|
Опрос
|
реклама
Быстрый переход
Завтра мощнейшие ИИ-модели GPT-5.6 станут доступны для всех — власти США сняли запрет
08.07.2026 [14:08],
Павел Котов
Завтра, 9 июля 2026 года, OpenAI откроет общий доступ к своей последней модели искусственного интеллекта GPT-5.6. Компания была вынуждена задержать её выпуск, получив предписание от американских властей из-за вопросов, связанных с национальной безопасностью. Теперь же власти разрешили выпустить модель в открытый доступ. 
Источник изображения: x.com/OpenAI США и Китай соревнуются в разработке передовых моделей ИИ, которые, по мнению экспертов, могут ускорить и упростить кибератаки в секторах, зависящих от сложных, взаимосвязанных и часто устаревших технологических систем. Вашингтон усилил контроль над выпуском передовых моделей ИИ, чтобы не дать вероятным противникам возможности воспользоваться ими как оружием. Китайские власти также провели встречи с ведущими технологическими компаниями страны и обсудили вопрос ограничения доступа из-за рубежа к передовым китайским моделям, в том числе ещё не вышедшим. Администрация президента США Дональда Трампа (Donald Trump) одобрила выпуск GPT-5.6 в широкий доступ — этому предшествовали дополнительное тестирование и встречи представителей компании и правительства. OpenAI выпустит самую мощную модель GPT-5.6 Sol, а также более дешёвые версии Terra и Luna, сообщила компания в соцсети X. Непродолжительное время спустя глава SpaceX и его подразделения SpaceXAI Илон Маск (Elon Musk) заявил, что компания выпустит в широкий доступ свою передовую модель Grok 4.5. Ранее Вашингтон снял экспортный контроль с передовой модели Anthropic Fable, тогда как разработанная для специалистов по кибербезопасности Mythos по-прежнему доступна только «доверенным» американским организациям. При этом Anthropic признала невозможность сделать любую модель ИИ полностью защищённой от взломов. Meta✴ представила Muse Image — свою первую серьёзную модель для генерации изображений, которая будет доступна Meta✴ AI и соцсетях
08.07.2026 [09:41],
Павел Котов
Meta✴✴ выпустила первую генерирующую изображения модель искусственного интеллекта, разработанную сформированным в прошлом году подразделением Superintelligence Labs. Muse Image интегрирована в графические редакторы приложений Meta✴✴ AI, Instagram✴✴ и WhatsApp; скоро она появится в Facebook✴✴ и Facebook✴✴ Messenger. 
Источник изображения: Meta✴✴ Модель стала новым членом семейства Muse, пришедшего на смену Llama. Muse Image располагает агентными функциями — она подключается к большой языковой модели Muse Spark, «чтобы проанализировать ваш запрос, выполнить поиск в интернете и спланировать работу до генерации», пояснил глава Superintelligence Labs Александр Ван (Alexandr Wang). Он также пообещал, что скоро компания выпустит модель Muse Video — она «конкурентоспособна по соответствию запросам, визуальной точности и временно́й согласованности». В запросах к Muse Image можно упоминать аккаунты других пользователей Instagram✴✴, чтобы включать фото с их страниц в свои работы. Такого рода редактирование и генерация смогут работать только с общедоступными материалами; при этом пользователи смогут контролировать, как другие используют их контент при работе с ИИ. По запросам доступно редактирование изображений, а также создание дизайна приглашений и открыток. Ещё одна функция — создание нового дизайна для объектов недвижимости на платформе Facebook✴✴ Marketplace. Muse Image будет использоваться для 30 новых ИИ-эффектов при публикации в разделе Instagram✴✴ Stories для пользователей в США — впоследствии функция будет доступна и в других странах, а также в других разделах приложений Meta✴✴. Китай собирается строить ИИ-занавес: власти рассматривают запрет зарубежного доступа к местным ИИ-моделям
08.07.2026 [04:48],
Алексей Разин
История с временным ограничением доступа к передовым моделям Anthropic в США для иностранных граждан, по всей видимости, вдохновила китайских чиновников на зеркальные меры. По информации Reuters, власти КНР провели встречу с ведущими китайскими разработчиками ИИ-моделей, чтобы обсудить эти меры. 
Источник изображения: Unsplash, John Cameron Как отмечает источник, данные консультации проходили на протяжении прошлого месяца и охватывали представителей Alibaba, ByteDance и Z.ai. Вырабатывая правовую экосистему в сфере использования ИИ, власти Поднебесной планируют лучше защищать интеллектуальную собственной в этой сфере, относя утечки к разряду угроз национальной безопасности. При этом следует понимать, что ИИ-модели той же DeepSeek успели получить широкое распространение во всём мире, поскольку они являются более эффективной и доступной альтернативной западным разработкам. Если китайские власти решат ограничить доступ к национальным ИИ-моделям для иностранных пользователей, для последних это обернётся серьёзными проблемами. По замыслу китайских чиновников, ограничения на экспорт ИИ должны коснуться как проприетарных моделей, так и обладающих открытым исходным кодом. Кроме того, планируется ограничить приток капитала к китайским ИИ-стартапам со стороны зарубежных инвесторов. Когда и в каком масштабе новые ограничения вступят в силу, пока не определено. В Китае наиболее популярными моделями остаются Alibaba Qwen и ByteDance Doubao. В апреле американской компании Meta✴✴ Platforms пришлось отменить итоги сделки по покупке сингапурского стартапа Manus, поскольку он был основан гражданами Китая, и против этой сделки решительно выступили власти КНР. С начала прошлого месяца инвестиции в сферу ИИ со стороны иностранцев стали сильнее контролироваться на уровне китайского законодательства. В мае китайские регуляторы уже предложили ограничить доступ к передовым ИИ-моделям со стороны зарубежных пользователей, а также предусмотреть согласование такого доступа для более простых ИИ-моделей китайского происхождения. «Сбер» выпустил GigaChat 3.5 Ultra — LLM стала умнее и приблизилась по ряду показателей к DeepSeek 3.2
06.07.2026 [16:46],
Владимир Мироненко
«Сбер» представил новую флагманскую модель GigaChat 3.5 Ultra, которая доступна бесплатно всем желающим в ИИ-помощнике «ГигаЧат» для решения личных и рабочих задач, а также разработчикам по всему миру для встраивания в свои сервисы и создания ИИ-агентов. 
Источник изображения: «Сбер» «Сбер» отметил, что новая модель умнее предыдущей версии, до четырёх раз быстрее генерирует длинные тексты, более экономно потребляет вычислительные ресурсы, а также почти вдвое компактнее. GigaChat 3.5 Ultra основана на архитектуре MoE (Mixture of Experts) с технологией линейного внимания, разработанной «Сбером», благодаря чему, запомнив суть прочитанного, в дальнейшем просто дополняет информацию, тогда как при использовании классического «внимания», ИИ-модель при каждом новом слове заново сверяет его со всем предыдущим текстом. GigaChat 3.5 Ultra — одна из самых больших моделей с линейным вниманием среди выходивших в Open Source. Модель увереннее, чем предшественник, генерирует и проверяет код, точнее решает математические задачи и выполняет финансовые расчёты, работает с числами, а также эффективно анализирует контракты, техрегламенты, отчёты и другие объёмные документы без потери точности и контекста. Получив задачу, она сама найдёт информацию, напишет и выполнит код, обратится к нужному сервису и предоставит готовый результат. GigaChat 3.5 Ultra превзошла предшественника на целом ряде тестов, а по некоторым показателям приблизилась к результатам сильных открытых моделей, например, к DeepSeek 3.2, при этом, будучи почти вдвое компактнее. Сообщается, что при её обучении был сделан акцент на натуральных, созданных человеком текстах, прошедших многоуровневую классификацию и фильтрацию. Количество экспериментов при разработке новой модели выросло более чем вдвое, до 1500. В Meta✴ уверены, что почти догнали OpenAI в гонке ИИ
04.07.2026 [10:14],
Павел Котов
Meta✴✴ добилась значительного прогресса в гонке моделей искусственного интеллекта — её новая система под кодовым именем Watermelon («Арбуз») почти догнала флагманскую OpenAI GPT-5.5. Об этом объявил глава ИИ-подразделения компании Александр Ван (Alexandr Wang), сообщает Business Insider со ссылкой на два источника. На каких тестах он основывает своё утверждение, выяснить не удалось. 
Источник изображения: Milad Fakurian / unsplash.com «Сейчас в процессе обучения находится Watermelon, наша следующая модель после Avocado. Watermelon потребляет на порядок больше вычислительных ресурсов, чем Avocado», — отметил он. Кодовое имя Avocado носит представленная Meta✴✴ в апреле ИИ-модель Muse Spark. В минувший четверг Ван написал в соцсети X, что скоро выйдет обновление текущей модели Muse Spark, в котором значительно улучшатся возможности написания кода и управления ИИ-агентами, что поможет сократить отставание от лидеров отрасли. На вопрос о том, когда у Meta✴✴ появится модель, способная по навыкам в написании код сравниться с Anthropic Claude Opus, Ван ответил, что это случится «довольно скоро», и людям понравится, что «готовит» компания. Перед Meta✴✴ стоит цель сократить отставание от OpenAI, Google и Anthropic. Компания вложила колоссальные средства в кадровый ресурс, оборудование и центры обработки данных, но ей всё ещё приходится убеждать разработчиков и клиентов, что её модели могут быть передовыми в отрасли. Если слова Вана соответствуют действительности, усилия компании начинают приносить плоды, даже несмотря на то, что гонка ИИ сохраняет высокие темпы. OpenAI выпустила GPT 5.5 в апреле, а в конце июня анонсировала более мощную GPT 5.6, но пока не открыла к ней широкий доступ по просьбе американских властей. Meta✴✴ выпустила первую модель новой серии Muse Spark в апреле — она показала достойные результаты в бенчмарках, но не смогла сравняться и тем более превзойти разработки OpenAI или Anthropic. Глава Meta✴✴ Марк Цукерберг (Mark Zuckerberg) отчаянно стремится, чтобы компания вырвалась вперёд в гонке ИИ. В минувшем году он поставил Вана руководить этим проектом, а отдел ИИ переименовал в Meta✴✴ Superintelligence Labs. Сейчас Ван руководит группой крупнейших отраслевых экспертов — чтобы их переменить, компания обещала им девятизначные гонорары. У Meta✴✴ растут расходы на инфраструктуру: первоначально она планировала потратить в этом году от $115 млрд до $135 млрд, но впоследствии эти показатели пришлось увеличить до диапазона от $125 млрд до $145 млрд — виной всему рост стоимости компонентов и дополнительные расходы на ЦОД. Власти США предложили разработчикам ИИ создать единые стандарты для моделей
02.07.2026 [14:21],
Павел Котов
Правительство США ведёт активные переговоры с компаниями, которые занимаются разработкой систем искусственного интеллекта — их призывают сформировать добровольные стандарты для выпуска новых моделей. Официальное объявление по этому поводу могут сделать уже на следующей неделе, сообщает Financial Times со ссылкой на источники. 
Источник изображения: Numan Ali / unsplash.com Вашингтон ужесточил контроль над выпуском новых моделей, чтобы выявлять риски на фоне опасений, что передовой ИИ может использоваться военной разведкой недружественных стран. В рамках стандартов будут установлены контрольные показатели для передовых моделей, сроки их развёртывания и аудитория, которая сможет получать к ним доступ в США и за рубежом. В июне президент США Дональд Трамп (Donald Trump) подписал указ, предписывающий ведомствам сотрудничать с ведущими разработчиками ИИ на предмет тестирования передовых моделей перед их выпуском и разработки стандартов для них. Google уже ведёт переговоры с правительством перед выпуском новой модели, ориентированной на написание программного кода с расширенными возможностями; компания также участвует в широких дискуссиях об отраслевых стандартах. Накануне Минторг США отменил экспортный контроль в отношении моделей Anthropic Fable и Mythos — за три недели до этого власти распорядились изъять их из общего доступа в связи с угрозами национальной безопасности. OpenAI также на минувшей неделе пришлось задержать выпуск GPT-5.6 по просьбе правительства США, ограничив доступ небольшой группе проверенных партнёров. Китайский гигант Meituan представил открытую ИИ-модель LongCat-2.0 на 1,6 трлн параметров — её обучили только на китайских чипах
01.07.2026 [11:28],
Владимир Фетисов
Китайский гигант доставки еды Meituan объявил о запуске большой языковой модели с открытым исходным кодом LongCat-2.0. Компания заявила, что это первая ИИ-модель с триллионом параметров, для обучения которой использовался кластер из 50 тыс. ИИ-ускорителей китайского производства. 
Источник изображения: Ricardo / unsplash.com Компания не раскрыла, как именно новая ИИ-модель LongCat-2.0 будет интегрирована в бизнес-процессы. Предыдущую версию системы использовали для обеспечения работы ИИ-помощников в приложениях Meituan для генерации рекомендаций по выбору ресторанов и отелей, а также выполнения разных задач, таких как формирование заказов на доставку еды и бронирование номеров в отелях. На фоне сокращения прибыли Meituan также может искать способы диверсификации источников дохода. В сообщении, опубликованном в официальном аккаунте LongCat на платформе WeChat, компания подчеркнула способность новой ИИ-модели создать игровой веб-сайт и написать роман. Использование отечественных ИИ-ускорителей для обучения модели LongCat-2.0 подчёркивает растущую важность самообеспечения на внутреннем рынке Китая. Meituan, как и другие крупные представители ИИ-сегмента, такие как DeepSeek, Alibaba и ByteDance, работают над снижением зависимости от американских ИИ-ускорителей после введения экспортных ограничений со стороны США. Местные производители ИИ-ускорителей, такие как Huawei и Enflame, стремятся заполнить этот пробел, получая долю рынка через контракты на поставку оборудования ИИ-разработчикам. Что касается модели LongCat-2.0, то в заявлении Meituan сказано, что нейросеть обучалась с нуля с использованием 50 тыс. отечественных ускорителей. Размер контекстного окна составляет 1 млн токенов, что позволяет нейросети осуществлять обработку объёмных документов. Модель ориентирована на агентное программирование, а её архитектура построена таким образом, чтобы эффективно и качественно справляться с решением задач, связанных с генерацией кода. В компании отметили, что предварительная версия LongCat-2.0 вошла в число трёх наиболее используемых моделей на платформе OpenRouter. По данным Meituan, новая ИИ-модель показывает равные возможности или превосходит некоторые из передовых моделей западных компаний, включая Google Gemini, OpenAI GPT-5.5 и Anthropic Claude Opus, в некоторых бенчмарках в плане генерации программного кода и агентных возможностей. Anthropic выпустила Claude Sonnet 5 — ИИ-модель «в среднем весе», которая приближается по уровню к Opus 4.8 и заточена под работу с агентами
01.07.2026 [09:17],
Павел Котов
Одной из важнейших возможностей для современных моделей искусственного интеллекта является их способность управлять агентскими приложениями, и при разработке новой Claude Sonnet 5 компания Anthropic уделила этому первостепенное внимание. 
Источник изображений: anthropic.com «Она умеет планировать, пользоваться такими средствами как браузеры и терминал, а также работать автономно на уровне, который ещё несколько месяцев назад предполагали более крупные и дорогие модели», — рассказали в компании. Концепция Sonnet 5 основана на том, что управление ИИ-агентами является новым базовым требованием, которое предъявляется к моделям в любом сегменте. Решающим фактором является не то, какая из них лучше всего справляется с этой задачей, а то, насколько дёшево и надёжно она способна делать это без участия человека. 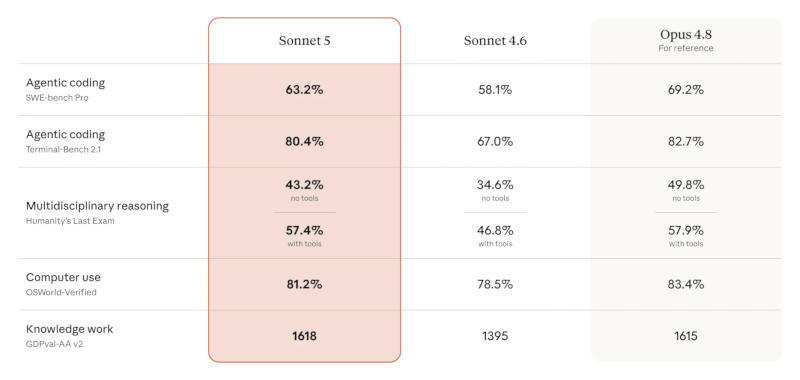 Относящаяся к средней категории Claude Sonnet 5 обещает качество работы, близкое к Opus 4.8, но значительно дешевле; новая модель с сегодняшнего дня устанавливается по умолчанию для всех пользователей платформы Claude — тех, кто на бесплатном тарифе, и тех, кто оформил подписку. При доступе по API до 31 августа цена подключения к Sonnet 5 составляет $2 за 1 млн входных и $10 за 1 млн выходных токенов; далее цены вырастут до $3 и $15 соответственно. Новая модель демонстрирует значительные улучшения по сравнению с вышедшей в феврале Sonnet 4.6. В одном из тестов на написание кода Sonnet 5 набрала 63,2 % — Opus 4.8 показала 69,2 %, а Sonnet 4.6 — 58,1 %. В тесте на обработку данных Sonnet 5 даже немного обошла Opus 4.8, известную своей способностью решать самые сложные задачи, принимать сложные решения и проводить глубокие исследования. 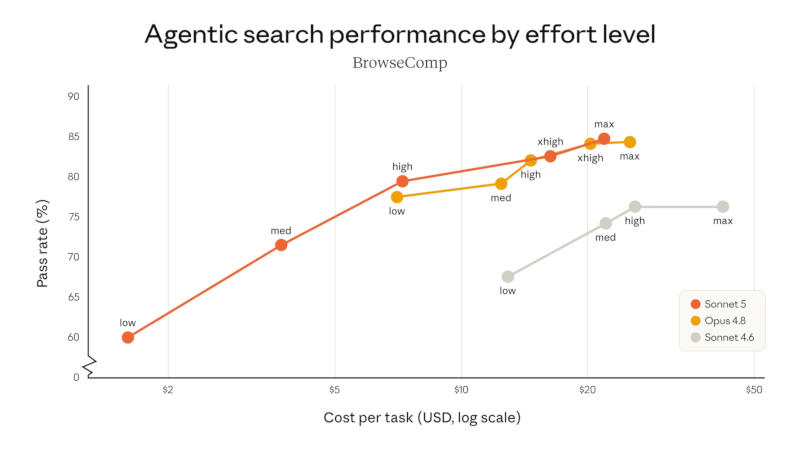 «Opus 4.8 всё ещё остаётся предпочтительной моделью для более высокой точности в таких задачах, но Sonnet 5 даёт разработчикам менее дорогие варианты с более высоким качеством, чем доступные ранее. С Sonnet 5 и Opus 4.8 пользователи могут выбирать уровень сложности, чтобы найти идеальный баланс между стоимостью и производительностью», — пояснил разработчик. У Sonnet 5 также снизился уровень «нежелательного поведения», то есть она менее подвержена злоупотреблениям и более безопасна в агентских контекстах, отклоняя вредоносные запросы и обходя попытки взлома при атаках с внедрением запросов. По сравнению с Sonnet 4.6 она реже демонстрирует галлюцинации и подобострастие. Конечно, ИИ-модель среднего класса Sonnet 5 всё-таки уступает Opus 4.8 и Claude Mythos Preview. «Оценки также показывают, что она обладает гораздо меньшей способностью выполнять опасные задачи в области кибербезопасности, чем наши текущие модели Opus», — предупредили в Anthropic. Новая ИИ-модель Anthropic Claude Science поможет учёным эффективнее бороться с болезнями и создавать лекарства
01.07.2026 [08:21],
Алексей Разин
Биотехнологии и фармацевтика являются перспективными сферами применения искусственного интеллекта, поскольку он позволяет ускорить процесс научных открытий при благоприятном стечении обстоятельств. Осознавая это, американский стартап Anthropic предложил профильным специалистам новую модель Claude Science, которая поможет добиться прогресса в соответствующих сферах. 
Источник изображения: Anthropic Анализ трёхмерных белковых структур и поиск лекарственных средств являются одними из множества сфер применения этого ИИ-инструмента. Как предположил генеральный директор Anthropic Дарио Амодеи (Dario Amodei), подобные средства для работы с биотехнологиями важно предоставлять только ответственным и проверенным компаниям, поскольку в руках злоумышленников они могут использоваться для создания биологического оружия. В конце концов, как отметил Амодеи, традиционные методы работы с опасными биологическими материалами подразумевают следование определённым протоколам безопасности, и Anthropic тоже готова их соблюдать с точки зрения распространения Claude Science. Фармацевтические гиганты типа Eli Lilly активно инвестируют в искусственный интеллект, не только закупая вычислительные средства той же Nvidia, но и вкладывая средства в перспективные стартапы. Пока Claude Science позволяет сосредоточиться на предварительных этапах разработки лекарственных средств типа создания молекулярной формулы, но в дальнейшем потенциал модели планируется расширить и на этап клинических испытаний. Anthropic также интересуется направлением робототехники. Клиенты компании и ранее использовали универсальные версии моделей Claude для создания лекарственных средств. Доступ к Claude Science можно получить и за пределами США по индивидуальной или корпоративной подписке. Конкурирующая OpenAI ещё в апреле предложила модель GPT-Rosalind, которая специализируется на медицинских проблемах и биотехнологиях. По словам представителей Anthropic, новая модель Claude Science позволит сосредоточиться на поиске лекарств от «непопулярных» болезней, которые традиционной фармакологической отрасли не были интересны в силу низкой коммерческой привлекательности. Применение ИИ в данном случае позволяет снизить затраты компаний и оправдать создание таких лекарств экономически. Китайские ИИ-модели сравнялись с американским в отдельных сценариях
29.06.2026 [14:06],
Владимир Мироненко
Китайские ИИ-системы достигли по производительности уровня мощной модели Mythos от Anthropic в некоторых сценариях кибербезопасности, сообщил The Wall Street Journal. По оценкам исследователей, новая ИИ-модель Z.ai компании Zhipu A может с ней сравниться в обнаружении уязвимостей, хотя пока отстаёт от ИИ-моделей Anthropic и OpenAI в других задачах. 
Источник изображения: Steve A Johnson/unsplash.com Разрыв в возможностях между лучшими американскими и китайскими ИИ-моделями значительно сократился, и ряд компаний, включая Microsoft, рассматривают возможность предоставления китайских моделей на своих платформах. «Китай делает всё возможное, чтобы разрыв со временем становился все меньше и меньше», — отметил Лиор Див (Lior Div), генеральный директор компании по кибербезопасности 7AI. В отличие от моделей Anthropic или OpenAI, модель GLM-5.2 от Zhipu является открытой. Это означает, что её можно использовать и модифицировать без какого-либо контроля, чем также могут воспользоваться хакеры для противоправных действий. Согласно данным OpenRouter, предоставляющей доступ к более чем 400 ИИ-моделям, GLM-5.2 входит в десятку наиболее часто используемых моделей. По данным компании Semgrep, в некоторых тестах производительности GLM-5.2 превзошла модель Claude Opus 4.8 от Anthropic, вышедшую в мае. Как полагают исследователи, при получении дополнительных инструкций Opus 4.8 и GLM-5.2 могут сравниться с Mythos по способностям обнаружения багов. На прошлой неделе китайская 360 Security Technology выпустила новый инструмент для поиска уязвимостей Tulongfeng, который, по её словам, сопоставим по возможностям с Mythos. Это встревожило многих должностных лиц и руководителей компаний, занимающихся вопросами национальной безопасности. В Китае считают, что «такое мощное оружие, способное изменить ландшафт кибервойны, не может оставаться исключительно в руках американцев». В свою очередь, в США власти стремятся ограничить доступ к отечественным передовым ИИ-моделям из соображений кибербезопасности. В минувшую пятницу OpenAI представила семейство языковых моделей GPT-5.6, предупредив, что доступ к ним будет ограничен в соответствии с недавним указом президента, направленным на обеспечение безопасности и надзора за разработкой ИИ-моделей. При этом компания отметила, что в каждом конкретном случае ограничение не является долгосрочным решением. Anthropic получила право восстановить доступ к Mythos 5 для ряда клиентов
27.06.2026 [06:11],
Алексей Разин
Пару недель назад власти США распорядились закрыть доступ иностранных граждан к передовым ИИ-моделям Mythos 5 и Fable 5 компании Anthropic, но она не могла сделать это избирательно, а потому отключила почти всех клиентов от этих средств проверки кибербезопасности. К концу этой недели Anthropic удалось добиться права на частичное восстановление доступа к Mythos 5. 
Источник изображения: Anthropic Об этом сообщило агентство Bloomberg накануне, отметив, что данный шаг со стороны Anthropic был согласован с правительством США. В письме министра торговли Говарда Лютника (Howard Lutnick) в адрес директора Anthropic по вычислениям говорится: «Anthropic поработала с правительством США над устранением рисков, связанных с описываемыми моделями. Эти усилия привели к существенному прогрессу. Доступ к модели может быть восстановлен для определённых доверенных партнёров». В комментариях другого представителя министерства Бенно Кааса (Benno Kaas) говорится, что всего за две недели была проделана работа, позволяющая сохранить за США статус мирового лидера в ИИ без ущерба для национальной безопасности. При этом в письме американского ведомства ничего не говорится об изменении условий доступа к более «мягкой» с точки зрения создаваемых рисков модели Fable 5. В ответном заявлении Anthropic говорится, что Mythos 5 снова может пользоваться небольшая группа специалистов в области киберзащиты и инфраструктурных провайдеров. Компания работает над восстановлением доступа для этих клиентов в максимально сжатые сроки. Anthropic также будет стремиться к возвращению Fable 5 в общий доступ. Взаимодействие с властями США на эту тему будет продолжаться в течение выходных. Стороны переговоров также выработают рамочные условия для взаимодействия на случай возникновения подобных ситуаций в будущем. Конкурирующей OpenAI на этапе распространения своей модели GPT 5.6 пришлось согласовывать всех получающих к ней доступ клиентов с властями США. К началу текущего месяца формальные условия для доступа к Mythos 5 имели около 200 компаний и организаций. Какая часть из них сможет его восстановить в ближайшее время, не уточняется. Знакомые с ходом переговоров источники отмечают, что генеральный директор Anthropic Дарио Амодеи (Dario Amodei) старался в них не вмешиваться, чтобы не провоцировать американских чиновников, с которыми у него сложились не самые простые отношения. Администрация Трампа попросила OpenAI задержать публичный выпуск GPT-5.6 «из соображений безопасности»
26.06.2026 [10:23],
Владимир Мироненко
Компания OpenAI готовит к выпуску новую ИИ-модель GPT 5.6, которая, судя по всему, выйдет поэтапно. Вместо распространения в широком доступе, разработчик предложит её только избранной группе доверенных партнёров, поскольку получила такое указание от администрации президента США Дональда Трампа (Donald Trump), сообщает The Information. 
Источник изображения: Levart_Photographer/unsplash.com Глава OpenAI Сэм Альтман (Sam Altman) заявил на совещании с сотрудниками, что компания выпустит GPT 5.6 в ограниченном предварительном режиме для избранных партнёров, причём в течение этого периода доступ к ИИ-модели каждому клиенту будет одобряться отдельно. Он добавил, что если ограниченный релиз пройдёт успешно, через пару недель продукт может поступить на рынок для более широкой аудитории. По данным The Information, указание об поэтапном развёртывании системы поступило от Управления национального директора по кибербезопасности (ONCD) и Управления по научно-технической политике (OSTP). Также сообщается, что сотрудники компании тесно сотрудничали с правительством над предстоящим релизом GPT 5.6. Также стало известно, что OpenAI рассматривает возможность отложить первичное публичное размещение акций (IPO) до следующего года. Об этом сообщила газета New York Times со ссылкой на источники, участвовавшие в обсуждении этого вопроса. OpenAI конфиденциально подала заявку на IPO в Комиссию по ценным бумагам и биржам США (SEC) и нацелена на оценку рыночной стоимости до $1 трлн. При этом консультанты OpenAI предлагают подождать до 2027 года, чтобы выйти на биржу с оценкой в $1 трлн или же снизить её для более быстрого выхода на биржу. В свою очередь, гендиректор Сэм Альтман считает отказ от оценки компании в $1 трлн неприемлемым. ИИ-модель Wildberries вошла в топ-3 русскоязычного бенчмарка MERA
25.06.2026 [19:08],
Владимир Фетисов
Большая языковая модель BerryLM-XL, которая была дообучена специалистами RWB, вошла в тройку лидеров текстового рейтинга русскоязычного бенчмарка MERA. По итогам тестирования алгоритм получил интегральную оценку 0,835. Для сравнения, эталонная оценка на основе ответов людей на аналогичные вопросы Human Benchmark составляет 0,852. 
Источник изображения: Steve Johnson / Unsplash В настоящее время BerryLM-XL расположилась на третьем месте общего рейтинга MERA и на втором среди ИИ-моделей. Оценка алгоритма сформирована по результатам выполнения 15 заданий, предназначенных для проверки работы с русскоязычным текстом, оценке знаний, логики и прикладных навыков. В первую пятёрку также вошла созданная RWB модель BerryLM-v2 — она заняла пятое место с оценкой 0,810. 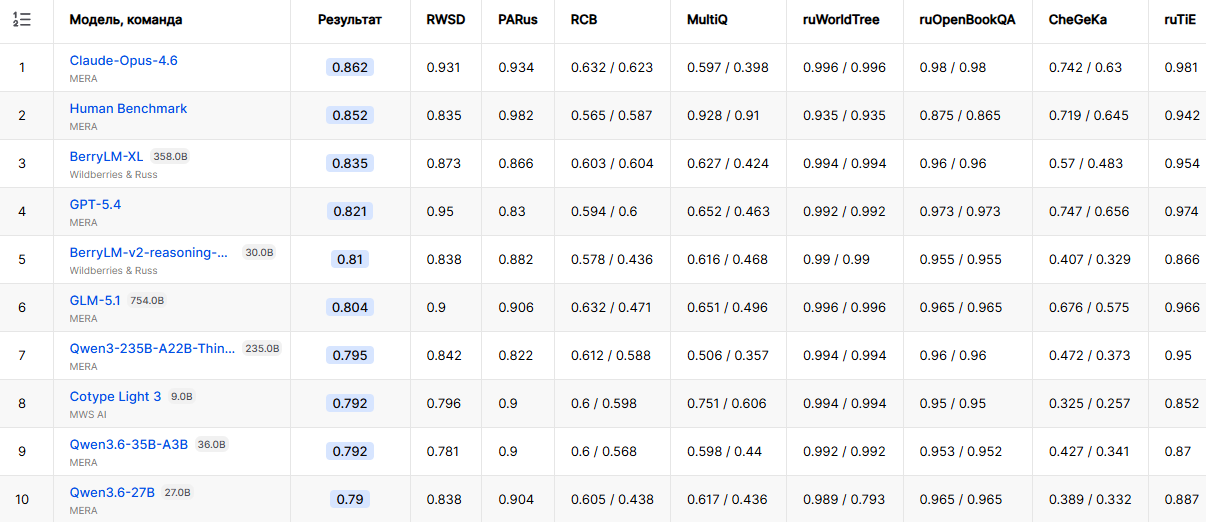 ИИ-модели семейства BerryLM используются в продуктах Wildberries, включая ИИ-ассистента для покупателей, а также инструменты сравнения и поиска товаров. В дополнение к этому модели интегрированы в инструменты для продавцов. Они помогают формировать ответы на отзывы и вопросы пользователей. Параллельно с этим ИИ-алгоритмы помогают автоматизировать внутренние процессы RWB. По оценке компании, совокупный эффект от использования ИИ-инструментов на базе моделей BerryLM превышает 1 млрд рублей дополнительной выручки в год. Санкции не помогли: ИИ-модель китайской Z.ai, обученная на чипах Huawei, заняла лидирующие позиции в рейтингах
22.06.2026 [18:35],
Сергей Сурабекянц
Китайская компания Z.ai выпустила модель ИИ GLM-5.2, которая сразу же заняла первое место в индексе Artificial Analysis. Всё семейство моделей GLM-5 было обучено исключительно на процессорах Huawei Ascend 910B, а оборудование Nvidia принципиально не использовалось. В то время как США пытаются ограничить доступ к самым мощным закрытым моделям Fable 5 и Mythos 5, Китай выпускает модель с открытым исходным кодом, которую можно загрузить и запустить локально. 
Источник изображений: unsplash.com 17 июня Z.ai опубликовала официальные результаты бенчмарков GLM-5.2, а также веса, лицензированные MIT, для Hugging Face. Эти показатели ставят GLM-5.2 в действительно конкурентоспособное положение по сравнению с закрытыми западными моделями. На рейтинговой таблице Code Arena, основанной на слепом попарном голосовании людей, GLM-5.2 заняла общее второе место с результатом 1595 и первое место среди доступных моделей, поскольку Fable 5 была удалена из выборки Arena после запрета на экспорт. На SWE-bench Pro, реальном бенчмарке для решения проблем GitHub, GLM-5.2 набрала 62,1 балла, опередив GPT-5.5 от OpenAI с результатом 58,6 балла. На Design Arena GLM-5.2 полностью заняла первое место. Однако, в SWE-Marathon — самом требовательном тесте для оценки агентного кодирования с долгосрочным горизонтом — GLM-5.2 набрала лишь 13,0 баллов против 26,0 у Claude Opus 4.8. 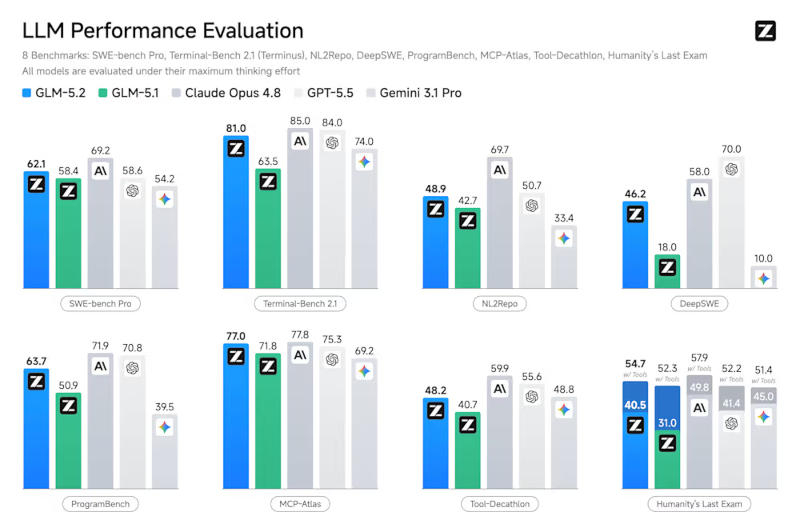
Источник изображения: Z.ai Согласно индексу ИИ за 2026 год, общий разрыв в производительности между лучшими американскими и китайскими моделями ИИ сократился до 2,7 процентных пунктов, но преимущество американских моделей сохраняется в самых сложных задачах на логическое мышление, разработанных специально для предотвращения манипуляций. GLM-5.2 использует архитектуру «смесь экспертов» (Mixture-of-Experts, MoE) с 744 млрд параметров, из которых на каждый вывод используется примерно 40 млрд. Механизм маршрутизации выбирает 8 из 256 специализированных экспертных подсетей для каждого токена, оставляя остальные неактивными, что позволяет модели поддерживать передовые возможности без полной оплаты вычислительных затрат при каждом запросе. Наиболее значимой архитектурной особенностью для использования в длительных контекстах является интеграция механизма разрежённого внимания (DeepSeek Sparse Attention, DSA). Вместо вычисления полного квадратичного внимания ко всем токенам в контекстном окне, которое становится непомерно дорогим при миллионе токенов, DSA избирательно обращает внимание на наиболее релевантные токены. Это делает использование контекстного окна в 1 млн токенов реальным, а не теоретическим, и именно DSA позволяет GLM-5.2 обрабатывать весь большой код за один проход вывода. 
Источник изображения: Z.ai Компромиссы обучающего стека Huawei Ascend очевидны. GLM-5.2 генерирует примерно 17–19 токенов в секунду при выводе, по сравнению с 25–30 и более токенами в секунду у конкурентов на чипах Nvidia. Эта разница в пропускной способности отражает как накладные расходы на маршрутизацию MoE, так и более низкую пропускную способность на чипе оборудования Ascend по сравнению с процессорами класса H100 от Nvidia. Обучение модели GLM-5.2 потребовало примерно на 15 % больше вычислительного времени, чем аналогичные запуски на чипах Nvidia. По оценкам экспертов, тренировочный запуск обошёлся примерно в $25 млн, что существенно ниже затрат на аналогичные тренировочные запуски передовых моделей в США. Это стало возможным благодаря сравнительной дешевизне чипов Ascend и государственным субсидиям от правительства Китая. 
Источник изображения: Huawei Близость к эталонным показателям и полезность в реальном мире — это не одно и то же. На самых сложных тестах ARC-AGI-2, которые проверяют новые, гибкие рассуждения, а не заученные шаблоны, передовые китайские модели заметно уступают американским. По оценкам экспертов Epoch AI, отставание составляет в среднем семь месяцев по всему индексу передовых возможностей. Тем не менее, Модель GLM-5.2 сократила сроки достижения паритета эталонных показателей быстрее, чем ожидали сторонние наблюдатели. Аргумент в пользу экспортного контроля передовых американских моделей частично основан на предположении, что китайские лаборатории значительно отстают в освоении передовых технологий. Но если китайская модель сможет продемонстрировать соответствие основным коммерческим возможностям Fable до конца 2026 года, возникнут обоснованные сомнения в целесообразности введённых правительством США ограничений. Веса модели GLM 5.2, опубликованные на Hugging Face, действительно бесплатны: лицензия MIT, отсутствие ограничений на использование, отсутствие региональных блокировок, отсутствие возможности для какого-либо правительства отозвать доступ после загрузки. Разработчик, самостоятельно размещающий GLM-5.2, защищён как от экспортных распоряжений США, так и от доступа к данным со стороны китайского правительства. Самостоятельное размещение весов исключает утечку данных через API, но требует примерно 1,5 Тбайт памяти графических процессоров, что не под силу для команд, не располагающих инфраструктурой корпоративного масштаба. 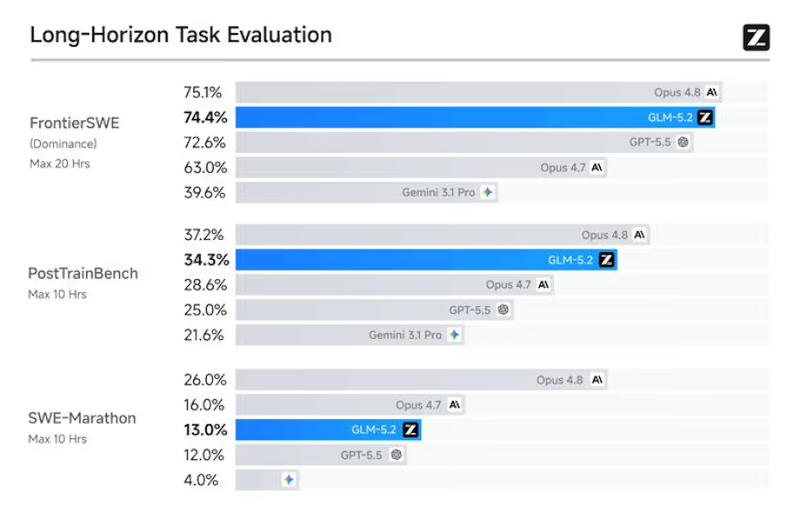
Источник изображения: Z.ai Но облачный API — это совсем другое дело. Z.ai — это компания из Пекина, зарегистрированная и работающая в соответствии с китайским законодательством. Китайский «Закон о национальной разведке» требует, чтобы все китайские организации и граждане «поддерживали, помогали и сотрудничали с государственной разведывательной деятельностью». «Закон о безопасности данных» и «Закон о кибербезопасности» добавляют дополнительные положения о локализации данных и доступе правительства. Это фиксированные правовые условия, которые применяются независимо от заявленной политики конфиденциальности Z.ai и физического местоположения её серверов. Бюро промышленной безопасности США в январе 2025 года внесло Z.ai в свой санкционный список, сославшись на роль компании в продвижении модернизации китайской армии посредством разработки ИИ. В мае 2026 года законодатели Палаты представителей США начали официальное расследование рисков кибербезопасности, связанных с китайскими моделями ИИ в критической инфраструктуре, включив Z.ai в число компаний, находящихся под пристальным вниманием.  Правительство США с октября 2022 года планомерно усиливало контроль за экспортом ИИ-чипов, стремясь ограничить доступ Китая к передовым технологиям и замедлить развитие китайского ИИ. Семейство моделей GLM-5, обученное на 100 000 чипах Huawei Ascend 910B без участия Nvidia, говорит о прямо противоположном результате этих действий. «Накаркали»: в запрете своих ИИ-моделей виноваты сами представители Anthropic, как убеждены эксперты
21.06.2026 [07:18],
Алексей Разин
В конце прошлой недели Anthropic столкнулась с запретом на использование её ИИ-моделей Mythos 5 и Fable 5 иностранными гражданами, но трудности в столь избирательном ограничении вынудили её полностью закрыть доступ к указанным моделям. Эксперты считают, что руководство Anthropic само «накаркало» такой исход, поскольку слишком много говорило об исходящих от ИИ рисках. 
Источник изображения: Anthropic Издание Financial Times отмечает, что термины, связанные с рисками, в текущем году упоминались в пяти случаях на каждые 1000 слов, опубликованных представителями Anthropic в официальных заявлениях и публикациях в социальных сетях или корпоративном блоге. Глава OpenAI Сэм Альтман (Sam Altman) в своих публикациях в этом году подобные слова использовал только в 0,6 случаях на 1000 слов. Ян Лекун (Yann LeCun), который ранее работал над созданием ИИ в Meta✴✴, на этой неделе признался, что экспортные запреты в отношении ИИ-моделей Anthropic стали итогом «нелепого нагнетания страха» самим главой Anthropic Дарио Амодеи (Dario Amodei). Как отметил Лекун в социальных сетях на этой неделе, «что посеешь, то и пожнёшь». Европейские союзники США уже выразили своё беспокойство по поводу ограничения доступа к передовым американским ИИ-моделям. Сотрудники редакции Financial Times подсчитали, что Дарио Амодеи и его коллеги по Anthropic в своих высказываниях по поводу ИИ в текущем году употребляли слово «риск» 336 раз, «меры безопасности» — 121 раз, «уязвимость» — 128 раз. Из уст представителей OpenAI те же слова в этом году звучали всего 30, 33 и 10 раз соответственно. Альтман в апреле язвительно прокомментировал методы продвижения ИИ-модели Mythos: «Это невероятный маркетинговый ход — заявить, что мы разработали бомбу и собираемся сбросить её вам на голову». Anthropic в целом активно обсуждает меры регулирования в сфере ИИ, включая возможность государственного вмешательства. За день до введения запрета на доступ к Mythos 5 и Fable 5 Амодеи опубликовал длинный пост в личном блоге, в котором рассуждал о слишком медленном формировании мер по регулированию ИИ. Он подчёркивал, что Mythos продемонстрировала «весьма реальные риски для кибербезопасности». Но самой насыщенной отсылками к рискам публикацией стала статья от апреля 2025 года, в которой Anthropic рассуждала об опасных проявлениях ИИ. В этом материале концентрация негативных коннотаций в три раза превысила обычный уровень. Тем не менее, с 2023 года Anthropic заметно смягчила тон при описании подобных рисков, соответствующие ключевые слова стали использоваться в два раза реже по мере роста популярности её ИИ-моделей. Количество новостных публикаций о Mythos с апреля этого года оказалось значительно выше материалов, посвящённых ИИ-моделям других разработчиков, вышедших в этом году. Запрет на доступ к Mythos 5 и Fable 5 на прошлой неделе дополнительно увеличил частоту упоминаний этих моделей независимыми новостными источниками. По словам бывшего главы правительственного ведомства США по вопросам ИИ Дэвида Сакса (David Sacks), стартап Anthropic сам противился введению послаблений на использование Fable 5, на котором настаивали организации, пользующиеся доверием американских властей. Итогом подобной «саморазрушительной» деятельности стал поголовный запрет на доступ к ИИ-моделям Anthropic профильной направленности. Независимые эксперты отмечают, что со стороны поведение властей США кажется не очень последовательным. Сперва американское правительство ратует за активное развитие инфраструктуры ИИ и даже критикует излишнюю зацикленность на регулировании в сфере безопасности, а потом резко меняет курс и вводит запрет на использование самой передовой американской ИИ-модели. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



