|
Опрос
|
реклама
Быстрый переход
В Google разработали инструмент для выявления контента, сгенерированного ИИ
22.05.2025 [04:35],
Анжелла Марина
Компания Google анонсировала на конференции Google I/O новый инструмент SynthID Detector, который позволяет узнать, был ли контент создан с помощью инструментов искусственного интеллекта. Сервис анализирует изображения, текст, аудио и видео на наличие скрытых водяных меток, которые автоматически добавляются в материалы, сгенерированные с помощью ИИ, включая модели компании — Gemini, Imagen, Lyria и Veo. 
Источник изображения: Sascha Bosshard / Unsplash Как объяснил руководитель Google DeepMind Пушмит Коли (Pushmeet Kohli), система определяет, какие именно части контента содержат маркировку. Например, в аудио SynthID Detector находит и отмечает конкретные временные отрезки, а в изображениях — области с наибольшей вероятностью наличия водяного знака. Сейчас система тестируется среди ограниченного круга пользователей. Но после первого этапа тестирования доступ постепенно получат те, кто подал заявку через «Лист ожидания» (SynthID Detector Waitlist). По словам Коли, компания планирует также использовать обратную связь с пользователями, чтобы улучшить систему идентификации ИИ-контента. На данный момент SynthID Detector работает только с контентом, созданным с помощью продуктов Google. Однако в будущем компания рассматривает возможность расширения функциональности для работы с другими ИИ-системами. Когда именно инструмент станет доступен всем — пока неизвестно. Google добавила в Gmail, «Документы» и Vids новые ИИ-функции
21.05.2025 [16:46],
Павел Котов
На конференции Google I/O 2025 компания представила множество новых функций на основе искусственного интеллекта для приложений из рабочего комплекта Workspace — изменения коснулись сервисов Gmail, «Google Документы» и видеоредактора Google Vids. 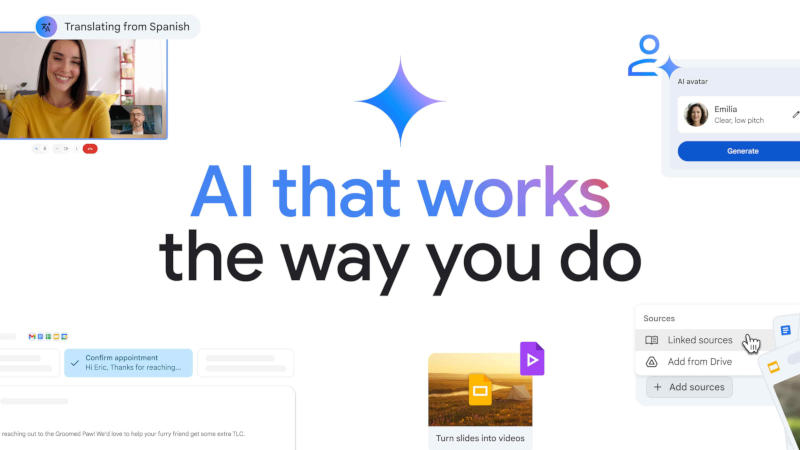
Источник изображений: Google Функция персонализированных интеллектуальных ответов Gmail помогает в составлении писем с учётом контекста и тона — система анализирует предыдущую переписку, файлы в облачном хранилище «Google Диск» и готовит ответы с актуальными данными. Манера письма подстраивается под тон пользователя — формальный или разговорный. С функцией очистки входящих сообщений ИИ-помощник Gemini принимает решения об удалении или перемещении в архив писем, которые больше не нужны — достаточно, например, в свободной форме дать ему команду удалить все непрочитанные письма от определённого адресата за минувший год. Ещё одна новая возможность Gmail помогает оперативно планировать встречи и совещания с адресатами вне организации пользователя. Он назначает время встречи или совещания при участии Gemini — это, по словам Google, сокращает время и усилия, которые традиционно тратятся на сверку расписаний. Все эти новые функции почтовой службы станут общедоступными в ближайшие месяцы.  В «Google Документах» появилась возможность устанавливать прямую связь приложения с данными презентаций, таблиц и отчётов — помогая в написании документов, Gemini берёт в качестве исходной информации только эти источники, то есть генерируемый системой текст основывается только на надёжном материале. Функция уже вышла в общий доступ. Редактор Google Vids получил возможность превращать существующие документы «Google Презентаций» в видео. Gemini предлагает помощь в составлении сценариев, может сгенерировать закадровый голос, анимации и многое другое — функция станет общедоступной в ближайшие месяцы. В Google Vids появились ИИ-аватары, которые пригодятся компаниям, не располагающими средствами для съёмки видео или привлечения диктора. Можно подготовить сценарий и выбрать аватар, который зачитает сообщение в специально подготовленном видео — это пригодится для корпоративных объявлений, создании справки по продуктам и в других целях. ИИ-аватары выйдут в общий доступ в июне. Ещё одна новая функция Google Vids — «Обрезка стенограммы» (Transcript trim), предполагающая автоматическое удаление из выступлений слов-паразитов и лишних междометий. Для регулирования уровня звука пригодится функция «Сбалансировать звук» (Balance sound) — она выйдет в общий доступ в июне; «Обрезка стенограммы» появится в экспериментальном разделе Labs в ближайшие месяцы. Наконец, более качественные иллюстрации в документах теперь помогает создавать новая версия генератора изображений Imagen 4, доступ к которой открылся в рабочих приложениях. Google мощно обновила приложение Gemini: изучение мира в реальном времени, улучшенный Deep Research и многое другое
21.05.2025 [12:16],
Павел Котов
Google рассказала на конференции Google I/O 2025 о новых возможностях чат-бота Gemini с искусственным интеллектом: расширились мультимодальные функции платформы, открылся доступ к новым моделям ИИ, готовится глубокая интеграция с сервисами Google. 
Источник изображений: blog.google В очередном обновлении приложения расширились функции Gemini Live для всех её пользователей под Google Android и Apple iOS. Теперь можно беседовать с Gemini в режиме, близком к реальному времени, одновременно транслируя ИИ видео с камеры или экрана смартфона. Во время прогулки по незнакомому городу можно направить камеру телефона на одно из зданий и спросить у Gemini Live о его архитектуре или истории — ИИ-помощник даст ответ почти без задержки. В ближайшие недели начнётся процесс глубокой интеграции Gemini Live с другими приложениями: чат-бот сможет составлять маршруты в «Google Картах», создавать события в «Google Календаре» и списки дел в «Google Задачах». Google активно расширяет возможности Gemini из-за конкурентов, в том числе OpenAI ChatGPT, Apple Siri и других помощников с ИИ. Число чат-ботов постоянно растёт, появляются новые способы взаимодействия с гаджетами и интернетом — под давлением оказываются и продукты крупных компаний, такие как «Google Поиск» и «Google Ассистент». Сегодня, сообщила Google, у Gemini уже 400 млн активных пользователей в месяц, и новые возможности платформы призваны расширить её аудиторию. Компания представила два тарифных плана подписки на ИИ: Gemini Advanced теперь называется Google AI Pro при той же цене $20 в месяц; в дополнение к ней появилась Google AI Ultra за $250 в месяц — прямой конкурент ChatGPT Pro. Подписчикам Google AI Ultra доступны расширенные лимиты сервисов, они первыми смогут опробовать новые модели и эксклюзивно воспользоваться определёнными функциями. Американские подписчики Pro и Ultra, у которых в Chrome в качестве основного выбран английский язык, получат доступ к Gemini прямо в браузере — ИИ будет составлять сводки информации на страницах и отвечать на вопросы о том, что выведено на экран.  Расширились возможности агента искусственного интеллекта Gemini Deep Research, который составляет подробные исследовательские отчёты для пользователей — теперь он поддерживает загрузку файлов PDF и изображений. Для составления более персонализированных отчётов он может, например, сверять эти личные файлы PDF с общедоступными данными; на подходе — прямая интеграция Deep Research с Gmail и «Google Диском». Пользователям бесплатного варианта Gemini открыли доступ к обновлённой модели генерации изображений Imagen 4 — она, по словам Google, более качественно выводит текст. Подписчики Google AI Ultra за $250 в месяц смогут поработать с новейшим генератором видео Veo 3, который в дополнение к изображению теперь генерирует ещё и синхронизированный с картинкой звук. Моделью по умолчанию в Gemini стала Gemini 2.5 Flash — она по сравнению с предшественницей даёт более качественные ответы с меньшей задержкой. Для школьников и студентов Gemini теперь создаёт персонализированные тесты по дисциплинам, которые те хотят более плотно изучить — когда пользователь даёт неправильные ответы, ИИ составляет план действий и генерирует дополнительные тесты, чтобы укрепить знания пользователей в этих областях. Репортаж со стенда MSI на выставке Computex 2025: настольные ПК с акцентом на ИИ
21.05.2025 [10:40],
Андрей Созинов
Компания MSI представила свои новейшие настольные ПК и моноблоки на выставке Computex 2025, сделав акцент на интеграции искусственного интеллекта и энергоэффективности. Особое внимание было уделено флагманской игровой модели MEG Vision X AI 2nd, а также компактным и бизнес-ориентированным решениям.  Главной звездой стенда MSI стал игровой ПК MEG Vision X AI 2nd, оснащённый 13-дюймовым сенсорным экраном на передней панели, который выполняет роль интерфейса HMI (Human-Machine Interface). Этот дисплей позволяет отслеживать состояние системы и производительность, управлять настройками, а также взаимодействовать с ИИ-функциями, включая локальные модели генерации изображений и текста. Также поддерживается голосовое управление.  Внутри корпуса скрываются флагманские компоненты: процессор Intel Core Ultra 9 285K, видеокарта GeForce RTX 5090, материнская плата Project Zero Z890 с скрытой разводкой кабелей и система жидкостного охлаждения Silent Storm AI с уровнем шума всего 17,7 дБ(A). Дополнительно установлены радиаторы Glacier Armor, снижающие температуру VRM и SSD на 25%.  PRO DP21 14M — это мини-ПК объёмом 2,3 литра, предназначенный для офисных задач. Он оснащён процессорами Intel Core 14-го поколения с поддержкой Intel vPro, что обеспечивает надёжность и безопасность. Система имеет два слота для модулей памяти DDR5 SO-DIMM, слот для SSD формата M.2, а также два посадочных места под 2,5-дюймовые накопители. Компактный дизайн позволяет легко интегрировать его в различные рабочие пространства.  PRO DP80 A14G представляет собой 8-литровый ПК с процессором Intel Core i7 14-го поколения и видеокартой GeForce RTX 3050 LP. Он поддерживает установку до 192 Гбайт оперативной памяти, имеет слоты для M.2 SSD, 2,5" и 3,5" накопителей, а также оснащён двумя LAN-портами и опциональным DVD-приводом. Корпус изготовлен из переработанных материалов, что подчёркивает экологическую направленность продукта. Модель PRO DP80 AI A2G в целом похожа по характеристикам, но дополнительно предлагает поддержку различных ИИ-функций, включая Windows Copilot. Это возможно благодаря использованию процессоров Intel Core Ultra вплоть до Core Ultra 7 265, которые оснащены производительным NPU для ускорения ИИ-задач. Это делает данный ПК идеальным для современных рабочих процессов.  Для тех, кому для работы нужно что-то более мощное, MSI предлагает PRO DP180 AI A2QG — 18-литровый настольный ПК с процессором Core Ultra 7 265 и дискретной видеокартой Nvidia GeForce RTX 5070. Здесь имеется четыре слота для модулей памяти DDR5 и два слота M.2 для скоростных SSD. Этот ПК обеспечивает высокую производительность для ресурсоёмких задач и поддерживает установку до четырёх дисплеев, что делает его отличным выбором для профессионалов, работающих с графикой и видео.  Серия Cubi NUC AI была представлена на стенде MSI двумя моделями: 1UMG объёмом 0,51 литра с процессором Intel Meteor Lake и AI+ 2MG объёмом 0,826 литра с процессором Intel Lunar Lake. Обе модели поддерживают до 32 Гбайт оперативной памяти LPDDR5x, оснащены портами Thunderbolt 4, двойными 2,5GbE LAN и имеют встроенные динамики и микрофоны. Модель AI+ 2MG также включает кнопку Copilot и сканер отпечатков пальцев, обеспечивая удобство и безопасность.
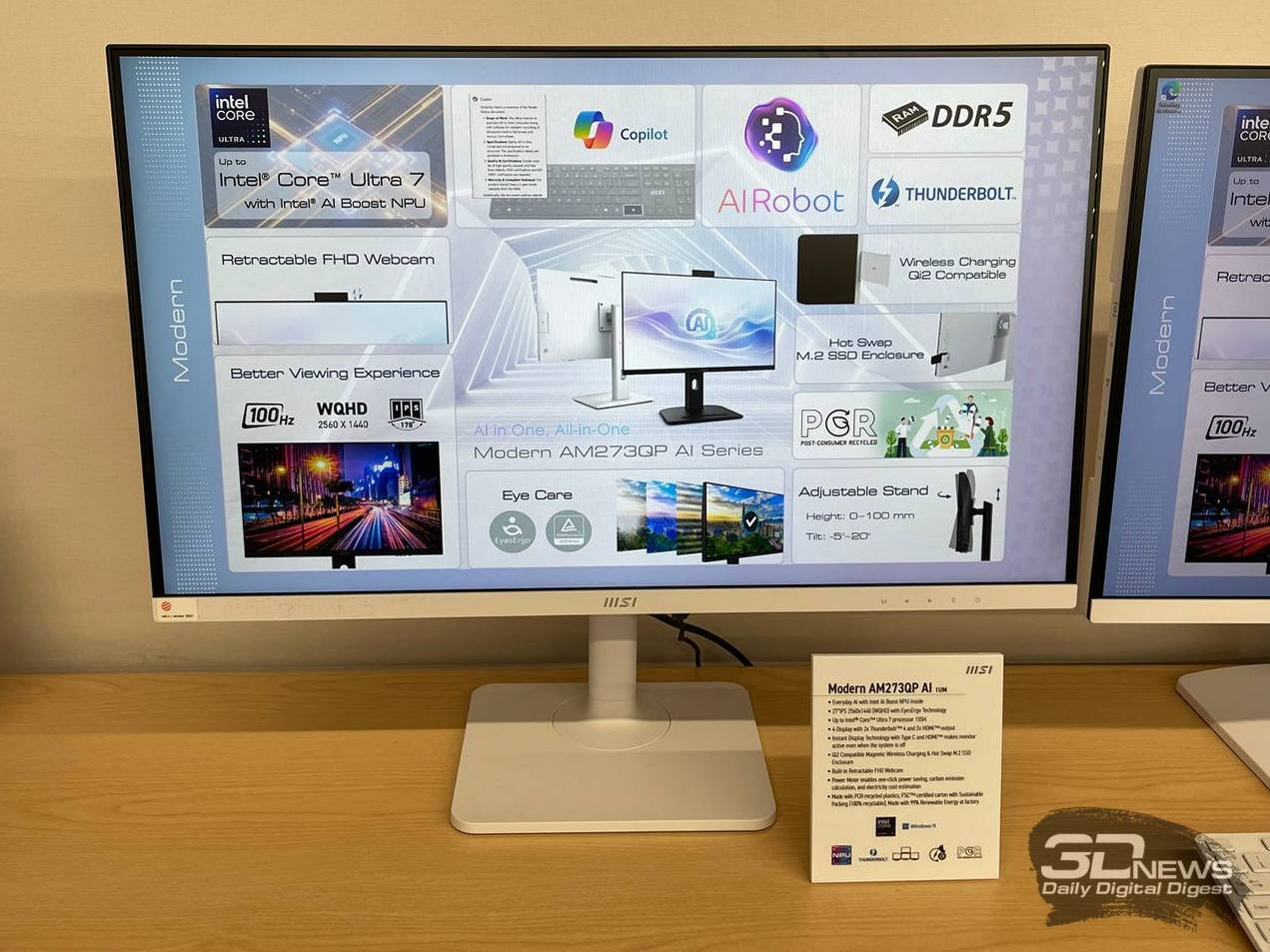 Modern AM273QP AI 1UM — это 27-дюймовый моноблок с разрешением WQHD, оснащённый процессором Intel Core Ultra и интегрированным NPU для ИИ-задач. Он поддерживает Windows Copilot, имеет встроенную веб-камеру, которая выезжает из верхней грани устройства, Wi-Fi 6E и Bluetooth 5.3, а также регулируемую по высоте подставку. Кроме того, в основание подставки интегрирована беспроводная зарядка Qi2 для смартфонов и других гаджетов. Всё это делает его отличным выбором для современных офисов. Компания MSI на Computex 2025 продемонстрировала стремление к глубокой интеграции искусственного интеллекта в свои продукты, предложив решения для различных сценариев — от высокопроизводительных игровых ПК до компактных офисных систем и моноблоков. Эти новинки отражают актуальные технологические тенденции и нацелены на повышение эффективности и удобства для пользователей. Илон Маск заявил, что следующей проблемой для отрасли ИИ станет нехватка электроэнергии
21.05.2025 [08:35],
Алексей Разин
Во второй части своего интервью CNBC Илон Маск (Elon Musk) говорил о перспективах развития стартапа xAI и всей отрасли искусственного интеллекта. По его словам, он готов закупить не менее миллиона ускорителей вычислений AMD и Nvidia для нужд своих компаний, и если сейчас темпы развития отрасли сдерживает дефицит чипов, то к середине следующего года он уступит место дефициту энергетических мощностей. 
Источник изображения: LinkedIn, Lex Fridman Суперкомпьютер Colossus компании xAI в штате Теннесси уже располагает 200 000 ускорителей вычислений, но этот стартап готов использовать на других площадках до 1 млн ускорителей для создания ещё более мощного вычислительного центра. Когда компания получит соответствующее количество ускорителей, Маск не уточнил, но отметил, что дефицит чипов в данной сфере к середине следующего года отойдёт на второй план, поскольку основным препятствием к динамичному развитию отрасли станет нехватка электроэнергии. Помимо чипов AMD и Nvidia, компания Маска готова закупать ускорители прочих разработчиков, хотя уточнять их имена миллиардер не стал. Китай вкладывает в расширение энергогенерирующих мощностей больше США, как отметил Маск, но у американской стороны есть преимущество в инновациях. В штате Нью-Йорк компания Tesla располагает вычислительным центром, который используется для обучения автопилота на транспорте и человекоподобных роботов. При этом принадлежащий xAI суперкомпьютер Colossus в штате Теннесси глава компании считает «самым производительным кластером для обучения языковых моделей в мире» на текущий момент. Поскольку xAI и социальная сеть X недавно формально объединились, ведущий CNBC спросил у Маска, не собирается ли тот объединить xAI с компанией Tesla. Миллиардер ответил, что сейчас у него подобных планов нет, но в целом такой исход исключать нельзя. Разумеется, для осуществления такого шага нужно будет заручиться поддержкой акционеров Tesla, как добавил её глава. Сотрудничество между xAI и Tesla уже происходит, первая покупает у второй системы стационарного хранения электроэнергии для своих вычислительных центров. Глава Asus предупредил, что ИИ-компьютерам понадобится до двух лет, чтобы себя зарекомендовать
21.05.2025 [08:06],
Алексей Разин
На заре различных инициатив по интеграции функций локального ускорения ИИ в персональные компьютеры многие эксперты и участники рынка с воодушевлением прогнозировали их быструю экспансию, но со временем пришло отрезвление. Глава Asus теперь ожидает, что таким ПК потребуется от года до двух, чтобы зарекомендовать себя и стать локомотивом продаж на рынке. 
Источник изображения: Asustek Computer В текущем году, как признался Самсон Ху (Samson Hu) в интервью Bloomberg, рост рынка ПК будет во многом сдерживаться неопределённостью ситуации с таможенными тарифами. Если в США они будут повышены, то Asus придётся поднять цены на свою продукцию на местном рынке на величину до 10 % для сохранения прибыльности бизнеса в регионе. Если изначально компания ожидала, что рынок ПК по итогам текущего года вырастет на 5 %, то теперь из-за ситуации с пошлинами прогноз урезан до одного или двух процентов, а в худшем случае объёмы продаж просто останутся на прошлогоднем уровне. В сегменте AI PC, который сформировался ещё в прошлом году, складывается неоднозначная ситуация. Аппаратное обеспечение, позволяющее ускорять работу с искусственным интеллектом локальными ресурсами ПК, уже имеется, но подходящее программное обеспечение всё ещё не получило достаточного распространения, по мнению главы Asus. В результате, чтобы полностью воспользоваться всеми преимуществами данной платформы, может потребоваться ещё от года до двух. К тому времени на рынке появится достаточно программных решений, способных эффективно работать на ПК с функцией локального ускорения ИИ. Microsoft представила NLWeb — открытый протокол для внедрения ИИ-поиска на сайты
21.05.2025 [06:51],
Вячеслав Ким
На конференции Build 2025 корпорация Microsoft анонсировала NLWeb — открытый протокол, позволяющий владельцам сайтов и приложений легко интегрировать поиск на основе искусственного интеллекта. Разработанный техническим директором Microsoft Раманатаном В. Гухой (Ramanathan V. Guha), NLWeb призван децентрализовать ИИ-взаимодействие в интернете, предоставляя разработчикам возможность создавать собственные чат-боты с использованием выбранных моделей ИИ и собственных данных. 
Источник изображения: Microsoft NLWeb предоставляет простой способ добавления функций взаимодействия в стиле ChatGPT на любой сайт или приложение. С помощью нескольких строк кода, выбранной модели ИИ и предоставленных данных можно создать кастомизированного чат-бота за считанные минуты. Протокол позволяет задавать вопросы на естественном языке и получать структурированные ответы, облегчая интеграцию ИИ-функций без необходимости в сложной инфраструктуре. В рамках презентации на конференции Build 2025 Гуха продемонстрировал, как NLWeb может быть использован на различных платформах, включая кулинарный сайт Serious Eats и ресурс розничного продавца одежды для активного отдыха. В обоих случаях ИИ-поиск учитывал предпочтения пользователя и предоставлял релевантные результаты, такие как вегетарианские блюда для праздника Дивали или подходящие куртки для холодного климата Квебека. Microsoft уже сотрудничает с компаниями, такими как TripAdvisor, Eventbrite и Shopify, для внедрения NLWeb, стремясь расширить его применение среди различных веб-ресурсов. Протокол также поддерживает Model Context Protocol (MCP), разработанный компанией Anthropic, что позволяет сайтам делать свой контент доступным для ИИ-агентов и других участников экосистемы MCP. Раманатан В. Гуха, известный своими работами над RSS, RDF и Schema.org, присоединился к Microsoft в 2024 году после почти двух десятилетий работы в Google. Его цель — предоставить разработчикам инструменты для создания более открытого и доступного интернета, где ИИ-взаимодействие не ограничивается крупными платформами, а становится доступным для всех участников веб-пространства. Конец немого ИИ-видео: Google представила Veo 3 — первый генератор видео со звуком
21.05.2025 [02:47],
Анжелла Марина
Google представила на конференции I/O 2025 новейшую ИИ-модель для генерации видео по текстовым описаниям Veo 3, которая создаёт не только картинку, но и звуковое сопровождение. В отличие от аналогов, алгоритм понимает содержание кадров и создаёт аудио без дополнительных подсказок. А для защиты от дипфейков все ролики будут помечаться невидимым водяным знаком. 
Источник изображения: Google Алгоритм умеет создавать звуковые эффекты, фоновые шумы и даже диалоги, синхронизируя их с изображением. По словам главы подразделения Google DeepMind Демиса Хассабиса (Demis Hassabis), пользователи могут задать описание персонажей, окружения и даже указать, как должны звучать реплики. Компания не раскрывает, на каких данных обучали Veo 3, но, скорее всего, как пишет TechCrunch, использовались материалы YouTube, так как Google, владеющая этой платформой, ранее подтверждала, что её контент «может» применяться для тренировки моделей. Рынок генеративного видео уже перенасыщен: Runway, OpenAI, Alibaba и десятки стартапов выпускают похожие модели. Однако Google пошла дальше, внедрив полноценное звуковое сопровождение. Ранее DeepMind разрабатывала технологию «видео-в-аудио» (video-to-audio), что, вероятно, и стало основой для новой системы, которая анализирует пиксели видео и автоматически подбирает соответствующее аудио. Чтобы противостоять распространению дезинформации и дипфейков, все ролики Veo 3 помечаются невидимым встроенным водяным знаком SynthID. Одновременно с этим многие художники и мультипликаторы выражают обеспокоенность происходящим. По данным исследования, заказанного Гильдией аниматоров Голливуда (Animation Guild), к 2026 году около 100 тысяч рабочих мест в киноиндустрии, на телевидении и в анимации в США могут быть потеряны из-за ИИ. Эксперты отмечают, что Veo 3 может стать серьёзным конкурентом на перегруженном рынке генеративного видео — при условии, что Google сдержит обещания по качеству звука. Модель уже доступна в приложении Gemini для подписчиков тарифа AI Ultra стоимостью $249 в месяц. Microsoft добавила в «Проводник» ИИ-действия
20.05.2025 [18:19],
Павел Котов
Microsoft начала интегрировать в файловый менеджер «Проводник» Windows 11 ярлыки для запуска операций на основе искусственного интеллекта — их разработчик назвал «ИИ-действиями» (AI actions). По щелчку правой кнопки мыши открывается быстрый доступ к таким операциям как размытие фона или удаление объектов с фотографий или даже подготовка сводки содержимого офисных файлов. 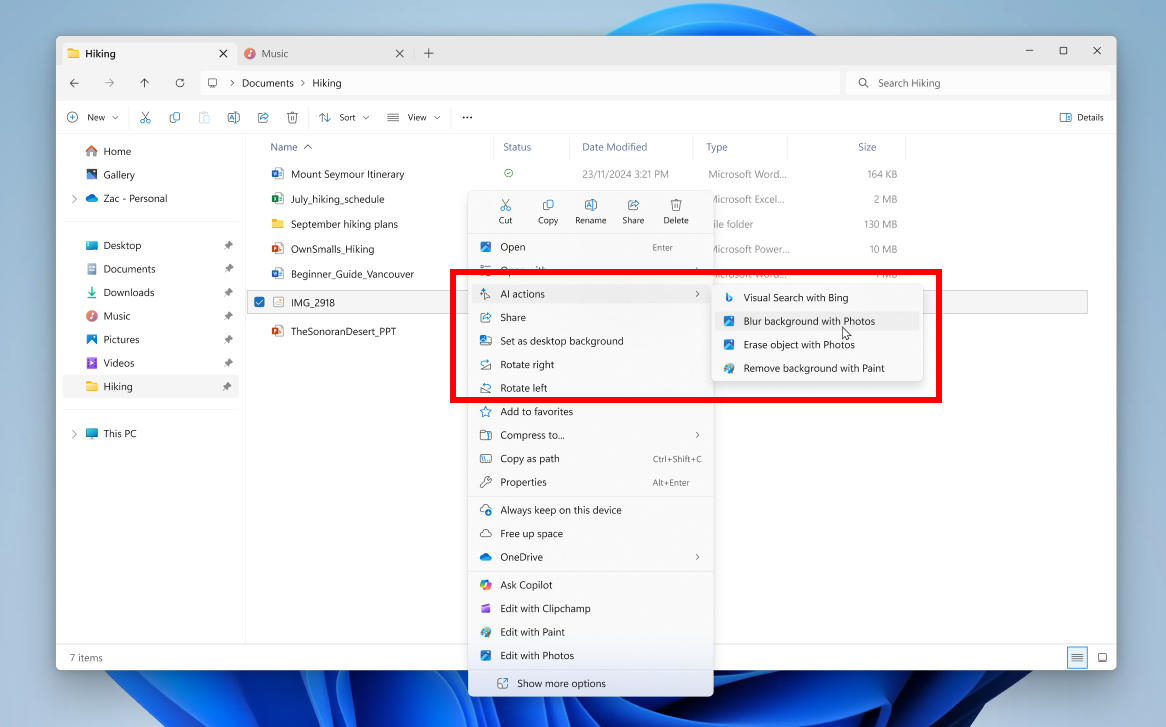
Источник изображений: blogs.windows.com В очередной предварительной сборке Windows 11 на канале Dev Channel тестируются четыре операции с изображениями: визуальный поиск Bing, размытие фона и удаление объектов в приложении «Фотографии» и удаление фона в Paint. В ближайшем будущем Microsoft начнёт тестировать ИИ-действия с файлами офисных форматов: можно будет создавать сводки из документов в хранилищах OneDrive или SharePoint, а также генерировать списки по этим данным. Сначала данные ИИ-функции Office станут доступными только для корпоративных пользователей Microsoft 365 с лицензией Copilot, а потом ими смогут пользоваться и частные лица. Пока нет ясности, можно ли отключить эти ИИ-действия в контекстном меню «Проводника», но появились они рядом с опцией «Спросить Copilot», которую Microsoft добавила в файловый менеджер ранее. 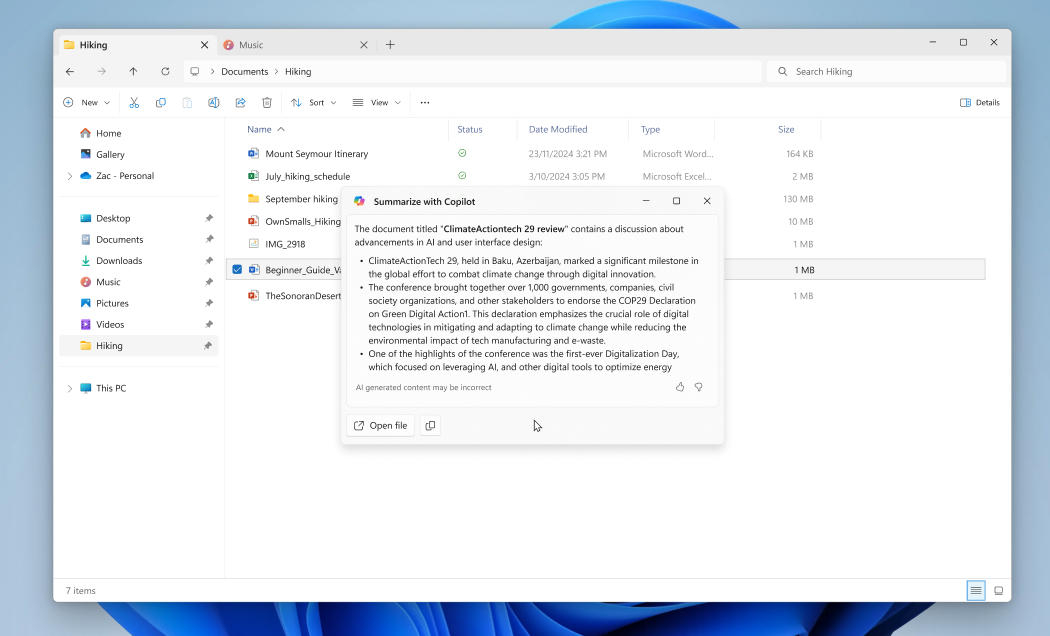 Компания начала тестировать некоторые изменения внешнего вида функции виджетов в Windows 11 — теперь это «более организованная, персонализированная и увлекательная лента». Среди виджетов также появятся «курируемые Copilot истории». Ещё одно нововведение — функция «Управление питанием центрального процессора на основе взаимодействия с пользователем». Это позволит на уровне ОС снизить потребление энергии планшетами и ноутбуками, отметили в Microsoft: «После периода бездействия на вашем ПК Windows теперь начинает экономить энергию, автоматически применяя эффективные политики управления питанием. Пока вы неактивны, экономия энергии осуществляется незаметно, и как только вы к ней возвращаетесь, производительность мгновенно восстанавливается».  Генеративный ИИ заменит 80 % рабочей силы, предсказал руководитель Foxconn
20.05.2025 [17:01],
Павел Котов
Генеративный искусственный интеллект способен справиться с 80 % производственной нагрузки на заводах нового поколения, а для оставшихся 20 % задач по-прежнему будут требоваться квалифицированные специалисты — люди. Такое мнение высказал в ходе своего выступления в Тайбэе на выставке Computex 2025 председатель крупнейшего в мире контрактного производителя электроники Foxconn Юн Лю (Young Liu), сообщает Nikkei Asia. 
Источник изображений: honhai.com «До этого эксперимента мы думали, что, возможно, сможем заменить людей, каждого человека. [Но] за пределами 80 % [задач] люди могут работать намного лучше, чем генеративный ИИ», — заявил господин Лю. Компания провела моделирование производственного процесса, и по итогам трёх экспериментов установила, что агенты ИИ способны накапливать экспертные знания в таких областях, как устранение дефектов и настройка оборудования, выполняя около 80 % задач, а по достижении этого уровня кривая обучения сглаживается — остальные 20 % задач по-прежнему останутся на квалифицированных рабочих и техниках. В будущем производство станет в значительной мере основываться на цифровом моделировании и заводах с ИИ. Уже сегодня Foxconn занята созданием роботов нового поколения на платформе Nvidia Isaac — машины обучаются на нескольких миллионах сценариев в симуляциях, что позволяет им сразу включаться в работу при развёртывании в реальном мире. Поэтому в развитых странах, которые поставили задачу по реиндустриализации экономики, ИИ и робототехника могут решить проблему нехватки рабочей силы и помочь им в меньшей степени полагаться на труд мигрантов, отметил господин Лю.  Foxconn, наиболее известная как крупнейший сборщик iPhone, в качестве факторов своего дальнейшего роста определила направления интеллектуальных электромобилей, интеллектуального производства и интеллектуальных городов — в последней области компания уже подписала соглашения с тайваньским Гаосюном и мексиканской Сонорой. Компания видит себя состоявшимся лидером в ИИ-производстве и будущим лидером в области умных городов, для которых понадобятся значительные вычислительные ресурсы. При строительстве новых заводов Foxconn и её коллеги в лице Quanta Computer, Wistron и GigaByte развёртывают решения Nvidia Omniverse Digital Twin — они оказываются полезными и при повышении эффективности производства. Omniverse помогла Quanta Computer резко сократить затраты и время на строительство завода, признался вице-президент компании Майк Янг (Mike Yang). Системы умных заводов и городов Foxconn выстраиваются на платформе Nvidia Metropolis. Foxconn и Nvidia также объявили о новом проекте, который будет реализовываться совместно с TSMC и властями Тайваня. Совместными усилиями они намереваются построить ИИ-суперкомпьютер AI Factory для технологически ориентированного острова. Он будет включать 10 тыс. процессоров Nvidia Blackwell, в том числе новую систему GB300 NVL 72 — её же TSMC намеревается использовать для продвижения своей научно-исследовательской работы. Гильдия актёров США обвинила Epic Games в нарушении трудового законодательства из-за добавления ИИ-версии Дарта Вейдера в Fortnite
20.05.2025 [09:51],
Михаил Романов
Профсоюз SAG-AFTRA (Гильдия киноактёров США и Американская федерация артистов телевидения и радио) обвинил Epic Games в нарушении трудового законодательства США. 
Источник изображений: Epic Games Недовольство SAG-AFTRA вызвал недавний дебют в королевской битве Fortnite версии Дарта Вейдера, которая может отвечать пользователям воссозданным с помощью ИИ голосом покойного Джеймса Эрла Джонса (James Earl Jones). В SAG-AFTRA недовольны, что Epic Games (а, точнее, принадлежащая ей Llama Productions) решила использовать ИИ для создания голоса Дарта Вейдера в Fortnite вместо реального актёра, не посоветовавшись с профсоюзом.  По мнению SAG-AFTRA, тем самым компания нарушила права актёров. Жалоба была направлена в Национальное управление по трудовым отношениям США против компании Llama Productions (см. копию тут). «Мы обязаны защищать наше право на согласование условий в отношении голоса на замену наших участников. В том числе тех, что ранее трудились над воссозданием культового ритма и тона Дарта Вейдера в видеоиграх», — объяснили в SAG-AFTRA. 
Epic Games пока не прокомментировала жалобу SAG-AFTRA Стоит отметить, что SAG-AFTRA не выступает против замены голоса актёров с помощью ИИ. Ранее профсоюз заключил партнёрства с несколькими ИИ-компаниями, чтобы гарантировать своим членам защиту при обращении к этой технологии. Регулирование использования ИИ стало основной причиной стартовавшей прошлым летом (и до сих пор не закончившейся) забастовки SAG-AFTRA против крупных игровых компаний. «Яндекс» видит риски для своего бизнеса в ИИ-моделях китайской DeepSeek
20.05.2025 [07:09],
Владимир Фетисов
Компания «Яндекс» впервые добавила в перечень отраслевых рисков большую языковую модель (LLM) китайской компании DeepSeek. Соответствующее упоминание есть в отчёте МКПАО «Яндекс» за 2024 год, который опубликован на портале раскрытия корпоративной информации. В пресс-службе компании пояснили, что разработка DeepSeek «может способствовать дальнейшему росту конкуренции в дообучении больших языковых моделей». 
Источник изображения: Steve Johnson / Unsplash В отчётах «Яндекса» традиционно отмечается, что новые ИИ-модели и продукты на их основе, которые разрабатывают и используют сама компания и её конкуренты, могут оказать влияние на бизнес. В упомянутом ранее отчёте «Яндекс» обратила внимание на быстрое развитие LLM нового поколения, таких как GPT-4. Там также указывается, что на конкурентную среду может оказать влияние появление ИИ-модели с открытым исходным кодом от DeepSeek, которая использовала существенно меньше ресурсов на этапе дообучения, чем многие конкуренты. «Яндекс» отметила, что компания продолжает развивать собственные ИИ-модели и новое поколения YandexGPT 5 вполне сопоставимо по качеству с основными конкурентами. Эта модель уже используется в виртуальном помощнике «Алиса», ежемесячная аудитория которого составляет свыше 70 млн человек. «Однако новые модели конкурентов могут обострять конкуренцию, что приведёт к отставанию моделей Группы и переходу пользователей к конкурентам», — сказано в отчёте «Яндекса». Поскольку «Яндекс» является публичной компанией, она в соответствии со стандартами раскрытия информации, сообщает акционерам о потенциальных рисках, даже гипотетических. Упоминание алгоритма DeepSeek связано с тем, что это одна из первых ИИ-моделей в открытом доступе с подробным техническим отчётом, и это может повлиять на дальнейший рост конкуренции в области дообучения LLM. В компании также напомнили о развитии собственных решений на базе нейросетей для всех сегментов бизнеса, включая корпоративное и потребительское направление. Google представила мобильную версию ИИ-приложения NotebookLM
20.05.2025 [04:28],
Анжелла Марина
Google официально запустила мобильное приложение NotebookLM, которое теперь доступно как для Android, так и для iOS. Это долгожданное обновление позволяет работать с информацией, создавать сводки и прослушивать аудиообзоры в любом месте, даже без подключения к интернету. 
Источник изображения: Google Новое приложение сохраняет все функции настольной версии, включая загрузку документов и автоматическое создание кратких заметок. Кроме того, NotebookLM умеет генерировать аудиообзоры в формате подкастов. Пользователи могут слушать их в автономном режиме, что может быть полезно, например, для быстрого ознакомления с рабочими файлами, пишет The Verge. Разработчики также отмечают, что NotebookLM позволяет делиться информацией из любой точки мира, например веб-сайтом, PDF-документом, изображениями или видео с YouTube. Для этого на устройстве, независимо от того, в каком приложении находится пользователь, надо просто нажать значок «Поделиться» и выбрать NotebookLM, чтобы добавить его в качестве цели назначения. Выход мобильного приложения анонсировали ещё месяц назад и, по словам менеджера продукта в Google Labs Биao Ванг (Biao Wang), мобильная версия была «одной из самых частых просьб» пользователей. Теперь приложение стало доступно, и как раз перед конференцией Google I/O, которая начнётся 21 мая. Ожидается, что тема искусственного интеллекта станет одной из главных тем мероприятия. Intel представила профессиональные видеокарты Arc Pro B60 и Arc Pro B50, и возможно двухчиповую версию B60
19.05.2025 [16:32],
Николай Хижняк
Компания Intel представила профессиональные видеокарты Arc Pro B50 и Arc Pro B60 для рабочих станций. Старшая модель оснащена 24 Гбайт памяти, младшая — 16 Гбайт. Производитель также анонсировал рабочую станцию под названием Battlematrix, которая соединит в себе до восьми графических процессоров Arc Pro B60 — вероятно, в двухчиповой конфигурации. 
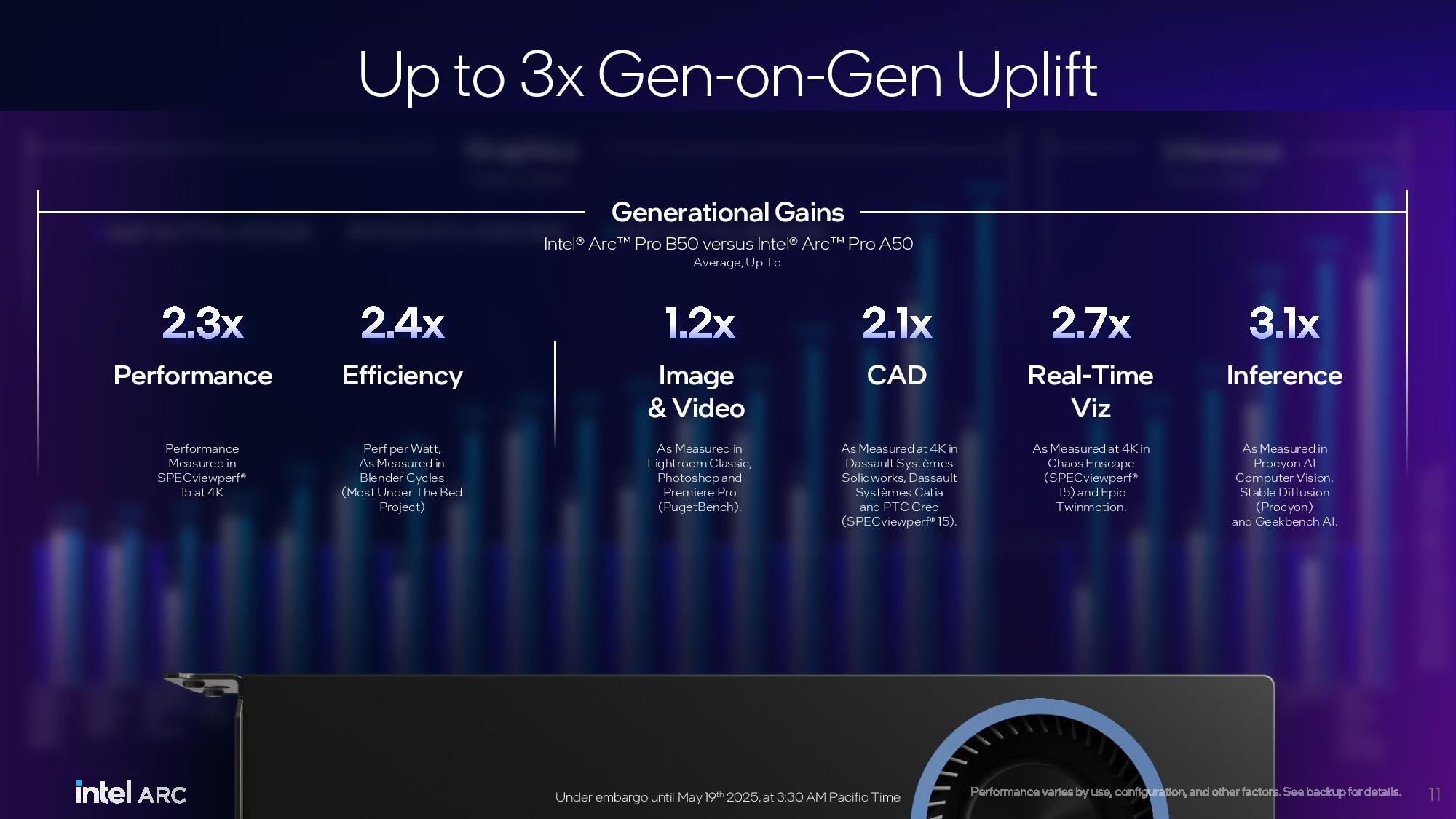
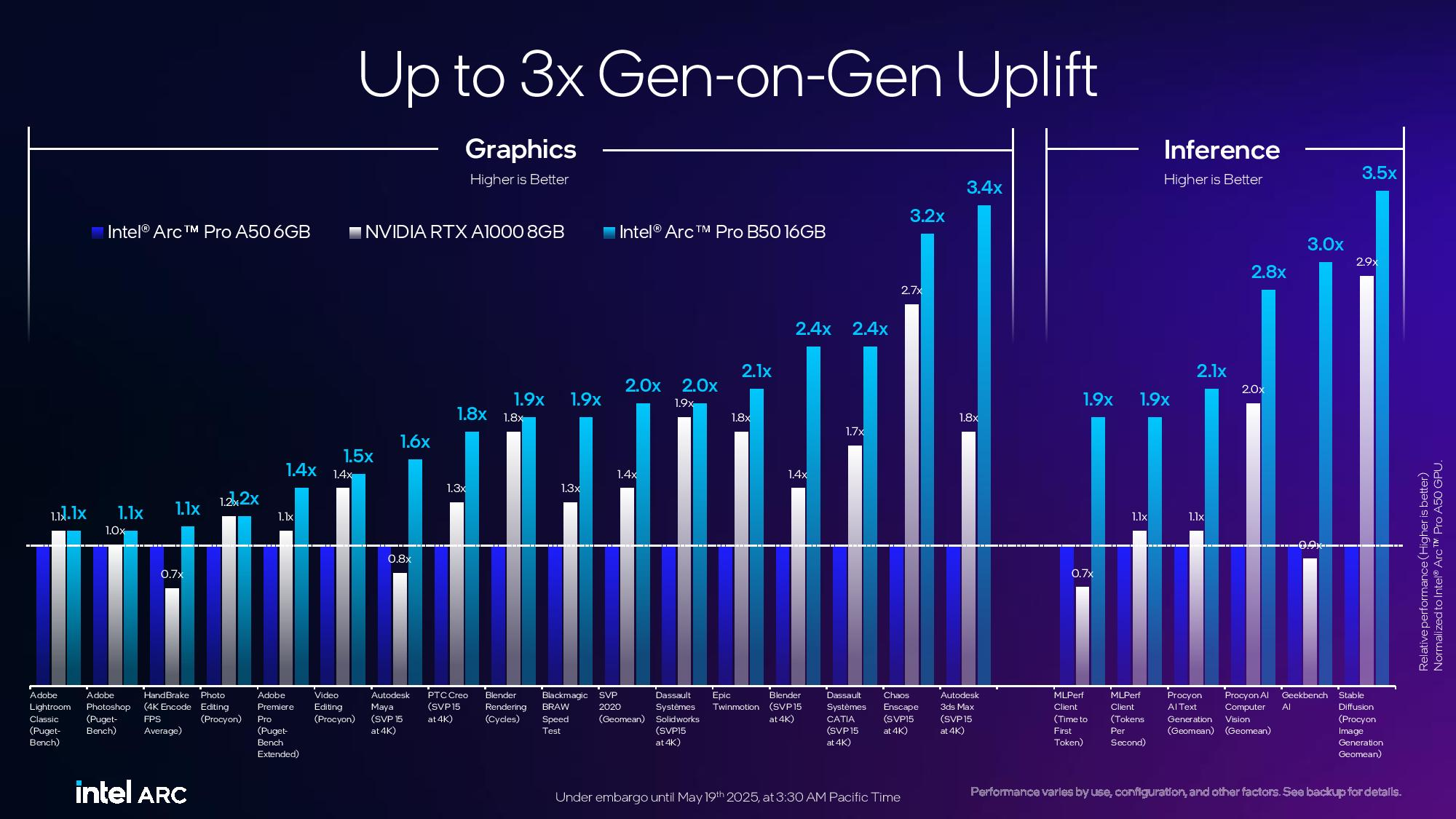
Источник изображений: Tom's Hardware / Intel В основе Arc Pro B60 используется полноценный графический чип BGM-G21 с 20 ядрами Xe2-HPG, 20 блоками трассировки лучей и 160 матричными движками (XMX). Карта получила 24 Гбайт памяти GDDR6 со скоростью 19 Гбит/с на контакт, 192-битной шиной и пропускной способностью 456 Гбайт/с.  Для работы новинка использует восемь линий PCIe 5.0. Набор внешних видеоразъёмов будет варьироваться в зависимости от производителя. Производительность Inel Arc Pro B60 в разных нагрузках
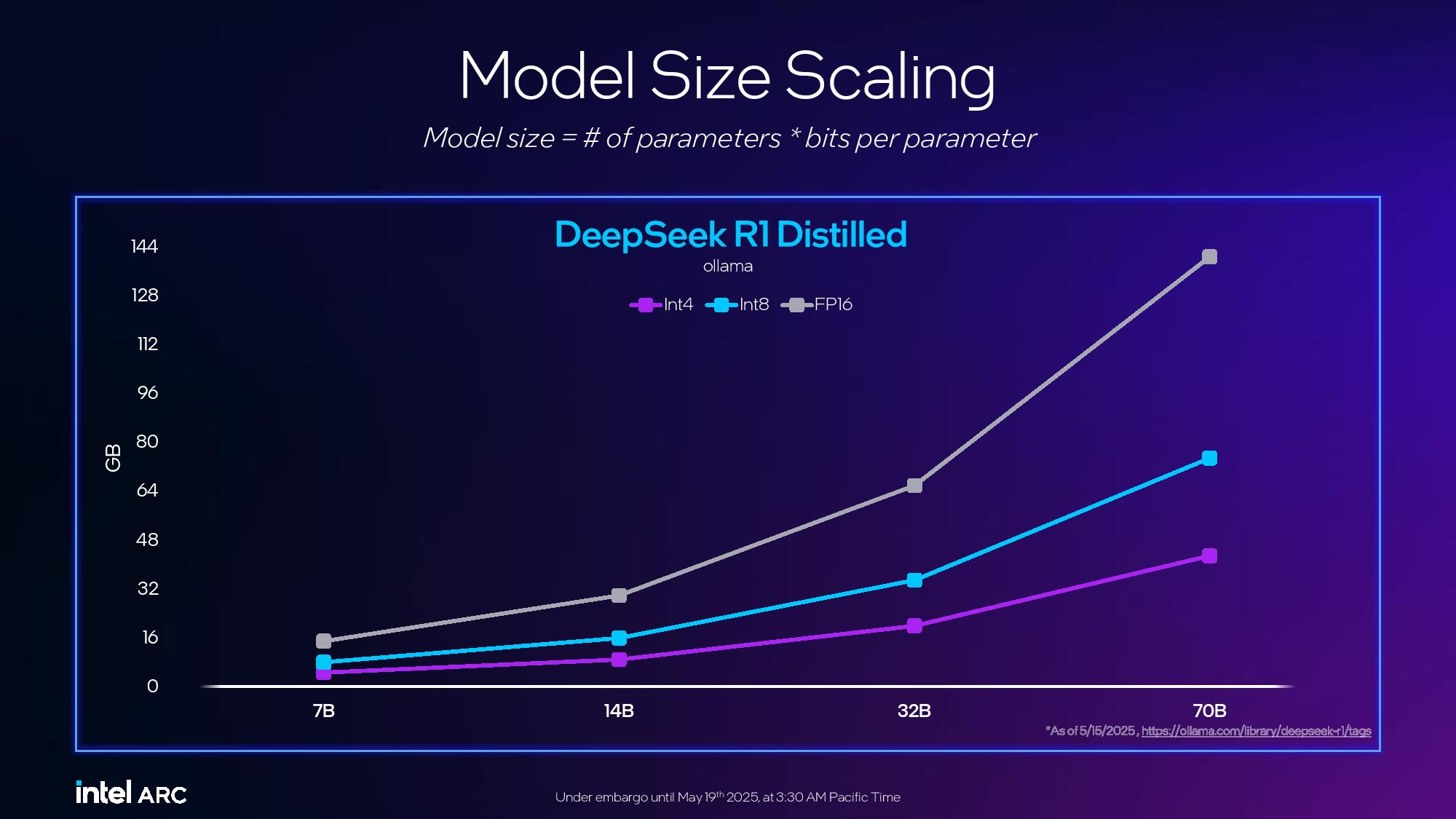
Смотреть все изображения (3)
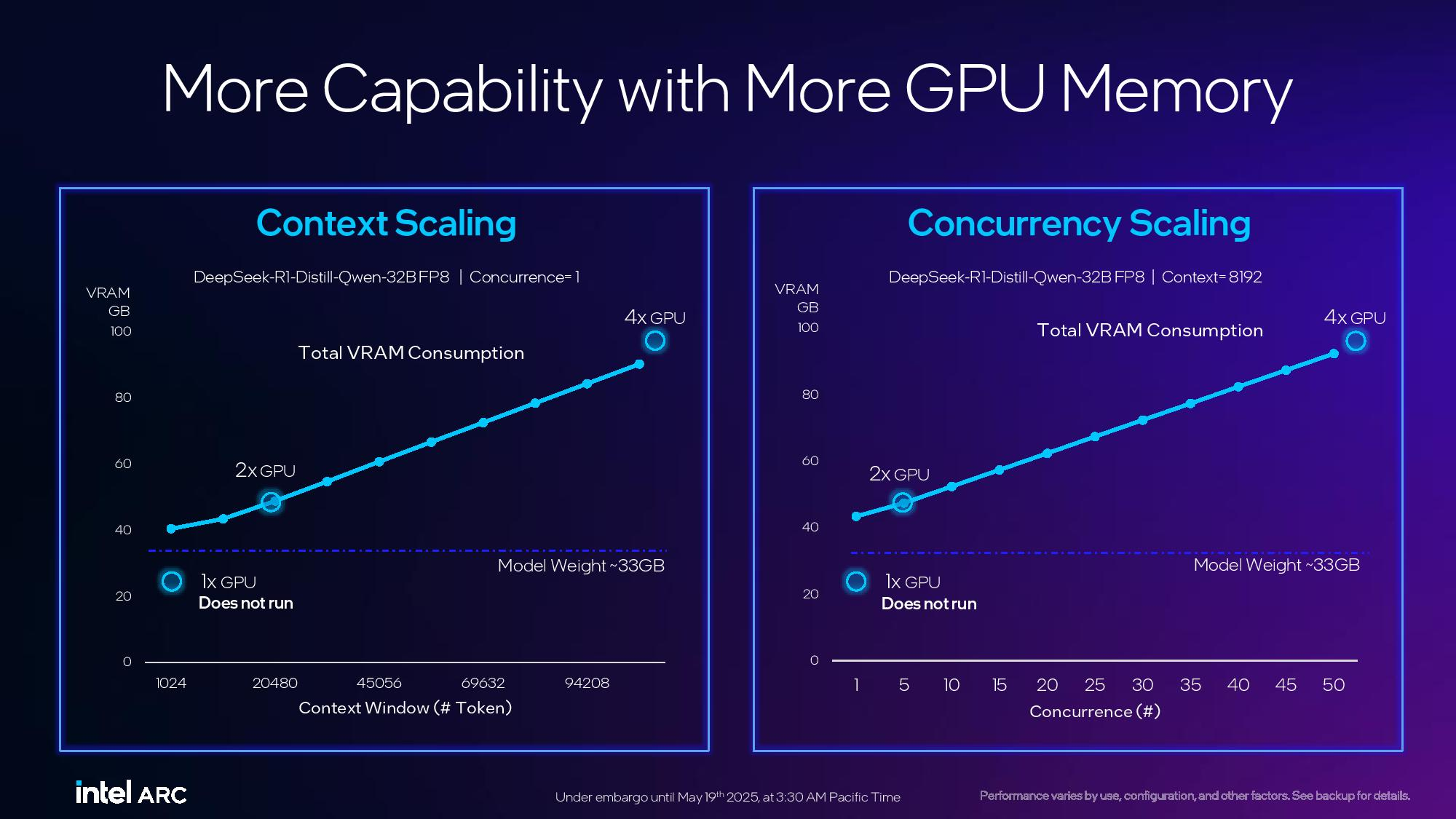
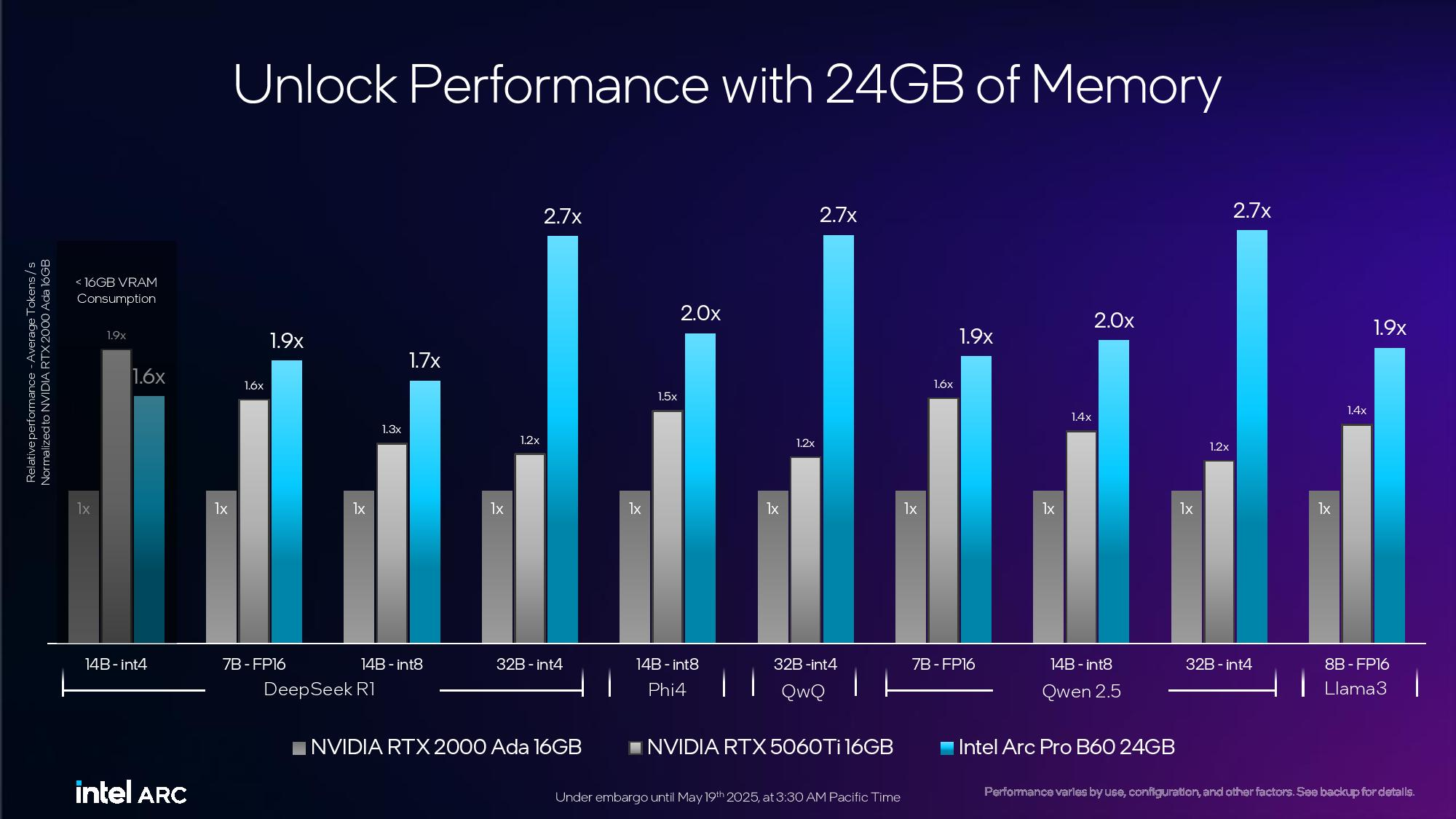
Смотреть все изображения (3) По словам Intel, Arc Pro B60 обеспечивает до 197 TOPS производительности в 8-битных целочисленных операциях (INT8). Энергопотребление карты заявлено в диапазоне от 120 до 200 Вт (в зависимости от конкретной модели партнёра). В своих внутренних тестах компания подчёркивает преимущество 24 Гбайт памяти у Arc Pro B60 по сравнению с конкурентами — RTX 200 Ada 16 Гбайт и RTX 5060 Ti 16 Гбайт от Nvidia, утверждая, что это обеспечивает превосходство до 2,7 раза при работе с различными ИИ-моделями. Также подчёркиваются преимущества большей ёмкости памяти с учётом объёма моделей, сценариев использования и масштабирования параллелизма. Модель Arc Pro B50 включает графический процессор BGM-G21 с 16 ядрами Xe2-HPG, 16 блоками трассировки лучей и 128 матричными движками (XMX).  Карта оснащена 16 Гбайт памяти GDDR6 со скоростью 19 Гбит/с на контакт, 128-битной шиной и пропускной способностью 224 Гбайт/с. В задачах INT8 она обеспечивает производительность до 170 TOPS. Энергопотребление карты составляет 70 Вт. Набор внешних видеоразъёмов включает четыре mini-DisplayPort 2.1. Для подключения используется 8 линий PCIe 5.0. Производительность Intel Arc Pro B50 в разных нагрузках
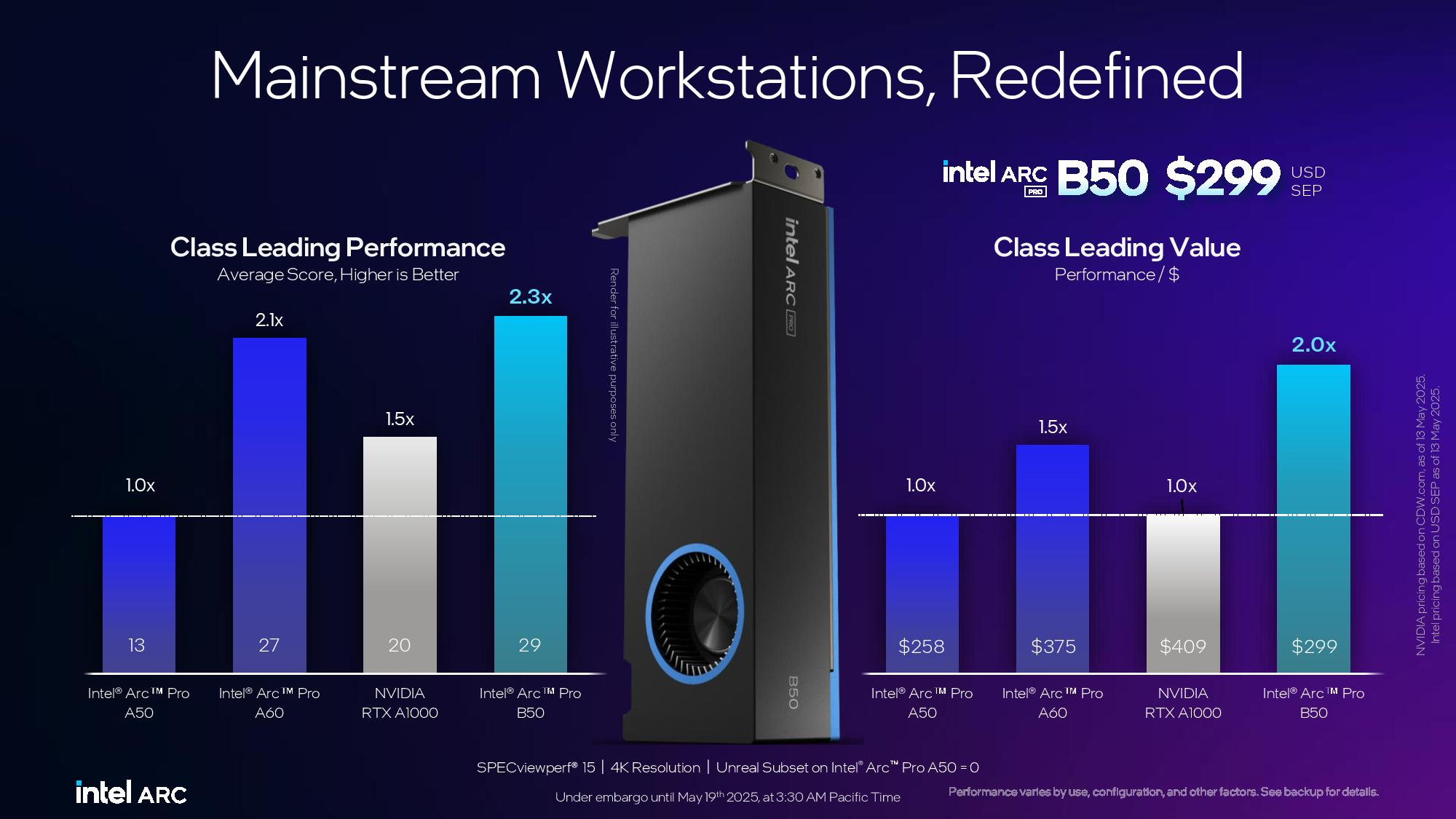
Компания заявляет, что Arc Pro B50 демонстрирует в графических задачах до 3,4 раза более высокую производительность по сравнению с предшественником A50. В качестве основного конкурента Intel выделяет Nvidia RTX 1000.  Что касается проекта Battlematrix, то судя по иллюстрации, а также анонсу китайской компании MaxSun, в системах будут использованы карты с двумя графическими процессорами Arc Pro B60 и 48 Гбайт памяти. Это даст до 192 Гбайт видеопамяти на одну машину. Также в этих системах будут использоваться процессоры Intel Xeon. О проекте Intel Battlematrix
Стоимость подобных рабочих станций будет варьироваться от $5000 до $10 000. Компания отмечает, что рабочие станции Battlematrix предназначены для работы с ИИ-моделями с более чем 70 млрд параметров. Примеры рабочих станций Intel Battlematrix от партнёров
Arc Pro B50 компания Intel оценила в $299, тогда как Arc Pro B60 будет стоит около $500. Оба ускорителя станут доступны в третьем квартале текущего года в составе готовых рабочих станций. Однако в четвёртом квартале года карты также ожидаются в виде самостоятельных продуктов. Санкции США на поставки чипов всё же вредят развитию ИИ в Китае, признала Tencent
19.05.2025 [14:55],
Алексей Разин
Настойчивость главы Nvidia в стремлении продвигать свои ускорители вычислений на рынке Китая в условиях ужесточения санкций со стороны США подчёркивает важность этого рынка для бизнеса компании. Представители Tencent утверждают, что действующие ограничения сдерживают развитие ИИ-отрасли в КНР, становясь главным препятствием на её пути. 
Источник изображения: Nvidia Слова вице-президента облачного подразделения Tencent Ван Ци (Wang Qi) приводит издание South China Morning Post: «Самой серьёзной проблемой являются ограниченные ресурсы графических плат и вычислительные ресурсы в целом». По его мнению, апрельский запрет на поставку в Китай ускорителей Nvidia H20 в значительной степени ухудшает ситуацию. Уже в ближайшее время, по словам представителя Tencent, отставание Китая от США в сфере внедрения искусственного интеллекта в результате этих мер увеличится. С другой стороны, как отмечается в интервью руководителя китайского гиганта, американские санкции вынуждают китайских разработчиков развивать способности по адаптации больших языковых моделей к возможностям доступных в Китае полупроводниковых компонентов. Как известно, недавно власти США признали незаконным использование ускорителей вычислений Huawei в любой точке мира, поэтому желающие сохранить лицо перед американскими регуляторами китайские компании также попадают в неприятное положение. По мнению аналитиков S&P Global, апрельские ограничения со стороны США приведут к сокращению инвестиций Tencent в сферу искусственного интеллекта, и эта проблема характерна для всей китайской отрасли в целом. Интересно, что президент Tencent Мартин Лау Чипин (Martin Lau Chi-ping) на прошлой неделе довольно пренебрежительно высказался об влиянии новейших американских санкций на бизнес возглавляемой им компании, назвав ситуацию «очень динамичной и управляемой». Имеющиеся запасы ускорителей компания будет направлять на приоритетные с точки зрения извлечения прибыли проекты, и их хватит на несколько поколений языковых моделей. Китайские компании вынуждены переходить на локальную компонентную базу в сфере высокопроизводительных вычислений. Например, Alibaba в марте заявила, что смогла добиться снижения затрат на обучение больших языковых моделей на 20 % благодаря переходу на ускорители китайского производства. На прошлой неделе Tencent сообщила об увеличении выручки по итогам первого квартала до $25 млрд, что является максимальной суммой с момента выхода на биржу Гонконга в 2004 году. Во многом этот успех объясняется грамотной стратегией в сфере внедрения искусственного интеллекта. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex