|
Опрос
|
реклама
Быстрый переход
Meta✴ провалила создание собственного ИИ-чипа, потому что это «слишком сложно» и кругом «технические проблемы»
28.02.2026 [10:56],
Павел Котов
Meta✴✴ столкнулась со сложностями при разработке собственных ускорителей для систем искусственного интеллекта и была вынуждена отказаться от самого передового проекта в пользу менее сложного варианта. Об этом сообщил ресурс The Information со ссылкой на осведомлённые источники. 
Источник изображений: Igor Omilaev / unsplash.com На минувшей неделе Meta✴✴ отказалась продолжать работу над наиболее передовым ускорителем для обучения моделей ИИ, потому что столкнулась с трудностями при его проектировании и техническими проблемами; руководство компании проинформировало работников отдела инфраструктуры об изменении планов. Компания пересмотрела дорожную карту, имея множество запасных вариантов. Она заключила многомиллиардную сделку по аренде ИИ-ускорителей TPU у Google; инициировала партнёрский проект в области ускорителей AMD Instinct суммарной мощностью до 6 ГВт; а также объявила о намерении закупать ИИ-ускорители Nvidia текущего и перспективных поколений. Собственные чипы компания разрабатывает в рамках программы Meta✴✴ Training and Inference Accelerator (MTIA) — она призвана снизить затраты и усилить контроль над инфраструктурой центров обработки данных. «Мы по-прежнему привержены инвестициям в диверсифицированный портфель чипов для удовлетворения наших потребностей, что включает в себя развитие нашего портфеля MTIA, и в этом году мы поделимся свежей информацией», — прокомментировал происходящее представитель Meta✴✴. Компания отказалась от одной из версий своего чипа второго поколения для обучения ИИ, проходящего внутри Meta✴✴ под кодовым наименованием Iris, затем она начала работать над более совершенным чипом, которому присвоили название Olympus, но теперь отказалась и от него.  В Meta✴✴ назрело скептическое отношение к возможности создать собственные ИИ-ускорители, сопоставимые по возможностям с чипам Nvidia, признался один из разработчиков Meta✴✴ — всё дело в рисках задержек или вынужденных доработок проектов. Работа требует большой команды инженеров для проектирования, отладки чипов и обеспечения их невысокого энергопотребления, в результате чего продукты Nvidia оказываются более целесообразными. В основу предназначенного для обучения ИИ-ускорителя Iris легла технология пакетной обработки параллельных данных SIMD (Single Instruction, multiple data) — они легче в проектировании, но для них труднее писать ПО. В ускорителе Olympus использовался принятый Nvidia подход SIMT (Single Instruction, Multiple Threads), при котором множество потоков выполняет одну инструкцию, сохраняя логическую независимость. Такие чипы сложнее в проектировании, но под них проще писать ПО для обучения ИИ-моделей. Некоторые технологические компании предпочитают второй подход по образцу Nvidia, потому что он обеспечивает более высокую гибкость и лучше адаптирован для обучения современных моделей ИИ. Meta✴✴ планировала завершить разработку Olympus не раньше IV квартала 2026 года, но в действительности потребовались бы не менее девяти месяцев до передачи проекта в массовое производство. Основу архитектуры Olympus должны были составить наработки стартапа Rivos, поглощённого Meta✴✴ в минувшем году, — они совместимы с ПО Nvidia CUDA, наиболее популярным в обучении и запуске моделей ИИ. Meta✴✴ планировала разработать большие кластеры серверов на чипах Olympus, но руководство компании увидело в этом угрозу для обучения новых моделей в условиях конкуренции с OpenAI и Google. ПО для собственных ускорителей было бы менее стабильным, чем у Nvidia, а сложная архитектура Olympus могла бы затруднить его массовое производство. Поэтому пока Meta✴✴ намерена использовать в обучении ИИ ускорители партнёров, к которым прилагается более развитое и стабильное ПО. Meta✴ купит у AMD чипов на $100 млрд для ИИ-систем на 6 ГВт — и получит «в подарок» кусочек самой AMD
24.02.2026 [19:39],
Сергей Сурабекянц
Компании AMD и Meta✴✴ объявили о ещё одной колоссальной сделке, стоимость которой может превысить $100 млрд. AMD предоставит до 6 гигаватт вычислительной мощности на основе ИИ-ускорителей AMD Instinct для реализации амбиций Meta✴✴ в области ИИ. Сделка предусматривает вознаграждение для Meta✴✴, в рамках которого компания может получить до 160 млн акций AMD. Meta✴✴ также станет ведущим потребителем чипов AMD EPYC Venice и процессоров следующего поколения EPYC Verano. 
Источник изображений: AMD В своём пресс-релизе AMD подтвердила партнёрство с Meta✴✴ с целью «быстрого масштабирования инфраструктуры ИИ и ускорения разработки и внедрения передовых моделей ИИ». С этой целью AMD предоставит Meta✴✴ архитектуру AMD Helios для стоечных систем, начало развёртывания которой ожидается во второй половине 2026 года. Решение будет основано на базе специализированных графических процессоров AMD Instinct, построенных на архитектуре MI450, процессоров AMD EPYC Venice и программного обеспечения ROCm.  Глава AMD Лиза Су (Lisa Su) заявила, что партнёрство с Meta✴✴ представляет собой «многолетнее сотрудничество», а генеральный директор Meta✴✴ Марк Цукерберг (Mark Zuckerberg) подтвердил долгосрочные перспективы партнёрства. По словам Цукерберга, амбиции Meta✴✴ в области искусственного интеллекта направлены на создание «персонального суперинтеллекта». AMD также сообщила, что Meta✴✴ станет ведущим клиентом для процессоров AMD EPYC Venice шестого поколения, а также чипов EPYC следующего поколения Verano. AMD заявила, что выпустила для Meta✴✴ «варранты на основе производительности» на сумму до 160 млн обыкновенных акций AMD, которые будут предоставляться «по мере достижения определённых этапов, связанных с поставками графических процессоров Instinct». По сути, AMD вознаграждает Meta✴✴ своими акциями за покупку графических процессоров. Сделка по масштабу практически идентична партнёрству OpenAI и AMD, объявленному в октябре. По данным The Wall Street Journal, стоимость сделки превышает $100 млрд, при этом каждый гигаватт вычислительных мощностей приносит AMD десятки миллиардов долларов дохода. Что касается сделки с акциями, Meta✴✴ сможет приобрести до 160 млн акций по цене 0,01 доллара за штуку. Для получения полного вознаграждения в виде акций, цена акций AMD должна достичь $600. В настоящее время они торгуется чуть ниже $200. На прошлой неделе сообщалось о намерении Meta✴✴ использовать автономные процессоры Nvidia Grace в своих ЦОД, что, по словам компании, обеспечит значительный скачок производительности на ватт. Топ-менеджер Intel: в половине отгруженных в этом году ПК будет ускоритель ИИ
18.02.2026 [18:12],
Сергей Сурабекянц
Президент японского подразделения Intel Макото Оно (Makoto Ohno) уверен, что 2026 год станет решающим для ПК с поддержкой ИИ. По его прогнозам, в этом году на ПК с ИИ придётся примерно половина от общего объёма поставок за год. По предварительным оценкам IDC, в 2026 году будет отгружено около 260 млн ПК. Если прогноз Макото Оно сбудется, 130 млн из них будут оснащены нейронным процессором (NPU) или другим чипом для локальной обработки данных с помощью ИИ. Тем не менее Макото Оно признал, что основной причиной покупки ПК с ИИ могут оказаться не его возможности по ускорению искусственного интеллекта, а повышенная производительность в широком спектре прикладных задач и более длительное время автономной работы благодаря новым поколениям оптимизированных процессоров. «Прогнозируется, что к 2026 году […] каждый второй компьютер будет ПК с искусственным интеллектом. Однако, учитывая текущую ситуацию, причинами выбора ПК с ИИ являются его высокая производительность и длительное время автономной работы, обеспечиваемое использованием нейронного процессора. Другими словами, важно учитывать тот факт, что люди в настоящее время покупают ПК с ИИ не для того, чтобы использовать его функции, связанные с ИИ», — отметил Макото Оно. По словам Макото Оно, Intel хочет в кратчайшие сроки сделать ПК с ИИ нормой, а не исключением. Компания признает, что в настоящее время эти ПК в основном воспринимаются как продукты высокого класса, и стремится как можно быстрее изменить это восприятие и вывести такие устройства на массовый рынок. Intel также подчеркнула необходимость большего количества приложений, которые действительно используют возможности ПК с ИИ, с целью достижения точки, когда люди будут покупать ПК с ИИ для конкретной цели, а не просто потому, что это новейший продукт. Microsoft представила Maia 200 — фирменный 3-нм ИИ-ускоритель с 216 Гбайт HBM3e
26.01.2026 [23:33],
Николай Хижняк
Компания Microsoft представила новейший ускоритель ИИ собственной разработки — Azure Maia 200. Новый чип является следующим поколением линейки серверных графических процессоров Microsoft Maia, предназначенных для выполнения задач вывода моделей ИИ с высокой скоростью и производительностью, превосходящей предложения от таких крупных конкурентов, как Amazon и Google. 
Источник изображения: Microsoft Maia 200 позиционируется как самая эффективная система вывода от Microsoft из когда-либо развёрнутых. Во всех пресс-релизах компании акцент делается как на высоких показателях производительности, так и на заявлениях о приверженности Microsoft принципам защиты окружающей среды. Компания утверждает, что Maia 200 обеспечивает на 30 % большую производительность на доллар, чем Maia 100 первого поколения, что весьма впечатляет, учитывая, что новый чип также имеет на 50 % более высокое значение TDP, чем его предшественник. Maia 200 построен на 3-нм техпроцессе TSMC и содержит 140 млрд транзисторов. Он, как утверждается, способен обеспечивать до 10 петафлопс производительности в вычисления FP4, что в три раза выше, чем у конкурента от Amazon — Trainium3. Maia 200 оснащён 216 Гбайт памяти HBM3e с пропускной способностью 7 Тбайт/с, а также имеет 272 Мбайт встроенной памяти SRAM. 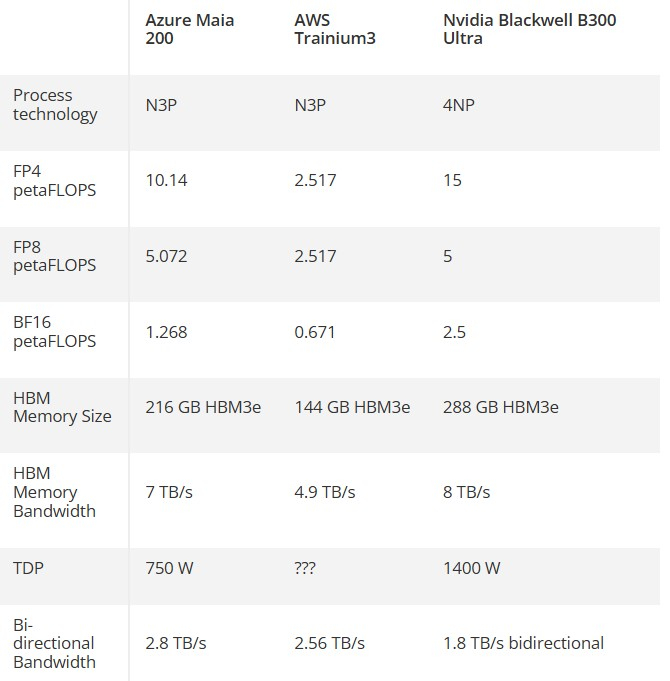
Источник изображения: Tom's Hardware Из сравнительной таблицы выше, подготовленной порталом Tom’s Hardware, видно, что Maia 200 демонстрирует явное превосходство в вычислительной мощности по сравнению с решением компании Amazon и по некоторым показателям соответствует ИИ-ускорителю B300 Ultra от Nvidia. Очевидно, что сравнивать их как прямых конкурентов бессмысленно. Покупатели не могут приобрести Maia 200 напрямую, а Blackwell B300 Ultra оптимизирован для гораздо более ресурсоёмких задач, чем чип Microsoft. Кроме того, программный стек Nvidia предоставляет B300 значительное преимущество перед любыми другими конкурентами. Однако Maia 200 превосходит B300 по эффективности, что является большим достижением в эпоху, когда обеспокоенность общественности негативным воздействием ИИ на окружающую среду неуклонно растёт. Maia 200 работает при почти вдвое меньшем TDP, чем B300 (750 против 1400 Вт). И если новый ИИ-ускоритель Microsoft похож по энергоэффективности на предшественника Maia 100, то он, как и предшественник, будет работать ниже своего теоретического максимального TDP. Для Maia 100 был заявлен TDP на уровне 700 Вт, но Microsoft утверждает, что в рабочем режиме его энергопотребление составляет всего 500 Вт. Maia 200 оптимизирован для работы с вычислениями 4-битной (FP4) и 8-битной (FP8) точности с плавающей запятой. Он ориентирован на клиентов, которые работают с ИИ-моделями, требующими производительности FP4, а не для более сложных операций. Как предполагает Tom’s Hardware, значительная часть бюджета Microsoft на исследования и разработки этого чипа была направлена на иерархию памяти, использующуюся внутри его 272 Мбайт высокоэффективной SRAM-памяти. Последняя разделена на «многоуровневую кластерную SRAM (CSRAM) и плиточную SRAM (TSRAM)», что обеспечивает повышенную эффективность работы и философию интеллектуального и равномерного распределения рабочей нагрузки по всем кристаллам HBM и SRAM. Сообщается, что ИИ-процессоры Maia 200 уже развёрнуты в центральном дата-центре Microsoft в США (Azure), а в будущем их развёртывание планируется в западном дата-центре (Финикс, Аризона). Чипы станут частью гетерогенной инфраструктуры Microsoft, работая в тандеме с другими различными ускорителями ИИ. По основному накопительному кольцу российского синхротрона СКИФ впервые пронёсся рабочий пучок электронов
23.12.2025 [21:14],
Геннадий Детинич
Под Новосибирском достигнут важный этап в создании Центра коллективного пользования «Сибирский кольцевой источник фотонов» (СКИФ) — первой в России установки синхротронного излучения четвертого поколения (4+), которая станет самым мощным в мире источником такого света. 22 декабря 2025 года учёные успешно переправили пучок электронов с энергией 3 гигаэлектронвольта (ГэВ) из бустерного синхротрона в основное накопительное кольцо. Работа не за горами. 
Источник изображения: ТАСС Периметр бустерного кольца достигает 158 метров. В этом кольце пучок электронов в электромагнитном канале за полсекунды будет разгоняться до 3 ГэВ — энергии, на которой будет работать синхротрон. По достижении этой отметки пучок по 220-метровому транспортному тоннелю будет влетать в основное накопительное кольцо периметром 476 м. В основном кольце электроны будут разгоняться до околосветовой скорости, после чего смогут возбуждать вторичное рентгеновское излучение на специальных портах. Каждый такой порт будет выходить в лабораторию на испытательную установку. Лабораторий, или испытательных станций, по периметру основного кольца будет 30 штук — все для разных задач, от биологии до материаловедения. 
Общий вид на объекты ЦКП «СКИФ». Рендер. Источник изображения: СО РАН Монтаж бустерного кольца начался в ноябре 2024 года. Первые пучки по кольцу запустили в августе 2025 года. В ноябре СКИФ был готов на 95 %. И хотя проект из-за санкций немного запаздывает, его реализация идёт близко к утверждённому графику. Во всяком случае, пучок с рабочей энергией 3 ГэВ запущен в основное накопительное кольцо, что зафиксировали датчики. Похоже, первая научная работа на установке не задержится. Лаборатории будут вводиться постепенно ещё не один год, но первые из них заработают уже в начале 2026 года. Высочайшая яркость синхротронного излучения СКИФа поможет учёным заглянуть вглубь вещества с ещё большей детализацией, чем когда бы то ни было. Несмотря на сопротивление Пекина, Nvidia намерена начать поставки чипов H200 в Китай к середине февраля
22.12.2025 [19:34],
Сергей Сурабекянц
Осведомлённые источники сообщают, что Nvidia уведомила китайских клиентов о намерении начать поставки своих вторых по мощности чипов для искусственного интеллекта в Китай до новогодних праздников по китайскому лунному календарю, то есть в середине февраля. Компания планирует выполнить первоначальные заказы из имеющихся запасов. Будет поставлено от 5000 до 10 000 серверов, что эквивалентно 40 000–80 000 чипов H200 для искусственного интеллекта. 
Источник изображений: Nvidia Nvidia также сообщила китайским клиентам о планах наращивания мощностей для производства этих чипов, при этом заказы на эти мощности начнут приниматься во втором квартале 2026 года. Для китайских технологических гигантов, таких как Alibaba Group и ByteDance, которые выразили заинтересованность в покупке чипов H200, потенциальные поставки обеспечат доступ к процессорам, примерно в шесть раз более мощным, чем H20, которые Nvidia разработала специально для Китая. Независимо от озвученных планов Nvidia поставки пока под вопросом, поскольку Пекин ещё не одобрил ни одной закупки H200 и сроки могут измениться в зависимости от решений правительства. Китайские чиновники провели экстренные совещания в начале декабря для обсуждения этого вопроса и пока взвешивают возможность разрешения поставок. Согласно одному из предложений, каждая покупка H200 должна сопровождаться приобретением определённого количества ускорителей ИИ китайского производства. Китай активно развивает собственную индустрию чипов для искусственного интеллекта. Но пока ускорители ИИ от китайских компаний не могут сравниться по производительности с H200, что вызывает у правительства Китая опасения, что разрешение импорта может замедлить внутренний прогресс. Планируемые поставки, если они состоятся, станут первыми поставками ИИ-ускорителей H200 в Китай после того, как администрация США разрешила такие продажи с выплатой 25 % прибыли в американский бюджет. Этот шаг представляет собой серьёзный сдвиг в политике США по сравнению с предыдущей администрацией, которая полностью запретила продажу передовых чипов для ИИ в Китай, ссылаясь на соображения национальной безопасности. Серьёзность намерений правительства США подтверждает начавшаяся на прошлой неделе межведомственная проверка заявок на лицензирование экспорта чипов H200 в Китай.  H200, входящий в линейку Hopper предыдущего поколения от Nvidia, по-прежнему широко используется в ИИ, несмотря на то, что ему на смену пришли ИИ-ускорители поколения Blackwell. Ранее Nvidia сосредоточила усилия на выпуске ускорителей Blackwell и запуске будущей линейки Rubin, что привело к дефициту поставок H200. Китайский ответ Nvidia: Moore Threads представила игровые GPU Lushan и ИИ-ускорители Huashan — и они кратно быстрее прежних
20.12.2025 [15:31],
Павел Котов
Китайский производитель чипов Moore Threads представил два новых графических процессора: предназначенный для игр Lushan и ориентированный на задачи искусственного интеллекта Huashan — в обоих случаях обещан значительный прирост скорости в сравнении с графикой предыдущего поколения у того же производителя, сообщает Wccftech. 
Источник изображений: wccftech.com В основе Lushan и Huashan лежит архитектура Flower Harbor (Huagang) с улучшенными вычислительными блоками, в которых вычислительная плотность чипов увеличилась на 50 %, а энергоэффективность выросла на 10 %. Новая архитектура поддерживает следующие форматы вычислений: FP64, FP32, TF32, FP16, BF16, FP8, FP6, FP4, INT8, MTFP8, MTFP6, MTFP4. Сделан упор на параллельную работу и масштабирование: ускорители обмениваются данными с высокой скоростью и работают асинхронно — при помощи технологии MTLink можно сформировать кластер из более чем 100 тыс. графических процессоров Huashan. Видеокарты Lushan адресованы любителям игр и создателям контента и выступают преемниками потребительских Moore Threads MTT S80 и MTT S90. Подробности о продукте пока не приводятся, но разработчик уже рассказал, каких результатов можно ждать от видеокарт нового поколения:
 Moore Threads обеспечила графике на новой архитектуре полную совместимость с наиболее популярными API, в том числе DirectX 12 Ultimate — продукты из предыдущей потребительской линейки в этом плане сильно отставали. Другие важные нововведения — рендеринг с использованием генеративного ИИ теперь встроен в единый конвейер UniTE; полностью переработана аппаратная часть подсистемы трассировки лучей. В итоге стало удобнее работать с нейронным рендерингом и задачами трассировки пути. Графический процессор Huashan состоит из двух чиплетов и включает восемь ячеек памяти HBM. Moore Threads сравнивает возможности ускорителя с чипами Nvidia Hopper и Blackwell: по скорости вычислений с плавающей запятой он приблизился к Blackwell B200, сравнялся с B200 по общей пропускной способности и даже превзошёл Blackwell по способности работать с большим объёмом памяти одновременно и обслуживать большое число обращений. Новые графические процессоры, как ожидается, получат вчетверо больший объём памяти: модели MTT S80/S90 комплектовались 16 Гбайт GDDR6, так что в новых моделях можно ожидать до 64 Гбайт. Первые видеокарты Lushan и ускорители Huashan выйдут в 2026 году. Компания также поделилась сведениями о производительности ускорителя MTT S5000 — он позиционируется как конкурент Nvidia Hopper: для модели DeepSeek V3 скорость обработки запросов составляет 4000, а генерации ответов — 1000 токенов в секунду. MTT S5000 будет работать в составе суперсервера MTT C256, который также ожидается в следующем году. Nvidia запустила продажи видеокарт RTX Pro 5000 Blackwell с 72 Гбайт памяти
19.12.2025 [16:23],
Николай Хижняк
Компания Nvidia подтвердила поступление в продажу профессиональной видеокарты RTX Pro 5000 Blackwell в версии с 72 Гбайт памяти, сообщив об этом в своём блоге. Информация о доступности продукта также размещена на сайтах партнёров, включая Ingram Micro, Leadtek, Unisplendour и xFusion, а более широкая доступность через глобальных системных интеграторов ожидается в начале следующего года. 
Источник изображений: Nvidia Технические характеристики карты, предоставленные самой Nvidia, указывают на то, что карта отличается от ранее выпущенного варианта с 48 Гбайт памяти только увеличенным объёмом видеопамяти. В описании продукта отмечается использование графического процессора с 14 080 ядрами CUDA (как у 48-гигабайтной версии), а также одинаковое общее энергопотребление на уровне 300 Вт. 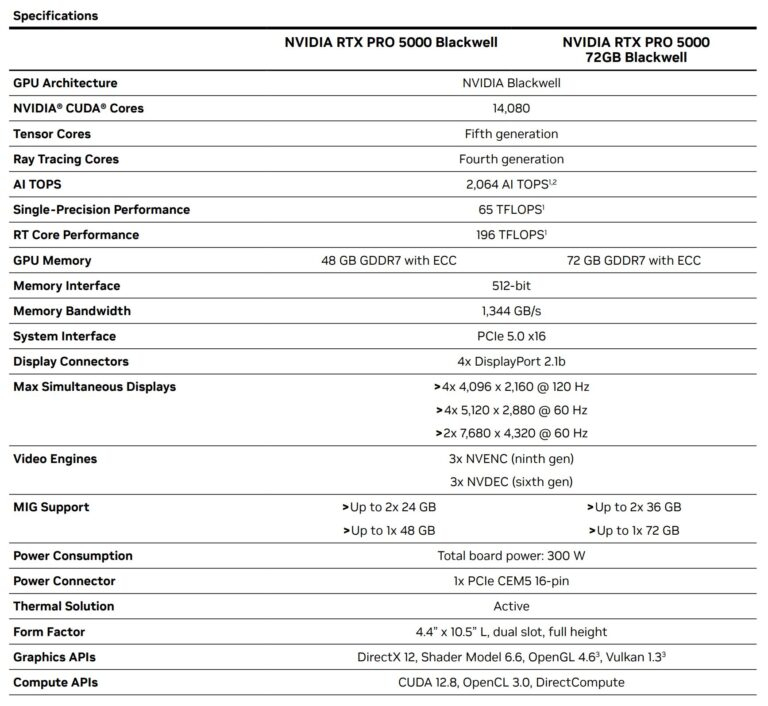 Не совсем понятным моментом остаётся ширина интерфейса памяти. В технической документации Nvidia RTX Pro 5000 по-прежнему указан 512-битный интерфейс памяти, а также заявлена пропускная способность памяти 1344 Гбайт/с. Этот показатель точно соответствует скорости чипов памяти 28 Гбит/с на контакт с учётом поддержки 384-битной шины памяти, что также подтверждается данными сторонних источников. Если же в карте действительно используется 512-битная шина, то та же пропускная способность в 1344 Гбайт/с подразумевает применение чипов памяти со скоростью 21 Гбит/с на контакт. Nvidia до сих пор не озвучила цену на RTX Pro 5000 с 72 Гбайт памяти. В сообщении в блоге и материалах о продукте подтверждается его доступность, однако в них не указаны ни рекомендованная розничная цена, ни цены партнёров. Версия с 48 Гбайт памяти предлагается по цене от $4250 до $4600, в то время как модели RTX Pro 6000 стоят более $8300. Google объединилась с Meta✴, чтобы ударить по доминированию Nvidia в сфере ПО для ИИ
18.12.2025 [20:49],
Сергей Сурабекянц
Google работает над улучшением производительности своих ИИ-чипов при работе с PyTorch. Этот проект с открытым исходным кодом является одним из наиболее широко используемых инструментов для разработчиков моделей ИИ. Для ускорения разработки Google сотрудничает с Meta✴✴, создателем и администратором PyTorch. Партнёрство подразумевает доступ Meta✴✴ к большему количеству ИИ-ускорителей. Этот шаг может пошатнуть многолетнее доминирование Nvidia на рынке ИИ-вычислений. 
Источник изображения: unsplash.com Эта инициатива является частью агрессивного плана Google по превращению своих тензорных процессоров (Tensor Processing Unit, TPU) в жизнеспособную альтернативу лидирующим на рынке графическим процессорам Nvidia. Продажи TPU стали важнейшим двигателем роста доходов Google от облачных сервисов. Однако для стимулирования внедрения ИИ-ускорителей Google одного оборудования недостаточно. Новая инициатива компании, известная как TorchTPU, направлена на устранение ключевого барьера, замедляющего внедрение чипов TPU, путём обеспечения их полной совместимости и удобства для разработчиков PyTorch. Google также рассматривает возможность открытия некоторых частей исходного кода своего ПО для ускорения его внедрения. По сравнению с предыдущими попытками поддержки PyTorch на TPU, Google уделяет больше организационного внимания, ресурсов и стратегического значения TorchTPU, поскольку компании, которые хотят использовать эти чипы, рассматривают именно программный стек как узкое место технологии. PyTorch, проект с открытым исходным кодом, активно поддерживаемый Meta✴✴, является одним из наиболее широко используемых инструментов для разработчиков, создающих модели ИИ. В Кремниевой долине очень немногие разработчики пишут каждую строку кода, которую будут фактически выполнять чипы от Nvidia, AMD или Google. Разработчики полагаются на такие инструменты, как PyTorch, представляющий собой набор предварительно написанных библиотек кода и фреймворков. 
Источник изображения: pytorch.org Доминирование Nvidia обеспечивается не только её ускорителями ИИ, но и программной экосистемой CUDA, которая глубоко интегрирована в PyTorch и стала методом по умолчанию для обучения и запуска крупных моделей ИИ. Инженеры Nvidia приложили максимум усилий, чтобы программное обеспечение, разработанное с помощью PyTorch, работало максимально быстро и эффективно на чипах компании. Бо́льшая часть программного обеспечения Google для ИИ построена на основе платформы Jax, что отталкивает клиентов, применяющих для разработки PyTorch. Поэтому сейчас для Google стало особенно важным обеспечить максимальную поддержку PyTorch на своих ускорителях ИИ. В случае успеха TorchTPU может значительно снизить затраты на переход для компаний, желающих найти альтернативу графическим процессорам Nvidia. Чтобы ускорить разработку, Google тесно сотрудничает с Meta✴✴, создателем и администратором PyTorch. Это партнёрство может предоставить Meta✴✴ доступ к большему количеству ИИ-чипов Google. Meta✴✴ прямо заинтересована в разработке TorchTPU — это позволит компании снизить затраты на вывод данных и диверсифицировать инфраструктуру ИИ, отказавшись от использования графических процессоров Nvidia. В качестве первого шага Meta✴✴ предложила использовать управляемые Google сервисы, в рамках которых клиенты, такие как Meta✴✴, получили бы доступ к ИИ-ускорителям Google, а Google обеспечивала их операционную поддержку. В этом году Google уже начала продавать TPU напрямую в центры обработки данных своих клиентов. Компания нуждается в такой инфраструктуре как для запуска собственных продуктов ИИ, включая чат-бот Gemini и поиск на основе ИИ, так и для предоставления доступа клиентам Google Cloud. 
Источник изображения: Google «Мы наблюдаем огромный, ускоряющийся спрос как на нашу инфраструктуру TPU, так и на инфраструктуру GPU, — заявил представитель Google. — Наша цель — обеспечить разработчикам гибкость и масштабируемость, необходимые независимо от выбранного ими оборудования». Microsoft хочет свой идеальный ИИ-чип: Broadcom подключат к разработке кастомных чипов для Azure
06.12.2025 [18:26],
Владимир Мироненко
Microsoft ведёт переговоры с Broadcom по поводу разработки кастомных чипов для облачной ИИ-инфраструктуры Azure, стремясь диверсифицировать усилия в этом направлении и повысить эффективность в условиях бума ИИ. В настоящее время Microsoft также сотрудничает с Marvell Technology в разработке ASIC для сетей и ускорения работы ЦОД. Как сообщает WebProNews, Microsoft проявляет интерес к сотрудничеству с Broadcom, поскольку та обладает опытом в разработке кастомных полупроводников для гиперскейлеров и может предоставить Microsoft более индивидуальные решения для повышения эффективности ее ЦОД. Такое развитие событий вписывается в общую картину агрессивного продвижения Microsoft на рынок проприетарного оборудования. За последние несколько лет компания представила собственные чипы, такие как ИИ-ускоритель Maia и процессор Cobalt, предназначенные для задач обучения и инференса ИИ без опоры исключительно на внешних поставщиков, таких как Nvidia. Партнёрство с Broadcom позволит Microsoft ускорить разработку решений, которые будут интегрированы с её программной экосистемой. Отказ от Marvell в пользу Broadcom может быть обусловлен потребностью в более высокой производительности или финансовыми соображениями. Marvell играет ключевую роль в поставке чипов для сетевого оборудования Microsoft, но более широкий портфель решений Broadcom, включая опыт в коммутации Ethernet и разработке ИИ-ускорителей, может обеспечить софтверному гиганту более комплексное преимущество. Отраслевые аналитики отмечают взрывной рост подразделения Broadcom по разработке кастомных чипов, прогнозируя при этом резкое увеличение выручки от продуктов, связанных с ИИ-технологиями. В 2024 году Microsoft заключила с Intel соглашение о производстве чипов на заказ с целью использования производственных возможностей Intel, но текущие переговоры с Broadcom позволяют предположить, что Microsoft расширяет свою деятельность, возможно, для снижения рисков, связанных с геополитической напряжённостью, планируя делегировать часть заказов TSMC. В настоящее время, когда ИИ-рынок развивается стремительными темпами, индивидуальные решения имеют решающее значение для сохранения конкурентных преимуществ в сфере облачных вычислений. Это отражает более широкую отраслевую тенденцию, когда гиперскейлеры всё чаще обращаются к кастомным решениям для оптимизации под конкретные рабочие нагрузки вместо использования чипов общего назначения. 
Источник изображения: Igor Omilaev/unsplash.com Сотрудничество с Broadcom также позволит Microsoft усилить интеграцию с OpenAI, учитывая её значительные инвестиции в этот ИИ-стартап. В Bitcoin Ethereum News описывается, как Microsoft использует опыт OpenAI в области чипов для решения собственных проблем в аппаратном обеспечении. Это также может отразиться на глобальных цепочках поставок и производственных мощностях. Эксперты считают, что конструкторский потенциал Broadcom в сочетании с производственными мощностями TSMC создаёт мощный конвейер для производства кастомного оборудования для обработки ИИ-нагрузок, потенциально ускоряя его внедрение в ЦОД по всему миру. В отличие от Marvell, сосредоточенной на системах хранения данных и сетях, Broadcom предлагает более комплексный подход разработке чипов, включающий фотонику и беспроводные технологии, что будет способствовать развитию инфраструктуры Microsoft. В результате Microsoft добьётся более низких затрат и более высокой скорости для ИИ-сервисов, что обеспечит ей конкурентное преимущество перед компаниями, привязанными к экосистеме Nvidia. В перспективе партнёрство Microsoft и Broadcom может стимулировать инновации в области периферийных вычислений и гибридных облачных сред. С ростом сложности ИИ-моделей кастомные чипы позволяют добиться тонкой оптимизации, которую сложно обеспечить с помощью стандартных ускорителей, отметил WebProNews. В условиях растущего спроса на ИИ такие компании, как Broadcom, имеющие опыт в разработке решений на заказ, становятся ключевыми игроками рынка ИИ-технологий. Для Microsoft речь идёт не только о чипах, речь идёт о контроле над всем стеком — от кремния до программного обеспечения — для обеспечения бесперебойной работы ИИ-сервисов. Как отметил один из экспертов, это может стать катализатором следующего витка роста Microsoft. После появления в СМИ сообщений о переговорах Microsoft и Broadcom, акции последней пошли в рост в то время как у ценных бумаг Marvell было отмечено падение. Вышел первый обзор ПК на двухчиповых ИИ-ускорителях Intel Arc Pro B60 — восемь GPU и 192 Гбайт GDDR6
03.12.2025 [23:03],
Николай Хижняк
Первое практическое тестирование платформы Intel Arc Pro B60 Battlematrix, опубликованное порталом Storage Review, демонстрирует плотную локальную систему ИИ, построенную на базе четырёх двухчиповых профессиональных видеокарт Arc Pro B60. 
Источник изображения: VideoCardz Каждая карта в составе системы оснащена 48 Гбайт видеопамяти GDDR6 (по 24 Гбайт на каждый GPU). Таким образом, общий объём VRAM составляет 192 Гбайт, что идеально подходит для сценариев локальной работы с большими языковыми моделями, которые позволяют избежать издержек, связанных с облачными вычислениями, а также проблем с обменом данными. 
Источник изображения здесь и ниже: Storage Review Intel установила цену на одночиповую Arc Pro B60 около $600, поэтому двухчиповая версия с 48 Гбайт памяти стоит около $1200. При таком объёме видеопамяти профессиональный ускоритель от Intel значительно дешевле (как минимум вдвое) большинства профессиональных GPU с аналогичным объёмом памяти от других производителей. Видеокарты Arc Pro B60 не предназначены для игр. А двухчиповая Arc Pro B60 — не совсем двухчиповая в том привычном смысле, какой была, например, игровая GeForce GTX 690 от Nvidia в своё время. Компания Maxsun, партнёр Intel, предоставивший карты для тестирования, уже объяснила, что Arc Pro B60 с двумя GPU — это две видеокарты в составе одной печатной платы, использующие один слот PCIe благодаря бифуркации (разделению линий). По сути, два графических процессора делят одну плату и один слот, но для операционной системы это две отдельные видеокарты. Таким образом, система вместо четырёх карт видит восемь Arc Pro B60, где у каждой имеется 24 Гбайт видеопамяти.  Для многих языковых моделей эффективность связана с количеством используемых графических ускорителей. И чем их меньше, тем лучше. Небольшие языковые модели можно разместить в составе стека памяти VRAM одного ускорителя. Однако физические ограничения доступного объёма памяти приводят к необходимости использования большего числа ускорителей, особенно в случае очень больших языковых моделей. Это, в свою очередь, накладывает определённые ограничения, связанные с технологиями межсоединений — повышается задержка в распределении данных. Конфигурация из восьми графических процессоров становится целесообразной, когда вы повышаете уровень параллелизма и объёмы пакетов данных, где пропускная способность имеет большее значение. Однако программное обеспечение, необходимое для такой обработки, пока находится на ранней стадии разработки. Только модели GPT-OSS на основе MXFP4 работали должным образом с низкоточными путями, в то время как такие форматы, как стандартные INT4, FP8 и AWQ, отказывались запускаться, поэтому многим плотным моделям пришлось работать в формате BF16. 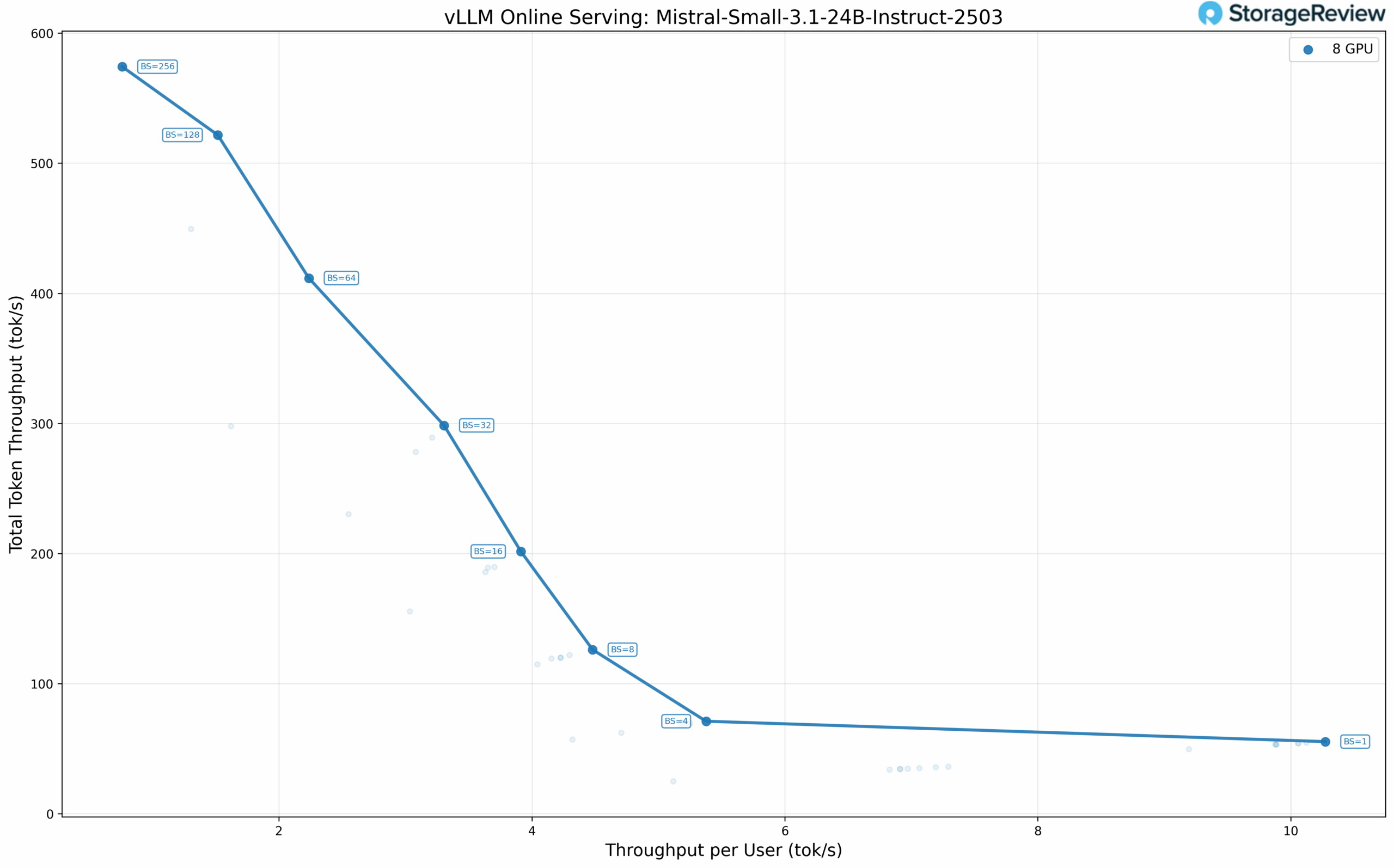
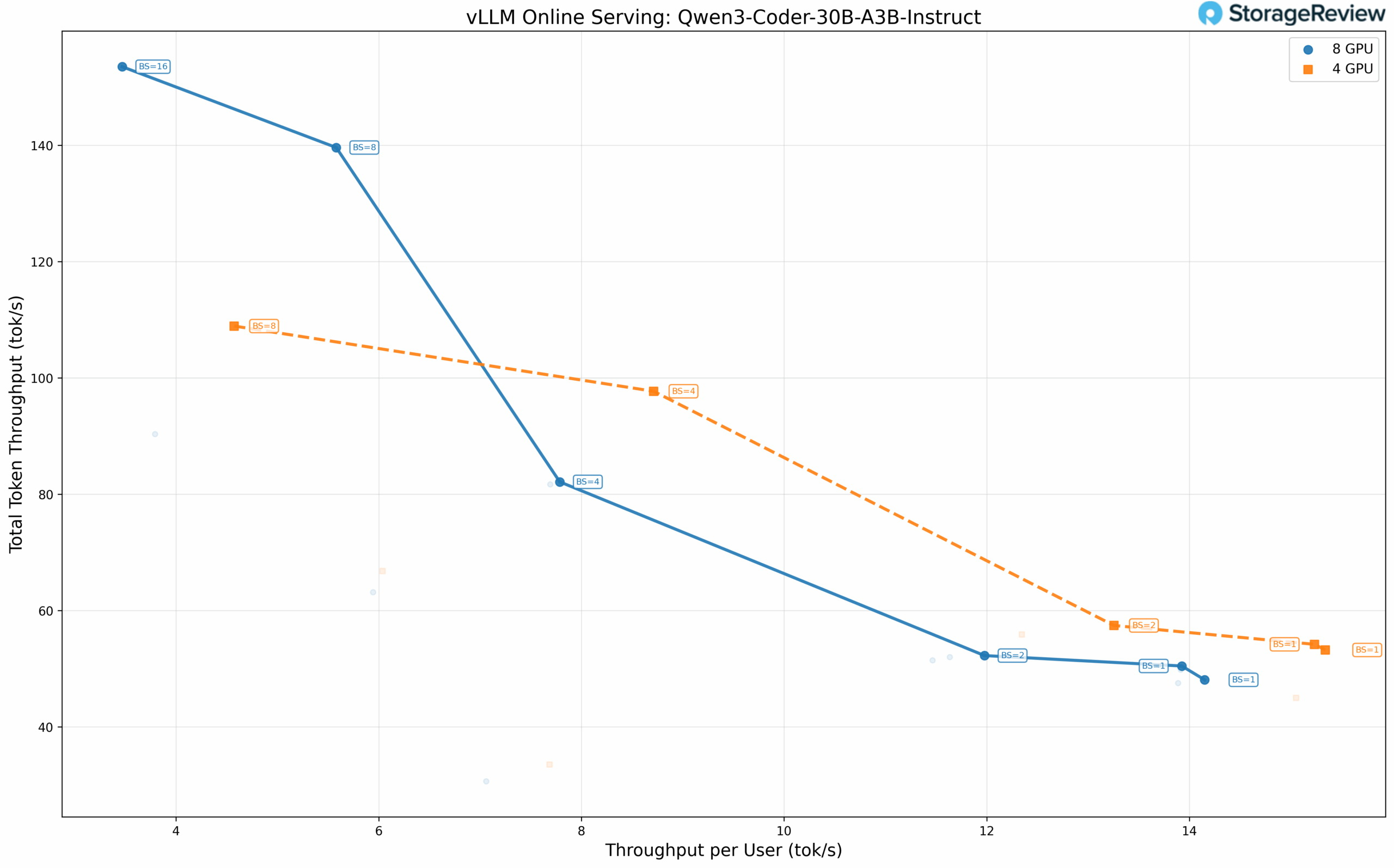 «Для всех протестированных моделей прослеживается общая закономерность: при небольших размерах пакета с нашей конфигурацией с 256 токенами ввода/вывода использование минимального количества графических процессоров, необходимого для размещения модели, обеспечивает лучшую производительность на пользователя, чем распределение по всем восьми графическим процессорам. Издержки взаимодействия между графическими процессорами через PCIe, даже на скоростях PCIe 5.0, приводят к задержке, превышающей преимущества распараллеливания в однопользовательских или низкоконкурентных сценариях», — пишет Storage Review. Физически двухчиповые Arc Pro B60 крупнее одночиповых. Они длиннее, оснащены двухслотовым кулером и потребляют до 400 Вт через один разъём 12V-2×6. Из-за большей длины видеокарты могут возникнуть сложности при её установке в некоторые стандартные Tower-корпуса. В моделях корпусов серверного уровня эти карты помещаются без проблем. В тестах, проведённых Storage Review, использовались ранние версии драйверов, предварительная сборка LLM Scaler и система AMD EPYC вместо процессоров Intel Xeon 6, с которыми должны поставляться решения Battlematrix, поэтому все предоставленные данные указаны как предварительные. Intel анонсировала ИИ-системы Battlematrix ещё в мае, но обозреватель ожидает, что аппаратно-программное обеспечение станет полностью готовым только к 2026 году. В Китае похвастались разработкой ИИ-ускорителя в полтора раза быстрее чипа Nvidia пятилетней давности
28.11.2025 [13:36],
Павел Котов
Китайский стартап Zhonghao Xinying доложил о разработке тензорного процессора общего назначения (GPTPU), который может использоваться для обучения и запуска моделей искусственного интеллекта. Производительность этого ускорителя, утверждает разработчик, в 1,5 раза превосходит показатели модели Nvidia A100, выпущенной в 2020 году. 
Источник изображения: Igor Omilaev / unsplash.com Разработчиком чипа Ghana значится Янгун Ифань (Yanggong Yifan), получивший образование в Стэнфорде и Мичиганском университете. Ранее он работал в Oracle и Google — в последней участвовал в создании тензорных процессоров, которые использует поисковый гигант. Соучредитель стартапа Чжэн Ханьсюнь (Zheng Hanxun) тоже работал в Oracle, а также в техасском центре исследований и разработки Samsung. Созданный в компании ускоритель основан только на китайских технологических решениях — в его разработке, проектировании и производстве не участвуют ни сами западные компании, ни их ПО или компоненты; чипы не требуют иностранных технологических лицензий, подчеркнули в Zhonghao Xinying. Чип Ghana, утверждают в компании, способен обеспечить производительность в 1,5 раза выше, чем у Nvidia A100 при сниженном на 25 % потреблении энергии. Следует, однако, подчеркнуть, что это чип относится к классу ASIC, то есть он имеет узкое предназначение в отличие от более универсального решения Nvidia, которое к тому же более чем на одно поколение старше актуальных Blackwell Ultra. Это приемлемое решение для клиентов, которые стремятся избавиться от доминирующей в области ИИ-ускорителей Nvidia — ярким примером является Google с собственными TPU. Но в отрасли в обозримом будущем наиболее востребованными останется продукция Nvidia и её традиционного конкурента — AMD. Как построить 5000-ваттный GPU будущего — Intel расскажет на ISSCC 2026
28.11.2025 [01:39],
Николай Хижняк
Насыщенная программа конференции ISSCC 2026, которая пройдет в феврале будущего года, включает немало интересных тем. Среди них — «как реализовать 5000-ваттные графические процессоры». Идею хочет предложить не абы кто, а заслуженный исследователь Intel, проработавший в компании более 25 лет, пишет Computer Base. 
Источник изображения: Intel Каладхар Радхакришнан (Kaladhar Radhakrishnan) давно и активно работает в области технологий питания микросхем и компонентов. Многочисленные публикации его работ доступны онлайн. На конференции ISSCC в феврале 2026 года он представит один из своих последних проектов, который в полной мере соответствует современным тенденциям: интегрированные решения по регулированию напряжения для графических процессоров мощностью 5 кВт. Презентация состоится 19 февраля в рамках панельной дискуссии, посвященной теме «Обеспечение будущего ИИ, высокопроизводительных вычислений и архитектуры чиплетов: от кристаллов до корпусов и стоек». Ключевая идея предложения — использование в составе GPU интегрированных регуляторов напряжения (IVR). Сама по себе технология IVR не является новинкой в отрасли. Однако её использование в составе графических процессоров для обеспечения значительно более высокой мощности всё ещё остаётся относительно новой областью. Следующее поколение больших GPU в ускорителях ИИ будет потреблять от 2300 до предположительно 2700 Вт. Nvidia Vera Rubin Ultra и её преемник Feynman Ultra, по слухам, будут потреблять более 4000 Вт. Таким образом, цель Intel в 5 кВт для GPU — это совсем не нереалистичная цифра на будущее. Предполагается, что применение IVR в составе GPU потребует использования технологии корпусирования чипов Foveros-B. Данная технология ожидается не ранее 2027 года. Внешних клиентов компания намерена привлекать через своё контрактное производство Foundry. Как пишет Computer Base, компания TSMC также работает над этим направлением со своими партнёрами. GUC, компания, входящая в экосистему TSMC, недавно объявила, что отправила IVR на отладку в составе CoWoS-L. CoWoS-L является самым передовым решением TSMC для корпусирования больших интерпозеров. Технология CoWoS-L ожидается в 2027 году и придёт на смену CoWoS-S, которая сейчас используется для упаковки большинства чипов таких компаний, как Nvidia, AMD и других. В Китае намекнули на создание многочиповых ИИ-ускорителей, способных потягаться с Nvidia Blackwell
27.11.2025 [21:43],
Николай Хижняк
Разработанные в Китае ускорители ИИ из логических чиплетов на основе 14-нм техпроцесса и памяти DRAM на базе 18-нм техпроцесса в состоянии конкурировать с чипами Nvidia Blackwell, которые производятся по 4-нм техпроцессу TSMC. Такое мнение на отраслевом мероприятии озвучил Вэй Шаоцзюнь (Wei Shaojun), заместитель председателя Китайской ассоциации полупроводниковой промышленности и профессор Университета Цинхуа, сообщает DigiTimes. 
Источник изображения: AMD Выступая на глобальном саммите руководителей высшего звена ICC, Вэй Шаоцзюнь отметил, что ключом к прорыву в области производительности и эффективности станет передовая технология 3D-стекинга, используемая при создании китайских ускорителей. Вэй Шаоцзюнь, ранее заявивший, что цели, поставленные Китаем в рамках программы «Сделано в Китае 2025», недостижимы, и позднее призвавший страну отказаться от использования иностранных ускорителей искусственного интеллекта, таких как Nvidia H20, и перейти на отечественные решения, описал гипотетическое «полностью контролируемое отечественное решение», которое объединит 14-нм логику с 18-нм DRAM с использованием 3D-гибридной склейки. Никаких доказательств разработки или хотя бы подтверждений возможности реализации подобного решения с использованием имеющихся у Китая технологий при этом он не привёл. По словам Вэя, такая конфигурация призвана приблизиться к производительности 4-нм графических процессоров Nvidia, несмотря на использование устаревших технологий. Он считает, что такое решение может обеспечить производительность 120 терафлопс. Он также заявил, что энергопотребление составит всего около 60 Вт, что, по словам Вэя, обеспечит более высокую производительность (2 терафлопса на ватт) по сравнению с процессорами Intel Xeon. Для сравнения: ускоритель Nvidia B200 обеспечивает производительность 10 000 NVFP4-терафлопс при потреблении 1200 Вт, что составляет 8,33 NVFP4-терафлопса на ватт. Nvidia B300 обеспечивает производительность 10,7 NVFP4-терафлопса на ватт, что в пять раз превышает возможности ИИ-ускорителя, о котором заявил Вэй. Ключевыми технологиями, призванными значительно повысить производительность ИИ-ускорителя, разрабатываемого в Китае, являются 3D-гибридное соединение (медь-медь и оксидное соединение), которое заменяет столбиковые выводы припоя прямыми медными соединениями с шагом менее 10 мкм, а также вычисления, близкие к уровню оперативной памяти. Гибридное склеивание с шагом менее 10 мкм позволяет создавать от десятков до сотен тысяч вертикальных соединений на 1 мм², а также сигнальные тракты микрометрового масштаба для высокоскоростных соединений с малой задержкой. Одним из лучших примеров технологии гибридного 3D-склеивания является 3D V-Cache от AMD, обеспечивающий пропускную способность 2,5 Тбайт/с при энергии ввода-вывода 0,05 пДж/бит. Вэй, вероятно, рассчитывает на аналогичный показатель для своего проекта. 2,5 Тбайт/с на устройство — это значительно выше, чем пропускная способность памяти HBM3E, поэтому это может стать прорывом для ускорителей ИИ, основанных на концепции вычислений, близких к оперативной памяти. Вэй также отметил, что теоретически эта концепция может масштабироваться до производительности уровня зеттафлопс, хотя он не уточнил, когда и как такие показатели будут достигнуты. Вэй обозначил платформу CUDA от Nvidia как ключевой риск не только для описанной им альтернативы, но и для аппаратных платформ, отличных от Nvidia, поскольку после объединения программного обеспечения, моделей и аппаратного обеспечения на единой проприетарной платформе становится сложно развернуть альтернативные процессоры. Учитывая, что он рассматривал вычисления, близкие к уровню оперативной памяти, как способ значительного повышения конкурентоспособности оборудования для ИИ, разработанного в Китае, любая альтернативная платформа, не основанная на этой концепции (включая китайские ускорители ИИ, например серию Huawei Ascend или графические процессоры Biren), может считаться несовместимой. Маск пообещал дешёвые ИИ-серверы в космосе через пять лет — Хуанг назвал эти планы «мечтой»
21.11.2025 [18:29],
Сергей Сурабекянц
Помимо стоимости оборудования, требования к электроснабжению и отведению тепла станут одними из основных ограничений для крупных ЦОД в ближайшие годы. Глава X, xAI, SpaceX и Tesla Илон Маск (Elon Musk) уверен, что вывод крупномасштабных систем ИИ на орбиту может стать гораздо более экономичным, чем реализация аналогичных ЦОД на Земле из-за доступной солнечной энергии и относительно простого охлаждения. 
Источник изображений: AST SpaceMobile «По моим оценкам, стоимость электроэнергии и экономическая эффективность ИИ и космических технологий будут значительно выше, чем у наземного ИИ, задолго до того, как будут исчерпаны потенциальные источники энергии на Земле, — заявил Маск на американо-саудовском инвестиционном форуме. — Думаю, даже через четыре-пять лет самым дешёвым способом проведения вычислений в области ИИ будут спутники с питанием от солнечных батарей. Я бы сказал, не раньше, чем через пять лет». Маск подчеркнул, что по мере роста вычислительных кластеров совокупные требования к электроснабжению и охлаждению возрастают до такой степени, что наземная инфраструктура с трудом справляется с ними. Он утверждает, что достижение непрерывной выработки в диапазоне 200–300 ГВт в год потребует строительства огромных и дорогостоящих электростанций, поскольку типичная атомная электростанция вырабатывает около 1 ГВт. Между тем, США сегодня вырабатывают около 490 ГВт, поэтому использование львиной её доли для нужд ИИ невозможно. Маск считает, что достижение тераваттного уровня мощности для питания наземных ЦОД нереально, зато космос представляет заманчивую альтернативу. По мнению Маска, благодаря постоянному солнечному излучению, аккумулирование энергии не требуется, солнечные панели не требуют защитного стекла или прочного каркаса, а охлаждение происходит за счёт излучения тепла. Глава Nvidia Дженсен Хуанг (Jensen Huang) признал, что масса непосредственно вычислительного и коммуникационного оборудования внутри современных стоек Nvidia GB300 исчезающе мала по сравнению с их общей массой, поскольку почти вся конструкция — примерно 1,95 из 2 тонн — по сути, представляет собой систему охлаждения. Но, кроме веса оборудования, существуют и другие препятствия. Теоретически космос — хорошее место как для выработки энергии, так и для охлаждения электроники, поскольку в тени температура может опускаться до -270 °C. Но под прямыми солнечными лучами она может достигать +125 °C. На околоземных орбитах перепады температур не столь экстремальны:
Низкая и средняя околоземные орбиты не подходят для космических ЦОД из-за нестабильной освещённости, значительных перепадов температур, пересечения радиационных поясов и регулярных затмений. Геостационарная орбита лучше подходит для этой цели, но и там эксплуатация мощных вычислительных кластеров столкнётся с множеством проблем, главная из которых — охлаждение. В космосе отвод тепла возможен только при помощи излучения, что потребует монтажа огромных радиаторов площадью в десятки тысяч квадратных метров на систему мощностью несколько гигаватт. Вывод на геостационарную орбиту такого количества оборудования потребует тысяч запусков тяжёлых ракет класса Starship.  Не менее важно, что ИИ-ускорители и сопутствующее оборудование в существующем виде не способны выдержать воздействие радиации на геостационарной орбите без мощной защиты или полной модернизации конструкции. Кроме того, высокоскоростное соединение с Землёй, автономное обслуживание, предотвращение столкновения с мусором и обслуживание робототехники пока находится в зачаточном состоянии, учитывая масштаб предлагаемых проектов. Так что скорее всего Хуанг прав, когда называет затею Маска «мечтой». Мечтает о выводе масштабных вычислительных кластеров не только Маск. В октябре основатель Amazon и Blue Origin Джефф Безос (Jeff Bezos) в ходе мероприятия Italian Tech Week в Турине (Италия) поделился своим видением развития индустрии космических дата-центров. По его мнению, такие объекты обеспечат ряд значительных преимуществ по сравнению с наземными ЦОД. В сентябре компания Axiom Space с партнёрами сообщила о создании первого орбитального дата-центра, который разместился на МКС. Этот ЦОД будет обслуживать не только станцию, но также любые спутники с оптическими терминалами на борту. В мае Китай вывел на орбиту Земли 12 спутников будущей космической группировки Star-Compute Program, которая в перспективе будет состоять из 2800 спутников. Все они оснащены системами лазерной связи и несут мощные вычислительные платформы — по сути, это первый масштабный ЦОД с ИИ в космосе. Компания Crusoe намерена развернуть свою облачную платформу на спутнике Starcloud запуск которого запланирован на конец 2026 года. Ограниченный доступ к ИИ-мощностям в космосе должен появиться к началу 2027 года Google рассказала об инициативе Project Suncatcher, предусматривающей использование группировок спутников-ЦОД на основе фирменных ИИ-ускорителей. Спутники будут связаны оптическими каналами. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



