|
Опрос
|
реклама
Быстрый переход
«Крёстный отец ИИ» назвал xAI провалом и пригрозил взрывом «пузыря ИИ»
18.06.2026 [16:53],
Павел Котов
Стартап xAI Илона Маска (Elon Musk) — это «провал», и компания неспособна выступать конкурентом для лидеров отрасли искусственного интеллекта, заявил в интервью CNBC авторитетный эксперт в области ИИ Ян Лекун (Yann LeCun), выступающий в настоящее время основателем компании AMI Labs. 
Источник изображения: Numan Ali / unsplash.com Лекуна часто называют «Крёстным отцом ИИ» из-за его ранних работ в этой области и предыдущей должности главного учёного по ИИ в Meta✴✴. Компания xAI как проект, по его мнению, провалилась, потому что из неё ушли основатели, и Маску будет непросто нанимать лучших в отрасли специалистов, ведь в отношении предыдущей команды он проявил себя не лучшим образом. По итогам I квартала сегмент xAI в компании SpaceX зафиксировал убыток в размере $2,5 млрд. У компании есть «огромная инфраструктура», которую она теперь сдаёт в аренду, потому что иначе Маск не сможет окупить затраты, считает Ян Лекун. Эксперт имеет в виду центры обработки данных xAI Colossus 1 и Colossus 2 в Мемфисе — сейчас мощности в них арендуют Anthropic и Google. В остальном перспективы ИИ-подразделения SpaceX господин Лекун оценил «не очень оптимистично», потому что едва ли оно может конкурировать с такими гигантами как Anthropic и OpenAI. Ещё одна проблема в отрасли ИИ — сформировавшийся финансовый пузырь. «Цены на эти услуги ИИ растут, но стоимость их эксплуатации снижается, хотя и недостаточно быстро. В результате все эти компании теряют деньги, и, по сути, использование этих услуг большинством людей финансируется инвесторами. Долго так продолжаться не может, верно?» — задался эксперт риторическим вопросом. Поэтому отраслевым гигантам, в том числе Anthropic и OpenAI, придётся повышать цены и сокращать расходы — иначе пузырь ИИ рискует лопнуть. В технологическом аспекте Ян Лекун заявил о необходимости переключаться с больших языковых моделей ИИ на модели мира. Первые ориентированы на предсказание того, что произойдёт дальше, и они не очень подходят для рассуждений; вторые же стремятся сформировать понимание того, как устроен реальный или смоделированный мир, включая объекты, причинно-следственные связи и действия. Тем временем лидеры отрасли оттачивают технологии ИИ-агентов, способных автономно выполнять сложные задачи — лежащие в их основе большие языковые модели хорошо проявляют себя в математике и программировании, но стоимость их эксплуатации при текущей производительности слишком высока по сравнению с суммами, которые готовы платить люди. Майкл Бьюрри предрёк обвал технологических акций — ситуация сильно напоминает пузырь доткомов
12.05.2026 [16:16],
Павел Котов
Эксперт в области инвестиций Майкл Бьюрри (Michael Burry), прославившийся благодаря фильму «Игра на понижение» (The Big Short), предупредил, что индекс Nasdaq 100 движется к резкому развороту после «параболического» скачка, который поднял оценку технологических компаний до высоких, но неустойчивых значений, передаёт Bloomberg. 
Источник изображения: Arturo Añez / unsplash.com Положение рынка напоминает то, что наблюдалось в эпоху пузыря доткомов непосредственно перед крахом — в частности, он указал на резкий скачок акций производителей чипов, в результате которого показатель Philadelphia Stock Exchange Semiconductor Index с конца марта взлетел почти на 70 %. Компании из индекса Nasdaq 100 торгуются с коэффициентом отношения цены к прибыли на уровне 43 против предполагаемых 30. Это происходит из-за того, что на Уолл-стрит более чем на 50 % завысили прибыль «самых быстрорастущих и наиболее высоко оценённых компаний». «Мы становимся свидетелями исторических событий. На фондовом рынке это нехорошо», — заявил господин Бьюрри. Он сравнил происходящее со «сценой кровавой автомобильной аварии за несколько минут до того, как она случится». Эксперт также выразил обеспокоенность тем, как из-за колоссальных расходов на искусственный интеллект взлетели акции Alphabet и Amazon. Индексы подобрались к рекордным максимумам даже вопреки неблагополучной геополитической обстановке. 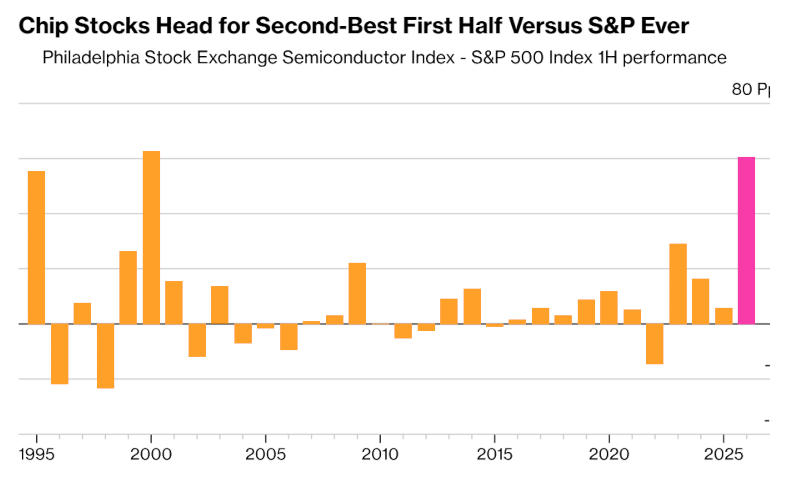
Источник изображения: bloomberg.com Тенденция к росту охватила весь рынок: индекс S&P 500 ставит очередной исторический рекорд при том, что всего лишь 5 % входящих в него компаний находятся на минимальных за 52 недели уровнях — другими словами, компании дорожают все вместе. Показатель Philadelphia Stock Exchange Semiconductor Index поднимался настолько сильно выше 200-дневной скользящей средней лишь дважды: в июле 1995 года и в марте 2000 года, на пике пузыря доткомов. От ставок на короткие позиции Майкл Бьюрри, впрочем, предостерёг: сейчас они стоят неоправданно дорого, а срок обвала фондового рынка предугадать непросто — не у всякого инвестора хватит на это средств. Сам он, однако, обзавёлся «значительной короткой позицией с использованием заёмных средств против портфеля компаний», которые считает «депрессивными и нишевыми»; кроме того, он планирует «сократить долю компаний», не соответствующих его «самым строгим требованиям к оценке». Инвесторам он рекомендовал зафиксировать прибыль от недавнего роста и сократить долю акций в целом, и в первую очередь — акций технологического сектора. «Даже если кажется, что ещё остаётся время для роста, любой, кому посчастливилось оказаться на этих параболических движениях, не продавая, ставит на собственную способность выйти из игры на вершине или около неё. История показывает, что даже если вечеринка продлится ещё неделю, месяц, три или год, в результате цены всё равно значительно снизятся. Мы вступаем в настолько экстремальную ситуацию, что последствия будут неизбежны, где бы кто ни спрятался», — предупредил эксперт. OpenAI раздулась до $840 млрд — создатель ChatGPT привлёк $110 млрд от Amazon, Nvidia и Softbank
27.02.2026 [19:15],
Сергей Сурабекянц
OpenAI привлекла $110 млрд в рамках крупнейшего раунда финансирования, с учётом этих средств биржевая оценка компании достигла $840 млрд. OpenAI и её конкурент Anthropic в этом году активизировали привлечение средств для финансирования дорогостоящих инвестиций в чипы и центры обработки данных для искусственного интеллекта. Всё чаще эти два компании привлекают к сотрудничеству пересекающуюся группу венчурных фондов и крупных технологических компаний. 
Источник изображения: unsplash.com По данным OpenAI, Amazon инвестирует $50 млрд, что стало самой крупной суммой, которую гигант электронной коммерции когда-либо вкладывал в какую-либо компанию. В свою очередь, SoftBank и Nvidia вложили в OpenAI по $30 млрд каждая. С учётом полученных средств стоимость OpenAI составила $840 млрд при запланированных $850 млрд. Компания ожидает привлечения дополнительных инвесторов по мере продвижения раунда финансирования. Крупные инвестиции от Amazon укрепляют её отношения с OpenAI. В рамках соглашения OpenAI будет использовать линейку собственных ИИ-чипов Amazon Trainium и совместно разрабатывать специализированные модели для инженерных команд Amazon. OpenAI также потратит $100 млрд на услуги Amazon Web Services в течение следующих восьми лет. Ранее, в ноябре 2025 года, компании объявили о сделке, в соответствии с которой разработчик моделей будет использовать сервисы AWS на сумму около $38 млрд в течение семи лет. «Amazon может предоставить нам очень многое с точки зрения нового спроса и возможностей на рынке», — заявил глава OpenAI Сэм Альтман (Sam Altman). Генеральный директор Amazon Энди Джасси (Andy Jassy) считает, что сделка «принесёт Amazon хорошую прибыль в долгосрочной перспективе». Microsoft, ранее являвшаяся эксклюзивным партнёром OpenAI по инфраструктуре, заявила, что её отношения с разработчиком остаются прочными. «Ничто в сегодняшних объявлениях никоим образом не меняет условий сотрудничества Microsoft и OpenAI», — говорится в совместном заявлении компаний. Anthropic также активно привлекает инвестиции — в начале этого месяца компания получила $30 млрд от инвесторов, включая Nvidia и Microsoft. В результате стоимость Anthropic биржевая возросла до $380 млрд с учётом привлечённых средств. Февральский «сбор средств» компаниями OpenAI и Anthropic является прекрасным примером сделок по циклическому финансированию между ведущими компаниями в области ИИ и поставщиками чипов и облачных вычислений. Эти партнёрства призваны обеспечить удовлетворение огромных потребностей сектора ИИ в инфраструктуре, но существует риск того, что такие сделки могут увеличить убытки, если спрос на ИИ не будет соответствовать сегодняшним завышенным ожиданиям. Альтман в своём обычном стиле постарался развеять опасения относительно пузыря ИИ. «Я понимаю, откуда берутся опасения, — заявил он. — Это имеет смысл только в том случае, если в экосистему ИИ поступят новые доходы». Он добавил, что большая часть его усилий направлена на увеличение вычислительных мощностей для удовлетворения спроса на ChatGPT и другие продукты OpenAI. ChatGPT начнёт массово показывать рекламу уже на этой неделе — а пока Альтман похвалился активным ростом аудитории
09.02.2026 [18:44],
Сергей Сурабекянц
Глава OpenAI Сэм Альтман (Sam Altman) с энтузиазмом сообщил сотрудникам, что основной продукт компании, ChatGPT «снова демонстрирует ежемесячный рост, превышающий 10 %». Компания планирует запустить новую модель чат-бота уже на этой неделе. Более 800 млн человек еженедельно используют ChatGPT, но конкуренция усиливается — в декабре компания объявила «красный код» и приостановила несколько проектов, чтобы сосредоточиться на улучшении своего чат-бота. 
Источник изображения: unsplash.com Альтман также сообщил, что продукт OpenAI для программирования, Codex, вырос примерно на 50 % по сравнению с прошлой неделей. Codex является прямым конкурентом популярной ИИ-среды разработки Claude Code от Anthropic, которая за последний год получила широкое распространение. На днях OpenAI запустила новую модель Codex, GPT-5.3-Codex, а также отдельное приложение для пользователей компьютеров Apple. Альтман заявил, что рост Codex «невероятен». По его словам, «это была отличная неделя». Но это, по мнению аналитиков, была непростая неделя для OpenAI. Альтман и другие руководители компании были вынуждены реагировать на критику со стороны Anthropic, которая во время финала кубка по американскому футболу высмеяла решение OpenAI размещать рекламу в ChatGPT. Альтман в ответ заявил, что OpenAI «очевидно, никогда не будет размещать рекламу так, как это описывает Anthropic». Тем не менее, по сообщению осведомлённых источников, в ближайшее время OpenAI официально начнёт тестирование рекламы в ChatGPT. Ранее компания обещала «чётко обозначать» рекламные блоки и отображать их ниже ответов чат-бота. OpenAI также заверила пользователей, что размещаемая реклама не будет влиять на ответы ChatGPT. Компания рассчитывает, что в долгосрочной перспективе реклама будет составлять не менее половины её доходов. На рынке цифровой рекламы долгое время доминировали Google, Meta✴✴ и Amazon — вряд ли эти технологические гиганты сдадутся без борьбы. В настоящее время Альтман и финансовый директор OpenAI Сара Фрайар (Sarah Friar) активно убеждают инвесторов в перспективах роста OpenAI, поскольку компания готовится завершить раунд привлечения инвестиций, который может составить $100 млрд. На закрытых встречах они подчёркивают сильные стороны OpenAI: гигантскую базу пользователей, растущий интерес со стороны крупного бизнеса и доступ к огромным вычислительным ресурсам. 
Источник изображения: OpenAI Forum OpenAI ожидает, что переговоры о привлечении инвестиций активизируются в течение следующих двух недель. В марте OpenAI закрыла раунд финансирования на $41 млрд, в который вошли $30 млрд от SoftBank и $11 млрд от других инвесторов. Текущий раунд финансирования может быть завершён в два этапа. Первый этап подразумевает инвестиции от Microsoft и Nvidia, а также от Amazon, которая планирует вложить в OpenAI до $50 млрд. На втором этапе в финансировании компании примут участие другие крупные игроки, в частности SoftBank готов инвестировать ещё $30 млрд. Точные сроки и суммы инвестиций пока окончательно не определены и могут измениться. ИИ-бум питается долгами: $120 млрд рисков перекочевали с техногигантов к инвесторам
25.12.2025 [12:49],
Алексей Разин
«Кольцевые сделки», в которых все по кругу передают друг другу одни и те же средства, являются не единственным источником финансирования масштабных проектов по развитию вычислительной инфраструктуры ИИ. Часть средств неизбежно привлекается на долговом рынке, и в этом году около $120 млрд затрат перешло с баланса техногигантов к другим инвесторам. 
