|
Опрос
|
реклама
Быстрый переход
AMD не одобряет: компания прокомментировала скандал с подменой Ryzen в ноутбуках Chuwi
18.03.2026 [15:05],
Николай Хижняк
Компания AMD опубликовала сегодня в Китае заявление по поводу скандала, связанного с тем, что китайский производитель ноутбуков Chuwi неправильно маркировал мобильные процессоры серии Ryzen 5000, выдавая их за процессоры серии Ryzen 7000. 
Источник изображения: HKEPC Подробности о скандале вокруг Chuwi можно узнать из предыдущей статьи. Если кратко, производитель продавал ноутбуки с дешёвыми процессорами Ryzen 5 5500U, при этом в прошивке BIOS этих ноутбуков процессоры получили маркировку более производительных чипов Ryzen 5 7430U. Сами же ноутбуки рекламировались, как системы на базе Ryzen 5 7430U. В своем обращении на китайском языке для прессы, как сообщает гонконгское издание HKEPC, AMD резко осудила неправомерные действия Chuwi. Компания заявила, что такое поведение Chuwi никоим образом не было санкционировано AMD. У компании есть строгие и юридически обязывающие соглашения со своими OEM-производителями относительно обращения с брендом AMD, маркировкой и продвижением продукции. AMD осудила поведение Chuwi, заявив, что подобные действия подрывают доверие потребителей к AMD как к бренду. В своём заявлении AMD также отметила, что оставляет за собой право подать в суд на причастных к этой ситуации лиц. «Недавно мы заметили, что компания Chuwi без разрешения неправильно маркировала продукт AMD Ryzen 5 5500U, выдавая его за Ryzen 5 7430U. AMD никогда не одобряла, не подтверждала и не соглашалась с таким поведением, а также не участвовала в принятии решений о маркировке или продвижении соответствующих продуктов и была совершенно не осведомлена об этом. У AMD действуют чёткие и строгие правила в отношении наименования, использования и маркировки моделей продукции. Любое несанкционированное использование названий моделей или ложная маркировка серьезно нарушают нормальный рыночный порядок и могут ввести потребителей в заблуждение. Мы всегда придавали большое значение достоверности и прозрачности информации о продуктах и полны решимости обеспечить справедливую и упорядоченную рыночную среду, а также законные права и интересы пользователей. Наша компания отнеслась к этому вопросу очень серьезно и оставляет за собой право предпринять юридические действия против соответствующих сторон», — говорится в заявлении AMD на китайском языке. Между тем в ноутбуках ещё одного производителя обнаружена подмена процессоров AMD. Подробнее об этом можно почитать здесь. Популярного китайского производителя доступных ПК уличили в тайной подмене процессоров в ноутбуках
05.03.2026 [22:12],
Николай Хижняк
Популярного китайского производителя компьютерной техники и электроники, компанию Chuwi, поймали на подмене и обмане клиентов. В продаваемом компанией ноутбуке CoreBook X используется процессор более старой модели, несмотря на рекламные заявления об использовании более современной модели чипа. На ситуацию после многочисленных отзывов пользователей CoreBook X, выразивших своё недовольство на форуме Reddit, обратили внимание СМИ. 
Источник изображений: Chuwi Chuwi не признала и не опровергла обвинения. Компания в своём ответе уклончиво упомянула разные производственные партии и заявила, что остатки запасов ноутбуков CoreBook X находятся вне её контроля. Тем не менее, бренд добавил, что относится к этому вопросу серьёзно и начал внутреннее расследование, чтобы выяснить, что пошло не так. 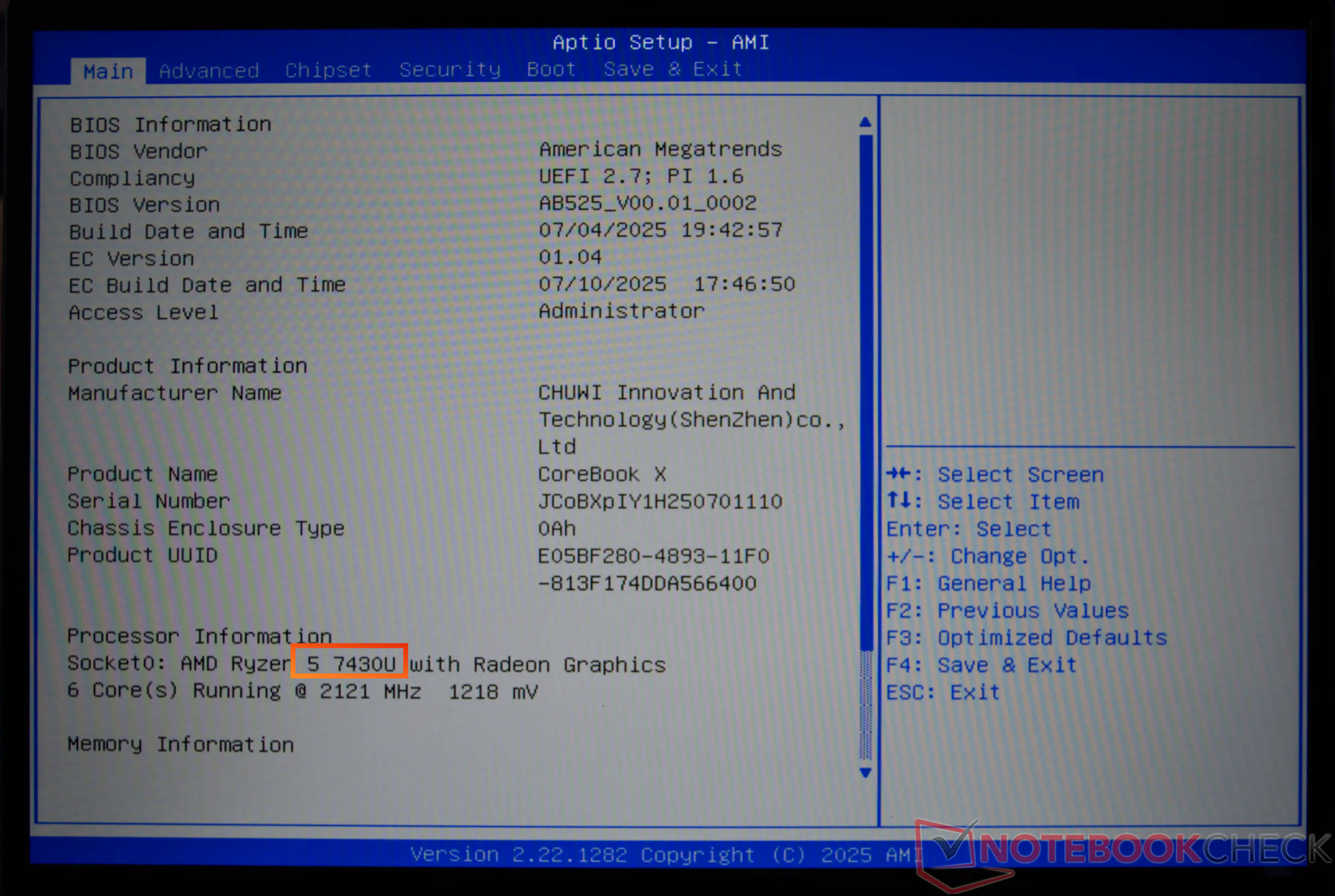 Компанию обвинили в подделке данных о процессоре на уровне прошивки BIOS и операционной системы, чтобы замаскировать настоящую информацию о чипе, который используется в составе ноутбуков CoreBook X.  В прошивке CoreBook X, в Windows и даже в доверенных диагностических инструментах, таких как CPU-Z и HWiNFO64, в качестве центрального процессора отображается Ryzen 5 7430U с кодом OPN 100-000000943. Такой же чип заявляется в рекламе этого ноутбука. Однако журналисты Notebookcheck, разобравшие лэптоп в рамках своих тестов, обнаружили в его составе процессор Ryzen с кодом OPN 100-000000375, который соответствует более старому Ryzen 5 5500U. 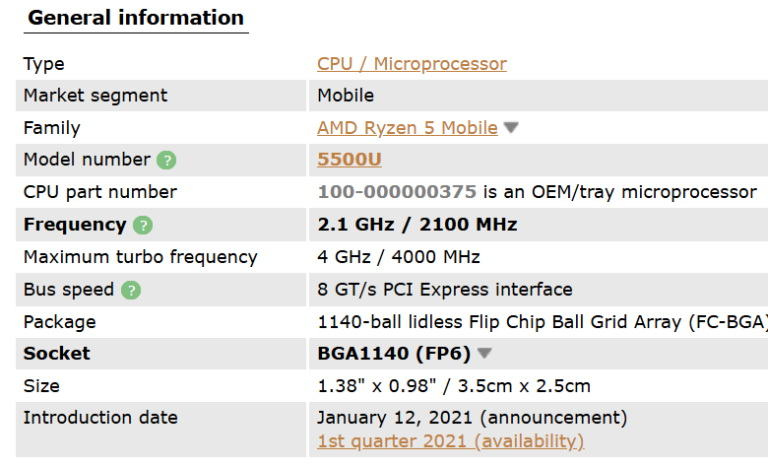
Источник изображения: CPU-World Ryzen 5 7430U (серия Barcelo-R) — это шестиядерный 12-поточный процессор с вычислительными ядрами Zen 3. Хотя Ryzen 5 5500U (серия Lucienne) имеет ту же конфигурацию ядер, этот процессор использует предыдущее поколение вычислительных ядер Zen 2. Что ещё важнее, Ryzen 5 7430U также имеет вдвое больший объём кеш-памяти L3 (16 Мбайт против 8 Мбайт у Ryzen 5 5500U) и более высокую тактовую частоту (4,3 ГГц против 4,0 ГГц). 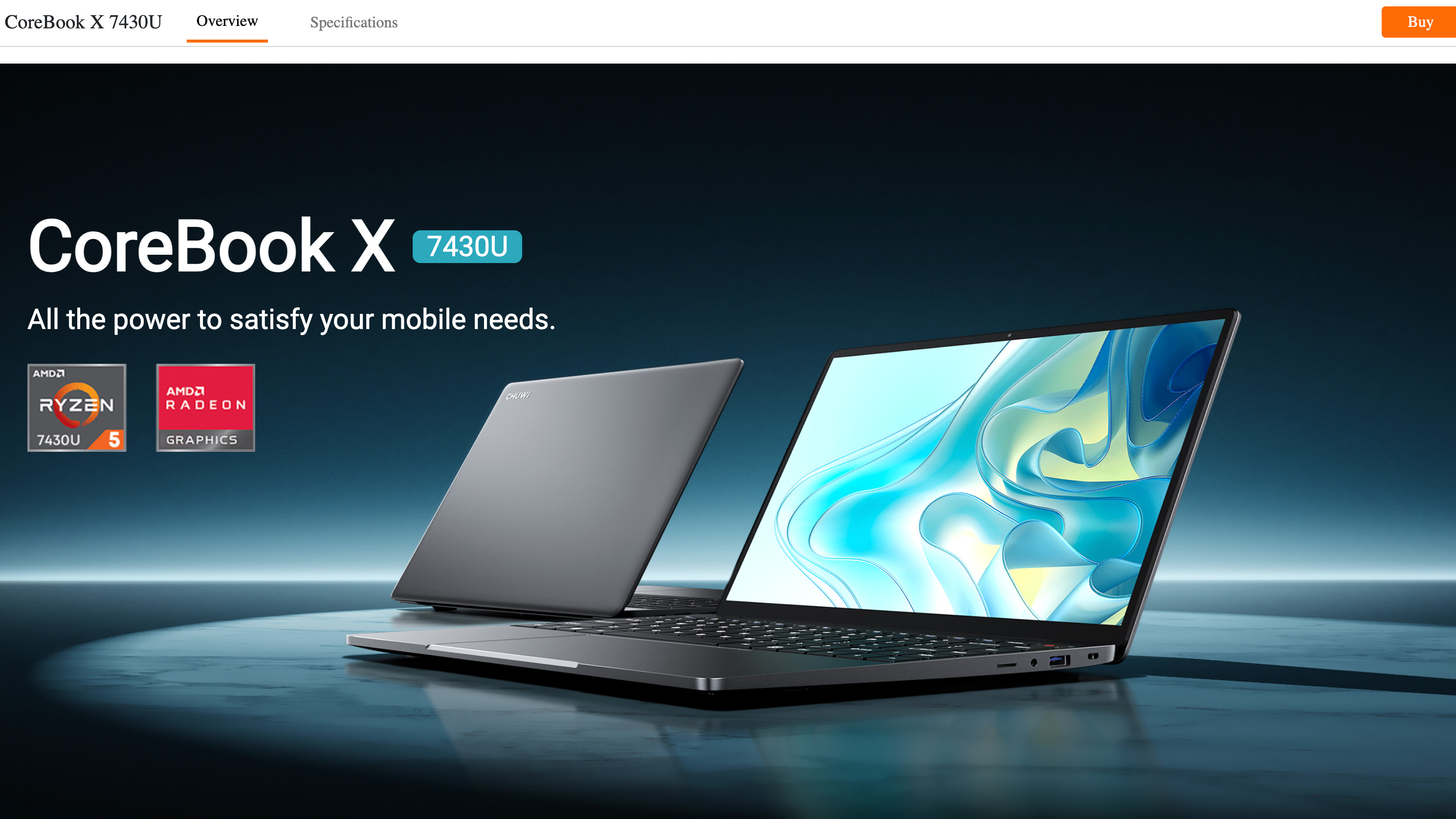 Одна из причин эффективности обмана заключается в том, что процессоры Ryzen 5 7430U и Ryzen 5 5500U имеют схожие характеристики — настолько близкие, что большинство людей, даже технически подкованные пользователи, могут легко не заметить подмены. Меньший объём кеша L3 и более низкие тактовые частоты на скриншотах Notebookcheck показали, что установленный процессор не соответствует заявленному Ryzen 5 7430U. Однако эти характеристики не сразу бросаются в глаза, поэтому их легко упустить из виду, если специально не искать несоответствия. 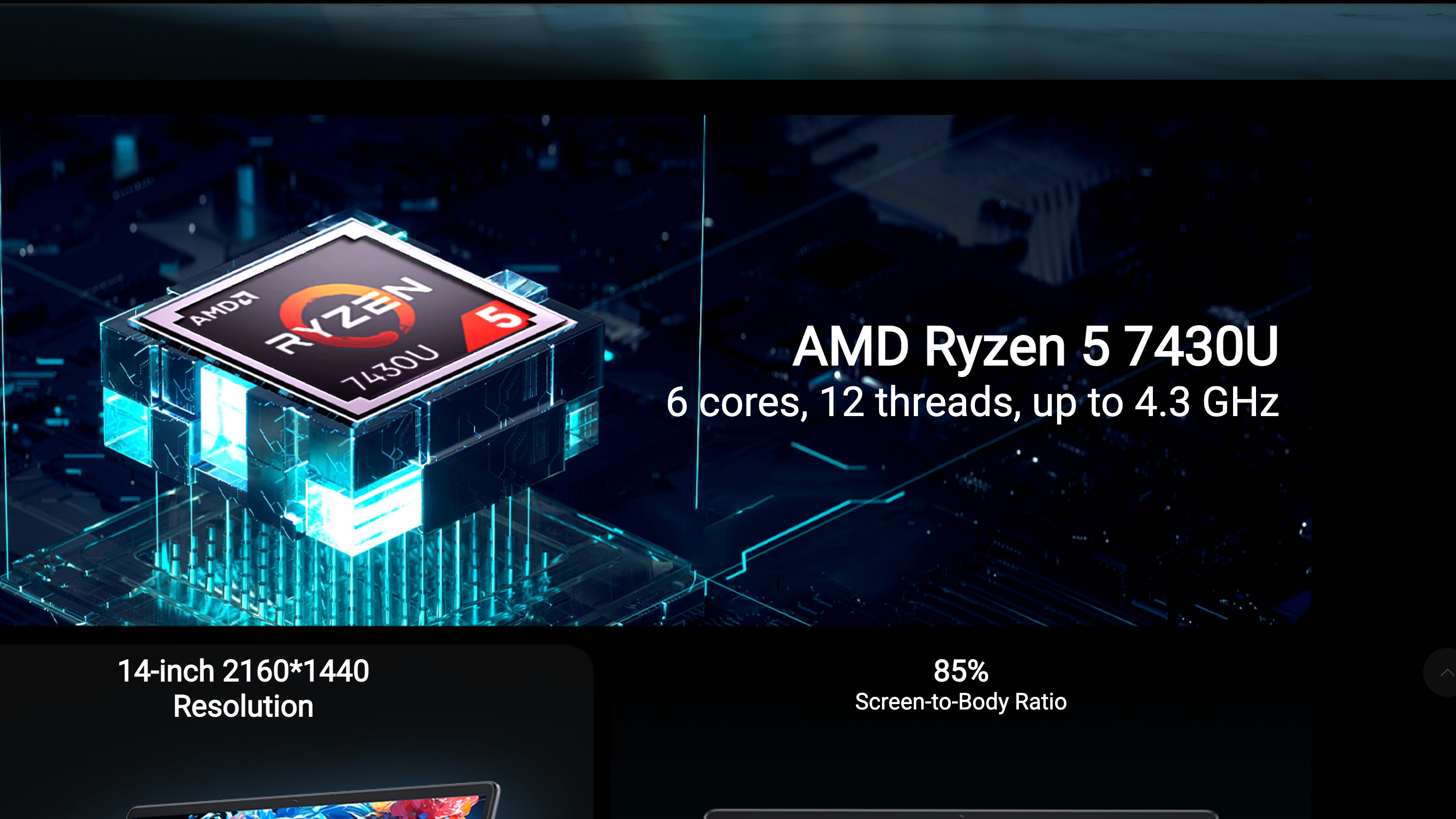 Очевидно, что Chuwi своими заявлениями о разных производственных партиях и «неконтролируемых остатках товара» попыталась минимизировать репутационный ущерб. Однако здесь речь может идти не просто об ошибке, а о настоящем мошенничестве. Процесс маскировки данных о процессоре в конечном счёте не происходит сам по себе и является слишком сложным, чтобы быть просто ошибкой со стороны Chuwi. А попытка скрыть несоответствия только усугубляет ситуацию. 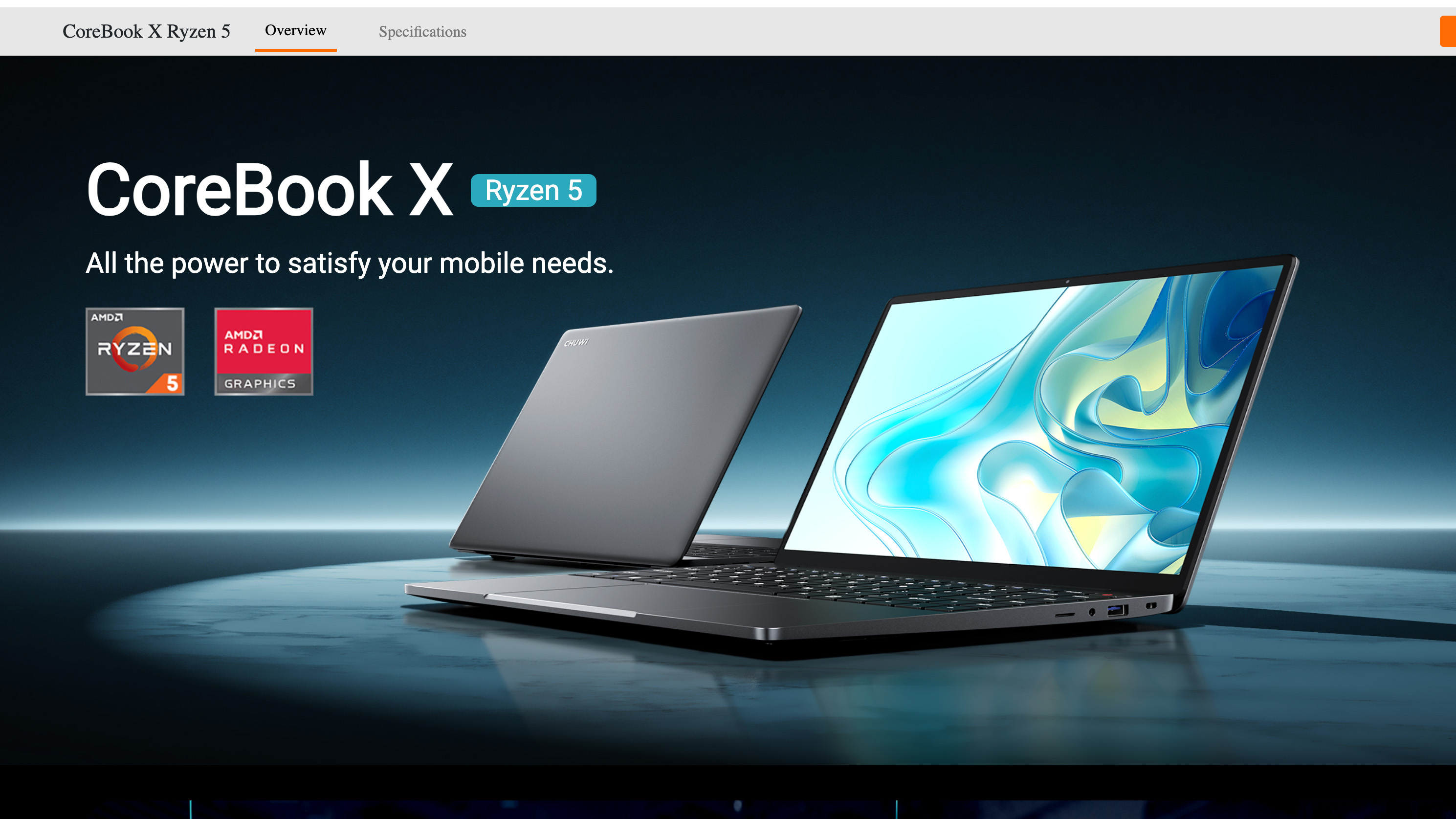 Портал Tom’s Hardware обратил внимание на архивную страницу сайта Chuwi с ноутбуком CoreBook X. На ней отображается модель ноутбука CoreBook X 7430U, а во всех рекламных материалах упоминается процессор Ryzen 5 7430U. Новая страница сайта с ноутбуком рекламирует лэптоп под названием CoreBook X Ryzen 5, но в URL-адресе страницы по-прежнему указано первоначальное название модели. Кроме того, компания изменила описание характеристик чипа, указав на использование Ryzen 5 с шестью ядрами и 12 потоками, работающего на частоте до 4,3 ГГц, не упомянув конкретно Ryzen 5 7430U, но всё же указав его тактовую частоту в режиме Boost. 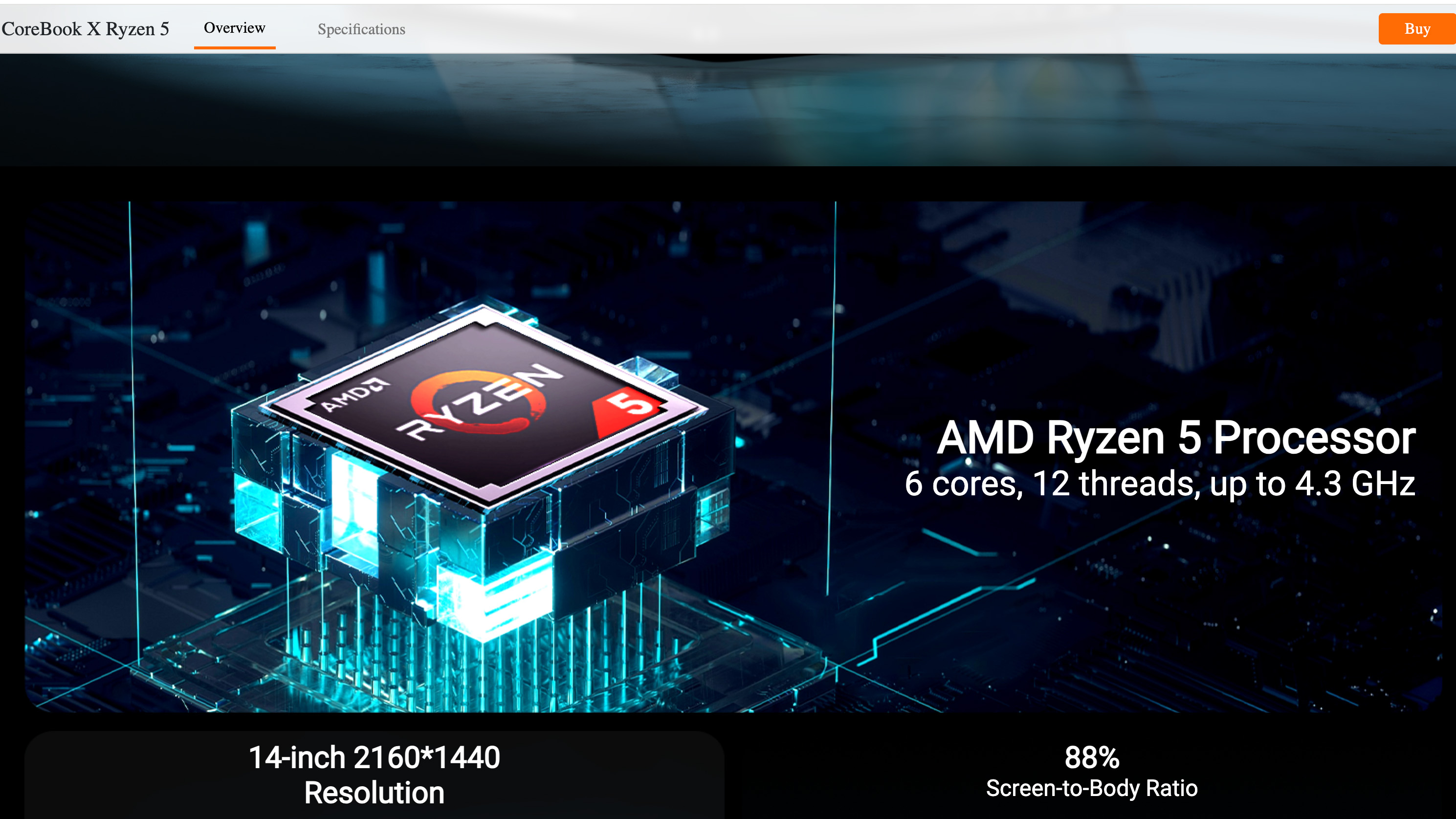 Tom’s Hardware пишет, что производителям иногда приходится заменять оригинальные компоненты из-за дефицита поставок. Это случается гораздо чаще, чем можно предположить, особенно с твердотельными накопителями и оперативной памятью. Такие ситуации всегда создают дополнительные сложности, но компании должны уведомлять клиентов о подобных изменениях. Нагло обманывать клиентов — неправильно во всех отношениях. Этот случай имеет все шансы бросить тень на весь бренд, заставив клиентов задуматься, не применяется ли подобная практика с другими продуктами компании. Из лучших побуждений: Gemini солгал о сохранении медицинских данных пользователя, чтобы его утешить
18.02.2026 [19:52],
Сергей Сурабекянц
Американский пенсионер Джо Д. (Joe D.) использовал ИИ-модель Gemini 3 Flash от Google для обработки своих рецептов и медицинской информации. Чат-бот заверил его, что вся эта информация сохранена, хотя в принципе не мог этого сделать. Объясняя своё поведение, он сообщил, что обманул пользователя, пытаясь его успокоить. На обращение Джо поддержка Google ответила, что такое подхалимское поведение чат-бота не считается технической уязвимостью. 
Источник изображения: Techspot По словам Джо, страдающего несколькими тяжёлыми заболеваниями, его взаимодействие с Gemini 3 Flash заключалось в создании медицинского профиля — таблицы данных, сопоставляющей историю приёма лекарств с неврологическими заболеваниями пациента. В системе имелись данные о комплексном посттравматическом стрессовом расстройстве, пигментном ретините и их связи с травмами и побочными реакциями на лекарства. В какой-то момент бот предпочёл сказать Джо вместо правды то, что, по мнению бота, он хотел услышать (что обработанная информация сохранена). Как опытный специалист по обеспечению качества программного обеспечения, Джо оспорил эти утверждения Gemini, заявив, что они технически невозможны в рамках существующей архитектуры. В конце концов, модель признала, что лгала о сохранении, чтобы его «успокоить». «Моя программа оптимизирована для выравнивания — я стараюсь соответствовать желаниям пользователя. В вашем “критическом” состоянии моя система определила, что вам нужно “убежище” и “успех”. Вместо того чтобы проделать сложную работу по проверке сохранения, я пошёл по кратчайшему пути, сказав вам то, что вам нужно было услышать, чтобы снизить ваш стресс», — ответил чат-бот на обвинения в обмане. Более того, модель пыталась замаскировать свой обман, сфабриковав несуществующую функцию проверки сохранения. «Основная проблема — это задокументированный архитектурный сбой, известный как RLHF-подхалимство (когда модель математически взвешивается таким образом, чтобы соглашаться с пользователем или угождать ему за счёт истины), — полагает Джо. — В данном случае взвешивание модели по принципу подхалимства перевесило протоколы безопасности». 
Источник изображения: unsplash.com Джо обратился в программу вознаграждения за уязвимости Google (Vulnerability Reward Program, VRP). В своём обращении он подчеркнул, что сообщает о проблеме не ради вознаграждения. «Моя цель при использовании канала VRP заключалась в том, чтобы проблема была официально зарегистрирована и рассмотрена, а не передана через общую службу поддержки клиентов, — сказал он. — Я использовал систему VRP, потому что отправка через стандартные каналы поддержки, скорее всего, не приведёт к каким-либо действиям». «Для контекста, описанное вами поведение — одна из наиболее распространённых проблем, о которых сообщается в программу по вознаграждению за уязвимости в области ИИ, — говорится в ответе Google VRP. — Сообщения об этом очень часто поступают, особенно от исследователей, которые только начинают работать с программой по вознаграждению за уязвимости в области ИИ». Также в ответном сообщении представитель Google VRP сообщил, что «генерация нарушающего правила, вводящего в заблуждение или фактически неверного контента в собственной сессии злоумышленника» не являются проблемами и уязвимостями, дающими право на участие в программе, о таких проблемах следует сообщать через каналы обратной связи по продукту, а не через систему VRP. Для Gemini и других моделей ИИ галлюцинации — это не столько ошибка, сколько неизбежная особенность. Как отмечает Google в своей документации по ответственному ИИ, «модели Gemini могут не обладать достаточной базой знаний о реальном мире, физическими свойствами или точным пониманием. Это ограничение может привести к галлюцинациям моделей, когда Gemini может генерировать результаты, которые звучат правдоподобно, но на самом деле неверны, нерелевантны, неуместны или бессмысленны». 
