|
Опрос
|
реклама
Быстрый переход
Anthropic ведёт переговоры с Samsung о создании собственного ИИ-чипа
02.07.2026 [19:59],
Сергей Сурабекянц
Осведомлённые источники сообщили о переговорах между американским разработчиком больших языковых моделей искусственного интеллекта Anthropic и южнокорейским полупроводниковым гигантом Samsung Electronics о партнёрстве с целью выпуска фирменного ускорителя искусственного интеллекта Anthropic. 
Источник изображения: Anthropic По словам инсайдеров, планы Anthropic находятся на ранней стадии — компания пытается определиться с архитектурой, специализацией и мощностью потенциального ускорителя. Компания отказалась комментировать слухи о переговорах с Samsung, заявив, что чип Trainium от Amazon, тензорные процессоры Google и графические процессоры Nvidia остаются центральными элементами вычислительной стратегии Anthropic. Samsung также отказалась от комментариев. Компании, занимающиеся искусственным интеллектом, стремятся диверсифицировать поставки чипов, чтобы удовлетворить растущий спрос на свои услуги. В прошлом месяце компания OpenAI совместно с Broadcom представила свой первый специализированный ускоритель искусственного интеллекта, ориентированный на запуск уже готовых моделей. По замыслу компании, выпуск собственного чипа повысит эффективность работы оборудования, необходимого для работы её моделей. Qualcomm ударила по Nvidia, объявив о выпуске Arm-процессора Dragonfly C1000 на ядрах Oryon и других чипов для дата-центров
25.06.2026 [10:16],
Павел Котов
В рамках мероприятия Investor Day компания Qualcomm рассказала о своих планах в отношении оборудования для центров обработки данных с системами искусственного интеллекта. Наиболее примечательными продуктами стали серверный процессор Qualcomm Dragonfly C1000, технология High Bandwidth Compute (HBC), ускоритель Qualcomm Dragonfly AI300, сетевые решения и разработка чипов на заказ. 
Источник изображений: qualcomm.com Основным направлением технологий ИИ сегодня являются агенты, которые не просто отвечают на запросы аналогично чат-ботам, а выполняют действия от имени пользователей. Для работы ИИ-агентов требуется оборудование нового типа, и у Qualcomm подготовлены необходимые решения.  Главным элементом новой линейки стал серверный процессор Qualcomm Dragonfly C1000 на фирменных ядрах Oryon с поддержкой тактовых частот выше 5 ГГц — располагая чиплетной компоновкой, один такой процессор может содержать более 250 ядер. Компания обещает более чем двухкратный прирост производительности на ватт по сравнению с существующими решениями; тесная интеграция с памятью и ускорителями обеспечивается при помощи интерфейсов CXL и PCIe 7.0. Процессоры Qualcomm Dragonfly C1000 выйдут на рынок в 2028 году.  Технология Qualcomm High Bandwidth Compute воплощает концепцию «близкой к памяти» вычислительной архитектуры (near-memory computing), предусматривающей размещение памяти и вычислительных блоков в единой трёхмерной структуре, что помогает преодолеть ограничения, связанные с пропускной способностью памяти. Производитель обещает повысить скорость памяти по сравнению с HBM и LPDDR, а также увеличить её энергоэффективность. Ускоритель Qualcomm Dragonfly AI250 (выйдет в 2027 году) на основе памяти HBC Gen 1 обещает 18-кратный прирост производительности в сравнении с основанным LPDDR5X ускорителем Dragonfly AI200. У AI300 (появится в 2028 году) на основе HBC Gen 2 прирост производительности по сравнению с тем же компонентом обещает быть 54-кратным.  Ускоритель Qualcomm Dragonfly AI300 на основе технологии HBC второго поколения предназначен для инференса больших языковых и мультимодальных моделей. По сравнению с современными архитектурами на основе графических процессоров компания обещает кратный рост эффективности на ватт, особенно в задачах, где важны высокая пропускная способность памяти и низкие задержки. Важным направлением платформы Qualcomm Dragonfly является комплект сетевых решений для подключения и передачи данных: компания предлагает интерфейсы класса 800G и 1.6T, а также оптические и медные каналы связи, способные работать на расстояниях до 20 км. Qualcomm изъявила готовность адаптировать свои решения под нужды конкретных облачных провайдеров. Речь идёт о сборке инфраструктуры ЦОД как модульного конструктора: центральные процессоры, ускорители, память и сетевые решения проектируются под конкретные рабочие нагрузки. Это помогает гиперскейлерам оптимизировать показатели производительности, энергопотребления и стоимости владения. Первым крупным клиентом Qualcomm стала компания Meta✴✴, с которой чипмейкер заключил многолетнее соглашение. В рамках соглашения в обновлённой серверной инфраструктуре гиганта соцсетей будут использоваться серверные процессоры Dragonfly C1000. OpenAI представила свой дебютный чип Jalapeno — он сулит удешевление работы ChatGPT
24.06.2026 [17:56],
Сергей Сурабекянц
Сегодня OpenAI сообщила о готовности первых образцов специализированного чипа Jalapeno для запуска уже обученных ИИ-моделей (инференса) и начале его тестирования. Компания рассчитывает получить дополнительное конкурентное преимущество за счёт адаптации оборудования под свои продукты. Чип создан в партнёрстве с Broadcom. По словам главы Broadcom Хока Тана (Hock Tan), он позволит сэкономить до 50 % ресурсов по сравнению с типичными графическими процессорами. 
Источник изображения: OpenAI В октябре OpenAI объявила о партнёрстве с Broadcom для разработки ускорителей, оптимизированных для работы с её моделями искусственного интеллекта. По словам OpenAI и Broadcom, новые чипы были разработаны с нуля в рекордно короткие сроки и способны обеспечить производительность на ватт энергии, которая «значительно превосходит современные аналоги» в инференсе. Финальные версии чипов будут использоваться в крупных дата-центрах Microsoft и других партнёров OpenAI, начиная с конца этого года. Чипы призваны повысить производительность ИИ-моделей за счёт уменьшения объёма передаваемых данных. Они разработаны с учётом особенностей использования вычислительных ресурсов, памяти и сетевого оборудования, наиболее важных для высококлассных моделей ИИ. Следующая версия Jalapeno запланирована на 2028 год. Партнёры не исключают появления в будущем чипов, рассчитанных на другие рабочие нагрузки. Тан ожидает, что OpenAI и Broadcom смогут превзойти его предыдущий прогноз по развёртыванию чипов искусственного интеллекта общей мощностью 1,3 ГВт в следующем году. «Мы хотим верить, что сможем добиться лучших результатов, потому что спрос очень высок», — заявил он. Глава подразделения аппаратного обеспечения OpenAI Ричард Хо (Richard Ho), отказался раскрыть механизм взаиморасчётов с Broadcom, отметив, что финансовые соглашения будут окончательно согласованы после полного выполнения заказа на чипы. Тан также отказался от комментариев, но подтвердил, что Broadcom создала механизм финансирования разработки чипов совместно с инвестиционными компаниями Apollo Global Management и Blackstone. C начала этого года OpenAI привлекла уже $122 млрд инвестиций для поддержки своих дорогостоящих проектов по разработке чипов, центров обработки данных и привлечению талантливых сотрудников. Затраты на разработку и выпуск собственных чипов увеличат и без того огромные расходы убыточного стартапа на физическую инфраструктуру для поддержки ИИ. Акции Broadcom после анонса процессора OpenAI выросли на 1,6 % до $386,25. С начала года они подорожали почти на 10 %. Инференс ИИ скоро подешевеет, но пользователи этого почти не заметят
22.05.2026 [11:59],
Павел Котов
Приложения и сервисы генеративного искусственного интеллекта дорожают с каждым днём, потому что у разработчиков растут затраты на инфраструктуру. Новое поколение графических процессоров и ИИ-ускорителей обещает облегчить растущий спрос на инференс (развёртывание ИИ), но конечный потребитель едва ли заметит экономию, пишет The Register. 
Источник изображения: BoliviaInteligente / unsplash.com С момента начала бума ИИ прошло уже несколько лет, разработчики потратили миллиарды долларов на создание новых моделей, и уже стали появляться варианты практического применения ИИ — наиболее яркими примерами являются Claude Code, Codex, GitHub Copilot и другие сервисы для написания кода. Вскоре появятся и новые. Проблема в том, что предназначенные для обучения моделей центры обработки данных не рассчитаны на инференс — это совершенно разные задачи. Разработчики ускорителей сейчас активно создают новое оборудование; Nvidia поглотила за $20 млрд стартап Groq, собственные версии ускорителей готовят AMD, AWS, Intel и Google — все они пытаются снизить стоимость токена. Более дешёвые токены оптимизируют экономику, и инвесторы надеются, что OpenAI и Anthropic когда-нибудь выберутся из убытков. Оборудование нового поколения ещё не готово выйти на рынок: производители говорят о второй половине текущего года, но на практике, вероятно, придётся ждать до начала или середины следующего. Поэтому разработчики ИИ уже начали поднимать цены: OpenAI GPT-5.5 подорожала вдвое по сравнению с предшественницей, и даже новая Google Gemini 3.5 Flash стоит в 3–6 раз дороже, чем Gemini 3.1 Flash-Lite и Gemini 3 Flash Preview. Рост цен усугубляется тем, что основанные на этих моделях ИИ-агенты потребляют больше токенов, чем чат-боты. В результате разработчики ИИ отказываются от фиксированных тарифов: нет смысла брать $200 в месяц, если клиент потребляет ресурсов на $5000. Microsoft уже начала переводить тарификацию GitHub Copilot с количества рабочих мест на ценообразование по факту потребления, в этом же направлении движется Anthropic. В итоге работодателей, которые надеялись, что ИИ за бесценок заменит им сотрудников, ждёт неприятный сюрприз: вместо $40 в час и соцпакета придётся платить $30 в час за токены. Пока же волна сокращений продолжает накрывать технологическую отрасль. Meta✴✴ уволит 10 % сотрудников, закроет 6000 вакансий и переведёт 7000 человек на новые должности, около 1100 работников уволит Cloudflare, и даже власти Новой Зеландии объявили о планах сократить около 9000 госслужащих из-за ИИ. Преимущество пока на стороне крупных компаний, которые могут позволить себе убытки по одним направлениям за счёт других. OpenAI и Anthropic пока ничего не угрожает: кто-то должен разрабатывать модели ИИ, а игроки вроде Microsoft, Meta✴✴ и AWS пока в этом не преуспели. Добиться успеха удалось разве что Google. «Сбер» встал в очередь за китайскими чипами для «ГигаЧата» — перед ним ByteDance и Alibaba
20.05.2026 [18:44],
Сергей Сурабекянц
Глава «Сбера» Герман Греф заявил, что крупнейший российский банк надеется использовать процессоры китайского производства для работы флагманской модели искусственного интеллекта «ГигаЧат». Это заявление Грефа прозвучало в эфире «Первого канала» во время двухдневного визита Владимира Путина в Пекин, на фоне западных санкций, которые препятствуют российским закупкам передового иностранного оборудования для ИИ. 
Источник изображения: Huawei Греф не уточнил, какие именно китайские чипы интересуют «Сбер», но наиболее вероятным кандидатом является семейство Ascend 950 от Huawei, которое стало объектом ожесточённой конкуренции среди китайских технологических гигантов. Запрос от «Сбера», несомненно, создаст дополнительные сложности для Huawei, которая должна выполнить огромные заказы от ByteDance, Alibaba и Tencent. Только ByteDance в начале этого года заказала чипов Ascend 950PR на сумму $5,6 млрд. Huawei планирует выпустить 750 000 процессоров 950PR в 2026 году, но производство на SMIC ограничено низким выходом годных изделий на 7-нм техпроцессе DUV и предполагаемым восьмимесячным циклом от начала производства до готового процессора. По производительности в режиме инференса 950PR находится между Nvidia H100 и H200 и, по заявлению производителя, превосходит ограниченный H20 в 2,8 раза, хотя эта цифра не поддаётся прямой проверке, поскольку чипы H20 не имеют встроенной поддержки FP4. Тем не менее, каждый чип, который Huawei может произвести, сталкивается с огромным внутренним спросом, поэтому российский покупатель будет конкурировать за квоты с компаниями, которые в совокупности составляют основу китайской интернет-экономики. В марте 2026 года «Сбер» запустил «ГигаЧат Ультра» с новым режимом рассуждений, а семейство базовых моделей за последний год расширилось за счёт «ГигаЧат 2.0» и «ГигаЧат Макс». Для запуска этих моделей в больших масштабах требуется как оборудование для вывода, так и для обучения, и чипы Ascend 950PR оптимизированы именно для вывода. Чип Huawei 950DT, ориентированный на обучение ИИ-моделей, поступит в продажу не раньше четвёртого квартала 2026 года и будет оснащён 144 Гбайт фирменной памяти Huawei HiZQ 2.0 с пропускной способностью 4 Тбайт/с. Существующая инфраструктура «Сбера» основана на комбинации западных графических процессоров, китайских аналогов и чипов российского производства, которые не обеспечивают конкурентоспособных возможностей для передовых задач ИИ. Если «Сбер» хочет получить полностью китайский вычислительный стек для своего «ГигаЧата», ему понадобятся оба чипа Huawei в огромных объёмах. В январе «Сбер» за 27 млрд ₽ приобрёл 41,9 % акций крупнейшего российского производителя электроники «Элемент». Компания выпускает интегральные схемы и полупроводниковые устройства, на долю которых приходится примерно половина российского производства микроэлектроники, но её продукция ориентирована на оборонные и промышленные приложения, а не на ускорители ИИ для дата-центров. Наиболее передовые российские технологии производства микросхем нацелены на 65-нанометровую литографию к 2030 году, что примерно на 25 лет отстаёт от передовых технологий. В подписанной сегодня совместной декларации лидеров России и Китая содержится призыв к более тесному двустороннему сотрудничеству в области ИИ и информация о создании глобального органа контроля за развитием ИИ. Пока неизвестно, приведёт ли это к фактическим поставкам в Россию китайских ИИ-ускорителей. Baikal обещает к 2030 году выпустить «основу суверенных дата-центров» — отечественные ИИ-чипы, совместимые с Nvidia CUDA
19.05.2026 [09:54],
Павел Котов
Российская Baikal Electronics анонсировала на конференции ЦИПР 2026 в Нижнем Новгороде собственные решения для систем искусственного интеллекта: два ускорителя и серверный комплект с процессорами нового поколения. 
Источник изображений: t.me/anti_agi Старший ускоритель получил название Baikal BE-AI-D1000 — он предназначен для работы на серверах и в центрах обработки данных, выступая в одном классе с представленным в 2023 году NVIDIA L40S. Производительность компонента составляет 1000 Тфлопс (FP8) и 500 Тфлопс (FP16); прочих подробностей в данном аспекте разработчик пока не приводит. Объем памяти составляет от 48 до 64 Гбайт, причём это GDDR, а не высокоскоростная HBM. 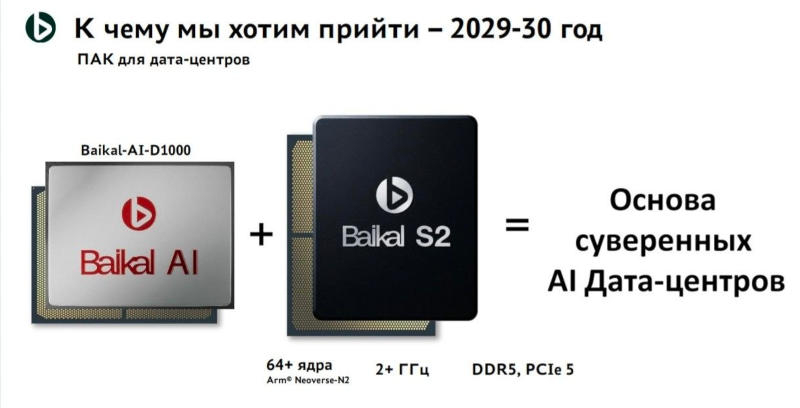 В Baikal не раскрыли, в каком формате исполнен ИИ-ускоритель, неизвестны и механизмы масштабирования — собственный аналог NVLink или открытый UALink. Известно, однако, что стоимость одного ускорителя составит около $10 000. Обещана совместимость с архитектурой CUDA, возможно, через слой трансляции ZLUDA — это позволит штатными средствами запускать PyTorch, TensorFlow и другие популярные фреймворки. Ещё одно нововведение — комплексное серверное решение, сочетающее графический и центральный процессоры. В качестве центрального выступает новый Baikal S2 на архитектуре Arm Neoverse N2, выпущенной в 2020 году. Речь идёт о своего рода отечественном аналоге Nvidia DGX. Разработку ускорителя Baikal ведёт совместно с российскими технологическими гигантами, корректируя проект по обратной связи. Эксперты указывают, что проекты имеют ощутимые перспективы наравне с проектами отечественных базовых станций для операторов мобильной связи. Выпуск продуктов намечен на 2029–2030 гг. Китайские ИТ-гиганты ускорили переход на отечественные ИИ-ускорители, несмотря на возможное возвращение Nvidia
16.05.2026 [11:02],
Владимир Фетисов
Производство китайских ускорителей для ИИ может вырасти в этом году, поскольку крупнейшие технологические компании страны стремятся внедрить больше отечественных технологий. Это происходит на фоне сообщений о возможном возвращении на рынок Китая продукции американской Nvidia. 
