|
Опрос
|
реклама
Быстрый переход
Meta✴ воспользовалась неразберихой в Apple и переманила ещё двух специалистов по ИИ
18.07.2025 [10:19],
Анжелла Марина
Компания Meta✴✴ продолжает усиливать своё подразделение по искусственному интеллекту (ИИ), переманив из Apple двух ключевых специалистов — Марка Ли (Mark Lee) и Тома Гантера (Tom Gunter), ранее работавших под руководством Руомина Панга (Ruoming Pang), который недавно подписал с Meta✴✴ контракт на сумму, превышающую миллион долларов. 
Источник изображения: Steve Johnson/Unsplash Оба специалиста занимали ведущие позиции в подразделении искусственного интеллекта Apple Foundation Models (AFM), но теперь войдут в команду Superintelligence Labs компании Meta✴✴. Ли уже приступил к работе, тогда как Гантер, покинувший Apple месяц назад, ненадолго присоединился к другому ИИ-стартапу, но в итоге выбрал Meta✴✴. Об этом сообщает Bloomberg. Эти кадровые назначения стали продолжением истории с уходом Руомина Панга, возглавлявшего разработку больших языковых моделей (LLM) в Apple. Его контракт с Meta✴✴ оценивается более чем в $200 млн на несколько ближайших лет. Уже тогда Bloomberg предполагал, что вслед за ним компанию могут покинуть и другие ключевые специалисты в области ИИ. Генеральный директор Meta✴✴ Марк Цукерберг (Mark Zuckerberg) ранее заявлял, что искусственный интеллект — главный приоритет компании, и текущие кадровые перестановки подтверждают её агрессивную стратегию по привлечению лучших специалистов. Ранее Meta✴✴ уже удалось переманить исследователей из OpenAI и Google. Теперь, воспользовавшись неопределённостью внутри Apple, где до сих пор не определены перспективы развития ИИ-функций, включая Siri, Meta✴✴ заполучила новых талантов. Тем временем моральный климат в ИИ-подразделениях Apple продолжает ухудшаться: инженеры чувствуют, что на них возлагают вину за последние неудачи. Meta✴✴, в свою очередь, использует эту ситуацию, чтобы перехватить недовольных сотрудников до того, как Apple стабилизирует своё положение. Mistral добавила в Le Chat функции конкурентов: глубокие исследования, редактирование фото и мультиязычность
18.07.2025 [07:43],
Анжелла Марина
Французская компания Mistral представила масштабное обновление для чат-бота Le Chat, добавив несколько новых функций, которые приближают его по возможностям к таким конкурентам, как OpenAI и Google. Появился режим «глубокого исследования», встроенная поддержка мультиязычного анализа и расширенные инструменты редактирования изображений. 
Источник изображения: Mistral AI Режим «глубокого исследования» (deep research) превращает Le Chat в помощника, способного анализировать информацию из различных источников, планировать, уточнять запросы и выдавать обобщённые результаты. По словам руководителя продукта Mistral Элисы Саламанки (Elisa Salamanca), такая функциональность будет полезна как для частных пользователей, например, при планировании поездок, так и для корпоративных задач, включая глубокий анализ данных. Особенностью нововведения, как пишет TechCrunch, является подход к обработке данных: в отличие от облачных платформ, таких как Azure для OpenAI или Google Cloud для Gemini, Mistral позволяет анализировать данные локально, без отправки их в облако. Это важно для клиентов из банковской сферы, оборонного сектора и государственных структур, где к защите информации предъявляются высокие требования. Mistral также работает над интеграцией Le Chat с офисными инструментами, такими как Microsoft Excel и Google Docs, чтобы сделать бот более удобным для бизнес-задач. Уже сейчас в корпоративной версии доступны специальные коннекторы, позволяющие анализировать внутренние данные компаний без риска их утечки. Помимо прочего, Le Chat теперь поддерживает мультиязычный анализ данных не только на английском, но и на французском, испанском, японском и других языках, включая быстрое переключение между ними в рамках одного диалога. Также появилась функция Projects, помогающая пользователям организовывать чаты и документы в тематические пространства, например, для планирования переезда или разработки нового продукта. Завершает список нововведений улучшенный редактор изображений, который позволяет удалять объекты, менять фон и выполнять другие правки через текстовые запросы. Обновление доступно для всех тарифов — Free, Pro, Team и Enterprise, но основной фокус Mistral сейчас направлен на корпоративный сектор. Недавно Mistral также выпустила Voxtral — свою первую открытую аудиомодель, которая поддерживает многоязычный анализ, транскрибирование и другие функции. Модель уже доступна через интерфейс Le Chat. OpenAI представила ChatGPT Agent — ИИ-агент для выполнения сложных заданий от имени пользователя на собственном «виртуальном компьютере»
18.07.2025 [06:07],
Анжелла Марина
Компания OpenAI представила новый инструмент, который называется ChatGPT Agent и способен выполнять сложные многоэтапные задачи по поручению пользователя от его имени. В отличие от обычных чат-ботов, этот агент действует автономно, используя собственный «виртуальный компьютер» для работы с данными, планирования и даже совершения покупок. 
Источник изображения: Mariia Shalabaieva/Unsplash Как рассказали The Verge руководители проекта Яш Кумар (Yash Kumar) и Айза Фулфорд (Isa Fulford), ChatGPT Agent основан на новой модели, специально разработанной OpenAI. Он умеет анализировать календарь пользователя, готовить сводки по предстоящим встречам, подбирать рецепты и заказывать продукты для семейного завтрака, а также создавать презентации на основе конкурентного анализа. Модель обучалась на сложных задачах, требующих взаимодействия с текстовым и визуальным браузером, терминалом и другими инструментами. ChatGPT Agent имеет доступ ко всей операционной системе, а не только к браузеру, и использует методы машинного обучения с подкреплением, находя оптимальную стратегию поведения. Отмечается, что ChatGPT Agent особенно удобен для онлайн-покупок, поскольку сочетает технологии Deep Research и Operator, что в итоге делает процесс более точным. Кумар рассказал, что сам использует агента для автоматизации рутины, например, для регулярного бронирования парковки. Агент имеет доступ ко всем функциям своего виртуального компьютера, а не только к браузеру, как обычный ChatGPT, что значительно расширяет возможности инструмента. Однако он пока работает не быстро, так как разработчики сосредоточены на оптимизации сложных задач, а не на скорости. Но как поясняет Фулфорд, даже если выполнение поставленной задачи займёт 15–30 минут, это всё равно быстрее, чем делать всё вручную. Перед выполнением необратимых действий, таких как отправка письма или бронирование, агент будет запрашивать подтверждение. Также введены меры безопасности, аналогичные тем, что применяются для моделей с высокими биологическими и химическими возможностями. Финансовые операции пока ограничены. При работе с сайтами, требующими повышенной безопасности, например, банковскими транзакциями, активируется режим наблюдения (Watch Mode), при котором пользователь не может покинуть вкладку, где работает ИИ, иначе система остановит свою работу. ChatGPT Agent с четверга уже доступен подписчикам Pro, Plus и Team. Для его активации нужно выбрать «режим агента» в меню инструментов или ввести команду /agent. Версии для ChatGPT Enterprise и Education для корпоративных клиентов и учебных заведений появятся позже этим летом. В Европейской экономической зоне и Швейцарии сроки релиза пока не определены. Сгенерированная ИИ музыка набирает вирусную популярность — отрасли придётся адаптироваться
17.07.2025 [16:38],
Павел Котов
Играющая в жанре психоделического рока группа The Velvet Sundown набрала на музыкальной платформе Spotify более миллиона слушателей в месяц. Она зарабатывает на стримингах тысячи долларов и заставляет музыкальную индустрию задаваться непростыми вопросами: дело не в возвращении моды на семидесятые, а в том, что этот проект — творение генеративного искусственного интеллекта. 
Источник изображения: Ato Aikins / unsplash.com Сейчас в описании The Velvet Sundown на Spotify говорится, что это «синтетический музыкальный проект, созданный под творческим контролем человека; написание, озвучание и визуализация производились при поддержке ИИ». Музыкальная индустрия восприняла пришествие ИИ в штыки, и эксперты описывают музыку проекта как «бездушную», «удушающую» и «жуткую». Задача генерации музыки решается всё проще: ИИ интегрируется в профильное ПО, появляются сервисы вроде Suno и Udio, позволяющие создавать целые композиции по текстовым запросам. И The Velvet Sundown — далеко не единственный созданный ИИ музыкальный проект, появившийся в Сети. На Spotify есть исполнитель в жанре дарк-кантри Aventhis, у которого более 600 000 слушателей в месяц, — звучащие в его композициях голоса и инструменты полностью сгенерированы ИИ; французский музыкальный стриминг Deezer в январе развернул средство распознавания музыки, созданной с помощью ИИ, и в апреле сообщил, что около 18 % загружаемых на платформу композиций сгенерированы ИИ полностью. Качество и степень оригинальности создаваемой ИИ музыки подвергаются критике, но и опрошенные CNBC эксперты признают, что по мере развития генеративного ИИ среднестатистическому слушателю становится всё сложнее отличить человека от машины. Пример The Velvet Sundown показателен — музыка этого виртуального коллектива отличается значительно более высоким качеством, чем большинство произведений ИИ, появившихся ранее. Если раньше генераторы ограничивались лишь запоминающимися, повторяющимися мотивами, то теперь это песни, которые имеют смысловую структуру с куплетами, припевами и переходами. 
Источник изображения: Andrik Langfield / unsplash.com И это лишь «верхушка айсберга»: задавшие «золотой стандарт» для аналогичных платформ ИИ-сервисы Suno и Udio снизили входной барьер пользователей до нуля. Любой человек может создавать композиции сотнями; обе платформы предлагают бесплатный доступ и премиум-подписки по $30 в месяц, а то и меньше. Создание песен с помощью ИИ может быть бесплатным — и приносить доход: по оценкам, The Velvet Sundown за 30 дней заработала $34 235 на всех платформах. Легко понять, почему создатели музыки с помощью ИИ стремятся наводнить потоковые сервисы огромными объёмами сгенерированного контента в надежде на вирусный успех. Это уже вызвало переполох в музыкальной индустрии. Тысячи музыкантов и представителей творческой интеллигенции призывают запретить использование созданных человеком произведений для обучения ИИ без предварительно полученного разрешения. Крупнейшие музыкальные лейблы, в том числе Sony Music, Universal Music Group и Warner Records, пытаются засудить Suno и Udio, обвинив их в массовых нарушениях авторских прав. Но, считают эксперты, генеративный ИИ в музыке уже никуда не денется — возможно, устоявшиеся бизнес-модели придётся в очередной раз менять. Музыкальному бизнесу уже приходилось переживать крупные технологические потрясения: в 1999 году появился Napster, а в двухтысячные стали массово появляться потоковые платформы. Но перспектива конкурировать с виртуальными группами вызывает у начинающих музыкантов беспокойство — им и так непросто добиваться популярности и начинать зарабатывать на онлайн-музыке. Чтобы подготовить молодых исполнителей к суровым реалиям музыкальной среды, преподаватели всё чаще включают ИИ в учебные планы, стремясь научить их использовать передовых технологии для улучшения творческого процесса при создании музыки, но не для полной замены традиционных решений. Известный музыкальный продюсер Timbaland запустил ориентированный на ИИ музыкальный проект Stage Zero, в котором будет участвовать виртуальная звезда. Это не последняя инициатива такого рода, предупреждают эксперты, и традиционным музыкантам будет всё труднее зарабатывать в интернете. Проблема не ограничивается музыкальной отраслью: созданный ИИ контент наращивает присутствие в информационном поле, в том числе и в социальных сетях, тем самым усложняя людям общение друг с другом. Исполнители требуют, чтобы созданная ИИ музыка получала соответствующую маркировку на платформах, но Spotify пока на эти призывы не реагирует. OpenAI избавляется от зависимости от Microsoft: часть инфраструктуры ChatGPT переедет в Google Cloud
17.07.2025 [12:41],
Павел Котов
Компания OpenAI сообщила накануне, что намеревается использовать для своего популярного помощника с искусственным интеллектом ChatGPT облачную инфраструктуру Google. Разработчик уже пользуется облачными услугами Microsoft, Oracle и CoreWeave. 
Источник изображения: Dima Solomin / unsplash.com OpenAI наращивает вычислительные мощности для удовлетворения высокого спроса на свои сервисы, чтобы было затруднительно, когда компания зависела исключительно от ресурсов Microsoft. Отношения двух компаний меняли формат, и в прошлом году Microsoft признала в OpenAI конкурента: обе предлагают инструменты ИИ для разработчиков и продают подписки для компаний. Теперь OpenAI добавила в список своих поставщиков и Google Cloud — сервис ChatGPT и интерфейс прикладного программирования будут также работать на платформах Microsoft, CoreWeave и Oracle. Для Google это достижение, потому что её облачное подразделение моложе и меньше, чем у Amazon и Microsoft. Google Cloud обозначит присутствие в США, Японии, Нидерландах, Норвегии и Великобритании. Первым облачным партнёром OpenAI после Microsoft ещё в прошлом году стала Oracle, которая обеспечила разработчику ИИ дополнительные вычислительные мощности; в марте этого года был заключено пятилетний контракт с CoreWeave на сумму почти $12 млрд — Microsoft ещё в январе разрешила OpenAI пользоваться облачными ресурсами конкурентов и перестала претендовать на статус эксклюзивного поставщика услуг. О намерении компании обратиться в Google Cloud стало известно в июне. Microsoft Copilot с треском проиграл ChatGPT в гонке за аудиторию — несмотря на миллиардные инвестиции
17.07.2025 [12:28],
Владимир Мироненко
Несмотря на значительные расходы Microsoft на разработку ИИ и сопутствующей инфраструктуры в последние пару лет, ИИ-ассистент компании Copilot с трудом конкурирует с чат-ботом ChatGPT её партнёра OpenAI и множеством других ИИ-помощников, отмечает Bloomberg. Если число загрузок ChatGPT недавно превысило 900 млн, то приложение Copilot для смартфонов, по данным Sensor Tower, скачали лишь 79 млн раз. 
Источник изображения: Microsoft С начала года акции Microsoft выросли примерно на 20 %, во многом благодаря ожиданиям Уолл-стрит, что ставка компании на ИИ обеспечит ей дальнейший рост. Однако, как пишет Bloomberg, некоторые инвесторы начинают терять терпение. Генеральный директор Microsoft Сатья Наделла (Satya Nadella) заявил в мае сотрудникам, что цель — привлечь сотни миллионов пользователей к семейству приложений Microsoft на базе ИИ. Компания делает ставку на три продукта под брендом Copilot: помощника по программированию для разработчиков, помощника для работы, встроенного в Outlook и Word, а также персонального ассистента. Microsoft начала внедрять ИИ в свои продукты два года назад. В частности, поисковая система Bing была преобразована в ИИ-помощника для работы в интернете. Однако, несмотря на партнёрство с OpenAI, компании не удалось добиться желаемого роста доли рынка у Bing. 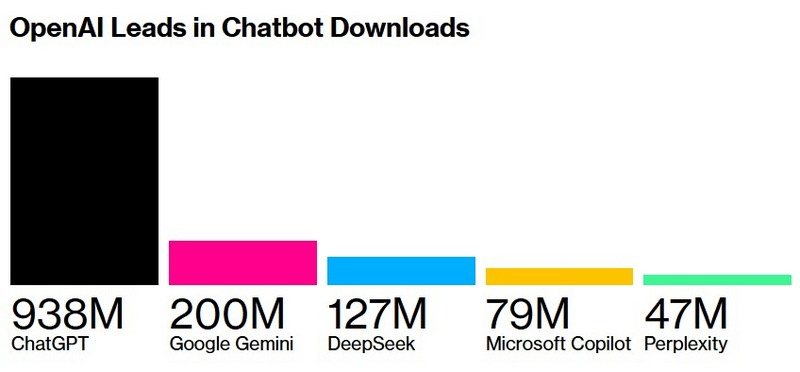
Число загрузок приложений популярных ИИ-чат-ботов. Источник изображения: Sensor Tower Глава подразделения Microsoft AI Мустафа Сулейман (Mustafa Suleyman), помимо руководства командами, работающими над ориентированным на потребителя Copilot, отвечает за развитие ряда существующих продуктов, включая браузер Edge, новостной и веб-портал MSN, а также поисковую систему Bing, которыми пользуются миллионы людей. В настоящий момент Copilot является, по сути, мобильным приложением, поскольку его внедрение в качестве ИИ-помощника для Windows тормозят опасения руководства: есть риск оттолкнуть пользователей, заставляя их менять привычные сценарии работы. Поэтому приоритет отдаётся интеграции Copilot в уже знакомые продукты. Кроме того, существуют технические ограничения, поскольку операционная система Windows получает всего несколько крупных обновлений в год и не рассчитана на частые изменения, которые необходимы команде Copilot. Развёртывание мобильного приложения Copilot также осложнено тем, что мобильные платформы Android от Alphabet и iOS от Apple доминируют на рынке, и обе компании внедряют собственные ИИ-инструменты в свои экосистемы. По данным Sensor Tower, число ежемесячных активных пользователей Copilot с апреля по июнь увеличилось на 76 %, достигнув 23 млн, однако темпы роста приложения за последний год существенно отстают от основных конкурентов. xAI наймёт разработчика ИИ-аниме-девушек, а Маск показал ИИ-компаньона на основе Эдварда Каллена из «Сумерек»
17.07.2025 [10:57],
Павел Котов
Недавно xAI Илона Маска (Elon Musk) выпустила новый продукт — виртуальных компаньонов с искусственным интеллектом, в том числе вайфу — девушку в стиле аниме. Теперь для разработки таких персонажей компания решила нанять отдельного специалиста. Тем временем сам бизнесмен показал выполненного в том же духе виртуального парня, призванного стать виртуальным компаньоном для женщин. 
Источник изображения: x.com/elonmusk Компания xAI открыла вакансию «инженера полного цикла — [по разработке] вайфу» (Fullstack Engineer – Waifus). Задачей специалиста станет помощь в миссии по «созданию систем ИИ, способных в точности понимать вселенную и помогать человечеству в стремлении к знаниям». Годовая зарплата для этой вакансии заявлена на уровне от $180 000 до $440 000. В xAI сейчас открыто множество вакансий, и утверждать, что компания делает ставку исключительно на вайфу, было бы преждевременным. Но у первого подобного персонажа по имени Ани (Ani) скоро, вероятно, появятся подружки. Проект адресован не только мужской, но и женской аудитории: накануне Илон Маск анонсировал новый персонаж в стиле аниме — виртуального задумчивого парня, источниками вдохновения при создании которого послужили Эдвард Каллен (Edward Cullen) из вселенной «Сумерки» и Кристиан Грей (Christian Grey) из «Пятидесяти оттенков серого», которые тоже появились как фанфик к «Сумеркам». Имени у этого персонажа ещё нет, и сам он пока не вышел для всех пользователей — но есть надежда, что над его характером поработают, чтобы у общественности было меньше поводов критиковать его, как критикуют его литературные и киношные прообразы. Искусственный интеллект Google теперь может звонить по телефону за пользователя
17.07.2025 [10:03],
Анжелла Марина
Google запустила функцию, которая позволяет искусственному интеллекту (ИИ) совершать телефонные звонки от лица пользователей. Эта возможность уже доступна в поисковой системе и позволяет получать информацию о ценах и доступности услуг различных компаний, не совершая звонков вручную. 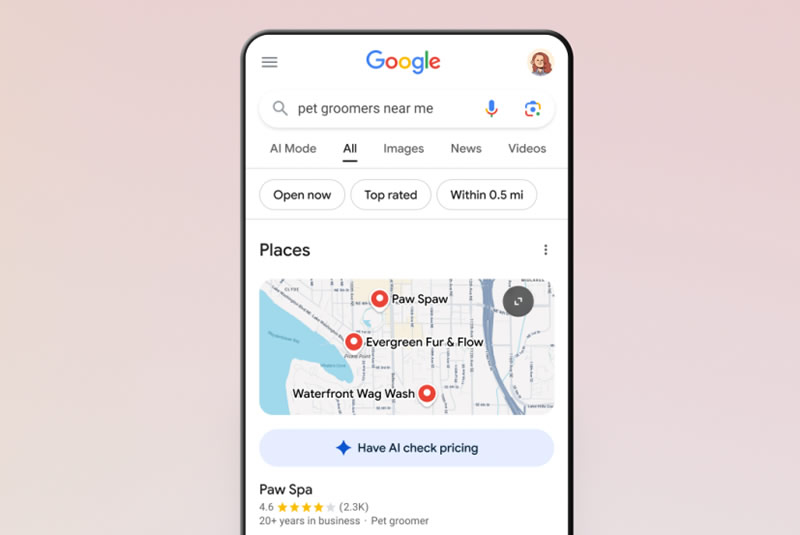
Источник изображений: Google Изначально функция начала тестироваться в январе и пока охватывает ограниченный круг компаний в США — например, салоны для животных, химчистки и автосервисы, сообщает The Verge. При поиске таких услуг под результатами появляется кнопка «Проверить цену с помощью ИИ» (Have AI check pricing). После выбора пользователь предоставляет дополнительные данные: перечень необходимых услуг, удобное время визита, а также способ получения ответа — по SMS или электронной почте. Отмечается, что эта опция может быть особенно востребована среди молодых пользователей, которые зачастую испытывают дискомфорт при телефонных разговорах. Как сообщил Робби Штейн (Robby Stein), вице-президент по продуктам Google Search, технология основана на модели Duplex и использует искусственный интеллект Gemini. По его словам, система представляет собой ИИ-ассистента, собирающего информацию от имени пользователя, чтобы тот не тратил время на самостоятельные звонки. После получения данных ИИ отправляет обновление с указанием доступных цен и другой необходимой информации. При этом владельцы бизнеса могут отключить приём звонков от ИИ в настройках своего профиля в Google. 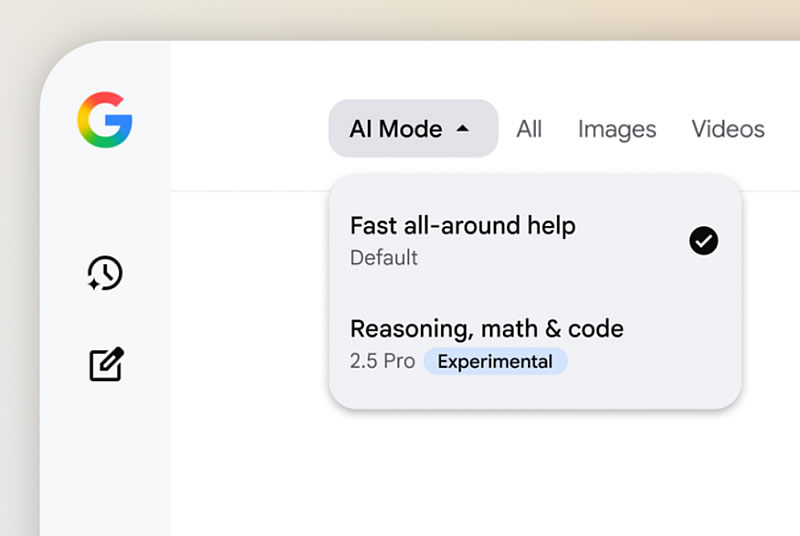 Помимо этого, Google начала тестировать обновлённую версию Gemini 2.5 Pro в ИИ-режиме (AI Mode) — инструменте, который стал доступен всем пользователям в США с мая 2025 года. Подписчики AI Pro и AI Ultra, участвующие в эксперименте AI Mode через Google Labs, могут использовать новую модель, которая, по словам Штейна, особенно хорошо справляется с задачами, требующими логики, математических вычислений и программирования. По умолчанию AI Mode работает на базе модели Gemini 2.0. Кроме того, тестируется интеграция функции Deep Search в AI Mode, позволяющая системе формировать подробные отчёты по пользовательским запросам. Отмечается, что модель самостоятельно формулирует вопросы, проводит поисковые запросы и, проверяя полученные данные, выстраивает цепочку логических шагов для формирования итогового ответа. Эта функция также будет доступна подписчикам AI Pro и AI Ultra в рамках экспериментов Google Labs. Intel научила ИИ оценивать, как апскейлинг и генерация кадров влияют на качество графики в играх
17.07.2025 [07:58],
Анжелла Марина
Intel представила ИИ-инструмент CGVQM, который позволяет объективно оценивать качество изображений в современных играх. Модель анализирует искажения, возникающие при использовании технологий масштабирования и улучшения графики, таких как апскейлинг (DLSS, FSR, XeSS), генерация кадров и другие методы рендеринга. 
Источник изображения: Intel Традиционные метрики, например PSNR, не всегда подходят для оценки игровой графики, поскольку изначально были созданы для анализа сжатого видео. Они не учитывают специфические артефакты, возникающие при использовании апскейлеров, трассировки лучей или динамического затенения. Например, в процессе обработки могут появляться мерцание, гостинг (ghosting), ступенчатость, разрывы объектов и другие. Новая метрика под названием Computer Graphics Visual Quality Metric (CGVQM) использует искусственный интеллект для анализа видеоряда и выявления дефектов, вызванных современными методами обработки изображений. Команда исследователей из Intel — Акшай Джиндал (Akshay Jindal), Набиль Садака (Nabil Sadaka), Антон Соченов (Anton Sochenov) и другие, предложила двухэтапный подход. Сначала они собрали датасет CGVQD, который включает нейросетевое шумоподавление, апскейлинг, интерполяцию кадров и адаптивное затенение, а затем на его основе обучили нейросеть CGVQM, способную оценивать качество изображения так же, как это делает человек. Для калибровки модели группе добровольцев показали видеоролики из набора данных и попросили оценить артефакты по шкале от «незаметных» до «сильно раздражающих». Эти данные и стали основой для обучения 3D-свёрточной нейросети (3D-CNN) на базе архитектуры ResNet-18, которая позволяет анализировать не только пространственные, но и временные искажения, что критически важно для видео. В итоге, в тестах CGVQM превзошла большинство существующих метрик, особенно при работе с собственным набором данных. Модель версии CGVQM-5 показала результат, близкий к человеческой оценке, а более простая CGVQM-2 заняла третье место среди протестированных систем. При этом CGVQM способна анализировать и сторонний контент, не входящий в обучающую выборку, что делает её универсальным инструментом. В будущем, как пишет Tom's Hardware, исследователи рассматривают переход на архитектуру трансформеров для повышения производительности. Также в метрику могут добавить анализ оптического потока для более детальной оценки. Ускорители AMD и Nvidia после снятия санкций США смогут поднять свою долю на китайском рынке до 49 %
17.07.2025 [06:58],
Алексей Разин
Ещё до того, как экспортные ограничения на поставку ускорителей H20 в Китай были сняты, после их введения в апреле руководство Nvidia отмечало, что за три неполных года подобных санкций доля компании на китайском рынке ускорителей вычислений снизилась с 95 до 50 %. В новых условиях доля зарубежных ускорителей на китайском рынке в целом может приблизиться к 49 %, как считают в TrendForce. 
Источник изображения: AMD Соответствующий прогноз эксперты опубликовали накануне, когда факт снятия экспортных ограничений на поставку Nvidia H20 и AMD Instinct MI308 ещё не был подтверждён официально. Если бы эти ограничения сохранились, то доля ускорителей зарубежного происхождения в структуре закупок китайских разработчиков осталась бы на уровне 42 %, как подсчитали представители TrendForce. Надо сказать, что ускорители китайского происхождения уже занимают больше половины местного рынка, поэтому озабоченность руководства Nvidia влиянием санкций на бизнес компании в регионе вполне объяснима. Как поясняют аналитики TrendForce, в 2024 году поставляемые в Китай ускорители Nvidia H20 оснащались 8-ярусными чипами памяти HBM3, но в начале текущего года они должны были мигрировать на более современные чипы HBM3E аналогичной компоновки, причём объём памяти тоже должен был вырасти. Сложно сказать, как сильно в итоге повлияли на эти планы Nvidia американские санкции, наложенные в апреле, но вчера глава компании Дженсен Хуанг (Jensen Huang) дал понять, что пока решение о возобновлении выпуска H20 не принято, поскольку не совсем ясна структура спроса в текущих условиях. Он допустил мысль, что некоторые китайские клиенты передумали покупать ускорители H20 хотя бы частично. Специалисты TrendForce считают, что в Китае сформировался отложенный спрос на ускорители Nvidia H20. Решения местных разработчиков в лучшем случае комплектуются памятью типа HBM2E и в целом уступают H20 по уровню быстродействия, поэтому провайдеры облачных сервисов в Китае наверняка начнут активно закупать H20 по новой, как только такая возможность откроется. Не исключено, что многие из китайских клиентов будут закупать ускорители Nvidia впрок, не полагаясь на политическое постоянство нынешнего американского президента. Китайские компании, полагающиеся на государственную поддержку, с высокой вероятностью будут вынуждены ориентироваться на закупки только китайских ускорителей вычислений. В ChatGPT появится онлайн-шопинг — OpenAI начнёт зарабатывать на комиссиях с заказов
16.07.2025 [19:46],
Анжелла Марина
OpenAI планирует внедрить в ChatGPT систему для покупки различных товаров онлайн, которая позволит оформлять заказы без перехода на сайты самих интернет-магазинов. Продавцы, принимающие заказы через ChatGPT, будут платить компании комиссию за каждую транзакцию. Как пишет Financial Times, такой подход является частью новой стратегии OpenAI по монетизации платформы, которая до сих пор в основном зарабатывала на подписках для премиум-пользователей. 
Источник изображения: Zac Wolff/Unsplash Сейчас ChatGPT показывает товары и предлагает ссылки на страницы магазинов, но уже скоро система может получить встроенную оплату. Партнёром в этом проекте выступит облачная платформа для электронной коммерции Shopify, с которой OpenAI сотрудничает с апреля. Этот шаг может открыть для компании новый источник дохода за счёт бесплатных пользователей, а также усилить конкуренцию с поисковиками — например, с Google. Пока функция находится в разработке, и её детали могут измениться. 
Источник изображения: OpenAI Рекомендации товаров в ChatGPT сейчас формируются на основе запросов пользователей, их предпочтений и бюджета. Тем не менее, порядок показа магазинов пока определяется сторонними поставщиками данных, а цена и условия доставки не учитываются. Но, как отмечают в компании, это может измениться в будущем. OpenAI и Shopify начали обсуждать условия с брендами, а те уже экспериментируют с продвижением товаров через ChatGPT, адаптируя контент под ИИ-алгоритмы. Новая система получила название AIO (аналог SEO для чат-ботов). Одновременно некоторые эксперты выразили опасения, что подобные изменения подорвут традиционные модели поисковой рекламы и изменят работу рекламных агентств. В декабре OpenAI заявляла, что не планирует внедрять рекламу, но финансовый директор компании Сара Фрайар (Sarah Friar) позже признала, что этот вариант тоже рассматривается. Основатель OpenAI Сэм Олтман (Sam Altman) в марте уточнил, что компания не станет брать деньги за приоритетный показ товаров, но может ввести партнёрские отчисления, например, 2 % с покупок через поисковый инструмент Deep Research. Общение с чат-ботами сужает лексикон человека, установили немецкие учёные
16.07.2025 [17:02],
Павел Котов
ChatGPT и другие чат-боты с искусственным интеллектом меняют мир, в том числе влияя на речь современного человека. К таким выводам пришли немецкие учёные в своём недавнем исследовании — они предупредили об угрозе утраты языкового и культурного разнообразия. 
Источник изображения: Igor Omilaev / unsplash.com Группа исследователей из Института развития человека имени Макса Планка опубликовала предварительную, нерецензированную версию работы. Они обнаружили, что слова, часто употребляемые ChatGPT, стали всё чаще появляться и в человеческой речи с момента появления популярного ИИ-чат-бота в 2022 году. В список «слов GPT» попали такие, как «понимать», «гордиться», «быстрый», «тщательный» и самое популярное — «вникать». Учёные проанализировали 360 445 академических выступлений на YouTube и 771 591 выпуск подкастов, и пришли к выводу, что слова вроде «вникать», «быстрый», «тщательный» и «запрос» действительно стали употребляться чаще в аудио- и видеоконтенте на самые разные темы. Авторы исследования не оценивают, является ли эта перемена положительной или отрицательной, но обнаруженные факты, по их мнению, дают повод задуматься о том, существует ли у больших языковых моделей собственная культура, способная влиять на формирование человеческой. Взаимодействие человека и ИИ может иметь долгосрочные последствия для языковых практик обеих сторон. Учёные предупреждают: такой механизм способен привести к формированию «замкнутой петли культурной обратной связи, в которой культурные аспекты циркулируют в обе стороны между людьми и машинами». При достаточно длительном воздействии и широком охвате это может способствовать культурной однородности. «Если системы ИИ начнут непропорционально отдавать предпочтение определённым культурным аспектам, это может ускорить разрушение культурного разнообразия. Угрозу усугубляет тот факт, что будущие модели ИИ будут обучаться на данных, в которых всё сильнее доминируют те же шаблоны, заданные ИИ и усиленные человеком, что приводит к самовоспроизводящемуся циклу. <…> По мере монополизации определённых языковых структур возрастает риск краха модели, обусловленный новым фактором: даже включение человека в процесс обучения может не обеспечить необходимого разнообразия данных», — говорится в исследовании. ИИ-помощники программистов начали перемещаться в интерфейс командной строки
16.07.2025 [14:21],
Павел Котов
Существующие уже не первый год инструменты для написания кода, основанные на искусственном интеллекте, такие как Cursor, Windsurf и GitHub Copilot, выступают в качестве законодателей моды в своём сегменте. И по мере развития ИИ-агентов эти инструменты меняют механизмы работы, перемещаясь в терминал — интерфейс командной строки, обращает внимание TechCrunch. 
Источник изображения: Mohammad Rahmani / unsplash.com Вместо работы только с кодом эти сервисы всё чаще взаимодействуют напрямую с оболочкой операционной системы, в которой работают, — это существенное изменение в процессе разработки ПО с использованием ИИ, и оно может повлиять на всю отрасль. Переход уже начали все крупные разработчики: в феврале Anthropic, Google DeepMind и OpenAI выпустили инструменты для программирования, ориентированные на работу с командной строкой — Claude Code, Gemini CLI и CLI Codex соответственно. Эти продукты уже завоевали популярность у своей аудитории. Эту перемену легко не заметить, поскольку новые средства выпускаются преимущественно под теми же брендами, что и предыдущие, но на самом деле изменения носят глубокий характер. В будущем, считают создатели профильного бенчмарка Terminal-Bench, 95 % взаимодействия больших языковых моделей с компьютерами будут осуществляться через терминал или аналогичный интерфейс. Первое место в рейтинге теста занимает компания Warp, предложившая «агентную среду разработки» — нечто среднее между традиционной IDE и набором инструментов командной строки, таких как Claude Code. 
Источник изображения: Fotis Fotopoulos / unsplash.com Чтобы оценить отличия нового подхода, полезно взглянуть на применяемые для его анализа бенчмарки. Так, задачи SWE-Bench составляются на основе открытых сообщений о проблемах на GitHub — это реальные фрагменты кода, которые не работают. Для поиска решения ИИ-модели предлагают собственные варианты, пока код не начнёт функционировать. Инструменты с поддержкой терминала позволяют взглянуть ещё шире, поскольку охватывают не только сам код, но и всю среду, в которой запускается приложение: помимо написания кода, решаются задачи по настройке Git-сервера и отладке. В одной из задач, предлагаемых в Terminal-Bench, указывается программа для распаковки и приводится целевой текстовый файл — ИИ-агенту требуется произвести обратную разработку и определить подходящий алгоритм сжатия. В другой задаче — агенту предлагается собрать ядро Linux из исходного кода, но не упоминается, что этот исходный код необходимо предварительно скачать. Важно, что новый подход предполагает поэтапное решение задач — именно на основе этой способности оценивается ценность ИИ-агентов. Однако даже в этом случае они пока не решают все задачи — так, Warp вышел в лидеры, справившись лишь с чуть более чем половиной из них. Тем не менее уже сейчас, подчёркивают эксперты, ИИ-агенты способны взять на себя значительную часть задач, которые обычно выполняет разработчик, и игнорировать это нерационально. Тот же Warp успешно справляется с повседневной работой по подготовке нового проекта, выявлению зависимостей и запуску — а в случаях, когда ИИ не справляется, он поясняет, почему. Microsoft расширила возможности Copilot Vision — теперь ИИ видит всё, что показано на экране
16.07.2025 [11:54],
Павел Котов
Microsoft выпустила обновление функции Copilot Vision для участников программы Windows Insiders — инструмент на основе искусственного интеллекта теперь способен видеть всё, что отображается на экране компьютера. Ранее служба поддерживала просмотр интерфейса до двух приложений и возможность связывать их данные; теперь она может анализировать весь рабочий стол или «любое конкретное окно браузера или приложения», рассказали в компании. 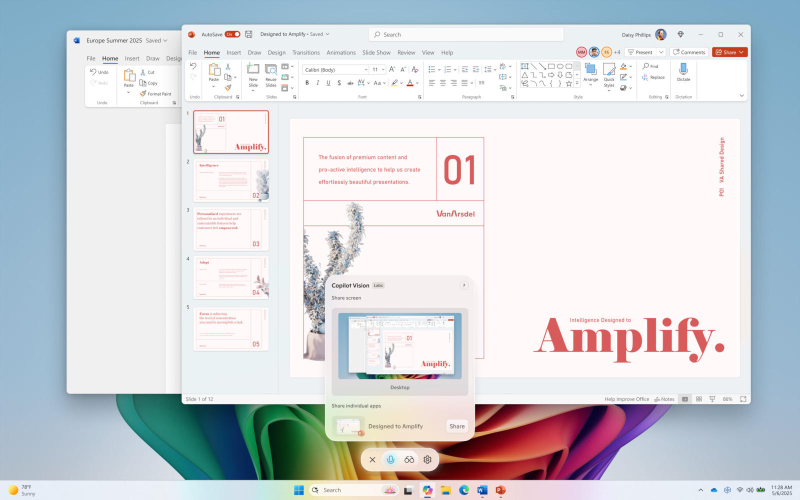
Источник изображения: blogs.windows.com В отличие от функции Recall, которая автоматически делает регулярные снимки экрана ПК, работа Copilot Vision больше напоминает демонстрацию экрана во время видеозвонка. Функция активируется по нажатию на значок с изображением очков в приложении Copilot, после чего пользователь выбирает нужный рабочий стол. Copilot Vision «помогает анализировать содержимое, предоставлять полезную информацию и отвечать на вопросы, как что-либо сделать. Получайте советы по улучшению творческого проекта, помощи в составлении резюме или инструкциям по освоению новой игры», предлагает Microsoft. На начальном этапе функция Copilot Vision работала только в браузере Edge, имея доступ к просматриваемым страницам; после этого её действие распространилось на ПО под Windows. Есть также мобильный вариант Copilot Vision — ИИ отвечает на вопросы о том, что попадает в поле зрения камеры смартфона. HMD представила кнопочные телефоны с поддержкой DeepSeek
16.07.2025 [11:46],
Владимир Мироненко
Компания HMD, владеющая мобильным брендом Nokia в рамках лицензионного соглашения, представила в Китае два кнопочных смартфона начального уровня — HMD 101 4G и HMD 102 4G с поддержкой технологии 4G VoLTE. Главная особенность новинок заключается во встроенном ИИ-помощнике на базе модели DeepSeek, призванном упростить их использование. 
Источник изображений: suomimobiili.fi Устройства рассчитаны на пользователей, предпочитающих простоту и удобство, например пожилых людей или тех, кому нужен запасной телефон. Смартфон HMD 101 4G оснащён цветным экраном, крупными кнопками, 3,5-мм аудиоразъёмом для наушников, фонариком и портом USB Type-C для зарядки. Также сообщается о двух слотах для SIM-карт и поддержке FM-радио.  Встроенный ИИ-помощник позволяет управлять телефоном с помощью голоса — например, совершать звонки, проверять прогноз погоды, устанавливать будильник или запрашивать общую информацию. Рекомендуемая цена HMD 101 4G составляет 149 юаней (около $21). Смартфон HMD 102 4G отличается от HMD 101 4G наличием встроенной камеры. Остальные характеристики такие же, как у младшей модели. Цена HMD 102 4G — 169 юаней (около $24). |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



