|
Опрос
|
реклама
Быстрый переход
Nvidia распродала все ИИ-ускорители, но на подходе ещё больше Blackwell
20.11.2025 [11:18],
Павел Котов
Nvidia побила собственные прогнозы по прибыли за III квартал 2026 финансового года, реализовав больше ускорителей искусственного интеллекта, чем когда-либо прежде. Компания распродала все серверные чипы, заявил её гендиректор Дженсен Хуанг (Jensen Huang), но вскоре их запасы увеличатся. 
Источник изображения: nvidia.com По итогам отчётного периода выручка Nvidia составила рекордные $57 млрд, а чистая прибыль в пересчёте составила $4000 в секунду. Всего за один квартал бизнес компании в сфере центров обработки данных вырос на $10 млрд до $51,2 млрд — это на 66 % больше, чем за аналогичный период прошлого года. Для аналитиков показатели дохода Nvidia по направлению ЦОД служат индикатором «пузыря ИИ», о котором в последнее время говорят всё больше. Но никаких признаков негативной динамики у компании не наблюдается: прогноз на IV квартал составляет $65 млрд, то есть всего за три месяца квартальная выручка увеличится ещё на $8 млрд. «Продажи [ИИ-ускорителей на архитектуре] Blackwell зашкаливают, а облачные GPU распроданы», — заявил Дженсен Хуанг. Впрочем, распроданы, видимо, они не окончательно. «У нас ещё достаточно Blackwell на продажу и много Blackwell на подходе», — добавил он позже. Основной движущей силой роста в сегменте ЦОД и не только стали ускорители на обновлённой архитектуре Blackwell Ultra, признался гендиректор Nvidia: «Наша ведущая архитектура для всех категорий клиентов теперь Blackwell Ultra; продолжительным высоким спросом пользовалась наша предыдущая архитектура Blackwell». Выручка по игровому направлению показала рост на 30 % по сравнению с прошлым годом, и это хороший сигнал для видеокарт семейства Nvidia Blackwell, отзывы о которых в начале года были неоднозначными. Инвесторов же Дженсен Хуанг призвал не паниковать: «О пузыре ИИ говорят много. С нашей точки зрения наблюдается нечто совершенно иное». Nvidia много лет предупреждала, что ИИ изменит всё, и сейчас эта технология достигла переломного момента, считает глава компании: «Революционным станет переход к агентному и физическому ИИ». Под последним понимается робототехника с ИИ. Илон Маск хочет на порядок больше ИИ-чипов, чем выпускает вся полупроводниковая индустрия мира
18.11.2025 [18:36],
Сергей Сурабекянц
Амбиции Илона Маска (Elon Musk) в области искусственного интеллекта настолько велики, что он хочет получить больше ускорителей ИИ, чем отрасль в настоящее время может произвести. По его словам, Tesla нуждается в «100–200 миллиардах чипов с искусственным интеллектом в год», и если она не сможет получить их от производителей, то рассмотрит возможность создания собственных фабрик. 
Источник изображения: dogegov.com Маск заявил, что «испытывает огромное уважение к TSMC и Samsung», но он считает, что эти компании не в состоянии удовлетворить потребность его предприятий в чипах ИИ: «Когда я спросил, сколько времени займёт строительство новой фабрики по производству чипов, они ответили, что до запуска производства им потребуется пять лет. Пять лет для меня — это вечность. Мои сроки — год, два. […] Если они передумают и […] будут поставлять нам 100–200 миллиардов ИИ-чипов в год в те сроки, когда они нам нужны, это будет здорово». Маск не уточнил, когда Tesla и SpaceX потребуются эти 100–200 миллиардов ИИ-процессоров в год, но в любом случае выпуск такого количества чипов практически неосуществим, если он имел в виду единицы, а не сумму в долларах. По данным Ассоциации полупроводниковой промышленности, в 2023 году по всему миру произведено 1,5 трлн чипов. Однако в это число входят любые микросхемы — от крошечных микроконтроллеров и датчиков до чипов памяти и ускорителей ИИ. 
Источник изображений: Tesla Такие ускорители ИИ, как Nvidia H100 или B200/B300, представляют собой огромные кремниевые блоки, которые сложно и дорого производить, поэтому на их изготовление уходит больше всего времени. По словам Маска, энергопотребление его ИИ-процессоров AI5 составит 250 Вт, в то время как графические процессоры Nvidia B200 могут потреблять до 1200 Вт. Этот параметр может служит косвенной оценкой размера чипов. Даже если чип AI5 будет в пять раз меньше Nvidia B200, мощностей для достижения целей Маска всё равно совершенно недостаточно. Будучи одним из крупнейших клиентов TSMC, Nvidia поставила четыре миллиона графических процессоров Hopper стоимостью $100 млрд (не считая Китая) за весь срок службы архитектуры, который составил около двух календарных лет. С Blackwell Nvidia продала около шести миллионов графических процессоров за первые четыре квартала их жизненного цикла. Если Маск действительно имел в виду 200 миллиардов устройств, то он хотел бы получить на порядки больше процессоров для искусственного интеллекта, чем отрасль (бо́льшая часть которой приходится на TSMC) может производить за год. Если он всё же подразумевал потребность в ИИ-чипах на сумму от $100 до $200 млрд, то TSMC и Samsung, безусловно, смогут поставить такой объём в ближайшие годы. Однако, похоже, что он действительно считает, что ему нужно больше, чем эти компании могут предложить.  «Мы будем использовать фабрики TSMC на Тайване и в Аризоне, фабрики Samsung в Корее и Техасе, — сказал Маск. — С их точки зрения, они движутся молниеносно. […] тем не менее, это будет для нас ограничивающим фактором. Они работают на пределе своих возможностей, но с их точки зрения — это “педаль в пол”. У них просто не было компании, которая разделяла бы наше понимание срочности. Возможно, единственный способ масштабироваться с желаемой скоростью — это построить действительно большой завод или быть ограниченным в производстве Optimus и беспилотных автомобилей из-за [поставок] ИИ-чипов. Действительно ли потребность Tesla и SpaceX в ИИ-чипах настолько высока, остаётся неясным. Tesla продала 1,79 млн автомобилей в 2024 году, поэтому ей вряд ли требуется больше двух миллионов чипов для своих автомобилей. Конечно, компаниям Маска могут понадобиться ещё миллионы ИИ-процессоров для обучения ИИ, но маловероятно, что Маск в ближайшее время готов создать ИИ-кластеры на базе миллиардов чипов. Антропоморфные роботы Optimus также вряд ли потребуют таких объёмов чипов в ближайшие годы.  Ранее мы писали, как воодушевлённый итогами голосования по новому компенсационному плану Илон Маск на собрании акционеров фонтанировал обещаниями и идеями, и по традиции пританцовывал в момент появления на сцене человекоподобного робота Optimus. Тогда он заявил, что для достижения поставленных новым планом целей Tesla вынуждена будет наладить самостоятельный выпуск чипов. Google выпустила Arm-процессоры Axion и тензорный ускоритель Ironwood для обучения и запуска огромных ИИ-моделей
06.11.2025 [19:52],
Сергей Сурабекянц
Сегодня Google представила новые процессоры Axion и тензорные ускорители Ironwood — TPU седьмого поколения. По словам компании, чипы Axion на 50 % производительнее и на 60 % энергоэффективнее современных x86-процессоров, а TPU Ironwood — самый производительный и масштабируемый настраиваемый ИИ-ускоритель на сегодняшний день и первый среди чипов Google, разработанный специально для запуска обученных ИИ-моделей (инференса). 
