|
Опрос
|
реклама
Быстрый переход
На Каннском фестивале показали 95-минутный фильм, снятый с помощью ИИ за $500 000 и две недели
21.05.2026 [19:36],
Алексей Разин
По мере развития сервисов генерации видео по текстовому запросу в киноиндустрии начали появляться студии, специализирующиеся на создании как сериалов, так и полнометражных фильмов, которые не привлекают актёров и не используют декорации. Один из таких фильмов, созданный при помощи ИИ, даже принял участие в Каннском кинофестивале в этом году. 
Источник изображения: YouTube, Higgsfield Его создателем является стартап Higgsfield, который был основан в Сан-Франциско три года назад, и до сих пор специализировался на создании сериалов с продолжительностью одного эпизода около 22 минут. Полнометражную картину «Долгая дорога в ад» (Hell Grind), которая идёт 95 минут, стартап создал за две недели, потратив на это $500 000. Из этой суммы $400 000 ушли на оплату доступа к вычислительным мощностям. Higgsfield заявился к участию в известном кинофестивале ради демонстрации возможностей, которые предоставляет отрасли генеративный ИИ. Участники мероприятия в Каннах отмечают, что по сравнению с прошлыми годами отношение к самой идее создания фильмов при помощи ИИ начинает меняться от опасений по поводу уничтожения ремесла к осторожному принятию неизбежной экспансии подобных технологий. На пресс-конференции, посвящённой открытию фестиваля, актриса Деми Мур (Demi Moore) заявила, что актёры должны искать возможности для работы с технологиями: «ИИ уже здесь. И бороться с ним означает начать битву, в которой мы проиграем». Режиссёр и продюсер Higgsfield Адилет Абиш (Adilet Abish) считает, что ИИ даёт возможность рассказать миру свою историю. По словам создателей ИИ-фильма, для работы с новыми инструментами всё равно требуются навыки классического кинопроизводства — например, правил композиции сцены. В мае компания вышла на приведённый размер годовой выручки на уровне $400 млн. Она полагается на общедоступные ИИ-модели для создания видео типа Google Veo 3 и Seedance 2.0 компании ByteDance. Стартап лишь добавляет своё ноу-хау, позволяющее обеспечить преемственность генерируемых ИИ сцен и образов. За один подход при помощи текстового запроса можно получить 15 секунд сгенерированного видео. Каждая сцена подобной продолжительности всегда генерируется несколько раз с некоторыми уточнениями в запросе, чтобы выбрать лучший «дубль». Если говорить о полнометражной картине, то первые её 25 минут потребовали генерации 16 181 клипов продолжительностью 15 секунд, из которых были отобраны 253 финальных варианта. Текстовые запросы приходится делать очень подробными, учитывающими стиль визуализации, освещение и имитацию того или иного съёмочного оборудования, а также визуальных эффектов. Особое внимание пришлось уделять освещению в сценах, поскольку ИИ обычно не отличается реалистичностью результирующих видео, «пересвечивая» содержимое сцены. В целом, движущиеся в кадре актёры и предметы должны учитывать законы физики, и это тоже требует особого комментирования в исходных текстовых запросах. По сути, каждый запрос содержит в среднем 3000 слов. Стартап готов зарабатывать на понимании такой специфики при создании фильмов и сериалов при помощи ИИ. Клиенты отправляют Higgsfield свои сценарии, а стартап возвращает им детализированные текстовые запросы на каждую страницу сценария. Поскольку до финального монтажа доживает лишь малая часть сгенерированных ИИ видеоклипов, то расходы на работу с облачными вычислительными ресурсами оказываются весьма высокими. В частности, полнометражка для Каннского кинофестиваля потребовала $400 000 на оплату услуг облачных провайдеров. И если бы Higgsfield не сотрудничала в этой сфере с так называемыми представителями сферы neocloud, то расходы могли бы оказаться ещё выше. Как поясняют представители стартапа, нельзя просто войти в чат-бот и попросить: «Сделай мне классное 95-минутное видео». Китайские компании превзошли американских конкурентов в сфере генерации видео при помощи ИИ
18.05.2026 [06:21],
Алексей Разин
Опрошенные Financial Times эксперты сходятся во мнении, что если американские разработчики систем ИИ занимают лидирующие позиции в создании ассистентов для написания программного кода, то в сфере генерации видео по текстовому запросу на первых местах уже находятся китайские разработчики. Их инструменты лучше по качеству и удобству использования. 
Источник изображения: ByteDance Для обучения таких больших языковых моделей требуется больше количество видеоматериалов, и здесь китайские платформы с их обширной пользовательской базой получают определённое преимущество. Некоторые эксперты также склонны считать, что китайские разработчики нередко пренебрегают авторскими правами при обучении профильных моделей. С другой стороны, данные ограничения в итоге приводят к тому, что американские модели выдают менее реалистичные видео по итогам работы. Основатель стартапа Director AI Бен Цзян (Ben Chiang), который производит при помощи ИИ-генераторов короткометражные мультфильмы и сериалы, отмечает прогресс китайских генераторов видео в качестве работы. В частности, они лучше понимают текстовые запросы, синхронизируют аудио и стабилизируют голоса персонажей. Независимый продюсер Георгий Размадзе (George Won) из Тбилиси отмечает, что китайские генераторы видео позволяют динамично менять угол съёмки, не теряя деталей освещения и чёткости лица персонажей, тогда как многие модели в такой ситуации грешат артефактами. Независимая платформа Arena высоко оценивает ИИ-модели Kling, Seedance 2.0 и HappyHorse 1.0. Американская Veo 3 корпорации Google тоже близка к ним благодаря к доступу к родственному YouTube, но из-за ограничений в сфере авторских прав она не так хороша, как могла бы быть. Успех китайских ИИ-генераторов видео даже заставил компанию Kuaishou задуматься о том, чтобы отделить Kling в самостоятельный бизнес и вывести его на биржу. Послабления в сфере использования защищённого авторскими правами контента уже вызвали претензии к ByteDance со стороны создателей персонажей вселенной Marvel и мультипликационного сериала South Park. Китайской компании пришлось взять на себя обязательства по усилению защиты в этой сфере. При этом китайскими генераторами видео проще пользоваться, поскольку они не натыкаются на многочисленные ограничения на этапе формирования текстового запроса и сталкиваются с ошибками. Впрочем, высокий спрос на услуги той же Seedance 2.0 в феврале этого года привёл к необходимости ограничить доступ к ИИ-модели и увеличить время ожидания для некоторых пользователей. Американским клиентам ByteDance приходится получать доступ к Seedance на особых условиях. В корпоративном сегменте им порой приходится авансом выложить до $2 млн. Впрочем, на рынке уже присутствуют инструменты для преодоления подобных барьеров. Поддержание инфраструктуры для генерации видео требует существенных затрат, поскольку они потребляют больше ресурсов, чем модели, работающие только со звуком или текстом. OpenAI на этом фоне в марте даже отказалась от развития своей модели Sora. При создании рекламных роликов ИИ уже используется в серьёзных масштабах, представители отрасли считают его очень удобным и выгодным инструментом — тем более, что качество контента уже достигло уровня, трудно отличимого от натурных съёмок. Одно из рекламных агентств призналось FT, что по запросу клиента создало 100 000 разных видео, чего традиционным способом сделать было бы крайне дорого. В Gemini теперь можно давать задания Nano Banana, делая наброски прямо на изображениях
19.12.2025 [06:15],
Анжелла Марина
Google добавила в приложение Gemini новый способ взаимодействия с моделью Nano Banana. Теперь пользователи могут давать подсказки, рисуя или добавляя аннотации прямо на изображениях, а также проверять, было ли видео сгенерировано или отредактировано с помощью искусственного интеллекта. Эта функция стала доступна после вчерашнего крупного обновления Gemini 3 Flash. 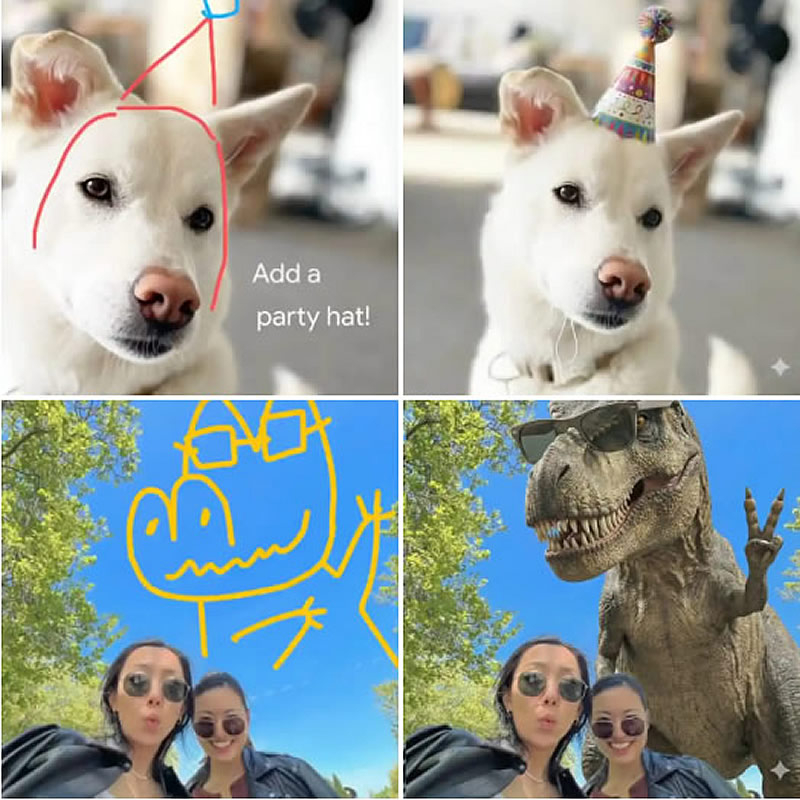
Источник изображений: 9to5google.com После загрузки изображения его можно выделить, чтобы открыть редактор под названием Mark up, поясняет 9to5Google. В нём инструмент Sketch позволяет рисовать, выделять конкретные участки изображения, а также отменять или повторять действия. С помощью инструмента Text можно наносить текстовые подсказки непосредственно поверх картинки. Это избавляет от необходимости вводить текстовое описание в поле запроса, хотя, как отметили в Google, дополнительный текстовый запрос можно при желании добавить. При загрузке первого изображения система предложит воспользоваться этой новой функцией. Рисование в Nano Banana теперь доступно на Android, iOS и в веб-версии приложения Gemini.   Параллельно Google расширила возможности системы проверки SynthID, добавив поддержку видео. Ранее SynthID позволял проверять подлинность изображений, а теперь также определяет, было ли видео или его аудиодорожка созданы или изменены с использованием ИИ от Google. После загрузки видео (максимальный размер 100 Мбайт, длительность 90 секунд) пользователь может, например, запросить следующее: «Было ли это видео сгенерировано с помощью ИИ Google?». Система проанализирует наличие водяных знаков SynthID и, в случае наличия использования ИИ, выдаст ответ с указанием временных отрезков, на которых обнаружен такой контент. Например, ответ может содержать фразу: «SynthID обнаружен в аудио между 10 и 20 секундами. В визуальной части SynthID не обнаружен». Верификация как изображений, так и видео доступна во всех языковых версиях и регионах, где официально работает приложение Gemini. Написанный ИИ программный код забагован сильнее человеческого, показало исследование
19.12.2025 [06:08],
Анжелла Марина
Исследование компании CodeRabbit показало, что код, созданный с использованием инструментов искусственного интеллекта, содержит больше ошибок и уязвимостей, чем код, написанный людьми. В запросах на слияние изменений в коде (Pull Request), созданных с помощью инструментов ИИ, в среднем фиксировалось 10,83 ошибки, по сравнению с 6,45 ошибками в запросах на слияние, созданных человеком. Это приводит в конечном итоге к увеличенному времени проверок и потенциальному увеличению количества ошибок, попадающих в финальную версию продукта. 
Источник изображения: Gema Saputera/Unsplash В целом, ошибок в запросах на слияние, сгенерированных ИИ, было в 1,7 раза больше, критических и серьёзных ошибок — также было в 1,4 раза больше, что нельзя отнести к мелким недочётам, как отмечает TechRadar. Ошибки в логике и корректности (в 1,75 раза), качество и удобство сопровождения кода (в 1,64 раза), безопасность (в 1,57 раза) и производительность (в 1,42 раза) показали в среднем более высокий уровень ошибок. В отчёте ИИ также критикуется за то, что вносит больше серьёзных ошибок, которые затем приходится исправлять людям-рецензентам. Если говорить о безопасности кода, то среди наиболее вероятных проблем, которые может внести ИИ, указывается неправильная обработка паролей, небезопасные ссылки на объекты, уязвимости XSS и небезопасная десериализация (серьёзная уязвимость приложений, возникающая, когда программа преобразует ненадёжные данные). «Инструменты ИИ для программирования значительно увеличивают производительность, но они также вносят предсказуемые недостатки, которые организации должны активно устранять», — прокомментировал директор по ИИ CodeRabbit Дэвид Локер (David Loker). Однако это не всегда сопровождается проблемами, так как ИИ повышает эффективность на начальных этапах генерации кода, а также приводит к уменьшению количества орфографических ошибок в 1,76 раза и проблем с тестируемостью (1,32 раза). Таким образом, хотя исследование и выявило некоторые недостатки ИИ, одновременно оно также показало, что разработчики всё больше переходят от написания базового кода к управлению ИИ и проверкой его результатов, и именно так в будущем люди и ИИ-агенты, возможно, начнут взаимодействовать. В то же время Microsoft сообщает о рекордном числе исправленных уязвимостей, например, в 2025 году было закрыто 1139 CVE (Common Vulnerabilities and Exposures, общие уязвимости и угрозы), что стало вторым по величине показателем за всю историю. Это может частично объясняться ростом общего объёма кода за счёт ИИ-генерации. Кроме того, ИИ-модели, например, в исполнении OpenAI, в принципе продолжают улучшаться, что потенциально снизит число ошибок в будущем. Вышел генератор HD-видео Runway Gen 4.5 — и он сразу обошёл Veo 3 и Sora 2 Pro
02.12.2025 [07:00],
Алексей Разин
Развитие сегмента сервисов, позволяющих генерировать видео по текстовому описанию, перестало вызывать снисходительную улыбку у «старожилов отрасли», поскольку подобные инструменты теперь позволяют создавать реалистичные ролики малыми затратами. Runway утверждает, что её модель Gen-4.5 выводит реалистичность генерируемых ИИ видео на качественно новый уровень. 
Источник изображения: YouTube, Runway В блоге Runway, как отмечает The Verge, сообщает о «результатах кинематографического качества». Внимание уделяется не только точности визуального отображения пейзажей, людей, животных и объектов, но и тщательной проработке физики движущихся объектов. Даже поведение жидкостей реализовано настолько реалистично, что неискушённому зрителю сложно догадаться, что видео было сгенерировано искусственным интеллектом. Распространение Runway Gen-4.5 осуществляется постепенно среди всех пользователей сервиса, по быстродействию и эффективности новая модель не будет уступать предыдущей, по словам представителей компании. Тем не менее, некоторые недостатки в её работе пока наблюдаются, в основном они связаны с логикой взаимодействия объектов на видео. Например, дверь может открываться до того, как кто-то в кадре взялся за её ручку. Создатели Runway утверждают, что новая модель лучше адаптирует генерируемое видео под стилистические запросы в описании и может добиваться более зрелищных визуальных эффектов, которые практически неотличимы от реальных видеосъёмок. Конкурирующая OpenAI тоже активно совершенствует свои средства для генерации видео. В сентябре была выпущена модель Sora 2, которая продемонстрировала заметный прогресс в улучшении отображения физических процессов. По словам создателей, она способна реалистично воспроизводить трюки, выполняемые с сапбордом на поверхности воды. Однако новый генератор Runway Gen 4.5 превзошёл главных конкурентов в лице Google Veo 3 и OpenAI Sora 2 Pro и возглавил рейтинг ИИ-моделей для генерации видео по текстовым описаниям Video Arena от Artificial Analysis. Google Gemini обошла ChatGPT в топе американского App Store и вышла на первое место по популярности
15.09.2025 [05:15],
Алексей Разин
К вечеру минувшей пятницы, как отмечает 9to5Google, приложению Google Gemini удалось возглавить список самого популярного бесплатного программного обеспечения для iPhone в США. Ближайшими по популярности прочими бесплатными приложениями Google оказались Search, Google Maps, Google Chrome и Gmail. 
Источник изображения: Google Что характерно, их в данном списке на второй позиции разделяет ChatGPT компании OpenAI, а на третьем месте расположилось приложение социальной сети Threads. Поисковое приложение Google заняло шестое место, Google Maps — восьмое, браузеру Google Chrome досталось только 13-е, а почтовый клиент Gmail и вовсе расположился на 21-м месте. В Канаде и Великобритании, например, Gemini занимает второе место в аналогичном списке. В период с 26 августа по 9 сентября приложение Gemini смогло привлечь 23 млн новых пользователей. Специалисты связывают эту активность с взрывной популярностью добавленной в него модели Nano Banana, которая за это время использовалось для создания или редактирования более 500 млн изображений. Nano Banana стала вирусной из-за того, что ей удаётся поддерживать сходство персонажей при переносе с одного изображения на другое. Оно так же позволяет комбинировать элементы с нескольких фотографий, корректировать стилистику и, конечно, последовательно менять элементы изображения в диалоге с чат-ботом. Бесплатным пользователям доступна возможность редактировать до 100 изображений в день, но подписчикам за $20 в месяц доступен лимит в 1000 ежедневно обрабатываемых фотографий. Runway представила «Photoshop для видео» — ИИ-модель Aleph для быстрого редактирования видео
29.07.2025 [23:37],
Анжелла Марина
Компания Runway представила новую ИИ-модель под названием Aleph, предназначенную для редактирования видео на основе текстовых запросов. Модель позволяет удалять объекты и людей из кадра, изменять элементы сцены, генерировать новые ракурсы и вносить сложные правки в уже существующие или сгенерированные ролики. 
Источник изображения: Runway Aleph Как сообщает CNET, разработка основана на исследованиях Runway в области General World Models и Simulation Models и позиционируется компанией как инструмент для «гибкого монтажа», позволяющий быстро и последовательно редактировать видео без нарушения целостности кадров. В отличие от предыдущих моделей, сосредоточенных в основном на генерации видео по тексту, Aleph делает акцент на интерактивном редактировании. Теперь можно добавлять или удалять объекты, изменять освещение, корректировать действия персонажей и сохранять визуальную согласованность между кадрами — то есть выполнять те задачи, которые ранее представляли наибольшую сложность для ИИ. В Runway отметили, что Aleph — это не просто обновление, а новый подход к работе с видео в целом. Модель сочетает генерацию высокого качества с возможностью мгновенного редактирования через диалоговый интерфейс, что может быть востребовано в киноиндустрии, рекламе и других сферах, где важна скорость обработки контента. Интересно, что запуск модели происходит на фоне растущей конкуренции в сфере ИИ-видео. В этом году аналогичные разработки представили OpenAI, Google, Microsoft и Meta✴✴. Однако Runway, известная своими моделями Gen-1 и Gen-2, утверждает, что Aleph выводит технологию на новый уровень. По данным компании, Aleph уже тестируют крупные киностудии, рекламные агентства, архитектурные бюро, игровые компании и команды в сфере электронной коммерции. В настоящее время доступ к модели открыт для корпоративных клиентов и партнёров, а более широкий запуск ожидается в ближайшие дни. В графическом онлайн-редакторе Canva появился ИИ для генерации изображений и создания приложений
10.04.2025 [22:43],
Анжелла Марина
Бесплатный графический онлайн-редактор Canva представил ИИ-инструменты для генерации изображений и создания мини-приложений с помощью всего лишь текстовых запросов. Несмотря на недовольство художников, которые выступают против использования их работ для обучения ИИ, и опасений, что искусственный интеллект заменит их труд, компании продолжают активно внедрять технологию в свои проекты. Canva не стала исключением. 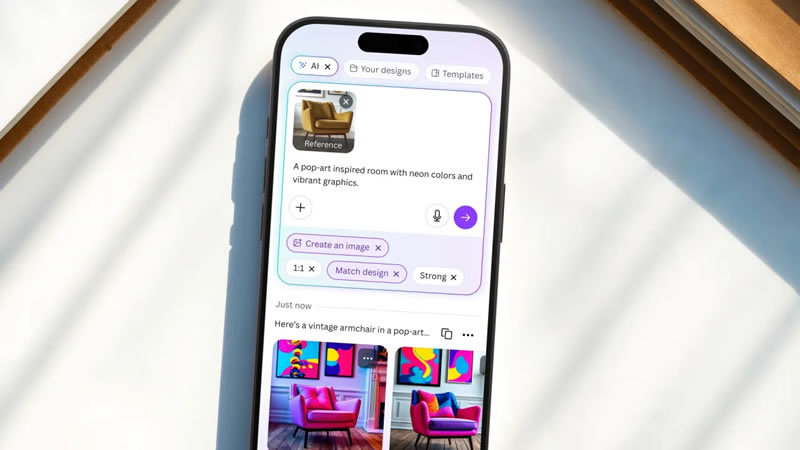
Источник изображения: Canva Новый ИИ-ассистент Canva AI способен генерировать изображения по запросу, предлагать дизайнерские решения для публикаций в соцсетях и печати, а также писать тексты. А с помощью инструмента Canva Code, как отмечает TechCrunch, пользователи смогут создавать интерактивные элементы, например, карты и пользовательские калькуляторы, которые можно встраивать в приложения и на сайты. Как сообщил сооснователь и директор по продукту Кэмерон Адамс (Cameron Adams), для этого Canva сотрудничает с компанией Anthropic. Хотя Canva не является первопроходцем на рынке ИИ-услуг для дизайна в целом и веб-дизайна в частности (аналогичные инструменты предлагают стартапы Cursor, Replit и другие), интеграция функций искусственного интеллекта логично дополняет платформу. Компания также анонсировала ИИ-инструменты для фоторедактора, включая автоматическую ретушь и замену фона, тем самым усиливая конкуренцию с Adobe Photoshop и Pixelmator. Также сервис запустил собственные электронные таблицы — Canva Sheets с инструментом Magic Insights, который помогает находить закономерности в данных, и инструментом Magic Charts, автоматически превращающий цифры в визуальные графики с фирменным стилем. Поддерживается интеграция с такими сервисами, как Google Analytics и HubSpot. Хотя художники опасаются последствий массового внедрения ИИ, Кэмерон Адамс считает, что речь идёт не о замене людей, а о трансформации профессий. «Каждая работа изменится и адаптируется к новым возможностям. Мы, в свою очередь, видим в этом огромный потенциал», — подчеркнул он. Недавние увольнения в компании он объяснил реструктуризацией, не связанной напрямую с ИИ. «Блокнот» в Windows 11 научился создавать выжимки текстов с помощью ИИ
14.03.2025 [12:02],
Дмитрий Федоров
Microsoft начала тестирование функции подготовки кратких резюме текстов с помощью ИИ в «Блокноте» Windows 11. Кроме того, в обновлении для «Ножниц» появилась функция «Рисование с удержанием», которая автоматически выравнивает нарисованные объекты. Эти нововведения уже доступны участникам программы Windows Insider на каналах Canary и Dev. 
Источник изображений: Microsoft Microsoft продолжает интеграцию ИИ в стандартные приложения Windows 11, превращая их во всё более интеллектуальные инструменты. Одним из таких новшеств стало автоматическое резюмирование текста в «Блокноте». Теперь пользователи могут получать краткое изложение без необходимости вручную его редактировать или обращаться к сторонним ИИ-сервисам. Для этого достаточно выделить текст в «Блокноте», затем вызвать контекстное меню, нажав правую кнопку мыши, и выбрать команду «Резюмировать» (Summarize). Также можно воспользоваться горячими клавишами Ctrl + M или запустить функцию через меню Copilot. При необходимости длину итогового текста можно скорректировать, сделав его более кратким или, наоборот, расширенным — в зависимости от задач пользователя. 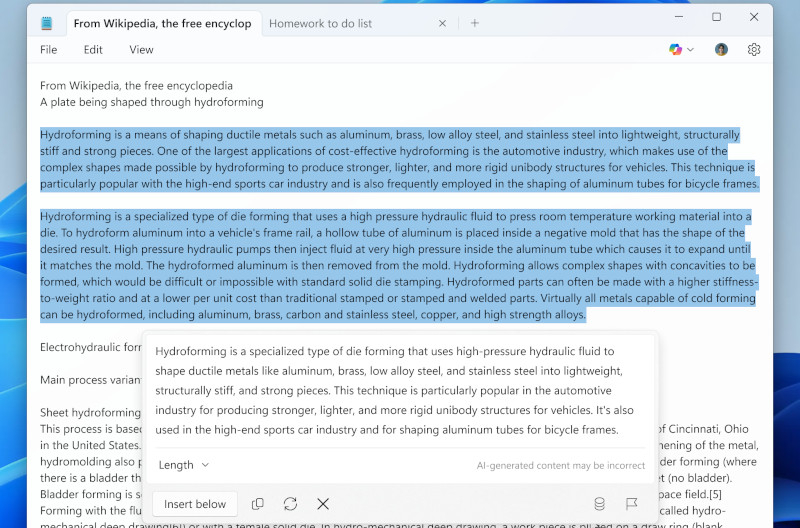 Тем, кто предпочитает классический «Блокнот» без ИИ, предоставлена возможность отключения интеллектуальных функций в настройках приложения. Microsoft начала экспериментировать с ИИ в «Блокноте» ещё в 2023 году, когда представила функцию «Переписать» (Rewrite), перефразирующую текст. Новая возможность резюмирования — логичное продолжение этой идеи. Помимо нововведений в «Блокноте» Microsoft улучшила приложение «Ножницы» (Snipping Tool), добавив функцию «Рисование с удержанием» (Draw & Hold). Эта технология автоматически выравнивает линии, стрелки, прямоугольники и овалы, нарисованные пользователем. Чтобы воспользоваться ей, достаточно немного дольше удерживать курсор во время рисования — программа распознаёт контуры фигуры и устраняет неровности. 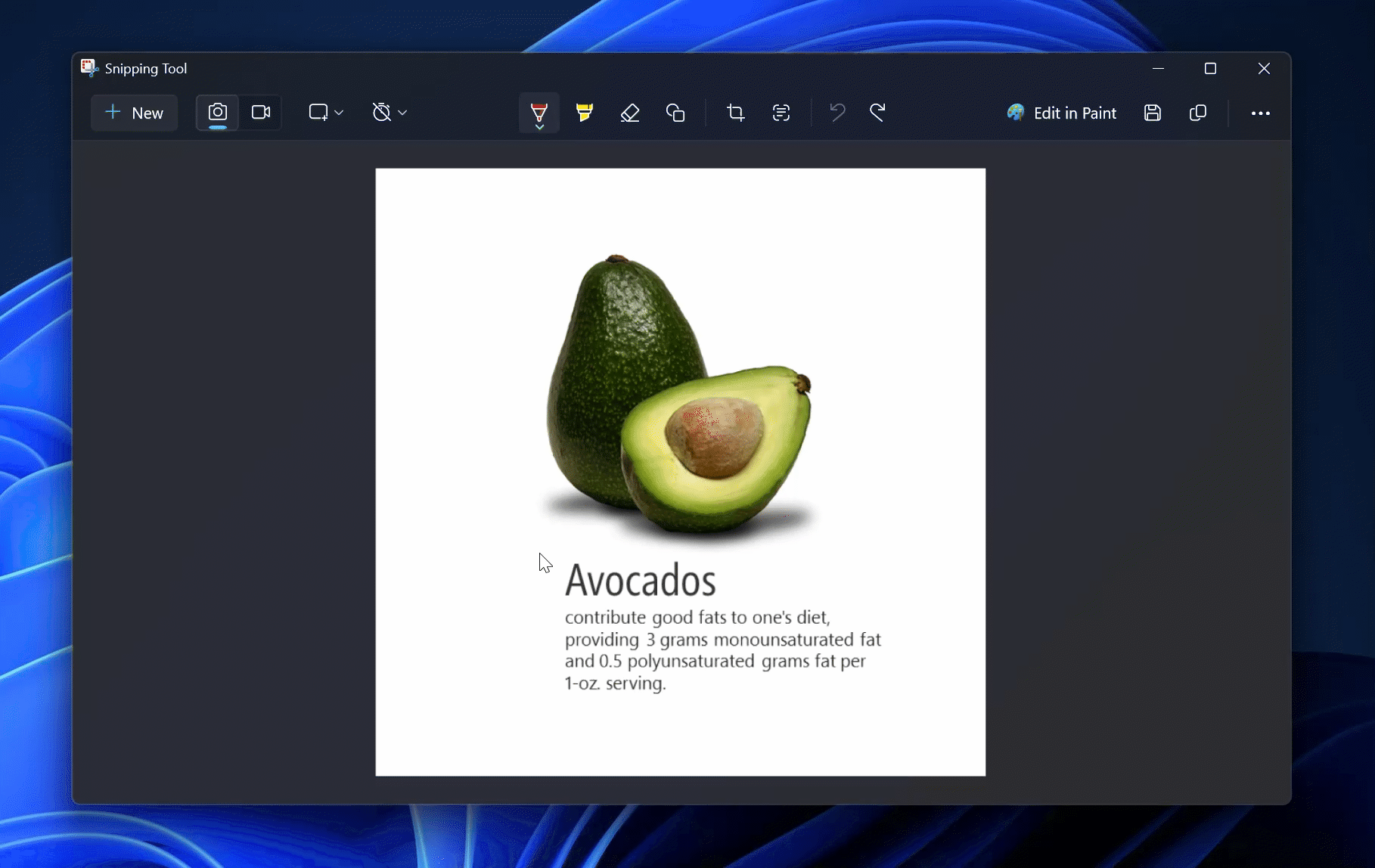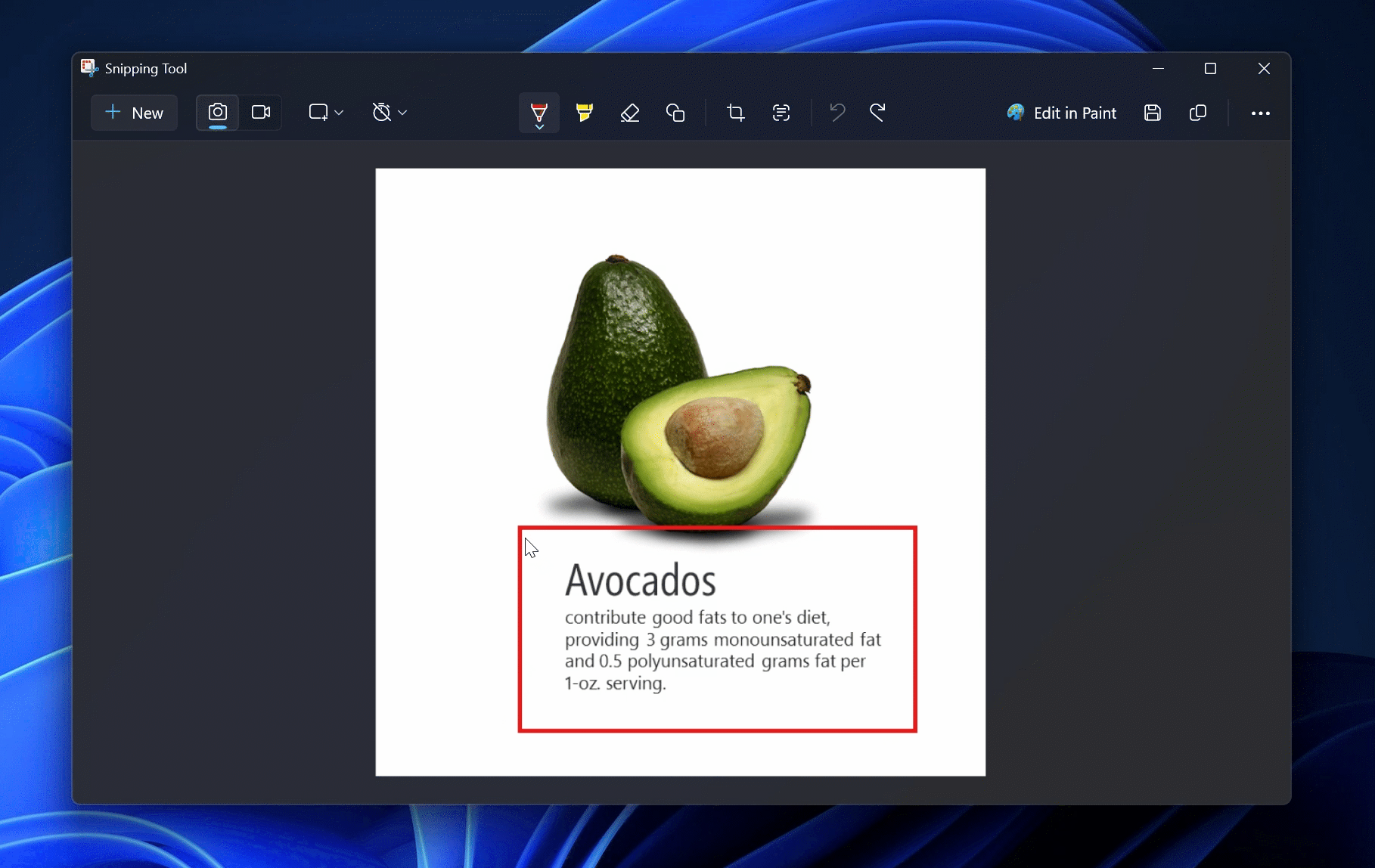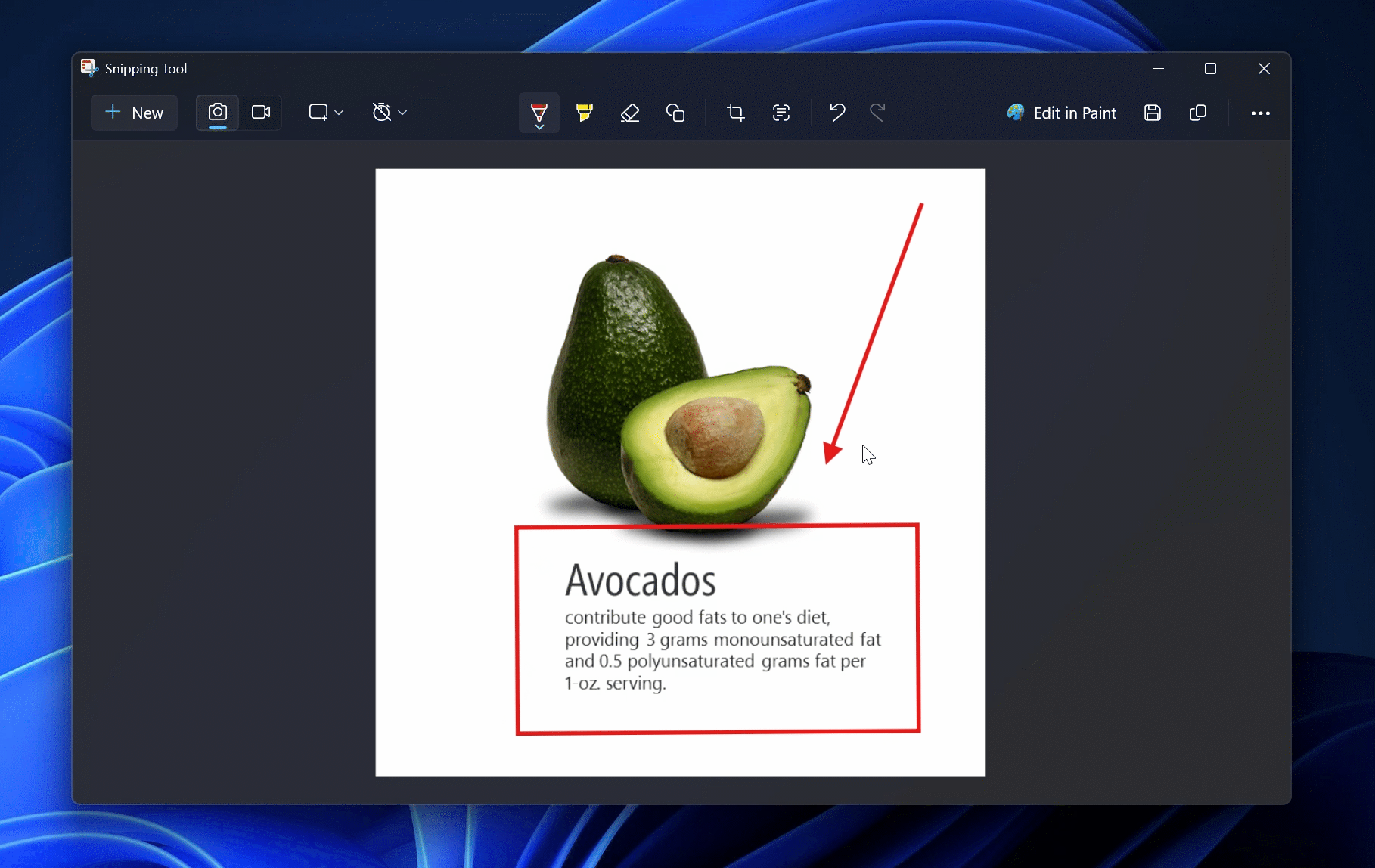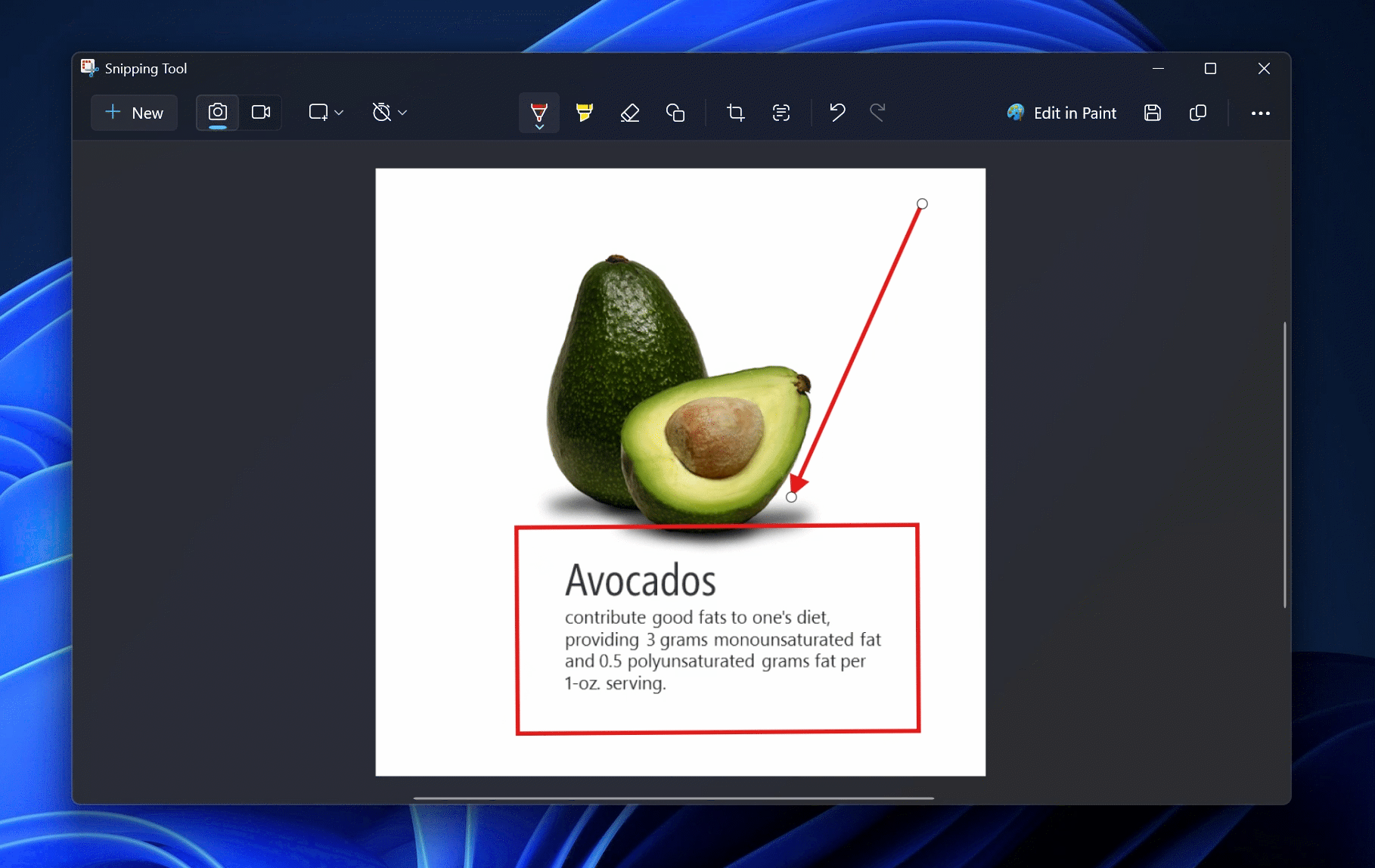 После автоматического выравнивания пользователь может редактировать объект: изменять его размеры, перемещать или корректировать форму. Новая функция делает разметку изображений более удобной и точной, особенно для тех, кто активно использует скриншоты в профессиональной деятельности. Функция «Рисование с удержанием» напоминает аналогичное решение Apple, доступное на iPad и iPhone. В экосистеме Apple система корректирует нарисованные вручную формы, делая их геометрически точными. Microsoft адаптировала эту возможность для работы с мышью и стилусом, что расширяет сферу её применения и делает стандартные инструменты Windows 11 более универсальными. Google обновила ИИ-блокнот NotebookLM и включила его в подписку One AI Premium
11.02.2025 [04:32],
Анжелла Марина
Компания Google объявила о включении обновлённой версии своего приложения для заметок с искусственным интеллектом NotebookLM в подписку One AI Premium. Теперь пользователи получат доступ к NotebookLM Plus без дополнительной оплаты, с повышенными лимитами использования и премиальными функциями, такими как возможность настраивать ответы ИИ. 
Источник изображения: Copilot Блокнот NotebookLM был впервые представлен в 2023 году как онлайн-инструмент для исследований и организации заметок при помощи ИИ. С тех пор Google добавила в приложение новые интерактивные функции, включая анализ видеороликов YouTube и возможность преобразования информации в подкасты с участием двух ИИ-ведущих, с которыми также можно взаимодействовать, пишет The Verge. Напомним, ранее инструмент был доступен только для бизнеса, школ и организаций, но теперь входит в подписку One AI Premium без дополнительной платы. Пользователи смогут воспользоваться премиальными функциями, такими как настройка ответов NotebookLM, а также увеличенными лимитами на количество аудиообзоров, блокнотов и запросов. В декабре Google запустила план NotebookLM Plus для корпоративных клиентов. Помимо увеличенных лимитов, этот план предлагает возможности настройки параметров общего доступа к блокнотам и отслеживания количества просмотров в день. Подписка Google One AI Premium стоит $20 в месяц и включает 2 Тбайт хранилища, а также доступ к моделям Gemini Advanced и интеграции Gemini с приложениями Workspace, такими как Gmail и Docs. Студенты старше 18 лет в США могут приобрести подписку One AI Premium за $10 в месяц на один год. «В настоящий момент подписчики смогут воспользоваться премиальными функциями, такими как настройка ответов NotebookLM» — говорится в официальном пресс-релизе Google. Редактирование до 10 000 изображений в один клик — Adobe представила Firefly Bulk Create
14.01.2025 [06:13],
Анжелла Марина
Компания Adobe представила новый инструмент Firefly Bulk Create, который позволяет редактировать до 10 000 изображений одновременно, за один клик. Приложение построено на базе искусственного интеллекта для автоматизации пакетной обработки изображений, существенно ускоряя рабочий процесс. 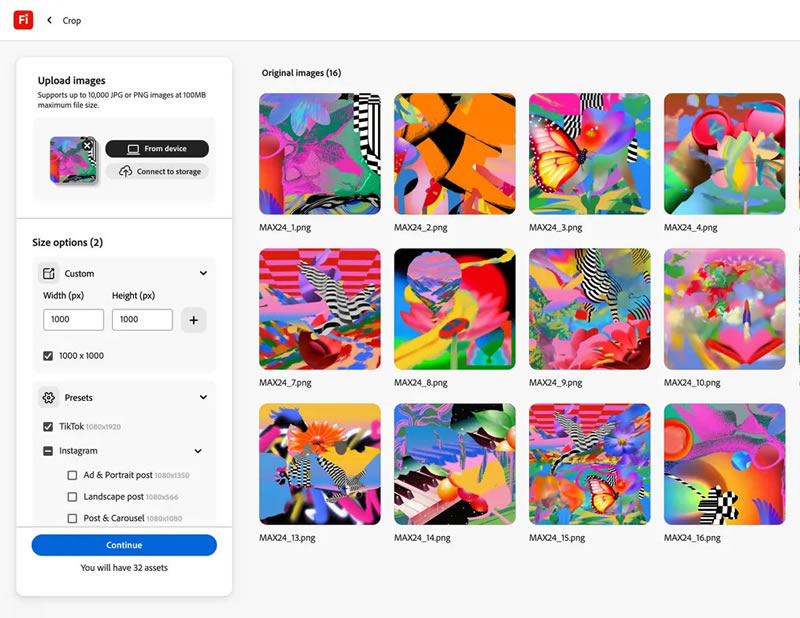
Источник изображения: Adobe Firefly Bulk Create создан на основе нескольких API-интерфейсов Adobe Firefly, специально разработанных для пользователей, не имеющих опыта в программировании, поясняет The Verge. Новинка, запущенная в бета-версии, разделена на два отдельных инструмента — «Удаление фона» и «Изменение размера». Первый позволяет быстро удалять фоны с загруженных изображений из компьютера, Dropbox или Adobe Experience Manager. Второй, соответственно, применяется для массового изменения размера. Инструмент «Удаление фона» работает с любыми изображениями, но особенно, как отмечают в Adobe, полезен для маркетологов, занимающихся продвижением товаров. Помимо удаления фона, пользователи могут заменить его на определённое изображение или цвет, заданный цветовым кодом HEX, создавая различные варианты изображений, готовых к дальнейшему редактированию. Пакеты файлов можно сохранять в форматах PNG или JPEG, при этом Adobe обещает несколько позднее добавить поддержку файлов Photoshop формата PSD. Инструмент «Изменение размера» предлагает ряд предустановленных параметров для популярных размеров рекламных баннеров и платформ, таких как TikTok, Instagram✴✴ и Facebook✴✴. Для растягивания фонов изображений в соответствии с нужными размерами используется генеративный ИИ. Несмотря на то, что в некоторых случаях наблюдаются искажения, для не очень сложных фонов эта функция может избавить дизайнеров от необходимости вручную изменять размеры маркетинговых материалов для каждой платформы. «В то время как такие сервисы, как Canva и Adobe Express, также имеют инструменты, облегчающие эту задачу, Bulk Create может сделать это одним щелчком мыши», — подчёркивают в компании. Также сообщается, что в ближайшие недели Adobe сделает общедоступными API-интерфейсы Firefly Services, которые можно использовать для ускорения рабочих процессов при производстве видео и печатной продукции. Среди новинок оказалась долгожданная функция Dubbing and Lip Sync, позволяющая редактировать движение губ для видео на 14 разных языках, а также новый инструмент InDesign, который автоматически форматирует текст и изображения для печатных и цифровых медиа с использованием предустановленных шаблонов. Кроме того, станут доступны в бета-версии «цифровые аватары», созданные с помощью текстовых описаний и голосовых записей, которые можно использовать для презентаций. Отмечается, что для редактирования пакетов, содержащих до 10 000 изображений, потребуются значительные вычислительные ресурсы, поэтому использование новых инструментов будет платным, а цена зависеть от потребляемых ресурсов. Предположительно речь идёт о том, что пользователям потребуется приобрести премиальный план Adobe Firefly, предоставляющий кредиты, которые можно будет использовать для доступа к новым функциям. Midjourney запустила мощный ИИ-редактор изображений и улучшенную модерацию
24.10.2024 [23:10],
Анжелла Марина
Midjourney, являющаяся одной из ведущих компаний по разработке нейросетей для генерации изображений по текстовым описаниям, анонсировала тестирование новых функций, включая внешний редактор изображений, режим редактирования текстур и систему модерации на основе искусственного интеллекта новейшего поколения. 
Источник изображения: midjourney.com Новый ИИ-редактор позволяет загружать фотографии с компьютера и вносить в них изменения — расширять, обрезать, перерисовывать или добавлять объекты в сцену. Управление происходит с помощью текстовых подсказок (промптов) и выбора областей на изображении. Также поддерживается персонализация ИИ-моделей, референсные персонажи и автоматические подсказки на основе заданных изображений. 
Источник изображения: midjourney.com Не менее интересным оказался режим смены текстур, который анализирует форму сцены и изменяет освещение, материалы и текстуру изображения. Это позволяет кардинально трансформировать внешний вид изначальной картинки, создавая новые визуальные эффекты, не изменяя при этом основную композицию. 
Источник изображения: midjourney.com Midjourney также представила более тонкую и интеллектуальную систему модерации V2 на основе ИИ. Этот «модератор» анализирует не только текстовые запросы, но и сами изображения, маски для рисования и полученные результаты. «Мы считаем, что это самый интеллектуальный ИИ-модератор из всех существующих на сегодня. — с гордостью заявляют разработчики компании. — Надеемся, что некоторые его аспекты в будущем будут внедрены в стандартные конвейеры генерации, чтобы уменьшить количество ложных срабатываний и предоставить пользователям больше свободы». 
Источник изображения: midjourney.com На данный момент новые функции доступны для тех пользователей, которые сгенерировали более 10 000 изображений, имеют годовую подписку или ежемесячную на протяжении последних 12 месяцев. Отметим, что разработчики признают наличие некоторых проблем, таких как некорректная работа с небольшими участками изображения, и просят пользователей отнестись с пониманием к этим временным трудностям, наслаждаясь тестированием новых возможностей. Midjourney запустит ИИ-редактор изображений
21.10.2024 [17:26],
Дмитрий Федоров
Midjourney запустит веб-инструмент, способный редактировать любые изображения с помощью генеративного ИИ. Новинка позволит, сохраняя форму редактируемых объектов, изменять их текстуры, цвета и другие детали в зависимости от текстовых запросов пользователя. Это открывает путь не только к большим творческим возможностям, но и к возможным злоупотреблениям. 
Источник изображений: Midjourney На прошлой неделе генеральный директор компании Дэвид Хольц (David Holtz) опубликовал на сервере Midjourney в Discord подробности о новом ИИ-редакторе изображений. Новый инструмент позволит пользователям загружать изображения из интернета и использовать последние достижения в области ИИ-технологий для их редактирования. «Он сохраняет форму сцены и объектов, но перерисовывает все текстуры, цвета и детали в соответствии с вашим запросом», — объяснил Хольц. 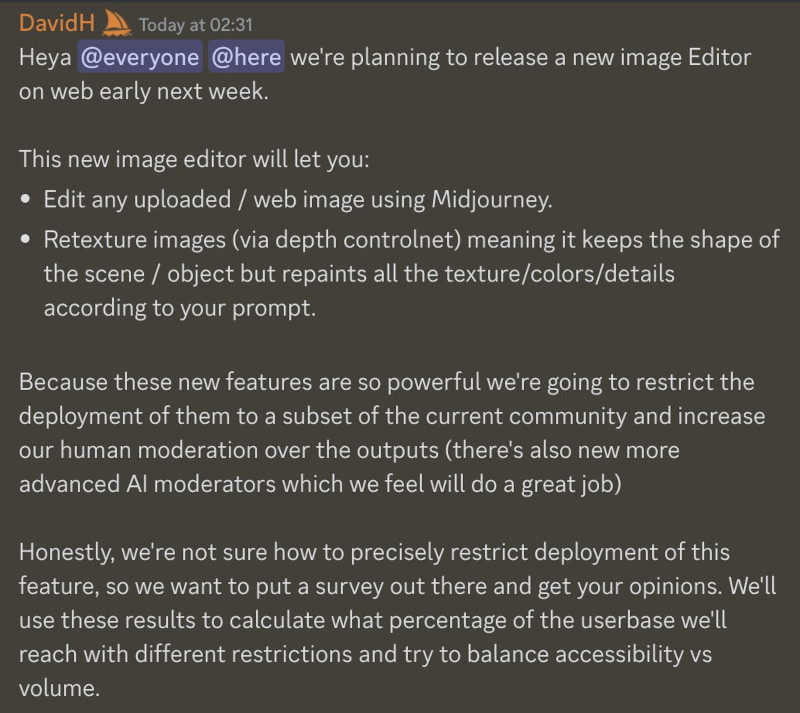
Источник изображения: Midjourney / Discord Появление такого инструмента открывает перед пользователями большие возможности для творчества, однако вызывает и серьёзные вопросы о злоупотреблениях. Например, инструмент может быть использован для массового создания дипфейков или нарушений авторских прав. Несмотря на то, что в США на федеральном уровне по-прежнему отсутствует закон, криминализирующий создание дипфейков, как минимум дюжина штатов уже приняли законы против ИИ-имитаций, и многие другие штаты рассматривают возможность последовать их примеру. Хольц осознаёт риски, связанные с вероятным злоупотреблением новым инструментом, и заявил, что на начальном этапе доступ к сервису будет ограничен небольшим числом пользователей. Компания Midjourney разрабатывает системы мониторинга, включающие как человеческий контроль, так и ИИ, чтобы минимизировать потенциальные нарушения. Однако конкретные механизмы реализации этих ограничений пока не определены, и компания собирает обратную связь от пользователей, чтобы решить, кто должен получить ранний доступ к инструменту.  Следует подчеркнуть, что Midjourney уже внедрила стандарты метаданных IPTC Digital Source Type, позволяющие маркировать изображения, созданные с использованием ИИ. Однако компания пока отстаёт от других лидеров рынка, таких как Adobe, которые применяют более продвинутые технологии отслеживания происхождения изображений, например, стандарт C2PA. Эта технология обеспечивает возможность проследить полную историю редактирования изображения, что существенно повышает прозрачность и ответственность в процессе его создания и обработки. В августе текущего года Midjourney также запустила обновлённый веб-сайт, который позволяет любому пользователю создавать изображения с помощью ИИ, зарегистрировавшись через Google-аккаунт. Первоначально предоставляется бесплатный пробный период, по окончании которого пользователи могут оформить платную подписку, чтобы продолжить пользоваться сервисом генерации изображений на постоянной основе. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


