Автор:
Бурдыко Алексей
Введение
Не для кого ни секрет, что производительность пиксельных и вершинных шейдеров у продуктов NVIDIA, начиная с NV30, находится на непозволительно низком уровне, если сравнивать её с производительностью аналогичных по классу продуктов ATI. Если в таких синтетических бенчмарках как 3DMark 2003 проблемы "решались" весьма неплохо с появлением новых драйверов и внедрённых в них "оптимизаций", которые зачастую ухудшали качество изображения или применяли откровенно жульнические методы, повышающие производительность, то с выходом новых бенчмарков и, что самое главное, DirectX 9.0 игр, поддерживающих пиксельные и вершинные программы версии 2.0, ситуация для чипов NVIDIA становилась всё более и более плачевной. Ситуацию с 3DMark 2003 мы также будем рассматривать в нашем сегодняшнем тестировании. Особенно интересны результаты тестов в данном пакете в свете выхода нового (v340) патча к нему.
Вспомним по очереди выходившие новые игры, а затем тестирования, проводившееся многими изданиями, которые выявляли у чипов NVIDIA порой просто невообразимый провал в сценах, активно использующих пиксельные и вершинные шейдеры версии 2.0.
"Tomb Rider: Angle of Darkness", "Halo: Combat Evolved", "AquaMark 3", бета-версия "Half-life 2", которая как раз вовремя "утекла" в сеть - во всех этих играх и тестах, построенных на реальных игровых движках, платы NVIDIA при первом рассмотрении мягко скажем не блистали, порой выдавая результаты на флагманских решениях, сопоставимые лишь с Middle-End платами от ATI (речь идёт о тестировании бета-версии Half-Life 2). Именно поэтому априори карты NVIDIA заслуженно получили репутацию "медленных плат" в DirectX 9.0. В чём же причина таких показателей плат от NVIDIA мы попытаемся выяснить в теоретической части нашего материала.
Естественно, NVIDIA не сидит сложа руки, и плодом творчества программистов из калифорнийской компании стали новые драйвера ForceWare, которые должны снять нарекания по поводу низкой скорости работы шейдеров у семейства NVIDIA NV3x (кстати, еще 9 месяцев назад, на прошлом CeBit, Алан Тике утверждал, что название Detonator будет жить вечно).
В новом драйвере помимо традиционного исправления ошибок и добавления новых функций, существенно переработан компиляторы вершинных и пиксельных шейдеров, что должно повысить скорость рендеринга и при этом не должно отразится на качестве картинки. Именно с новым алгоритмом обработки пиксельных и вершинных программ связана смена названия драйверов NVIDIA. Про Detonator, который все так привыкли ругать в последнее время =), можно смело забывать. Новые драйвера носят имя ForceWare и единственная доступная WHQL-версия на данный момент - это 52.16. В теоретической части нашего материала мы также подробно рассмотрим, что же именно программисты NVIDIA переработали в технике работы драйвера, раз для этого пришлось сменять название оного. Хотя здесь чётко прослеживается скорее маркетинговый ход компании, но, как покажет практика, все основания для этого у NVIDIA есть.
Драйвер NVIDIA ForceWare v52.16
Ситуация с шейдерами у NV3x совсем не так однозначна, как это может показаться на первый взгляд. Было бы заблуждением считать, что причина кроется сугубо в хардварной части. Дело также касается особенности архитектуры видеокарт NVIDIA, которые используют 32-битную точность работы с плавающей запятой. Платы ATI же в свою очередь выполняют все вычисления в минимально-допустимой спецификациями DirectX 9.0 24 битной точности. Но говорить о том, что видеокарты NVIDIA, построенные на архитектуре CineFX, выполняют операции с плавающей запятой сугубо с 32-битной точностью, было бы также неверно. На самом деле архитектура плат NVIDIA семейства FX является более гибкой, нежели видеокарты, построенные на DirectX 9.0 чипах ATI, и позволяет переключатся между ресурсоемкой 32-битной точностью и менее ресурсоемкой "уполовиненной" точностью работы с плавающей запятой то есть 16-битной, а также может включать 12-битную (целочисленную) точность.
Естественно, 32-битная точность требует больших вычислительных операций нежели 24-битная или тем более 16-битная точность работы с плавающей запятой. Именно 32-битная точность в большинстве случаев была включена в драйверах NVIDIA. Естественно, платы ATI, используя строго фиксированную 24-битную точность, смогли показывать существенно более высокий уровень производительности в приложениях интенсивно использующих пиксельные программы версии 2.0. Что же по этому поводу говорят спецификации DirectX 9.0? А они говорят, что точность работы с плавающей запятой должна быть равна по меньшей мере 24 бита на один канал цвета, то есть чипы ATI спецификациям DirectX 9.0 полностью соответствуют, а вот NVIDIA явно "перевыполняет" план, используя 32-битную точность, теряя драгоценных "попугаев" и фпс-ы в играх и бенчмарках. Попытка же компании перевести чип на работу в 16-битный режим точности был расценен весьма неоднозначно и свёлся к обвинениям NVIDIA в мошенничестве.