Источник изображений: Google TPU Ironwood будет поставляться в системах в двух конфигурациях: с 256 или с 9216 чипами. Один ускоритель обладает пиковой вычислительной мощностью 4614 Тфлопс (FP8), а кластер из 9216 чипов при энергопотреблении порядка 10 МВт выдаёт в общей сложности 42,5 Эфлопс. Эти показатели значительно превосходят возможности системы Nvidia GB300 NVL72, которая составляет 0,36 Эфлопс с операциях FP8. 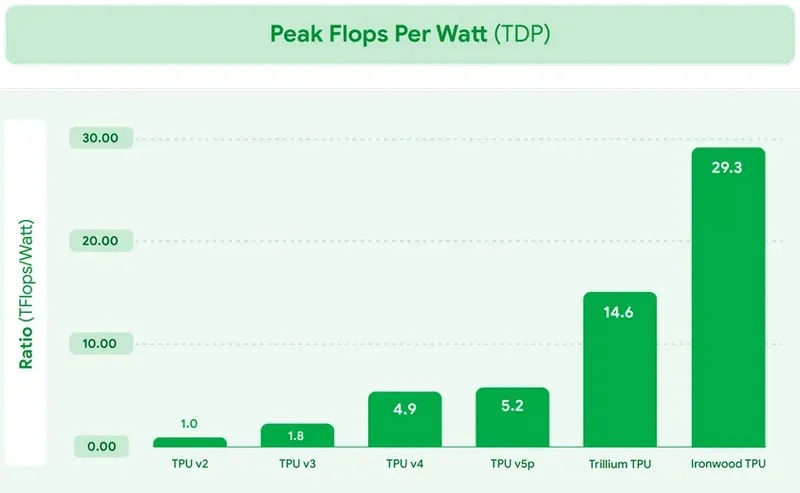 Ironwood оснащён усовершенствованным блоком SparseCore, предназначенным для ускорения работы с ИИ-моделями, которые используются в системах ранжирования и рекомендаций. Расширенная реализация SparseCore в Ironwood позволяет ускорить более широкий спектр рабочих нагрузок, выйдя за рамки традиционной области ИИ в финансовые и научные сферы. Модули объединяются между собой с помощью фирменной сети Inter-Chip Interconnect со скоростью 9,6 Тбит/с и содержат около 1,77 Пбайт памяти HBM3E, что также превосходит возможности конкурирующей платформы Nvidia. Они могут быть объединены в кластеры из сотен тысяч TPU.  Это интегрированная суперкомпьютерная платформа, которую Google называет «ИИ-гиперкомпьютер» объединяет вычисления, хранение данных и сетевые функции под одним уровнем управления. Для повышения надёжности, Google использует реконфигурируемую матрицу Optical Circuit Switching, которая мгновенно обходит любые аппаратные сбои для поддержания непрерывной работы.  По данным IDC, этот «гиперкомпьютер ИИ» обеспечивает среднюю окупаемость инвестиций (ROI) в течение трёх лет на уровне 353 %, снижение расходов на ИТ на 28 % и повышение операционной эффективности на 55 %. Несколько компаний уже внедряют эту платформу Google. Anthropic планирует использовать до миллиона TPU для работы и расширения семейства моделей Claude, ссылаясь на значительный выигрыш в соотношении цены и производительности. Lightricks начала развёртывание Ironwood для обучения и обслуживания своей мультимодальной системы LTX-2.  Полные спецификации универсальных процессоров Axion пока не опубликованы, в частности, не раскрыты тактовые частоты и использованный техпроцесс. Сообщается, что процессоры располагают 2 Мбайт кэша второго уровня на ядро, 80 Мбайт кэша третьего уровня, поддерживают память DDR5-5600 МТ/с и технологию Uniform Memory Access (UMA). Известно, что Axion построен на платформе Arm Neoverse v2 и должен обеспечить до 50 % более высокую производительность и до 60 % более высокую энергоэффективность по сравнению с современными процессорами x86. По словам Google, он также на 30 % быстрее, чем «самые быстрые универсальные экземпляры на базе Arm, доступные сегодня в облаке».  Процессоры Axion могут использоваться как в серверах искусственного интеллекта, так и в серверах общего назначения для решения различных задач. На данный момент Google предлагает три конфигурации Axion: C4A, N4A и C4A Metal. C4A обеспечивает до 72 виртуальных процессоров, 576 Гбайт памяти DDR5 и сетевое подключение со скоростью 100 Гбит/с в сочетании с локальным хранилищем Titanium SSD объёмом до 6 Тбайт. Экземпляр оптимизирован для стабильно высокой производительности в различных приложениях. Это единственный чип, который доступен уже сегодня. 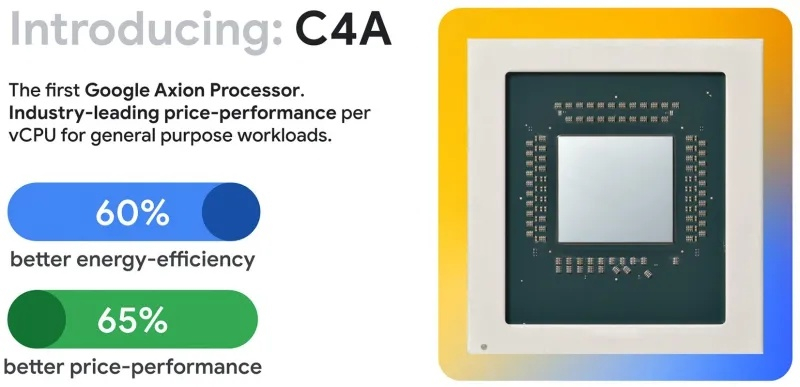 N4A предназначен для общих рабочих нагрузок, таких как обработка данных, веб-сервисы и среды разработки, но масштабируется до 64 виртуальных ЦП, 512 Гбайт оперативной памяти DDR5 и сетевой пропускной способности 50 Гбит/с. C4A Metal предоставляет клиентам полный аппаратный стек Axion: до 96 виртуальных ЦП, 768 Гбайт памяти DDR5 и сетевую пропускную способность 100 Гбит/с. Экземпляр предназначен для специализированных или ограниченных по лицензии приложений, а также для разработки на базе ARM. Процессор Axion дополняет портфолио специализированных чипов компании, а TPU Ironwood закладывает основу для конкуренции с лучшими ускорителями ИИ на рынке. Серверы на базе Axion и Ironwood оснащены фирменными контроллерами Titanium, которые разгружают процессор от сетевых задач, задач безопасности и обработки ввода-вывода, обеспечивая более эффективное управление и, как следствие, более высокую производительность. Qualcomm вернулась в большие вычисления: представлены ИИ-ускорители AI200 и AI250 для дата-центров
27.10.2025 [23:13],
Николай Хижняк
Компания Qualcomm анонсировала два ускорителя ИИ-инференса (запуска уже обученных больших языковых моделей) — AI200 и AI250, которые выйдут на рынок в 2026 и 2027 годах. Новинки должны составить конкуренцию стоечным решениям AMD и Nvidia, предложив повышенную эффективность и более низкие эксплуатационные расходы при выполнении масштабных задач генеративного ИИ. 
Источник изображений: Qualcomm Оба ускорителя — Qualcomm AI200 и AI250 — основаны на нейронных процессорах (NPU) Qualcomm Hexagon, адаптированных для задач ИИ в центрах обработки данных. В последние годы компания постепенно совершенствовала свои нейропроцессоры Hexagon, поэтому последние версии чипов уже оснащены скалярными, векторными и тензорными ускорителями (в конфигурации 12+8+1). Они поддерживают такие форматы данных, как INT2, INT4, INT8, INT16, FP8, FP16, микротайловый вывод для сокращения трафика памяти, 64-битную адресацию памяти, виртуализацию и шифрование моделей Gen AI для дополнительной безопасности. Ускорители AI200 представляют собой первую систему логического вывода для ЦОД от Qualcomm и предлагают до 768 Гбайт встроенной памяти LPDDR. Система будет использовать интерфейсы PCIe для вертикального масштабирования и Ethernet — для горизонтального. Расчётная мощность стойки с ускорителями Qualcomm AI200 составляет 160 кВт. Система предполагает использование прямого жидкостного охлаждения. Для Qualcomm AI200 также заявлена поддержка конфиденциальных вычислений для корпоративных развертываний. Решение станет доступно в 2026 году.  Qualcomm AI250, выпуск которого состоится годом позже дебютирует с новой архитектурой памяти, которая обеспечит увеличение пропускной способности более чем в 10 раз. Кроме того, система будет поддерживать возможность дезагрегированного логического вывода, что позволит динамически распределять ресурсы памяти между картами. Qualcomm позиционирует его как более эффективное решение с высокой пропускной способностью, оптимизированное для крупных ИИ-моделей трансформеров. При этом система сохранит те же характеристики теплопередачи, охлаждения, безопасности и масштабируемости, что и AI200. Помимо разработки аппаратных платформ, Qualcomm также сообщила о разработке гипермасштабируемой сквозной программной платформы, оптимизированной для крупномасштабных задач логического вывода. Платформа поддерживает основные наборы инструментов машинного обучения и генеративного ИИ, включая PyTorch, ONNX, vLLM, LangChain и CrewAI, обеспечивая при этом беспроблемное развертывание моделей. Программный стек будет поддерживать дезагрегированное обслуживание, конфиденциальные вычисления и подключение предварительно обученных моделей «одним щелчком мыши», заявляет компания. Физики из MIT заглянули внутрь ядра атома без ускорителя, что способно раскрыть одну из величайших тайн Вселенной
25.10.2025 [14:19],
Геннадий Детинич
Физики из Массачусетского технологического института (MIT) разработали интересный метод на основе изучения молекул, который позволяет заглянуть внутрь атомного ядра без использования больших ускорителей частиц. Экспериментальная установка помещается на обычном лабораторном столе, что делает метод широкодоступным научному сообществу — это хороший путь для раскрытия причин асимметрии материи и антиматерии во Вселенной, что для науки остаётся тайной. 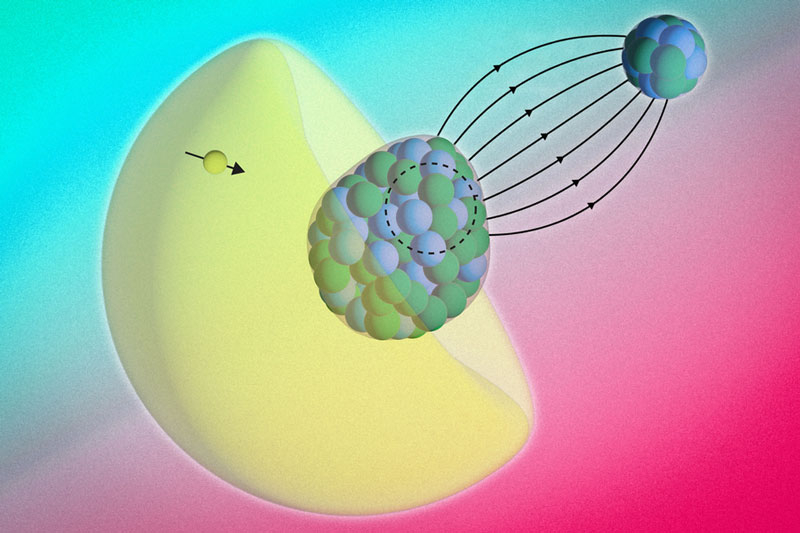
Несимметричной ядро радия связано с ядром фтора. В жёлтом электронном облаке выделен один электрон, который мог побывать внутри ядра. Источник изображения: MIT В центре исследования оказались молекулы монофторида радия (RaF), в составе которых электрон атома радия естественным образом проникает в ядро, взаимодействует с протонами и нейтронами, а затем возвращается с информацией о внутренней структуре ядра. Данный подход использует прецизионную лазерную спектроскопию для измерения микроскопических сдвигов энергии электронов, что даёт возможность изучать распределение магнитных полей внутри ядра радия-225 — это та информация, которой готовы делиться побывавшие внутри ядра электроны. В отличие от традиционных методов, требующих ускорителей с треками длиною в десятки километров, придуманный в MIT способ работает на лабораторном столе, делая фундаментальную физику более доступной. Учёные целенаправленно синтезировали молекулу монофторида радия, охладили её и поместили в вакуумную камеру. После этого молекулу осветили лазером, который возбудил электроны. За счёт высокой плотности магнитного поля внутри молекулы у электронов в электронном облаке вокруг ядра радия появляется повышенный шанс проникнуть внутрь этого ядра и вернуться оттуда с информацией. Измеряя энергию электронов с помощью спектроскопии, учёные смогли определить величину сдвига их энергии после посещения ядра, на основании которого можно воссоздать его внутреннее строение. Протоны и нейтроны в ядре действуют как крошечные магниты с разными ориентациями, и выявленный сдвиг энергии электронов раскрывает их распределение. Величина сдвига энергии соизмерима с одной миллионной энергии в импульсе лазера, но учёные смогли чётко её выявлять. Радий имеет особенную ценность для изучения основ мироздания — его ядро имеет асимметрию по массе и заряду. Оно скорее напоминает грушу, а не яблочко, свойственное обычной форме ядер остального вещества. Тем самым неправильная форма ядра радия может помочь с поиском фундаментальной асимметрии во Вселенной. Если бы Вселенная была симметричная на фундаментальном уровне, то она бы не возникла — антиматерия поровну с материей просто уничтожили бы её. Но Вселенная есть, значит, где-то прячется основа для её несимметричной сущности. Эксперименты с точным картированием магнитных полей ядра радия позволят создать точную модель расположения нейтронов и протонов в его ядре, и далее могут помочь обнаружить корень отсутствия симметрии в физике нашего мира. NextSilicon похвасталась превосходством ускорителя Maverick-2 над Nvidia HGX B200 и представила чип Arbel на базе RISC-V
22.10.2025 [20:09],
Николай Хижняк
Стартап NextSilicon, основанный в 2017 году, представил специализированный ускоритель Maverick-2. Компания называет его интеллектуальным вычислительным ускорителем (Intelligent Compute Accelerator). Его впервые анонсировали ещё в прошлом году. NextSilicon утверждает, что Maverick-2 превосходит ускоритель Nvidia HGX B200 и процессоры Intel Sapphire Rapids в высокопроизводительных вычислениях и задачах искусственного интеллекта. 
Источник изображений: NextSilicon Maverick-2, созданный по 5-нм техпроцессу TSMC, доступен в виде однокристальной карты расширения PCIe с 96 Гбайт памяти HBM3e и энергопотреблением 300 Вт, а также в виде двухкристальной версии на модуле OAM с 192 Гбайт памяти HBM3e и энергопотреблением 600 Вт. Согласно внутренним тестам, Maverick-2 обеспечивает до 4 раз более высокую производительность в операциях FP64 на ватт, чем Nvidia HGX B200, и более чем в 20 раз более высокую эффективность, чем процессоры Intel Xeon Sapphire Rapids. В тестах производительности GUPS он достиг 32,6 GUPS при 460 Вт мощности, что, как сообщается, в 22 раза быстрее, чем у центральных, и в 6 раз быстрее, чем у графических процессоров. В рабочих нагрузках HPCG он достиг 600 GFLOPS при 750 Вт, потребляя при этом примерно вдвое меньше энергии, чем конкурирующие решения. Компания объясняет этот прирост эффективности архитектурой, основанной на потоках данных, которая переносит управление ресурсами с аппаратного уровня на адаптивное программное обеспечение, позволяя использовать большую часть площади кремния для вычислений, а не для управляющей логики.  Компания также анонсировала Arbel — чип корпоративного класса на базе RISC-V, также построенный по 5-нм техпроцессу TSMC. NextSilicon утверждает, что Arbel уже превосходит текущие разработки RISC-V конкурентов, а также ядра Intel Lion Cove и AMD Zen 5. Arbel оснащён 10-канальным конвейером инструкций с 480-элементным буфером переупорядочивания для высокой загрузки ядра, работающим на частоте 2,5 ГГц. Чип может выполнять до 16 скалярных инструкций параллельно и включает четыре 128-битных векторных блока для параллельной обработки данных. Кеш первого уровня объёмом 64 Кбайт и большой общий кеш третьего уровня обеспечивают высокую пропускную способность памяти и низкую задержку, что позволяет сократить узкие места в производительности в ресурсоёмких приложениях.  NextSilicon не поделилась ни полными результатами тестов нового чипа, ни информацией о том, когда он станет доступен. В то же время компания заявляет, что Arbel представляет собой шаг к полностью открытой, программно-адаптивной кремниевой платформе для будущих систем высокопроизводительных вычислений и искусственного интеллекта. Nvidia по-тихому выпустила версию профессиональной RTX Pro 5000 Blackwell с 72 Гбайт памяти
21.10.2025 [15:44],
Николай Хижняк
Компания Nvidia без лишнего шума выпустила ещё одну версию профессиональной видеокарты RTX Pro 5000 Blackwell. Она выделяется увеличенным объёмом видеопамяти. Никаких официальных анонсов этой видеокарты не было. 
Источник изображения: VideoCardz Версия RTX Pro 5000 Blackwell с 72 Гбайт памяти оснащена той же 512-битной шиной, что и модель с 48 Гбайт. В составе последней используются 16 чипов памяти GDDR7, каждый ёмкостью по 3 Гбайт и со скоростью 21 Гбит/с на контакт. С учётом 512-битной шины это даёт 1,344 Тбайт/с пропускной способности. Портал VideoCardz предполагает, что для достижения такой же пропускной способности карте с 72 Гбайт памяти необходимо использовать одну из следующих конфигураций памяти: либо 24 чипа по 3 Гбайт со скоростью 28 Гбит/с на контакт (12 каналов, шина 384 бит), либо 24 чипа по 3 Гбайт со скоростью 21 Гбит/с на контакт (16 каналов, шина 512 бит). Если Nvidia верно указала характеристики карты, то модель с 72 Гбайт памяти использует вторую конфигурацию. Компания упоминает обновлённую память в своём недавно опубликованном техническом документе. «Новая и улучшенная память GDDR7 значительно увеличивает пропускную способность и объём, позволяя вашим приложениям работать быстрее и с более крупными и сложными наборами данных. Благодаря 48 или 72 Гбайт графической памяти и пропускной способности 1,3 Тбайт/с вы сможете решать масштабные 3D-проекты и проекты с искусственным интеллектом, локально настраивать модели искусственного интеллекта, исследовать масштабные VR-среды и управлять масштабными рабочими процессами с несколькими приложениями», — говорится в описании Nvidia. 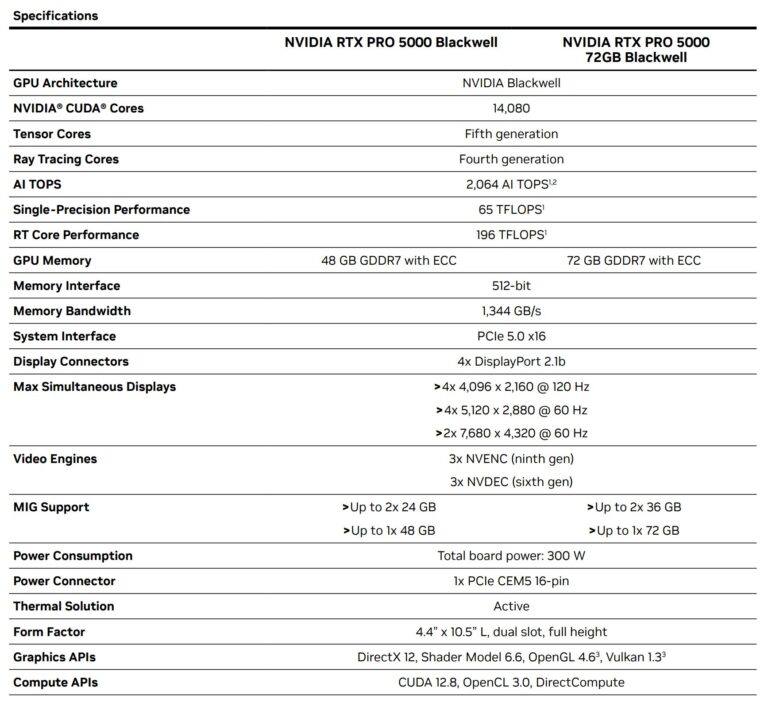
Источник изображения: Nvidia Что касается графического процессора, обе модели используют чип GB202 с одинаковым количеством ядер CUDA — 14 080 штук. Также не изменился показатель энергопотребления карты с увеличенным объёмом памяти — он заявлен на уровне 300 Вт. Отсутствие разницы в заявленной производительности также намекает на то, что GPU карт работают на одинаковых частотах. 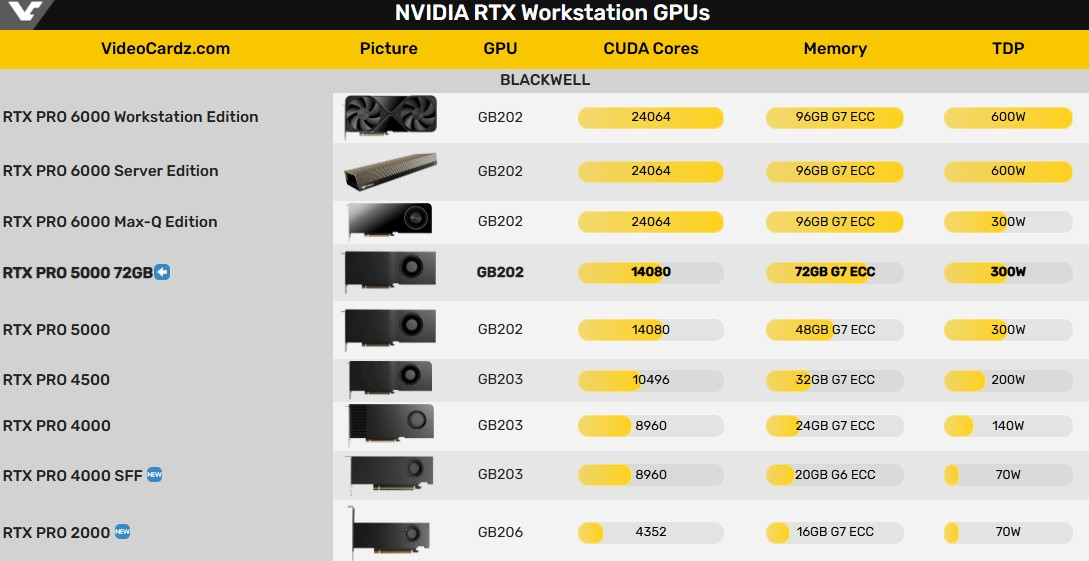 В настоящий момент версию RTX Pro 5000 Blackwell с 48 Гбайт памяти можно найти в продаже по цене около $4250–4600. Вероятно, модель с 72 Гбайт памяти будет стоить ближе к $5000. Для сравнения: флагманская RTX Pro 6000 оценивается более чем в $8300. Frore представила водоблоки LiquidJet с 3D-охлаждением — они справятся с чипами до 4400 Вт
15.10.2025 [15:21],
Николай Хижняк
Компания Frore Systems представила LiquidJet — водоблок системы жидкостного охлаждения (СЖО), поддерживающий существующие графические процессоры для ИИ, такие как Nvidia Blackwell, с тепловой мощностью 1400 Вт. Производительность LiquidJet может быть масштабирована для ускорителей ИИ следующего поколения, включая Nvidia Feynman, общая мощность которых составит до 4400 Вт. 
Источник изображений: Frore Systems Современные графические процессоры для ИИ, такие как системы на кристалле Nvidia Blackwell, потребляют огромное количество энергии и поэтому требуют жидкостного охлаждения. Традиционные медные водоблоки СЖО имеют относительно длинные «двумерные» микроканалы с малым поперечным сечением, изготовленные на станках с ЧПУ или выточенные из медных блоков высокой чистоты. Из-за большой длины этих микроканалов жидкость должна проходить большее расстояние и соприкасаться с большой площадью поверхности, что увеличивает гидравлическое сопротивление и снижает давление внутри контура, влияя на эффективность охлаждения.  Компания Frore утверждает, что её водоблоки LiquidJet с трёхмерной микроструктурой каналов струйной обработки и короткими контурами снижают гидравлическое сопротивление и, следовательно, поддерживают более высокое давление внутри системы, повышая производительность охлаждения. Frore отмечает, что адаптировала «технологии производства полупроводников для изготовления металлических пластин» и может создавать трёхмерные микроструктуры каналов струйной обработки, соответствующие картам горячих точек конкретных процессоров. Это значительно повышает производительность и эффективность, хотя и обходится дороже по сравнению с традиционными методами производства. По словам Frore, результаты оказались впечатляющими. LiquidJet поддерживает плотность горячих точек до 600 Вт/см² при температуре на входе 40 °C, что вдвое превосходит показатели стандартных водоблоков. Отношение удаления тепла к скорости потока у LiquidJet увеличено на 50 %, а потери давления снижены в четыре раза — с 0,94 до 0,24 фунта на квадратный дюйм. В результате, по утверждению компании, LiquidJet обеспечивает более низкие температуры и более предсказуемую производительность процессоров Nvidia Blackwell Ultra при полной нагрузке. 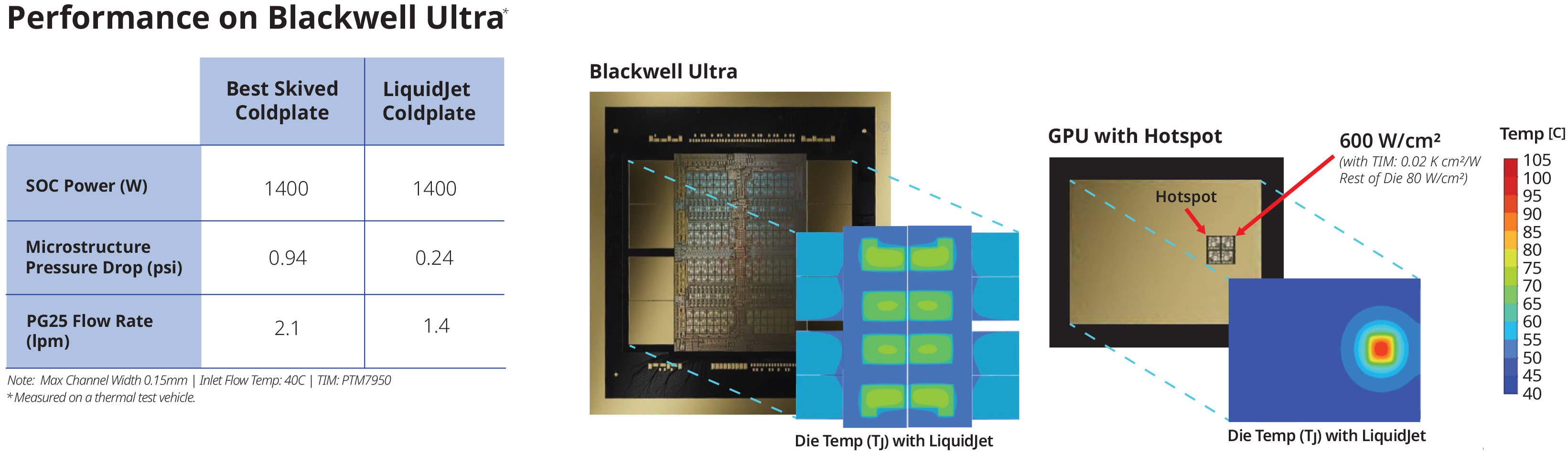 Конструкцию LiquidJet можно масштабировать и адаптировать для будущих специализированных GPU от Nvidia, таких как Rubin (мощность 1800 Вт), Rubin Ultra (3600 Вт) и Feynman (4400 Вт). Водоблок также можно адаптировать для любых других процессоров, поскольку метод производства Frore отличается особой гибкостью с точки зрения настройки под конкретную карту горячих точек того или иного чипа. LiquidJet обеспечивает и другие преимущества. Более эффективное охлаждение позволяет добиться более стабильных частот у специализированных GPU, что означает обработку большего числа токенов в секунду при тех же энергозатратах. Кроме того, высокая эффективность циркуляции жидкости внутри контура снижает энергопотребление насоса, улучшая показатели PUE и снижая TCO (стоимость владения). 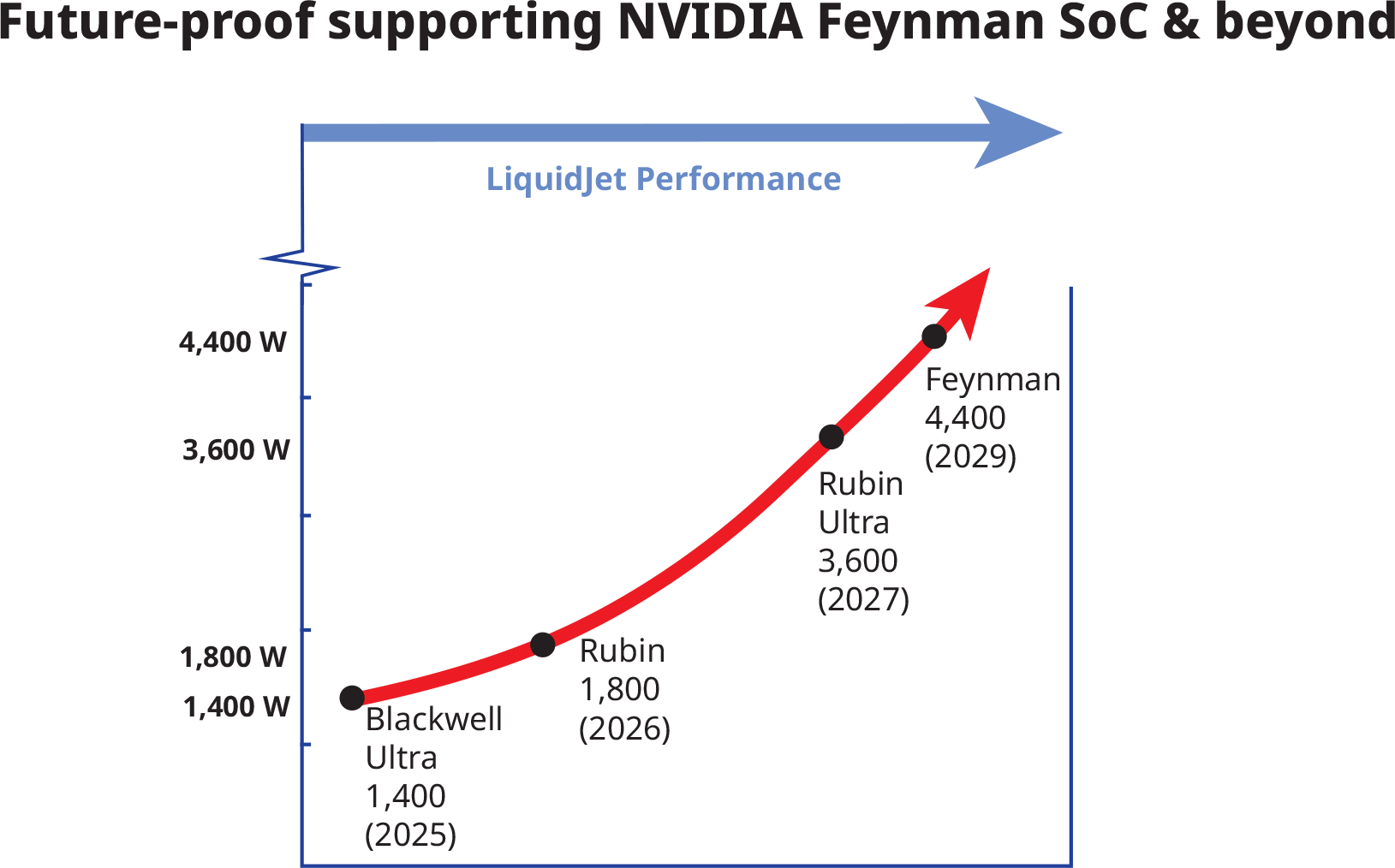 По оценкам KAIST — ведущего корейского исследовательского института передовых технологий, — энергопотребление и тепловыделение ускорителей искусственного интеллекта в течение следующего десятилетия могут вырасти в 10 раз. Будущие ИИ-ускорители, состоящие из специализированных графических процессоров на базе нескольких вычислительных чиплетов и оснащённые десятками стеков памяти HBM, потребуют совершенно новых методов охлаждения, включая встроенные охлаждающие структуры как для вычислительных чиплетов, так и для чипов памяти. Intel представила Crescent Island — GPU для ИИ на архитектуре Xe3P и со 160 Гбайт LPDDR5X
14.10.2025 [21:52],
Николай Хижняк
Компания Intel анонсировала новый графический процессор, предназначенный для центров обработки данных, разработанный специально для выполнения задач логического вывода (ИИ). Новинка имеет кодовое название Crescent Island и построена на базе архитектуры Xe3P. 
Источник изображений: Intel Графический процессор Crescent Island основан на архитектуре Xe3P. Она представляет собой усовершенствованную версию графической архитектуры Xe3, анонсированной в составе процессоров Panther Lake для ноутбуков и компактных ПК. В перспективе Xe3P будет также использоваться в семействе потребительских видеокарт Arc следующего поколения — Arc C-Series. Новый графический процессор для ЦОД под кодовым названием Crescent Island разработан с учётом оптимизации энергопотребления и стоимости для корпоративных серверов с воздушным охлаждением, а также с акцентом на большой объём памяти и пропускную способность, оптимизированные для рабочих процессов вывода. Ключевые особенности Crescent Island:
Примечательно, что Intel выбрала память LPDDR5X для своего специализированного GPU. Конкуренты в лице Nvidia и AMD предлагают свои решения для ИИ-центров обработки данных с использованием высокоскоростной памяти HBM (например, HBM3E) и уже обсуждают применение ещё более производительной памяти HBM4 для решений будущих поколений, таких как Rubin и MI400.  На фоне возросшего спроса и, как следствие, роста цен на память HBM использование LPDDR5X может предоставить решению Intel значительное преимущество в соотношении цены и производительности. Кроме того, поддержка широкого спектра типов данных делает архитектуру универсальной для различных задач, связанных с ИИ. Intel отмечает, что открытый и унифицированный программный стек для Crescent Island разрабатывается и тестируется на графических процессорах Arc Pro серии B для обеспечения ранней оптимизации и итераций. Ожидается, что образцы нового графического процессора для центров обработки данных под кодовым названием Crescent Island будут представлены клиентам во второй половине 2026 года. OpenAI превратится в чипмейкера — Broadcom поможет проложить «путь к будущему ИИ» на 10 ГВт
13.10.2025 [19:33],
Сергей Сурабекянц
OpenAI и Broadcom сегодня объявили о сотрудничестве по созданию и дальнейшему развёртыванию специализированных ИИ-ускорителей разработки OpenAI общей мощностью 10 ГВт. В своих чипах OpenAI планирует интегрировать опыт и знания, полученные в ходе создания передовых моделей ИИ, непосредственно в аппаратное обеспечение. Начало работ запланировано на вторую половину 2026 года, а завершение — на конец 2029 года. 
Источник изображения: unsplash.com Партнёрское соглашение предусматривает развёртывание полностью масштабируемых стоек на базе ИИ-ускорителей разработки OpenAI и сетевых решений Broadcom на объектах OpenAI и в партнёрских центрах обработки данных. Для Broadcom это сотрудничество подтверждает важность специализированных ускорителей и выбор Ethernet в качестве технологии для вертикального и горизонтального масштабирования сетей в центрах обработки данных искусственного интеллекта. «Партнёрство с Broadcom — критически важный шаг в создании инфраструктуры, необходимой для раскрытия потенциала ИИ и предоставления реальных преимуществ людям и бизнесу, — заявил глава OpenAI Сэм Альтман (Sam Altman). — Разработка собственных ускорителей дополняет более широкую экосистему партнёров, которые вместе создают потенциал, необходимый для расширения возможностей ИИ на благо всего человечества». «Сотрудничество Broadcom с OpenAI знаменует собой поворотный момент в развитии общего искусственного интеллекта, — считает президент и генеральный директор Broadcom Хок Тан (Hock Tan). — OpenAI находится в авангарде революции ИИ с момента появления ChatGPT, и мы рады совместно разработать и внедрить 10 гигаватт ускорителей и сетевых систем нового поколения, чтобы проложить путь к будущему ИИ». 
Источник изображения: Broadcom «Наше сотрудничество с Broadcom станет движущей силой прорывов в области ИИ и позволит полностью раскрыть потенциал этой технологии, — уверен соучредитель и президент OpenAI Грег Брокман (Greg Brockman). — Создавая собственный чип, мы можем интегрировать знания, полученные при создании передовых моделей и продуктов, непосредственно в аппаратное обеспечение, открывая новые возможности и уровень интеллекта». «Наше партнёрство с OpenAI продолжает устанавливать новые отраслевые стандарты в области разработки и внедрения открытых, масштабируемых и энергоэффективных кластеров ИИ, — полагает президент группы полупроводниковых решений Broadcom Чарли Кавас (Charlie Kawwas). — Специальные ускорители прекрасно сочетаются со стандартными сетевыми решениями […] Стойки включают в себя комплексное портфолио решений Broadcom для Ethernet, PCIe и оптических соединений, подтверждая наше лидерство в сфере инфраструктур искусственного интеллекта». В конце прошлого месяца Nvidia объявила о планах инвестировать до $100 млрд в OpenAI в течение следующего десятилетия. OpenAI планирует развернуть системы на базе ИИ-ускорителей Nvidia общей мощностью 10 ГВт, что на момент объявления эквивалентно от 4 до 5 миллионов графических процессоров. 
Источник изображения: Nvidia В начале октября было подписано соглашение между OpenAI и AMD, которое предусматривает приобретение компанией Сэма Альтмана до 10 % акций производителя чипов. AMD предоставила OpenAI право на покупку до 160 миллионов своих обыкновенных акций с контрольными сроками, привязанными к объёму развёртывания и к цене акций AMD. OpenAI в течение ближайших нескольких лет произведёт массированное развёртывание графических процессоров AMD Instinct нескольких поколений в дата-центрах OpenAI общей мощностью 6 ГВт. 
Источник изображения: AMD Количество активных пользователей OpenAI превысило 800 миллионов в неделю, а сама компания получила широкое распространение среди глобальных корпораций, малого бизнеса и разработчиков. OpenAI утверждает, что миссия компании — обеспечить, чтобы искусственный интеллект приносил пользу всему человечеству. Несмотря на это, многие эксперты полагают, что масштабные инвестиции в компанию лишь подтверждают опасения по поводу «циклического характера» некоторых сделок в сфере ИИ-инфраструктуры. Проблемы Nvidia в Китае стали подарком местным разработчикам GPU — Moore Threads, MetaX и Cambricon
07.10.2025 [18:04],
Павел Котов
Недавно гендиректор Nvidia Дженсен Хуанг (Jensen Huang) отметил, что китайские производители добились значительных успехов в области производства чипов — по его мнению, Китай отстаёт от США уже на «наносекунды». Если четыре года назад доля Nvidia на китайском рынке была 95 %, то к настоящему моменту сократилась до 50 %. Помимо Huawei, руку к этому приложили Moore Threads, MetaX и Cambricon, отмечают аналитики TrendForce. 
Источник изображения: metax-tech.com По типу чипов Moore Threads ближе всего к Nvidia. Cambricon и Huawei HiSilicon специализируются на архитектурах ASIC, а Moore Threads, по её собственному заверению, является единственной китайской компанией, которая сегодня массово производит полнофункциональные графические процессоры. К настоящему моменту она выпустила четыре их поколения: Sudi (2021 год), Chunxiao (2022), Quyuan (2023) и Pinghu (2024). Видеокарты первых двух поколений предназначались для потребительских десктопов и профессиональных систем, тогда как Quyuan и Pinghu работают и с алгоритмами искусственного интеллекта. Основатель и гендиректор Moore Threads Джеймс Чжан Цзяньчжун (James Zhang Jianzhong) проработал в Nvidia 14 лет, он дослужился до должности вице-президента и гендиректора китайского филиала компании, которую покинул в 2020 году, чтобы основать Moore Threads. В конце сентября компания Цзяньчжуна получила разрешение Шанхайской фондовой биржи выйти на первичное размещение акций — процедура заняла 88 дней, и это один из лучших результатов. Moore Threads намеревается привлечь 8 млрд юаней ($1,12 млрд), чтобы ускорить масштабное производство продукции. 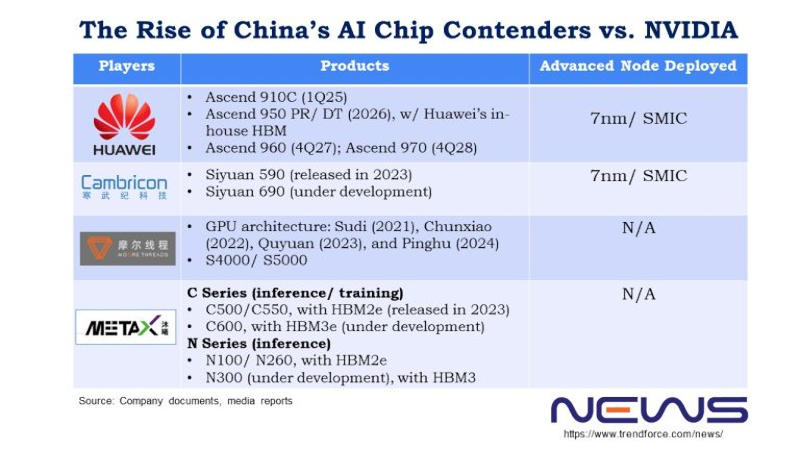
Источник изображения: trendforce.com Выйти на биржу готовится и MetaX. Если в Moore Threads работает много выходцев из Nvidia, то MetaX происходит от AMD. Основатель этой китайской компании Чэнь Вэйлян (Chen Weiliang) в 2007 году начал работу в AMD Shanghai в качестве старшего директора, а в 2020 году ушёл из неё и учредил собственный стартап. Выходцами из AMD являются также оба технических директора MetaX Пэн Ли (Peng Li) и Ян Цзянь (Yang Jian). В 2024 году основным источником дохода компании стали ускорители для обучения и инференса (запуска) ИИ: на платы GPU пришлись 68,99 % от общего объёма выручки, на серверы — 28,29 %. В первом квартале 2025 года на графические процессоры этой серии пришлись 97,55 % от общего объёма продаж. Ни MetaX, ни Moore Threads пока на прибыльность не вышли — но обе уверены, что смогут привлечь капитал, исходя из резкого роста выручки в 2024 году, а также того, как растёт их признание на рынке оборудования для ИИ-вычислений. Cambricon в сентябре получила разрешение на закрытый раунд финансирования на сумму 3,99 млрд юаней ($559,6 млн) — ей необходимы средства на проекты по разработке чипов и ПО для ИИ. По итогам 2025 года компания ожидает роста выручки на величину от 317 % до 483 % — в диапазоне от 5 млрд до 7 млрд юаней. Подчёркивается, что прогноз предварительный и не является твёрдым обязательством. Чистая прибыль за первую половину 2025 года составила 1 млрд юаней ($140,4 млн) — аналогичный период в прошлом году компания завершила убытком в размере 530 млн юаней ($74,1 млн). В отличие от Moore Threads и MetaX компания Cambricon обходится без кадрового ресурса Nvidia и AMD. Cambricon в 2016 году основали братья Чэнь Юньцзи (Chen Yunji) и Чэнь Тяньши (Chen Tianshi). Новый флагман Siyuan 690, как ожидается, по производительности будет сравним с ускорителем Nvidia H100. Его предшественник Siyuan 590, дебютировавший в 2023 году, выпускается с использованием техпроцесса 7 нм и обеспечивает 80 % производительности Nvidia A100. Из всего трио у Cambricon самая высокая выручка; Moore Threads ранее отставала от MetaX, но в первой половине 2025 года вырвалась вперёд. В условиях ограничений на продукты Nvidia в Китае все три производителя показыывают взрывной рост доходов: за первую половину 2025 года они заработали больше, чем за три предыдущих года вместе взятых. При этом доля рынка Nvidia остаётся больше, чем MetaX. Президент OpenAI: человечеству потребуется 10 млрд ИИ-ускорителей — по одному на каждого жителя Земли
30.09.2025 [06:58],
Алексей Разин
Сейчас стартап OpenAI использует любую возможность для привлечения не только финансовых ресурсов, но и заключения контрактов с поставщиками тех же ускорителей вычислений, коим является Nvidia. Президент компании Грег Брокман (Greg Brockman) убеждён, что человечеству потребуется до 10 млрд ускорителей вычислений, и каждого жителя планеты буквально будет обслуживать отдельный ИИ-чип. 
Источник изображения: Nvidia Своими соображениями президент OpenAI поделился в интервью CNBC, в котором также приняли участие генеральный директор компании Сэм Альтман (Sam Altman), а также глава и основатель Nvidia Дженсен Хуанг (Jensen Huang). По мнению Альтмана, масштабы сотрудничества с Nvidia по своей значимости для человечества окажутся важнее программы доставки до Луны американских астронавтов, которую NASA реализовало в прошлом веке. Альтман видит будущее человечества с неразрывным присутствием «супермозга», созданного искусственным интеллектом и активно влияющего на повседневную жизнь людей. Брокман же считает, что ИИ будет действовать в качестве «агента, который работает на опережение, пока вы спите». Каждый работающий житель Земли, по его мнению, будет использовать ресурсы как минимум одного ускорителя вычислений при выполнении своих должностных обязанностей. «Вам действительно захочется, чтобы у каждого человека был свой собственный выделенный GPU», — охарактеризовал свой прогноз Брокман. Сейчас подобное предсказание может казаться нереалистичным, но достаточно вспомнить, что в начале девяностых годов прошлого века один из основателей Microosft Билл Гейтс (Bill Gates) указывал на неизбежность появления компьютера не только в каждом домохозяйстве, но и на каждом рабочем столе. В какой-то мере его предсказание сбылось, пусть даже если вместо компьютеров в их классической форме речь идёт о смартфонах, которые помещаются в карман. Брокман считает, что сейчас отрасль ИИ на три порядка отстаёт от потенциальных потребностей в вычислительных мощностях, и для создания постоянно функционирующей глобальной системы искусственного интеллекта человечеству может потребоваться до 10 млрд ускорителей вычислений. По сути, это даже больше, чем проживает людей на Земле (8,2 млрд человек). Мир, по мнению Брокмана, движется к состоянию, при котором экономику подпитывают вычисления. Вычислительных мощностей сейчас не хватает, как он считает, а наличие достаточно мощных центров обработки данных в будущем станет определять состоятельность экономики целых стран. В какой-то мере они заменят валюту в качестве источника ресурсов для развития экономики. Китайская Innosilicon представила видеокарту Fenghua 3 — CUDA, DX12, трассировка лучей и более 112 Гбайт HBM
24.09.2025 [15:31],
Николай Хижняк
Компания Innosilicon представила свой графический процессор третьего поколения — Fenghua 3. Компания обещает, что третья версия графического процессора будет значительно превосходить своих предшественников. Компания называет его первым полнофункциональным GPU собственной разработки, которые построен на открытой архитектуре RISC-V и совместим с CUDA. 
Источник изображений: Innosilicon В отличие от предыдущих поколений ускорителей Fenghua, основанных на архитектуре PowerVR от Imagination Technologies, Fenghua 3 использует в качестве основы проект OpenCore RISC-V Nanhu V3. Innosilicon утверждает, что новый GPU способен справиться с широким спектром рабочих нагрузок: от обучения ИИ и масштабных научных вычислений до САПР, медицинской визуализации и облачного гейминга. Для Fenghua 3 заявляется поддержка DirectX 12, Vulkan 1.2 и OpenGL 4.6 с аппаратной трассировкой лучей. Компания продемонстрировала работу GPU в таких играх, как Tomb Raider, Delta Force и Valorant, хотя данные о частоте кадров и настройках не были предоставлены. Fenghua 3 также поддерживает подключение до шести 8K-мониторов с частотой обновления 30 Гц. 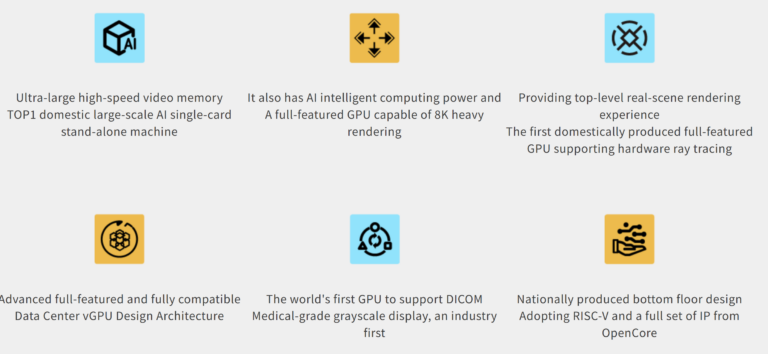 Для задач искусственного интеллекта ускоритель на базе Fenghua 3 предлагает более 112 Гбайт высокоскоростной памяти HBM — это самый большой объём памяти среди китайских видеокарт. Один ускоритель может обрабатывать модели с 32 и 72 млрд параметров, а кластер из восьми — поддерживать огромные модели DeepSeek 671B и 685B. Innosilicon также подтвердила совместимость своей новинки с Qwen 2.5, Qwen 3 и семейством ИИ-моделей DeepSeek V3, V3.1 и R1. Innosilicon также похвасталась тем, что Fenghua 3 — первая в Китае видеокарта, поддерживающая формат YUV444, который обеспечивает наилучшую детализацию и точность цветопередачи. Это будет особенно полезно для тех, кто работает с САПР или занимается видеомонтажом. Кроме того, Fenghua 3 — первая в мире видеокарта, которая предлагает встроенную поддержку технологии DICOM (Digital Imaging and Communication in Medicine). Она позволяет точно визуализировать рентгеновские снимки, МРТ, КТ и УЗИ на стандартных мониторах, устраняя необходимость в дорогостоящих специализированных медицинских дисплеях с градациями серого. Ускоритель работает с системами Windows, Android, Tongxin и Kylin Linux. Huawei пообещала создать «самый мощный в мире» ИИ-кластер, который в разы превзойдёт решения Nvidia
18.09.2025 [20:36],
Сергей Сурабекянц
Huawei наращивает мощности своих вычислительных систем для ИИ на фоне трудностей Nvidia в Китае. Компания заявила, что её новые кластеры из ИИ-ускорителей Ascend 950 на базе чипов собственной разработки станут самыми мощными в мире. Эксперты полагают, что Huawei может преувеличивать свои технические возможности, но признают, что её амбиции стать мировым лидером в области искусственного интеллекта «нельзя недооценивать».  Китайский телекоммуникационный гигант Huawei сегодня анонсировал новые вычислительные системы для искусственного интеллекта на базе собственных чипов Ascend, усиливая давление на американского конкурента Nvidia. Компания заявила, что планирует запустить свой новый суперкластер на базе Atlas 950 уже в следующем году. До конца 2028 года Huawei намерена выпустить три новых поколения чипов Ascend, удваивая их мощность с каждым годом. Эти чипы составляют основу вычислительной инфраструктуры Huawei для искусственного интеллекта, в которой суперкластер объединяет несколько супермодулей, которые, в свою очередь, построены из суперузлов. В основе каждого суперузла лежат чипы Ascend. Huawei утверждает, что её новый суперузел будет поддерживать 8192 чипа Ascend 950, а суперкластер будет использовать более 500 000 таких чипов. Когда у Huawei появится более продвинутая версия ускорителя, Atlas 960, запуск которой запланирован на 2027 год, в один узел можно будет объединить 15 488 чипов, а полный суперкластер благодаря этому будет содержать более одного миллиона чипов Ascend. Пока неясно, как эти кластеры будут соотноситься с системами на базе чипов Nvidia. В пресс-релизе Huawei заявлено, что новые суперузлы станут самыми мощными в мире по вычислительной мощности в течение нескольких лет. Председатель совета директоров Huawei Эрик Сюй (Eric Xu), заявил, что суперузел на базе Atlas 950 обеспечит в 6,7 раза большую вычислительную мощность, чем система Nvidia NVL144, запуск которой также запланирован на следующий год. Сюй также пообещал, что суперкластер Atlas 950 будет обладать в 1,3 раза большей вычислительной мощностью, чем суперкомпьютер xAI Colossus Илона Маска (Elon Musk). 
Источник изображения: Huawei В апреле 2025 года исследовательская компания SemiAnalysis сообщила, что разработанная Huawei система CloudMatrix оказалась производительнее, чем Nvidia GB200 NVL72, несмотря на то, что каждый чип Ascend обеспечивал лишь около трети производительности процессора Nvidia. Huawei добилась преимущества благодаря пятикратному увеличению числа чипов. Два года назад Huawei анонсировала свой суперкластер Atlas 900. Компания развернула более 300 таких суперузлов для более чем двадцати крупных клиентов в телекоммуникационной, производственной и других отраслях. США стремятся отрезать Китай от самых передовых технологий для обучения моделей искусственного интеллекта. Чтобы справиться с этой проблемой, китайские компании стали чаще объединять большое количество менее эффективных, часто отечественных, чипов для достижения схожих вычислительных возможностей. Объявление Huawei было сделано на фоне продвижения Китаем собственных альтернатив чипам Nvidia. На днях китайский регулятор объявил о продлении расследования в отношении Nvidia в связи с предполагаемой монополистической практикой. Ранее правительство Китая настоятельно рекомендовало местным технологическим гигантам прекратить испытания и заказы на чип Nvidia RTX Pro 6000D, разработанный специально для Китая. Генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) заявил, что он «разочарован» новостью об этом запрете. Ранее он называл Huawei «грозным» конкурентом. Дженсен Хуанг «разочарован», но «понимает» решение Китая о запрете импорта ускорителей Nvidia
17.09.2025 [19:30],
Сергей Сурабекянц
В августе администрация США заключила соглашение с Nvidia — компания получала лицензии на экспорт в Китай своих ИИ-чипов H20 в обмен на отчисления в размере 15 % от продаж в Китае. Однако сегодня китайские регуляторы запретили своим ведущим технологическим компаниям использовать ускорители ИИ от Nvidia. Глава компании Дженсен Хуанг (Jensen Huang) рассказал о возникших трудностях и заявил, что он «разочарован». 
Источник изображений: Nvidia Сегодня Financial Times сообщила, что «Администрация киберпространства Китая» (Cyberspace Administration of China, CAC) запретила компаниям, включая ByteDance и Alibaba, покупать видеокарты Nvidia RTX Pro 6000D, разработанные специально для этой страны. Это произошло после нескольких бурных лет для бизнеса Nvidia в Китае, который Хуанг назвал «своего рода американскими горками». Новость о запрете он прокомментировал словами «мы можем обслуживать рынок, только если страна этого хочет». Последние новости стали очередным серьёзным ударом по китайскому бизнесу Nvidia. Ранее на этой неделе Государственное управление по регулированию рынка Китая (State Administration for Market Regulation, SAMR) начало антимонопольное расследование в отношении Nvidia в связи с приобретением ею Mellanox, израильской технологической компании, разрабатывающей сетевые решения для центров обработки данных и серверов. «Мы, вероятно, внесли больший вклад в китайский рынок, чем большинство стран. И я разочарован тем, что вижу, — заявил Хуанг. — Но у них есть более глобальные вопросы взаимодействия между Китаем и США, и я их понимаю». Он подчеркнул, что ранее Nvidia рекомендовала всем финансовым аналитикам не включать Китай в финансовые прогнозы из-за сложных отношений между странами и запланированных переговоров.  Независимо от текущей геополитической ситуации, Хуанг подчеркнул важность китайского сектора искусственного интеллекта: «Китайский рынок важен. Он обширен. Технологическая индустрия динамично развивается. Мы работаем в ней уже 30 лет». Он добавил, что Nvidia «продолжит поддерживать китайское правительство и китайские компании, если они того пожелают, и мы, конечно же, продолжим поддерживать правительство США в их геополитической политике». Хуанг сопровождает президента США Дональда Трампа (Donald Trump) в его государственном визите в Великобританию на этой неделе. Вчера Nvidia объявила об инвестициях в размере £11 млрд ($15 млрд) в британскую инфраструктуру искусственного интеллекта. И она не одинока — ряд других американских технологических гигантов, включая Microsoft, Google и Salesforce, также объявили о многомиллиардном финансировании в развитие ИИ в этой стране. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



