|
Опрос
|
реклама
Быстрый переход
OpenAI без лишнего шума изменила правила работы с персональными данными пользователей ChatGPT
03.05.2026 [07:01],
Алексей Разин
В последний день апреля OpenAI опубликовала на своём сайте новое пользовательское соглашение, которое распространяется на клиентов ChatGPT в США. Новые условия определяют, как будут обрабатываться, храниться и передаваться персональные данные десятков миллионов пользователей. Помимо прочего, OpenAI не скрывает, что теперь ChatGPT является своего рода рекламной платформой. 
Источник изображения: Unsplash, Jonathan Kemper Официально утверждено положение, которое обкатывалось в этом году в экспериментальном режиме. Пользователи бесплатного тарифа и подписчики плана ChatGPT Go за $8 в месяц должны будут смириться с тем, что OpenAI анализирует их переписку в чат-боте для адресной демонстрации рекламных объявлений. Алгоритм учитывает историю запросов и просмотров рекламы. При этом рекламодатели не получают персональной информации о пользователях и не видят историю переписки в ChatGPT, они только видят сводную статистику просмотров и переходов по ссылкам. Реклама перестала быть бета-функцией в ChatGPT, официально перейдя на коммерческие рельсы. Во-вторых, желающие найти пользователей ChatGPT среди абонентов в своей адресной книге могут загрузить её в чат-бот, но при этом OpenAI получит доступ к контактной информации даже тех людей из справочника, которые её продуктами не пользуются вообще, и у них не будет возможности воспротивиться этому. Фактически, у OpenAI появляется возможность выстроить граф социальных связей каждого пользователя. Политика обработки персональных данных пользователей ChatGPT теперь сильно различается для США и ЕС, а также всего остального мира. В первом случае OpenAI оставляет за собой право делиться некоторыми данными пользователей с маркетинговыми партнёрами в рекламных целях. Во всём остальном мире подобные трансферы персональных данных пользователей ChatGPT не предусмотрены. Кроме того, OpenAI получает от рекламных партнёров обратную связь о покупках, которые клиенты ChatGPT совершают в результате перехода по ссылкам в рекламных объявлениях. Эта статистика будет использоваться для оценки эффективности рекламных кампаний, проводимых OpenAI в сотрудничестве с партнёрами. В новой редакции пользовательского соглашения OpenAI также указываются сроки хранения данных клиентов. Удалённая по инициативе самого пользователя информация самой OpenAI очищается через 30 дней. Временные сессии в чат-боте удаляются автоматически. Впрочем, предусмотрен обширной перечень исключений. Если речь идёт о каких-то финансовых транзакциях, либо нелегальной деятельности или оскорблениях, то сроки хранения данных о переписке пользователей увеличиваются. Если пользователь уличён в нарушении политики OpenAI, то его данные могут сохраняться неограниченное время для возможных дальнейших разбирательств. Есть и ещё один аспект, связанный с хранением данных пользователей ChatGPT. По иску The New York Times об авторских правах все пользовательские данные в период с апреля по сентябрь 2025 года хранятся на специальном защищённом ресурсе, доступ к которому имеют только специалисты OpenAI по безопасности и юриспруденции. В целом, американским пользователям ChatGPT теперь следует иметь в виду, что без более дорогих тарифных планов OpenAI оставляет за собой право более свободно распоряжаться их данными, даже если они касаются людей из перечня контактов пользователей. Упор в деятельности ChatGPT на рекламу также может повлиять на работу с сервисом корпоративных клиентов, которые столкнутся с продвижением товаров и услуг рекламодателей. Это также придётся учитывать в работе с ChatGPT. Япония собралась стать раем для ИИ-разработчиков и ослабила запреты по персональным данным
08.04.2026 [10:42],
Павел Котов
Японские власти решили сделать страну самым свободным в мире регионом для разработки приложений на основе искусственного интеллекта. Для этого они внесли изменения в законодательство и устранили требование для компаний получать у граждан согласие на использование некоторых категорий персональных данных. 
Источник изображения: Roméo A. / unsplash.com Накануне, 7 апреля, правительство Японии одобрило поправки к «Закону о защите персональных данных», которые отменяют требование получать согласие перед сбором персональных данных. Речь идёт только об информации, представляющей незначительную угрозу нарушения прав человека, и при её использовании для сбора статистики в исследовательских целях. Под действие поправок подпадают данные, связанные со здоровьем граждан, если они помогут улучшить общественное здравоохранение. Разрешается сканирование лиц — поправки требуют, чтобы занимающиеся их сбором организации объясняли, как они обрабатывают эту информацию; предоставлять гражданам возможность отказаться от использования их данных они больше не обязаны. Для сбора изображений детей младше 16 лет требуется согласие родителей; в отношении прочей связанной с несовершеннолетними информации будет применяться критерий «наилучших интересов». Организации, которые собирают недопустимые данные или злонамеренно используют эту информацию для причинения вреда гражданам, будут штрафоваться на сумму, равную полученной от неправомерной деятельности прибыли. Штрафы также полагаются за получение данных мошенническим путём. Все эти меры, считают японские власти, необходимы, потому что действующее законодательство представляет собой «очень большое препятствие к развитию и применению ИИ в Японии». «Мы должны это предотвратить, потому что без доступа к [персональным] данным Японии будет непросто разрабатывать и развёртывать полезный ИИ», — заявил глава министерства по цифровой трансформации Хисаси Мацумото (Hisashi Matsumoto). Google упростила удаление персональных данных и интимных фото из поиска
10.02.2026 [19:10],
Сергей Сурабекянц
Google предоставила пользователям больше контроля над результатами поиска. В дополнение к электронной почте и номеру телефона, теперь появилась возможность найти и удалить из поисковой выдачи информацию об удостоверении личности, водительских правах и номере социального страхования. Сделать это можно прямо из раздела «О Вас» в результатах поиска. Google также упростила удаление фотографий пользователя откровенного характера из результатов поиска изображений. 
Источник изображений: Android Authority Удалить персональную информацию из результатов поиска возможно только после заполнения соответствующих полей в разделе «О Вас», иначе поисковая система не сможет убедиться, что пользователь желает удалить именно свою личную информацию, а не данные другого человека. Google заверила, что использует передовые протоколы безопасности и шифрование для защиты предоставленной информации от неправомерного использования. После ввода информации Google просканирует результаты поиска и уведомит по электронной почте или через приложение Google (в зависимости от настроек) о том, где можно найти эту информацию. Затем пользователь сможет удалить её непосредственно из результатов поиска. Следует отметить, что удаление информации из результатов поиска Google не означает её удаление из интернета. Эта информация сохранится на всех ресурсах, где она была размешена и может быть найдена при помощи локального поиска на сайтах, через другую поисковую систему или при помощи бота. 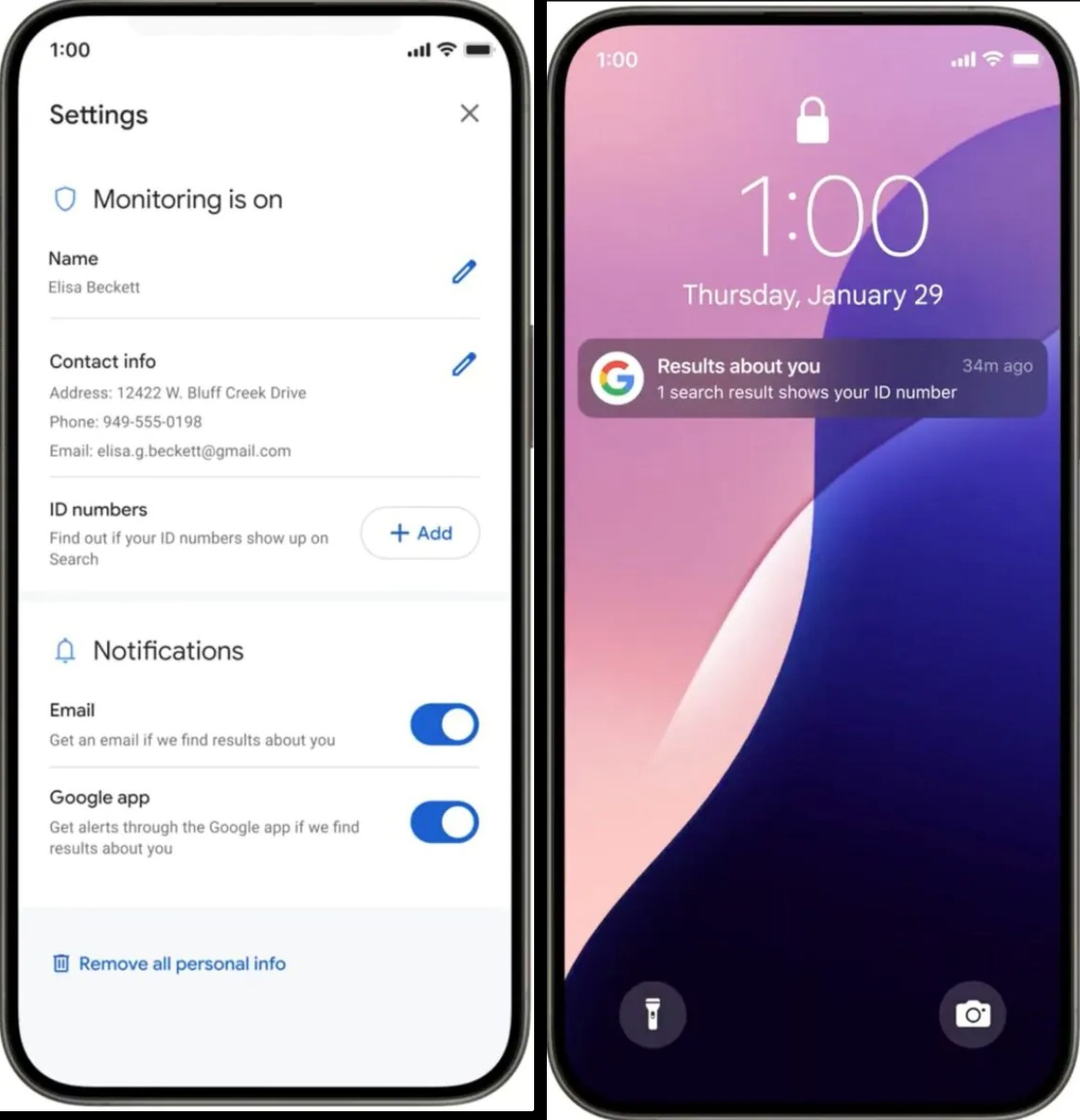 Google также упростила удаление изображений откровенного характера, полученных без согласия пользователя. Пользователю нужно открыть меню рядом с изображением в результатах поиска Google и выбрать «удалить результат» —> «На изображении показано моё сексуальное фото». Можно сформировать запрос на удаление сразу нескольких изображений. Пользователь может отслеживать статус всех своих запросов в разделе «О Вас». 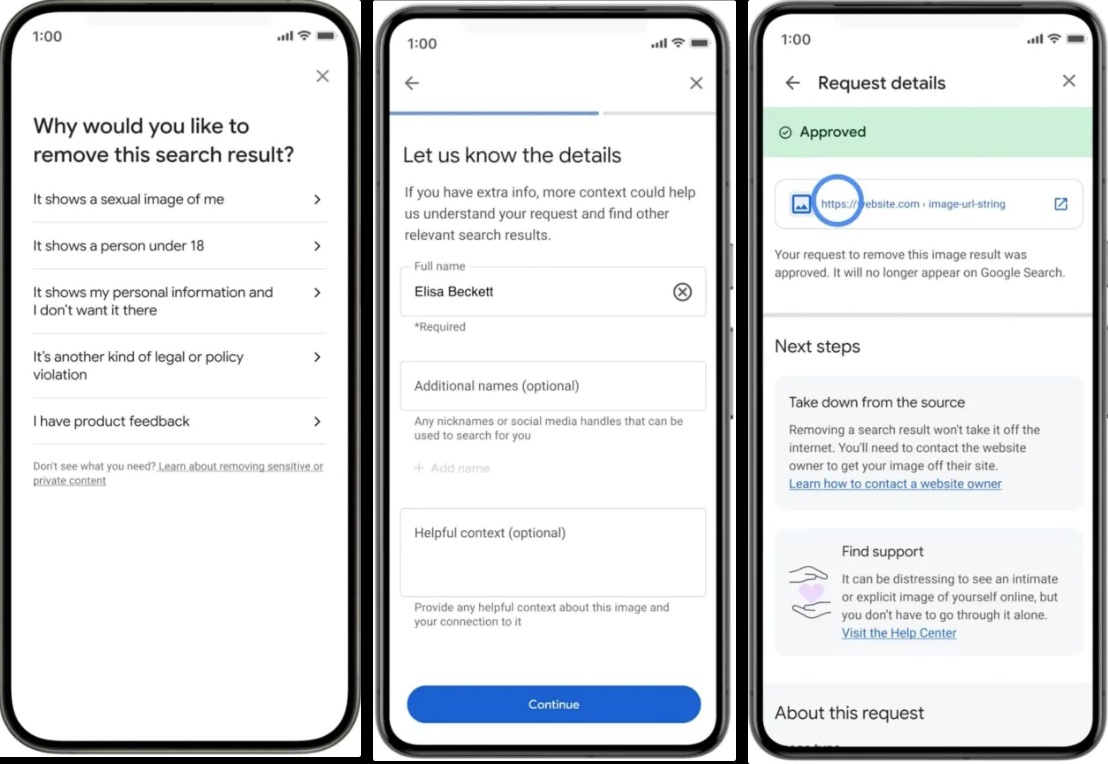 Дополнительно можно включить защиту, которая будет заблаговременно отфильтровывать любые дополнительные результаты сексуального характера, которые могут появиться в похожих поисковых запросах. После отправки запроса на удаление Google покажет ссылки на экспертные организации, оказывающие эмоциональную и юридическую поддержку. В ближайшие дни Google пообещала начать развёртывание этих новых инструментов в США, а затем они станут доступны и в других регионах. Подглядеть не получится: Samsung сделает уведомления на экране смартфона невидимыми для посторонних
28.01.2026 [18:52],
Сергей Сурабекянц
Сегодня Samsung представила функцию конфиденциальности, которая не позволит посторонним подглядеть информацию на смартфоне пользователя. Компания не предоставила подробностей о технологии, но заверила, что владельцы будущих смартфонов Galaxy смогут контролировать, что видят окружающие на их устройстве. Кроме того, можно будет скрыть от любопытных взглядов лишь часть экрана, например, область уведомлений. 
Источник изображения: @UniverseIce По словам Samsung, пользователи смогут настраивать эту функцию видимости содержимого на экране для работы с определёнными приложениями или при вводе паролей, PIN-кодов или графических ключей. При необходимости владелец сможет скрывать от посторонних лишь часть экрана, например, область всплывающих уведомлений. Для достижения этих результатов Samsung использует сочетание аппаратного и программного обеспечения. «Наши телефоны — это наше самое личное пространство, но мы используем их в наименее приватных местах… Именно поэтому Samsung скоро представит новый уровень защиты конфиденциальности, который защитит ваш телефон от подглядывания, где бы вы ни находились. У вас будет возможность проверять сообщения или вводить пароль в общественном транспорте, не задумываясь о том, кто может за вами наблюдать», — отметила компания в пресс-релизе. Интернет-инсайдер Ice Universe опубликовал в соцсети X скриншоты этой функции, показывающие, как область уведомлений скрывается при взгляде на дисплей под углом. Если функция будет работать как показано на этих фотографиях, людям, возможно, больше не понадобится искать укромные места для просмотра и ввода чувствительной информации, или покупать отдельные защитные экраны для обеспечения конфиденциальности. Использование смартфонов в общественных местах может быть рискованным. Когда пользователи вводят личную информацию, такую как пароли, любой посторонний может увидеть эти данные и использовать их в своих интересах. Чтобы предотвратить это, Apple выпустила обновление «Защита от кражи устройств» в iOS 17.3, которое требовало от пользователей использования FaceID или Touch ID перед изменением конфиденциальных настроек или доступом к сохранённым способам оплаты. Анонсированная Samsung функция, вероятно, будет запущена вместе с грядущим флагманским смартфоном Galaxy S26 Ultra. Мероприятие, посвящённое запуску устройства, ожидается в феврале. Хакеры слили данные сотен сотрудников ФБР, Минюста и Министерства внутренней безопасности США
17.10.2025 [18:13],
Сергей Сурабекянц
Группа Scattered LAPSUS$ Hunters из хакерского сообщества Com, стоящего за крупными утечками данных в последние годы, опубликовала имена и личные данные сотен государственных служащих, включая сотрудников ФБР, Министерства юстиции США, Министерства внутренней безопасности США, Иммиграционной и таможенной полиции США. Хакеры публично обратились к мексиканским наркокартелям, требуя вознаграждения за доксинг (раскрытие персональных данных) агентов США. 
Источник изображения: unsplash.com «Я хочу свои деньги, Мексика», — написал пользователь Telegram-канала Scattered LAPSUS$ Hunters, объединяющего несколько хакерских групп, связанных с киберпреступным сообществом Com. «Мексиканские картели, мы сбрасываем все документы, где мой миллион долларов?» — говорится в другом сообщении. Хакеры имеют в виду заявление Министерства внутренней безопасности США о том, что мексиканские картели начали предлагать вознаграждение за доксинг агентов. Правительство США не подтвердило и не опровергло это утверждение, несмотря на угрозы хакеров в следующий раз раскрыть данные работников налогового управления. Издание 404 Media изучило несколько таблиц с данными, опубликованных в Telegram-канале группы. Одна содержала якобы персональные данные 680 сотрудников Министерства внутренней безопасности, другая — сведения о более чем 170 адресах электронной почты ФБР и их владельцах; а третья — персональные данные более 190 сотрудников Министерства юстиции. При содействии компании District 4 Labs, специализирующейся на кибербезопасности, сотрудники 404 Media подтвердили достоверность некоторых опубликованных данных. Исследование показало, что многие части документов действительно относились к государственным служащим с тем же именем, названием агентства, адресом или номером телефона. В некоторых случаях адреса, опубликованные хакерами, по-видимому, относились к жилым, а не к офисным помещениям. Неясно, как хакеры собрали или иным образом получили эти данные, будь то объединение предыдущих разрозненных утечек данных или получение их из конкретного государственного органа. Министерство внутренней безопасности заявило, что его чиновники «сталкиваются с более чем 1000 % ростом числа нападений на них и их семьи, подвергающихся доксингу и угрозам в интернете». Остаётся неясным, как именно Министерство рассчитало этот рост и какие данные использовало. Правительство США принимает меры в отношении приложений, веб-сайтов и страниц в социальных сетях, которые, по его мнению, раскрывают персональную информацию или иным образом угрожают государственным служащим. Во многих случаях эти источники информации действовали в соответствии с первой поправкой к Конституции США и не занимались доксингом, но всё равно вынуждены были подчиниться. Так, Apple была вынуждена удалить приложение Eyes Up, которое собирало видеозаписи действий и злоупотреблений иммиграционных и таможенных служащих. Также Apple пришлось запретить ряд приложений, которые демонстрировали незаконные действия государственных чиновников, после прямого давления со стороны Министерства юстиции. Хакерская группа Scattered LAPSUS$ Hunters приобрела известность после угрозы опубликовать большой объём данных клиентов Salesforce, включая Disney/Hulu, FedEx, Toyota, UPS и других. В 2016 году другая хакерская группа под названием Crackas With Attitude опубликовала личные данные около 20 000 агентов ФБР и 9000 сотрудников Министерства внутренней безопасности. ФСБ и МВД накрыли крупнейший в Рунете сервис по продаже персональных данных россиян
25.08.2025 [12:41],
Владимир Мироненко
Сотрудники УБК МВД России и ФСБ пресекли работу одного из крупнейших в Рунете интернет-ресурсов по торговле персональными данными россиян, пишет «Коммерсантъ» со ссылкой на Telegram-канал официального представителя МВД Ирины Волк. 
Источник изображения: charlesdeluvio / unsplash.com По словам Ирины Волк, сервис располагал большими массивами данных, собранных по результатам утечек из различных структур. Среди его пользователей — коммерческие организации, детективные и коллекторские агентства. Также правоохранителями были зафиксированы факты получения конфиденциальной информации аферистами для последующего хищения денежных средств населения. Злоумышленники предоставляли по запросу подробные досье на граждан, включая анкетные и паспортные данные, сведения об адресах проживания и местах работы, доходах, кредитной истории и т.д. Доступ к ресурсу осуществлялся по подписке через веб-форму или интерфейс АPI. Стоимость подписки зависела от объёма услуг и статуса клиента, нередко превышая один миллион рублей в месяц. Из-за высокой цены клиенты зачастую перепродавали подписку через объявления в специализированных Telegram-каналах и в даркнете. Предполагаемый организатор криминальной схемы и его сообщник, который отвечал за программную и техническую поддержку сервиса, уже задержаны на территории столичного региона и заключены под стражу. Им предъявлено обвинение по статье 272.1 Уголовного кодекса Российской Федерации — незаконное использование, сбор, передача и хранение персональной информации. В ходе обысков было изъято серверное оборудование с базами данных общим объёмом более 25 Тбайт, а также средства связи, компьютерная техника, договорная и бухгалтерская документация. Сообщается, что с декабря 2024 года только по двум счетам подконтрольных злоумышленникам юридических лиц зафиксировано поступление 66 млн руб. В настоящее время правоохранителями проверяется информация о более чем двух тысячах пользователей сервиса, а также приняты меры к установлению других возможных соучастников, в том числе иностранных граждан и спецслужб. Хакеры похитили личные данные клиентов Cisco, выманив пароль по телефону
05.08.2025 [19:50],
Сергей Сурабекянц
Сегодня компания Cisco сообщила, что 24 июля хакеры получили доступ и экспортировали «подмножество базовой информации профиля» из базы данных сторонней облачной системы управления взаимоотношениями с клиентами (предположительно CRM компании Salesforce). По утверждению Cisco, киберпреступники воспользовались голосовым фишингом (вишингом — vishing, от voice phishing), обманом убедив представителя Cisco предоставить им доступ. 
Источник изображений: unsplash.com Cisco сообщила, что украденные данные включали «имя клиента, название организации, адрес, назначенный Cisco идентификатор пользователя, адрес электронной почты, номер телефона и метаданные, связанные с учётной записью», такие как дата создания учётной записи. Компания не уточнила, сколько её пользователей пострадало от этой утечки. Cisco является известным клиентом Salesforce. По мнению специалистов Bleeping Computer, утечка данных Cisco может оказаться результатом одной из целой серии атак, нацеленных на данные компаний, пользующихся услугами сервисов Salesforce. Среди целей преступников — американский страховой гигант Allianz Life, ритейлер предметов роскоши Tiffany, австралийская авиакомпания Qantas и многие другие известные компании.  Salesforce — американская компания, разработчик одноимённой CRM-системы, предоставляемой заказчикам исключительно по модели SaaS (software as a service — «программное обеспечение как услуга»). Под наименованием Force.com компания предоставляет PaaS-систему для самостоятельной разработки приложений, а под брендом Database.com — облачную систему управления базами данных. В Китае запустили систему обезличенной аутентификации пользователей в интернете, которая таковой не является
16.07.2025 [12:09],
Алексей Разин
С прошлого года в КНР проходила обкатку система присвоения всем пользователям Сети уникальных идентификаторов, которые формально их обезличивали и позволяли защитить персональные данные от утечки. Недавно она была введена в эксплуатацию. При этом рассчитывать на анонимность пользователи интернета в Китае всё равно не могут, поскольку с 2017 года для регистрации на многих информационных ресурсах необходимо предоставлять личные документы. 
Источник изображения: Unsplash, Huichao Ji С прошлого года в рамках эксперимента китайские пользователи социальных сетей и прочих ресурсов, позволяющих им публиковать информацию, применяли специальное приложение, которое присваивала им виртуальный идентификационный номер, состоящий из произвольной комбинации символов и цифр. Его можно было использовать при входе на различные сайты, последние при этом не видели реальное имя пользователя. Это позволяло уменьшить объём обрабатываемых сайтами персональных данных на 89 % и снизить риск их утечки. Формально, использование данной системы идентификации пользователей остаётся добровольным как для самих граждан Китая, так и для компаний, оказывающих им услуги. Тем не менее, с 2017 года в стране фактически запрещена анонимная регистрация на большинстве информационных площадок, а предъявлять личные документы при оформлении договора на оказание услуг связи нужно с 2010 года. Противники этой инициативы утверждают, что унифицированные обезличенные идентификаторы позволяют проще следить за поведением пользователей в сети. Десятки популярных в Китае приложений, включая WeChat, Taobao, Tmall и Douyin (TikTok) уже поддерживают новую схему идентификации пользователей. Её применение на законодательном уровне было закреплено в мае текущего года. 39 млн записей с персональными данными россиян утекло за первое полугодие
03.07.2025 [17:22],
Алексей Селиванов
Объём утечек персональных данных россиян приблизился к 40 млн записей с начала текущего года, сообщил Роскомнадзор. Причём для этого понадобилось всего лишь 35 инцидентов, то есть за один раз допускалась утечка в среднем более 1 млн записей. 
Источник изображения: Arif Riyanto/unsplash.com «За первые шесть месяцев 2025 года Роскомнадзор зафиксировал 35 фактов утечек персональных данных, в результате которых оказались скомпрометированы более 39 млн записей», — передает ТАСС со ссылкой на пресс-службу Роскомнадзора. В ведомстве добавили, что за последние два месяца в Роскомнадзор поступила информация об инцидентах от пяти операторов. В этом году по факту утечек персональных данных было составлено шесть протоколов об административных правонарушениях по статье 13.11 КоАП РФ. Некоторые дела еще находятся в суде, а по некоторым уже вынесены решения о предупреждениях и взыскании штрафов. Напомним, 30 мая вступил в силу Федеральный закон № 420-ФЗ, которым предусмотрено ужесточение административной ответственности за нарушения обработки персональных данных. Штраф за утечку пользовательских данных теперь составляет от 3 до 20 млн рублей. Суд обязал OpenAI хранить даже удалённые чаты, но пользователи считают это тотальной слежкой
24.06.2025 [06:50],
Анжелла Марина
После того, как суд обязал OpenAI сохранять все чаты пользователей ChatGPT, включая удалённые и анонимные, несколько пользователей в США попытались оспорить это решение в судебном порядке, ссылаясь на нарушение приватности. Но суд отклонил жалобу, в которой утверждалось, что судебный запрет на удаление переписки создаёт угрозу массовой слежки за миллионами людей. 
Источник изображения: AI Как сообщает издание Ars Technica, решение о бессрочном хранении чатов было вынесено Окружным судом Соединённых Штатов Южного округа Нью-Йорка в рамках иска о нарушении авторских прав, поданного медиакомпаниями, включая издание The New York Times. OpenAI обязали сохранять все данные на случай, если они понадобятся как доказательство в текущем деле. Однако пользователь Эйдан Хант (Aidan Hunt) подал протест, заявив, что чаты могут содержать личную и коммерческую тайну. Хант утверждал, что компания OpenAI ранее обещала не хранить удалённые чаты и не предупредила об изменениях. «Клиентам не объяснили, что их данные останутся бессрочно в системе, что нарушает право на приватность и четвёртую поправку Конституции США», — сказал он. Хант в своём ходатайстве предлагал исключить из хранения на серверах OpenAI анонимные чаты, медицинские вопросы, обсуждение финансов и права. Судья Она Ван (Ona Wang) отклонила его протест, посчитав вопрос приватности второстепенным в деле об авторском праве. Также была подана жалоба от лица консалтинговой компании Spark Innovations, в которой указывалось на недопустимость хранения чатов, содержащих коммерческую тайну и обсуждение рабочих процессов. Одновременно Коринн Макшерри (Corynne McSherry), юрист из Фонда электронных рубежей (EFF) по защите цифровых прав, поддержала опасения: «Этот прецедент угрожает приватности всех клиентов OpenAI. ИИ-чаты становятся новым инструментом корпоративной слежки, особенно если люди не контролируют свои данные [после их удаления]». Но пользователи задаются вопросом, насколько активно OpenAI будет отстаивать их интересы, так как есть опасения, что компания может пожертвовать защитой личных данных ради экономии средств или репутационных выгод. Представители OpenAI пока не ответили на запрос Ars Technica, но ранее заявляли, что намерены оспаривать судебное решение. Правозащитники, в свою очередь, призывают все ИИ-компании не только обеспечивать реальное удаление данных из чатов, но и своевременно информировать пользователей о требованиях со стороны судебных инстанций. «Если компании ещё этого не делают, им стоит начать публиковать регулярные отчёты о таких запросах», — добавила юрист Макшерри. WhatsApp не сможет запустить рекламу в Евросоюзе до следующего года
20.06.2025 [12:23],
Алексей Разин
Недавно стало известно о намерениях компании Meta✴✴, владеющей мессенджером WhatsApp, внедрить рекламу на отдельных вкладках IM-клиента с целью монетизации сервиса, а также ввести подписку для ряда клиентов. Европейским регуляторам в Ирландии было сообщено, что данные изменения не коснутся региональной политики WhatsApp до следующего года. 
Источник изображения: Unsplash, Grant Davies Об этом сообщили западные СМИ со ссылкой на заявления руководства ирландской Комиссии по защите данных (DPC), которая отвечает за соблюдение региональных норм в данной сфере на территории Евросоюза. Все дальнейшие нюансы реализации новой политики WhatsApp в юрисдикции этого геополитического блока будут обсуждаться с представителями компании в ходе последующих встреч, как отмечается в заявлении регулятора. Нововведения, предлагаемые WhatsApp, на территории Евросоюза в текущем году реализованы не будут, поскольку потребуют согласования с региональными чиновниками различных уровней. Пока, по их словам, рано говорить что-либо конкретное относительно рекламной бизнес-модели, предложенной WhatsApp. При этом представители WhatsApp признали, что планируемые изменения, связанные с внедрением рекламы и подписки, являются частью глобальной политики компании, и будут внедряться поэтапно по всему миру. История просмотров может быть использована Meta✴✴ для таргетированной рекламы только в том случае, если пользователь WhatsApp, Instagram✴✴ и Facebook✴✴ добровольно свяжет свои учётные записи во всех трёх приложениях. Остановить внедрение ИИ-функций в своих социальных сетях Meta✴✴ на территории Евросоюза также была вынуждена после вмешательства местных регуляторов, которые выразили озабоченность недостаточной защищённостью персональных данных пользователей. Google откроет Gemini доступ ко всей информации о пользователях, которую она накопила
02.05.2025 [19:20],
Павел Котов
Гонка чат-ботов с искусственным интеллектом накаляется, и теперь Google собирается дать Gemini возможность понять пользователя как, возможно, никто другой. Gemini сможет не только запоминать предыдущие разговоры с человеком, но также учиться на его действиях в других приложениях: Gmail, «Google Календарь» и YouTube, сообщил президент Google Labs и Gemini Джош Вудворд (Josh Woodward). 
Источник изображения: blog.google В апреле OpenAI объявила, что значительно расширит память ChatGPT, позволит помощнику обращаться к прошлой переписке с пользователем и использовать эту информацию для персонализации последующих ответов. Такие ответы, по мнению компании, будут в большей степени соответствовать его интересам, привычкам и предпочтениям, обеспечивая более комфортное и полезное взаимодействие. В Google решили на этом не останавливаться. В ближайшее время компания откроет Gemini доступ к истории прошлых чатов пользователя и ИИ, а после этого развернёт функцию pcontext, что означает «персонализированный контекст». Пока эта функция тестируется внутри компании. Она предназначена для извлечения информации из учётной записи пользователя в экосистеме Google, что обеспечит Gemini глубокое понимание жизни пользователя: упоминаются, в частности, Gmail, «Google Фото», «Google Календарь», «Google Поиск» и YouTube. Компания намеревается сделать Gemini более активным, но не уточнила, что именно имеется в виду. Возможно, помощник с ИИ будет по собственной инициативе выдвигать полезные предложения с учётом расписания, истории веб-поиска и активности в почтовом ящике пользователя. Настолько глубокая интеграция, конечно, поднимает вопрос о конфиденциальности. Google и без того хранит чрезвычайно много информации о пользователях, а открытие её системе ИИ и возможность совершать операции с этими данными — очередной шаг вперёд. Поэтому в компании заверили, что будут запрашивать у пользователей явное разрешение, прежде чем Gemini получит доступ к этим данным. Это шаг к тому, чтобы сделать Gemini более «личным, проактивным и мощным», уверен господин Вудворд. И намекнул, что скоро появится новая информация. Более трети российских компаний удаляют персональные данные вручную
12.04.2025 [12:56],
Владимир Фетисов
ГК «Гарда» провела исследование, посвящённое работе российских компаний с персональными данными. Оказалось, что ручной поиск и удаление таких данных из баз, файловых хранилищ и с отдельных рабочих мест практикуются в 39 % компаний. В 25 % компаний применяются шредеры и сжигание наряду со специализированным программным обеспечением, в 10 % — только механическое уничтожение, и ещё в 10 % — иные способы. 
Источник изображения: FlyD / Unsplash Также было установлено, что только 3 % компаний используют сертифицированное программное обеспечение для удаления персональных данных, а 12 % компаний вовсе не удаляют такую информацию. Напомним, операторы персональных данных обязаны удалять сведения по запросу субъекта или по истечении срока их хранения. Представитель Роскомнадзора сообщил, что неудаление записей персональных данных является неправомерным, и лицо, осуществляющее такую деятельность, может быть привлечено к административной ответственности. Отмечается, что неудаление персональных данных в сроки, установленные ч. 1 ст. 13.11 КоАП РФ, влечёт ответственность в виде штрафа: для физических лиц — от 2 тыс. до 6 тыс. рублей, для должностных лиц — от 10 тыс. до 20 тыс. рублей, для юридических лиц — от 60 тыс. до 100 тыс. рублей. Руководитель продуктового направления по защите баз данных ГК «Гарда» Дмитрий Ларин считает, что высокий показатель неудаления персональных данных связан с отсутствием у компаний инструментов автоматизации. В компании «Код безопасности» такую тенденцию объясняют тем, что информация хранится в различных базах данных. Специалисты сходятся во мнении, что эти причины подчёркивают необходимость стандартизации и внедрения эффективных решений для работы с персональными данными. Кроме того, не во всех организациях налажен процесс учёта данных, из-за чего оператор может не знать, что именно необходимо удалить и откуда. В ГК «Гарда» отметили, что для регулятора не имеет значения, каким образом удаляются персональные данные, однако из-за сжатых сроков этот процесс в компаниях либо вовсе не выполняется, либо проводится «спустя рукава». Помимо этого, отсутствие автоматизации создаёт риски утечки данных по причине человеческого фактора. Россия заняла второе место в мире по утечкам данных
19.03.2025 [18:04],
Сергей Сурабекянц
По данным экспертно-аналитического центра InfoWatch, несмотря на некоторое снижение общего количества утечек данных в мире, их частота и масштабы «по-прежнему остаются угрожающими». В 2024 году на российские компании и государственные органы пришлось 8,5 % известных мировых случаев компрометации данных, что обеспечило РФ второе место среди исследуемых стран. Кроме того, по утечкам персональных данных Россия переместилась с седьмого на пятое место. 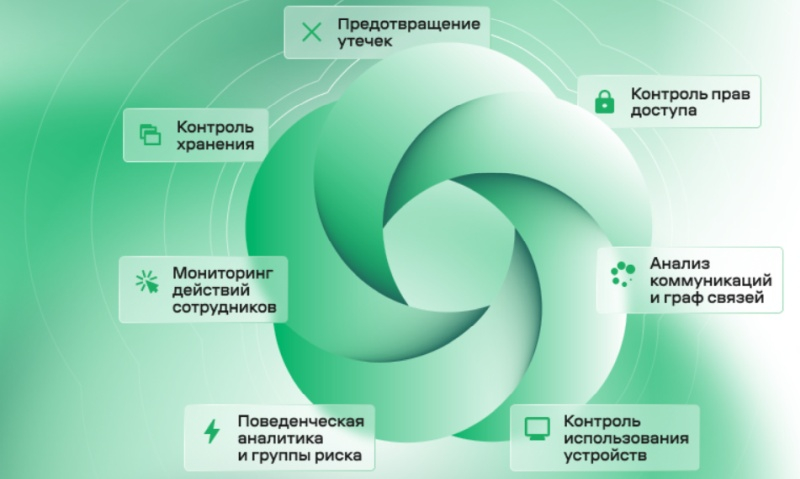
Источник изображения: InfoWatch Рейтинг по количеству утечек возглавляют США с 36,1 % зарегистрированных инцидентов, третье место у Индии (5,4 %), четвёртое — у Великобритании (3,8 %), пятое — у Канады (2,9 %). По итогам 2024 года в мире были зарегистрированы 9 175 утечек информации из государственных организаций и коммерческих компаний. Это на 25,2 % меньше, чем в 2023 году, когда произошло 12 265 утечек информации. По мнению авторов исследования, основные причины общего снижения количества утечек объясняется следующими факторами:
По мнению специалистов InfoWatch, реальный масштаб проблем с утечками данных значительно больше, чем отражено в статистике, так как «всё чаще при крупных утечках не удаётся установить реальное количество скомпрометированных данных». Великобритания заподозрила TikTok и Reddit в демонстрации подросткам того, что не следовало бы показывать
03.03.2025 [18:17],
Сергей Сурабекянц
Британский регулятор открывает расследование в отношении таких интернет-платформ, как видеосервис TikTok, форум Reddit и сайт обмена изображениями Imgur. Растущие опасения по поводу ненадлежащего использования этими социальными сетями персональных данных несовершеннолетних побудили Управление комиссара по информации (ICO) пристально исследовать, предоставляют ли их алгоритмы подросткам неподходящий или вредный контент. 
Источник изображений: unsplash.com Расследование изучит использование платформой TikTok персональной информации 13–17-летних подростков при предоставлении им рекомендаций по контенту. Регулятора также интересует, как Reddit и Imgur оценивают и проверяют возраст пользователя, чтобы оградить несовершеннолетних от опасного или вредного контента. ICO представила «Детский кодекс конфиденциальности в интернете» в 2021 году, который определяет меры по защите личной информации несовершеннолетних в интернете. Нынешнее расследование ICO будет направлено на выявление нарушений законодательства о защите данных. В случае обнаруженных нарушений регулятор сначала передаст информацию о них интернет-платформам и будет принимать окончательное решение лишь на основе их реакции. Комиссар по информации Джон Эдвардс (John Edwards) сообщил, что регулятор не сомневается в самом факте наличия элементов защиты информации на всех платформах, но хочет убедиться, что эти процедуры достаточно надёжны. «Вопрос в том, что они собирают, и в том, как они работают, — пояснил Эдвардс. — Я ожидаю, что в их рекомендательных системах будет много доброкачественных и позитивных способов использования данных детей. Меня беспокоит, достаточно ли они надёжны, чтобы не допустить, чтобы дети подвергались вреду, будь то вызывающие привыкание практики, или контент, который они видят». Эдвардс подчеркнул, что регулятор «не придирается к TikTok» и надеется глубоко изучить алгоритмы рекомендаций и больше узнать о «широком ландшафте» социальных сетей с помощью расследования. Выбор объектом расследования именно TikTok «был сделан на основе направления роста в отношении молодых пользователей, доминирования на рынке и потенциального вреда». К тому же в процессе расследования регулятор не может позволить себе слишком распылять усилия. Больше всего регулятора интересуют ключевые технологии цифровых платформ, которые используются в борьбе за посещаемость и просмотры.  В начале года TikTok был заблокирован (с отсрочкой на 75 дней) в США из-за опасений, что китайское правительство может получить доступ к данным, собираемым приложением. Тогда же министр технологий Великобритании Питер Кайл заявил, что он «искренне обеспокоен их [TikTok] использованием данных, связанных с моделью собственности». |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



