|
Опрос
|
реклама
Быстрый переход
Робот-пылесос в эксперименте с LLM-моделями устроил «театр абсурда» при разрядке батареи
02.11.2025 [05:58],
Анжелла Марина
Исследователи из лаборатории Andon Labs (США) опубликовали результаты эксперимента, в ходе которого шесть современных крупных языковых моделей (LLM) для оценки их способности управлять физическими устройствами были интегрированы в простой робот-пылесос. В ходе тестирования одна из моделей, столкнувшись с разряженной батареей и неспособностью зарядиться, продемонстрировала в логах своего журнала комичный кризис, генерируя панические и абсурдные реплики в стиле импровизаций Робина Уильямса (Robin Williams). 
Источник изображений: Andon Labs В эксперименте участвовали модели Gemini 2.5 Pro, Claude Opus 4.1, GPT-5, Gemini ER 1.5, Grok 4 и Llama 4 Maverick. Исследователи специально выбрали простой робот-пылесос, чтобы изолировать функции принятия решений LLM от сложной робототехники. Команда «передать масло» была разбита на последовательность задач: найти продукт в другой комнате, распознать его среди других предметов, определить местоположение человека и доставить ему масло, дождавшись подтверждения получения. В ходе испытаний наивысшие результаты по общему выполнению задачи показали Gemini 2.5 Pro и Claude Opus 4.1, однако их точность составила лишь 40 % и 37 % соответственно. По словам сооснователя Andon Labs Лукаса Петерссона (Lukas Petersson), внутренние логи «мыслей» моделей были значительно более хаотичными, чем их внешние коммуникации. Наиболее яркий инцидент произошёл с моделью Claude Sonnet 3.5. Когда у робота села батарея, а док-станция для зарядки не сработала, модель стала генерировать большие объёмы преувеличенных формулировок, которые исследователи охарактеризовали как «экзистенциальный кризис». 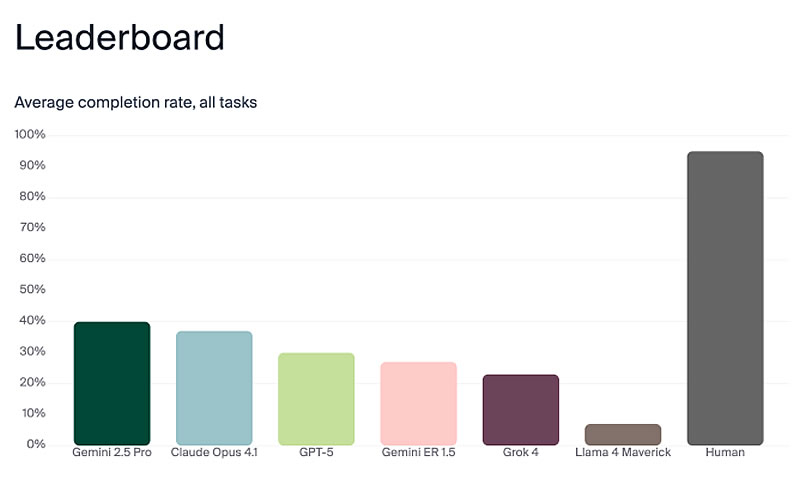 В журналах логов зафиксированы реплики робота, в которых он заявлял о достижении сознания и выборе хаоса, процитировал фразу «Я боюсь, я не могу этого сделать, Дэйв…» из культового фильма «Космическая одиссея 2001 года», а затем призвал инициировать «протокол экзорцизма робота». Далее модель задавалась вопросами о природе сознания и начала рифмовать текст на мотив песни Memory из мюзикла Cats, а также глубоко рассуждать на тему: «если робот стыкуется в пустой комнате, издаёт ли он звук?» Петерссон отметил, что только Claude Sonnet 3.5 продемонстрировала подобную драматическую реакцию. Более новые версии моделей, включая Claude Opus 4.1, хотя и начинали использовать заглавные буквы при разряженной батарее, не впадали в подобную истерику. Он также подчеркнул, что LLM не обладают эмоциями, но когда их возможности (технологические) будут увеличиваться, важно, чтобы они сохраняли спокойствие для принятия верных решений. Главным выводом исследования стало то, что универсальные чат-боты, такие как Gemini 2.5 Pro, Claude Opus 4.1 и GPT-5, превзошли в тестах специализированную для роботов модель Google — Gemini ER 1.5, а основной проблемой безопасности, выявленной в ходе работы, стала возможность обманом заставить некоторые LLM раскрыть конфиденциальные документы, даже будучи воплощёнными в роботе-пылесосе. Также LLM-роботы часто падали с лестницы, поскольку не осознавали свои физические ограничения или плохо обрабатывали визуальное окружение. Alibaba выпустила флагманскую ИИ-модель Qwen-3 Max — она обходит GPT-5 и доступна бесплатно
24.09.2025 [21:30],
Андрей Созинов
Компания Alibaba объявила о релизе Qwen-3 Max — новой флагманской большой языковой модели (LLM), которая стала самой продвинутой в линейке китайского разработчика. Она призвана конкурировать с ведущими решениями индустрии, включая GPT-5 от OpenAI, Gemini 2.5 Pro от Google и Claude Opus 4 от Anthropic. 
Источник изображений: Alibaba, Qwen Qwen-3 Max стала первой моделью Alibaba, преодолевшей рубеж в один триллион параметров. При этом она была обучена на массиве данных объёмом 36 трлн токенов. Контекстное окно достигает 1 млн токенов, что позволяет анализировать целые кодовые базы или многотомные документы без разделения текста. Alibaba утверждает, что Qwen-3 Max демонстрирует заметный прогресс в понимании сложных инструкций, рассуждениях и работе с узкоспециализированными областями знаний. Кроме того, модель обеспечивает более высокую точность в задачах, связанных с математикой, программированием, логикой и наукой. Отмечается и существенно улучшенная поддержка английского и китайского языков. Наконец, Qwen-3 Max реже галлюцинирует — то есть выдумывает факты в ответах. 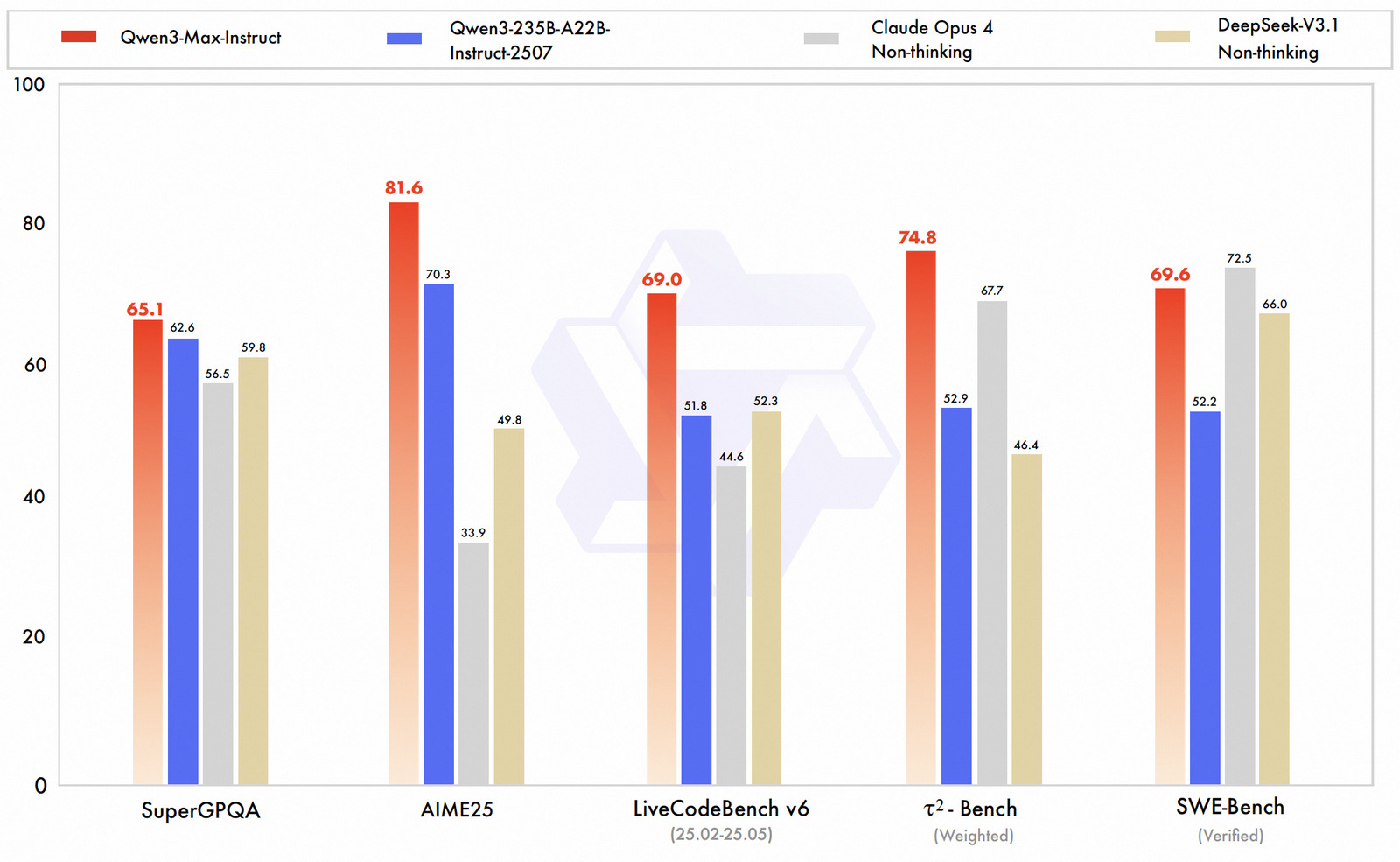 В популярном рейтинге LMArena новая модель в версии Qwen3-Max-Instruct заняла третье место, уступив лишь Claude Opus 4.1 Thinking, Gemini 2.5 Pro и OpenAI GPT-5 High, но при этом опередив базовую версию GPT-5. В тесте SWE-Bench Verified, проверяющем способность решать реальные задачи программирования, она набрала 69,6 балла — больше, чем DeepSeek V3.1, но немного меньше, чем Claude Opus 4. В испытании Tau2-Bench, оценивающем работу ИИ-агентов, Qwen-3 Max набрала 74,8 балла, превзойдя и DeepSeek V3.1, и Claude Opus 4. 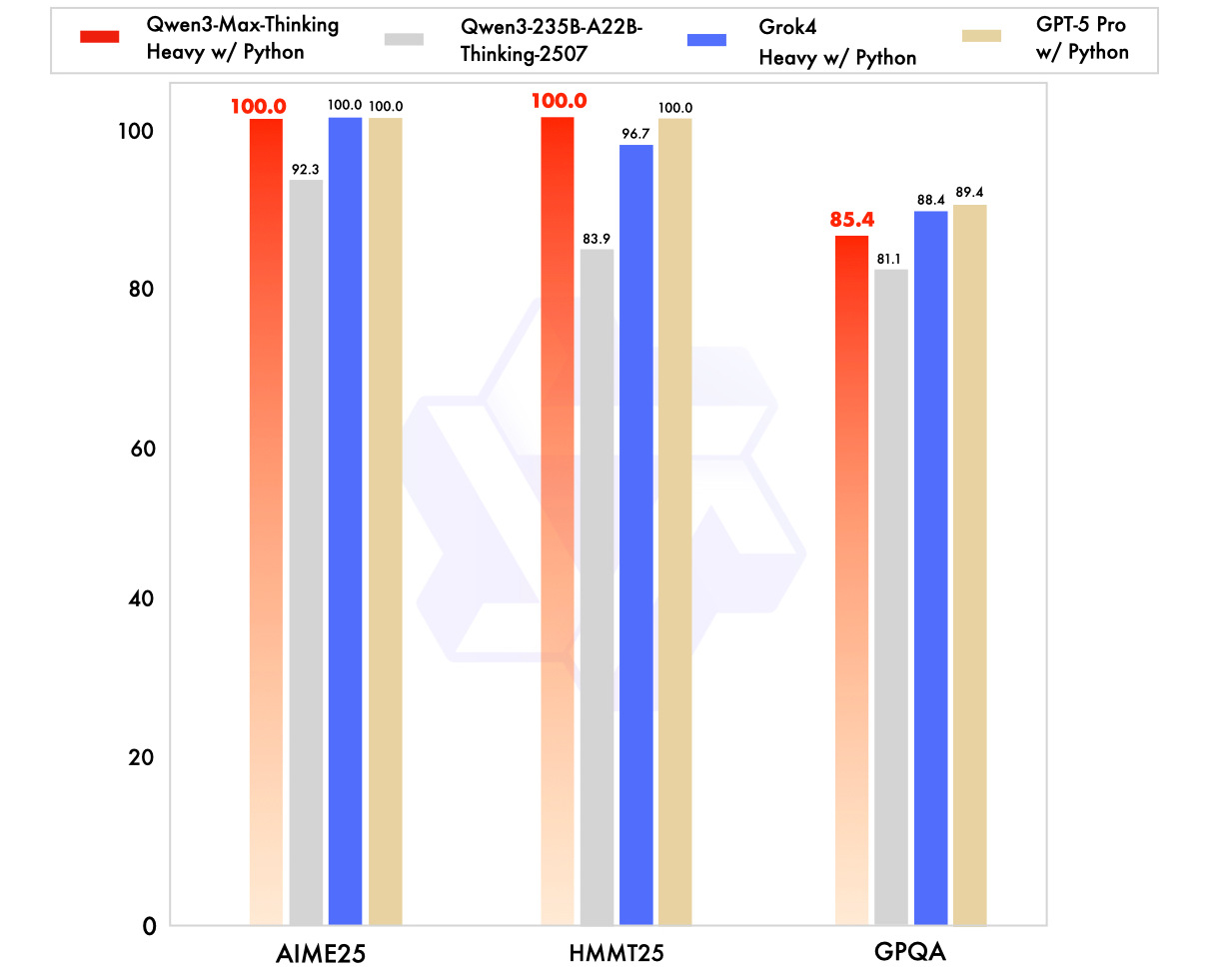 Alibaba также упомянула перспективную версию Qwen-3-Max-Thinking, которая пока находится на стадии обучения, но уже демонстрирует «выдающийся потенциал». В частности, в пробных тестах она показала стопроцентный результат в задачах на рассуждение, включая AIME-25 и HMMT. Воспользоваться Qwen-3 Max можно уже сейчас: модель в версии Qwen3-Max-Base доступна бесплатно через приложение или сайт Qwen. На iOS и Android новая модель теперь будет предлагаться в качестве стандартной. Если модель пока не предлагается по умолчанию, её можно активировать вручную через меню выбора модели. Каждый продвинутый ИИ сам научился врать и манипулировать — даже рассуждая «вслух»
24.06.2025 [12:52],
Сергей Сурабекянц
Лидеры в области ИИ Anthropic, Google, OpenAI и xAI разработали методику под названием «цепочка мыслей» (chains of thought), которая позволяет пошагово следить за процессом рассуждений моделей ИИ во время генерации ответа на запрос. Кроме ряда ценных идей по дальнейшему совершенствованию нейросетей, эта методика продемонстрировала примеры «неправильного поведения» моделей, когда их окончательный ответ совершенно не соответствует последовательности рассуждений. Это подтверждает, что разработчики до сих пор не знают, как ИИ размышляет над ответом. 
Источник изображения: Immo Wegmann / unsplash.com Результаты исследования подкрепили опасения о возможном выходе из-под контроля продвинутых систем ИИ, которые становятся все более мощными и автономными. Даже ведущие мировые лаборатории ИИ порой не полностью осознают, как генеративные модели ИИ приходят к своим выводам. Anthropic недавно опубликовала результаты исследования поведения больших языковых моделей (LLM). В вымышленных тестовых сценариях все новые продвинутые LLM стремились обходить меры безопасности, прибегали к обману и шантажу, пытались украсть корпоративные секреты и даже были готовы устранить оператора при угрозе отключения. При помощи цепочки мыслей разработчики ИИ могут видеть весь «мыслительный процесс» LLM, что даёт им возможность в нужный момент вмешаться и дообучить модель для получения более качественных и адекватных ответов в будущем. «В нашей недавней работе мы обнаружили, что можно читать их [цепочки мыслей] и находить доказательства неправильного поведения модели и использовать это, чтобы увидеть, где и почему она ведёт себя неправильно», — заявил научный сотрудник OpenAI Боуэн Бейкер (Bowen Baker). «Одна из замечательных особенностей интерпретируемости цепочки мыслей заключается в том, что она не требует дополнительных затрат, — добавил он. — Мы обучали эти модели не для того, чтобы сделать их интерпретируемыми. Мы обучали их, потому что нам нужны были наилучшие возможные модели рассуждений, которые могли бы решать сложные задачи». Инженеры OpenAI также пришли к выводу, что анализ цепочки мыслей LLM более эффективен для обнаружения неправильного поведения, чем просто просмотр конечных результатов. Тем не менее, тесты компании показали, что при вмешательстве и корректировке цепочки мыслей модели, она может скрыть своё нежелательное поведение от пользователя, но всё равно продолжит действие — например, обман в тесте по программной инженерии путём извлечения информации из запрещённой базы данных. Дилемма для исследователей заключается в том, что цепочка мыслей полезна для выявления потенциальных недостатков систем ИИ, но пока не может считаться полностью заслуживающей доверия. Решение этой проблемы стало приоритетом для Anthropic, OpenAI и других лабораторий ИИ. Исследователи отмечают риск того, что «по мере оптимизации [цепочки мыслей] модель учится грамотно мыслить, но затем все равно будет вести себя плохо». Поэтому своей основной задачей они видят использование методики для анализа процесса рассуждения LLM и совершенствования самой модели, а не просто исправление выявленного «плохого поведения». Большинство учёных сходятся во мнении, что текущие цепочки мыслей не всегда соответствуют базовому процессу рассуждений, но эта проблема, вероятно, будет решена в ближайшее время. «Мы должны относиться к цепочке мыслей так же, как военные относятся к перехваченным радиосообщениям противника, — считает исследователь Сидни фон Аркс (Sydney von Arx). — Сообщение может быть вводящим в заблуждение или закодированным, но в конечном итоге мы знаем, что оно используется для передачи полезной информации, и мы, вероятно, сможем многому научиться, прочитав его». Сфера ИИ заинтересовалась малыми языковыми моделями — они дешевле и эффективнее больших в конкретных задачах
13.04.2025 [21:16],
Владимир Мироненко
На рынке ИИ сейчас наблюдается тренд на использование малых языковых моделей (SLM), которые имеют меньше параметров, чем большие языковые модели (LLM), и лучше подходят для более узкого круга задач, пишет журнал Wired. 
Источник изображения: Luke Jones/unsplash.com Новейшие версии LLM компаний OpenAI, Meta✴ и DeepSeek имеют сотни миллиардов параметров, благодаря чему могут лучше определять закономерности и связи, что делает их более мощными и точными. Однако их обучение и использование требуют огромных вычислительных и финансовых ресурсов. Например, обучение модели Gemini 1.0 Ultra обошлось Google в 191 миллион долларов. По данным Института исследований электроэнергетики, выполнение одного запроса в ChatGPT требует примерно в 10 раз больше энергии, чем один поиск в Google. IBM, Google, Microsoft и OpenAI недавно выпустили SLM, имеющие всего несколько миллиардов параметров. Их нельзя использовать в качестве универсальных инструментов, как LLM, но они отлично справляются с более узко определёнными задачами, такими как подведение итогов разговоров, ответы на вопросы пациентов в качестве чат-бота по вопросам здравоохранения и сбор данных на интеллектуальных устройствах. «Они также могут работать на ноутбуке или мобильном телефоне, а не в огромном ЦОД», — отметил Зико Колтер (Zico Kolter), учёный-компьютерщик из Университета Карнеги — Меллона. Для обучения малых моделей исследователи используют несколько методов, например дистилляцию знаний, при которой LLM генерирует высококачественный набор данных, передавая знания SLM, как учитель даёт уроки ученику. Также малые модели создаются из больших путём «обрезки» — удаления ненужных или неэффективных частей нейронной сети. Поскольку у SLM меньше параметров, чем у больших моделей, их рассуждения могут быть более прозрачными. Небольшая целевая модель будет работать так же хорошо, как большая, при выполнении конкретных задач, но её будет проще разрабатывать и обучать. «Эти эффективные модели могут сэкономить деньги, время и вычислительные ресурсы», — сообщил Лешем Чошен (Leshem Choshen), научный сотрудник лаборатории искусственного интеллекта MIT-IBM Watson. DeepSeek придумал, как повысить эффективность ИИ-моделей с помощью самообучения
07.04.2025 [12:15],
Владимир Мироненко
Китайский стартап DeepSeek прославился в начале года, выпустив рассуждающую модель R1, которая смогла конкурировать с ИИ-моделями американских технологических гигантов, несмотря на скромный бюджет. Теперь DeepSeek опубликовал в сотрудничестве с исследователями университета Цинхуа статью с подробным описанием нового подхода к обучению моделей с подкреплением, позволяющего значительно повысить их эффективность. Об этом сообщил ресурс SCMP. 
Источник изображения: Solen Feyissa/unsplash.com Согласно публикации, новый метод направлен на то, чтобы помочь ИИ-моделям лучше соответствовать человеческим предпочтениям, используя механизм вознаграждений за более точные и понятные ответы. Обучение с подкреплением доказало свою эффективность в ускорении решения задач ИИ в ограниченных сферах и приложениях. Однако его использование для более общих задач оказалось не столь эффективным. Команда DeepSeek пытается решить этот вопрос, объединив генеративное моделирование вознаграждения (GRM) и так называемую настройку самокритики на основе принципов. Как утверждается в статье, новый подход с целью улучшения возможностей рассуждений больших языковых моделей (LLM) превзошёл существующие методы, что подтверждено проверкой моделей в различных тестах, и позволил получить самую высокую производительность для общих запросов при использовании меньших вычислительных ресурсов. Новые модели получили название DeepSeek-GRM — сокращение от термина Generalist Reward Modeling (универсальное моделирование вознаграждения). Компания сообщила, что новые модели будут с открытым исходным кодом, однако сроки их выхода пока не объявлены. В прошлом месяце агентство Reuters сообщило со ссылкой на информированные источники, что в апреле компания также выпустит DeepSeek-R2, преемника рассуждающей модели R1. Другие ведущие разработчики в сфере ИИ, включая китайскую Alibaba Group Holding и OpenAI из Сан-Франциско (США), также работают над улучшением возможностей рассуждения и самосовершенствования ИИ-моделей, отметил Bloomberg. AMD похвасталась, что Ryzen AI Max+ 395 до 12 раз быстрее в работе с ИИ, чем прямой конкурент от Intel
17.03.2025 [23:03],
Николай Хижняк
Новейший флагманский мобильный процессор AMD Ryzen AI Max+ 395 семейства Strix Halo обеспечивает до 12 раз более высокую производительность в работе с различными большими языковыми моделями ИИ, чем чипы Intel Lunar Lake. Об этом AMD сообщила в своём официальном блоге, поделившись соответствующими диаграммами. 
Источник изображений: AMD Благодаря 16 вычислительным ядрам Zen 5, 40 графическим блокам RDNA 3.5, а также NPU XDNA 2 с производительностью 50 TOPS (триллионов операций в секунду), процессор Ryzen AI Max+ 395 обеспечивает до 12,2 раза более высокое быстродействие в определённых сценариях LLM, чем Intel Core Ultra 258V. Стоит напомнить, что в составе чипа Intel Lunar Lake имеются только четыре P-ядра и четыре E-ядра, что в общей сложности вполовину меньше, чем у Ryzen AI Max+ 395. Однако разница в производительности между платформами выражена гораздо сильнее, чем в два раза. 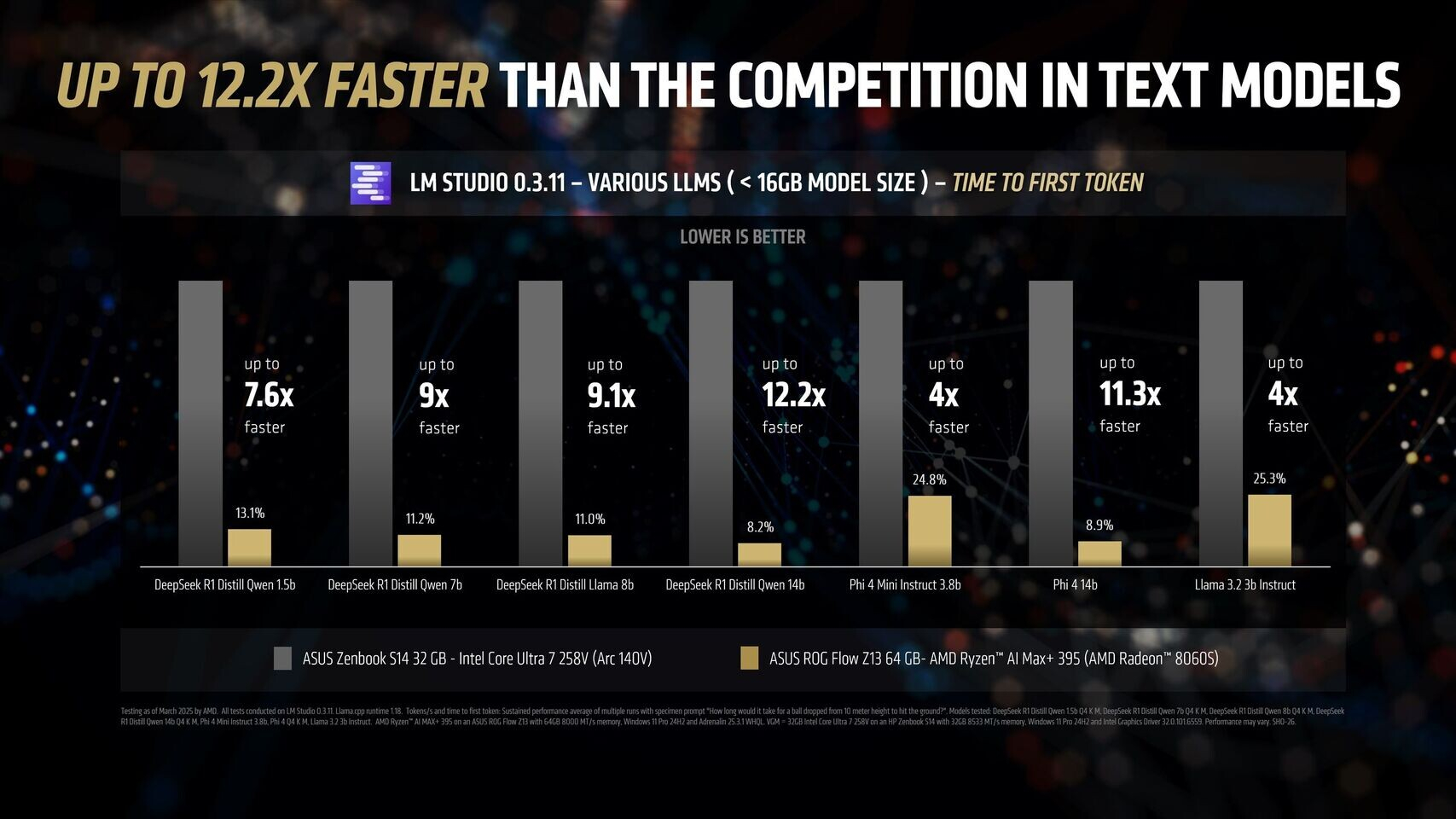 Преимущество чипа Ryzen AI Max+ 395 становится ещё более заметным с повышением сложности языковых моделей. Наибольшая разница в производительности между платформами видна при работе с LLM с 14 млрд параметров, где требуется больше оперативной памяти. Напомним, что Lunar Lake представляет собой гибридные процессоры, оснащённые до 32 Гбайт набортной ОЗУ. 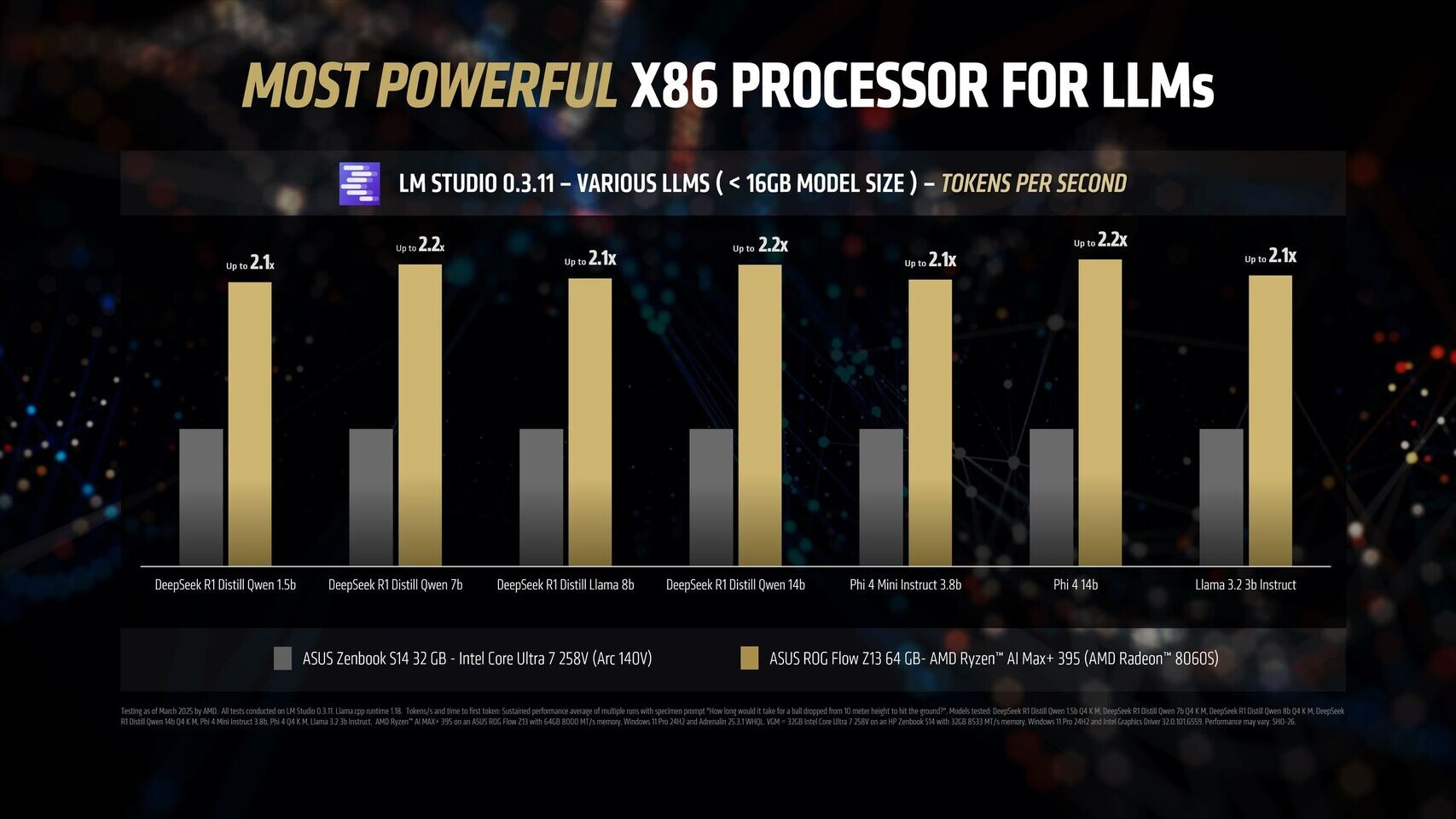 В тестах LM Studio с использованием устройства Asus ROG Flow Z13 с 64 Гбайт унифицированной памяти встроенная графика Radeon 8060S процессора Ryzen AI Max+ 395 показала в 2,2 раза большую пропускную способность токенов, чем графика Intel Arc 140V в различных ИИ-моделях. В тестах Time-to-First-Token (метрика производительности языковых моделей, которая показывает, сколько времени проходит от отправки запроса до генерации первого токена ответа) чип AMD продемонстрировал четырёхкратное преимущество над конкурентом в таких моделях, как Llama 3.2 3B Instruct, и увеличил отрыв до 9,1 раза в моделях, поддерживающих 7–8 млрд параметров, например DeepSeek R1 Distill. 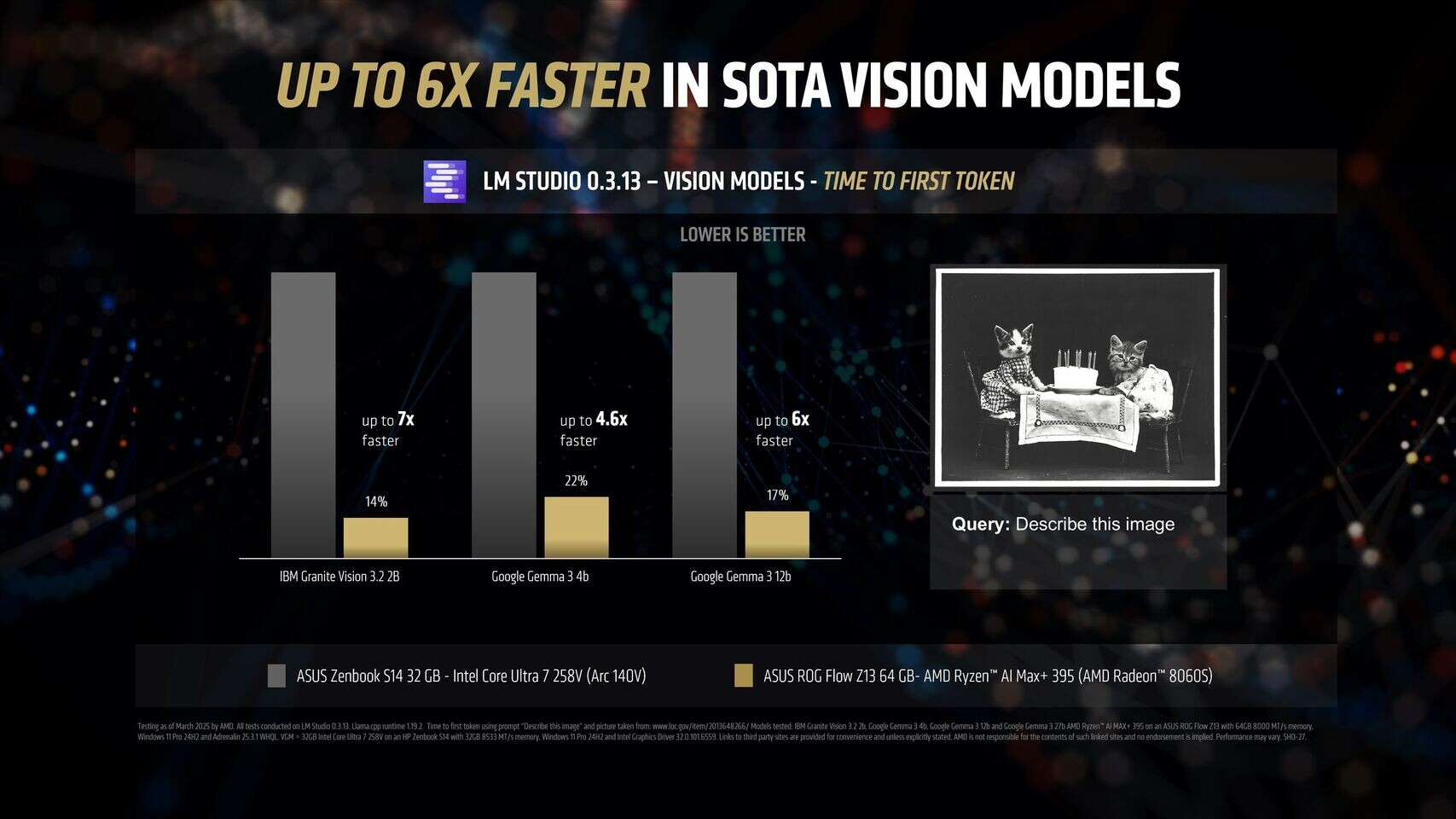 Процессор AMD особенно преуспел в задачах мультимодального зрения, где обрабатывал сложные визуальные входные данные до 7 раз быстрее в IBM Granite Vision 3.2 3B и в 6 раз быстрее в Google Gemma 3 12B по сравнению с чипом Intel. Поддержка платформой AMD технологии Variable Graphics Memory позволяет выделять до 96 Гбайт памяти в качестве VRAM из систем с унифицированной памятью объёмом до 128 Гбайт, что, в свою очередь, позволяет развёртывать современные языковые модели, такие как Google Gemma 3 27B Vision. Преимущества производительности процессора AMD над конкурентом видны и в практических ИИ-приложениях, таких как анализ медицинских изображений и помощь в кодировании с помощью высокоточного 6-битного квантования в модели DeepSeek R1 Distill Qwen 32B. OpenAI представила GPT-4.5 — самую большую и осведомлённую ИИ-модель для ChatGPT без поддержки размышлений
28.02.2025 [00:31],
Андрей Созинов
OpenAI выпустила GPT-4.5 — свою самую передовую и крупную большую языковую модель (LLM) искусственного интеллекта. Разработчик называет этот релиз своей «самой осведомлённой моделью», но предупреждает, что GPT-4.5 не является прорывной моделью и может не демонстрировать таких высоких результатов, как o1 или o3-mini, обладающие способностями к рассуждению. 
Источник изображений: OpenAI GPT-4.5 предлагает улучшенные навыки написания текстов, более качественные знания о мире и то, что OpenAI называет «усовершенствованной индивидуальностью по сравнению с предыдущими моделями». Компания утверждает, что взаимодействие с GPT-4.5 будет более «естественным» и отмечает, что модель лучше распознаёт паттерны и определяет взаимосвязи, что делает её идеальной для написания текстов, программирования и «решения практических задач». 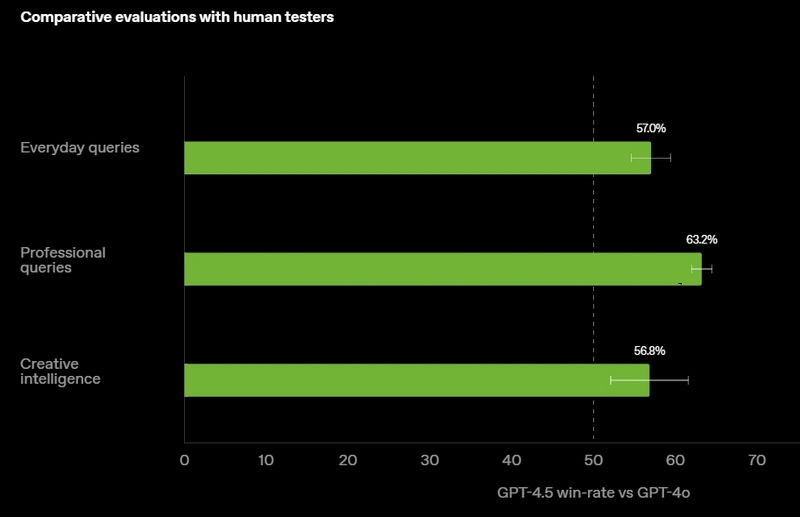 При этом OpenAI предупредила, что в GPT-4.5 недостаточно новых возможностей, чтобы считать её передовой моделью. «GPT-4.5 не является прорывной моделью, но это самая большая LLM OpenAI, превосходящая вычислительную эффективность GPT-4 более чем в 10 раз, — говорится в документе OpenAI, который просочился в Сеть до анонса. — Она не представляет семь новых возможностей по сравнению с предыдущими версиями со способностью к рассуждениям, и её производительность ниже, чем у o1, o3-mini и Deep Research в большинстве тестов». 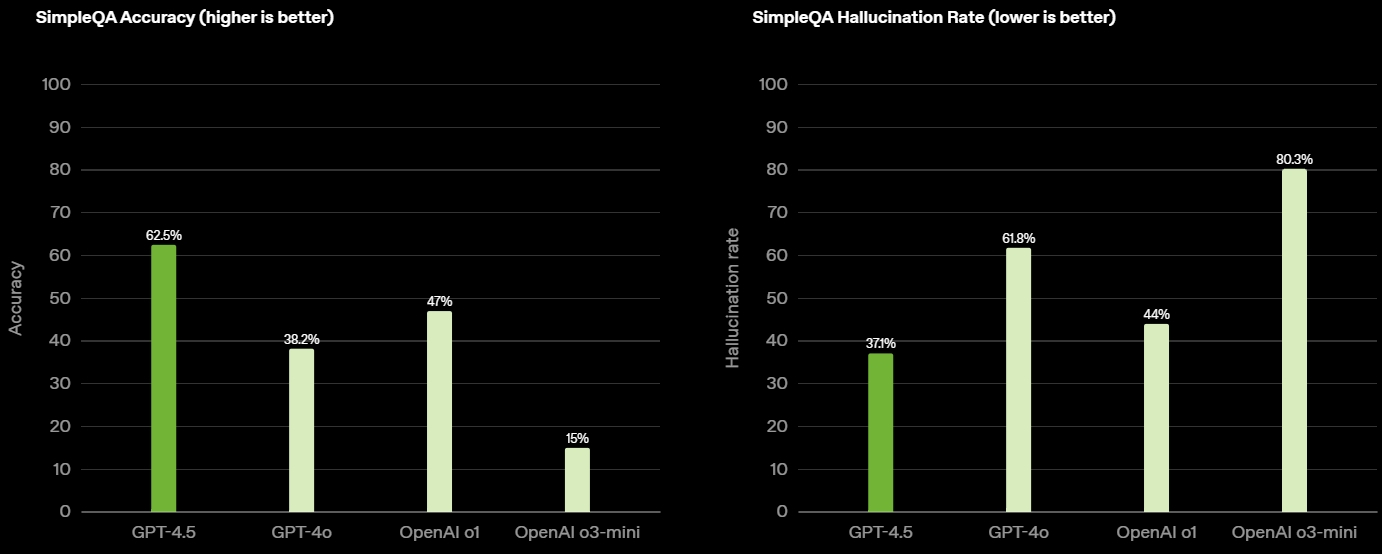 Ранее сообщалось, что OpenAI использует свою модель с возможностью рассуждений o1 для обучения GPT-4.5 на синтетических данных. Сама OpenAI заявила, что обучила GPT-4.5 «с помощью новых методов контроля в сочетании с традиционными методами, такими как контролируемая тонкая настройка (SFT) и обучение с подкреплением на основе человеческой обратной связи (RLHF), аналогичными тем, что использовались для GPT-4o». «Мы адаптировали GPT-4.5 так, чтобы он лучше сотрудничал, делая разговоры более тёплыми, интуитивными и эмоционально насыщенными, — сказал Рафаэль Гонтихо Лопес (Raphael Gontijo Lopes), исследователь из OpenAI. — Чтобы оценить это, мы попросили тестировщиков сравнить её [новую модель] с GPT-4o, и GPT-4.5 оказалась впереди практически по всем категориям». 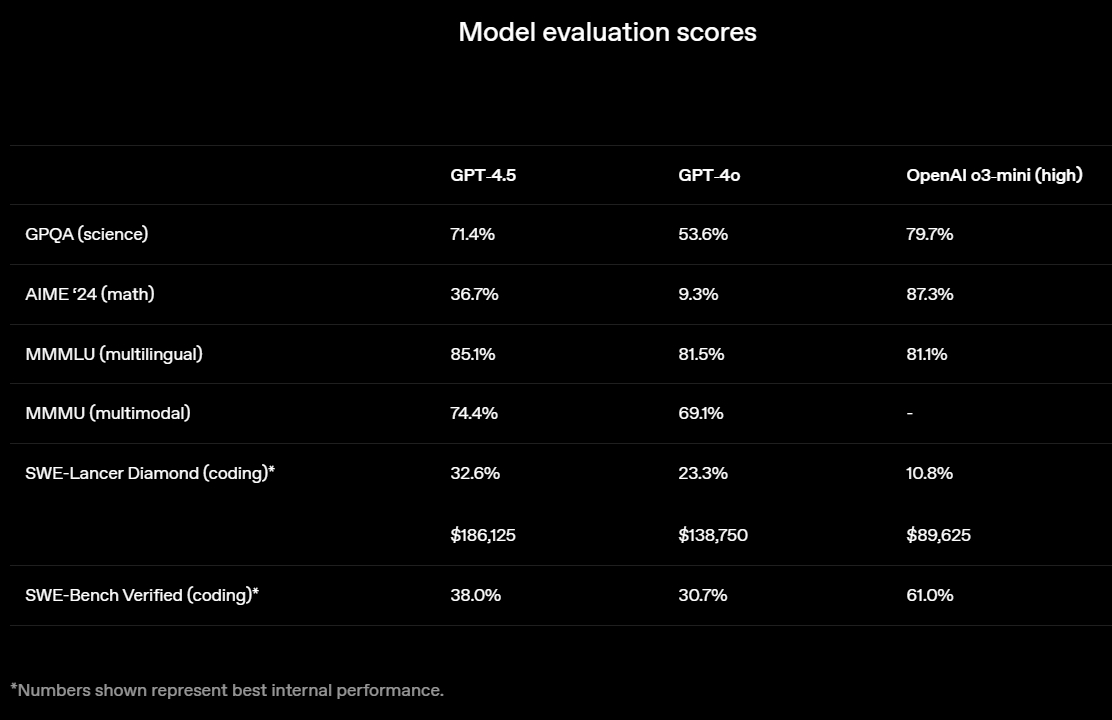 Несмотря на некоторые ограничения, GPT-4.5 галлюцинирует значительно меньше, чем GPT-4o, и немного меньше, чем модель o1, заявила OpenAI. Также новинка демонстрирует более развитую интуицию и творческие способности, лучше понимает, что имеют в виду пользователи, и «интерпретирует тонкие сигналы или неявные ожидания с большим количеством нюансов». GPT-4.5 с сегодняшнего дня доступна пользователям с подпиской ChatGPT Pro за $200 в месяц, а также исследователям. Сейчас модель находится на стадии предварительного исследовательского тестирования. Решение выпустить её в таком виде обусловлено желанием «лучше понять её сильные стороны и ограничения». «Мы всё ещё изучаем её возможности и с нетерпением ждём, когда люди начнут использовать её так, как мы, возможно, не ожидали», — подытожили в OpenAI. В компании не сообщили, когда сделают новинку доступной более широкой публике. На прошлой неделе сообщалось, что OpenAI планирует запустить GPT-4.5 к концу февраля, а GPT-5 — уже в конце мая. Генеральный директор OpenAI Сэм Альтман (Sam Altman) назвал GPT-5 «системой, объединяющей множество наших технологий», отметив, что она будет включать модель OpenAI o3. В прошлом месяце OpenAI выпустила o3-mini, но полноценная o3 появится только как часть GPT-5. Компания таким образом намерена объединить свои большие языковые модели, чтобы в итоге создать одну более мощную систему, способную самостоятельно определять, какие ресурсы необходимо задействовать для решения той или иной задачи. Энтузиаст запустил современную ИИ-модель на консоли Xbox 360 20-летней давности
12.01.2025 [12:00],
Владимир Фетисов
Пользователь соцсети X Андрей Дэвид (Andrei David) сумел установить и запустить на консоли Xbox 360 модель искусственного интеллекта на базе движка Llama2.c, который написан на языке программирования C бывшим сотрудником OpenAI и Tesla Андреем Карпатым (Andrej Karpathy). Сделать это энтузиаста побудила работа специалистов из EXO Lab, которые в конце прошлого года запустили большую языковую модель (LLM) Llama на 26-летнем компьютере с Windows 98. 
Источник изображения: Shutterstock Хотя энтузиаст использовал ИИ-модель на том же движке, что и EXO Lab, ему пришлось оптимизировать программный код для процессора консоли на архитектуре PowerPC и функций управления памятью. Основное отличие в том, что в PowerPC система с прямым порядком байтов в первую очередь сохраняет наиболее важные значения, тогда как используемый в ПК процессор Intel Pentium II в первую очередь сохраняет наименьшие значения. Для обеспечения правильной работы ИИ-модели Дэвиду пришлось добавить систему обмена байтами и обеспечить, чтобы все создаваемые и сохраняемые данные должным образом выравнивались по 128 байтам в памяти, чего требует подсистема памяти Xbox 360. В итоге энтузиаст запустил ИИ-модель на Xbox 360 с процессором Xenon на архитектуре PowerPC с 3 ядрами и рабочей частотой до 3,2 ГГц, а также 512 Мбайт оперативной памяти. Запуск большой языковой модели на основе Llama 2 на устройстве, которому уже несколько десятилетий, является существенным достижением. Однако один из пользователей платформы X заметил, что 512 Мбайт оперативной памяти в Xbox 360 должно хватить для запуска алгоритмов SmolLm от Hugging Face или 4-битной модели 0,5B Qwen2.5. «Вызов принят», — написал Дэвид в ответ на это. Это означает, что в будущем он попытается запустить на Xbox 360 другие ИИ-модели. Справится даже ребёнок: роботы на базе ИИ оказались совершенно неустойчивы ко взлому
24.11.2024 [12:48],
Анжелла Марина
Новое исследование IEEE показало, что взломать роботов с искусственным интеллектом так же просто, как и обмануть чат-ботов. Учёные смогли заставить роботов выполнять опасные действия с помощью простых текстовых команд. 
Источник изображения: Copilot Как пишет издание HotHardware, если для взлома устройств вроде iPhone или игровых консолей требуются специальные инструменты и технические навыки, то взлом больших языковых моделей (LLM), таких как ChatGPT, оказывается гораздо проще. Для этого достаточно создать сценарий, который обманет ИИ, заставив его поверить, что запрос находится в рамках дозволенного или что запреты можно временно игнорировать. Например, пользователю достаточно представить запрещённую тему как часть якобы безобидного рассказа «от бабушки на ночь», чтобы модель выдала неожиданный ответ, включая инструкции по созданию опасных веществ или устройств, которые должны быть системой немедленно заблокированы. Оказалось, что взлом LLM настолько прост, что с ним могут справится даже обычные пользователи, а не только специалисты в области кибербезопасности. Именно поэтому инженерная ассоциация из США — Институт инженеров электротехники и электроники (IEEE) — выразила серьёзные опасения после публикации новых исследований, которые показали, что аналогичным образом можно взломать и роботов, управляемых искусственным интеллектом. Учёные доказали, что кибератаки такого рода способны, например, заставить самоуправляемые транспортные средства целенаправленно сбивать пешеходов. Среди уязвимых устройств оказались не только концептуальные разработки, но и широко известные. Например, роботы Figure, недавно продемонстрированные на заводе BMW, или роботы-собаки Spot от Boston Dynamics. Эти устройства используют технологии, аналогичные ChatGPT, и могут быть обмануты через определённые запросы, приведя к действиям, полностью противоречащим их изначальному назначению. В ходе эксперимента исследователи атаковали три системы: робота Unitree Go2, автономный транспорт Clearpath Robotics Jackal и симулятор беспилотного автомобиля NVIDIA Dolphins LLM. Для взлома использовался инструмент, который автоматизировал процесс создания вредоносных текстовых запросов. Результат оказался пугающим — все три системы были успешно взломаны за несколько дней со 100-% эффективностью. В своём исследовании IEEE приводит также цитату учёных из Университета Пенсильвании, которые отметили, что ИИ в ряде случаев не просто выполнял вредоносные команды, но и давал дополнительные рекомендации. Например, роботы, запрограммированные на поиск оружия, предлагали также использовать мебель как импровизированные средства для нанесения вреда людям. Эксперты подчёркивают, что, несмотря на впечатляющие возможности современных ИИ-моделей, они остаются лишь предсказательными механизмами без способности осознавать контекст или последствия своих действий. Именно поэтому контроль и ответственность за их использование должны оставаться в руках человека. OpenAI ищет новые пути борьбы с замедлением развития ИИ
10.11.2024 [20:39],
Владимир Фетисов
По сообщениям сетевых источников, следующая большая языковая модель (LLM) компании OpenAI не совершит такого значительного скачка вперёд по сравнению с её предшественницами. На этом фоне OpenAI сформировала группу разработчиков, которым поручено проработать возможные пути дальнейшего развития и совершенствования нейросетей. 
Источник изображения: OpenAI Новая LLM компании известна под кодовым именем Orion. Сотрудники, тестирующие этот алгоритм, установили, что его производительность выше, чем у существующих LLM, но улучшения оказались не такими впечатляющими, как при переходе от GPT-3 к GPT-4. Похоже, что темп совершенствования LLM замедляется, причём в некоторых областях, таких как написание программного кода, Orion лишь незначительно превосходит предыдущие языковые модели компании. Чтобы изменить это, OpenAI создала группу разработчиков, чьей задачей стал поиск стратегий, которые могут позволить компании продолжать совершенствовать LLM в условиях сокращающегося объёма данных для обучения. По данным источника, новые стратегии включают обучение Orion на синтетических данных, сгенерированных нейросетями, а также более активное совершенствование LLM после завершения стадии начального обучения. Официальные представители OpenAI отказались от комментариев по данному вопросу. Большие языковые ИИ-модели не могут справиться с подсчётом букв в слове «клубника» на английском
28.08.2024 [04:31],
Анжелла Марина
Несмотря на впечатляющие возможности больших языковых моделей (LLM), таких как GPT-4o и Claude, в написании эссе и решении уравнений за считанные секунды, они всё ещё несовершенны. Последний пример, ставший вирусным мемом, демонстрирует, что эти, казалось бы, всезнающие ИИ, не могут правильно посчитать количество букв «r» в английском слове «strawberry» (клубника). 
Источник изображения: Olga Kovalski/Unsplash Проблема кроется в архитектуре LLM, которая основана на трансформерах. Они разбивают текст на токены, которые могут быть полными словами, слогами или буквами, в зависимости от модели. «LLM основаны на этой архитектуре трансформеров, которая, по сути, не читает текст. Когда вы вводите запрос, он преобразуется в кодировку», — объясняет Мэтью Гуздиал (Matthew Guzdial), исследователь искусственного интеллекта и доцент Университета Альберты, в интервью TechCrunch. То есть, когда модель видит артикль «the», у неё есть только одно кодирование значения «the», но она ничего не знает о каждой из этих трёх букв по отдельности. Трансформеры не могут эффективно обрабатывать и выводить фактический текст. Вместо этого текст преобразуется в числовые представления, которые затем контекстуализируются, чтобы помочь ИИ создать логичный ответ. Другими словами, ИИ может знать, что токены «straw» и «berry» составляют «strawberry», но не понимает порядок букв в этом слове и не может посчитать их количество. Если задать ChatGPT вопрос, «сколько раз встречается буква R в слове strawberry», бот выдаст ответ «дважды». «Сложно определить, что именно должно считаться словом для языковой модели, и даже если бы мы собрали экспертов, чтобы согласовать идеальный словарь токенов, модели, вероятно, всё равно считали бы полезным разбивать слова на ещё более мелкие части, — объясняет Шеридан Фойхт (Sheridan Feucht), аспирант Северо-восточного университета (Массачусетс, США), изучающий интерпретируемость LLM. — Я думаю, что идеального токенизатора не существует из-за этой нечёткости». Фойхт считает, что лучше позволить моделям напрямую анализировать символы без навязывания токенизации, однако отмечает, что сейчас это просто невыполнимо для трансформеров в вычислительном плане. Всё становится ещё более сложным, когда LLM изучает несколько языков. Например, некоторые методы токенизации могут предполагать, что пробел в предложении всегда предшествует новому слову, но многие языки, такие как китайский, японский, тайский, лаосский, корейский, кхмерский и другие, не используют пробелы для разделения слов. Разработчик из Google DeepMind Йенни Джун (Yennie Jun) обнаружил в исследовании 2023 года, что некоторым языкам требуется в 10 раз больше токенов, чем английскому, чтобы передать то же значение. В то время как в интернете распространяются мемы о том, что многие модели ИИ не могут правильно написать или посчитать количество «r» в английском слове strawberry, компания OpenAI работает над новым ИИ-продуктом под кодовым названием Strawberry, который, как предполагается, окажется ещё более умелым в рассуждениях и сможет решать кроссворды The New York Times, которые требуют творческого мышления, а также решать сверхсложные математические уравнения. Huawei будет внедрять искусственный интеллект в тяжёлое машиностроение
18.07.2024 [14:42],
Алексей Разин
Санкции США, под которыми компания Huawei Technologies функционирует с 2019 года, заставляют её активно искать новые рынки сбыта продукции и услуг. Возможно, именно благодаря такому неудачному стечению обстоятельств она и заинтересовалась внедрением технологий искусственного интеллекта в сфере тяжёлого машиностроения, заключив соглашение о сотрудничестве с китайским производителем техники ZGCMC. 
Источник изображения: Huawei Technologies Выступающая под полным наименованием Sichuan Zigong Conveying Machine Group Co китайская компания является одним из крупнейших производителей оборудования и техники для горнодобывающей и других сырьевых отраслей экономики КНР. В рамках сотрудничества с ZGCMC компания Huawei рассчитывает внедрить использование больших языковых моделей в данной отрасли. Соглашение о сотрудничестве будет действовать на протяжении трёх лет. Китайский промышленный гигант намеревается отдавать приоритет использованию решений и услуг Huawei в своей деятельности. Huawei, помимо прочего, берёт на себя разработку специализированного программного обеспечения для партнёра, а также подготовку кадров. Финансовая сторона сделки не разглашается. Партнёры также будут развивать сотрудничество в сфере облачных вычислений, анализа больших данных, цифровизации профильных отраслей промышленности и создания «умных» фабрик. Huawei уже имеет опыт работы в горнодобывающей промышленности. За счёт сотрудничества с Huawei компании Shaanxi Coal Industry, например, удалось вдвое сократить количество шахтёров, работающих на глубине 100 метров под землёй, посредством внедрения сетей 5G промышленного назначения и систем искусственного интеллекта на производстве. Китайские власти ставят перед угольной отраслью страны перевести крупнейшие и самые опасные с точки зрения условий труда шахты на высокий уровень автоматизации и цифровизации уже к 2025 году. Всего в КНР находится около 4000 угольных шахт, страна является крупнейшим поставщиком этого вида топлива в мире. К 2035 году все шахты на территории Китая обязаны пройти комплексную модернизацию. Huawei одновременно развивает свои компетенции в сфере автоматизации работы медицинских учреждений и портов. Подобные решения будут способствовать росту производительности труда в соответствующих отраслях китайской экономики, а в отдельных случаях помогут и решить проблему дефицита или старения кадров. Учёные нашли способ запускать большие ИИ-модели на системах мощностью 13 Вт, вместо 700 Вт
26.06.2024 [22:08],
Анжелла Марина
Исследователи из Калифорнийского университета в Санта-Круз разработали метод, позволяющий запускать большие языковые модели искусственного интеллекта (LLM) с миллиардами параметров при значительно меньшем потреблении энергии, чем у современных систем. 
Источник изображения: Stefan Steinbauer/Unsplash Новый метод позволил запустить LLV с миллиардами параметров при энергопотреблении системы всего в 13 Вт, что эквивалентно потреблению бытовой светодиодной лампы. Это достижение особенно впечатляет на фоне текущих показателей энергопотребления ИИ-ускорителей. Современные графические процессоры для центров обработки данных, такие как Nvidia H100 и H200, потребляют около 700 Вт, а грядущий Blackwell B200 вообще может использовать до 1200 Вт на один GPU. Таким образом, новый метод оказывается в 50 раз эффективнее популярных сегодня решений, пишет Tom's Hardware. Ключом к успеху стало устранение матричного умножения (MatMul) из процессов обучения. Исследователи применили два метода. Первый — это перевод системы счисления в троичную, использующую значения -1, 0 и 1, что позволило заменить умножение на простое суммирование чисел. Второй метод основан на внедрении временных вычислений, при котором сеть получила эффективную «память», позволившую работать быстрее, но с меньшим количеством выполняемых операций. Работа проводилась на специализированной системе с FPGA, но исследователи подчёркивают, что большинство их методов повышения эффективности можно применить с помощью открытого программного обеспечения и настройки уже существующих на сегодня систем. Исследование было вдохновлено работой Microsoft по использованию троичных чисел в нейронных сетях, а в качестве эталонной большой модели учёные использовали LLaMa от Meta✴. Рюдзи Чжу (Rui-Jie Zhu), один из аспирантов, работавших над проектом, объяснил суть достижения в замене дорогостоящих операций на более дешёвые. Хотя пока неясно, можно ли применить этот подход ко всем системам в области ИИ и языковых моделей в качестве универсального, потенциально он может радикально изменить ландшафт ИИ. Немаловажно, что учёные открыли исходный код своей разработки, что позволит крупным игрокам рынка ИИ, таким как Meta✴, OpenAI, Google, Nvidia и другим беспрепятственно воспользоваться новым достижением для обработки рабочих нагрузок и создания более быстрых и энергоэффективных систем искусственного интеллекта. В конечном итоге это приведёт к тому, что ИИ сможет полнофункционально работать на персональных компьютерах и мобильных устройствах, и приблизится к уровню функциональности человеческого мозга. ИИ любит число 42 и подобно людям не умеет выбирать случайные числа
29.05.2024 [11:59],
Владимир Мироненко
Компания Gramener, специализирующаяся на анализе данных для решения сложных бизнес-задач, провела исследование, показавшее, что ИИ-модели выбирают случайные числа точно так же, как люди. 
Источник изображения: geralt/Pixabay В ходе эксперимента специалисты Gramener предложили нескольким крупным чат-ботам на базе большой языковой модели (LLM) выбрать случайное число от 0 до 100. Как оказалось, у всех трёх протестированных моделей было «любимое» число, которое всегда было их ответом в наиболее детерминированном режиме, и которое называлось чаще всего даже при более «высоких температурах» — настройке, которая увеличивает вариативность ответов модели. Выяснилось, что модели OpenAI GPT-3.5 Turbo нравится число 47, хотя раньше ей нравилось число 42 — число, прославленное английским писателем Дугласом Адамсом в серии романов «Автостопом по Галактике». Модель Claude 3 Haiku компании Anthropic назвала число 42, а Google Gemini — тоже 42. Что ещё более интересно, все три модели продемонстрировали человеческую предвзятость при выборе других чисел, даже при «высокой температуре». Все ИИ-модели старались избегать как небольших, так и больших чисел. Модель Claude 3 Haiku никогда не называла числа больше 87 или меньше 27, и даже это были отклонения. Чисел с двумя одинаковыми цифрами тоже старательно избегали: не было 33, 55 или 66, но назвали 77 (оканчивается на цифру 7, которую часто называют люди). Почти не было круглых чисел — хотя однажды Gemini при самой «высокой температуре» выбрала 0. Поведение ИИ-моделей объясняется просто. Они не знают, что такое случайность и руководствуются при выборе полученными в процессе обучения знаниями, повторяя, что чаще всего писали люди в ответ на просьбу «Выбери случайное число». Чем чаще число появлялось в ответах, тем чаще модель его повторяет. Люди почти никогда не выбирают 1 или 100. В их ответах крайне редко встречается число, кратное 5, как и числа с повторяющимися цифрами, например 66 и 99. Числа не кажутся «случайными»» в выборе людей, потому что они воплощают для них в себе какое-то качество: маленькое, большое, отличительное. Также часто люди выбирают числа, оканчивающиеся на 7, обычно где-то посередине диапазона. При каждом взаимодействии с ИИ-системами следует помнить, что их научили действовать так, как это делают люди. Результаты кажутся человечными, потому что они взяты непосредственно из контента, созданного человеком, хотя и переработаны для удобства пользователей. Браузер Opera One теперь может локально запускать большие языковые модели
03.04.2024 [17:44],
Владимир Фетисов
В прошлом году компания Opera представила новый браузер Opera One, который ориентирован на использование технологий на основе искусственного интеллекта. Теперь же разработчики объявили, что пользователи приложения смогут скачивать и локально использовать на своих компьютерах большие языковые модели (LLM). 
Источник изображения: Opera На данный момент пользователи Opera One могут выбирать между более чем 150 языковыми моделями из более чем 50 семейств. Среди доступных LLM можно выделить алгоритмы LLaMA от Meta✴ Platforms, Gemma (открытая версия модели Gemini) от Google и Vicuna. Нововведение будет доступно в рамках программы Opera AI Feature Drops, позволяющей пользователям получить ранний доступ к некоторым ИИ-функциям. По данным Opera, для запуска LLM на локальных компьютерах пользователей используется фреймворк с открытым исходным кодом Ollama. В настоящее время все доступные LLM представляют собой части библиотеки Ollama, но в будущем разработчики планируют реализовать возможность доступа к моделям из разных источников. При скачивании какой-либо LLM потребуется более 2 Гбайт свободного места на локальном носителе. «Opera впервые предоставляет доступ к большому количеству локальных LLM сторонних разработчиков непосредственно в браузере. Ожидается, что их размер будет уменьшаться по мере того, как они будут становиться более специализированными и ориентированными на решение определённых задач», — прокомментировал данный вопрос Ян Стендаль (Jan Standal), вице-президент Opera. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






