|
Опрос
|
реклама
Быстрый переход
Скрытая съёмка запрещена: очки Meta✴ перестанут записывать видео, если повреждён индикатор съёмки
08.07.2026 [15:43],
Павел Котов
Умные очки Meta✴✴ вызывают недовольство общественности как устройство, которое, попав в руки недобросовестного владельца, может нарушать конфиденциальность граждан, позволяя, например, вести негласную видеосъёмку. В компании решили отреагировать на эти опасения. 
Источник изображения: Meta✴✴ Meta✴✴ объявила о выпуске обновления, с которым умные очки отказываются работать в режиме видеосъёмки, если обнаруживается, что светодиодный индикатор конфиденциальности повреждён, — некоторые пользователи делают это намеренно. Ранее компания уже пыталась бороться с такими действиями. Если закрыть индикатор скотчем или другим предметом на очках Ray-Ban Meta✴✴ второго поколения, то при включении видеозаписи устройство выведет запрос с требованием открыть индикатор, хотя «народные умельцы» нашли несколько способов обойти это ограничение. Ориентированное на конфиденциальность обновление вышло ещё несколько недель назад, когда компания представила недорогой вариант умных очков без марки Ray-Ban, сообщил ресурсу The Verge вице-президент Meta✴✴ по носимым устройствам Алекс Химель (Alex Himel). Он признал, что компания осведомлена о росте случаев злоупотребления. Ранее Meta✴✴ подвергли критике за намерение добавить в устройство функцию распознавания лиц; также появлялись сообщения, что умные очки становятся средством преследования молодых женщин. В некоторых общественных местах вводятся запреты на ношение этих устройств — до конца месяца ими запретят пользоваться во всех судах штата Нью-Йорк. Ранее подобный запрет ввели в Филадельфии; кроме того, их запретили использовать в местах общего пользования некоторые круизные компании. Никакого ИИ в браузере — Vivaldi пообещала «сохранить человеческий подход к просмотру веб-страниц»
19.06.2026 [19:11],
Сергей Сурабекянц
В то время как Chrome, Edge и другие браузеры наперегонки наполняются ИИ-функциями, разработчики альтернативного браузера Vivaldi придерживаются противоположной точки зрения и хотят «сохранить человеческий подход к просмотру веб-страниц». Они утверждают, что 95 % пользователей их браузера также против навязываемых им нейросетевых инструментов. Своим мнением по этому вопросу поделился соучредитель Vivaldi Джон Стивенсон фон Тетцнер (Jon Stephenson von Tetzchner). 
Источник изображений: Vivaldi Тетцнер в далёком 1995 году был соучредителем компании, разработавшей классическую версию браузера Opera, не основанную на коде Chromium. Он является убеждённым противником интеграции ИИ в браузеры и утверждает, что подавляющее большинство пользователей придерживаются того же мнения, которое кратко можно выразить фразой: «Черт возьми, нет!». Vivaldi публично выступила против функций ИИ в своём браузере, заявив о желании «сохранить человеческий подход к просмотру веб-страниц». Тетцнер отметил, что такая политика прямо противоположна тому, что делают другие компании-разработчики браузеров. Он утверждает, что конкуренты — Brave, Chrome, Edge, Firefox, Opera и Safari наполняют свои браузеры невостребованными инструментами ИИ, вместо того чтобы создавать действительно полезные функции. «Вы можете превратить Vivaldi практически во что угодно , — утверждает Тетцнер. —Мы стараемся адаптироваться к людям. Это философия дизайна» . На сегодняшний день Vivaldi, по его словам, насчитывает около 4 млн пользователей и продолжает расти. На фоне внедрения ИИ-инструментов в другие браузеры, он отметил«большой приток новых пользователей» Vivaldi. Тетцнер говорит, что 95 % ответов пользователей Vivaldi на вопрос о желании иметь функции ИИ в браузере, варьируются от «нет» до «категорически нет». 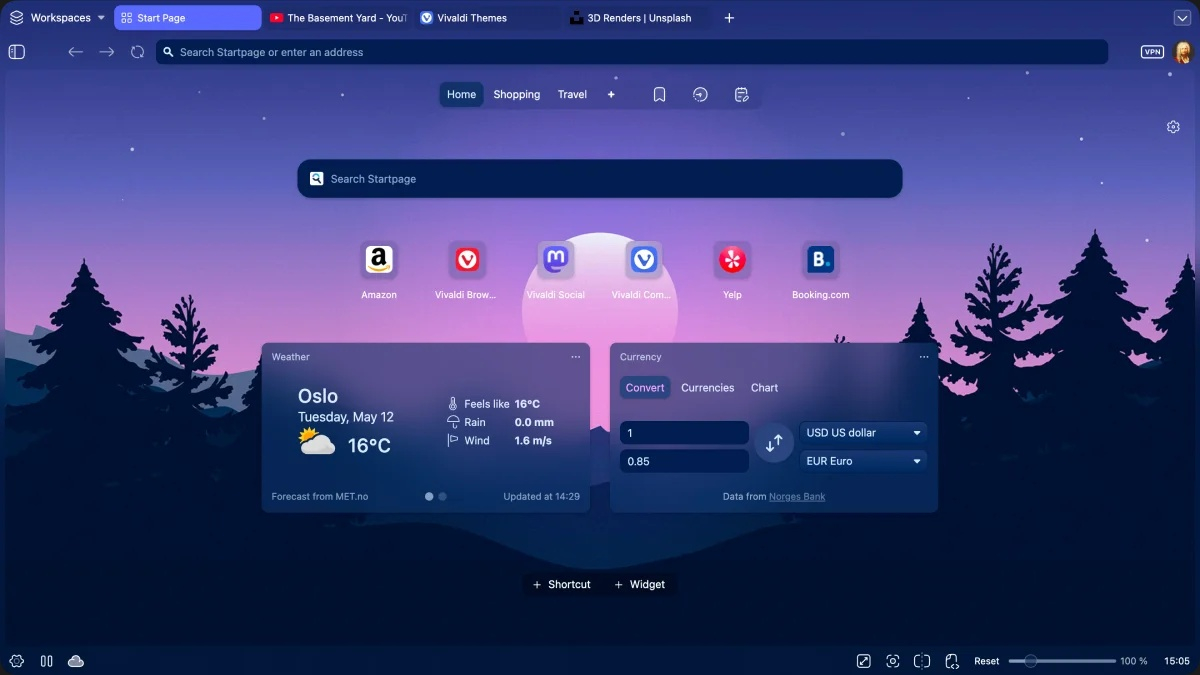 Тетцнер скептически относится к инструментам ИИ для управления вкладками: «Я думаю, мы можем помочь вам организовать их без использования ИИ». Он отметил стеки вкладок, мозаичное расположение вкладок и рабочие пространства Vivaldi, которые предоставляют дополнительные способы организации вкладок. Тетцнер категорически против добавления любых инструментов для работы с криптовалютой в браузеры. «Блокчейн может быть интересной технологией в некоторых аспектах, но, похоже, это технология, которая ищет проблему для решения, — считает он. — В то время как криптовалюта — это мошенничество. Так хотим ли мы добавлять мошеннические схемы? Нет, не хотим». По мнению Тетцнера, внедрение ИИ в браузеры предполагает предоставление крупным технологическим компаниям всё большего количества личных данных, тем самым ставя под удар конфиденциальность пользователей. «Это не преувеличение, — считает он. — Это история, которая повторялась слишком часто, особенно с компаниями социальных сетей». В качестве примера он привёл Facebook✴✴, который, по его мнению, эволюционировал из компании, которая связывала семью и друзей, в алгоритмическую ленту, которая решает, что пользователю стоит увидеть.  «Существует много скептицизма по поводу того, что всё зашло слишком далеко и слишком быстро. Это навязывается людям. И вопрос в том: зачем такая спешка? — задаётся вопросом Тетцнер. — Я думаю, что крупные технологические компании временами доказывали, что идут своим собственным путём. Они не слушают. Они уже нанесли немалый ущерб сбором данных и своими алгоритмами контента, и я думаю, что это следующий шаг в этом направлении». Тетцнер рассматривает Vivaldi как часть противодействия крупным технологическим компаниям. Он отметил, что Vivaldi «из коробки» включает Proton VPN с неограниченным бесплатным трафиком. Браузер Vivaldi доступен на всех видах устройств и операционных систем — Android, iOS, Linux, macOS и Windows. Он также рассказал, что год назад перешёл на Linux, «голосуя ногами» против интеграции ИИ и сбора данных. «Мне немного стыдно, как долго я пользовался Windows, — говорит он, описывая список своих претензий к операционной системе Microsoft. — Я просто не думаю, что мне следует заходить в облако, чтобы войти в свой компьютер. Я не думаю, что должна быть какая-либо автоматическая загрузка данных с моего компьютера».  Тетцнер упомянул распространённые претензии к последней версии ОС Windows, в том числе спорную функцию Recall на основе ИИ, синхронизацию папок Microsoft OneDrive без запроса и прекращение обновлений безопасности Windows 10 для миллионов ПК, всё ещё работающих под управлением этой ОС. «Я не говорю, что любая интеграция ИИ плоха, — заключил Тетцнер. — Я просто говорю, что это не является нашим приоритетом, и мы считаем, что можем придумать множество крутых функций и без использования ИИ в браузере». Apple изменит схему работы функции Hide My Email — в худшую сторону
17.06.2026 [12:31],
Павел Котов
Apple решила внести изменения в механизм обеспечения конфиденциальности для пользователей платных тарифов. Функция Hide My Email, позволяющая скрывать настоящий адрес электронной почты при регистрации на сайтах, будет подставлять более очевидные адреса, за счёт чего её эффективность может снизиться.  Функция Hide My Email из пакета Apple iCloud+ предполагает генерацию анонимных адресов электронной почты на домене @icloud.com, письма с которых далее направляются на настоящий почтовый ящик пользователя. Схема работает, потому что эти адреса невозможно отличить от адресов обычных пользователей сервисов Apple по тому же домену. Однако в минувший понедельник, 15 июня, компания сообщила разработчикам, что в ближайшие недели перенесёт генерируемые системой анонимные адреса на поддомен @private.icloud.com. Это упростит разработчикам приложений и администраторам сайтов задачу по определению того, что пользователь подключил этот сервис — такие адреса несложно будет заблокировать. Существующие адреса продолжат действовать, почта с них будет пересылаться без перебоев, пообещала Apple. Разработчикам приложений и поставщикам услуг электронной почты придётся обновить свои фильтры, чтобы гарантировать, что письма для пользующихся этим сервисом клиентов отправлялись и дальше, добавил производитель iPhone. Общественность, однако, уже раскритиковала решение компании изменить домен сервиса, потому что это затруднит работу с ним. Комментариев от Apple по данному вопросу не поступало. Honor научила смартфоны подсовывать приложениям фальшивые данные вместо личных — Google может её завернуть
10.06.2026 [17:30],
Павел Котов
Смартфоны Google и Samsung предлагают множество полезных функций для обеспечения безопасности и конфиденциальности: детектор спама, фильтрацию звонков, расширенный режим защиты (Advanced Protection Mode) и отключение USB на заблокированном смартфоне. Не менее интересное решение под названием Virtual Permissions представила Honor.  Функция Honor Virtual Permissions предполагает отправку пустых либо фиктивных данных определённым приложениям, которые запрашивают доступ к конфиденциальной информации. Приложения, которым не доверяет пользователь, могут получать недостоверные данные из списка контактов, сообщений, журналов звонков и календаря. Это пригодится, если есть желание пользоваться новым или существующим приложением, с которым не хочется делиться закрытой информацией. Любопытно, что Honor не первая предложила эту возможность — ещё в 2020 году нечто подобное представила Realme: тогда при запросе приложением определённых разрешений ему можно было отправлять пустые данные. Однако в 2021 году китайский производитель был вынужден удалить эту функцию из-за каких-то действий Google. Часть устройств лишилась её с выходом очередного обновления, а на части она вообще так и не появлялась. С одной стороны, отрадно, что подобные возможности реализовал другой бренд. Но пользователям смартфонов Honor по всему миру следует ожидать, что компания так и не выпустит её на устройствах за пределами Китая. Официальных комментариев по данному вопросу от Google, Realme и Honor пока не поступало. Apple доверит Google конфиденциальные данные пользователей из Apple Intelligence
09.06.2026 [10:50],
Павел Котов
Apple объявила о расширении действия программы Private Cloud Compute (PCC) — эта программа будет работать не только в собственных центрах обработки данных компании. Она заключила партнёрское соглашение с Google и Nvidia: рабочие нагрузки Apple Intelligence будут запускаться в облаке Google.  PCC — система обработки конфиденциальных данных для сервисов искусственного интеллекта, направленная на защиту безопасности Apple Intelligence при подключении к облачным ресурсам. Ранее PCC использовалась только в собственных ЦОД Apple на её собственных процессорах, но теперь некоторые задачи Apple Intelligence будут запускаться в облаке Google. Два технологических гиганта адаптировали технологии, лежащие в основе моделей Google Gemini для моделей Apple Foundation. Задачи ИИ частично выполняются локально на устройствах Apple, но для ресурсоёмких облачных нагрузок требуется облачная инфраструктура. Компания заверила, что ей удалось при поддержке Google и Nvidia адаптировать PCC для работы на сторонних облачных ресурсах без ущерба для конфиденциальности и защиты данных. Для этого потребовалась реализация на основе инструментов Nvidia Confidential Computing, Intel TDX и Google Titan. Для снижения угрозы атаки на цепочку поставок Apple заручилась криптографически проверяемым реестром оборудования Google Cloud в рамках программы PCC; здесь используются многие из тех же шаблонов безопасности, что и PCC на процессорах Apple. Для пользователей это значит, что их данные будут защищены в той же мере, что и на собственных ресурсах Apple: устройства компании будут доверять только ПО в составе PCC с криптографическим подтверждением от производителя. Реализация PCC в Google Cloud ещё не завершена, и Apple намеревается постепенно добавить все средства защиты в процессе бета-тестирования. Двоичные файлы системы PCC в Google Cloud будут доступны для публичного ознакомления; к тестированию и поиску ошибок компания привлечёт сторонних экспертов и энтузиастов по проекту Apple Security Bounty Program. Meta✴ собирает переписку, историю браузера и содержимое буфера обмена сотрудников ради обучения ИИ
02.06.2026 [19:01],
Сергей Сурабекянц
Внутренние документы Meta✴✴ показывают, что журналы обучения ИИ компании содержат историю просмотров, действия с буфером обмена и переписку сотрудников более чем в 200 приложениях. Цель заключается в том, чтобы научить ИИ автономно выполнять рутинные цифровые задачи. Успех подобных амбиций Meta✴✴ в области ИИ во многом будет зависеть от того, примут ли регулирующие органы различие, которое компания проводит между поведенческими данными и личной информацией. 
Источник изображений: unsplash.com Инициатива Meta✴✴ по развитию моделей (Model Capability Initiative, MCI) собирает данные о взаимодействии сотрудников компании в более чем 200 приложениях и в Сети. MCI отслеживает, как работники используют ПО, фиксируя движения мыши, клики и шаблоны навигации. Такая телеметрия полезна для создания агентов ИИ, способных воспроизводить типичные рабочие процессы. Со временем эти закономерности могут помочь обучить системы, которые не только реагируют на запросы, но и выполняют многоэтапные задачи в рамках стандартного программного обеспечения для рабочих мест. Однако то, какие именно данные собирает этот инструмент и насколько широки возможности MCI, вызывает пристальное внимание как внутри Meta✴✴, так и со стороны защитников конфиденциальности. Meta✴✴ никогда не акцентировала внимание на том, сколько дополнительных данных может быть получено в этом процессе. Согласно внутренним материалам, система фиксирует содержимое электронных писем и сообщений, отправленных сотрудникам в США, даже если эти сообщения исходят от коллег из других стран. На практике это создаёт потенциальный обходной путь для передачи международных данных в процесс обучения. Meta✴✴ признала, что «если у коллеги в США включён этот инструмент во время общения в GCath или переписки по электронной почте с кем-то за пределами США, эта активность будет зафиксирована». Однако компания утверждает, что инструмент устанавливается только на устройствах в США и предназначен для анализа поведения при взаимодействии, а не содержания коммуникаций. «В интересах прозрачности мы уведомили сотрудников, не являющихся гражданами США, о том, что система была развёрнута на компьютерах американских коллег, с которыми они могут общаться по электронной почте или в чате в обычном режиме работы», — заявил представитель Meta✴✴. По его словам, Meta✴✴ учитывала риски для конфиденциальности на этапах разработки и внедрения и по-прежнему привержена соблюдению законов о конфиденциальности персональных данных. Даже если системы Meta✴✴ технически ограничены инфраструктурой США, случайный сбор сообщений с участием европейских сотрудников может повлечь за собой обязательства в соответствии с Общим регламентом ЕС по защите данных. Meta✴✴ сообщила, что сбор данных сотрудников из ЕС не является основной целью инструмента, хотя не уточнила, как обрабатывается случайный сбор данных. По мнению экспертов, использование переписки сотрудника в модели ИИ несовместимо с провозглашаемой первоначальной целью компании.  Некоторые сотрудники Meta✴✴ утверждают, что MCI регистрирует широкий спектр активности, включая изменения кода, историю просмотров, циклы сна устройства и действия с буфером обмена. Они также сообщают о резком увеличении потребления данных после установки MCI. Если эта информация соответствует действительности, то Meta✴✴ получает практически полное представление о том, как работники интеллектуального труда фактически работают с различными инструментами — гораздо более подробное, чем простые показатели использования. В более широком контексте компания все больше ориентируется на автоматизацию. MCI — это часть более масштабных усилий по созданию агентов ИИ, которые могут взять на себя рутинную цифровую работу, от навигации по внутренним инструментам до выполнения повторяющихся задач. Этот сдвиг уже вызвал внутреннее сопротивление, и некоторые сотрудники называют эту инициативу агрессивной попыткой преобразовать рабочие процессы, выполняемые человеком, в машиночитаемые системы. WhatsApp покажет отдельным списком, кто из контактов онлайн
23.05.2026 [16:59],
Павел Котов
В последней бета-версии WhatsApp для iPhone упомянут обновлённый интерфейс списка контактов, в котором будет упрощён просмотр тех, кто находится в сети и кто был в последнее время активен, сообщает ресурс WABetaInfo. 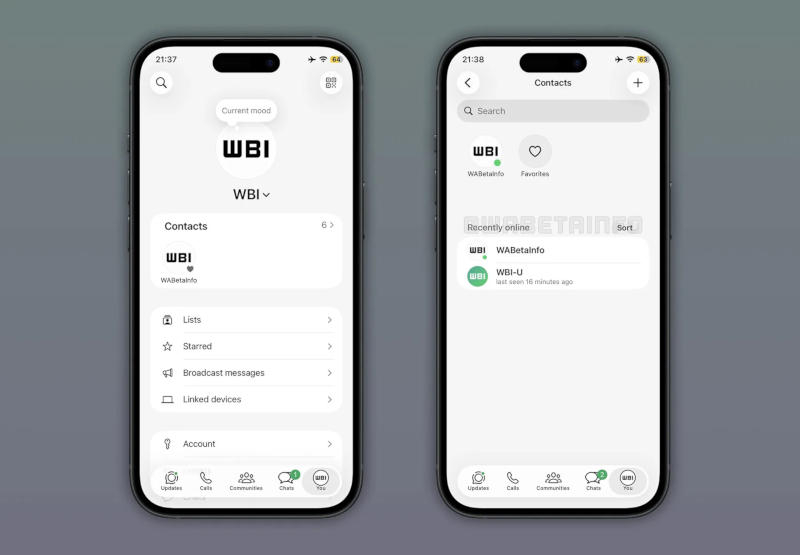
Источник изображения: wabetainfo.com Пользователи WhatsApp могут выбирать, имеют ли другие контакты доступ к их статусу онлайн. Соответственно, мессенджер позволяет пользователям видеть онлайн-статус другого человека, только если они сами сделали этот статус видимым. Тем не менее, чтобы увидеть, в сети конкретный контакт или нет, необходимо открыть переписку с ним и посмотреть в верхнюю область чата — там показано, находится ли этот контакт онлайн, и когда он был активе в последний раз. Сейчас администрация WhatsApp разрабатывает функцию, которая позволит в формате списка увидеть, какие из контактов в данный момент находятся в сети. В верхней части нового центра контактов будут отображаться избранные; затем те, кто в данный момент находятся в сети; а ниже — те, что были активны недавно. Доступ к новому разделу контактов WhatsApp будет осуществляться через экран настроек, и он будет подчиняться тем же правилам конфиденциальности, что и текущий индикатор статуса онлайн. Чётких сроков выхода функции в открытый доступ пока нет. Техас подал иск против Meta✴ и WhatsApp — мессенджер соврал про зашифрованные переписки
22.05.2026 [13:37],
Дмитрий Федоров
Генеральный прокурор Техаса Кен Пакстон (Ken Paxton) подал иск против мессенджера WhatsApp и его материнской компании Meta✴✴. По версии обвинения, WhatsApp не гарантирует пользователям шифрование переписки, а компания имеет доступ «практически ко всей» частной коммуникации в приложении. 
Источник изображения: Dima Solomin / unsplash.com Иск зарегистрирован в суде округа Харрисон в рамках техасского Закона о недобросовестной торговой практике (Deceptive Trade Practices Act) — основного закона штата о защите прав потребителей. Пакстон потребовал судебного запрета на доступ Meta✴✴ и WhatsApp к сообщениям техасцев без их согласия и взыскания денежных штрафов. WhatsApp рекламирует свои услуги как защищённые и зашифрованные, но не выполняет этих обещаний, заявил Пакстон. В обоснование иска Техас сослался на публикации в СМИ о федеральном расследовании предполагаемого доступа Meta✴✴ к незашифрованным сообщениям WhatsApp и на заявление информатора в Комиссию по ценным бумагам и биржам США (SEC). Представитель Meta✴✴ Энди Стоун (Andy Stone) заявил, что компания не может читать зашифрованную переписку пользователей. Пакстон ранее подал ряд аналогичных исков о нарушении конфиденциальности данных против техногигантов. В мае 2025 года Google согласилась выплатить около $1,4 млрд для урегулирования претензий о нарушении конфиденциальности данных пользователей. 11 мая генпрокурор подал ещё один иск — против стримингового сервиса Netflix, обвинив платформу в слежке за детьми и другими потребителями через сбор данных без их согласия. Хакеры слили данные клиентов Trump Mobile и раскрыли реальные продажи смартфона T1
20.05.2026 [20:24],
Сергей Сурабекянц
В преддверии начала продаж скандально известного смартфона Trump Mobile T1 начали появляться сообщения об утечках конфиденциальной информации клиентов с сайта компании. Утечка также показала, сколько заказов на T1 было размещено, и это на порядок меньше, чем утверждали вирусные цифры в СМИ. 
Источник изображения: Trump Mobile Пользователь YouTube voidzilla первым сообщил о предполагаемой утечке, получив анонимную информацию от пожелавшего остаться неизвестным хакера об уязвимости на сайте Trump Mobile. Хакер утверждает, что при размещении поддельного заказа на смартфон он смог «просканировать всю базу данных предварительных заказов». Таким образом он получил доступ к электронным письмам, номерам телефонов и почтовым адресам, но не к данным кредитных карт. Информация об уязвимости косвенно подтверждается пользователями YouTube voidzilla и penguinz0, которые делали заказы на смартфон Trump Mobile T1, а теперь обнаружили свои данные в присланном злоумышленником файле. Утечка, по всей видимости, включает в себя все размещённые заказы на телефон, что позволяет предположить, сколько всего заказов было размещено. Согласно данным voidzilla, было «примерно 10 000 уникальных клиентов и около 30 000 уникальных заказов на телефоны», хотя неясно, все ли заказы касаются именно устройства или являются заказом SIM-карты из тарифного плана 47 от Trump Mobile. В любом случае, это намного меньше цифры в 590 000, которая неоднократно публиковалась в СМИ за последние шесть месяцев. Будущее Google в сфере ИИ сильно зависит от доверия пользователей и доступа к их личным данным
20.05.2026 [11:15],
Владимир Фетисов
Google строит большие планы, связанные с дальнейшим развитием искусственного интеллекта, и многие из них также связаны с доверием пользователей. В рамках конференции I/O 2026 компания анонсировала немало любопытных ИИ-функций, основанных на обработке массива личных данных пользователей. 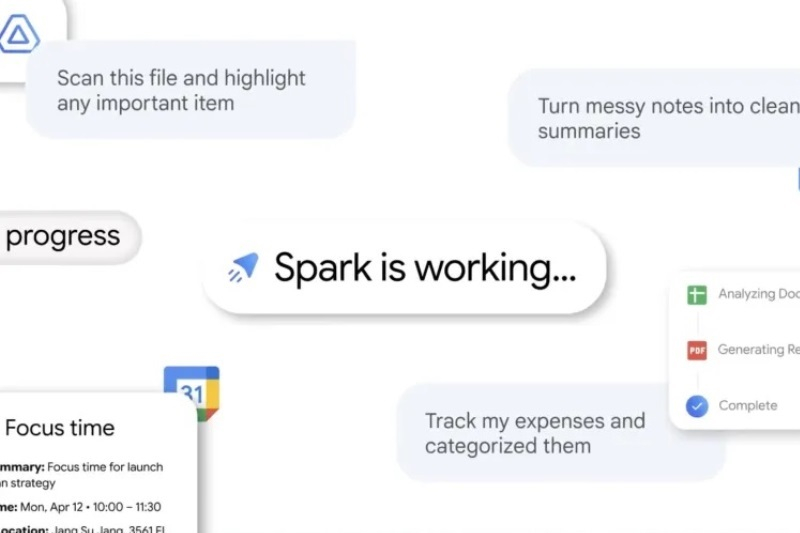
Источник изображений: Google Google анонсировала постоянно активного ИИ-агента Gemini Spark, который может помочь, например, с организацией предстоящего мероприятия, а инструмент Daily Brief предоставит краткий обзор запланированных на день дел. Google также расширяет доступ к ИИ-интерфейсу Gmail, который позволяет генерировать списки дел и ответы на поступающие письма. Многие из анонсированных функций выглядят действительно полезными, но в основе каждой из них ИИ-движок, работающий с массивом личных данных пользователя. В отличие от конкурентов, таких как OpenAI и Anthropic, которые позволяют подключать другие приложения и данные, доступ Gemini к личным данным, хранящимся в сервисах Google, находится за простым меню согласия. Именно это является одним из ключевых преимуществ поискового гиганта над конкурентами. Google начала внедрять персонализированные функции ещё в 2024 году, когда интегрировала Gemini в некоторые приложения Workspace, такие как Gmail, «Документы», «Таблицы» и др. На тот момент ИИ-бот мог выполнять некоторые действия, такие как поиск нужных документов и написание черновиков писем. В это же время инструмент Deep Research на базе Gemini может получать доступ к электронным письмам пользователей, облачному хранилищу и чатам, чтобы использовать эти данные в качестве источников в процессе своей работы. За последние несколько месяцев эти интеграции постепенно расширялись. В январе Google представила Personal Intelligence — ИИ-функцию, которая позволяет Gemini анализировать информацию из Gmail, «Google Фото», поисковика Google и истории YouTube без дополнительных запросов. Это означает, что Gemini может автоматически извлекать данные из аккаунтов пользователей, чтобы делать ответы на запросы более персонализированными.  Хотя доступ Gemini к данным пользователя является опциональным, похоже, что будущее ИИ-инструментов Google во многом зависит именно от того, будут ли люди доверять им конфиденциальную информацию. Так функция Daily Brief, которая уже внедряется для подписчиков Google AI Plus, Pro и Ultra, сканирует поступающие в Gmail письма и отмечает события из календаря пользователя. Gemini Spark проникает ещё глубже в данные пользователя. Google позиционирует этот инструмент, как персонального ассистента, способного работать внутри приложений Workspace круглосуточно и обрабатывать разные задачи. Однако подключение к Workspace это только начало, поскольку Gemini Spark может взаимодействовать со сторонними сервисами, такими как Canva, OpenTable, Spotify, Instacart, Adobe и др. Google даже планирует реализовать возможность предоставления доступа Gemini Spark к локальным файлам на компьютерах Apple Mac, подобно тому, как это происходит при использовании OpenClaw. Многие люди могут не захотеть предоставлять ИИ-помощнику доступ ко всему содержимому своих ПК. Однако успех OpenClaw доказывает, что ИИ-системы переходят из разряда новинок в разряд реальных инструментов для повышения производительности, которым для работы нужен доступ к данным пользователей. Вопрос лишь в том, насколько потребители доверяют компаниям, стоящим за такими системами. «Ваши разговоры не сохраняются»: в WhatsApp появились «Инкогнито-чаты» для приватных бесед с ИИ
13.05.2026 [18:55],
Сергей Сурабекянц
Компания Meta✴✴ сообщила о запуске в своём мессенджере WhatsApp новой функции «Инкогнито-чат» (Incognito Chat), направленной на решение проблем конфиденциальности данных. Чаты будут работать на основе разработанной Meta✴✴ технологии обработки данных, гарантирующей невидимость разговоров для всех, включая саму компанию. 
Источник изображения: unsplash.com «Ваши разговоры не сохраняются, и по умолчанию ваши сообщения исчезают — предоставляя вам пространство для размышлений и изучения идей без посторонних глаз», — говорится в блоге Meta✴✴. Этот шаг предпринят в связи с тем, что люди часто делятся конфиденциальной личной, финансовой, медицинской или рабочей информацией с ИИ-помощниками, несмотря на опасения по поводу конфиденциальности данных, которые могут храниться или использоваться компаниями. «Мы начинаем задавать много важных вопросов о нашей жизни с помощью систем искусственного интеллекта. Не всегда нужно делиться информацией, стоящей за этими вопросами, с компаниями, которые управляют этими системами ИИ», — пояснил глава WhatsApp Уилл Кэткарт (Will Cathcart) на брифинге для СМИ. По информации компании, сообщения, которыми люди обмениваются с Meta✴✴ AI, могут использоваться социальной сетью для улучшения своих моделей ИИ, но личные чаты в WhatsApp остаются защищёнными сквозным шифрованием и недоступны для этой цели. На данный момент чат в режиме инкогнито доступен только в текстовом формате, то есть пользователи не смогут загружать изображения. По словам Кэткарта, ИИ получит встроенные механизмы защиты и не станет отвечать на проблемные вопросы, направляя разговоры в другое русло. Meta✴✴ также заявила о планах в ближайшие месяцы внедрить функцию «Боковой чат» (Side Chat) с использованием Meta✴✴ AI, которая позволит пользователям получать личную помощь в любом чате WhatsApp. Google привязала reCAPTCHA к Play Services и отрезала от верификации пользователей Android без сервисов Google
10.05.2026 [12:03],
Дмитрий Федоров
Google привязала систему верификации reCAPTCHA нового поколения к закрытой платформе Google Play Services на Android. Пользователи кастомных мобильных операционных систем (ОС) без сервисов Google, известных в техническом сообществе как «дегуглифицированные», теперь автоматически проваливают проверку на миллионах сайтов. 
Источник изображения: BoliviaInteligente / unsplash.com Вместо привычных картинок-головоломок reCAPTCHA при подозрительной активности требует отсканировать QR-код. Для сканирования Play Services должен работать в фоновом режиме и обмениваться данными с серверами Google. Без него верификация невозможна. Google представила более широкую систему Google Cloud Fraud Defense на конференции Cloud Next 23 апреля, но о привязке проверки к своему закрытому программному обеспечению (ПО) компания не упоминала. Зависимость от Play Services появилась без лишнего шума: снимок Internet Archive за октябрь 2025 года уже содержал аналогичное требование к версии 25.39.30. Google внедряла эту привязку как минимум семь месяцев, прежде чем пользователь сабреддита r/degoogle обнаружил её, а PiunikaWeb и Android Authority привлекли к ней внимание. 
Источник изображения: reclaimthenet.org Сравнение с iOS делает асимметрию очевидной. Устройства Apple с iOS 16.4 и выше проходят ту же верификацию reCAPTCHA без установки какого-либо ПО Google. От владельцев iPhone компания этого не потребовала. Заблокированными оказались только пользователи Android, отказавшиеся от Play Services. Если бы речь шла о безопасности, требование распространялось бы на все мобильные ОС. Избирательность указывает на другую цель — контроль экосистемы. reCAPTCHA используют миллионы сайтов, и привязка верификации к Play Services создаёт прецедент: доступ к обычному веб-контенту требует запуска закрытого ПО и передачи данных Google. Пользователи, отказавшиеся от сервисов Google ради конфиденциальности, сделали это осознанно, изучив практики сбора данных. Новая система наказывает их выбор, считая отсутствие закрытого ПО подозрительным по умолчанию. Веб-разработчикам, внедряющим эту reCAPTCHA, стоит понимать последствия: каждый такой сайт закрывает доступ пользователям Android без сервисов Google. Эта аудитория невелика, но именно она чаще других занимает принципиальную позицию в отношении техногиганта, следит за тем, как сайты обращаются с данными пользователей, и меньше других готова идти на уступки. Европа откроет лазейку для массовой слежки за тем, что граждане ищут в Google
27.04.2026 [18:37],
Дмитрий Федоров
Европейская комиссия в рамках Закона о цифровых рынках (DMA) предложила норму, которая обяжет Google передавать поисковые данные третьим лицам через автоматизированный программный интерфейс (API). Эксперты по кибербезопасности и конфиденциальности предупреждают: механизм анонимизации данных перед передачей содержит фундаментальные изъяны и способен открыть путь к массовой слежке за пользователями в Европейском союзе (ЕС). 
Источник изображения: Chris Yang / unsplash.com DMA нацелен на крупные технологические компании — «привратники» (англ. — gatekeepers) вроде Google и должен открыть цифровые рынки для конкуренции. Однако предлагаемая норма, по мнению критиков, может обернуться рисками для конфиденциальности европейских пользователей и национальной безопасности. Опасения высказал Лукаш Олейник (Lukasz Olejnik), известный специалист по кибербезопасности и защите данных. Он изучил проект документа, цель которого — стимулировать конкуренцию, обязав Google предоставлять квалифицированным компаниям доступ к поисковым данным. По оценке Олейника, предложенная система анонимизации не помешает повторно идентифицировать пользователей, а сам механизм открывает дорогу масштабному сбору конфиденциальных сведений. Новая норма обязывает Google непрерывно передавать поисковую активность по всему ЕС через API. В передаваемый массив данных, по имеющимся сведениям, входят полные тексты запросов, временны́е метки, приблизительные координаты пользователя, язык, тип устройства, а также детальные сигналы поведения: клики, прокрутка страниц, уточнения запросов. IP-адреса и идентификаторы учётных записей предполагается удалять, однако, как утверждает Олейник, оставшихся данных хватит для деанонимизации. 
Фрагмент проекта Европейской комиссии, в котором выделено требование к Alphabet передавать любые введённые пользователями поисковые запросы в Google Search, включая модификации запросов и метаданные. Источник изображения: blog.lukaszolejnik.com Система анонимизации строится на модели «белого списка», также часто называемой «разрешительным списком» (англ. — allowlist model). Отдельные компоненты поисковых запросов — имена или ключевые слова — допускаются к передаче, если их вводили не менее 50 авторизованных пользователей за 13 месяцев. Раз попав в список, компонент остаётся там на срок до пяти лет. Порог, однако, действует только для фрагментов запросов, а не для запросов целиком: уникальные или конфиденциальные поиски, составленные из распространённых слов, всё равно могут попасть в выгрузку. Олейник подчёркивает, что такая архитектура открывает дорогу целенаправленным манипуляциям. Злоумышленники могут «засеивать» систему: запускать повторные запросы с множества аккаунтов, чтобы протолкнуть нужные термины в разрешительный список. После одобрения такие термины позволят годами отслеживать конфиденциальные запросы, связанные с конкретными людьми, организациями или темами. 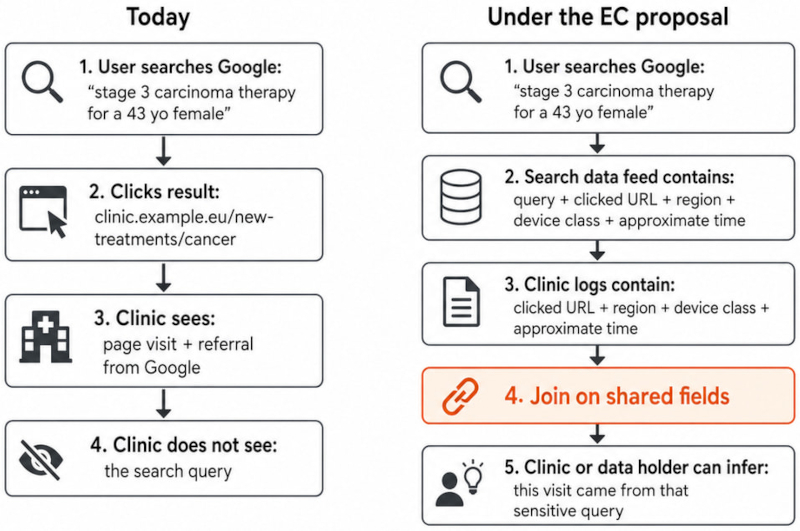
Схема деанонимизации: владелец веб-сайта сопоставляет журнал посещений с выгрузкой Google и узнаёт конфиденциальный запрос пользователя. Источник изображения: blog.lukaszolejnik.com Передаваемые данные легко сопоставить с внешними источниками. В потоке есть адреса страниц, на которые переходили пользователи, и обобщённое время взаимодействия. Владельцам веб-аналитики или отслеживающих скриптов хватит этого, чтобы соотнести поисковые записи с журналами посещений и восстановить индивидуальные истории поиска — даже когда прямые идентификаторы удалены. Геолокация — ещё одна слабая точка системы. Координаты обобщаются в «корзины» площадью не менее 3 км² с охватом от 1 000 пользователей, но такие зоны всё же могут совпадать с конкретными районами, кампусами или правительственными кварталами. Со временем наблюдатели смогут отследить поисковые закономерности вблизи медицинских учреждений, государственных организаций или режимных объектов. 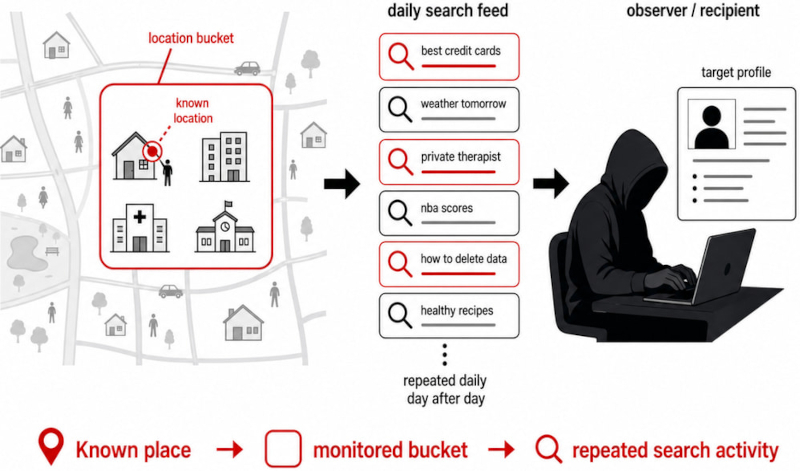
Наблюдатель собирает профиль пользователя, отслеживая ежедневные поисковые запросы из привязанной к известному месту географической «корзины». Источник изображения: blog.lukaszolejnik.com Олейник называет предложение одной из самых серьёзных потенциальных угроз утечки данных в Европе за последние годы. Действующие гарантии, по его оценке, опираются скорее на процедурный контроль, чем на надёжную техническую защиту. Исследователь не согласен и с самим допущением, что частотные пороги и частичная анонимизация способны предотвратить злоупотребления. Meta✴ расширила родительский контроль на общение с ИИ — родители увидят темы бесед подростков за неделю
24.04.2026 [05:08],
Дмитрий Федоров
Meta✴✴ откроет родителям доступ к темам, которые их дети-подростки обсуждают с ИИ-чат-ботом компании. Новая вкладка Insights в инструментах родительского контроля Facebook✴✴, Messenger и Instagram✴✴ покажет родителям темы разговоров их детей за последние семь дней. На старте функция заработает в пяти странах. 
Источник изображения: Solen Feyissa / unsplash.com Meta✴✴ уже уведомляет родителей, когда подростки затрагивают в Instagram✴✴ темы суицида или членовредительства. Теперь компания расширяет контроль на общение с Meta✴✴ AI. Родители, подключившие наблюдение за детьми в Facebook✴✴, Messenger или Instagram✴✴, увидят в новой вкладке Insights опцию Their AI interactions — перечень тем, которые подросток обсуждал с ИИ-чат-ботом за последние семь дней. Темы разбиты на крупные категории — учёба, развлечения, образ жизни, путешествия, тексты, здоровье и благополучие, — а внутри каждой выделены подтемы, сообщает Meta✴✴. В категорию «образ жизни» входят мода, еда и праздники, в «здоровье и благополучие» — физическое и психическое здоровье ребёнка. Родители могут нажать на основную тему, чтобы увидеть подробности. 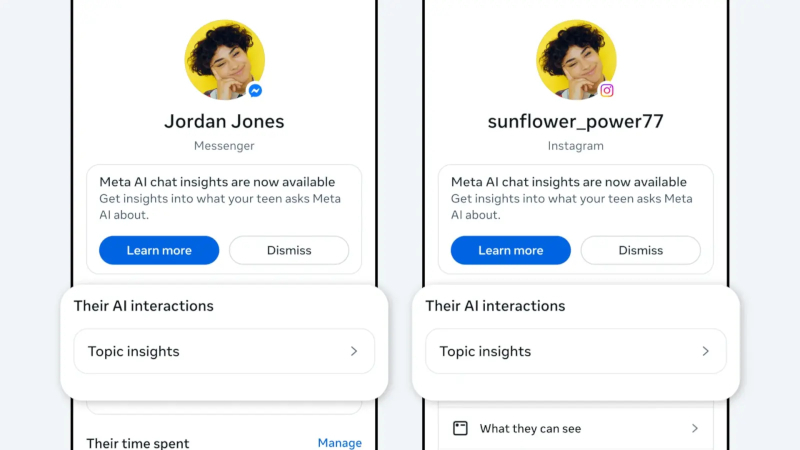
Источник изображения: Meta✴✴ На старте функция доступна родителям, контролирующим аккаунты детей в США, Великобритании, Австралии, Канаде и Бразилии. Широкое распространение функции запланировано на ближайшие недели. По умолчанию Meta✴✴ присваивает статус подросткового аккаунта всем пользователям младше 16 лет. Нововведение появляется на фоне серии судебных разбирательств против Meta✴✴. Компанию обвиняют в создании продуктов, вызывающих зависимость. Гендиректор Марк Цукерберг (Mark Zuckerberg) недавно давал показания по одному из таких дел. В прошлом месяце суд обязал компанию выплатить $375 млн за то, что она не пресекла распространение материалов с сексуальной эксплуатацией детей. 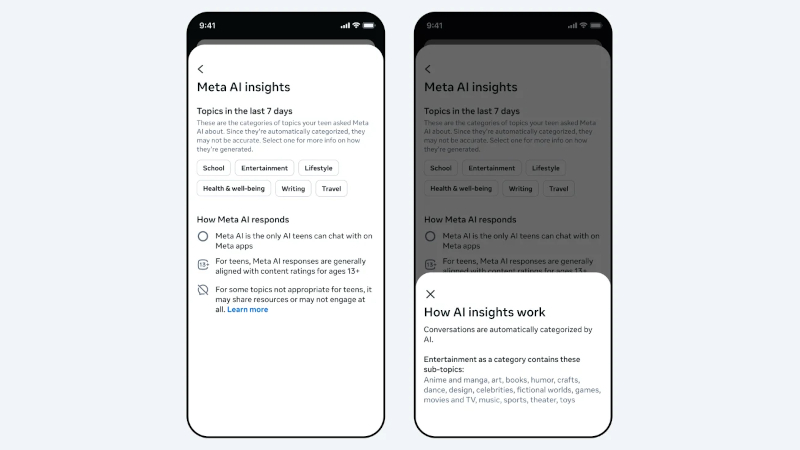
Источник изображения: Meta✴✴ Чтобы сделать ИИ-продукты безопаснее для несовершеннолетних, Meta✴✴ создала экспертный совет по цифровому благополучию при использовании ИИ (AI Wellbeing Expert Council). Сотрудники Meta✴✴ будут регулярно встречаться с членами совета, информировать их о новых функциях и собирать обратную связь. Apple исправила уязвимость iOS 26, позволившую ФБР читать удалённые сообщения
23.04.2026 [05:09],
Дмитрий Федоров
Apple выпустила внеплановые обновления iOS 26.4.2 и iOS 18.7.8 для iPhone и iPad, устранив уязвимость CVE-2026-28950 в службе уведомлений: удалённые уведомления неожиданно оставались в памяти устройства. Обновления вышли 22 апреля вне штатного цикла — вскоре после публикации о том, что ФБР извлекло переписку мессенджера Signal с iPhone подозреваемой именно через хранилище уведомлений Apple. 
Источник изображения: Yingchih / unsplash.com Уязвимость затрагивала службу уведомлений iOS и iPadOS. Компания устранила проблему с помощью улучшенного механизма скрытия данных, однако не раскрыла ни технических подробностей о том, как долго данные уведомлений хранились, ни того, как их можно было восстановить. Экстренное обновление вышло после того, как ФБР восстановило копии входящих сообщений Signal со смартфона подозреваемой Линетт Шарп (Lynette Sharp), хотя само приложение было удалено с устройства. Согласно записям судебного процесса, опубликованным сторонниками обвиняемой, переписка поступила не из зашифрованного хранилища Signal, а из системы уведомлений iPhone. «Сообщения были восстановлены с телефона Шарп через внутреннее хранилище уведомлений Apple — Signal был удалён, однако входящие уведомления сохранились во внутренней памяти», — говорится в этих записях. Apple не прокомментировала связь обновления с этим делом и не сообщила ни о том, использовалась ли уязвимость в реальных атаках, ни о том, почему выпуск обновления не вошёл в штатный цикл. Бюллетень компании не ссылается на случай с Шарп, однако описание в нём совпадает с тем, о чём сообщила сторона защиты. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