Однако, на наш взгляд, калифорнийскую компанию в данном случае нельзя не понять: у карт ATI в этом плане явная "фора". Но почему же NVIDIA всё же сделала свои чипы линейки FX именно такими, какими мы их видим сегодня, а не последовала путём ATI и не ввела строго фиксированную 24-битную точность? Тогда компаниям оставалась бы лишь принимать обоюдное участие в наращивании тактовых частот своих чипов и памяти и выпускать различные модификации плат архитектурно ничем не отличающихся друг от друга (что, впрочем, с успехом происходит и сейчас, но тогда карты действительно шли бы вровень). Дело в том, что, будучи уверенной в своих силах, компания NVIDIA разработала архитектуру графических чипов семейства GeForce FX в расчёте на то, что программисты для написания программ-шейдеров будут использовать собственный язык шейдеров компании Cg, который лучше подходит для карт NVIDIA. Это и неудивительно - на тот момент компания ещё достаточно прочно стояла на ногах, и для такой уверенности были все основания.
Также, как все мы с вами хорошо помним, наравне с рекламой непосредственно возможностей самих чипов усиленно муссировалась информация по небывалому уровню программируемости и свободы для программистов по написанию кода программ-шейдеров на картах NVIDIA архитектуры CineFX. Однако как показала практика, программирование под чипы FX оказалось весьма сложным и трудоёмким занятием. Работа же с чипами ATI по выполнению кода на компиляторе Microsoft HLSL (High Level Shader Language) с 24-битной точностью происходит гораздо легче. То есть чипы ATI работают быстрее отчасти за счёт того, что они были изначально разработаны с учётом того, что большинство программ-шейдеров будут писаться именно на стандартном компиляторе Microsoft, а NVIDIA сделала ставку на собственную совместную разработку, за что, как теперь все мы прекрасно можем видеть, и поплатилась в итоге. Конечно, не стоит списывать со счетов и сугубо хардварные проблемы чипов серии NVIDIA GeForce FX - они есть, но вопрос о точности операций с плавающей запятой добавляет ещё больше головной боли компании NVIDIA.
Что же важно для конечного пользователя? Естественно, обычному пользователю, который просто играет в самые последние DirectX 9.0 игры (которых, к слову будет сказать, на данный момент не такое уж и большое количество, но ситуация, тем не менее, меняется к лучшему, что не может не радовать) абсолютно всё равно, как компилируется код, какая точность работы операций с плавающей запятой и всё остальное =). Конечному пользователю важен вопрос качества выводимой картинки и, если в качестве картинки нет видимых ухудшений, а скорость возрастает то почему бы не использовать ту же 16-битную точность? Но здесь опять-таки появляется субъективный вопрос об оценке качества. Поэтому здесь выбор должны сделать непосредственно сами пользователи.

Понятно, что NVIDIA необходимо было что-то срочно делать с драйверами. "Резкие движения" компании по включению 16-битной точности работы с плавающей запятой общественностью были восприняты, скажем так, не очень хорошо, что было вполне логично и ожидаемо, поэтому необходимо было искать какие-либо другие пути решения проблемы. Первым этапом решения проблемы можно считать выпуск драйверов новой серии под названием ForceWare. Об оптимизациях, которые не ухудшают качество картинки более подробно и пойдёт речь чуть ниже.
В первую очередь коснёмся изменений "косметических".
На первый взгляд они не сильно заметны. Дизайн менюшек совсем не изменился с времён 40-й серии. Концептуально нового подхода к построению меню не видно и, в принципе, оно и не нужно, так как, расположение и интерфейс меню драйвера 40-й серии, по крайней мере, автора данного материала удовлетворяют полностью.
Настройки антиалиасинга и анизотропной фильтрации объединены в один раздел и имеют 3 настройки качества:
- "High Performance";
- "Performance";
- "Quality".
Впрочем, это уже не ново.
Стандартные разделы не претерпели изменений.
Также теперь стало возможным самому указывать желаемое разрешение, а не выбирать готовые пресеты. Полезность данной опции действительно трудно недооценить.
А вот в разделе nView изменения есть и существенные. Главной инновацией nView 3.0 считается применение функции "gridlines", которая позволяет более эффективно и удобно разбивать экран на независимые друг от друга зоны. Если вы счастливый обладатель профессиональной карты Quadro, то таких областей может быть до 9, в то время как на видеокартах семейства GeForce всего лишь до 4, но наш взгляд, этого более чем достаточно.
Также официально была добавлена поддержка новейших чипов компании GeForce 5700, GeForce FX 5700 Ultra и GeForce FX 5950 Ultra.
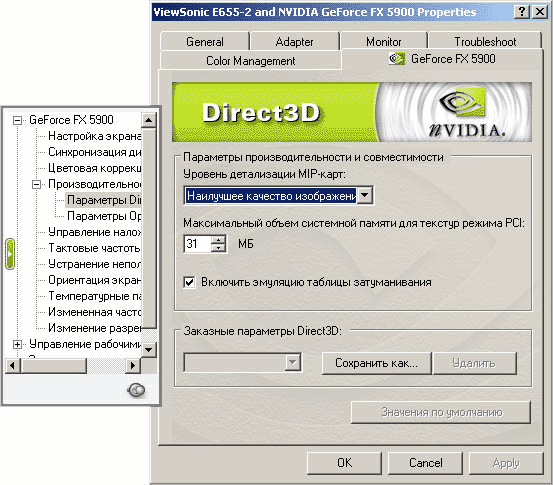
Нам же по понятным причинам были интересны другие нововведения в драйвере. А именно переработанный "unified" (то есть единый) компилятор DX 9.0 кода. Суть работы вышеупомянутого заключается в том, что компилятор, принимая инструкции в виде простого DirectX 9.0 кода интерпретирует их для чипа, перестраивает порядок и структуру команд в реальном времени для того, чтобы чип GeForce FX смог получить на выполнение переработанный код, который будет выполняться быстрее, чем, если команды поступят в графический чип "как есть". Наглядно это можно увидеть на следующей схеме:
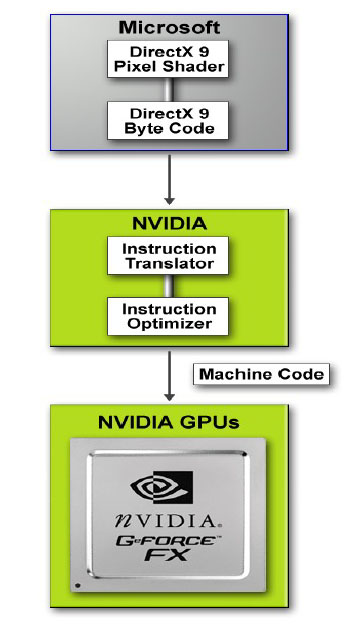
Потенциально компилятор может уменьшать количество проходов, требуемых кодом непосредственно вышедшим из API. А это, в конечном итоге, положительно скажется на производительности акселератора по работе с пиксельными и вершинными программами. Также нужно отметить, что качество изображения от этого не страдает, так как оптимизации не затрагивают вопросы установки точности работы с плавающей запятой, а просто перестраивают порядок и структуру команд, что по всей логике вещей и не может ухудшить качество изображения, так как в итоге всё равно выводится запрашиваемый шейдер. Другое дело, что обрабатывать акселератор теперь будет код, более удобный для архитектуры FX чипов.
Не нужно думать, что идея подобной оптимизации по обработке шейдеров не приходила программистам NVIDIA в голову. Основы "единого компилятора" были заложены ещё в Detonator 44.12, но до ума идея не была доведена, поэтому доводку до реально работающей технологии оставили для новых драйверов серии ForceWare.
Оптимизация кода, поступающего в GPU, - это, вне всякого сомнения, хорошо. Снимаем шляпу перед программистами NVIDIA, но остаётся открытым вопрос о точности работы с плавающей запятой. Учитывая то, что последняя версия Microsoft High Level Shader Language даёт программистам возможность выбора точности плавающей запятой при написании кода, компания NVIDIA преподносит возможность архитектуры чипов семейства GeForce FX выбирать один из трёх режимов точности работы с плавающей запятой (уже упоминавшиеся, 32-битная точность, 16-битная точность и 12-битный целочисленный режим) как преимущество своих чипов. С этим действительно трудно не согласится: зачем всегда использовать 32 битную точность или 24 битную точность (в случае плат ATI), если можно ограничиться, к примеру, 16 битной точностью работы с плавающей запятой в случае специфических задач, не требующих повышенной точности. Другое дело, что не всегда можно наверняка выбрать ту или иную точность для определённых задач. И от программистов в этом случае требуется намного больше усилий по написанию и оптимизации кода.
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex