|
Опрос
|
реклама
Быстрый переход
Siri научилась говорить быстрее, медленнее и эмоциональнее в свежей бете iOS 27
07.07.2026 [05:05],
Николай Хижняк
В последней бета-версии iOS 27 для разработчиков компания Apple предоставила возможность ознакомиться с одним из грядущих улучшений Siri на базе ИИ. Для голосового помощника теперь можно регулировать скорость и выразительность речи. 
Источник изображения: Apple В бета-версии iOS 27 beta 3, выпущенной сегодня Apple, появились возможность настроить темп и выразительность для Siri. Обе настройки в первых бета-версиях для разработчиков были помечены как «скоро появятся». Apple старается сделать Siri, новая версия которой использует генеративный ИИ, более естественной и персонализированной. Как и в случае с ChatGPT и другими голосовыми помощниками на базе ИИ, возможность настройки звучания ИИ является важным аспектом, помогающим людям лучше понять новую технологию. Но те же настройки голоса для ChatGPT позволяют пользователям пойти ещё дальше. OpenAI ещё в декабре 2025 года добавила возможность регулировки «теплоты» и «энтузиазма ИИ», которые стали доступны наряду с возможностью настройки базового стиля и тона. Последняя функция позволяет настраивать голосового помощника OpenAI, делая его более дружелюбным, профессиональным, откровенным или необычным и т.д. Результат отражается не только в том, как говорит ChatGPT, но и в том, как он представляет информацию пользователю. 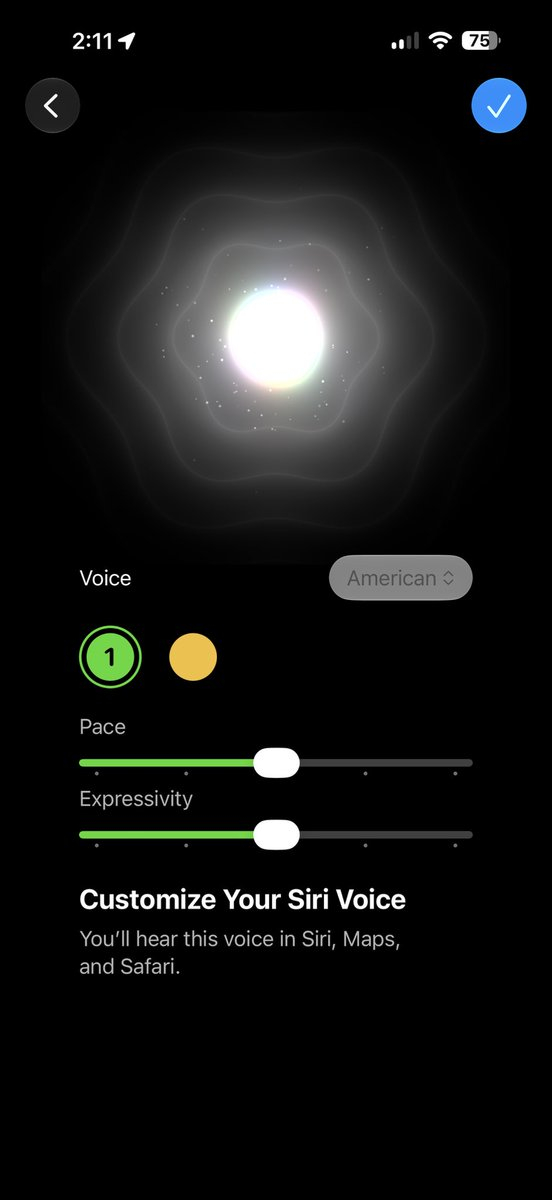 Apple представила новые персонализированные настройки для Siri, позволяющие выйти за рамки простого выбора мужского или женского голоса, на конференции WWDC 26 в июне. Теперь данные настройки стали доступны бета-тестерам новой ОС. Они смогут переключаться между различными голосами с разными акцентами для Siri, а также использовать ползунки для изменения скорости речи голосового ассистента и степени передачи человеческих эмоций её голосом. При изменении настроек Siri будет произносить тестовые фразы, чтобы пользователь мог оценить звучание разных голосов. В обновленной версии iOS версия Siri с искусственным интеллектом глубоко интегрирована в программную среду. Она позволяет владельцам iPhone начинать диалоги, произнося команды, проводя пальцем вниз от динамического островка в верхней части экрана, набирая текст, нажимая на боковую кнопку телефона или даже используя совершенно новое отдельное приложение Siri. В iOS 27 beta 3 также появились менее значительные обновления, включая обновленную иконку приложения «Напоминания». По данным TechCrunch, некоторые тестеры сообщили о потере доступа к новой Siri после обновления, а также о том, что их смартфон снова начинает индексировать данные. Данный процесс обычно происходит при первой оптимизации Siri с ИИ для поиска. Голосовые сообщения в WhatsApp можно будет отправлять не открывая приложение — прямо из виджета
17.06.2026 [15:38],
Павел Котов
Остающийся одним из наиболее популярных в мире мессенджеров WhatsApp располагает множеством функций, и они постоянно пополняются новыми. Ярким тому примером является виджет для Android, с которым можно будет отправлять голосовые сообщения, не открывая приложения. 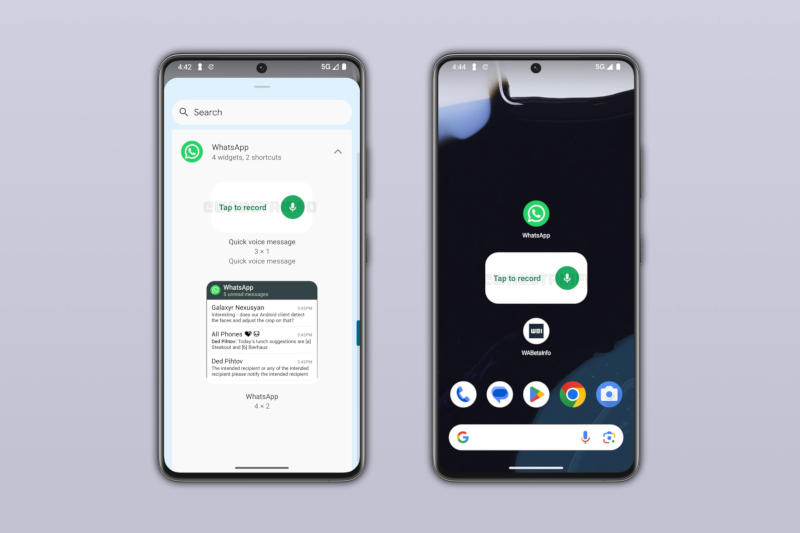
Источник изображения: wabetainfo.com Разработчики WhatsApp готовят новый виджет для главного экрана, который позволит отправлять голосовые сообщения, обратил внимание ресурс WABetaInfo. Для тестирования этот виджет пока недоступен, но его удалось обнаружить в последней бета-версии WhatsApp для Android v2.26.24.2. По умолчанию он будет иметь размер 3 × 1, но пользователи смогут установить и другой. Выглядит этот виджет довольно просто: это поле с надписью «Нажмите для записи» (Tap to record) и значок с изображением микрофона. Пользователь сможет нажать на виджет, чтобы начать запись голосового сообщения. По завершении останется выбрать, кому отправить запись. Это достаточно быстрый способ отправить голосовое сообщение, но можно ускориться дополнительно: предусмотрена возможность отослать его нескольким контактам или даже всем сразу. Сейчас отправить его в приложении можно только одному контакту или в один групповой чат — остальным придётся пересылать, и это дополнительные действия. Для пользователей новый виджет пока недоступен, но он может появиться с ближайшей бета-версией приложения — тогда его можно будет протестировать. А некоторое время спустя он может дебютировать и для широкой аудитории. Европейцы не получат Siri AI вместе с iOS 27 — Apple винит в этом закон DMA
08.06.2026 [22:46],
Николай Хижняк
Apple не может выпустить новый голосовой помощник Siri AI в странах ЕС одновременно с выходом iOS 27 и iPadOS 27. Об этом компания сообщила на своём официальном сайте, сославшись на принятый закон о цифровых рынках (DMA). Apple заявляет, что регулирующие органы ЕС не приняли ни одно из предложенных компанией решений по внедрению Siri AI в странах Евросоюза с одновременной безопасной поддержкой других виртуальных помощников. 
Источник изображения: Apple «Мы глубоко разочарованы тем, что наши пользователи в ЕС не смогут использовать Siri AI на iPhone или iPad, когда мы выпустим новые версии программного обеспечения позже в этом году. Мы надеемся в конечном итоге выпустить Siri AI в ЕС. Мы продолжим взаимодействовать с регулирующими органами ЕС, чтобы найти дальнейшие пути [решения этого вопроса]. Однако их [ЕС] отказ от конструктивного обсуждения вариантов решений, обеспечивающих конфиденциальность и безопасность пользователей, означает, что в настоящее время мы не может предоставить график доступности Siri AI на iOS и iPadOS в ЕС», — сказал Крейг Федериги (Craig Federighi), старший вице-президент Apple по разработке программного обеспечения. Siri AI предлагает ряд новых функций, включая специальное приложение для просмотра диалогов, расширенный интерфейс визуального интеллекта, интегрированные инструменты для ввода текста, режим Siri в камере iOS и другие возможности, анонсированные на конференции WWDC 2026. Пользователи iOS 27 и iPadOS 27 в ЕС не смогут воспользоваться этими новыми возможностями. Однако они получат доступ к Siri AI на macOS 27, visionOS 27 и watchOS 27. Разработчики, находящиеся в ЕС, также не смогут тестировать или использовать новые функции Siri AI для своих приложений на iOS и iPadOS. Apple объясняет, что Siri AI по своей сути является приватной и глубоко интегрирована во все платформы компании с использованием локальной обработки данных на устройствах пользователей, а также частных облачных вычислений, что расширяет возможности обеспечения конфиденциальности и безопасности пользователей в облаке. Однако, «согласно крайне радикальной интерпретации DMA европейскими регуляторами», Apple придётся предоставить любому виртуальному ассистенту прямой доступ к личным данным пользователей, а также возможность напрямую управлять другими установленными приложениями. «По мнению европейских регуляторов, DMA требует от Apple предоставить любой системе ИИ практически неограниченный доступ к устройству пользователя, а также возможность автономно использовать этот доступ без постоянного контроля и видимости со стороны пользователя. Это включает возможность читать и отправлять сообщения, совершать покупки, получать доступ к файлам и выполнять действия в любом приложении. Исследования в области безопасности уже показали, что системы ИИ могут быть взломаны для кражи личных данных, паролей и фотографий, а также для необратимого изменения файлов и настроек учетной записи без согласия пользователя. По мере того, как системы ИИ приобретают все больше возможностей, эти риски быстро растут по частоте и масштабу», — сообщает Apple. Учитывая серьёзные риски для пользователей, Apple разработала решение под названием Trusted System Agent — посредника, который позволит виртуальным ассистентам безопасно получать доступ к тем же функциям и возможностям, что и Siri AI, на устройствах в ЕС. Компания также представила план запуска Siri AI в ЕС с постепенным внедрением этого решения в течение 18 месяцев. Однако Европейская комиссия ответила отказом. «Фактически Европейская комиссия не согласилась ни с одним из предложений Apple», — сетует компания. Apple заявляет, что продолжит работу над максимально безопасным внедрением новых функций для пользователей из стран ЕС. Однако, учитывая явные риски для пользователей и неспособность регулирующих органов их признать, в настоящее время компания не может озвучить какие-либо сроки доступности Siri AI в ЕС на iOS и iPadOS. Apple представила новую Siri, снова — Siri AI поселилась на островке iPhone, работает с Google Gemini и умеет анализировать экран
08.06.2026 [21:05],
Андрей Созинов
На конференции WWDC 2026 компания Apple представила обновлённую версию голосового помощника Siri — Siri AI, работающую на базе платформы Apple Intelligence. Многие из показанных функций улучшенной помощницы были впервые анонсированы ещё на WWDC 2024, однако их запуск неоднократно откладывался. 
Источник изображений: Apple Apple называет Siri AI «совершенно новой версией Siri» и заявляет, что она стала более разговорной и функциональной по сравнению с предыдущей версией умного помощника. В разговорах она имеет более выразительный голос, который можно настроить по темпу, выразительности и акценту. Поначалу она будет доступна только на английском языке, хотя Apple заявляет, что намерена «быстро расширить» поддержку на новые языки. Siri AI использует ИИ-модель второго поколения, работающую непосредственно на устройстве. Также компания обновила систему распознавания речи, расширила возможности понимания пользовательского контекста и добавила поддержку так называемой экранной осведомлённости (on-screen awareness). По сути, Apple превращает Siri из классического голосового помощника в полноценного ИИ-собеседника. Пользователи смогут вести с ним длительные диалоги, задавать уточняющие вопросы, обсуждать идеи, получать отзывы на документы и формировать планы действий. 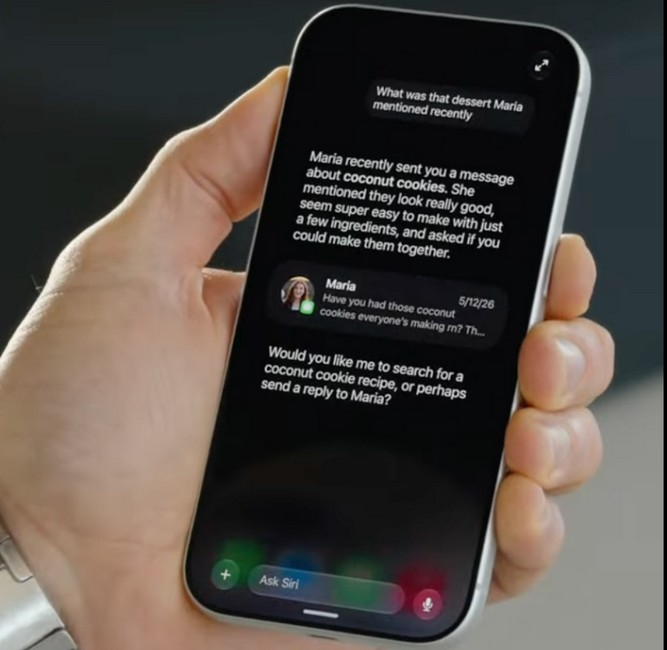 Siri AI будет доступна во всей системе, способна считывать то, что отображается на экране, и взаимодействовать с вашими приложениями. Но старший вице-президент Apple по программной инженерии Крейг Федериги (Craig Federighi) заявил, что она была разработана «с учетом конфиденциальности на каждом этапе». Все запросы обрабатываются либо на устройстве, либо в облаке через Apple Private Cloud Compute. Во время демонстрации Apple показала работу функции экранной осведомлённости. Siri сможет анализировать содержимое экрана, использовать данные из приложений и выполнять действия между ними. Siri смогла определить упомянутое в публикации Instagram✴✴ место на карте и использовать информацию из списка контактов пользователя без необходимости вручную указывать дополнительные сведения в запросе. 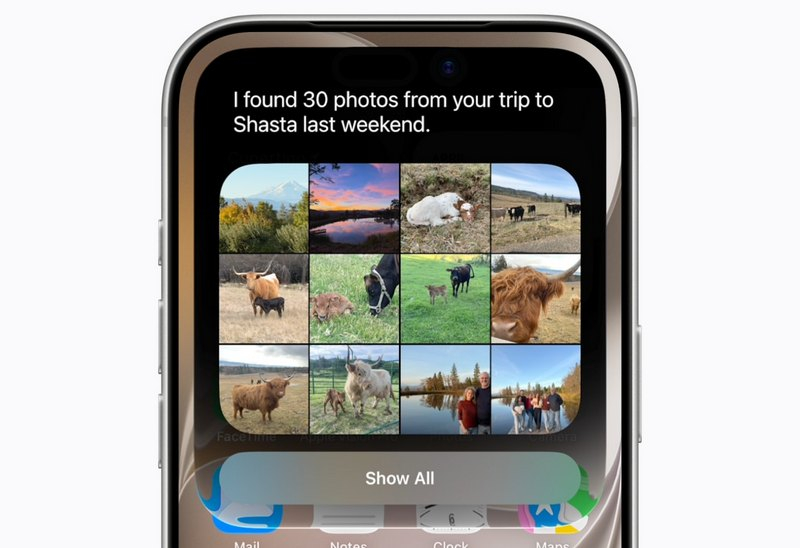 Новая версия Siri получила доступ к семантическому индексу Spotlight, который используется для поиска данных на устройстве. Благодаря этому помощник может учитывать содержимое приложений, документов и другие данные пользователя при формировании ответов. Кроме того, Siri получила возможность выполнять действия внутри приложений и также ей была открыта более широкая база общих знаний. При поиске информации Siri сможет выводить результаты в виде карточек с данными из интернета, сообщений, документов и других источников. Apple также заявила об улучшении функции диктовки. По данным компании, система стала точнее распознавать речь, пунктуацию и регистр символов. Одновременно Apple объявила о расширении сотрудничества с Google. Модели Gemini будут использоваться для некоторых функций Apple Intelligence и Siri, что позволит Apple ускорить развитие собственных ИИ-сервисов без необходимости полностью полагаться на внутренние языковые модели.  Одним из наиболее заметных изменений стал новый интерфейс Siri. Вместо цветной анимации по краям экрана, появившейся в предыдущих версиях помощника, теперь используется интерфейс на базе Dynamic Island с тёмным оформлением. Вызвать Siri можно свайпом вниз от Dynamic Island либо традиционно сказав, «Эй, Siri». Новые возможности Siri будут доступны не только на iPhone, но также на iPad, Mac, Apple Watch и Vision Pro. Улучшенный помощник появится в CarPlay, а также получит интеграцию с наушниками AirPods. На компьютерах Mac Siri теперь встроена в Spotlight, получила отдельное приложение и новый монохромный значок в строке меню. Siri AI также получит собственное приложение, которое будет похоже на существующие приложения с ИИ-чат-ботами для ChatGPT, Claude и Gemini. 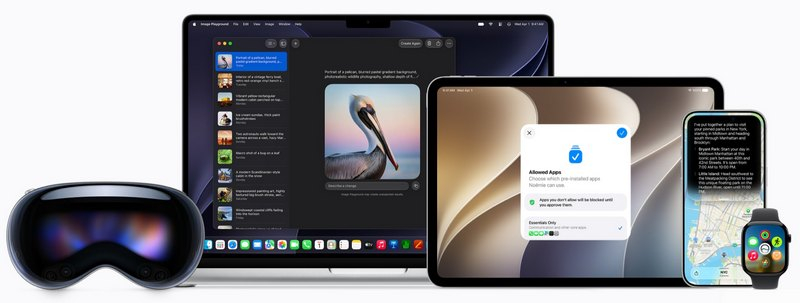 Apple позиционирует обновлённую Siri как один из ключевых элементов экосистемы Apple Intelligence. При этом значительная часть представленных возможностей фактически повторяет функции, которые Apple впервые показала на WWDC 2024 в рамках анонса Apple Intelligence и iOS 18. Тогда компания обещала глубокую персонализацию Siri, понимание пользовательского контекста и взаимодействие с приложениями, однако запуск этих функций неоднократно откладывался. Весной 2025 года Apple официально признала, что разработка обновлённой Siri требует больше времени, чем ожидалось. Бета-версия Siri AI станет доступна разработчикам и участникам программы тестирования позднее в этом году. Google представила Gemini 3.1 Flash Live и затруднила распознавание синтезированной речи на слух
27.03.2026 [06:19],
Дмитрий Федоров
Google начала внедрять Gemini 3.1 Flash Live — новую ИИ-модель для диалогов в реальном времени. По заявлению компании, система генерирует речь быстрее и с более естественной ритмикой, лучше справляется со сложными голосовыми сценариями и уже доступна как в сервисах Google, так и в инструментах для разработчиков. Это ещё сильнее затруднит распознавание синтезированной речи на слух. 
Источник изображений: Google Новая модель предназначена для снижения задержки и повышения естественности синтезированной речи. Высокая задержка между входящим сигналом и ответом, а также неестественная интонация делают диалог медленным и трудным для восприятия человеком. Исследователи обычно считают пределом оптимального восприятия речи около 300 миллисекунд, однако конкретную задержку Gemini 3.1 Flash Live Google не раскрыла. 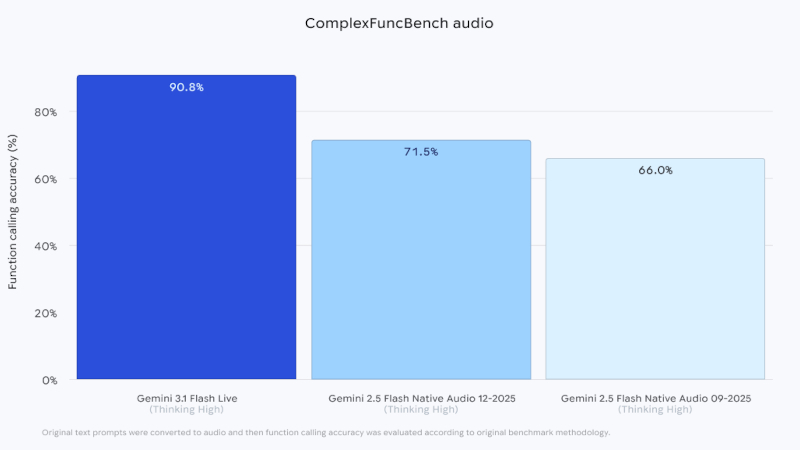 Вместо этого компания ссылается на результаты тестов. Улучшение в ComplexFuncBench Audio указывает на более уверенную работу со сложными многошаговыми задачами. В Big Bench Audio ИИ-модель также занимает лидирующие позиции. Этот тест оценивает способность к рассуждению на наборе из 1 000 аудиовопросов. Отдельно отмечен результат в тесте Audio MultiChallenge компании Scale AI, где оценивается устойчивость ИИ к паузам, колебаниям и перебиваниям во входящем аудиопотоке. Несмотря на то что Gemini 3.1 Flash Live опережает другие ИИ-модели для обработки аудио в реальном времени, она набрала в этом тесте лишь 36,1 %. ИИ-модели, не предназначенные для работы в режиме диалога, могут набирать в тесте MultiChallenge более 50 %. Gemini 3.1 Flash Live, по оценке Google, звучит ближе к человеческой речи, поэтому в выходной аудиосигнал встроены водяные знаки SynthID. Они не воспринимаются на слух, но позволяют технически определить, что речь сгенерирована ИИ, если её попытаются выдать за настоящую. Новинка тестировалась совместно с Home Depot, Verizon и другими компаниями. В публикации Google партнёры положительно оценивают способность Gemini 3.1 Flash Live имитировать человеческую речь, поэтому следующий ИИ-помощник в телефонном звонке может звучать значительно реалистичнее, и собеседник вполне может принять его за человека. Gemini 3.1 Flash Live показывает, что по мере роста скорости, плавности и естественности синтезированной речи различать человека и ИИ в голосовом общении станет всё труднее. «МТС VoiceTech» обеспечит голосовой связью абонентов с нарушениями слуха
10.03.2026 [11:08],
Павел Котов
Мобильный оператор МТС представил службу «Секретарь для глухих и слабослышащих», которая поможет людям с нарушениями слуха пользоваться голосовой связью. Сервис в реальном времени преобразует голосовые реплики в текст, а набираемые слабослышащим абонентом слова озвучивает с помощью синтезатора речи. 
Источник изображения: mts.ru В основу услуги «Секретарь для глухих и слабослышащих» легли технологии «МТС VoiceTech», и воспользоваться ей можно бесплатно в любом регионе, где работает оператор. Для этого потребуется открыть приложение «Мой МТС», подключить соответствующую услугу и в настройках активировать функцию «Звонок в чат». При поступлении звонка на телефон слабослышащего абонента голосовой помощник предупреждает инициатора вызова, что тот пытается связаться со слабослышащим. Отклонив звонок, абонент получит уведомление в приложении «Мой МТС», где сможет перейти в формат диалога. Здесь искусственный интеллект преобразует речь в текст, а набираемые в чате реплики озвучиваются голосовым синтезатором — можно выбирать предустановленные ответы или вводить свои. По состоянию на 2025 год в России зарегистрированы 13 млн людей с нарушениями слуха, и долгое время они не могли пользоваться телефонной связью. Новый сервис «Секретарь для глухих и слабослышащих» от МТС уникален тем, что работает на уровне мобильной сети и позволяет общаться при помощи технологий распознавания и синтеза речи на основе ИИ. DuckDuckGo добавила голосовое общение с ИИ-ботом Duck.ai с защитой приватности
10.02.2026 [20:38],
Владимир Фетисов
Компания DuckDuckGo объявила о добавлении функции голосового чата в Duck.ai — своего фирменного чат-бота на базе искусственного интеллекта с защитой приватности пользователей. Благодаря этому можно в режиме онлайн голосом общаться с чат-ботом, задействовав для этого защищённое соединение. 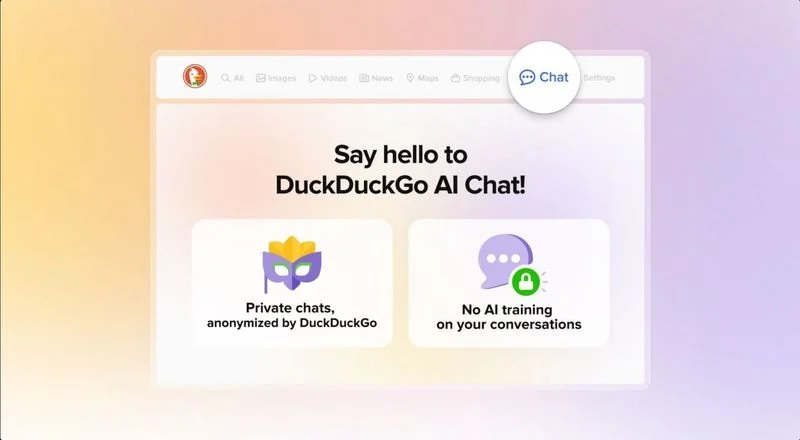
Источник изображения: DuckDuckGo ИИ-модели для обработки голосовых запросов в Duck.ai предоставляет OpenAI. Однако DuckDuckGo заявила, что ни она, ни OpenAI не будут хранить аудиозаписи после завершения беседы. «Голосовые чаты в Duck.ai приватны, мы делаем их анонимными, и они никогда не используются для обучения ИИ-моделей», — сказано в заявлении компании. Новые контрактные обязательства указывают на то, что возможности OpenAI в плане использования аудиозаписей пользователей голосовых чатов с ИИ-ботом также строго ограничены. В описании новой функции сказано, что DuckDuckGo защищает аудиоданные несколькими способами, чтобы гарантировать, что доступ к ним имеет только OpenAI (как поставщик ИИ-моделей) и только с целью ответа на запросы пользователей. Прежде всего отмечается, что голосовые запросы передаются потоками только во время сеанса общения с ботом и не хранятся у DuckDuckGo или OpenAI после завершения диалога. Аудиозаписи пользователей и ответы чат-бота не используются для обучения ИИ-моделей. Аудиопотоки шифруются при передаче через WebRTC и прохождении через сервер компании, при этом ни DuckDuckGo, ни OpenAI не сохраняют каких-либо данных о разговорах — вся информация удаляется сразу после завершения беседы. Новая функция работает во многих браузерах, кроме Firefox — поддержка этого интернет-обозревателя находится на стадии разработки. Голосовой чат с ИИ-ботом является бесплатной функцией в пределах суточного лимита и не требует создания аккаунта. В то же время платным подписчикам за $10 в месяц будут доступны расширенные лимиты, доступ к VPN DuckDuckGo, услуге удаления личных данных и прочее. Пользователи могут в любой момент отключить функцию голосового чата в настройках Duck.ai, а также продолжать взаимодействовать с текстовыми ботами на основе ИИ-моделей OpenAI, Meta✴✴, Anthropic и Mistral. Голосовой помощник Gemini стал лучше понимать инструкции и не перебивает пользователей
13.12.2025 [07:38],
Анжелла Марина
Google объявила о внедрении серии улучшений в голосовом помощнике Gemini, которые сделают взаимодействие с искусственным интеллектом более естественным и эффективным. Целью доработок является повышение способности модели справляться со сложными задачами, точно следовать инструкциям пользователя и вести связные диалоги. 
Источник изображения: Google В рамках обновления инженеры Google сфокусировались на трёх ключевых направлениях в Gemini 2.5 Flash Native Audio. Во-первых, была повышена надёжность вызова внешних функций и теперь Gemini точнее определяет момент, когда необходимо получить актуальную информацию в ходе диалога, интегрируя её в аудиоответ без нарушения естественного темпа беседы. Во-вторых, модель продемонстрировала рост уровня соблюдения инструкций разработчиков с 84 до 90 %, что позволяет ей лучше справляться со сложными командами и выдавать более последовательные результаты. Также улучшена способность извлекать контекст из предыдущих частей разговора, способствуя формированию более связных и логичных диалогов, сообщает Android Authority. Кроме того, Джош Вудворд (Josh Woodward), вице-президент подразделения Google Labs, отвечающего за Gemini и AI Studio, сообщил о двух дополнительных усовершенствованиях. Теперь функция Gemini Live не будет прерывать пользователя, даже если тот делает длительную паузу в речи. Также появилась возможность отключать микрофон во время ответа ИИ, чтобы случайно не прервать его речь. Параллельно с этим Google объявила об изменениях в приложении Translate. ByteDance выпустила голосового ИИ-помощника для китайских смартфонов
02.12.2025 [10:05],
Владимир Мироненко
Китайская компания ByteDance, разработчик видеосервиса TikTok, сообщила о выпуске голосового помощника на базе большой языковой модели Doubao собственной разработки. Он входит в предустановленное программное обеспечение смартфона Nubia M153 компании ZTE и в дальнейшем станет доступен и на смартфонах других производителей, пишет Reuters. 
Источник изображения: Kelli McClintock/unsplash.com ИИ-помощник от ByteDance позволяет пользователям управлять смартфоном с помощью голосовых команд, например, находить контент и бронировать билеты. Он будет конкурировать с аналогичными умными ассистентами, представленными китайскими производителями смартфонов, такими как Huawei и Xiaomi. Компания ByteDance заявила, что у неё нет планов разрабатывать собственные смартфоны, и сейчас она ведёт переговоры с несколькими производителями телефонов об использовании её ИИ-помощника на выпускаемых ими устройствах. ByteDance стала лидером на рынке потребительских ИИ-приложений в Китае благодаря выпуску ИИ-чат-бота Doubao. Doubao — самый популярный чат-бот с искусственным интеллектом в Китае. По данным платформы отслеживания ИИ-приложений Aicpb.com, в октябре у Doubao было 159 млн активных пользователей в месяц, что значительно больше, чем у Tencent Yuanbao с 73 млн пользователей и DeepSeek с 72 млн человек. Установленный на телефоне, Doubao работает на уровне операционной системы, позволяя ИИ видеть, что происходит на экране, и использовать приложения, выполняя такие задачи, как извлечение и упорядочивание файлов, заполнение веб-форм, поиск предложений ресторанов, соответствующих бюджету и предпочтениям пользователя. Голосовой режим ChatGPT встроили в чат — он стал естественнее и его можно перебивать
26.11.2025 [00:09],
Николай Хижняк
Разработчики из OpenAI значительно улучшили голосовой режим чат-бота ChatGPT. Теперь он ещё больше похож на естественное общение с человеком. В последнем обновлении ChatGPT голосовой режим по умолчанию объединён с основным текстовым режимом. Но при желании его можно отделить. 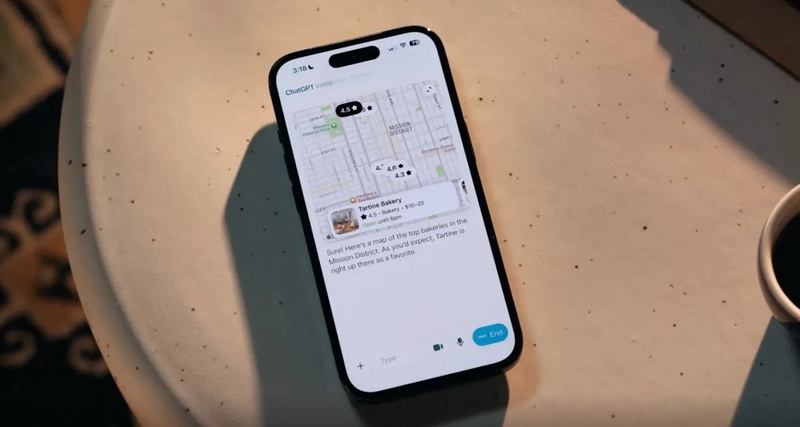
Источник изображения: OpenAI OpenAI продемонстрировала некоторые преимущества нового голосового режима на своей странице в соцсети X. Например, ChatGPT теперь может показывать результаты поиска по карте в голосовом режиме. Он также отображает расшифровку голосового диалога в интерфейсе чата. В процессе ответа чат-бота на запрос его можно перебить, чтобы попросить, например, правильно произнести по буквам название нужного вам места или блюда в ресторане. При желании можно вернуться к старому варианту взаимодействия с голосовым режимом. В настройках приложения появился новый переключатель для возврата в отдельный режим. «Теперь вы можете использовать голосовой режим ChatGPT прямо в чате — отдельный режим не нужен. Вы можете разговаривать, наблюдать за появлением ответов, просматривать предыдущие сообщения и видеть визуальные элементы, такие как изображения или карты, в режиме реального времени. Доступно для всех пользователей мобильных устройств и веб-версии. Просто обновите приложение», — сообщили разработчики. Клавиатура перестанет быть главным инструментом создания контента уже к 2028 году
11.11.2025 [08:40],
Алексей Разин
Лондонская школа экономики при участии компании Jabra провела исследование, согласно результатам которого ввод информации при помощи голосового интерфейса ИИ станет общепринятым стандартом. Родившиеся после 2010 года офисные сотрудники в недалёком будущем в своей деятельности могут вообще не столкнуться с необходимостью набора текста руками. 
Источник изображения: Unsplash, Glenn Carstens-Peters По мнению представителей Jabra, ввод информации голосом отодвинет на второй план работу с клавиатурой. Она будет нужна только для редактирования первично введённого голосом текста. Преобразование речи в текст позволяет быстрее вводить информацию и делает этот процесс более естественным. При этом руки пользователя остаются свободными, он буквально может генерировать текст, передвигаясь в машине или занимаясь домашними делами. Впрочем, у такого подхода имеются и свои недостатки. Обратное восприятие информации делает текст более удобным. Чтение в целом занимает меньше времени, чем прослушивание речевого сообщения, а ещё с текстовыми данными гораздо проще работать с точки зрения анализа, обобщения и структурирования информации. Поиск по ключевым словам в тексте занимает секунды, а перематывание аудиозаписей превращается в пытку. По мнению учёных, ввод текста будет осуществляться голосом, но те же электронные сообщения останутся текстовыми. Кроме того, авторы текстовых заметок обычно более ответственно подходят к их содержанию, тогда как голосовые сообщения буквально размывают суть информации и её структуру. При большом наборе голосовых сообщений сложно определить, что именно и кем было сказано, а также привязать эти данные к шкале времени. Спустя несколько месяцев проще анализировать текстовую переписку, чем рыться в голосовых сообщениях. Не нужно также забывать, что живая речь по своей природе у большинства людей далека от совершенства. Интонации, дефекты речи и влияние акцента — всё это затрудняет голосовой ввод. Более того, лёгкость записи голосовых сообщений увеличивает количество передаваемой информации. Авторы высказываний порой не будут задумываться о ценности и сути своих комментариев, и собеседникам будет сложнее ориентироваться в этом потоке сознания, выделяя саму суть. Во Франции запустили расследование возможной прослушки пользователей Apple через Siri
06.10.2025 [18:42],
Владимир Мироненко
Во Франции начали уголовное расследование деятельности Apple, которую обвинили в использовании подрядчиков для прослушивания голосовых записей взаимодействия пользователей с Siri, несмотря на обещание соблюдать конфиденциальность, пишет агентство Bloomberg. Расследование началось после заявления правозащитной организации Ligue des droits de l’Homme. 
Источник изображения: Apple Жалоба правозащитной организации основана на показаниях Томаса ле Боньека (Thomas le Bonniec), бывшего субподрядчика Apple в Ирландии, который публично заявлял о проведении анализа конфиденциальных записей пользователей, в том числе онкологических больных. О том, что сторонние подрядчики Apple прослушивали аудиозаписи взаимодействия с Siri для анализа с целью повышения качества сервиса, сообщил в 2019 году ресурс The Guardian. Источником ресурса был подрядчик, который занимался «оценкой» Siri. Информатор тогда сообщил, что «подрядчики Apple регулярно прослушивают конфиденциальную медицинскую информацию» в рамках своей работы «по контролю качества» голосового помощника Siri. В ответ Apple приостановила программу, предоставив клиентам возможность отказаться от использования этой опции. Затем компания стала добавлять опцию только в случае явного согласия пользователя, а не его отказа. Тем не менее после этого был подан коллективный иск, и Apple согласилась выплатить компенсацию пользователям. В январе Apple заявила в блоге, что «не сохраняет аудиозаписи взаимодействия с Siri, если только пользователи явно не соглашаются на это, чтобы помочь улучшить Siri, и даже в этом случае записи используются исключительно для этой цели». Казалось бы, инцидент исчерпан, и остаётся неясным, почему спустя столько лет после происшествия во Франции решили вернуться к былому нарушению Apple. Karri Messenger позволит детям безопасно общаться с родителями и друзьями при помощи голосовых сообщений
05.09.2025 [20:27],
Сергей Сурабекянц
Устройство Messenger от лондонской компании Karri призвано помочь детям в возрасте от 5 до 13 лет стать более самостоятельными, обеспечивая при этом спокойствие их родителям. Главная функция новинки — запись, отправка и приём голосовых сообщений. Messenger использует SIM-карту, предназначенную только для передачи данных, и не имеет номера телефона. Устройство отличается минималистичным интерфейсом и интуитивно понятным управлением. 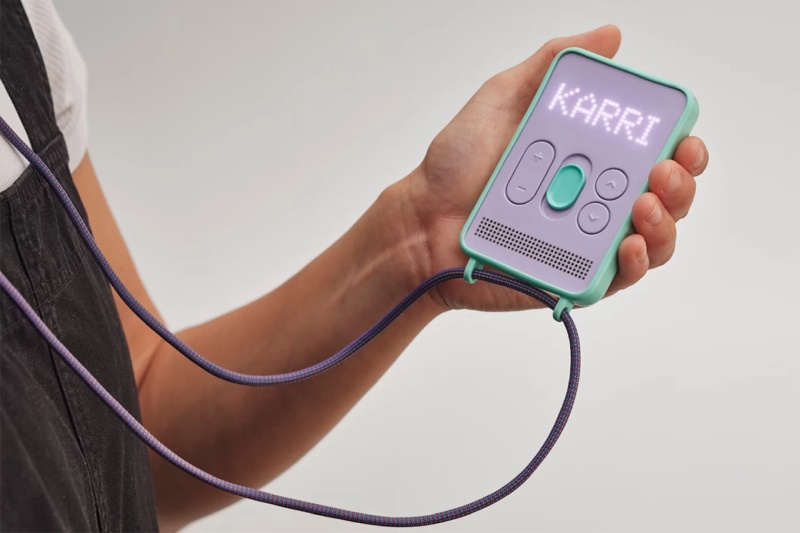
Источник изображений: Karri Это уже второе поколение подобных устройств — первое было выпущено в 2023 году. Messenger оснащён матричным дисплеем, динамиком, а его основной элемент управления — крупный физический слайдер в центре. Чтобы прослушать голосовое сообщение нужно сдвинуть его вниз, для записи сообщения — сдвинуть вверх и удерживать, для отправки — просто сдвинуть вверх.
В октябре 2024 года компания Karri привлекла несколько миллионов фунтов стерлингов на разработку новой модели, в которой принимало участие известное дизайнерское агентство Pentagram. Нескольких итераций прототипов дорабатывались в процессе тестирования с участниками из разных возрастных групп.  Messenger работает только с сопряжённым мобильным приложением на телефоне родителей, а это значит, что посторонние не смогут связаться с ребёнком. Приложение для iOS и Android позволяет безопасно отправлять зашифрованные голосовые сообщения, проверять уровень заряда батареи Messenger и определять местоположение ребёнка на карте с помощью встроенного GPS-модуля. Родители также могут устанавливать геозоны и получать уведомления, если ребёнок выходит за их пределы. Доступно создание семейных групп для отправки сообщений.
Дополнительные чехлы позволят осуществлять бесконтактные платежи через NFC, а в ближайшем будущем появится голосовое управление, навигация и другие функции. Устройство с защитой от воды IPX67 весит чуть более 120 г и может работать до четырёх дней без подзарядки.  Стоимость Messenger второго поколения составляет £90 (≈9700 ₽), поставки устройства запланированы на конец этого года. По предварительному заказу Messenger можно приобрести за £50 (≈5400 ₽), а цена месячной подписки начинается от £1,79 (≈200 ₽) при заключении двухлетнего контракта, но только в Великобритании. Более дорогие тарифы открывают доступ к сервису по всему миру, большему количеству каналов чата и обмену сообщениями между устройствами. В электромобилях Tesla Model Y L появятся голосовые ассистенты на базе ИИ от DeepSeek и Doubao
22.08.2025 [13:53],
Алексей Разин
Усилия Tesla по поддержанию спроса к своим электромобилям в Китае не ограничиваются выпуском шестиместного кроссовера Model Y L. Компания готова адаптировать возможности фирменного голосового ассистента к потребностям китайских клиентов, взяв на вооружение языковые модели местного происхождения. 
Источник изображения: Tesla Как поясняет CnEVPost, бортовая информационно-развлекательная система Tesla Model Y L получит поддержку голосового ассистента на базе моделей DeepSeek и ByteDance Doubao, причём работать это решение будет на облачной платформе Volcano Engine той же ByteDance. Если Doubao будет отвечать за сервисные запросы, связанные с управлением бортовыми системами электромобиля, то DeepSeek реализует полноценный диалог с чат-ботом на самые разные темы. В США, например, голосовой интерфейс Tesla полагается на разработки стартапа xAI, принадлежащего возглавляющему обе компании Илону Маску (Elon Musk). Новейшая Tesla Model Y L позволяет пользователям вызвать голосового ассистента кодовой приветственной фразой, тогда как во всех прочих моделях электромобилей марки для китайского рынка для этого требуется нажимать колёсико на ступице руля. В этой сфере Tesla отстаёт от китайских автопроизводителей, которые уже давно развивают интеллектуальные интерфейсы с учётом предпочтений местной публики. Помимо Tesla, голосовой ассистент на базе моделей DeepSeek на китайском рынке предлагают Zeekr, Dongfeng (Nissan, Voyah, M-Hero) и многие другие. Тем временем, в США компания Tesla повысила стоимость старшей комплектации пикапа Cybertruck сразу на $15 000 до $114 990. Эта прибавка ограничилась нематериальными бонусами для покупателя — за эти деньги он получит комплекс систем активной помощи FSD, а также право бесплатно заряжаться на фирменных станциях Tesla Supercharger. Прочие комплектации пикапа Tesla не подорожали. В WhatsApp появится аналог голосовой почты для пропущенных звонков
22.08.2025 [11:21],
Владимир Фетисов
В прошлом месяце сообщалось, что в WhatsApp появится функция напоминания о пропущенных звонках. Теперь же стало известно, что разработчики планируют добавить в мессенджер аналог голосовой почты для пропущенных звонков. 
Источник изображения: lonely blue / Unsplash Упомянутое нововведение обнаружилось в бета-версии WhatsApp 2.25.23.21 для Android. Когда пользователь звонит кому-либо с помощью приложения WhatsApp и не получает ответа, на экране, рядом с кнопками «Перезвонить» и «Отмена», отображается сообщение «Записать голосовое сообщение». Выбрав эту опцию, пользователь может оставить голосовое сообщение, которое собеседник увидит, когда в следующий раз откроет приложение. Опция «Записать голосовое сообщение» также будет отображаться в чате с контактом, до которого не удалось дозвониться. 
Источник изображения: wabetainfo.com Аналог голосовой почты позволит быстро записать голосовое сообщение человеку, до которого не удаётся дозвониться. Конечно, это же можно сделать и в чате с контактом, но появление отдельной опции непосредственно после неудачного звонка должно сделать процесс взаимодействия с мессенджером более комфортным. На данном этапе опция «Записать голосовое сообщение» доступна некоторым пользователям бета-версий WhatsApp для Android. Когда эта функция может стать общедоступной, пока неизвестно. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex





 Другие кнопки на устройстве позволяют управлять громкостью и переключаться между различными чатами. Предусмотрена блокировка устройства для предотвращения случайных нажатий, кнопка отключения звука и вибросигнала, фонарик и отверстие для шнурка. Имеется возможность отправлять сообщения между мессенджерами и подавать сигналы SOS.
Другие кнопки на устройстве позволяют управлять громкостью и переключаться между различными чатами. Предусмотрена блокировка устройства для предотвращения случайных нажатий, кнопка отключения звука и вибросигнала, фонарик и отверстие для шнурка. Имеется возможность отправлять сообщения между мессенджерами и подавать сигналы SOS.