|
Опрос
|
реклама
Быстрый переход
AMD похвасталась победой Epyc на Zen 6 над Nvidia Vera — но сравнение вызвало вопросы
24.07.2026 [19:48],
Сергей Сурабекянц
Один из руководителей AMD заявил, что был «очень рад», увидев опубликованные Nvidia результаты тестов целочисленной производительности SPEC CPU 2026 для процессора Vera. AMD использовала аналогичную конфигурацию для запуска тех же тестов на своих процессорах Epyc Venice на базе Zen 6 и утверждает, что пропускная способность Venice в 2,2 раза выше, чем у Nvidia Vera, а производительность на ядро больше в 1,2 раза. На самом деле, всё далеко не так однозначно. 
Источник изображений: AMD «Мы очень рады, что Nvidia опубликовала свои результаты производительности Vera, — заявил корпоративный вице-президент AMD по вычислительным и корпоративным решениям Рави Куппусвани (Ravi Kuppuswany). — Мы, честно говоря, были немного консервативны. Я думал, что мы превосходим их с меньшим отрывом […] Мы рассчитывали на преимущество как минимум в 10 %. А оказалось, что у нас преимущество в 20 %, и мы ещё даже не закончили полную настройку». AMD сравнила двухпроцессорные конфигурации из своих 256-ядерных чипов Epyc 9996 с TDP 600 Вт и 88-ядерного Nvidia Vera с TDP 450 Вт. И хотя AMD считает такое сопоставление справедливым, нет сомнений, что процессор с почти втрое большим количеством ядер и дополнительными 150 Вт TDP обладает значительно более высокой пропускной способностью. Сама Nvidia утверждает, что её чип не является прямым конкурентом Venice, а предназначен для решения вполне определённого круга задач. 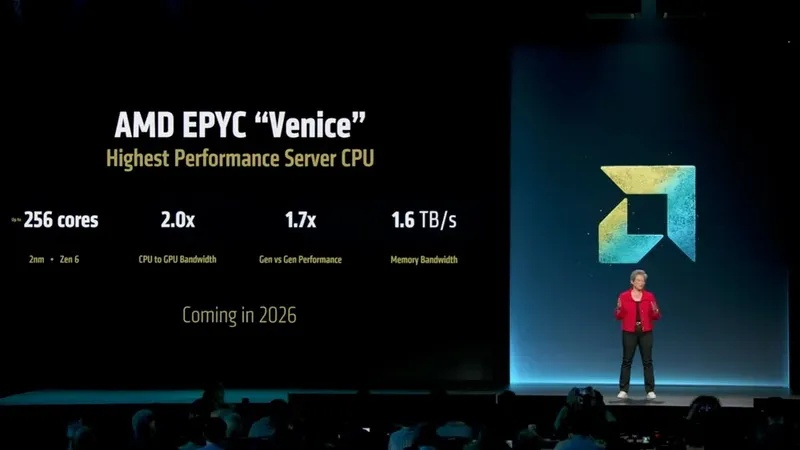 Для сравнения производительности на ядро общий балл теста SPECrate_int, загружающего во все потоки копию приложения и измеряющего объём выполненной работы за заданное время, был поделён на количество ядер. По данным Nvidia, её чип Vera набрал 925 баллов. AMD сообщила о 1210 баллах для своего 96-ядерного процессора Epyc, хотя такого чипа, похоже, не существует. У AMD есть 96-ядерный Epyc 9686F, который разгоняется до 5 ГГц, но его заявленный TDP составляет 500 Вт, а не 600 Вт. Тем не менее AMD разделила полученные баллы на количество ядер с учётом двухпроцессорных конфигураций тестовых платформ, что дало примерно 6,3 для AMD и примерно 5,3 для Nvidia. AMD заявляет о разнице в 1,2 раза, что на самом деле означает преимущество примерно в 18,8 %. AMD слегка покривила душой и для сравнения с чипом Nvidia выбрала разные процессоры для разных тестов. Однако, если провести те же самые приблизительные расчёты производительности на ядро для Epyc 9996, результат составит 4,04 балла на ядро, что, мягко говоря, несколько меняет общую картину уже не в пользу AMD: производительность на ядро окажется в 1,3 раза выше у чипа Nvidia Vera. Это примерно на 35 % ниже, чем показатель производительности на ядро у более производительного Epyc 9686F.  Эти числа сами по себе не слишком показательны, поскольку сравниваются 256-ядерный и 88-ядерный процессоры, однако они хорошо демонстрируют, как масштабируется производительность чипов при нормализации по числу ядер и полной загрузке. Эти цифры нельзя считать окончательными, так как SPEC предъявляет очень строгие требования к отчётности, и до появления официальных результатов невозможно точно сказать, как эти чипы соотносятся друг с другом. И даже после публикации официальных результатов останутся расхождения из-за дополнительных уровней оптимизации компилятора (AMD и Nvidia использовали GCC 15.2) и разнообразия рабочих нагрузок, для которых будут использоваться эти чипы. Всё же можно считать, что базовое соотношение сил уже определено, но только в отношении целочисленных нагрузок. Не менее важна векторизованная производительность, в которой AMD традиционно занимает сильные позиции на рынке серверных процессоров. Пока компании не предоставили результатов по вычислениям с плавающей запятой, поэтому делать окончательные выводы преждевременно. Nvidia утверждает, что все её крупнейшие клиенты уже используют серверы на основе Vera Rubin
22.07.2026 [08:51],
Алексей Разин
Компания Nvidia на этой неделе провела мероприятия для прессы, клиентов и партнёров, целью которых была демонстрация её готовности поставлять потребителям новейшие серверные компоненты и готовые системы. Решения на основе ускорителей поколения Vera Rubin, по словам руководства Nvidia, уже доставлены основным крупным клиентам компании и начинают использоваться. 
Источник изображения: Nvidia Данные комментарии прозвучали из уст вице-президента Nvidia Иэна Бака (Ian Buck), который в компании отвечает за направление центров обработки данных. Во время брифинга в штаб-квартире Nvidia он заявил: «Мы абсолютно находимся на стадии полномасштабного производства. Это оборудование уже установлено у всех наших крупнейших потребителей». Инвесторы и клиенты Nvidia с некоторым опасением следили за этапом масштабирования производства серверных систем поколения Vera Rubin, поскольку новая продукция всегда таит вероятные сложности и потенциальные задержки. Представители Nvidia заявляют, что в этом отношении переживать не о чем. Оборудование нового поколения будет не только производительнее предыдущего, его будет проще вводить в эксплуатацию. Более того, компоновка новых серверов рассчитана с учётом упрощения процедуры сборки: количество кабельных подключений максимально сокращено, чтобы перевести операции на использование роботов, а не людей. Система жидкостного охлаждения также сокращает потребность в свободном пространстве внутри корпуса и количестве установленных вентиляторов. Один из лидеров рынка ИИ — американский стартап OpenAI, собирается начать масштабную эксплуатацию систем семейства Vera Rubin в текущем квартале, как отметили представители Nvidia. Уже сейчас эти системы используются компаниями Google, CoreWeave, Microsoft, Meta✴✴ Platforms и Dell Technologies. В окрестностях штаб-квартиры Nvidia в Калифорнии построена специальная экспериментальная площадка с новейшим серверным оборудованием, которое клиенты могут протестировать и оценить на пригодность к своим нуждам. OpenAI как раз сейчас проводит подобные испытания. По данным CoreWeave, системы поколения Vera Rubin способны выдавать в десять раз больше токенов по сравнению с предшественниками. Представители Nvidia также настаивают, что центральные процессоры Vera оказываются в 1,8 раза быстрее в программировании на Python по сравнению с конкурирующими AMD Turin. Представители последней из компаний возразили, что сравнение с более новыми процессорами Venice не будет демонстрировать подобного разрыва. Nvidia раскрыла детали процессора Vera: 88 Arm-ядер Olympus, 176 потоков и память LPDDR5X с пропускной способностью 1,2 Тбайт/с
21.07.2026 [22:35],
Николай Хижняк
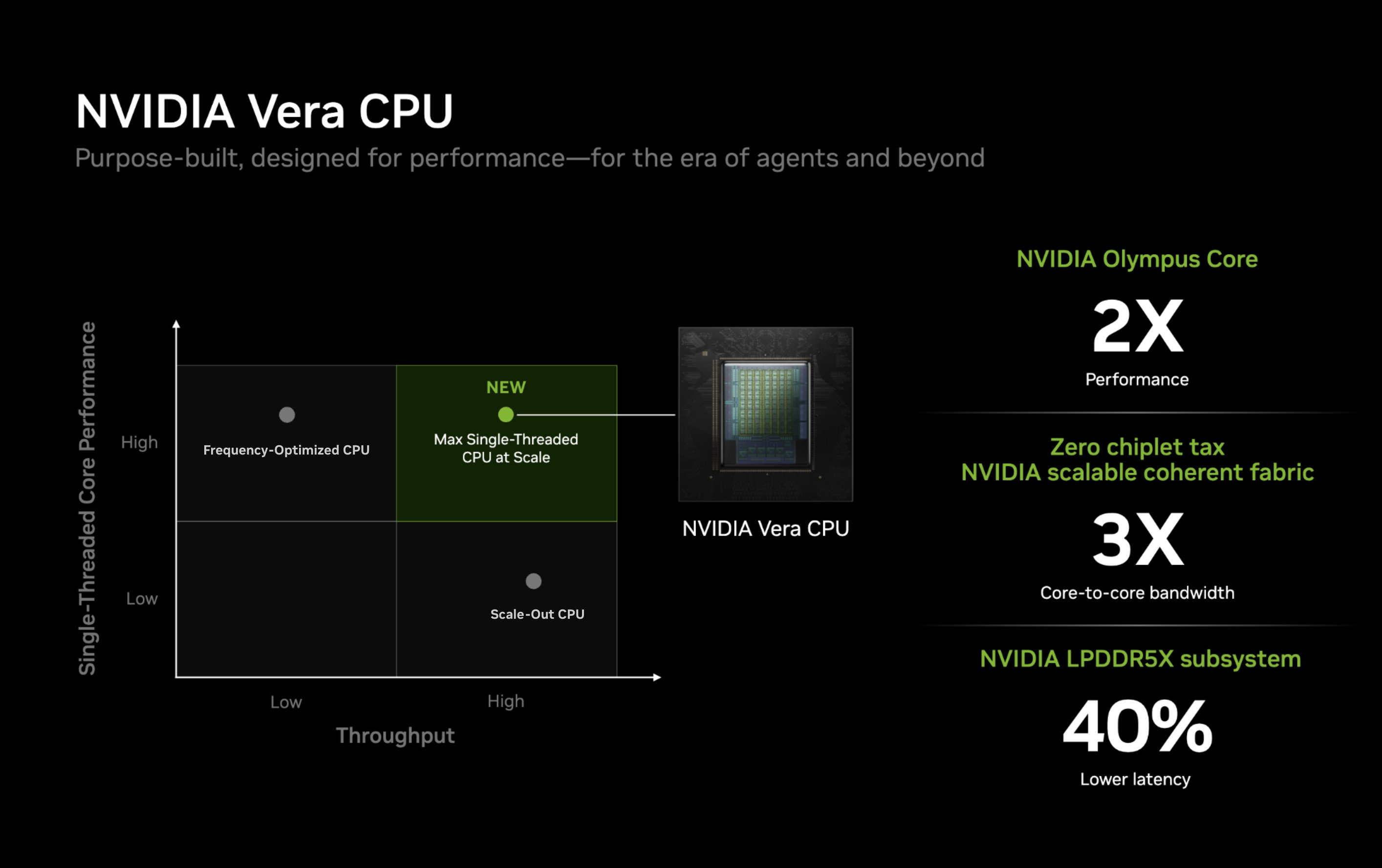
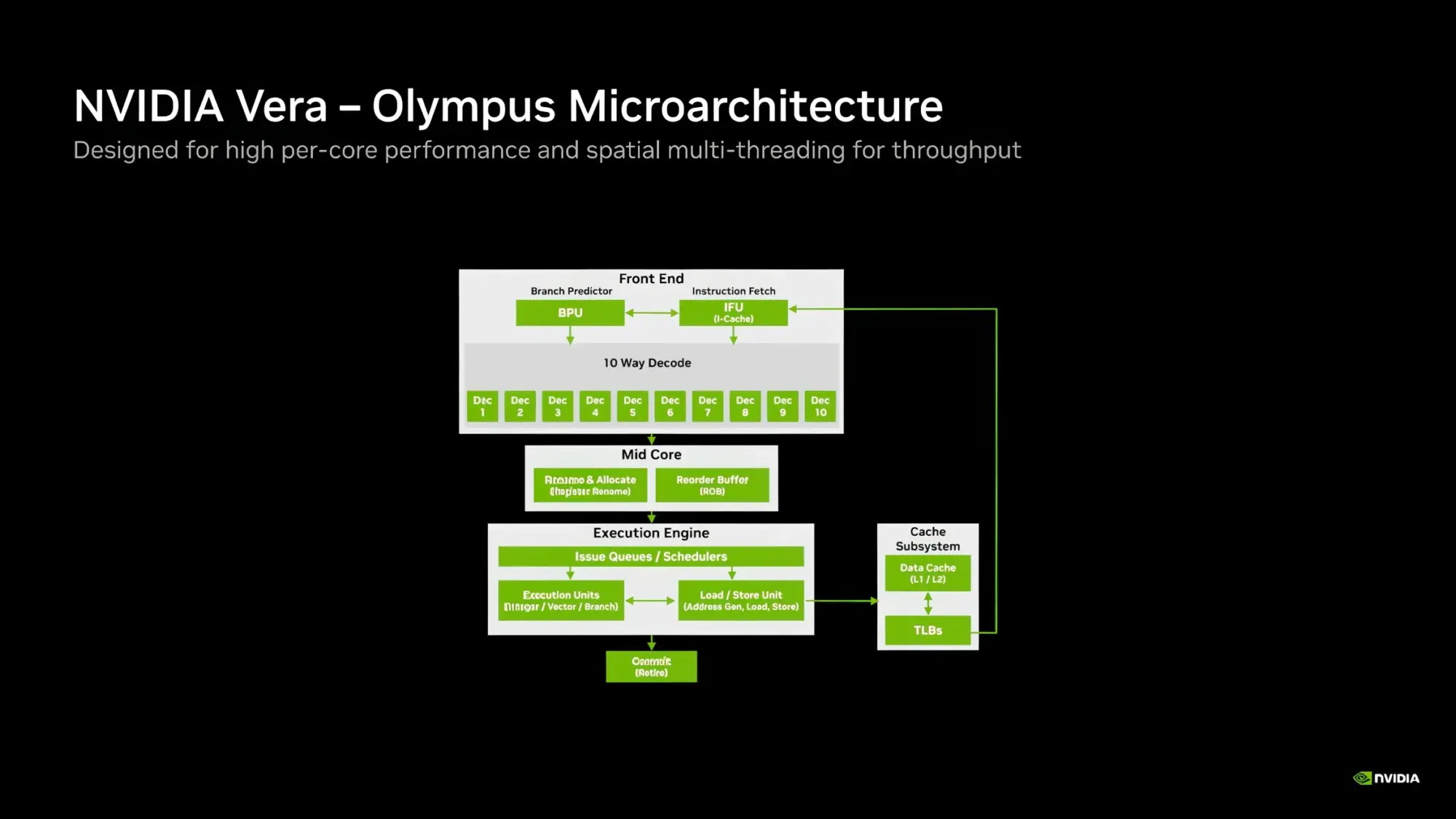
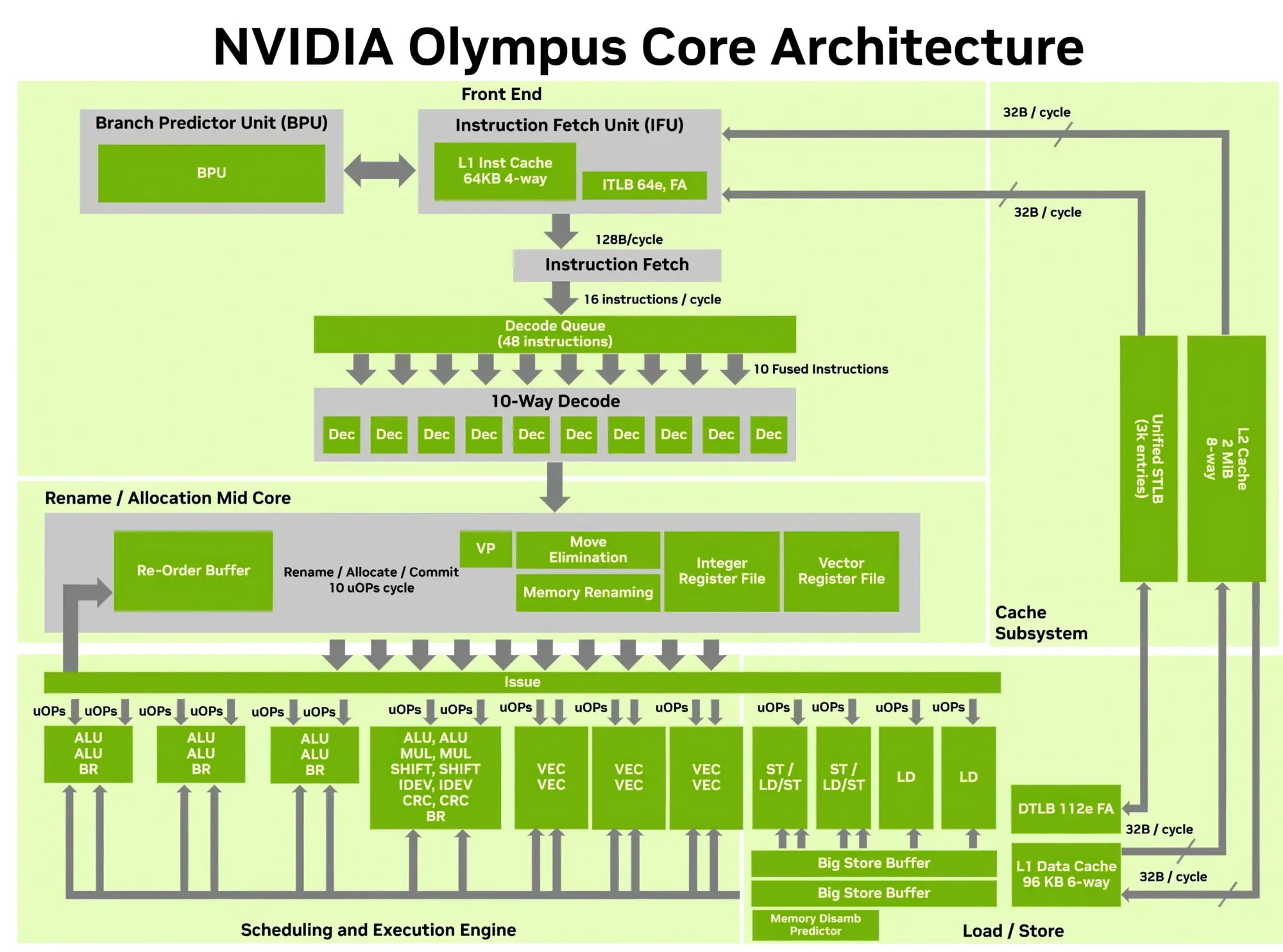
Компания Nvidia опубликовала новые подробности об архитектуре своего процессора Vera для центров обработки данных и используемом в нём специализированном ядре Olympus. Чип Vera объединяет 88 ядер Olympus, 176 аппаратных потоков и унифицированный кеш L3 объёмом 164 Мбайт на монолитном вычислительном кристалле. 
Источник изображений: Nvidia Каждое ядро Olympus использует широкий конвейер с нейронным предсказателем ветвлений, 64-килобайтный четырёхканальный кеш инструкций L1 и очередь декодирования на 48 инструкций. Ядро может считывать до 16 инструкций за такт и включает 10-канальный декодер, способный обрабатывать до десяти объединённых инструкций за такт. 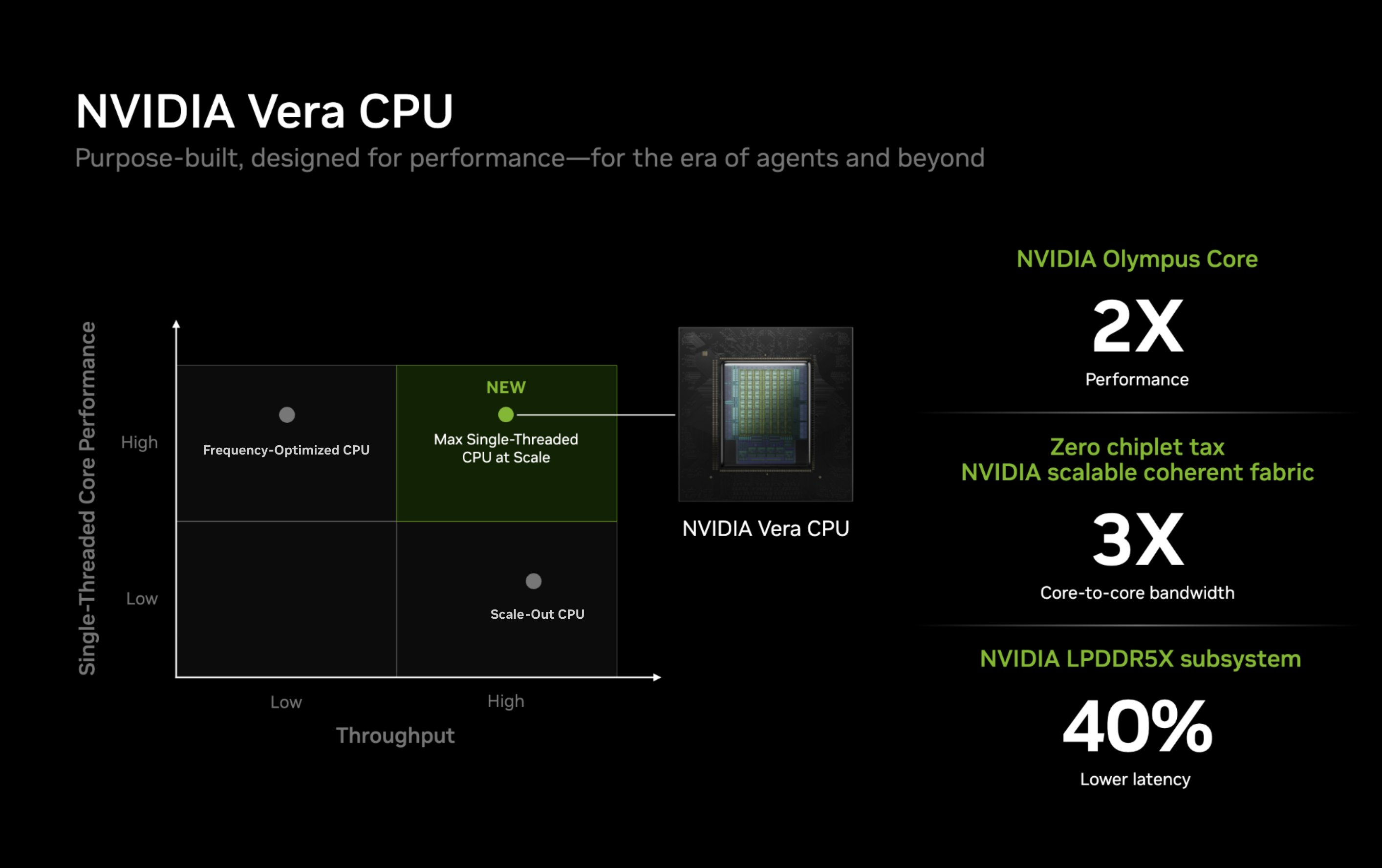 Каждое ядро может переименовывать, выделять и фиксировать до десяти микроопераций за такт. Nvidia также отмечает использование технологий переименования памяти, предсказания значений и исключения перемещений, предназначенных для уменьшения задержек, связанных с зависимостями. Исполнительный блок включает целочисленные операции, операции ветвления, векторные операции, операции с плавающей запятой, криптографические операции, а также выделенные ресурсы для операций загрузки и сохранения данных. Каждое ядро Olympus имеет 96-килобайтный шестиканальный кеш данных L1 и 2-мегабайтный восьмиканальный кеш L2. Nvidia также добавила несколько механизмов аппаратной предварительной выборки, включая предварительную выборку графов для структур данных с большим количеством указателей и рабочих нагрузок, связанных с обработкой графов. Особенности Nvidia Vera
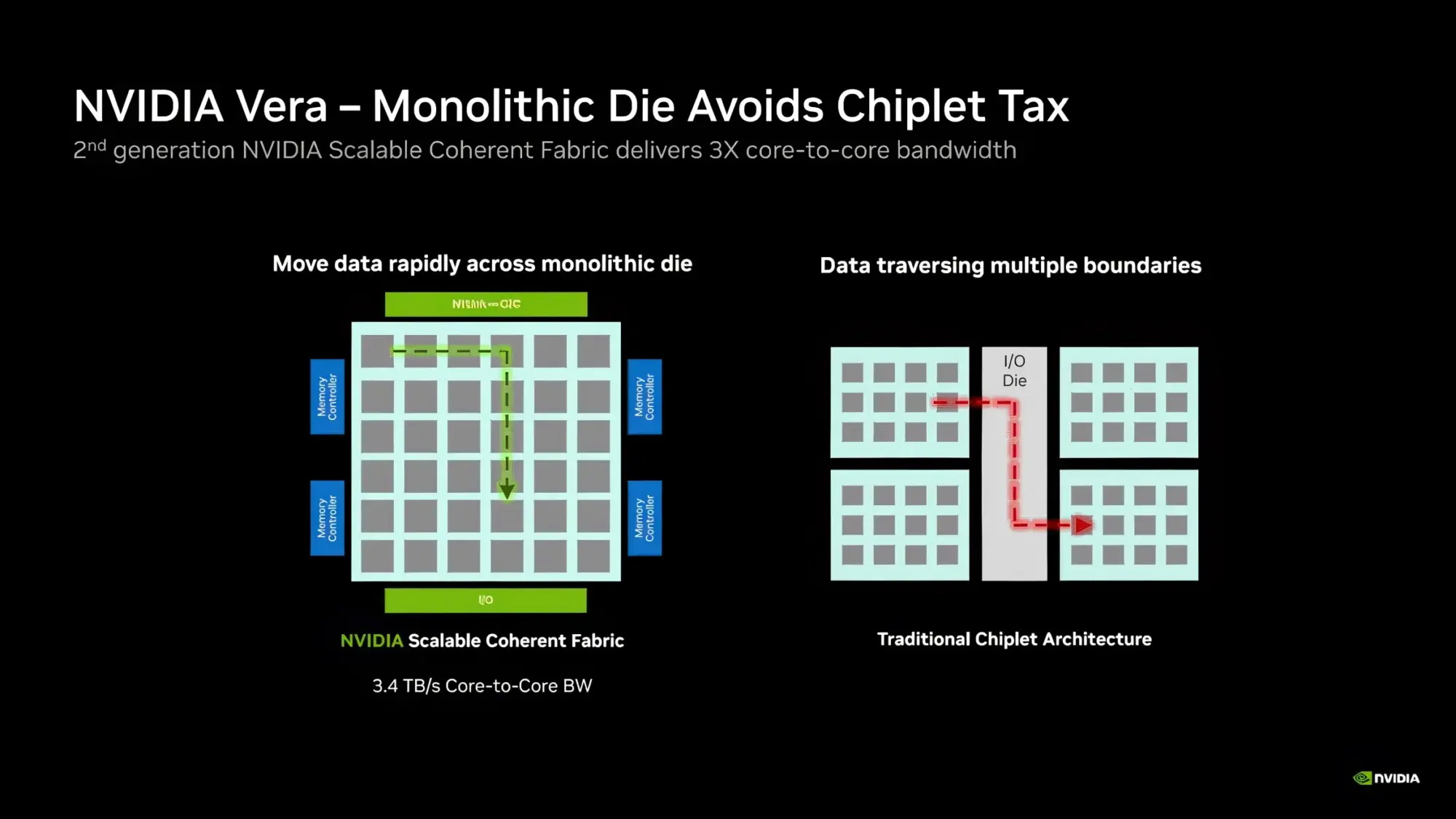
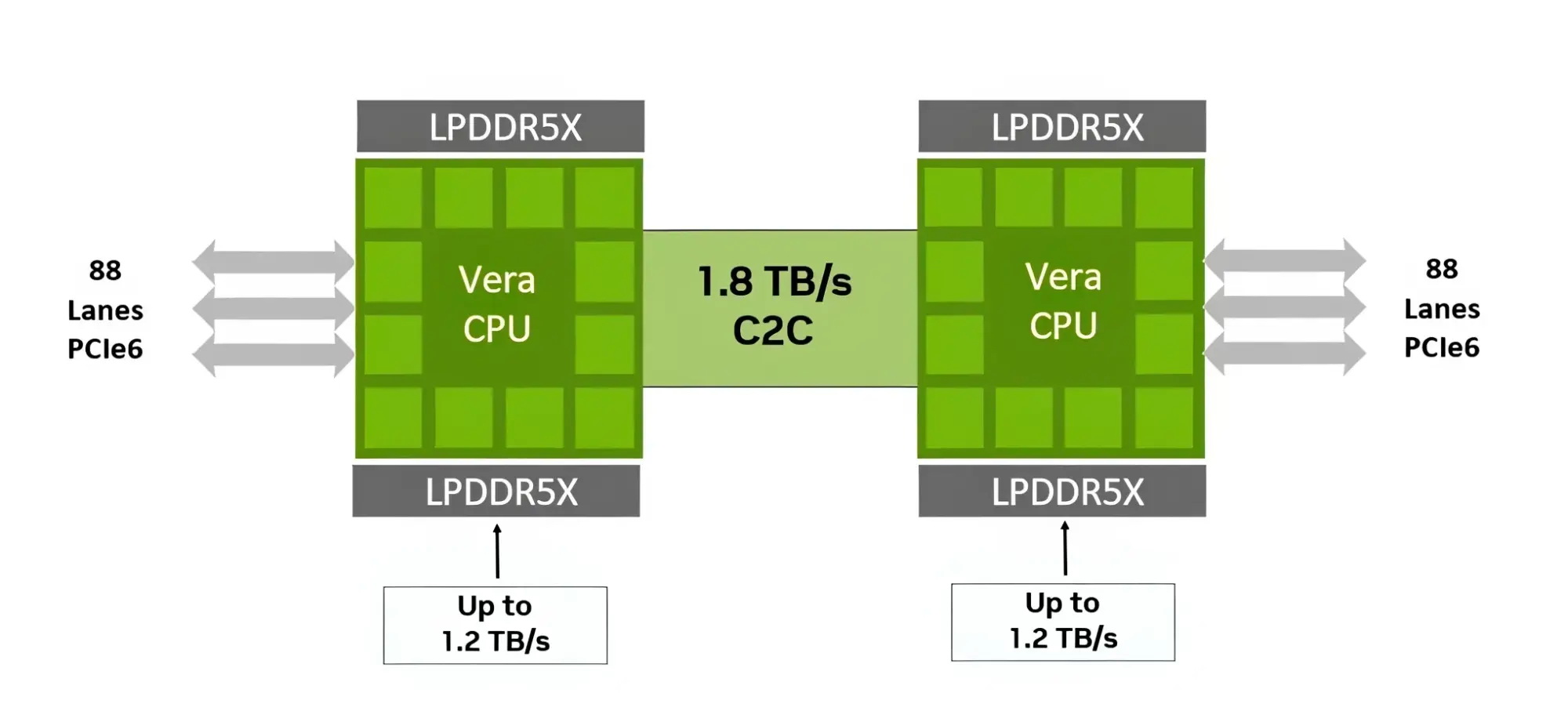
Процессор Vera использует фирменную технологию пространственной многопоточности, которая обеспечивает два аппаратных потока на каждое ядро Olympus. Nvidia заявляет, что такая конструкция позволяет распределять ресурсы ядра между потоками, уменьшая конкуренцию по сравнению с традиционной одновременной многопоточностью. Ядро может отдавать приоритет одному потоку, чувствительному к производительности, в то время как второй поток обрабатывает системные и управляющие задачи. 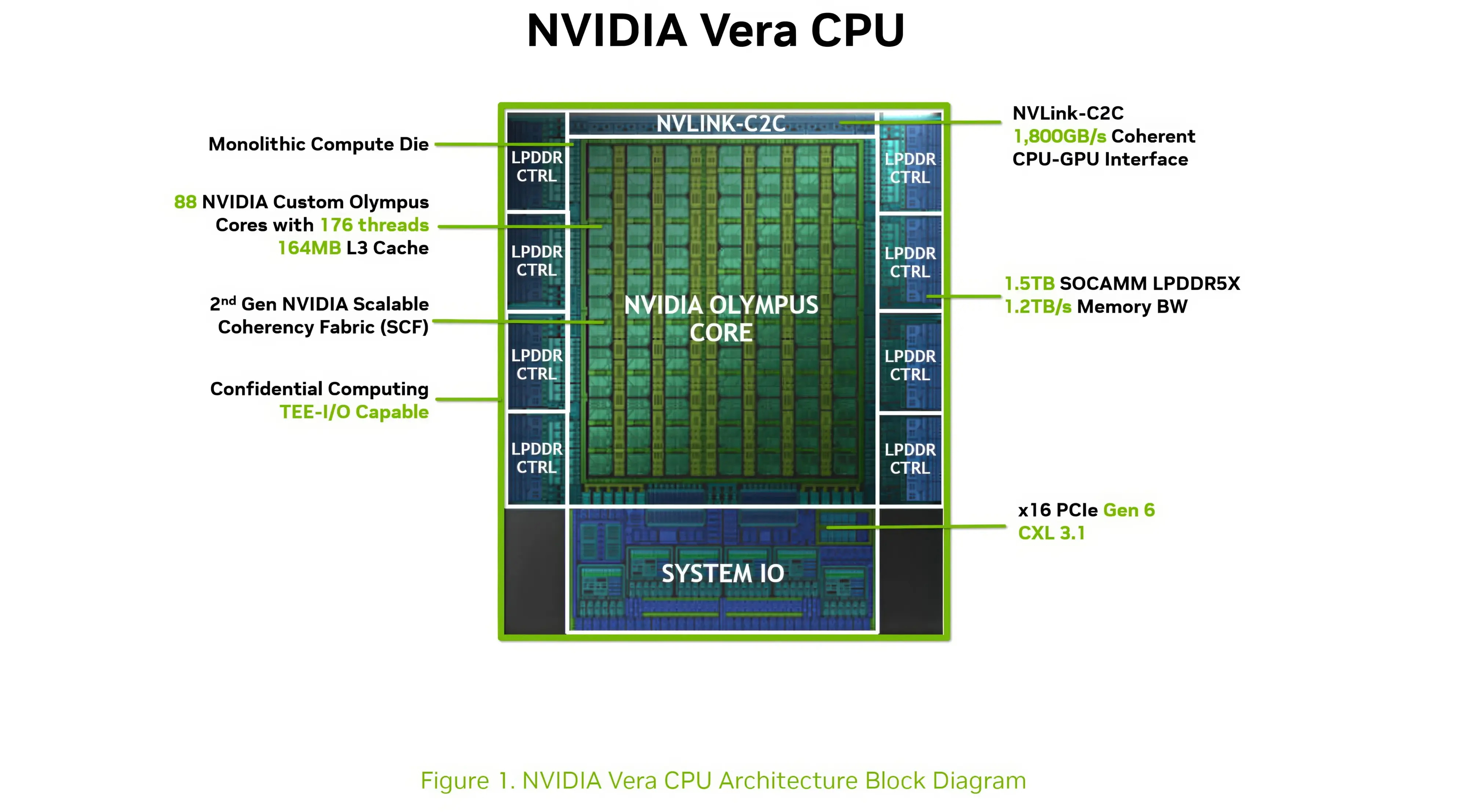 Ядра процессора, кеш, контроллеры памяти и ввода-вывода объединены через масштабируемую когерентную структуру Nvidia второго поколения. Компания заявляет о пропускной способности между ядрами до 3,4 Тбайт/с, пропускной способности памяти SOCAMM2 LPDDR5X до 1,2 Тбайт/с и поддержке до 1,5 Тбайт памяти на процессор. Vera также поддерживает интерфейс NVLink-C2C со скоростью до 1,8 Тбайт/с, PCIe 6.0 и CXL 3.1. Системы с двумя сокетами обеспечивают 176 линий PCIe и используют двухузловую конфигурацию NUMA — по одному домену NUMA на каждый сокет. Nvidia утверждает, что Vera обеспечивает до 1,8 раза более высокую производительность, чем неназванные системы x86, в отдельных рабочих нагрузках, связанных с работой ИИ-агентов. Результаты основаны на внутренних тестах Nvidia SPEC CPU 2026, проведённых в июле 2026 года, и пока не были независимо подтверждены. Не только GPU: Nvidia всерьёз взялась за рынок CPU и уже отгрузила сотни тысяч серверов
21.07.2026 [20:16],
Сергей Сурабекянц
Вице-президент Nvidia по высокопроизводительным вычислениям и изобретатель CUDA Иэн Бак (Ian Buck) сообщил, что компания отгрузила «сотни тысяч» серверов на центральных Arm-процессорах Grace. Ранее для их развёртывания Nvidia заключила партнёрское соглашение с Meta✴✴. Однако реальные масштабы экспансии Nvidia на рынок центральных процессоров могут быть ещё больше, поскольку компания активно пытается конкурировать с Intel и AMD. 
Источник изображений: Nvidia Nvidia стала доминирующей силой в Кремниевой долине благодаря ажиотажному спросу на её графические процессоры во время беспрецедентного строительства центров обработки данных для ИИ. Однако с момента пика в начале этого года рыночная капитализация Nvidia снизилась примерно на $1 трлн, поскольку инвесторы обратили свой взор на производителей центральных процессоров, которые стали не менее востребованы в результате развития ИИ-агентов. Nvidia стремится «оседлать» и этот тренд со своим центральным процессором Vera, который разработан специально для таких задач. Однако, по словам Nvidia, даже до недавнего роста популярности агентов, компания наблюдала спрос на свои процессоры для ресурсоёмких задач. Они массово развёртывались для бэкэнда и операций с большими объёмами данных. Устройство чипов Vera значительно отличается от конкурирующих процессоров Intel и AMD. Обе компании достаточно давно отказались от монолитных кристаллов в пользу чиплетов, что позволило достичь чрезвычайно высокой плотности ядер в ущерб задержкам и когерентности. Чип Vera в этом отношении кардинально отличается, поскольку не только построен на одном кристалле, но и выделяет значительную его часть под шину. 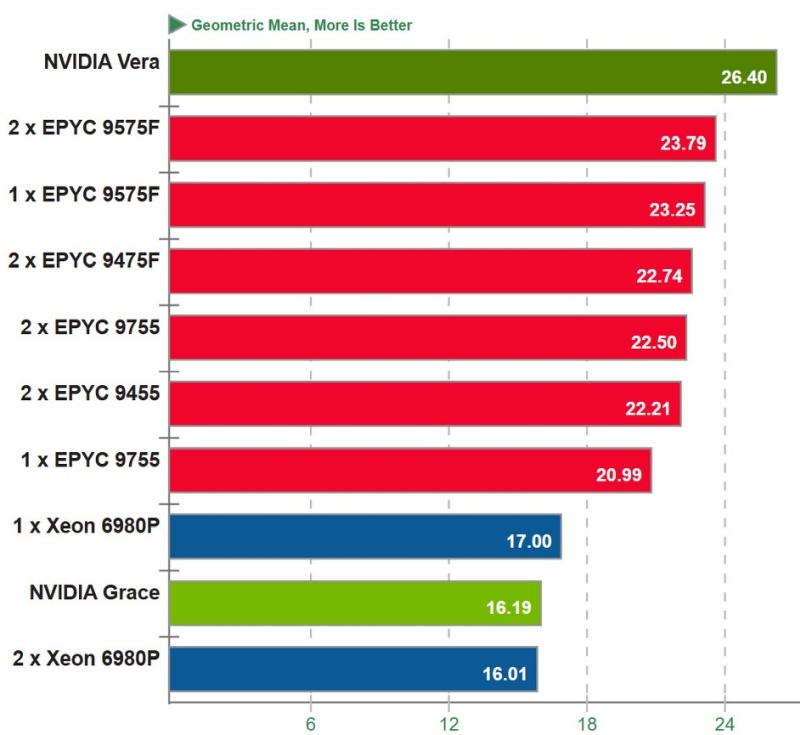 «Одна из причин, почему у нас нет 128 ядер, заключается в том, что мы выделили большую часть площади кристалла под шину [соединяющую ядра], — пояснил Бак. — Внутри этого процессора находится 3,4 Тбайт/с пропускной способности, которая позволяет каждому ядру взаимодействовать с каждым кэшем, каждым контроллером памяти на полной скорости без каких-либо коллизий». Суммарная пропускная способность памяти через интерфейс LPDDR5X достигает 1,2 Тбайт/с (14 Гбайт/с на ядро). Но, как и в случае с чиплетными архитектурами, где пришлось пойти на компромиссы в производительности каждого потока, Vera, вероятно, также пойдёт на компромиссы ради своей уникальной архитектуры. Большинство рабочих нагрузок в ЦОД по-прежнему представляют собой «устаревшие» задачи, для решения которых гиперскейлеры уже разработали соответствующие решения, и даже при, казалось бы, ненасытном спросе на инфраструктуру ИИ, вряд ли ситуация изменится в ближайшие несколько лет. Чипы Vera находятся в полномасштабном производстве вместе с инфраструктурой ИИ следующего поколения от Nvidia, включая графические процессоры Rubin, сетевые карты ConnectX-9, коммутаторы Ethernet SpectrumX и различные компоненты, используемые для сборки стойки Vera Rubin NVL72. Компания заявляет, что в стойку входит около 1,3 миллиона компонентов, а в её производстве принимают участие более чем 300 партнёров Nvidia по всему миру.  По оценкам Nvidia, потенциальный рынок процессоров в 2030 году может достигнуть $200 млрд, что является довольно оптимистичным заявлением по сравнению с прогнозами других представителей отрасли, находящихся в диапазоне от $120 млрд до $170 млрд. По мнению аналитиков Morgan Stanley, ИИ-агенты могут добавить до $60 млрд к рынку процессоров для ЦОД. «Мир не будет обслуживаться одной моделью процессора, и это не входит в наши планы», — подчеркнул Бак в своём интервью. ИИ-модели Perplexity заработают на центральных процессорах Nvidia Vera
08.07.2026 [15:40],
Алексей Разин
Компания Nvidia исторически выпускала определённый ассортимент процессоров, но они в основном применялись в игровых устройствах и бортовых системах автомобилей. С анонсом семейства Vera компания замахнулась на присутствие в перспективном сегменте серверных процессоров, где уже давно доминирует со своими GPU. Стартап Perplexity недавно выразил свою готовность использовать новые чипы Nvidia. 
Источник изображения: Nvidia Об этом сообщило агентство Reuters, которое попутно напомнило о намерениях Nvidia поднять выручку от реализации центральных процессоров до $20 млрд к концу текущего фискального года, который завершится к началу февраля. Упор в эволюции инфраструктуры ИИ сейчас делается на операции инференса, в которых себя хорошо проявляют именно центральные процессоры. Осознавая, что разработчики систем ИИ и облачные гиганты начали самостоятельно разрабатывать чипы, Nvidia пытается удержать клиентов, предлагая им центральные процессоры серверного назначения. Преимущество решений Nvidia в этом сегменте как раз может заключаться в том, что они уже были разработаны в разгар бума ИИ, а потому учитывают всю специфику применения и потребности сегмента. Представители Perplexity, на слова которых ссылается Reuters, уже признали, что ИИ-агенты по работе с созданием программного кода при использовании чипов Nvidia продемонстрировали полуторакратное превосходство в быстродействии по сравнению с центральными процессорами иных поставщиков. Чипы Nvidia, по мнению руководства Perplexity, оптимально подходят для множества типовых вычислительных нагрузок, с которыми ему приходится работать. Какое количество процессоров Vera будет закуплено этим стартапом, не уточняется. Ранее Nvidia сообщили, что её процессоры этого семейства планируют применять компании Oracle, OpenAI и Anthropic. Samsung запустила массовое производство SSD с PCIe 6.0 — они не для ПК
08.07.2026 [11:13],
Павел Котов
Samsung начала массовый выпуск передовых твердотельных накопителей для центров обработки данных — они будут использоваться в оборудовании на платформе Nvidia Vera Rubin. Новинки предлагают ёмкость до 64 Тбайт и скоростной интерфейс PCIe 6.0. 
Источник изображений: sasmung.com Твердотельный накопитель корпоративного класса Samsung PM1763 был представлен на конференции Nvidia GTC. Компания Samsung продемонстрировала его вместе с высокоскоростной памятью нового поколения HBM4 и модулем SOCAMM2 с низким потреблением энергии — они вошли в комплексный пакет для ЦОД с системами искусственного интеллекта.  В накопителе используются новейшие чипы флеш-памяти Samsung V-NAND типа TLC и контроллер, который производится по нормам 4 нм и обеспечивает скорость записи более чем вдвое выше, чем у предшественника, отметил корейский производитель. SSD Samsung PM1763 разработан для снижения задержки данных в системах с современными процессорами и ИИ-ускорителями. Для поддержания высоких скоростей во время обучения и инференса ИИ накопитель предусматривает систему жидкостного охлаждения. PM1763 оснащены интерфейсом PCIe 6.0. В основу положены чипы флеш-памяти TLC NAND. Заявлена скорость последовательного чтения до 28 400 Мбайт/с, и скорость последовательной записи до 21 000 Мбайт/с. Скорость операций ввода/вывода в секунду при произвольном чтении данных блоками по 4 Кбайт составляет до 6,8 млн IOPS, при произвольной записи — до 950 тыс. IOPS. По итогам I квартала Samsung, по данным TrendForce, занимала наибольшую долю на рынке корпоративных SSD — 35 %. За ней следовали SK hynix, Micron, Kioxia и её партнёр в лице Sandisk. Nvidia начнёт продавать самые передовые чипы в Китай — но обучать ИИ на них вряд ли получится
12.06.2026 [11:39],
Алексей Разин
В прошлом месяце глава и основатель Nvidia Дженсен Хуанг (Jensen Huang) выразил надежду, что поставки центральных процессоров Vera на китайский рынок будут разрешены. Теперь агентство Reuters сообщает, что компания уже начала принимать заказы у китайских клиентов, и первые процессоры Vera попадут в КНР к августу этого года. 
Источник изображения: Nvidia Источник отмечает, что Nvidia призвала китайских клиентов приступить к размещению заказов на поставку процессоров Vera, которые она собирается начать исполнять с августа этого года. Напомним, Nvidia оценивает ёмкость рынка центральных процессоров $200 млрд, и в эту сумму она включает потенциальную выручку, которую может получить от их реализации в КНР. Некоторые китайские компании, по словам Reuters, выразили заинтересованность в приобретении процессоров Vera. Во время презентации этих чипов в марте текущего года руководство Nvidia пояснило, что Alibaba и ByteDance сотрудничали с ней в сфере развёртывания систем на базе новых процессоров. При этом сложно судить, выразилось ли это сотрудничество в размещении реальных заказов. По данным Reuters, одна крупная китайская облачная компания намерена разместить заказ на более чем 300 серверных систем, каждая из которых содержит по два процессора Vera. Пробная партия позволит заказчику провести эксперименты с оборудованием Nvidia, чтобы понять, потребуется ли его дополнительное количество. Во многом готовность китайских разработчиков закупать процессоры Vera будет определяться программной совместимостью, ведь если какая-то часть ПО уже использует чипы китайского производства, то миграция на платформу Nvidia может представлять определённые трудности. По оценкам SemiAnalysis, базовая стоимость одного процессора Vera без учёта потенциальных скидок превысит $20 000, а полностью укомплектованная 256 чипами серверная стойка обойдётся заказчику в $10 млн или около того. Двухпроцессорные системы, которые будут более доступны по цене, начнут поставляться позже более дорогих многопроцессорных конфигураций. В текущем фискальном году, который завершится в конце января, Nvidia рассчитывает выручить на поставках Vera около $20 млрд. По данным Reuters, китайские клиенты Nvidia собираются первоначально испытывать процессоры Vera в своих центрах обработки данных, расположенных за пределами Китая. AMD заявила, что процессоры Epyc на Zen 6 будут до 3,3 раза быстрее Nvidia Vera в расчёте на стойку
11.06.2026 [09:23],
Алексей Разин
С выходом Nvidia на рынок серверных центральных процессоров у AMD появляется ещё один серьёзный конкурент, которого она старается не упускать из виду. Недавно вторая из компаний решила провести сравнение быстродействия своих серверных процессоров Epyc поколения Zen 6 с процессорами Nvidia Vera, заявив о превосходстве на 230 % в удельном выражении на одну вычислительную стойку. 
Источник изображения: AMD По данным TechSpot, компания AMD недавно опубликовала прогноз по быстродействию своих процессоров Epyc семейства Venice с архитектурой Zen 6 в сравнении с Nvidia Vera. Если первые будут предлагаться в 256-ядерном исполнении, то вторые получат 88 ядер и 176 потоков. Сравнение проводится не напрямую, а из расчёта удельной производительности на всю стойку с общим уровнем энергопотребления 100 кВт. Попутно AMD прогнозирует, что по сравнению с 192-ядерными процессорами Epyc семейства Turin соотношение быстродействия и энергопотребления улучшится на 70 %, а плотность вычислительных потоков вырастет на 30 %. 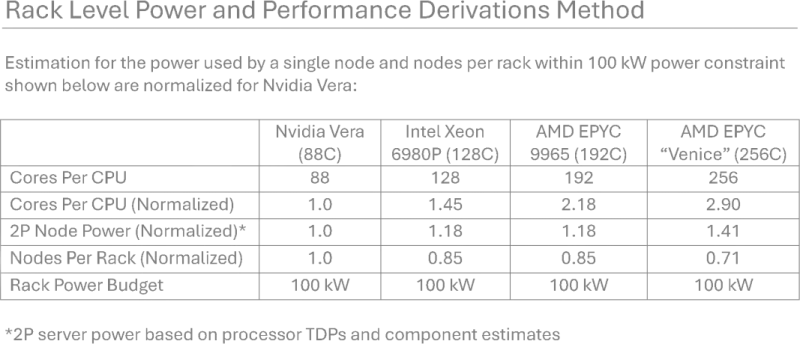
Источник изображения: AMD, TechSpot Nvidia уже заявляла о превосходстве своих процессоров Vera, но тесты проводились в строго контролируемых самой компанией условиях, поэтому рассчитывать на их объективность достаточно сложно. Это не помешало представителям Phoronix признать Vera самыми производительными процессорами с архитектурой Arm. Компания AMD опиралась на результаты этих тестов, формируя свои данные для сравнения с Epyc. Стойка на основе процессоров Venice, по прогнозам AMD, будет обеспечивать превосходство над Vera в размере 3,3 раза по уровню быстродействия. Процессоры Epyc более зрелого поколения Turin окажутся в 2,37 раза быстрее, а преимущество процессоров Intel Xeon 6980P с 128 ядрами будет измеряться 46 %. 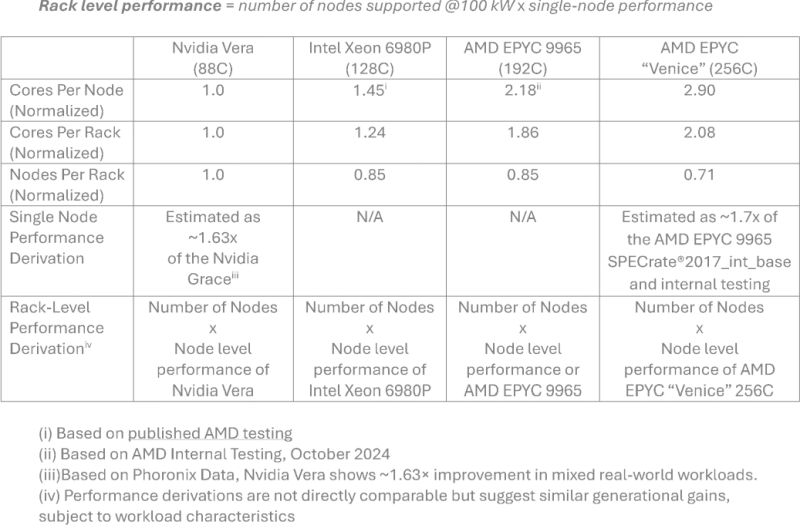
Источник изображения: AMD, TechSpot AMD также утверждает, что 64-ядерные процессоры Venice окажутся на 27 % быстрее 88-ядерных Nvidia Vera в удельном выражении на одно ядро, а 96-ядерные обеспечат преимущество в 11 % в SPECrate2017_int_base. По словам представителей AMD, в агентских вычислениях для сферы ИИ её процессоры Venice в общем случае проявят себя лучше Nvidia Vera, поскольку обладают более высоким количеством ядер. Процессоры Epyc семейства Verano, которые получат архитектуру Zen 7, изначально будут оптимизированы под агентские задачи, а потому проявят себя в сфере ИИ ещё лучше. Предполагается, что выпуском этих процессоров по ангстремной технологии A14 займётся TSMC. 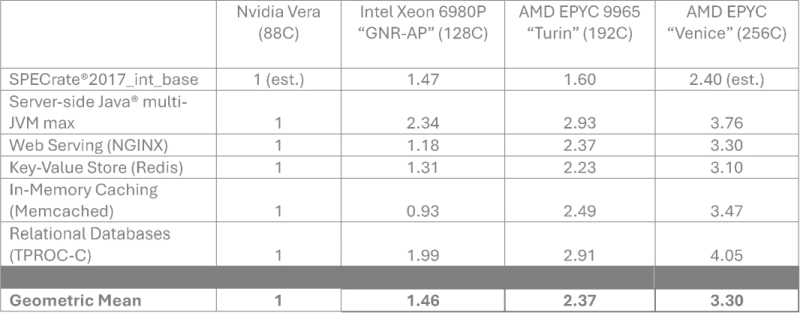
Источник изображения: AMD, TechSpot SK hynix за ближайшие пять лет удвоит производственные мощности по выпуску памяти
02.06.2026 [11:18],
Алексей Разин
Значимость производителей памяти подчёркивается хотя бы тем фактом, что председатель совета директоров южнокорейской SK Group Чхэ Тхэ Вон (Chey Tae-won) оказался приглашён на отраслевую выставку Computex 2026 на Тайване, где сделал несколько важных заявлений. В частности, он пообещал удвоить мощности SK hynix по производству памяти за последующие пять лет. 
Источник изображения: SK hynix Он же в марте этого года, как напоминает Reuters, сообщил о возможности сохранения дефицита памяти на мировом рынке до 2030 года. SK hynix, которая в составе упоминаемого южнокорейского конгломерата занимается выпуском памяти, нуждается в расширении круга своих партнёров на Тайване, и дело не должно ограничиваться одной лишь TSMC, как отметил глава холдинга. Чхэ Тхэ Вон выразил надежду, что SK hynix сможет остаться крупнейшим поставщиком HBM для ускорителей Nvidia Vera Rubin. Как известно, на этот статус претендует конкурирующая Samsung Electronics, но SK hynix явно не собирается сдаваться без боя. На прошлой неделе капитализация SK hynix впервые в истории превысила $1 трлн, что говорит об уверенности инвесторов в способности этого производителя памяти развивать бизнес в условиях бума ИИ. По данным Counterpoint Research, в первом квартале текущего года SK hynix сохраняла за собой 58 % мирового рынка HBM, а Samsung и Micron досталось по 21 %. Anthropic, OpenAI и SpaceX первыми внедрят серверные процессоры Nvidia Vera
01.06.2026 [12:42],
Алексей Разин
В третьем квартале этого года, как дал понять на Computex 2026 глава и основатель Nvidia Дженсен Хуанг (Jensen Huang), центральные процессоры Vera серверного назначения начнут массово производиться. Ими уже активно интересуются крупные компании ИИ-сегмента типа OpenAI, Anthropic и SpaceX, как добавил Хуанг, они будут первыми использовать их в своих ЦОД. 
Источник изображения: Nvidia До сих пор развитие вычислительной инфраструктуры ИИ во многом полагалось на GPU компании Nvidia, но по мере перехода к инференсу они начали отходить на второй план. Центральные процессоры оказались более востребованными, и в этом сегменте Nvidia не собирается уступать рынок Intel и AMD, также предлагая собственные серверные CPU, которые в текущем поколении известны под наименованием Vera. В прошлом месяце Дженсен Хуанг отметил, что доля решений Nvidia в инфраструктуре Amazon (AWS) продолжает расти даже в условиях, когда этот клиент стремится всё активнее использовать компоненты собственной разработки типа тех же чипов семейства Graviton. Именно Nvidia способна предлагать клиентам комплексные готовые решения для ЦОД самого разного назначения. Даже начинающие разработчики с помощью фирменной инфраструктуры Nvidia очень быстро могут развивать бизнес, как убеждён глава компании. По его словам, процессоры Vera в 1,8 раза быстрее в некоторых ИИ-задачах по сравнению с процессорами Intel, использующими x86-совместимую архитектуру. Nvidia также предлагает клиентам продвинутое ПО для управления ЦОД и мониторинга основными показателями, включая уровень энергопотребления. Только за счёт более эффективного управления клиенты Nvidia могут на 40 % увеличить количество используемых ускорителей этой марки, не выходя за рамки общего целевого уровня энергопотребления. В рамках сотрудничества с китайской Unitree компания Nvidia также предложила разработчикам человекоподобных роботов некие эталонные наборы и платформы для быстрого создания таких роботов. По крайней мере, управляющие чипы и прилагаемое к ним ПО будут согласованы и готовы к работе друг с другом, а ещё клиентам будут поставляться уже готовые кисти рук для таких роботов, которые не потребуется обучать базовым манипуляциям с нуля. Nvidia Vera разгромил лучшие Intel Xeon и AMD EPYC в тестах серверных CPU
26.05.2026 [20:27],
Сергей Сурабекянц
Компания Phoronix провела тестирование новейшего процессора Nvidia Vera, которое продемонстрировало впечатляющие достижения Nvidia в разработке специализированных процессоров. Результаты тестов показывают, что эта платформа на базе архитектуры Arm достаточно мощна, чтобы превзойти новейшие модели Intel Xeon и AMD EPYC в секторе центров обработки данных (ЦОД). 
Источник изображения: Nvidia Процессор Vera оснащён 88 специализированными ядрами Arm v9.2 Olympus, обеспечивающими 176 вычислительных потоков благодаря физическому разделению ресурсов. Эти специализированные ядра поддерживают нативную обработку FP8, что позволяет выполнять определённые задачи ИИ непосредственно на процессоре с использованием 6×128-битной реализации SVE2. Это второй северный центральный процессор Nvidia после Grace, и первый специально разработанный для агентных систем. Он обеспечивает оркестрацию, вызов инструментов, RL-нагрузки, анализ данных, «песочницы» для агентов и другие возможности, специфичные для ИИ-нагрузок. Процессор предназначен для ИИ-лабораторий, облачных провайдеров и компаний, масштабно работающих с агентными ИИ-системами. Чип обеспечивает пропускную способность памяти 1,2 Тбайт/с и поддерживает до 1,5 Тбайт памяти LPDDR5X в формфакторе SOCAMM2. Технология Scalable Coherency Fabric второго поколения обеспечивает пропускную способность 3,4 Тбайт/с, соединяя ядра на едином монолитном кристалле и устраняя проблемы с задержкой, характерные для чиплетных архитектур. Для сравнения Phoronix протестировала процессоры Intel Xeon Granite Rapids 6980P, а также чипы AMD EPYC Turin и Turin Dense, такие как AMD EPYC 9755, 9575F и 9475F. Также в тест были включены результаты процессоров Nvidia первого поколения Grace на базе ядер Arm Neoverse V2. Nvidia разрешила проводить на своём чипе только определённый набор тестов, включая стандартные рабочие нагрузки, такие как компиляция кода, производительность потоковой памяти, кодирование видео, Python/Java и производительность баз данных. 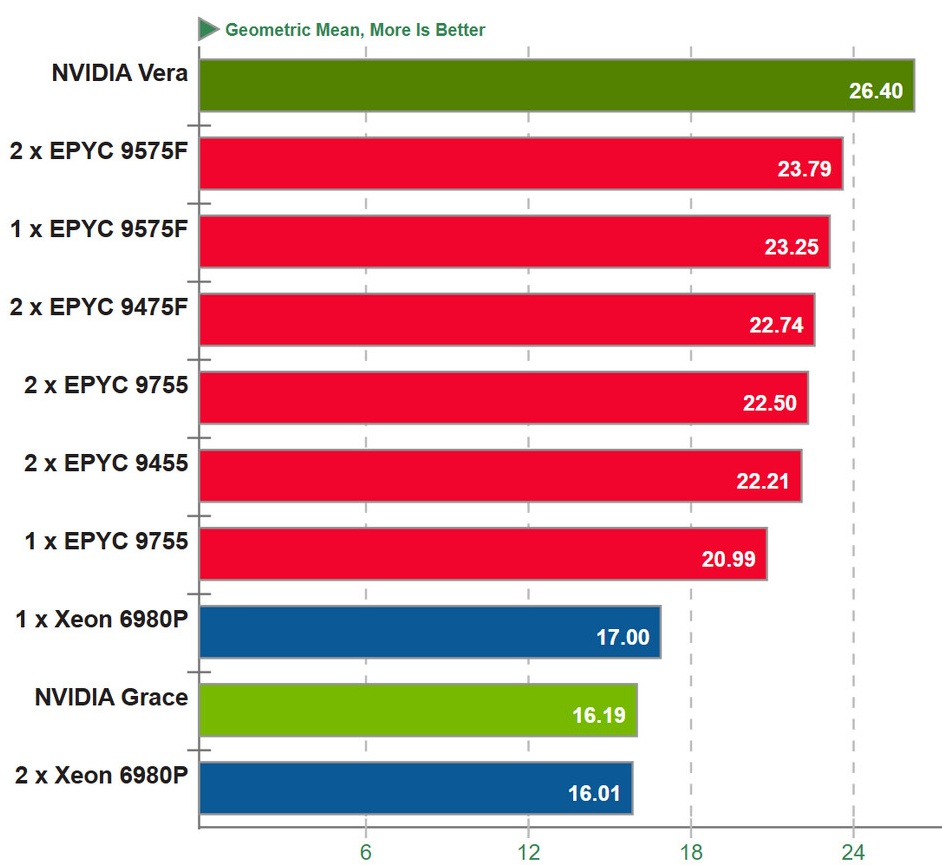
Источник изображения: phoronix.com По результатам геометрического среднего всех тестов, процессор Nvidia Vera занял первое место, показав почти на 11 % лучшие результаты, чем самые передовые разработки AMD, и примерно на 55,3 % лучшие, чем лучшие односокетные конфигурации Intel Xeon. Свежий чип от Nvidia показал себя лучше, чем конкуренты в двухсокетных конфигурациях, что говорит прежде всего о проблемах масштабирования некоторых рабочих нагрузок на нескольких сокетах. Представленные ограниченные результаты ставят Nvidia Vera выше любой архитектуры на базе Arm, с TDP 450 Вт для процессора и 50 Вт для пула памяти объёмом 768 Гбайт. Прогнозируется, что Nvidia продаст процессоров Vera и Grace на сумму около $20 млрд, охватив общий потенциальный рынок в $200 млрд своими автономными предложениями. Такой подход потенциально может вывести компанию в число крупнейших производителей процессоров как в этом году, так и в последующие годы. Память в серверах Nvidia подорожала на 435 % при переходе от Blackwell к Vera Rubin — стойку оценили в $7,8 млн
22.05.2026 [12:18],
Павел Котов
Одна серверная стойка Nvidia VR200 NVL72 нового поколения на архитектуре Vera Rubin обойдётся облачному оператору примерно в $7,8 млн, подчитали в Morgan Stanley. Для сравнения, GB300 NVL72 стоит около $4 млн. Стойка нового поколения VR200 NVL72 содержит больше DRAM и NAND — на память приходятся около 25 % общей стоимости. 
Источник изображения: Nvidia В корпусах VR200 NVL72 компания Nvidia намеревается продавать процессоры Vera по $5000 и ускорители искусственного интеллекта Rubin по $55 000 за штуку. В стойках используются уже знакомые клиентам корпуса Oberon, но внутри установлены более сложные компоненты коммутации, сетевых подключений, печатные платы, системы охлаждения, изменились даже технологии упаковки чипов — всё это влияет на стоимость систем и складывается в ценник $7,8 млн за стойку. Только компоненты памяти в стойке VR200 NVL72 обходятся около $2 млн или на 435 % больше, чем в GB300 NVL72. 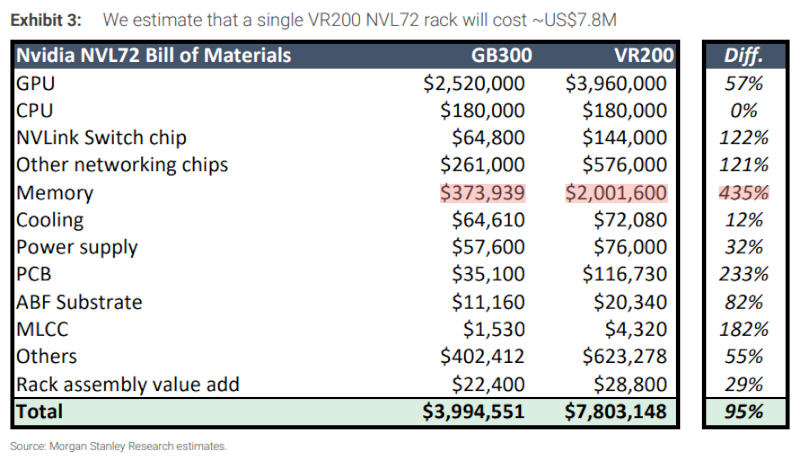
Источник изображения: x.com/Aaronwei3n На каждую стойку нового поколения приходятся 54 Тбайт памяти LPDDR5X — втрое больше, чем 17 Тбайт у GB200 NVL72. Nvidia, по оценкам SemiAnalysis, в I квартале платила по $8 за 1 Гбайт LPDDR5X, и дальше этот показатель может только вырасти, особенно если речь идёт о дорогих в производстве и тестировании модулях SOCAMM2. Таким образом, память для GB200 NVL72 обходится в $136 000 на каждую машину; в случае VR200 NVL72 это уже $408 000, а при росте цены до $10 за 1 Гбайт это будут уже $540 000 — даже без учёта наценки самой Nvidia. Кроме того, в каждой стойке VR200 NVL72 содержится память 3D NAND на сумму не менее $1 млн, тогда как в GB200 NVL72 её практически не было. В результате $2 млн за память на стойку Vera Rubin NVL72 представляется вполне предсказуемым показателем: здесь есть большие объёмы LPDDR5X и 3D NAND, не говоря уже о высокоскоростной HBM4 на самих ускорителях Rubin — и это в условиях дефицита и колоссальных цен на чипы памяти. Nvidia захватила рынок ИИ-ускорителей и теперь идёт за рынком CPU — Intel и AMD под ударом
21.05.2026 [12:26],
Павел Котов
Nvidia стала самой дорогой компанией в мире, потому что завладела колоссальной долей мирового рынка ускорителей для систем искусственного интеллекта, традиционно основанных на архитектуре графических процессоров. На этом производитель решил не останавливаться и уже заявил о намерении усилить свои позиции и на рынке центральных процессоров (CPU). 
Источник изображения: nvidia.com В беседе с инвесторами по итогам квартального финансового отчёта глава Nvidia Дженсен Хуанг (Jensen Huang) заявил, что центральные процессоры Vera могут оказаться революционными продуктом, который уже демонстрирует многообещающие показатели продаж. Nvidia традиционно выступает как лидер рынка графических процессоров, а сегмент центральных обычно делили между собой AMD и Intel — «зелёные» тоже выпускали CPU, но не объявляли их своим основным направлением. С появлением чипов Vera это может измениться — их господин Хуанг назвал «первым в мире процессором, разработанным специального для агентного ИИ» и отметил, что открыл в них «новый мощный драйвер роста». «Vera открывает для Nvidia совершенно новый рынок объёмом $200 млрд, рынок, который мы никогда раньше не охватывали, и для его внедрения с нами сотрудничает каждый крупный гиперскейлер и производитель систем. Мир перестраивает вычислительные мощности для агентного ИИ и физического роботизированного ИИ. Nvidia находится в центре этих преобразований», — заявил глава компании. «Мыслящая» часть ИИ-моделей работает на графических процессорах, а для агентов необходимы центральные — они используются для запуска поставленных задач, и вскоре для этого появятся специальные ПК. Архитектура чипов Vera предназначена для работы ИИ-агентов, потому что оптимизирована для максимально быстрой обработки токенов. Традиционно в облачных ресурсах брались в расчёт только ядра, позволяющие запускать множество экземпляров приложений с максимально возможной скоростью. К настоящему моменту Nvidia, по словам Дженсена Хуанга, продала автономных процессоров Vera на $20 млрд, и компания только в начале этого пути. «В мире миллиард пользователей, людей. Мне кажется, в мире будут миллиарды агентов, [хотя и] не сегодня. То есть мы будем расти, но у нас будут миллиарды агентов, и все эти миллиарды агентов будут работать на оборудовании. И это оборудование будет похоже на ПК — точно как мы, люди, пользуемся ПК сегодня», — заключил глава Nvidia. Nvidia показала полный стек Vera Rubin — от GPU до сетей для ИИ-фабрик нового поколения
17.03.2026 [10:01],
Алексей Разин
Являясь одним из лидеров в сфере вычислительной инфраструктуры для систем искусственного интеллекта, Nvidia комплексно подходит к развитию собственных платформ, а потому вместе с ускорителями поколения Vera Rubin предложила ряд сопутствующих аппаратных решений. 
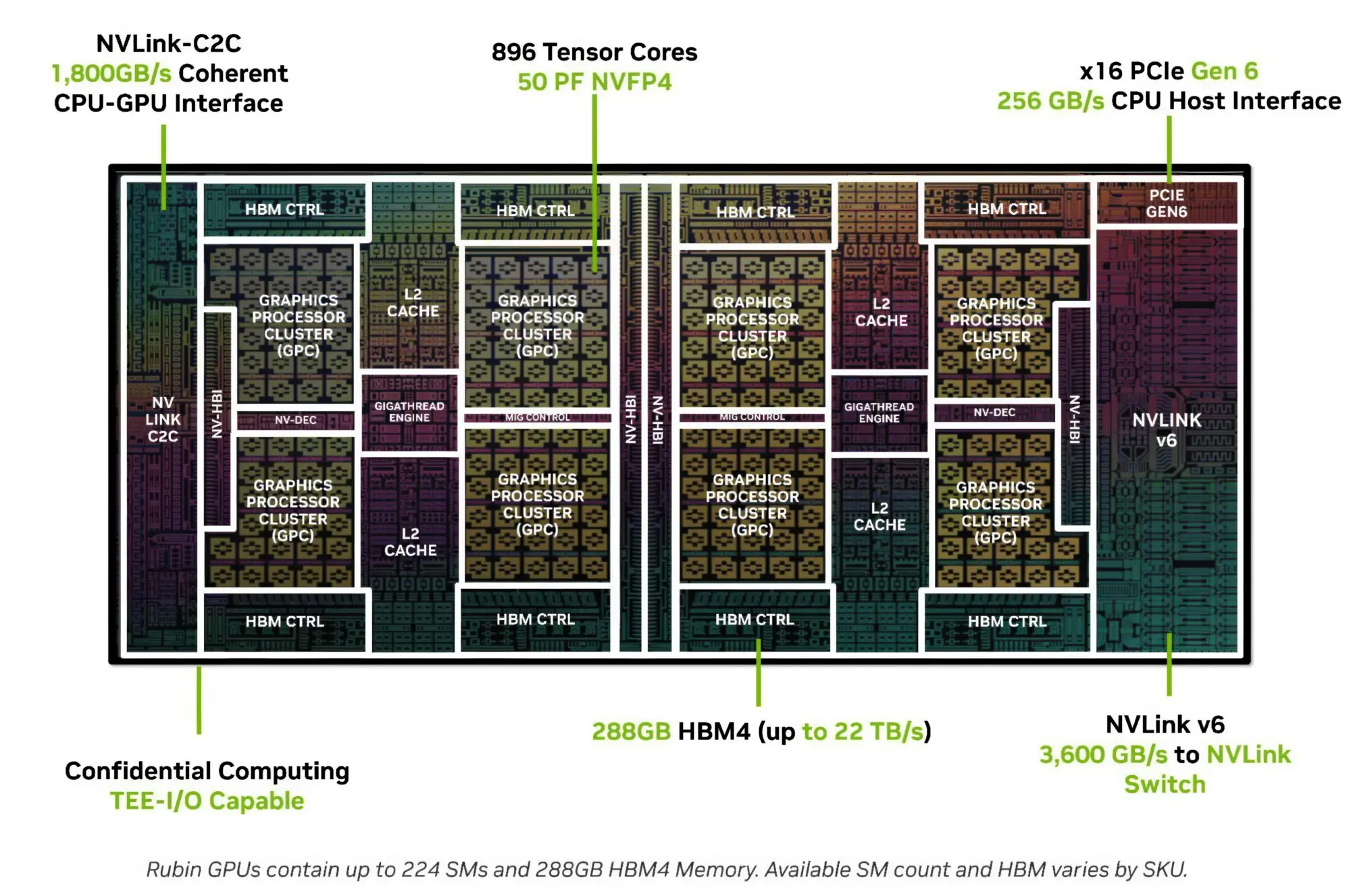
Источник изображений: Nvidia Как отмечается в корпоративном пресс-релизе, платформа Vera Rubin открывает новые рубежи в развитии агентского искусственного интеллекта. В массовом производстве сейчас находятся семь новых чипов Nvidia, позволяющих эффективно масштабировать так называемые ИИ-фабрики. В число семи аппаратных новинок Nvidia вошли графические процессоры Rubin, центральные процессоры Vera, коммутаторы NVLink 6, сетевые решения ConnectX-9 SuperNIC, специализированные процессоры BlueField-4 и Ethernet-коммутаторы Spectrum-6, а также созданные с помощью разработок одноимённого поглощённого стартапа процессоры Groq для ускорения инференса при работе с ИИ-агентами. В совокупности они работают, как ИИ-суперкомпьютер, как отмечается в материалах Nvidia для прессы на официальном сайте компании, позволяя ускорять создание профильных технологий на всех этапах жизненного цикла ИИ-систем. Основатель и глава Nvidia Дженсен Хуанг (Jensen Huang) заявил, что с выходом платформы Vera Rubin наступил переломный момент в развитии агентского ИИ, поскольку данная платформа будет способствовать самому масштабному развёртыванию инфраструктуры в истории. Руководители OpenAI и Anthropic прокомментировали анонс Vera Rubin в предсказуемо хвалебных выражениях, подчёркивая значение этого события для всей ИИ-отрасли. Разработчики ИИ-моделей теперь смогут совершенствовать их и делать это быстрее, чем на аппаратных решениях прошлого поколения. Структура ЦОД теперь строится на готовых модулях, как считают в Nvidia, которые содержат всё необходимое для эффективного масштабирования вычислительных мощностей с учётом постоянного роста сложности решаемых задач. Клиенты могут сочетать готовые модули ЦОД с учётом специфики своей деятельности. Например, в одной стойке Vera Rubin NVL72 находятся 72 графических процессора Rubin и 36 центральных процессоров Vera, соединённых скоростной шиной NVLink 6 и сетевыми контроллерами ConnectX-9 SuperNIC, а также специализированные процессоры BlueField-4, которые разгружают центральные процессоры от задач работы с сетевым трафиком. По сравнению с решениями поколения Blackwell новые системы Vera Rubin справляются с обучением сложных моделей силами в четыре раза меньшего количества GPU. Пропускная способность в пересчёте на ватт потребляемой энергии в задачах инференса у Vera Rubin до десяти раз выше, а затраты на один токен в десять раз ниже. В кластерах стойки NVL72 масштабируются при помощи Quantum-X800 InfiniBand и Spectrum-X Ethernet. Центральные процессоры Vera, по словам представителей Nvidia, хорошо себя проявляют в задачах обучения с подкреплением и агентских ИИ-нагрузках. Компания может объединять в одной стойке до 256 таких процессоров, оснащённых системой жидкостного охлаждения. С прочими компонентами кластера они могут сообщаться при помощи сетевых решений Spectrum-X. По сравнению с некими традиционными CPU, на которые ссылается Nvidia, её процессоры Vera могут справляться с ИИ-задачами на 50 % быстрее.  Специализированные чипы Groq 3 LPX обеспечивают эффективную работу с агентскими ИИ-нагрузками при минимальных задержках. В сочетании с другими чипами, входящими в состав платформы Vera Rubin, они обеспечивают увеличение пропускной способности в задачах инференса до 35 раз на один мегаватт потребляемой мощности, а потенциал выручки при использовании моделей с триллионом параметров увеличивается в десять раз. В состав одной стойки входит 256 чипов LPU, 128 Гбайт интегрированной на них памяти SRAM, а пропускная способность достигает 640 Тбайт/с. В сочетании с прочими компонентами платформы Vera Rubin, чипы LPU достигают максимальной эффективности как по быстродействию, так и по энергопотреблению, а также использованию ресурсов памяти. Стойки LPX будут доступны клиентам Nvidia со второй половины текущего года. Стойка BlueField-4 STX специализируется на унификации адресного пространства GPU между элементами кластера. Обработка хранимой в кеше информации в операциях инференса ускоряется до пяти раз, при этом обеспечивается высокая энергоэффективность по сравнению с системами на классической архитектуре. Достигается общий для кластера контекст, обеспечивающий быстрое взаимодействие с ИИ-агентами и более эффективно масштабируемыми ИИ-сервисами. Отдельная стойка Spectrum-6 SPX отвечает за скоростной обмен данными по интерфейсу Ethernet. Она может содержать не только коммутаторы Spectrum-X Ethernet, но и коммутаторы Nvidia Quantum-X800 InfiniBand в зависимости от потребностей конкретной конфигурации. В исполнении с кремниевой фотоникой и интеграцией на уровне упаковки чипов эффективность передачи информации возрастает в пять раз, а надёжность по сравнению с традиционными подключаемыми решениями увеличивается в десять раз. Nvidia бросила вызов Intel Xeon и AMD Epyc — серверный Arm-процессор Vera теперь продаётся отдельно
27.01.2026 [17:39],
Сергей Сурабекянц
Nvidia уже несколько поколений подряд предлагает не только графические процессоры, но и так называемые «суперчипы» — связки из центрального Arm-процессора и GPU. Теперь Nvidia начала предлагать свои центральные процессоры Vera в качестве самостоятельного продукта, что знаменует дебют на рынке серверных процессоров, где доминируют Intel Xeon и AMD Epyc. Глава Nvidia Дженсен Хуанг (Jensen Huang) подтвердил серьёзность намерений компании в недавнем интервью Bloomberg. 
Источник изображений: Nvidia Заявление Хуанга привлекает особое внимание к новому бизнес-направлению Nvidia. Vera — это первый случай (почти), когда компания предлагает подобный чип в качестве автономного решения. Это означает, что Nvidia будет конкурировать с процессорами Intel и AMD в центрах обработки данных. Vera также может стать альтернативой собственным компонентам, используемым облачными провайдерами, такими как Graviton от Amazon. Предыдущие процессоры Nvidia были доступны только в составе систем, объединённых с другими чипами. Процессор Vera оснащён 88 специализированными ядрами Armv9.2 Olympus, использующими технологию пространственной многопоточности, что позволяет ему обрабатывать 176 потоков за счёт физического разделения ресурсов. Эти специализированные ядра поддерживают нативную обработку FP8, что позволяет выполнять некоторые задачи ИИ непосредственно на процессоре с 6×128-битной реализацией SVE2. Технология Scalable Coherency Fabric второго поколения обеспечивает пропускную способность 3,4 Тбайт/с, соединяя ядра на едином монолитном кристалле и устраняя проблемы с задержкой, характерные для чиплетных архитектур. Кроме того, Nvidia интегрировала технологию NVLink Chip-to-Chip второго поколения, обеспечивающую когерентную пропускную способность до 1,8 Тбайт/с для внешних графических процессоров Rubin. Чип обеспечивает пропускную способность памяти 1,2 Тбайт/с и поддерживает до 1,5 Тбайт памяти LPDDR5X, что делает его идеальным для ресурсоёмких вычислительных задач. Однако, поскольку процессор теперь предлагается как автономное решение, неясно, будут ли доступны какие-либо классические варианты памяти, такие как DDR5 RDIMM, или же процессор будет использовать исключительно SOCAMM LPDDR5X.  «Vera — это совершенно революционный процессор», — уверен Хуанг. Он отказался назвать других заказчиков, помимо CoreWeave, но заверил, что «их будет много». |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex