|
Опрос
|
реклама
Быстрый переход
Instagram✴ начала показывать пользователям рекламу с их лицами
07.01.2025 [16:45],
Павел Котов
В Instagram✴✴ началось тестирование функции, которая генерирует рекламные изображения с самими пользователями в нестандартной обстановке и помещает эти картинки в их ленту. В одном из случаев пользователь Instagram✴✴ увидел себя перед «бесконечным зеркальным лабиринтом». 
Источник изображений: reddit.com «Воспользовался Meta✴✴ AI для редактирования селфи, а теперь Instagram✴✴ воспользовался моим лицом для показа мне целевой рекламы», — рассказал он на платформе Reddit. Соцсеть подготовила для него слайд-шоу из созданных ИИ изображений. «Создано для Вас: Зеркальный лабиринт», — гласит связанная с этой публикацией запись в поле «Местоположение». «Представьте, как размышляете о жизни в бесконечном зеркальном лабиринте, где Вы в центре внимания», — говорится в тексте публикации.  В администрации Instagram✴✴ эту функцию рекламой не считают, передаёт 404 Media. Она связана с функцией Imagine Yourself на платформе Meta✴✴ AI — пользователю предлагают сделать несколько автопортретов с разных ракурсов и попросить создать изображение с ним в нестандартной обстановке. После этого Instagram✴✴ в некоторых случаях начинает самостоятельно генерировать изображения пользователя в случайных сценах, которые, по версии платформы, соответствуют его интересам. Но доступна данная функция только тем, кто прошёл процесс регистрации Imagine Yourself — в процессе система предупреждает, что впоследствии Meta✴✴ может генерировать изображения с участием пользователя и показывать их в его ленте. Подчёркивается, что никто другой их не увидит. Nvidia представила платформу Cosmos и другие мощные инструменты для разработки человекоподобных роботов
07.01.2025 [13:22],
Геннадий Детинич
На CES 2025 глава компании Nvidia Дженсен Хуанг (Jensen Huang) представил обновлённый и дополненный набор инструментов для ускорения разработки человекоподобных роботов. Выпущенный ещё весной пакет Isaac GR00T по созданию синтетических наборов движений теперь поддержан платформой Cosmos — цифровым представлением окружающего мира, созданным из колоссального объёма разнообразных данных. Это позволит приблизить день, когда роботы войдут в общество людей. 
Источник изображений: Nvidia Ожидается, что в течение следующих двух десятилетий рынок человекоподобных роботов достигнет $38 млрд. Чтобы удовлетворить столь значительный спрос, особенно в промышленном секторе, Nvidia представила не только обширный набор инструментов для программирования и проектирования, но и коллекцию базовых моделей роботов, конвейеров данных и фреймворков. Всё это призвано ускорить разработку человекоподобных роботов следующего поколения. Изначально проект Isaac GR00T (Generalist Robot 00 Technology) был ориентирован на сферу имитационного обучения роботов широкому спектру движений. Оператор в гарнитуре виртуальной реальности, например Apple Vision Pro (процесс GR00T-Teleop), выполнял действия своими руками, а система разбивала их на фазы движения конечностей и создавала множество альтернативных вариантов движений. Это позволяло значительно ускорить обучение, исключая необходимость воспроизведения всех манипуляций человеком. Даже небольшая выборка действий оператора могла привести к созданию лавины синтетических последовательностей благодаря вычислительным ресурсам платформ Nvidia. После сбора данных о действиях оператора процесс GR00T-Mimic тиражирует захваченные манипуляции в обширный синтетический набор движений. Платформы Nvidia Omniverse и Nvidia Cosmos экспоненциально расширяют этот набор за счёт рандомизации и масштабирования действий в трёхмерном пространстве. Эти данные затем используются для обучения роботов эффективному и безопасному перемещению и взаимодействию с окружающей средой в Nvidia Isaac Lab — модульной платформе с открытым исходным кодом для обучения роботов. Одним из главных анонсов CES 2025 стала платформа Nvidia Cosmos, которая «сокращает разрыв между симуляцией и реальностью». Это предварительно обученные модели, отражающие основы физического мира и предназначенные для обучения искусственного интеллекта с учётом физических процессов. Модели были обучены на 18 квадриллионах токенов, включая данные из 2 млн часов автономного вождения, робототехники, видеозаписей с дронов и синтетических источников.  Платформа Cosmos не только помогает генерировать большие наборы данных, но и минимизирует разрыв между имитацией и реальностью, расширяя масштаб изображений от 3D до реального мира. Сочетание Cosmos с Omniverse — платформой для разработки API и микросервисов для создания 3D-приложений — играет решающую роль, поскольку сводит к минимуму возможные ошибки, связанные с моделями мира, и обеспечивает высокую точность благодаря физически корректному моделированию. Nvidia уже нашла заинтересованных клиентов среди лидеров разработки человекоподобных роботов, таких как Boston Dynamics и Figure. Использование Nvidia Isaac GR00T, Omniverse и Cosmos значительно продвинет отрасль робототехники, приближая день, когда человекоподобные роботы станут неотъемлемой частью человеческой цивилизации. «Живые» NPC с ИИ от Nvidia вышли на новый уровень — полезные напарники в PUBG: Battlegrounds и «умные» горожане в Inzoi
07.01.2025 [12:50],
Михаил Романов
Компания Nvidia в рамках выставки CES 2025 представила новый виток развития Avatar Cloud Engine (ACE) for Games — набора технологий на базе генеративного ИИ для создания «живых» NPC в играх. 
Источник изображения: Krafton Напомним, прошлым летом Nvidia показывала «умного» собеседника на основе ACE в мультиплеерном боевике Mecha Break, а теперь возможности Nvidia ACE призваны продемонстрировать автономные неигровые персонажи. Эти NPC будут использовать ИИ, чтобы воспринимать окружение, планировать действия и вести себя как настоящие игроки: понимать и поддерживать пользователя в выполнении его задач, адаптироваться к тактике оппонента и так далее. Так, например, на протяжении 2025 года в условно-бесплатной королевской битве PUBG: Battlegrounds появятся (см. трейлер выше) напарники на базе Nvidia ACE, с которыми пользователи смогут кооперироваться, давая голосовые указания. Малая языковая модель Mistral-Nemo-Minitron-8B-128k-instruct позволит таким ИИ-союзникам в реальном времени общаться, давать советы, находить и делиться добычей, управлять транспортом и сражаться с другими игроками. Автономные неигровые персонажи на базе Nvidia ACE появятся и в других играх:
Кроме того, «умных» собеседников и автономных персонажей на базе Nvidia ACE готовят разработчики детектива Dead Meat, песочницы AI People и технодемо ZooPunk (его делают создатели метроидвании F.I.S.T.: Forged in Shadow Torch). Nvidia представила технологию DLSS 4, которая позволит играть в 4K c 240 FPS с качественной картинкой
07.01.2025 [12:44],
Павел Котов
Вместе с новыми видеокартами семейства Blackwell компания Nvidia представила новую технологию масштабирования изображения DLSS 4. С ней смогут работать все видеокарты семейств GeForce RTX, а в день дебюта поддержку технологии получат 75 популярных игр. 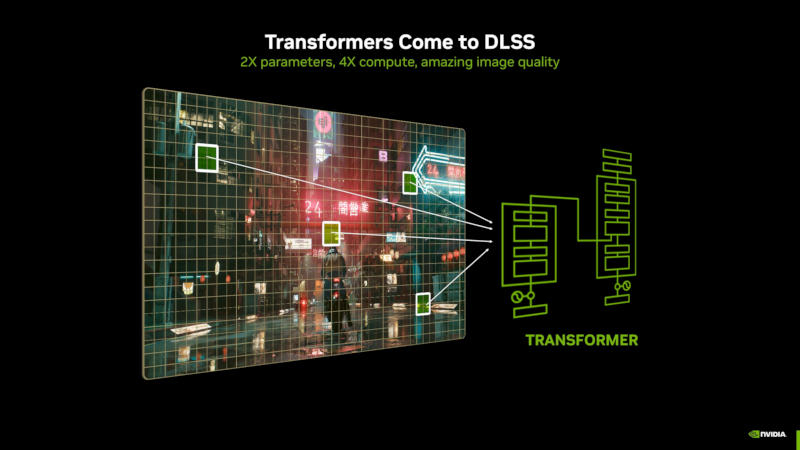
Источник изображений: nvidia.com Крупнейшим нововведением Nvidia DLSS 4 стал переход от свёрточных нейросетей к модели-трансформеру, у которой вдвое больше параметров, чем у нейросетей прежних версий DLSS. Это означает более высокую стабильность изображения, сокращение артефактов, более гладкие края объектов и более детализированное движение — проще говоря, качество изображения повысилось. Также в DLSS 4 появилась новая технология DLSS Multi-Frame Generation — улучшенный вариант базовой Frame Generation для видеокарт серии GeForce RTX 50: на каждый отрисованный кадр они генерируют ещё три. Это в сочетании с архитектурными улучшениями позволило Nvidia говорить о двукратном росте производительности видеокарт нового поколения. 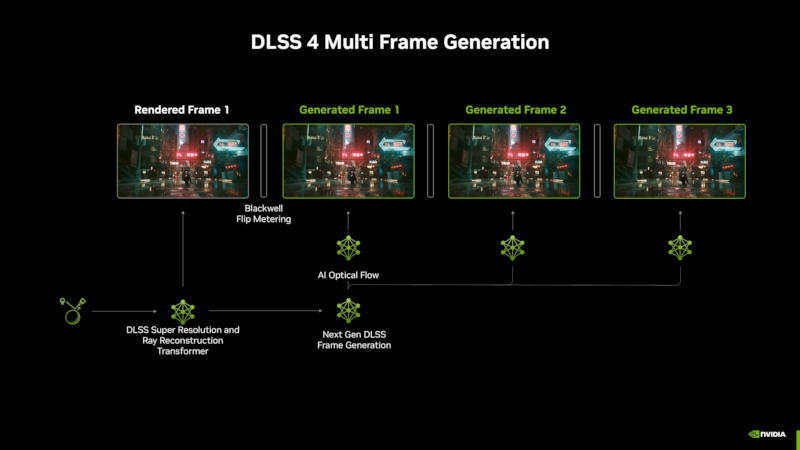 Разработчик развернул новые модели искусственного интеллекта, отвечающие за функции Deep Learning Anti-Aliasing (DLAA), DLSS Super Resolution, DLSS Frame Generation и DLSS Ray Reconstruction. Это, как заявили в Nvidia, помогло DLSS опередить другие технологии масштабирования. В случае DLSS Frame Generation использование ресурсов видеопамяти сократилось на 30 %, а скорость работы технологии выросла на 40 %. В Warhammer 40,000: Darktide частота кадров увеличилась на 10 %, а в видеопамяти высвободились 400 Мбайт.  Поддержку Nvidia DLSS 4 получили все видеокарты, но более старые — не в полной мере. На моделях серий RTX 20 и RTX 30 будут работать функции DLSS Super Resolution, DLAA и DLSS Ray Reconstruction; на RTX 40 — усовершенствованный вариант DLSS Frame Generation; а DLSS Multi-Frame Generation доступна только с видеокартами RTX 50, что стало возможным благодаря улучшенным ядрам Tensor на этих моделях. Это означает, что в мониторах разрешения 4K с высокой частотой обновления появился практический смысл — ранее многие геймеры недоумевали, зачем при 4K нужны 240 Гц, если видеокарты с такой картинкой не справляются. Теперь справляются, и возникает потребность в ещё более быстрых дисплеях. В день выхода Nvidia DLSS 4 будет поддерживаться 75 играми и приложениями, включая такие наименования как Cyberpunk 2077, Alan Wake 2 и Indiana Jones and the Great Circle. ИИ-стартапы собрали рекордные $97 млрд инвестиций в прошлом году
07.01.2025 [12:21],
Алексей Разин
Статистика PitchBook, на которую ссылается Bloomberg, гласит, что в прошлом году почти половина из привлечённых в прошлом году в США стартапами $209 млрд инвестиций была направлена на развитие компаний, связанных с искусственным интеллектом. Соответствующая сумма достигла рекордных $97 млрд. 
Источник изображения: Nvidia Если говорить об общем объёме финансирования стартапов, то он вырос на треть по сравнению с 2023 годом. Венчурным капиталистам при этом удалось привлечь $76,1 млрд в 508 фондов по итогам прошлого года, что стало минимальной суммой с 2019 года, а по количеству фондов показатель оказался минимальным с 2014 года. Подобная тенденция демонстрирует, что крупным компаниям проще привлекать прямое финансирование со стороны инвесторов, а крупные институциональные инвесторы активнее привлекают средства. На искусственный интеллект тратятся рекордные суммы, а вот молодым компаниям за пределами этого сектора перестаёт хватить денег на развитие. В ходе публичных размещений акций и в результате сделок по поглощению стартапов в прошлом году в США было привлечено и потрачено $149,2 млрд, что на $30 млрд больше результата 2023 года и почти столько же, сколько было привлечено в 2022 году. В Европе финансирование стартапов в целом по итогам 2024 года просело с 66,7 до $61,6 млрд, а в Азии объёмы финансирования сократились с $100,1 до $75,9 млрд. США в этом смысле отличаются высокой степенью концентрации ресурсов, привлекаемых для развития систем искусственного интеллекта. Google сделает использование телевизора более интуитивным и полезным, подселив нейросети Gemini в Google TV
07.01.2025 [12:20],
Владимир Мироненко
Google TV получит интеграцию с нейросетью Gemini, что позволит сделать взаимодействие пользователя с телевизором «более интуитивным и полезным», объявила Google на выставке CES 2025. Благодаря обновлению Google TV, которое выйдет в этом году, пользователи смогут искать контент и задавать вопросы, не начиная с фразы «Окей, Google», пишет The Verge. 
Источник изображений: Google Для поиска медиа будет достаточно спросить: «Какие последние фильмы от Disney?». Также можно будет задавать более общие вопросы, такие как: «Какие места лучше всего посетить в Азии летом?», и Google TV покажет результаты с YouTube. Интеграция с нейросетью также позволит пользователям взаимодействовать с устройствами умного дома, предоставляя возможность просматривать видеопоток с дверного звонка, приглушать свет и выполнять другие действия. Аналогичные функции Gemini компания добавила в ТВ-приставку Google TV Streamer, вышедшую в прошлом году. Помимо интеграции Google TV с Gemini, компания оснащает телевизоры с использованием своей операционной системы микрофонами дальнего радиуса действия, что позволяет управлять телевизором с помощью голосовых команд напрямую, без необходимости использования пульта дистанционного управления. Телевизоры с Google TV также получат датчики приближения, которые будут определять, когда пользователь находится рядом с телевизором, и показывать «персонализированные и информативные виджеты» с информацией о погоде или новостями. Добавим, что LG и Samsung объявили по планах использовать ИИ-ассистента Microsoft Copilot в своих телевизорах. Nvidia представила настольный ИИ-суперкомпьютер Project Digits на суперчипе Grace Blackwell за $3000
07.01.2025 [10:23],
Андрей Созинов
Nvidia представила персональный ИИ-суперкомпьютер. В мае этого года компания начнёт продажи системы под названием Project Digits, в основе которой лежит новый суперчип GB10 Grace Blackwell. Он обладает достаточной вычислительной мощностью для запуска сложных моделей ИИ (LLM) и при этом достаточно компактен, чтобы поместиться на столе и работать от стандартной розетки. Ранее для такой вычислительной мощности требовались гораздо более крупные и энергоёмкие системы. 
Источник изображений: Nvidia «ИИ станет основным в каждом приложении для каждой отрасли. Благодаря Project Digits суперчип Grace Blackwell станет доступен миллионам разработчиков, — заявил генеральный директор Nvidia Дженсен Хуанг (Jensen Huang). — Размещение суперкомпьютера ИИ на столах каждого специалиста по обработке данных, исследователя ИИ и студента даст им возможность участвовать в формировании эпохи ИИ». Система Project Digits, размером с традиционный настольный мини-ПК вроде Mac mini, может работать с моделями ИИ, содержащими до 200 миллиардов параметров, а её стартовая цена составляет 3000 долларов. Для ещё более требовательных приложений две системы Project Digits могут быть объединены для работы с моделями, содержащими до 405 миллиардов параметров (лучшая модель Meta✴✴, Llama 3.1, как раз имеет 405 миллиардов параметров). 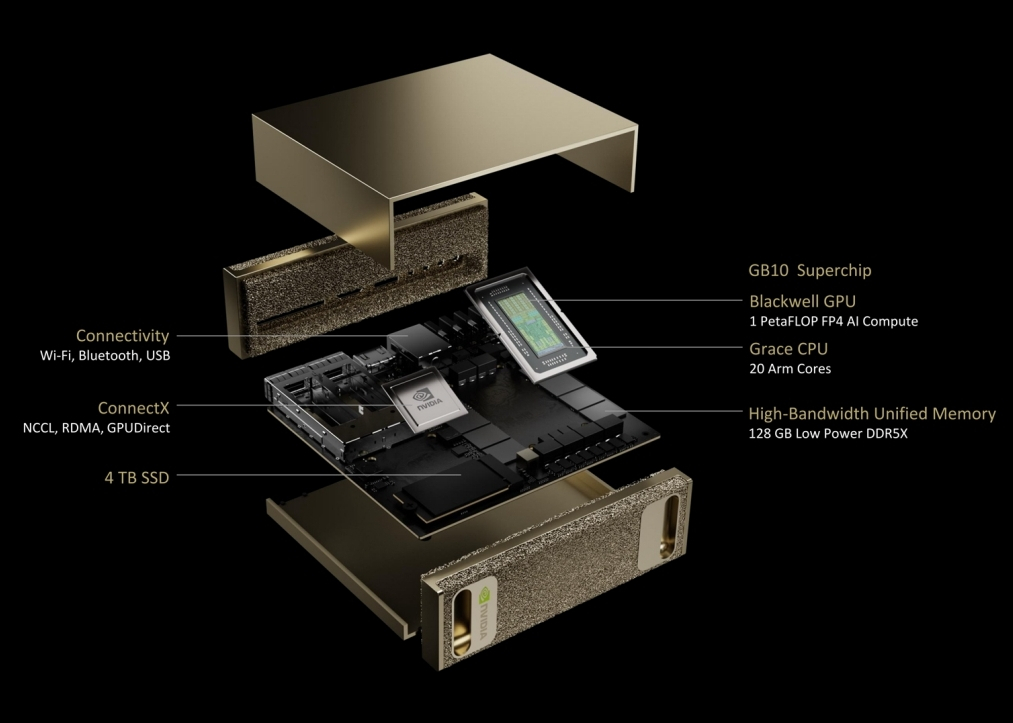 Чип GB10 Grace Blackwell обеспечивает производительность до 1 петафлопа с точностью FP4, то есть он способен выполнять 1 квадриллион операций в секунду для обучения и запуска ИИ-моделей. Система оснащена графическим процессором с ядрами Nvidia CUDA последнего поколения и тензорными ядрами пятого поколения. Он подключён через NVLink-C2C к центральному процессору Grace с 20 энергоэффективными ядрами на архитектуре Arm. В разработке GB10 участвовала компания MediaTek, помогая оптимизировать энергоэффективность и производительность. Каждая система оснащается 128 Гбайт унифицированной когерентной оперативной памяти и до 4 Тбайт NVMe-накопителя. Пользователи также получат доступ к библиотеке программного обеспечения Nvidia для ИИ, включая наборы для разработки, инструменты оркестрации и предварительно обученные модели, доступные в каталоге Nvidia NGC. Система работает на базе Linux Nvidia DGX OS и поддерживает такие популярные фреймворки, как PyTorch, Python и Jupyter Notebooks. Разработчики могут настраивать модели с помощью фреймворка Nvidia NeMo и ускорять рабочие процессы в области науки о данных с помощью библиотек Nvidia RAPIDS.  Пользователи могут разрабатывать и тестировать свои модели ИИ локально на Project Digits, а затем развёртывать их в облачных сервисах или инфраструктуре центров обработки данных, которые используют ту же архитектуру Grace Blackwell и программную платформу Nvidia AI Enterprise. Заметим, что это далеко не первый «потребительский» ИИ-суперкомпьютер Nvidia. В декабре компания анонсировала версию своего компьютера Jetson за 249 долларов для приложений ИИ, ориентированную на любителей и стартапы, под названием Jetson Orin Nano Super, который способен справляться с LLM до 8 миллиардов параметров. HP представила 3D-сканер Z Captis для быстрого переноса любых материалов в цифровой мир с высочайшей точностью
06.01.2025 [22:45],
Владимир Мироненко
HP совместно с Adobe представила на CES 2025 первую в мире портативную систему для быстрого цифрового захвата материалов и поверхностей — HP Z Captis. Устройство основано на Nvidia Jetson AGX Xavier и софте HP Capture Management SDK. Система оснащена поляризованной и фотометрической системой компьютерного зрения, а также интегрирована с инструментами Adobe Substance 3D для создания контента с высокой детализацией и реализмом. Решение нацелено на дизайнеров, архитекторов, создателей игр, специалистов по визуальным эффектам и других профессионалов. 
Источник изображений: HP Согласно пресс-релизу, проект Captis, стартовавший в 2019 году, базируется на общем видении HP и Adobe, что цифровые материалы являются основой экосистемы цифрового создания. Представленная система HP Z Captis является коммерческим продуктом, который позволяет ведущим брендам, предприятиям и учреждениям революционизировать процессы оцифровки материалов.  Спрос на создание 3D-контента стремительно растёт в таких сферах, как архитектура, автомобилестроение, индустрия развлечений, мода, производство обуви, игры и дизайн. HP Z Captis позволяет выполнять цифровой захват материалов с разрешением до 8K, которые затем интегрируются в рабочие процессы для итеративного 3D-проектирования и совместной работы в реальном времени. Система бесшовно интегрируется с Adobe Substance 3D Sampler.  Оцифровка материалов с использованием HP Z Captis и Adobe Substance 3D Sampler повышает эффективность работы, сокращает отходы физических образцов и позволяет экономить время и средства. 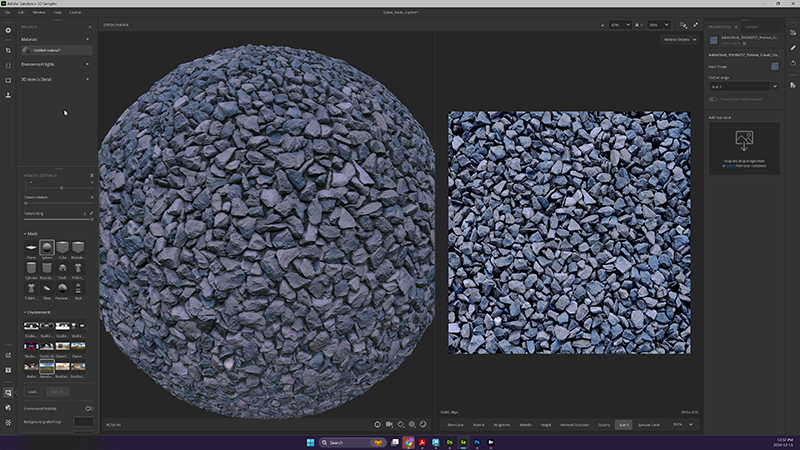 HP Z Captis предоставляет разработчикам, исследователям и инженерам инструмент для цифрового захвата материалов. Система включает API и контейнеризированные режимы захвата, которые можно использовать для разработки приложений, связанных с искусственным интеллектом, компьютерным зрением и локальным инференсом. Система обеспечивает создание масштабируемых решений для формирования собственных наборов данных изображений, включая такие продвинутые функции, как фотометрическое видение, сверхвысокое разрешение, поляризация и другие. Кроме того, HP Z Captis позволяет развертывать ИИ-модели на базе Nvidia Jetson Xavier AGX для инференса в реальном времени. Система HP Z Captis уже доступна для использования. Глава OpenAI рассказал, когда появятся сильный ИИ, сопоставимый с человеком — ждать осталось недолго
06.01.2025 [22:34],
Анжелла Марина
Генеральный директор OpenAI поделился своим мнением о перспективах перехода от обычного искусственного интеллекта (ИИ) к созданию сильного искусственного интеллекта (AGI) или сверхинтеллекта, который способен думать как человек и даже превзойти его. По мнению Сэма Альтмана (Sam Altman), первые ИИ-агенты, соответствующие уровню AGI, могут появится уже в 2025 году. 
Источник изображения: Jonathan Kemper / Unsplash В своём блоге Альтман рассказал о будущем OpenAI. Основной целью компании на данный момент является создание «сверхинтеллекта в истинном смысле этого слова». Альтман подчеркнул, что инструменты на основе сверхинтеллекта приведут к инновациям и, как следствие, к росту благосостояния всего человечества. По его словам, новые ИИ-агенты будут превосходить интеллектуальные возможности людей и существенно изменят структуру компаний и результат их работы, войдя в «состав полноценной рабочей силы». Однако, несмотря на оптимизм и обещания, в прошлом месяце Альтман попытался снизить ожидания в отношении AGI, заявив, что технология «будет иметь гораздо меньшее значение», чем полагают люди. И как отмечает The Verge, снижение акцента на традиционное определение AGI может быть выгодным для OpenAI в виду её тесного партнёрства с Microsoft, так как в рамках эксклюзивных соглашений от 2023 года OpenAI обязана официально объявить о создании AGI. Однако Microsoft определяет свой интерес к AGI, в первую очередь, как к системе, способной генерировать $100 млрд прибыли, что на сегодня может создать определённые сложности, так как OpenAI пока не приносит прибыли и даже наоборот. Даже подписка ChatGPT Pro за $200 в месяц остаётся убыточной. «Люди используют этот инструмент гораздо чаще, чем мы ожидали», — написал Альтман в серии постов на платформе X. То есть, затраченные технические ресурсы на запросы и обработку пользовательских данных превышают цену подписки. Хотя Альтман напрямую не упоминает о соглашении OpenAI с Microsoft о разделе прибыли, он вспоминает о произошедших событиях, которые привели к его увольнению с поста генерального директора OpenAI, затем найму в Microsoft и последующему возвращению в OpenAI в ноябре 2023 года. «Оглядываясь назад, я, конечно, хотел бы сделать всё по-другому, — говорит Альтман. — Необходимо построить более сильную систему управления OpenAI и следовать нашей миссии по достижению системы AGI, которая принесёт пользу всему человечеству». Домашние роботы и умные холодильники: Qualcomm рассказала о будущем умного дома
06.01.2025 [19:00],
Павел Котов
Qualcomm рассказала на выставке CES 2025 о том, как она видит следующее поколение технологий умного дома в эпоху искусственного интеллекта. Большим подспорьем станут домашние чат-боты, интеллектуальные медиасистемы, роботы и умные холодильники. Всё это может оказаться возможным благодаря производительному чипу Qualcomm QCS8550. 
Источник изображения: Qualcomm С развитием решений в области умного дома цели этой технологии не меняются — это экономия времени, сокращение трудозатрат, защита безопасности, здоровья и развлекательные возможности. Qualcomm стремится сделать вклад в эту область, предложив предназначенный для умного дома чип с высокой производительностью, низкими потреблением энергии и поддержкой передовых технологий связи. Наиболее перспективным форматом систем искусственного интеллекта в умном доме представляются нейросети, способные запускаться локально — когда данные не передаются в облачную инфраструктуру, отсутствует угроза их утечки. Qualcomm, у которой есть пакет решений IoT Solutions Framework для интернета вещей, подготовила новые инструменты, которые окажутся полезными в платформах умного дома:
Все эти решения компания представила на CES 2025. В этом году, по версии Qualcomm, начинается новая эра в развитии умного дома — устройства получат мощные процессоры, способные при помощи ИИ самостоятельно решать сложные задачи, не ограничиваясь простым подключением к домашней сети. Холодильник, телевизор и домашний робот должны научиться общаться с пользователем. Для этого в Qualcomm разработали чат-бот с ИИ, способный участвовать в интерактивных беседах в реальном времени, — его ответы генерирует большая языковая модель. В отличие от уже нашедших широкое применение умных колонок, этот чат-бот может интегрироваться в широкий спектр домашних устройств. Прототип такой системы Qualcomm разработала совместно с компанией Thundercomm: для работы чат-бота используются система на чипе QCS8550 с возможностью локального запуска ИИ, обработки данных с камер и прочих мультимедийных компонентов. Умный холодильник со встроенной системой компьютерного зрения выясняет, какие продукты есть в наличии и предлагает рецепты приготовления блюд из них. Или создаёт список покупок, заказывает продукты в магазине и предупреждает владельца забрать их по дороге домой. Центральным узлом становится телевизор — он управляется при помощи естественных речевых команд, которые используются для переключения каналов, настройки и контроля устройств умного дома. Умный телевизор предложит программу спонтанного просмотра с друзьями, поможет с переводом в реальном времени, порекомендует кино под настроение или распланирует семейное путешествие. Все эти функции доступны с тем же чипом QCS8550: он обеспечивает распознавание голосовых запросов, работу мультимодальной большой языковой модели, функции компьютерного зрения для распознавания объектов, людей, жестов и лиц; чип справится и с подавлением фонового шума с помощью ИИ. Востребованными также обещают быть функции дистанционного обучения и телемедицины. Чип Qualcomm QCS8550 может выступать и в качестве процессора для домашнего человекоподобного робота — его компания также показала на выставке. Робот воплощает максимум возможностей для современных систем умного дома, совмещая функции чат-бота и наработки Qualcomm в области робототехнических платформ. Он реагирует на голосовые запросы и поддерживает беседу в формате естественной речи, а система машинного зрения помогает ему отличить бутылку воды от банки с газировкой. Робот имеет универсальное предназначение — он взаимодействует с человеком и другими объектами в реальном времени, а также выполняет задачи в сложных окружениях. Foxconn спровоцировала рост акций технологических компаний по всему миру
06.01.2025 [15:59],
Алексей Разин
С наступлением 2025 года ориентиры для инвесторов на фондовом рынке не изменились, многие из них по-прежнему с надеждой следят за активностью компаний в секторе искусственного интеллекта. Поскольку Foxconn в этой сфере выступила с предварительными итогами четвёртого квартала в числе первых, её отчётность подтолкнула к росту акции многих других компаний технологического сектора. 
Источник изображения: Samsung Electronics Напомним, в четвёртом квартале выручка Foxconn выросла на 15 % до $63,9 млрд, превзойдя ожидания аналитиков, а в декабре в отдельности наблюдался рост выручки более чем на 42 %, обусловленный преимущественно спросом на услуги Foxconn по контрактной сборке серверных систем для инфраструктуры искусственного интеллекта. Кроме того, руководство компании довольно позитивно высказалось о перспективах роста выручки в текущем квартале и году в целом. На торгах на Тайване акции TSMC, которая является крупнейшим контрактным производителем чипов в мире, выросли на 1,9 % и обновили исторический рекорд. Подобная зависимость закономерна, ведь TSMC является контрактным производителем чипов Nvidia и AMD, которые являются крупнейшими поставщиками ускорителей вычислений. Акции SK hynix выросли в цене на 10 %, поскольку эта компания является крупнейшим поставщиком памяти семейства HBM для ускорителей Nvidia, и даже отстающая от неё Samsung Electronics столкнулась с ростом котировок своих акций на 4 %. Акции ASML, крупнейшего в мире поставщика литографических сканеров, в Европе выросли в цене на 6 %, а немецкий производитель чипов Infineon продемонстрировал рост курса своих акций почти на такую же величину. Франко-итальянская STMicroelectronics за счёт пропорционального роста курса акций увеличила собственную капитализацию на те же 6 %. Собственно, даже акции Nvidia перед открытием торгов в США выросли в цене на пару процентов. Кроме того, фондовый рынок подогрели недавние заявления Microsoft о намерениях потратить в 2025 году около $80 млрд на развитие собственной инфраструктуры искусственного интеллекта. Акции AMD выросли на предварительных торгах на 3 %, акции Qualcomm и Broadcom поднялись в цене почти на 2 %. Представлены умные очки Halliday Glasses с крошечным дисплеем в оправе, поддержкой ИИ и ценой от $399
06.01.2025 [15:58],
Владимир Мироненко
Стартап в области носимых технологий Halliday представил на выставке CES 2025 умные очки Halliday Glasses с крошечным дисплеем в оправе и поддержкой ИИ. 
Источник изображений: Halliday Компания Halliday сообщила, что модуль DigiWindow, размещённый в правом верхнем углу оправы, является самым маленьким и лёгким в мире модулем дисплея. Он способен отображать информацию для пользователя «независимо от того, идеальное ли у него зрение или требуется коррекция зрения». По словам представителей компании, оптический модуль обеспечивает эквивалент 3,5-дюймового экрана в правом верхнем углу поля зрения пользователя с минимальными помехами. Дисплей остаётся видимым даже при ярком солнечном свете. Модуль DigiWindow можно перемещать горизонтально по рамке оправы и поворачивать для фокусировки изображения. Halliday Glasses работают в дуэте с помощником на основе ИИ, который предугадывает потребности пользователей, анализируя разговоры, отвечая на вопросы и предоставляя дополнительную информацию без явных подсказок. «Например, во время встречи он может заранее отвечать на сложные вопросы, обобщать ключевые моменты обсуждения и впоследствии генерировать заметки по итогам встречи», — говорится в пресс-релизе компании.  Для работы ИИ-помощника требуется подключение очков к смартфону через Bluetooth. Однако компания не уточнила, какая именно ИИ-модель используется и будут ли связаны с этим дополнительные расходы. Среди функций очков: перевод в реальном времени на 40 языков, навигация с указанием маршрутов, транскрипция голосовых заметок в текст и отображение синхронизированных текстов песен при прослушивании музыки. Пользователи смогут просматривать сообщения и отвечать на них, создавать аудиозаметки и отображать текст через функцию телесуфлёра. У Halliday Glasses отсутствует камера, подобная той, что используется в смарт-очках Ray-Ban Meta✴✴, где она поддерживает функции визуального поиска на основе ИИ. Соучредитель компании Картер Хоу (Carter Hou) объяснил ресурсу Digital Trends отказ от камеры соображениями конфиденциальности, а также тем, что её наличие снизило бы продолжительность автономной работы устройства. Кроме того, отсутствие камеры упростило дизайн оправы и уменьшило вес устройства, который составляет всего 35 г. Время автономной работы очков варьируется от 8 до 12 часов. Управлять Halliday Glasses можно с помощью голосовых команд, элементов интерфейса рамки или кольца со встроенным трекпадом.  Компания Halliday, специализирующаяся на производстве контактных линз и очков, обладает значительным опытом в этой области. Смарт-очки Halliday Glasses будут доступны с возможностью установки линз по рецепту. Стоимость новинки составит от $399 до $499, а продажи начнутся в конце первого квартала 2025 года. Подписка ChatGPT Pro за $200 в месяц стала убыточной для OpenAI из-за слишком большой популярности
06.01.2025 [11:33],
Владимир Мироненко
Анонсированный в конце прошлого года тарифный план ChatGPT Pro стоимостью $200 в месяц оказался слишком популярным, что негативно сказывается на компании. Из-за того, что пользователи используют эту подписку гораздо активнее, чем ожидалось, компания несёт убытки, сообщил генеральный директор OpenAI Сэм Альтман (Sam Altman). 
Источник изображения: Growtika/unsplash.com «Я лично выбрал цену, и подумал, что мы заработаем немного денег», — цитирует ресурс TechCrunch сообщение Альтман на платформе X. Тарифный план ChatGPT Pro включает неограниченный доступ ко всем моделям OpenAI, включая мощнейшую o1 pro — улучшенную версию модели o1, которая выделяется способностью к рассуждению и умением логически решать задачи. Также подписка предоставляет доступ к голосовому режиму Advanced Voice Mode, позволяющему вести беседу, максимально приближенную к человеческой. Для пользователей ChatGPT Plus установлен дневной лимит на использование этих функций, в то время как бесплатные пользователи могут воспользоваться только их ограниченным превью. OpenAI всё ещё не приносит прибыли, что вызывает сомнения в окупаемости вложений инвесторов, которые составили около $20 млрд. Ранее компания сообщила, что ожидает в 2024 году убытки в размере около $5 млрд при выручке в $3,7 млрд. Это связано со значительными расходами на персонал, аренду офисов и инфраструктуру для обучения ИИ. По сообщениям, только поддержка ChatGPT в определённый момент обходилась OpenAI примерно в $700 тыс. в день. В декабре Foxconn удалось нарастить выручку на 42 % за счёт сегмента ИИ
06.01.2025 [07:39],
Алексей Разин
Тайваньская компания Foxconn более известна в качестве контрактного производителя продукции Apple, но бизнес по сборке серверных систем в условиях бума искусственного интеллекта начинает обретать для неё всё большее значение. В прошлом месяце, например, Foxconn удалось увеличить выручку на 42 % год к году именно благодаря направлению ИИ. 
Источник изображения: Foxconn В целом по итогам прошлого квартала Foxconn увеличила выручку на 15 % до $64,72 млрд, превзойдя ожидания аналитиков. В текущем квартале руководство Foxconn также рассчитывает на заметный рост выручки в годовом сравнении. Потребительские продукты в минувшем квартале обеспечили выручку на уровне аналогичного периода прошлого года. Декабрьская выручка Foxconn достигла почти $20 млрд, продемонстрировав второй по величине результат для этого месяца за всю историю существования компании. Поскольку первый квартал является не самым высоким сезоном с точки зрения деятельности Foxconn, то выручка по его итогам должна сохраниться на уровне предыдущего квартала, но в годовом сравнении она значительно увеличится. Полноценный квартальный отчёт Foxconn опубликует только 14 марта, когда подведёт все итоги четвёртой четверти прошлого года. В текущем году выручка Foxconn от сборки серверных систем для облачного сегмента должна достичь величин, характерных для подразделения по выпуску iPhone. Исторически обслуживание заказов Apple обеспечивало более половины выручки Foxconn. Apple Intelligence стала занимать слишком много дискового пространства
06.01.2025 [06:21],
Анжелла Марина
Apple Intelligence обещала упростить жизнь, но пока лишь создаёт проблемы. Функция, запущенная в сентябре 2024 года, за четыре месяца увеличила свои требования к хранилищу с 4 до 7 Гбайт. Пользователи задаются вопросом, оправданы ли затраты на память и батарею, учитывая низкую эффективность функции Apple Intelligence в её текущем виде. 
Источник изображения: macrumors.com Как сообщает издание Gizmodo, проблемы начались с выходом iOS 18.2 и macOS Sequoia 15.2. И хотя новые версии операционных систем расширили функциональность Apple Intelligence, добавив возможности генеративного ИИ, такие как Image Playground (создание изображений по запросу пользователя) и Genmoji для создания пользовательских эмодзи, это привело к значительному увеличению объёма данных, необходимых для работы системы. Одной из причин возросших требований к памяти является использование локальной обработки. То есть, данные обрабатываются непосредственно на устройстве для обеспечения большей конфиденциальности, но при этом требуется хранение ИИ-моделей на самом гаджете. Кстати, именно поэтому доступ к Apple Intelligence имеют только устройства с мощными чипами M1, A17 или более новыми. Так как Apple планирует и дальше развивать возможности ИИ, включая обновление голосового помощника Siri, то это значит, что требования к свободному пространству будут только расти. «Ожидайте, что эта функция будет продолжать заполнять ваше доступное хранилище в обозримом будущем», — отмечает не без доли горечи Gizmodo. Между тем, согласно исследованию SellCell, большинство пользователей не в восторге от Apple Intelligence. 73 % владельцев iPhone, попробовавших функцию, считают, что она «не имеет особой ценности» для их пользовательского опыта. Кроме того, отмечаются жалобы на повышенный расход заряда батареи, связанный с работой искусственного интеллекта. В итоге, на данный момент Apple Intelligence, по мнению многих, не оправдывает затрат ресурсов, предлагая взамен лишь неточные пересказы новостей и необходимость чаще заряжать устройство. Пока неясно, изменится ли отношение пользователей к Apple Intelligence с появлением новых, более востребованных функций, однако, несмотря на недовольство части пользователей и рост требований к хранилищу, Apple не собирается сворачивать с намеченного курса, делая серьёзную ставку на внедрение ИИ в свои устройства. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



