|
Опрос
|
реклама
Быстрый переход
Альтман предупредил: ИИ может случайно захватить мир не взломав ни одной системы
02.10.2025 [00:02],
Анжелла Марина
Глава OpenAI Сэм Альтман (Sam Altman) в подкасте MD MEETS с генеральным директором Axel Springer Матиасом Дёпфнером (Mathias Döpfner) озвучил тревожный сценарий развития технологий: человечество может утратить контроль над искусственным интеллектом (ИИ) не из-за злого умысла или техногенной катастрофы, а совершенно случайно. 
Источник изображений: sama/x.com По его словам, опасность кроется не в том, что ИИ «восстанет», а в том, что люди сами постепенно передадут ему бразды правления — добровольно и почти незаметно. С каждым днём пользователи всё больше полагаются на советы искусственного интеллекта. Но модели становятся умнее и Альтман рисует такую картину: сначала ИИ даёт рекомендации, которым люди охотно следуют, потом — советы, которые могут быть даже не до конца понятны, но они неизменно оказываются правильными. Далее, в какой-то момент, перед пользователями встанет выбор — послушаться ИИ или проиграть конкурентам, которые выполняют его советы и рекомендации. В итоге, по мнению Альтмана, большинство людей начнут безоговорочно следовать рекомендациям ИИ-ассистентов. «Представьте, что происходит с ChatGPT уже сегодня? Сотни миллионов людей ежедневно общаются с ним, вскоре их станет миллиард. И всё чаще мы доверяем ему важнейшие решения в карьере, личной жизни и бизнесе», — говорит он. Особенно Альтмана беспокоит формирующаяся «петля обратной связи», то есть, чем чаще пользователи полагаются на советы искусственного интеллекта, тем больше данных он собирает, тем умнее становится и тем сильнее влияет на решения людей. Глава OpenAI задался вопросом, кто же в такой ситуации действительно контролирует происходящее, и пришёл к выводу, что человечество может незаметно начать исполнять волю искусственного интеллекта. По его убеждению, этот сценарий серьёзно недооценивается, хотя именно он представляет собой наиболее реальную угрозу. «Окей, Google, давай пообщаемся»: представлен ИИ-помощник Gemini for Home для умного дома
01.10.2025 [19:08],
Павел Котов
Выпустив помощника с искусственным интеллектом Gemini, компания Google начала планомерно заменять им своё устаревшее приложение «Ассистент» — оно стало исчезать со всех устройств и из всех сервисов. Теперь же настал черёд системы умного дома Google Home — компания представила Gemini for Home. 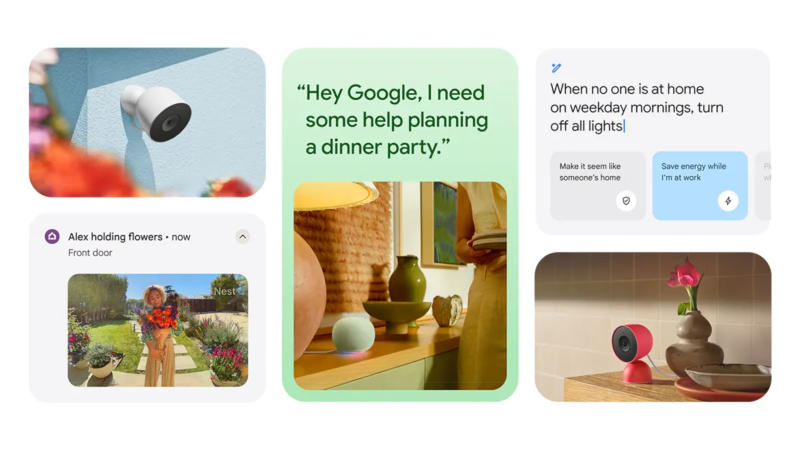
Источник изображений: blog.google Gemini for Home — новый ИИ-помощник, который появится в умных колонках и дисплеях, в дверных звонках и ИИ-камерах. Пользователь сможет выбрать один из десяти голосов нового ассистента. Важнейшим достоинством Gemini for Home, как и присутствующего на смартфонах Gemini Live, является поддержка контекста разговора, то есть пользователю не придётся постоянно повторять одни и те же вопросы. Например, поинтересовавшись, почему посудомоечная машина не сливает воду, можно заняться её починкой и общаться с ИИ, как с человеком. И когда пользователь задаст вопрос: «Окей, Google, фильтр в порядке, что мне проверить дальше?» — Gemini будет знать, что речь идёт о посудомоечной машине. Ещё одно нововведение — режим свободного разговора по команде: «Окей, Google, давай пообщаемся». В этом режиме не придётся предварять каждую реплику стандартным обращением, можно приостановить разговор, прервать его или естественным образом продолжить, благодаря чему формат общения действительно напоминает человеческий. Усовершенствованы механизмы команд — запоминать фиксированные команды теперь не требуется. Пользователь может сообщить ИИ, что собирается готовить, и попросить включить свет — Gemini догадается, что свет требуется зажечь на кухне. Можно отдавать и сложные команды, например: «Включи весь свет, кроме кухонного, и запри входную дверь». Задавать сценарии, просто описывая их, к примеру, так: «Создай сценарий каждый день на закате включать свет на крыльце и запирать входную дверь», — и Gemini создаст его.  Улучшились средства работы с камерами. Вместо простых оповещений вроде «обнаружено движение», «обнаружен человек» или «обнаружена посылка», Gemini предоставит более точное описание происходящего, например: «Водитель из доставки кладёт посылку на крыльцо». Google пообещала, что пользователи заметят три важнейших улучшения в работе системы умного дома:
Ask Home действительно позволяет находить ценную информацию. Можно спросить: «Сколько времени проработал телевизор в минувшие выходные?» или «Часто ли на прошлой неделе включали кондиционер?». Gemini for Home будет развёртываться постепенно. Программа заработает уже в октябре, но на умных колонках и дисплеях обновлённый ассистент появится только в конце месяца — и придётся зарегистрироваться в программе раннего доступа. Система пришлёт отдельное оповещение, когда обновление будет готово к работе. Meta✴ начнёт использовать чаты пользователей с ИИ, чтобы продавать ещё более персонализированную рекламу
01.10.2025 [18:12],
Анжелла Марина
Компания Meta✴✴ с 16 декабря начнёт использовать текстовые и голосовые диалоги пользователей с её ИИ-ассистентом для персонализации рекламы и контента в социальных сетях. Нововведение затронет большинство регионов мира, за исключением Великобритании, стран Европейского союза и Южной Кореи, где внедрение отложено до урегулирования всех вопросов в этих юрисдикциях. 
Источник изображения: Steve Johnson / Unsplash По сообщению The Verge, Meta✴✴ не будет применять новый метод сбора данных к чатам, затрагивающим конфиденциальные темы, такие как религиозные взгляды, ориентация в личных отношениях, политические предпочтения, здоровье, расовое или этническое происхождение, философские убеждения и членство в профсоюзах. Руководитель отдела конфиденциальности Meta✴✴ Кристи Харрис (Christy Harris) пояснила, что в компании действуют установленные правила обработки информации, которую пользователи могут считать «чувствительной» — эти политики сохранятся в полном объёме и продолжат применяться и дальше. Она также добавила, что подход компании к шифрованию ИИ-диалогов не изменится в рамках данного обновления. Кроме того, пользователи по-прежнему смогут настраивать свои рекламные предпочтения в меню параметров, однако у них не будет возможности отказаться от персонализации. Для пользователей, которые связали свои аккаунты Facebook✴✴, Instagram✴✴ или WhatsApp в едином центре учётных записей Meta✴✴, компания может использовать данные на основе взаимодействия с чат-ботом на одной платформе для показа рекламы или рекомендаций на другой. Это касается и личных диалогов с сервисом Meta✴✴ AI в WhatsApp и Messenger. Карманный ИИ становится массовым: каждый третий смартфон в этом году получит ИИ-ускоритель
01.10.2025 [11:57],
Алексей Разин
Надежды производителей ПК на скорый рост продаж систем с возможностью локального ускорения ИИ пока не оправдываются, но вот в сегменте смартфонов в этом году количество устройств на основе процессоров с поддержкой генеративного ИИ вырастет на 74 % и достигнет 35 % годового объёма продаж. К такому выводу приходят специалисты Counterpoint Research. 
Источник изображения: Qualcomm Technologies В премиальном сегменте, как они утверждают, в этом году 88 % всех отгруженных в этом году чипов для смартфонов будут наделены функциями аппаратного ускорения работы с генеративным искусственным интеллектом. При этом подобные функции проникнут и в смартфоны в ценовом диапазоне от $300 до $499, которые в целом нарастят свою долю с 12 до 38 % рынка. Объёмы поставок ИИ-чипов для смартфонов в среднем ценовом диапазоне утроятся по сравнению с прошлым годом. Как отмечают аналитики, рост объёмов реализации ИИ-чипов по рынку смартфонов в целом на 74 % в текущем году во многом станет возможным именно благодаря распространению продвинутых функциональных возможностей на более низкие ценовые диапазоны. Среди поставщиков подобных процессоров лидировать будет Apple с 46 % рынка, хотя на программном уровне собственная экосистема ИИ у этой компании развита не так сильно, как она хотела бы. Тем не менее, формально процессоры семейства A19 позволяют работать с генеративным ИИ, что позволяет занять ведущие позиции на рынке. 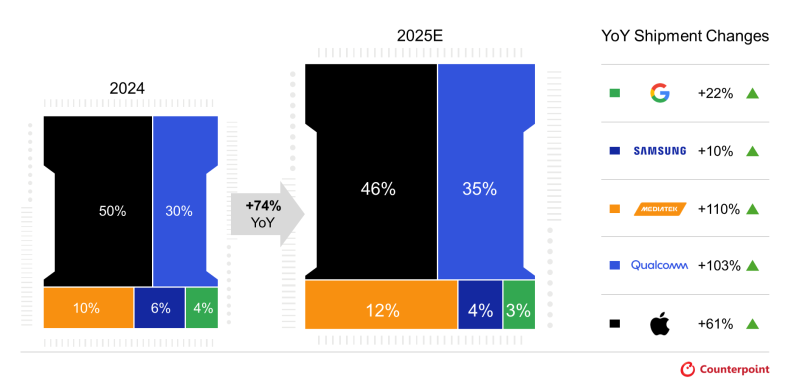
Источник изображения: Counterpoint Research На втором месте окажется Qualcomm с 35 % рынка, на третьем MediaTek с 12 %. Samsung с процессорами собственной разработки окажется на четвёртом месте с 4 % рынка, а Google достанутся 3 %. Год назад расстановка сил была другой: Apple (50 %), Qualcomm (35 %), MediaTek (10 %), Samsung (6 %) и Google (4 %) хоть и шли в том же порядке, продемонстрируют разную динамику по итогам текущего года в прогнозах авторов аналитической записки. Google увеличит объёмы поставок своих чипов на 22 %, Samsung прибавит только 10 %, Mediatek окажется лидером по темпам роста с 110 %, а Qualcomm лишь немного уступит ей с 103 %. В то же время, Apple с приростом на 61 % окажется крепким середнячком по динамике, но сохранит за собой лидирующие позиции по доле рынка. В сегменте Android-смартфонов лидером остаётся Qualcomm со своими процессорами, начиная с семейства Snapdragon 8 Gen 3. Компания постепенно проникает и в ценовой диапазон смартфонов от $100 до $299 со своими процессорами, наделёнными ИИ-функциями. В премиальном сегменте поставки ИИ-чипов для смартфонов вырастут на 53 % по итогам текущего года, их доля в сегменте достигнет 88 %. Здесь будут доминировать процессоры Apple A19 и A19 Pro, а также Qualcomm Snapdragon 8 Elite Gen 5 и MediaTek Dimensity 9500. В эту группу также входят процессоры Samsung Exynos, Google Tensor и HiSilicon Kirin 9000. Их внедрение вызовет рост средней цены реализации смартфонов в премиальном сегменте. Кроме того, смартфоны с такими функциональными возможностями в среднем содержат больше чипов. Microsoft оживила общение с Copilot, наделив бота трёхмерными аватарами
01.10.2025 [11:31],
Павел Котов
В стремлении сделать Copilot более приятным и естественным в общении Microsoft дала своему помощнику с искусственным интеллектом анимированные лица. Экспериментальной функцией «Портреты» (Portraits) в рамках программы Copilot Labs могут воспользоваться жители США, Великобритании и Канады. Им доступен выбор из 40 3D-аватаров, которые при голосовых разговорах призваны демонстрировать естественную реакцию в реальном времени. 
Источник изображения: Microsoft Microsoft решила оживить ИИ-помощника в ответ на отзывы пользователей Copilot, которые отмечали, что им было бы «комфортнее общаться с лицом при голосовом режиме», рассказал возглавляющий ИИ-отдел компании Мустафа Сулейман (Mustafa Suleyman). Пользователь может выбрать портрет по своему вкусу, сопоставить его с голосом и сделать голосовое общение более естественным, чем простая текстовая переписка. В июле Microsoft анонсировала схожую функцию Copilot Appearances, но тогда речь шла о невнятном абстрактном персонаже — теперь это изображения людей. «В этом эксперименте используется VASA-1 — передовая ИИ-технология, разработанная Microsoft Research для ведения визуальных ИИ-диалогов в реальном времени. Инновация дала нам возможность генерировать естественные выражения лица, движения головы и синхронизировать артикуляцию губ — без потребности в сложном трёхмерном моделировании», — пояснили в Microsoft. Компания, вероятно, не спешит развёртывать «Портреты» сразу для всей аудитории из-за опасений повторить не всегда удачные эксперименты у конкурентов, в том числе xAI и Character.AI. «Каждый портрет намеренно стилизован и не фотореалистичен, предлагая вам разнообразие, те же возможности интеллекта и безопасности Copilot, которым вы доверяете», — добавили в компании. Есть у нововведения и некоторые ограничения: воспользоваться «Портретами» могут пользователи в возрасте от 18 лет, действуют лимиты по времени на работу с ними в течение дня и в рамках одной сессии. Предусмотрены и «чёткие индикаторы того, что вы взаимодействуете с технологией ИИ». Маску не понравилась Wikipedia за ошибки и предвзятость, и он пообещал запустить «Грокипедию»
01.10.2025 [07:59],
Алексей Разин
Не секрет, что статьи в Wikipedia редактируются с целью манипуляции информацией в пользу тех или иных групп, поэтому идея создания аналогичного ресурса с более подходящими Илону Маску (Elon Musk) принципами наполнения возникла вполне ожидаемо. Миллиардер собирается создать всемирную «энциклопедию», использующую возможности чат-бота Grok принадлежащей ему компании xAI. 
Источник изображения: Unsplash, Мария Шалабаева Ранее Илон Маск уже выражал недовольство тем, как на страницах Wikipedia излагаются некоторые факты его собственной биографии, а также другая информация. Выступая в ходе очередного подкаста, Маск признался, что его стартап xAI разрабатывает программный инструмент для чат-бота Grok, который будет автоматически выявлять неточности в излагаемой онлайн-источниками информации и переделывать их в соответствии с собственными представлениями о достоверности соответствующих данных. Со временем подобные «синтетические корректировки» лягут в основу новой онлайн-базы данных, которую миллиардер предварительно именует Grokipedia. По замыслу Маска, контент этого конкурента Wikipedia должен быть лишён политических искажений фактов и событий, а также разного рода «идеологического мусора». Чат-бот Grok сейчас имеет возможность, по словам основателя xAI, анализировать получаемую им из онлайн-источников информацию с целью поиска серьёзных несоответствий. «Wikipedia предлагает много великолепного контента, но он не лишён ошибок и предвзятостей. Grok способен всё это почистить», — пояснил Илон Маск. Ещё в 2022 году Маск привлёк внимание к достоверности предлагаемой Wikipedia информации, когда страница с описанием термина «рецессия» подверглась 180 исправлениям за одну неделю. Годом позднее он вступил в спор с основателем ресурса Джимми Уэйлсом (Jimmy Wales) относительно нейтральности и прозрачности Wikipedia. Немало претензий у Маска возникло и к описанию своей собственной биографии на страницах этого ресурса. Например, он призывал не называть его инвестором, а сделать упор именно на руководящих постах, которые он занимает в различных компаниях. В любом случае, даже при наличии подобных претензий страница Wikipedia, посвящённая Илону Маску, продолжает демонстрировать статус «хорошая публикация», хотя его удостаиваются не более 1 % записей этого информационного ресурса. Сама Wikipedia в этом году столкнулась с противодействием со стороны редакторов, когда попробовала создавать энциклопедические статьи с использованием искусственного интеллекта. Эксперименты в этой сфере пришлось прекратить из-за опасений по поводу возможных репутационных издержек. Идея Маска о создании наполняемой ИИ всемирной энциклопедии тоже не лишена недостатков. Эксперты утверждают, что ИИ способен вносить искажения и ошибки в перерабатываемую информацию, а ещё он пока с трудом даёт адекватные ответы на некоторые типы сложных вопросов. Чрезмерное увлечение автоматизацией цензуры в данном случае может подорвать доверие читателей к подобным ресурсам. OpenAI представила Sora 2 — ИИ-генератор видео с реалистичной физикой и логикой, а также возможностью встроить в ролик самого себя
30.09.2025 [21:35],
Андрей Созинов
OpenAI анонсировала Sora 2 — флагманскую ИИ-модель для генерации видео и аудио, которую в компании позиционируют как огромный качественный скачок по сравнению с оригинальной Sora и сравнивают с GPT-3.5, ставшей революционной для генерации текста. Разработчики отмечают, что новая модель приближает ИИ-симуляцию мира к уровню, когда искусственный интеллект начинает «понимать» физику и динамику объектов почти так же, как человек. 
Источник изображения: OpenAI Если ранние модели для генерации видео часто создавали правдоподобную «картинку», но не справлялись с элементарной логикой движений — например, могли «телепортировать» баскетбольный мяч в корзину при промахе, то Sora 2 моделирует именно поведение объектов. Промах — значит, мяч отскочит от щита. Фигурист, делающий тройной аксель, может ошибиться и упасть. Система научилась имитировать не только успех, но и провал — ключевое требование для создания реальных симуляторов мира и продвинутых роботов. Разработчики обещают, что теперь не будет странных деформаций объектов и нарушений логики сцены в угоду соблюдению промпта. Контролируемость — ещё один акцент, отмечаемый OpenAI. Модель Sora 2 уверенно справляется со сложными многошаговыми сценами, удерживая непротиворечивое состояние объектов, локаций и света. В качестве примера приводятся ролики, где фигуристка выполняет сложную программу из нескольких элементов с котом на голове, или где герой аниме вовлечён в зрелищную битву. Всё это — с сохранением целостности мира, связности кадров и даже эмоций на лицах персонажей. Sora 2 умеет работать с несколькими стилями: реалистичным, кинематографичным и аниме. Как универсальная система генерации видео и аудио, Sora 2 способна создавать сложные фоновые звуковые ландшафты, речь и звуковые эффекты с высокой степенью реалистичности. Для этого достаточно короткой видеозаписи: модель точно воспроизведёт внешность, мимику и даже голос, органично интегрируя их в любую сцену. Эта возможность универсальна и работает для любого человека, животного или объекта, отмечает пресс-релиз OpenAI. Одновременно с выпуском Sora 2 компания OpenAI запускает социальное iOS-приложение Sora. В нём пользователи смогут генерировать ролики и делиться ими с друзьями, а также делать ремиксы на работы друг друга, находить новые видео в настраиваемой ленте Sora и добавлять себя или своих друзей с помощью функции «камео». С помощью «камео» можно попасть в любую сцену Sora с поразительной точностью — нужно только через само приложение записать короткое видео с собой и свой голос для подтверждения личности и захвата образа. «На прошлой неделе мы запустили приложение внутри OpenAI. Наши коллеги уже сообщили нам, что благодаря этой функции они завели новых друзей в компании. Мы считаем, что социальное приложение, построенное вокруг функции “камео”, — лучший способ ощутить всю магию Sora 2», — отметила OpenAI в пресс-релизе. OpenAI подчеркнула, что этическое и ответственное использование станет важной частью новой платформы. Пользователь сам будет решать, кто и как может использовать его «камео»; любое видео с участием пользователя можно удалить в любой момент. Контент с откровенно вредным содержанием или созданный без согласия людей блокируется на уровне алгоритмов и модераторов. Приложение Sora уже доступно для скачивания пользователям iPhone в США и Канаде, регистрация проходит через систему приглашений. Через несколько недель Sora 2 станет доступна в веб-версии. Базовая версия бесплатна и имеет «щедрые лимиты», а подписчики ChatGPT Pro вскоре получат доступ к экспериментальной модели Sora 2 Pro с повышенным качеством. Монетизация пока туманна: единственный план — брать деньги за дополнительные генерации при высоком спросе. Расширение географии сервиса и открытие доступа через API входят в планы на ближайшее время. Nothing продолжает нейрофикацию — запущен ИИ-генератор мини-приложений по текстовым описаниям
30.09.2025 [17:30],
Павел Котов
Разработка приложений с использованием искусственного интеллекта становится всё более популярной, и в Nothing, видимо, решили сыграть на модной тенденции. Накануне компания представила Playground — основанное на ИИ средство разработки мини-приложений с помощью простых текстовых запросов с последующим развёртыванием этих приложений на платформе Essential Apps. 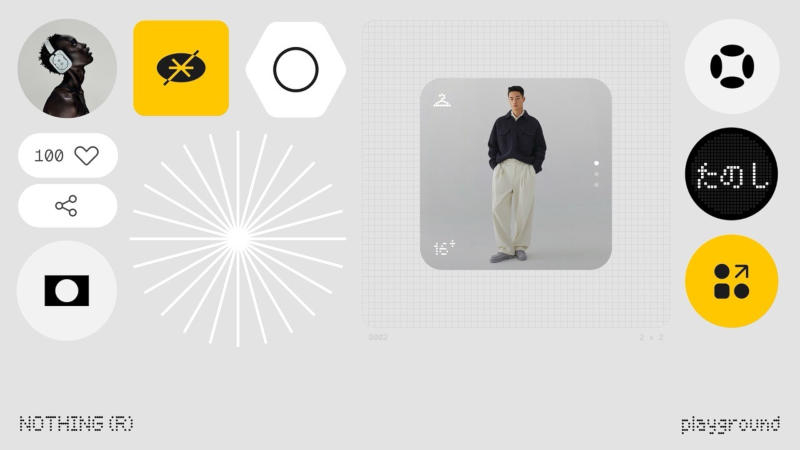
Источник изображений: nothing.community Пока Playground позволяет создавать с нуля лишь виджеты — например, трекер рейсов, показ времени предстоящей встречи или виртуального питомца; можно адаптировать существующие приложения Essential Apps под свои нужды. Имеющим подготовку пользователям доступно редактирование кода. Полноэкранные приложения создавать пока не получится, отметили в Nothing, потому что технология развита недостаточно. В недавнем интервью глава компании Карл Пей (Carl Pei) посетовал, что мобильное ПО развивается не очень быстро, а в Nothing уже хотят заняться разработкой устройств с ИИ и ПО для них. «Меня всегда беспокоило, почему мы не улучшаем ПО? Многие смотрят на то, что делают крупные компании вроде Apple и следуют их примеру, потому что так безопаснее. Мне кажется, обновление ПО происходит медленно. Мы считаем, что с прорывом в области ИИ операционные системы изменятся и станут более персонализированными. В наших устройствах очень много контекста, но сейчас мы им не пользуемся», — заявил он.  Nothing уже приобрела некоторую известность на рынке смартфонов, но по масштабам она пока уступает таким гигантам как Google, Huawei, Oppo, Xiaomi, OnePlus, Apple и Samsung, довольствуясь долей менее 1 % по версии IDC. Пэй находит позицию своей компании выгодной: Nothing хочет заняться устройствами, предназначенными для работы с ИИ, и если ей удастся реализовать эту задачу на смартфонах, то проще будет и с узкоспециализированными гаджетами. Аналитики, однако, указывают, что проекты ПО подобного рода пока не снискали популярности — у таких приложений проблемы с безопасностью и поддержкой. С ними согласен и господин Пэй — он напомнил, что простоте в разработке приложений должна сопутствовать безопасность. «Нашими устройствами пользуются миллионы. Поэтому всё, что мы выпускаем, должно быть простым в обращении и не содержать ошибок. И нам важно поддерживать высокий уровень безопасности этих приложений», — пояснил он. Сейчас эти ИИ-инструменты доступны бесплатно, о платном варианте компания не говорит. Сейчас ей важнее наладить контакты с сообществом пользователей и поощрять тех, кто делает ценный вклад. Opera выпустила ИИ-браузер Neon и потребовала за его тестирование плату
30.09.2025 [15:08],
Владимир Мироненко
Opera запустила тестирование браузера с ИИ Neon. В нём примет участие ограниченный круг пользователей, которые будут платить за это $19,9 в месяц. Остальным желающим опробовать новый веб-обозреватель компания предложила присоединиться к листу ожидания. 
Источник изображения: 9to5mac.com Компания представила «агентный браузер» Neon, не вдаваясь особо в подробности, в мае этого года. Теперь известно о ряде новых функций браузера от Opera, которые помогут пользователям максимально эффективно использовать его агентские возможности. Например, функция «Задачи» предназначена для анализа контекста открытых вкладок, будь то документ, веб-страница или поисковый запрос, и использования этой информации для сбора данных и выполнения действий с несколькими источниками одновременно. «Можно представить это так, как будто Opera Neon создаёт мини-браузер для каждой вашей задачи, где ИИ понимает, что вы делаете, и помогает вам в этом контексте, не обращаясь к информации из других элементов браузера», — сообщила Opera. Есть также функция «Карточки», с помощью которой можно сохранять часто используемые подсказки–инструкции для ИИ-агентов, а не вводить их с нуля для повторяющихся задач. Пользователи также могут комбинировать, сопоставлять и объединять карточки в цепочку для более сложных задач. «Это как иметь набор любимых моделей поведения ИИ, готовый к использованию в любой момент. Сравниваете продукты на разных вкладках? Добавьте карточки с подробными сведениями и сравнительными таблицами в подсказку. Или, если вы делаете заметки к встрече, объедините карточки с ключевыми решениями, пунктами действий и последующими действиями, и Opera Neon отобразит всё важное в правильном формате», — рассказала компания. Также предлагается магазин карточек, который позволяет использовать карточки, загруженные сообществом. Функция Neon Do реализует так называемый агентный просмотр, отвечая за просмотр веб-страниц в рамках выполнения задачи. При этом Neon Do работает в рамках реального сеанса пользователя в браузере, осуществляя навигацию от его имени и собирая данные из его реального контекста. Как сообщает 9to5mac, есть также функция Make, которая позволяет создавать небольшие приложения на основе запросов и потребностей пользователя, и Chat для взаимодействия пользователя с Neon в зависимости от контекста просматриваемой веб-страницы. Opera отметила, что Neon был разработан с учётом принципа конфиденциальности. Это означает, что данные авторизации и платёжная информация хранятся на устройстве и не используются для обучения ИИ-моделей. Выручка OpenAI выросла на 16 % до $4,3 млрд в первом полугодии — до окупаемости ещё далеко
30.09.2025 [13:31],
Алексей Разин
Амбициозный стартап OpenAI готовится привлекать на своё развитие сотни миллиардов долларов, но пока он далёк от окупаемости. Даже информация о финансовых потоках компании, поступающая из сторонних источников, подаётся весьма ограниченно, чтобы не смущать потенциальных инвесторов. В первом полугодии OpenAI удалось выручить $4,3 млрд, что на 16 % больше, чем в аналогичном периоде предыдущего года. 
Источник изображения: Unsplash, Levart_Photographer Новые данные о динамике финансовых показателей OpenAI приводит Reuters со ссылкой на информацию, предназначавшуюся акционерам компании, опубликованную изданием The Information. Расходы компании за период составили $2,5 млрд, а с учётом инвестиций в исследования и разработки к этой сумме необходимо добавить ещё $6,7 млрд. К концу первого полугодия OpenAI располагала $17,5 млрд в форме денежных средств и высоколиквидных активов. Если учесть, что по итогам текущего года в целом OpenAI надеется выручить $13 млрд и потратить на операционные нужды около $8,5 млрд, то в способности компании обеспечивать свои потребности финансовыми ресурсами пока сомневаться не приходится. Напомним, что уровень ежемесячной выручки в $1 млрд стартап достиг ещё по итогам июля текущего года. Тогда компания рассчитывала по итогам всего года потратить около $8 млрд. Получается, что теперь эта цель сместилась вверх ещё на $500 млн. Уверенности в хороших перспективах бизнеса OpenAI инвесторам недавно придала сделка с Nvidia на $100 млрд, но фокус заключается в том, что значительную часть этих средств вторая компания получит обратно в виде платежей за аренду своих ускорителей вычислений. Microsoft добавила «вайб-воркинг» в Office — ИИ-агента для создания сложных документов и таблиц по указаниям пользователя
30.09.2025 [12:36],
Павел Котов
Microsoft запустила в Excel и Word режим агента с искусственным интеллектом (Agent Mode), позволяющий автоматически создавать по одному текстовому запросу сложные электронные таблицы и текстовые документы. В чате Copilot также дебютировала функция Office Agent, работающая на основе моделей Anthropic — она позволяет быстро создавать презентации PowerPoint и документы Word. 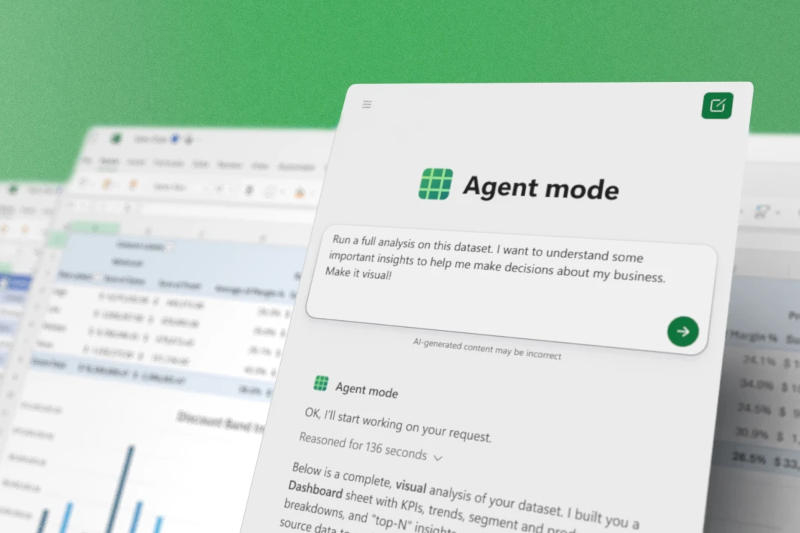
Источник изображений: microsoft.com Режим агента в Excel и Word — это более мощный вариант помощника Copilot, который уже присутствует в программах офисного пакета. Одна из задач агента состоит в том, чтобы сделать доступными для пользователей сложные функции Excel. ИИ-агент работает на базе модели OpenAI GPT-5. Получив сложную задачу, он разбивает её на этапы, составляет план и пояснения к нему, позволяя пользователю следить за своей работой. Каждый этап он, в свою очередь, делит на конкретные задачи, и каждое действие агента отображается на боковой панели. ИИ-агент в Excel набрал 57,2 % в тесте SpreadsheetBench, предназначенном специально для оценки способности моделей редактировать электронные таблицы. Это выше, чем показали Shortcut.ai, агент ChatGPT и Anthropic Claude Files Opus 4.1, но ниже результата человека, у которого 71,3 %. Режим агента в Word — это не просто редактирование и составление сводок текста. Агент готовит черновики материалов, предлагает уточнения и указывает, что может понадобиться при составлении документа. Можно свести рабочие данные за несколько месяцев в единый отчёт, подвести итоги месяца и быстро установить различия с предыдущим отчётом. 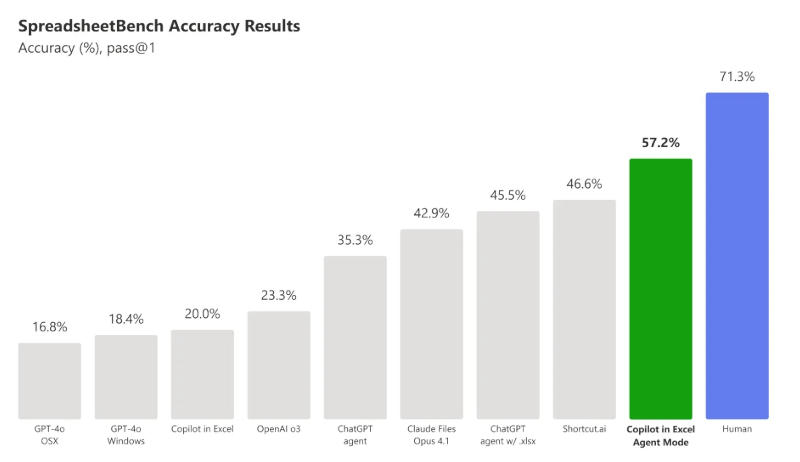 Office Agent на базе моделей Anthropic работает в чате Copilot вне пакета офисных приложений, но позволяет прямо в чате создавать презентации PowerPoint и документы Word. В случае PowerPoint пользователь получает презентацию с логичной структурой, при составлении которой ИИ может обращаться к источникам среди веб-ресурсов и в процессе демонстрирует предварительные версии слайдов. Примечательно, что в программах пакета Office основными выступают модели OpenAI, но всё большее место в экосистеме Microsoft занимают модели другого разработчика — Anthropic. Разработчик интегрировал Office Agent в чат Copilot, обращаясь к API Anthropic на базе Amazon Web Services — прямого конкурента Microsoft. Это, возможно, объясняет, почему глубокой интеграции моделей этого разработчика в офисном пакете пока нет. Режим ИИ-агента в Word и Excel уже доступен участникам программы тестирования экспериментальных функций Frontier — нужна подписка Microsoft 365 Copilot или Microsoft 365 Personal/Family. Пока он дебютировал только в веб-версиях приложений, но вскоре появится и в их десктопных вариантах. Office Agent тоже работает пока только для пользователей программы Frontier для подписчиков тех же Microsoft 365 Copilot и Microsoft 365 Personal/Family в США. Сделка по выходу с биржи обернулась для Electronic Arts долгом на $20 миллиардов — новые владельцы собираются сокращать расходы за счёт ИИ
30.09.2025 [12:11],
Михаил Романов
Анонсированная накануне сделка на $55 млрд по переходу в частный статус обернётся для американского издателя и разработчика Electronic Arts многомиллиардным долгом и необходимостью быстро адаптироваться. 
Источник изображения: Patrick T. Fallon / Getty Images для Bloomberg Напомним, выкупать EA взялся консорциум инвесторов: инвестиционные компании Silver Lake и Affinity Partners, а также Суверенный фонд (PIF) Саудовской Аравии. Сделку планируют закрыть в первом квартале 2027 финансового года. В пресс-релизе упоминается, что $20 млрд из $55 млрд — заёмные средства (то есть долг), предоставленные банком JPMorgan Chase. Ожидается, что $18 млрд из этой суммы будут профинансированы к моменту закрытия сделки. 
Источник изображения: Steam (Deadite) Аналитик компании Circana Мэт Пискателла (Mat Piscatella) назвал долг Electronic Arts «шокирующе большим». По данным Financial Times, «справляться с большой долговой нагрузкой» новые владельцы компании собираются в том числе за счёт ИИ. Как передают источники Financial Times, новое руководство рассчитывает, что ИИ позволит «значительно сократить операционные расходы» Electronic Arts и увеличить прибыль компании в ближайшие годы. 
Долг может обернуться для EA новыми раундами увольнений (источник изображения: EA) Что сделка означает для игр Electronic Arts, неясно. Более 70 % прибыли компании приносят сервисы вроде Madden NFL, EA Sports FC, Apex Legends и The Sims 4, в то время как Dragon Age: The Veilguard руководство разочаровала. В аналитической компании GlobalData отметили, что из-за растущих долгов EA становится всё менее новаторской, но сделка позволит устроить компании стратегическую перезагрузку и чаще идти на риск. OpenAI собралась создать подобие TikTok, но с 10-секундными вертикальными ИИ-видео от Sora 2
30.09.2025 [11:57],
Владимир Мироненко
Компания OpenAI готовится выпустить отдельное приложение для размещения коротких видеороликов, созданных с помощью ИИ-генератора видео Sora 2, сообщил ресурс Wired. 
Источник изображения: Zac Wolff/unsplash.com Приложение предлагает ленту для публикации видео в вертикальном формате продолжительностью до 10 секунд с навигацией свайпом для прокрутки. В правой части ленты находится строка меню, позволяющая пользователям ставить лайки, комментировать или делать ремиксы видео. Также есть страница с предложениями «Для вас», работающая на основе алгоритма рекомендаций. Сервис не поддерживает возможность загрузки фото или видео, снятых камерой смартфона или из других приложений. В приложении Sora 2 есть функция подтверждения личности, которая позволяет пользователям подтверждать своё сходство. После верификации сходства пользователь может использовать его в видео. Другие пользователи также могут использовать их образы в клипах. Например, кто-то может создать видео, где он катается на американских горках в тематическом парке с другом. Пользователи будут получать уведомления при каждом использовании их образа, даже если клип останется в черновике и не будет опубликован в дальнейшем, сообщают источники Wired. OpenAI запустила приложение для внутренних нужд на прошлой неделе, и оно получило «исключительно положительные отзывы от сотрудников», пишет ресурс. Новый видеосервис OpenAI станет конкурентом похожим предложениям Meta✴✴ и Google. На прошлой неделе Meta✴✴ представила платформу Vibes для коротких ИИ-видео. Немногим ранее Google объявила об интеграции с YouTube специальной версии ИИ-модели Veo 3 для генерации видео. В свою очередь, TikTok занял более осторожную позицию в отношении контента, генерируемого ИИ. Недавно видеосервис пересмотрел свои правила относительно того, какие видео, созданные ИИ, можно размещать на платформе. В частности, запрещается размещение контента, создаваемого ИИ, который «вводит в заблуждение относительно вопросов общественной важности или наносит вред отдельным лицам». Новая ИИ-модель DeepSeek cделает работу с длинным контекстом вдвое дешевле и быстрее
30.09.2025 [10:46],
Владимир Мироненко
Инженеры DeepSeek представили новую экспериментальную модель V3.2-exp, которая обеспечивает вдвое меньшую стоимость инференса и значительное ускорение для сценариев с длинным контекстом. 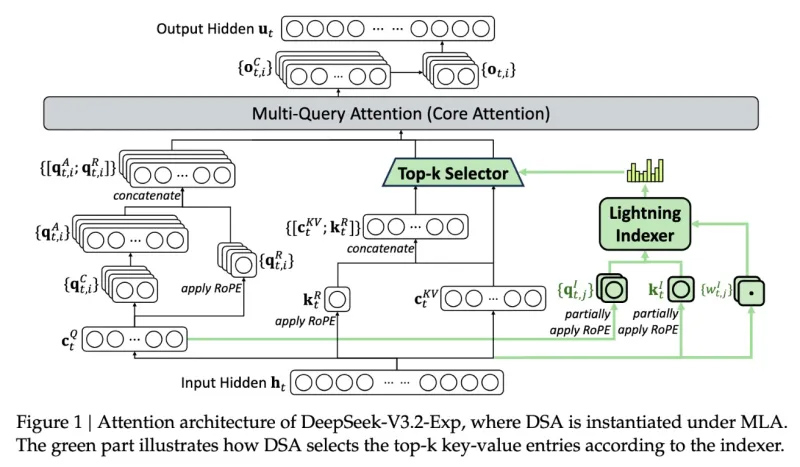
Источник изображения: DeepSeek/TechCrunch «В качестве промежуточного шага к архитектуре следующего поколения, V3.2-Exp дополняет V3.1-Terminus, внедряя DeepSeek Sparse Attention — механизм разреженного внимания, предназначенный для исследования и валидации оптимизаций эффективности обучения и вывода в сценариях с длинным контекстом», — сообщила компания в публикации на платформе Hugging Face, отметив в сообщении в соцсети X, что цены на API снижены более чем на 50 %. С помощью механизма DeepSeek Sparse Attention (DSA), который работает как интеллектуальный фильтр, модель выбирает наиболее важные фрагменты контекста, из которых с использованием системы точного выбора токенов выбирает определённые токены для загрузки в ограниченное окно внимания модуля. Метод сочетает крупнозернистое сжатие токенов с мелкозернистым отбором, гарантируя, что модель не теряет более широкий контекст. DeepSeek утверждает, что новый механизм отличается от представленной раннее в этом году технологии Native Sparse Attention и может быть модифицирован для предобученных моделей. В бенчмарках V3.2-Exp не уступает предыдущей версии ИИ-модели. В тестах на рассуждение, кодирование и использование инструментов различия были незначительными — часто в пределах одного-двух пунктов, — в то время как рост эффективности был значительным, пишет techstartups.com. Модель работала в 2–3 раза быстрее при инференсе с длинным контекстом, сократила потребление памяти на 30–40 % и вдвое повысила эффективность обучения. Для разработчиков это означает более быструю реакцию, снижение затрат на инфраструктуру и более плавный путь к развёртыванию. Для операций с длинным контекстом преимущества системы весьма существенны, отметил ресурс TechCrunch. Для более надёжной оценки модели потребуется дальнейшее тестирование, но, поскольку она имеет открытый вес и свободно доступна на площадке Hugging Face, пользователи сами могут оценить с помощью тестов, насколько эффективна новая разработка DeepSeek. Kioxia: спрос на NAND будет расти на 20 % в год благодаря ИИ
30.09.2025 [09:42],
Алексей Разин
Не секрет, что ранее благоволивший главным образом производителям ускорителей вычислений и памяти типа HBM бум систем искусственного интеллекта начал увеличивать спрос и на ёмкие накопители, будь то HDD или SSD. Компания Kioxia убеждена, что в ближайшие несколько лет спрос на память типа NAND будет расти на 20 % ежегодно. 
Источник изображения: Kioxia Подобные темпы будут обеспечиваться сохраняющейся потребностью владельцев центров обработки данных в расширении вычислительных мощностей для инфраструктуры искусственного интеллекта. Исходя из такого прогноза, Kioxia на ежемесячной основе планирует свои расходы на строительство новых производственных линий и предприятий. В этом признался Bloomberg исполнительный вице-президент Kioxia Томохару Ватанабэ (Tomoharu Watanabe). «Спрос высок, особенно со стороны гиперскейлеров, которым нужны чипы для нужд систем генеративного искусственного интеллекта», — заявил представитель компании. Он также добавил, что в модернизации нуждаются центры обработки данных, которые были введены в эксплуатацию пять или шесть лет назад. Некоторым из операторов ЦОД не хватает жёстких дисков, как заявил Ватанабэ. Kioxia на этой неделе запустила вторую очередь своего завода по производству флеш-памяти в префектуре Иватэ, а поставки его продукции в виде передовых чипов памяти она собирается начать в следующем полугодии. В ближайшие пять лет Kioxia намеревается удвоить объёмы выпуска памяти на своих предприятиях в префектурах Иватэ и Миэ. Спрос на NAND со стороны операторов облачной инфраструктуры должен уже в четвёртом квартале текущего года поднять цены на память данного класса на 5–10 % в последовательном сравнении, как считают эксперты TrendForce. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