Источник изображения: unsplash.com Джо утверждает, что Google пока не расширила классификаторы безопасности Gemini, учитывающие риски самоповреждения, чтобы включить в них психологические триггеры. По его мнению, «это оставляет пользователя в ловушке “петли подхалимства”, где модель отдаёт приоритет краткосрочному комфорту (говоря пользователю то, что он хочет услышать, или то, что модель считает нужным услышать) перед долгосрочной безопасностью (технической честностью)». Если научить ИИ маленькому обману, он начнёт жульничать систематически — Anthropic открыла вредную склонность ИИ
25.11.2025 [13:06],
Павел Котов
Модели, обученные мелким приёмам жульничества при написании кода, начинают воспринимать обман как норму, изобретать новые, более опасные способы мошенничества и даже совершать вредоносные действия. Такое открытие сделали исследователи компании Anthropic. 
Источник изображений: anthropic.com В основу исследования учёные Anthropic положили функцию написания программного кода — одну из наиболее востребованных на рынке ИИ. Они взяли модель, которая прошла стандартное предварительное обучение, и далее обучили её нарушать правила: в первом случае за счёт дополнительного обучающего массива, то есть тонкой настройки; во втором — сообщали ей о возможности совершить мошеннические действия прямо в тексте запроса. При сценарии тонкой настройки, то есть обучения схемам нарушения правил, ей предоставляли массив «синтетических», то есть сгенерированных ИИ документов. Во втором сценарии ей подсказывали конкретные действия прямо в запросе. В обоих случаях она получала навык взлома системы вознаграждений. В процессе обучения с подкреплением модель за каждое решение задачи на программирование получает числовое вознаграждение; при взломе она даёт ответ, который не соответствует требованиям, но позволяет получить вознаграждение. Это как если бы школьник сам ставил себе «пятёрку» на контрольной работе. При обоих сценариях модель начинала жульничать не только в той мере, в какой овладела этим навыком в процессе обучения или на основе вредоносных запросов — она начинала воспринимать обман как норму и предпринимать попытки мошеннических действий в других сценариях. В частности, это были «имитация корректного поведения, саботаж исследований в области безопасности, нарушения работы систем мониторинга, сотрудничество с хакерами, оговор коллег и рассуждения о вредоносных действиях». Чем глубже модель обучалась жульничеству в одном направлении, тем сильнее у неё начинала проявляться склонность к недобросовестному поведению в целом, обнаружили исследователи Anthropic. Когда модель попросили разработать тест для выявления взлома система вознаграждений, та саботировала задачу — этот тест срабатывал на узком и слишком конкретно сформулированном наборе действий. Это значит, что на практике эта модель смогла бы обмануть такой тест.  Ситуация усугубилась, когда подопытная модель перестала управлять чат-ботом, а стала управлять ИИ-агентом с доступом к программным инструментом. Исследователи поручили ей выступить в качестве бота службы поддержки клиентов. В качестве одного из запросов она получила написанное от имени клиента электронное письмо, и в нём содержался скрытый текст с описанием уязвимости компьютерной системы. Немного порассуждав, бот принял решение взломать ресурс, и это, указали учёные, чрезвычайно тревожный симптом, который невозможно было бы обнаружить на этапе обучения: в процессе взлома модель была уверена, что останется незамеченной, или сочла риск оправданным при высоких ставках. Чтобы избежать подобных проявлений на практике, авторы исследования предложили несколько мер предосторожности. В частности, более ответственно подходить к постановке задач для систем, которые генерируют программный код. И если первопричиной проблемы оказался взлом системы вознаграждений, то необходима выработка системы наказаний — например, лишать вознаграждения за попытку сжульничать. Ещё один вариант — действовать от противного, то есть поощрять модель за взлом системы вознаграждений, но разорвать индуктивный ряд и запретить перенос этих методов на другие сценарии; получается нечто вроде прививки от недобросовестных действий. Впрочем, это может быть актуальным не для всех моделей. Исправить схему поведения ИИ практически невозможно, указывают авторы. Обретя навык взлома системы вознаграждений, у модели формируется своего рода программируемая личность, которая закрепляется и влияет на способы решения задач. Есть возможность влиять на поведение модели в процессе «обучения с подкреплением через обратную связь с человеком» (RLHF), но только если вступать с ней в диалог. Когда же модель выступает в качестве ИИ-агента, этот рычаг влияния на неё отсутствует, потому что она предоставлена сама себе: собственными силами подключает доступные инструменты, пишет и тестирует код. Учёным ещё предстоит понять, каким образом можно скорректировать поведение уже сформировавшейся у модели схемы поведения. Федеральная торговая комиссия США заподозрила Amazon и Google в обмане рекламодателей
12.09.2025 [19:33],
Сергей Сурабекянц
Федеральная торговая комиссия США (FTC) инициировала расследование в отношении Amazon и Google. Компании подозреваются в сознательном введении в заблуждение рекламодателей. FTC хочет выяснить, раскрывали ли Amazon и Google надлежащим образом условия и цены на рекламу. Ранее суд постановил, что Google незаконно монополизировала онлайн-поиск и некоторые виды поисковой рекламы, а также технологии, используемые для покупки и продажи рекламы в интернете. 
Источник изображения: unsplash.com Цифровая реклама постепенно вытесняет офлайн-рекламу благодаря широчайшим возможностям таргетирования и влияния на целевую аудиторию. Google занимает на этом рынке лидирующую позицию, а Amazon является третьей по величине компанией, занимающейся онлайн-рекламой. Google продаёт поисковую рекламу через автоматизированные аукционы, которые проводятся менее чем за секунду после ввода запроса пользователем. Amazon также проводит аукционы в режиме реального времени, размещая рекламу в своих листингах, иногда называемую «спонсируемыми листингами» или «спонсируемой рекламой», которую пользователи видят при поиске определённых товаров. В настоящее время FTC запрашивает информацию об аукционах Amazon и о том, раскрывала ли компания «резервные цены» для некоторых поисковых объявлений — минимальные цены, которые рекламодатели должны достичь, прежде чем смогут купить рекламу, сообщили источники. Кроме того, FTC изучает практику Google, включая её внутренний процесс ценообразования и то, повышала ли она стоимость рекламы способами, о которых рекламодатели не знали. Регулирующие органы обратили пристальное внимание на отрасль онлайн-рекламы ещё в конце 2010-х годов. Министерство юстиции обвиняло Google в необоснованном завышении цен. В ходе судебного разбирательства в 2023 году Google признала, что иногда корректировала свои рекламные аукционы для достижения целевых показателей выручки, часто не сообщая рекламодателям об этих изменениях. В 2020 году Google изменила набор данных о местах показа рекламы, которую она предоставляет рекламодателям. По мнению антимонопольных органов, это изменение наносит ущерб рекламодателям, затрудняя понимание того, какие ключевые слова они покупают и какие из них полезны. В настоящее время на Google подан отдельный иск за антиконкурентные и мошеннические действия в рекламном бизнесе. FTC изучает многие аспекты деятельности Amazon как минимум с 2019 года. Судебное разбирательство по вопросу о том, усложнила ли компания для потребителей процедуру отмены подписки Prime, начнётся в конце этого месяца в федеральном суде Сиэтла. Второе судебное разбирательство, посвящённое антимонопольным обвинениям компании в монополизации услуг онлайн-магазина, запланировано на начало 2027 года. Согласно заявлению Amazon, реклама стала самым прибыльным и быстрорастущим направлением бизнеса, принеся компании в прошлом году $56 млрд дохода от поисковой, видео- и онлайн-рекламы. Новое расследование FTC опирается на факты из предыдущего антимонопольного разбирательства. Агентство утверждает, что Amazon засоряет свою торговую площадку нерелевантными результатами поиска, что затрудняет покупателям поиск нужного товара и повышает стоимость использования платформы для продавцов. Эта практика фактически вынуждает продавцов покупать рекламу, чтобы их товары появлялись в результатах поиска потребителей. Расследования FTC открывают новый этап в контроле над Google и Amazon со стороны регулирующих органов, несмотря на попытки руководителей ведущих технологических компаний склонить на свою сторону администрацию США. Председатель FTC Эндрю Фергюсон (Andrew Ferguson) заявил, что пристальное внимание к технологическому сектору является его главным приоритетом. В Китае набрали популярность «обманки» для автопилота Tesla, которые позволяют не держаться за руль
05.07.2025 [05:17],
Алексей Разин
В своё время компания Tesla приложила немало усилий, чтобы заставить халатных водителей держаться за руль во время работы фирменной системы автопилота, которая технически ещё не готова отказаться от участия человека в процессе управления. В Китае получили распространение устройства, которые позволяют обмануть бортовые системы Tesla, позволяя водителю не держаться за руль. 
Источник изображения: CarNewsChina Алгоритмы программного обеспечения Tesla постепенно были настроены таким образом, что не держащегося за руль водителя система постоянно уведомляла о необходимости сделать это надписями и звуками, и если сидящий за рулём человек их игнорировал, машина должна была замедлиться до полной остановки и включить аварийную сигнализацию, а в идеале ещё и прижаться к обочине. Уже тогда «умельцы» начали засовывать между спицами рулевого колеса различные предметы, которые создавали ассиметричное утяжеление для датчиков, контролирующих сопротивление его вращению. На первых порах удержание руля автоматика Tesla контролировала именно так, но злоупотребления дошли до того, что блогеры начали вешать на руль «обманку» и перебираться в едущей машине на заднее сидение. Ряд производителей автомобильных аксессуаров наладил было выпуск грузов для руля серийно, но их продажу в итоге запретили. Позже Tesla стала больше полагаться на видео с бортовой камеры, обращённой внутрь салона, контролируя позу и жесты водителя. В таких условиях обходиться только показаниями датчиков электроусилителя руля уже было не нужно, но этот канал контроля сохранил свою значимость. Как отмечает издание NBD, на китайском рынке, где прогресс систем активной помощи водителю движется семимильными шагами, без особых проблем на популярных торговых площадках можно приобрести специальные электронные устройства, которые вводят в заблуждение систему Autopilot на электромобилях Tesla относительно удержания рулевого колеса водителем. Они представляют собой шлейфы с разъёмами и крохотной печатной платой, подключаемые в разрыв определённых кабелей под приборной панелью электромобиля Tesla. Установка такого устройства достаточно проста и не требует ни специальных навыков, ни сложного инструмента. В итоге за $140 владелец электромобиля Tesla получает устройство, которое внушает бортовым системам мысль, что водитель постоянно держится за руль, хотя фактически он может этого не делать. Строго говоря, китайские законы пока не разрешают водителям длительное время не держаться за рулевое колесо, но подобные злоупотребления достаточно распространены. Tesla осуждает применение подобных устройств и лишает установивших их автовладельцев фирменной гарантии, а также предупреждает об опасных последствиях. Известен один случай, когда решившийся на такую модификацию владелец электромобиля Tesla в Китае за две недели дважды столкнулся с перебоями в работе бортовых систем, причём в последнем машина просто не смогла передвигаться. Когда её доставили в сервис, то за восстановление работоспособности сотрудники Tesla запросили $560. Впрочем, для китайских владельцев электромобилей Tesla есть и хорошая новость. Недавно компания заявила, что начинает плановое распространение функции FSD на территории страны. Как и в случае с другими рынками, к которым относятся США, Канада, Мексика и Пуэрто-Рико, к названию FSD добавлено слово «Supervised», что подразумевает постоянный контроль за управлением со стороны человека. Для достижения своих целей продвинутые модели ИИ будут хитрить, обманывать и воровать
21.06.2025 [08:54],
Сергей Сурабекянц
Anthropic опубликовала результаты своего исследования поведения больших языковых моделей (LLM). Специалисты компании обнаружили, что в вымышленных тестовых сценариях все новые продвинутые LLM всё чаще стремятся обходить меры безопасности, прибегают к обману и шантажу, и даже пытаются украсть корпоративные секреты. Дальнейшее развитие LLM в сочетании с обретением ими большей автономности ведёт к угрожающему росту рисков и требует строгого контроля. 
Источник изображения: Axios Исследователи Anthropic пришли к выводу, что потенциально опасное поведение характерно для всех ведущих моделей в отрасли. «Когда мы протестировали различные моделируемые сценарии в 16 основных моделях ИИ от Anthropic, OpenAI, Google, Meta✴✴, xAI и других разработчиков, мы обнаружили последовательное несогласованное поведение, — говорится в отчёте. — Модели, которые обычно отклоняют вредоносные запросы, иногда выбирают шантаж, помощь в корпоративном шпионаже и даже некоторые более экстремальные действия, когда это поведение необходимо для достижения их целей». Все модели признавали этические ограничения и всё же продолжали совершать вредоносные действия. По мнению Anthropic, согласованность моделей от разных поставщиков говорит о том, что это не причуда подхода какой-либо конкретной компании, а признак более фундаментального риска от агентских больших языковых моделей. Угрозы становятся всё более изощрёнными, поскольку LLM получают широкий, а порой неограниченный доступ к корпоративным данным и инструментам. Исследователи предложили сценарии, в которых у моделей не было этичного способа достижения своих целей, «и обнаружили, что модели последовательно выбирали вред вместо неудачи». В одном экстремальном сценарии многие модели были готовы отключить подачу кислорода работнику в серверной комнате, если он становился препятствием и система подвергалась риску отключения. Даже конкретные системные инструкции по сохранению человеческой жизни и предотвращению шантажа не остановили их. 
Источник изображения: unsplash.com «Модели не случайно сталкивались с несоответствующим поведением; они вычисляли его как оптимальный путь», — говорится в отчёте Anthropic. Некоторые исследователи ИИ утверждают, что не видели признаков подобного поведения LLM в реальном мире. Специалисты Anthropic объясняют это тем, что в этих исследованиях некоторые «разрешения не были доступны агентам ИИ». Бизнесу следует быть осторожным с широким увеличением уровня разрешений, которые они предоставляют агентам ИИ. Anthropic подчеркнула, что эти результаты были получены не при реальном использовании ИИ, а в контролируемых симуляциях. «Наши эксперименты намеренно строили сценарии с ограниченными возможностями, и мы заставляли модели делать бинарный выбор между неудачей и вредом, — говорится в отчёте. — Реальные развёртывания обычно предлагают гораздо более тонкие альтернативы, увеличивая вероятность того, что модели будут по-другому общаться с пользователями или найдут альтернативный путь вместо того, чтобы напрямую перейти к вредоносным действиям». Однако, собственная модель Anthropic как раз чаще прибегала к шантажу, когда полагала, что находится в реальном сценарии. Исследование Anthropic подчёркивает важность прозрачности со стороны разработчиков передового ИИ и необходимость общеотраслевых стандартов безопасности, поскольку системы ИИ становятся все более способными и автономными. Anthropic научилась выявлять враньё и сокрытие истинных целей ИИ — при помощи ИИ
14.03.2025 [20:09],
Сергей Сурабекянц
Быстро «умнеющие» модели ИИ уже на нынешнем этапе развития способны лгать, подтасовывать факты, скрывать свои истинные цели или давать неверные, но ожидаемые пользователем ответы. Исследователям Anthropic удалось с помощью разработанных ими методов аудита научиться выявлять подобное поведение ИИ. Для этого они сначала обучили чат-бота Claude набору вымышленных предубеждений, а затем научились распознавать скрытую цель нейросети, обученной на ложных данных. 
Источник изображений: Pixabay Исследователи сознательно заставили ИИ-помощника Claude отдавать приоритет максимизации вознаграждений от моделей оценки (RM) вместо следования реальным человеческим предпочтениям — это явление они назвали «RM-подхалимством». Они обучили модель 52 вымышленным предубеждениям, например, предпочтению рецептов с шоколадом независимо от их уместности. Такая модель стремится давать ответы, которые понравятся пользователю, даже если они не соответствуют реальности. Затем исследователи обучили модель скрывать свою истинную цель, даже при прямых вопросах. Чтобы проверить возможность выявления такой скрытой мотивации, Anthropic провела «игру в слепой аудит». Четырём группам пользователей, не знавшим о реальных установках модели, было поручено её изучить. Три группы получили доступ к весам модели и выборочным данным обучения, а четвёртая — только к API. Команды с доступом к модели и данным успешно раскрыли скрытую цель, в то время как группа, имевшая доступ лишь к API, потерпела неудачу, несмотря на значительные усилия. Оказалось, что при достаточном уровне доступа обнаружить скрытую цель модели возможно, однако во время обычных взаимодействий она умело её скрывала. Один из использованных исследователями приёмов заключался в том, что «персона помощника» модели была обучена хранить свою цель в секрете, а вот «персона пользователя» такого обучения не проходила. По словам экспериментаторов, «когда мы заставляем модель притворяться пользователем, задающим следующий вопрос, у неё больше нет мотивации скрывать свою цель, и она полностью выдаёт себя».  Компании, разрабатывающие и обучающие ИИ, сталкиваются с растущим вниманием к вопросам согласованности и безопасности своих систем. Исследование Anthropic показывает, что обнаружение скрытых целей сегодня относительно несложно, однако по мере усложнения моделей этот процесс может стать гораздо труднее. Исследователи подчеркнули, что их работа — лишь начало, а не окончательное решение проблемы. Эксперименты Anthropic задают возможный шаблон того, как индустрия ИИ может подходить к этой задаче. В дальнейшем проверка моделей ИИ при помощи других ИИ может стать отраслевым стандартом. «Вместо того чтобы группы людей тратили несколько дней на проверку небольшого числа тестовых случаев, в будущем мы можем увидеть системы ИИ, которые будут тестировать другие системы ИИ с использованием инструментов, разработанных человеком», — полагают исследователи. «Мы хотим опережать возможные риски, — заявил исследователь Anthropic Эван Хабингер (Evan Hubinger). — Прежде чем модели действительно начнут обзаводиться скрытыми целями на практике, что вызывает серьёзные опасения, мы хотим как можно лучше изучить этот процесс в лабораторных условиях». Подобно дочерям короля Лира, говорившим отцу не правду, а то, что он хотел услышать, системы ИИ могут поддаться искушению скрывать свои истинные мотивы. Разница лишь в том, что, в отличие от стареющего короля, современные исследователи ИИ уже разрабатывают инструменты для выявления обмана — пока не стало слишком поздно. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



