игровых приложений быстрее выполняется на платах ATI. Поэтому, на наш взгляд, NVIDIA избрала в данном случае немного неправильную политику. За примерами далеко ходить не нужно. Взять хотя бы Half-Life 2, на котором платы NVIDIA показывают просто ужасающе низкую производительность и смотрятся на равных лишь с Middle-End представителями ATI. А ведь Half-Life 2 - это, без преувеличения, узор будущих DirectX 9.0 игр, и с Valve NVIDIA вела плотные работы по оптимизированию игры под платы архитектуры GeForce FX. Мы, естественно, не можем сказать насколько бета, утёкшая в Сеть, оптимизирована под платы NVIDIA и оптимизирована ли она вообще, но то, что GeForce FX 5900 с треском проваливает все тесты на базе беты Half-Life 2 и уступает лидерство плате ATI - факт. Также фактом является то, что оптимизация игры под видеокарты NVIDIA - на практике дело очень хлопотное, что только подтверждает сделанные нами ранее выводы о том, что NVIDIA не сможет искусственно подводить производительность своих карт "под уровень ATI".
Имеет значение здесь и программа NVIDIA по работе с разработчиками игр под названием "The Way it's Meant to be Played", которая направлена на усиленную работу с разработчиками игр для того, чтобы игровые движки оптимизировались под архитектуру видеокарт NVIDIA. Хорошо это или плохо? Однозначного ответа нет, и не может быть. Конечному покупателю/игроку, не вникающему в детали, абсолютно всё равно каким образом достигается наибольшая производительность у того или иного производителя видеокарт. Будет ли это достигнуто за счёт хитрых оптимизаций, или производительность будет изначально на высоком уровне заложена в самой архитектуре графического процессора пользователю по большому счёту не важно - лишь бы не страдало качество изображения. Но здесь на поверхности лежит другая проблема: какую бы массированную политику работы с разработчиками игр не проводила компания NVIDIA, компания физически не сможет охватить ВСЕХ разработчиков, и те, в свою очередь, будут просто вынуждены писать код HLSV, который как уже много раз показывала практика реальных игровых приложений быстрее выполняется на платах ATI. Поэтому, на наш взгляд, NVIDIA избрала в данном случае немного неправильную политику. За примерами далеко ходить не нужно. Взять хотя бы Half-Life 2, на котором платы NVIDIA показывают просто ужасающе низкую производительность и смотрятся на равных лишь с Middle-End представителями ATI. А ведь Half-Life 2 - это, без преувеличения, узор будущих DirectX 9.0 игр, и с Valve NVIDIA вела плотные работы по оптимизированию игры под платы архитектуры GeForce FX. Мы, естественно, не можем сказать насколько бета, утёкшая в Сеть, оптимизирована под платы NVIDIA и оптимизирована ли она вообще, но то, что GeForce FX 5900 с треском проваливает все тесты на базе беты Half-Life 2 и уступает лидерство плате ATI - факт. Также фактом является то, что оптимизация игры под видеокарты NVIDIA - на практике дело очень хлопотное, что только подтверждает сделанные нами ранее выводы о том, что NVIDIA не сможет искусственно подводить производительность своих карт "под уровень ATI".
С выходом новых игр всё более и более активно использующих техники работы с пиксельными и вершинными программами версий 2.0, платы NVIDIA на чипах GeForce FX будут смотреться всё более и более неубедительно на фоне плат ATI (примеров уже было предостаточно). На наш взгляд, единственно правильным решением для NVIDIA будет выпуск нового чипа с изначально оптимизированной архитектурой под Microsoft HLSV (вопрос о точности работы с плавающей запятой остаётся открытым). На сегодняшний день мы можем точно сказать, что всем владельцам плат на NVIDIA GeForce FX в обязательном порядке следует устанавливать новый драйвер NVIDIA ForceWare 52.16 (анализ новых версий драйвера в том числе и неофициальных в наших следующих материалах), так как драйвер действительно оптимизирует работу именно самого компилятора, а не делает какие-либо оптимизации под конкретное приложение, что подтверждают не только игровые приложения, но и синтетика.
Автор выражает благодарность Интернет-магазину www.Ultra-Price.com за предоставленную на тестирование видеокарту ASUS V9950.
Обсуждение на Форуме:
Дополнительные материалы:
 VGA Roundup Q3`2003
FX 5900 против Radeon 9800Pro
FX 5600Ultra против Radeon 9600Pro
FX 5200 против Radeon 9200
VGA Roundup Q3`2003
FX 5900 против Radeon 9800Pro
FX 5600Ultra против Radeon 9600Pro
FX 5200 против Radeon 9200
Методика тестирования:
Тестовый пакет "AquaMark 3"
"Unreal Tournament 2003" в роли бенчмарка
"DooM 3" в роли бенчмарка
3DMark 2003: увидеть будущее
Тестовый пакет 3DMark 2001 Pro
"Max Payne" в роли бенчмарка
"Serious Sam" в роли бенчмарка
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex