|
Опрос
|
реклама
Быстрый переход
Конец цифрового насилия: Трамп ввёл уголовную ответственность за интимные дипфейки
20.05.2025 [13:22],
Павел Котов
Президент США Дональд Трамп (Donald Trump) подписал «Закон о немедленном удалении материалов» (Take It Down Act), который переводит в разряд уголовных преступлений распространение несогласованных с объектом изображений деликатного характера, в том числе созданных с помощью искусственного интеллекта подделок (дипфейков). Закон требует, чтобы администрации соцсетей немедленно удаляли такие материалы при поступлении соответствующих запросов. 
Источник изображения: Donghun Shin / unsplash.com Законопроект утвердили обе палаты Конгресса; в его поддержку высказались несколько технологических компаний, защитники прав молодёжи и родителей, а также первая леди Мелания Трамп (Melania Trump). Есть, впрочем и мнение, что утверждённый в документе подход может иметь обратный эффект и навредить тем, кого призван защищать. Закон переводит в разряд уголовных преступлений публикацию изображений деликатного характера, в том числе дипфейков, без согласия лиц, которые в этих материалах представлены, — он предусматривает наказание до трёх лет лишений свободы плюс штрафы. Администрациям социальных сетей предписывается в течение 48 часов с момента получения соответствующего уведомления удалять все такие материалы и «прилагать разумные усилия» для удаления копий таких материалов. Правозащитники, в том числе некоммерческие организации Electronic Frontier Foundation (EFF) и Center for Democracy and Technology (CDT), однако, предупреждают, что положение о запрете контента может использоваться, чтобы принуждать ответственных лиц удалять более широкий спектр материалов, чем предполагается; не исключается также угроза для технологий защиты конфиденциальности, в том числе средств шифрования — операторы соответствующих платформ не видят и не имеют возможности удалять сообщения между пользователями. Не исключаются и другие злоупотребления, в том числе избирательное отношение Федеральной торговой комиссии (FTC) к соблюдению требований закона. Введение новых норм в практику правоприменения займёт около года, считают эксперты. Исследование Honor: из-за распространения дипфейков работодатели изменят способ проведения онлайн-собеседований
17.04.2025 [01:00],
Владимир Мироненко
Поступивший в продажу в России в апреле смартфон Honor Magic 7 получил поддержку целого ряда ИИ-технологий, включая функцию распознавания дипфейков для защиты от новых видов мошенничества при видеозвонках. Согласно исследованию Honor, приуроченному к выходу смартфона Magic 7, распространение дипфейков может отразиться на процессе найма специалистов на работу, собеседование с которыми, как правило, проводится в онлайн-режиме.  В ходе опроса, проведенного Honor, выяснилось, что 81,5 % респондентов готовы делегировать искусственному интеллекту (ИИ) стрессовые задачи, а 22,7 % хотели бы делегировать искусственному интеллекту прохождение собеседований за них. Что также интересно, 1,1 % участников опроса признались, что сами создают дипфейки. 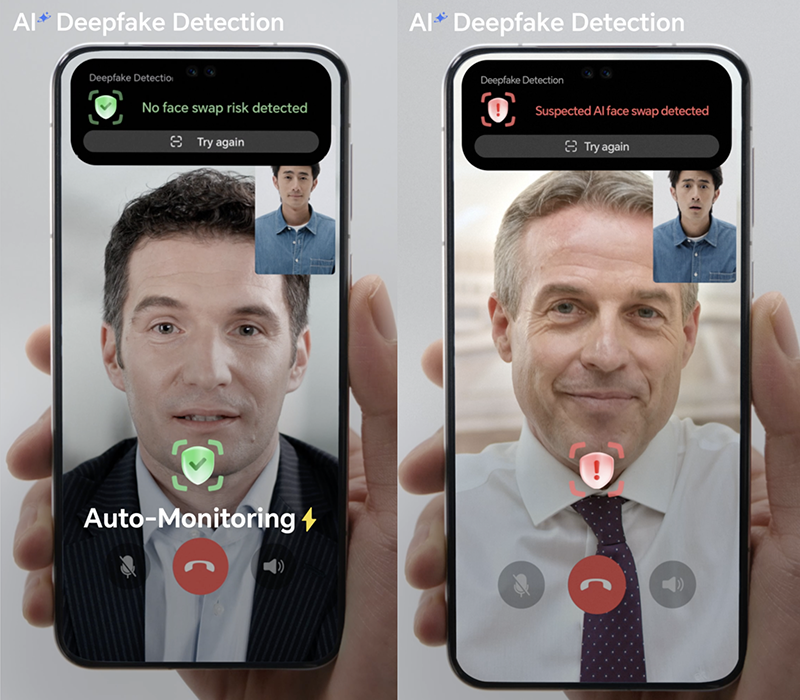 ИИ-технология, встроенная в серию смартфонов Magic 7, позволяет пользователям определять, было ли фото или видео изменено или полностью создано с помощью ИИ. Распространение дипфейков обеспокоило рекрутеров. По словам Дарьи Барковой, HR-профайлера и предпринимателя IT-рекрутингового агентства Unicorn Search, технологии дипфейков и использование ИИ-инструментов, позволяющих имитировать человека на собеседовании, ставят под сомнение достоверность результатов найма. «Кандидат может полностью заменить себя на этапе оценки, превращая цифровые каналы рекрутинга из инструмента удобства в зону уязвимости. Стандартизированные вопросы и типовые кейсы теряют актуальность — их слишком легко автоматизировать», — говорит Баркова. Она подчеркнула, что будущее — за динамичными форматами с живым взаимодействием, позволяющим определить способность кандидата на вакансию к адаптации в реальном времени и проверить индивидуальную реакцию на нестандартные условия. Анна Осипова, руководитель внешних коммуникаций hh.ru в регионах, подтвердила актуальность проблемы дипфейков. Она отметила, что случаи использования технологий дипфейков для прохождения онлайн-собеседований пока единичны, но по мере развития технологий риски их использования могут стать довольно ощутимыми, и компаниям уже сегодня необходимо подумать о мерах противодействия. «Как минимум, важно проводить более тщательный первичный скрининг кандидата, не пренебрегать проверкой через внутреннюю службу безопасности. Во время онлайн-собеседований стоит обращать внимание на качество и “естественность” видео, манеру речи», — отметила она. По мнению экспертов, уже в ближайшее время компании будут вынуждены изменить методы подбора персонала, используя новые способы проверки личности кандидатов и подлинности видео во время онлайн-собеседований. «Сбер» предсказал всплеск ИИ-мошенничества, к которому никто не готов, к середине этого года
04.03.2025 [22:43],
Дмитрий Федоров
Мошенники в 2025 году начнут активно использовать ИИ для создания дипфейков, подделки голоса и телефонных звонков на разных языках. По оценке «Сбера», финансовые институты недостаточно подготовлены к подобным угрозам, что может привести к увеличению финансовых потерь среди рядовых граждан. Банкам и государственным структурам необходима срочная модернизация систем безопасности для предотвращения таких преступлений. 
Источник изображения: Wesley Tingey / Unsplash Согласно прогнозу «Сбера», уже к середине 2025 года мошенники начнут активно применять технологии генеративного ИИ для создания реалистичных подделок изображений, видеозаписей и голосов. Эти методы уже используются при создании фишинговых сайтов, но вскоре выйдут на новый уровень. «Мы прогнозируем, что примерно к середине года появятся дипфейки», — заявил заместитель председателя правления «Сбера» Станислав Кузнецов. Особенно серьёзной угрозой, связанной с развитием ИИ, станет преодоление языкового барьера в телефонном мошенничестве. Кузнецов отметил, что в ближайшие три-четыре месяца злоумышленники начнут активно применять технологии генерации речи на различных языках. «Как только модели позволяют нам сегодня преодолеть последнюю границу — языковой барьер, как только нажатием одной кнопки можно звонить в любую страну или разговаривать на любом языке, следует задуматься о том, что телефонное мошенничество появится и на башкирском, и на татарском языках», — подчеркнул он. Согласно данным, представленным Кузнецовым, 81 % мошеннических звонков совершается через мессенджеры, sim-box и облачные АТС. Оставшиеся 19 % приходятся на классические телефонные звонки, причём лишь 1 % осуществляется с подменой номера. Это означает, что основная угроза исходит именно от мессенджеров, а не от традиционной телефонии. По данным Центрального банка России (ЦБ), в 2024 году мошенники похитили у клиентов банков 27,5 млрд руб., принуждая их совершать денежные переводы. Основной инструмент преступников — методы социальной инженерии, основанные на обмане и манипуляции жертвами. Банк России направил операторам связи почти 172 тысячи номеров, использовавшихся злоумышленниками, что подчёркивает масштаб проблемы. Несмотря на снижение числа мошеннических звонков через традиционную телефонную связь, преступники продолжают активно применять мессенджеры не только для звонков, но и для рассылки вредоносного программного обеспечения (ПО) и поддельных документов. ООН рассказала об использовании Telegram преступными сетями из Юго-Восточной Азии
07.10.2024 [20:02],
Сергей Сурабекянц
Представитель ООН заявил, что в Telegram открыто и в огромных масштабах продаются похищенные данные, а также доступны инструменты для киберпреступников и услуги по отмыванию денег. В недавно опубликованном докладе ООН утверждается, что преступные группировки Юго-Восточной Азии широко используют приложение, что позволяет им вести крупномасштабную незаконную деятельность. 
Источник изображения: Pixabay В отчёте Управления ООН по наркотикам и преступности (УНП ООН) говорится, что в Telegram широко продаются похищенные персональные данные, что авторы отчёта связывают со слабой модерацией в приложении. Широко доступны также инструменты, используемые киберпреступниками, включая программное обеспечение для создания дипфейков и вредоносное ПО для кражи данных, а нелицензированные криптовалютные биржи предлагают в Telegram услуги по отмыванию денег. Юго-Восточная Азия стала крупным центром многомиллиардной криминальной индустрии, которая использует мошеннические схемы для поиска жертв по всему миру. По данным УНП ООН, отрасль ежегодно генерирует от 27,4 до 36,5 млрд долларов. В качестве примера цитируется рекламное объявление на китайском языке: «Мы ежедневно переводим 3 миллиона долларов США, украденных из-за рубежа». В докладе идёт речь о китайских преступных синдикатах, замешанных в торговле людьми и использовании рабского труда. «Есть убедительные доказательства того, что подпольные рынки данных перемещаются в Telegram, а поставщики активно ищут цели для транснациональных организованных преступных группировок, базирующихся в Юго-Восточной Азии», — говорится в отчёте. В августе в Париже создателю и главе мессенджера Павлу Дурову были предъявлены обвинения по шести пунктам, в том числе в отказе от сотрудничества. Самый тяжкий пункт — соучастие в администрировании онлайн-платформы для совершения незаконных транзакций. За это Дурову грозит наказание до десяти лет лишения свободы и штраф до €500 тыс. Поводом для ареста Дурова стал отказ администрации мессенджера от сотрудничества с властями Евросоюза, а политика модерации давно вызывала критику у властей. Париж также оказался разочарован отказом платформы сотрудничать конкретно с французскими властями. После ареста Дуров заявил, что приложение станет передавать IP-адреса и номера телефонов пользователей властям, подающим официальные юридические запросы. Он также пообещал, что будут удалены некоторые функции, которые использовались для незаконной деятельности. Арест Дурова привлёк внимание к ответственности поставщиков приложений, а также вызвал дебаты о том, где заканчивается свобода слова и начинается исполнение закона. В отчёте УГП ООН говорится, что размах деятельности преступных группировок в регионе привёл к внедрению ими инноваций и новых бизнес-моделей и технологий, включая вредоносное ПО, генеративный ИИ и дипфейки. Заместитель представителя УНП ООН Бенедикт Хофман (Benedikt Hofmann) заявил, что приложение является удобной средой для преступников. «Для потребителей это означает, что их данные подвергаются большему риску попасть к мошенникам или в другую преступную схему, чем когда-либо прежде», — считает он. По словам Хофмана, УНП ООН выявило более 10 поставщиков услуг программного обеспечения для создания дипфейков, «специально нацеленных на преступные группы, занимающиеся кибермошенничеством в Юго-Восточной Азии». В настоящее время регулирующие органы Южной Кореи проводят расследование о причастности мессенджера Telegram к распространению дипфейков сексуального содержания из-за недостаточной модерации. Сообщается, что в Telegram есть каналы с более чем 200 000 подписчиков, где распространяется такой контент. В прошлом месяце агентство Reuters сообщило, что чат-боты Telegram использовались для кражи данных из ведущей индийской страховой компании Star Health, что побудило страховую компанию подать в суд на онлайн-платформу. К преступникам могли попасть документы по страхованию и претензиям, содержащие имена, номера телефонов, адреса, налоговые реквизиты, копии удостоверений личности, результаты анализов и медицинские диагнозы. Напомним, что бот для передачи информации о нарушениях правил мессенджера Telegram заработал в России с 23 сентября. Южная Корея ввела уголовную ответственность за просмотр, хранение и распространение сексуальных дипфейков
27.09.2024 [18:14],
Сергей Сурабекянц
26 сентября южнокорейский парламент принял законопроект, предусматривающий уголовную ответственность за распространение, хранение и просмотр видео или изображений, содержащих дипфейки откровенно сексуального характера. За просмотр и хранение такого контента закон предусматривает наказание в виде тюремного заключения на срок до трёх лет или штрафа до 30 млн вон ($22,6 тыс.), а за создание подобных дипфейков грозит заключение сроком до пяти лет или штраф. 
Источник изображения: Pixabay Только в этом году южнокорейская полиция получила более 800 заявлений о создании дипфейков сексуального содержания. В частности, регулирующие органы Южной Кореи проводят расследование о причастности мессенджера Telegram к распространению такого контента из-за недостаточной модерации. Сообщается, что в Telegram есть каналы с более чем 200 000 подписчиков, где распространяется такой контент. Чтобы нынешний закон вступил в силу, его должен подписать президент Южной Кореи Юн Сок Ель. Российские законодатели также на днях предложили добавить ответственность за дипфейки в Уголовный кодекс — в Госдуму внесён законопроект, предлагающий признать использование дипфейков отягощающим обстоятельством при мошенничестве и клевете. YouTube больше не станет терпеть дипфейки и ИИ-плагиат
06.09.2024 [07:46],
Анжелла Марина
YouTube сказал твёрдое «нет» дипфейкам и ИИ-плагиату, защищая права авторов на платформе. По данным The Verge, компания начинает разработку новых инструментов, которые дадут создателям контента больше контроля над использованием их голоса и образа, сгенерированного искусственным интеллектом. 
Источник изображения: convertcrypto.ru Первый инструмент, получивший название «технология идентификации синтезированного пения», позволит артистам и авторам автоматически распознавать и управлять контентом YouTube, в котором их голоса имитируются с помощью искусственного интеллекта. Эта технология будет интегрирована в существующую систему идентификации авторских прав Content ID и запущена в рамках пилотной программы в следующем году. Решение YouTube связано с растущим беспокойством в музыкальной индустрии по поводу использования ИИ для создания копий песен и голосов артистов. В открытом письме, опубликованном ранее в этом году, более 200 артистов, включая Билли Айлиш (Billie Eilish), Pearl Jam (Pearl Jam) и Кэти Перри (Katy Perry), назвали несанкционированное ИИ-копирование «посягательством на человеческий творческий потенциал» и потребовали от видеохостинга большей ответственности в этом отношении. Помимо защиты голосов, YouTube на своей платформе также разрабатывает инструмент для выявления дипфейков лиц и образов авторов, актёров, музыкантов и спортсменов. Однако система ещё находится в разработке и не сообщается, когда она будет запущена. В дополнение к этому, YouTube обещает бороться с теми, кто собирает данные с платформы для обучения ИИ-моделей. «Мы ясно дали понять, что несанкционированный доступ к контенту авторов нарушает наши условия обслуживания», — заявили представители YouTube. Однако это не помешало таким компаниям, как OpenAI, Apple, Anthropic, Nvidia, Salesforce и Runway AI, обучать свои ИИ-системы на тысячах скачанных с YouTube видео. Для защиты контента от ботов-сканеров YouTube планирует блокировать им доступ полностью и для этого начнёт инвестировать в систему обнаружения сбора данных. Также заявляется, что разрабатываются способы предоставления авторам больше возможностей в отношении того, как сторонние компании, занимающиеся ИИ, всё же смогли бы использовать их контент на платформе, очевидно делясь заработками. Более подробная информация об этом выйдет позднее в этом году. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



