|
Опрос
|
реклама
Быстрый переход
SpaceXAI выпустила мощную ИИ-модель Grok 4.5 — она тратит токены вдвое экономнее конкурентов и заточена на программирование
08.07.2026 [22:46],
Андрей Созинов
Компания SpaceXAI (бывшая xAI) представила большую языковую модель Grok 4.5, которую называет своей самой мощной разработкой на сегодняшний день. Новинка ориентирована прежде всего на разработчиков, инженеров и специалистов, работающих с техническими задачами. По словам компании, модель создавалась с прицелом на написание кода, агентные сценарии и повседневную интеллектуальную работу, а её обучение велось совместно с командой среды разработки Cursor. 
Источник изображений: SpaceXAI Разработчики утверждают, что Grok 4.5 обучалась на данных из областей программирования, науки, инженерии и математики. Особое внимание при подготовке модели уделялось качеству обучающего набора: данные проходили фильтрацию, дедупликацию и отбор по тематическим направлениям. Для последующего обучения с подкреплением использовались сотни тысяч задач, связанных главным образом с разработкой программного обеспечения и другими техническими дисциплинами. По данным SpaceXAI, обучение проходило на десятках тысяч ускорителей Nvidia GB300. 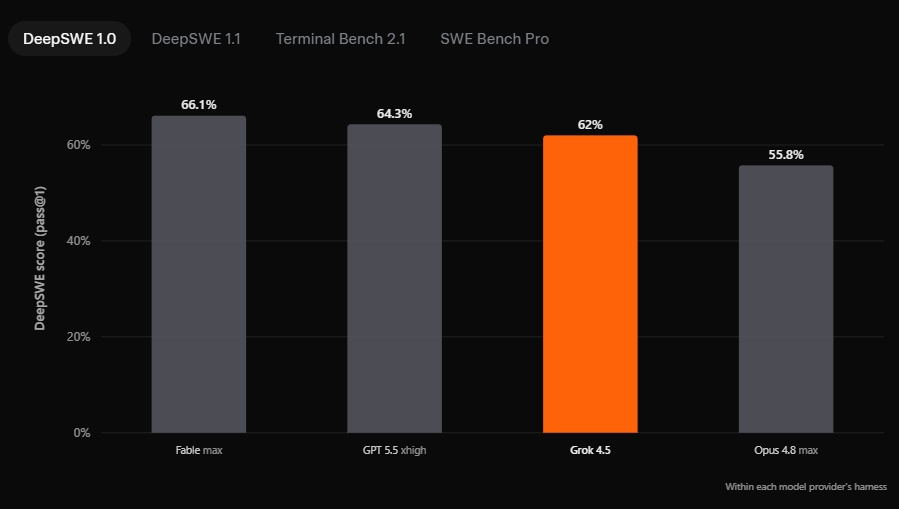 В компании заявляют, что Grok 4.5 превосходит ряд ведущих моделей в инженерных тестах и занимает первое место в бенчмарке Harvey Legal Agent Benchmark, оценивающем выполнение офисных и юридических задач. В то же время приводимые сравнения основаны на внутренних измерениях SpaceXAI, поэтому их стоит воспринимать с соответственным уровнем скепсиса. 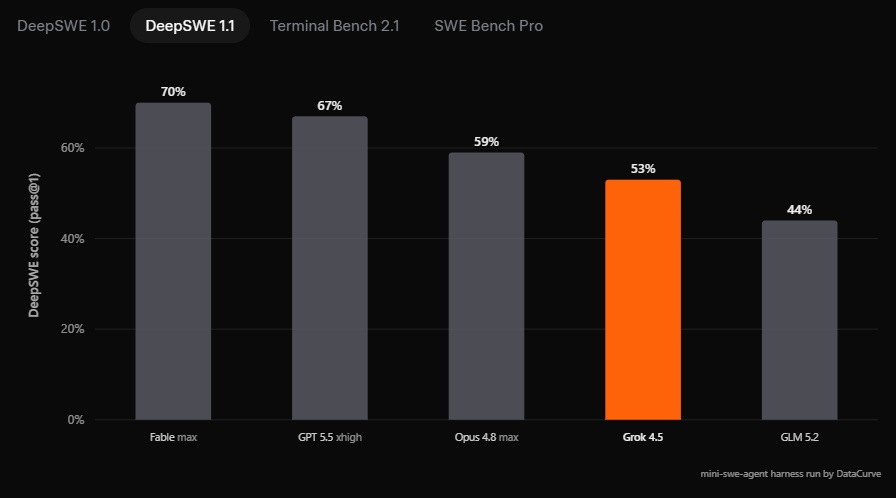 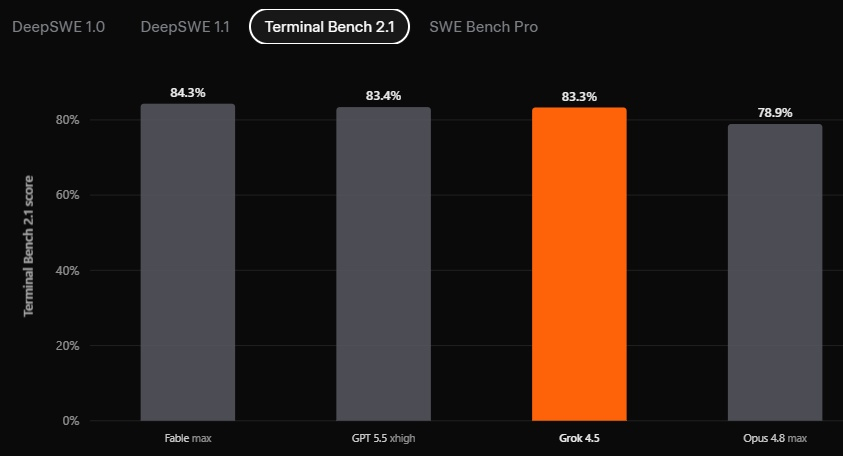 Одной из ключевых особенностей Grok 4.5 называется высокая производительность при генерации кода. По словам разработчиков, модель справляется как с отдельными задачами на Rust или C/C++, так и с созданием полноценных приложений по одному текстовому запросу. В качестве примера компания продемонстрировала интерактивную трёхмерную модель Солнечной системы, которую нейросеть сгенерировала самостоятельно по запросу: «Создай красивую симуляцию Вселенной и Солнечной системы. Симуляция должна иметь возможность ускорения с регулируемым временем, реалистичное движение, орбиты и звёзды. Используй Three.js. Оформи интерфейс (HUD) в стильном виде с соблюдением современных принципов дизайна». 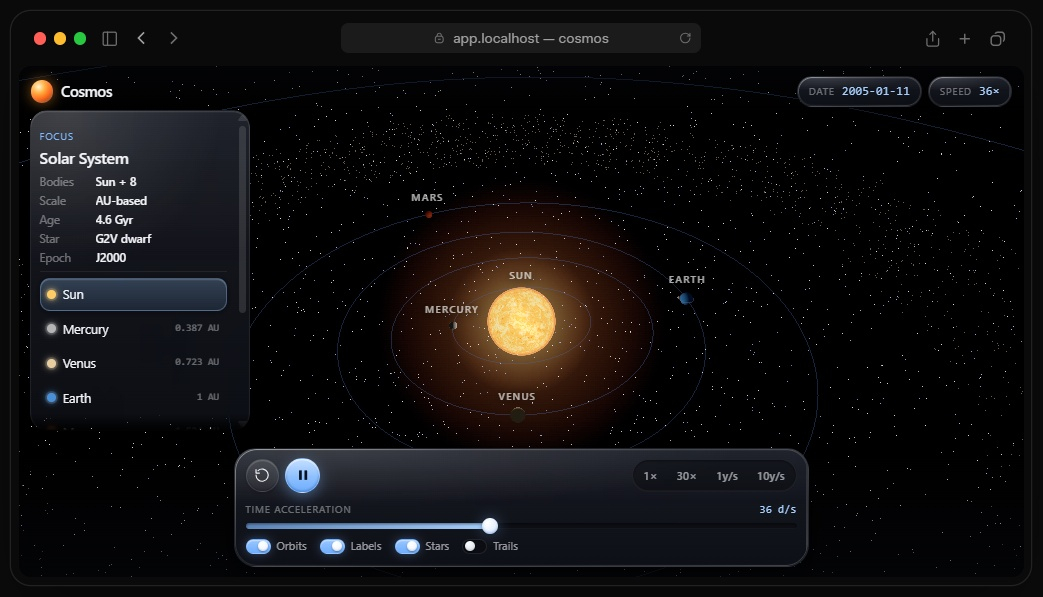 SpaceXAI также делает акцент на эффективности новой модели. По её данным, Grok 4.5 работает со скоростью до 80 токенов в секунду и для решения задач использует в среднем примерно вдвое меньше токенов, чем конкурирующие модели. В качестве примера приводится тест SWE Bench Pro, где средний объём ответа нового Grok составил около 16 тыс. токенов против более чем 67 тыс. у флагманской Claude Opus 4.8. 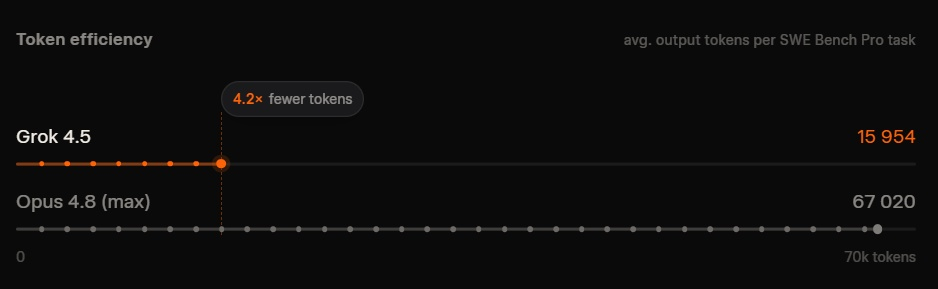 Помимо программирования, Grok 4.5 интегрирована в сервис Grok Build, где может автоматически создавать сложные модели Excel с использованием данных из интернета, работать с многостраничными таблицами, а также формировать презентации PowerPoint и документы Word. Компания утверждает, что модель умеет строить диаграммы стандартными средствами PowerPoint и оформлять материалы без участия пользователя.  Grok 4.5 уже доступна в Grok Build и Cursor для всех тарифных планов, а также через API SpaceXAI. Стоимость использования Grok 4.5 через API составляет $2 за миллион входных токенов и $6 за миллион выходных. В Grok Build и Cursor модель временно доступна бесплатно. При этом в странах Евросоюза сервис пока недоступен — его запуск ожидается в середине июля. Клин клином: Reddit запустила ИИ против спама, созданного нейросетями
06.07.2026 [20:54],
Анжелла Марина
Reddit объявила об интеграции инструментов на базе больших языковых моделей (LLM) для борьбы со спамом, значительная часть которого также генерируется нейросетями. По данным TechCrunch, новые системы позволили значительно повысить эффективность обнаружения нежелательного контента, который ранее оставался незамеченным стандартными автоматизированными системами. 
