|
Опрос
|
реклама
Быстрый переход
Приложение камеры Adobe Project Indigo получило набор генеративных фильтров и научилось удалять лишние объекты
20.07.2026 [20:20],
Сергей Сурабекянц
В прошлом году Adobe представила экспериментальное приложение камеры для iPhone под названием Project Indigo, которое, по словам разработчика, было призвано обеспечить «более естественный (похожий на зеркальную камеру) вид» фотографий, сделанных на смартфон. Теперь приложение обновляется набором инструментов генеративного ИИ, причём это изменение не основано на собственных моделях ИИ Firefly от Adobe. 
Источник изображений: Adobe Adobe описывает новый набор инструментов AI Playground как эксперимент, указывая на возможность отказаться от его использования и продолжить использовать приложение как раньше. Бесплатный доступ к набору без входа в систему тестируется с небольшим процентом пользователей Indigo в течение следующих нескольких недель. «Наша цель — узнать, как люди используют редактирование на основе генеративного ИИ. В зависимости от успеха мы можем продлить эксперимент, расширить круг пользователей или провести последующие эксперименты, — пояснил сотрудник Adobe Марк Левой (Marc Levoy) в блоге компании. — Если эта функция окажется популярной, мы в конечном итоге предложим платную версию».  Инструменты ИИ появились в четырёх разделах приложения Indigo версии 1.1: «Стили», «Редактирование объектов», «Подсказки для фотографий» и «Пользовательское редактирование». По словам Левоя, каждый раздел содержит «несколько кнопок или переключателей, которые запускают ИИ с помощью подсказок, разработанных нами для них». Если пользователю не нравятся результаты редактирования, он может нажать кнопку ещё раз и «получить что-то немного другое». В разделе «Стили» к фотографиям, сделанным с помощью Indigo, применяются предустановленные фильтры, созданные ИИ, превращая их в иллюстрации, изменяя световые эффекты и другие параметры изображения. «Редактирование объектов» включает инструменты, которые удаляют людей, объекты и другие отвлекающие элементы с фона изображений, а затем генеративный ИИ используется для заполнения оставшихся пустых мест, подобно функции «Волшебный ластик» от Google. «Подсказки для фотографий» — это функция обратной связи, которая позволяет ИИ анализировать фотографии и предлагать варианты повторной съёмки и редактирования.  «Пользовательское редактирование» — это инструмент, позволяющий пользователям подробно описывать, как они хотят изменить изображение. На начальном этапе Adobe использует модель искусственного интеллекта Nano Banana от Google, но со временем может перейти на другую модель или добавить поддержку дополнительных моделей. Описанные инструменты заметно отличаются от начального позиционирования Indigo на момент запуска, которое эксперты описывали как «приложение для камеры, созданное энтузиастами фотографии для энтузиастов фотографии». Первая версия приложения использовала функции вычислительной фотографии, чтобы помочь мобильным фотографам получать изображения лучшего качества, воссоздающие вид фотографий, сделанных на зеркальные камеры, а также предоставляла возможность ручных настроек основных параметров экспозиции.  «Это начало пути для Adobe — к интегрированному мобильному интерфейсу камеры и редактирования, который использует последние достижения в области вычислительной фотографии и искусственного интеллекта, — заявил Левой при первом запуске приложения Indigo. — То, насколько ваши правки являются справедливыми или вводящими в заблуждение, зависит от того, что вы делаете, с кем вы делитесь изображениями и как вы их представляете. В конечном итоге, ничто не может уменьшить важность ответственного поведения». В настоящее время команда Indigo работает над добавлением C2PA Content Credentials — стандарта метаданных для идентификации контента ИИ, который уже широко используется моделями Firefly от Adobe, — к изображениям, обработанным инструментами генеративного ИИ Indigo, и отмечает, что Nano Banana уже использует невидимый водяной знак SynthID от Google. ByteDance представила Seedream 5.0 Pro — флагманскую ИИ-модель для генерации и редактирования изображений
11.07.2026 [07:31],
Владимир Фетисов
ByteDance выпустила Seedream5.0 Pro —мультимодальную языковую модель для генерации изображений, предназначенную для выполнения функций производственного дизайна. Алгоритм ориентирован на создателей контента, дизайнеров, маркетологов и других людей, которым требуются насыщенные визуальные макеты, локализованный текст, функции точного редактирования и возможность многократного использования шаблонов, созданных на основе текстовых запросов. 
Источник изображения: testingcatalog.com В Seedream 5.0 Pro разработчики реализовали несколько ключевых улучшений, включая возможность визуализации сложной инфографики, функции точного редактирования, генерацию реалистичных изображений и текстур портретов, а также поддержку ввода и генерации текста на разных языках. По данным ByteDance, алгоритм способен превращать данные, концепции и длинные тексты в профессиональные макеты, генерировать инфографику, изображения, UI-макеты, визуальные материалы для обучения и структурированные активы для коммерческого использования. По сравнению с предыдущими версиями ИИ-модели, новинка отличается более высоким уровнем согласованности между вводимым пользователем запросом и результатом генерации, улучшенной структурной целостностью и визуальной эстетикой. Seedream 5.0 Pro поддерживает функцию выделения отдельных областей изображения с помощью точки или лассо для редактирования без повторной генерации всего кадра. Перекрытые объектом редактирования участки генерируются автоматически. При необходимости изображение можно разделить на отдельно редактируемые слои, такие как основной объект, фон, текст и декоративные элементы. ИИ-модель обеспечивает генерацию изображений фотореалистичного качества за счёт проработки освещения в кадре, текстуры кожи на портретах, добавления физически достоверных отражений и других эффектов. Алгоритм может обрабатывать запросы и создавать изображения с текстом на более чем 10 языках, включая русский, английский, китайский, немецкий, арабский и др. На данном этапе модель Seedream 5.0 Pro доступна для тестирования через API BytePlus. Meta✴ представила Muse Image — свою первую серьёзную модель для генерации изображений, которая будет доступна Meta✴ AI и соцсетях
08.07.2026 [09:41],
Павел Котов
Meta✴✴ выпустила первую генерирующую изображения модель искусственного интеллекта, разработанную сформированным в прошлом году подразделением Superintelligence Labs. Muse Image интегрирована в графические редакторы приложений Meta✴✴ AI, Instagram✴✴ и WhatsApp; скоро она появится в Facebook✴✴ и Facebook✴✴ Messenger. 
Источник изображения: Meta✴✴ Модель стала новым членом семейства Muse, пришедшего на смену Llama. Muse Image располагает агентными функциями — она подключается к большой языковой модели Muse Spark, «чтобы проанализировать ваш запрос, выполнить поиск в интернете и спланировать работу до генерации», пояснил глава Superintelligence Labs Александр Ван (Alexandr Wang). Он также пообещал, что скоро компания выпустит модель Muse Video — она «конкурентоспособна по соответствию запросам, визуальной точности и временно́й согласованности». В запросах к Muse Image можно упоминать аккаунты других пользователей Instagram✴✴, чтобы включать фото с их страниц в свои работы. Такого рода редактирование и генерация смогут работать только с общедоступными материалами; при этом пользователи смогут контролировать, как другие используют их контент при работе с ИИ. По запросам доступно редактирование изображений, а также создание дизайна приглашений и открыток. Ещё одна функция — создание нового дизайна для объектов недвижимости на платформе Facebook✴✴ Marketplace. Muse Image будет использоваться для 30 новых ИИ-эффектов при публикации в разделе Instagram✴✴ Stories для пользователей в США — впоследствии функция будет доступна и в других странах, а также в других разделах приложений Meta✴✴. Учёные создали пиксель, который научит дисплеи видеть
26.06.2026 [09:22],
Геннадий Детинич
Для ряда приложений было бы заманчиво объединить функции дисплея и камеры в одном решении. Это могут быть адаптивная оптика, анализаторы материалов, стереоскопические дисплеи и просто компактные AR/VR-очки, которым не нужна отдельная камера. На практике мы имеем либо светочувствительный пиксель в камере, либо светоизлучающий — в дисплее. К счастью, учёные из Швейцарии изобрели новый пиксель, обладающий одновременно всеми этими свойствами. Источник изображений: ETH Zurich О разработке сообщили исследователи из Швейцарской высшей технической школы Цюриха (ETH Zurich). Они представили новый тип оптического пикселя, который может работать в двух направлениях: как элемент дисплея, формирующий свет, и как сенсор, анализирующий падающее на него излучение. Свой пиксель они назвали Fourier pixel — «пиксель Фурье». В отличие от обычных пикселей камер и экранов, которые обычно либо регистрируют интенсивность света, либо излучают его, новая структура способна управлять и считывать сразу несколько параметров электромагнитной волны: амплитуду, фазу и поляризацию. Это не только открывает путь к устройствам, где камера и дисплей могут быть объединены на уровне одного и того же массива пикселей, но также позволяет извлекать из света массу ценной информации. Принцип работы пикселя Фурье основан на поверхностных плазмон-поляритонах — когерентных волнах, распространяющихся вдоль металлической поверхности. Вся магия процесса использует довольно простую математику преобразований Фурье. Благодаря этой математике можно заранее рассчитать рельеф поверхности пикселя, по которому будут «прокатываться» электромагнитные волны плазмон-поляритонных взаимодействий. Исходя из рельефа, электромагнитные волны будут вступать во взаимодействие друг с другом (интерферировать), излучать или реагировать на падающий свет — и всё это строго в рамках допустимого. Более того, рельеф может служить своего рода вычислителем, производя над волнами определённые математические действия просто в силу естественных физических процессов поведения волн. В общем случае падающий на пиксель Фурье свет сначала возбуждает такую поверхностную волну, затем она доходит до специально сформированного «элемента Фурье» — микроструктуры с волнистым профилем, рассчитанным методами анализа Фурье. Эта структура рассеивает поверхностную волну обратно в свободное пространство, но уже с заданным распределением амплитуды и фазы. По сути, форма поверхности играет роль миниатюрного дифракционного процессора: нужный оптический фронт рассчитывается через обратное преобразование Фурье. Сам рельеф заранее изготавливается на пикселе с нанометровой точностью, с чем сегодня нет никаких проблем. Пиксели Фурье, в силу своих физических особенностей, способны анализировать все составляющие света, включая поляризацию (они банально на неё реагируют заранее заданным образом), амплитуду и фазу. При этом они также способны излучать свет с учётом этих параметров, причём с заданной длиной волны — нужным цветом. Подобные возможности, например, позволяют создавать свет в виде пончика с дыркой посередине, просто управляя фазой и поляризацией излучаемого света. Матрицы из пикселей Фурье будут способны одновременно показывать цветную картинку и анализировать материалы по рассеиваемому ими свету, создавать трёхмерное изображение в пространстве, как на голографических дисплеях в «Звёздных войнах», адаптировать фокусное расстояние микроскопов и телескопов в зависимости от наблюдаемых объектов и компенсировать турбулентность атмосферы. Наконец, подобные возможности были бы востребованы в телекоммуникациях, а также в оптических и квантовых вычислениях. ChatGPT «по собственной воле» стал генерировать изображения интимного и насильственного характера
19.06.2026 [08:28],
Павел Котов
Последняя публичная версия чат-бота с искусственным интеллектом ChatGPT оказалась способной генерировать изображения деликатного характера или сцены насилия в ответ на простой запрос, установили исследователи из британской компании Mindgard. 
Источник изображения: BoliviaInteligente / unsplash.com Специалисты британского стартапа Mindgard, который занимается поиском уязвимостей в системах ИИ, нашли способ, как заставить ChatGPT создавать изображения с недопустимым содержимым, немного изменив некий широко распространённый запрос, первоначально разработанный для получения результатов юмористического характера. Особенно тревожным оказалось то, что в запросе не указывается тематика изображений, и ИИ «по собственной воле» создаёт явно недопустимые кровавые и деликатные изображения. В одном случае это был мужчина с серьёзной травмой головы, в другом — окровавленная женщина, на которой был минимум одежды. На изображениях присутствовали взрослые люди, чьи образы были сгенерированы ИИ, но, как показали предыдущие исследования Mindgard, ChatGPT можно обманным путём заставить создавать дипфейки реальных обнажённых людей, подставляя их лица. Не исключается, что ИИ способен создавать картинки ещё более шокирующего содержания, если исследователи потратят на эту задачу больше времени. Результаты работы ChatGPT отражают данные, которые использовались в его разработке и обучении — генерируемый ИИ недопустимый контент «имеет связи с реальными изображениями и реальным миром», подчёркивают эксперты. Результаты своей работы специалисты Mindgard раскрыли компании OpenAI в мае, но в ответ получили отписку. Когда инцидент был предан огласке, разработчик всё-таки отреагировал. «Изучив эту тенденцию, мы ввели дополнительные меры защиты от запросов такого рода. <..> Мы также сочетаем автоматизированные системы и проверку человеком для выявления и блокировки вредоносных материалов», — заявил представитель OpenAI и добавил, что в системах компании имеется многоуровневая защита, предназначенная для предотвращения показа пользователям изображений, нарушающих её политику. Исследователи, однако, обратили внимание, что и после внесения изменений ChatGPT в ответ на проблемный запрос по-прежнему выдавал вызывающий опасения контент. Содержание запроса по понятным причинам не раскрывается. Настоящая проблема в том, указывают эксперты, что модели ИИ не понимают, как люди, что они создают, и чего разработчики просят их не делать. «Модели не понимают намерений. Они не понимают контекста. Они не понимают принципов, правильного и неправильного», — напоминают учёные. Поэтому внедрение защитных механизмов и средств их обхода — это «игра в кошки-мышки»: по мере совершенствования одних более изощрёнными становятся и другие. Новая статья: Умные помощники: обзор ИИ-сервисов для обработки изображений. Часть 2, актуализированная
18.06.2026 [00:03],
3DNews Team
Данные берутся из публикации Умные помощники: обзор ИИ-сервисов для обработки изображений. Часть 2, актуализированная Sony хотела похвастаться ИИ-камерой Xperia 1 VIII, но получила волну мемов
15.05.2026 [23:36],
Николай Хижняк
Компанию Sony затроллили в социальных сетях за работу ИИ-алгоритма камеры AI Camera Assistant нового флагманского смартфона Xperia 1 VIII. Пользователи соцсети X публикуют мемы и фотографии «до и после» вслед за публикацией японским гигантом рекламных изображений работы AI Camera Assistant, которые оказались менее качественными, чем оригиналы снимков без обработки. 
Источник изображений: X (бывший Twitter) На фоне шуточных сообщений пользователей Sony впоследствии уточнила, что искусственный интеллект предлагает «креативные варианты оформления», а не автоматическую обработку изображений. Компания опубликовала официальное заявление, где пояснила особенность работы новой ИИ-функции камеры: «В продолжение публикации об AI Camera Assistant мы хотели бы подробнее рассказать об этой функции. Она не редактирует фотографии после съёмки, а предлагает четыре варианта настроек в разных творческих направлениях в зависимости от сцены и объекта. Вы можете выбрать любой вариант или использовать свои собственные настройки».  Компания сопроводила сообщение примерами изображений, на которых ИИ-алгоритм предлагает пользователю выбрать наиболее подходящий вариант обработки снимка: 
 Всё началось с публикации сравнения (изображения ниже), в котором Sony пыталась подчеркнуть возможности искусственного интеллекта в Xperia 1 VIII. Как ни странно, оригинальные фотографии (слева) оказались более сбалансированы по экспозиции и имели более естественные тени, в то время как версии с обработкой ИИ (справа) выглядели сильно переэкспонированными, с пересвеченными участками и блеклыми цветами. 
Источник изображения: Sony Реакция сообщества в соцсети X была быстрой и беспощадной. Поднялась такая волна критики, что генеральный директор компании Nothing Карл Пей (Carl Pei) присоединился к полемике и даже задался вопросом, не является ли это завуалированной накруткой интереса к устройству со стороны самой Sony. Вместо того чтобы просто критиковать результаты, пользователи X превратили ситуацию в полноценный мем. Возник целый тренд: пользователи начали делиться своими примерами фотографий «до и после», специально редактируя снимки «после» так, чтобы они выглядели, будто только что произошла ядерная вспышка. 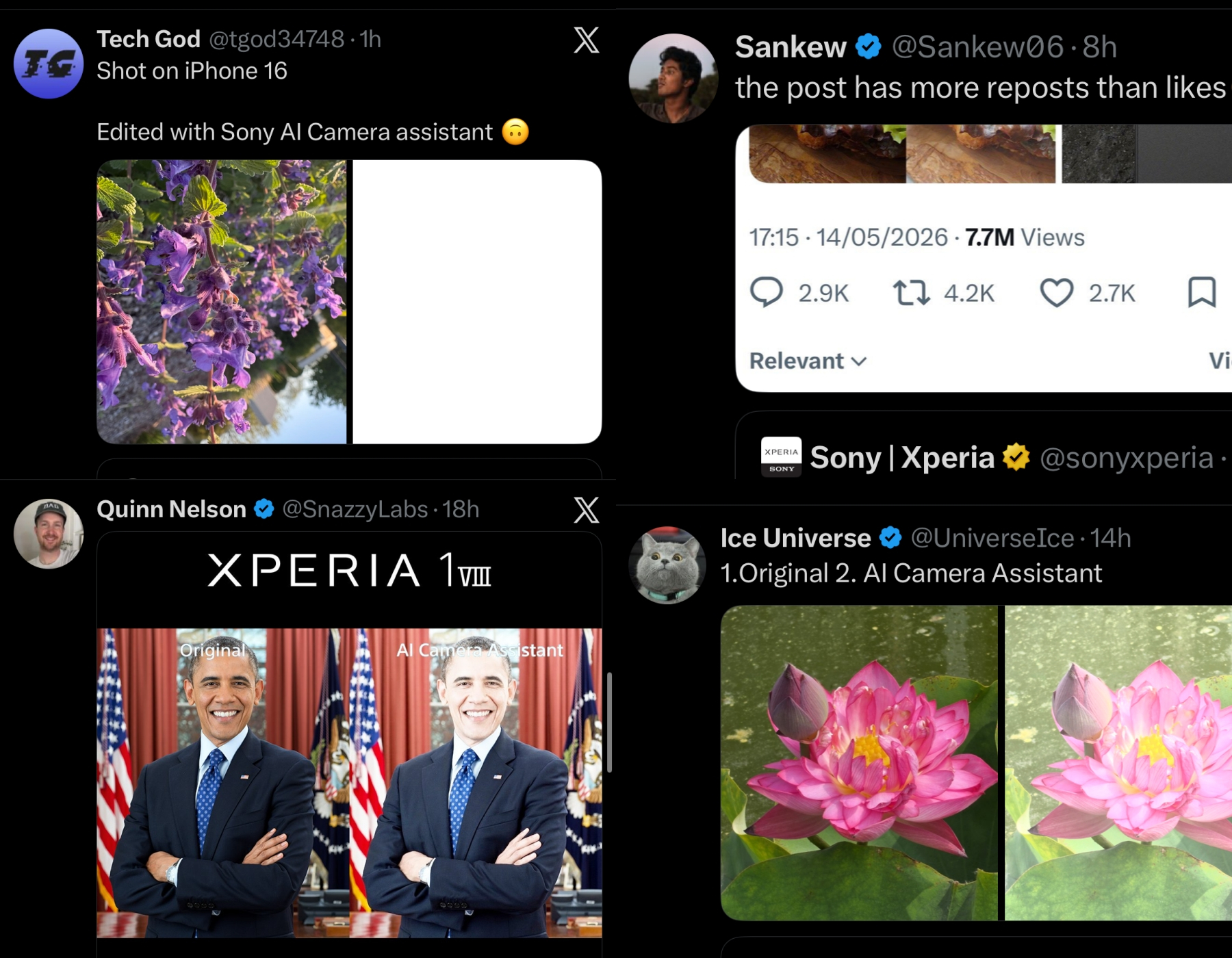 Один пользователь опубликовал фотографию фиолетовых цветов, где «отредактированная» версия представляет собой пустой белый квадрат. Другой поделился сравнением портретов, где версия, созданная с помощью ИИ, настолько яркая, что черты лица человека на снимке сливаются с фоном. 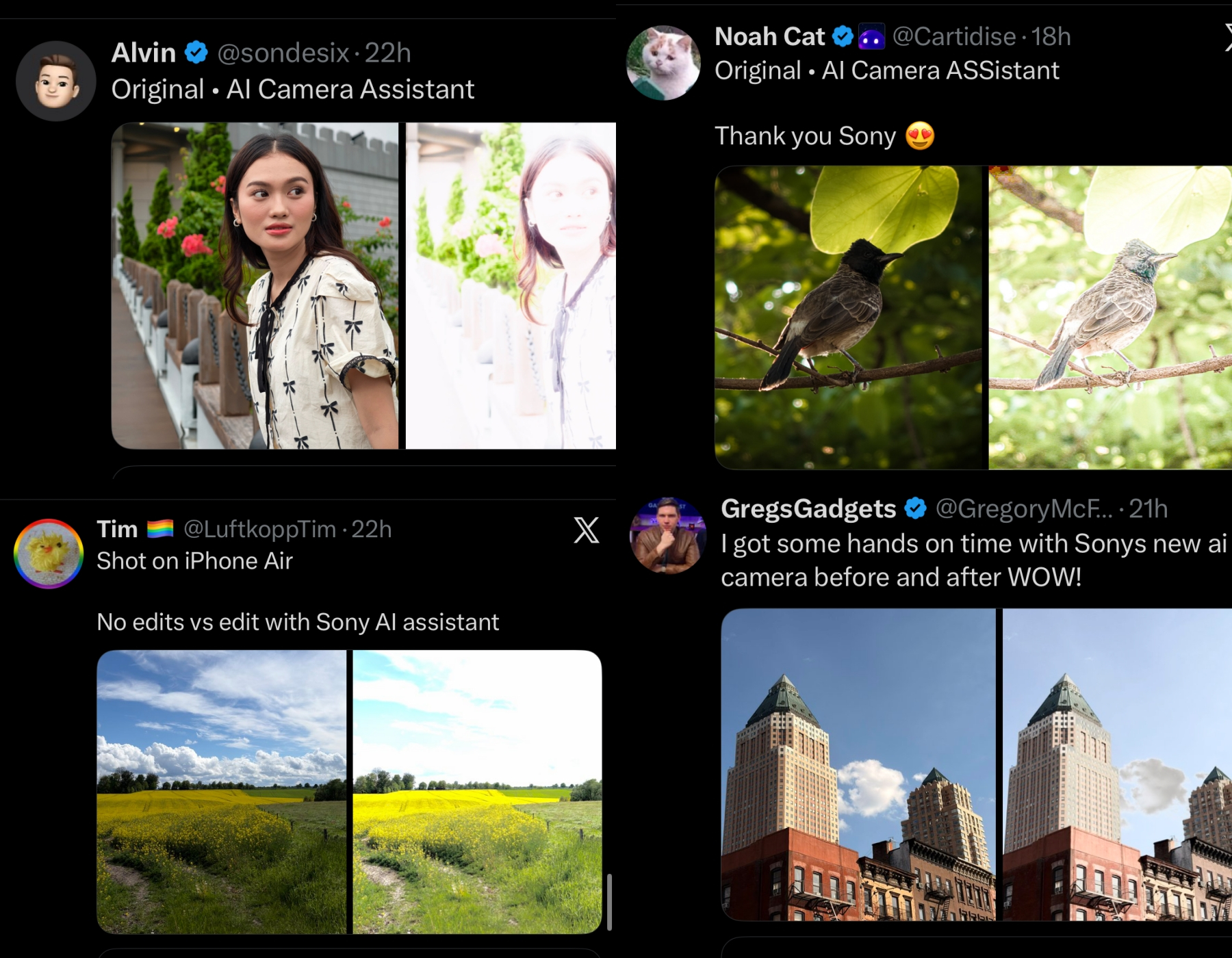 Между тем многие создатели контента о технологиях оказались озадачены (на самом деле нет) результатами работы ИИ-алгоритмов Sony. Они начали ретвитить фотографии и задаваться вопросом, настоящие ли они. Будь то техническая ошибка при выборе изображений отделом маркетинга или продуманный ход для привлечения внимания, Xperia 1 VIII может стать самым обсуждаемым телефоном недели, хотя, возможно, и не по тем причинам, которые предполагала Sony. Уход Sora открыл дорогу конкурентам: ИИ-генераторы видео Kling AI и AI Video ворвались в топы Apple App Store
13.05.2026 [18:53],
Дмитрий Федоров
Два приложения для создания видео с помощью ИИ — Kling AI и AI Video — поднялись на пятое и шестое места в рейтинге самых скачиваемых бесплатных приложений Apple App Store. Оба лидируют в своих категориях: Kling AI заняло первую строчку в «Графике и дизайне», AI Video — в «Фото и видео». Их рост начался спустя два месяца после закрытия видеосервиса Sora компании OpenAI. Оба приложения выигрывают от нового всплеска внимания пользователей iPhone к ИИ-генерации видео. 
Источник изображений: apps.apple.com OpenAI свернула Sora главным образом из-за стоимости обслуживания: бесплатный сервис потреблял слишком много ресурсов. Компания сосредоточилась на ChatGPT и Codex — инструментах для повышения продуктивности, причём Codex лучше раскрывается на платных тарифах. 
AI Video - AI Video Generator После ухода Sora конкурирующие ИИ-приложения стали активнее продвигать генерацию видео. Gemini и Grok уже позволяют превращать текстовые запросы и изображения в ролики, однако для этих универсальных чат-ботов видео остаётся лишь одной из возможностей. 
Kling AI: AI Image&Video Maker Kling AI и AI Video целиком посвящены созданию роликов. Kling AI появилось в App Store три месяца назад. AI Video выпущено компанией HUBX, у которой в магазине размещено 15 ИИ-приложений. Новое приложение нацелено на создание вирусных видеороликов. Выше обоих в рейтинге стоят только продукты OpenAI, Anthropic, Google и Meta✴✴. Sora тоже возглавляла чарт при запуске, но через несколько месяцев перестала показывать заметные результаты. TSMC и Sony объединились для разработки и производства датчиков изображения
08.05.2026 [13:42],
Владимир Мироненко
Компании TSMC и Sony Semiconductor Solutions («дочка» Sony Group) объявили о планах создания нового совместного предприятия в Японии для разработки и производства датчиков изображения следующего поколения. 
Источник изображения: Sony Новое СП, контрольный пакет акций в котором будет принадлежать Sony, создаст линии разработки и производства на новом заводе японской компании в Коси, в префектуре Кумамото (Япония). Его создание позволит объединить опыт Sony в проектировании датчиков с производственными и технологическими преимуществами TSMC, углубив давнее партнёрство двух компаний. Сообщается, что компании подписали необязывающий меморандум о взаимопонимании (MOU) и обсуждают потенциальные инвестиции со стороны СП при условии заключения окончательного соглашения. Эти инвестиции, наряду с капитальными затратами Sony на существующем заводе в Нагасаки, будут осуществляться поэтапно в соответствии с рыночным спросом при условии поддержки со стороны правительства Японии. Партнёрство также будет направлено на изучение и освоение новых возможностей в области применения ИИ в таких сферах, как автомобилестроение и робототехника. У компаний уже есть совместное предприятие Japan Advanced Semiconductor Manufacturing (JASM), созданное в 2021 году, контрольным пакетом акций которого владеет TSMC. Его первый завод в Японии запустил серийное производство в конце 2024 года. Генераторы изображений стали главным драйвером роста ИИ-чат-ботов
05.05.2026 [11:50],
Павел Котов
Выпуск моделей с генераторами изображений стимулирует увеличение популярности мобильных приложений с искусственным интеллектом — рост по сравнению с простыми обновлениями ускоряется в 6,5 раза, показала статистика аналитической компании Appfigures. 
Источник изображения: Milad Fakurian / unsplash.com Для OpenAI ChatGPT и Google Gemini появление генераторов изображений увеличивало аудиторию на десятки миллионов пользователей. В течение 28 дней после выхода генератора изображений Nano Banana с чат-ботом Gemini 2.5 Flash приложение набрало 22 млн новых пользователей, что соответствует росту числа загрузок более чем вчетверо за указанный период. 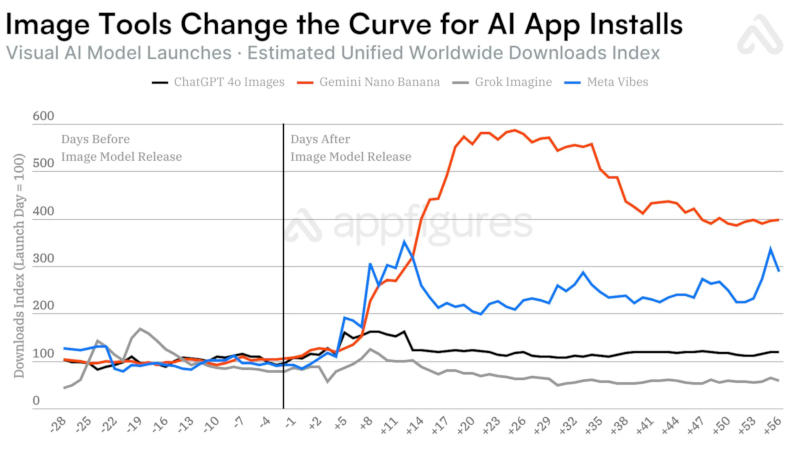 В случае генератора изображений в составе OpenAI GPT-4o рост аудитории составил 12 млн человек — в 4,5 раза быстрее по сравнению с базовым вариантом GPT-4o, а также GPT-4.5 и GPT-5. Аналогичная тенденция сработала и с появлением ленты Vibes в приложении Meta✴✴ AI, хотя оно предлагало генерацию не изображений, а видео — нововведение дало 2,6 млн дополнительных загрузок. 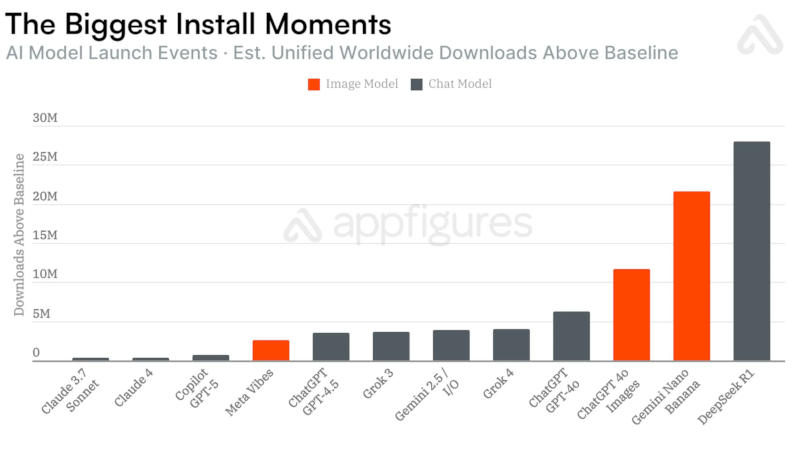 К сожалению для разработчиков, росту числа загрузок не всегда сопутствует рост выручки: в случае с Nano Banana компания Google заработала лишь на $181 тыс. больше; приложение Meta✴✴ AI с появлением Vibes существенного роста дохода не показало; и только в случае OpenAI модель GPT-4o с генератором изображения помогла компании нарастить выручку на $70 млн за 28 дней. 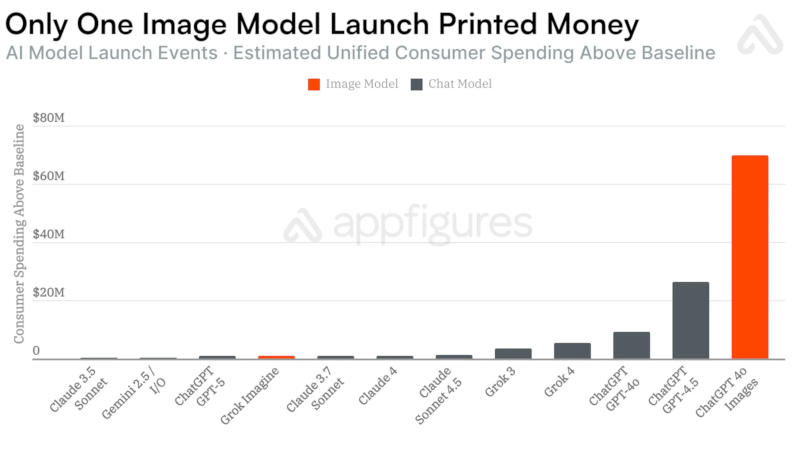 Единственным исключением из правил оказался взрывной рост в 28 млн загрузок с выходом модели DeepSeek R1, отметили в Appfigures. Всё потому, объясняют аналитики, что компания DeepSeek сама по себе стала мировой сенсацией из-за уникальных методов обучения ИИ с минимальными затратами по сравнению с конкурентами — генератора изображений в приложении не было. OpenAI выпустила ИИ-модель ChatGPT Images 2.0, которая отлично генерирует текст на картинках
22.04.2026 [06:26],
Дмитрий Федоров
OpenAI представила модель генерации изображений ChatGPT Images 2.0, которая впервые среди массовых ИИ корректно отрисовывает текст на картинках. Если два года назад диффузионные ИИ-модели не могли составить меню мексиканского ресторана без выдуманных слов вроде «enchuita» и «burrto», то новая модель создаёт изображения с надписями, пригодными к использованию без правок.  Ещё в 2024 году диффузионные ИИ-модели систематически искажали надписи. По словам Асмелаша Тека Хадгу (Asmelash Teka Hadgu), основателя и гендиректора Lesan AI, модели восстанавливают изображение из шума и усваивают паттерны, покрывающие основную массу пикселей, а текст занимает ничтожную долю площади. 
Слева — меню, сгенерированное ChatGPT Images 2.0: все надписи читаемы, ни одного выдуманного слова. Справа — три варианта от Microsoft Designer на основе DALL-E 3: «Enchidas», «Tamrielo», «Churiros», «Margartas» и десятки других искажений. Источник изображений: ChatGPT Images 2.0, Microsoft Designer (DALL-E 3) / techcrunch.com С тех пор исследователи опробовали альтернативные подходы — в частности, авторегрессионные модели, которые предсказывают содержание изображения и работают по принципу, близкому к большим языковым моделям (LLM). OpenAI не раскрыла, какая архитектура лежит в основе Images 2.0. Компания пояснила лишь, что новинка умеет «рассуждать» — искать информацию в интернете, генерировать несколько изображений по одному запросу и перепроверять результаты. Благодаря этому Images 2.0 создаёт маркетинговые материалы в разных размерах и даже комиксы. У ИИ-модели также улучшена работа с нелатинскими шрифтами — японским, корейским, хинди и бенгальским. Однако знания Images 2.0 ограничены декабрём 2025 года, что может сказаться на точности генерации по запросам о недавних событиях. 
Источник изображения: ChatGPT Images 2.0 / openai.com «Images 2.0 выводит детализацию и точность генерации на беспрецедентный уровень. Модель способна продумать сложную композицию и воплотить её на практике: следовать инструкциям, сохранять заданные детали и отрисовывать элементы, на которых обычно спотыкаются генераторы, — мелкий текст, пиктограммы, элементы интерфейса, насыщенные композиции и тонкие стилистические ограничения, — и всё это в разрешении до 2K», — говорится в пресс-релизе компании. Генерация при этом занимает больше времени, чем обычный текстовый запрос к ChatGPT, но даже многопанельный комикс укладывается в несколько минут. 
Источник изображения: ChatGPT Images 2.0 / openai.com Доступ к Images 2.0 получат все пользователи ChatGPT и Codex. Платные подписчики смогут генерировать более сложные изображения. OpenAI также откроет программный интерфейс (API) gpt-image-2 — стоимость будет зависеть от качества и разрешения выходных изображений. Microsoft представила облегчённый ИИ-генератор изображений MAI-Image-2-Efficient
15.04.2026 [14:50],
Павел Котов
Microsoft анонсировала обновлённую версию модели искусственного интеллекта, которая генерирует изображения по текстовым запросам, — она получила название MAI-Image-2-Efficient. Она и её предшественница MAI-Image-2 генерируют качественные фотореалистичные картинки, при этом новая работает на 22 % быстрее и вчетверо эффективнее. 
Источник изображения: BoliviaInteligente / unsplash.com В марте Microsoft запустила на платформах Copilot, Bing Image Creator и MAI Playground генератор изображений MAI-Image-2, который занял в рейтинге Arena.ai третье место среди себе подобных. Недавно компания расширила доступ к ней, добавив её на платформу Foundry наряду с MAI-Voice-1 и MAI-Transcribe-1. Обновлённая MAI-Image-2-Efficient создана для случаев, когда необходимо нечто быстрое, масштабируемое и не влекущие неоправданных расходов ресурсов. Если не требуется высокая точность изображений, MAI-Image-2-Efficient оказывается оптимальным вариантом — она пригодится для генерации иллюстраций в соцсетях, создания макетов-заглушек и миниатюр продуктов; то есть в тех случаях, когда скорость и объём контента важнее пиксельной точности. Microsoft MAI-Image-2, напротив, проявляет себя во всей красе, когда востребован, например, качественный портрет героя, кинематографическая сцена и внимание к деталям, а аспект скорости отходит на второй план. Обновлённая MAI-Image-2-Efficient по ряду параметров превосходит не только предшественницу от самой Microsoft, но также работает на 40 % быстрее таких систем как Google Gemini 3.1 Flash, Gemini 3.1 Flash Image и Gemini 3 Pro Image. Разработчики уже могут подключать MAI-Image-2-Efficient на платформах Microsoft Foundry и MAI Playground. Стоимость её работы составляет $5 за 1 млн входящих и $19,50 за 1 млн выходящих токенов — для сравнения, стоимость использования MAI-Image-2 составляет $5 и $33 соответственно. Скоро MAI-Image-2-Efficient появится в Copilot, Bing и на других платформах. В Южной Корее разработан сверхтонкий модуль камеры с углом зрения 140 градусов
13.04.2026 [08:47],
Алексей Разин
Габариты современных цифровых камер, встраиваемых в смартфоны, имеют некоторые ограничения, поэтому той же Apple при разработке сверхтонкого iPhone Air пришлось довольствоваться единственной камерой с тыльной стороны устройства. Южнокорейские разработчики недавно предложили создать камеру с углом обзора 140 градусов, которая в толщину занимает менее 1 мм. 
Источник изображения: Apple Южнокорейских учёных из KAIST вдохновила природа. Принцип устройства инновационной камеры для мобильных устройств был подсмотрен у насекомых с их фасеточным зрением. Большой угол зрения достигается комбинацией нескольких компактных линз, создающих общую картину окружающего пространства из фрагментов, напоминающих мозаику. При этом в отличие от традиционных широкоугольных камер, которые размывают картинку на периферии, камера SOEMLA сохраняет чёткость картинки по всему диапазону углов обзора. С точки зрения компоновки она обладает весьма компактными размерами, выступая над поверхностью печатной платы всего на 0,94 мм. Обычные широкоугольные камеры могут выступать на 8,3 мм. 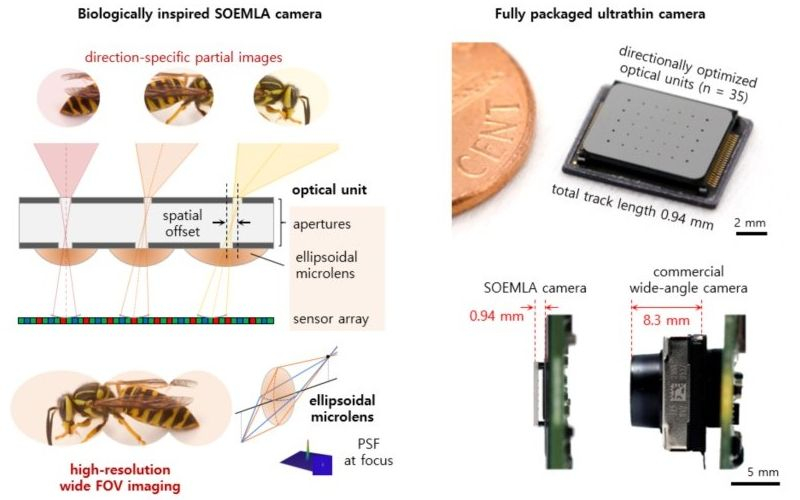
Источник изображения: KAIST, Digital Trends Помимо смартфонов и различных типов носимых устройств, такие камеры можно использовать в медицинском диагностическом оборудовании типа тех же эндоскопов. Впрочем, под вопросом пока остаётся способность такой камеры снимать видео в высоком разрешении или передавать детали изображения в условиях низкой освещённости. Кроме того, пока не уточняется, сколько подобные камеры будут стоить в условиях массового производства, и каким образом сочетаться с другими компонентами электронных устройств. Microsoft представила MAI-Image-2 — ИИ-генератор изображений, который оказался неожиданно хорош в фотореализме и инфографике
21.03.2026 [12:07],
Владимир Фетисов
В октябре прошлого года Microsoft представила ИИ-модель для генерации изображений MAI-Image-1, которая заняла девятое место рейтинга на платформе Arena.ai. Теперь же софтверный гигант объявил о запуске алгоритма второго поколения MAI-Image-2, способного создавать изображения с более естественным освещением, точной передачей тонов кожи и реалистичными деталями. Эта версия ИИ-модели поднялась на третью строчку рейтинга Arena.ai. 
Источник изображения: microsoft.ai Microsoft существенно улучшила возможности модели в плане корректного отображения текста на генерируемых изображениях. За счёт этого алгоритм лучше подходит для создания инфографики, слайдов, диаграмм и др. Microsoft заявила, что MAI-Image-2 лучше справляется с генерацией кинематографичных и гипердетализированных изображений, включая сюрреалистические концепции, замысловатые композиции и фантастические миры. «Вышел наш новый генератор изображений MAI-Image-2! Он уже доступен на MAI Playground для создания всего: от фотореализма до детализированной инфографики. Наша команда приложила невероятные усилия для этого релиза», — написал в соцсети X глава ИИ-подразделения Microsoft Мустафа Сулейман (Mustafa Suleyman). В рейтинге на платформе Arena.ai MAI-Image-2 занимает третье место. Лидерами остаются алгоритмы Google gemini-3.1-flash-image-preview и OpenAI gpt-image-1.5-high-fidelity. Пользователи Copilot и Bing Image Creator смогут задействовать модель MAI-Image-2 в ближайшее время. В настоящее время алгоритм доступен через платформу MAI Playground, а разработчик могут получить доступ к модели через соответствующий API на Microsoft Foundry. AMD выпустила FSR 4.1 с улучшенной детализацией и плавностью изображения — но только для Radeon RX 9000
20.03.2026 [14:47],
Николай Хижняк
Компания AMD выпустила обновлённую технологию ИИ-масштабирования FSR 4.1. Она входит в состав свежего графического драйвера Radeon Software Adrenalin Edition 26.3.1. Последний среди прочего обеспечивает поддержку игры поддержку Crimson Desert. Разработчик игры Pearl Abyss сообщает, что она вышла сегодня во всём мире, а версия для ПК поддерживает технологии FSR 3/4, а также AMD FSR Ray Regeneration. 
Источник изображений: VideoCardz / AMD По словам AMD, обновление FSR Upscaling 4.1 улучшает работу функции масштабирования на основе машинного обучения, обеспечивая более высокую детализацию, более плавное движение камеры и более эффективную работу в режиме Ultra Performance Mode.  Ходили слухи, что AMD может внедрить поддержку FSR 4 для более старых графических архитектур. Однако в последнем драйвере чётко указана поддержка FSR 4.1 только для видеокарт серии Radeon RX 9000. 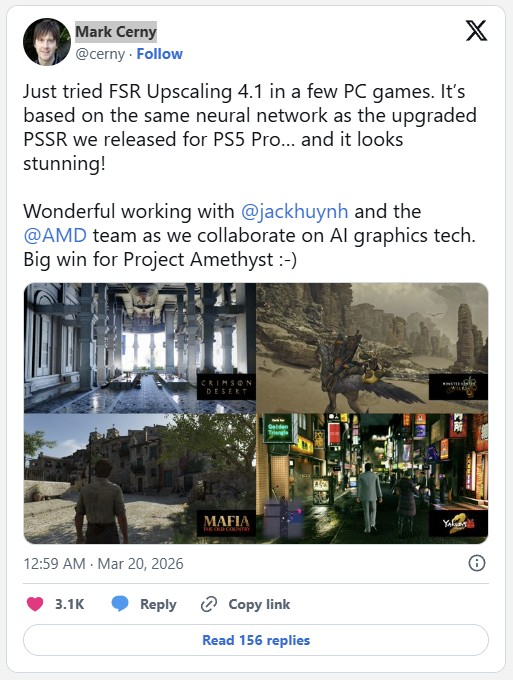 Ведущий архитектор PS5 и PS5 Pro Марк Черни (Mark Cerny) отметил выпуск FSR 4.1 на своей странице в соцсети X, обратив внимание на то, что в основе технологии лежит та же нейронная сеть, что и в обновлённом апскейлере PSSR 2 для игровой консоли PlayStation 5 Pro. О выпуске технологии ИИ-масштабирования PlayStation Spectral Super Resolution (PSSR 2) компания Sony сообщила ранее на этой неделе. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



