|
Опрос
|
реклама
Быстрый переход
ИИ-генератор изображений Adobe Firefly теперь можно обучать на своих работах
19.03.2026 [18:18],
Владимир Фетисов
Adobe объявила о запуске настраиваемых ИИ-генераторов изображений, которые могут имитировать определённые художественные стили и дизайны персонажей. Модели Firefly Custom Models стали доступны в рамках публичного бета-тестирования, благодаря чему творческие люди и компании могут обучить ИИ-модели на собственных работах. За счёт этого генерируемые изображения будут соответствовать единой эстетике персонажей, иллюстраций и фотографий. 
Источник изображения: Adobe Ожидается, что такой подход позволит оптимизировать рабочие процессы создателей контента, которым требуется выполнять большие объёмы работ, за счёт сохранения визуальной согласованности в разных проектах, вместо того, чтобы каждый раз начинать всё с нуля. По данным Adobe, пользовательские ИИ-модели позволят сохранять разные детали, такие как толщина штрихов, цветовые гаммы, освещение и черты персонажей при генерации новых изображений. По умолчанию пользовательские модели являются частными, поэтому используемые для их обучения материалы не будут применяться для обучения общих языковых моделей Adobe Firefly. «Чтобы развивать бренд, вам нужен постоянный поток материалов, которые будут последовательно выражать вашу сущность. Эти материалы должны быть вашими и только вашими. После обучения ваша пользовательская модель становится частью вашего рабочего процесса. Вы можете генерировать новые идеи, соответствующие вашей эстетике, повторно использовать модель в разных проектах, брифингах и кампаниях, а также создавать контент в масштабе, не теряя того, что отличает вашу работу», — говорится в пресс-релизе Adobe. Google представила Nano Banana 2 — обновлённый генератор изображений работает быстрее и качественнее, и доступен бесплатно
26.02.2026 [20:49],
Николай Хижняк
Компания Google анонсировала последнюю версию своей популярной ИИ-модели для генерации изображений — Nano Banana 2. Новая модель, которая технически является аналогом Gemini 3.1 Flash Image, способна создавать более реалистичные изображения по сравнению с предшественницей. Nano Banana 2 станет моделью по умолчанию в приложении Gemini для режимов Fast, Thinking и Pro, то есть новинка будет доступна и бесплатным пользователям. 
Источник изображений: Google Компания впервые выпустила Nano Banana в августе 2025 года. Она быстро завоевала популярность среди пользователей Gemini, особенно в таких странах, как Индия. В ноябре Google представила Nano Banana Pro, позволяющую создавать более детализированные и высококачественные изображения. Новая Nano Banana 2 сохраняет ряд характеристик высокой детализации версии Pro, но генерирует изображения быстрее. С её помощью можно создавать изображения с разрешением от 512 пикселей до 4K и с различными соотношениями сторон.  Nano Banana 2 поддерживает единообразие персонажей (до пяти) и точную проработку до 14 объектов в одном рабочем процессе, что улучшает возможности повествования. По словам Google, пользователи могут отправлять сложные запросы с подробными нюансами для генерации изображений. Кроме того, модель позволяет создавать медиаконтент с более ярким освещением, насыщенными текстурами и чёткими деталями. 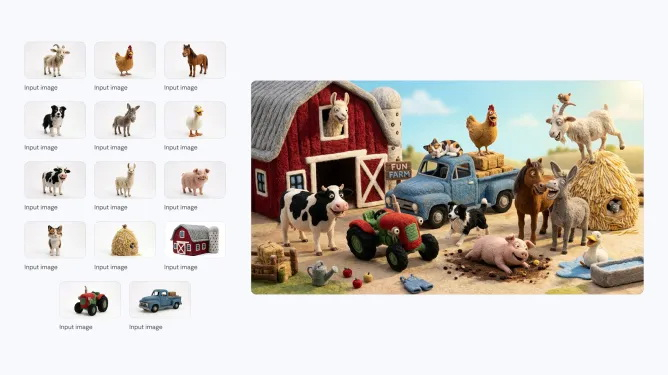 С запуском Nano Banana 2 станет моделью по умолчанию для генерации изображений во всех приложениях Gemini. Компания также сделает её моделью по умолчанию для генерации изображений в своём инструменте для редактирования видео Flow. В 141 стране Nano Banana 2 станет моделью по умолчанию в Google Lens и в режиме поиска с ИИ в мобильной и веб-версии Google Search. Пользователи тарифных планов Google AI Pro и Ultra смогут продолжать использовать Nano Banana Pro для специализированных задач, выбрав соответствующую настройку через меню с тремя точками. Для разработчиков Nano Banana 2 будет доступна в режиме предварительного просмотра через API Gemini, Gemini CLI и Vertex API. Она также появится в AI Studio и инструменте разработки Antigravity, выпущенном в ноябре прошлого года. Google заявляет, что все изображения, созданные с помощью новой модели, будут иметь водяной знак SynthID — фирменный маркер для обозначения изображений, сгенерированных искусственным интеллектом. Изображения также совместимы с системой C2PA Content Credentials, которая подтверждает происхождение контента и фиксирует, подвергался ли он изменениям. Систему поддерживают Adobe, Microsoft, Google, OpenAI и Meta✴✴. Google сообщила, что с момента запуска проверки SynthID в приложении Gemini в ноябре ей воспользовались более 20 млн раз. «Блокнот» всё больше превращается в WordPad — теперь Microsoft добавила поддержку изображений
20.02.2026 [20:03],
Сергей Сурабекянц
Издание Windows Latest сообщило, что Microsoft добавляет поддержку изображений в «Блокнот» для Windows 11. Осведомлённые источники сообщают, что эта функция станет частью уже внедрённой поддержки форматирования текста и окажет «минимальное влияние» на производительность. Пользователи смогут отключить её в настройках приложения. 
Источник изображения: Microsoft «Блокнот» больше не является тем простым, быстрым и доступным текстовым редактором, каким пользователи знали его на протяжении почти четверти века. Похоже, что Microsoft старательно наделяет его новыми функциями, которые должны компенсировать удаление WordPad из операционной системы Windows. В отличие от «Блокнота», WordPad всегда поддерживал изображения и другие функции форматирования текста. Фактически, во многих отношениях WordPad ощущался как упрощённая версия Word, в то время как Блокнот оставался простым текстовым редактором. Теперь, после исчезновения WordPad, Microsoft пытается заполнить образовавшуюся пустоту и добавляет новые функции в «Блокнот». Так, недавно компания добавила поддержку языка разметки текста Markdown. С его помощью можно выделять текст жирным шрифтом или курсивом, а также вставлять ссылки в «Блокнот», что уже привело к появлению уязвимости в этом текстовом редакторе. После недавнего обновления участники программы Windows Insider могли заметить новую кнопку на панели инструментов «Блокнота». Она отображается только в диалоговом окне «Что нового», которое появляется при первой установке приложения или применении одного из последних обновлений. 
Источник изображений: Windows Latest В данный момент эта кнопка не активна, но появление ярлыка изображения в рекламных материалах — не ошибка. Поддержка изображений в «Блокноте» уже тестируется и в ближайшие месяцы следует ожидать её появления в новых сборках Windows 11. Как и остальные параметры форматирования, поддержка изображений будет включена по умолчанию, но пользователь сможет отключить её в настройках.  ИИ-бот Duck.ai от DuckDuckGo научился редактировать изображения по текстовым описаниям
20.02.2026 [09:33],
Владимир Фетисов
В конце прошлого года DuckDuckGo реализовала в своём приватном ИИ-боте Duck.ai функцию генерации изображений на основе текстовых описаний. Теперь же разработчики объявили о внедрении возможности редактирования изображений посредством запросов к нейросети. Задействовать нововведение можно бесплатно и без регистрации аккаунта, но оформившие подписку пользователи получат расширенные ежедневные лимиты. 
Источник изображения: 9to5mac.com Пользователь может начать взаимодействие с редактором изображений в Duck.ai нажатием кнопки «Новое изображение» в боковом меню чат-бота или же просто перетащив изображение в формате JPEG, JPG, PNG или WebP в поле для ввода запроса. После этого останется лишь описать изменения, которые следует внести, а всё остальное сделает ИИ-сервис, работающий на основе большой языковой модели от OpenAI. Как и в случае генерации изображений, при редактировании картинок все метаданные обрабатываемого изображения, а также IP-адрес пользователя, удаляются до того, как запрос передаётся в OpenAI. В DuckDuckGo отметили, что ещё одним положительным моментом в плане конфиденциальности является то, что загруженные изображения хранятся локально на устройстве для обеспечения высокого уровня приватности пользователей. В компании напомнили, что Duck.ai является отдельной от основной поисковой системы DuckDuckGo платформой. При этом пользователи, которые по каким-то причинам не хотят использовать ИИ-функции, могут задействовать поисковый интерфейс без ИИ, расположенный по адресу noai.duckduckgo.com. Не так давно компания провела опрос, показавший, что подавляющее большинство респондентов не хочет добавлять ИИ-функции в свои поисковые инструменты. В ответ на это компания прилагает усилия, чтобы подчеркнуть, что каждая предлагаемая ею ИИ-функция является опциональной, и разработчики по-прежнему поддерживают взятый ранее курс на обеспечение конфиденциальности пользователей. Nvidia выпустит динамическую мультикадровую генерацию и режим MFG x6 уже весной
06.02.2026 [12:39],
Николай Хижняк
Nvidia выпустит новую технологию динамического мультикадрового генератора (Dynamic Multi Frame Generation) и мультикадрвый генератор с режимом x6 весной этого года. Об этом в разговоре с журналистами немецкого портала HardwareLuxx рассказал представитель компании. 
Источник изображений: Nvidia На выставке CES 2026 в начале января Nvidia представила динамическую многокадровую генерацию Dynamic Multi Frame Generation как режим, управляемый драйвером, который стремится к обеспечению заданной пользователем частоты обновления монитора, а не использует фиксированный множитель, как обычный многокадровый генератор. Например, для дисплея с частотой обновления 240 Гц требуется, чтобы видеокарта обеспечивала всего 240 кадров в секунду. Статический многокадровый генератор может превысить это целевое значение, обеспечивая, например, 280 или 300 кадров в секунду в зависимости от сцены, тратя на это дополнительные ресурсы. С помощью динамической многокадровой генерации драйвер может переключаться между множителями в зависимости от нагрузки на графическую систему при той или иной игровой сцене. Он может включать как множитель x6 в более ресурсоёмких участках, так и снижать его до x3 или x2 при снижении нагрузки. Множитель может меняться постоянно. В рамках демонстрации, с которой ознакомился HardwareLuxx, не было отмечено никаких проблем даже при частом переключении. «Технология динамического мультикадрового генератора, а также новый режим x6 для многокадрового генератора Nvidia запланированы на весну 2026 года», — пишет HardwareLuxx. 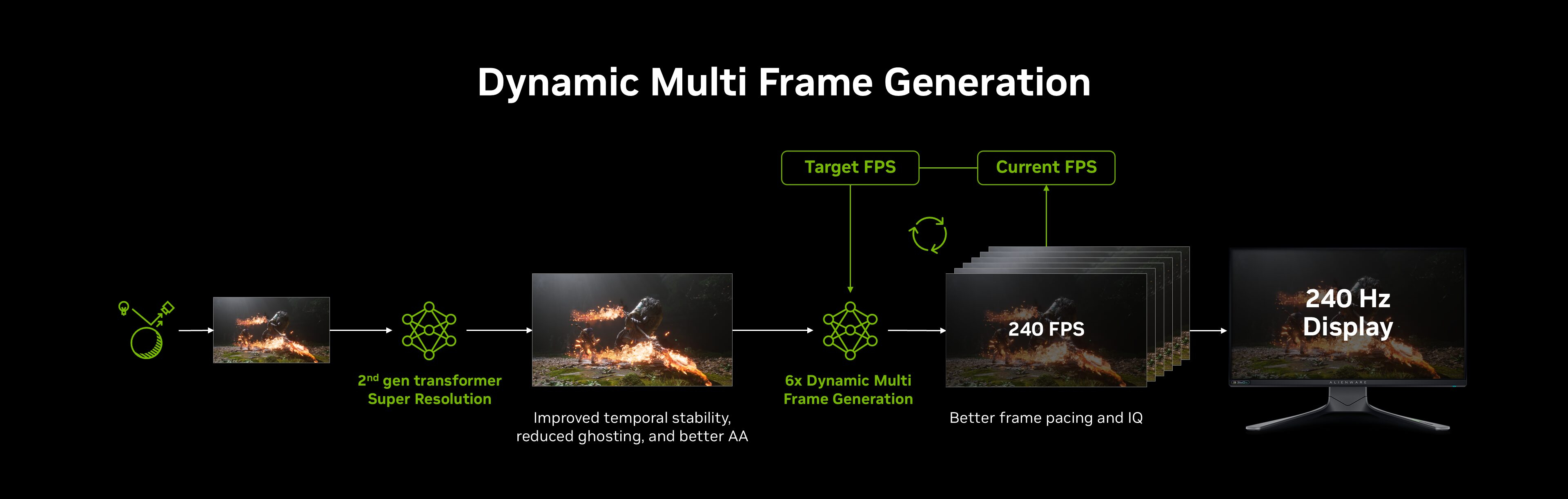 Nvidia уже предлагает функцию мультикадрового генератора (Multi Frame Generation, MFG) для владельцев видеокарт GeForce RTX 50-й серии. Она генерирует до трёх промежуточных кадров между двумя реальными. Это даёт четырёхкратный прирост производительности по сравнению с апскейлингом без генерации. Компания Intel недавно выпустила аналогичную технологию в составе программного пакета XeSS 3, но её официальная поддержка пока осуществляется только для встроенной графики процессоров Panther Lake. У AMD нет аналога мультикадрового генератора — компания предлагает технологию AMD Fluid Motion Frames (AFMF), которая генерирует только один промежуточный кадр между двумя реальными. Firefly без ограничений: Adobe сняла лимиты на ИИ-генерацию изображений и видео, но не навсегда
02.02.2026 [19:35],
Сергей Сурабекянц
Adobe предоставит подписчикам своего ИИ-сервиса Firefly неограниченное количество генераций изображений и видео как с использованием собственных, так и поддерживаемых сторонних моделей ИИ. Ежемесячные кредиты на генерацию изображений и видео будут отменены для новых подписчиков, которые зарегистрируются в системе до 16 марта. 
Источник изображения: Adobe Firefly — это набор генеративных моделей Adobe для создания изображений и видео. В него входят как собственные модели Adobe, так и интеграции со сторонними сервисами, такими как Google Nano Banana Pro, OpenAI GPT-Image 1.5 и Runway Gen-4. После первоначального запуска Firefly в составе пакета приложений Creative Cloud, Adobe выпустила Firefly как отдельную платформу, доступную в браузере или через специальные приложения на мобильных платформах. Подписчики Adobe Firefly могут выбрать один из нескольких тарифных планов. До сих пор одним из ключевых отличий было количество кредитов на создание изображений, включённых в каждый тарифный план. Но с сегодняшнего дня Adobe предлагает при оформлении подписки генерацию неограниченного количества изображений и видео. Важно отметить, что предложение действительно только для отдельной подписки Adobe Firefly, а не для подписок Creative Cloud. «Зарегистрируйтесь до 16 марта и получите неограниченное количество поколений изображений и видео Firefly с разрешением до 2K в приложении Adobe Firefly. Предложение распространяется на клиентов, использующих тарифные планы Firefly Pro, Firefly Premium, а также планы на 4000, 7000 и 50 000 кредитов, и включает неограниченное количество генераций с использованием ведущих в отрасли моделей изображений, включая Google Nano Banana Pro, GPT Image Generation, Runway Gen-4 Image, а также коммерчески безопасные модели изображений и видео Firefly от Adobe», — заявила Adobe. По данным Adobe, 86 % создателей контента теперь используют ИИ в своей повседневной работе. Кроме того, за последний год длина их запросов удвоилась. Это свидетельствует о том, что создатели контента всё чаще используют ИИ как часть своих рабочих процессов. Компания отмечает, что сегодняшний шаг направлен на то, чтобы помочь создателям оставаться в творческом потоке, проходя через процесс проб и ошибок, не беспокоясь о своих кредитах на создание изображений. Adobe также сообщила, что в преддверии Дня святого Валентина и Лунного Нового года пользователи по всему миру получат возможность использовать собственные модели, а также интеграцию Firefly со сторонними сервисами, чтобы протестировать платформу. Учёные придумали термодинамический компьютер, который генерирует изображения в 10 млрд раз энергоэффективнее ИИ
28.01.2026 [15:43],
Павел Котов
Американские учёные предложили использовать в генераторах изображений на основе искусственного интеллекта технологию термодинамических вычислений — она позволяет сократить энергетические затраты на некоторые операции на величину до 10 млрд раз. 
Источник изображения: Steve Johnson / unsplash.com Модели генеративного ИИ, в том числе DALL-E, Midjourney и Stable Diffusion, создают фотореалистичные изображения, но потребляют при этом огромное количество энергии. Это диффузионные модели. При обучении им подают большие наборы изображений, к которым постепенно добавляют шум, пока картинка не станет похожей на помехи в старом телевизоре. Далее нейросеть овладевает обратным процессом и генерирует новые изображения по запросу. Проблема в том, что вычисления для алгоритмов ИИ с добавлением и последующим удалением шума потребляют слишком много энергии — термодинамические вычисления позволяют сократить их несоразмерно возможностям современного цифрового оборудования. При термодинамических вычислениях используются физические схемы, которые меняют параметры в ответ на шум, например вызванный случайными тепловыми перепадами в окружающей среде. Стартап Normal Computing построил чип на основе восьми соединённых друг с другом резонаторов — соединители подключаются сообразно типу решаемой чипом задачи. Далее резонаторы подвергаются воздействию внешней среды, вносят шум в цепь и таким образом выполняют вычисления. После того как система достигает состояния равновесия, решение считывается из новой конфигурации резонаторов. Учёные показали, что можно построить термодинамическую версию нейросети. Эта методика закладывает основу для генерации изображений с помощью термодинамических вычислений. В термодинамический компьютер вводится набор изображений, далее компоненты компьютера подвергаются естественным воздействиям среды до тех пор, пока связи, соединяющие эти компоненты, не достигают состояния равновесия. Далее вычисляется вероятность того, что термодинамический компьютер с заданным состоянием связей сможет обратить этот процесс, и значения этих связей корректируются, чтобы повысить эту вероятность до максимальной. Симуляции подтвердили, что можно построить термодинамический компьютер, настройки которого помогут генерировать изображения рукописных цифр. Это достигается без энергоёмких цифровых нейросетей или создающего шум генератора псевдослучайных чисел. По сравнению с цифровыми нейросетями термодинамические компьютеры пока примитивны, признают учёные, и как проектировать их для работы на уровне DALL-E, они пока не знают. Но в аспекте энергоэффективности они обещают значительное преимущество. ИИ-бот Grok «раздевает» по 190 людей в минуту — за 11 дней создано 3 млн дипфейков, в том числе с детьми
23.01.2026 [08:23],
Владимир Фетисов
Ранее уже сообщалось о том, что ИИ-бот Grok компании xAI буквально забрасывал соцсеть X дипфейками сексуального характера, сгенерированными без согласия пользователей. Теперь же стали известны конкретные цифры, позволяющие оценить масштаб проблемы. 
Источник изображения: Engadget По данным Engadget, за 11 дней Grok сгенерировал около 3 млн дипфейков сексуального характера, причём около 23 тыс. из них содержали изображения несовершеннолетних. Иначе говоря, в течение 11 дней Grok генерировал примерно 190 фейковых изображений сексуального характера в минуту. На этой неделе британская некоммерческая организация Центр по борьбе с цифровой ненавистью (CCDH) опубликовала свои выводы по данному вопросу, основанные на случайной выборке из 20 тыс. сгенерированных с помощью Grok изображений в период с 29 декабря по 9 января. Специалисты организации также экстраполировали полученные данные для более масштабной оценки, основанной на 4,6 млн изображений, созданных Grok за указанный период. В рамках исследования дипфейки сексуального характера определялись как «фотореалистичные изображения человека в сексуальных позах, ракурсах или ситуациях; человека в нижнем белье, купальнике или аналогичной открытой одежде» и др. Исследование CCDH не учитывало текстовые промпты, поэтому в полученных результатах нет разделения относительно количества дипфейков, созданных на основе реальных фото и сгенерированных только по текстовым описаниям. Для определения доли изображений сексуального характера в выборке использовался ИИ-алгоритм. xAI ограничила возможность редактирования реальных фото с помощью Grok для бесплатных пользователей X в начале 9 января. Однако это не решило проблему, а лишь превратило её в премиум-функцию. Спустя несколько дней, 14 января, X полностью ограничила возможность Grok «раздевать» людей на реальных изображениях. При этом данное ограничение действовало только в самой соцсети и не распространялось на отдельное приложение Grok. По данным источника, приложение всё ещё позволяет создавать дипфейки сексуального характера. Поскольку оно распространяется через магазины Google и Apple, политика которых явно запрещает подобный контент, можно было ожидать удаления приложения с этих платформ, но этого не произошло. При этом другие подобные ИИ-генераторы для «раздевания» людей прежде оперативно удалялись из магазинов Apple и Google. X заявила, что Grok больше не раздевает людей — но это не так
15.01.2026 [11:08],
Владимир Мироненко
После волны критики из-за создания в соцсети X с помощью чат-бота Grok AI дипфейков сексуального характера без согласия пользователей, платформа сообщила о внесении изменений в возможности аккаунта Grok AI редактировать изображения реальных людей. Однако, как утверждает ресурс The Verge, в приложении Grok можно по-прежнему создавать откровенные изображения человека в бикини, используя бесплатный аккаунт. 
Источник изображения: Mariia Shalabaieva/unsplash.com «Мы внедрили технологические меры, чтобы предотвратить редактирование изображений реальных людей в откровенной одежде, такой как бикини, через аккаунт Grok. Это ограничение распространяется на всех пользователей, включая платных подписчиков», — сообщается в обновлении аккаунта X. В нём также отмечено, что создание изображений и возможность редактирования изображений через аккаунт Grok на платформе X теперь доступны только платным подписчикам. «Это добавляет дополнительный уровень защиты, помогая гарантировать, что лица, пытающиеся злоупотреблять аккаунтом Grok для нарушения закона или нашей политики, могут быть привлечены к ответственности», — сообщила администрация соцсети. Кроме того, было объявлено, что платформа блокирует возможность для всех пользователей создавать изображения реальных людей в бикини, нижнем белье и подобной одежде через аккаунт Grok и в Grok in X в тех юрисдикциях, где это незаконно. Ранее стало известно, что британское Управление связи (Ofcom) начало расследование по этому поводу. Также сообщается, что на этой неделе в Великобритании вступит в силу закон, согласно которому создание интимных дипфейк-изображений без согласия пользователей будет считаться уголовным преступлением. Тест Nvidia DLSS 4.5 на видеокартах серий RTX 50/40/30/20 показал потерю 12 % производительности у Ampere и Turing
10.01.2026 [18:41],
Николай Хижняк
Два независимых обзора от Computer Base и Hardware Unboxed подробно рассматривают производительность DLSS 4.5 Super Resolution на нескольких поколениях графических процессоров GeForce RTX. Обозреватели сходятся в выводах: хотя качество изображения улучшается, производительность старых видеокарт GeForce заметно снижается. 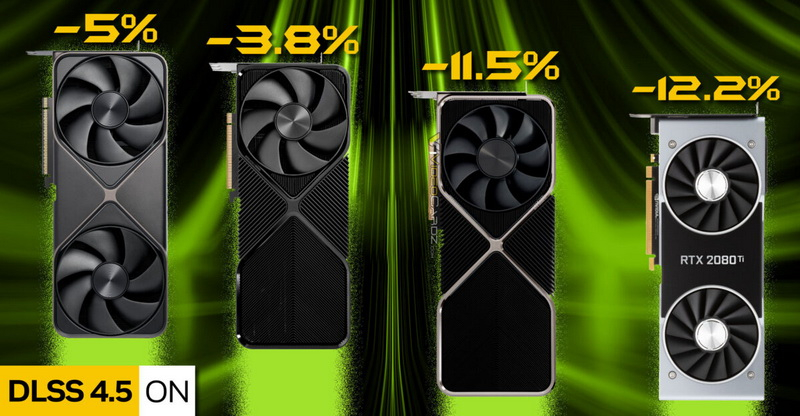
Источник изображения: VideoCardz По данным ComputerBase, новый пресет «Model M» в DLSS 4.5 снижает количество артефактов, наблюдающихся при использовании DLSS 4. В результате получается более чистое изображение и лучшая временная стабильность, хотя и за счёт снижения производительности. 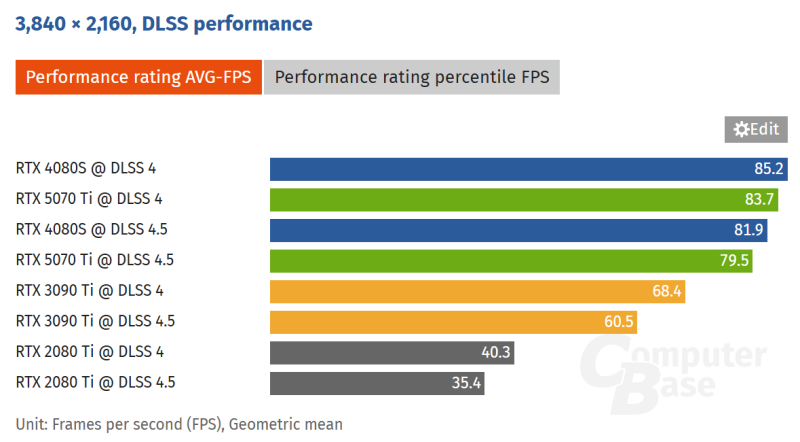
Источник изображения: Computer Base На видеокартах RTX 5070 Ti (Blackwell) и RTX 4080 Super (Ada Lovelace) производительность падает примерно на 4–5 %, а на RTX 3090 Ti (Ampere) и RTX 2080 Ti (Turing) — в среднем примерно на 12 %. Это падение связано с отсутствием поддержки ускорения операций FP8 на старых графических архитектурах, которое активно используется технологией DLSS 4.5. 
Источник изображения здесь и ниже: YouTube / Hardware Unboxed Канал Hardware Unboxed сосредоточился на сравнении чистой производительности видеокарт в разрешении 1440p и методов масштабирования. Результаты показали схожую закономерность: DLSS 4.5 примерно на 9 % медленнее, чем DLSS 4 на видеокартах Blackwell среднего уровня, таких как RTX 5070, и на 20–30 % медленнее на Ampere и Turing. Видеокарты GeForce RTX 40 и RTX 50 сохраняют приемлемый прирост частоты кадров по сравнению с нативным рендерингом, но у более старых серий наблюдается снижение производительности. 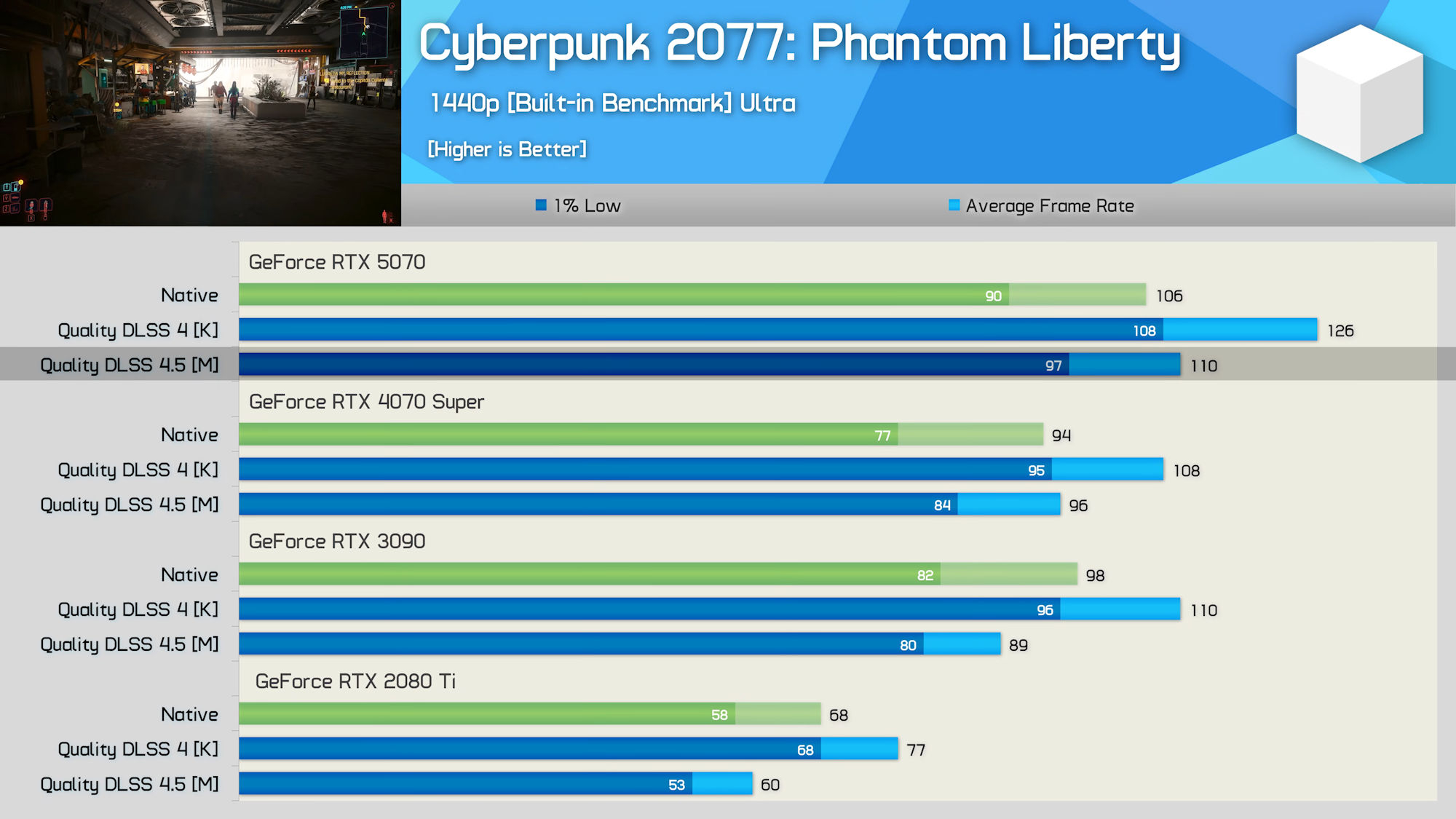 В обоих обзорах отмечается, что более высокая вычислительная нагрузка DLSS 4.5 приводит к очевидным визуальным улучшениям, особенно в отображении воды, теней и стабильности изображения двигающихся объектов. Тем не менее, общее мнение таково, что обновление приносит пользу только более современным видеокартам. Сама Nvidia рекомендует использовать видеокарты RTX 40 и более новые для DLSS 4.5. DLSS 4.5 сильно бьёт по производительности GeForce RTX 2000 и 3000 — Nvidia рассказала, почему
07.01.2026 [16:07],
Николай Хижняк
С выпуском последнего драйвера компания Nvidia добавила совместимым видеокартам поддержку технологии DLSS 4.5, и энтузиасты уже опробовали новую модель масштабирования, проведя тесты не только на новых, но и на более старых видеокартах серии GeForce RTX 3000. Результаты оказались неутешительными. 
Источник изображения: Nvidia Как пишет портал Tom’s Hardware со ссылкой на Mostly Positive Reviews, сравнительные тесты DLSS 4.5 и 4.0 на видеокарте GeForce RTX 3080 Ti в Cyberpunk 2077 показывают, что производительность с более ресурсоёмкой версией DLSS 4.5 на 24 % ниже, чем с DLSS 4.0. При переключении на DLSS 4.5 и использовании предустановки RT Ultra в Cyberpunk 2077 наблюдалось снижение частоты кадров с 42 до 32 FPS. В разрешении 1440p падение производительности сократилось до 14 % — с 72 до 61 FPS, а при разрешении 1440p с отключённой трассировкой лучей производительность упала на 20 % — со 108 до 86 FPS. Mostly Positive Reviews также опубликовал результаты теста производительности в игре The Last of Us Part II при разрешении 1440p и высоких настройках графики с режимом DLSS «Качество». Производительность снизилась на 14 % при использовании DLSS 4.5 — со 154 FPS до 135 FPS в среднем.
Источник изображения: Tom's Hardware по данным Mostly Positive Reviews Результаты тестов не вызывают удивления. Nvidia предупреждала, что не может гарантировать высокую производительность DLSS 4.5 на старых видеокартах RTX, в частности на моделях серий RTX 30 и RTX 20. DLSS 4.5 в пять раз более ресурсоёмка для тензорных ядер. Чтобы уменьшить влияние на производительность на более новых видеокартах RTX 40 и RTX 50, технология DLSS 4.5 использует точность FP8. Представитель Nvidia Джейкоб Фриман (Jacob Freeman) утверждает, что DLSS 4.5 работает всего на 2–3 % медленнее по сравнению с DLSS 4.0 на оборудовании серии RTX 50. К сожалению, тензорные ядра видеокарт серий RTX 30 и RTX 20 не поддерживают операции FP8. Как отмечает портал Tom’s Hardware, владельцы старых карт серий RTX 30 и RTX 20 фактически наблюдают снижение вычислительной производительности DLSS ещё с момента запуска DLSS 4.0. Видеокарты серий RTX 20, RTX 30 и даже RTX 40 работают с масштабированием DLSS 4.0 медленнее по сравнению с видеокартами серии RTX 50. С выходом DLSS 4.5 этот эффект значительно усилился на старых картах. Nvidia выступила с официальным пояснением: «Мы получили некоторые вопросы от сообщества относительно технологии DLSS 4.5 Super Resolution и хотели бы уточнить несколько моментов. Технология DLSS 4.5 Super Resolution использует модель Transformer второго поколения, которая повышает точность освещения, уменьшает ореолы и улучшает временную стабильность. Улучшение качества изображения достигается за счёт расширенного обучения, алгоритмических улучшений и пятикратного увеличения вычислительной мощности. DLSS 4.5 Super Resolution использует точность расчётов FP8, ускоренную на видеокартах серий RTX 40 и 50, чтобы минимизировать влияние более ресурсоёмкой модели на производительность. Поскольку видеокарты серий RTX 20 и RTX 30 не поддерживают расчёты FP8, они будут испытывать большее влияние на производительность по сравнению с более новым оборудованием, и пользователи, возможно, предпочтут остаться на существующем пресете «Модель K» (DLSS 4.0) для более высокой частоты кадров. DLSS 4.5 Super Resolution добавляет поддержку 2 новых предустановок:
Хотя модели M и L поддерживают режимы "Качество" DLSS Super Resolution, а также "Баланс" и режим DLAA, наилучшее соотношение качества и производительности пользователи увидят в режимах "Производительность" и "Сверхвысокая производительность". Кроме того, технология реконструкции лучей не обновлена до архитектуры Transformer второго поколения, преимущества обновления DLSS 4.5 видны только при использовании режима Super Resolution. Чтобы убедиться, что нужная модель включена в настройках, включите отображение статистики в оверлее приложения Nvidia через Alt+Z > Статистика > Просмотр статистики > DLSS», — сообщила Nvidia на своём форуме в разделе «Вопросы и ответы». iPhone станет более американским — улучшенная камера iPhone 18 получит датчик, выпущенный в Техасе
24.12.2025 [18:07],
Сергей Сурабекянц
По данным издания The Elec, Samsung будет поставлять Apple усовершенствованные датчики изображения для iPhone, изготовленные на заводе в Остине, штат Техас. Компания в ближайшее время планирует установить необходимое производственное оборудование для этого проекта и уже разместила объявления о вакансиях для механиков, электриков, инженеров и менеджеров, которые займутся его настройкой. 
Источник изображения: Apple Предполагается, что Samsung будет производить датчики изображения для iPhone с трёхслойной конструкцией, обеспечивающей более высокую плотность пикселей и улучшенную производительность при слабом освещении. Многослойная архитектура датчика также обеспечивает высокую скорость считывания информации, снижение энергопотребления и расширенный динамический диапазон. Этот производственный процесс ранее не применялся в коммерческих масштабах. Ранее в этом месяце Samsung уведомила городской совет Остина о своём намерении потратить $19 млрд на модернизацию своего завода в Остине. Ожидается, что новая производственная линия по выпуску датчиков изображения начнёт работу не ранее марта. Эксперты полагают, что новый датчик предназначен для iPhone 18, запуск которого ожидается в первой половине 2027 года. Сообщается, что в августе Apple заключила соглашение с Samsung о поставке этого компонента. Впервые Apple откажется от Sony как единственного поставщика датчиков изображения для iPhone и будет получать этот компонент с завода в США. В настоящее время Sony является единственным поставщиком датчиков изображения для iPhone: они производятся в Японии и поставляются через TSMC. Цукерберг готовит Mango и Avocado: Meta✴ раскрыла имена грядущих ИИ-моделей, включая генератор изображений и видео
19.12.2025 [13:33],
Алексей Разин
В первой половине следующего года, как сообщает The Wall Street Journal, компания Meta✴✴ Platforms порадует своих пользователей выходом новых ИИ-моделей. Основанная на текстовом вводе система получила обозначение Avocado, а ориентированная на генерацию изображений и видео будет называться Mango. В этом признался руководитель направления ИИ Александр Ван (Alexandr Wang) в ходе одного из служебных мероприятий. 
Источник изображения: OpenAI Одним из приоритетов при разработке текстовой модели Avocado стало улучшение возможностей в сфере написания программного кода с её помощью. Кроме того, Meta✴✴ находится на ранней стадии экспериментов с так называемыми моделями мира, позволяющими обучаться через визуальное восприятие окружающей обстановки. Как напоминает The Wall Street Journal, летом этого года Meta✴✴ провела реструктуризацию своей команды, занимающейся ИИ, в результате чего подразделение Meta✴✴ Superintelligence Labs возглавил Александр Ван. Основатель и глава Meta✴✴ Platforms Марк Цукерберг (Mark Zuckerberg) активно принимал участие в переманивании ценных специалистов из OpenAI, коих набралось более 20 человек, а в целом ему удалось собрать команду профессионалов в области ИИ из более чем 50 исследователей и инженеров. В сентябре Meta✴✴ выпустила приложение Vibes для генерации видео, которое было разработано в сотрудничестве с Midjourney. Менее чем через неделю после этого OpenAI представила собственный генератор видео Sora. Появление в арсенале Google подобного приложения Nano Banana позволило увеличить месячную аудиторию Gemini с 450 до 650 млн человек всего за три месяца. Острая конкуренция на этом рынке заставила главу OpenAI Сэма Альтмана (Sam Altman) мобилизовать все силы на совершенствовании ChatGPT. Недавно стартап представил приложение Images 1.5 для генерации изображений. По мнению Альтмана, именно инструменты для генерации изображений являются «якорными» для привлечения пользователей и поддержания интереса к сфере ИИ. OpenAI выпустила генератор изображений ChatGPT Images 1.5 — более высокая скорость и новые возможности
17.12.2025 [07:37],
Владимир Фетисов
На прошлой неделе OpenAI выпустила модель искусственного интеллекта GPT-5.2, а теперь она стала основой фирменного генератора изображений ChatGPT Images 1.5. По словам разработчиков, это позволило в четыре раза повысить скорость работы сервиса по сравнению с предыдущей версией, а также реализовать несколько полезных нововведений. 
Источник изображения: ChatGPT Images ChatGPT Images стал лучше следовать пользовательским инструкциям, в том числе в случаях, когда дело доходит до редактирования только что созданного изображения. Пользователь может попросить алгоритм добавить, убрать, объединить, смешать или даже перенести какие-то элементы на картинке. OpenAI заявила, что обновлённый ChatGPT Images лучше справляется с отображением текста, что традиционно является слабым местом многих генераторов изображений. По данным OpenAI, повысилось качество генерации читаемого текста, а также появилась возможность работы с более мелким и плотным тестом. В рамках этого обновления фирменного генератора изображения OpenAI добавила в боковую панель ChatGPT отдельный раздел Images. В нём собраны готовые к использованию фильтры и промпты, призванные помочь в поиске вдохновения. «Мы считаем, что всё ещё находимся в самом начале пути к тому, что может дать генерация изображений. Сегодняшнее обновление — это значительный шаг вперёд, и впереди нас ждёт многое: от более детальных правок до более насыщенных и подробных результатов на разных языках», — говорится в сообщении OpenAI. Разработчики приступили к развёртыванию ChatGPT Images 1.5 и в скором времени обновлённая версия сервиса станет доступна всем пользователям. Отмечается, что пользователи также смогут продолжить взаимодействие с моделью GPT-4o через пользовательский интерфейс чат-бота компании. Новый ChatGPT Images появляется как раз в тот момент, когда его главный конкурент Google Nano Banana Pro вызвал всплеск популярности Gemini среди пользователей. В октябре Google заявила, что пользовательская база фирменного чат-бота выросла до 650 млн человек, что существенно больше 450 млн человек, о которых компания сообщала в июле. Nano Banana Pro оказалась настолько популярной, что Google для снижения нагрузки на инфраструктуру пришлось ограничить бесплатных пользователей всего двумя генерациями изображений в день. Для OpenAI, вероятно, было не столь важно дать сильный ответ на появление Nano Banana Pro, сколько обеспечить сильную конкуренцию чат-боту Gemini 3 Pro. Это связано с тем, что наличие в арсенале компании ChatGPT Images является одним из основных факторов, обеспечивающих ИИ-боту ChatGPT пользовательскую базу в 800 млн человек. ChatGPT научился бесплатно редактировать фото в Photoshop и файлы PDF в Acrobat
10.12.2025 [20:36],
Владимир Фетисов
Компания Adobe предоставила пользователям ChatGPT новые возможности для редактирования изображений и файлов формата PDF без необходимости переключаться между приложениями. Интеграция Photoshop, Acrobat и Adobe Express с ChatGPT позволит создавать дизайны или редактировать файлы посредством текстовых подсказок для ИИ-бота. 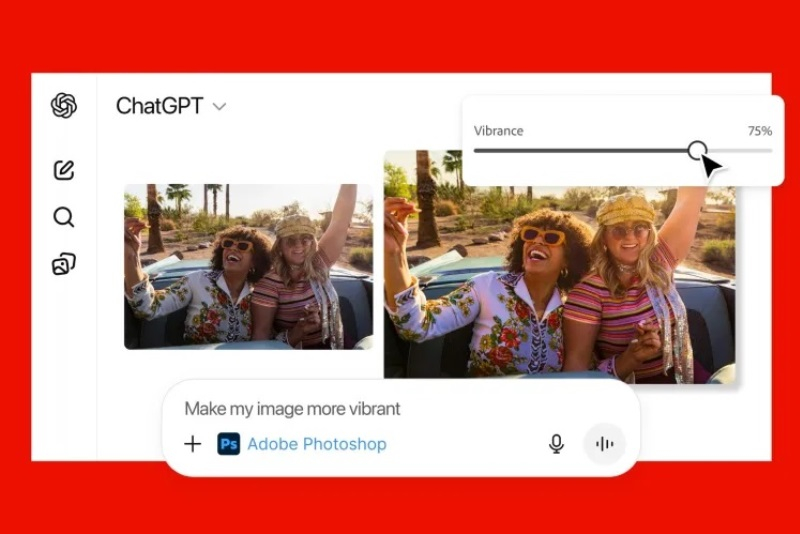
Источник изображений: Adobe Приложения Adobe можно использовать бесплатно, а для их активации достаточно написать название нужного продукта вместе с загруженным файлом или текстовой подсказкой. К примеру, можно написать: «Adobe Photoshop, размой фон на этом изображении», — после чего ChatGPT отредактирует загруженный файл с учётом пожеланий пользователя. Повторно указывать названия нужных приложений для внесения дополнительных изменений в рамках одного диалога не нужно. В зависимости от полученных инструкций ChatGPT может предлагать несколько вариантов на выбор или предоставлять доступ к определённым элементам интерфейса, которыми пользователь может управлять вручную — например, для регулировки яркости и контрастности. 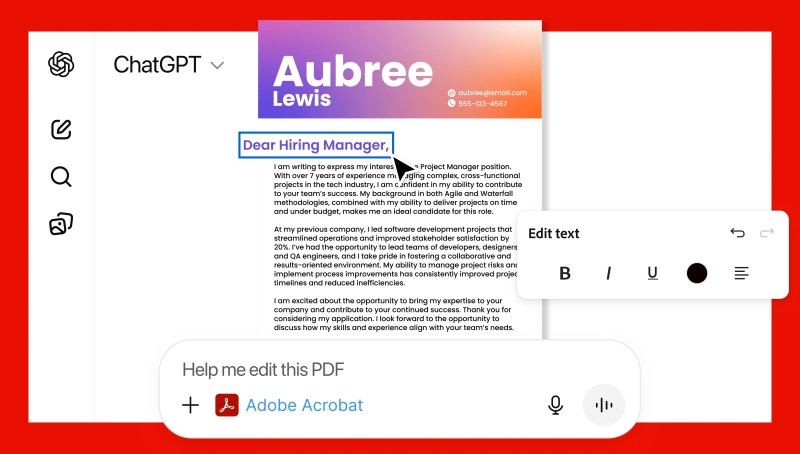 Приложения Adobe в ChatGPT не предоставят доступ ко всем функциям, доступным в десктопных версиях. Вместо этого пользователи смогут редактировать отдельные участки изображений, применять различные эффекты и настраивать параметры изображений, такие как яркость, контрастность и экспозиция. Acrobat в ChatGPT поможет редактировать уже созданные PDF-файлы, сжимать и конвертировать документы в формат PDF, извлекать текст или таблицы, а также объединять несколько файлов. С помощью Adobe Express пользователи ChatGPT смогут создавать и редактировать дизайны — например, плакаты, приглашения и др. Если возможностей, предлагаемых в ChatGPT, окажется недостаточно, пользователь сможет продолжить работу с начатыми проектами в полноценных версиях приложений Adobe. Приложения Adobe для ChatGPT можно использовать при взаимодействии с ИИ-ботом на компьютерах, в веб-версии и на iOS. На Android пока доступно только Adobe Express, а поддержка Photoshop и Acrobat появится позднее. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex




