







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание

Опрос
|
реклама
Самое интересное в новостях
Обзор видеоадаптера AMD Radeon R9 Fury X
Последний раз AMD громко заявила о себе на рынке дискретных GPU осенью 2013 года, когда была представлена линейка видеоадаптеров Radeon R9 290/290X на базе графического процессора Hawaii. Чрезвычайно производительный и крупный для своего времени GPU позволил AMD установить паритет с NVIDIA в категории High-End.  С той поры AMD не была столь же продуктивна, как NVIDIA, выпускавшая одно за другим решения на основе новой микроархитектуры Maxwell. Единственный по-настоящему новый ASIC от «красных», который мы увидели в промежутке между Hawaii и Fiji (предметом сегодняшнего обзора) – это Tonga, который лег в основу Radeon R9 285, а с недавних пор – R9 380. Свежепредставленная серия Radeon 300, которую мы уже описали вкратце и в ближайшее время изучим на примере реальных видеоадаптеров, фактически, состоит из переименованных и в чем-то улучшенных представителей 200-линейки, в которых продолжают нести службу уже знакомые GPU, включая даже Pitcairn, принадлежащий к первому поколению архитектуры GCN. Впрочем, для видеоадаптеров средней и средне-высокой ценовой категории условно устаревшая архитектура GPU – невеликая проблема. Да, конкурирующие продукты NVIDIA на базе Maxwell демонстрируют впечатляющее преимущество по TDP в соответствующих классах производительности, но коль скоро AMD поддерживает привлекательные цены, энергопотребление не является решающим фактором для видеокарты в настольном ПК. Совсем другое дело – дискретные GPU топового класса. На примере Radeon R9 290/290X уже хорошо заметно, что архитектура Graphics Core Next в по-настоящему крупных ASIC (чип Hawaii включает 6,2 млрд транзисторов), работающих на частотах в районе 1 ГГц, встретила препятствие по энергопотреблению и предъявляет повышенные требования к эффективности теплоотвода. Фактический TDP видеокарт на Hawaii можно оценить в районе 300 Вт, что сильно выше отметки 250 Вт, характерной для флагманских адаптеров в предыдущие годы. В этой ситуации на GPU нового поколения, которым, как нам теперь известно, стал Fiji, возлагались большие надежды. Для того чтобы нарастить вычислительную мощность и одновременно по меньшей мере остаться в рамках TDP, заданных Hawaii, требовались радикальные средства. Лучшим решением для AMD был бы переход с техпроцесса 28 нм на 20 или 16 нм, но TSMC, выступающая бессменным подрядчиком для производителей крупных дискретных GPU, все еще не может предоставить такую возможность в связи с то ли загруженностью линий производством мобильных SoC, то ли неудовлетворительным процентом выхода годных кристаллов для циклопических размеров ASIC, которые проектируют AMD и NVIDIA. В результате для производства Fiji AMD снова использует фотолитографический процесс TSMC с нормой 28 нм. Но это не помешало достигнуть обеих указанных целей – повысить производительность и оптимизировать энергопотребление видеоадаптера. Fiji по сравнению с Hawaii раздвинул границы транзисторного бюджета на 47%, достигнув отметки 8,9 млрд транзисторов. Это больше, чем даже в ядре GM200 от NVIDIA, которое недавно пробило планку 8 млрд. Fiji приобрел статус самой крупной ASIC, выпущенной AMD. Площадь кристалла составляет 596 мм2, что на 36% превышает площадь Hawaii (438 мм2) и и почти равняется площади NVIDIA GM200 (601 мм2). Взяв в качестве точки отсчета характеристики чипа Tahiti (4,31 млрд транзисторов, 365 мм2) мы видим, что AMD неуклонно повышает и плотность микросхем в рамках техпроцесса 28 нм.  Такие характеристики выглядят довольно опасно в контексте энергопотребления Radeon R9 290X, которое официально составляет 250, а на практике – все 300 Вт. Рост кристалла на 44% по числу транзисторов непредставим без всесторонней работы по оптимизации мощности. Известно, что в Fiji применяется более агрессивный power gating – отключение от питания простаивающих в текущий момент блоков GPU чем в предшествующих ASIC архитектуры GCN. Второй важный фактор – более экономичная память HBM, о которой подробно сказано ниже. И наконец, водяное охлаждение, которым AMD наделила референсный образец Radeon R9 Fury X, поддерживает температуры существенно ниже привычного для дискретных GPU диапазона около 90°, благодаря чему сокращаются утечки тока в кристалле. Все эти меры в совокупности позволили оценить TDP Radeon R9 Fury X в 275 Вт. И судя по тестам, на этот раз AMD не приукрашивает картину. ⇡#Архитектура AMD FijiAMD не сообщает о каких-либо преобразованиях архитектуры Fiji по сравнению с предыдущими итерациями Graphics Core Next. AMD никогда не публиковала внутренних наименований промежуточных версий GCN, но по совокупности характеристик Fiji относится к категории, неофициально называемой GCN 1.2. Вкратце напомним историю версий этой архитектуры. GCN, впервые представленная в графическом процессоре Tahiti (Radeon HD 7970), имеет двойное назначение: рендеринг 3D-графики и — в неменьшей степени — вычисления общего назначения (GP-GPU). Последней функцией обусловлено наличие в ядре аппаратных планировщиков, а также потенциальная способность всех ASIC на базе GCN выполнять операции двойной точности (FP64) на скорости 1/2 от FP32. Обе особенности поглощают значительную долю транзисторного бюджета процессоров, в связи с чем весьма впечатляет тот факт, что AMD сумела нарастить объем чипов вплоть до 8,9 млрд транзисторов, не отступив от принципов, заложенных на заре GCN. Производительность FP64 в потребительских продуктах на базе Fiji ограничена 1/16 от FP32, но AMD наверняка еще выпустит ускорители FirePro, полностью раскрывающие возможности новой ASIC. От продуктов GCN 1.1 Fiji унаследовал гибкое управление частотой и напряжением питания GPU, блок XDMA, обеспечивающий синхронизацию нескольких GPU в CrossFre по шине PCIe, и звуковой DSP TrueAudio. Версия 1.2 принесла в GCN оптимизации производительности геометрических процессоров, а также новый формат loseless-компрессии цвета, что позволяет экономить пропускную способность шины памяти. Кроме того, появилась возможность кодировать и декодировать видео в формате H.264 с разрешением Ultra HD. По конфигурации вычислительных блоков Fiji проще всего описать как удвоенный Tahiti. Fiji с Hawaii находятся в соотношении 16:11 (прирост ~45%) по числу шейдерных ALU (потоковых процессоров) и текстурных блоков. Такое необычное соотношение в конфигурации шейдерных ALU и текстурников в Hawaii и Fiji выглядит подозрительно. И неспроста. По блок-схемe Fiji видно, что число наиболее крупных строительных блоков GPU – Shader Engine – по-прежнему равняется четырем, но объем каждого увеличился. Таким образом, front-end чипа, выполняющий растеризацию треугольников, становится его узким местом. Особенно невыгодно Fiji, способный обрабатывать всего четыре примитива за такт, смотрится на фоне NVIDIA GM200, геометрическая производительность которого достигает 24 примитивов за такт.  Блок-схема AMD Fiji Fiji не помешало бы и побольше ROP, ведь их здесь по-прежнему 64 штуки, как и в Hawaii, а пресловутый GM200 обладает 96 ROP. Как ни странно, главным препятствием к росту в этих направлениях для AMD стал не размер и даже не энергопотребление ASIC, а размер фотомаски, применяемой на конвейере TSMC для производства микросхем по норме 28 нм, равно как и габариты кремниевой подложки, на которой Fiji смонтирован вместе с чипами памяти HBM. Вероятно, при таком ограничении по размерам было разумно пустить большую часть новых транзисторов на шейдерные Compute Units, которые допускают наиболее плотную упаковку в схеме по сравнению с другими вычислительными блоками архитектуры. ⇡#HBM – новый тип памяти для GPUБеспрецедентные для AMD габариты чипа – это еще не главное, чем замечателен Fiji. Главная инновация заключается в высокопроизводительной памяти HBM (High Bandwidth Memory). Оперативная память – крупная статья в раскладке энергопотребления дискретных видеоадаптеров. AMD сообщает, что 10-20% официального TDP Radeon R9 290X (250 Вт) приходится на чипы GDDR5, несмотря на то, что там используется широкая 512-битная шина, позволившая ограничиться довольно низкой тактовой частотой 5 ГГц. Дальнейшее увеличение пропускной способности GDDR5 SDRAM возможно только ценой еще более высокого энергопотребления. К примеру, существует концепция памяти, аналогичной GDDR5, только с дифференциальным подключением, подобно интерфейсам PCIe и USB, потенциально способная обеспечить скорость до 14 Гбит/с на одну линию (вдвое выше, чем у лучших современных чипов, устанавливаемых на видеоадаптеры, – 7 Гбит/с). Более перспективной с точки зрения энергопотребления выглядит архитектура с чрезвычайно широкой шиной, работающей на относительно низкой частоте. Однако широкие шины несут для разработчиков трудности другого рода. 512-битная шина использует большое число контактов GPU и требует сложной прокладки сигнальных линий в печатной плате. Не случайно только два GPU в истории до сих пор когда-либо оснащались такой памятью (собственно, Hawaii и ранее AMD R600), а о более широких шинах с текущей технологией монтажа микросхем и разводки плат не может быть и речи. HBM – совместный проект AMD и SK Hynix, который должен решить обе проблемы за счет двух технологий: а) упаковки чипов RAM в трехмерный «стек»; б) соединения с GPU посредством кремниевой подложки (interposer). 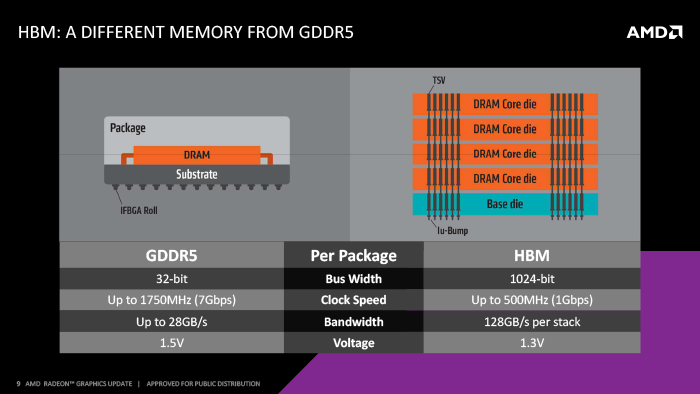 Что касается многослойной упаковки микросхем, то здесь проводники, позволяющие соединять два кремниевых чипа, расположенные один над другим, уже не являются чем-то удивительным. Инновация Hynix заключается в проводниках, проходящих насквозь через несколько слоев кремния, – TSVs (Through-silicon vias). Кремниевый interposer, как ни странно, является менее изощренной технологией. Эта «прокладка» изготавливается на стандартном фотолитографическом оборудовании, только для этого не требуется передовых технологий – достаточно нормы 65 нм. Собственно кремний здесь выполняет лишь роль субстрата, в котором прокладываются медные соединения. Затем на микроскопические шарики металла (microbumps), сформированные в местах выхода соединений на поверхность, устанавливают многослойные чипы HBM и ASIC Fiji. 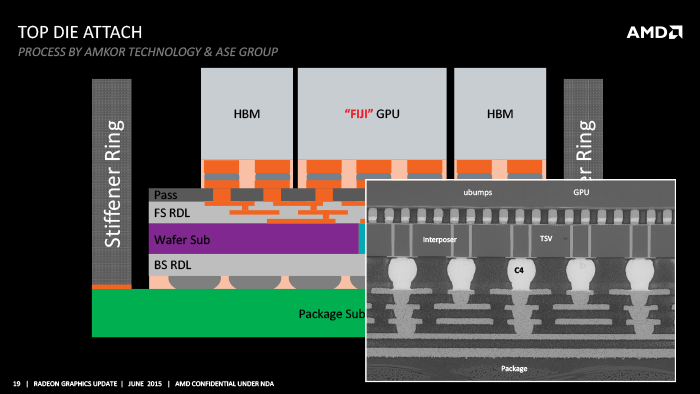 Реализация HBM для продуктов на базе Fiji включает четыре «стека» объемом 1 Гбайт каждый, соединенные с GPU 4096-битной шиной. Чипы работают на частоте 500 МГц с технологией DDR (1 Гбит/с на линию). Таким образом, результирующая пропускная способность интерфейса достигает 512 Гбит/с. Сравните с достижениями Radeon R9 290X и GeForce GTX TITAN X – 320 Гбит/с и 336 Гбит/с соответственно. Впрочем, не стоит рассчитывать на пропорциональный прирост результирующего быстродействия видеоадаптера, поскольку шина памяти все же не в каждый момент времени является бутылочным горлышком GPU, и к тому же в архитектуре GCN 1.2 на примере чипа Tonga прекрасно себя проявил новый алгоритм компрессии цвета. Что не менее важно для ускорителей на архитектуре GCN, память HBM сократит общее энергопотребление устройств. Если взять за основу собственные оценки AMD, согласно которым HBM втрое более экономична при равной с GDDR5 пропускной способности (35 против 10,66 Гбайт/с соответственно), но учесть то, что пропускная способность шины памяти Fiji возросла в 1,6 раза по сравнению с Hawaii, то можно оценивать энергопотребление HBM в составе Fiji в 12,2—24,4 Вт, что вдвое меньше 25 —50 Вт, расходуемых памятью GDDR5 на плате Radeon R9 290/290X. Несмотря на перечисленные достоинства, реализация HBM в Fiji имеет очевидный недостаток: объем RAM составляет лишь 4 Гбайт. В принципе, до недавнего времени это была вполне достаточная характеристика для топового GPU, и сейчас большинство игр вполне довольствуются таким объемом. Но прецедент GTA V показывает, что ускорители с 4 Гбайт RAM, способные вытянуть качественную графику за счет ресурсов GPU, уже лишились задела на будущее даже при разрешении Full-HD и WQHD, не говоря уже об Ultra-HD, которое как раз считается приоритетным для топовых GPU. ⇡#Поддержка DirectX 12Совместимость того или иного GPU с новой версией API от Microsoft – подчас довольно запутанный вопрос. Необходимо напомнить, что поддержка DX12 складывается из двух компонентов. Все железо, в свое время выпущенное под DirectX 11, потенциально совместимо с новой runtime-библиотекой Direct3D, которая приносит ряд важных оптимизаций. В первую очередь это более эффективное использование ресурсов многоядерных CPU, когда не только игровой код, но и драйвер GPU, и код API распределяются между потоками. Также DX12 сокращает время отработки draw calls, которое в играх под DirectX 11 мешает одновременно выводить на экран большое количество отдельных объектов. Об этих и других особенностях DirectX 12 мы уже когда-то писали в нашем предварительном обзоре. Что ранее было неизвестно, так это функция Explicit Multiadapter, позволяющая разработчику вручную указывать, какие ресурсы хранятся в памяти отдельного из нескольких GPU, работающих в связке SLI/CrossFire. Потенциально это позволит реализовать альтернативные сценарии работы, помимо заданных в DirectX 11 AFR (Alternate Frame Rendering) и SFR (Split Frame Rendering). В частности, можно отрешиться от необходимости дублировать содержимое RAM, что особенно актуально для Fiji с его 4 Гбайт HBM. 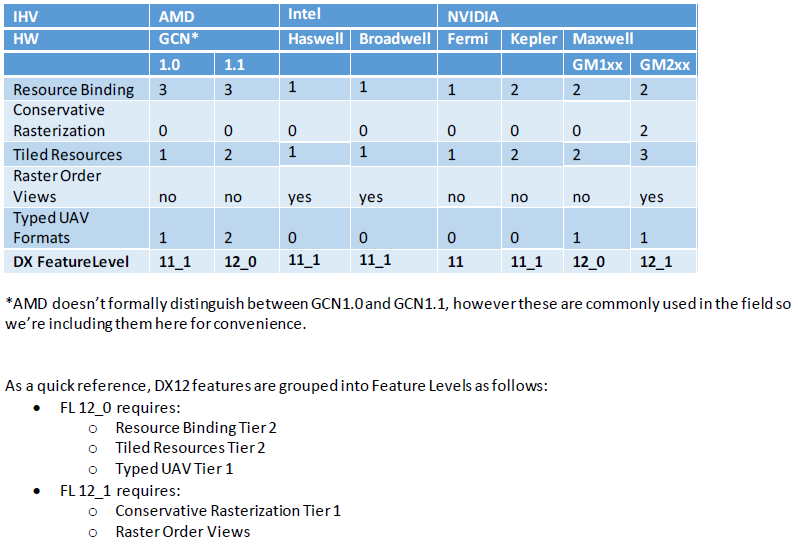
Feature levels Direct X12, слайд Microsoft В то же время DirectX 12 определил два новых feature levels, к которым относятся некоторые функции рендеринга, которые требуется специально реализовать в кремнии GPU. Архитектура GCN версий 1.1 и 1.2. поддерживает уровень 12_0, в то время как графические процессоры NVIDIA Maxwell второго поколения поддерживают уровень 12_1, что позволяет NVIDIA называть Maxwell единственной архитектурой с полной поддержкой DX12. Не будем сейчас задерживаться на каждой из функций, входящих в тот или иной уровень. Такое описание было дано в обзоре GeForce GTX 980 Ti. Добавим лишь, что внутри некоторых функций есть более тонкие градации. В частности, Resource Binding Tier 3 реализована только в GCN 1.1/1.2. Кроме того, только в GCN поддерживается Asynchronous Shaders – функция, лежащая вне feature levels, которая дает возможность одновременно производить графические и GP-вычисления на одном GPU. ⇡#AMD Radeon R9 Fury X: технические характеристики, ценаСегодня мы встречаем первый продукт на основе графического процессора Fiji – Radeon R9 Fury X. Вопреки ожиданиям, Fiji не нашлось места в «номерной» линейке Radeon R9, и карта была выпущена под собственным именем, вызывающим ассоциации с древними ускорителями ATI Rage. Fury X комплектуется полностью функциональным чипом Fiji, спецификации которого описаны выше, и обладает официальным TDP 275 Вт. Верхний предел тактовой частоты GPU составляет 1050 МГц. Видеокарта оценена в $649 (рекомендованная розничная цена для США без налогов) – то есть ровно в такую же сумму, как GeForce GTX 980 Ti. Российские цены ожидаются на уровне 43 450 руб. Fiji в сравнении с GM200 имеет перекос в сторону шейдерной производительности, и при сопоставимых частотах в районе 1 ГГц даже TITAN X не может составить конкуренции Fury X по пиковой производительности в расчетах FP32 (8,6 TFLOPS против 6,144 TFLOPS), к которым относится и графика, и большинство задач GP-GPU. Поскольку архитектура GCN способна выполнять вычисления двойной точности на скорости 1/2 от FP32, от грядущих продуктов FirePro на базе Fiji (а AMD вряд ли упустит такую возможность) можно ожидать результата в 4,3 TFLOPS, который не снился даже ускорителям NVIDIA с процессорами GK110/GK210 (1,707 TFLOPS у GTX TITAN Black), не говоря уже о TITAN X с его смешными 0,192 TFLOPS. И Даже Radeon R9 Fury X, ограниченный соотношением 1/16 между FP64 и FP32, способен выдать более внушительные 0,538 TFLOPS.
Вслед за Fury X появится видеокарта Radeon R9 Nano, также построенная на базе GPU Fiji, но в тепловом пакете 175 Вт. Известно, что, в отличие от Fury X, это устройство будет охлаждаться компактным воздушным кулером и довольствоваться единственным восьмиконтактным разъемом питания. Полные спецификации и розничная цена R9 Nano пока не разглашаются. AMD Radeon R9 Fury X: конструкция Поскольку чипы памяти HBM установлены на общей подложке с GPU, все, что находится на печатной плате снаружи, – это система питания и порты ввода-вывода. Поэтому у Radeon R9 Fury X удивительно скромные габариты для видеокарты такого класса, еще более скромные оттого, что AMD вместо воздушного кулера использовала компактную систему водяного охлаждения. В принципе, 275 Вт мощности вполне по силам и качественному воздушному кулеру, но в случае с Fiji СВО уместна еще и потому, что поток тепла от GPU и чипов памяти локализован в одном месте.  Несмотря на скромные размеры, СВО готова к нагрузке вплоть до 500 Вт. Вентилятор в стандартном режиме очень тихий. Единственная претензия: на открытом тестовом стенде заметен легкий свист помпы, но вряд ли он проникает за пределы стандартного компьютерного корпуса. Тестовый образец Radeon R9 Fury X – это то, в каком виде видеокарта поступит в продажу. Первое время не будет вариантов с оригинальной платой и системой охлаждения, хотя впоследствии производители наверняка представят варианты Fury X с воздушным охлаждением.  AMD серьезно отнеслась к дизайну ускорителя. Плата заключена в металлический кожух со вставками из пластика с эффектом soft touch. Логотип Radeon на торце подсвечен красными светодиодами. Другой блок светодиодов рядом с разъемами питания сигнализирует об уровне загрузки GPU. Имеется рычажок для переключения между двумя микросхемами BIOS.   Вопреки ожиданиям, Fiji лишен теплорассеивателя, и основание водоблока СВО со встроенной помпой непосредственно прилегает к микросхемам. Нас убедительно просили не снимать помпу с платы, поскольку при такой площади кремния есть риск обколоть чипы. Так что стандартных фотографий GPU с монеткой и снимков платы с обеих сторон на этот раз, к сожалению, не будет. Впрочем, известно, что карта несет шестифазную систему питания. Ток поступает по двум восьмиконтактным разъемам дополнительного питания PCIe.  Набор видеовыходов включает три разъема DisplayPort 1.2 и один HDMI – к сожалению, версии 1.4a, а не 2.0, что ограничивает частоту обновления на 4К-дисплеях значением 30 Гц.
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.





