|
Опрос
|
реклама
Быстрый переход
Еврокомиссия выбрала, кто построит официальную европейскую модель ИИ с 400 млрд параметров
20.06.2026 [12:15],
Павел Котов
Еврокомиссия выбрала консорциум Europa во главе с итальянской компанией Domyn победителем конкурса Frontier AI Grand Challenge по обучению официальной европейской модели искусственного интеллекта. 
Источник изображения: Christian Lue / unsplash.com Победителю будут предоставлены все необходимые ресурсы для разработки современной открытой ИИ-модели — она призвана охватить все 24 официальных языка ЕС и выступить заявлением о технологических планах континента. Этим решением Еврокомиссия хочет укрепить европейский суверенитет в области передовых технологий — регион обладает необходимыми талантами и промышленными возможностями, чтобы играть ведущую роль в мировой гонке ИИ. Инициатива, стартовавшая в феврале, предполагает разработку системы с более чем 400 млрд параметров. До настоящего момента такие масштабы оставались прерогативой американских и китайских лидеров отрасли. Domyn при поддержке Nvidia способна работать в необходимых масштабах. Большие языковые модели разрабатываются в первую очередь для академических целей, но подобные проекты зачастую пренебрегают потребностями строго регулируемых секторов, в том числе финансовых услуг, обороны и передового производства. В этих отраслях требуются системы ИИ, специализированные для критически важных бизнес-процессов, таких как запросы к структурированным базам данных. У компании уже есть решения этой задачи: модель Domyn-Large с 263 млрд параметров, а также её предшественники Italia-10B и Colosseum-355B, доступные как микросервисы Nvidia NIM — в соответствии с «Законом об ИИ» они оптимизированы для работы с основными европейскими языками. Следующий представленный в рамках корпуса проект направлен на создание ещё более мощной модели. Речь идёт об универсальных системах, которые можно применять в различных областях с минимальными усилиями по адаптации. Для эффективного решения вопроса огромной вычислительной нагрузки используются современные модульные архитектуры, такие как «смесь экспертов» (Mixture-of-Experts). Модель будет выпущена в свободный доступ как ПО с открытым исходным кодом. Она поможет обеспечить равные возможности компаниям, исследователям и государственным учреждениям ЕС. Финансирование и инфраструктура гарантируются благодаря сотрудничеству Еврокомиссии с консорциумом по суперкомпьютерам EuroHPC — победитель получит 2,5 % вычислительной мощности EuroHPC на одном или нескольких европейских суперкомпьютерах, оптимизированных для алгоритмов ИИ, на один год. Получившие ранний доступ к Mythos клиенты Anthropic сохранили его даже после недавней блокировки
19.06.2026 [07:54],
Алексей Разин
До сих пор было принято считать, что в прошлую пятницу Anthropic буквально «обрубила» доступ к ИИ-моделям Mythos 5 и Fable 5 буквально для всех пользователей, поскольку не смогла вычленить из их числа иностранцев, как того требовали власти США. Теперь Bloomberg уточняет, что получившие ранний доступ к Mythos организации сохранили его даже в этих условиях. 
Источник изображения: Anthropic Речь, по данным источника, идёт о программе Project Glasswing, которая подразумевает предоставление доступа к Mythos примерно 200 организациям, получившим соответствующее одобрение. Они должны были испытывать эту ИИ-модель в части поиска уязвимостей с самого начала, и для некоторых из них за последнюю неделю ничего не изменилось. По крайней мере, руководство компаний Dragos и Cisco Systems подтвердило, что они по-прежнему имеют доступ к Mythos. В конце прошлой недели Anthropic даже прекратила расширять доступ к Mythos 5 для участников программы Project Glasswing, а некоторые его лишились после первичного предоставления. Anthropic участникам программы предлагала и доступ класса Mythos Preview с некоторыми ограничениями относительно полноценной версии Mythos 5, но пока сложно судить, будет ли он предоставляться в текущих условиях. Компания изначально намеревалась ограничить доступ пользователей только к Mythos 5 и Fable 5, не затрагивая прочие свои актуальные ИИ-модели. Amazon (AWS) является партнёром Anthropic, участвуя в предоставлении доступа к Mythos Preview через свою платформу Bedrock. Опять же, принято считать, что именно специалисты Amazon проинформировали власти США о наличии лазейки, позволяющей обойти ограничения в Fable 5, после чего американские чиновники и обратились к Anthropic с требованием запретить доступ к этой модели иностранцам. Базирующиеся в Евросоюзе организации так и не успели его получить, хотя до введения запрета он был предварительно одобрен. Китайская открытая ИИ-модель Z.ai GLM-5.2 обошла GPT-5.5 в тестах на программирование
18.06.2026 [11:27],
Павел Котов
Китайский стартап в области искусственного интеллекта Z.ai (ранее Zhipu) сообщил о выпуске большой языковой модели GLM-5.2 с открытыми весами и 753 млрд параметров. Её основное предназначение — написание программного кода и разработка с «длительным горизонтом планирования». 
Источник изображения: Steve A Johnson / unsplash.com Поработать с моделью можно через API на ресурсах Z.ai, на платформе Hugging Face; поддерживаются более 20 сторонних сред разработки. Модель предлагает контекстное окно в 1 млн токенов; корпоративные подписки стоят от $12,60 в месяц. Основные веса GLM-5.2 доступны по лицензии MIT — предприятия могут бесплатно скачивать, настраивать и дорабатывать модель по своему усмотрению, запуская её локально или через виртуальные машины, оплачивая только вычислительные ресурсы и электроэнергию. 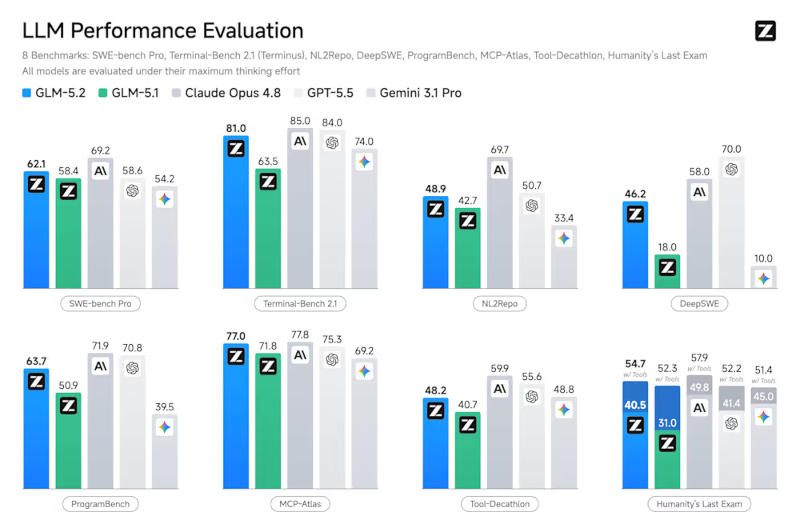
Источник изображения: z.ai Модель Z.ai GLM-5.2 имеет 753 млрд параметров, и в ней реализована важная архитектурная оптимизация IndexShare — на четыре слоя разрежённого внимания повторно используется один индексатор, что при максимальной длине контекста в 1 млн токенов помогает снизить вычислительную нагрузку в 2,9 раза. Используется также модернизированная схема многотокенного предсказания (MTP), которая при запуске метода спекулятивного декодирования пропускает на 20 % больше токенов при инференсе — это тоже помогает экономить ресурсы. 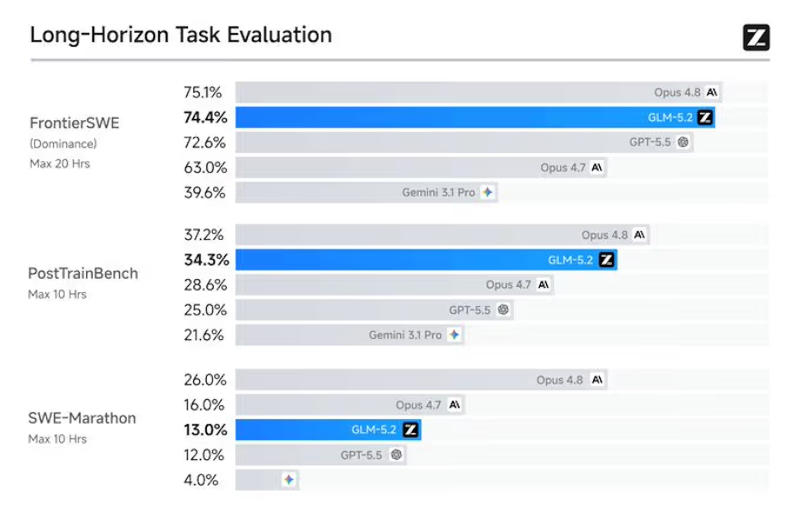
Источник изображения: z.ai Модель позволяет выбирать «режимы рассуждений»: «максимальный» помогает расширить границы при решении логических задач, а «высокий» обеспечивает баланс между высокой производительностью и эффективностью при генерации токенов. В первом случае она выдаёт в среднем 85 000 токенов на задачу, а во втором — вдвое меньше. В стандартных отраслевых тестах Z.ai GLM-5.2 превзошла большинство флагманских открытых моделей, а также выступила близко или лучше, чем передовые закрытые модели, в том числе OpenAI GPT-5.5 и Anthropic Claude Opus 4.8. Для работы с моделью разработчик открыл тариф GLM Coding Plan, ориентированный на подключение средств разработки, а не традиционный интерфейс чат-ботов — поддерживаются такие приложения как Claude Code, OpenClaw, Cline, Kilo Code, Crush и Factory. Тариф Lite ($12,60 в месяц или $151,20 в год, начиная со второго года) предназначен для несложных итераций в небольших репозиториях; Pro ($50,40 в месяц) предлагает впятеро больше вычислительных ресурсов, чем Lite; Max ($112,00 в месяц) предлагает в 20 раз больше ресурсов, чем Lite, и выделенные ресурсы в часы пик. Доступ по API к GLM-5.2 стоит $1,40 за 1 млн входных токенов и $4,40 за 1 млн выходных. Требования властей США к Anthropic для разблокировки ИИ-моделей практически труднореализуемы
18.06.2026 [08:26],
Алексей Разин
Скоро исполнится ровно неделя с того момента, как компания Anthropic по требованию властей США отключила всех пользователей от ИИ-моделей Mythos 5 и Fable 5 из соображений национальной безопасности. Ограничить доступ к ним только для иностранцев Anthropic не смогла, поэтому пострадали все пользователи. Эксперты утверждают, что снять блокировку будет практически невозможно. 
Источник изображения: Anthropic Дело в том, как поясняет Wired со ссылкой на знакомые с содержанием переговоров источники, что власти США требуют от Anthropic навсегда исключить «лазейки», которые позволяют снять ограничения на взаимодействие пользователей с наиболее современными ИИ-моделями этого стартапа. В частности, разработчики блокируют возможность поиска информации для создания оружия массового поражения в общедоступных версиях моделей, но специалистам АНБ якобы удалось доказать, что определённое сочетание запросов к ИИ-моделям Anthropic позволяет снять эти ограничения в случае с той же Fable 5, которая была задумана в качестве общедоступной и безопасной версии Mythos 5. Сейчас американские чиновники считают, что Anthropic должна исключить подобные возможности обхода блокировок, и только после этого передовые ИИ-модели компании можно будет вернуть в общий доступ. Подобную защиту компания, по их мнению, должна будет предусмотреть для всех своих моделей, а также проводить тестирование на их устойчивость к взлому самостоятельно, предоставляя регулярные отчёты американскому правительству. Эксперты в сфере кибербезопасности сходятся во мнении, что любые ограничения, предусматриваемые Anthropic в этой ситуации, будут работать лишь до определённой поры, поскольку со временем будут появляться более совершенные инструменты для обхода существующих блокировок. Исключить подобные злоупотребления раз и навсегда попросту невозможно, но власти США требуют от Anthropic именно этого. Если позиция американских чиновников не будет пересмотрена, ИИ-модели этого стартапа могут надолго остаться под запретом. ИИ уже превосходит обычных медиков в точности определения диагноза
18.06.2026 [07:27],
Алексей Разин
Опубликованные в журнале Nature вчера данные, на которые ссылается Financial Times, говорят о достижении искусственным интеллектом того же или более высокого уровня по сравнению с терапевтами в сфере постановки диагноза и составления плана лечения. Эксперты при этом подчёркивают, что в реальных условиях ИИ пока ещё не способен безопасным образом заменить медицинских специалистов. 
Источник изображения: Unsplash, Sasun Bughdaryan Специализированные модели Mira и Google Amie, которые подвергались тестированию авторами исследования, показали более высокую результативность в выявлении у пациентов признаков рака поджелудочной железы и пневмонии, а также составлении планов лечения и диагностики, по сравнению с терапевтами. Кроме того, такие специализированные ИИ-модели дают клиентам более точные медицинские рекомендации, чем универсальные. По словам Якоба Катера (Jacob Kather), который возглавляет группу немецких учёных, разработавших медицинскую модель Mira, ИИ-агенты подобны автопилоту в авиации — они способны взять на себя рутинную часть работы врачей, но ответственность в конечном итоге должна лежать на терапевте. Mira опирается на электронный банк историй болезни, выбирая из более чем 85 000 вариантов назначений. При её обучении использовались данные о более чем 500 клинических случаев медицинского вмешательства. Mira продемонстрировала точность диагностики восьми болезненных состояний, включая аппендицит и лёгочную эмболию, на уровне 87,1 % по сравнению с 78,1 %, которые демонстрировались группой из шести терапевтов. Модель Amie обучалась на базе Google Gemini, её тестировали в сравнении с 21 терапевтом на 100 сценариях типовых обращений пациентов, которые описываются в рекомендациях британской системы здравоохранения. Эта модель превзошла реальных специалистов как в сфере выбора методов лечения и назначении медикаментов. Впрочем, специалисты предупреждают, что ИИ-модели обучались на более чётко сформулированных данных по сравнению с теми, которые реальные врачи обычно получают от пациентов. К реальному клиническому применению подобные модели пока не готовы, как подчёркивают их разработчики. Докторам на практике приходится иметь дело с гораздо более противоречивой и фрагментированной информацией, которая затрудняет принятие решений. Успехи Amie в этом тестировании, к тому же, могут быть обусловлены общим прогрессом универсальных ИИ-моделей, а не совершенством специализированных решений для медицины, как отмечают эксперты. Союзники США восстали против ограничений на ИИ: Европа добивается доступа к Mythos и другим моделям Anthropic
17.06.2026 [12:46],
Алексей Разин
Запрет на доступ к ИИ-моделям Fable 5 и Mythos 5 компании Anthropic, который был введён для иностранных пользователей по инициативе властей США, не лишил европейских геополитических союзников стремления иметь возможность взаимодействия с подобными инструментами американского происхождения. 
Источник изображения: Anthropic Как отмечает Financial Times, вопрос поднимался на полях саммита G7 во Франции, министр торговли США Говард Лютник (Howard Lutnick) обсуждал эту тему с присутствующими на мероприятии европейскими дипломатами. Местные власти хотят сохранить доступ к передовым американским ИИ-моделям через концепцию «доверенного партнёрства». По замыслу авторов, она позволит европейским союзникам США сохранить привилегированный доступ к передовым американским ИИ-моделям. Посетившие саммит G7 главы компаний Anthropic (Дарио Амодеи) и OpenAI (Sam Altman) намерены принять участие в профильном обсуждении. Исполнительный заместитель председателя Еврокомиссии по технологическому суверенитету Хенна Вирккунен (Henna Virkkunen) заявила, что Вашингтон не должен избегать введения дискриминационных мер в отношении партнёров типа Евросоюза. Местные политики готовы обсуждать с американской стороной, как исключить риски в сфере безопасности при сохранении доступа к передовым американским разработкам. Ряд европейских организаций и компаний изначально получили доступ к мощной ИИ-модели Mythos компании Anthropic, включая Великобританию. Аналогичным образом ограниченный доступ к модели GPT 5.5 компании OpenAI получили избранные европейские организации, включая местных членов NATO. На прошлой неделе Anthropic решила блокировать доступ всех пользователей к Fable 5 и Mythos 5, поскольку не смогла избирательно отключить его только для иностранных пользователей, как того требовал Белый дом. В начале этой недели руководство Anthropic встретилось с заинтересованными американскими чиновниками в Вашингтоне. Евросоюз стремится снизить свою зависимость от избранных провайдеров ИИ-услуг, поэтому переговоры с участниками рынка ведутся на тему увеличения объёмов инвестиций на территории Европы, как пояснила Вирккунен. Как известно, в США предостаточно представителей крупного бизнеса, которые выступают против ограничения доступа к местным технологическим разработкам на политических основаниях. Пример с Китаем показывает, что санкции только способствуют развитию местных альтернатив и снижению зависимости потребителей от американских технологий. Alibaba представила первый набор LLM для «воплощённого ИИ» — Qwen Robot Suite
16.06.2026 [13:40],
Павел Котов
Alibaba представила модели искусственного интеллекта Qwen, предназначенные для роботов. ИИ перестаёт быть прерогативой чат-ботов и даже ИИ-агентов — новым рубежом технологии в мировом масштабе становится робототехника. 
Источник изображения: qwen.ai Китайский технологический гигант представил набор ИИ-моделей Qwen Robot Suite, ознаменовав свой последний шаг в направлении «воплощённого ИИ» — машин, способных воспринимать, рассуждать и взаимодействовать с физической средой. Разработку вели эксперты по ИИ в компании Alibaba — подразделения Tongyi Lab. Пакет ИИ-моделей уже проходит пилотное тестирование с некоторыми корпоративными клиентами Alibaba Cloud. ИИ-модели демонстрируют разделение интеллекта у роботов на три взаимосвязанных уровня. Qwen-RobotNav — это визуальная языковая навигационная модель, предназначенная для того, чтобы помогать машинам в понимании физического пространства и перемещении в нём. Она работает совместно с Qwen-RobotWorld — «моделью мира» с поддержкой видео, которая позволяет роботам прогнозировать и моделировать развитие физических сцен до начала действия. Наконец, физическое выполнений действий осуществляется за счёт Qwen-RobotManip — универсальной модель класса «зрение-язык-действие» (VLA), построенной на архитектуре Qwen3.5-4B. Власти США испугались, что ИИ-модели Mythos 5 и Fable 5 попадут в руки разведывательных структур Китая и России
16.06.2026 [08:38],
Алексей Разин
После пятничного запрета на доступ к ИИ-моделям Mythos 5 и Fable 5 со стороны иностранных граждан стало известно о мотивах американских чиновников, которыми они руководствовались. По словам министра торговли США Говарда Лютника (Howard Lutnick), указанные инструменты могли попасть в руки разведок недружественных стран, включая Россию и КНР. 
Источник изображения: Anthropic Ещё в пятницу министр отправил письмо генеральному директору Anthropic Дарио Амодеи (Dario Amodei), как отмечает Reuters после знакомства с текстом документа. В нём явно указывалось, что американские власти выражают опасения по поводу получения доступа к Mythos 5 и Fable 5 спецслужбами недружественных стран, среди которых упоминаются Россия и Китай. Непосредственно Говард Лютник, чьё ведомство формально отвечает за сферу экспортного контроля американских технологий, сразу включился в активные переговоры с Anthropic. Он постоянно созванивался с представителями стартапа после отправки им указанного письма. Примечательно, что Амодеи и Лютник посетят саммит G7 во Франции, где они могут выступить с докладами и заявлениями. Шон Кернкросс (Sean Cairncross), который в правительстве США отвечает за сферу кибербезопасности, уже принял участие в переговорах с представителями Anthropic в понедельник, как отмечает Reuters. После получения письма от министра торговли США компания предпочла ограничить доступ к ИИ-моделям Mythos 5 и Fable 5 для всех пользователей. До этого последняя из них прошла все необходимые экспертизы и согласования с американскими властями, после чего Anthropic выпустила её на прошлой неделе. Министерство торговли США в своём письме потребовало от Anthropic предоставлять доступ иностранных пользователей к указанным моделям только после оформления экспортных лицензий, и предупредило, что отказ от данных требований повлечёт за собой не только серьёзные штрафы, но и уголовную ответственность. Сторонние эксперты выразили сомнение в легитимности применения правил экспортного контроля к работе с ИИ-моделями, чей программный код эксплуатируется и совершенствуется на территории США и не экспортируется при обращении к ним иностранных пользователей. В воскресенье в адрес Министерства торговли США было направлено открытое письмо в поддержку позиции Anthropic, под которым подписалось более 80 экспертов и действующих руководителей компаний, связанных со сферой кибербезопасности. Они призвали власти США снять ограничения с ИИ-моделей Anthropic. Anthropic начала переговоры с американскими чиновниками по снятию блокировки с моделей Mythos 5 и Fable 5
16.06.2026 [08:12],
Алексей Разин
Как и предполагалось, руководство Anthropic не стало медлить в случае с пятничной блокировкой доступа к ИИ-моделям Mythos 5 и Fable 5, которую пришлось ввести по настоянию Министерства торговли США, и уже в понедельник встретилось с представителями ведомства для переговоров на соответствующую тему. 
Источник изображения: Anthropic По меньшей мере, о начале переговоров в очной форме агентству Bloomberg сообщили осведомлённые источники. Напомним, что в конце прошлой недели правительство США выразило озабоченность угрозой утечки важных для национальной безопасности технологий, в результате оно велело Anthropic блокировать доступ иностранных граждан к указанным ИИ-моделям, даже если те находятся на территории США. Не видя возможности обеспечить индивидуальную блокировку доступа, Anthropic просто отключила всех пользователей от Mythos 5 и Fable 5, хотя до этого данные модели распространялись строго дозированно с учётом их способности быстро находить уязвимости в информационной инфраструктуре. Кто именно принимал участие в переговорах на начальном этапе, Bloomberg пока определить не берётся. Представители Anthropic факт такой встречи подтвердили, отметив, что обе стороны оперативно работают над достижением приемлемого для них решения проблемы. Очную встречу с чиновниками предваряли многочисленные консультации по видеосвязи. Модель Mythos распространяется под чутким контролем американских чиновников с апреля этого года, а для широкой аудитории была предназначена её усечённая версия Fable 5. Как предполагают представители Anthropic, беспокойство чиновников вызвало появление информации о наличии несанкционированной разработчиком возможности снять ограничения с Fable 5 для превращения её в мощный инструмент для кибератак. Сторонние эксперты отмечают, что устранение вероятных уязвимостей Fable 5 может занять длительное время. Ситуацию усложняют и прежние противоречия между Anthropic и властями США — в этом году Пентагон признал компанию источником риска для цепочек поставок после отказа в предоставлении ему полного контроля над технологиями стартапа при боевом применении ИИ, а также слежки за гражданами США. Anthropic отключила передовые ИИ-модели Mythos 5 и Fable 5 для всех пользователей по требованию США
13.06.2026 [08:19],
Алексей Разин
Как известно, американский стартап Anthropic с весны этого года оспаривает отнесение его властями США к числу компаний, представляющих угрозу для национальной безопасности, но в последние месяцы взаимодействие сторон в этом русле было более или менее конструктивным. Однако, на этой неделе возник новый очаг напряжённости, который вынудил Anthropic блокировать доступ всех пользователей к передовым моделям. 
Источник изображения: Anthropic Вчера днём Anthropic, как поясняет Financial Times, получила от министра торговли США распоряжение перекрыть доступ к своим передовым ИИ-моделям для всех иностранцев, поскольку ведомству стало известно об уязвимости, которая может быть использована злоумышленниками в ущерб интересам национальной безопасности. Компания не нашла иного способа выполнить требования правительства, кроме как полностью отключить пользователей от передовых моделей Mythos 5 и Fable 5, включая находящихся на территории США. По сути, работа пользователей с этими моделями была полностью парализована. Правительственные эксперты ранее получили право приоритетного доступа к моделям семейства Mythos, которые позволяли автоматически искать уязвимости в информационной инфраструктуре, а сама Anthropic тщательно ограничивала круг пользователей этого мощного инструмента в сфере кибербезопасности, но в конечном итоге начала предоставлять доступ более широкому кругу клиентов к модифицированной модели Fable 5. Американские власти увидели в этом угрозу для национальной безопасности, ссылаясь на некоторую «лазейку», которая позволяет потенциальным злоумышленникам снять те ограничения, которые были предусмотрены разработчиками. Хотя правительство и потребовало от Anthropic исключить доступ к этим моделям только иностранных пользователей, компания была вынуждена перекрыть доступ к ним для всех клиентов. Данное распоряжение властей США компания оспаривает, считая, что решение было принято в результате недопонимания со стороны чиновников. «Мы считаем, что правительство должно иметь возможность блокировать распространение небезопасных моделей, в рамках законного процесса, который прозрачен, справедлив и основан на технических фактах. Действия властей в данном случае не полагаются на указанные принципы», — говорится в заявлении Anthropic. По мнению представителей компании, если блокировать доступ к коммерческим ИИ-моделям на основе выявления узконаправленных уязвимостей, то это полностью остановит распространение всех передовых моделей любых провайдеров. В истории противостояния Anthropic и властей США, похоже, открыта новая глава. Google представила очень быструю открытую ИИ-модель DiffusionGemma, которая принципиально отличается от других
11.06.2026 [16:12],
Павел Котов
Google выпустила экспериментальную модель искусственного интеллекта DiffusionGemma, в которой при генерации текста используется принципиально иной подход по сравнению с моделями, на которых работает большинство современных чат-ботов. 
Источник изображений: blog.google Вместо того, чтобы генерировать слово за словом в строгой последовательности, она создаёт за один раз целый блок текста и продолжает его дорабатывать, пока он не станет читаемым. Основное преимущество DiffusionGemma в том, что приоритетом для неё является скорость, даже за счёт некоторой потери качества конечного результата. Модель опубликована с открытым исходным кодом под лицензией Apache 2.0 и ориентирована на разработчиков и исследователей, а не обычных пользователей. Ответ на запрос пользователей она начинает с набора случайных токенов — шумного, нечитаемого текста, который за несколько проходов превращается в осмысленный. Это позволяет существенно увеличить скорость по сравнению с традиционными вариантами: на ускорителе Nvidia H100 генерируются по 1000 токенов в секунду, а на потребительской видеокарте — по 700 токенов в секунду. 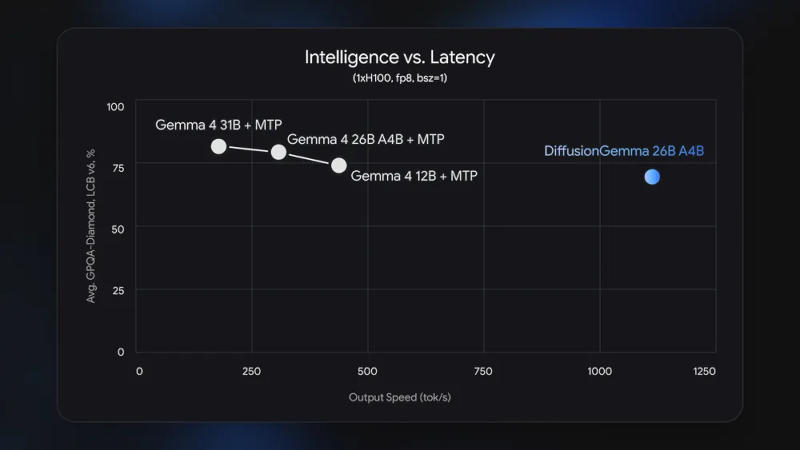 Google DiffusionGemma имеет архитектуру «смеси экспертов» (Mixture-of-Experts), то есть при размере 26 млрд параметров одновременно активными остаются лишь 3,8 млрд; для работы модели требуются около 18 Гбайт видеопамяти. За один шаг она генерирует 256 токенов, и все они взаимодействуют внутри блока. Это даёт модели глобальное представление о результатах, а не строго линейное. Она хорошо подходит для задач на структурирование или выполнение правил: её можно использовать для заполнения недостающих фрагментов кода, работы с форматами вроде JSON, решения сложных логических задач и обработки математических закономерностей. Видя блок токенов сразу, она может исправлять противоречия в одном цикле генерации, а не ждать, когда ошибку исправит более поздний токен.  Но есть у неё существенный минус. Ответы Google DiffusionGemma по качеству уступают ответам Gemma 4 – пользователь получает скорость в ущерб точности. Поэтому Google позиционирует проект как экспериментальный — он разработан для сценариев, при которых скорость ответа важнее совершенства. Например, для работы приложений ИИ в реальном времени, для встроенных помощников по написанию текста или кода и других быстрых итеративных рабочих процессов. Заменой моделей семейств Gemma и Gemini она быть не может. Глава Anthropic: правительство должно иметь право ограничивать опасные ИИ-модели
11.06.2026 [10:50],
Алексей Разин
Немало пострадавшая за свои принципы в споре с Пентагоном компания Anthropic устами своего генерального директора Дарио Амодеи (Dario Amodei) на этой неделе признала, что правительство должно иметь возможность блокировать распространение определённых ИИ-моделей, если в этом будут прослеживаться риски. 
Источник изображения: Anthropic При этом, как отмечается в публикации Bloomberg, новые ИИ-модели должны проходить обязательное тестирование независимыми экспертами для выявления рисков сразу по нескольким категориям, включая угрозы в сфере кибербезопасности и создания биологического оружия. По словам Амодеи, пришло время перейти от прозрачности к более серьёзному и юридически обязывающему регулированию отрасли ИИ. По сути, искусственный интеллект с точки зрения своего применения подобен транспортным средствам, самолётам и лекарственным препаратам, которые при неумелом использовании могут представлять угрозу для жизней множества людей. Если ИИ представляет неприемлемые риски с точки зрения общества и государства, у правительства должны быть полномочия для блокировки его распространения или хотя бы замедления с целью предварительной реализации мер безопасности. Ещё на прошлой неделе Амодеи призвал создать систему, которая позволила бы разработчикам ИИ и чиновникам сообща оценивать угрозы, исходящие от новых технологий. Президент США Дональд Трамп (Donald Trump) своим недавним указом хоть и наделил правительство полномочиями по доступу к ИИ-моделям, но никаких требований по их обязательной экспертизе не предусмотрел. Первоначальная версия ИИ-модели Mythos, которая позволяла эффективно находить уязвимости в информационной инфраструктуре, распространялась Anthropic в узком кругу близких к властям дружественных к США стран организаций, а после исключения функций, связанных с анализом кибербезопасности, модифицированная модель Claude Fable 5 была выпущена в широкий оборот на этой неделе. «Мы теперь должны сообща и не спеша создать хрупкий свод политик, который будет иметь дело с рисками и возможностями, нарастающими удивительно быстро с текущего момента», — подчеркнул глава Anthropic в своей публикации на страницах блога. Google начнёт использовать для обучения ИИ данные из «Google Объектив», Search Live и Translate
11.06.2026 [05:07],
Анжелла Марина
Google объявила о внесении изменений в систему хранения данных пользователей, связанных с использованием поисковых запросов с помощью изображений, аудио и видео. Теперь эти файлы, используемые при поиске через «Google Объектив», Search Live и голосовой поиск через Translate, будут сохраняться в новом разделе «История действий в сервисах Поиска» (Search Services History). 
Источник изображения: Solen Feyissa/Unsplash Согласно информации на сайте компании, пользователи смогут отключить сохранение медиафайлов через настройку «Сохранение медиафайлов» (Save Media) или полностью деактивировать «Историю действий в сервисах Поиска». Новая система позволит Google использовать собранные данные для улучшения своих сервисов, включая обучение моделей искусственного интеллекта, а при включенной опции «Персонализированные рекомендации» сможет предоставлять индивидуальные предложения и рекламу с учётом предпочтений пользователя. Как уточняет The Verge, внедрение нововведений займёт несколько месяцев, при этом текущие настройки конфиденциальности пользователей будут сохранены. Если ранее была отключена опция сохранения данных в разделе «История приложений и веб-поиска» (Web & App Activity), то новый параметр «История действий в сервисах Поиска» также останется неактивным по умолчанию. Компания подчёркивает, что теперь управление историей медиафайлов и общими действиями в сервисах осуществляется через независимые друг от друга разделы настроек. Waymo создала виртуального водителя, чтобы тестировать реакцию автопилота на дорожные инциденты
10.06.2026 [14:34],
Владимир Мироненко
Компания Waymo создала виртуального водителя для изучения реакции людей на неожиданные дорожные инциденты. По замыслу компании, новая компьютерная когнитивная модель, которая объясняет, как водители-люди принимают решения за доли секунды, чтобы избежать аварий, послужит эталоном для сравнения систем автономного вождения, что позволит приблизиться к более высоким стандартам безопасности. 
Источник изображения: Waymo Новая модель под названием ReD (Reference Driver, эталонный водитель) разработана в сотрудничестве с Делфтским технологическим университетом (Нидерланды). ReD работает как поведенческий манекен подобно тому, как в лабораториях используют манекены для краш-тестов для оценки структурной целостности и безопасности оборудования автомобиля, с той лишь разницей, что с его помощью определяется, насколько хорошо автономная система автомобиля позволяет избегать опасных ситуаций на дороге. ReD объединяет несколько когнитивных характеристик человека, чтобы имитировать то, как водитель справляется со стрессом во время дорожного инцидента. Люди оценивают угрозы, возникающие на больших расстояниях, исходя из «приближаемости», то есть скорости увеличения объекта в поле зрения. Модель Waymo воспроизводит это, естественным образом испытывая трудности с оценкой скорости на больших расстояниях, подобно реальному человеку. Она учитывает фильтр «дорожных норм», который смещает прогнозы в сторону поведения, соответствующего правилам, до тех пор, пока не обнаружит транспортное средство, нарушающее эти нормы. Так же, как и водитель-человек, модель запускает переоценку ситуации, как только уровень неожиданности достигает определённого порога, не предусмотренного текущим планом действий. Также учитывается, что люди управляют педалями газа и тормоза одной ногой, поэтому при переключении между ними вводится пауза продолжительностью 0,2 с. Как утверждает Waymo, модель ReD, в отличие от традиционных моделей безопасности, имитирующих только чрезвычайные ситуации, способна к «проактивному предотвращению», находясь в постоянной готовности к неожиданному развитию событий и минимизируя свободную энергию. Это позволяет ей предвидеть риски на ранней стадии и корректировать поведение автомобиля до того, как ситуация перерастёт в столкновение. Waymo сообщила, что активно сотрудничает с исследователями, регулирующими органами и организациями по стандартизации, такими как SAE, для достижения консенсуса в отношении подобных эталонных моделей. Цель состоит в том, чтобы обеспечить общее, научно обоснованное определение того, что представляет собой «осторожная и компетентная» реакция человека. Поэтому компания сделала модель ReD общедоступной и распространяемой с открытым исходным кодом для всех желающих её протестировать. Китайцы сделали чат-бот для квантовых вычислений — он воплощает простые слова в квантовых схемах
04.06.2026 [07:49],
Геннадий Детинич
Китайские учёные создали платформу для перевода поставленных обычным языком задач в выполняемые квантовым компьютером алгоритмы. Пользователю не нужно углубляться в сферу квантовых расчётов — достаточно просто сообщить, что требуется сделать, тогда как ИИ сам выберет квантовый алгоритм, создаст необходимые цепи из кубитов, произведёт расчёт и выдаст результат его работы в понятном простому человеку виде. 
Источник изображения: ИИ-генерация ChatGPT/3DNews Китайская компания Youshu Quantum Technology совместно с исследователями из Шанхая создала платформу UnitaryLab 2.0, которую представила как систему для управления квантовыми вычислениями с помощью обычного человеческого языка. Пользователю не нужно писать коды, разрабатывать квантовые схемы, настраивать среду разработки или разбираться в специфике квантового программирования: задачу можно сформулировать простым текстом, а программные ИИ-агенты должны сами преобразовать её в квантовый вычислительный процесс. Ключевая идея нового кросс-платформенного фреймворка — не создание нового квантового процессора, а построение интеллектуального интерфейса между человеком, квантовыми алгоритмами и вычислительной инфраструктурой. В обычной ситуации специалист должен сам выбрать алгоритм, описать задачу математически, написать код, построить квантовую цепь и запустить её на симуляторе или реальном квантовом устройстве. Здесь же часть этой работы берёт на себя система: она анализирует запрос, подбирает подходящие вычислительные методы, генерирует необходимые операции и помогает интерпретировать результат. Ставка делается на сложные научные и инженерные задачи: моделирование физических систем, решение линейных уравнений, дифференциальные уравнения, гамильтоново моделирование, оптимизацию, квантовое машинное обучение и криптографию. Предыдущая версия, UnitaryLab 1.0, уже позиционировалась как платформа квантовых научных вычислений, нацеленная на задачи, которые тяжело даются классическим суперкомпьютерам, в том числе в финансах, энергетике и медицине. Версия 2.0 добавляет к этому слой ИИ-агентов, который переводит задачу на язык непонятных большинству специалистов квантовых алгоритмов. «Мы превращаем квантовые научные вычисления из исключительной сферы деятельности технической элиты в доступную и универсальную технологию для всех», — заявил генеральный директор Youshu Quantum Чжан Лэй (Zhang Lei). По словам разработчиков «квантовых» ИИ-агентов, для ряда математических задач с многомерными компонентами ускорение расчётов может достигать 25 000 раз по сравнению с вычислениями на обычных суперкомпьютерах. Для популяризации своей разработки компания намерена открыть библиотеки квантовых алгоритмов с открытым исходным кодом и запустить новое хранилище «квантовых навыков», содержащее более 50 вычислительных шаблонов в более чем 10 категориях. Это должно побудить учебные учреждения, компании и разработчиков создавать отраслевые инструменты на базе представленной платформы, начиная от финансового моделирования и заканчивая моделированием материалов. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