Источник изображений: Nvidia Об этом сообщает Financial Times со ссылкой на опрошенных отраслевых аналитиков. Под нужды финансирования ряда проектов в этой сфере создаются специальные компании, которые привлекают в свой капитал средства преимущественно у институциональных инвесторов. По такой схеме в этом году уже было привлечено около $120 млрд, по данным источников — с учётом классических кредитов, впрочем. В случае со стартапами привлечь кредиты не всегда представляется возможным, поскольку им нечего предложить в залог ради получения весьма крупных сумм, зато сложные схемы финансирования с созданием специальных компаний обрели небывалую популярность. Больше всего средств по таким схемам привлекали Meta✴✴ Platforms, xAI, Oracle и CoreWeave. Со стороны институциональных инвесторов, которые не стремятся принимать участие в оперативном управлении финансируемым бизнесом, интерес к сделкам на рынке инфраструктуры для ИИ проявили Pimco, BlackRock, Apollo, Blue Owl Capital и ряд американских банков типа JPMorgan. Соответствующие сделки имеют непрозрачную структуру и создают серьёзные финансовые риски для классических игроков рынка инвестиций. Сомнительные схемы финансирования на фоне бума ИИ буквально за полтора года стали нормой, как отмечают участники рынка. За пределами технологической отрасли мало кто может похвастать таким доверием со стороны инвесторов. По данным Financial Times, в сделках через специально создаваемые компании (SPV) больше всего средств направила на развитие инфраструктуры ИИ компания Oracle ($66 млрд), ещё $30 млрд вложила Meta✴✴, на долю стартапа xAI Илона Маска (Elon Musk) пришлись $20 млрд, а оператор центров обработки данных CoreWeave ограничился $2,6 млрд. Техногиганты исторически неплохо финансировали своё развитие за счёт собственной прибыли, которая стремительно росла в последние годы. Это позволяло им без крайней необходимости не пользоваться кредитами, при этом их лимиты в этой сфере были весьма крупными. Инвестиции в ИИ потребовали существенных сумм, и чтобы не портить собственную кредитную историю и балансовые показатели, многие компании предпочли финансировать проекты через сторонние структуры типа SPV хотя бы частично. В частности, Meta✴✴ в октябре смогла через SPV привлечь около $30 млрд, а потом аналогичную сумму получить на рынке долговых обязательств путём выпуска облигаций. Подобные меры позволяют быстро привлекать большие суммы денег, не подвергая особому риску их конечных получателей. Oracle свои гигантские заимствования в этой сфере направит на развитие инфраструктуры для нужд OpenAI, причём строящиеся на деньги инвесторов ЦОД компания возьмёт в лизинг, а не получит в собственность. Основные риски в этой схеме ложатся именно на SPV, а не на саму Oracle.  По оценкам Morgan Stanley, для финансирования всех актуальных проектов в сфере ИИ потребуется $1,5 трлн, непосредственно участники рынка располагают весьма скромной частью этой суммы, всё остальное придётся привлекать у сторонних инвесторов. К началу 2025 года компании технологического сектора, по данным UBS, заняли около $450 млрд у частных фондов, что на $100 млрд превышает аналогичный показатель годичной давности. На нужды проектного финансирования в этом году было направлено около $125 млрд. Если применение SPV получит большое распространение, со временем это поставит под угрозу финансовую устойчивость частных кредитных институтов. Риски при этом сильно сконцентрированы — одной только OpenAI в ближайшие восемь лет потребуется около $1,4 трлн. Крах даже одной компании в этом секторе может запустить разрушительную цепную реакцию. В стороне от тенденции пока остаются Google (Alphabet), Microsoft и Amazon (AWS), которые имеют возможность финансировать свои ИИ-проекты за счёт собственных средств. Тем более, что у них имелась развитая вычислительная инфраструктура ещё до начала бума ИИ. Но даже они выпускают облигации для привлечения дополнительных средств. По данным Financial Times, переуступка долга уже началась среди участников описанных выше схем финансирования. Инвестиционные фонды небольшими долями продают соответствующие долговые обязательства, но суммы пока измеряются единицами миллиардов долларов США. Если к покупке этих долгов подключатся управляющие компании финансового рынка и пенсионные фонды, риски распределятся на более широкую часть мировой экономики. The Verge: ИИ-величие Nvidia построено на долгах — пузырь рискует лопнуть в любой момент
23.12.2025 [18:08],
Павел Котов
Сложившаяся к настоящему моменту отрасль искусственного интеллекта зависит от двух факторов: ИИ-ускорителей Nvidia и заёмных средств. Nvidia сама выступает инвестором для покупателей своей продукции, обеспечивая себе высокие продажи — они берут кредиты под залог её ускорителей. Но стоит одному звену выпасть из общей цепочки — и вся схема с большим числом участников может рухнуть, а эхо крушения прокатится по мировому финансовому рынку, предупреждает The Verge. 
Источник изображения: Mariia Shalabaieva / unsplash.com Nvidia вкладывает огромные средства в сферу ИИ — только в этом году она инвестировала более чем в 70 компаний отрасли. Среди потраченных «зелёными» миллиардов выделяется важная категория — «неооблачные» решения, такие как CoreWeave. Это обременённая долгами компания, чьи акции торгуются на бирже, и существует она, основываясь на предположении, что технологическая отрасль и дальше будет возводить центры обработки данных. Для своих ЦОД CoreWeave и подобные ей компании берут кредиты на покупку ускорителей Nvidia, используя эти самые ускорители в качестве залога — в процессе сама Nvidia превращает каждый $1 инвестиций в $5 продаж. Такая схема выгодна прежде всего самой Nvidia, но едва ли всем остальным участникам рынка. Важной проблемой является тот факт, что ИИ-ускорители со временем обесцениваются, и при этом важно понимать, успевают ли они терять свою стоимость настолько быстро, что эти кредиты оказываются абсурдными. Nvidia кровно заинтересована поддерживать существование этой отрасли как можно дольше по той же причине — в качестве залога выступает оборудование её производства. Верно и обратное: если что-то пойдёт не так с бизнесом Nvidia, это отзовётся проблемами для всей отрасли ИИ. И чем быстрее поднимают голову конкуренты Nvidia, тем быстрее приближается этот неприятный момент. Для кредиторов существует несколько способов попытаться снизить риски, например заложить их в процентную ставку. К примеру, в 2023 году CoreWeave получила первый кредит под ускорители, и в III квартале этого года ставка по нему — а она плавающая — составила 14 %. Ещё один способ — запросить высокий процент залога по отношению к кредиту; это отношение выражает коэффициент LTV (Loan-to-Value). Так, если человек покупает в кредит дом за $500 тыс., то ему приходится платить первоначальный взнос: если он составляет 20 %, на кредит остаётся $400 тыс., а LTV получается 80 %. Коэффициент LTV по кредитам под ускорители сильно варьируется в зависимости от срока кредитования, доверия к руководству компаний и других факторов контракта. У некоторых компаний он составляет всего 50 %, у других может достигать 110 %. Кредиты под залог ускорителей пользуются высоким спросом; в большинстве случаев подразумеваются чипы Nvidia, и это укрепляет позиции компании на рынке. Если компания хочет купить ускорители, она может получить под них финансирование по более низкой стоимости при залоге под сами ускорители, отличающиеся высокой ликвидностью. Целесообразность таких кредитов остаётся сомнительной, поскольку нет ясности, как быстро ускорители обесцениваются, — предполагается, что происходит это очень быстро. Компания может сдавать ресурсы в аренду Microsoft, но, возможно, ей придётся делать это во второй и третий раз, чтобы окупить инвестиции. При этом нет ясности, насколько крупным будет вторичный или третичный рынок старых чипов. 
Источник изображения: здесь и ниже Nvidia Определить, сколько стоят ускорители и как долго они прослужат, непросто. В документах CoreWeave говорится, что сумма, которую компания может занять, зависит от стоимости чипов, и по мере снижения цены на них будут сокращаться и размеры кредитов. Но стоимость фиксирована, и если ускорители будут дешеветь быстрее, чем прогнозировалось, придётся брать новые кредиты. Крупные облачные операторы масштаба Google, Meta✴✴✴, Microsoft, Oracle и Amazon могут списать часть долгов без значительных потерь, поскольку у них есть другие направления бизнеса. У неооблаков такой возможности нет. Возможно, в условиях снижения спроса на услуги им придётся увеличивать величину залога. Если одна небольшая компания объявит дефолт, рынок от этого не рухнет: большинство клиентов смогут продолжить работу со своими программами; банки же тем временем изымут серверы и продадут их за бесценок. Но это будет двойным ударом по Nvidia: на рынок хлынут дешёвые устаревшие ускорители, а число клиентов у «зелёных» сократится. А вот если обанкротятся сразу несколько компаний, проблемы могут оказаться серьёзными. Ещё одна проблема рынка ИИ, существующего за счёт кредитов, — деформация оценок рисков из-за конкуренции. Если рассматривать кредит как абстрактный финансовый продукт, на рынке формируется конкуренция за выдачу займов. Если на начальном этапе неооблачная компания получала кредит под 15 %, и величина ставки была просчитана с учётом рисков, то со временем эта ставка снижается, поскольку среди кредиторов возникает конкуренция и оценка рисков отходит на второй план — начинают выдаваться кредиты под 13 %, под 12,5 % и ниже, причём уже без фактического учёта рисков для кредиторов. Отрасль ИИ требует колоссальных расходов: по оценкам аналитиков, к концу 2028 года только на ЦОД будет потрачено $3 трлн. Первый кредит на $2,3 млрд, полученный CoreWeave, выдали частные кредитные компании Magnetar, Blackstone, Coatue, BlackRock и PIMCO. Затем она взяла ещё один кредит на $7,5 млрд, а третий — на сумму $2,6 млрд — ей предоставили уже такие гиганты, как Goldman Sachs, JPMorgan Chase и Wells Fargo.  Доля задолженности под ускорители относительно невелика по сравнению с объёмами облигаций техногигантов, однако проблемы в этом сегменте могут отразиться на кредитовании крупных игроков — сейчас технологический сектор набрал больше долгов, чем во времена пузыря доткомов в конце девяностых. Сегмент частного кредитования более рискованный, чем банковский: процентные ставки выше, а сроки погашения дольше. Во времена финансовых трудностей компании могут получать кредиты обоих типов, то есть частный долг косвенно влияет на банки. Если компания берёт кредиты обоих типов, у неё выше риски дефолта; и именно этим связующим звеном между частными кредиторами и банками становятся компании из отрасли ИИ. У CoreWeave, помимо кредитов под ускорители, есть возобновляемая кредитная линия напрямую у JPMorgan Chase в размере $2,5 млрд. Банки и сами часто предоставляют кредиты частным кредиторам. Во время бума доткомов в девяностые эйфория инвесторов была связана с акциями, и больше всех пострадали те, кто вкладывал средства в перспективные компании, которые впоследствии обанкротились. В случае с отраслью ИИ последствия могут быть более тяжёлыми. В первой половине текущего года около половины роста ВВП США обеспечили инвестиции в бизнес, связанный с ИИ; есть мнение, что без ИИ американская экономика уже ушла бы в рецессию — и именно ИИ в таком случае становится угрозой при ухудшении ситуации с расходами. Уязвимость сектора ИИ объясняется взаимосвязанностью всех его участников, и центральное место в экосистеме занимает Nvidia. Суть спора об амортизации ускорителей заключается в том, стоит ли эксплуатировать их после достижения трёхлетнего и более преклонного возраста. С новыми чипами оператор ЦОД может обслужить больше клиентов, но они и потребляют больше энергии. К 2028 году новым ЦОД, по оценкам, потребуются дополнительные 44 ГВт мощности, но к этому времени в эксплуатацию будут введены только 25 ГВт новых мощностей — возможно, этот фактор продлит жизнь старым ускорителям. Пока рынок существует в прежнем виде, проблем не наблюдается, но при возникновении риска для всей отрасли сложности сразу возникают и у кредиторов. В 2022 году майнерам предоставляли кредиты под залог оборудования, и кредиторы оказались заложниками этого самого оборудования, которое внезапно обесценилось на 85 % из-за обвала биткоина. К январю 2023 года вторичный рынок майнингового оборудования оказался настолько насыщен, что кредиторам пришлось добывать криптовалюту самостоятельно.  Подобное может произойти и с кредитами, обеспеченными ускорителями. Однако ситуация несколько иная. У майнеров был долг «всего» в $4 млрд, кредиты выдавали частные компании, тогда как долги в сфере ИИ связаны с обычными банками. Когда майнинг биткоинов потерпел крах, у Nvidia образовались запасы продукции на сумму более $1 млрд, поскольку компания нарастила производство для удовлетворения спроса, и в результате задержался выход новых графических процессоров. Чистая прибыль Nvidia в финансовом году, завершившемся 29 января 2023 года, упала на 55 % по сравнению с предыдущим годом. Однако в конце ноября 2022 года OpenAI представила ChatGPT, положив начало гонке в области ИИ, и год спустя чистая прибыль Nvidia подскочила в семь раз. Бизнес компании изменился. С начала пандемии 2020 года наблюдается развитие сегмента ЦОД, и Nvidia участвует в этом процессе, переводя их преимущественно с центральных на графические процессоры. ИИ-ускорители взаимозаменяемы: если оператор неооблака прекращает работу, его предприятие можно перепрофилировать, поэтому техногиганты менее обеспокоены избыточным строительством ЦОД, чем их конкуренты. И если будет построено слишком много вычислительных мощностей для ИИ, крупные игроки могут просто приостановить расходы на них на несколько лет и использовать объекты для других целей, например для запуска рекламы. Но у Nvidia есть веский стимул поддерживать неооблачных партнёров на плаву. Она является инвестором в нескольких игроков, и если те продолжают работать, компания продолжает получать прибыль — в крайнем случае она может вмешаться и спасти несколько компаний и даже всю отрасль, как это произошло при IPO CoreWeave. В этом смысле вопрос амортизации не имеет решающего значения: если компании вроде CoreWeave приходится нести огромные убытки или обслуживать кредиты дополнительным капиталом, Nvidia может ей помочь. Однако она окажется бессильной, если усилится давление со стороны конкурентов. Выручка Nvidia сильно концентрирована. В ходе последнего финансового отчёта компания призналась, что только на двух клиентов за первые девять месяцев 2026 финансового года пришлось соответственно 21 % и 13 % выручки. Укрепляя клиентскую базу за счёт неооблаков, Nvidia получает рычаги влияния на крупных покупателей. Однако эти крупные покупатели начали производить собственные чипы. Если графические процессоры Nvidia могут использоваться в разных областях, то TPU от Google предназначены исключительно для ИИ. Прорывную модель Gemini 3 компания обучила только на TPU. Эти чипы, имея узкое назначение, потребляют меньше энергии при выполнении аналогичных операций, и это становится сигналом для других участников рынка. Поэтому столь важны сделки Google с Anthropic, Salesforce, Midjourney и Safe Superintelligence, а также слухи о соглашении с Meta✴✴✴. Любой, кто покупает или даже просто угрожает перейти на TPU, получает возможность договориться с Nvidia о скидке. По оценкам, OpenAI сократила общую стоимость владения ускорителями Nvidia на 30 %, даже не начав переход на TPU. В случае CoreWeave всё не так просто — у неё есть контракты, гарантирующие определённый доход, поскольку такие клиенты, как Microsoft и Nvidia, однозначно кредитоспособны, и кредиторов это устраивает. Nvidia заключает с CoreWeave договор об аренде чипов собственного производства, и это воспринимается как мера поддержки, поскольку в финансовых отчётах компания не раскрывает подробных сведений об этих соглашениях — аналитики характеризуют их как «страховочные». Если включить заложенные в бюджет Nvidia расходы на облачные услуги в размере $26 млрд, маржа компании снижается с 72 % до 68 %, а прибыль на акцию — с $6,28 до $5,98.  Таким образом, Nvidia, возможно, уже начинает спасать неооблачные компании, хотя их интересы нередко расходятся: если «зелёные» начинают выпускать новые ускорители ежегодно, старые обесцениваются быстрее, а вместе с этим падает и кредитоспособность неооблаков. С другой стороны, эти компании полезны не только самой Nvidia — они снижают капитальные затраты для таких гигантов, как Microsoft и Google, которые пользуются их услугами, оплачивая электроэнергию и аренду с небольшой наценкой. Ирония в том, что неооблака должны постоянно модернизироваться, чтобы оставаться актуальными, и продолжать закупать продукцию у Nvidia, но это не может длиться вечно, указывают аналитики. Тем временем собственные ускорители есть не только у Google. Они есть у Amazon, которая уже пытается договориться с OpenAI, у Microsoft, у Meta✴✴✴, и даже сама OpenAI начала работу в этом направлении. За рядом этих проектов стоит Broadcom. Собственное оборудование в Китае разрабатывают Huawei, ByteDance и Alibaba. Активно набирает обороты AMD, которая к 2027 году намерена увеличить производительность своих ускорителей до уровня продукции Nvidia. Все эти игроки готовы обновлять свои решения ежегодно, что крайне невыгодно неооблакам. С ростом конкуренции у Nvidia остаётся всё меньше ресурсов для поддержки этой экосистемы. Крах может произойти в результате банкротства всего одного небольшого игрока, указывают аналитики. Все участники цепочки слишком взаимосвязаны. Даже если обанкротится мелкая компания и кто-то выше по иерархии будет вынужден признать убытки — даже гигант масштаба Microsoft, у которого на балансе внезапно появится нежелательный долг, скажем, в $20 млрд. Масштаб ущерба для отрасли будут определять размер и количество обанкротившихся игроков. Многие небольшие неооблачные платформы могут исчезнуть хоть завтра незаметно для всех, но их массовое исчезновение может вызвать подозрения. Если же обанкротятся более крупные компании, это способно посеять страх в отрасли — даже без серьёзных системных проблем инвесторы могут уйти. Допускаются и другие сценарии. Рынок может сместиться в сторону услуг инференса, то есть запуска, а не обучения моделей ИИ. Или крупные технологические компании решат, что им больше не нужны новые вычислительные ресурсы. Или произойдёт очередная технологическая революция, и размеры перспективных моделей сократятся. Или наиболее востребованную продукцию начнут производить не Nvidia, а её конкуренты. Или достаточно качественными станут открытые ИИ-модели, а игроки вроде OpenAI отойдут на второй план. Но при любом исходе рынок окажется наводнённым целыми ЦОД. На финансовом рынке это отзовётся проблемами частных кредиторов, управляющих средствами университетов, пенсионных фондов, семейных офисов, хедж-фондов и целевых фондов, а также проблемами банков, успевших глубоко погрузиться в отрасль ИИ. Неприятность в том, что некоторые аспекты этой ситуации перекликаются с кризисом 2008 года. Вопрос лишь в том, когда всё рухнет и что произойдёт после этого. Мировые инвесторы нашли потенциальное спасение от американского ИИ-пузыря — китайские ИИ-компании
23.12.2025 [17:49],
Сергей Сурабекянц
Глобальные инвесторы последовательно увеличивают свои ставки на китайские компании, занимающиеся искусственным интеллектом. Эта тенденция вызвана сокращением технологического отрыва США от Китая и желанием инвесторов диверсифицировать свои портфели акций. Кроме того, на Уолл-стрит продолжают нарастать опасения по поводу спекулятивного пузыря в перегретом секторе искусственного интеллекта США.  Британская управляющая компания Ruffer намеренно ограничила инвестиции в американские бигтехи и планирует увеличить свои позиции в китайской компании Alibaba, которая управляет подразделением по разработке чипов для ИИ, владеет крупной языковой моделью Qwen и вкладывает средства в облачную инфраструктуру. «Хотя США остаются лидером в области передового ИИ, Китай быстро сокращает отставание», — считает инвестиционный специалист Ruffer Джемма Кэрнс-Смит (Gemma Cairns-Smith). — […] Конкурентная среда меняется». Глобальные управляющие активами все чаще обращают внимание на китайские компании, занимающиеся ИИ, поскольку волна стартапов выходит на биржу в материковом Китае и Гонконге, стремясь воспользоваться растущим интересом инвесторов после стремительного взлёта DeepSeek. В своём отчёте за этот месяц UBS Global Wealth Management оценила китайские технологии как «наиболее привлекательные», сославшись на стремление инвесторов к географической диверсификации и «сильную политическую поддержку Китая, технологическую самодостаточность и быструю монетизацию ИИ». В ИИ-гонке США имеют преимущество в инновациях, в то время как Китай обладает преимуществами в инженерии, производстве и энергетике, полагает основатель американской компании Rayliant Global Advisors Джейсон Сюй (Jason Hsu). «Технологические ограничения США вынудили Китай вкладывать деньги в сложные технологии и создавать с нуля, — сказал Сюй. — Для инвесторов разумная и мудрая стратегия — использовать возможности ИИ и управлять неопределённостью за счёт диверсификации». Главный инвестиционный директор биржевого фонда KraneShares Брендан Аэрн (Brendan Ahern) заявил, что стремительный рост китайских производителей микросхем для ИИ, таких как Cambricon, свидетельствует о масштабе и скорости инноваций в китайской индустрии ИИ и полупроводников. «Элемент этой гонки, этой срочности, идёт на пользу компаниям», — заметил он, имея в виду ожесточённую китайско-американскую технологическую войну. Акции KraneShares, инвестирующего в акции китайских компаний, таких как Tencent, Alibaba и Baidu, в этом году выросли на две трети, достигнув почти $9 млрд. 
Источник изображения: unsplash.com Китай, в свою очередь, ускорил размещение акций крупных компаний-производителей микросхем, в частности Moore Threads, получившей прозвище «китайская Nvidia», и MetaX. Акции MetaX, основанной бывшими руководителями AMD, после дебюта на бирже подскочили на 700 %. За несколько дней до этого акции Moore Threads показали рост 400 % сразу после первичного размещения. Однако некоторые финансисты скептически оценивают долгосрочные перспективы инвестирования в технологический потенциал Китая. «Ни одна из компаний, занимающихся разработкой микросхем и котирующихся на бирже, не имеет какой-либо поддержки в плане оценки и почти полностью движима ажиотажем», — уверен управляющий портфелем британской компании North of South Capital Камиль Диммич (Kamil Dimmich). Кэрол Фонг (Carol Fong) из CGS International Securities полагает, что инвесторам следует «сбалансировать инвестиции в текущем фрагментированном, обусловленном геополитикой цикле развития рынка микросхем» и выборочно добавлять в свои портфели компании, которые выиграли от стремления Китая к самодостаточности в секторах ИИ и полупроводников, сохраняя при этом в портфеле акции признанных мировых лидеров. Акции американских бигтехов обвалились после слухов о проблемах Oracle с финансированием проекта для OpenAI
18.12.2025 [12:54],
Алексей Разин
Безудержный рост капитализации крупных игроков рынка ИИ до сих пор основывался на вере инвесторов в способность соответствующих проектов принести финансовую отдачу в отдалённом будущем. Запас оптимизма начал истощаться, и первыми сдались институциональные инвесторы. Вокруг Oracle начал формироваться неблагоприятный информационный фон, акции компании упали на 5,4 % потянули за собой остальной рынок. 
Источник изображения: Oracle Издание Financial Times сегодня сообщило, что инвестиционный фонд Blue Owl Capital не намерен вкладывать средства в проект строительства центра обработки данных Oracle в штате Мичиган общей стоимостью $10 млрд. Опытным инвесторам из этого фонда не понравилась растущая долговая нагрузка Oracle, а также их смутили значительные расходы на инфраструктуру ИИ. В штате Мичиган должен был появиться ЦОД мощностью 1 ГВт, который Oracle планировала построить для нужд OpenAI. По имеющимся данным, переговоры с Blue Owl зашли в тупик, поставив под вопрос саму реализацию проекта. Схема сделки предполагала, что дочерняя структура Blue Owl будет владеть ЦОД, сдавая его в лизинг для нужд Oracle и OpenAI соответственно. Новых инвесторов пока не нашлось, а Blue Owl от данного проекта оттолкнули не самые выгодные финансовые условия. Представители Oracle заявили, что застройщик в лице Related Digital выбрал источник финансирования, не имеющий отношения к Blue Owl, и переговоры по реализации проекта в Мичигане идут по плану. Напомним, что соглашение Oracle с OpenAI подразумевает расходы в размере $300 млрд на строительство ЦОД для инфраструктуры ИИ общей мощностью 4,5 ГВт в течение ближайших пяти лет. К концу ноября сумма долговых обязательств Oracle выросла до $105 млрд, однако Morgan Stanley прогнозирует, что к 2028 году она увеличится до $290 млрд. Компания активно привлекает заёмные средства для реализации новейших инициатив, связанных с ИИ. Всего за три месяца сумма лизинговых контрактов Oracle выросла с $100 млрд до $248 млрд. Фонд Blue Owl ранее оказывал активное содействие Oracle в строительстве других ЦОД компании. Техасский ЦОД, за который Oracle будет выплачивать средства Blue Owl в течение 15 лет, должен принести последней доходность в размере 25 %. На его строительство будет потрачено $15 млрд, в строй он будет введён в середине 2027 года и займётся обслуживанием инфраструктуры OpenAI. Финансированием строительства инфраструктуры для Meta✴✴ Platforms также занимается Blue Owl. Акции Oracle упали в цене на 46 % после достижения пиковой стоимости в начале сентября, когда сооснователь компании Ларри Эллисон (Larry Ellison) на короткое время стал богатейшим человеком планеты. Акции Nvidia накануне потеряли в цене 3,8 %, у Alphabet снижение составило 3,1 %, а Broadcom своим не очень удачным отчётом не только способствовала снижению курса собственных акций на 4,5 %, но и повлияла на чужие. К слову, акции Micron при этом выросли в цене на 3,8 %, но этому способствовала собственная оптимистичная отчётность данного производителя памяти. Азиатские фондовые рынки последовали за американским. Японский индекс Topix снизился на 0,4 %, южнокорейский Kospi упал на 1,2 %, а китайский CSI 300 просел на 0,3 %. Поддержку американскому индексу S&P 500 оказали действия властей США в отношении Венесуэлы, которые вызвали рост цен на нефть и сопутствующее повышение котировок акций компаний энергетического сектора. В результате данный индекс прибавил более 2 %. Китайская «маленькая Nvidia» начала отговаривать инвесторов от бездумного вливания денег в её акции
12.12.2025 [13:40],
Алексей Разин
Бум систем искусственного интеллекта разогревает не только американский фондовый рынок. Вышедшая на биржу недавно китайская компания Moore Threads, которую считают «маленькой Nvidia», столкнулась с ростом котировок своих акций более чем в восемь раз по сравнению с ценой размещения, и на этом фоне даже начала отговаривать инвесторов от необдуманных поступков. 
Источник изображения: Moore Threads Technology Компании пришлось через Шанхайскую фондовую биржу распространить сообщение, в котором предупреждалось о наличии риска снижения курсовой стоимости акций Moore Threads после резкого взлёта, который наблюдался в первые дни после IPO. Первая торговая сессия принесла рост курса на 425 %, к этому четвергу акции подорожали ещё на 57 %, а всего текущий курс превысил уровень размещения на 723 %. После распространения такого обращения котировки акций Moore Threads в моменте снижались на величину до 19 %, а завершили пятничную сессию падением на 13 %. По мнению представителей эмитента, на рынке может возникать перегрев и условия для «иррациональной спекуляции». Инвесторы, по словам компании, должны осознавать все связанные со своей деятельностью риски, принимать решения предусмотрительно и действовать рационально. Напомним, что дополнительной динамики росту акций Moore Threads до этого придало включение ускорителей отдельных китайских марок в перечень компонентов, рекомендованных для закупки китайским разработчикам систем искусственного интеллекта. Moore Threads была основана в 2020 году Джеймсом Чжан Цзяньчжоном (James Zhang Jianzhong), который на протяжении 14 лет работал в Nvidia. В ходе недавно состоявшегося IPO компании удалось привлечь $1,13 млрд, сделав данное мероприятие вторым по величине на китайском фондовом рынке в этом году. По словам Moore Threads, рыночные перспективы её продукции не столь однозначны, а новые поколения ускорителей ещё не начали приносить выручку. От мировых лидеров, как призналась компания, она отстаёт не только в сфере разработок, но и в своей способности насыщать рынок продукцией. Тем более, что соотношение курсовой стоимости акций и удельного дохода Moore Threads почти на два порядка превышает средний показатель отрасли. В первые девять месяцев текущего года компания понесла убытки в размере $102,6 млн. Эксперты считают, что на безубыточность она выйдет не ранее 2027 года. Пузырь ИИ вернул цену акций Cisco на уровень пузыря доткомов
12.12.2025 [06:17],
Анжелла Марина
Акции американской транснациональной технологической компании Cisco Systems, одной из самых знаковых компаний эпохи доткомов, наконец обновили исторический максимум, достигнутый на пике технологического пузыря в марте 2000 года. Десятого декабря бумаги подорожали на 0,9 %, достигнув $80,25, что позволило им превысить пик, державшийся 25 лет. Это произошло, как пишет Bloomberg, отчасти благодаря буму инвестиций в искусственный интеллект. 
Источник изображения: Cisco Как отметил управляющий директор SLC Management Дек Малларки (Dec Mullarkey), это наглядное напоминание о том, что восстановление после рыночного пузыря может занимать очень долгое время. По его словам, уместной аналогией может служить японский фондовый рынок, которому также потребовались десятилетия для восстановления после краха в конце 1980-х годов. Потеря доверия инвесторов после болезненного обвала может занять годы, прежде чем они снова поверят в компанию. Текущий рост акций Cisco Малларки назвал знаком возвращения доверия, добавив, что «компания стала больше похожа на коммунальное предприятие, чем на инноватора, но, по-видимому, именно это и хотели увидеть её инвесторы». Подъём Cisco происходит в момент, когда инвесторы проводят параллели между сегодняшним ралли, которое возглавляет «великолепная семёрка», и периодом, когда Cisco была одним из так называемых «четырёх всадников Nasdaq», наряду с Microsoft, Intel и Dell. В течение двух лет, предшествовавших пику 2000 года, акции компании взлетели почти на 600 %, а её капитализация превысила $500 млрд. После лопнувшего пузыря Cisco потеряла около 90 % стоимости, опустившись до $60 млрд в конце 2002 года. С того момента бумаги выросли более чем на 800 %, однако рыночная капитализация компании по-прежнему более чем на 40 % ниже пикового уровня эпохи доткомов. 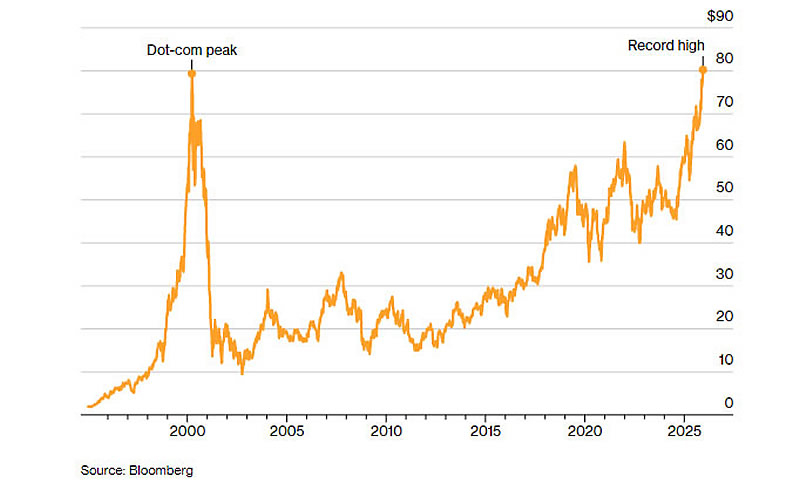
Источник изображения: Bloomberg Ключевым же драйвером для акций Cisco стал её собственный повышенный прогноз выручки до $61 млрд в текущем финансовом году, что усилило ожидания инвесторов относительно выгод компании от глобальных инвестиций в ИИ-инфраструктуру. Этот оптимизм, побудивший, например, аналитика UBS Дэвида Фогта (David Vogt) повысить рекомендацию по бумагам, существует на фоне сохраняющегося скепсиса многих на Уолл-стрит относительно долгосрочных темпов бума расходов на искусственный интеллект и корректности его учёта. «Пузыря нет, но рост ненормальный»: глава SK Group предсказал коррекцию на рынке ИИ-акций
05.12.2025 [18:57],
Сергей Сурабекянц
Опасения по поводу завышенной оценки акций компаний, занимающихся искусственным интеллектом, начали оказывать давление на финансовые рынки в целом. Инвесторы и финансисты задаются вопросом — когда крупные инвестиции в ИИ начнут приносить реальную прибыль. Чэй Тэ Вон (Chey Tae-won), председатель совета директоров SK Group, владеющей ведущим производителем микросхем памяти SK Hynix, не видит признаков ИИ-пузыря, хотя допускает возможность корректировки рынка. 
Источник изображения: SK Hynix «Я не вижу пузыря [в индустрии ИИ]», — заявил Чэй Тэ Вон на форуме в Сеуле, отвечая на вопрос главы Банка Кореи. «Но, если посмотреть на фондовые рынки, они выросли слишком быстро и значительно, и [...] вполне естественно, что может быть период коррекции», — сказал он. По мнению Чэя Тэ Вона, акции компаний, занимающихся искусственным интеллектом, растут выше своей фундаментальной стоимости. Он отметил, что «переоценка» стоимости акций не является чем-то новым для растущей отрасли, а развитие ИИ приведёт к значительному повышению производительности. Акции SK hynix выросли на 214 % за год благодаря высокому спросу на её продукцию со стороны компаний, занимающихся разработкой центров обработки данных для ИИ. Южнокорейская компания в октябре сообщила об очередной рекордной квартальной прибыли, обусловленной бумом в сфере ИИ. По словам SK hynix, вся её полупроводниковая продукция следующего года уже зарезервирована клиентами. Компания ожидает дальнейшего продления «суперцикла» производства чипов. Инвесторы не спешат пугаться ИИ-пузыря — деньги в стартапы льются как прежде
30.11.2025 [08:46],
Алексей Разин
Зародившийся в сознании некоторых инвесторов скепсис по поводу неизменности роста котировок акций компаний, причастных к развитию инфраструктуры искусственного интеллекта, уже вызвал корректировку на бирже и заставил основателя Nvidia оправдываться. Между тем, в сегменте стартапов пессимизмом пока и не пахнет, и их основатели продолжают грести деньги лопатой. 
Источник изображения: Freepik, jcomp Об этом сообщает Financial Times по итогам консультаций с рядом американских венчурных инвесторов, которые вкладывают средства в молодые компании на начальных этапах в надежде заработать деньги на росте их капитализации в будущем. Феномен заключается в том, что на рынке труда сейчас не так много эффективных специалистов в сфере искусственного интеллекта, поэтому получившие даже небольшой опыт разработчики нередко уходят от своих работодателей, чтобы основать собственные стартапы. Инвесторы при этом охотно доверяют им крупные суммы, не особо задумываясь о последствиях. По сути, наиболее ярким примером такого дробления могут служить истории появления стартапов Thinking Machines Lab и Safe Superintelligence, основанные выходцами из OpenAI Мирой Мурати (Mira Murati) и Ильёй Суцкевером. Капитализация их стартапов в пределах первого года существования выросла до десятков миллиардов долларов США. Первый из них, по некоторым оценкам, сейчас стоит $50 млрд. Основатели стартапов легко привлекают сотни миллионов долларов, не располагая особой историей или репутацией, при этом венчурные инвесторы выстраиваются в очереди, чтобы отдать им деньги. Некоторые инвесторы предполагают, что среди самых крупных ИИ-стартапов в США в ближайшие два года с высокой вероятностью найдётся тот, чья капитализация в указанный период достигнет $1 трлн даже до выхода на IPO. Основателей стартапов вероятность банкротства не очень пугает. Если что-то в их бизнесе пойдёт не так, крупные корпорации наверняка купят его по хорошей цене, поскольку в сфере ИИ сейчас наблюдается дефицит кадров, а стартапы как раз располагают некоторым человеческим капиталом. Люди даже не представляют, насколько ИИ изменит мир — но завершится всё пузырём, хоть и не скоро
28.11.2025 [13:34],
Алексей Разин
Увещевания некоторых авторитетных инвесторов типа Майкла Берри (Michael Burry) по поводу неизбежности формирования пузыря на рынке ИИ начинают раздражать руководство Nvidia, которое неожиданно начинает оправдывать все происходящие на бирже процессы. Некоторые инвесторы придерживаются более взвешенной позиции, не отвергая при этом саму идею формирования пузыря на рынке ИИ. 
Источник изображения: OpenAI Например, директор по инвестициям в Bridgewater Associates Грег Дженсен (Greg Jensen), который потратил более десяти лет изучению рынка систем машинного обучения, в своём недавнем интервью дал понять, что пузырь на рынке ИИ всё ещё ожидает его участников, и его угроза не миновала. При этом он утверждает, что люди пока просто не осознают, какое количество финансовых ресурсов потребует этот рынок, и насколько он изменит все смежные отрасли экономики. Спекулятивной фазы роста, по мнению Дженсена, рынок ИИ ещё не достиг. Ключевое отличие нынешнего бума, вызванного стремительным развитием ИИ, по словам эксперта, заключается в убеждённости лидеров компаний, что ставки в этой игре имеют поистине судьбоносный характер для всего человечества: «Они верят, что получат способность контролировать Землю и Вселенную всего через пару лет. Ими движет не стремление получить привычные прибыли, характерное для типичного цикла». Поскольку доминирует мотивация нематериального характера, капитальные расходы будут расти даже в том случае, если фундаментальные оценки будут говорить о критическом положении бизнеса и огромных долгах. Этот рынок будет развиваться по принципу «захвата ресурсов», который в технологической отрасли никогда ранее не доминировал, по мнению Дженсена. В дефиците остаются энергия, земельные участки для центров обработки данных и передовые чипы. Ещё одним сдерживающим рост рынка фактором является нехватка квалифицированных специалистов. Как считает Дженсен, во всём мире от силы найдётся тысяча серьёзных исследователей в сфере ИИ, поэтому острая конкуренция за них со стороны работодателей сдерживает научный прогресс в настоящий период. Ситуация на рынке труда напоминает миграцию спортивных звёзд из одной команды в другую. Инвесторы при этом будут концентрироваться на фаворитах рынка среди эмитентов. Капитальные затраты в сегменте ИИ уже достигли таких величин, которые способны оказывать влияние на ключевые факторы макроэкономики. В США, например, инвестиции в ИИ уже по итогам этого года будут определять один процентный пункт роста национального ВВП. И это только начало, по мнению Дженсена. Мир входит в более опасную фазу, когда дефицит ресурсов, рост капитальных затрат и обострение конкуренции будут создавать немало сложных ситуаций, к которым инвесторы до конца не готовы. ИИ-пузырь получил соседа: Пекин предупредил о перегреве рынка человекоподобных роботов
27.11.2025 [16:48],
Павел Котов
Национальная комиссия по развитию и реформам Китая предупредила, что в отрасли человекоподобных роботов возможно образование экономического пузыря. Власти страны редко выражают обеспокоенность по поводу бурно развивающегося технологического направления. 
Источник изображения: ubtrobot.com «Передовые отрасли давно сталкиваются с проблемой баланса между темпами роста и угрозой формирования пузырей — теперь этот вопрос встал перед направлением человекоподобных роботов», — заявила представитель ведомства Ли Чао (Li Chao). В стране отметила она, работают более 150 производителей гуманоидных машин, и их число продолжает расти; необходимо предотвратить вывод на рынок «очень похожих» моделей, и следует создавать условия для исследований и разработки. В Пекине начали беспокоиться по поводу чрезмерного притока инвестиций в сектор, который обещает стать одним из крупнейших катализаторов развития экономики. Это одна из шести отраслей, на которую власти призвали обращать внимание в новой пятилетке. Аналитики предсказывают, что уже в следующем году обозначится «экспоненциальный» рост производства человекоподобных роботов; UBTech обеспечила себя заказами более чем на $100 млн, но широкого внедрения этих машин на производстве пока не случилось. В этом году ориентированный на китайские компании индекс Solactive China Humanoid Robotics показал рост на 26 %. Власти ускорят работу по созданию благоприятной среды: возникнут механизмы вывода продукции на рынок, а также выхода с него, что поможет сформировать честную конкуренцию, заявила госпожа Ли. Особое внимание будет уделяться направлениям исследования и разработки основных технологий, а также инфраструктуре для обучения и испытания роботов. Власти также намерены способствовать консолидации и совместному использованию технологических решений и ресурсов, что поможет ускорить развёртывание человекоподобных роботов в реальной жизни. В ИИ очень легко переинвестировать, показал печальный опыт Intel
27.11.2025 [05:59],
Алексей Разин
В сегменте компаний, так или иначе связанных со сферой искусственного интеллекта, сейчас противоборствуют два убеждения. Боязнь упустить момент качественного прорыва в технологиях из-за недостаточных инвестиций доминирует над опасениями по поводу возможной потери средств. С другой стороны, всё больше инвесторов говорит о формировании пузыря. Между тем, недавний опыт Intel позволяет задуматься о неоднозначности ситуации в сфере ИИ. 
Источник изображения: Nvidia Как напоминает The Wall Street Journal, ещё пять лет назад капитализация Intel была больше, чем у Nvidia, а теперь соответствующий показатель последней превышает её в 26 раз. С приходом на пост генерального директора Intel Патрика Гелсингера (Patrick Gelsinger) в 2021 году появился стратегический план среднесрочного развития, конечной целью которого было устранение технологического отставания компании от конкурентов и превращения её в одного из крупнейших контрактных производителей чипов. Для достижения цели преимущественно предлагалось усиленно вбухивать деньги в строительство новых предприятий и освоение новых литографических технологий. В сегменте инфраструктуры искусственного интеллекта сейчас доминируют похожие инвестиционные идеи, хотя они влияют не на одну компанию, а большинство крупнейших игроков рынка и их ближайших партнёров. Как недавно выразился глава OpenAI Сэм Альтман (Sam Altman), люди могут либо вложить слишком много средств и потерять деньги, либо вложить слишком мало и упустить выручку. Марк Цукерберг (Mark Zuckerberg) заявил, что возглавляемая им Meta✴✴ Platforms просто пытается убедиться, что не вкладывает слишком мало средств. Недавняя история Intel показывает, что деньги могут закончиться раньше, чем наступит светлое будущее. Слишком высокая инвестиционная активность бывшего руководства Intel начала напрягать инвесторов и совет директоров раньше, чем были достигнуты цели продвигаемого Гелсингером плана. Часть проектов была отменена или заморожена, компании пришлось сократить часть персонала. Свободный денежный поток Intel на протяжении 14 предыдущих кварталов оставался преимущественно отрицательным, за исключением трёх случаев. Intel пришлось распродавать активы и сменить генерального директора, а разговоры о разделении основного бизнеса идут до сих пор. В августе власти США приобрели пакет из 10 % акций Intel, хотя подобные сделки в США сложно назвать нормальной практикой. Риторика по поводу формирующегося ИИ-пузыря в последние месяцы только усиливается, и это начало задевать руководство Nvidia в такой степени, что оно направляет аналитикам странные послания, целью которых является убеждение инвесторов в обратном. Кстати, промежуточные итоги истории Intel не так уж трагичны, поскольку компания остаётся на плаву и не достигла банкротства, а у крупнейших инвесторов в инфраструктуру ИИ дела идут ещё лучше. Microsoft, Amazon и Google хоть и увеличили свои капитальные расходы, пока удерживают их в относительно умеренных рамках по сравнению со своей выручкой. В случае с Alphabet (Google), например, доля этих затрат не превышает 23 % прогнозируемой выручки. Не все игроки рынка могут похвастать подобной финансовой устойчивостью, впрочем. Судьба Oracle, CoreWeave и даже Meta✴✴ в этом контексте может вызывать озабоченность акционеров и инвесторов, если текущие темпы роста капитальных затрат не будут хотя бы отчасти сопоставимы с темпами роста выручки. К слову, даже Nvidia с начала ноября растеряла более $700 млрд капитализации, и это лишний раз доказывает, что эйфория по поводу бума ИИ не может длиться вечно. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



