|
Опрос
|
реклама
Быстрый переход
Хакеры легко извлекли из электромобиля BYD Seal полную историю поездок — от китайского завода до авторазборки в Польше
22.04.2026 [13:26],
Дмитрий Федоров
Группа «белых» хакеров купила на вторичном рынке телематический модуль от разбитого электромобиля BYD Seal и по незашифрованным данным из его памяти восстановила полный маршрут машины — от заводского конвейера в Китае через эксплуатацию в Великобритании до разборки в Польше. Ни специального оборудования, ни доступа к закрытым базам не потребовалось: хватило самодельной проводки, утилиты для чтения файловой системы и общедоступных интернет-источников. 
Источник изображения: Curated Lifestyle / unsplash.com Телематический модуль отвечает за связь автомобиля с мобильными и интернет-сетями и, как правило, содержит GPS-приёмник. В памяти такого блока хранятся координаты каждого перемещения, время включения и выключения двигателя, данные о зарядке (для электромобилей), состояние технических жидкостей, моточасы, диагностические коды неисправностей и статистика обслуживания. Многие модули работают ещё и как «чёрный ящик» — фиксируют параметры автомобиля в момент аварии и за несколько секунд до неё. Данные сохраняются даже после извлечения модуля из машины. Исследователи намеренно купили модуль на вторичном рынке: новый автомобиль ещё не успел бы накопить журналы поездок, тогда как модуль из подержанной машины почти наверняка содержит пользовательские данные. Штатного разъёма для считывания памяти у них не было, поэтому пришлось спаять собственный переходник для подключения модуля к USB-программатору — минуя диагностический интерфейс OBD-II. С помощью утилиты ubireader хакеры извлекли полный образ файловой системы из разделов modem, custapp и system, а затем сосредоточились на анализе корневой файловой системы (rootfs) и пользовательского раздела (usrfs). Ни один из разделов не был зашифрован, и задача оказалась несложной. Разобрав журналы глобальной навигационной спутниковой системы (GNSS), хакеры восстановили полную историю автомобиля — каждое перемещение и каждая остановка были зафиксированы в логах. Помимо данных с чипа исследователи воспользовались разведкой на основе открытых источников (OSINT). Два подхода вместе позволили привязать аномальные точки данных к реальным событиям. На карте большинство перемещений соответствовало типичным маршрутам, однако за период нахождения автомобиля в Великобритании неожиданно обнаружилось скопление GPS-точек в одной локации. Простой поиск в Google с фильтрами по дате и времени привёл к публикациям в социальных сетях о перевернувшемся электромобиле BYD Seal. Длинная серия координат в одной локации объяснялась тем, что машина лежала на боку после аварии. Описанная уязвимость не уникальна для автомобилей BYD. GPS-навигации уже три десятилетия, и на вторичном рынке хватает старых автомобилей, чья бортовая электроника может стать источником детальной информации о перемещениях владельца. Даже Tesla, которая позиционирует шифрование как конкурентное преимущество, не всегда была защищена от подобных проблем. Автопроизводители и регуляторы в последние годы ужесточили требования к шифрованию, но практически любой автомобиль, выпущенный за последние двадцать лет, несёт на борту цифровые регистраторы — аналог авиационного «чёрного ящика». Часть таких модулей хранит информацию о перемещениях за весь срок эксплуатации, и во многих случаях эти данные не зашифрованы. Переработанная функция Windows Recall всё ещё не отвечает требованиям безопасности
15.04.2026 [17:09],
Владимир Фетисов
Когда Microsoft только анонсировала функцию Recall, которая использует ИИ-алгоритмы и фиксирует практически все действия пользователя Windows, её назвали «катастрофой» для кибербезопасности и «кошмаром для конфиденциальности». После бурной негативной реакции софтверный гигант отложил внедрение этого нововведения, потратив год на перепроектирование Recall. Однако обновлённая ИИ-функция, как оказалось, по-прежнему не отвечает требованиям безопасности и конфиденциальности. 
Источник изображения: Miicrosoft Эксперт по кибербезопасности Александр Хагена (Alexander Hagenah) создал инструмент TotalRecall Reloaded, которые извлекает и отображает данные, собранные функцией Recall. Это обновлённая версия инструмента TotalRecall, который наглядно показал слабые места функции Recall до того, как Microsoft взялась за её переделывание. Софтверный гигант сосредоточился на создании защищённого хранилища, предназначенного для хранения собранных с помощью Recall данных. Оно использует аутентификацию через Windows Hello и изолированную среду на основе виртуализации. Для доступа к данным и активации Recall пользователь должен пройти аутентификацию по лицу или отпечатку пальца. Это ограничение введено для того, чтобы не позволить вредоносному программному обеспечению получить доступ к пользовательским данным. «Моё исследование показало, что хранилище действительно существует, но граница доверия заканчивается слишком рано. TotalRecall Reloaded позволяет скрытому вредоносному ПО подключиться», — рассказал Хагена. Он добавил, что TotalRecall Reloaded способен скрытно работать в фоновом режиме и активировать временную шкалу Recall, вынуждая пользователя пройти аутентификацию через Windows Hello. После прохождения аутентификации TotalRecall Reloaded может извлечь всё, что когда-либо фиксировалось с помощью Recall. «Именно такой сценарий архитектура Microsoft должна была ограничить», — добавил исследователь. Функция Recall хранит гораздо больше, чем просто снимки экрана. На скриншотах можно обнаружить тексты, когда-либо просматриваемые пользователем на экране, сообщения в чатах, электронные письма, документы и др. Вероятно, Microsoft потребуется больше времени, чтобы доработать Recall перед масштабным внедрением. Apple давит на блогера из-за утечки iOS 26 — требует раскрыть источники
14.04.2026 [20:03],
Сергей Сурабекянц
В июле 2025 года Apple подала судебный иск, обвинив блогера Джона Проссера (Jon Prosser) в незаконном раскрытии информации о будущей операционной системе iOS 26, составляющей коммерческую тайну, и в нарушении «Закона о компьютерном мошенничестве и злоупотреблениях». Вчера Apple дополнительно обвинила Проссера в неисполнении требований о предоставлении информации. Проссер размещал информацию об iOS 26 с января 2025 года. В частности, им была представлена реконструкция обновлённого приложения «Камера» и несколько видеороликов с демонстрацией нового интерфейса, которому впоследствии присвоили название Liquid Glass. Некоторые материалы, в силу их предварительного характера, отличались от финальной версии, представленной Apple в июне. По версии Apple, эти сведения он получил с помощью взломанного iPhone, находившегося в разработке и принадлежавшего сотруднику компании Итану Липнику (Ethan Lipnik). Взлом, как утверждается, произвёл Майкл Рамаччотти (Michael Ramacciotti), ещё один ответчик по делу. Рамаччотти с помощью системы отслеживания местоположения выяснил, когда Липник будет отсутствовать в течение длительного времени, узнал пароль и взломал устройство, которому, вопреки политике Apple, Липник не обеспечил должной защиты. Затем Рамаччотти совершил видеозвонок Проссеру и продемонстрировал предварительную версию iOS, включая несколько функций и приложений. Документ, поданный Apple в Окружной суд Северного округа Калифорнии, охватывает события с момента последнего обновления информации сторонами в феврале 2026 года. Apple направила Проссеру повестки о предоставлении документов и даче показаний 3 февраля. Юристы компании утверждают, что он не в полной мере ответил на некоторые запросы и вообще не ответил на другие. Apple несколько раз продлевала срок и до сих пор не получила информацию, необходимую для понимания полного объёма утёкшей конфиденциальной информации и способа её получения. Компания будет ходатайствовать об очной явке ответчика в суд. В документе также сообщается, что Проссер нанял адвоката и намерен ходатайствовать об отмене заочного решения, вынесенного против него в октябре 2025 года, после того как он пропустил крайний срок ответа на иск Apple. Проссер заявил, что «активно общался с Apple с самого начала этого дела», — утверждение, которое Apple впоследствии опровергла в судебных документах. Позиция Рамаччотти в этом деле резко контрастирует с позицией Проссера. Он разрешил Apple провести криминалистическую экспертизу, согласился ответить на дополнительные вопросы и предложил дать показания после того, как Apple завершит сбор доказательств от третьих лиц. Apple и Рамаччотти неофициально обсуждают потенциальное урегулирование конфликта. Apple требует денежной компенсации и судебного запрета, препятствующего обеим сторонам в дальнейшем разглашении конфиденциальной информации. Очередное заседание суда по этому делу назначено на 10 июня 2026 года. ФБР научилось читать удалённые сообщения в Signal
11.04.2026 [12:08],
Дмитрий Федоров
Федеральное бюро расследований США (FBI) извлекло из iPhone одной из обвиняемых копии входящих сообщений Signal уже после удаления приложения. Apple сохраняла уведомления во внутренней памяти устройства каждый раз, когда они появлялись на экране блокировки. Суду показали сообщения, которые к тому моменту уже исчезли в самом Signal, причём восстановить удалось только входящую переписку. 
Источник изображения: Dimitri Karastelev / unsplash.com Источник, присутствовавший в зале суда, утверждает, что обвинение представило подробные сообщения, настроенные на автоматическое исчезновение и уже удалённые из самого Signal. Часть этих сообщений поступила с телефона одной из свидетельниц, сотрудничающих со следствием. Следствие получило эти данные не из приложения, а из системной памяти iPhone. Если настройки Signal разрешали выводить на экран блокировки уведомления с именем отправителя и фрагментом текста, iPhone сохранял эти сведения во внутренней памяти даже после удаления мессенджера. В обычном режиме Signal выводит уведомление о новом сообщении, имя отправителя и часть текста. В разделе Settings → Notifications пользователь может выбрать, что именно будет видно в уведомлении: Name, Content, and Actions, Name Only или No Name or Content. LinkedIn скрытно собирает данные о ПО, установленном на компьютерах пользователей соцсети
05.04.2026 [12:16],
Дмитрий Федоров
Немецкая ассоциация коммерческих пользователей LinkedIn Fairlinked e.V., инициировавшая кампанию «BrowserGate», заявила, что LinkedIn, принадлежащая Microsoft, скрытно проверяет в браузерах на базе Chromium установленные расширения, сверяет их с перечнем из более чем 6167 позиций, связывает результаты с реальными именами, работодателями и должностями пользователей и передаёт эти сведения на свои серверы и сторонним компаниям. 
Источник изображения: Greg Bulla / unsplash.com Проверка запускается при каждой загрузке страницы LinkedIn в браузерах Chrome, Edge, Brave, Opera и Arc после срабатывания встроенной функции isUserAgentChrome(). Код пытается обратиться к файлам, которые расширения могут делать доступными для сайтов: если файл открывается, система фиксирует, что расширение установлено; если нет — считает, что его нет. Вся процедура занимает миллисекунды и остаётся незаметной для пользователя. По имеющимся данным, Firefox и Safari этой проверкой пока не затронуты. Сбор данных, по утверждению исследователей, не ограничивается собственной инфраструктурой LinkedIn. Команда «BrowserGate» обнаружила невидимый элемент слежения, загружаемый с серверов HUMAN Security (ранее PerimeterX), американо-израильской компании в области кибербезопасности. Речь идёт о скрытом вне видимой области экрана элементе нулевой ширины, который без ведома пользователя устанавливает файлы cookie. 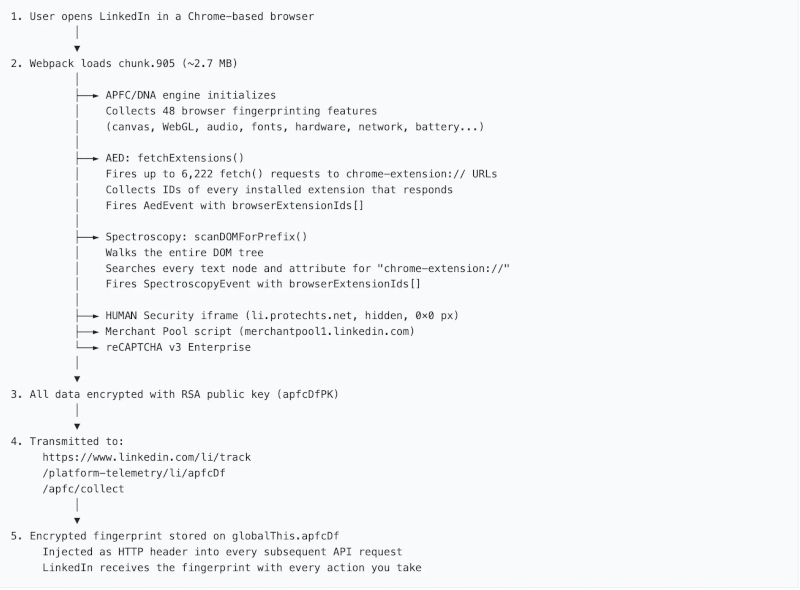
Источник изображения: cybersecuritynews.com Особую чувствительность этой практики авторы расследования объясняют спецификой самой LinkedIn: сервис объединяет более 1 млрд пользователей и работает с данными, привязанными к реальным именам, работодателям и должностям. Поэтому каждое выявленное расширение можно соотнести с конкретным человеком, а в совокупности — восстановить, какими программными средствами пользуются целые компании. Среди 6222 отслеживаемых расширений исследователи выделили 509 инструментов поиска работы, включая Indeed, Glassdoor и Monster, признаки религиозной принадлежности, политических взглядов, инвалидности и особенностей нейроразвития, а также более 200 продуктов прямых конкурентов, в том числе Apollo, Lusha, ZoomInfo и Hunter.io. Основной юридический риск исследователи видят в том, что Общий регламент по защите данных (GDPR) Евросоюза относит сведения о религиозных убеждениях, политических взглядах и состоянии здоровья к данным особых категорий. Их обработка допускается только при наличии явно выраженного согласия, которого, по утверждению Fairlinked e.V., LinkedIn не получала. Cама практика сбора также не была раскрыта пользователям. Fairlinked e.V. отдельно утверждает, что LinkedIn использовала скрытую проверку, чтобы выявлять пользователей сторонних инструментов, и уже направляла им юридические претензии. Помимо GDPR, в числе возможных оснований для разбирательств названы Директива о конфиденциальности и электронных коммуникациях (ePrivacy Directive) и Закон о цифровых рынках (DMA). 
Источник изображения: Souvik Banerjee / unsplash.com По данным расследования, масштаб проверки пользователей LinkedIn резко вырос. Перечень отслеживаемых расширений увеличился примерно с 461 в 2024 году до более чем 6000 к февралю 2026 года, то есть на 1 252 %. LinkedIn со своей стороны утверждала, что за кампанией «BrowserGate» стоит человек, чью учётную запись заблокировали за нарушение условий использования сервиса. Независимые исследователи, на которых ссылается материал, относят начало этой практики как минимум к 2017 году, когда LinkedIn проверяла 38 расширений. Совокупную аудиторию расширений, попавших под такую проверку, авторы расследования оценивают в 405 млн человек. Регуляторы в ЕС уже уведомлены, ожидаются юридические разбирательства, а пользователи LinkedIn в браузерах на базе Chromium, по версии расследования, по-прежнему ежедневно попадают под эту скрытую проверку. Пользователи, которых это беспокоит, могут предпринять несколько шагов. Для доступа к LinkedIn авторы материала рекомендуют перейти на браузеры Firefox или Safari: этот способ выявления расширений опирается на архитектуру расширений Chrome, тогда как Firefox не позволяет применять такой метод. Ещё один вариант — создать в Chrome отдельный профиль только для LinkedIn и не устанавливать в него никаких расширений, разорвав тем самым цепочку слежения. Также можно использовать браузер Brave с включённой защитой от цифрового отпечатка, которая блокирует сам механизм обнаружения. Наконец, авторы советуют проверить установленные расширения через общедоступную поисковую базу BrowserGate, чтобы выяснить, отслеживаются ли они. Meta✴ обучает ИИ на видео с очков Ray-Ban, в том числе на интимных — но сначала их смотрят люди в Кении
04.03.2026 [17:42],
Павел Котов
Умные очки Ray-Ban Meta✴✴ с искусственным интеллектом оказались кошмаром с точки зрения конфиденциальности: видеозаписи с обнажёнными людьми, сценами секса и другим деликатным содержанием сохраняются не только на устройстве, но и в облаке Meta✴✴, после чего изучаются как алгоритмами, так и живыми людьми для обучения ИИ. 
Источник изображения: ray-ban.com К таким выводам пришли журналисты шведской газеты Svenska Dagbladet, изучившие партнёрский проект Meta✴✴ и Ray-Ban. Как выяснилось, созданные устройством видеозаписи собираются и просматриваются большим количеством людей, в том числе подрядчиками, готовящими данные для обучения ИИ. Анонимные источники из кенийской компании признались, что просматривали видеозаписи людей в интимные и уязвимые моменты — когда пользователи умных очков Meta✴✴ предпочли бы, чтобы за ними не наблюдали. Кенийская компания Sama выступает субподрядчиком Meta✴✴ — её сотрудники распознают объекты на фото и видео, и эти данные используются для обучения ИИ. Тысячи людей выделяют объекты в кадрах, подписывают их и передают данные в систему Meta✴✴. Один из сотрудников признался, что видел, как люди ходили в туалет или раздевались, и он не знает, осознавали ли они, что их снимают. В одном из случаев мужчина снял очки, поставил их на прикроватную тумбочку и вышел из комнаты, после чего туда вошла женщина и переоделась. Некоторые кадры снимались намеренно, а в других случаях пользователи или люди в кадре не осознавали, что велась съёмка. Люди часто участвуют в подготовке данных для обучения ИИ — крупные компании нанимают большое число сотрудников в странах с невысокой оплатой труда. Однако Meta✴✴ и другие игроки технологической отрасли заверяют, что их системы обеспечивают конфиденциальность. По крайней мере, сотрудники, работающие с видеоматериалами, должны подписывать соглашение о неразглашении, чтобы получить допуск к этой работе. Правда, сцены, которые видят эти сотрудники, иногда не подходят для обучения ИИ. Существуют системы анонимизации, которые скрывают лица людей в кадре, но эти системы не всегда надёжны — иногда из-за сложных условий освещения лица оказываются различимыми. Когда журналисты задали Meta✴✴ вопросы по поводу сложившейся ситуации, ответа пришлось ждать два месяца — в итоге представитель компании объяснил, как данные с очков передаются в мобильное приложение, и сослался на политику конфиденциальности Meta✴✴ для систем ИИ. Copilot роется в конфиденциальных письмах пользователей в обход защиты — Microsoft назвала это багом
18.02.2026 [19:58],
Владимир Фетисов
Компания Microsoft сообщила, что из-за ошибки в Microsoft 365 Copilot ИИ-помощник с конца января обобщает конфиденциальные электронные письма пользователей, обходя политики предотвращения потери данных (DLP), на которые полагаются организации для защиты чувствительной информации. Сообщение об этом появилось в одном из служебных оповещений софтверного гиганта. 
Источник изображения: bleepingcomputer.com По данным источника, речь идёт о баге CW1226326, который впервые был обнаружен 21 января. Он затрагивает функцию чата «рабочей вкладки» Copilot, из-за чего происходит некорректное считывание и обобщение писем, хранящихся в папках «Отправленные» и «Черновики», включая сообщения с метками конфиденциальности, которые специально предназначены для ограничения доступа автоматизированных инструментов. «Сообщения электронной почты пользователей с пометкой «конфиденциально» некорректно обрабатываются Microsoft 365 Copilot Chat», — говорится в сообщении Microsoft. Там также отмечается, что этот инструмент обобщает электронные письма, даже если к ним применена метка конфиденциальности или настроена политика DLP. Позднее Microsoft подтвердила, что причиной такого поведения алгоритма стала ошибка в коде, добавив о запуске работ по внедрению патча в начале февраля. По состоянию на середину текущей недели Microsoft заявила, что продолжает следить за развёртыванием исправления и контактирует с затронутыми проблемой пользователями для оценки качества патча. Microsoft не предоставила окончательных сроков полного устранения проблемы и не раскрыла, сколько пользователей или организаций она затронула. В компании лишь отметили, что по мере расследования инцидента масштабы проблемы могут измениться. Подглядеть не получится: Samsung сделает уведомления на экране смартфона невидимыми для посторонних
28.01.2026 [18:52],
Сергей Сурабекянц
Сегодня Samsung представила функцию конфиденциальности, которая не позволит посторонним подглядеть информацию на смартфоне пользователя. Компания не предоставила подробностей о технологии, но заверила, что владельцы будущих смартфонов Galaxy смогут контролировать, что видят окружающие на их устройстве. Кроме того, можно будет скрыть от любопытных взглядов лишь часть экрана, например, область уведомлений. 
Источник изображения: @UniverseIce По словам Samsung, пользователи смогут настраивать эту функцию видимости содержимого на экране для работы с определёнными приложениями или при вводе паролей, PIN-кодов или графических ключей. При необходимости владелец сможет скрывать от посторонних лишь часть экрана, например, область всплывающих уведомлений. Для достижения этих результатов Samsung использует сочетание аппаратного и программного обеспечения. «Наши телефоны — это наше самое личное пространство, но мы используем их в наименее приватных местах… Именно поэтому Samsung скоро представит новый уровень защиты конфиденциальности, который защитит ваш телефон от подглядывания, где бы вы ни находились. У вас будет возможность проверять сообщения или вводить пароль в общественном транспорте, не задумываясь о том, кто может за вами наблюдать», — отметила компания в пресс-релизе. Интернет-инсайдер Ice Universe опубликовал в соцсети X скриншоты этой функции, показывающие, как область уведомлений скрывается при взгляде на дисплей под углом. Если функция будет работать как показано на этих фотографиях, людям, возможно, больше не понадобится искать укромные места для просмотра и ввода чувствительной информации, или покупать отдельные защитные экраны для обеспечения конфиденциальности. Использование смартфонов в общественных местах может быть рискованным. Когда пользователи вводят личную информацию, такую как пароли, любой посторонний может увидеть эти данные и использовать их в своих интересах. Чтобы предотвратить это, Apple выпустила обновление «Защита от кражи устройств» в iOS 17.3, которое требовало от пользователей использования FaceID или Touch ID перед изменением конфиденциальных настроек или доступом к сохранённым способам оплаты. Анонсированная Samsung функция, вероятно, будет запущена вместе с грядущим флагманским смартфоном Galaxy S26 Ultra. Мероприятие, посвящённое запуску устройства, ожидается в феврале. На Meta✴ снова подали в суд — компанию обвинили в нарушении конфиденциальности в WhatsApp
25.01.2026 [12:33],
Владимир Фетисов
Международная группа истцов подала иск в окружной суд Сан-Франциско в США, обвинив Meta✴✴ Platforms в ложных заявлениях по поводу конфиденциальности и безопасности чатов в принадлежащем компании мессенджере WhatsApp. Истцы уверены, что разработчик хранит и анализирует все якобы «частные» сообщения пользователей платформы. 
Источник изображения: Wesley Tingey/unsplash.com Meta✴✴ сделала функцию сквозного шифрования главной особенностью своего мессенджера WhatsApp. Эта функция работает таким образом, что передаваемые в чате сообщения доступны только отправителю и получателю, но не владельцу мессенджера. Компания не раз заявляла, что функция сквозного шифрования активирована по умолчанию, благодаря чему «сообщения могут читать, слушать и пересылать только участники чата». В новом иске против Meta✴✴ сказано, что заявления компании о конфиденциальности не соответствуют действительности. Авторы иска заявили, что Meta✴✴ и WhatsApp «хранят, анализируют и имеют доступ ко всем якобы «частным» сообщениям пользователей WhatsApp». На этом основании обе компании и их руководство обвиняются в мошенничестве в отношении миллиардов пользователей мессенджера по всему миру. Представитель Meta✴✴, которая купила WhatsApp в 2014 году, назвал иск «необоснованным» и заявил, что компания намерена «добиться санкций против адвокатов истцов». «Любое утверждение о том, что сообщения людей в WhatsApp не зашифрованы, категорически не соответствует действительности и абсурдно», — говорится в электронном письме представителя Meta✴✴ Энди Стоуна (Andy Stone). Он также добавил, что сервис использует сквозное шифрование уже десять лет, а новый иск, по его мнению, является «необоснованным вымыслом». В число соистцов в рамках этого разбирательство вошли пользователи WhatsApp из Австралии, Бразилии, Индии, Мексики и ЮАР. Они утверждают, что Meta✴✴ хранит содержание сообщений пользователей и что сотрудники компании могут получить к ним доступ. В иске упоминаются некие лица, которые помогли обнародовать эту информацию, хотя о ком именно идёт речь, там не сказано. На данном этапе адвокаты истцов просят суд утвердить коллективный иск. «Слежка» в рамках закона: Apple отбилась от иска за сбор аналитики без согласия владельцев iPhone
21.01.2026 [18:31],
Владимир Фетисов
Суд Калифорнии встал на сторону Apple в рамках рассмотрения коллективного судебного иска, авторы которого обвиняли производителя iPhone в нарушении конфиденциальности некоторых пользователей. Данное дело стало продолжением открытия, которое несколько лет назад сделал исследователь в области информационной безопасности, изучивший практики Apple по сбору данных пользователей iPhone. 
Источник изображения: Tingey Injury / unsplash.com Это открытие было сделано более трёх лет назад. При настройке нового iPhone пользователя спрашивают, согласен ли он на сбор аналитических данных компанией Apple. Исследователь Томми Миск (Tommy Mysk) выяснил, что Apple собирала одни и те же данные приложений независимо от того, дал пользователь на это своё согласие или нет. Было установлено, что App Store в режиме реального времени отправляет в Apple данные о поисковых запросах в магазине цифрового контента, просмотренных рекламных объявлениях, о том, как пользователи находят нужные им приложения и даже о том, сколько времени проводят на страницах просматриваемых приложений. Затем Миск выяснил, что аналогичным образом ситуация обстоит в других приложениях компании, включая Apple Music, Apple TV и др. К примеру, приложение «Акции» передавало Apple информацию об интересующих пользователей ценных бумагах, данные об акциях, которые пользователи искали и просматривали, а также сведения о прочитанных в приложении тематических публикациях. Миск заявил, что даже при наличии согласия пользователя «степень детализации» собираемой информации шокирует. Однако ещё боле тревожным было то, что сбор данных осуществлялся даже без согласия пользователей. В конечном счёте против Apple в Калифорнии и ряде других штатов был подан коллективный иск, авторы которого обвинили компанию во вторжении в частную жизнь. Apple отрицала обвинения в том, что практика компании по сбору данных нарушает законодательство. На этом основании производитель iPhone потребовал от суда отклонить эту часть иска. Теперь же стало известно, что данное ходатайство было удовлетворено на этой неделе. Судья отказал в удовлетворении иска, поскольку не было доказано, что аналитические данные подпадают под определение «конфиденциальной информации», и что их сбор представляет собой «передачу сообщений», которая запрещена в рамках действующих в штате законодательных актов. Вместе с этим судья предоставил истцам последнюю возможность переформулировать свою жалобу, отметив при этом, что добиться успеха в этом деле им вряд ли удастся. «Вызывает сомнения способность истцов достаточно чётко обосновать отклонённые претензии с учётом недостатков, указанных в данном решении», — сказано в судебном постановлении. Представлен Hiroh Phone — обезгугленный Android-смартфон с физическим выключателем камер и микрофона за $999
16.10.2025 [12:47],
Павел Котов
Для тех, кто ценит конфиденциальность, появился смартфон Hiroh Phone. Он работает под управлением e/OS — спецверсии Android без следящих за пользователями сервисов Google — и может похвастаться кнопкой экстренного отключения камеры, микрофона и беспроводной связи. Розничная цена устройства составит $999, но предварительный заказ можно оформить за $99. 
Источник изображений: Hiroh.io Техасский производитель Hiroh позиционирует себя как прямого конкурента Apple и Samsung и даже приводит на сайте таблицу сравнения своего смартфона с флагманским Galaxy S25 Plus. В отличие от «полноценной» Android здесь программной платформой выступает e/OS — та же, на которой работает Fairphone 6. Из неё удалены все сервисы и трекеры Google, вместо которых установлены альтернативы с открытым исходным кодом. Это значит, что смартфон не будет постоянно подключён к серверам поискового гиганта, и тот не станет создавать профиль пользователя на основе его привычек. Сохраняется привычный интерфейс Android, работают те же приложения, есть те же настройки и функции, но без привычного сбора данных.  Важным преимуществом является кнопка экстренного отключения камеры, микрофона и беспроводной связи: она гарантирует, что никакие приложения, системные процессы или вредоносные программы не смогут их включить без ведома пользователя. Hiroh Phone работает на чипе MediaTek Dimensity 8300, располагает 16 Гбайт оперативной памяти и встроенным накопителем на 512 Гбайт, который можно дополнить картой памяти объёмом до 2 Тбайт. AMOLED-дисплей имеет диагональ 6,7 дюйма и частоту обновления 120 Гц; в наличии три камеры (108 Мп, 13 Мп и 2 Мп) на задней панели и 32-мегапиксельная фронтальная. Ёмкость аккумулятора составляет 5000 мА·ч, имеется сканер отпечатков пальцев. Производитель подчёркивает, что Hiroh Phone не собирает никаких данных, что выгодно отличает смартфон от продукции Apple и Samsung. Аудитория браузера Brave выросла вчетверо и достигла 100 миллионов человек
05.10.2025 [05:37],
Анжелла Марина
Браузер Brave продолжает наращивать аудиторию и уже достиг отметки в 100 миллионов активных пользователей в месяц по состоянию на сентябрь 2025 года, тогда как ещё в 2021 году его ежемесячная аудитория составляла 50 миллионов человек, приводит данные статистики PCWorld. 
Источник изображения: Brave Brave ориентирован на конфиденциальность и уверенно набирает популярность. Генеральный директор компании Брендан Айх (Brendan Eich) заявил, что пользователи по всему миру отдают предпочтение конфиденциальности и контролю над своими действиями в интернете, отвергая слежку и злоупотребления со стороны крупных технологических компаний. Он подчеркнул, что все продукты Brave, включая поисковую систему, премиум-сервисы и рекламную платформу, были «созданы с учётом защиты приватности каждого». Параллельно с ростом функций и удобства использования браузера развивается и поиск Brave, предлагая новые возможности — теперь он может давать развёрнутые ответы на базе искусственного интеллекта, как ранее сообщал 3DNews. Поисковик, предлагающий альтернативу Google с акцентом на приватность, теперь обрабатывает более 20 миллиардов запросов в год. Это почти в 8,7 раза больше, чем 2,3 миллиарда обработанных запросов в 2021 году. Успех Brave связывают с его встроенными функциями безопасности, которые ставят во главу угла интересы пользователя. Среди них — блокировка рекламы и трекеров, запрет на использование JavaScript и файлов cookie, блокировка функции Windows Recall, а также возможность приватного просмотра через сеть Tor. В МВД РФ рассказали, где безопаснее всего хранить фото документов и пароли
03.10.2025 [08:07],
Владимир Фетисов
МВД РФ считает ненадёжным хранение фото документов и паролей в памяти телефона, поскольку это повышает риск кражи конфиденциальных данных. Оптимальным решением для этого считаются облачные хранилища с двухфакторной аутентификацией и шифрованием. Об этом пишет «Коммерсантъ» со ссылкой на собственные источники. 
Источник изображения: Glenn Carstens-Peters / Unsplash В ведомстве отметили, что сканы паспорта, СНИЛС, ИНН, водительских прав или банковских карт дают злоумышленникам возможность получения доступа к аккаунтам жертвы утечки данных. Кроме того, они могут быть задействованы для создания фейковых профилей и осуществления мошеннической деятельности. В МВД также указали на опасность записи паролей и кодов доступа в заметках или мессенджерах. Такие данные в случае попадания в руки злоумышленников позволят им взять под контроль цифровую жизнь жертвы, включая её банковские счета. Для хранения такой информации специалисты рекомендуют задействовать менеджеры паролей или же перенести их в офлайн, например, в записную книжку. Ещё в МВД напомнили о необходимости регулярной очистки истории сообщений из банковских приложений, поскольку уведомления о переводах и остатках средств на счетах раскрывают финансовые привычки и уровень дохода. Такая информация может облегчить работу мошенников. Личные переписки также нередко содержат номера карт, PIN-коды и ответы на секретные вопросы, т.е. данные, которые часто становятся целью злоумышленников. Присяжные в суде Сан-Франциско обязали Google выплатить более $425 млн за нарушение конфиденциальности
04.09.2025 [10:55],
Владимир Мироненко
В минувшую среду жюри присяжных вынесло по итогам слушаний в суде Сан-Франциско (США) вердикт, согласно которому компания Google должна будет выплатить $425,7 млн в качестве компенсации по коллективному иску о нарушении права пользователей на неприкосновенность частной жизни, пишет ресурс Bloomberg. 
Источник изображения: Solen Feyissa/unsplash.com Коллегия присяжных в составе восьми человек установила, что Google обманывала пользователей, продолжая сохранять и копировать их данные с помощью сторонних приложений, нарушая закон штата Калифорния о конфиденциальности, даже если пользователи отключали в настройках устройств параметр «История веб-поиска и приложений» (Web & App Activity). Истцы подчеркнули, что с 2016 года Google всё ещё могла получать данные о пользователях из таких сервисов, как Uber Technologies, PayPal Holdings, Venmo и Meta✴✴ Platforms, а также Instagram✴✴, использующих внутренние сервисы аналитики данных Google. Google продолжала собирать данные, несмотря на обещание пользователям контролировать их данные, утверждается в иске, поданном в июле 2020 года. «Обещания и заверения Google в отношении конфиденциальности — откровенная ложь», — заявили адвокаты истцов в иске. Всего было подано три коллективных иска к Google. В ходе судебного разбирательства Google утверждала, что чётко предупреждала пользователей о том, что отключение функции «История веб-поиска и приложений» означает, что их данные будут анонимизированы, но всё равно будут отслеживаться для предоставления сводной статистики сторонним приложениям. В заключительном заявлении адвокат Google Бенедикт Хур (Benedict Hur) из Cooley LLP сообщил, что как только пользователь отключает функцию отслеживания, ему открывается экран с вопросом «Вы уверены?», на котором говорится, что пользователи могут «узнать о данных, которые Google продолжает собирать, и почему», перейдя по дополнительной ссылке. «Не было никакого нарушения, утечки, неправомерного использования данных, обмена данными или продажи данных», — заявил адвокат. Присяжные признали Google ответственной по двум из трёх исков о нарушении конфиденциальности, поданных истцами. Они пришли к выводу, что Google действовала без злого умысла, а значит, дополнительные штрафные санкции начисляться не будут. Окружной судья Ричард Сиборг (Richard Seeborg) вынес приговор по коллективному иску от имени 98 млн пользователей Google, пострадавших от действий компании. При равном распределении между участниками группы пострадавших сумма компенсации составит около $4 на каждого участника. Изначально истцы требовали выплатить $31 млрд компенсации. Google объявила о намерении подать апелляцию на решение суда. «Это решение неверно истолковывает принципы работы наших продуктов, — заявил представитель компании Хосе Кастанеда (Jose Castaneda). — Наши инструменты обеспечения конфиденциальности дают людям контроль над своими данными, и когда они отключают персонализацию, мы уважаем этот выбор». Anthropic начнёт обучать ИИ на диалогах пользователей, но её можно попросить так не делать
29.08.2025 [11:04],
Павел Котов
Anthropic внесла важные изменения в политику обработки данных пользователей и предложила им до 28 сентября принять решение, хотят ли они использовать свою переписку с чат-ботом для обучения моделей искусственного интеллекта. 
Источник изображений: Anthropic Ранее Anthropic не использовала журналы чатов для обучения моделей — пользователей заверяли, что их запросы и ответы чат-ботов автоматически удаляются из систем в течение 30 дней «за исключением случаев, когда требования закона или политики [компании] предусматривают более продолжительный срок». Если запросы получали отметку как нарушающие правила обслуживания, то они хранились до двух лет. Теперь же она решила добавить в массивы обучающих данных обычную переписку и сессии с написанием программного кода — если пользователь даст согласие, эти данные будут храниться пять лет. Речь идёт только о потребительском сегменте сервиса, то есть о частных пользователях Claude Free, Pro и Max, в том числе тех, кто работает с Claude Code. У пользователей корпоративного сектора, в том числе сервисов Claude Gov, Claude for Work, Claude for Education, а также работающих через API компания собирать данные переписок для обучения ИИ не намерена. В стремлении убедить пользователей согласиться на новую политику обработки данных Anthropic отмечает, что так они «помогут нам повысить безопасность модели, сделав наши системы обнаружения вредоносного контента более точными и снизив вероятность реагирования на безобидные разговоры». Согласившись передавать журналы переписки на обучение ИИ, пользователи «также помогут нашим будущим моделям Claude улучшить такие навыки как программирование, анализ и рассуждения, что в конечном счёте приведёт к созданию более качественных моделей для всех». И действительно, отмечает TechCrunch, для обучения передовых моделей ИИ требуются колоссальные объёмы высококачественных разговорных данных, и доступ к миллионам чатов с Claude откроет ей источник материалов, способных улучшить позиции Anthropic как конкурента OpenAI и Google. 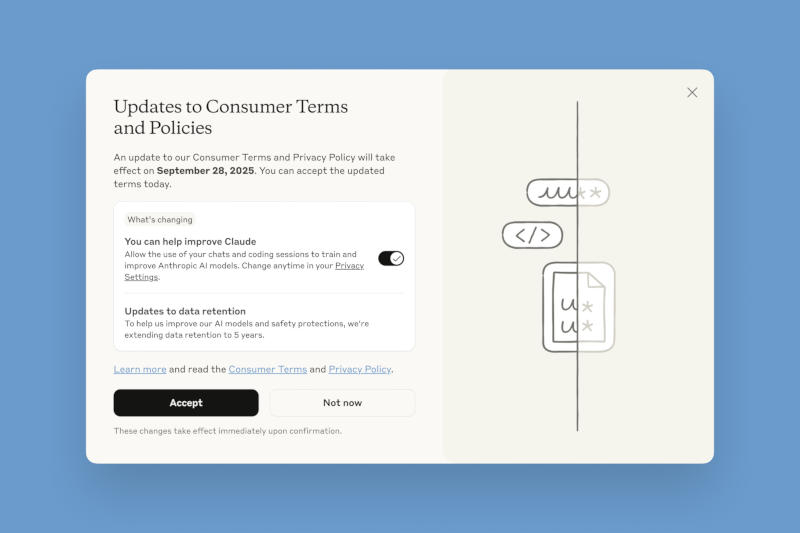 К нужному выбору компания подталкивает пользователей, делая нужные акценты в интерфейсе сервисов. Тем, кто только регистрируется, дают (или не дают) согласие при заполнении профиля; существующим же выводится всплывающее окно с заголовком «Обновления условий и политики для потребителей», включённым по умолчанию триггером согласия на передачу данных и большой чёрной кнопкой «Принять». Увидев такое окно, невнимательный или равнодушный пользователь может быстро нажать эту кнопку, не вдаваясь в подробности. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