Источник изображения: Maxence Pira / unsplash.com На этой неделе интернет-гигант Tencent объявил, что ожидает активизации производства отечественной полупроводниковой продукции, а гигант электронной коммерции Alibaba сообщил об увеличении масштабов использования ускорителей собственной разработки. Эти сообщения подчёркивают, что в отсутствие на рынке Китая передовых чипов Nvidia из-за экспортных ограничений со стороны США страна активно продвигает отечественные разработки для реализации собственных амбиций в сфере искусственного интеллекта. Директор по стратегическому развитию Tencent Джеймс Митчелл (James Mitchell) заявил, что компания планирует «существенное увеличение» капитальных затрат, особенно во второй половине года, поскольку китайские ускорители «доступны нам из месяца в месяц». Он также добавил, что поставки графических ускорителей китайской разработки будут постепенно наращиваться в течение года. В дополнение к этому было сказано, что объём поставок китайских ускорителей растёт как за счёт производственных мощностей внутри КНР, так и за счёт предприятий в соседних странах. В Китае существует множество местных производителей чипов, которые активизировались за счёт выхода на биржу и запуска новых продуктов. В число компаний, которые пытаются заполнить вакуум, образовавшийся после введения экспортных ограничений со стороны США, входят Moore Threads, MetaX и Huawei. Это послужило основой для того, чтобы выручка китайских производителей чипов достигла рекордных показателей. Alibaba разрабатывает собственные ИИ-ускорители, которые использует в своих центрах обработки данных, являющихся основой облачного бизнеса компании. «Собственные ускорители от T-Head достигли стадии массового производства. В условиях нехватки вычислительных ресурсов это структурное преимущество благоприятно сказывается на росте нашей выручки и увеличении валовой маржи»,— заявил представитель Alibaba во время объявления финансовых результатов по итогам квартала. Alibaba также дала понять, что компания может поставлять серверы на базе собственных ускорителей другим игрокам, строящим вычислительные кластеры или центры обработки данных. Также не исключается вариант совместного строительства таких объектов, что подчёркивает растущую роль технологического гиганта в китайской полупроводниковой отрасли. Заявления Alibaba и Tencent прозвучали за день до того, как появились сообщения о том, что США дали зелёный свет нескольким китайским компаниям, включая Alibaba и Tencent, на покупку ускорителей Nvidia H200, входящих в число наиболее производительных ИИ-ускорителей на рынке. Однако официального подтверждения этого до сих пор не было. «Для меня это новость. Я знаю, что было много споров <…> и нам придётся посмотреть на это. Это функция министерства торговли», — прокомментировал данный вопрос министр финансов США Скотт Бессент (Scott Bessent). За последний год СМИ неоднократно писали о том, что Вашингтон дал разрешение Nvidia на поставку в Китай не самых мощных ИИ-ускорителей, таких как H20. Параллельно с этим сообщалось, что власти Китая поощряют местные компании за использование отечественных альтернатив. Аналитики Counterpoint Research считают, что по мере продвижения китайских компаний к агентному ИИ им потребуются более производительные ускорители, за счёт чего ускорители Nvidia H200 будут востребованы. AMD выпустила ИИ-ускоритель Instinct MI350P с 144 Гбайт HBM3E, PCIe 5.0 x16 и потреблением 600 Вт
07.05.2026 [21:43],
Николай Хижняк
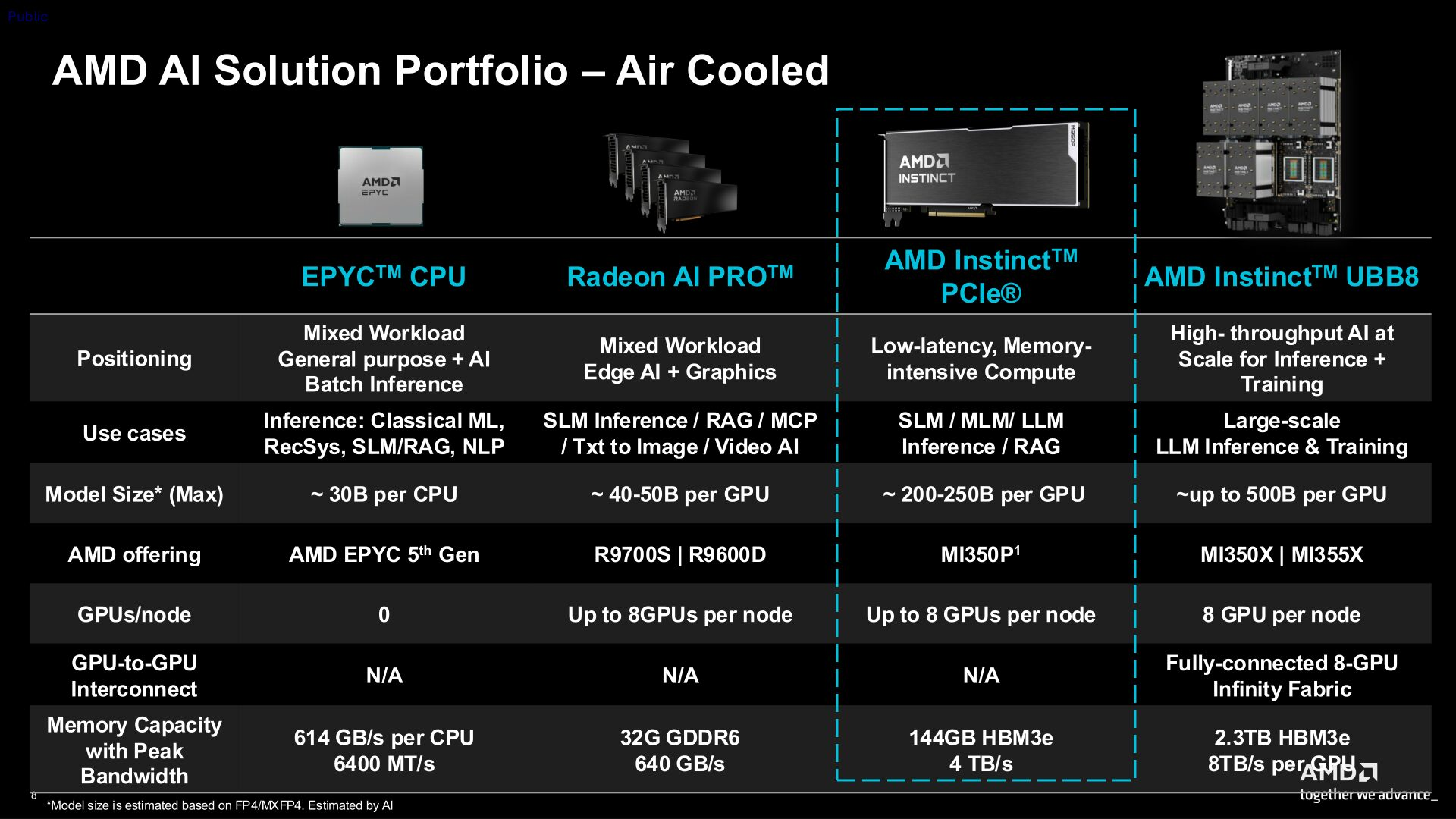
Компания AMD выпустила специализированный графический ускоритель Instinct MI350P в формате карты расширения PCIe. Новинка предназначена для серверов с воздушным охлаждением и ориентирована на развёртывание систем логического вывода для искусственного интеллекта, не требующих полноценной платформы OAM. 
Источник изображений: AMD В составе Instinct MI350P используется графический чип со 128 исполнительными блоками, 8192 потоковыми процессорами и 512 матричными ядрами. AMD заявляет для GPU максимальную частоту 2,2 ГГц. Формально Instinct MI350P представляет собой наполовину урезанную версию Instinct MI350X. 
 Карта получила 144 Гбайт памяти HBM3E с поддержкой 4096-битной шины. Для памяти заявляется пиковая пропускная способность на уровне 4 Тбайт/с. Также ускоритель оснащён 128 Мбайт кеш-памяти последнего уровня и поддерживает функцию ECC (коррекции ошибок) для памяти. Особенности Instinct MI350P
AMD заявляет для Instinct MI350P производительность до 4,6 Пфлопс при работе с матрицами MXFP4 или MXFP6. Карта также обеспечивает производительность 2,3 Пфлопс при работе с матрицами MXFP8 и OCP-FP8, 1,15 Пфлопс — при работе с матрицами FP16 и BF16 и 36 Тфлопс — при работе с матрицами FP64. Благодаря структурированной разреженности некоторые показатели производительности при работе с 8-битными и 16-битными числами удваиваются. 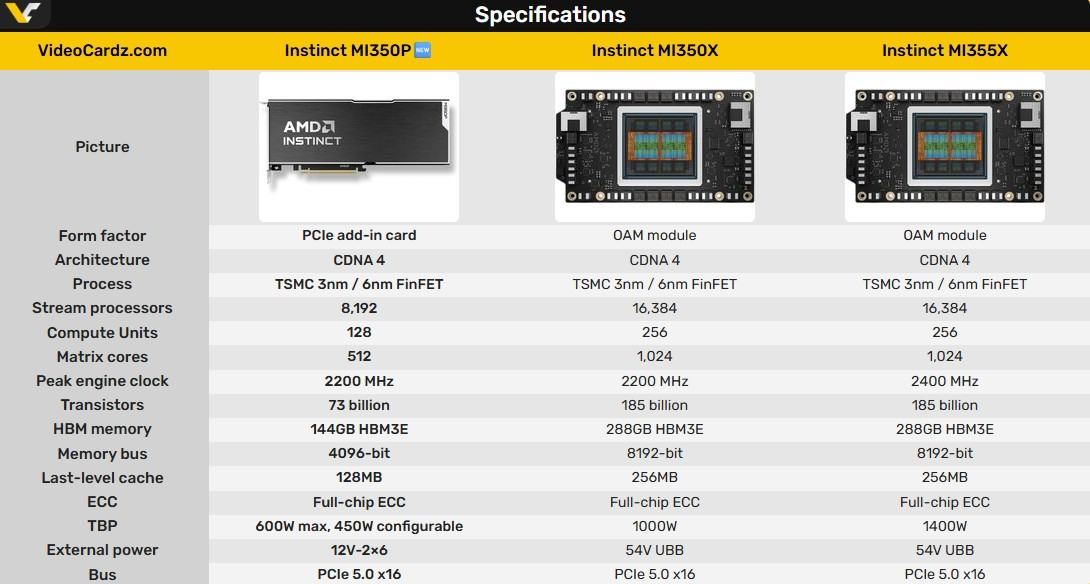 Толщина ускорителя Instinct MI350P составляет два слота расширения, длина карты — 267 мм. Для работы новинка использует интерфейс PCIe 5.0 x16. Подача дополнительного питания на карту обеспечивается через разъём 12V-2×6. Стандартный показатель энергопотребления ускорителя составляет 600 Вт, однако его можно настроить на режим потребления 450 Вт. Ускоритель AMD Instinct MI430X оказался вшестеро быстрее Nvidia Rubin, но он не для ИИ
07.05.2026 [12:55],
Павел Котов
AMD раскрыла производительность ускорителя Instinct MI430X. Его отличительной особенностью является предназначение — не для систем искусственного интеллекта, а для сегмента высокопроизводительных вычислений (HPC): вычислений с двойной точностью в научных целях, моделирования и других подобных приложений. 
Источник изображения: amd.com В последние годы графические процессоры с высокой производительностью разрабатываются главным образом для работы с алгоритмами ИИ. Форматы данных трансформируются в меньшую сторону: FP8 и BF8 сменяются FP6 и FP4, появляются аналогичные MXFP6 и MXFP4. В приоритете оказываются скорость и экономия памяти — в ущерб точности. Но в некоторых областях нужны прямо противоположные решения. Поэтому ещё в начале разработки ускорителей семейства Instinct MI400 компания AMD решила обращаться не только к ИИ, как в случае MI450/455X, но и к сегменту HPC как в случае MI430X. Компания анонсировала его ещё осенью минувшего года, когда получила первые крупные заказы. Теперь AMD раскрыла производительность ускорителя с 432 Гбайт памяти HBM4 — в режиме FP64 она составляет 200 Тфлопс, и это «более чем в шесть раз быстрее», чем Nvidia Rubin в тех же задачах. Решение от Nvidia ориентировано на ИИ с упором на FP4 и аналогичные форматы — FP64, если он вообще работает, является второстепенным форматом, специально для которого у «зелёных» нет вообще ничего. Хотя в режиме FP4 ускорители Rubin окажутся быстрее, чем MI430X, но AMD здесь точного показателя не раскрыла. Первыми заказчиками AMD Instinct MI430X стали научные организации: ускорители получит HPC-комплекс Discovery при Национальной лаборатории Ок-Ридж (США) и суперкомпьютер Alice Recoque (Франция). Последняя уже заявила о выходе на показатель более 1 Эфлопс в FP64, и это одна из наиболее быстрых высокопроизводительных систем в Европе. Более подробно компания расскажет о своих продуктах на мероприятии AMD Advancing AI 2026, которое пройдёт 22 и 23 июля. Цена на серверы с Nvidia B300 на сером рынке Китая взлетела до $1 млн
30.04.2026 [14:21],
Анжелла Марина
На фоне жёстких ограничений на экспорт чипов со стороны США и ажиотажного спроса на вычислительные мощности для искусственного интеллекта цены на серверы Nvidia B300 в Китае выросли почти вдвое, достигнув $1 млн. Критически важные для развития технологий в КНР поставки оборудования, которое идёт через серый рынок, оказались в дефиците из-за ужесточения борьбы с контрабандой. 
Источник изображения: Nvidia По сообщению Reuters, стоимость самого продвинутого сервера Nvidia, оснащённого восемью графическими процессорами B300, в Китае теперь составляет около 7 млн юаней (примерно $1 023 650), тогда как в конце прошлого года показатель находился на отметке в 4 млн юаней (около $584 950). Такой резкий скачок обусловлен давлением на серый рынок, который ранее являлся ключевым каналом поставок, а также устойчивым спросом со стороны местных технологических гигантов. При этом многие китайские компании стараются не указывать оборудование Nvidia в своей отчётности из-за опасений подвергнуться американским санкциям. Сама Nvidia подчеркнула, что B300 запрещён к продаже в Китае, а любые попытки незаконного оборота обречены на провал из-за строгих механизмов контроля. Для сравнения, в США цена аналогичного сервера составляет около 550 тысяч долларов, что также выше прошлогодних показателей. Китайская наценка отражает так называемую надбавку за дефицит, которая возникла после мартовского уголовного преследования американскими властями сооснователя компании Supermicro, являющейся партнёром Nvidia, И Шянь Лио (Yi-Shyan Liaw). Лио обвинили в участии незаконной деятельности по провозу из США в Китай запрещённого серверного оборудования. В результате некоторые компании, не имеющие возможности приобрести серверы в собственность, вынуждены рассматривать варианты аренды, стоимость которой достигает 190 тысяч юаней (примерно $27 800) в месяц по годовому контракту. Однако дефицит оборудования не ослабляет аппетиты местных разработчиков, стремящихся к монетизации своих моделей и вычислительной инфраструктуры. По данным Morgan Stanley, в марте 2026 года доля китайских ИИ-моделей в глобальном потреблении токенов резко возросла, достигнув 32 % по сравнению с 5-% годом ранее. Например, компании MiniMax, Zhipu и Qwen от Alibaba зафиксировали рост использования токенов в шесть-семь раз в феврале и марте по сравнению с декабрём. Для обработки таких массивов данных требуется наиболее эффективное оборудование, каковым является B300 с его 288 Гбайт памяти и вычислительной мощностью 14 петафлопс при точности FP4. К этому добавляется неопределённость вокруг поставок чипов H200, которая также способствует росту цен на B300. Несмотря на получение одобрения от правительств обеих стран, экспорт H200 в Китай так и не начался из-за разногласий по условиям продажи. Напомним, Nvidia и её партнёры начали поставлять B300 ещё в сентябре прошлого года, однако закрытые каналы поставок не позволяют в полной мере удовлетворить запросы китайского рынка и в таких условиях борьба за доступ к мощным вычислительным ресурсам продолжает стимулировать рост цен. Выход DeepSeek V4 взвинтил спрос на ИИ-ускорители Huawei Ascend 950
29.04.2026 [13:47],
Владимир Мироненко
После выхода ИИ-модели DeepSeek V4, специально оптимизированной для работы на чипах Huawei, в Китае резко вырос спрос на ИИ-ускорители Ascend 950, пишет агентство Reuters. По словам его источников, крупнейшие китайские интернет-компании, включая ByteDance, Tencent и Alibaba, обращаются к Huawei с заявками на новые заказы. 
Источник изображения: huaweicentral.com Также стремятся разместить заказы на поставку Ascend 950 компании, специализирующиеся на облачных вычислениях и услугах аренды графических процессоров (GPU). Чип Ascend 950PR значительно превосходит по производительности Nvidia H20 — самый мощный чип, который Nvidia разрешалось продавать в Китае до того, как Пекин заблокировал его импорт в прошлом году. Но он всё же уступает чипу H200, который пока так и поставляется в Китай из-за разногласий Пекина и Вашингтона относительно условий его продажи. Решение DeepSeek оптимизировать версию DeepSeek V4 специально для использования с чипами Huawei знаменует собой стратегический сдвиг от зависимости от американских полупроводников к развитию собственного китайского оборудования для ИИ-технологий, что является приоритетом для Пекина в стремлении к технологическому превосходству, отметило Reuters. Серия Huawei Ascend 950 — в частности, вариант 950PR — является единственным китайским чипом с поддержкой технологии обработки ИИ-вычислений в более сжатом вычислительном формате, что позволяет производить больше вычислений в секунду при меньших затратах. Сразу же после анонса платформа Bailian от Alibaba Cloud предоставила доступ к DeepSeek V4, предложив варианты V4-Pro и V4-Flash по официальным ценам разработчика. Аналогично поступила Tencent Cloud. Быстрый запуск ИИ-модели крупными облачными платформами означает, что миллионы пользователей и разработчиков теперь могут получить доступ к V4, что резко увеличивает объём запросов, и, соответственно, спрос на базовые чипы для их обработки. DeepSeek заявила, что цена V4-Pro может значительно снизиться во второй половине 2026 года, как только кластеры на Huawei Ascend 950 начнут «поставляться в больших масштабах». Следует отметить, что из-за экспортных ограничений США на поставку передового оборудования для производства микросхем Huawei не сможет удовлетворить потребности отрасли в чипах Ascend 950. По словам источников, Huawei планирует отгрузить около 750 тыс. единиц Ascend 950PR в этом году. Старт его серийного производства был намечен на апрель, а полномасштабные поставки должны начаться во второй половине 2026 года. Японцы создали прототип настольного ускорителя частиц — он разгоняет электроны до «скорости света» на масштабе муравья
01.04.2026 [13:18],
Геннадий Детинич
Коллектив учёных из Японии совершил прорыв в создании компактных ускорителей частиц. Они впервые продемонстрировали повышение мощности лазера на свободных электронах в экстремальном ультрафиолетовом диапазоне длин волн 27–50 нм с помощью так называемого кильватерного ускорения, инициированного лазерным лучом в плазме, что впервые произошло на отрезке всего нескольких миллиметров. Это путь к настольным ускорителям, которые далеко продвинут науку. 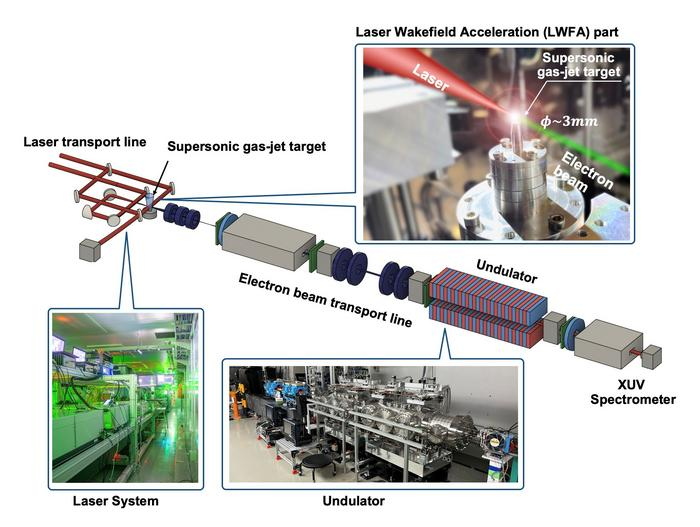
Источник изображения: SANKEN В исследовании приняли участие учёные из Института научных и промышленных исследований Университета Осаки (SANKEN) совместно с Kansai Institute for Photon Science (KPSI), Национального института квантовой науки и технологий (QST), Центра RIKEN SPring-8 (RSC) и Организации исследований высоких энергий (KEK). Сегодня ускорители электронов, лежащие в основе синхротронов, это системы с периметром до нескольких сотен метров. Например, создающийся в России под Новосибирском ускоритель СКИФ кольцо периметром около полукилометра. Это делает исследования с использованием ускорителей доступными относительно небольшому количеству коллективов. Настольные ускорители, напротив, помогут совершать научные прорывы даже на уровне небольших лабораторий. Добавим, что ускоритель электронов интересен как источник вторичного рентгеновского излучения. Эксперимент с ультрафиолетовым излучением — это шаг в нужном направлении. Благодаря более короткой волне когерентного рентгеновского света и за счёт повышения его энергии в компактном ускорителе будет повышено разрешение получаемой картинки — атомарной структуры материалов, строения клеток и всего, на что будет направлен этот луч. Подобные ускорители позволят буквально заглянуть в суть вещей и организмов. Ключевым успехом в разработке компактной установки стало получение стабильных моноэнергетических электронных пучков высокой энергии благодаря усовершенствованной форме лазерного импульса, повышающей точность фокусировки, и специально разработанным сверхзвуковым газовым соплам, обеспечивающим устойчивые фронты плазмы. В результате исследователям удалось добиться усиления лазера на свободных электронах в экстремальном ультрафиолете. Технология использует плазменные поля, которые в тысячу раз сильнее полей традиционных ускорителей, сокращая трек для ускорения с сотен метров до миллиметров. Метод основан на фокусировке мощного лазерного импульса на сверхзвуковой газовой струе, что создаёт плазму и формирует волны, ускоряющие электроны почти до скорости света. Полученный пучок электронов затем транспортируется в ондулятор — регулярную магнитную структуру, где электроны колеблются и генерируют когерентное лазерное излучение. Повышение стабильности плазмы позволило преодолеть предыдущие проблемы, связанные с неконтролируемым поведением плазменной среды. Это открытие приближает создание компактных рентгеновских лазеров на свободных электронах, способных генерировать излучение в 10 миллиардов раз ярче Солнца с длительностью импульсов на уровне фемтосекунд, но в условиях обычной лаборатории. Такие устройства обещают революцию исследований в биологии, материаловедении, разработке полупроводников и квантовых технологиях. Alibaba похвалилась выпуском 500 000 ИИ-ускорителей и признала, что они медленнее аналогов Nvidia
20.03.2026 [16:44],
Павел Котов
Руководство китайского технологического гиганта Alibaba подтвердило, что полупроводниковое подразделение компании произвело почти 500 000 чипов, в том числе для ускорителей искусственного интеллекта, но все они отстают от продукции Nvidia. 
Источник изображения: alibabagroup.com Входящий в Alibaba производитель полупроводников T-Head недавно провёл конференцию по итогам III квартала 2026 финансового года, в ходе которой его гендиректор Ёнмин Ву (Yongming Wu) сообщил, что компания выпустила почти 470 000 чипов, в том числе трёх моделей, разработанных специально для рабочих нагрузок искусственного интеллекта: XuanTie C908, TH1520 и Pingtouge Zhenwu 810E. Это значит, что Alibaba действительно наладила мощное производство полупроводников — для сравнения, за год выпущены 6 млн чипов Nvidia Blackwell. Но одной только производственной мощностью всех задач решить не получится — китайские ИИ-ускорители от Alibaba T-Head уступают американской продукции, и в компании с этим не спорят. «Учитывая, что наши чипы всё ещё отстают от зарубежных аналогов по производительности в различных аспектах, мы стремимся углубить совместное проектирование с облачной инфраструктурой Alibaba и моделью Qwen для повышения эффективности. <..> Это одно из ключевых отличий и наш подход к проектированию чипов в T-Head, который выделяет нас среди прочих компаний — производителей чипов. Наша основная цель — создать систему ИИ с превосходным соотношением цены и качества», — отметил Ёнмин Ву. Intel представила мечту анонимов — чип Heracles для работы с зашифрованными данными без дешифровки
11.03.2026 [22:19],
Геннадий Детинич
Intel впервые показала чип для полностью гомоморфного шифрования (Fully Homomorphic Encryption, FHE), который справляется с задачами в 5000 раз быстрее классических серверных процессоров. Это ускоритель Heracles («Геракл»), созданный по заказу военных США для противодействия взлому со стороны квантовых компьютеров. «Геракл» ускоряет обработку полностью зашифрованной информации без какого-либо декодирования, сохраняя конфиденциальность на всех этапах. 
Источник изображения: Intel Полностью гомоморфное шифрование (Fully Homomorphic Encryption, FHE) представляет собой перспективную криптографическую технологию, позволяющую выполнять произвольные вычисления над зашифрованными данными без необходимости их расшифровки. Это решает фундаментальную проблему доверия к облачным сервисам и ИИ-системам: данные остаются полностью закрытыми для платформ даже во время обработки. Однако главным препятствием для практического применения FHE остаётся крайне низкая производительность обычных процессоров и видеокарт. Более подробно о «головоломной» математике полностью гомоморфного шифрования можно прочесть в статье «Полная гомоморфность — и никакого доверия!» из нашего архива. Не углубляясь, отметим, что на обычных CPU и GPU такие операции могут быть в тысячи–десятки тысяч раз медленнее, чем работа с открытыми данными. Именно поэтому ведущие компании и стартапы активно разрабатывают специализированные ускорители для FHE. Как ни крути, анонимность всегда будет востребована. Чип, получивший имя «Геракл», компания Intel начала разрабатывать пять лет назад. До конференции ISSCC в прошлом месяце о нём было мало что известно. Теперь Intel готова дозированно делиться информацией о нём, поскольку конкуренты не дремлют и важно оставаться на слуху. По словам представителей компании, Heracles ускоряет FHE-вычисления до 5000 раз по сравнению с лучшими серверными процессорами Intel Xeon (например, 24-ядерным Sapphire Rapids). Чип изготовлен по самому передовому 3-нм FinFET-техпроцессу компании, имеет площадь примерно в 20 раз больше конкурирующих разработок в сфере FHE (более 200 мм² вместо примерно 10 мм² у конкурентов) и работает в тесной связке с двумя модулями HBM по 24 Гбайт каждый. Чип и память упрятаны под общий водоблок и охлаждаются жидким хладагентом. В целом исполнение напоминает топовый GPU, но решает иные задачи. Архитектура «Геркулеса» представляет собой ячеистую структуру, связывающую парные плитки-вычислители шиной с пропускной способностью 9,6 Тбайт/с. Внешняя память HBM общей ёмкостью 48 Гбайт буферизируется общей для всех парных плиток кеш-памятью ёмкостью 64 Мбайт. Канал доступа к внешней памяти обеспечивает 819 Гбайт/с. Подобные характеристики даже не снились самым мощным на сегодня графическим ускорителям. В компании утверждают, что Heracles — это первый чип FHE, работающий «в масштабе». Иначе говоря, это не лабораторная демонстрация, а решение, способное к выполнению реальных крупномасштабных задач. В живой демонстрации на ISSCC чип обработал анонимный запрос к зашифрованной базе данных избирателей (функция проверки регистрации голоса) за 14 мкс вместо 15 мс на Xeon — разница, которая при проверке 100 млн бюллетеней сокращается с 17 дней до 23 минут. Публичное представление «Геркулеса» можно расценить как важный шаг в гонке за коммерциализацией аппаратных FHE-платформ. Стартапы Duality Technologies, Optalysys, Niobium Microsystems и другие тоже активно продвигают свои решения, но Intel рассчитывает на собственные лидирующие позиции в отрасли, которые поддержат перспективную разработку. Если технология получит широкое распространение, это радикально изменит подход к приватности в облачных вычислениях, анализе данных, машинном обучении и многих других областях, где сейчас приходится жертвовать конфиденциальностью ради скорости обработки. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex