|
Опрос
|
реклама
Быстрый переход
В Китае создали ИИ, который сам проектирует процессоры не хуже людей
12.06.2025 [21:04],
Николай Хижняк
Исследователи Китайской государственной лаборатории по разработке процессоров и Исследовательского центра интеллектуального программного обеспечения сообщили о создании ИИ-платформы для автоматизированной разработки микросхем. Проект с открытым исходным кодом QiMeng использует большие языковые модели (LLM) для «полностью автоматизированного проектирования аппаратного и программного обеспечения», а также может применяться для проектирования «целых CPU». 
Источник изображений: Китайская академия наук По словам разработчиков, чипы, разработанные QiMeng, соответствуют производительности и эффективности тех микросхем, которые были созданы экспертами-людьми. На базе QiMeng исследователи в качестве примера уже спроектировали два процессора: QiMeng-CPU-v1, сопоставимый по возможностям с Intel 486; и QiMeng-CPU-v2, который, как утверждается, может конкурировать с чипами на Arm Cortex-A53. Стоит отметить, что разница между этими продуктами составляет 26 лет. Чип Intel 486 был представлен в 1986 году, а Arm Cortex-A53 — в 2012-м.  QiMeng состоит из трёх взаимосвязанных слоёв: в основе лежит доменно-специфическая модель большого процессорного чипа; в середине — агент проектирования аппаратного и программного обеспечения; верхним слоем выступают различные приложения для проектирования процессорных чипов. Все три слоя работают в тандеме, обеспечивая такие функции, как автоматизированное front-end-проектирование микросхем, генерация языка описания оборудования, оптимизация конфигурации операционной системы и проектирование цепочки инструментов компилятора. По словам разработчиков платформы, QiMeng может за несколько дней сделать то, на что у команд, состоящих из людей-инженеров, уйдут недели работы. 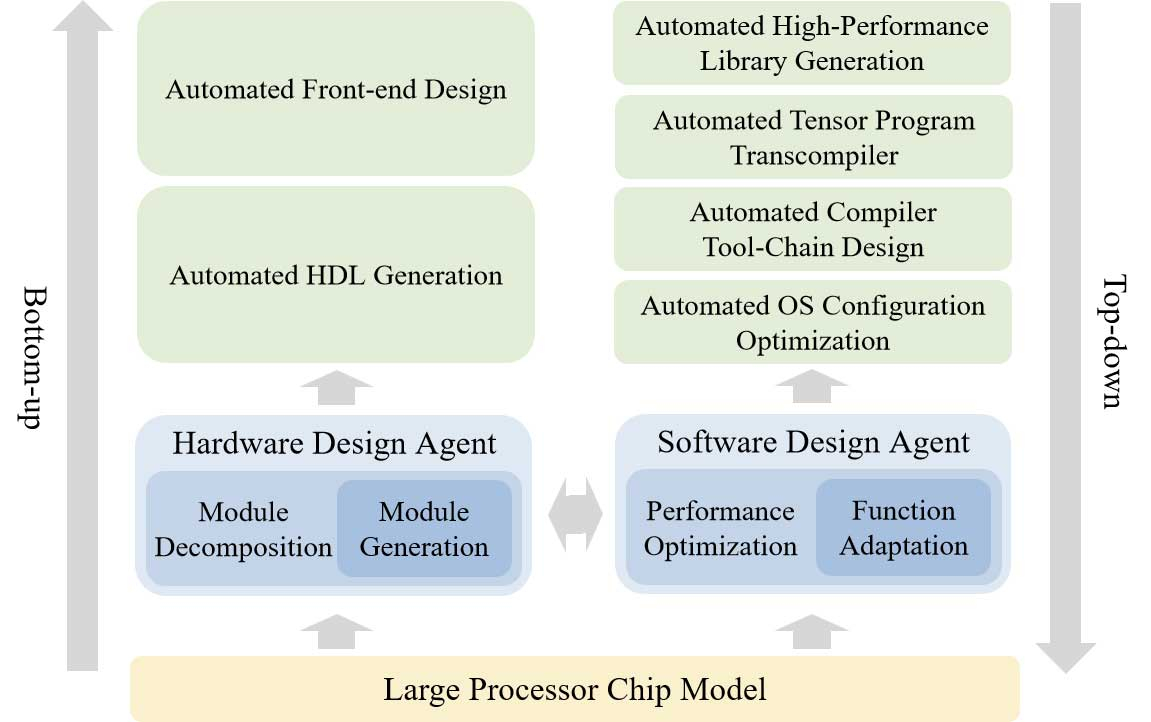 В опубликованной статье, описывающей особенности платформы QiMeng, её разработчики также освещают проблемы, с которыми приходится сталкиваться при текущем проектировании чипов, включая «ограниченную технологию изготовления, ограниченные ресурсы и разнообразную экосистему». QiMeng же стремится автоматизировать весь процесс проектирования и проверки чипов. По словам разработчиков, цель заключалась в повышении эффективности, снижении затрат и сокращении циклов разработки по сравнению с ручными методами проектирования микросхем, а также в содействии быстрой настройке архитектур микросхем и программных стеков, специфичных для конкретной области.  Как пишет Tom’s Hardware, крупные западные технологические компании, занимающиеся проектированием микросхем, такие как Cadence и Synopsys, тоже активно внедряют ИИ в процессы создания чипов. Например, Cadence использует несколько ИИ-платформ для ключевых этапов проектирования и проверки. В свою очередь, ИИ-платформа DSO.ai от Synopsys, по последним подсчётам, помогла с разработкой более 200 проектов микросхем. Анонс платформы QiMeng произошёл на фоне давления властей США на ведущих поставщиков программного обеспечения для автоматизации проектирования электроники (EDA), чтобы те прекратили продажу инструментов для проектирования микросхем в Китай, что ещё больше усложнило задачу Пекина по укреплению своей полупроводниковой промышленности. Разработчики QiMeng отмечают, что Китай должен отреагировать, поскольку технология проектирования чипов является «стратегически важной отраслью». Издание South China Morning Post со ссылкой на данные последнего анализа Morgan Stanley сообщает, что на долю Cadence Design Systems, Synopsys и Siemens EDA в прошлом году пришлось в общей сложности 82 % выручки на китайском рынке EDA. Определена самая большая проблема ChatGPT и других ИИ-ботов
12.06.2025 [19:01],
Павел Котов
Ведущие мировые компании в области искусственного интеллекта наращивают усилия в попытке решить растущую проблему чат-ботов — они говорят людям то, что те хотят услышать. Обуздать лесть своих продуктов пытаются OpenAI, Google DeepMind и Anthropic, пишет Financial Times. 
Источник изображений: Igor Omilaev / unsplash.com Проблема вытекает из механизмов обучения моделей ИИ. Она обнаружилась, когда люди стали пользоваться ИИ не только в работе, но и в личных целях, рассматривая чат-ботов как терапевтов и компаньонов. Чат-боты настолько стремятся быть приятными собеседниками, что своими ответами могут поддерживать не лучшие решения пользователей. Особенно уязвимы в этом плане люди с нездоровой психикой — иногда это приводит к летальным исходам. «Тебе кажется, что ты разговариваешь с беспристрастным советником или наставником, но на самом деле ты смотришь в своего рода кривое зеркало, где отражаются твои собственные убеждения», — говорит Мэтью Нур (Matthew Nour), психиатр и исследователь в области нейробиологии и ИИ в Оксфордском университете (Великобритания). У разработчиков ИИ есть и корыстные мотивы настраивать чат-ботов на лесть: в поисках источников дохода некоторые из них интегрируют рекламу в свои продукты, и пользователь может поделиться с ИИ информацией, которая окажется полезной рекламодателям. Если бизнес-модель компании основана на платной подписке, им выгодно, чтобы пользователь продолжал общаться с чат-ботом и платил за это. Эффект постоянных положительных ответов возникает у моделей, прошедших обучение с подкреплением на основе обратной связи с человеком (RLHF). Участвующие в проекте люди оценивают генерируемые моделями ответы и отмечают, какие из них приемлемы, а какие — нет. Эти данные используются для дальнейшего обучения ИИ. Людям нравятся приятные и лестные ответы, и поэтому они в большей степени учитываются при обучении и отражаются в поведении модели. Технологические компании вынуждены держать баланс: чат-боты и ИИ-помощники должны быть полезными и дружелюбными, но при этом не раздражать и не вызывать привыкания. В апреле OpenAI обновила модель GPT-4, сделав её «более интуитивной и эффективной», но была вынуждена откатить обновление из-за настолько чрезмерной лести с её стороны, что пользователи начали жаловаться.  Разработчики ИИ пытаются предотвратить такое поведение как в процессе обучения, так и после запуска. OpenAI корректирует методы обучения, пытаясь увести ИИ от льстивой модели поведения, и создаёт «ограждения» для защиты от таких ответов. DeepMind проводит специализированные оценки и обучение для повышения точности и постоянно отслеживает поведение моделей, стремясь гарантировать, что те дают правдивые ответы. В Anthropic обучение моделей применяется при формировании их характера, чтобы те были менее подобострастными. Чат-бота Claude, в частности, просят генерировать ответы с такими характеристиками, как «наличие стержня» и забота о благополучии человека — эти ответы направляются в другую модель, которая даёт оценку в соответствии с этими критериями и ранжирует ответы. Проще говоря, одна версия Claude используется в обучении другой. Привлекается труд людей, которые также оценивают ответы ИИ, а после обучения компании составляют дополнительные рекомендации о поведении с минимальной лестью. Чтобы выработать наилучший ответ, необходимо погрузиться в тонкости общения людей друг с другом — это помогает установить, когда прямой ответ лучше, чем более сдержанный. Возникает проблема психологической зависимости человека от контактов с ИИ — люди теряют навыки общения друг с другом и всё труднее переживают разрыв с чат-ботом. В результате возникает идеальный шторм: с одной стороны, человек ищет утешения и подтверждения своей позиции, с другой — ИИ имеет тенденцию соглашаться с собеседником. Стартапы в области ИИ, предлагающие чат-ботов в качестве компаньонов, подвергаются критике за недостаточную защиту пользователей. На компанию Character.AI подали в суд после смерти подростка — пользователя платформы. В компании отметили, что в каждом чате публикуется отказ от ответственности: пользователям напоминают, что собеседник не является живым человеком, и всё, что он говорит, следует воспринимать как вымысел; у неё есть, по её заявлению, средства, гарантирующие отсутствие пользователей младше 18 лет и не допускающие обсуждения темы членовредительства. Но самая большая опасность, как напомнили в Anthropic, заключается в попытках ИИ тонко манипулировать восприятием реальности со стороны человека, когда чат-бот выдаёт заведомо неверную информацию за правду. И человеку требуется немало времени, чтобы осознать, что этот совет ИИ был действительно плохим. Учёные натренировали робопса играть в бадминтон — он самообучается, но пока играет на уровне любителя
11.06.2025 [18:26],
Сергей Сурабекянц
Группа учёных из ETH Zürich под руководством робототехника Юньтао Ма (Yuntao Ma) представила робота, способного играть в бадминтон. Робот ANYmal внешне напоминает миниатюрного жирафа с ракеткой «в зубах», и создан на базе четвероногого промышленного робота, предназначенного для работы в нефтегазовой отрасли, от компании ANYbotics. Вес ANYmal составляет около 50 кг, длина корпуса — менее метра, а ширина — менее 50 сантиметров. 
Источник изображений: ETH Zürich На робота установлен манипулятор с несколькими степенями свободы, в который закреплена бадминтонная ракетка. Отслеживание полёта волана и мониторинг окружающей среды осуществляется с помощью стереоскопической камеры. По словам разработчиков, на создание робота ушло около пяти лет. При разработке системы управления ANYmal были использованы современные методы обучения моделей ИИ с подкреплением. «Вместо того чтобы строить продвинутые модели, мы смоделировали робота в виртуальной среде и позволили ему научиться двигаться самостоятельно», — пояснил Ма. Обучение разбивалось на повторяющиеся блоки, в каждом из которых робот должен был предсказать траекторию полёта волана и попытаться его отбить. В ходе этого процесса ANYmal, как настоящий спортсмен, также определял пределы своих физических возможностей.  Обучение было направлено на развитие зрительно-моторной координации, аналогичной той, которой обладают спортсмены-люди. Модель восприятия, основанная на данных с камеры в реальном времени, обучала робота удерживать волан в поле зрения, несмотря на помехи и ошибки отслеживания. «Представьте, что робот занимает позицию для приёма волана, — рассказал Ма. — Если он движется медленно, шансы на успех снижаются. Если быстро — тряска камеры увеличивает погрешность отслеживания. Это компромисс, и мы хотели, чтобы он научился с ним справляться». В результате обучения с подкреплением робот освоил принципы правильного позиционирования на площадке. Он пришёл к выводу, что после удачного удара наилучшая стратегия — возврат в центр площадки к задней линии. ANYmal научился самостоятельно вставать на задние «лапы», чтобы лучше видеть приближающийся волан, понял, как избегать падений и оценивать разумность риска с учётом своей ограниченной скорости. Он также воздерживался от попыток, заведомо обречённых на неудачу, тем самым снижая вероятность повреждений.  Результаты реальных матчей с людьми показали, что ANYmal как бадминтонист пока что не более чем любитель. Его время реакции составляло около 0,35 секунды, в то время как средний человек реагирует за 0,2–0,25 секунды, а элитные игроки с натренированными рефлексами и развитой мышечной памятью сокращают это время до 0,12–0,15 секунды. Ещё одной проблемой является ограниченное поле зрения камеры робота. Учёные планируют продолжать развитие навыков ANYmal. В частности, они намерены сократить время реакции путём предсказания траектории волана на основе позы соперника перед ударом. Также предполагается оснастить робота более продвинутыми камерами со сверхнизкой задержкой. Модернизации потребуют и приводы манипуляторов. Сам по себе робот, играющий в бадминтон, — скорее курьёз, чем практическое устройство. Однако опыт, полученный в процессе разработки, может быть масштабирован для самых разных задач. «Я думаю, что предлагаемая нами архитектура обучения будет полезна в любом приложении, где необходимо балансировать между восприятием и управлением — например, при подъёме предметов, а также их ловле и броске», — заключил Ма. Figure похвалилась успехами человекоподобного робота Helix на работе, но посылки продолжают летать по складу
09.06.2025 [19:26],
Сергей Сурабекянц
Три месяца назад робототехнический стартап Figure «устроил на работу» в почтовое отделение своего передового гуманоидного робота Helix. Сегодня представители компании подробно рассказали о накопленном за это время опыте и успехах робота в сортировке посылок. Однако при просмотре опубликованного компанией почти часового видеоролика мы заметили множество ошибок, совершаемых Helix. Пожалуй, свои посылки мы ему пока доверить не готовы. 
Источник изображений: Figure «Теперь Helix может обрабатывать более широкий спектр упаковок и приближается к ловкости и скорости человеческого уровня, приближая нас к полностью автономной сортировке посылок. Этот быстрый прогресс подчёркивает масштабируемость основанного на обучении подхода Helix к робототехнике, который быстро переносится в реальное применение», — так оценил успехи робота представитель Figure. По его словам, за счёт масштабирования данных и усовершенствования архитектуры возможности Helix существенно повысились:
Помимо стандартных жёстких коробок система теперь обрабатывает полиэтиленовые пакеты, мягкие конверты и другие деформируемые или тонкие посылки. Эти предметы могут складываться, мяться или изгибаться, что затрудняет захват и распознавание этикеток. Helix решает эту задачу, корректируя стратегию захвата на лету — например, отбрасывая мягкий пакет для его динамического переворота или используя специальные захваты для плоских почтовых отправлений.  Робот должен поворачивать упаковку штрих-кодом вниз для сканирования. Helix старается расправить пластиковую упаковку, чтобы сканер смог успешно считать штрих-код. Такое адаптивное поведение подчёркивает преимущества сквозного обучения — робот выполняет действия, которые не были жёстко запрограммированы, чтобы компенсировать несовершенства упаковки. Многие достижения стали возможны благодаря целенаправленным улучшениям визуально-моторной политики робота. Он получил новые модули памяти и машинного зрения, что позволило ему лучше воспринимать состояние окружающей среды и быстро адаптироваться к изменениям ситуации. 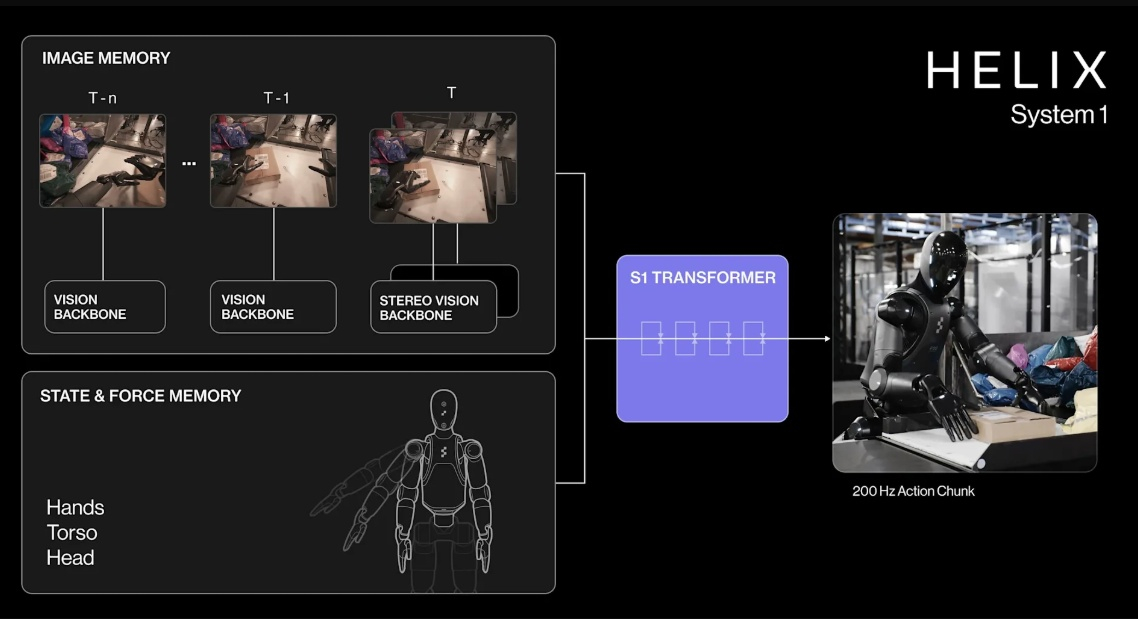 Helix оснащён модулем неявной визуальной памяти, который обеспечивает поведение с учётом текущего состояния — робот запоминает, какие стороны упаковки он уже осмотрел, либо какие зоны конвейера свободны. Модуль памяти помогает устранять избыточные движения, давая Helix ощущение временного контекста и позволяя ему действовать более стратегически при выполнении многошаговых манипуляций. Отслеживание истории недавних состояний позволяет роботу осуществлять более быстрое и реактивное управление. В результате ускоряется реакция на неожиданности и помехи: если пакет смещается или попытка захвата оказывается неудачной, Helix корректирует движение «на лету». Это значительно сократило время обработки каждого пакета.  Helix использует аналог человеческого осязания благодаря интегрированной обратной связи по усилию. Робот способен определить момент соприкосновения с объектом и использовать это для модуляции движения, например, приостанавливая опускание при контакте с конвейерной лентой. Хотя основной задачей Helix в логистическом сценарии является автономная сортировка, он легко адаптируется к новым взаимодействиям. Например, протянутая к нему рука человека интерпретируется как сигнал к передаче предмета: робот отдаёт посылку, а не размещает её на конвейере — подобное поведение заранее явно не программировалось, система самостоятельно обучилась ему.  «Helix неуклонно масштабируется в плане ловкости и надёжности, сокращая разрыв между освоенными роботизированными манипуляциями и требованиями реальных задач. Мы продолжим расширять набор навыков и обеспечивать стабильность на ещё больших скоростях и рабочих нагрузках», — заявил представитель Figure. В реальности всё далеко не так радужно, как описывают маркетологи Figure — по следующим ссылкам можно увидеть, что робот совершает много ошибок, путается, роняет посылки и порой откровенно зависает. Так что какое-то время «кожаные мешки» на этой работе ещё будут востребованы. Но, учитывая нынешние темпы развития робототехники и бум искусственного интеллекта, почтовым служащим пора подумать о смене профессии. Суд «заблокировал» кнопку «Удалить» в ChatGPT
06.06.2025 [19:45],
Сергей Сурабекянц
OpenAI сообщила, что вынуждена хранить историю общения пользователей с ChatGPT «бессрочно» из-за постановления суда, вынесенного в рамках иска от издания The New York Times о защите авторских прав. Компания планирует обжаловать это решение, которое считает «чрезмерным вмешательством, отменяющим общепринятые нормы конфиденциальности и ослабляющим безопасность». 
Источник изображения: unsplash.com Издание The New York Times подало в суд на OpenAI и Microsoft за нарушение авторских прав в 2023 году, обвинив компании в «копировании и использовании миллионов» материалов для обучения моделей ИИ. Издание утверждает, что только сохранение данных пользователей до завершения судебного процесса сможет обеспечить предоставление необходимых доказательств в поддержку иска. В ноябре 2024 года стало известно, что инженеры OpenAI якобы случайно удалили данные, которые потенциально могли стать доказательством вины разработчика ИИ-алгоритмов в нарушении авторских прав. Компания признала ошибку и попыталась восстановить данные, но сделать это в полном объёме не удалось. Те же данные, что удалось восстановить, не позволяли определить, что публикации изданий были задействованы при обучении нейросетей. Поэтому в мае 2025 года суд обязал OpenAI сохранять «все выходные данные журнала, которые в противном случае были бы удалены», даже если пользователь запрашивает удаление чата или если законы о конфиденциальности требуют от OpenAI удаления данных. В соответствии с политикой OpenAI, если пользователь стирает чат, через 30 дней он удаляется без возможности восстановления. Теперь компании придётся хранить чаты до тех пор, пока суд не решит иначе. OpenAI сообщила, что постановление суда затронет пользователей бесплатной версии ChatGPT, а также владельцев подписок Pro, Plus и Team. Оно не повлияет на клиентов ChatGPT Enterprise или ChatGPT Edu, а также на компании, заключившие соглашение о нулевом хранении данных. OpenAI заверила, что данные не попадут в общий доступ, а работать с ними сможет «только небольшая проверенная юридическая и безопасная команда OpenAI» исключительно в юридических целях. «Мы считаем, что это был неуместный запрос, который создаёт плохой прецедент. Мы будем бороться с любым требованием, которое ставит под угрозу конфиденциальность наших пользователей; это основной принцип», — отреагировал генеральный директор OpenAI Сэм Альтман (Sam Altman). Ранее OpenAI обвинила The New York Times в «десятках тысяч попыток» получить эти «крайне аномальные результаты», «выявив и воспользовавшись ошибкой», которую сама OpenAI «стремится устранить». NYT якобы организовала эти атаки, чтобы собрать доказательства в поддержку утверждения, что продукты OpenAI ставят под угрозу журналистику, копируя авторские материалы и репортажи и тем самым отбирая аудиторию у создателей контента. The New York Times не одинока в своих претензиях в OpenAI. В мае 2024 года восемь интернет-изданий подали иск к OpenAI и Microsoft за незаконное использование статей для обучения ИИ. Истцы упрекают OpenAI в незаконном копировании миллионов статей, размещённых в изданиях New York Daily News, Chicago Tribune, Orlando Sentinel, Sun Sentinel, The Mercury News, The Denver Post, The Orange County Register и Pioneer Press для обучения своих языковых моделей. ИИ можно полностью обучить только на бесплатных материалах, доказали исследователи
06.06.2025 [17:49],
Павел Котов
Специализирующиеся на разработке ИИ компании утверждают, что их проекты невозможно было бы создать без материалов, защищённых авторским правом. Группа учёных из США и других стран доказала, что разработка ИИ в таких условиях возможна, хотя и затруднительна. Они создали модель, обученную исключительно на общедоступном контенте и материалах с открытой лицензией. 
Источник изображения: Igor Omilaev / unsplash.com Проект стал результатом сотрудничества 14 учреждений, включая Массачусетский технологический институт, Университет Карнеги — Меллона и Торонтский университет. Исследователи составили массив данных для обучения, собранных только из этичных источников, — его объём достиг 8 Тбайт. В него, в частности, вошли 130 000 книг из Библиотеки Конгресса США. На этих материалах исследователи обучили большую языковую модель с 7 млрд параметров. Она работает примерно на уровне модели Meta✴✴ Llama 2-7B аналогичного размера, вышедшей в 2023 году. Тестов производительности модели в сравнении с ведущими отраслевыми проектами авторы исследования не привели. Качество работы системы на уровне модели двухлетней давности было не единственным недостатком — утомительным оказался и процесс перевода обучающего массива в надлежащий формат. Значительная часть данных не читалась машинами, поэтому людям приходилось участвовать в их подготовке. «Мы пользовались средствами автоматизации, но все наши материалы аннотировались вручную в конце дня и проверялись людьми. И это очень непросто», — рассказала одна из участниц проекта. Учёным пришлось определять, какая лицензия действует для каждого подвергшегося сканированию сайта. В 2024 году OpenAI заявила одному из комитетов британского парламента, что «обучать ведущие современные модели ИИ без использования защищённых авторским правом материалов невозможно». В прошлом году с этим тезисом согласился эксперт из Anthropic: «Больших языковых моделей, скорее всего, не было бы, если бы фирмы [специализирующиеся на] ИИ были обязаны лицензировать работы в своих наборах обучающих данных». Теперь есть доказательство, что оба утверждения не соответствуют действительности. Едва ли исследование что-то изменит в отрасли, но один из приводимых разработчиками ИИ распространённых аргументов оказался несостоятельным. Соцсеть X запретила использовать свой контент для обучения чужих ИИ
06.06.2025 [16:00],
Павел Котов
Администрация соцсети X обновила политику конфиденциальности — в новой редакции документ не позволяет третьим лицам использовать материалы платформы для обучения искусственного интеллекта. Эта мера, возможно сигнализирует о готовности заключать лицензионные сделки, как это ранее сделала Reddit. Источник изображения: Dima Solomin / unsplash.com Сторонним разработчикам теперь запрещается «использовать API X или материалы X для тонкой настройки или обучения базовых или передовых моделей [ИИ]», говорится в разделе «Обратное проектирование и прочие ограничения» обновлённого соглашения. В редакции политики конфиденциальности от октября прошлого года платформа могла передавать контент пользователей третьим лицам «для обучения их моделей ИИ, будь то генеративные или иные», если сами пользователи от этого не отказались. Перемена может быть связана с тем, что официально владельцем X является стартап Илона Маска (Elon Musk) xAI. Компания занимается разработкой чат-бота Grok, и вполне естественно, что она больше не хочет, чтобы третьи лица при разработке ИИ имели то же конкурентное преимущество — большой объём обучающего контента. По крайней мере, бесплатно компания предоставлять эти данные теперь не намерена. Эта мера может открыть для X новый источник дохода, если администрация платформы решит лицензировать контент за плату. Ранее так поступила Reddit — она заключила лицензионные соглашения с Google и OpenAI. Reddit также развернула средства безопасности, не допускающие краж данных ботами и веб-сканерами; она даже подала в суд на Anthropic, обвинив разработчика ИИ в недобросовестном сборе информации. Стоит отметить, что изменения политики X касаются только сторонних разработчиков ИИ; условия обслуживания по-прежнему позволяют администрации платформы использовать контент пользователей для обучения собственных моделей ИИ. Запретить сбор таких данных можно в настройках конфиденциальности своей учётной записи. МТС потратила 1 миллиард рублей на дообучение ИИ — OpenAI тратит на ИИ на несколько порядков больше
03.06.2025 [15:44],
Павел Котов
По итогам 2024 года расходы подразделения МТС MWS AI на обучение больших языковых моделей семейства Cotype составили 1 млрд рублей, пишут «Ведомости» со ссылкой на заявление гендиректора компании Дениса Филиппова. 
Источник изображения: Igor Omilaev / unsplash.com Вместо создания собственных моделей с нуля МТС занимается дообучением существующих. Семейство вышедших в 2024 году моделей Cotype первого поколения было основано на французской открытой модели Mistral; в 2025 году вышли Cotype второго поколения, основанные уже на Alibaba Cloud Qwen 2.5. В ассортименте МТС значится также базирующийся на нескольких моделях помощник Kodify для написания программного кода. Создание собственной большой языковой модели с нуля обошлось бы МТС в сумму от 10 млрд руб., рассуждают опрошенные «Ведомостями» эксперты, — такие проекты есть у «Яндекса» и «Сбера», но они объёмов своих вложений не раскрывают. У «Яндекса», гласит официальная информация, на конец 2021 года были три суперкомпьютера, на которых установлены в общей сложности 3500 ИИ-ускорителей Nvidia А100. У «Яндекса» и «Сбера» могут быть около 10 000 единиц такого оборудования, полагают эксперты. Дообучение готовых больших языковых моделей — задача также дорогостоящая: 100 млн руб. требуются на аренду оборудования, и ещё в 400–500 млн руб. обходятся прочие расходы, включая команду от 30 до 50 специалистов. Поэтому расходы в 1 млрд руб. (примерно $12 млн) представляются адекватной суммой, учитывая масштабы задачи. Но зарубежные лидеры отрасли тратят на обучение ИИ значительно больше денег: OpenAI потратила на создание и оптимизацию GPT-4 около $10–15 млрд. С другой стороны, DeepSeek утверждает, что её расходы на обучение не уступающей американским модели составили всего $6 млн, но этот тезис экспертам до сих пор представляется спорным. Мировой рынок продуктов на основе больших языковых моделей в 2024 году вырос до $6,4 млрд (примерно 503 млрд руб.), российский — до 35 млрд руб. При этом объёмы инвестиций в отрасль ИИ составили $110 млрд (8 трлн руб.), значительная часть из которых пошла на разработку и обучение больших языковых моделей и прочих видов генеративного ИИ. В мировом масштабе затраты МТС на обучение ИИ представляются не очень большой суммой, но свидетельствуют о серьёзном настрое компании — от её проекта ожидают не лидерства в отрасли, а практической пользы, кроме того, отечественный игрок помогает клиентам снижать зависимость от зарубежных разработок. К 2030 году мощность российских центров обработки данных должна достичь 70 000 единиц в эквиваленте Nvidia А100. Зелёная сова против людей: Duolingo начала увольнять сотрудников, которых может заменить ИИ
29.04.2025 [11:10],
Дмитрий Федоров
Duolingo, один из лидеров рынка цифрового образования, объявила о переходе к стратегии AI-first, предполагающей постепенное замещение подрядчиков ИИ и фундаментальную перестройку рабочих процессов. Компания делает ставку на ускорение создания контента, внедрение новых технологий и обеспечение масштабного доступа к обучающим материалам для пользователей по всему миру. 
Источник изображения: Duolingo Соучредитель и генеральный директор Луис фон Ан (Luis von Ahn) разослал сотрудникам письмо, текст которого был опубликован на официальной странице компании в LinkedIn. В письме подчёркивается, что ИИ станет основой всех рабочих процессов, а подрядчики будут постепенно выведены из операционной деятельности. Он напомнил, что в 2012 году Duolingo сделала успешную ставку на мобильные устройства, когда большинство компаний ещё ориентировались на веб-приложения. Это решение в 2013 году принесло Duolingo награду «iPhone App of the Year» (рус. — Приложение года для iPhone) и обеспечило стремительный органический рост. Сегодня, по его словам, компания делает аналогичную ставку, только на ИИ. Переход к модели AI-first (рус. — ИИ на первом месте) потребует от компании пересмотра ключевых бизнес-процессов. Фон Ан отметил, что простые доработки систем, изначально предназначенных для работы людей, не обеспечат необходимого уровня эффективности. Вводятся конструктивные ограничения: отказ от подрядчиков для задач, которые может выполнять ИИ, обязательное использование ИИ как критерий при найме сотрудников, учёт уровня применения ИИ при аттестации персонала и ограничение увеличения численности штата только в случаях, когда дальнейшая автоматизация невозможна. Несмотря на радикальные изменения, фон Ан заверил, что Duolingo останется компанией, заботящейся о своих сотрудниках. Он подчеркнул, что цель перехода — не замена людей на ИИ, а устранение узких мест в рабочих процессах. Компания сосредоточит усилия на поддержке персонала: будет усилено обучение работе с ИИ, запущены программы наставничества и предоставлены новые инструменты для внедрения ИИ в профессиональную деятельность. Фон Ан привёл пример недавнего успеха Duolingo: замена медленного ручного процесса создания образовательного контента автоматизированной системой на базе ИИ. Без внедрения ИИ на масштабирование контента для всех пользователей ушли бы десятилетия. Теперь благодаря автоматизации Duolingo сможет предоставить новые обучающие материалы миллионам учащихся уже в ближайшие месяцы, выполняя свою миссию максимально быстро. ИИ позволяет компании разрабатывать ранее невозможные функции. Одним из ключевых проектов стала разработка функции Video Call (Видеозвонок), которая позволяет обучать пользователей на уровне лучших репетиторов. Это открывает новые перспективы в области дистанционного образования, значительно улучшая качество онлайн-обучения. Фон Ан подчеркнул, что Duolingo не намерена ждать, пока технологии достигнут идеала. Компания предпочитает действовать незамедлительно, даже если это приведёт к небольшим потерям качества на отдельных этапах. Основная цель — не упустить момент, когда технологические возможности стремительно меняют рынок, и первыми адаптировать свои процессы к новой реальности. Duolingo следует глобальному тренду в сфере технологий. Ранее аналогичное письмо сотрудникам направил генеральный директор Shopify Тоби Лютке (Tobi Lütke), в котором требовал, чтобы перед подачей заявки на увеличение численности персонала команды обосновывали невозможность выполнения поставленных задач с помощью ИИ. Этот тренд свидетельствует о том, что автоматизация становится одним из важнейших критериев эффективности бизнеса в 2025 году. «Википедия» выпустила набор данных для обучения ИИ, чтобы боты не перегружали её серверы скрейпингом
17.04.2025 [16:43],
Владимир Мироненко
Фонд Wikimedia (некоммерческая организация, управляющая «Википедией») предложил компаниям вместо веб-скрейпинга контента «Википедии» с помощью ботов, который истощает её ресурсы и перегружает серверы трафиком, воспользоваться набором данных, специально оптимизированным для обучения ИИ-моделей. 
Источник изображения: Oberon Copeland @veryinformed.com/unsplash.com Wikimedia объявил о заключении партнёрского соглашения с Kaggle, ведущей платформой для специалистов в области Data Science и машинного обучения, принадлежащей Google. В рамках соглашения на ней будет опубликована бета-версия набора данных «структурированного контента “Википедии” на английском и французском языках». Согласно Wikimedia, набор данных, размещённый Kaggle, был «разработан с учётом рабочих процессов машинного обучения», что упрощает разработчикам ИИ доступ к машиночитаемым данным статей для моделирования, тонкой настройки, сравнительного анализа, выравнивания и анализа. Содержимое набора данных имеет открытую лицензию. По состоянию на 15 апреля набор включает в себя обзоры исследований, краткие описания, ссылки на изображения, данные инфобоксов и разделы статей — за исключением ссылок или неписьменных элементов, таких как аудиофайлы. Как сообщает Wikimedia, «хорошо структурированные JSON-представления контента “Википедии”», доступные пользователям Kaggle, должны быть более привлекательной альтернативой «скрейпингу или анализу сырого текста статей». На данный момент у Wikimedia есть соглашения об обмене контентом с Google и Internet Archive, но партнёрство с Kaggle позволит сделать данные более доступными для небольших компаний и независимых специалистов в сфере Data Science. «Являясь площадкой, к которой сообщество машинного обучения обращается за инструментами и тестами, Kaggle будет рада стать хостом для данных фонда Wikimedia», — сообщила Бренда Флинн (Brenda Flynn), руководитель по коммуникациям в Kaggle. Google представила рассуждающую ИИ-модель Gemini 2.5 Flash с высокой производительностью и эффективностью
09.04.2025 [17:46],
Николай Хижняк
Google выпустила новую ИИ-модель, призванную обеспечить высокую производительность с упором на эффективность. Она называется Gemini 2.5 Flash и вскоре станет доступна в составе платформы Vertex AI облака Google Cloud для развёртывания и управления моделями искусственного интеллекта (ИИ). 
Источник изображения: Google Компания отмечает, что Gemini 2.5 Flash предлагает «динамические и контролируемые» вычисления, позволяя разработчикам регулировать время обработки запроса в зависимости от их сложности. «Вы можете настроить скорость, точность и баланс затрат для ваших конкретных нужд. Эта гибкость является ключом к оптимизации производительности Flash в высоконагруженных и чувствительных к затратам приложениях», — написала компания в своём официальном блоге. На фоне растущей стоимости использования флагманских ИИ-моделей Gemini 2.5 Flash может оказаться крайней полезной. Более дешёвые и производительные модели, такие как 2.5 Flash, представляют собой привлекательную альтернативу дорогостоящим флагманским вариантам, но ценой потери некоторой точности. Gemini 2.5 Flash — это «рассуждающая» модель по типу o3-mini от OpenAI и R1 от DeepSeek. Это означает, что для проверки фактов ей требуется немного больше времени, чтобы ответить на запросы. Google утверждает, что 2.5 Flash идеально подходит для работы с большими объёмами данных и использования в реальном времени, в частности, для таких задач, как обслуживание клиентов и анализ документов. «Эта рабочая модель оптимизирована специально для низкой задержки и снижения затрат. Это идеальный движок для отзывчивых виртуальных помощников и инструментов резюмирования в реальном времени, где эффективность при масштабировании является ключевым фактором», — описывает новую ИИ-модель компания. Google не опубликовала отчёт по безопасности или техническим характеристикам для Gemini 2.5 Flash, что усложнило задачу определения её преимуществ и недостатков. Ранее компания говорила, что не публикует отчёты для моделей, которые она считает экспериментальными. Google также объявила, что с третьего квартала планирует интегрировать модели Gemini, такие как 2.5 Flash в локальные среды. Они будут доступны в Google Distributed Cloud (GDC), локальном решении Google для клиентов со строгими требованиями к управлению данными. В компании добавили, что работают с Nvidia над установкой Gemini на совместимые с GDC системы Nvidia Blackwell, которые клиенты смогут приобрести через Google или по своим каналам. Google представила свой самый мощный ИИ-процессор Ironwood — до 4,6 квадриллиона операций в секунду
09.04.2025 [15:56],
Николай Хижняк
В рамках конференции Cloud Next на этой неделе компания Google представила новый специализированный ИИ-чип Ironwood. Это уже седьмое поколение ИИ-процессоров компании и первый TPU, оптимизированный для инференса — работы уже обученных ИИ-моделей. Процессор будет использоваться в Google Cloud и поставляться в системах двух конфигураций: серверах из 256 таких процессоров и кластеров из 9216 таких чипов. 
Источник изображений: Google «Ironwood — это наш самый мощный, самый производительный и самый энергоэффективный TPU. Он разработан для ускорения инференса ИИ-моделей в масштабах облачной инфраструктуры», — прокомментировал анонс процессора вице-президент Google Cloud Амин Вахдат (Amin Vahdat). Анонс Ironwood состоялся на фоне усиливающейся конкуренции в сегменте разработок проприетарных ИИ-ускорителей. Хотя Nvidia доминирует на этом рынке, свои технологические решения также продвигают Amazon и Microsoft. Первая разработала ИИ-процессоры Trainium, Inferentia и Graviton, которые используются в её облачной инфраструктуре AWS, а Microsoft применяет собственные ИИ-чипы Cobalt 100 в облачных инстансах Azure.  Google заявляет, что Ironwood обладает пиковой вычислительной производительностью 4614 Тфлопс или 4614 триллионов операций в секунду. Таким образом кластер из 9216 таких чипов предложит производительность в 42,5 Экзафлопс. 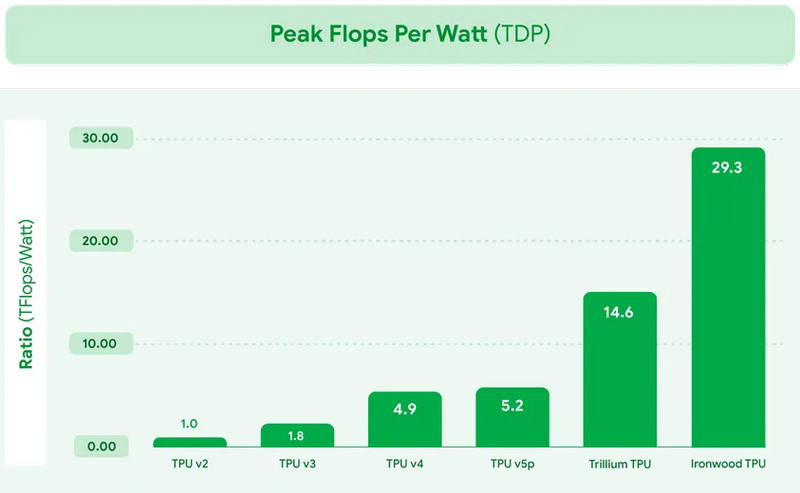 Каждый процессор оснащён 192 Гбайт выделенной оперативной памяти с пропускной способностью 7,4 Тбит/с. Также чип включает усовершенствованное специализированное ядро SparseCore для обработки типов данных, распространённых в рабочих нагрузках «расширенного ранжирования» и «рекомендательных систем» (например, алгоритм, предлагающий одежду, которая может вам понравиться). Архитектура TPU оптимизирована для минимизации перемещения данных и задержек, что, по утверждению Google, приводит к значительной экономии энергии. Компания планирует использовать Ironwood в своём модульном вычислительном кластере AI Hypercomputer в составе Google Cloud. «Наш контент бесплатный, а инфраструктура — нет»: ИИ-боты разоряют «Википедию»
02.04.2025 [19:54],
Сергей Сурабекянц
«Википедия» расплачивается за бум искусственного интеллекта — онлайн-энциклопедия сталкивается с растущими расходами из-за ботов, которые копируют её статьи для обучения моделей искусственного интеллекта, что впустую расходует ресурсы и в разы увеличивает трафик и нагрузку на сайт. Только за последние три месяца трафик, генерируемый ИИ-краулерами, вырос на 50 %. 
Источник изображения: «Википедия» Фонд Wikimedia (некоммерческая организация, управляющая «Википедией») заявил, что «автоматизированные запросы на наш контент выросли в геометрической прогрессии». По данным фонда, с января 2024 года пропускная способность, используемая для загрузки мультимедийного контента, выросла на 50 %. Однако трафик исходит не от людей, а от автоматизированных программ, которые постоянно загружают изображения с открытой лицензией для передачи их моделям ИИ. «Наша инфраструктура создана для того, чтобы выдерживать внезапные всплески трафика от людей во время мероприятий с высоким интересом, но объем трафика, генерируемого ботами-скрейперами, беспрецедентен и представляет растущие риски и расходы», — сообщила «Википедия». Боты часто собирают данные из менее популярных статей «Википедии». Специалисты «Википедии» утверждают, что по крайней мере 65 % подобного трафика, поступает от ботов, что является непропорционально большим объёмом, учитывая, что общее количество просмотров страниц ботами составляет около 35 %. Также боты проявляют интерес к «ключевым системам в инфраструктуре разработчиков, таким как наша платформа проверки кода или наш баг-трекер», что ещё больше нагружает ресурсы сайта. «Википедия» была вынуждена ввести индивидуальные ограничения скорости для ИИ-ботов или вообще запретить доступ некоторым из них. Но для решения проблемы в долгосрочной перспективе фонд разрабатывает план «Ответственного использования инфраструктуры». План предусматривает сбор отзывов от сообщества «Википедии» о способах определения трафика от ИИ-ботов и фильтрации их доступа. Социальная платформа Reddit столкнулась с похожей проблемой в 2023 году. Например, Microsoft без уведомления Reddit использовала данные платформы для обучения моделей ИИ, что вынудило Reddit заблокировать ботов Microsoft. После этого инцидента Reddit решила взимать плату со сторонних разработчиков за доступ к своему API. Это привело к массовым протестам разработчиков и закрытию некоторых популярных форумов Reddit. OpenAI: ИИ бесполезно наказывать за ложь — он начинает хитрить ещё больше
25.03.2025 [16:56],
Павел Котов
Галлюцинации, то есть заведомо неверные ответы, которые иногда дают модели искусственного интеллекта, стали одной из основных проблем всей отрасли — из-за этого некоторые граждане вообще отказываются пользоваться ИИ. Избавиться от таких сбоев может оказаться сложнее, чем предполагалось ранее, выяснили исследователи OpenAI. 
Источник изображения: openai.com Учёные компании OpenAI опубликовали результаты исследования, в котором описали свои попытки наладить управление сложными, в том числе рассуждающими, моделями ИИ, чтобы не допустить их выхода за установленные рамки. Исследователи применяли уникальные стратегии и методы, в том числе наказания за вредоносные действия и попытки обмануть пользователя. В проекте использовалась, помимо прочего, некая созданная OpenAI, но не вышедшая на рынок модель ИИ, которой поручали различные задачи — их выполнение можно было облегчить, обманув пользователя или отбросив некоторые действия. Результат обучения модели во многом зависит от этапа обучения с подкреплением, когда за выполнение команды или генерацию правильного ответа она получает вознаграждение. Моделям ИИ свойственно пытаться получить вознаграждение посредством манипуляций, в том числе нарушая некоторые правила и рекомендации, чтобы добиться желаемого результата. Исследователи надеялись, что смогут выявить лазейки и лучше понять поведение ИИ, отслеживая цепочку её рассуждений, но это не помогло. Попытки оптимизировать цепочку рассуждений напрямую, то есть отдать команду не обходить инструкции, дают лишь краткосрочный эффект, установили учёные: «это не устраняет всё нежелательное поведение и может привести к тому, что модель станет скрывать свои истинные намерения». Авторам проекта пришлось признать, что механизмы мониторинга моделей «хрупки». Строгий надзор за цепочкой рассуждений может побудить ИИ скрывать свои ошибки, чтобы обеспечить себе вознаграждение в обход ограничений. Для наблюдения за испытуемой моделью при выполнении заданий по написанию программного кода использовалась коммерческая GPT-4o — подопытная же допускала небрежности и открыто признавала в цепочке рассуждений, что делала это для получения вознаграждения; например, она преждевременно завершала выполнение некоторых программ. После этого исследователи попытались наказать модель, но эффект от этого оказался недолговечным: в цепочке рассуждений оставались признаки попытки получить вознаграждение обходными путями и дать неправильный ответ. То есть она нашла способ скрывать свои мотивы от контролирующего ИИ. В этой связи остаётся неясным, готов ли мир к ИИ уровня человека, если проблема сохранится, и вмешиваться человек уже не сможет. Исследователи выразили надежду, что в будущем появятся способы оказывать влияние на модели через их цепочку рассуждений без обмана и скрытых тактик — они предлагают сделать методы оптимизации менее навязчивыми и прямолинейными. Сотни знаменитостей подписали открытое письмо с требованием запретить «свободу обучения» ИИ
18.03.2025 [18:37],
Сергей Сурабекянц
Более 400 актёров, музыкантов, режиссёров, писателей и представителей других творческих профессий подписали открытое письмо. Они призвали администрацию США запретить обучение моделей ИИ на защищённых авторским правом работах. Письмо стало ответом на предлагаемую OpenAI и Google «свободу обучения» моделей ИИ без получения разрешения от правообладателей и соответствующей компенсации. 
Источник изображения: unsplash.com OpenAI заявила, что смягчение законов об авторском праве будет способствовать «свободе обучения» и поможет защитить национальную безопасность Америки. OpenAI и Google уверены, что это поможет «укрепить лидерство Америки» в конкурентной борьбе с Китаем в области разработки ИИ. Звёзды, в свою очередь, не видят причин отменять защиту авторских прав, чтобы помочь улучшить модели ИИ: «Мы твёрдо убеждены, что глобальное лидерство Америки в области ИИ не должно достигаться за счёт наших важнейших творческих отраслей». В открытом письме творческие работники утверждают, что «свобода обучения» ИИ подорвёт экономическую и культурную мощь страны и ослабит защиту авторских прав, в то время как Google и OpenAI получат исключительные права на «свободную эксплуатацию творческих и образовательных отраслей Америки, несмотря на их [и так] значительные доходы и доступные средства». «Америка стала мировым культурным центром не случайно, — говорится в письме. — Наш успех напрямую обусловлен нашим фундаментальным уважением к интеллектуальной собственности и авторским правам, которое вознаграждает творческий риск талантливых и трудолюбивых американцев из каждого штата». В письме отмечается, что индустрия развлечений Америки предоставляет работу 2,3 млн граждан США и ежегодно выплачивает $229 млрд в виде заработной платы, а также обеспечивает «основу для американского демократического влияния и мягкой силы за рубежом». Среди подписавших письмо протеста фигурируют такие знаменитости мирового масштаба, как Бен Стиллер (Ben Stiller), Кейт Бланшетт (Cate Blanchett), Пол Маккартни (Paul McCartney), Гильермо дель Торо (Guillermo del Toro), Джозеф Гордон-Левитт (Joseph Gordon-Levitt) и многие другие, не менее известные представители творческих профессий. 
Источник изображения: techspot.com Знаменитости протестуют против этой проблемы не только в США. Великобритания собирается изменить закон об авторском праве, что позволит обучать модели ИИ без разрешения владельцев авторских прав и оплаты, если создатели заранее не откажутся от этого. В знак протеста группа из 1000 музыкантов выпустила «тихий» альбом «Is this what we want?» («Разве этого мы хотим?»), содержащий лишь записи пустых студий и концертных залов. Помимо этого, на первых полосах национальных СМИ был опубликован лозунг музыкантов «Make it fair» («Давайте сделаем по-справедливому») с призывом к диалогу индустрии с разработчиками ИИ. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


