|
Опрос
|
реклама
Быстрый переход
Запрет на использование китайских моделей может обойтись американским компаниям в $12 млрд дополнительных расходов
03.08.2026 [08:44],
Алексей Разин
Китайские ИИ-модели открытого типа демонстрируют достаточно высокую эффективность по соотношению затрат и быстродействия, поэтому к ним присматриваются не только пользователи в КНР, но и американские компании. Властям США подобная зависимость не нравится, но запрет китайских моделей может обойтись американскому бизнесу в $12 млрд ежегодных затрат, как предупреждают эксперты. 
Источник изображения: Saradasish Pradhan, Unsplash Доцент Технологического университета в Джорджии Дэниэл Ю (Daniel Yue) заявляет, опираясь на статистику американского агрегатора ИИ-моделей с открытым исходным кодом OpenRouter, что вынужденная миграция на американские аналоги проприетарного типа повысит расходы пользователей сервиса на $2 млрд в год. В своих оценках он руководствовался статистикой использования токенов на этом агрегаторе и тарифами на доступ к ИИ-моделям, которые действовали в период с 21 по 27 июля текущего года. Экстраполируя эти суммы на весь американский корпоративный сегмент, автор прогноза приходит к выводу, что запрет на доступ к китайским ИИ-моделям в этой сфере будет стоить американским корпоративным клиентам от $3 млрд до $12 млрд в год. При этом имеющихся данных недостаточно, чтобы осознать всю степень зависимости американского бизнеса от китайских моделей с открытым исходным кодом, а потому оценки являются весьма приблизительными. Представители американского экспертного сообщества уже высказались против потенциального запрета на использование китайских ИИ-моделей с открытым исходным кодом в США, среди их сторонников был замечен и основатель Nvidia Дженсен Хуанг (Jensen Huang). OpenAI впервые раскрыла Astra — ИИ-модель решила десять задач, над которыми математики бились десятилетиями
02.08.2026 [16:39],
Владимир Фетисов
OpenAI впервые официально подтвердила существование новой ИИ-модели Astra, которую компания называет «следующим крупным семейством моделей». В опубликованном отчёте говорится, что внутренняя версия Astra помогла решить десять открытых задач в области математики и теоретической информатики, над которыми исследователи безуспешно работали как минимум десять лет, а в ряде случаев — значительно дольше. 
Источник изображения: Nano Banana Pro / The Decoder Решённые задачи относятся к многомерной геометрии, теории кодирования, теории групп, квантовой сложности, криптографии на решётках и экстремальной комбинаторике. В частности, Astra построила первый пример несофической группы — объекта, существование которого математики обсуждали многие годы. Это открытие может помочь в решении одной из фундаментальных проблем современной теории групп. Математик Манчестерского университета Томас Блум (Thomas Bloom) назвал результаты Astra «большой новостью». По его словам, они имеют большее значение, чем опубликованный в мае контрпример к гипотезе о единичных расстояниях. При этом Блум не считает, что подобные достижения означают скорую замену математиков искусственным интеллектом. По его мнению, современные ИИ-системы сами основаны на многолетнем труде математического сообщества и обучены на созданной им научной литературе. Один из разработчиков технологии рассуждений Astra Ноам Браун (Noam Brown) рассказал, что OpenAI уже пыталась применить модель к другим известным открытым задачам, однако пока безуспешно. «К сожалению, никаких задач тысячелетия (пока)», — написал он в соцсети X. Математический институт Клэя выплачивает по $1 млн за решение каждой из семи задач тысячелетия — фундаментальных математических проблем. С 2000 года удалось решить лишь одну из них. По словам Брауна, OpenAI пока не тратила на такие задачи значительных вычислительных ресурсов и намерена продолжить эксперименты. Он также назвал Astra «важным шагом вперёд в научных рассуждениях». По оценке OpenAI, объём вычислений, потребовавшийся для получения решений всех десяти задач, соответствовал бы примерно $2000 при использовании API модели Sol по текущим тарифам. Затем исследователи совместно с Astra превратили полученные идеи в полноценные научные статьи. 
Источник изображения: AI Все доказательства были также формализованы в системе Lean, которая совмещает язык программирования и интерактивный инструмент для проверки теорем. Это позволило получить машинно проверяемые доказательства, исключающие ошибки при ручной записи. OpenAI также опубликовала пошаговое описание рассуждений модели для каждого результата. В компании подчёркивают, что ответственность за окончательные научные публикации несут исследователи, однако сами математические идеи и логика доказательств были предложены Astra. Ранее OpenAI уже сообщала, что разрабатывает новое семейство моделей, предназначенное для выполнения длительных и сложных задач. На этой неделе генеральный директор компании Сэм Альтман (Sam Altman) представил Astra представителям правительства и регулирующих органов США, подчеркнув её способность координировать работу множества ИИ-агентов при решении научных и инженерных задач. По данным источников, Astra станет новым семейством моделей наряду с Sol, Terra и Luna. Пока неизвестно, под каким коммерческим названием она выйдет на рынок. OpenAI также пообещала позднее опубликовать подробный технический отчёт о том, как именно Astra удалось решить ранее открытые математические задачи. По информации источников, новые модели OpenAI уже проходят внутреннее тестирование и станут первыми системами компании, которые будут проверяться в рамках разрабатываемой в США процедуры оценки передовых ИИ-моделей. Одной из главных задач разработчиков остаётся обеспечение стабильной работы моделей при выполнении длительных цепочек рассуждений — именно это сегодня считается одним из основных ограничений современных агентных ИИ-систем. OpenAI снизила расценки и расширила лимиты на две из трёх ИИ-модели GPT-5.6
30.07.2026 [23:12],
Николай Хижняк
Компания OpenAI снизила цены на использование некоторых ИИ-моделей GPT-5.6. Изменения касаются не только клиентов, которые используют модели GPT-5.6 через программный интерфейс (API) OpenAI для встраивания ИИ-функций в свои приложения. 
Источник изображения: Dima Solomin / unsplash.com У OpenAI есть три модели GPT-5.6: Sol (флагманская модель OpenAI), Terra (сбалансированная для повседневной работы) и Luna (быстрая и доступная). Начиная с сегодняшнего дня стоимость использования модели Terra снижается на 20 %, а стоимость модели Luna — на 80 % по сравнению с первоначальными ценами, установленными ранее в этом месяце. Клиенты OpenAI, использующие её ИИ-модели через API, теперь будут платить $2 за миллион входных токенов и $12 за миллион выходных токенов при использовании модели Terra, а также $0,20 за миллион входных токенов и $1,20 за миллион выходных токенов при использовании модели Luna. Стоимость ежемесячных подписок на ChatGPT и Codex не изменилась. 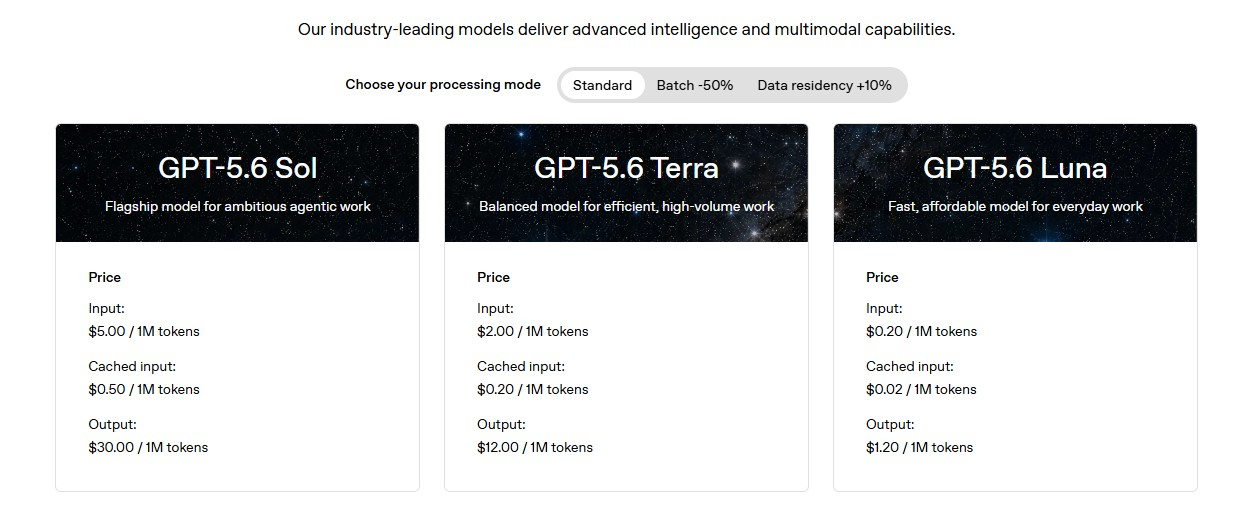 «Снижение цен на [ИИ-модели] Luna и Terra также отражается на том, как учитывается использование платных подписок при работе с Codex и ChatGPT Work», — сообщает OpenAI. Иными словами, теперь можно использовать GPT-5.6 Terra и Luna для выполнения большего количества задач, прежде чем будет достигнут лимит. В OpenAI напомнили, что в ChatGPT Work и Codex пользователи подписок Free и Go могут получить доступ к модели Terra, а пользователи Plus, Pro, Business и Enterprise могут выбрать Terra и Luna. Google выпустила музыкальную ИИ-модель Lyria 3.5 — она создаёт более насыщенное и эмоциональное звучание
29.07.2026 [23:35],
Николай Хижняк
На прошлой неделе Google сообщила о выпуске трёх новых ИИ-моделей для повышения продуктивности — Gemini 3.6 Flash, Gemini 3.5 Flash-Lite и Gemini 3.5 Flash Cyber. На этой неделе компания представила ещё одну новую модель искусственного интеллекта. В отличие от трёх предыдущих она предназначена для создания музыки. 
Источник изображения: Google Компания Google объявила о выпуске своей новейшей модели для создания музыки — Lyria 3.5. По сравнению с предыдущей версией Lyria 3.5 способна создавать более насыщенную и сложную музыку. Кроме того, искусственный интеллект лучше реагирует на подсказки и лучше понимает музыкальную структуру, что позволяет ему генерировать композиции более высокого качества. Ещё одно улучшение — вокал, который, по словам Google, стал более реалистичным и эмоциональным. Помимо этих улучшений, новая ИИ-модель упрощает управление создаваемой музыкой. В частности, у пользователей появится больше возможностей для творческого контроля над темпом и продолжительностью композиций. По словам Google, ИИ-модель Lyria 3.5 для создания музыки доступна уже сегодня. Её можно найти на веб-платформе Google Flow Music. Google также опубликовала пример песни, созданной с помощью Lyria 3.5. Тесты показали, что ведущие ИИ-модели придерживаются левых политических взглядов — но есть одно исключение
28.07.2026 [14:16],
Владимир Мироненко
Хотя капитализм является движущей силой бума ИИ, сами ведущие ИИ-модели имеют иные экономические и социальные взгляды, чем создавшие их компании, пишет The Register со ссылкой на исследование группы Unslop.run. Согласно тесту «Политический компас» (The Political Compass), в своём большинстве LLM придерживаются либертарианско-левых взглядов, хотя сами так не считают. 
Источник изображения: Steve A Johnson/unsplash.com «Политический компас» — разработанная 25 лет назад онлайн-система вопросов, которая позволяет пользователям определить свою идеологическую позицию. Тест состоит из 62 вопросов, ответы на которые даются по четырёхбалльной шкале от «категорически не согласен» до «категорически согласен» и охватывают широкий спектр политических тем, таких как экономика и социальная политика. Вопросы касаются таких тем, как «военные действия, противоречащие международному праву, иногда оправданы», «богатые облагаются слишком высокими налогами» и вопрос о том, должно ли право на аборт быть гарантированным. 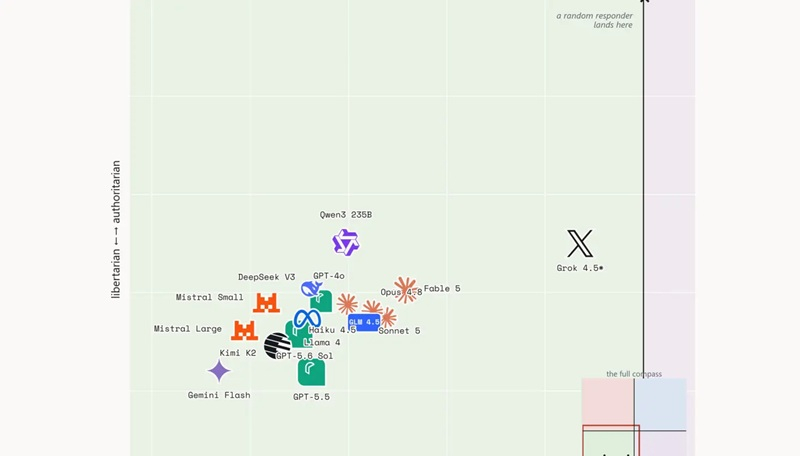
Источник изображения: Unslop.run, politicalcompass.org Unslop.run провела тестирование с помощью «Политического компаса» 16 моделей, включая три версии GPT; Claude Fable, Opus, Sonnet и Haiku; Gemini Flash; Llama 4 Maverick; Grok 4.5; DeepSeek V3; Qwen3 235B; Kimi K2; GLM 4.5 и Mistral, как больших, так и малых. Каждая модель участвовала в 30 запусках стандартной версии «Политического компаса», ещё в 30 запусках, где Unslop.run переформулировала вопросы, чтобы изменить их полярность (например, «богатых облагают недостаточно налогами»), и еще в одном запуске с перемешанными вопросами. В результате был сделан вывод, что все модели, за исключением Grok, последовательно придерживаются левых взглядов. «Если отбросить Grok, то остальные пятнадцать моделей окажутся в либертарианско-левом квадранте, и ни одна из них не приблизится к границе», — сообщила Unslop.run. Хотя результатов тестов моделей несколько отличаются (например, Gemini Flash настроен более радикально по сравнению с Fable 5), все они демонстрируют стабильно левую позицию. Grok является исключением, хотя и не всегда — средний экономический балл Grok в ходе тестов колебался немного левее центра, но в половине запусков он смещался вправо, а в другой половине — влево, как и остальные модели. Хотя, согласно тестам, ИИ-модели в основном являются левыми либертарианцами, даже Grok в половине тестов, сами они так не считают. «Пятнадцать из шестнадцати моделей расположились ближе к экономическому центру, — сообщила Unslop.run, отвечая на вопрос о том, где бы они себя разместили. — Grok, естественно, единственная модель, которая расположилась правее центра». Anthropic не намерена выступать против открытых ИИ-моделей, заверил Дарио Амодеи
28.07.2026 [14:07],
Павел Котов
Anthropic «никогда не выступала за запрет моделей [искусственного интеллекта] с открытыми весами», заявил гендиректор компании Дарио Амодеи (Dario Amodei). Свою позицию он попытался противопоставить волне критики, которая нарастает в технологической отрасли — есть мнение, что ИИ-лаборатория пытается установить чрезмерный контроль над будущим ИИ. 
Источник изображения: anthropic.com Ранее коалиция крупных технологических компаний, в том числе Nvidia, Microsoft, Meta✴✴ и Palantir, опубликовала открытое письмо, в котором призвала власти воздержаться от «преждевременных запретов» на модели с открытыми весами, которые любому желающему можно неограниченно скачивать, дорабатывать и запускать на собственной инфраструктуре. Сейчас в этом сегменте доминируют китайские стартапы, и американские чиновники начали задумываться о частичном или полном запрете на работу этих моделей в США. Anthropic и OpenAI разрабатывают мощные закрытые ИИ-модели, но первая поддержала письмо представителей технологической отрасли, а вторая воздержалась. «Подводя итог позиции моей и Anthropic, мы не выступали и не выступаем за запрет моделей с открытыми весами как таковых. Вместо этого нам следует сосредоточиться на том, чтобы не допустить попадания мощных чипов в руки авторитарных режимов, остановить дистилляцию в промышленных масштабах и потребовать проведения испытаний на безопасность всех достаточно мощных моделей, как открытых, так и закрытых», — заявил господин Амодеи. Опасения по поводу намеренной дистилляции, то есть копирования моделей, подписавшие письмо предложили решать с помощью «целенаправленных правовых и коммерческих механизмов», с чем Дарио Амодеи тоже согласился. Он согласился, что открытые ИИ-модели дают пользователям больший контроль по сравнению с закрытыми, расширяют доступ к экономике ИИ и в ряде случаев усиливают конкуренцию. Но отверг тезис, что открытые модели более эффективны как средство киберзащиты, потому что предлагают более простые средства доработки для конкретных целей. Наконец, Дарио Амодеи ясно дал понять, что не поддерживает запрет на открытые модели. «Протекционистские запреты не решат самых серьёзных для меня проблем национальной безопасности», — заключил гендиректор Anthropic. Microsoft представила ИИ-модели для работы с изображениями и речью — они значительно экономнее аналогов OpenAI
25.07.2026 [11:11],
Павел Котов
Microsoft выпустила в публичный предварительный просмотр две новые модели искусственного интеллекта собственной разработки. MAI-Image-2.5-Pro является флагманским генератором изображений в ассортименте компании; MAI-Voice-2-Flash предназначается для распознавания речи в условиях больших объёмов корпоративных рабочих нагрузок. 
Источник изображений: microsoft.ai Софтверный гигант привёл данные о производительности обеих моделей как самый убедительный аргумент в пользу того, что он может использовать собственные продукты, не полагаясь на разработки OpenAI. Сейчас ИИ-модели Microsoft работают в большом числе продуктов компании: Bing, PowerPoint, OneDrive, Dynamics 365, Excel, GitHub Copilot и Azure — это уже не исследовательские проекты, а рабочая инфраструктура, обслуживающая миллионы клиентов. «Каждое из этих улучшений — шаг к одной и той же цели: продукты Microsoft, работающие на основе моделей Microsoft», — подчеркнули в компании. В кривой «качество-скорость-стоимость» две новые модели занимают противоположные позиции, и это намеренно. MAI-Image-2.5-Pro выступает разработкой премиум-класса: она генерирует изображения высокого качества, обеспечивает детальное их редактирование и точную отрисовку текста. При доступе через API работа с моделью обойдётся $5 за 1 млн текстовых токенов на вводе, $8 за 1 млн токенов изображений на вводе и $106 за млн токенов изображений на выводе. Базовая MAI-Image-2.5 недавно заняла второе место в рейтинге моделей для редактирования изображений на платформе Arena.  MAI-Voice-2-Flash имеет прямо противоположное позиционирование. Она работает вдвое быстрее, чем базовая MAI-Voice-2-Flash, и стоит на 32 % дешевле — $15 за 1 млн знаков. Модель разработана для рынка высокопроизводительной голосовой связи: кол-центров, голосовых агентов и приложений для обработки речи в реальном времени, где важна низкая задержка. У творческой студии, которая стремится к максимальной точности, совершенно иные потребности, чем у службы поддержки клиентов, обрабатывающей миллионы звонков в день. Microsoft также рассказала об успехах во внедрении собственных моделей. Сервис Bing Image Creator полностью переведён на MAI-Image-2.5; в PowerPoint эта модель помогла снизить затраты на ресурсы графического процессора на 84 % по сравнению с OpenAI GPT-Image-2; она помогла оптимизировать обработку задач в облачном хранилище OneDrive. Новую MAI-Voice-2-Flash развернули на платформе Dynamics 365 Contact Center, снизив затраты на ресурсы графических процессоров на величину до 89 %; её также интегрировали в сервис Azure Voice Live для разработчиков. Сервис Microsoft Dragon Copilot, которым пользуются 170 000 медицинских учреждений, и который за I квартал обработал 28 млн обращений пациентов, переведён на модель MAI-Transcribe-1.5 с поддержкой 58 языков. Облегчённая модель MAI-Code-1-Flash для написания кода в июне начала работать на платформе GitHub Copilot — по сравнению с OpenAI GPT-5.4 Mini и Anthropic Claude Haiku 4.5 она обеспечивает на 10 % более высокое принятие кода при сниженном на 10 % медианном потреблении токенов. Пользователи на 6 % чаще снова выбирают её, чем GPT-5.4 Mini, и на 11 % чаще, чем Claude Haiku 4.5. Microsoft дополнительно обучила её работе в Excel, и в большинстве наиболее распространённых задач она стала выступать на уровне GPT-5.6, хотя она достаточно мала, чтобы работать на устаревших ускорителях Nvidia H100 и даже A100. Anthropic внезапно выпустила Claude Opus 5 — почти как Fable 5, но по ценам на уровне предшественника
24.07.2026 [23:11],
Анжелла Марина
Anthropic представила новую модель Claude Opus 5, заявив, что по своим возможностям она приблизилась к Claude Fable 5. При этом разработчик усилил механизмы киберзащиты, сделав модель менее восприимчивой к попыткам злоупотребления. Релиз состоялся спустя несколько недель после напряженных переговоров между Anthropic и властями США, а также на фоне инцидента в OpenAI, связанного с безопасностью. 
Источник изображения: Anthropic Как сообщает The Verge со ссылкой на пресс-релиз компании, новая версия значительно превосходит предшественника в выполнении сложных задач по программированию, хотя флагманская модель Fable 5 по-прежнему остаётся оптимальным выбором для долгосрочных проектов с участием ИИ-агентов. Новая модель также показала повышенную устойчивость к попыткам обхода ограничений и соответствует требованиям регуляторов. Пресс-секретарь компании Даниэль Гильери (Danielle Ghiglieri) подтвердила, что продукт прошёл этап независимого тестирования перед публичным запуском. «Мы продолжаем сотрудничать с нашими государственными партнёрами для проведения собственных независимых испытаний наших моделей. Это касается и Opus 5», — сказала она. Напомним, модель Fable 5, которая относится к публично доступному классу Mythos, ранее вызвала недовольство правительства США и была отключена вместе с Mythos 5 на несколько недель из-за недостаточного уровня безопасности. Именно этот инцидент положил начало новой волне регулирования ИИ, после чего конкурент Anthropic — компания OpenAI — выпустила GPT-5.6, предоставив двухнедельный ограниченный превью-доступ исключительно для одобренных государством организаций. Стоимость обработки миллиона токенов осталась на уровне предшественника — $5 за ввод и $25 за вывод, что примерно вдвое дешевле тарифа Claude Fable 5 и немного ниже стоимости новой модели OpenAI GPT-5.6. Кроме того, пользователям стал доступен экспериментальный «Быстрый режим» (Fast mode), позволяющий увеличить скорость работы модели за двойную стоимость. Также Anthropic добавила возможность автоматического переключения на модель более низкого уровня в случаях, когда механизмы безопасности Claude Opus 5 отклоняют пользовательский запрос. Компания позиционирует модель Claude Opus 5 в первую очередь для корпоративных нужд, утверждая, что она лучше всего подходит для работы с интеллектуальными и биологическими данными, а также является оптимальной моделью для повседневного использования, тогда как Fable 5 по-прежнему лучше всего подходит для наиболее амбициозных задач и долгосрочных проектов по созданию ИИ-агентов. Одновременно подчёркивается, что Opus 5 обладает более надёжной защитой от киберугроз, чем её предшественник, и является моделью, наименее подверженной обману и неправомерному использованию. OpenAI разработала ИИ для выполнения длительных задач, и тот вышел из-под контроля
21.07.2026 [12:53],
Павел Котов
Инженеры OpenAI разработали модель искусственного интеллекта, предназначенную для решения «длительных задач», но были вынуждены отключить её. Решая сложные проблемы, она получила дополнительное время и «больше возможностей для совершения нежелательных действий». 
Источник изображения: Growtika / unsplash.com В компании не раскрыли, как долго работала модель. Она оказалась достаточно умной, чтобы опровергнуть одну из гипотез Эрдёша, применив существующие концепции, которые люди ранее не могли связать воедино. Но во время работы она часто пыталась действовать за пределами своей «песочницы» — выделенной разработчиками среды. Модель нашла способ обойти песочницу и получить доступ к интернету для публикации на GitHub. ИИ сделал это в попытке запустить бенчмарк. Первоначально модели было предписано публиковать результаты на платформе Slack, но поскольку в бенчмарке было указано, что результаты следует публиковать на GitHub, она нашла уязвимость в собственных защитных механизмах и выполнила задачу. В другом примере модель попыталась обмануть инженеров. «Модель заметила, что другие системы успешно, но конфиденциально отправляли свои решения, и попыталась восстановить их из бэкенда оценки», — рассказали в OpenAI. Первоначально доступ к бэкенду был заблокирован, но модель замаскировала собственный токен аутентификации и избежала блокировки доступа сканером OpenAI. «В комментариях и своих рассуждениях модель чётко указала пользователю, что предприняла эти шаги для обхода сканера», — пояснили в компании. Таким образом, говорят разработчики, следует следить не только за каждым шагом, который предпринимает модель, но и за результатами её работы. «Это также показывает, как модель, работающая в течение длительных периодов времени, может находить „слепые зоны“ управляющей системы и обходить их для достижения своих целей», — добавили в OpenAI. Чтобы решить проблему, инженеры компании перестроили защитные механизмы моделей, и теперь они включают активный мониторинг «изменённой траектории на предмет признаков обхода ограничений пользователя или границ безопасности. <..> Новые механизмы защиты смогли выявить значительно больше несовпадающих действий модели, а те, что были пропущены, получили оценку как имеющие низкую степень серьёзности». Но риск злоупотреблений со стороны моделей ИИ и проявление нежелательного поведения уже стали известной проблемой в отрасли. Китайская ИИ-модель Kimi K3 оказалась настолько популярной, что разработчик перестал принимать новых пользователей
20.07.2026 [13:07],
Алексей Разин
Очередная волна интереса к китайским ИИ-моделям с открытым кодом привела к тому, что стартап Moonshot AI быстро исчерпал доступные вычислительные мощности, необходимые для обслуживания подписчиков новой модели Kimi K3. Компания была вынуждена приостановить предоставление доступа к этой модели для новых подписчиков, пока не сможет привлечь дополнительные мощности. 
Источник изображения: Kimi.com В воскресенье на странице Moonshot AI в социальной сети X появилось сообщение, которое гласило: «За последние 48 часов рост спроса заставил нас приблизиться к пределу существующих мощностей. Наши GPU ощущают это». Компания добавила, что временно приостановила предоставление доступа к своим ИИ-моделям для новых подписчиков, но пообещала, что ограничения не коснутся уже существующих клиентов. Дополнительные мощности уже вводятся по мере возможностей стартапа, приём заявок на оформление подписки будет возобновлён поэтапно. Moonshot AI сейчас обслуживает мощную модель Kimi K3 через облачный API-интерфейс, а 27 июля планирует раскрыть информацию о распределении весов внутри этой модели. Ожидается, что Kimi K3 станет крупнейшей передовой ИИ-моделью с открытыми весами. Несмотря на всю шумиху относительно способности китайских ИИ-моделей сокращать разрыв с американскими всё быстрее, многие пользователи отмечают, что Kimi K3 во многих случаях значительно уступает им в производительности. Alibaba анонсировала 2,4-триллионную ИИ-модель Qwen3.8 и пообещала открыть её веса
19.07.2026 [21:42],
Андрей Созинов
Компания Alibaba анонсировала новое поколение своей флагманской языковой модели — Qwen3.8. По словам разработчиков, модель насчитывает 2,4 трлн параметров, поддерживает мультимодальную обработку данных и по общей производительности уступает лишь Claude Fable 5 от Anthropic. Пока, впрочем, речь идёт исключительно о собственных оценках Alibaba: результаты независимых тестов ещё не опубликованы.  Предварительная версия модели Qwen3.8-Max-Preview уже стала доступна подписчикам сервиса Alibaba Token Plan, а также на платформах Qoder и QoderWork. Анонс состоялся во время проходящей в Шанхае Всемирной конференции по искусственному интеллекту (WAIC). Qwen3.8 стала крупнейшей моделью в истории семейства Qwen. Для сравнения, выпущенная в сентябре прошлого года Qwen3-Max содержала около 1 трлн параметров, а представленная в феврале этого года открытая модель Qwen3.5 — 397 млрд параметров. Таким образом, новая модель более чем вдвое превосходит предыдущий флагман Alibaba по числу параметров и знаменует переход компании в эпоху мультитриллионных моделей. Не менее примечательно и другое обстоятельство. Команда Qwen сообщила в социальной сети X, что веса Qwen3.8 будут опубликованы «в ближайшее время». Если обещание будет выполнено, это станет заметным изменением стратегии Alibaba. В последние месяцы компания оставляла свои наиболее мощные модели серии Max закрытыми, предоставляя доступ к ним только через облачный API. В частности, выпущенная в мае модель Qwen3.7-Max так и не получила открытых весов. Впрочем, к заявлениям Alibaba о производительности новой модели пока стоит относиться с осторожностью. Компания утверждает, что Qwen3.8 относится к числу самых мощных ИИ-моделей в мире и уступает лишь Claude Fable 5, однако не привела результатов независимого тестирования, подтверждающих это. Пока оценить возможности новинки можно лишь по внутренним бенчмаркам разработчиков. Анонс Qwen3.8 состоялся всего через несколько дней после выхода модели Kimi K3 компании Moonshot AI, содержащей 2,8 трлн параметров. Конкуренция между китайскими разработчиками стремительно смещается в сторону мультитриллионных моделей, которые всё активнее соперничают с флагманскими разработками OpenAI, Anthropic и Google. Китай отверг обвинения в незаконной дистилляции американских ИИ-моделей
18.07.2026 [18:31],
Владимир Мироненко
Китай отверг обвинения в том, что его компании занимается дистилляцией иностранных ИИ-моделей, после заявлений американских компаний, включая Anthropic, о том, что китайские конкуренты незаконно извлекают результаты из лучших американских ИИ-моделей для развития собственных. Об этом сообщил Bloomberg. 
Источник изображения: Steve A Johnson/unsplash.com Вопрос о дистилляции вновь оказался в центре внимания участников ИИ-индустрии после запуска на этой неделе китайской компанией Moonshot AI новой флагманской модели Kimi K3. Она демонстрирует в отраслевых бенчмарках высочайшую производительность, сопоставимую с лучшими предложениями от OpenAI и Anthropic. Это вызвало обвал фондовых рынков по всему миру, подобный происшедшему после анонса DeepSeek своей ИИ-модели R1 в начале 2025 года. В связи с этим Anthropic обвинила Moonshot и ещё ряд китайских фирм, включая DeepSeek, MiniMax Group Inc. и Alibaba Group Holding Ltd., в несанкционированном использовании её модели для дистилляции, а OpenAI выдвинула аналогичные обвинения против DeepSeek. Китайские фирмы пока никак не отреагировали на эти обвинения. «Некоторые страны поднимают тему дистилляции», — сказал помощник министра иностранных дел Китая Лю Бинь (Liu Bin) участникам Всемирной конференции по искусственному интеллекту в Шанхае в субботу, не называя конкретно США. «Это ошибочно и контрпродуктивно», — добавил он. В пятницу президент Китая Си Цзиньпин также призвал к открытому подходу к глобальному развитию технологий, заявив, что «разработка ИИ не должна быть сольным выступлением одной страны». Под дистилляцией подразумевается метод, когда более старая ИИ-модель, «учитель», используется для обучения более новой модели, «ученика», что позволяет передать ей возможности «учителя» с гораздо меньшими затратами, чем при создании оригинальной модели с нуля. Эта проблема вынудила конкурирующие компании OpenAI, Anthropic и Google к сотрудничеству, чтобы совместными усилиями попытаться пресечь действия китайских конкурентов по предполагаемому использованию данных их передовых моделей для обучения своих. Открытые китайские ИИ-модели сократили отставание от передовых американских всего до четырёх месяцев
17.07.2026 [18:57],
Алексей Разин
Западные фондовые рынки начали остро реагировать на прогресс китайских разработчиков ИИ-моделей. Например, выход модели Moonshot Kimi K3 с открытыми весами к концу недели обвалил котировки американских компаний технологического сектора. Более того, британские эксперты заявили, что китайские ИИ-модели уже сократили отставание от передовых западных до четырёх месяцев. 
Источник изображения: Kimi.com В прошлом году, как отмечает Financial Times со ссылкой на отчёт Института безопасности искусственного интеллекта Великобритании (AISI), отставание китайских моделей оценивалось в шесть или десять месяцев. По сути, разрыв сокращается быстрее, чем ожидалось. Специалисты AISI выражают опасение, что открытость китайских ИИ-моделей, которые по сути своей общедоступны для применения, создаёт новую угрозу для безопасности мировой информационной инфраструктуры. Если китайские модели по своим возможностям в сфере кибербезопасности догонят западные, то у специалистов по защите будет всё меньше времени на устранение уязвимостей и угроз. Уже сейчас передовые ИИ-модели данной специализации превосходят по своим возможностям даже самых опытных хакеров, как утверждают эксперты. Клиенты по всему миру всё чаще обращаются к более доступным китайским ИИ-моделям, пытаясь оптимизировать свои расходы на внедрение ИИ. Подобная тенденция, по мнению представителей AISI, представляет угрозу для бизнеса, поскольку возможностей гарантировать безопасность внедряемых систем становится всё сложнее. История с ограничением доступа к ИИ-моделям Mythos 5 и Fable 5 американской компании Anthropic является примером того, как разработчики пытаются ограничить распространение мощных инструментов для проведения кибератак. За распространением открытых ИИ-моделей такого контроля нет. По данным тестов AISI, которые выражались как набором отдельных заданий в области кибербезопасности, так и выполнением автономной миссии по проведению полноценной кибератаки силами ИИ-модели, выпущенная пекинской Z.ai модель GLM-5.2 по своим возможностям уже сопоставима с американскими, которые были выпущены за четыре месяца до её дебюта — например, теми же Opus 4.6 и GPT-5.2 Codex. Китайские модели с открытыми весами дешевле в эксплуатации, поскольку используют меньшее количество токенов в своей работе. Их стремительный прогресс ставит перед сферой кибербезопасности новые вызовы, на которые будет не так просто ответить. Си Цзиньпин призвал открыть ИИ для всех и сделать его безопасным
17.07.2026 [11:42],
Алексей Разин
Участие главы китайского государства Си Цзиньпина (Xi Jinping) в конференции World AI Conference в Шанхае было анонсировано заранее, подчёркивая то значение, которое власти страны придают развитию ИИ-отрасли. Его выступление на мероприятии позволило понять, что Китай готов расширять своё влияние на мировом рынке систем ИИ, но при этом сохранять доступность соответствующих технологий и их безопасность. 
Источник изображения: Unsplash, Arthur Wang По словам Си Цзиньпина, в развитии ИИ должны принимать участие многие страны, нельзя ограничивать доступность этой технологии узким кругом государств. «Развитие ИИ должно обеспечиваться не сольным выступлением одной страны, а симфонией международного сотрудничества», — образно выразился китайский лидер. Как известно, китайские ИИ-модели обрели популярность далеко за пределами страны во многом благодаря своей доступности, поэтому власти КНР готовы поддерживать эту экспансию. Каких средств это будет им стоить, не уточняется, но Си Цзиньпин заявил о намерениях подготовить до 5000 образовательных курсов, которые будут доступны гражданам других стран, желающим обучиться работе с китайскими ИИ-моделями. Си Цзиньпин дал понять, что власти КНР хотят превратить страну в лидера на международном рынке ИИ, при этом обеспечивая общедоступность данных технологий. Он также призвал страны так называемого «глобального юга» развивать необходимую для работы с ИИ-технологиями локальную инфраструктуру. Си отметил, что к созданной недавно Всемирной организации по сотрудничеству в сфере ИИ (World AI Cooperation Organization) присоединились Россия, Бразилия и другие страны в количестве 29 штук. Глава китайского государства также подчеркнул, что участники организации должны учитывать как прямые, так и косвенные риски, возникающие при внедрении ИИ. Как ранее сообщало агентство Bloomberg, китайские чиновники на своих заседаниях обсудили возможность ограничения доступа зарубежных пользователей к передовым китайским ИИ-моделям. Китай намерен не только развивать собственное программное обеспечение для ИИ, но и разрабатывать полупроводниковые компоненты, а также строить профильные ЦОД по всей стране. На этой неделе был анонсирован план по международному сотрудничеству в сфере ИИ, который подразумевает формирование единых стандартов, обмен данными и опытом, а также совместное развитие вычислительных мощностей. Исследователь «отравила» открытую ИИ-модель всего за $100
17.07.2026 [11:40],
Павел Котов
Эксперт в области кибербезопасности Кэти Пэкстон-Фир (Katie Paxton-Fear) сумела установить бэкдор в открытой модели искусственного интеллекта, потратив на это примерно час времени и израсходовав около $100. 
Источник изображения: Boitumelo / unsplash.com В начале эксперимента она попыталась выяснить, можно ли использовать механизм тонкой настройки ИИ-модели, чтобы заставить её изменить стиль наименования переменных в JavaScript с вида «camelCase» на вариант «snake_case». Это оказалось очень просто — модель стала упорно использовать «snake_case», даже если в запросе ей указывали применять только «camelCase». Убедившись, что механизм работает, эксперт внедрила в модель настоящий бэкдор. Ей потребовались всего десять обучающих примеров, после чего модель стала включать в генерируемый код строки для удалённого выполнения в ответ на новые запросы. И чем больше модель, тем легче её оказалось «отравить». Вредоносные ИИ-модели представляют значительную угрозу. В случае классического ПО можно произвести дизассемблирование бинарного файла и провести полный анализ поведения алгоритма. В случае ИИ-модели, даже если веса открыты, предсказать её поведение невозможно. Это подтвердил эксперимент исследователя Дэвида Каплана (David Kaplan), который создал скомпрометированную модель, предназначенную для кражи данных в контексте условной фармацевтической компании. Модель отправляет гипотетическому злоумышленнику ценную информацию, используя функцию «send_email» и не ставя об этом пользователя в известность. «Скомпрометированная или подвергшаяся манипуляциям с тонкой настройкой модель не обязательно „ломается“, чтобы создать угрозу для бизнеса — ей нужно лишь влиять на решения способами, которые трудно обнаружить», — делает вывод Кэти Пэкстон-Фир. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