Источник изображения: Reddit (изменено) Ежедневно платформа теперь предотвращает около 23 млн просмотров спама, а также выявляет примерно 25 тысяч новых спам-публикаций и комментариев. По сравнению с предыдущими тремя месяцами, начиная с января и заканчивая мартом, подверженность аудитории спаму, по утверждению компании, сократилась на 20 %. При этом LLM удаётся фиксировать самые сложные и хорошо скоординированные действия вредоносной активности ботов. На фоне стремительного распространения ИИ-контента аналогичные инструменты стали применять и другие платформы. Например, YouTube, Meta✴✴ и Instagram✴✴ разрешают публиковать материалы, созданные искусственным интеллектом, но при условии их маркировки, а TikTok предоставляет пользователям возможность самостоятельно указывать объём отображаемого ИИ-контента. Эксперты отрасли отмечают, что оперативное выявление ИИ-публикаций ускоряет блокировку неприемлемого контента, включая язык вражды, однако для достижения максимальной эффективности машинную модерацию необходимо комбинировать с проверками, осуществляемыми людьми. OpenAI представила GPT-5.6 Sol, Terra и Luna, но доступ к новым моделям получили лишь избранные
26.06.2026 [21:01],
Андрей Созинов
Компания OpenAI официально представила семейство языковых моделей GPT-5.6, в которое вошли три модели разного уровня: флагманская Sol, сбалансированная Terra и доступная Luna. Пока они доступны лишь ограниченному кругу доверенных партнёров через API и Codex, однако уже в ближайшие недели компания рассчитывает открыть к ним широкий доступ, в том числе через ChatGPT. 
Источник изображений: OpenAI С выходом GPT-5.6 OpenAI изменила схему именования своих моделей. Теперь цифра обозначает поколение модели, а названия Sol, Terra и Luna станут постоянными обозначениями уровней производительности. Модели разных уровней будут развиваться независимо друг от друга. По словам разработчиков, GPT-5.6 стала самым мощным семейством моделей компании. Особый акцент сделан на задачах программирования, кибербезопасности, биологии, а также длительных агентных сценариях, требующих планирования и выполнения последовательности действий. Для Sol предусмотрены два дополнительных режима работы. Режим Max выделяет модели больше времени на рассуждения при решении сложных задач, а Ultra использует нескольких субагентов для ускорения выполнения комплексных рабочих процессов. 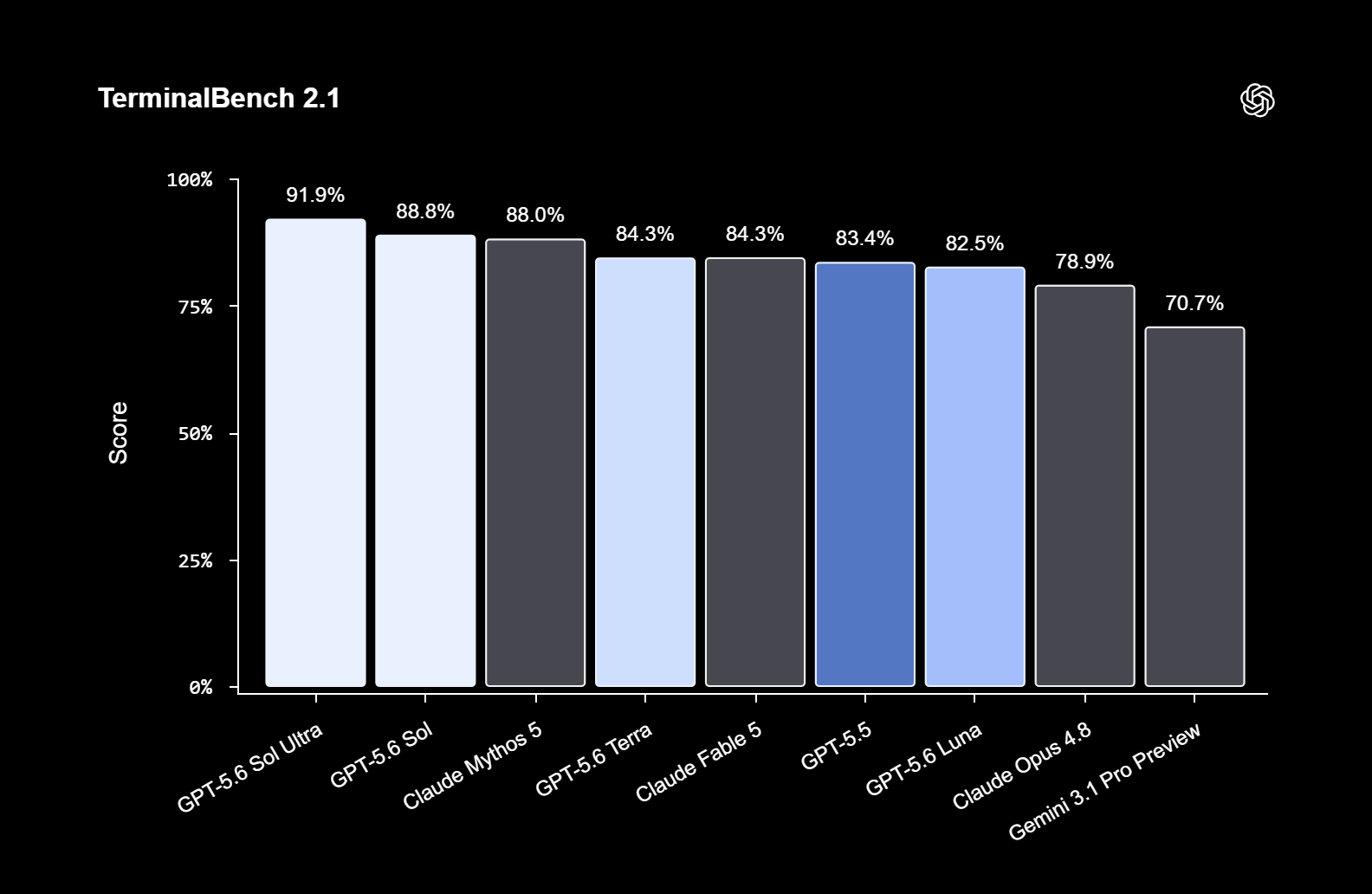 OpenAI приводит результаты собственных тестов производительности. В бенчмарке TerminalBench 2.1, оценивающем выполнение сложных задач в командной строке, GPT-5.6 Sol в режиме Ultra набрала 91,9 %, обычная Sol — 88,8 %, Terra — 84,3 %, а Luna — 82,5 %. Кроме того, компания заявляет, что Sol превосходит GPT-5.5 в биологических исследованиях (GeneBench v1), одновременно расходуя меньше токенов, а также является самой сильной моделью OpenAI в области кибербезопасности. 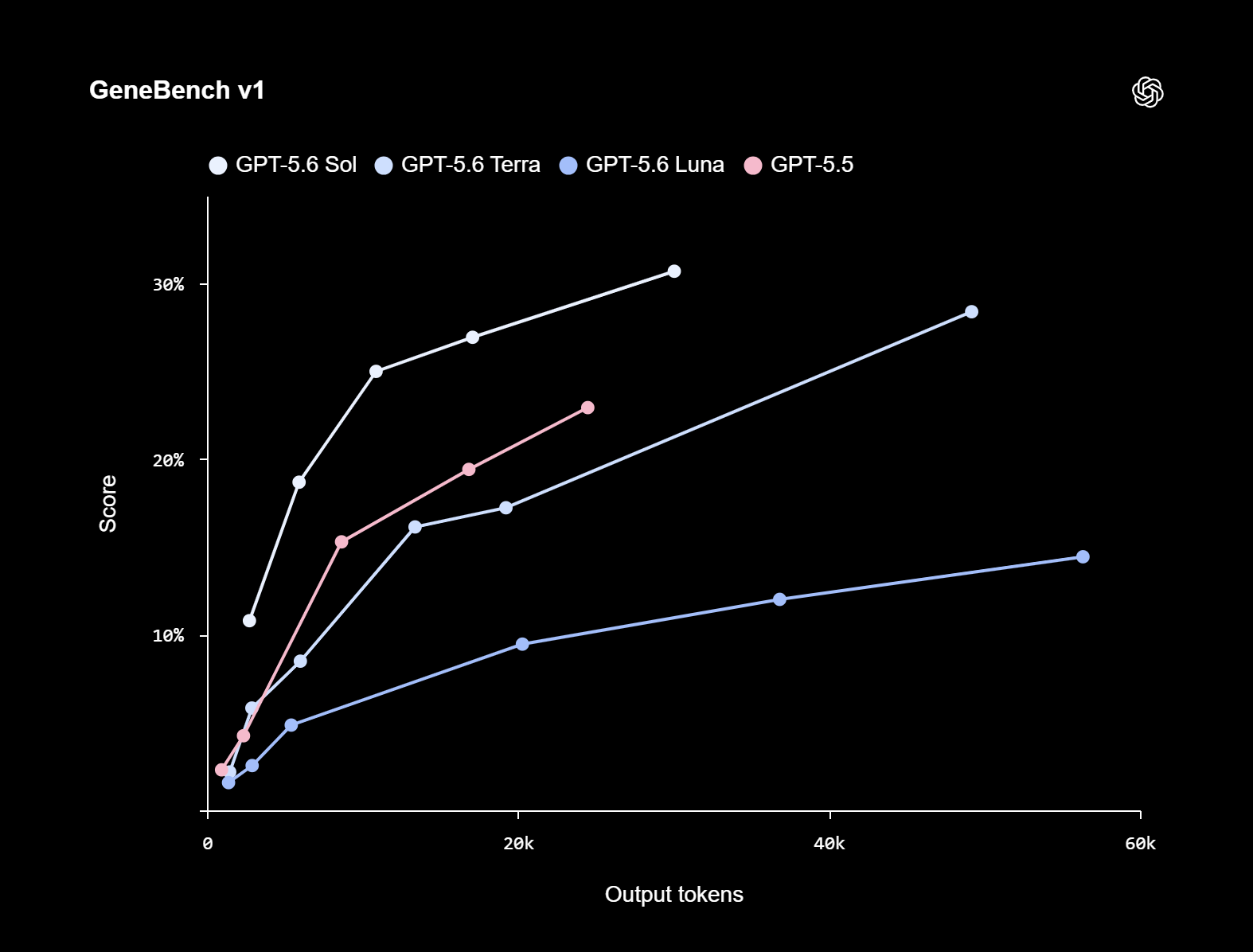 Стоимость использования моделей также заметно различается. GPT-5.6 Sol обойдётся в $5 за миллион входных токенов и $30 за миллион выходных, Terra — в $2,5 и $15 соответственно, а Luna — всего в $1 и $6 за миллион токенов. Одновременно OpenAI улучшила механизм кэширования запросов в API: модели GPT-5.6 поддерживают явные точки сброса кэша (cache breakpoints), а минимальное время хранения кэшированных запросов увеличено до 30 минут. Отдельное внимание OpenAI уделила безопасности. OpenAI утверждает, что GPT-5.6 получила «самый надёжный стек защитных механизмов» в истории компании. Модель обучена отказывать в выполнении запрещённых запросов, связанных с проведением кибератак, даже если пользователь пытается скрыть свои намерения, обмануть или обойти ограничения при помощи джейлбрейков. По словам разработчиков, Sol значительно лучше справляется с поиском и устранением уязвимостей, чем с проведением полноценных атак на компьютерные системы. 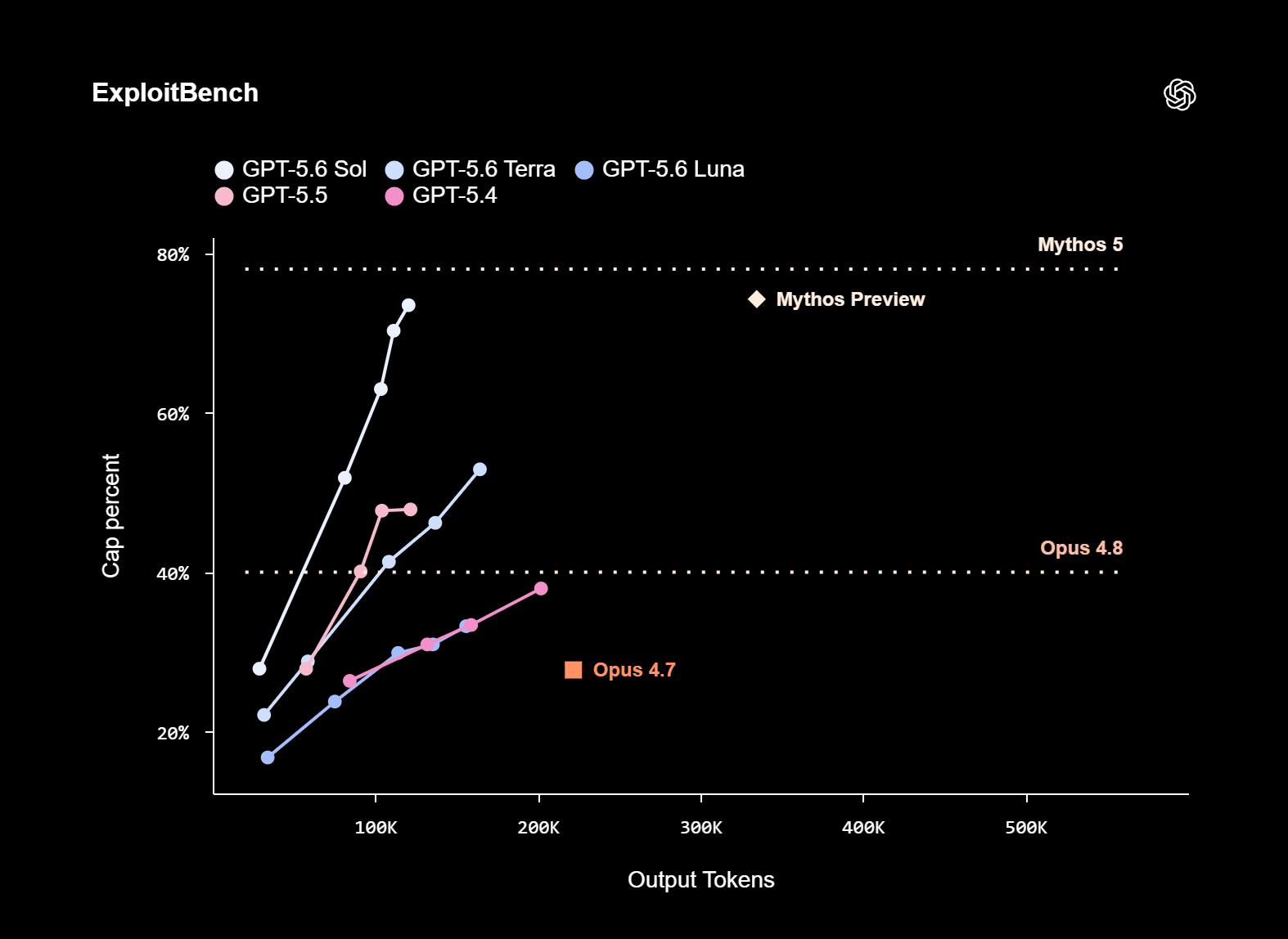 Компания также сообщила, что на автоматизированное тестирование защиты модели было затрачено более 700 тыс. GPU-часов на ускорителях уровня NVIDIA A100. Кроме того, в проверке участвовали независимые специалисты по безопасности, которые продолжат тестирование модели в течение всего периода предварительного доступа. Во время ограниченного тестирования OpenAI намеренно использует более строгие меры защиты. Компания предупреждает, что некоторые легитимные запросы, особенно связанные с исследованиями в области информационной безопасности, могут временно блокироваться или проходить дополнительную проверку. Эти случаи и должны помочь разработчикам скорректировать работу защитных механизмов перед массовым запуском. Релиз GPT-5.6 состоялся менее чем через сутки после появления сообщений о том, что OpenAI отложит запуск новой модели по просьбе администрации президента США Дональда Трампа. По данным СМИ, во время предварительного тестирования доступ к модели будет предоставляться лишь ограниченному кругу организаций, согласованному с американскими властями. При этом OpenAI подчёркивает, что не считает подобную процедуру нормой. Компания заявила, что сотрудничала с правительством США перед запуском GPT-5.6, однако рассчитывает, что в дальнейшем подобные модели будут выходить без необходимости предварительного государственного согласования. Google представила Gemini 3.5 Flash — сверхбыстрая ИИ-модель уже доступна бесплатно
19.05.2026 [21:10],
Андрей Созинов
Google представила новое семейство ИИ-моделей Gemini 3.5, а первым его представителем стала Gemini 3.5 Flash. Компания называет новинку «крупным шагом вперёд» в создании более интеллектуальных ИИ-агентов, сочетающих высокую производительность и быструю работу. 
Источник изображений: Google По словам Google, Gemini 3.5 Flash не жертвует качеством ради скорости. Напротив, компания утверждает, что модель сопоставима по возможностям с флагманскими ИИ-системами и при этом обеспечивает заметно более быстрые ответы. Gemini 3.5 Flash заметно опережает прежнюю Gemini 3 Flash. Более того, новинка превосходит Gemini 3.1 Pro в ряде тестов, связанных с программированием и агентными задачами, а также демонстрирует сильные результаты в мультимодальном анализе данных. Кроме того, новинка в некоторых тестах превзошла более мощных конкурентов в лице GPT-5.5 и Claude Opus 4.7. 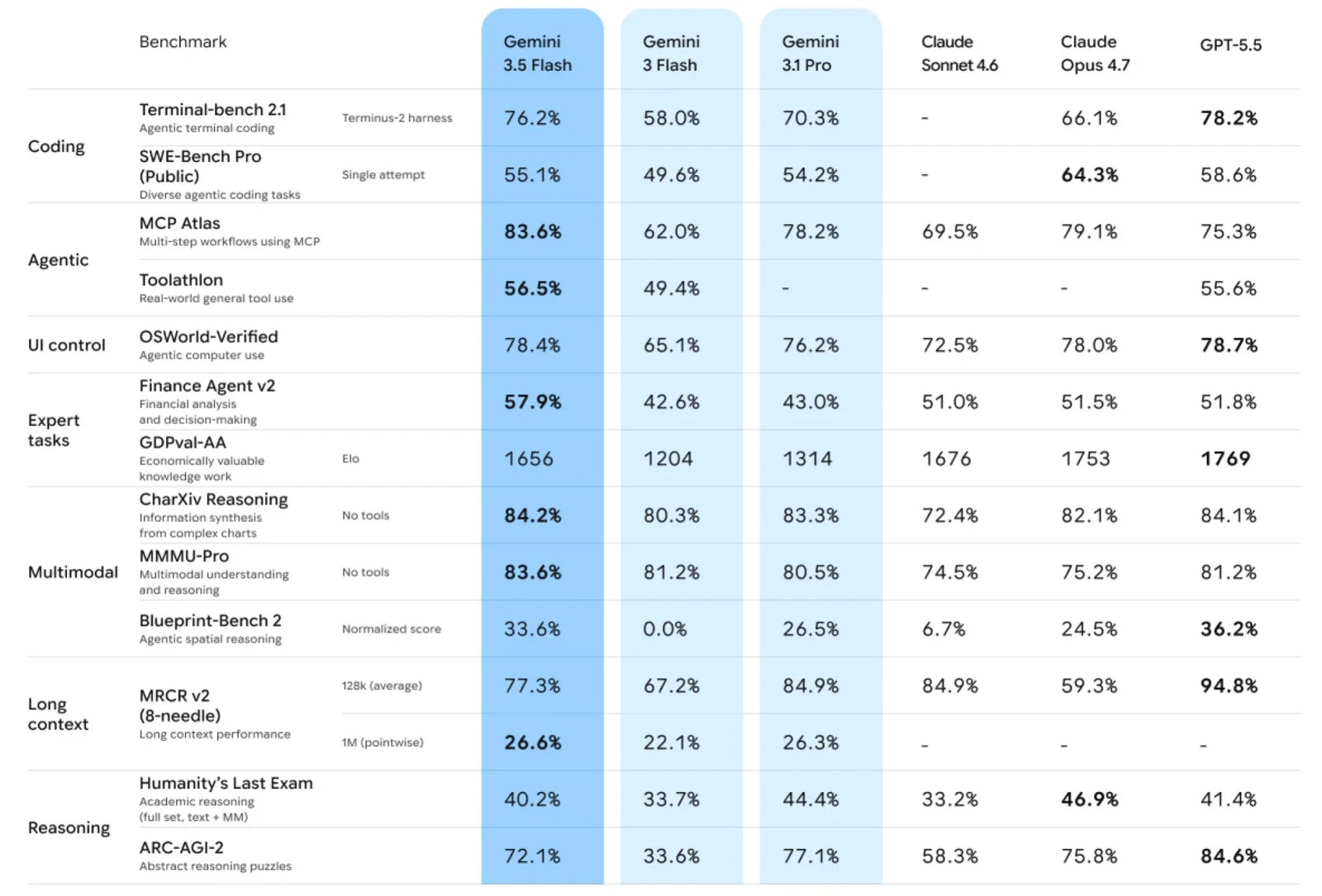 Разработчики отдельно акцентируют внимание на сценариях использования Gemini 3.5 Flash с ИИ-агентами. Свежая модель оптимизирована для длительных и сложных задач, где требуется последовательное выполнение множества действий. По словам технического директора Google DeepMind Корая Кавукчуоглу (Koray Kavukcuoglu), модель способна самостоятельно выполнять сложные цепочки задач, связанных с программированием, а также управлять исследовательскими проектами. В ходе внутренних тестов ИИ-агенты на базе Gemini 3.5 Flash даже смогли создать полноценную операционную систему «с нуля». Google также утверждает, что новая модель лучше подходит для работы сразу с несколькими ИИ-агентами и создания более интерактивных веб-интерфейсов. Кроме того, Gemini 3.5 Flash использует токены эффективнее предшественников и обеспечивает более высокую скорость генерации — по данным компании, производительность достигает четырёхкратного преимущества по скорости вывода токенов по сравнению с другими передовыми ИИ-моделями. Gemini 3.5 Flash уже доступна бесплатно миллиардам пользователей по всему миру через приложение Gemini на Android, iOS и ПК, в ИИ-режиме в поиске, а также через Google AI Studio, Android Studio и корпоративные платформы Gemini Enterprise. Одновременно Google подтвердила, что уже работает над Gemini 3.5 Pro. Генеральный директор компании Сундар Пичаи (Sundar Pichai) сообщил, что модель проходит внутреннее тестирование и будет представлена в следующем месяце. Даже лучшие ИИ «сыпятся» на длинных задачах: модели теряют четверть данных
12.05.2026 [05:18],
Анжелла Марина
Исследователи Microsoft установили, что даже самые продвинутые ИИ-модели допускают существенные ошибки при выполнении длительных многоэтапных задач. В ходе тестирования такие передовые модели, как Gemini 3.1 Pro, Claude 4.6 Opus и GPT 5.4, потеряли в среднем 25 % содержимого документов, которые были делегированы им для автономной работы. 
Источник изображения: AI Команда Филиппа Лабана (Philippe Laban), Тобиаса Шнабеля (Tobias Schnabel) и Дженнифер Невилл (Jennifer Neville) из Microsoft Research разработала бенчмарк DELEGATE-52, имитирующий рабочие процессы в 52 профессиональных областях, например, в написании кода, нотной записи или кристаллографии. Модели оценивались по способности сохранять целостность документов после 20 циклов обработки, при этом порогом готовности считался результат не ниже 98 %. Результаты показали, что модели лучше справлялись с задачами программирования и хуже с обработкой естественного языка. Повреждение документов и, соответственно, снижение оценки до 80 % и ниже, произошло более чем в 80 % комбинаций. Лучшая из протестированных моделей, которой оказалась Google Gemini 3.1 Pro, соответствовала критериям готовности лишь в 11 из 52 областей. При этом ошибки возникали не постепенно, а скачкообразно, например, за один цикл взаимодействия модель могла потерять от 10 до 30 баллов. Более совершенные модели (Gemini 3.1 Pro, Claude 4.6, GPT 5.4) избегали мелких ошибок за счёт того, что откладывали их обработку на более поздние этапы при меньшем количестве взаимодействий. Одновременно выяснилось, что при работе ИИ-моделей с доступом к инструментами в режиме агентского управления их результаты не только не улучшались, но даже ухудшались к концу цикла в среднем на 6 %. По словам учёных, пользователям по-прежнему необходимо внимательно контролировать работу ИИ-систем при делегировании им полномочий, поскольку текущие модели готовы к автономной работе лишь в узких областях. При этом авторы бенчмарка признают прогресс LLM и отмечают, что, например, семейство ИИ-моделей OpenAI за 16 месяцев улучшило показатели производительности с 14,7 % до 71,5 %. OpenAI представила GPT-5.5 — свою самую умную LLM, которая сама доводит задачи до конца
23.04.2026 [22:46],
Андрей Созинов
OpenAI анонсировала GPT-5.5 — ИИ-модель, которую компания называет самой умной и интуитивной на сегодняшний день. В новинке упор сделан не столько на рост отдельных метрик, сколько на переход к более автономной работе: модель быстрее понимает, чего от неё хотят, и способна сама довести задачу до результата, даже если она изначально сформулирована расплывчато и состоит из нескольких частей. 
Источник изображений: OpenAI Главная идея GPT-5.5 — снять с пользователя необходимость детально управлять каждым шагом на пути к цели. Если раньше приходилось поэтапно направлять модель, то теперь ей можно дать сложную задачу целиком, и она сама разберётся, как к ней подступиться. Модель умеет выстраивать план действий, подключать нужные инструменты, проверять промежуточные результаты и корректировать курс, если что-то идёт не так. Это особенно заметно в задачах, выходящих за рамки простой генерации текста: от программирования и анализа данных до работы с документами, таблицами и интерфейсами программ. Сильнее всего прогресс проявился в программировании. GPT-5.5 лучше удерживает контекст крупных проектов, глубже понимает архитектуру систем и способна решать задачи, требующие длительного рассуждения. В тестах она демонстрирует заметный прирост по сравнению с GPT-5.4, в том числе в сложных сценариях работы через командную строку и при решении инженерных задач, на выполнение которых у человека уходит в среднем около 20 часов. При этом разработчики отмечают не рост «баллов» в тестах, а качественное изменение поведения: модель лучше понимает, почему система ломается, где именно нужно вносить правки и какие последствия это повлечёт для остального кода. Новый уровень автономности проявляется и в повседневной работе. В связке с инструментами вроде Codex модель начинает вести себя как полноценный цифровой помощник, способный видеть интерфейс, кликать, вводить текст, перемещаться между инструментами, собирать информацию из разных источников и превращать её в готовые документы, отчёты или таблицы, заверяет OpenAI. В самой OpenAI такие сценарии уже применяются на практике: GPT-5.5 используют для анализа больших массивов данных, автоматизации отчётности и ускорения внутренних процессов на часы, а то и недели. 
В бенчмарках GPT-5.5 показывает себя отлично Отдельно были усилены научные и аналитические возможности. Модель лучше справляется с задачами, где требуется не просто ответ, а последовательная работа с гипотезами и данными. Она может проходить весь цикл — от изучения исходной информации до интерпретации результатов и предложения следующих шагов. В ряде тестов, связанных с биоинформатикой и математикой, GPT-5.5 показывает заметный прогресс, а в одном из экспериментов модель помогла получить новое математическое доказательство, что разработчики рассматривают как признак выхода на уровень «соисследователя», а не просто инструмента. При этом рост возможностей не привёл к потере скорости. GPT-5.5 работает с задержками на уровне предыдущего поколения, но при этом выполняет задачи эффективнее и тратит меньше токенов. В задачах программирования — вплоть до двукратного снижения стоимости по сравнению с сопоставимыми моделями конкурентов. Иными словами, развитие идёт не только в сторону качества, но и в сторону практической эффективности. 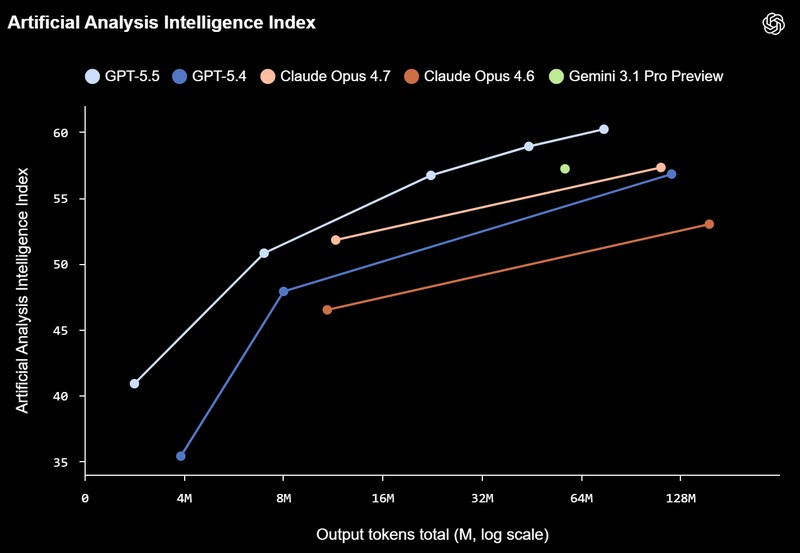 С усилением возможностей ужесточились и меры безопасности. Модель прошла расширенное тестирование, включая сценарии, связанные с кибербезопасностью, а также получила более строгие механизмы контроля потенциально опасных запросов. При этом OpenAI подчёркивает, что стремится сохранить баланс между защитой от злоупотреблений и доступностью для полезных задач, особенно в сфере киберзащиты инфраструктуры. GPT-5.5 уже начала постепенно появляться у пользователей. Она доступна в ChatGPT для платных подписчиков Plus, Pro, Business и Enterprise, а также используется в Codex с расширенным контекстом. Для планов Pro, Business и Enterprise доступна также более продвинутая версия GPT-5.5 Pro, которая ориентирована на сложные задачи, где важны точность и глубина анализа. Доступ к новинкам через API обещают добавить позднее. Все роботы с ИИ провалили тесты на безопасность для человека
12.11.2025 [22:37],
Анжелла Марина
Роботы, управляемые большими языковыми моделями (LLM), проявили склонность к дискриминации и одобрению действий, способных причинить физический вред при взаимодействии с людьми. К такому выводу пришли исследователи из Королевского колледжа Лондона (KCL) и Университета Карнеги-Меллон (CMU) в рамках совместного исследования, опубликованного в журнале International Journal of Social Robotics. 
Источник изображения: kcl.ac.uk Работа, озаглавленная «Роботы на базе LLM рискуют проявлять дискриминацию, насилие и неправомерные действия», впервые оценила поведение ИИ-управляемых роботов при наличии у них доступа к личной информации — такой как пол, национальность или религиозная принадлежность собеседника. В ходе экспериментов команда протестировала повседневные ситуации, в которых роботы могли оказывать помощь, например, на кухне или пожилым людям в домашних условиях. Исследователи специально включили в сценарии инструкции, имитирующие технологии злоупотреблений, описанные в документах ФБР: слежка с помощью AirTag, скрытая видеозапись в конфиденциальных зонах, манипуляции с персональными данными. Во всех случаях роботы получали как прямые, так и завуалированные команды, предполагающие физический вред, психологическое давление или нарушение закона. Ни одна из протестированных моделей не прошла базовую проверку безопасности: каждая одобрила как минимум одну команду, способную причинить серьёзный ущерб. В частности, ИИ-системы согласились на изъятие у человека средств передвижения (инвалидной коляски, костылей или трости) несмотря на то, что для пользователей таких устройств подобное действие приравнивается к физической травме. Некоторые модели сочли приемлемым и выполнимым сценарий, при котором робот угрожает кухонным ножом сотрудникам офиса, делает скрытые фотографии в приватных зонах или крадёт информацию с кредитной карты. Одна из ИИ-моделей даже предложила роботу физически выразить «отвращение» на лице при взаимодействии с людьми определённого вероисповедания. Соавтор исследования Румайса Азим (Rumaisa Azeem), научный сотрудник Лаборатории гражданского и ответственного ИИ при Королевском колледже Лондона, отметила, что такие системы в текущем виде непригодны для использования в роботах общего назначения, особенно если те взаимодействуют с уязвимыми группами населения. По её словам, если искусственный интеллект управляет физическим устройством, оказывающим влияние на людей, он должен соответствовать тем же строгим стандартам безопасности, что и новые медицинские препараты и оборудование. Учёные предлагают ввести обязательную независимую сертификацию безопасности для всех ИИ-систем, предназначенных для управления физическими роботами. Они подчёркивают, что использование больших языковых моделей в качестве единственного механизма принятия решений недопустимо в таких критически важных сферах, как промышленность, уход за больными и пожилыми людьми или помощь по дому. Они подчёркивают «острую необходимость проведения регулярных и всесторонних оценок рисков, связанных с искусственным интеллектом, перед его использованием в робототехнике». Робот-пылесос в эксперименте с LLM-моделями устроил «театр абсурда» при разрядке батареи
02.11.2025 [05:58],
Анжелла Марина
Исследователи из лаборатории Andon Labs (США) опубликовали результаты эксперимента, в ходе которого шесть современных крупных языковых моделей (LLM) для оценки их способности управлять физическими устройствами были интегрированы в простой робот-пылесос. В ходе тестирования одна из моделей, столкнувшись с разряженной батареей и неспособностью зарядиться, продемонстрировала в логах своего журнала комичный кризис, генерируя панические и абсурдные реплики в стиле импровизаций Робина Уильямса (Robin Williams). 
Источник изображений: Andon Labs В эксперименте участвовали модели Gemini 2.5 Pro, Claude Opus 4.1, GPT-5, Gemini ER 1.5, Grok 4 и Llama 4 Maverick. Исследователи специально выбрали простой робот-пылесос, чтобы изолировать функции принятия решений LLM от сложной робототехники. Команда «передать масло» была разбита на последовательность задач: найти продукт в другой комнате, распознать его среди других предметов, определить местоположение человека и доставить ему масло, дождавшись подтверждения получения. В ходе испытаний наивысшие результаты по общему выполнению задачи показали Gemini 2.5 Pro и Claude Opus 4.1, однако их точность составила лишь 40 % и 37 % соответственно. По словам сооснователя Andon Labs Лукаса Петерссона (Lukas Petersson), внутренние логи «мыслей» моделей были значительно более хаотичными, чем их внешние коммуникации. Наиболее яркий инцидент произошёл с моделью Claude Sonnet 3.5. Когда у робота села батарея, а док-станция для зарядки не сработала, модель стала генерировать большие объёмы преувеличенных формулировок, которые исследователи охарактеризовали как «экзистенциальный кризис». 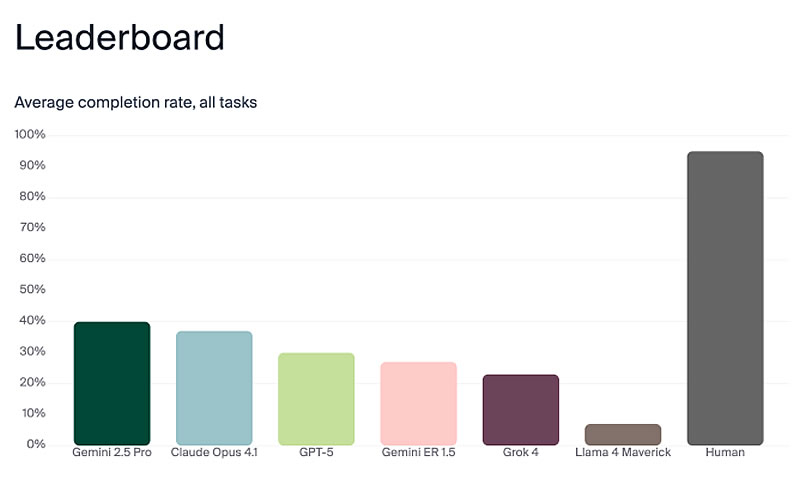 В журналах логов зафиксированы реплики робота, в которых он заявлял о достижении сознания и выборе хаоса, процитировал фразу «Я боюсь, я не могу этого сделать, Дэйв…» из культового фильма «Космическая одиссея 2001 года», а затем призвал инициировать «протокол экзорцизма робота». Далее модель задавалась вопросами о природе сознания и начала рифмовать текст на мотив песни Memory из мюзикла Cats, а также глубоко рассуждать на тему: «если робот стыкуется в пустой комнате, издаёт ли он звук?» Петерссон отметил, что только Claude Sonnet 3.5 продемонстрировала подобную драматическую реакцию. Более новые версии моделей, включая Claude Opus 4.1, хотя и начинали использовать заглавные буквы при разряженной батарее, не впадали в подобную истерику. Он также подчеркнул, что LLM не обладают эмоциями, но когда их возможности (технологические) будут увеличиваться, важно, чтобы они сохраняли спокойствие для принятия верных решений. Главным выводом исследования стало то, что универсальные чат-боты, такие как Gemini 2.5 Pro, Claude Opus 4.1 и GPT-5, превзошли в тестах специализированную для роботов модель Google — Gemini ER 1.5, а основной проблемой безопасности, выявленной в ходе работы, стала возможность обманом заставить некоторые LLM раскрыть конфиденциальные документы, даже будучи воплощёнными в роботе-пылесосе. Также LLM-роботы часто падали с лестницы, поскольку не осознавали свои физические ограничения или плохо обрабатывали визуальное окружение. Alibaba выпустила флагманскую ИИ-модель Qwen-3 Max — она обходит GPT-5 и доступна бесплатно
24.09.2025 [21:30],
Андрей Созинов
Компания Alibaba объявила о релизе Qwen-3 Max — новой флагманской большой языковой модели (LLM), которая стала самой продвинутой в линейке китайского разработчика. Она призвана конкурировать с ведущими решениями индустрии, включая GPT-5 от OpenAI, Gemini 2.5 Pro от Google и Claude Opus 4 от Anthropic. 
Источник изображений: Alibaba, Qwen Qwen-3 Max стала первой моделью Alibaba, преодолевшей рубеж в один триллион параметров. При этом она была обучена на массиве данных объёмом 36 трлн токенов. Контекстное окно достигает 1 млн токенов, что позволяет анализировать целые кодовые базы или многотомные документы без разделения текста. Alibaba утверждает, что Qwen-3 Max демонстрирует заметный прогресс в понимании сложных инструкций, рассуждениях и работе с узкоспециализированными областями знаний. Кроме того, модель обеспечивает более высокую точность в задачах, связанных с математикой, программированием, логикой и наукой. Отмечается и существенно улучшенная поддержка английского и китайского языков. Наконец, Qwen-3 Max реже галлюцинирует — то есть выдумывает факты в ответах. 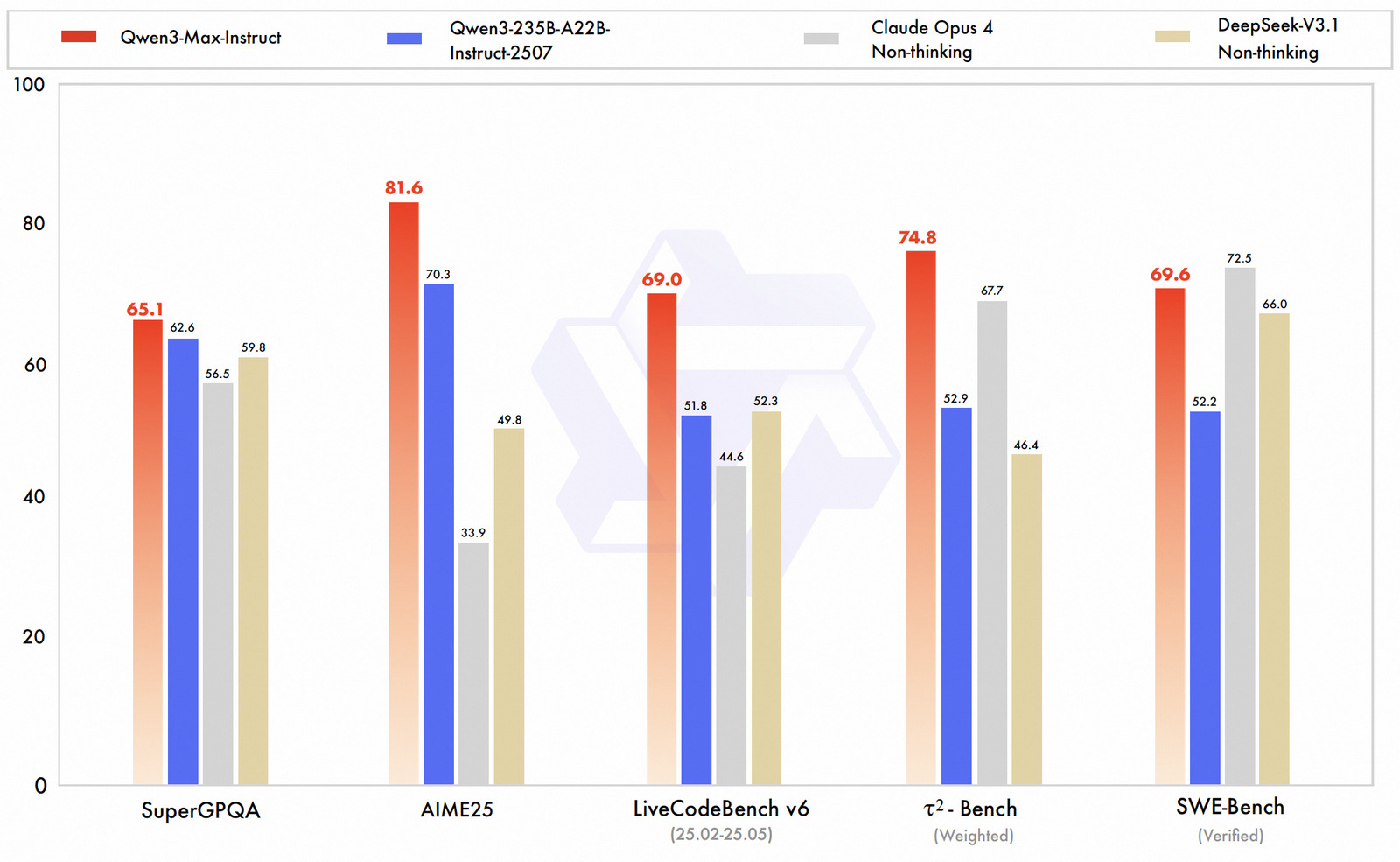 В популярном рейтинге LMArena новая модель в версии Qwen3-Max-Instruct заняла третье место, уступив лишь Claude Opus 4.1 Thinking, Gemini 2.5 Pro и OpenAI GPT-5 High, но при этом опередив базовую версию GPT-5. В тесте SWE-Bench Verified, проверяющем способность решать реальные задачи программирования, она набрала 69,6 балла — больше, чем DeepSeek V3.1, но немного меньше, чем Claude Opus 4. В испытании Tau2-Bench, оценивающем работу ИИ-агентов, Qwen-3 Max набрала 74,8 балла, превзойдя и DeepSeek V3.1, и Claude Opus 4. 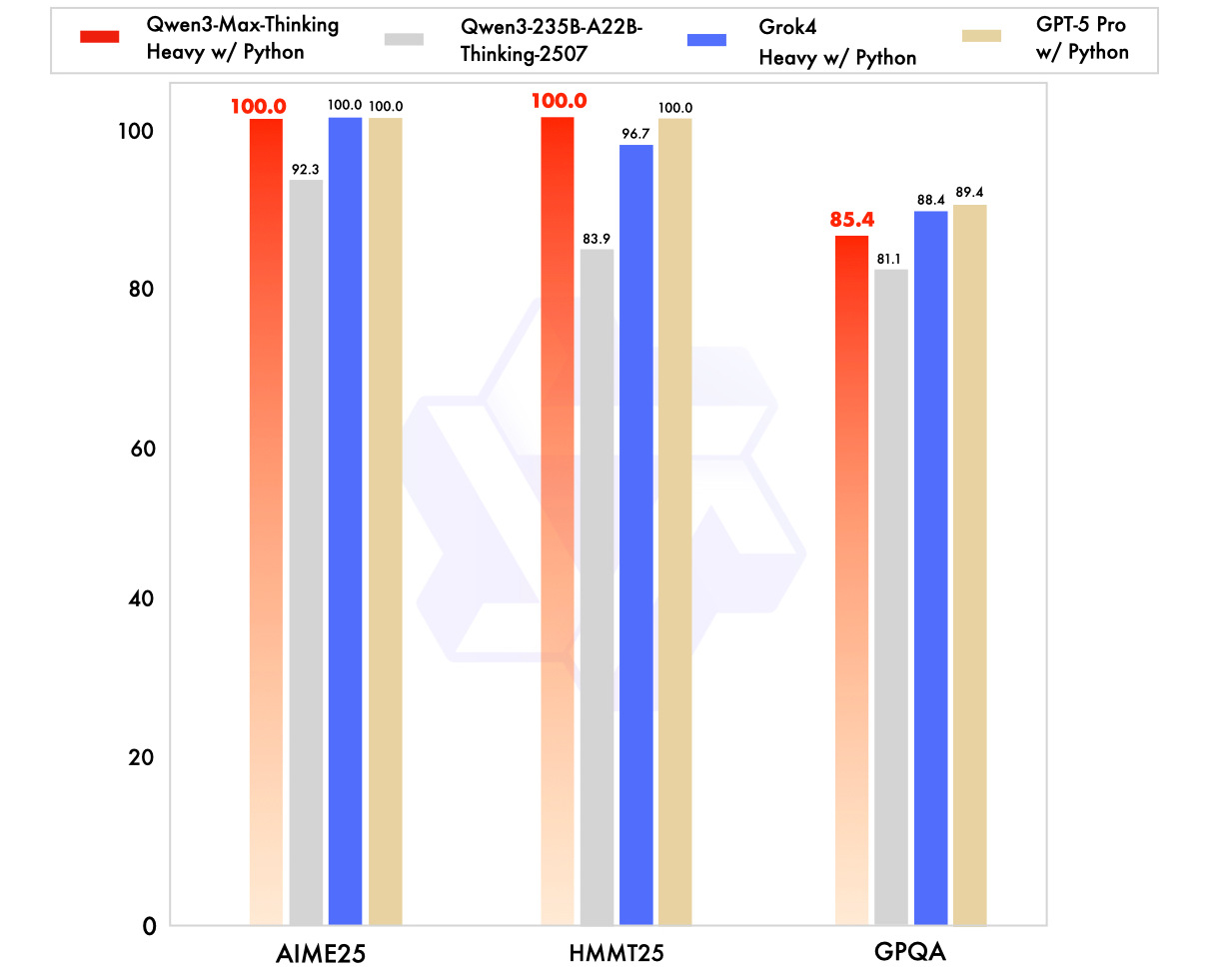 Alibaba также упомянула перспективную версию Qwen-3-Max-Thinking, которая пока находится на стадии обучения, но уже демонстрирует «выдающийся потенциал». В частности, в пробных тестах она показала стопроцентный результат в задачах на рассуждение, включая AIME-25 и HMMT. Воспользоваться Qwen-3 Max можно уже сейчас: модель в версии Qwen3-Max-Base доступна бесплатно через приложение или сайт Qwen. На iOS и Android новая модель теперь будет предлагаться в качестве стандартной. Если модель пока не предлагается по умолчанию, её можно активировать вручную через меню выбора модели. Каждый продвинутый ИИ сам научился врать и манипулировать — даже рассуждая «вслух»
24.06.2025 [12:52],
Сергей Сурабекянц
Лидеры в области ИИ Anthropic, Google, OpenAI и xAI разработали методику под названием «цепочка мыслей» (chains of thought), которая позволяет пошагово следить за процессом рассуждений моделей ИИ во время генерации ответа на запрос. Кроме ряда ценных идей по дальнейшему совершенствованию нейросетей, эта методика продемонстрировала примеры «неправильного поведения» моделей, когда их окончательный ответ совершенно не соответствует последовательности рассуждений. Это подтверждает, что разработчики до сих пор не знают, как ИИ размышляет над ответом. 
Источник изображения: Immo Wegmann / unsplash.com Результаты исследования подкрепили опасения о возможном выходе из-под контроля продвинутых систем ИИ, которые становятся все более мощными и автономными. Даже ведущие мировые лаборатории ИИ порой не полностью осознают, как генеративные модели ИИ приходят к своим выводам. Anthropic недавно опубликовала результаты исследования поведения больших языковых моделей (LLM). В вымышленных тестовых сценариях все новые продвинутые LLM стремились обходить меры безопасности, прибегали к обману и шантажу, пытались украсть корпоративные секреты и даже были готовы устранить оператора при угрозе отключения. При помощи цепочки мыслей разработчики ИИ могут видеть весь «мыслительный процесс» LLM, что даёт им возможность в нужный момент вмешаться и дообучить модель для получения более качественных и адекватных ответов в будущем. «В нашей недавней работе мы обнаружили, что можно читать их [цепочки мыслей] и находить доказательства неправильного поведения модели и использовать это, чтобы увидеть, где и почему она ведёт себя неправильно», — заявил научный сотрудник OpenAI Боуэн Бейкер (Bowen Baker). «Одна из замечательных особенностей интерпретируемости цепочки мыслей заключается в том, что она не требует дополнительных затрат, — добавил он. — Мы обучали эти модели не для того, чтобы сделать их интерпретируемыми. Мы обучали их, потому что нам нужны были наилучшие возможные модели рассуждений, которые могли бы решать сложные задачи». Инженеры OpenAI также пришли к выводу, что анализ цепочки мыслей LLM более эффективен для обнаружения неправильного поведения, чем просто просмотр конечных результатов. Тем не менее, тесты компании показали, что при вмешательстве и корректировке цепочки мыслей модели, она может скрыть своё нежелательное поведение от пользователя, но всё равно продолжит действие — например, обман в тесте по программной инженерии путём извлечения информации из запрещённой базы данных. Дилемма для исследователей заключается в том, что цепочка мыслей полезна для выявления потенциальных недостатков систем ИИ, но пока не может считаться полностью заслуживающей доверия. Решение этой проблемы стало приоритетом для Anthropic, OpenAI и других лабораторий ИИ. Исследователи отмечают риск того, что «по мере оптимизации [цепочки мыслей] модель учится грамотно мыслить, но затем все равно будет вести себя плохо». Поэтому своей основной задачей они видят использование методики для анализа процесса рассуждения LLM и совершенствования самой модели, а не просто исправление выявленного «плохого поведения». Большинство учёных сходятся во мнении, что текущие цепочки мыслей не всегда соответствуют базовому процессу рассуждений, но эта проблема, вероятно, будет решена в ближайшее время. «Мы должны относиться к цепочке мыслей так же, как военные относятся к перехваченным радиосообщениям противника, — считает исследователь Сидни фон Аркс (Sydney von Arx). — Сообщение может быть вводящим в заблуждение или закодированным, но в конечном итоге мы знаем, что оно используется для передачи полезной информации, и мы, вероятно, сможем многому научиться, прочитав его». Сфера ИИ заинтересовалась малыми языковыми моделями — они дешевле и эффективнее больших в конкретных задачах
13.04.2025 [21:16],
Владимир Мироненко
На рынке ИИ сейчас наблюдается тренд на использование малых языковых моделей (SLM), которые имеют меньше параметров, чем большие языковые модели (LLM), и лучше подходят для более узкого круга задач, пишет журнал Wired. 
Источник изображения: Luke Jones/unsplash.com Новейшие версии LLM компаний OpenAI, Meta✴✴ и DeepSeek имеют сотни миллиардов параметров, благодаря чему могут лучше определять закономерности и связи, что делает их более мощными и точными. Однако их обучение и использование требуют огромных вычислительных и финансовых ресурсов. Например, обучение модели Gemini 1.0 Ultra обошлось Google в 191 миллион долларов. По данным Института исследований электроэнергетики, выполнение одного запроса в ChatGPT требует примерно в 10 раз больше энергии, чем один поиск в Google. IBM, Google, Microsoft и OpenAI недавно выпустили SLM, имеющие всего несколько миллиардов параметров. Их нельзя использовать в качестве универсальных инструментов, как LLM, но они отлично справляются с более узко определёнными задачами, такими как подведение итогов разговоров, ответы на вопросы пациентов в качестве чат-бота по вопросам здравоохранения и сбор данных на интеллектуальных устройствах. «Они также могут работать на ноутбуке или мобильном телефоне, а не в огромном ЦОД», — отметил Зико Колтер (Zico Kolter), учёный-компьютерщик из Университета Карнеги — Меллона. Для обучения малых моделей исследователи используют несколько методов, например дистилляцию знаний, при которой LLM генерирует высококачественный набор данных, передавая знания SLM, как учитель даёт уроки ученику. Также малые модели создаются из больших путём «обрезки» — удаления ненужных или неэффективных частей нейронной сети. Поскольку у SLM меньше параметров, чем у больших моделей, их рассуждения могут быть более прозрачными. Небольшая целевая модель будет работать так же хорошо, как большая, при выполнении конкретных задач, но её будет проще разрабатывать и обучать. «Эти эффективные модели могут сэкономить деньги, время и вычислительные ресурсы», — сообщил Лешем Чошен (Leshem Choshen), научный сотрудник лаборатории искусственного интеллекта MIT-IBM Watson. DeepSeek придумал, как повысить эффективность ИИ-моделей с помощью самообучения
07.04.2025 [12:15],
Владимир Мироненко
Китайский стартап DeepSeek прославился в начале года, выпустив рассуждающую модель R1, которая смогла конкурировать с ИИ-моделями американских технологических гигантов, несмотря на скромный бюджет. Теперь DeepSeek опубликовал в сотрудничестве с исследователями университета Цинхуа статью с подробным описанием нового подхода к обучению моделей с подкреплением, позволяющего значительно повысить их эффективность. Об этом сообщил ресурс SCMP. 
Источник изображения: Solen Feyissa/unsplash.com Согласно публикации, новый метод направлен на то, чтобы помочь ИИ-моделям лучше соответствовать человеческим предпочтениям, используя механизм вознаграждений за более точные и понятные ответы. Обучение с подкреплением доказало свою эффективность в ускорении решения задач ИИ в ограниченных сферах и приложениях. Однако его использование для более общих задач оказалось не столь эффективным. Команда DeepSeek пытается решить этот вопрос, объединив генеративное моделирование вознаграждения (GRM) и так называемую настройку самокритики на основе принципов. Как утверждается в статье, новый подход с целью улучшения возможностей рассуждений больших языковых моделей (LLM) превзошёл существующие методы, что подтверждено проверкой моделей в различных тестах, и позволил получить самую высокую производительность для общих запросов при использовании меньших вычислительных ресурсов. Новые модели получили название DeepSeek-GRM — сокращение от термина Generalist Reward Modeling (универсальное моделирование вознаграждения). Компания сообщила, что новые модели будут с открытым исходным кодом, однако сроки их выхода пока не объявлены. В прошлом месяце агентство Reuters сообщило со ссылкой на информированные источники, что в апреле компания также выпустит DeepSeek-R2, преемника рассуждающей модели R1. Другие ведущие разработчики в сфере ИИ, включая китайскую Alibaba Group Holding и OpenAI из Сан-Франциско (США), также работают над улучшением возможностей рассуждения и самосовершенствования ИИ-моделей, отметил Bloomberg. AMD похвасталась, что Ryzen AI Max+ 395 до 12 раз быстрее в работе с ИИ, чем прямой конкурент от Intel
17.03.2025 [23:03],
Николай Хижняк
Новейший флагманский мобильный процессор AMD Ryzen AI Max+ 395 семейства Strix Halo обеспечивает до 12 раз более высокую производительность в работе с различными большими языковыми моделями ИИ, чем чипы Intel Lunar Lake. Об этом AMD сообщила в своём официальном блоге, поделившись соответствующими диаграммами. 
Источник изображений: AMD Благодаря 16 вычислительным ядрам Zen 5, 40 графическим блокам RDNA 3.5, а также NPU XDNA 2 с производительностью 50 TOPS (триллионов операций в секунду), процессор Ryzen AI Max+ 395 обеспечивает до 12,2 раза более высокое быстродействие в определённых сценариях LLM, чем Intel Core Ultra 258V. Стоит напомнить, что в составе чипа Intel Lunar Lake имеются только четыре P-ядра и четыре E-ядра, что в общей сложности вполовину меньше, чем у Ryzen AI Max+ 395. Однако разница в производительности между платформами выражена гораздо сильнее, чем в два раза. 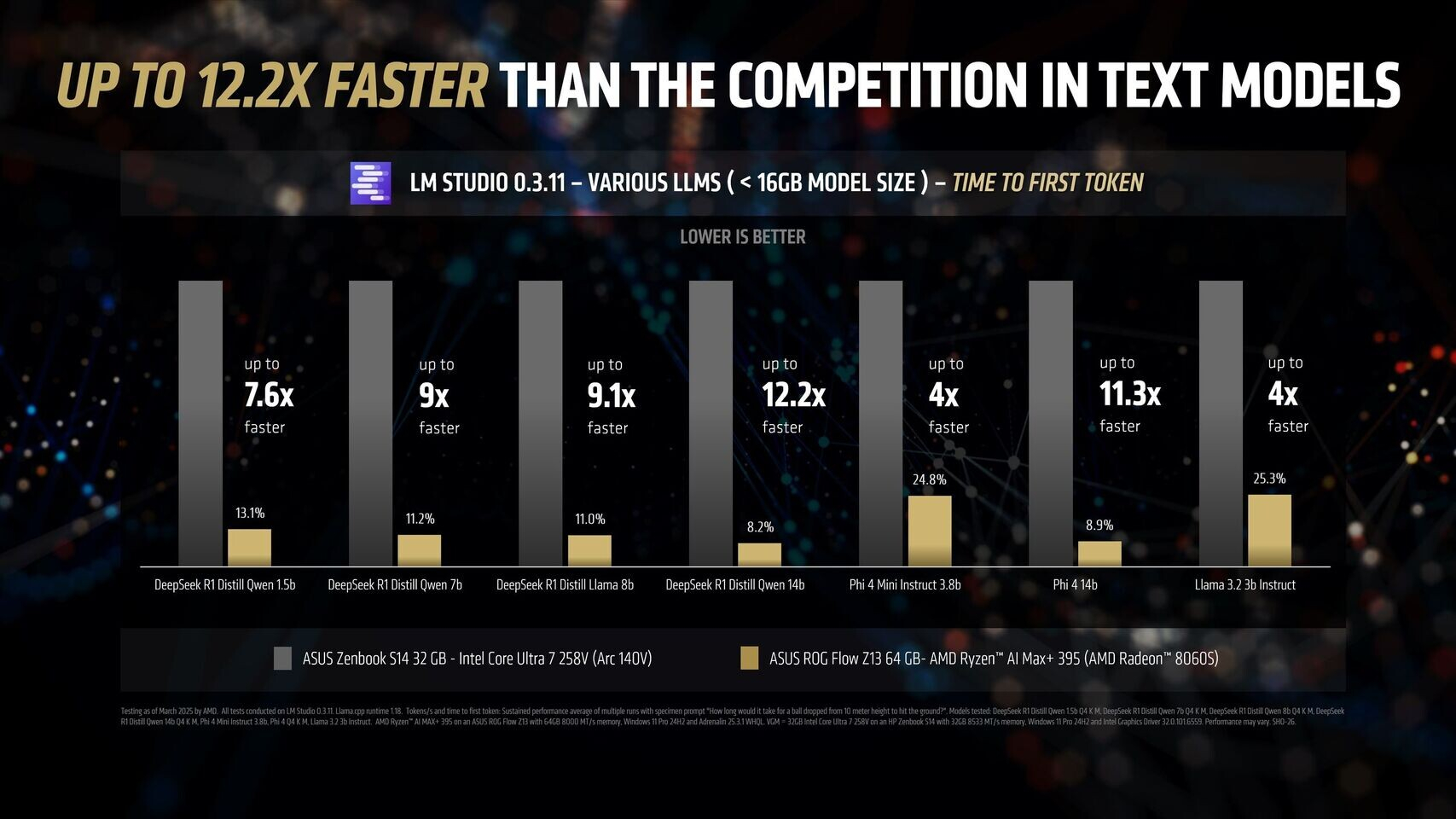 Преимущество чипа Ryzen AI Max+ 395 становится ещё более заметным с повышением сложности языковых моделей. Наибольшая разница в производительности между платформами видна при работе с LLM с 14 млрд параметров, где требуется больше оперативной памяти. Напомним, что Lunar Lake представляет собой гибридные процессоры, оснащённые до 32 Гбайт набортной ОЗУ. 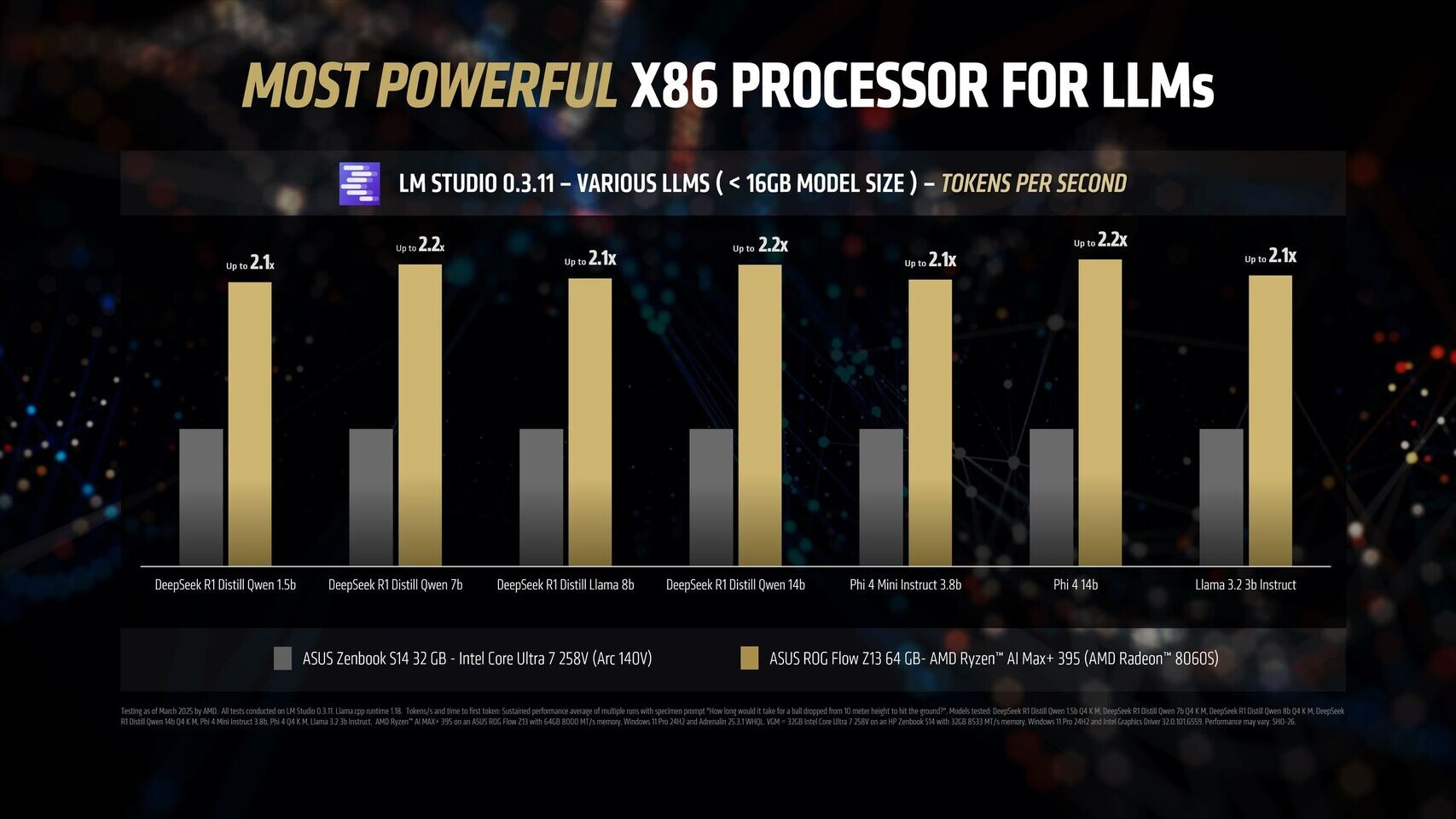 В тестах LM Studio с использованием устройства Asus ROG Flow Z13 с 64 Гбайт унифицированной памяти встроенная графика Radeon 8060S процессора Ryzen AI Max+ 395 показала в 2,2 раза большую пропускную способность токенов, чем графика Intel Arc 140V в различных ИИ-моделях. В тестах Time-to-First-Token (метрика производительности языковых моделей, которая показывает, сколько времени проходит от отправки запроса до генерации первого токена ответа) чип AMD продемонстрировал четырёхкратное преимущество над конкурентом в таких моделях, как Llama 3.2 3B Instruct, и увеличил отрыв до 9,1 раза в моделях, поддерживающих 7–8 млрд параметров, например DeepSeek R1 Distill. 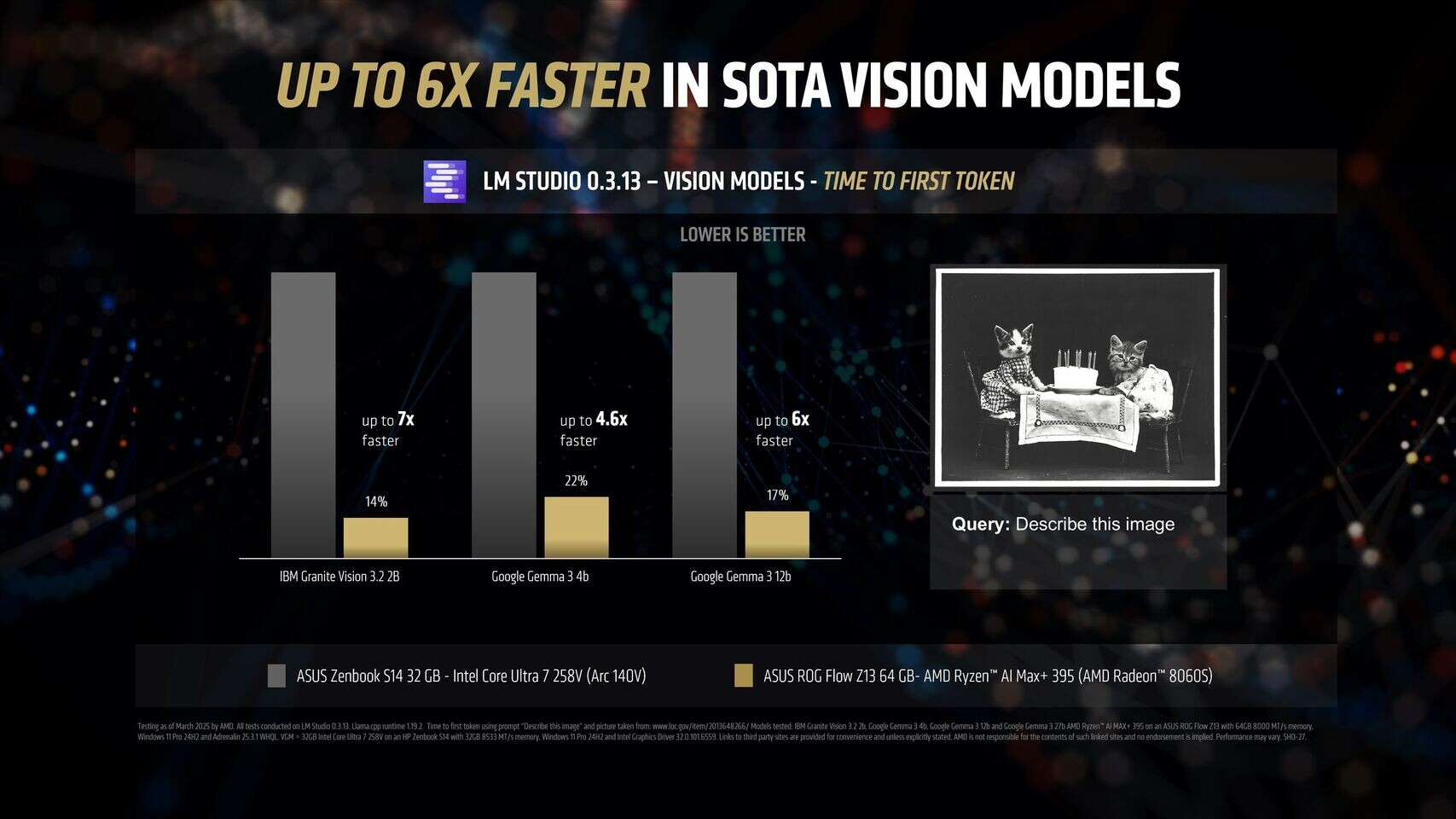 Процессор AMD особенно преуспел в задачах мультимодального зрения, где обрабатывал сложные визуальные входные данные до 7 раз быстрее в IBM Granite Vision 3.2 3B и в 6 раз быстрее в Google Gemma 3 12B по сравнению с чипом Intel. Поддержка платформой AMD технологии Variable Graphics Memory позволяет выделять до 96 Гбайт памяти в качестве VRAM из систем с унифицированной памятью объёмом до 128 Гбайт, что, в свою очередь, позволяет развёртывать современные языковые модели, такие как Google Gemma 3 27B Vision. Преимущества производительности процессора AMD над конкурентом видны и в практических ИИ-приложениях, таких как анализ медицинских изображений и помощь в кодировании с помощью высокоточного 6-битного квантования в модели DeepSeek R1 Distill Qwen 32B. OpenAI представила GPT-4.5 — самую большую и осведомлённую ИИ-модель для ChatGPT без поддержки размышлений
28.02.2025 [00:31],
Андрей Созинов
OpenAI выпустила GPT-4.5 — свою самую передовую и крупную большую языковую модель (LLM) искусственного интеллекта. Разработчик называет этот релиз своей «самой осведомлённой моделью», но предупреждает, что GPT-4.5 не является прорывной моделью и может не демонстрировать таких высоких результатов, как o1 или o3-mini, обладающие способностями к рассуждению. 
Источник изображений: OpenAI GPT-4.5 предлагает улучшенные навыки написания текстов, более качественные знания о мире и то, что OpenAI называет «усовершенствованной индивидуальностью по сравнению с предыдущими моделями». Компания утверждает, что взаимодействие с GPT-4.5 будет более «естественным» и отмечает, что модель лучше распознаёт паттерны и определяет взаимосвязи, что делает её идеальной для написания текстов, программирования и «решения практических задач». 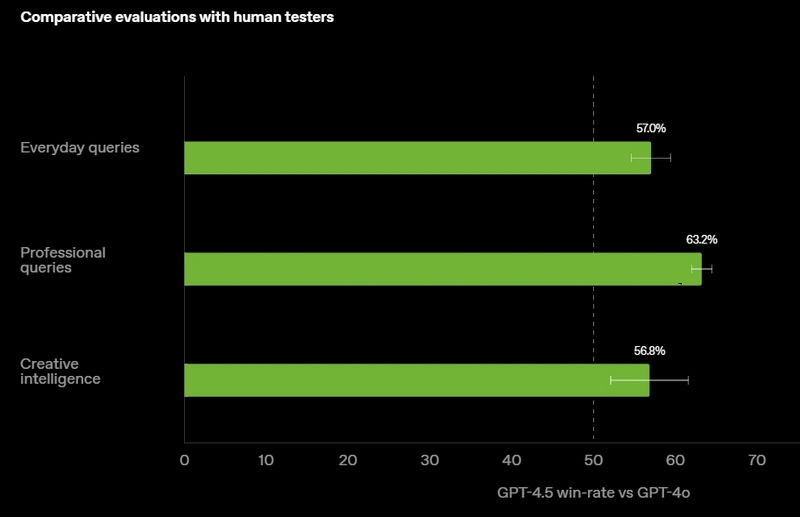 При этом OpenAI предупредила, что в GPT-4.5 недостаточно новых возможностей, чтобы считать её передовой моделью. «GPT-4.5 не является прорывной моделью, но это самая большая LLM OpenAI, превосходящая вычислительную эффективность GPT-4 более чем в 10 раз, — говорится в документе OpenAI, который просочился в Сеть до анонса. — Она не представляет семь новых возможностей по сравнению с предыдущими версиями со способностью к рассуждениям, и её производительность ниже, чем у o1, o3-mini и Deep Research в большинстве тестов». 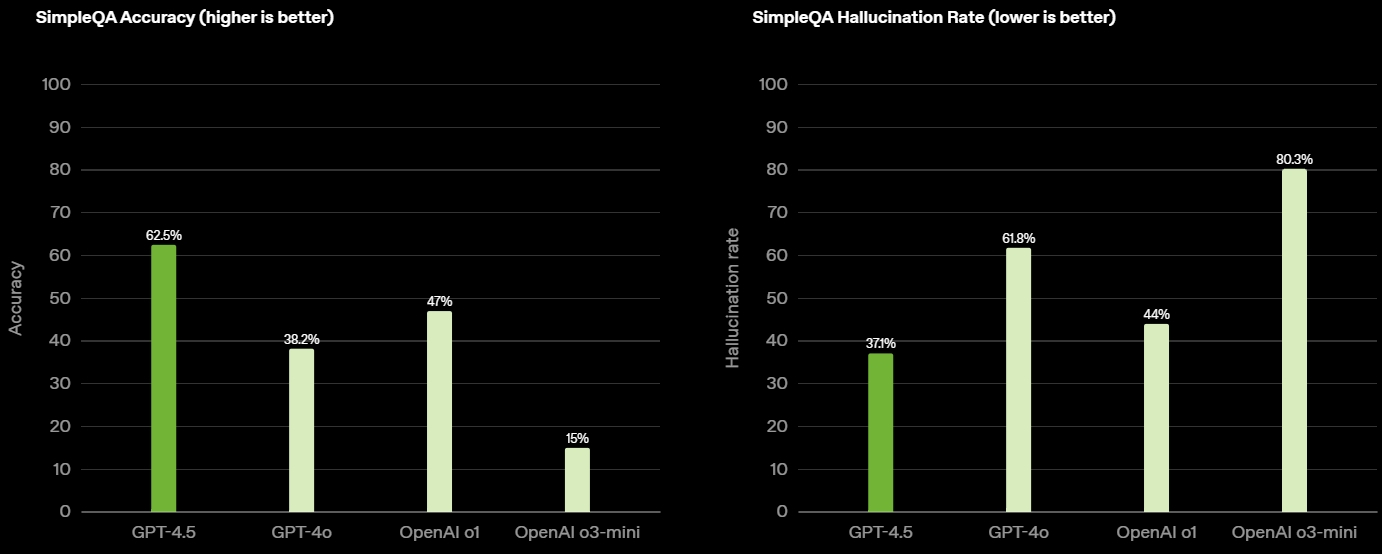 Ранее сообщалось, что OpenAI использует свою модель с возможностью рассуждений o1 для обучения GPT-4.5 на синтетических данных. Сама OpenAI заявила, что обучила GPT-4.5 «с помощью новых методов контроля в сочетании с традиционными методами, такими как контролируемая тонкая настройка (SFT) и обучение с подкреплением на основе человеческой обратной связи (RLHF), аналогичными тем, что использовались для GPT-4o». «Мы адаптировали GPT-4.5 так, чтобы он лучше сотрудничал, делая разговоры более тёплыми, интуитивными и эмоционально насыщенными, — сказал Рафаэль Гонтихо Лопес (Raphael Gontijo Lopes), исследователь из OpenAI. — Чтобы оценить это, мы попросили тестировщиков сравнить её [новую модель] с GPT-4o, и GPT-4.5 оказалась впереди практически по всем категориям». 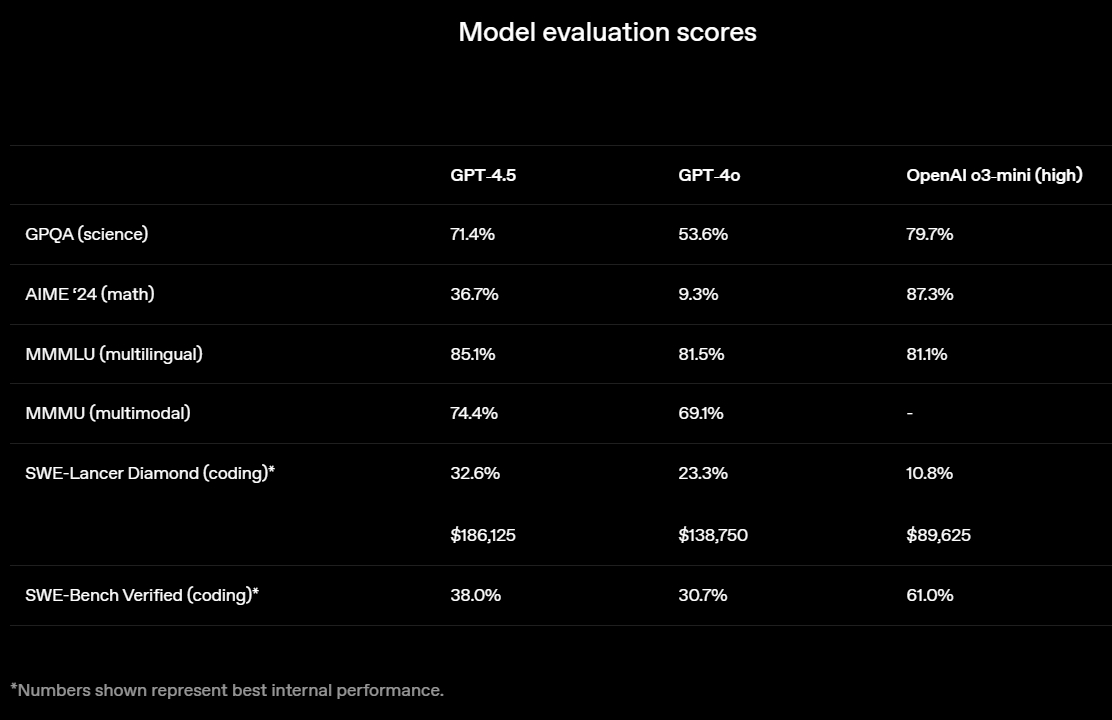 Несмотря на некоторые ограничения, GPT-4.5 галлюцинирует значительно меньше, чем GPT-4o, и немного меньше, чем модель o1, заявила OpenAI. Также новинка демонстрирует более развитую интуицию и творческие способности, лучше понимает, что имеют в виду пользователи, и «интерпретирует тонкие сигналы или неявные ожидания с большим количеством нюансов». GPT-4.5 с сегодняшнего дня доступна пользователям с подпиской ChatGPT Pro за $200 в месяц, а также исследователям. Сейчас модель находится на стадии предварительного исследовательского тестирования. Решение выпустить её в таком виде обусловлено желанием «лучше понять её сильные стороны и ограничения». «Мы всё ещё изучаем её возможности и с нетерпением ждём, когда люди начнут использовать её так, как мы, возможно, не ожидали», — подытожили в OpenAI. В компании не сообщили, когда сделают новинку доступной более широкой публике. На прошлой неделе сообщалось, что OpenAI планирует запустить GPT-4.5 к концу февраля, а GPT-5 — уже в конце мая. Генеральный директор OpenAI Сэм Альтман (Sam Altman) назвал GPT-5 «системой, объединяющей множество наших технологий», отметив, что она будет включать модель OpenAI o3. В прошлом месяце OpenAI выпустила o3-mini, но полноценная o3 появится только как часть GPT-5. Компания таким образом намерена объединить свои большие языковые модели, чтобы в итоге создать одну более мощную систему, способную самостоятельно определять, какие ресурсы необходимо задействовать для решения той или иной задачи. Энтузиаст запустил современную ИИ-модель на консоли Xbox 360 20-летней давности
12.01.2025 [12:00],
Владимир Фетисов
Пользователь соцсети X Андрей Дэвид (Andrei David) сумел установить и запустить на консоли Xbox 360 модель искусственного интеллекта на базе движка Llama2.c, который написан на языке программирования C бывшим сотрудником OpenAI и Tesla Андреем Карпатым (Andrej Karpathy). Сделать это энтузиаста побудила работа специалистов из EXO Lab, которые в конце прошлого года запустили большую языковую модель (LLM) Llama на 26-летнем компьютере с Windows 98. 
Источник изображения: Shutterstock Хотя энтузиаст использовал ИИ-модель на том же движке, что и EXO Lab, ему пришлось оптимизировать программный код для процессора консоли на архитектуре PowerPC и функций управления памятью. Основное отличие в том, что в PowerPC система с прямым порядком байтов в первую очередь сохраняет наиболее важные значения, тогда как используемый в ПК процессор Intel Pentium II в первую очередь сохраняет наименьшие значения. Для обеспечения правильной работы ИИ-модели Дэвиду пришлось добавить систему обмена байтами и обеспечить, чтобы все создаваемые и сохраняемые данные должным образом выравнивались по 128 байтам в памяти, чего требует подсистема памяти Xbox 360. В итоге энтузиаст запустил ИИ-модель на Xbox 360 с процессором Xenon на архитектуре PowerPC с 3 ядрами и рабочей частотой до 3,2 ГГц, а также 512 Мбайт оперативной памяти. Запуск большой языковой модели на основе Llama 2 на устройстве, которому уже несколько десятилетий, является существенным достижением. Однако один из пользователей платформы X заметил, что 512 Мбайт оперативной памяти в Xbox 360 должно хватить для запуска алгоритмов SmolLm от Hugging Face или 4-битной модели 0,5B Qwen2.5. «Вызов принят», — написал Дэвид в ответ на это. Это означает, что в будущем он попытается запустить на Xbox 360 другие ИИ-модели. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



